
The last three chapters have dealt with analysis of the system. Chapter 5 looked at ways of capturing requirements using context diagrams and use cases. Chapters 6 and 7 presented approaches for identifying and characterizing classes and objects inherent in the problem. Analysis looks at key concepts and structures in the system that are independent of how the solution is implemented.
Now we're ready for design. Design specifies a particular solution that is based on the analysis model in a way that optimizes the system. The ROPES process divides design into three categories according to the scope of decisions made: architectural, mechanistic, and detailed. This chapter discusses the first: architectural design.
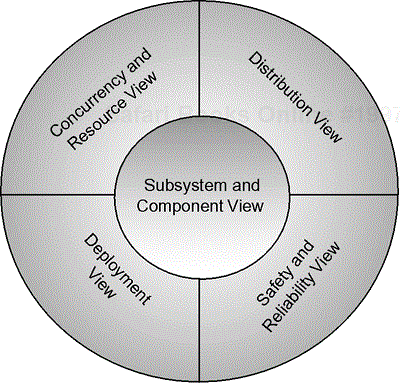
Architectural design identifies the key strategies for the large-scale organization of the system under development. The ROPES process identifies five important views of architecture: subsystem and component, concurrency and resource, distribution, safety and reliability, and deployment. This chapter presents the features available in the UML for architectural design and shows how they can be applied to real-time systems.
Notation and Concepts Discussed | ||
|---|---|---|
Design Phases | Component | Component Diagram |
Architectural Design | Multiprocessor Systems | Task Diagram |
Active Object | Deployment Diagram | |
Node | ||
By now you should have a good grasp of the process and products of analysis. Analysis identifies the criteria of acceptance of any solution. The first part of analysis studies system-environment interaction and explores and captures this interaction with context and use case diagrams. The second part of analysis drills down inside the system to identify the fundamental concepts that must be represented in the system's structure and dynamics. These concepts are captured as classes and objects.
Design is the process of specifying a specific solution that is consistent with the analysis model. Design is all about optimization and therefore is driven by the set of required quality of service properties of the system, such as reusability, timeliness, schedulability, throughput, memory usage, safety, reliability, and so on. The ROPES process divides design into three categories—architectural, mechanistic, and detailed design—as shown in Figure 8-1. Architectural design details the largest software structures, such as subsystems, packages, and tasks. The mechanistic design includes classes working together to achieve common goals. Detailed design specifies the internal primitive data structures and algorithms within individual classes. The three categories are described in greater detail in Table 8-1.

Table 8-1. Phases of Design
Design Phase | Scope | What Is Specified |
|---|---|---|
Architectural | System-wide Processor-wide |
|
Mechanistic | Collaboration-wide |
|
Detailed | Intra-object |
|
For simple systems, most of the design effort may be spent in the mechanistic and detailed levels. For larger systems, including avionics and other distributed real-time systems, the architectural level is crucial to project success. This chapter focuses on architectural design.
The design process can be either translative or elaborative. Translative design takes the analysis model and, using a translator, produces an executable system more or less autonomously. Great care must be put into the design of the translator, which is often highly customized for a particular problem domain and business environment. Translation is the focus of the model-driven architecture (MDA) and query/view/translate (QVT) initiatives within the OMG. As with any approach, there are benefits and detriments to translation. On the one hand, these approaches separate the realization details from the logical aspects, facilitating the portability and reuse of the intellectual property held in the models. On the other hand, the applications may have lowered performance and increased complexity. Nonetheless, the MDA approach is popular, particularly for designs that are expected to have a long lifetime.
Elaborative design adds increasing amounts of design detail until the system is fully specified. This is done either by adding detail to the analysis model, maintaining a single model of the system of increasing detail, or by maintaining two separate models. Each approach has pros and cons. Maintaining a single model is less work and less error prone than maintaining two models, but the design information “pollutes” the analysis model. On the other hand, maintaining two models by hand is error-prone but has the advantage of separation of concerns.
In practice, I recommend a combination of elaborative and translative design. Certain aspects are easy to add via translation (such as target source language and OS targeting), while others, such as the application of architectural design patterns, as most easily applied via elaboration. The UML is process-independent and applies equally to whatever design is selected.
The analysis model identifies objects, classes, and relationships but does not specify how they are organized into large-scale structures. As shown in Table 8-1, architectural design is concerned with large-scale design decisions involving collaborations of packages, tasks, or processors.
The ROPES process defines two fundamental kinds of architecture—logical and physical.[1] Logical architecture refers to the organization of things that exist only at design time—that is, the organization of classes and data types. Logical architecture is concerned with how models are themselves organized; this organization can be simple or very complex, depending on the needs and structure of the team(s) using it. The logical architecture is unrelated to the organization of the system at runtime, although one logical architecture pattern is to mirror the physical architectural structure. Figure 8-2 shows the roles of logical and physical architectures.
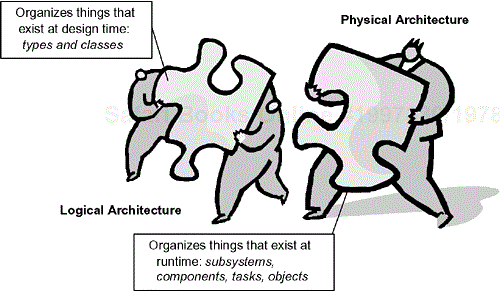
The primary place that architectural design work is done is, naturally enough, the architectural design part of the design phase. Here, strategic design decisions are made in each of the five views (or four views, if the subsystem architecture is already defined in the systems engineering part). These views will be detailed in the next section.
For the most part, architecture is done through the application of architectural design patterns. A design pattern is a generalized solution to a commonly occurring problem. Design patterns have three primary parts: a problem to be solved, the solution (the pattern), and a set of consequences. With architectural design patterns, the problem to be solved is always based in optimizing some small set of system QoS properties at the expense of others. Certain patterns optimize safety but by increasing recurring cost or complexity. Other patterns enhance reusability but at the expense of average execution time. Still others optimize predictability of execution time at the expense of optimal worst-case execution time (see [9] for many different architectural patterns for real-time systems).
Patterns can be mixed and matched as necessary, although clearly some mixes won't make any sense. It is common, for example, to mix a pattern for primary subsystem organization with another pattern for allowing distributed objects to communication and another pattern for concurrency management and another pattern for fault management and still another pattern for mapping to the underlying hardware. This gives rise to the notion of different aspects of architecture. The complete architecture of the system is the melding together of all the architectural patterns used. In the ROPES process, we identify five different views of architecture. It is common to have at least one pattern from each (and in some cases, more than one pattern in each) mixed together to form the complete system architecture.
There are many ways to organize a design model. The ROPES process recommends a logical architecture based on the concept of domains. A domain is an independent subject area that generally has its own vocabulary. Domains provide a means by which your model can be organized; or partitioned into its various subjects, such as User Interface, Hardware, Alarm Management, Communications, Operating System, Data Management, Medical Diagnostics, Guidance and Navigation, Avionics, Image Reconstruction, Task Planning, and so on.
This way, a domain is just a UML package used in a particular way. UML packages contain model elements, but, other than providing a namespace, packages have no semantics and are not instantiable.[2] The UML does not provide a criterion for what should go in one package versus another, but domains do. For this reason, we represent domain as a «domain» stereotyped package that includes a mission, specifically “hold classes and types around the common subject matter.” The use of domains does not dictate how objects will be organized and deployed at runtime however; that is what the physical architecture is all about.
Figure 8-3 shows a typical domain diagram—a package diagram that shows the relations of the domains themselves and the classes within the domains. In the figure, we see that the Alarm domain contains classes around the concept of alarm management—a couple of types of alarms, an alarm manager, and an alarm filter policy class. The alarms must be displayed in a list, so the Alarm Manager associates with a Text List class that is a user interface element and so is found in the User Interface domain. Alarms themselves are displayed as text, so the Alarm class (in the Alarm domain) associates with the Text class in the User Interface domain. Alarms must also be annunciated, so the Alarm Manager associates with the Speaker class in the Hardware domain. Also, the user needs to be able to acknowledge and silence the alarm and so the Alarm Manager associates with a Button class from the Hardware domain.

Physical architecture is concerned with the organization of things that exist at runtime. Although packages (and therefore domains) don't exist at runtime (being solely design-time concepts), they provide a place for the definition of the classes that will be used via instantiation in the various subsystems.
