
The OMG has adopted a standard way to capture timeliness, performance, and schedulability properties of real-time systems. This profile doesn't invent any new techniques, but rather codifies what people were already doing when capturing timeliness and related properties. The profile uses stereotypes, tagged values, and constraints with specific names. The primary benefit is the ability to exchange timeliness properties among different tools, such as UML modeling tools and schedulability analysis tools.
Notations and Concepts Discussed | ||
|---|---|---|
UML Profiles | General Resource Subprofile | Real-Time CORBA Subprofile |
Time Subprofile | ||
Schedulability Subprofile | Concurrency Subprofile | |
A UML profile is a variant of the UML that is specialized in some minor ways. A UML profile is allowed to contain specialized versions (called stereotypes) of the metamodel elements defined in the UML metamodel, user-defined values (properties or tags) attached to these elements, and additional well-formedness rules (constraints). A profile is not allowed to break existing UML semantics, although it is allowed to specialize them. A profile may additionally provide new graphical icons and diagrams and domain-specific model libraries. The purpose of a profile is to provide UML that is tailored for a particular vertical market domain or technology area. Thus, it is possible to have a profile for testing, for modeling quality of service, for modeling business processes, and so on. Each of these is, at its core, vanilla UML, but with some (very) minor extensions and specializations to allow it to apply in a more obvious way to the specific domain.
Because a profile is not allowed to change the semantics of the modeling language in any important or fundamental way, what are the advantages of profiling? The primary advantages are creating profiles that allow us to standardize idioms and design patterns common in a particular domain, and that allow tools to exchange models that use the profile. We shall see later that these are precisely the advantages provided for the UML Profile for Schedulability, Performance, and Time (also called the RT UML profile, or RTP) and the other profiles discussed in this chapter. As a variant of the standard, it has all the disadvantages of a standard—lack of tool support, lack of trained staff, lack of reference materials, and so on. Standardizing the profile mitigates such effects but does not remove them—since they appeal to a subset of the UML user community, tools may offer only limited support.
Nevertheless, profiles can be useful in modeling specific domains, especially when the members of the domain can agree on the contents and notations for the domain. A profile is simply a coherent set of specialized metamodel elements (stereotypes), named values (properties or tagged values), and rules (constraints). Once defined, a profile allows us to use these stereotypes as a part of our basic language in which to express user models, and if done well, the profile provides a richer vocabulary that is more closely aligned with the problem domain to which it is being applied.
The UML uses stereotypes for a couple of purposes. First, and most common, is to indicate which metamodel element is typing a model element on a diagram. For example, a class box shows you the operations within the interface, and the stereotype interface identifies that this is an interface and not a class. The second primary use for a stereotype is to indicate a specialized kind of metamodel element defined within a profile.[1] Note that you are not allowed to add fundamentally new metamodel elements to a profile—they must be specializations of existing metaclasses in the metamodel.
Stereotypes are shown in one of two ways. Either a textual annotation is attached to the metaclass being stereotyped, such as a class, relation, or node, or the default icon for the metaclass is replaced with a special icon. Figure 4-1 shows both approaches being used. Several stereo types are used. The first is for the «active» class. An «active» class owns the root of a thread and is how the concurrency model for a system is constructed with UML; instances “contained” via the composition relation (such as the instances of the MQueue class in the figure) run in the context of the thread owned by the instance of the composite active class. The UML 1.x used a class with a heavy boarder as the icon for this kind of class, while in UML 2.0 the icon is a class box with a double line border on the left and right ends. Both forms are shown in Figure 4-1.
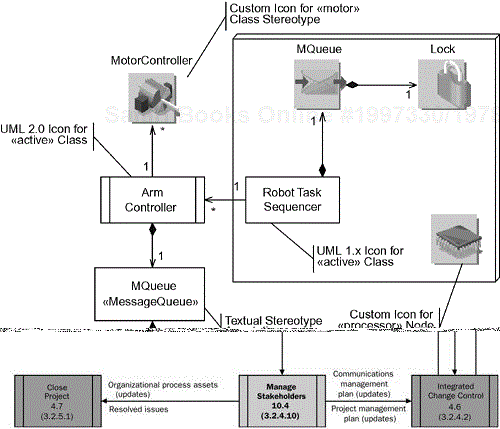
The MQueue class is stereotyped—it is a “special” kind of class called a «MessageQueue». The MQueue class also contains, via composition, a Lock class, which is likewise stereotyped to be a «Semaphore». The same stereotypes, using the textual notation option, are also shown on the figure. The MotorController class is also stereotyped to be a «motor». Last, any metaclass can be stereotyped—the node shown in the figure is stereotyped to be a «Processor», but they can be applied to any kind of metaclass in the UML.
Stereotypes exist so users (and people building profiles) can add their domain's specific concepts to their modeling language in an easy, lightweight way.
To some degree, just stereotyping something may be useful because it indicates that it is in a class of entity in your domain's conceptual landscape. Using such stereotypes may clarify the model to domain experts trying to construct or understand your system. However, stereotypes are more useful when they contain special values that apply (only) to that kind of stereotype. The first way in which stereotypes are customized is by adding what is called a tagged value or property. A tagged value is a property name–value pair. It is common to identify special kinds of values that apply to this stereotype and not others, and to capture these in the model.
The tagged value provides the definition of the kind of information added to the stereotype. The actual values for particular instantiations of the stereotype (e.g., user classes based on the stereotype) are added by assigning or using the tagged values in constraints anchored to the stereotype).
A constraint is a user-defined rule or rule of correctness. The UML has many constraints in its metamodel defining the legal uses for classes, associations, and other model elements. However, these are necessarily highly generalized because the UML can be used to model systems in many domains. A constraint is a way in which a user can express a restriction that makes sense in the particular domain from which a model element is drawn. Figure 4-2 shows a typical use of constraints, combining tagged values that are defined for the stereotype.

For example, a stereotype «Semaphore» might have a tagged value called “capacity,” which indicates the number of active users of a resource. In the figure, the tagged value is explicitly set to 1. Similarly, a «MessageQueue» might have a maxSize tagged value, an «active» class might have tags such as IsPeriodic, period, and so on. A «processor» node might have tagged values such as memory size, CPU speed, and endian orientation. A constraint is the classic way to specify specific values for the tags that are valid for a stereotype. Constraints, as can be seen in the figure, are normally shown inside of note boxes and within curly braces to set them off from semantic-free comments.
Given that we can use constraints to specify the values associated with the tags, how do we define the tags themselves? There are two common ways. The first, shown in Figure 4-3a, is to use a property sheet that shows in a context-sensitive way what tags are available for a particular stereotype. The second, shown in Figure 4-3b, is to show the relevant tags in a compartment labeled «tags». Either can be used, depending on your particular UML design tool and personal preference.


A profile is a metamodel of some particular domain of interest, expressed using a coherent set of UML stereotypes with associated tagged values that are used via constraints, possibly accompanied by a model library specific to the domain(s) of interest. The constraint on this definition is that all of the elements of this domain metamodel must be expressed as stereotypes of predefined UML metaclasses, such as class, association, node, component, and so on. A profile is not allowed to “break” normal UML semantics, but it is permitted to subset them, specialize them, and extend them, as well as add notations as needed.
The so-called RT UML Profile (RTP), more formally known as the UML Profile for Schedulability, Performance, and Time, was submitted in response to a Request for Proposal (RFP) written up by the Real-Time Analysis and Design Working Group (RTAD) of the OMG, of which I am a cochair, as well as a co-submitter of the profile. The purpose of the profile was to define a common, standard way in which timeliness and related properties could be specified, and the primary benefit of the profile was seen to be the ability to exchange quantitative properties of models among tools. Specifically, we wanted to be able to define a standard way for users to annotate their models with timely information, and then allow performance analysis tools read those models and perform quantitative analysis on them.
A consortium of several companies was formed to respond to the RFP. The result was the profile as it was approved and voted to be adopted in 2001. Following the voting, the Finalization Task Force (FTF) was formed to remove defects and resolve outstanding issues. The FTF has completed its work and the profile is now maintained by the Revision Task Force (RTF).
The RFP specifically calls for submissions that “define standard paradigms for modeling of time-, schedule- and performance-related aspects of real-time systems.” This does not in any way mean that these things cannot be modeled in the UML without this profile. Indeed, the approach the submissions team took was to codify the methods already in use to model time, schedulability, and performance, and then define a standard set of stereotypes and tags. Thus, the tag SApriority allows the user to specify the priority of an active class in a way that a performance analysis tool knows how to interpret.
