
Once the system's external environment is defined, the analyst must identify the key objects and classes and their relationships within the system itself. This chapter presents several strategies that have proven effective in real-time systems development for the identification of the key objects and classes. These strategies may be used alone or in combination. Relationships and associations among classes and objects enable higher-level behaviors. This chapter goes on to identify some rules for uncovering and testing these relationships.
Notation and Concepts Discussed | ||
|---|---|---|
Object Identification Strategies | Class Relationships | Sequence Diagrams |
Object Associations | Class Diagrams | |
In this chapter, we discuss object and class identification and how to infer relationships and associations among them. Chapter 7 deals with the definition and elaboration of object behavior and state. The topics covered in the two chapters form the basis of all object-oriented analysis.
The use case and context diagrams constructed in the previous step provide a starting point for object-oriented analysis per se. The end result will be a structural model of the system that includes the objects and classes identified within the system, their relationships, and generalization hierarchies. This structural model will be complemented by the behavioral model (see Chapter 7) and the entire analysis model will be elaborated in design.
Chapter 1 discussed, among other things, the lifecycles of the ROPES process. Remember that the ROPES process exists simultaneously on three timescales—macro (the entire project), micro (the production of a single prototype or system “increment”) and nano (the minute-to-minute development steps). The nanocycle is very akin to the Extreme Programming or Agile Methods approach[1]—the idea is to construct aspects of the system with a philosophy of continual testing and validation. Object collaborations are constructed to realize the use cases, but these collaborations themselves are constructed iteratively in very rapid cycles of object identification–class specification–collaboration validation. This is the essence of the nanocycle shown in Figure 6-1.
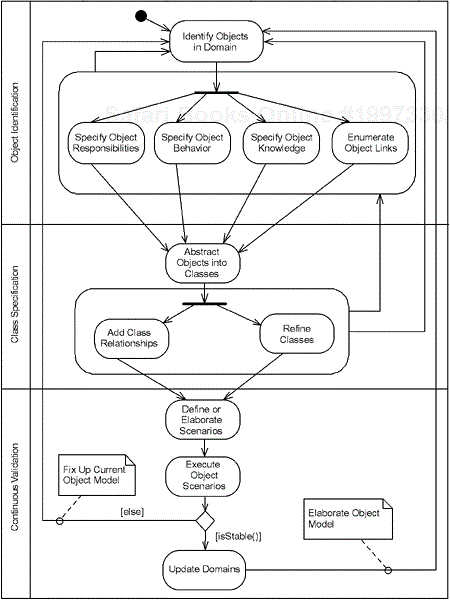
This chapter focuses on the microcycle phase of object domain analysis. The task is to take the requirements (captured in the requirements phase of the microcycle), possibly in the context of the systems architecture (specified in the optional systems engineering phase of the microcycle), and construct the essential or domain model. The domain model identifies the key concepts from the application domain necessary to realize the use case requirements and refine them in various ways. Figure 6-1 shows how the nanocycle proceeds. Object domain analysis is a process of discovery that works as much by free association as by sequential processes, but the key is continual validation. If a use case will ultimately be realized by a collaboration of 50 objects instantiated from a set of 35 classes, what we do not want to do is put down 50 objects or 35 classes and then beat on them until it more or less works.[2] Instead we want to construct the collaboration in very small pieces, validating each portion of the collaboration before we move on to the next.
It has been said that the best way not to have defects in a system is to not put them in the system in the first place. The nanocycle typically proceeds by identifying one or two objects, getting them to work in isolation, refactoring and refining them as necessary through testing and debugging, then moving on and adding the next object or class, validating the expanded collaboration, refactoring and refining as necessary, then adding the next object or two, and so on. In this way, we construct a system from pieces that are known (and demonstrated!) early to be of high quality and with few, if any, defects. By the time the entire collaboration is constructed, it typically works very well. Compare that with the more common approach of drawing a diagram with the 50 objects and then beating on it for days or weeks until it seems to work, only to discover later all the defects that had not been uncovered.
Now let's look at a number of strategies for identifying the objects and, subsequently, the classes inherent in a system. It's important to connect the object model with the preceding use case model for a couple of reasons.
First, the use case model drives the object model. Each use case will be realized by a set of objects working together. In the UML, this is called a collaboration. As a model element, a collaboration is represented as an oval, similar to a use case but with a dashed line (see Figure 6-2). The collaboration represents a set of objects, assuming specific roles in order to achieve the use case. By concentrating on a use case at a time, we can have help guide our analytic efforts in fruitful directions.

Second, if we make sure to connect the identified objects to the use case model, we are more likely to build the best system that actually meets the requirements. Some developers ignore the requirements of a system, but they do so at their own peril. It is unfortunately too common to add features to a system so that it does more than is actually required while at the same time failing to meet the specified requirements. Both of these problems can be avoided by letting the use case model drive the object analysis.
Once the object model has been created for the use case, the system-level use cases can be refined to take into account the identified objects and their relations. This allows checking that the object model actually does meet the requirements specified in the use cases as well as illustrating how the objects work together to do it.
In object domain analysis, we want to avoid introducing design, because we want to construct a model of the underlying application domain first. If we are constructing a model of an ECG system Display Waveforms use case, first we want to focus on the essential concepts of that use case, things that are meaningful to the physicians and nurses who will use the system: the heart rate, arrhythmias, scaling in time in (12.5, 25, or 50 mm/sec display speeds are common), scaling in amplitude, and so on. We don't want to worry yet about internal queues to hold data, whether we will use spinlocks or mutex semaphores, how many task threads there are, and so on. The users of the system don't care about those things, but if the system doesn't allow scaling in those two dimensions, if it doesn't understand or produce a heart rate, then the system is fundamentally wrong. The essential or domain model is the construction of an object (and class) model that includes these key concepts and their essential relationships. Later, in design, we will refine the domain model into a design model, but first we need to get the domain model correct.
Every application domain has its own specialized vocabulary and concepts. In actuality, a system is always constructed from elements taken from a large number of domains. Some of these domains are closely related to the problem space while others are closely related to the solution space. For example, in our anesthesia system, the problem-domain domains might be Cardiology, Physiology, and Anesthesiology, as shown in Figure 6-3. These are realized in terms of the more concrete domains of computer science, which are ultimately realized in terms of hardware of various kinds.
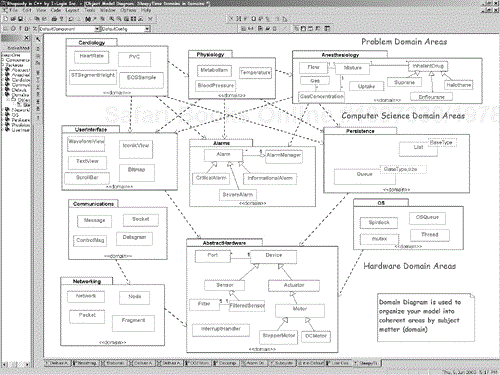
The domain diagram[3] in Figure 6-3 shows several things of interest. First, domains implemented in the UML as a stereotype of Package, and as such hold types and classes. In the UML, packages are used to organize models and have no existence at runtime. The UML does not provide guidance as to how the packages should be organized or how elements should be partitioned into packages.
In the ROPES process, packages are used to organize the model in specific ways by providing specific guidance. In the ROPES process, a domain is a stereotype of Package that adds a criterion for element inclusion—the element falls within the subject matter of concern of the domain. Thus, domains serve to represent what the ROPES process calls the logical architecture—that is, the organization of things that exist at design time. We can see that each of these packages only contains types and classes relevant to that particular subject matter; the User Interface domain, for example, has user interface things—WaveforView, TextView, IconicView, Scrollbar, and so on—while the Abstract Hardware domain contains things like sensors and actuators. Other types of organization are, of course, possible, but this one has been successful at organizing systems from tiny to huge, allowing teams to effectively collaborate.
In object domain analysis, objects are uncovered using the strategies outlined in the following section; once they are typed into classes, each class is placed into the relevant domain. Each class is placed into only a single domain—in fact, one test for the usefulness of the identified classes and the domain selection is that each class falls in exactly one domain. If a class seems to fall in multiple domains, then the class is probably overly complex and should be decomposed into its independent concepts. For example, consider the ECG concept of a waveform—this is both the organization of a set of data samples and a way to visualize this information on a display. In the model in Figure 6-3, “Waveform” is broken up into the notion of the information (the waveform per se) and the notion of a WaveformView.
The use of domains as a model-organizational principle has a number of advantages. First, domains themselves tend to be stable and can isolate the majority of your model from things that are likely to change. For example, suppose that you're not sure whether you're going to implement the system in Windows CE, XP, or VxWorks. By creating a set of OS domain concepts that are isolated from the system, you are ensuring that most of the system will be relatively unaffected by your ultimate decision. Domains can even be subclassed from an abstract domain (such as AbstractOS), which provides the essential concepts of the domain, into specific realizations (such as WindowsCE or VxWorks). This also allows the system to be ported among different domains, such as when you change the OS or networking architecture. Furthermore, if your company produces different products that will work on the same platform environment, then domains help by providing a reusable infrastructure onto which different application or problem domains can sit.