Domain structure usually does not completely reflect the physical architecture. For example, the physical architecture may have the notion of a Power Subsystem, which is constructed from instances of the classes defined in various domains. For example, the Power Subsystem may contain instances of many classes from a number of different domains, as shown in Figure 8-4. Using the standard name-scoping operator (::), the name of the domain package precedes the name of the class. So, for example, Hardware_Domain::Switch is the class Switch in the Hardware_Domain package, while Communications_Domain:: Message_Transaction is the Message_Transaction class in the Communications_Domain package.[3]
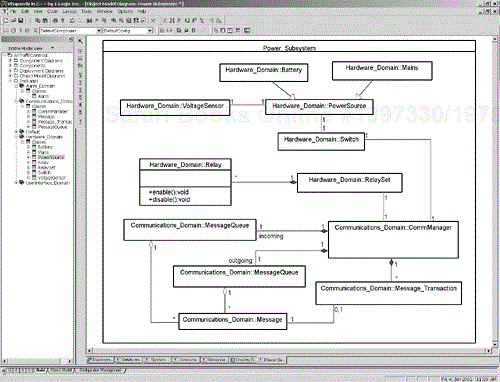
That being said, often there may be specialized domains containing classes only instantiated in one subsystem. For example, classes from a Guidance and Navigation domain will be likely instantiated solely in a Navigation subsystem. Most domains are more general than that, however, and are represented in many, if not all, subsystems.
Physical architecture refers to the large-scale organization elements of the system at runtime, so these elements must be instantiable things. The typical elements are subsystems, components, and «active» objects, but other specialized forms, such as a channel (a kind of subsystem) may be used. These large-scale organizational elements don't do much, in and of themselves, but they organize the more primitive instances that do the real work and provide management oversight and delegation of requests and messages to the appropriate objects. They allow us to view and understand the system at different levels of abstraction. This is crucial for the construction and understanding of large complex systems. We need to look at assemblies of parts and refer to them as a single, albeit more abstract, element. Figure 8-5 shows a common set of abstraction levels.
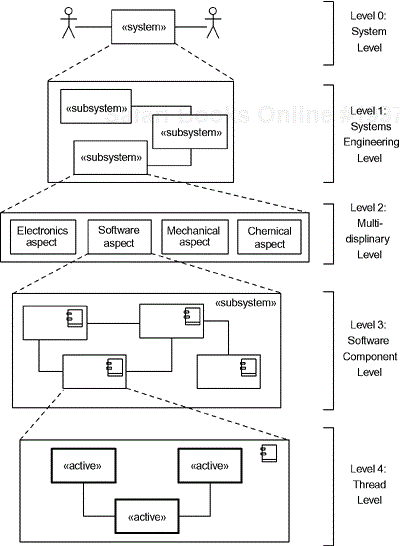
The most abstract level in the figure is the complete system (Level 0), such as “Mars Sample Return Mission.” The next level down is the systems engineering level (Level 1), where subsystems are defined and their interfaces specified. In the Mars project example, subsystems might be “Deep Space Network,” “Launch Vehicle,” “Orbiter,” “Lander,” “Spacecraft,” and “Ground System.” In a systems engineering environment, these are not yet broken down into software and hardware. There can be multiple sublevels at this level of abstraction, before the system is further decomposed into hardware and software aspects. For example, the “Spacecraft” could be decomposed into (sub)subsystems such as “Guidance and Navigation,” “Avionics,” “Attitude Control,” “Communications,” and “Power Management.”
Next, we've decomposed the system into the engineering disciplines (Level 2): electronic, mechanical, chemical, and software. If a system uses commercial, off-the-shelf (COTS) hardware, then this step may be skipped, but if you are developing custom hardware it may be very important. Notice that hardware/software decomposition is done primarily at the subsystem level rather than at the system level. For example, a jet's attitude control subsystem can be thought of as being composed of electronic aspects (processors, relays, motors, valve controls, a variety of sensors and serial connections), mechanical parts (reaction wheels, thruster assemblies, fuel lines and mixers, and enclosures), chemicals (fuel mixture and oxygen), and, of course, software (the “smarts” to receive and interpret commands, control electronic parts that control mechanical parts that work with chemicals).
The software for the subsystem may then be decomposed into its major architectural units, components, or software subsystems (Level 3). These are the major replaceable pieces of software that comprise the subsystem. For example, the components for the attitude control subsystem might include a TCP/IP communications protocol stack, math library, PID control loops for reaction wheels and thrusters, fuel management component, reaction wheel control component, and so on.
Lastly, we see the thread level (Level 4). This is the level at which concurrency is managed. Some components may be passive in the sense that they execute in the thread of the caller. However, there will be at least one component (or software subsystem) that creates and executes at least one thread. These threads will be owned by design-level «active» objects that also aggregate, via composition, the so-called primitive objects that ultimately perform application services. Here, if desired, the different kinds of concurrency units (processes, threads, fibers, and so on) may be specified, if that level of detail is required.
The last level is the object level (not shown). These are the primitive objects that do the real work of the system. In any particular system, there may be either a greater or fewer number of these abstraction levels depending on the complexity and scale of the system. For a cardiac pacemaker, you might represent only the system level and the thread level of architecture, while in our Mars project example, you might ultimately have as many as 8 or 10 levels. Not all of these levels need to be visible to all developers, of course.
The physical architecture may be constructed from virtually any model organization and so is thought of as distinct from the organization of the model per se, although it is possible to organize your model around the physical architecture. The high-level physical architecture is usually constructed in with systems engineering phase of the ROPES spiral but may be deferred to the architectural design phase if the systems engineering phase is omitted.
The ROPES process identifies the five views of (physical) architecture. These focus on more-or-less independent aspects of the large-scale runtime structure of the system. Of course, ultimately there is only one system. Limiting our perspective of the system to a single aspect allows us to focus on that aspect. The term view, used in this way, refers to showing a subset of the system model to allow a keener examination of some particular aspect.
These aspects are not completely independent and in a well-formed model certainly should not conflict with one another. The best way to think about this is to understand that there is a single model underlying the system that includes the architecture. The views just look at parts of the single model that are related to each other in specific ways. So these are not independent aspects, but a filtered view that only shows certain aspects at a time.
The five views of architecture defined in the ROPES process are shown in Figure 8-6.
These views of architecture capture structure aspects and so are typically described with UML structural diagrams. A concurrency task diagram, for example, is nothing more than a class diagram showing the structural elements related to the concurrency view—things like «active» objects, message queues, semaphores, and the like. When architectural behavior is being described, it is usually the interaction of the architectural elements that is of primary concern, so primarily sequence diagrams are used. To show the behavior of the architectural element in isolation, the functionality is usually divided up into use cases for the element and then each of these may be detailed with a state chart or activity chart.
Figure 8-7 shows a system view for an air traffic control system, using Rhapsody.

We see in Figure 8-7 the System object ACME_AirTrafficControlSystem and its environmental context. This consists of the actors[4] with which the system interacts.
The subsystem and component view (or subsystem view for short) identifies the large-scale pieces of the system and how they fit together. As previously mentioned, this is usually created during the systems engineering phase, but it may also be done later in the architectural design phase for projects not using a systems engineering phase. Subsystem architecture is captured using a subsystem diagram, which is really a class diagram that shows primarily the subsystems and their relations.
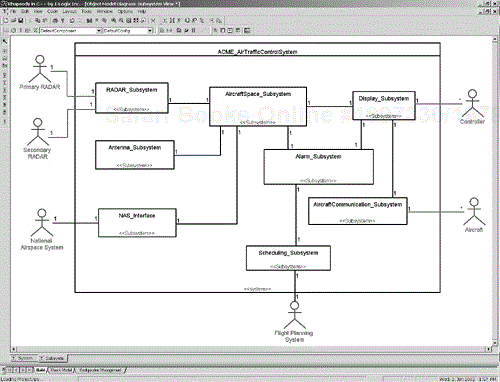
In a software-only development in which we are not concerned about the underlying hardware (or at least not very concerned), a subsystem is a runtime organization of software. It is a large-scale object that contains, via composition, part objects that do the real work of the subsystem. The criteria for inclusion in the subsystem is common behavioral purpose, that is, the objects included in the subsystem are there because they contribute to the subsystem's use case realization. Software subsystems give us a way to think about systems at different levels of decomposition rather than just as a flat sea of relatively undifferentiated objects.