Several guiding principles were adhered to during the creation of the proposal. First and foremost, the existing UML cannot be changed in a profile. We also did not want to limit how users might want to model their systems. We all felt that there is no one right way to model a system, and we wanted to allow the users freedom to choose the modeling approach that best suited their needs. We did not want to require the user to understand the detailed mathematics of the analytic methods to be applied, and we wanted the approach used to be scalable. By scalable, we meant that for a simple analysis, adding the quantitative information should be simple and easy, but for more complex models it was all right to require additional effort. In general, if the analysis or the model were 10 times more complex, then one might reasonably expect 10 times the effort in entering the information. We wanted to provide good support for the common analytical methods such as rate monotonic analysis (RMA) and deadline monotonic analysis (DMA), but we did not want to limit the profile to only such methods. We did not want to specify the analytic methods at all, but concentrate instead on how to annotate user models so that such analysis could easily be done. And finally, we wanted to support the notion that analytic tools could synthesize models and modify the user models to improve performance or schedulability, if appropriate.
Figure 4-4 shows the use cases for the profile.[2] The analysis method providers are actors[3] that define the mathematical techniques for analysis and provide tools and models to execute the analysis of user models. The infrastructure providers are actors that provide infrastructures, such as real-time operating systems, distribution middleware such as CORBA ORBs, or other kinds of frameworks or libraries that might be incorporated into user systems. These use cases are important because the performance of these infrastructures can greatly affect the performance of the overall system. If such an infrastructure provider supplies a quantitative model of their infrastructure, this would allow the modeler to better analyze their system. Finally we have the modelers (you guys) that build user models. The Modelers actor represents the people constructing models and wanting to annotate and analyze them. It is the use cases associated with this actor on which I will focus.

The Modeler use cases are used to create the user models, to perform the quantitative analysis on these models, and to implement the analyzed models. The expected usage paradigm for the profile is shown in Figure 4-5.

In this figure, the user enters the model into a UML modeling tool, such as Rhapsody from I-Logix, as well as entering the quality of service properties of the elements. A modeling analysis tool, such as Rapid RMA from Tri-Pacific Corporation, inputs the model (most likely via XMI), converts it as necessary into a quantitative model appropriate for the analysis, and applies the mathematical techniques used to analyze the model. Once the analysis is complete, the modeling analysis tool updates the user model—perhaps just to mark it as schedulable or perhaps to reorder task priorities to improve performance. Once the model is adequate and validated, the application system is generated from the updated UML model.
Because the profile is quite large it is divided into subprofiles for improved understandability and usage. Figure 4-6 shows the organization of the profile. It is possible, for example, that some user might want to use one or a smaller number of parts of the profile but not other parts. By segmenting the profile into subprofile packages, the user isn't burdened with all of aspects of the entire profile unless he or she actually needs them.

The three primary packages of the profile are shown in Figure 4-6. The general resource modeling framework contains the basic concepts of real-time systems and will generally be used by all systems using the framework. This package is subdivided into three smaller subprofiles: RT Resource Modeling, RT Concurrency, and RT Time Modeling. The first of these defines what is meant by a resource—a fundamental concept in real-time systems. The second of these defines a more detailed concurrency model than we see in the general UML metamodel. The last specifies the important aspects of time for real-time systems, time, durations, and time sources, such as timers and clocks.
The second main package of the profile is called analysis models. In this package, we provide subpackages for different kinds of analytic methods. The Schedulability Analysis (SA) package defines the stereotypes, tags, and constraints for common forms of schedulability analysis. Likewise, the Performance Analysis (PA) package does the same thing for common performance analysis methods. These packages use the concepts defined in the resource, concurrency, and time subprofiles mentioned earlier. The RSA profile specializes the SA profile. As new analytic methods are added, it is anticipated that they would be added as subprofiles in the analysis models package.
The last primary package is the infrastructure package. In this package, infrastructure models are added. The RFP specifically called for a real-time CORBA infrastructure model, but it is anticipated that other infrastructure vendors would add their own packages here if they wish to support the profile.
In the specification of the profile, each of these packages supplies a conceptual metamodel modeling the fundamental concepts of the specific domain, followed by a set of stereotypes and their associated tagged values and constraints. We will discuss each of these subprofiles in turn and finally provide a more complete example of using the overall profile to provide a user model ready for schedulability analysis.
To aid in understanding and tracking down where tags and stereotypes are defined, each tag or stereotype is preceded with a code identifying which subprofile defined the item. Thus, things beginning with “GRM” are defined in the general resource model subprofile, things beginning with PA are to be found in the performance analysis subprofile, and so on.
Because UML is undergoing a major internal reorganization as a result of the UML 2.0 effort, the RTP will need to undergo a similar level of revision to make it consistent with the new UML standard. The RTAD as a group has decided (rightly, I believe) that this cannot be done within the confines of the Revision Task Force (RTF) that maintains the profile but will require a new request for proposal (RFP) with new submissions. As of this writing, the new RFP is scheduled to be written in the coming months.
As you might guess, the most important concepts in the GRM subprofile are resource and quality of service. A resource is defined to be a model element with finite properties, such as capacity, time, availability, and safety. A quality of service is a quantitative specification of a limitation on one or more services offered by a resource.
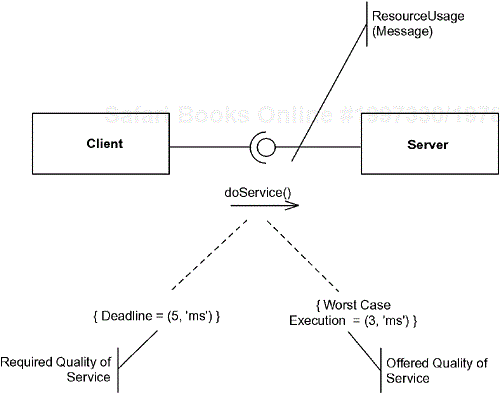
The general resource model is built on a classic client-server model. The client requests services to be executed by the server. This service request is called a resource usage and may be accompanied by one more qualities of service (QoS) parameters. QoS parameters come in two flavors—offered and required. The client may require some performance QoS from the service during the execution of the service, while the server may provide a QoS parameter. If the offered QoS is at least as good as required, then the QoS parameters are said to be consistent. Figure 4-7 shows this relation schematically.
The basic domain model of resources is shown in Figure 4-8 and the model for static resource usage is shown in Figure 4-9. We see that a descriptor “types” an instance. These classes are subclassed so that a resource (a kind of descriptor) likewise types a ResourceInstance. Resources provide ResourceServices (which type corresponding Resource ServiceInstances), each of which can have an associated quality of service characteristic (and corresponding QoS values on the instance side). This strong separation of specifications and instances allows us to perform either static analysis on the specifications or dynamic analysis on the instances of those specifications.


An important basis for dynamic models, the causality loop relates the notion of an event occurrence with the execution of a scenario. An event describes a change in state and may be (among others) a stimulus generation or a stimulus reception. A stimulus, from the UML specification, is an instance of communication between objects. This causality loop is shown in Figure 4-10. In it, we see that a scenario associates with a set on instances that receive stimuli. Each stimulus is created by a stimulus generation and results in a stimulus reception.

The dynamic resource usage model is used to analyze more complex situations than the much simpler static resource usage model. The static model assumes that properties can be assigned to types and the details of the scenarios need not be characterized. In the dynamic usage model, the internal instances of the executing scenarios are given precise QoS values for analysis. We see in Figure 4-11 that a scenario is composed to an ordered set of ActionExecutions, each of which can have required QoS values. The scenario can also have one or more ResourceServiceInstances, each of which can have an offered QoS value. The ResourceServiceInstances belong to ResourceInstances used in the scenario. Tables 4-1 to 4-6 list the stereotypes defined in this subprofile, along with the applicable metaclasses, tags, and descriptions.