Over the years, I've consulted in an extremely varied set of problem domains, from medical systems to factory automation to avionics and fire control (weapons control systems). The good part about consulting in such a broad range of fields is that it is extraordinarily interesting and one gets to learn daily.[4] The bad part about that is that one is expected to sound intelligent about the problem almost immediately.[5] For any consultant to be successful in that kind of environment, he or she must have some effective strategies for working with engineers and managers who understand their problem domain very well but who are often neophytes when it comes to the application of the UML to their problems. Table 6-1 outlines what I have found to be the most effective of these object-identification strategies.
Table 6-1. Object Discovery Strategies
Strategy | Description |
|---|---|
Underline the noun | Used to gain a first-cut object list, the analyst underlines each noun or noun phrase in the problem statement and evaluates it as a potential object. |
Identify causal objects | Identify the sources of actions, events, and messages; includes the coordinators of actions. |
Identify services (passive contributors) | Identify the targets of actions, events, and messages as well as entities that passively provide services when requested. |
Identify messages and information flow | Messages must have an object that sends them and an object that receives them as well as, possibly, another object that processes the information contained in the messages. |
Identify real-world items | Real-world items are entities that exist in the real world, but that are not necessarily electronic devices. Examples include respiratory gases, air pressures, forces, anatomical organs, and chemicals. |
Identify physical devices | Physical devices include the sensors and actuators provided by the system as well as the electronic devices they monitor or control. In the internal architecture, they are processors or ancillary electronic widgets. |
Identify key concepts | Key concepts may be modeled as objects. Bank accounts exist only conceptually, but are important objects in a banking domain. Frequency bins for an on-line autocorrelator may also be objects. |
Identify transactions | Transactions are finite instances of associations between objects that persist for some significant period of time. Examples include bus messages and queued data. |
Identify persistent information | Information that must persist for significant periods of time may be objects or attributes. This persistence may extend beyond the power cycling of the device. |
Identify visual elements | User interface elements that display data are objects within the user interface domain such as windows, buttons, scroll bars, menus, histograms, waveforms, icons, bitmaps, and fonts. |
Identify control elements | Control elements are objects that provide the interface for the user (or some external device) to control system behavior. |
Apply scenarios | Walk through scenarios using the identified objects. Missing objects will become apparent when required actions cannot be achieved with existing objects. |
This chapter discusses all these strategies, but note that the analyst need not use them all on any specific project. These approaches are not orthogonal and the objects they find will overlap to a significant degree. In fact, many subsets of the strategies will find the exactly the same set of objects. Some methods will fit some analysts' approaches better than others. It is common to select three or four strategies on a given project and apply them more or less simultaneously. As with all modeling strategies, use those that work well for you and discard the ones that do not.
The first strategy works directly with the written problem or mission statement. Underline each noun or noun phrase in the statement and treat it as a potential object. Objects identified in this way can be put into four categories:
Objects of interest or their classes
Actors
Uninteresting objects
Attributes of objects
The point of the exercise is to find objects within the first category—objects of interest or their classes. Actors have usually already been identified in the use case model, but occasionally some new ones are identified here. Uninteresting objects are objects that have no direct relevance to your system. Attributes also show up as nouns in the problem statement. Sometimes an attribute is clearly just a property of an object. When in doubt, tentatively classify the noun as an object. If subsequent analysis shows the object is insufficiently interesting, it can be included as an attribute of some other object.
Let's see how this works by looking at an elevator, a real-time system familiar to everyone. We begin with a problem statement for an elevator system with the noun phrases emphasized:
A software system must control a set of eight Acme elevators for a building with 20 floors. Each elevator contains a set of buttons, each corresponding to a desired floor. These are called floor request buttons, since they indicate a request to go to a specific floor. Each elevator as well has a current floor indicator above the door. Each floor has two buttons for requesting elevators called elevator request buttons, because they request an elevator.
Each floor has a sliding door for each shaft arranged so that two door halves meet in the center when closed. When the elevator arrives at the floor, the door opens at the same time the door on the elevator opens. The floor does have both pressure and optical sensors to prevent closing when an obstacle is between the two door halves. If an obstruction is detected by either sensor, the door shall open. The door shall automatically close after a timeout period of 5 seconds after the door opens. The detection of an obstruction shall restart the door closure time after an obstruction is removed. There is a speaker on each floor that pings in response to the arrival of an elevator.
On each floor (except the highest and lowest), there are two elevator request buttons, one for UP and one for DOWN. On each floor, above each elevator door, there is an indicator specifying the floor that the elevator is currently at and another indicator for its current direction. The system shall respond to an elevator request by sending the nearest elevator that is either idle or already going in the requested direction. If no elevators are currently available, the request shall pend until an elevator meets the above-mentioned criterion. Once pressed, the request buttons are backlit to indicate that a request is pending. Pressing an elevator request button when a request for that direction is already pending shall have no effect. When an elevator arrives to handle the request, the backlight shall be removed. If the button is pressed when an elevator is on the floor to handle the request (i.e., it is slated to go in the selected direction), then the door shall stop closing and the door closure timer shall be reset.
To enhance safety, a cable tension sensor monitors the tension on the cable controlling the elevator. In the event of a failure in which the measured tension falls below a critical value, then four external locking clamps connected to running tracks in the shaft stop the elevator and hold it in place.
Many of these are clearly redundant references to the same object (synonyms). Others are not of interest. The elevator cable, for example, is not nearly as interesting to the safety system as the cable tension sensor.[6] Likewise, the passengers (clearly actors) are not as interesting as the buttons they push and the indicators they read, which are likely to be inside the scope of the system under development. Other objects clearly need not be modeled at all.
A list can be constructed from the emphasized noun phrases of the likely candidate objects by this kind of analysis. Table 6-2 shows object quantities, where specified, with parentheses.
Table 6-2. Candidate Objects
system (1) | elevator (8) | building (1) |
floor (20) | request | button |
floor request button (8*20) | elevator request button (20*2) | current floor indicator (8) |
door (20*8 + 8) | optical sensor | obstruction |
pressure sensor | speaker | UP button |
door half | elevator door | indicator |
DOWN button | floor door | secondary pressure sensor |
internal door set | OPEN button | CLOSE button |
elevator control panel | alarm | central station |
EMERGENCY CALL button | elevator request | door closure timer |
electrical power | telephone | elevator occupants |
Stop-Run Switch | switch | message |
emergency locks | alarm area | mechanical locking clamp |
pressure sensor | tracks | electrical power source |
Some likely attributes of a couple of these objects are shown in Table 6-3.
Table 6-3. Object Attributes
Object | Attribute |
|---|---|
Elevator | Direction Status Location |
Button | Backlight |
Alarm | Status |
Cable tensor sensor | Cable tension Critical tension |
You can see that this strategy quickly identified many objects but also identified nouns that are clearly not interesting to the analyst.
Once the potential objects are identified, look for the most behaviorally active ones. These are objects that
Produce or control actions
Produce or analyze data
Provide interfaces to people or devices
Store information
Provide services to people or devices
Contain other types of fundamental objects
The first two categories are commonly lumped together as causal objects. A causal object is an object that autonomously performs actions, coordinates the activities of component objects, or generates events. Many causal objects eventually become active objects and serve as the root composite object of a thread.[7] Their components execute within the context of the thread of the owner composite.
Clearly, the most behaviorally active objects are few in number:
Floor
Elevator
Door
Button
Request
Indicator
Cable tension sensor
Mechanical locking clamp
Passive objects are less obvious than causal objects. They may provide passive control, data storage, or both. A simple switch is a passive control object. It provides a service to the causal objects (it turns the light on or off on request), but does not initiate actions by itself. Passive objects are also known as servers because they provide services to client objects.
Simple sensors are passive data objects. An A/D converter might acquire data on command and return it to an actor, or as the result of an event initiated by an active object. Printers and chart recorders are common passive service providers because they print text and graphics on command. A hardware passive service provider might be a chip that performs a cyclic redundancy check computation over a block of data.
For each message, there is an object that sends it, an object that receives it, and potentially, another object that processes it. Messages are the realization of information flows. Information flows, taken from older data flow diagram techniques, specify information flowing from one object to another. Information flow is usually applied in early analysis, while later analysis takes into account the packaging of these flows into messages and service calls. This strategy is very similar to the strategy of identifying service calls, but it can be applied earlier in analysis or at a higher level of abstraction. The UML 2.0 specification allows for information flows to be drawn on class diagrams; these will become associations among the classes of those objects acting as conduits for the specific messages derived from the flows.
Figure 6-4 shows an example of information flows in UML 2.0. This diagram captures, at a high level of abstraction, the information flowing from one class to another. Flows are classifiers in UML and so they can be defined using standard classifier techniques—statecharts, activity diagrams, operations, and attributes. These flows can be described by showing a class box stereotyped «flow» somewhere on the diagram, usually close to the flow between the objects. Notice that the flow between objects is shown as a stereotype of dependency.