The subsystem concept can be used in a couple of ways. Subsystems can be used to reason about systems before they are broken down into hardware and software parts, as discussed in the previous section. You may also use subsystems as a software-only concept. In either case, a subsystem is a really big object that provides well-defined interfaces and delegate service requests to internal hidden parts. How you use these UML building blocks is up to you. UML provides a vocabulary but it's up to you to write the story.
If you use a component-based development approach, the components are also architectural elements. The UML has a different icon for components, although UML 1.x is not prescriptive about the differences between a component and a subsystem. In the UML, a subsystem is basically a big object that contains part objects that do the real work of the subsystem. A component, on the other hand, is a replaceable part of the system. Typically, components use a component framework for loading and unloading components, component identification, and so on. In the UML 2.0, a component is a kind of structured classifier, and a subsystem is a kind of component. This doesn't address how components and subsystems should be used. Is a component bigger or smaller than a subsystem? How should they be mixed and matched? The UML does not say anything about these issues. As a general rule, I recommend that subsystems be the largest-scale parts of a system and that these may be internally decomposed into components, as desired.
The UML component diagram is just another structural diagram, one that emphasizes the component aspects of the system. An example of a component diagram is given in Figure 8-9, which shows the components for the Display_Subsystem of the ACME_AirTrafficControl System.

There are patterns that can help you effectively use these elements to architecturally structure your system. [9] provides a number of the ones that have particular relevance to real-time and embedded systems.
The concurrency and resource view of the system architecture focuses on the management of resources and the concurrent aspects of system execution. Because of the importance of this aspect, it is the subject of several chapters in [9].
By concurrent, we mean that objects may execute in parallel rather than sequentially. We are stating that we neither know nor care about the relative order of execution of actions between the threads[5] except where specifically mentioned. These points of synchronization are often called rendezvous and are the hard parts of concurrency modeling. Sharing data and information is a common reason for threads to rendezvous and synchronize. Another is the need to control and coordinate asynchronously executing system elements.
A resource is an element that has a finite and quantifiable aspect to its provided service. For example, it may allow only one actor at a time access its internal data. Since the hard parts of concurrency have to do with the sharing of resources, resources are treated in the same architectural view as concurrency.
Figure 8-10 shows a task diagram for the Alarm_Subsystem done in UML—a class diagram that emphasizes the task structure. All the «active» objects are shown with a heavy border (standard UML). Additionally, they may have «task» stereotype. Some of the classes show the stereotype as text while others use an icon. Similarly, the figure contains two «resource» objects—AlarmList and ListView. The first is associated with a semaphore (shown to its left) that manages the serialization of requests. The second is managed by its owning thread, Alarm_Annunciation_Thread, which, incidentally, has a «MessageQueue» object to manage information sharing.
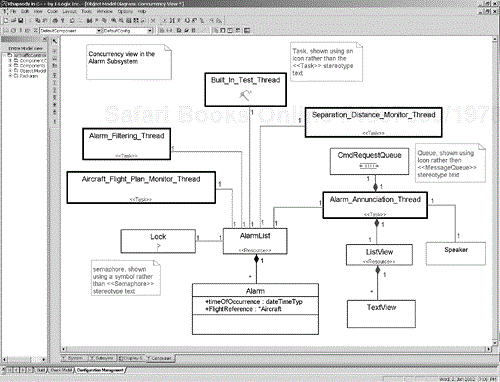
«Active» objects are the primary means for modeling concurrency in the UML. An «active» object owns the root of a thread and manages the execution of the thread and delegation of messages from the thread message queue to the appropriate objects.
There are a number of common strategies for identifying threads that will be later reified as «active» objects:
Single event groups
Event source
Related information
Interface device
Recurrence properties
Target object
Safety level
The single event groups strategy creates a separate thread for every event, and that event pends on its occurrence. This strategy is useful for simple systems but doesn't scale up to large complex systems well.
The event source strategy creates a thread for each source of an event and pends on any event from that source. It is useful when you have a small number of event sources and relatively simple designs.
The related information strategy creates a thread that manages all data within a topic or subject matter, such as all information related to cardiac health. In an anesthesia machine, this information might include pulse rate (from a blood pressure monitor), heart rate (from an ECG monitor), preventricular contraction count, cardiac output, stroke volume, temperature of the blood coming from the superior vena cava and emptying in the right atrium, and so on. This information comes from a variety of sources and a single thread could manage it. This strategy is effective for sensor fusion applications that require significant processing of data from disparate sources. Further, this strategy tends to reduce the number of thread rendezvous, which can be a source of significant overhead.
The interface device strategy is a specialized form of event source strategy that is used for systems with multiple data and command buses. One or more threads are spawned to manage the bus traffic and related processing.
The recurrent properties strategy is a demonstrably optimal strategy for thread selection when schedulability of the threads is an important concern. The recurrence properties include whether or not the event set processed by the thread is periodic (time-based) or aperiodic (event-based). Periodic tasks execute and do work every so often with a defined frequency of execution. It is common to have several periodic tasks, each handling events that occur in a common time frame, such as one for the 10 ms-based events, one for the 100 ms-based events, and another for the 250 ms-based events. Aperiodic events can either be handled by a general aperiodic event handler, or you can introduce a separate thread for each aperiodic event (as in the single event group strategy). Most systems must process a combination of periodic and aperiodic events.
The target object strategy creates a thread for a few special objects that are the target of events from disparate sources. For example, database or data manager objects sometimes have threads assigned to them so they can do appropriate processing when processing cycles are available.
The safety level strategy creates threads for managing safety and reliability functionality, such as the execution of periodic built-in tests (BITs), stroking watchdogs, monitoring actuation to ensure that it is proceeding correctly, and so on.
No matter how you come up with the set of threads you decide you want to use, the common development approach is to first construct the collaborations—sets of objects working together to realize a use case—then identify the set of threads and create an «active» object for each thread. Each primitive object from the collaboration is aggregated via composition by the appropriate «active» object allowing it to execute in the appropriate thread.
The distribution view deals with how objects find and collaborate with each other even though they may be in different address spaces. The distribution view includes policies for how the objects communicate, including the selection and use of communication protocols. In asymmetric distribution architectures, an object is dedicated to a particular address space at design time. This makes finding that object simple during runtime because the other objects can be granted a priori knowledge about how to locate and contact the object in question. In symmetric distribution architectures, the location of an object isn't decided until runtime. Symmetric architectures are useful for a complex system that must dynamically balance processing load over multiple processors. When objects become ready to run, the distributed OS runs the object in an optimal locale, based on the current loadings on the various processors. This improves overall performance but at a cost—increased complexity. How, for example, can objects find each other during runtime? This is the subject of the distribution patterns in [9].
The broker architecture in Figure 8-11 is used to mediate communication among distributed objects. In this case, the objects are to participate in a possibly distributed communications subclass of the Communicating Object class. We see that this class has the stereotype «CORBAInterface». Rhapsody produces the CORBA interface description language (IDL) automatically for you; for other tools, you will probably have to write the IDL manually. The IDL generates code that produces the Client_Side_Proxy and Server_Side_Proxy classes. These encapsulate information on how to serialize the data and contact the broker. The Broker object is typically purchased from an object request broker (ORB) vendor and provides connection and naming (and a whole host of other) distribution services. The Bridge object allows ORBs to communicate across multiple networks. In a sufficiently capable tool, you will only have to write the classes you want to communicate and specify that they have the «CORBAInterface» interface, and the tool will generate all the rest of the code for the distribution. In less capable tools, each of these classes will need to be generated by hand.