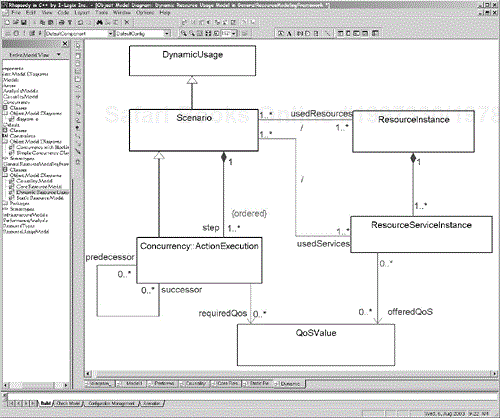
Table 4-1. General Resource Model Stereotypes
Stereotype | Applies to (metaclasses) | Tags | Description |
|---|---|---|---|
«GRMacquire» | Stimulus, Message, Action, ActionExecution, Operation, Reception, Method, ActionState, Transition, SubactivityState | GRMblocking, GRMexclServ | An operation or invocation that acquires access rights to an exclusive resource |
«GRMcode» (subclass of «GRMrealize») | Abstraction | GRMmapping | Relates a logical element model to the component that contains its code |
«GRMdeploys» (subclass of «GRMrealize») | Abstraction | GRMmapping | Identifies where logical model elements are deployed |
«GRMrealize» | Abstraction | GRMmapping | A realization mapping |
«GRMrelease» | Stimulus, Message, ActionExecution, Action, Operation, Reception, Method, ActionState, Transition, SubactivityState | GRMexclServ | An operation or invocation that releases and exclusive resource acquired previously |
«GRMrequires» (subclass of «GRMrealize») | Abstraction | GRMmapping | A specification of a requirement environment for one or more logical elements |
Table 4-2. General Resource Model Tag Type Definitions
Tag | Type | Multiplicity | Description |
|---|---|---|---|
GRMblocking | Boolean | [0..1] | AcquireService::isBlocking |
GRMexclServ | Reference to an Action, Action Execution, Operation, Method, ActionState, or SubactivityState | [0..1] | |
GRMmapping | GRMMappingString | [0..1] | This tag value should be used only if the mapping details are not fully specified by the realization relationship itself. |
The time modeling subprofile specifies the stereotypes and tags for modeling time and related concepts. These are detailed in Table 4-3.
Table 4-3. Time Subprofile Stereotypes
Stereotype | Applies to (metaclasses) | Tags | Description |
|---|---|---|---|
«RTaction» | Action, Action Execution, Stimulus, Message, Method, ActionSequence, ActionState, SubactivityState, Transition, State | RTstart RT end RTduration | An action that takes time |
«RTclkInterrupt» (subclass of «RTstimulus») | Stimulus, Message | RTtimeStamp | A clock interrupt |
«RTclock» (subclass of «RTtiming Mechanism») | Instance, DataType, Classifier, ClassifierRole, Object, DataValue | RTclockId | A clock mechanism |
«RTdelay» (subclass of «RTaction») | Action, ActionExecution, Stimulus, Message, Method, ActionSequence, ActionState, SubactivityState, Transition, State | RTduration | A pure delay activity |
«RTevent» | Action, ActionExecution, Stimulus, Message, Method, ActionSequence, ActionState, SubactivityState, Transition, State | RTat | An event that occurs at a known time instant |
«RTinterval» | Instance, Object, Classifier, DataType, DataValue | RTintStart, RTintEnd, RTintDuration | A time interval |
«RTnewClock» | Operation | An operation that creates a new clock mechanism[4] | |
«RTnewTimer» | Operation | RTtimerPar | An operation that creates a new timer[4] |
«RTpause» | Operation | A pause operation on a timing mechanism[5] | |
«RTreset» | Operation | An operation that resets a timing mechanism[5] | |
«RTset» | Operation | RTtimePar | An operation that sets the current value of a timing mechanism[5] |
«RTstart» | Operation | An operation that starts a timing mechanism[5] | |
«RTstimulus» | Stimulus, ActionExecution, Action, ActionSequence, Method | RTstart, RTend | A timed stimulus |
«RTtime» | DataValue, Instance, Object, DataType, Classifier | RTkind, RTrefClk | A time value or object |
«RTtimeout» (subclass of «RTstimulus») | Stimulus, ActionExecution, Action, ActionSequence, Method | RTtimestamp (inherited) | A timeout signal or a timeout action |
«RTtimer» (subclass of «RTtiming Mechanism») | DataValue, Instance, Object, ClassifierRole, Classifier, DataType | RTduration, RTperiodic | A timer mechanism |
«RTtimeService» | Instance, Object, ClassifierRole, Classifier | A time service | |
«RTtiming Mechanism» | DataValue, Instance, Object, ClassifierRole, Classifier, DataType | RTstability, RTdrift, RTskew, RTmaxValue, RTorigin, RTresolution, RTaccuracy, RTcurrentVal, RToffset, RTrefClk | A timing mechanism |
[4] The stereotype can only used on operations that are declared for a model element that is stereotyped «RTtimeService». [5] The stereotype can only be used operations that are declared for a model element that is stereotyped as «RTtimingMechanism» or one of its subclasses. | |||
Table 4-4. Time Subprofile Tag Definitions
Tag | Type | Multiplicity | Description |
|---|---|---|---|
RTstart | RTtimeValue | [0..1] | A starting time |
RTend | RTtimeValue | [0..1] | An ending time |
RTduration | RTtimeValue | [0..1] | The length of time for the referenced stereotype |
RTclockID | String | [0..1] | Name of a clock |
RTat | RTtimeValue | [0..1] | Time of event occurrence |
RTintStart | RTtimeValue | [0..1] | Start of a time interval |
RTintEnd | RTtimeValue | [0..1] | End of a time interval |
RTintDuration | RTtimeValue | [0..1] | Duration of a time interval |
RTtimerPar | RTtimeValue | [0..1] | The time parameter |
RTkind | Enumeration of ('dense', 'discrete') | [0..1] | Discrete or continuous time |
RTrefClk | Reference to a model element stereotyped as «RTclock», or String | [0..1] | Reference clock; must point to or name a model element that is stereotyped «RTclock» |
RTperiodic | Boolean | [0..1] | Identifies whether the timer is periodic |
RTstability | Real | [0..1] | The ability of the mechanism to measure the progress of time at a consistent rate (an offered QoS characteristic) |
RTdrift | Real | [0..1] | The rate of change of the skew (an offered QoS characteristic) |
RTskew | Real | [0..1] | Identifies how well the mechanism tracks the reference clock (an offered QoS characteristic) |
RTmaxValue | RTtimeValue | [0..1] | The current value cannot be exceeded (an offered QoS characteristic) |
RTorigin | String | [0..1] | A clearly identified timed event from which it proceeds to measure time |
RTresolution | RTtimeValue | [0..1] | The minimal time interval that can be recognized by the mechanism (an offered QoS characteristic) |
RToffset | RTtimeValue | [0..1] | The difference between two clocks |
RTaccuracy | RTtimeValue | [0..1] | The maximal offset of a clock over time |
RTcurrentVal | RTtimeValue | [0..1] | The current value of a timing mechanism |
Tagged values hold values that are taken from its type. TimeValues can be expressed in a number of forms:
| hr “:” min “:” sec | |
| year “/” month “/” day | |
| Mon, Tues, etc. | |
| <number> PDF <time unit> specifies a probability density function ns, ms, us, s, min, hr, days, wks, mos, yrs | |
Arrival patterns are specified with the RTArrivalPattern tag. There are several kinds: bounded, bursty, irregular, periodic, and unbounded. Formally, the syntax is
RTArrivalPattern ::= <bounded-string> | <bursty- string> | <irregular-string> | <periodic-string> | <unbounded-string> bounded-string ::= " 'bounded' ," <time-value> "," <time-value> <bursty-string> ::= " 'bursty' ," <time-value> "," <integer> <irregular-string> ::= " 'irregular' ," <time-value> [ '," <time-value> ]* <periodic-string> ::= " 'periodic' ," <time-value> [ "," <time-value>] <unbounded-string> ::= " 'unbounded' ," <PDF-string>
Bound arrival patterns are specified with the keyword bounded, followed by a lower and upper bound, as in “bounded, (0, 'ms'), (15, 'ms').” A bursty arrival pattern means that the arrival of events is correlated in time, that is, the arrival of one event makes it more likely that another event will arrive soon after. Bursty arrival patterns are specified with the bursty key word followed by a time value (indicating the burst interval) and an integer value (indicating the maximum number of events in that interval, as in “bursty, (20, 'ms'), 100).” An irregular arrival pattern describes a series of arrival times. It is specified using the keyword irregular, followed by a list of time values, as in “irregular, (10, 'ms'), (15, 'ms'), (5, 'ms').” The asterisk (*) in the grammar means that the term can be repeated an arbitrarily number of times. Periodic arrival patterns are very common. They are indicated with the keyword period and a time value indicating the period. The period value may optionally be followed by another time value that indicates the maximal deviation from the period (sometimes called jitter), as in “periodic, (100, 'ms), (500, 'us').” Finally, an unbounded arrival pattern is one in which the arrival times are drawn as a renewal process from an underlying probability density function, as described below. An example would be “unbounded, normal (100, 'ms'), (15, 'ms')” to specify a normal (Gaussian) distribution with a mean of 100 ms and a standard deviation of 15 ms.