Embedded systems need to model the information or behavior of real-world objects even though they are not part of the system per se. For example, an anesthesia system must model the relevant properties of patients, even though customers are clearly outside the anesthesia system. Typical customer objects will contain attributes such as
Name
Social Security number
Address
Phone number
Insurance reference
Weight
Sex
Height
An ECG monitor might model a heart as containing
Heart rate
Cardiac output
Frequency of preventricular contractions
Electrical axis
In anesthesia systems, modeling organs as “sinks” for anesthetic agent uptake can aid in closed loop control of agent delivery and prevent toxemia.
This strategy looks at things in the real world that interact in the system. Not all of the aspects of these real-world objects are modeled, only the ones relevant to the system. For example, the color of the heart or its neural control properties won't typically be modeled within an ECG system. Those aspects are irrelevant to the use cases realized by the ECG monitor. However, modeling its beat and PVC rate, as well as cardiac output is appropriate and relevant. If the system manipulates information about its actors, then the system should model at least their relevant aspects as objects.
Real-time systems interact with their environment using sensors and actuators in a hardware domain. The system controls and monitors these physical devices inside and outside the system and these objects are modeled as objects. Devices must also be configured, calibrated, enabled, and controlled so that they can provide services to the system. For example, deep within the inner workings of the system, processors typically perform initial power-on self-tests (POSTs) and periodic (or continuous) built-in tests (BITs). Devices frequently have nontrivial state machines and must provide status information on command. When device information and state must be maintained, the devices may be modeled as objects to hold the information about their operational status and available services.
For example, a stepper motor is a physical device that can be modeled as an object with the attributes and behaviors, as shown in Table 6-4.
Normally, only the interfaces to physical devices are actually modeled within this kind of class because the object presents an interface to client objects within the system. The object itself usually focuses on the communication with the device to achieve its client's purposes and not how the device actually works. The only exception to this rule is in constructing simulation systems, in which case modeling the internal behavior of the device is the point of the object.
Key concepts are important abstractions within the domain that have interesting attributes and behaviors. These abstractions often do not have physical realizations, but must nevertheless be modeled by the system. Within the User Interface domain, a window is a key concept. In the banking domain, an account is a key concept. In an autonomous manufacturing robot, a task plan is the set of steps required to implement the desired manufacturing process. In the design of a C compiler, functions, data types, and pointers are key concepts. Each of these objects has no physical manifestation. They exist only as abstractions modeled within the appropriate domains as objects or classes.
Transactions are objects that must persist for a finite period of time and that represent the interactions of other objects. Some example transaction objects are outlined in Table 6-5.
Table 6-5. Example Transaction Objects
Object 1 | Object 2 | Association | Transaction Object |
|---|---|---|---|
Woman | Man | Marriage | Marriage object:
|
Woman | Man | Marriage | Divorce object:
|
Controller | Actuator | Controls | Control message over bus |
Alarming Class | Alarm Manager | Issues alarms | Silence Alarm |
Customer | Store | Buys things at | Order Return |
Display System | Sensor | Displays values for | Alarm Error |
Elevator Request Button | Elevator | Issues request to | Request for elevator |
Floor Request Button | Elevator | Issues request to | Request for floor |
Task Plan | Robot Arm | Controls | Command |
In the elevator case study, an elevator request is clearly a transaction. It has a relatively short life span, either
Beginning when the (future) passenger pushes the elevator request button and ending when the elevator arrives and opens its doors, or
Beginning when the passenger pushes the floor request button and ending when the elevator arrives at its destination and opens its doors.
Other examples of transactions are alarms and (reliable) bus messages. Alarms must persist as long as the dangerous condition is true or until explicitly handled, depending on the system. Alarms will typically have attributes such as
Alarm condition
Alarm priority
Alarm severity[8]
Time of occurrence
Duration of condition
Reliable message transfer requires that a message persist at the site of the sender until an explicit acknowledgement is received. This allows the sender to retransmit if the original message is lost. Bus messages typically have attributes such as
Message type
Priority
Source address
Target address
Message data
Cyclic redundancy check
Persistent information is typically held within passive objects such as stacks, queues, trees, and databases. Either volatile memory (RAM or SRAM) or long-term storage (FLASH, EPROM, EEPROM, or disk) may store persistent data.
A robot must store and recall task plans. Subsequent analysis of the system may reveal other persistent data. For example, the information in Table 6-6 may be persistent.
Table 6-6. Persistent Information Objects
Information | Storage Period | Description |
|---|---|---|
Task plans | Unlimited | Programs for the robotic system must be constructed, stored, recalled for editing, and recalled for execution. |
Errors | Between service calls | An error log holding the error identifier, severity, location, and time/date of occurrence will facilitate maintenance of the system. |
Equipment alarms | Until next service call | Equipment alarms indicate conditions that must be brought to the attention of the user, even though they may not be errors. Tracking them between service calls allows analysis of the reliability of the system. |
Hours of operation | Between service calls | Hours of operation aid in tracking costs and scheduling service calls. |
Security access | Unlimited | Stores valid users, their identifiers, and passwords to permit different levels of access. |
Service information | Unlimited | Service calls and updates performed can be tracked, including when, what, and by whom. |
Such data can be used for scheduling equipment maintenance, and may appear in monthly or yearly reports.
Many real-time systems interact directly or indirectly with human users. Real-time system displays may be as simple as a single blinking LED to indicate power status or as elaborate as a full GUI with buttons, windows, scroll bars, icons, and text. Visual elements used to convey information to the user are objects within the user interface domain.
In many environments, user interface (UI) designers specialize in the construction of visual interaction models or prototypes that the developers implement.
For example, consider the sample screens for the elevator central control station shown in Figures 6-5 through 6-7.



We see a number of common visual elements:
Window
Rectangle
Rounded panel
Horizontal scroll bar
Scroll button (left, right, up, down)
Button
Menu bar
Menu selection
Drop-down menu
Menu item
List box
Text
Icon (for alarm silence)
Each of these is an object within the UI domain for the elevator central station. These UI objects are depicted in an object message diagram later in this chapter.
Control elements are entities that control other objects. These are specific types of causal objects. Some objects, called composites, often orchestrate the behaviors of their part objects. These may be simple objects or may be elaborate control systems, such as
PID control loops
Fuzzy logic inference engines
Expert system inference engines
Neural network simulators
Some control elements are physical interface devices that allow users to enter commands. The elevator case study has only a few:
Button (elevator and floor)
Switch (elevator and floor)
Keyboard (central station only)
Mouse (central station only)
The application of use case scenarios is another strategy to identify missing objects as well as to test that an object collaboration adequately realizes a use case. Using only known objects, step through the messages to implement the scenario. When “you can't get there from here,” you've probably identified one or more missing objects.
In mechanical terms, this is done by refining the use case scenario. Remember from Chapter 5 that the structural context for a use case scenario is the system and the actors participating in the scenario. This means that a use case scenario cannot show objects internal to the system because they are not yet known. However, once you have identified and captured the set of objects in the collaboration, you can replace the single System object with the set of objects in the collaboration. This provides a more detailed or refined view of the scenario and ensures that the collaboration does, in fact, realize the use case.
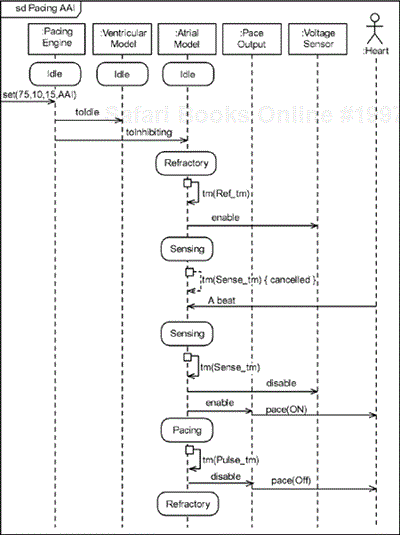
For example, consider the use case scenario in Figure 6-8. It shows the black-box behavior of the pacemaker with respect to the actors Pacing Engine and Heart (and the Communications Subsystem). Using the object identification strategies previously mentioned, let's assume we can construct the model in Figure 6-9. We can now refine the scenario by elaborating the scenario with the set of identified objects, as shown in Figure 6-10. This is now a white-box view that we can relate directly to our black-box use case view. This more refined view of the same scenario, shown in Figure 6-8, shows how the objects in the collaboration work together. Note, for example, that when the Programmer instructs the pacemaker to go into AAI pacing mode, the Pacing Engine tells the Atrial Model to go to Inhibited model and the Ventricular Model to go to Idle mode. Figure 6-10 even shows the relationship between the scenario and the state models (not shown) of the Atrial Model and Ventricular Model objects.
