
The first primary aspect of the UML involves the specification of structure; that is, the organization of elements that exist at runtime, their internal organization, and the organization of elements in interactions. Additionally, the structural aspects of the UML allow you to identify the design-time types of these elements that exist at runtime and the relations among both the type and the instances of those types.
Notation and Concepts Discussed | ||
|---|---|---|
Advantages of Objects | Structured Classes | Packages |
Interfaces and Ports | Stereotypes | Components |
Architecture | Classes and Objects | Constraints |
Subsystems | Relations | Tags |
The Unified Modeling Language™ (UML) is used to express the constructs and relationships of complex systems. It was created in response to a request for proposal (RFP) issued by the Object Management Group (OMG), the organization that owns the UML standard. Dozens of people from many different companies worked on the UML and several calendar years went into its creation. The OMG accepted it as a standard in November 1997. The success of the UML is unprecedented; it has been widely adopted and used in the creation of all kinds of systems, including real-time and embedded systems. These systems range from the small (e.g., cardiac pacemakers) to the large (e.g., fighter aircraft) and from the mundane (e.g., printers) to the exotic (e.g., spacecraft frameworks). Systems in many vertical markets, including telecom, office automation, factory automation, robotics, avionics, military, medical, and automotive, have been modeled in the UML and implemented. I have consulted with companies building widely different systems all created with the UML and found that with the proper and intelligent application of the UML, they have been able to make significant (30% to 80%) improvements in time-to-market, quality, and reusability of corporate intellectual property (IP). All done with the UML, as it is specified in the standard, without modification or extension.[1]
That having been said, there exist a number of extensions to the UML. Some are proprietary extensions, claiming to offer some improvement in this way or that. Others are standardized extensions, in the form of a UML “profile”—a specialized version of the UML that is extended in only small ways to make it more applicable to some particular subject domain. In my role as cochair of the Real-Time Analysis and Design Working Group (RTAD) within the OMG, I have even participated in the creation of some of these extensions. Nevertheless, I stand by my assertion that the UML is completely sufficient for the modeling and creation of real-time and embedded systems. What the profiles have done is simply to codify a particular way in which the UML has been used. For example, the UML Profile for Schedulability, Performance and Time (also called the Real-Time Profile, or RTP) [3], does little more than codify what developers were already doing in UML to capture real-time and performance aspects of the systems they were creating. Profiles like the RTP enable better exchange of models, particularly between modeling creation tools, such as Rhapsody®, and schedulability analysis tools, such as RapidRMA™.[2] The RTP is the subject of Chapter 4.
As of this writing the UML standard is 1.5 [1].[3] However, work is almost completed for a major revision to the UML, version 2.0 [2]. A submission from the U2P consortium, of which I-Logix was a key contributor, was adopted in the spring of 2003. The submission is now undergoing finalization. At this time, the expectation is that the new version will be released in the spring of 2004. The metamodel and notations for the UML 2.0 submissions are fairly stable at this time, although there may be small deviations from what is ultimately released as the new standard.
UML is more complete than other methods in its support for modeling complex systems and is particularly well suited for real-time embedded systems. Its major features include
Well-defined object model for defining system structure
Strong dynamic modeling with modeling of both collaborative and individual behavior
Support for different model organizations
Straightforward representation of concurrency aspects
Models of physical topology (deployment)
Support for object-oriented patterns to facilitate design reuse
Throughout this book, these features will be described in more detail and their use shown by examples. This chapter explores the structural aspects of the UML at the fine- and coarse-grained abstraction level.
The UML has a rather rich set of structural elements and provides diagrammatic views for related sets of them. The UML is intentionally, recursively self-similar in its structural and dynamic concepts. That is, the same set of concepts may be used at different levels of abstraction, from the largest system and subsystems down to small, simple objects. Nevertheless, some concepts are used more at the smaller scale and others more at the larger scale.
A number of elementary structural concepts in the UML show up in user models: object, class, data type, and interface. These structural elements form the basis of the structural design of the user model. In its simplest form, an object is a data structure bound together with operations that act on that data. An object only exists at runtime; that is, while the system is executing, an object may occupy some location in memory at some specific time. The data known to an object are stored in attributes—simple, primitive variables local to that object. The behaviors that act on that data are called methods; these are the services invoked by clients of that object (typically other objects) or by other methods existing within the object.
Structured methods look at a system as a collection of functions decomposed into more primitive functions. Data is secondary in the structured view and concurrency isn't dealt with at all. The object perspective is different in that the fundamental decompositional unit is the object. So what is an object?
The short form:
An object is a cohesive entity that has attributes, behavior, and (optionally) state.
The long form:
Objects represent things that have both data and behavior. Objects may represent real-world things, like dogs, airfoil control surfaces, sensors, or engines. They may represent purely conceptual entities, like bank accounts, trademarks, marriages, or lists. They can be visual things, like fonts, letters, ideographs, histograms, polygons, lines, or circles. All these things have various features, such as
Attributes (data)
Behavior (operations or methods)
State (memory)
Identity
Responsibilities
For example, a real-world thing might be a sensor that can detect and report both a linear value and its rate of change.
Table . Sensor Object
Attributes | Behavior | State | Identity | Responsibility |
|---|---|---|---|---|
|
|
| Instance for robot arm joint |
|
The sensor object contains two attributes: the monitored sensor value and its computed rate of change (RoC). The behaviors support data acquisition and reporting. They also permit configuration of the sensor. The object state consists of the last acquired/computed values. The identity specifies exactly which object instance is under discussion. The responsibility of the sensor is defined to be how it contributes to the overall system functionality. Its attributes and behaviors must collaborate to help the object achieve its responsibilities
An airline flight is a conceptual thing, but is nonetheless an important object as well.