The time subprofile identifies the most common probability density functions (PDFs) used with event time distributions—Bernoulli, binominal, exponential, gamma, histogram, normal, Poisson, and uniform. Each of these has one or more parameters qualifying the mathematical properties of the distribution. Bernoulli distribution has a single real parameter specifying the probability (in the range of 0 to 1). Binomial distributions have two parameters, a real (the probability) and an integer (the number of trials). Exponential distributions have a single real parameter, the mean, as in “exponential 100.” Gamma distributions have two parameters; the first is an integer k, and the mean from the formula in Equation 4-1.
A histogram distribution is a set of real number pairs, followed by a single real number. Each number pair indicates the start of an interval and the probability of occurrence within that interval. The last single number defines the ending point for the last interval, as in “histogram, 10, 0.10, 20, 0.50, 30, 0.30, 40, 0.1, 50.” A normal distribution is characterized by a mean and standard deviation, as in “normal, 90.5, 8.5.” A Poisson distribution has a mean, as in “poisson, 80.5.” Lastly, a uniform distribution is characterized by a starting and ending points, as in “uniform 50.0, 150.0.”
Timing information can be applied to action executions using a set of defined “timing marks,” including
RTstart: The time the action begins or the stimulus is sent.
RTend: The time the action ends or the stimulus response has completed
RTduration: The length of time the of an action execution or the stimulus response, that is, RTduration = RTend - RTstart for the same action execution or stimulus
These timing marks are used in timing expressions captured in constraints applied against the actions or stimuli, as in
{ RTend - RTstart < (10, 'ms') }
which specifies that the time that a stimulus is received until the initiated action completes is less than 10 ms.
Such timing specifications are often made on sequence diagrams, such as that in Figure 4-12. We see some of the messages stereotyped as «RTstimulus» and the actions stereotyped as «RTaction». Timing information is added as tags associated with the stereotypes. In addition, there are some “anonymous timing marks” that allow the annotation of the progress of time during the execution of the scenario.

The concurrency subprofile refines the core UML's somewhat vague notions of concurrency. The domain model for the profile's concurrency subprofile is shown in Figure 4-13. The most central concept is that of ConcurrentUnit. A ConcurrentUnit is a kind of ActiveResource, which in turn is a kind of ResourceInstance, a domain concept discussed in Section 4.2.1. An ActiveResource is a resource instance that is able to generate its own stimuli concurrently, that is, independent from other activities. A ConcurrentUnit runs a main scenario and may have one or more StimuliQueues. Because it is a subclass of ResourceInstance, it may also own (via composition) an unbounded number of ResourceServiceInstances (instances of services provided by resources). This is what most closely corresponds to the notions of thread, task, and process found in the operating systems literature.
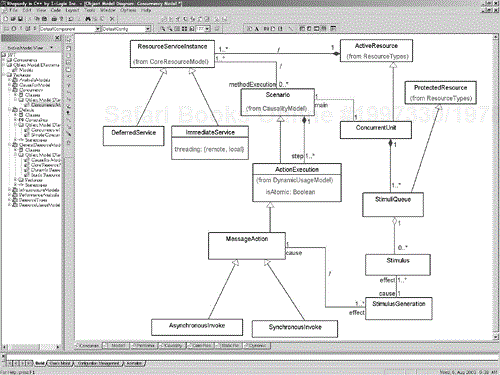
ConcurrentUnits then have a main() operation that invokes the main scenario, which in turn is composed of a set of ActionExecutions and associates with one or more resource service instances. These resource service instances may be either deferred or immediate, and if immediate, they may be either local or remote. An immediate service instance handles incoming requests immediately, spawning new threads to do so if required (local threading) or assumes an existing thread will handle it (the remote threading). When a service instance is deferred, the request or stimulus waits until the receiving server is ready to process it. The ConcurrentUnits may collaborate by sending stimuli to each other—this is done via the execution of either synchronous or asynchronous message actions.
This domain model is cast into the UML standard as a set of stereotypes and tags, as shown in Tables 4-5 and 4-6.
The scenario shown in Figure 4-14 illustrates how the concurrency subprofile tags can be used to indicate relevant quality of service properties. The Atrial Timer and the AtrialModel instances are both active and own their own thread of execution (“ConcurrentUnit,” in the profile's parlance). In addition, the Atrial Timer is also an «RTtimer» stereotype. Various messages are stereotyped to allow the appropriate tags to be attached to the message to specify their qualities of service. For example, the toInhibiting message is stereotyped to be a «RTevent» with the RTat tag specified: { RTat = (0, 'ms') } . The set() operation that sets the value and starts the timer is stereotyped to be a «RTstart» kind. Some of the action executions are stereotyped to be either «CRSynch» or «CRAsynch» depending on whether they execute in the thread of the caller («CRSynch») or not («CRAsynch»). Some are also stereotyped to be «RTAction» so that the tag RTDuration can specify the execution time QoS for the action.
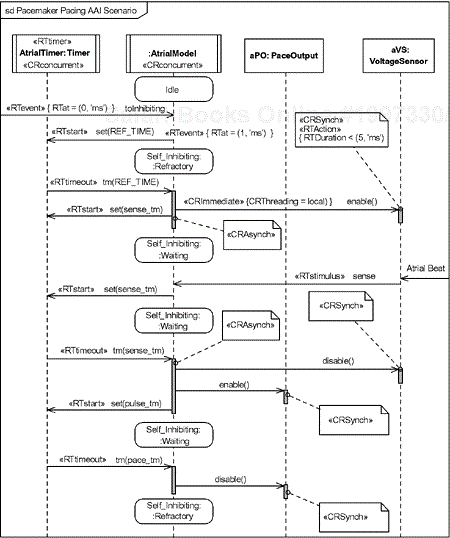
Table 4-5. Concurrency Subprofile Stereotypes
Stereotype | Applies to (metaclasses) | Tags | Description |
|---|---|---|---|
«CRaction» | Action, ActionExecution, Stimulus, Message, Method, ActionState, SubactivityState, Transition, State | CRatomic | An action execution |
«CRasynch» | Action, ActionExecution | An asynchronous invocation | |
«CRconcurrent» | Node, Component, Artifact, Class, Instance | CRmain | A concurrent unit concept |
«CRcontains» | Usage | A generalized usage concept | |
«CRceferred» | Operation, Reception, Message, Stimulus | A deferred receive | |
«CRimmediate» | Operation, Reception, Message, Stimulus | {remote, local} | An instance of an immediate service |
«CRmsgQ» | Instance, Object, Class, ClassifierRole | A stimulus queue | |
«CRSynch» | Action, ActionExecution | A synchronous invocation |
Table 4-6. Concurrency Tags
Tag | Type | Multiplicity | Description |
|---|---|---|---|
CRatomicRTend | Boolean | [0..1] | Whether an «CRAction» is interruptible or atomic. |
CRmain | A reference to a method, or a string that contains a path to a method | [0..1] | Identifies the main method of a concurrent unit, such as a thread. |
CRthreading | enumeration of { 'remote', 'local'} | [0..1] | Identifies whether the invocation of «CRImmediate» stereotype of an operation, method, or reception or the sending of a stimulus is remote or local. |
The previous subprofiles, the general resource model, time, and concurrency subprofiles, do provide useful stereotypes and tags for the specification of important qualities of service, but the schedulability subprofile is where the concepts come together for the most common types of schedulability analysis.