Selecting a distribution architecture is highly driven by the QoS of the collaboration. The most relevant QoS to drive the distribution architecture include
Performance
Worst case
Average case
Predictability
Throughput
Average
Burst
Reliability
Of message delivery
Of message integrity
Recurring (e.g., hardware) cost
Of course, in real-time and embedded systems performance can be crucial to success. In hard real-time and safety-critical systems, worst-case delivery time is the most important. For example, control loops are notoriously sensitive to time delays. To implement distributed closed-loop control systems, you want an architecture with short and predictable worst-case delivery times for certain messages, implying that a priority-based message delivery scheme might be the most appropriate. In such a case, using an asymmetric architecture (or some variant of the observer pattern) with a predictable priority-based transport protocol might fit the system performance needs—for example, an asymmetric distribution on top of a bit-dominance protocol, such as the CAN bus protocol. Ethernet is a common, but less-than-optimal choice in such cases, as it is based on a Collision-Detect Multiple Access (CDMA) protocol, meaning that while the bus is multimastered, collisions (multiple sources attempting to transmit at the same time) can occur. When they occur with the Ethernet protocol, the senders stop trying to transmit and retry later at random times. This means that Ethernet networks saturate at about 30% utilization. Above that point, Ethernet spends an inordinate amount of time resolving transmission collisions and little time actually sending information. Ethernet can be used for hard real-time distribution when very lightly loaded (meaning that collisions are rare) or when the message delivery time is a small part of the overall execution budget.
In so-called soft real-time systems, the average performance is a more important criterion that worst-case performance. Average performance may be measured in terms of average length of time for message delivery or in “mean-lateness” of the messages. Such systems usually don't care if a small set of the messages is late when the system is under load, as long as the average response is sufficient. It may even, in some case, be permissible to drop some messages altogether when the system is under stress. For example, a broker pattern with a CDMA transport protocol such as UDP transport protocol on top of an Ethernet network protocol will serve this purpose well if the average load is low. For systems in which peak loads are few and far between, and individual message delivery times are not crucial, CDMA can be a good choice. Interestingly, many systems are built on TCP/IP even when it is a demonstrably poor choice given the quality of service requirements for the system.
Time Division Multiple Access (TDMA) protocols work by dividing up available communication time among the devices on the bus. Each device gets to transmit for a certain period of time and then passes along a master token to the next device on the bus. TDMA protocols have low communication arbitration overhead but don't scale up to large numbers of devices well. Further, like a round robin approach to task scheduling, such a system is not responsive in an event-driven application because an event requiring transmission must wait until the owning device has the master token.
Priority-based protocols typically have more overhead on a per-message basis, but allow higher-priority messages through first at the expense of lower-priority messages, making it a natural fit for systems in which scheduling is primarily priority-driven. Bit-dominance protocols are a common way to achieve priority-based messaging. In a bit-dominance protocol, each sender listens to what appears on the bus while it's transmitting; low-priority bits are the passive state of the bus and high-priority bits are the active state. If a higher-priority bit occurs in the bus when it sent out a lower-priority bit, then it assumes that it is in conflict with a device trying to send out a higher-priority message, and it drops out to retry later. The device sending out the higher-priority message wins and keeps transmitting. For example, this is how the CAN bus protocol works. Each message contains a priority sequence called a message identifier, followed by the message contents. If each message has a unique identifier, then it has a unique position in the priority scheme.
An issue with the CAN bus protocol is that it allows only 8 bytes of data per message, requiring larger messages to be fragmented into multiple bus messages during transmission and reassembled at the receiver end. The SCSI bus is another example of a priority-based transmission protocol, but the SCSI bus is also a parallel bus meaning that it can achieve greater bandwidth. Complicating its use as a general message passing bus, however, is the fact that the priority is not based on the message but on the device transmitting the message.
Reliability for distribution means the reliability of correct message delivery. There are many reasons why messages might not be properly delivered, such as attenuation due to distance, interference with electrical noise, temporary or permanent failure of the media or associated device, and software or hardware design flaws. These things may be handled by adding complexity into the communications protocol to check the integrity of messages and to retry transmission if the message is either corrupted or not delivered. Of course, redundant buses are a solution as well, with the advantage of improved reliable and timeliness in the presence of errors, but at a higher recurring cost.[6]
Software solutions for message integrity usually require the addition of some level of redundancy, such as a parity bit (very light weight), checksum (lightweight), or cyclic redundancy check (CRC). Of these, the best is CRC because it will identify all single and dual bit errors as well as a very high percentage of multiple-bit errors. CRCs are somewhat more complex to compute than a checksum, but a table-driven CRC computation can be very fast and hardware chips are available that can compute a CRC from a serial bit stream.
Another approach is the use of Hamming codes. Hamming codes are codes that are differentiated by what is called a Hamming distance—the minimum number of bit errors necessary to come up with an incorrect, but valid code. For example, in an 8-bit byte, the codes in Table 8-2 have a Hamming distance of 2 because they require two bits to be modified before you can come up with another valid code.
The use of Hamming codes provides some protection against bit errors because it requires multiple bit errors to construct another valid possibility.
It is even possible to send the message multiple times (usually twice, if error detection is required, and thrice if error correction is needed). If the message data is sent twice, then the second copy can be sent as a ones-complement of the original so that stuck-at bit errors can be detected.
The safety and reliability view examines how system redundancy is defined and managed, in order to raise system reliability and safety. The safety and reliability architecture is concerned with correct functioning in the presence of faults and errors. Redundancy may be used in many ways to get different degrees and types of safety and reliability.
In Figure 8-12, heterogeneous redundancy (also known as diverse redundancy) is used to provide protection from failures and errors. The Primary Radar channel processing surface reflection RADAR information produces three-dimensional position (in terms of direction, range, and azimuth) as well as velocity using the Doppler effect. The Secondary channel uses the beacon return codes to get a transponder code from the aircraft and the aircraft's position and velocity information.
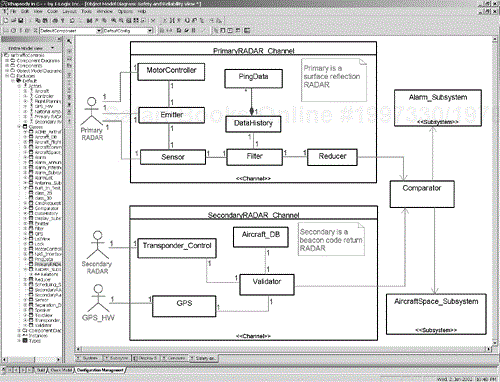
Reliability is a measure of the up-time or availability of a system—specifically, it is the probability that a computation will successfully complete before the system fails. It is normally estimated with mean time between failure (MTBF). MTBF is a statistical estimate of the probability of failure and applies to stochastic failure modes.
Reducing the system downtime increases reliability by increasing the MTBF. Redundancy is one design approach that increases availability because if one component fails, another takes its place. Of course, redundancy only improves reliability when the failures of the redundant components are independent.[7] The reliability of a component does not depend on what happens after the component fails. Whether the system fails safely or not, the reliability of the system remains the same. Clearly the primary concern relative to the reliability of a system is the availability of its functions to the user.
Safety is distinct from reliability. A safe system is one that does not incur too much risk to persons or equipment. A risk is an event or condition that can occur but is undesirable. Risk is the product of the severity of the incident and its probability. The failure of a jet engine is unlikely, but the consequences can be very high. Thus the risk of flying in a plane is tolerable; even though it is unlikely that you would survive a crash from 30,000 feet, such an incident is an extremely rare occurrence. At the other end of the spectrum, there are events that are common, but are of lesser concern. There is a risk that you can get an electric shock from putting a 9-volt battery in a transistor radio. It could easily occur, but the consequences are small. Again, this is a tolerable risk.
The key to managing both safety and reliability is redundancy. For improving reliability, redundancy allows the system to continue to work in the presence of faults because other system elements can take up the work of the broken one. For improving safety, additional elements are needed to monitor the system to ensure that it is operating properly; other elements may be needed to either shut down the system in a safe way or take over the required functionality.
The deployment view focuses on how the software architecture maps onto the physical devices such as processors, disk drives, displays, and so on. The UML uses the concept of a node to represent physical devices. Nodes are often stereotyped to indicate the kind of hardware they represent. Some developers may only differentiate between processors (devices that execute code that you write) and devices (ones that don't), while others prefer to identify more detail such as whether a device is a stepper motor, DC motor, thermometer, IR sensor, and so on.
Figure 8-13 is a typical UML deployment diagram. Most stereotypes are shown using icons, but text in guillemots (e.g., «Bus») can be used as easily; it is a matter of personal preference. This deployment diagram shows two «Bus» devices, several different processors, redundant flight recorder devices, and redundant display controllers. The diagram also indicates some of the components executing on selected processors.