Table . Airline Flight Object
Attributes | Behavior | State | Identity | Responsibility |
|---|---|---|---|---|
|
| Current location (x, y, z, t) |
|
|
Certain of these characteristics (i.e., attributes, behaviors, or state) may be more important for some objects than for others. One could envision a sensor class that had no state—whenever you asked it for information, it sampled the data and returned it, rather than storing it internally. An array of numbers is an object that may have interesting information but doesn't have any really interesting behaviors.
The key idea of objects is that they combine these properties into a single cohesive entity. The structured approach to software design deals with data and functions as totally separate entities. Data flow diagrams show both data flow and data processes. Data can be decomposed if necessary. Independently, structure charts show the static call tree to decompose functions (somewhat loosely related to the data processes). Objects, on the other hand, fuse related data and functions together. The object is the fundamental unit of decomposition in object-oriented programming.
Abstraction is the process of identifying the key aspects of something and ignoring the rest. A chair is an abstraction defined as “a piece of furniture with at least one leg, a back, and a flat surface for sitting.” That some chairs are made of wood while others may be plastic or metal is inessential to the abstraction of “chair.” When we abstract objects we select only those aspects that are important relative to our point of view. For example, as a runner, my abstraction of dogs is that they are “high-speed teeth delivery systems.” The fact that they may have a pancreas or a tail is immaterial to my modeling domain. In Figure 2-1, we see a number of concrete instances of sensors being abstracted in a common concept.
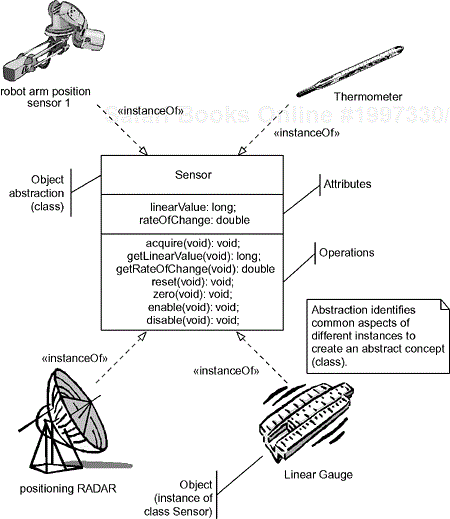
Objects exist at runtime; at some point in time, objects (at least software objects) occupy a memory address located in a computer. A class is the specification for a set of objects. Classes exist at design time. A class is the “type” of some set of objects, in the same way that “int” is the “type” of a variable x that may assume different values at runtime, such as 3 and –17, or “double” is the “type” of a variable y that may assume the value 45.5 during runtime. A class specifies both the structure and the defined behavior of the objects instantiated from it. All objects of a class have their own copies of the very same set of typed attributes. Thus, if a thermometer is an instance of class Sensor, then it will have an attribute named linearValue, of type long, and another attribute called rateOfChange, of type double. Each object, in fact, has its own copy of these attributes with which it is free to manipulate and manage, but structurally the objects are all identical.
Similarly, each object has the same set of methods (functions) defined by the class. However, the objects “share” the code for these, so you don't end up replicating identical code when you have many instances of the same class. The methods are provided the information as to which object is being manipulated when the method is called—usually invisibly to the programmer.
In their simplest expression, classes are nothing more than abstract data types (ADTs) bound together with operators that manipulate that information. This is a low-level perspective and doesn't capture all of the richness available in the object paradigm. Software developers use such ADTs and operators as low-level mechanisms all the time—stacks, queues, trees, and all the other basic data structures are nothing more than objects with specific operations defined. Consider these common ADTs that appear in the table on page 85.
At a low level of abstraction, these are merely ADTs bound together with separate functions to provide the services. Because the concept of a stack is meaningless without both the operations and the data, it makes the most sense to bind these things tightly together—they are different aspects of a single concept. This is called strong cohesion—the appropriate binding together of inherently tightly coupled properties.
Classes have two important features. Classes may (and usually do) contain attributes. These structural features hold the data or information known to the object. Also, classes have methods—behavioral features that provide services that usually manipulate the object's attributes. Classes may also have state machines, a topic that will be discussed in Chapter 3.
Attributes, in OO-speak, refer to the data encapsulated within an object or specified within a class. It might be the balance of a bank account, the current picture number in an electronic camera, the color of a font, or the owner of a trademark. Some objects may have just one or a small number of simple attributes. Others may be quite rich. In some object-oriented languages, all instances of data types are objects, from the smallest integer type to the most complex aggregate. In C++, in deference to minimizing the differences between C and C++, variables of the elementary data types, such as int and float, are not really objects. Programmers may treat them as if they are objects[4] but C++ does not require it.
Data Structure | Attributes | Operations |
|---|---|---|
Stack | TopOfStack: int Size: int Element: DATA | Push Pop Full Empty |
Queue | Head: int Tail: int Size: int Element: DATA | Insert Remove Full Empty |
Linked List | Next: Node pointer Previous: Node pointer Element: DATA | Insert Remove Next Previous |
Tree | Left: Node pointer Right: Node pointer Element: DATA | Insert Remove Next Previous |
As mentioned, a class is a union of the specification of an abstract data type with the operations that act on that data. Strictly speaking, a class contains methods—the implementation of operations. An operation is defined in the UML as “a service that an instance of the class may be requested to perform.” Operations have a formal parameter list (a typed list of named values passed to and/or from the operation) and a return value. The parameters and return value are optional. A method is said to be the implementation of an operation; reflexively, an operation specifies a method.