The core domain model for the schedulability subprofile is shown in Figure 4-15. This domain model connects to the other domain models in that many of the domain classes are subclasses of classes in the previous subprofiles. For example, SAction is a subclass of Timed Action (from the TimedEvents package in the time subprofile), Trigger is a subclass of UsageDemand (from the ResourceUsageModel of the general resource model subprofile), RealTimeSituation is a subclass of AnalysisContext (from the ResourceUsageModel of the general resource model subprofile), an ExecutionEngine is a subtype of ActiveResource, Processor, and ProtectedResource (all from the ResourceTypes package of the general resource model subprofile), an SResource is a subclass of ProtectedResource (ibid), and SchedulableResource is a subclass of both SResource and ActiveResource.
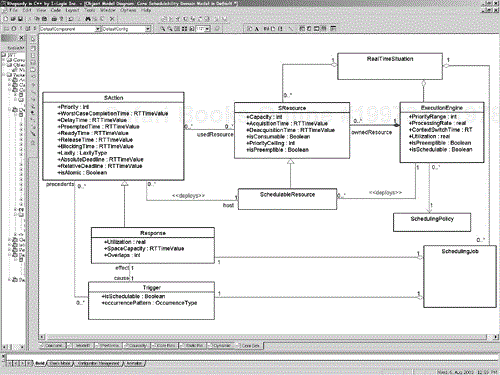
An SAction, or schedulable action, may contain nested actions. The QoS properties of an SAction may be derived, if necessary, from the QoS properties of its subordinate parts. SActions have a large number of tags that can be used for schedulability analysis, such as SApriority, SAblocking, SAworstCase (worst-case completion time), and so on, as well as those inherited from its superclass TimedAction. These actions engine may be a CPU, operating system, or virtual machine running the scheduling job. A scheduling job is associated with a trigger that starts it off and a response—a sequence of actions that is separately schedulable on an execution engine. A response is a subclass of SAction but adds a few more QoS aspects, such as utilization, slack time, spare capacity, and how many instances of the response may overlap their execution in the case of missed deadlines.
An SResource is a kind of protected resource that is accessed during the execution of a scheduling job. Because it may be shared among concurrently executing actions, it must be protected with a mutual exclusion lock such as a semaphore or by a policy that prevents simultaneous access. Examples of an SResource are a shared queue or A/D converter. A SchedulableResource is a kind of SResource that is used to execute one or a set of actions. This domain class represents a task, thread, or process in the OS world. These domain concepts are mapped into the stereotypes and tagged values identified in Tables 4-7 through 4-12.
Table 4-7. Schedulability Subprofile Stereotypes
Stereotype | Applies to (metaclasses) | Tags | Description |
|---|---|---|---|
«SAaction» (subclass of «RTaction» and «CRAction») | Action, ActionExecution, Stimulus, Message, Method, ActionState, SubactivityState, Transition | SApriority, SAbctualPty, SAblocking, SAbeady, SAdelay, SArelease, SApreempted, SAworstCase, SAlaxity, SAabsDeadline, SAaelDeadline, SAusedResource, SAhost | A schedulable action |
«SAengine» | Node, Instance, Object, Classifier, ClassifierRole | SAschedulingPolicy, SAaccessPolicy, SArate, SAcontextSwitch, SApriorityRange, SApreemptible, SAutilization, SAschedulable, SAresources | An execution engine |
«SAowns» (subclass of «GRMrealize») | Abstraction | Identifies ownership of resources. | |
«SAprecedes» | Usage | ||
«SAresource» | Classifier, ClassifierRole, Instance, Object, Node | SAaccessControl, SAconsumable SAcapacity, SAacquisition, SAdeacquisition, SAptyCeiling, SApreemptible | A resource |
«SAresponse» (subclass of «SAAction») | Action, ActionExecution, Stimulus, Message, Method | SAutilization, SAspare, SAslack, SAoverlaps | A response to a stimulus or action |
«SAschedulable» (subclass of «SAResource») | Classifier, ClassifierRole, Instance, Object, Node | A schedulable resource | |
«SAscheduler» | Classifier, ClassifierRole, Instance, Object | SAschedulingPolicy, SAexecutionEngine | A scheduler |
«SAprecedes» | Usage | A precedence relationship between actions and triggers | |
«SAsituation» | Collaboration, Collaboration Instance, ActivityGraph | A schedulability analysis context | |
«SAtrigger» (subclass of «SAaction») | Message, Stimulus | SAschedulable, SAprecedents | A trigger |
«SAusedHost» | Usage | Identifies schedulable resources used for execution of actions. | |
«SAuses» | Usage | Identifies sharable resources. |
Table 4-8. SAAction Tagged Values
Tag | Type | Multiplicity | Description |
|---|---|---|---|
SApriority | integer | [0..1] | Maps to operating system priority |
SAblocking | RTtimeValue | [0..1] | Time that the action may be prevented from execution by a lower-priority task that owns a required resource |
SAdelay | RTtimeValue | [0..1] | The length of time that an action that is ready to run must wait while acquiring and releasing resources |
SApreempted | RTtimeValue | [0..1] | The length of time a ready-to-run action is prevented from running by a higher-priority task |
SAready | RTtimeValue | [0..1] | The length of time between when an action is ready to run until it begins execution |
SArelease | RTtimeValue | [0..1] | The instant of time at which an action becomes ready to run |
SAworstCase | RTtimeValue | [0..1] | The longest period of time required for an action to complete its execution, including all the overheads (blocking, delay, preemption, etc.) |
SAabs Deadline | RTtimeValue | [0..1] | The final instant of time by which an action must be complete |
SAlaxity | Enumeration of { “Hard,” “Soft”} | [0..1] | Specifies the kind of deadline, hard or soft |
SArel Deadline | RTtimeValue | [0..1] | For soft deadlines, specifies the desired time by which the action is complete |
SAused Resource | Reference to a model element that is stereotyped «SAResource» | [0..*] | Identifies a set of resources this action may use during execution |
SAhost | Reference of a model element that is stereotyped «SASchedulable» | [0..1] | Identifies the schedulable resource on which the action executions, in effect, a deployment relation |
start time (inherited from TimedAction) | RTtimeValue | [0..1] | The start time of the action |
end time (inherited from TimedAction) | RTtimeValue | [0..1] | The ending time of the action |
duration (inherited from TimedAction) | RTtimeValue | [0..1] | The total duration of the action (not used if start and end times are specified) |
isAtomic (inherited from Concurrent Action) | Boolean | [0..1] | Identifies whether or not the action may be preempted |
Table 4-9. SAEngine Tagged Values
Tag | Type | Multiplicity | Description |
|---|---|---|---|
SAaccess Policy | Enumeration: { 'FIFO', 'Priority Inheritance', 'NoPreemption', 'HighestLocker', 'PriorityCeiling'} | [0..] | Access control policy to arbitrate simultaneous access requests |
SArate | Float | [0..1] | A relative speed factor for the execution engine, expressed as a percentage |
SAcontext Switch | Time function | [0..1] | The length of time (overhead) required to switch scheduling jobs |
SApriority Range | integer range | [0..1] | A set of valid priorities for the execution engine (OS dependent) |
SApreemptible | Boolean | [0..1] | Indicates whether or not the execution engine may be preempted once it begins the execution of an action |
SAutilization | Percentage (Real) | [0..1] | A computed result indicating the percentage of usage of the execution engine |
SAscheduling Policy | Enumeration: {'RateMonotonic', 'Deadline Monotonic', 'HKL', 'FixedPriority', 'Minimum LaxityFirst', 'Maximum AccurredUtility', 'MinimumSlack Time' } | [0..1] | A set of scheduler that schedule jobs on this execution engine |
SAschedulable | Boolean | [0..1] | A computed result indicating whether or not the jobs executing on the execution engine can be guaranteed to meet their timeliness requirements |
SAresources | Reference to an element stereotyped «SAResource» | [0..*] | Resources owned by the execution engine |
Table 4-10. SAResponse Tagged Values
Tag | Type | Multiplicity | Description |
|---|---|---|---|
SAutilization | Percentage (Real) | [0..1] | The percentage of the period of the trigger during which the response is using the schedulable resource |
SAslack | RTtimeValue | [0..1] | The difference between the amount of time required to complete the work and the amount of time remaining in the period |
SAspare | RTtimeValue | [0..1] | The amount of execution time that can be added to a scheduling job without affecting the schedulability of low-priority scheduling jobs in the system |
SAoverlaps | Integer | [0..1] | In the case of soft deadlines, the number of instances that may overlap their execution because of missed deadlines |
Table 4-11. SAResource Tagged Values
Tag | Type | Multiplicity | Description |
|---|---|---|---|
SAaccess Control (inherited from Protected Resource) | Enumeration: { 'FIFO', 'Priority Inheritance', 'NoPreemption', 'HighestLockers', 'Distributed PriorityCeiling' } | [0..1] | Access control policy for handling requests from scheduling jobs, such as FIFO, Priority Ceiling, etc. |
SAcapacity | Integer | [0..1] | The number of permissible concurrent users (e.g., as in counting semaphore) |
SAacqusition | RTtimeValue | [0..1] | The time delay of an action between the request to access a resource and the granting of that access |
SA deacquisition | RTtimeValue | [0..1] | The time delay of an action between the request to release a resource and the action being able to continue |
SA Consumable | Boolean | [0..1] | Indicates that the resource is consumed by the use |
SAPtyCeiling | Integer | [0..1] | The priority of the highest-priority scheduling job that can ever access the resource |
SA preemptible | Boolean | [0..1] | Indicates whether the resource can be preempted while in use |
Table 4-12. SATrigger Tagged Values
Tag | Type | Multiplicity | Description |
|---|---|---|---|
SA schedulable | Boolean | [0..1] | A computed value when the trigger is schedulable |
SAprecedents | Reference to a model element stereotyped as «SAAction» | [0..1] | Actions that execute prior to the trigger |
SAoccurrence | RTArrival Pattern | [0..1] | How often the trigger occurs, such as periodically |
All this probably seems confusing, more from the plethora of stereotypes and tags than from their inherent complexity. In actual fact, you will most likely use a small subset of the stereotypes and tags in any given analysis of schedulability. Different kinds of analysis will tend to use different stereotypes and tags.