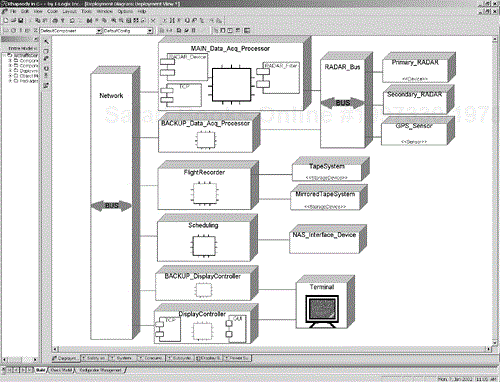
The primary use for the deployment view is to represent asymmetric deployment architectures. Then the hardware platform can be schematically represented and the mapping of software subsystems and components can be detailed. For asymmetric systems this is particularly important to understanding how the software on the different processors will collaborate and permits performance analysis. You can either nest the software components inside the system or use a dependency from the component or software subsystem to indicate that the node supports or executes that software element. Figure 8-13 shows a couple of nodes with components nested inside them. Any software element can be shown in this way, but showing components and subsystems this way makes the most sense.
For symmetric architectures, the deployment diagram is perhaps less interesting, but only marginally so. The underlying hardware is even then a mixture of symmetric and asymmetric aspects. The interesting part, the execution of software elements on the nodes, is in principle not known when the deployment diagram is drawn at design time. In some cases, a software element might even migrate from one node to another. The UML provides the «becomes» stereotype of the dependency relation to indicate that an element might move from one node to another, such as might happen in the event of a fault on the original processor.
System architectural design is broader in scope than just software and involves the hardware architecture as well, including electronic and mechanical design. Naturally, hardware architecture has a great impact on the software architecture. Together, hardware and software architectures combine to form the system architecture. In most embedded systems, the system architecture is by necessity a collaborative effort among engineers from a wide variety of disciplines, including software, electronics, mechanics, safety, and reliability. The system design must ensure that all the pieces will ultimate fit together and achieve the system objectives in terms of functionality, performance, safety, reliability, and cost.
The software must ultimately map to the electronic, mechanical, and chemical aspects of the system. This mapping occurs primarily at the architectural and detailed levels of design. The detailed design level deals with the physical characteristics of the individual hardware components and ensures that low-level interface protocols are followed. The architectural level maps the large-scale software components such as subsystems, packages, and tasks onto the various processors and devices. Mechanistic design is insulated away from most aspects of physical architecture.
It is crucial to the success of the system that the electrical and software engineers collaborate on these decisions. If the electrical engineers don't understand the software needs, they are less able to adequately accommodate them. Similarly, if the software engineers don't have a sufficient understanding of the electronic design, their architectural decisions will be at best sub-optimal, and at worst unworkable. For this reason, both disciplines must be involved in device specification, particularly processors, memory maps, and communication buses. It is an unfortunate truth that many systems do not meet their functional or performance requirements when this collaboration is missing in the development process.
The software concerns for each processor are as follows:
Envisioned purpose and scope of the software executing on the processor
The computational horsepower of the processor
Availability of development tools such as compilers for the selected language, debuggers, and in-circuit emulators
Availability of third-party components, including operating systems, container libraries, communication protocols, and user interfaces
Previous experience and internal knowledge with the processor
How the processors are linked together is another far-reaching set of electronic design decisions. Should the communication media be arranged in a bus or star topology? Should it be bus-mastered or master-slave? Should it arbitrate on the basis of priority or fairness? Point-to-point or multidrop? How fast must the transmission rate be? These are the requirements of just the physical communications media. The software must layer appropriate communications protocols on top of that to ensure timely and reliable message exchange.
Naturally, these electronic design decisions can have a tremendous impact on the software architecture. Smaller processors can be used if there are more of them and they are linked together appropriately, or a smaller number of larger processors can do the same work. If the bus mastering is not arbitrated in hardware, it becomes more difficult to implement a peer-to-peer communications protocol required for distributed processing. Only by working together can the electronic and software engineers find an optimal solution given the system constraints. The optimal solution itself is specific to both the application domain and the business goals and approaches.
Within the confines of the physical architecture, the software itself has large-scale structures. The UML defines a subsystem as a subordinate system within a larger system [1]. In the embedded world, it is useful to further constrain our use of the term to mean an integrated set of software components residing on a single physical processor.[8] These components will typically be packages that contain other packages, tasks, objects, and classes. Software architecture then becomes the process of designing subsystems, packages, and tasks and their interconnections.
UML 2.0, as discussed previously, has elaborated the concept of a subsystem to be a kind of structured class with internal parts, which may connect to other elements via ports. Ports and interfaces aren't required to use subsystems, but they do aid in the encapsulation of the subsystem internal structure and its isolation of the subsystem internals from the environment. Figure 8-14 shows an example that has ports with and without required and offered interfaces and associations between subsystems that are not mediated by ports.

Subsystems are often organized as a set of layered elements, each of which may itself be decomposed into smaller parts. Many complex systems have several layers ordered hierarchically from the most abstract (closest to the system problem domain) down to the most concrete (closest to the underlying hardware). For example,
Application
User interface
Communication
OS
Hardware abstraction
The OSI seven-layer reference model is a common layered architecture for communications protocols, as shown in Figure 8-15. The lollipop at the left of each subsystem represents its interface, a set of classes and objects that may be externally accessed via its ports.[9]

In the layered architecture pattern [9], the basic organization is a set of client-server relationships among the layers. The more abstract layers are the clients that invoke the services of the more concrete layers. This one-way dependency makes it possible to use the same lower-level server layers in different contexts because they know nothing of their clients. Similarly, since the lower layers offer a well-defined set of interfaces, they can be replaced with different lower layers, making the entire subsystem easily portable to other physical environments.
A layered implementation strategy would build each layer independently and link them together as they are completed. However, this approach has been proven to be risky and expensive in practice because fundamental (i.e., architectural and requirement) flaws that affect the overall subsystem functionality are not caught until post-integration. A better implementation strategy is to implement vertical slices, as shown in Figure 8-16.
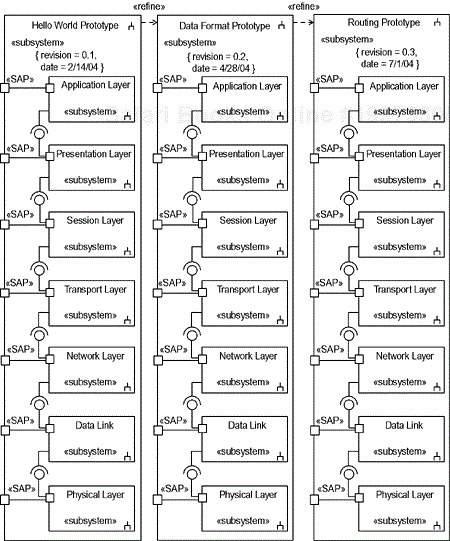
Each vertical slice implements only the portion of each layer relevant to the purpose of the slice. This approach to implementation is called iterative prototyping and each slice is called a prototype. The prototypes are implemented so that each prototype builds on the features implemented in its predecessors. The sequence of prototypes is decided based on which features logically come first as well as which represent the highest risk. With risk-based development, higher-risk items are explored and resolved as early as possible. This typically results in less rework and a more integrated, reliable system.
Figure 8-16 shows a set of subsystems with a refinement relation between successive versions. The refinement relation is a stereotyped dependency in which one model element represents a more refined version of another. Also note that two tagged property values are used to indicate the version and date using the normal { tag = value} syntax.
A more complete set of prototypes for Figure 8-16 might include those shown in Table 8-3.