All instantiable classes have two special operations defined: a constructor, which knows how to properly make an instance of the class, and a destructor, which knows how to properly remove an instance of that class. Constructors may be parameterless—the so-called default constructor—and will use default values of any creational parameters, including the allocation of memory and creation of links to other objects. It is not uncommon to have a number of parameterized constructors as well, which bypass one or more defaults. Constructors are invoked whenever an object is created. A common example is if the “++” operator is defined for a class, then X++ (post increment) actually creates a new instance of the class (of which object X is an instance), although this may be optimized away in some cases. Destructors are parameterless and properly destroy the object, including removing allocated memory when necessary. Improperly written destructors are a common cause of memory leaks and care should be taken to ensure that they properly deallocate any memory that the object exclusively owns.
Not all classes are instantiable. Abstract classes are not instantiated because their specification is not complete. That is, they define an operation but not a corresponding method. In order to create an instance of such a class, the abstract class must be subclassed (see Generalization, later in this chapter) and the subclass must provide a method. In C++ terms, abstract classes contain at least one pure virtual operation shown with the unlikely syntax of assigning the operation the value of zero. For example,
void resetDevice(s: initialValue) = 0
Abstract classes and abstract (i.e., “pure virtual”) operations are identified by italics.
Figure 2-2 shows the relationship between classes (the template, or “cookie cutter”) and objects (the instance, or “cookie”). The class defines the features, both structural and behavioral, for all instances of objects for which it is the type. Classes can be shown as a simple named rectangle (called “canonical form”) or in a more detailed form. In the detailed form, attributes and methods may be listed in separate compartments, as they are in the figure. The objects are instances of the class and, when shown, depict a “snapshot” of the system at some point in time. This allows us to identify particular values of the attributes at the instant the snapshot was taken. Note that the object name is underlined, but all that is really necessary is to observe the presence of the colon (:), which separates the name of the object, called the role name (such as ThePatientThermometer) from the class that specifies it (such as Sensor).
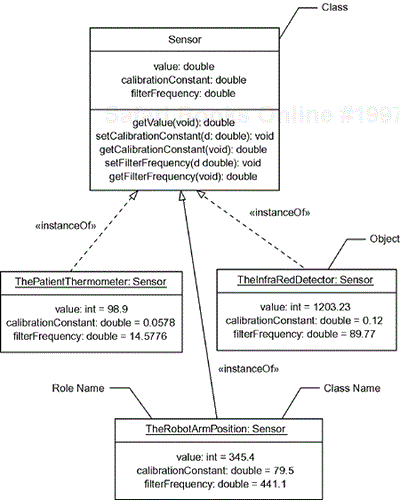
Figure 2-3 is similar to a diagram you'd find in the design of a system. The figure shows both classes (e.g., TaskPlan) and object (e.g., Elbow: Motor) as well as associations (relations between classes). Both canonical (simple) and detailed forms of classes are shown.

It isn't necessary to show any of the features of a class or object on a diagram, or if shown, it isn't necessary (or usually wise) to include all of the attributes or operations. Figure 2-3 shows some of the attributes and methods of the classes. Note that the attributes include their types and the methods include their parameters and return types. The marks by the class features indicate the visibility of those aspects.
The UML provides notation to indicate four levels of visibility. When a feature (attribute, method, or operation) is public, it may be proceeded by a “+”, as they are in the figure. Public visibility means that the feature may be accessed by anyone. Protected visibility (indicated by a preceding hash mark, #) means that the feature may be accessed by subclasses (see Generalization in the section on Relations, later in this chapter) but not by clients of the class. Clients may be able to gain access to the data, but must go through a public method do to so. Private visibility is even more restricted than protected—only methods inside the same class may access the feature. The last level of visibility, package, is rarely used. It is indicated with a tilde (“~”) and means the feature is visible to any element in the same package.
The lines connecting the classes and objects in the figure are called associations and allow the objects to collaborate, that is, to send and receive messages. This will be discussed in more detail later.
Usually diagrams are constructed exclusively with classes rather than by mixing in objects. Because classes are universal, class diagrams define sets of possible object configurations. An object may come and go during the execution of the system, so an object diagram is always a snapshot of the system at some specific point in time. Object diagrams, part of what is known as a system's instance model, may be useful, but class diagrams are far more common.
An interface is a specification of a named contract offered by a class. It primarily consists of a collection of operations, but in UML 2.0, interfaces may also include attributes and a special form of a state machine called a protocol state machine. While not required, interfaces allow you to separate out the specification of a set of services from the implementation of those services. As we've seen, a class contains methods, which include the lines of code that implement the service. An operation is a specification of the service that does not include this implementation. To be well formed, the operation should define the signature for invoking the service, including the required parameters and return value (if any), plus the preconditional and postconditional invariants of the operation. Preconditional invariants are things that must be true prior to the invocation of the service, while postconditional invariants are things that the operation guarantees are true upon its completion.