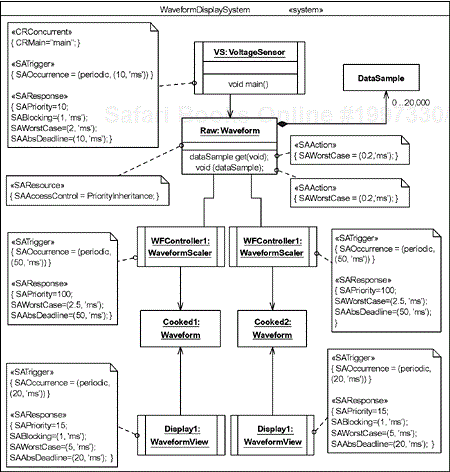
For example, look at the model in Figure 4-16. It contains five active objects, each of which owns a thread. The properties of these threads, such as the occurrence pattern (“periodic”), the period, worst-case execution time, and so on are all provided as tagged values in the constraints. In this case, the higher the value of the priority, the lower the priority; in the model; the classes with priority 100 are the lowest priority threads. Note that the lowest priority threads have no blocking term because, by definition, they cannot be blocked, only preempted. There are also three resources (waveform queues), different instances of the same class, Waveform. To perform schedulability analysis on this model is straightforward.
First, remember the global RMA analysis inequality shown in Equation 4-2.
in which Cj is the worst-case execution time for task j, Tj is the period of task j, Bj is the blocking time for task j, and n is the number of tasks.
Inserting the information from the tags into the inequality, we get Equation 4-3.
Since the inequality is true, we can guarantee that the system is schedulable; that is, it will always meet its deadlines, regardless of task phasings.
More detailed analysis can be done by looking at the sequences of actions rather than merely at the active objects. This is usually done if the global RMA analysis fails, indicating that the system can't be guaranteed (by that analysis) to be schedulable. The global analysis method is often overly strong—just because it can't be guaranteed by the method to be schedulable doesn't mean that it isn't. It just means that the analytic method can't guarantee it. However, a more detailed analysis may be able to guarantee it.
A more detailed analysis might analyze a specific scenario, or class of scenarios. Such a scenario is shown in Figure 4-17. This sequence diagram uses both the sd and the par operators, so that the interaction subfragments (separated by operand separators) are running concurrently. The scenario is schedulable if it can be demonstrated that all of its concurrent parts can meet their deadlines, including any preemption due to the execution of peer concurrent interactions.
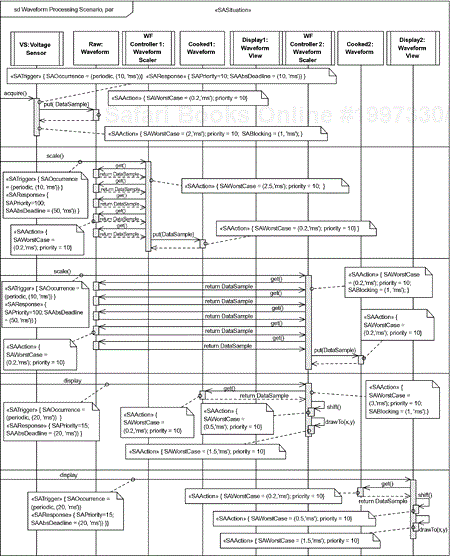
In this scenario, the timing and scheduling information is provided in a more detailed view from which the global summary may be constructed. For example, in the first parallel interaction fragment, the acquire() method is stereotyped to be both an SAtrigger (so it can have an occurrence pattern and period) and an SAresponse (so it can have a priority and a deadline). The timing properties of each of the call actions are defined. Since priority inheritance is used to limit priority inversion, an action may be blocked by, at most, a single lower- priority action. The blocking time for the overall sequential thread of execution is the largest blocking term for any of its subactions.
The performance analysis (PA) subprofile is concerned with annotating a model for computation of system performance. Specifically, this profile uses the concepts and tags defined in the resource, concurrency, and time subprofiles to create stereotypes and tags that are useful for adding quantitative measures of performance, so that overall system performance analysis may be performed. Note that is this different from schedulability analysis, which analyzes a system to ensure whether it can meet its schedulability requirements.
Performance analysis is inherently instance-based (as opposed to class- or type-based). Scenarios, sequences of steps for which at least the first and last steps are visible, are associated with a workload or a response time. Open workloads are defined by streams of service requests that have stochastically characterized arrival patterns, such as from a Poisson or Gaussian distribution. Closed workloads are defined by a fixed number of users or clients cycling among the clients for service requests.
Scenarios, as we have seen, are composed of scenario steps, which are sequences of actions connected by operators such as decision branches, loops, forks, and joins. Scenario steps may themselves be composed of smaller steps. Scenario steps may use resources via resource demands, and most of the interesting parts of performance analysis have to do with how a finite set of resource capabilities are shared among their clients. Resources themselves are modeled as servers.
Performance measures are usually modeled in terms of these resources, such as the percentage of resource utilization or the response time of a resource to a client request. Within those broad guidelines, these measures may be worst case, average case, estimated case, or measured case.
Performance analysis is normally done either with queuing models or via simulation. Queuing models assume that requests may wait in a FIFO queue until the system is ready to process them. This waiting time is a function of the workload placed on the resources as well as the time (or effort) required by the system to fulfill the request once started. In simple analysis, it may only require the arrival rates of the requests and the response time or system utilization required to respond. More detailed analyses may require distributions of the request occurrences as well. Simulation analysis logically “executes” the system under different loads. A request in process is represented as a logical token and the capacity of the system is the number of such tokens the may be in process at one time. Because of bottlenecks, blocking, and queuing, it is possible to compute the stochastic properties of the system responses.
The domain model for performance modeling is shown in Figure 4-18. As discussed earlier, a scenario is associated with a workload, the latter being characterized in terms of a response time and a priority. Scenarios use resources and are composed of scenario steps. Resources may be passive or active processors resources. The elements of this domain model which are subclasses of elements in other profiles are shown with the base elements colored and the packages from whence they are defined are shown using the scope dereference operator “::”.
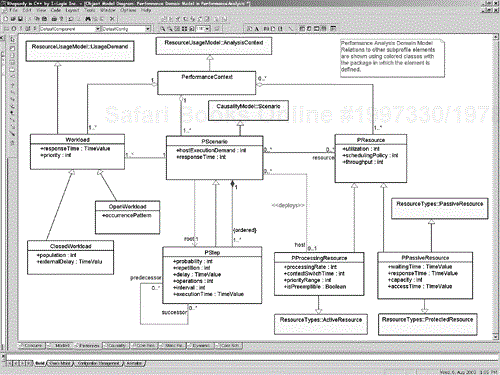
These domain concepts are used to identify stereotypes of UML elements, and the domain concept attributes are defined as tags in the performance analysis profile. Tables 4-13 through 4-18 give the stereotypes, the applicable UML metaclasses, the associated tags, and a brief description.