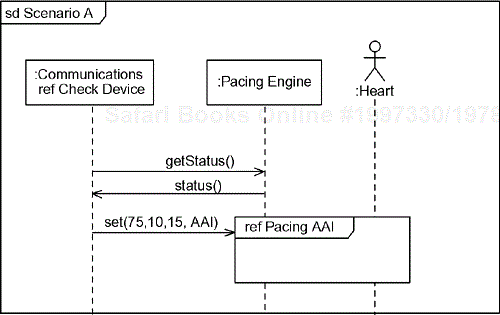
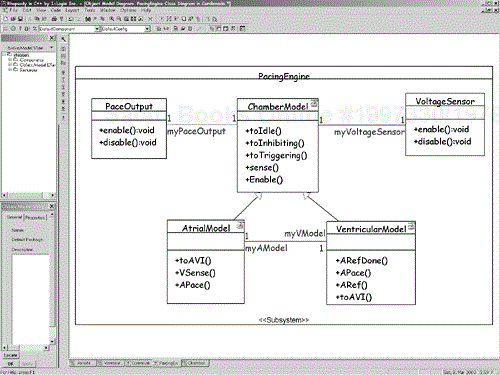
Early in the analysis, some objects seem to relate to others even though it is not always clear exactly how. The first step is to identify the existence of such associations. We discuss the characterization of associations later in this chapter.
There are a few strategies for the identification of object relationships. Each relies on the fact that objects send messages to other objects and every message implies an association. Table 6-7 shows the most common strategies used to identify associations.
Table 6-7. Object Association Strategies
Strategy | Description |
|---|---|
Identify messages | Each message implies an association between the participating objects. |
Identify message sources | The sensors that detect information or events and the creators of information or events are all message sources. They pass information on to other objects for handling and storage. |
Identify message storage depots | Message storage depots store information for archival purposes or provide a central repository of information for other objects. The depots have associations with the message sources as well as the users of that information. |
Identify message handlers | Some objects centralize message dispatching and handling. They form connections to either or both message sources and message storage depots. |
Identify whole/part structures | Whole/part relations will become aggregation or composition relationships among objects. Wholes often send messages to their parts. |
Identify more/less abstract structures | Some objects are related to each other by differences in levels of abstraction. It is not uncommon for a single higher-level abstraction to be implemented by a tightly knit set of objects at a more concrete level of abstraction. The larger object in this case will become a composite object and the smaller objects, its component parts. The relationship among them will become a composition relation. |
Apply scenarios | Walk through scenarios using the identified objects. The scenarios explicitly show how the messages are sent between objects. |
In our elevator example, there are a number of associations, shown in Table 6-8.
Table 6-8. Elevator Object Associations
Message Source | Message Target | Message |
|---|---|---|
Elevator request button | Elevator gnome | Requests an elevator |
Elevator gnome | Elevator | Request status |
Elevator gnome | Elevator | Add destination for elevator |
Elevator | Elevator gnome | Accept destination |
Elevator | Floor speaker | Arrival event beep |
Elevator floor sensor | Elevator | Location |
Cable tension sensor | Locking clamps | Engage |
Central station | Locking clamps | Release |
Cable tension sensor | Central station | Alarm condition |
Elevator | Central station | Status |
Floor request button | Elevator | Add destination |
Run-stop switch | Elevator | Stop/run |
Run-stop switch | Central station | Stop/run |
Alarm button | Central station | Alarm condition |
Elevator | Door | Open/close |
Class and object diagrams capture these associations. A line drawn between two objects represents a link (instance of an association) between those objects, supporting the transmission of a message from one to the other.
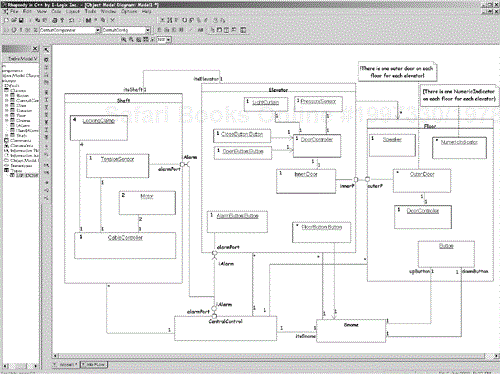
The object diagram in Figure 6-11 shows the general structure of the identified objects and their neighbors. The system consists of 38 high-level objects: 8 shafts, 8 elevators, 20 floors, and one central station and one elevator gnome. The numbers at the upper lefthand corner of the object represents the instance count, that is, the number of instances of the object in the enclosing context. The shaft, elevator, and floor are all composites that strongly aggregate their components. The instance counts of their components as per instance of their context. That is, each Elevator has 20 instances of Floor Request Button.
The UML defines an attribute to be “a named property of a type.” In this sense, attributes are “smaller” than objects—they have only a primitive structure and, of themselves, no operations other than get_ and set_. Practically speaking, attributes are the data portion of an object. A sensor object might include attributes such as a calibration constant and a measured value. Attributes are almost always primitive and cannot productively be broken down into smaller pieces. If you find attributes to be structurally nonprimitive or behaviorally rich, then they should usually be modeled as objects owned (via composition) by the main object, rather than as attributes of that main object. For example, if a sensor has a simple scalar calibration constant, then it would be appropriate to model it as an attribute of the sensor object. If, however, the sensor object has an entire set of calibration constants, the calibration constants should be each be modeled as an object aggregated unidirectionally by the sensor object with a 1-* multiplicity. The set of constants would probably be managed by a container class (added in design), as shown in Figure 6-12. It is important to remember that modeling the table in this way does not necessarily entail any additional overhead in terms of performance or memory usage but does provide superior encapsulation of concerns and easier maintenance.

Sometimes the primary attributes of an object are obvious, but not always. Developers can ask themselves some key questions to identify the most important attributes of objects:
What information defines the object?
On what information do the object's operations act?
What does the object know?
Are the identified attributes rich in either structure or behavior? (If so, they are probably objects in their own right rather than simple attributes.)
What are the responsibilities of the object? What information is necessary to fulfill these responsibilities?
The Elevator class provides a good example of a real-time class with attributes. Let's ask these questions about this class:
What information defines the object? The Elevator is a physical thing that must be controlled. To fulfill its function it must know where it is, where it is going (destination list), its current direction, its operational status, and its error history.
On what information do the object's operations act? It has a goto() operation, which must act on where it is, its current direction, and its state (moving, stopped, etc.).
What does the object know? It knows where it is, where it is going, and what it is doing right now.
Are the identified attributes rich in either structure or behavior? If so, they are probably objects rather than attributes. The Elevator has a door that has state (open, closed, opening, closing), interlocks with the floor door, and operations. The door is probably a separate object.
What are the responsibilities of the object? What information is necessary to fulfill these responsibilities? The Elevator's primary responsibility is to transport passengers from one floor to another safely. It needs the attributes of where it is, in which direction it is traveling, a list of current destinations, and its current state.
There are cases in which an object with no attributes is valid within the domain. A button is a reasonable class, but what attributes does it have? Probably none. Some composite objects are only aggregates of many objects with no data specific in and of themselves. Other objects contain only functions and so are often called functoids or (in UML-speak) class utilities.
In object domain analysis, we are not particularly concerned with the visibility of the attributes (or of the operations). Later, in design, we will mark them as public (+'), private (-) or protected (#). If you'd like to mark your best guess as to visibility when you enter these features, that's fine, but it isn't a primary focus.
Of all the objects identified in the problem statement, many are structurally identical. In the elevator case study, for example, there are eight elevators, all the same. Similarly, there are scads[9] of buttons, but they all appear to be structurally identical. Each is activated by depression, acknowledges with a backlight, and so on. Objects that are identical in structure are said to be of the same class. The next analysis activity is to propose candidate classes for the identified objects.
Classes are abstractions of objects. Objects that are identical in type (even if different in specific value) are abstracted into a class. In the elevator example, buttons differ by purpose. Floor request buttons reside within the elevator and request a destination for that specific elevator. Elevator request buttons reside on the floor and request any elevator to come to the floor and take passengers in a specific direction. Each button is structurally identical and differs only in its context. It depresses when pushed and issues a message when released. When the message is accepted, the button is backlit. The button appears to be a good choice for a candidate class.
Similarly, other objects can be abstracted into candidate classes:
Elevator
Door
Floor
Speaker
Floor indicator
Elevator indicator
and so on. From these classes, specific objects, such as “Elevator #2 Request Button for Floor #8,” may be instantiated. Classes so identified can be put in a class diagram for a simpler structural view than the object diagram, especially since the object model of a system changes over time (as objects are created and destroyed).
Class diagrams are the single most important diagrams in object-oriented analysis and design. They show the structure of the system in terms of classes and objects, including how the objects and classes relate to each other. Class diagrams are the primary road map of the system and its object-oriented decomposition. They are similar to object diagrams except they show primarily classes rather than instances. Object diagrams are inherently snapshots of the system at some point in time, showing the objects and the links among them that exist at that instant in time. Class diagrams represent, in an important sense, all possible such snapshots and are therefore more “universal.” For this reason, almost all structural modeling of systems is done with class diagrams rather than object diagrams.