In UML 1.x, interfaces could only have operations (specifications of methods) but not any implementation; neither could they have attributes or state machines. In UML 2.0, interfaces may have attributes but they are virtualized, meaning that any realizing class must provide an attribute of that type. A class is said to realize an interface if it provides a method for every operation specified in the interface, and an attribute for every virtualized attribute in the interface. The class methods must have the same names, parameters, return values, preconditions, and postconditions of the corresponding operations in the interface. In UML 2.0, interfaces may also have protocol state machines for the specification of the allowed set of sequences of operation invocation for realizing classes. Protocol state machines will be discussed in the next chapter.
Interfaces may be shown in two forms. One looks like a class except for the key word interface placed inside guillemots, as in «interface». This form, called a stereotype in UML, is used when you want to show the operations of the interface. The other form, commonly referred to as the “lollipop” notation, is a small named circle on the side of the class. Both forms are shown in Figure 2-4. When the lollipop is used, only the name of the interface is apparent. When the stereotyped form is used, a list of operations of the interface may be shown. In the figure, the Sensor class is said to depend on the interface iFilter, while the Filter class realizes that interface. In UML 2.0, interfaces may be specified from either “end.” The UML 1.x interface (the lollipop end in Figure 2-4) specified provided interfaces, that is, features that the realizing class agrees to provide to its client. The other end (the socket in the figure) is a required interface. This allows consistency checking between what is expected and what is provided in the interfaces.
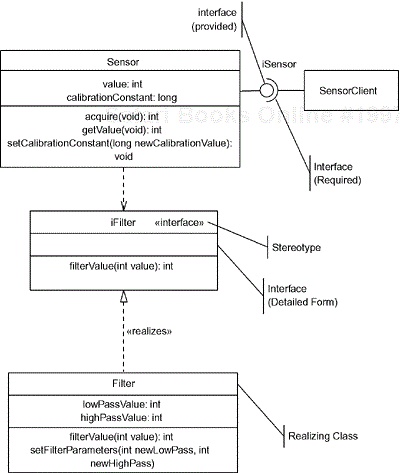
Interfaces are used to ensure interface compliance, that is, the client class can consistently and correctly invoke the services of a server class. There is another means to ensure interface compliance that uses the generalization relation from what is called abstract classes (classes that may not be directly instantiated). Abstract classes define operations but not methods, just as an interface does, and so may be used to ensure interface compliance. Either (or both, for that matter) approach can be used to ensure that the clients and servers connect correctly at runtime. Generalization and other class relations are discussed in the Section 2.3.4.
The low-level unit of behavior of an object is an action. There are several kinds of actions defined within the UML. The most common one, called a CallAction, invokes a method defined in the receiving object. Actions may appear in methods (they also appear in state machines, as we will see in the next chapter). Activities, discussed later, are types of behaviors that may be methods. In structured software development, explicit calls were shown on structure charts. While this has the advantage of showing the set of invoked services, it has a number of serious disadvantages, including that the order of calls isn't shown in structure charts, nor are conditional branches, nor is there any way to show other, possibly asynchronous communications. This last is the most serious limitation because much of the communication between objects in real-time systems takes place using techniques other than simple function calls.
In the UML, the logical interface between objects is done with the passing of messages. A message is an abstraction of data and or control information passed from one object to another. Different implementations are possible, such as
A function call
Mail via a real-time operating system (RTOS)
An event via a RTOS
An interrupt
A semaphore-protected shared resource service call
An Ada rendezvous
A remote procedure call (RPC) in a distributed system
Early analysis identifies the key messages between objects that collaborate. Later, design elaborates an implementation strategy that defines the synchronization and timing requirements for each message. Internally, the object translates the messages into method calls, event receptions, commands, or data to munch on, as appropriate. Messages generally only occur between object pairs that share a link (an instance of an association that is defined between the classes of those objects). Figure 2-5 illustrates how messages flow between objects in a running system.
Logically, an object's interface is the facade that it presents to the world and is defined by the set of protocols within which the object participates. An interface protocol consists of invariants, which include three things:
Preconditions
Signature
Postconditions
The preconditions are the conditions guaranteed to be true before the message is sent or received. For example, if a parameter is an enumerated type Color, the possible values are preconditions. If a parameter is a pointer that is expected to point to a valid object, then the validity of the pointer is a precondition. Ensuring that preconditions are met is normally the responsibility of the object sending the message. Postconditions are the things guaranteed to be true by the time the message is processed and are the responsibility of the receiver of the message. Postconditions include that the return values are well formed and within range, and the service is properly completed. Other postconditions might be that only a certain set of exceptions will be thrown in the presence of a fault. The message signature is the exact mechanism used for message transfer. This can be a function call with the parameters and return type or RTOS message post/pend pair, or bus message protocol. Most invariants are specified using UML constraints, a topic covered in Section 2.6.
The interface should reflect the essential characteristics of the object that require visibility to other objects. Objects should hide inessential details, especially their internal design. The reasons for this are obvious—if a client knows how a server object is structured, client class developers will use that information. As soon as that information is used, the server object structure is no longer free to vary without breaking its clients. This is nothing more or less than the concept of “data hiding,” which has been around since the dawn of time.[5] By publishing only enough information to properly use the provided services, objects enforce strong encapsulation. In C++, for example, common practice is to hide data members (making the private or protected visibility), but to publish the operations that manipulate the data (making them public).
Most classes, objects, and interfaces are small things. To do anything system-wide, many of these small things need to work together. And to work together, they must relate in some way. The UML provides three primary kinds of relations—association, generalization, and dependency—to link together your model elements so that they may collaborate, share information, and so on. The most fundamental of these is association, because associations enable collaborations of objects to invoke services, and will be considered first.