Table 8-3. Vertical Slice Prototypes
# | Prototype Name | Description |
|---|---|---|
1 | Hello World | Implement enough of each layer (and stub the remainder) to send a message from one node to another. |
2 | Data Format | Mostly presentation layer—implement data encode, decode and network data format conversions. Also include timed ACK/NAK transport layer protocol. |
3 | Routing | Mostly network and data link layers to control routing of messages. |
4 | Flow Control | Data link Xon/Xoff flow control, and message CRCs to implement data integrity checks with automatic retry on message failure. |
5 | Connections | Connections and sessions (transport, data link, session layers). |
6 | Performance | Performance tuning of all layers to optimize throughput. |
Note how the later prototypes build on the services implemented in their predecessors. This is the essence of the iterative prototyping development philosophy—gradually adding capability until the entire system is complete. Naturally, iterative prototyping applies to more than just communication protocol design. Any sufficiently complex piece of software can be broken down into a set of hierarchical layers in a client-server topology.[10]
It is common for these components to contain one or more threads. The concurrency model is another piece of architectural design that can greatly impact system performance. In a soft real-time environment, average throughput must be ensured, but individual deadlines are not crucial to system correctness. In hard real-time environments, however, each deadline must be met and the concurrency model must ensure the ability of the system to meet all deadlines. For most multitasking systems, this is a nontrival problem because the exact arrival patterns are not periodic and synchronous. Commonly, the system must respond to periodic events with vastly different periods as well as aperiodic events that may be bursty. Concurrency design is the subject of the latter half of this chapter.
The last primary architectural goal is to design the global error handling policies to ensure correct system performance in the presence of faults.[11] Many strategies are possible, ranging from each object assuming full responsibility for all errors to a single global error handler that decides the correct action to take in all error conditions. Most systems are a hybrid of such approaches. One popular strategy is to have multiple levels of error handling with the general rule that each error will be handled at the point at which enough context is available to make the correct decision. An object with enough redundancy of its data members (such as triple storage for important data) might process an invalid data value by reconstructing the appropriate data value or assigning a default value in the event of an error. A subsystem might reboot itself and let the remainder of the system function when it discovers some particular error. Some errors may require a global handler to intervene and coordinate a correct system shutdown, such as in the event of a failure in a nuclear power plant.
Error handling policies are usually at least as complex as the primary software functionality and may result in systems three times as large and an order of magnitude more complex. Complicating error handling is the fact that it is highly system dependent, yet only through clear error handling policies can safety-critical systems be deployed safely.[12] This is an important aspect of the software architecture. [7] discusses the fundamental concepts of safety and reliability in the context of embedded system and [9] provides set of architectural design patterns for optimizing various aspects of system safety and reliability.
The UML represents hardware/software mapping with deployment diagrams. There are a number of important diagrammatic elements, as shown in Figure 8-17. The icon of primary importance on deployment diagrams is the node. Nodes represent processors, sensors, actuators, routers, displays, input devices, memory, custom PLAs, or any physical object of importance to the software. Typically, nodes are stereotyped to indicate the type of node. Interconnects represent physical interconnections among nodes. They are most commonly electronic, but can as easily be optical or telemetric.
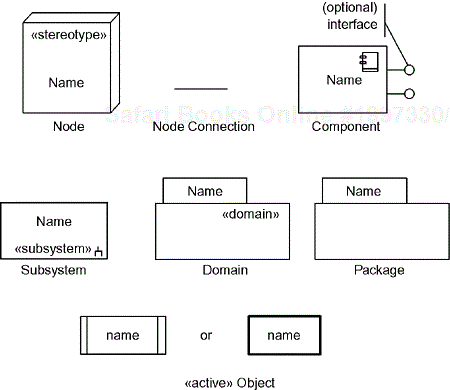
Classes are part of the logical architecture of the system. That it, the represent the logical concepts of the system and low they are inherently linked together. Subsystems, components, tasks, and objects are part of the physical architecture. A component is an artifact of development that exists at runtime. Typical components are executables, libraries, files, configuration tables, and so on. Such software artifacts end up deployed on hardware—this is represented by the node and may communicate across physical linkages. See Figure 8-17.
Nodes are often divided into two fundamental kinds—those that run software that we produce (processors) and those that do not (devices). These are often stereotyped into more specific kinds of hardware, such as DC motors, stepper motors, laser ranger finders, displays, buttons, keyboards, pressure sensors, and the like. You don't have to stereotype the nodes, but many people do and like to use special icons to represent the various hardware devices.
There are always many ways that a logical architecture can be mapped to a physical architecture. In fact, the same logical architectural elements may end up instantiated in multiple components. For example, many components may have to communicate with each other across a bus. They may all contain classes to assist the marshalling and unmarshalling of resources for bus transfer.
Processor nodes are occasionally shown containing classes or objects, but usually processor nodes contain components that may be broken down into subcomponents and tasks (represented as «active» objects). To show tasks, include the «active» objects in the component on the diagram. Of course, these components are the realization of objects and classes, but classes and objects usually only appear on class and object, not deployment, diagrams.
Figure 8-18 shows a simple deployment diagram for a telescope position control system. The user interface consists of an LCD display and two rotary encoder knobs, which are tied to the same processor. The positioning subsystem consists of two independent subsystems, each containing a stepper motor and an independent sensor. The processors are linked across an Ethernet network, and both use Ethernet controller boards to access the network.
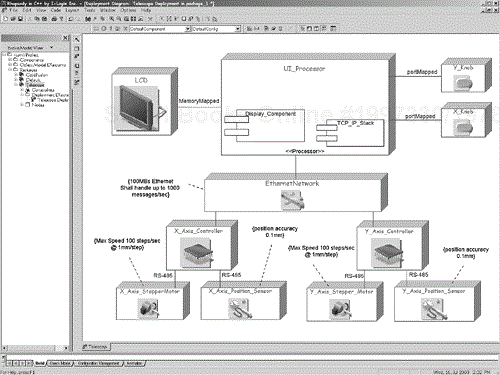
This figure shows two methods for specifying the software running on the processors. The first is shown in the UI Processor node. This node contains software components; in this case, a Display component and a TCP/IP protocol stack. The stereotype «processor» is shown textually. The other two notation processors, controllers for the x and y axes, use the iconic form to show their stereotype. The devices are also shown using iconic stereotype forms.
Real-time systems typically have multiple threads of control executing simultaneously. A thread can be defined as a set of actions that execute sequentially, independent from the execution of action in other threads. Actions are statements executing at the same priority in a particular sequence or perform some cohesive function. These statements can belong to many different objects. The entirety of a thread is also known as a task. Multiple objects typically participate within a single task. Commonly, a distinction is made between heavyweight and lightweight threads. Heavyweight threads use different data address spaces and must resort to expensive messaging to communicate data among themselves. Such threads have relatively strong encapsulation and protection from other threads. Lightweight threads coexist within an enclosing data address space. Lightweight threads provide faster inter-task communication via this shared global space, but offer weaker encapsulation. Some authors use the terms thread or task to refer to lightweight threads and process to refer to heavyweight threads. We use thread, task, and process as synonyms in this book, with the understanding that if these distinctions are important, the «active» object would be more specifically stereotyped as «process», «task», or «thread».
The UML can show concurrency models in a several ways. The primary way is to stereotype classes as «active»; other ways include orthogonal regions (and-states) in statecharts, forks and joins in activity diagrams, and the par operator in UML 2.0 sequence diagrams.
Class and object diagrams can use the stereotype «active» or the active object stereotype icon to represent threads. By including only classes and objects with this stereotype, we can clearly show the task structure. A task diagram is nothing more than a class diagram showing only active objects, the classes and objects associated with concurrency management such as semaphores and queues, and the relations among these classes and objects.
Class and object models are fundamentally concurrent. Objects are themselves inherently concurrent and it is conceivable that each object could execute in its own thread.[13] During the course of architectural design, the objects are aligned into a smaller set of concurrent threads solely for efficiency reasons. Thus the partitioning of a system into threads is always a design decision.
In UML, each thread is rooted in a single active object. The active object is a structured class that aggregates the objects participating within the thread. It has the general responsibility to coordinate internal execution by the dispatching of messages to its constituent parts and providing information to the underlying operating system so that the latter can schedule the thread. By only showing the classes with the «active» stereotype on a single diagram, you can create a system task diagram.
The appropriate packaging of objects into nodes and threads is vital for system performance. The relationships among the threads are fundamental architectural decisions that have great impact on the performance and hardware requirements of the system. Besides just identifying the threads and their relationships to other threads, the characteristics of the messages must themselves be defined. These characteristics include
Message arrival patterns and frequencies
Event response deadlines
Synchronization protocols for inter-task communication
“Hardness” of deadlines
Answering these questions is at the very heart of multithreaded systems design.