So far in this book, we've already seen plenty of class diagrams. One of the disadvantages of building real systems (as opposed to constructing examples for books) is that in real systems you always come up with more classes than you can conveniently put on a single diagram even if you go to 2-point font and E-size plotter paper. Developers need criteria for dividing up their class structures into different diagrams that make the system understandable, accessible, and modifiable in the various ways that the stakeholders need. Different methodologies have different solutions for this. The ROPES process has a simple process rule: Every diagram should have a single important concept it is trying to show. This is called the mission of the diagram. Common missions for a class diagram include these:
Show the context of an architectural class or object (a context diagram)
Show the architectural elements within a system and how they relate (a subsystem diagram or component diagram)
Show the parts within a structured class (a class structure diagram)
Show the architectural elements that work together to provide redundancy, replication, or fault tolerance (a structure reliability or structure safety diagram)
Show how the architectural or collaborating elements distribute across multiple address spaces (a deployment diagram)
Show how instances distribute themselves across multiple address spaces with respect to their communication (a distribution diagram)
Show the classes within a collaboration realizing a use case at an object-domain level of abstraction (a essential object diagram or essential class diagram)
Show the classes within a collaboration, including the design refactoring and inclusion of design elements (a class design diagram)
Show the information flow among types or instances (a data flow or information flow diagram
Show the classes within a package or domain
Show the package organization of the model (a package diagram)
Show the classes within a single generalization taxonomy (an inheritance diagram)
Show the classes related to the concurrency or resource model (a task diagram)
Show the classes related to access of a single resource of particular significance (a resource diagram)
Show a view of structural elements bound together by a coupled set of constraints (a constraint diagram)
Show a set of instances and their links for a typical or exception condition or state of the system (an object diagram)
Show the abstraction of a set of design elements into a design pattern (a design pattern diagram)
With a little thought, I'm sure you can come up with even more specific missions for class diagrams. Note that many of these missions are common enough to be given specific names, such as task diagram, but this doesn't mean that the diagram type is different, only its usage. The mission of a diagram focuses on why we want to construct a particular diagram and how it helps us, but the same set of elements (class, object, package, component, node) may all appear on the same diagram type. So these aren't fundamentally different diagrams. Systems are organized this way to help us understand all their relevant aspects. Organizing the diagrams by missions makes sense aids comprehension and defect-identification. A common complaint about the UML is that there are too many different diagrams, but really there are only a handful. There are, however, just a few diagram types, but many missions or purposes to which these few diagrams may be applied.
In the UML 1.x, an associative class clarified associations that had interesting structure or behavior. In the UML 2.0, all associations are classifiers and so may be shown as a stereotyped class where useful. In distributed systems, the classic example of an associative class is a bus message class. In addition to the information being sent from one object to another, the message object may contain additional information specific to the relationship and even the link instance. For example:
Message priority
Message route
Session identifiers
Sequence numbers
Flow control information
Data format information
Data packaging information
Time-to-live information for the message
Protocol revision number
Data integrity check information
In a transaction-oriented system, associative classes also contain information specific to the transaction.
An associative class is used when information does not seem to belong to either object in the association or belongs to both equally. Marriage is an association between two people objects. Where do the following attributes belong?
Date of marriage
Location of marriage
Prenuptial agreement
Clearly, these are attributes of the marriage and not the participants.
Figure 6-13 shows a case of an associative class. In this distributed system model, one subsystem contains the sensor class and acts as a server for the data from the sensors. The client subsystem displays this data to the user. The association between the measurement server and measurement client is of interest here.

One way to implement the association is to have the client explicitly ask whenever it wants data to display. Another is to have the server provide the data whenever it becomes available. However, neither option may be the best use of a finite-bandwidth bus. Additionally, what if another client wants to be added to the recipient list for the data? Some buses provide the ability to broadcast such data, but most target a specific recipient.
The associative class solution provided here uses a session. A session is a negotiated agreement between two communicating objects. Sessions save bandwidth because they negotiate some information up front so that it need not be passed within each message. Nonsessioned (connectionless) communications are similar to postcards. Each and every time a postcard is mailed, it must contain the complete destination and source addresses. A session is more like a phone call. Once the destination is dialed and the connection established, the communication can be any length or complexity without resending or reconnecting.
In this case, the session contains two important pieces of information: the source and the target addresses. Two session subtypes are defined based on the update policy. The update policy can be either episodic or periodic. Episodic, in this context, means that the server sends data when it changes—that is, when an episode occurs. Periodic means that the server must send the data at a fixed interval. Episodic sessions in this example have a maximum update rate to make sure that a bursty system does not overload the bus. Periodic sessions have a defined update rate.
The measurement server contains two operations to assist in session management. The first is Register Client. This operation accepts the registration of a new client and participates in the negotiated construction of a session object. The Deregister Client operation removes a registered client.
The measurement client contains two operations to support its role in negotiating the session: Accept Server and Break Connection.
Who owns the session? Arguments can be made for both the server and the client. The server must track information about the session so that it knows when and how to issue updates. The client initiates the session and must also know about update policy and rates. The solution shown in Figure 6-13 is that the session is an associative class and contains attributes about the relationship between the two primary classes. Because this is a distributed system, the implementation would involve creating two coordinating session objects (or a single distributed object), one on each processor node, providing session information to the local client or server.
Generalization is a taxonomic relationship between classes. The class higher in the taxonomic hierarchy is sometimes called the parent, generalized, base, or superclass. The class inheriting properties from the base class is called the child, specialized, derived, or subclass. Derived classes have all the properties of their parents, but may extend and specialize them.
Using Aristotelian logic and standard set theory, generalizing along a single characteristic guarantees that the classes are disjoint.[10] When the set of subclasses enumerates all possible subclasses along the characteristic, the subclassing is said to be complete.
Consider our elevator example. An elevator has many buttons—ones to go to a floor, one to open the door, one to close the door, one to send an alarm, and so on. An elevator might have 30 different button instances in it, but how many classes do we have? Are the buttons different in terms of their structure or behavior? No—they all work the same way—you push them and they report a press event; when you release them, they report a release event; when selected, they will be backlit, and so on. They only differ in their usage not in their type, and should be modeled as different instances of a single class. In other environments, there may be buttons that differ in their structure and behavior.
The button subclasses in Figure 6-14 are specialized along the lines of behavior. Simple buttons issue an event message when pressed, but have no state memory. Toggle buttons jump back and forth between two states on sequential depressions. Multistate buttons run through a (possibly elaborate) state machine with each depression. Group buttons deselect all other buttons within the group when depressed.

In the UML, generalization implies two things: inheritance and substitutability. Inheritance means that (almost) everything that is true of a superclass is also true of all of its subclasses. This means that a subclass has all of its parent's attributes, operations, associations, and dependencies. If the superclass has a statechart to define its behavior, then the subclass will inherit that statechart. The subclass is free to both specialize and extend the inherited properties. Specialization means that the subclass may polymorphically redefine an operation (or statechart) to be more semantically appropriate for the subclass. Extension means that the subclass may add new attributes, operations, associations, and so on.
Substitutability means that an instance of a subclass may always be substituted for an instance of its superclass without breaking the semantics of the model. This is known as the Liskov Substitution Principle (LSP) [3]. The LSP states that a subclass must obey polymorphic rules in exactly the same manner as its superclass. For example,
class Animal {
public:
virtual void speak(void) = 0; // virtual base
class
};
class dog: public Animal {
public:
void speak(void) { cout << "Arf!" << endl; };
};
class fish: public Animal {
public:
void speak(void) { cout << "Blub! " << endl; };
};
class cat: public Animal {
public:
void speak(void) {
cout << "<Aloof disdain>" << endl; };
};
void main(void) {
Animal *A;
dog d;
fish f;
cat c;
A = &d;
A->speak();
A = &c;
A->speak();
A = &f;
A->speak();
};
The base class (Animal) accesses the three subtypes through a pointer (A). Nonetheless, the access to the speak() method for each is identical, satisfying the LSP.
For the LSP to work, the relationship between the superclass and subclass must be one of specialization or extension. Whatever is true of the superclass must also be true of the subclass because the subclass is a type of its superclass. A dog is an animal, so all of the things true about all animals are also true about dogs. All of the behaviors common to all animals can also be performed by dogs. If the abstraction animal had an attribute or behavior that was not true of dogs (such as being able to produce free oxygen via photosynthesis), a dog would not be a type of animal.
That being said, a subclass is free to specialize the behavior of a superclass. The speak() method defined within animal is an example. Each subclass does a different thing while still meeting the requirement of supporting the behavior speak(). Locomote() is another example. Dogs, cats, fish, and birds all locomote, but they implement it differently. This is what is meant by specialization.