The most fundamental kind of relation between classes in the UML is the association. An association is a design-time relation between classes that specifies that, at runtime, instance of those classes may have a link and be able to request services of one another.
The UML defines three distinct kinds of associations: association, aggregation, and composition. An association between classes means simply that at some time during the execution of the system objects instantiated from those classes may have a link that enables them to call or somehow invoke services of the other. Nothing is stated about how that is accomplished, or even whether it is a synchronous method call (although this is most common) or some kind of distributed or asynchronous message transfer. Think of associations as conduits that allow objects to find each other at runtime and exchange messages. Associations are shown as lines connecting classes on class diagrams.
The direction of navigability of the association may be specified by adding an (open) arrowhead. A normal line with no arrowheads (or showing an arrowhead at both ends) means that the association is bi-directional; that is, an object at either end of the association may send a message to an object at the other end. If only one of the objects can send a message to the other and not vice versa, then we add an open arrowhead (we'll see later that the type of arrowhead matters) pointing in the direction of the message flow. Thus we see that an AlarmingObject object can send a message to an AlarmManager object, but not vice versa. This does not imply that the AlarmingObject object cannot retrieve a value from an AlarmManager object because it can call a method that returns such a value. It means, however, that an object of type Alarming Manager cannot spontaneously send a message to an AlarmingObject object because it doesn't know, by design, how to find it.
Every association has two or more ends; these ends may have role names. These name the instances with respect to the class at the other end of the association. It is common practice to give the role name on the opposite end of the association to the pointer that points to that instance. For example, in Figure 2-6, the Alarm class might contain a pointer named myView to an instance of type TextView. To invoke a service on the linked instance of TextView an action in an operation in the Alarm class would deference the pointer, as in
myView->setText(“Help!”)

Although somewhat less common, association labels may also be used, such as between the AlarmingClass and AlarmManager classes. The label is normally used to help explain why the association exists between the two classes. In this case, the label “Creates alarms for” indicates that is how the AlarmingClass intends to use the AlarmManager. To get the directionality of the label you can add an arrowhead next to the label to show the speaking perspective. The UML specification calls out an arrowhead with no associated arrow (as shown between the Alarm Manager and ListView classes), but more commonly tools use the characters “^”, “>”, “<”, and “V” in the label itself to indicate speaking perspective. Note also that the speaking perspective of the label is unrelated to the association direction. In the association between Alarm Manager and ListView messages flow from the AlarmManager only, but the association label speaks from the ListView perspective.
The multiplicity is probably the most important property of an association end. The multiplicity of an association end indicates the possible numbers of instances that can participate in the association role at runtime. This may be
A fixed number, such as “1” or “3”
A comma separated list, such as “0,1” or “3,5,7”
A range, such as “1..10”
A combination of a list and a range, such as “1..10, 25”, which means “one to 10, inclusive, or 25”
An asterisk, which means “zero or more”
An asterisk with an endpoint, such as “1..*” which means “one or more”
In Figure 2-6, we see multiplicities on all the associations. Multiplicity is shown at the role end of the class to which it applies. Thus each Alarm object associates with zero or one TextView objects, and each ListView object associates with exactly zero or more TextView objects. The AlarmManager uses instance multiplicity to show that there is exactly one instance in the context of the shown collaboration. Since there is only one, it isn't necessary to show a 1 on all the association ends that attach to it. All of these adornments, except for perhaps multiplicity, are optional and may be added as desired to further clarify the relation between the respective classes.
An association between classes means that at some point during the lifecycle of instances of the associated classes, there may be a link that enables them to exchange messages. Nothing is stated or implied about which of these objects comes into existence first, which other object creates them, or how the link is formed.
In UML 1.x, an associative class was a special kind of class that was used when the association itself had features of interest. Perhaps the most common example is the association between a Man class and a Woman class called “Marriage.” The marriage has attributes, such as date, duration, and location, and operations such as createPrenuptual Agreement(), which are not really features of the collaborating objects themselves. In UML 2.0, associative classes were discarded, and all associations may have these features, as desired. Figure 2-7 shows such an associative class notation where the Charging association has attributes of the connection between the Battery and Charger.

An aggregation is a specialized kind of association that indicates a “whole-part” relation exists between two classes. The “whole” end is marked with a white diamond, as in Figure 2-7. For example, consider, the classes Message List and Message. The Message List class is clearly a “whole” that aggregates possibly many Message elements. The diamond on the aggregation relation shows that the Message List is the “whole.” The asterisk (*) on the myMsg association end indicates that the list may contain zero or more Message elements. If we desired to constrain this to be no more than 100 messages we could have made the multiplicity “0..100.”
Since aggregation is a specialized form of association, all of the properties and adornments that apply to associations also apply to aggregations, including navigation, multiplicity, role names, and association labels.
Aggregation is a relatively weak form of “whole-part,” as we'll see in a moment. No statement is made about lifecycle dependency or creation/destruction responsibility. Indeed, aggregation is normally treated in design and implementation identically to association. Nevertheless, it can be useful to aid in understanding the model structure and the relations among the conceptual elements from the problem domain.
Composition is a strong form of aggregation in which the “whole” (also known as the “composite”) has the explicit responsibility for the creation and destruction of the part objects. Because of this, the composite exists before the parts come into existence and continues to exist (although sometimes not for very long) after they are destroyed. If the parts have a fixed multiplicity with respect to the composite, then it is common for the composite to create those parts in its constructor and destroy them in its destructor. With nonfixed multiplicities, the composite dynamically creates and destroys the part objects during its execution. Because the composite has creation and destruction responsibility, each part object can only be owned by a single composite object, although the part objects may participate in other association and aggregation relations. Composition is also a kind of association so it can likewise have all of the adornments available to ordinary associations.