There are a few special types used in the tag definitions above. Specifically, SchedulingEnumeration, PAperfType, and PAextOpValue. The SchedulingEnumeration type specifies various scheduling policies that may be in use. These are commonly exclusive. The PA profile defines the following types of scheduling policies:
FIFO: First-in-first-out scheduling
HeadOfLine: Cyclic executive scheduling
PreemptResume: Preemptive multitasking scheduling
ProcSharing: Processor sharing, or round-round scheduling
PrioProcSharing: Priority round-round scheduling
LIFO: Last-in-first-out scheduling
Table 4-13. Performance Subprofile Stereotypes
Stereotype | Applies to (metaclasses) | Tags | Description |
|---|---|---|---|
«PAclosedLoad» | Action, ActionExecution, ActionState, SubactivityState, Stimulus, Message, Method, Operation, Reception | PArespTime, PApriority, PApopulation, PAextDelay | A closed workload |
«PAcontext» | Collaboration, Collaboration InstanceSet, ActivityGraph | A performance analysis context | |
«PAhost» | Classifier, Node, ClassifierRole, Instance, Partition | PAutilization, PAschdPolicy, PArate, PActxtSwT, PAprioRange, PApreemptible, PAthroughput | An execution engine that hosts the scenario |
«PAopenLoad» | Action, ActionExecution, ActionState, SubactivityState, Stimulus, Message, Method, Operation, Reception | PArespTime [0..*,] PApriority, PAoccurrence | An open workload |
«PAresource» | Classifier, Node, ClassifierRole, Instance, Partition | PAutilization, PAschdPolicy, PAschdParam, PAcapacity, PAaxTime, PArespTime, PAwaitTime, PAthroughput | A passive resource |
«PAstep» | Messasge, ActionState, Stimulus, SubactivityState | PAdemand, PArespTime, PAprob, PArep, PAdelay, PAextOp, PAinterval | A step in a scenario |
Table 4-14. PAclosedWorkload Tagged Values
Tag | Type | Multiplicity | Description |
|---|---|---|---|
PArespTime | PAperfValue | [0..*] | Time required for completion of the scenario from the start of the scenario |
PApriority | Integer | [0..1] | Priority of workload |
PApopulation | Integer | [0..1] | The size of the workload (i.e., the number of system users) |
PAextDelay | PAperfValue | [0..1] | The delay between the completion of one response and the start of the next for each member of the population of system users |
Table 4-15. PAhost Tagged Values
Tag | Type | Multiplicity | Description |
|---|---|---|---|
PAutilization | Real | [0..*] | The mean number of concurrent users |
PSschdPolicy | Scheduling Enumeration | [0..1] | Policy by which host schedules workloads |
PArate | Real | [0..1] | Processing rate of the scenario execution |
PActxtSwT | PAperfValue | [0..1] | Context switch time |
PAprioRange | Integer range | [0..1] | Valid range for priorities of workloads |
PApreemptable | Boolean | [0..1] | Whether scheduled workloads may be preempted |
PAthroughput | Real | [0..1] | Number of workloads completed per unit time |
Table 4-16. PAopenLoad Tagged Values
Tag | Type | Multiplicity | Description |
|---|---|---|---|
PArespTime | PAperfValue | [0..*] | Time required for completion of the scenario from the start of the scenario |
PApriority | Integer | [0..1] | The priority of workload |
PAoccurrence | RTarrivalPattern | [0..1] | The arrival pattern of the workload |
Table 4-17. PAresource Tagged Values
Tag | Type | Multiplicity | Description |
|---|---|---|---|
PAutilization | Real | [0..*] | The mean number of concurrent users |
PAschdPolicy | Scheduling Enumeration | [0..1] | Policy by which host schedules workloads |
PAcapacity | Integer | [0..1] | Number of workloads that can be handled simultaneously, i.e. the maximum number of concurrent users of the system |
PAaxTime | PAperfValue | [0..1] | Resource access time, that is, the time required to acquire or release the resource |
PArespTime | PAperfValue | [0..1] | Time required for the resource to complete its response |
PAwaitTime | PAperfValue | [0..1] | The time between when a resource access is requested and when it is granted |
PAthroughput | Real | [0..1] | Number of workloads that can be completed per unit time |
Table 4-18. PAstep Tagged Values
Tag | Type | Multiplicity | Description |
|---|---|---|---|
PAdemand | PAperfValue | [0..*] | The total demand of the step on its processing resource |
PArespTime | PAperfValue | [0..*] | The total time to execute the step, including the time to access and release any resources |
PAprob | Real | [0..1] | In stochastic models, the probability that this step will be executed (as opposed to alternative steps) |
PArep | Integer | [0..1] | The number of times the step is repeated |
PAdelay | PAperfValue | [0..*] | Delay between step execution |
PAextOp | PAextOpValue | [0..*] | The set of operations of resources used in the execution of the step |
PAinterval | PAperfValue | [0..*] | The time interval between successive executions of a step when the step is repeated within a scenario |
The PAperfValue is a performance value type of the form
“(“ <source-modifier> “,” <type-modifier> “,” <time-value> “)”
The source modifier is a string that may be any of the following:
'req' (for required)
'assm' (for assumed)
'pred' (for predicted)
'msr' (for measured)
The type modifier may be any of the following expressions:
'mean' <integer>, for average
'sigma' <integer>, for variance
'kth mom' <integer>, for kth moment
'max' <real>, for maximum
'percentile' <real>, for percentage value
'dist', for probability distribution
The time value is defined by the specification of RTtimeValue provided in the section of schedulability.
For example:
{ PAdemand = 'msr', 'mean', (20, 'ms')) }
{ PAdelay = 'req', 'max', (500, 'us')) }
{ PArespTime = 'mean, 'sigma', (100, 'ms')) }
PAestOpValue is a string used to identify an external operation and either the number of repetitions of the operation or a performance time value. The format is of the form
"(" <String> "," <integer> | <time-value> ")"
where the string names the external operation and the integer specifies the number of times the operation is invoked. The time value is of type PAperValue and specifies a performance property of the external operation.
The three figures that follow, Figures 4-19 through 4-21, provide an example model that can be analyzed for performance. Figure 4-19 shows the object structure of the system to be analyzed—an engine control system that includes a Doppler sensor for detecting train velocity, an object that holds current speed (and uses a filtering object to smooth out high-frequency artifacts), and an engine controller that uses this information to adjust engine speed—plus two views for the train operator, a textual view of the current speed (after smoothing) and a histogram view that shows the recent history of speed.

Figure 4-20 shows how these objects are deployed. In this case, there are four distinct processing environments. A low-power acquisition module reads the emitted light after it has been reflected off the train track and computes an instantaneous velocity from this, accounting for angle and at least in a gross way for reflection artifacts. This process runs at a relative rate of 10. Since the reference is the 1MBit bus, this can be considered to be 10MHz. Note the “$Util” in the constraint attached to the processor—this is where a performance analysis tool would insert the computed utilization once it has performed the mathematical analysis.

As with all the processors, this computer links to the others over a 1Mbit CAN bus link. The CAN bus uses its 11-bit header (the CAN bus also comes in a 29-bit header variety) to arbitrate message transmission using a “bit dominance” protocol,[6] a priority protocol in which each message header has a different priority.
The controller computer runs the TrainSpeed object and its associated data filter. It runs at the same rate as the acquisition module. The EngineController and Engine objects run on the Engine computer, which also runs at the 10MHz rate. The last computer is much faster, running at 2,000 times the rate of the bus, 2GHz. It runs the display software for showing the current speed (via the SpeedView object) and the histogram of the speed (via the SpeedHistory object).