Subclasses are also free to extend their inherited structure by adding new behaviors or attributes. We can add some new behaviors to the dog and cat classes that are not true of animals in general.
class dog: public Animal {
public:
void speak(void) { cout << "Arf!" << endl; };
void slobber(float slobberIndex);
void AttackJogger(int fearLevel);
};
class cat: public Animal {
public:
void speak(void) {
cout << "<Aloof disdain>" << endl; };
void ClawFurniture(long ClawLength);
void SnubOwner(void);
};
Now dogs can slobber() and AttackJogger() while cats can ClawFurniture() and SnubOwner(). Animals in general (and fish for that matter) can perform none of these charming behaviors.
Frequently, base classes cannot be instantiated without being first specialized. Animal might not do anything interesting, but dogs, cats, and fish do. When a class is not directly instantiated, it is called an abstract class. C++ classes are made abstract by the inclusion of a pure virtual function. A C++ virtual function is a class method that is denoted by the keyword virtual. It need only be so indicated in one class in the inheritance tree, and it will be virtual for all derived classes. A virtual function is made pure virtual with the peculiar syntax of assigning the function declaration the value zero. For example,
class widget {
public:
virtual void doSomething() = 0;
};
Note that in C++, constructors and destructors cannot be made pure virtual. Furthermore, if a C++ class contains a virtual function, it is a logical error not to define the destructor as virtual.[11] C++ does not allow virtual constructors.
Generalization relationships form class hierarchies with the most general classes at the top and the most specialized classes at the bottom. Structuring these hierarchies is done by using three complementary approaches:
Extension: Derived classes extend the capabilities of the parent class (top-down).
Specialization: Derived classes specialize the capabilities of a parent (top-down).
Bubbling up: Attributes and behaviors that are common in peer children become attributes and behaviors of the parent class (bottom up).[12]
The first strategy, extension, means that a subclass can add behaviors and attributes to those it inherits from its parents. This is an example of the Open-Closed Principle (OCP) [4]. The OCP states that for maximum reusability, a class should be open for extension but not modification. The focus of the OCP is that changes in a well-designed class hierarchy should be made by subclassing rather than modifying the hierarchy itself. Another term for this concept is programming by difference. The developer finds a class in the hierarchy that is close to what is needed, subclasses it, and extends the subclass to meet the particular needs. The OCP focuses on reuse, but it applies equally well to the construction of class hierarchies. Subclasses may extend the capabilities of their parents without modifying the parents.
LSP applies not only to features such as attributes, operations, and states. It also applies to constraints. Following the generalization principle of “any subclass must be at least able to do what the parent class can,” constraints should be loosened in subclasses not tightened. This makes sense if you look at a feature or quality of service of a superclass and ask the question, “Can the subclass do this?” Put another way, a subclass inherits all of the features (and constraints) of the superclass, although it may be some additional ones. The rule is substitutability. That is, a constraint in a subclass must be consistent with constraints in the superclass. For example,
If an offered interface has a timing requirements, such as “worst-case execution time = 18 ms +/– 2 ms,” then any subclass must meet this, but it may do better, such as “worst case execution time = 16 ms +/– 1.5ms”; but it cannot fail to meet those constraints without violating substitutability. For example, a subclass of the previously mentioned class can't use the constraint “25 ms +/– 1ms” or even “17ms +/– 5ms.”
Required interfaces have similar restrictions. If a class B meets the required interface of the superclass, then it should also meet the required interface for any subclass.
Subranges for values being sent to the class realizing the interface may be extended in the subclass, but not further constrained; this is because every value sent to the superclass must be valid while being sent to the subclass.
Subranges for values being returned from the class realizing the interface may be constrained but not extended; this is because every value returned by the subclass in this case may also be returned by the superclass and so maintains substitutability. The fact that it doesn't return all possible values isn't a problem. However, if the subclass returned a value beyond what the superclass could do, this could break a client.
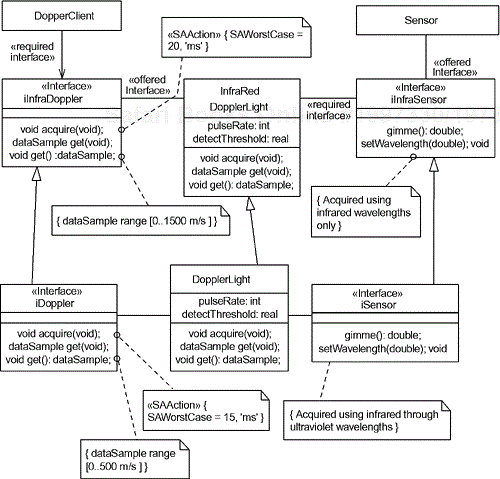
Figure 6-15 shows how constraints are properly propagated to subclasses. It is, perhaps, counterintuitive that an InfraredDopplerLight is the superclass and DopplerLight is the subclass, but the InfraredDopplerLight allows sensing wavelengths to be set only in the infrared range, while the DopplerLight can use a wider range of light wavelengths. In this example, this arrangement of generalization allows substitutability to preserved:
The iInfraDopplerLight interface provides an operation acquire() with a specified worst-case execution time of 20ms. The subclass interface iDoppler provides the same operation with a specified worst-case execution of 15ms. The subclass can be substituted for the superclass and meet the interface requirements
The iInfraDopplerLight interface has an operation get(), which returns a data sample in the range of 0..1500. The subclassed interface iDoppler::get() returns a data sample in the range of 0..500. This is likewise consistent since every value returnable from the subclass is valid for the superclass (and therefore for its clients) so any client usage of the iDopper in the role of an iInfraDoppler is correct.
The iInfraSensor interface has a setWavelength() operation that accepts parameters only in the infrared range. The subclass interface iSensor::setWavelength() allows all the parameters that can be passed to it from an iInfraSensor client as well as more, since it can also take wavelengths in the visible and ultraviolet range.
As an exercise, decide how to arrange the following in a generalization taxonomy: shape, square, rectangle. This simple problem has caused more debate than you might think!
Generalization is useful because of the substitutability of the subclass whenever a superclass is used. Consider Figure 6-16. A client needs to use the Queue superclass to store strings (OMString is a type provided by the Rhapsody tool and so is used here).[13] Sometimes, a client might need to store more elements that there is main memory available for storage, so a CachedQueue (a subclass of Queue) can be substituted, to cache elements out to disk as necessary.
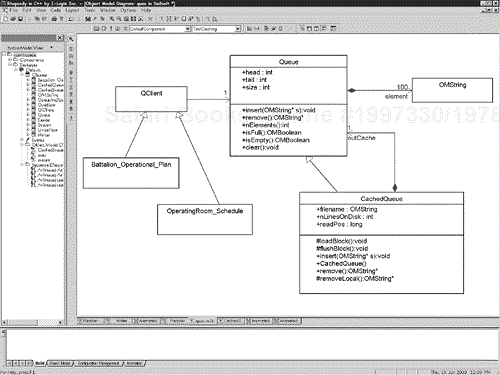
Figure 6-16 shows a simple example of extending a subclass. The Queue superclass provides several methods—insert(), remove(), nElements(), isFull(), and isEmpty()—as well as some attributes—head, tail, and size (all of type int). It also has a composition relation to OMString (the type of elements that it stores). The source code for this class is shown in Code Listing 6-1 (Queue.h, the c++ header file) and Code Listing 6-2 (Queue.cpp, the implementation file). This code is generated from the I-Logix Rhapsody tool, so it contains some macros (such as GUARD_OPERATION, which allocates a mutex to protect the Queue class from mutual exclusion problems) and other aspects that are autogenerated and may be pretty much be ignored. You can see by looking at the model in Figure 6-16 and the source code that the Queue class is fairly straightforward.