Composition has two common presentations: nested class boxes and a filled-in diamond. Figure 2-7 shows both forms. The Power Subsystem, for example, is a composite class that contains parts of type Charger, Battery, and Switch. The Button class is also a composite that contains a single Light part. These parts are not objects exactly—they are object roles. These roles are played by objects executing in the system at runtime but may be played by different objects at different times. Similarly, the lines connecting the parts are not links (which occur between objects) but connectors that occur between roles.
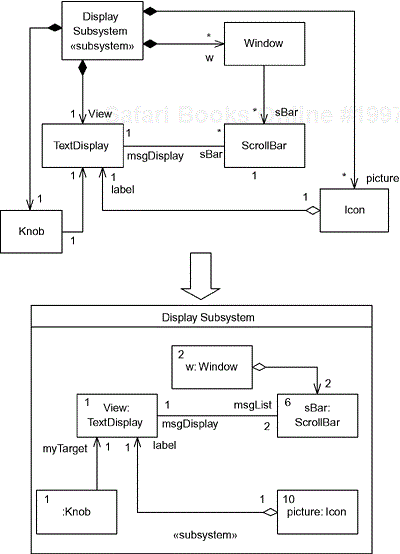
With the containment presentation, there is an issue as to how to show the multiplicity of the part (by definition, the multiplicity on the whole end of a composition is exactly 1). Since there is no line on which to place the multiplicity, it is common to put the multiplicity in one of the upper corners of the part class or in square brackets after the part name. This is called instance multiplicity. We see that the Power Subsystem contains either one or two objects of type Switch, zero or more objects of type Charger, and zero to two objects of type Battery. The Display Subsystem has exactly one Knob but an unspecified number of Messages.
The two forms of composition are subtly different. The filled-in diamond shows relations between classes, but when these classes are nested within the composite class they need to be objects, or more precisely, object roles (called “parts”). In addition to making the classes into parts, the composite class environment may add additional constraints, often in terms of more precisely specifying multiplicity. Figure 2-8 shows an example of this, a set of composition relations with the filled diamond at the top and a representation of the very same system with the nested notation below. Notice that the composition role names in the upper part of the figure become the part names in the lower part. Also note that the multiplicity of the parts is, in this case, more precisely specified—for example, “*” Windows becomes “2” window parts in the lower figure. The refinement of multiplicities is optional—“*” could have remained “*” had we desired.
The most common implementation of an association, as we will see later in Code Listing 2-4, is an object pointer (in C++) or an object reference (in Java). This is true regardless of which kind of association it is—an ordinary association, an aggregation, or a composition. There are many other ways of implementing an association—including nested class declaration, object identifier reference (as in a MS Windows handle or a CORBA object ID), an operating system task ID, and so on—but using a pointer is the most common.
Composition plays a very important role in the scalability of the UML by enabling objects to be defined in terms of parts, which are defined to be roles played by objects in the running system. These (part) objects themselves are typed by their class, of course, and those classes may themselves have parts. Thus, in UML we have the ability nest composite structures arbitrarily deeply—a crucial feature for scalability of the UML to very large systems. This important topic will be discussed soon in Section 2.4.2.
In a couple of places in Figure 2-7 notice that a class has a special adornment called a stereotype. Stereotypes are used in several ways. In one sense, a stereotype simply “metatypes” the role of a commonly used icon, such as the rectangle in Figure 2-7. A subsystem is special kind of class but we still use a class box to show it. To indicate that we mean a subsystem and not an ordinary class, we add the stereotypes. Subsystems are discussed later in this chapter, in Section 2.4.
The other usage of a stereotype is to tailor the UML to meet a specific need or purpose. It is part of the lightweight extension mechanism defined within the UML. A stereotype is a user-defined kind of element that is based on some already-defined element in the UML, such as Class, Operation, Association, and so on. You can create your own stereotypes if you wish, adding your problem-domain vocabulary to the UML. Stereotypes must always “subtype” an existing metaclass, such as Class, Component, Package, Association, and so on already defined in the UML specification. Stereotypes are usually shown by attaching the stereotype name in guillemots with the stereotyped element or shown using a user-defined icon.
The generalization relation in the UML means that one class defines a set of features, which are either specialized or extended in another. Generalization may be thought of as an “is a type of” relation and therefore only as having a design-time impact, rather than a runtime impact.
Generalization has many uses in class models. First, generalization is used as a means to ensure interface compliance, much in the same way that interfaces are used. Indeed, it is the most common way to implement interfaces in languages that do not have interfaces as a native concept, such as in C++. Also, generalization can simplify your class models because you can abstract a set of features common to a number of classes into a single superclass, rather than redefining the same structure independently in many different classes. In addition, generalization allows for different realizations to be used interchangeably; for example, one realization subclass might optimize worst-case performance while another optimizes memory size and yet another optimizes reliability because of internal redundancy.
Generalization in the UML means two things. First, it means inheritance—that subclasses have (at least) the same attributes, operations, methods, and relations as the superclasses they specialize. Of course, if the subclasses were identical with their superclasses, that would be boring, so subclasses can differ from their superclasses in either or both of two ways—by specialization or by extension.