The greatest advantage of a task diagram is that the entire set of threads for the system can be shown on a single diagram, albeit at a high conceptual level. It is easy to trace back from the diagram into the requirements specification and vice versa. Elaborating each thread symbol on the task diagram into either a lightweight task diagram or an object diagram means that the threads can be efficiently decomposed and related to the class, object, and behavioral models.
Figure 8-19 shows a task diagram for an elevator model; the primitive objects—the ones that do the actual management of the elevator system—are subsumed within the shown «active» classes. The diagram shows a number of useful things. First, notice that the structured classes for the various subsystems (Floor, Elevator, Shaft, Central Station, and Gnome) contain the task threads, and the task threads will internally contain the primitive objects. The tasks are shown with the heavy border. Some of the tasks show that they associate with semaphores and queues, which can be identified with the icons (or could be identified with textual stereotypes).
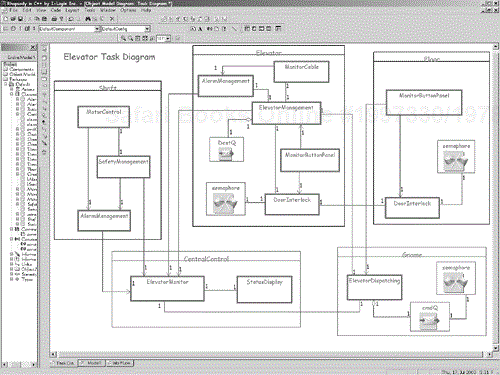
Within each processor, objects are busy collaborating to achieve the goals of that subsystem. However, on the system task diagram, only the threads and concurrency management classes are shown. Remember that each thread is rooted in a single «active» composite object that receives the events for that thread and dispatches them to the appropriate object within the thread.
The associations among the threads are shown using conventional association notation. These associations indicate that the threads must communicate in some fashion to pass messages.
Rumbaugh [2] has suggested a means by which concurrent threads can be diagrammed using the statecharts. He notes that concurrency with objects generally arises by aggregation; that is, a composite object is composed of component objects, some of which may execute in separate threads. In this case, a single state of the composite object may be composed multiple states of these components.
«active» objects respond to events and dispatch them to their aggregate parts. This process can be modeled as a finite state machine. The other orthogonal component is due to the thread itself having a number of states. Since the active object represents the thread characteristics to the system, it is very natural to make this an orthogonal component of the active object.
Figure 8-20 shows the two orthogonal components of a typical «active» object class. The dashed line separates the orthogonal components of the running superstate. Each transition in the event processing component can only take place while the «active» object is in one of the substates of the running superstate of the thread component. After all, that is the only time it actual consumes CPU cycles. On the other hand, if the running thread becomes preempted or suspended, the event processing component will resume where it left off, as indicated by the history connector.
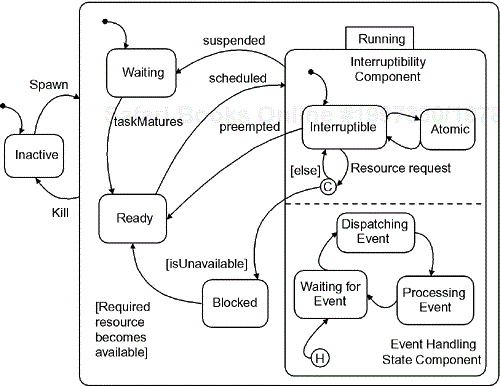
Table 8-4 provides a brief description of the states.
Table 8-4. States of the Active Object Thread Component
State | Description |
|---|---|
Inactive | Thread is not yet created. |
Waiting | Thread is not ready to run, but is waiting for some event to put it in the ready state. |
Ready | Thread is ready to run and is waiting to execute. It is normally stored in a priority FIFO queue. |
Running | Thread is running and chewing up CPU cycles. This superstate contains two orthogonal, concurrent components. |
Interruptible | The thread is running and may be preempted. This is substate of the interruptibility component of the running state. |
Atomic | The thread is running but may not be preempted. Specifically, task switching has been disabled. This is substate of the interruptibility component of the running state. |
Blocked | Thread is waiting for a required resource to become available so that it may continue its processing. |
Waiting for event | The thread is waiting for an event to handle. This is substate of the Event Handling state component of the running state. |
Dispatching Event | The object is handling an incoming event and deciding which aggregates should process it. This is substate of the Event Handling state component of the running state. |
Processing Event | The designated aggregate of the active object composite is responding to the event. This is substate of the Event Handling state component of the running state. |
During analysis, classes and objects were identified and characterized and their associations defined. In a multitasking system, the objects must be placed into threads for actual execution. This process of task thread definition is two-fold:
Identify the threads.
Populate the threads with classes and objects from the analysis and design process.
There are a number of strategies that can help you define the threads based on the external events and the system context. They fall into the general approach of grouping events in the system so that a thread handles one or more events and each event is handled by a single thread.
There are conditions under which an event may be handled by more than one thread. One event may generate other propagated events, which may be handled by other threads. For example, the appearance of waveform data may itself generate an event to signal another thread to scale the incoming data asynchronously. Occasionally, events may be multicast to more than one thread. This may happen when a number of threads are waiting on a shared resource or are waiting for a common event that permits them all to move forward independently.
Internal and external events can be grouped in a variety of ways into threads. The following are some common event grouping strategies.
Single Event Groups: In a simple system, it may be possible to create a separate thread for each external and internal event. This is usually not feasible in complex systems with dozens or even hundreds of possible events or when thread switch time is significant relative to the event response timing.
Sequential Processing: When it is clear that a series of steps must be performed in a sequential fashion, they may be grouped within a single thread.
Event Source: This strategy groups events from a common source. For example, all the events related to ECG numerics may be grouped into one thread (such as HR Available, ECG Alarms, etc.), all the noninvasive blood pressure (NIBP) data in another, the ventilator data in another, the anesthetic agent in another, and the gas mixing data in yet another. In an automobile, sources of events might be the ignition, braking, and engine control systems. In systems with clearly defined subsystems producing events that have roughly the same period, this may be the simplest approach.
Interface Device (Port): This grouping strategy encapsulates control of a specific interface within a single thread. For example, the (periodic) SDLC data can be handled in one thread, the (episodic) RS232 data to the external models by another, and the (episodic) user buttons and knobs by another. This strategy is a specialization of the event source grouping strategy.
Related Information: Consider grouping all waveforms to be handled by a single thread, and all measured numeric parameters within another thread. Or all information related to airfoil control surfaces in each wing and tail section might be manipulated by separate threads. This grouping may be appropriate when related data is used together in the user problem domain. Another name for this grouping is functional cohesion.
Arrival Pattern: If data arrives at a given rate, a single periodic thread could handle receiving all the relevant data and dispatching it to different objects as necessary. Aperiodic events might be handled by a single interrupt handler and similarly dispatch control to appropriate objects. Generally, this grouping may be most useful with internal events, such as timer interrupts, or when the periods of events naturally cluster around a small set of periods. Note that this is the primary strategy for identifying threads that have deadlines—use of other policies with time-constrained event responses can lead to priority inversion unless the designers are especially careful.
Target Object/Computationally Intense Processing: One of the purposes of rendezvous objects is to encapsulate and provide access to data. As such, they are targets for events, both to insert and remove data. A waveform queue object server might have its own thread for background scaling and manipulation, while at the same time participating in threads depositing data within the queue object and removing data for display.
Purpose: Alarms serve one purpose—to notify the system user of anomalies, so that he or she can take corrective action or vacate the premises, whichever seems more appropriate. This might form one event group. Safety checks within a watchdog thread, such as checking for stack overflow or code corruption, might form another. This purpose might map well to a use case.
Safety Concerns: The system hazard analysis may suggest threads. One common rule in safety-critical systems is to separate monitoring from actuation. In terms of thread identification, this means that a thread that controls a safety-relevant process should be checked by an independent thread. From a safety perspective, it is preferable to run safety checks on a separate processor, so that common-mode hardware and software faults do not affect both the primary and the safety processing simultaneously.
During concurrency design, you must add events to groups where appropriate so that each event is represented in at least one group. Any events remaining after the initial grouping can each be considered independently. As mentioned earlier, it is recommended that thread actions with hard deadlines use the arrival-pattern strategy to ensure a schedulable set of threads. Create a task diagram in which the processing of each group is represented by a separate thread. Most events will only occur within a single thread, but sometimes events must be dispatched to multiple threads.