Example 6-1. Queue.h
/*****************************************************
Rhapsody : 5.0
Login : Bruce
Component : DefaultComponent
Configuration : TestCaching
Model Element : Queue
//! Generated Date : Wed, 18, Jun 2003
File Path : DefaultComponentTestCachingQueue.h
*****************************************************/
#ifndef Queue_H
#define Queue_H
//#[ ignore
#define _OMFLAT_IMPLEMENTATION 1
//#]
#include <oxf/oxf.h>
#include "fstream.h"
#include "stdio.h"
#include "Default.h"
#include <oxf/omreactive.h>
#include <oxf/state.h>
#include <oxf/event.h>
//## package Default
//----------------------------------------------------
// Queue.h
//----------------------------------------------------
class Overflow;
class Underflow;
//## class Queue
class Queue : public OMReactive {
//// Constructors and destructors ////
public :
//## operation Queue()
Queue(OMThread* p_thread = OMDefaultThread);
//## auto_generated
virtual ~Queue();
//// Operations ////
public :
//## operation clear()
void clear();
//## operation get(int)
OMString get(int index);
//## operation insert(OMString*)
virtual void insert(OMString* s);
//## operation isEmpty()
virtual OMBoolean isEmpty();
//## operation isFull()
virtual OMBoolean isFull();
//## operation nElements()
virtual int nElements();
//## operation remove()
virtual OMString* remove();
//// Additional operations ////
public :
//## auto_generated
int getHead() const;
//## auto_generated
void setHead(int p_head);
//## auto_generated
int getSize() const;
//## auto_generated
void setSize(int p_size);
//## auto_generated
int getTail() const;
//## auto_generated
void setTail(int p_tail);
//## auto_generated
Overflow* getItsOverflow() const;
//## auto_generated
void setItsOverflow(Overflow* p_Overflow);
//## auto_generated
Underflow* getItsUnderflow() const;
//## auto_generated
void setItsUnderflow(Underflow* p_Underflow);
//// Framework operations ////
public :
//## auto_generated
int getElement() const;
//## auto_generated
virtual OMBoolean startBehavior();
protected :
//## auto_generated
void cleanUpRelations();
//// Attributes ////
protected :
int head; //## attribute head
int size; //## attribute size
int tail; //## attribute tail
//// Relations and components ////
protected :
OMString* element[100]; //## link element
Overflow* itsOverflow; //## link itsOverflow
Underflow* itsUnderflow; //## link itsUnderflow
};
#endif
/****************************************************
File Path : DefaultComponentTestCachingQueue.h
*****************************************************/
Example 6-2. Queue.cpp
/*****************************************************
Rhapsody : 5.0
Login : Bruce
Component : DefaultComponent
Configuration : TestCaching
Model Element : Queue
//! Generated Date : Wed, 18, Jun 2003
File Path : DefaultComponentTestCachingQueue.cpp
*****************************************************/
#include <oxf/omthread.h>
#include "Queue.h"
#include "Overflow.h"
#include "Underflow.h"
//## package Default
//----------------------------------------------------
// Queue.cpp
//----------------------------------------------------
//## class Queue
Queue::Queue(OMThread* p_thread) {
setThread(p_thread, FALSE);
{
for(int pos=0;pos<100;pos++)element[pos]=NULL;
}
itsOverflow = NULL;
itsUnderflow = NULL;
//#[ operation Queue()
size=100;
head=tail=0;
//#]
}
Queue::~Queue () {
cleanUpRelations();
}
void Queue::clear() {
//#[ operation clear()
head=tail=0;
//#]
}
OMString Queue::get(int index) {
//#[ operation get(int)
return *element[index];
//#]
}
void Queue::insert(OMString* s) {
//#[ operation insert(OMString*)
if (isFull())
throw Overflow();
else {
element[head] = s;
head = (head+1) % size;
};
//#]
}
OMBoolean Queue::isEmpty() {
//#[ operation isEmpty()
if ( head == tail) return TRUE;
else return FALSE;
//#]
}
OMBoolean Queue::isFull() {
//#[ operation isFull()
return ( (head+1) % size == tail);
//#]
}
int Queue::nElements() {
//#[ operation nElements()
if (head >= tail) return head-tail;
else return size-(tail-head)+1;
//#]
}
OMString* Queue::remove() {
//#[ operation remove()
OMString* s;
if (isEmpty())
throw Underflow();
else {
// cout << "element[" << tail << "]=";
s = element[tail];
// cout << *s << "??" << s->GetLength()
// << endl;
tail = (tail+1) % size;
return s;
}
//#]
}
int Queue::getHead() const {
return head;
}
void Queue::setHead(int p_head) {
head = p_head;
}
int Queue::getSize() const {
return size;
}
void Queue::setSize(int p_size) {
size = p_size;
}
int Queue::getTail() const {
return tail;
}
void Queue::setTail(int p_tail) {
tail = p_tail;
}
int Queue::getElement() const {
int iter=0;
return iter;
}
Overflow* Queue::getItsOverflow() const {
return itsOverflow;
}
void Queue::setItsOverflow(Overflow* p_Overflow) {
itsOverflow = p_Overflow;
}
Underflow* Queue::getItsUnderflow() const {
return itsUnderflow;
}
void Queue::setItsUnderflow(Underflow* p_Underflow) {
itsUnderflow = p_Underflow;
}
void Queue::cleanUpRelations() {
if(itsOverflow != NULL)
{
itsOverflow = NULL;
}
if(itsUnderflow != NULL)
{
itsUnderflow = NULL;
}
}
OMBoolean Queue::startBehavior() {
OMBoolean done = FALSE;
done = OMReactive::startBehavior();
return done;
}
/*****************************************************
File Path : DefaultComponentTestCachingQueue.cpp
*****************************************************/
The Queue class is subclassed by the CachedQueue class, which inherits these features. The CachedQueue class adds two some new methods—flushBlock(), loadBlock(), and removeLocal()—and some new attributes as well. The child class extends the functionality of the parent by providing new behaviors.
Note that the CachedQueue subclass internally contains two normal queues—one for the input cache and one for the output cache. The input cache is strongly aggregated by the CachedQueue already because it is a kind of Queue, and the Queue class has a strong aggregation to an array of OMStrings. The other is done by aggregating a separate Queue subclass with the role name outCache for storing things as they come off the disk. Thus, data is inserted by a client into the input cache (directly aggregated by CachedQueue), or data may be written out to disk when that cache gets full, or the oldest data may reside in the indirectly aggregated output cache via the composition relation to the Queue class (role name outCache).
Specializing the CachedQueue as a subclass of Queue redefines some of the class's (virtual) behaviors, particularly, insert() and remove(). The code for the insert() and remove() operations of the Queue class is relatively simple, but more complex than Queue::insert() and Queue:: remove, as shown in Code Listing 6-3 and 6-4.
In the simple Queue class, the insert() operation checks to see whether there is room and, if so, sticks it in, doing the necessary math on the head pointer. In the CachedQueue, if there isn't room, then the input cache must be flushed out to disk, the input cache cleared, and the data inserted.
Similarly, the Queue::remove() operation is very simple—if there is any data, return it, otherwise throw an exception. The CachedQueue:: remove() operation is more complex: If the data is in the output cache, then get it from there; if the output cache is empty and there is data on disk, then load the next block from the disk and then get it from there. If there is no data in the output cache or on disk but there is data in the input cache, then get it from there. Lastly, if there is no data anywhere, throw an underflow exception.
Example 6-3. CachedQueue.h
/*****************************************************
Rhapsody : 5.0
Login : Bruce
Component : DefaultComponent
Configuration : TestCaching
Model Element : CachedQueue
//! Generated Date : Wed, 18, Jun 2003
File Path : DefaultComponentTestCachingCachedQueue.h
*****************************************************/
#ifndef CachedQueue_H
#define CachedQueue_H
//#[ ignore
#define _OMFLAT_IMPLEMENTATION 1
//#]
#include <oxf/oxf.h>
#include "fstream.h"
#include "stdio.h"
#include "Default.h"
#include <oxf/omprotected.h>
#include "Queue.h"
//## package Default
//----------------------------------------------------
// CachedQueue.h
//----------------------------------------------------
class Overflow;
class Underflow;
//## class CachedQueue
class CachedQueue : public Queue {
OMDECLARE_GUARDED
//// Constructors and destructors ////
public :
//## operation CachedQueue()
CachedQueue(OMThread* p_thread =
OMDefaultThread);
//## auto_generated
~CachedQueue();
//// Operations ////
public :
//## operation insert(OMString*)
void insert(OMString* s);
//## operation remove()
OMString* remove();
//## operation removeLocal()
OMString* removeLocal();
protected :
// write out the input cache to disk. Writing will
// append at the end of the file
//## operation flushBlock()
void flushBlock();
// loadBlock reads the next block off disk -
// loading occurs at the FRONT of the file.
//## operation loadBlock()
void loadBlock();
//// Additional operations ////
public :
//## auto_generated
OMString getFilename() const;
//## auto_generated
void setFilename(OMString p_filename);
//## auto_generated
int getNLinesOnDisk() const;
//## auto_generated
void setNLinesOnDisk(int p_nLinesOnDisk);
//## auto_generated
long getReadPos() const;
//## auto_generated
void setReadPos(long p_readPos);
//## auto_generated
Queue* getOutCache() const;
//## auto_generated
Queue* newOutCache();
//## auto_generated
void deleteOutCache();
//// Framework operations ////
public :
//## auto_generated
virtual OMBoolean startBehavior();
protected :
//## auto_generated
void initRelations();
//## auto_generated
void cleanUpRelations();
//// Attributes ////
protected :
OMString filename; //## attribute filename
int nLinesOnDisk; //## attribute nLinesOnDisk
long readPos; //## attribute readPos
//// Relations and components ////
protected :
Queue* outCache; //## link outCache
};
#endif
/*****************************************************
File Path : DefaultComponentTestCachingCachedQueue.h
*****************************************************/
Example 6-4. CachedQueue.cpp
/*****************************************************
Rhapsody : 5.0
Login : Bruce
Component : DefaultComponent
Configuration : TestCaching
Model Element : CachedQueue
//! Generated Date : Wed, 18, Jun 2003
File Path : DefaultComponentTestCachingCachedQueue.cpp
*****************************************************/
#include <oxf/omthread.h>
#include "CachedQueue.h"
#include "Overflow.h"
#include "Underflow.h"
//## package Default
//----------------------------------------------------
// CachedQueue.cpp
//----------------------------------------------------
//## class CachedQueue
CachedQueue::CachedQueue(OMThread* p_thread) {
setThread(p_thread, FALSE);
initRelations();
//#[ operation CachedQueue()
// constructor must clear any debris in the
// cache file.