Lastly, Figure 4-21 shows an example of execution. Note that the execution on the different processors is modeled in parallel regions in the sequence diagram (the interaction fragments within the par operator scope), and within each the execution is sequential. Messages are sent among the objects residing on different processors, as you would expect, and the time necessary to construct the message, fragment it (if necessary—the CAN bus messages are limited to 8 bytes of data), transmit it, reassemble the message on the target side, do the required computational service, and then repeat the process to return the result is all subsumed within the execution time of the operation. A more detailed view is possible that includes these actions, (construct, fragment, transmit, receive, reconstruct, invoke the desired service, construct the response message, fragment it, transmit it, reassemble it on the client side, extract the required value, and return it to the client object). However, in this example, all those smaller actions are considered to be executed within the context of the invoked service, so that calls to TrainSpeed.getSpeed() are assumed to include all those actions. For an operation invoked across the bus that requires 1 ms to execute, the bus transmission alone (both ways) would require on the something a bit less than 200 us, assuming that a full 8 bytes of data (indicating the object and service to be executed) are sent. There will be a bit more overhead to parse the message and pass it off to the appropriate target object. Thus, the time overhead for using the CAN bus shouldn't be, in general, more than 500 us to 1 ms unless large messages are sent (requiring message fragmentation) or unless the message is of low priority and the bus is busy. This does depend on the application protocol used to send the messages and the efficiency of the upper layers of the protocol stack.

The RFP for the RTP requires that submissions include the ability to analyze real-time CORBA (RT CORBA) models. CORBA stands for Common Request Broker Architecture and is a middleware standard also owned by the Object Management Group. A detailed discussion of CORBA is beyond the scope of this book but a short description is in order.
CORBA supports systems distributed across multiple processor environments. The basic design pattern is provided in [4]:
The Broker Pattern extends the Proxy Pattern through the inclusion of the Broker—an “object reference repository” globally visible to both the clients and the servers. This broker facilitates the location of the servers for the clients, so that their respective locations need not be known at design time. This means that more complex systems that can use symmetric deployment architecture, such as required for dynamic load balancing, can be employed.
![Broker Pattern (Simplified). From [4]](http://imgdetail.ebookreading.net/system_admin/3/0321160762/0321160762__real-time-uml__0321160762__graphics__04fig22a.gif)
![Broker Pattern (Elaborated). From [4].](http://imgdetail.ebookreading.net/system_admin/3/0321160762/0321160762__real-time-uml__0321160762__graphics__04fig22b.gif)
The domain model for real-time CORBA is shown in Figure 4-23. Note that the RTCorb (Real-Time CORBA Orb) is a processing environment and the domain models contain RTCclients and RTCservers as expected. All the domain concepts are prefaced with RTC, while the profile stereotypes and tags are prefaced with RSA (real-time CORBA schedulability analysis). The following tables show the defined stereotypes.
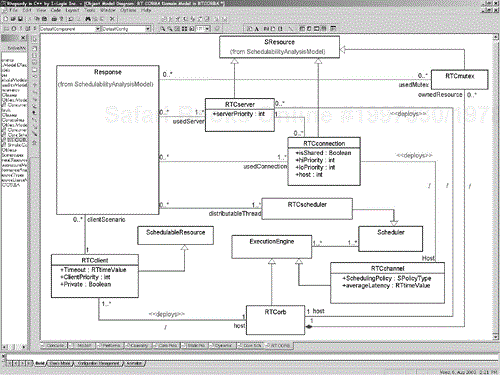
An RSAschedulingPolicy is one of the following enumerated values: { 'FIFO', 'RateMonotonic', 'DeadlineMonotonic', 'HKL', 'FixedPriority', 'MinimumLaxityFirst', 'MaximizeAccruedUtility', 'MinimumSlackTime'}.
An SAschedulingPolicy is one of the following enumerated values: { 'FIFO', 'PriorityInheritance', 'NoPreemption', 'HighestLockers', 'PriorityCeiling'}.
Table 4-19. Real-Time CORBA Stereotypes
Stereotype | Applies to (metaclasses) | Tags | Description |
|---|---|---|---|
«RSAchannel» | Classifier, ClassifierRole, Instance, Object, Node | RSAscheduling Policy, RSAaverage Latency | An instance of a communication channel between RT CORBA ORBs |
«RSAclient» (subclass of «SAschedRes») | Classifier, ClassifierRole, Instance, Object, Node | RSAtimeout, RSAclPrio, RSAprivate, RSAhost | An RT CORBA client |
«RSAconnection» (subclass of «SAschedRe» and «SAResource») | Classifier, ClassifierRole, Instance, Object, Node | SAAccessControl, RSAshared, RSAhiPrio, RSAloPrio, RSAhost, RSAserver | An RT CORBA connection |
«RSAmutex» (subclass of «SAResource») | Classifier, ClassifierRole, Instance, Object, Node | SAAccessControl, RSAhost | An RT CORBA mutex |
«RSAorb» (subclass of «SAEngine» ) | Classifier, ClassifierRole, Instance, Object, Node | SAscheduling Policy | An RT CORBA ORB |
«RSAserver» (subclass of «SAResource» ) | Classifier, ClassifierRole, Instance, Object, Node | RSAsrvPrio, SACapacity | An RT CORBA server |
Table 4-20. RSAchannel Tags
Tag | Type | Multiplicity | Description |
|---|---|---|---|
RSA scheduled Policy | Enumeration | [0,1] | Policy by which an RSAchannel is Scheduling |
RSAaverage Latency | RTtimeValue | [0,1] | Latency of the channel |
Table 4-21. RSAclient Tagged Values
Tag | Type | Multiplicity | Description |
|---|---|---|---|
RSAtimeout | RTtimeValue | [0,1] | Timeout |
RSAclPrio | Integer | [0,1] | Client priority |
RSAprivate | Boolean | [0,1] | Accessibility of client |
RSAhost | Reference to an element stereotyped as «RSAorb» | [0,1] | Hosting ORB |
Table 4-22. RSAconnection Tagged Values
Tag | Type | Multiplicity | Description |
|---|---|---|---|
SAAccess Control | Enumeration of { Priority Inheritance, Distributed PriorityCeiling} | [0,1] | Access control for the resource |
RSAshared | Boolean | [0,1] | If the resource is shared among clients |
RSAhiPrio | Integer | [0,1] | Highest priority for connection |
RSAloPrio | Integer | [0,1] | Lowest priority for the connection |
RSAhost | Reference to an element stereotyped as «RSAchannel» | [0,1] | Hosting channel |
RSAserver | Reference to an element stereotyped as «RSAserver» | [0,1] | Server of connection |
Table 4-23. RSAmutex Tagged Values
Tag | Type | Multiplicity | Description |
|---|---|---|---|
SAAccess Control | Enumeration of { Priority Inheritance, Distributed PriorityCeiling} | [0,1] | Access control for the resource |
RSA Host | Reference to an element stereotyped as «RSAorb» | [0,1] | Hosting ORB |
The UML Profile for Schedulabilty, Performance, and Time defines semantic model of real-time concepts. These are divided up into several subprofiles—the general resource model, the time model, the concurrency model, the schedulability model, the performance model, and the CORBA infrastructure model. Each of these models has a set of related concepts, represented by stereotypes and properties (tagged values). To use the profile, select (or create) the appropriate classes in your user model and apply the stereotypes. Once these stereotypes are applied, the tagged values may be specific assigned values. Such annotated models can then be analyzed for schedulability. The next several chapters focus on the utilization of the elements of the UML (and RTP) to specify, design, and construct systems.
[1] Stereotypes were originally specified as they are so that tools wouldn't have to provide extensible schemas for their repositories while still enabling some limited extensions by users. In the four-level meta-architecture described in Chapter 2, they are approximately metalevel 1.5. Alternatively, we can specialize the UML at the level of M2 by defining new classes using the language in which the UML itself is defined—the MetaObject Facility (MOF).
[2] Use cases are discussed in more detail in the next chapter. For now, just think of uses cases as specifying coherent clumps of requirements, focused around a particular usage of the system.
[3] Objects outside the scope of the system that interact with the system in important ways.
[6] A bit dominance protocol works like this: Any node on the bus can transmit during a specified begin-transmit interval. When it transmits, it also independently listens to what actually appears on the bus. Bits can be either dominant or passive, meaning that if two nodes try to write different bits to the bus in the same interval, the dominant will “win” and actually appear on the bus, while the passive will lose. If a node detects that it has put out a passive bit but a dominant bit occurs on the bus, then it loses (that message has a lower priority) and drops off to try again later. In this way, the message header determines the priority of the message to be transmitted, and 211 messages of different priority are possible.