Subclasses can specialize operations or state machines of their superclasses. Specializing means that the same operation (or action list on the statechart) is implemented differently than in the superclass. This is commonly called polymorphism. In order for this to work, when a class has an association with another which is a superclass, at runtime an instance of the first can invoke an operation declared in the second, and if the link is actually to an subclass instance, the operation of the subclass is invoked rather than that of the superclass.
This is much easier to see in the example presented in Figure 2-9. The class MsgQueue is a superclass and defines standard queue-like behavior, storing Message objects in a FIFO fashion with operations such as insert() and remove(). CachedQueue specializes and extends MsgQueue (the closed arrowhead on the generalization line points to the more general class). The Communicator class associates with the base class MsgQueue. If it needs to store only a few messages, a standard in-memory queue, that is, an instance of MsgQueue, works fine. But what if some particular instance of Communicator needs to store millions of messages? In that case, the instance can link to an instance of the Cached Queue subclass. Whether Communicator actually links to an instance of MsgQueue or one of its subclasses is unknown to the instance of Communicator. It calls the insert() or remove() operations as necessary. If the connected instance is of class MsgQueue, then the correct operations for that class are called; if the connected instance is of class CachedQueue, then the operations for that class are invoked instead, but the client of the queue doesn't know (or care) which is invoked.
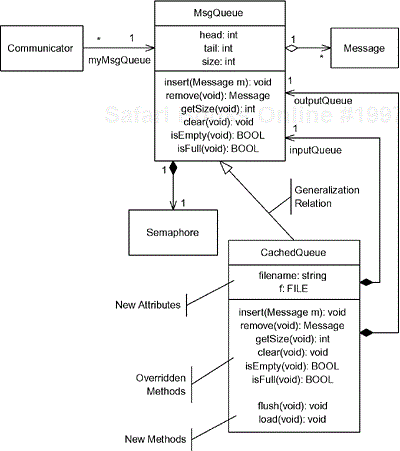
It is common not to show methods in the subclass unless they override (redefine) methods inherited from the superclass, but this is merely a stylistic convention. Remember that a CachedQueue is a MsgQueue, so that everything that is true about the latter is also true of the former, including the attributes, operations, and relations. For example, CachedQueue aggregates zero or more Message objects and has a composition relation to the class Semaphore because its superclass does. However, in this case, the operations for insert and remove are likely to work differently.
For example, MsgQueue::insert() might be written as shown in Code Listing 2-1:
Example 2-1. MsgQueue::insert() Operation
void MsgQueue::insert(Message m) {
if (isFull())
throw OVERFLOW;
else {
head = (head + 1) % size;
list[head] = m;
};
};
However, the code for the insert operation in the subclass must be more complex. First, note that the subclass contains (via composition) two MsgQueues, one for input buffering and one for output buffering. The CachedQueue::insert() operation only uses the MsgQueue instance playing the inputQueue role. If this is full, then it must write the buffer out to disk and zero out the buffer. The code to do this is shown in Code Listing 2-2.
Example 2-2. CachedQueue::insert() Operation
void CachedQueue::insert(Message m) {
if (inputQueue->isFull()) {
// flush the full queue to disk and then
// clear it
flush();
inputQueue->clear();
};
inputQueue->insert(m);
};
Similarly, the operations for remove(), getSize(), clear(), isEmpty(), and isFull() need to be overridden as well to take into account the use of two internal queues and a disk file.
Note that in the UML attributes cannot be specialized. If the superclass defines an attribute of time sensedValue and it has a type int, then all subclasses also have that attribute and it is of the same type. If you need to change the type of an attribute, you should use the «bind» stereotype of dependency, a topic discussed in Section 2.3.5. Subclasses can also extend the superclass—that is, they can have new attributes, operations, states, transitions, relations, and so on. In Figure 2-9, CachedQueue extends its base class by adding attributes filename and f and by adding operations flush() and load().
The other thing that generalization means in the UML is substitutability; this means that any place an instance of the superclass was used, an instance of the subclass can also be used without breaking the system in any overt way. Substitutability is what makes generalization immensely useful in designs.
Association, in its various forms, and generalization are the key relations defined within the UML. Nevertheless, there are several more relations that are useful. They are put under the umbrella of dependency. The UML defines four different primary kinds of dependency—abstraction, binding, usage, and permission, each of which may be further stereotyped. For example, «refine» and «realize» are both stereotypes of the abstraction relationship, and «friend» is a stereotype of permission. All of these special forms of dependency are shown as a stereotyped dependency (a dashed line with an open arrowhead).
Arguably, the most useful stereotypes of dependency are «bind», «usage», and «friend». Certainly, they are the most commonly seen, but there are others. The reader is referred to [2] for the complete list of “official” stereotypes.
The «bind» stereotype binds a set of actual parameters to a formal parameter list. This is used to specify parameterized classes (templates in C++-speak or generics in Ada-speak). This is particularly important in patterns because patterns themselves are parameterized collaborations, and they are often defined in terms of parameterized classes.
A parameterized class is a class that is defined in terms of more primitive elements, which are referred to symbolically without the inclusion of the actual element that will be used. The symbolic name is called a formal parameter and the actual element, when bound, is called an actual parameter. In Figure 2-10, Queue is a parameterized class that is defined in terms of two symbolic elements—a class called Element and an int called Size. Because the exact elements that these parameters refer to are not provided in the definition of Queue, Queue is not an instantiable class—those undefined elements must be given definitions before an instance can be created. The «bind» dependency does exactly that, binding a list of actual elements to the formal parameter list. In the case of MsgQueue, Element is replaced by the class Message and the int Size is replaced by the literal constant 1000. Now that the actual parameters are specified and bound, MsgQueue is an instantiable class, meaning that we can create objects of this class at runtime.