Frequently, one or more of these groupings will emerge as the primary decomposition strategy of the event space, but it is also common to mix grouping strategies. When the grouping seems complete and stable, you have identified an initial set of threads that handle all events in your system. As the product development evolves, events may be added to or removed from groups, new groups may suggest themselves, or alternative grouping strategies may present themselves. This will lead the astute designer to alternative designs worth consideration.
Once you have identified a good set of threads, you may start populating the groups with objects. Note that I said “objects” and not “classes. “Objects are specific instances of classes that may appear in different threads or as an interface between threads. There are classes that only create a single instance in an application (singletons), and there are classes that instantiate to multiple objects residing within a single thread, but generally, classes instantiate a number of objects that may appear in any number of threads. For example, there may be queues of threads, queues of waveform data, queues of numeric data, queues of network messages, command queues, error queues, alarm queues, and so on. These might appear in a great many threads, even though they are instances of the same class (queue).
So far, we have looked at what constitutes a thread, some strategies to select a set of threads, and how to populate threads with objects. The remainder of this chapter provides ways to define how the threads communicate with each other.
There are a number of strategies for inter-task communication. The simplest by far is to use the OS to send messages from one thread to another. While this approach maintains encapsulation and limits coupling among threads, it is expensive in terms of compute cycles and is relatively slow. Lightweight expeditious communication is required in many real-time systems in order for the threads to meet their performance requirements. In this chapter, we consider some methods for inter-task communication that are both lightweight and robust. [9] details the rendezvous pattern as a means of specifying arbitrarily complex rules for synchronizing tasks.
The two main reasons for thread communication are to share information and to synchronize control. The acquisition, manipulation, and display of information may occur in different threads with different periods, and may not even take place on the same processor, necessitating some means of sharing the information among these threads. Synchronization of control is also very common in real-time systems. In asynchronous threads that control physical processes, one thread's completion (such as emptying a chemical vat) may form a precondition for another process (such as adding a new volatile chemical to the vat). The thread synchronization strategy must ensure that such preconditions are satisfied.
When threads communicate, the rendezvous itself has attributes and behavior, which makes it reasonable to model it as an associative class. The important questions to ask about thread synchronization are these:
Are there any preconditions for the threads to communicate? A precondition is generally a data value that must be set, or some object must be in a particular state. If a precondition for thread synchronization exists, it should be checked by a guarding condition before the rendezvous is allowed to continue.
What should happen if the preconditions are not met, as when the collaborating thread is not available? The rendezvous can
Wait indefinitely until the other thread is ready (a waiting rendezvous)
Wait until either the required thread is ready or a specified period has elapsed (timed rendezvous)
Return immediately (balking rendezvous) and ignore the attempt at thread communication
Raise an exception and handle the thread communication failure as an error (protected rendezvous)
If data is to be shared via the rendezvous class, what is the relationship of the rendezvous object with the object containing the required information? Options include
The rendezvous object contains the information directly.
The rendezvous object holds a reference to the object containing the information, or a reference to an object serving as an interface for the information.
The rendezvous object can temporarily hold the information until it is passed to the target thread.
Remember that objects must ensure the integrity of their internal data. If the possibility exists that shared data can be simultaneously write or write-read accessed by more than a single thread, then it must be protected by some mechanism, such as a mutual-exclusion semaphore, as is done in Figure 8-19. In general, synchronization objects must handle
Preconditions
Access control
Data access
Rendezvous objects control access to resources and classical methods exist to handle resource usage in a multitasking environment. In the simplest case, resources can be simultaneously accessed—that is, access is nonatomic. Many devices use predetermined configuration tables burned into FLASH or EPROM memory. Since processes can only read the configuration table, many threads can access the resource simultaneously without bad effects.
Data access that involves writing requires some form of access control to ensure data integrity. Clearly, if multiple internal attributes must be simultaneously updated, another reader thread cannot be permitted to read these values while only some of them are updated.
In large collections of objects, it may be necessary to allow read accesses in one or more portions of the database even while other sections are being updated. Large airline reservation databases must function in this fashion, for example. Algorithms to control these processes are well defined and available in texts on relational and object databases.
Thread priority is distinct from the importance of the actions executed by the thread. Priority in a preemptive priority scheme determines the required timeliness of the response to the event or precondition. For example, in an ECG monitor, waveform threads must have a high priority to ensure that they run often enough to avoid a jerky appearance. ECG waveforms have tight timeliness requirements. On the other hand, a jerky waveform is not as important to patient outcome as sounding an alarm when the patient is at risk. An asystole alarm is activated when the monitor detects that the heart is no longer beating. Clearly, bringing this to the attention of the physician is very important, but if the alarm took an extra second to be annunciated, it would not affect patient outcome. Such an alarm is very important, but does not have a very high urgency, as compared with some other events.
In rate monotonic scheduling (RMS), the assignment of priorities is simple: The priority of all threads is inversely proportional to their periods. The shorter the period, the higher the priority. The original RMS scheme assumed that the deadline is equal to the period. When this is not true, the priority should be assigned based on the deadline, rather than the period. In general, the RMS scheduling makes intuitive sense—threads with short deadlines must be dealt with more promptly than those with longer deadlines. It is not uncommon to find a few exceptions to the rule, however. RMS scheduling and the associated mathematics of proving schedulability are beyond the scope of this book. For a more detailed look, see [7,8].
Analysis is all about the development of a consistent logical model that describes all possible acceptable solutions to a problem. Design is about optimization—selecting a particular solution that optimizes some set of design criteria in a way that is consistent with the analysis model.
Architectural design consists of the specification of the kind and quantity of devices, the media and rules they use to communicate, and the large-scale software components mapping to the physical architecture. The units of software architecture are subsystems and threads. Subsystems are typically layered sets of packages arranged in a hierarchical fashion. Threads cut through all layers, although they are rooted in a single active object.
The software architecture must map to the set of physical devices. The UML shows this mapping with the deployment diagram. This diagram shows not only nodes and communication paths, but also large-scale software components.
The iterative refinement implementation strategy builds these layered subsystems using vertical slices passing through all layers as well. Each vertical slice constitutes an iterative prototype. Prototypes build on the services defined in the previous prototypes. The order of prototypes is determined by the required services as well as the level of risk. Elaborating high-risk prototypes early lowers overall project risk with a minimum of rework.
The specification of the concurrency model is very important to performance in real-time systems. The concurrency model identifies a relatively small number of threads and populates these threads with the objects identified in the analysis model. Inter-task communication allows threads to share information and to synchronize control. This is often accomplished using a rendezvous pattern to ensure robust exchange of information.
The next step is to specify the middle layer of design, known as mechanistic design. This level of design focuses on the collaboration of small groups of classes and objects. In the process of mechanistic design we add classes to optimize information or control flow and to specify details that have been so far ignored.
[1] Some authors use the terms logical and physical differently; in some methodologists' views, a logical model is one devoid of physical constraints (e.g., memory or speed) and a physical model is one with such constraints added. I find this unsatisfying because until the system is completely specified, the models are almost always partially logical and partially physical so that this distinction becomes more a shade of gray than a true dichotomy.
[2] Meaning that you cannot create an instance of a package at runtime. Packages are a purely design-time organizational concept.
[3] We could also have nested the package inside the subsystem as a notational alternative.
[4] An actor is an object outside the scope of the system that has interactions of interest with the system as the system executes.
[5] In this book thread and task are treated identically. There are some detailed design differences, but both are units of concurrency and may be treated the same at the architectural level. If, in your design, that distinction becomes important, you can make it clear by using appropriate stereotypes, such as «process», «thread», «task», or «fiber».
[6] Recurring cost is the cost per shipped item.
[7] Strict independence isn't required to achieve a beneficial effect. Weakly correlated failure modes still offer improved tolerance to faults over tightly correlated failure modes.
[8] Many other people use the notion of subsystem to refer to a more loosely-associated set of objects that work to achieve a common set of use cases, even though they may appear within multiple processors. This is also a reasonable perspective.
[9] These are service access points (SAPs) in OSI nomenclature.
[10] The formal inductive proof of this statement is left as an exercise.
[11] Note that a requirement for fault tolerance almost always translates to a hard deadline for fault detection and handling, even in otherwise soft real-time systems.
[12] Something for you to think about the next time you fly off to visit grandma.