filename = "C:\cachefile.txt";
nLinesOnDisk = 0;
readPos = 0; // start of file
// ios::trunc clears out the file when the
// CachedQueue is constructed
ofstream cacheFile(filename, ios::trunc);
//#]
}
CachedQueue::~CachedQueue() {
cleanUpRelations();
}
void CachedQueue::flushBlock() {
GUARD_OPERATION
//#[ operation flushBlock()
// open file for writing, appending at the end
// write out the strings in the buffer
// then clear the local buffer
OMString* s;
ofstream cacheFile (filename, ios::in|ios::app);
cout << "—-> OPENED " << filename << " for
Writing" << endl;
while (!isEmpty()) {
s = removeLocal();
// get the data from the input side
cacheFile << *s << endl;
// write it to disk
// cout << "W<- " << *s << endl;
// show it ++nLinesOnDisk;
};
cacheFile.close();
cout << "Write file closed" << endl;
clear();
//#]
}
void CachedQueue::insert(OMString* s) {
GUARD_OPERATION
//#[ operation insert(OMString*)
// check if there is room in the local store.
// if not, then write the buffer to disk (appending)
// clear it, then insert the new string
// using the superclass's insert();
if (isFull())
flushBlock();
Queue::insert(s);
//#]
}
void CachedQueue::loadBlock() {
GUARD_OPERATION
//#[ operation loadBlock()
// preconditions, there is at least one block
// in the cacheFile
// (checked by examining nBlocksOnDisk
// prior to calling this
#define MAXLENGTH 100
char buf[MAXLENGTH]; // buffer for input
OMString* s;
int j=1;
ifstream cacheFile(filename);
cout << "—-> OPENED " << filename << " for reading" << endl;
cacheFile.seekg(readPos);
while (!cacheFile.eof() && !outCache->isFull() && nLinesOnDisk>0) {
cacheFile.getline(buf, MAXLENGTH);
s = new OMString((char*) buf);
outCache->insert(s);
// cout << "Loading string <—" << *s << endl;
—nLinesOnDisk;
}; // end while
readPos = cacheFile.tellg();
cacheFile.close();
cout << "Read file closed" << endl;
/*
// check on the outcache
int n = outCache->nElements();
int t = outCache->getTail();
// cout << "LoadBlock done. OutCache now has "
// << n << " elements" << endl;
for (j=0; j < n; j++) {
cout << "[" << t << "]" << outCache->get(t)
<< endl;
t = (t+1) % outCache->getSize();
};
cout << "done showing the elements" << endl;
*/
//#]
}
OMString* CachedQueue::remove() {
GUARD_OPERATION
//#[ operation remove()
// if there is stuff in the output cache, return
that
// else if there's stuff on disk, pull it off and
return the first
// else if there's stuff in the input buffer,
then return that
// else through an exception OMString* s;
if (outCache->nElements()>0) {
//cout << "CachedQueue.remove path 1 "
<< endl;
s = outCache->remove();
}
else if (nLinesOnDisk>0) {
//cout << "CachedQueue.remove path 2 "
<< endl;
loadBlock();
s = outCache->remove();
}
else if (nElements()>0) {
//cout << "CachedQueue.remove path 3 " << endl;
s = removeLocal();
}
else {
//cout << "CachedQueue.remove path 4 " << endl;
throw Underflow();
}
// cout << "CachedQueue::remove got string: "
<< *s << endl;
return s;
//#]
}
OMString* CachedQueue::removeLocal() {
GUARD_OPERATION
//#[ operation removeLocal()
return Queue::remove();
//#]
}
OMString CachedQueue::getFilename() const {
return filename;
}
void CachedQueue::setFilename(OMString p_filename) {
filename = p_filename;
}
int CachedQueue::getNLinesOnDisk() const {
return nLinesOnDisk;
}
void CachedQueue::setNLinesOnDisk(int p_nLinesOnDisk) {
nLinesOnDisk = p_nLinesOnDisk;
}
long CachedQueue::getReadPos() const {
return readPos;
}
void CachedQueue::setReadPos(long p_readPos) {
readPos = p_readPos;
}
Queue* CachedQueue::getOutCache() const {
return outCache;
}
Queue* CachedQueue::newOutCache() {
outCache = new Queue(getThread());
return outCache;
}
void CachedQueue::deleteOutCache() {
delete outCache;
}
void CachedQueue::initRelations() {
outCache = newOutCache();
}
void CachedQueue::cleanUpRelations() {
{
deleteOutCache();
outCache = NULL;
}
}
OMBoolean CachedQueue::startBehavior() {
OMBoolean done = FALSE;
done = Queue::startBehavior();
outCache->startBehavior();
return done;
}
/*****************************************************
File Path : DefaultComponentTestCachingCachedQueue.cpp
*****************************************************/
The last strategy for constructing generalization hierarchies works from the leaves of the inheritance tree. After structuring the hierarchy, siblings subclassed from the same parent are examined for attributes and behaviors in common. If all siblings have the same property, it belongs to the parent rather than being replicated in each sibling. If the characteristic is common to some, but not all, of the siblings, then it may indicate a class is needed between the parent and the similar siblings.
Figure 6-17 shows an inheritance tree for bus messages. Each child class inherits the attributes Priority, Source Address, and Destination Address. We see, however, that each message has a Contents attribute. Event Report and Sequenced Event Report messages must identify the event in their Contents field. ACKs and NAKs must identify the message to which they are responding in their Contents field. Since all siblings have the Contents attribute, it can be moved up into the parent class, Bus Message.

Event Report and Sequenced Event Report messages share ACK Timeout and Number of Retries attributes. These do not appear in the ACK and NAK messages. Therefore, these may be abstracted into a class between Event Report and Bus Message and Sequenced Event Report and Bus Message. This is called Reliable Message because protocol mechanisms exist to support retransmission if no response to them is received. Figure 6-18 shows the resulting reorganization.

Of course, the astute analyst may mix all three strategies. It is possible to extend, specialize, and bubble up all at the same time.
This chapter discussed the first half of analysis—the identification of objects, classes, and relationships. Many strategies can be used to identify objects and classes—underlining the nouns, identifying the physical devices, looking for persistent data, and so on. These objects have attributes and behaviors that allow them to fulfill their responsibilities. Classes are abstractions of objects so that all objects instantiated from a particular class are structurally identical.
To support collaboration of objects, classes have relationships to each other. These may be associations among class instances, such as association or aggregation, or they may be relationships between classes, such as generalization. Objects use these associations to communicate by sending messages to each other.
The other half of analysis is concerned with defining the behavior of the classes. As we shall see in Chapter 7, class behaviors may be classified in three different ways—simple, state, and continuous. The dynamic properties of these classes allows them to use their structure to meet the system responsibilities in real time.
[1] The usage of the nanocycle in the context of larger-scoped timeframes is why I consider XP or AM to be “one third of a good process.”
[2] Or, even worse, let the customers beat on it until you fix it.
[3] Which is nothing more than a class diagram showing the domains as packages.
[4] Which has dropped me square in the middle of what I call the knowledge paradox: The more I learn, the less I know. I figure by the time I'm 60, I'll have learned so much that I will actually know nothing whatsoever! So far, I'm on target ;-)
[5] Good looks and charm only get you so far when they actually want to fly the thing!
[6] That is, it need not be modeled within the system. The cable tension sensor, however, must be modeled.
[7] Although the thread model for the system isn't determined until architectural design, as discussed in Chapter 8.
[8] Priority and severity are orthogonal concepts. Priority refers to how a scheduler will resolve execution order when multiple events are waiting to be handled (and is a combination of importance and urgency); the severity refers to how bad the outcome of the fault condition may be if unhandled. These concepts are discussed in more detail in [5].
[9] Scad: A technical term meaning “a lot.” Antonym: scootch.
[10] By disjoint we mean that the classes represent nonoverlapping or orthogonal alternatives. Male and female, for example, are disjoint sets. Fuzzy sets are inherently nondisjoint and allow partial membership. Object subclasses are assumed to be crisp sets (all-or-none membership) rather than fuzzy.
[11] Just one of many such opportunities provided by the C++ language.
[12] Note that restriction of the parent class is not included. All popular object-oriented languages allow the augmentation or extension of a class, but not restriction (removal of a behavior or attribute). To do so breaks the fundamental tenant of inheritance—that the child is a type of its parent—and therefore violates the LSP.
[13] Note that in a properly defined container class we would probably use parameterized classes to isolate the container functionality from the type being contained, but that would only muddy the waters of this particular example so we use a specific type with a specific size for simplicity.