The diagram shows three common forms for the «bind» dependency. Form 1 is the most common, but the other forms are prevalent as well.
The usage relation indicates some element requires the presence of another for its correct operation. The UML provides a number of specific forms such as «call» (between two operations), «create» (between classifiers, e.g. classes), «instantiate» (between classifiers), and «send» (between an operation and a signal). Of these, «call» is common, as well as an unspecified «usage» between components, indicating that one component needs another because some of the services in one invoke some set of services in the other.
The permission relation grants permission for a model element to access elements in another. The «friend» stereotype is a common one between classes, modeling the friend keyword in C++. «access» is similar to Ada's use keyword, granting access of a namespace of one Ada package to another. The «import» relation adds the public elements of one namespace (such as a UML package) into another.
UML is a graphical modeling language, although, perhaps surprisingly, the notation is less important than the semantics of the language. Nevertheless, there is a common set of graphical icons and idioms for creating these views of the underlying model. We call these views “diagrams.” UML has been unjustly criticized for having too many diagram types—class diagrams, package diagrams, object diagrams, component diagrams, and so on. The fact is that these are all really the same diagram type—a structural diagram. Each of these diagrams emphasizes a different aspect of the model but they may each contain all of the elements in the others. A package diagram may contain classes and a class diagram may contain objects, while a component diagram might have objects, classes, and packages. In truth, the UML has one structural diagram, which we call by different names to indicate the primary purpose of the diagram.
We use diagrams for a number of purposes: as a data entry mechanism, as a means to understand the contents of the model, and as a means to discuss and review the model. The model itself is the totality of the concepts in your system and their relations to one another. When we use diagrams as a data entry mechanism, we add, modify, or remove elements to the underlying model as we draw and manipulate the diagrams.
The most common diagrams you'll draw are the class diagrams. These diagrams emphasize the organization of classes and their relations. The other aspects are used as needed, but class diagrams provide the primary structural view.
In real systems, you cannot draw the entire system in a single diagram, even if you use E-size plotter paper and a 4-point font. As a practical matter, you must divide up your system into different structural views (behavioral views will be described later). How, then, can we effectively do this? What criteria should we use to decide how many diagrams we need and what should go on them?
In the ROPES process, we use a simple criterion for decomposing the views of the system into multiple diagrams. The ROPES process introduces the concept of a mission of an artifact—its “purpose for existence.” For diagrams, the mission is straightforward—each diagram should show a single important concept. This might be to show the elements in a collaboration of objects or classes realizing a use case, or a generalization taxonomy, or the contents of a package. Usually, every element of your model appears in some diagram somewhere, but it is perfectly reasonable for it to appear in several diagrams. For example, a class might be involved in the realization of three use cases (resulting in three different diagrams), be a part of a generalization taxonomy, and also be contained in a package of your model. In this case, you might expect it to appear in five different diagrams. It is also not necessary for all aspects of the class to be shown in all views. For example, in the class diagrams showing collaborations, only the operations and attributes directly involved in the mission of that collaboration would be shown; in a diagram showing generalization, only the features added or modified by that class would be shown; in a diagram showing the contents of the package that owns the class, you probably wouldn't show any attributes or operations.
Which of the views is right? The answer is all of them. Just because a feature of a class or some other element isn't shown doesn't mean or imply that the feature doesn't exist or is wrong. The semantics of the class or model element is the sum of the semantic statements made in all diagrams in which it appears. Indeed, you can define model elements without explicitly drawing them on diagrams at all but instead adding them to the model repository directly. One of the most valuable things that modeling tools provide, over simple drawing tools, is the maintenance of the semantic information about the structure and behavior of your system.
Normally, you don't draw object diagrams directly. Most often, classes and class relations are drawn and these imply the possible sets of objects and their relations. If for some reason you want to depict particular configurations of the runtime system the object diagrams are the appropriate venue. A case in which you do is the composite structure diagram. This is a diagram that shows a composite class and its parts (as object roles). This diagram is used as the primary view for showing the hierarchical structure of a system, as we will see in Section 2.4.2.
Of course, the UML model must ultimately map to source code. In Java and C++, the mapping is straightforward. The source code for such the class diagram in Figure 2-4 (in Java) is the most straightforward because Java contains interfaces as a native concept. The Java source code would look like Code Listing 2-3.
Example 2-3. Class Diagram in Java
public class SensorClient {
protected myISensor iSensor;
public void displayValue(void) {
int sensedValue = iSensor.getValue();
System.out.println(value);
};
}; // end class SensorClient
interface iSensor {
int acquire(void);
int getValue(void);
void setCalibrationConstant(long
newCalibrationConstant);
}; // end interface iSensor
public class Sensor implements iSensor {
protected iFilter myIFilter;
int value;
long calibrationConstant;
public int acquire(void){ /* method here */ };
public int getValue(void) {
return myIFilter.filter(value); };
public void setCalibrationConstant(long
newCalibrationConstant) {
calibrationConstant =
newCalibrationConstant;
};
}; // end class Sensor
interface iFilter {
public int filterValue(int value);
}; // end interface iFilter
public class Filter implements iFilter {
int lowPass;
int highPass;
public int filtervalue(int value) {
/* method here */
};
public setFilterParameters(int newLowPass,
int newHighPass) {
lowPass = newLowPass;
highPass = newHighPass;
};
}; // end class Filter
In C++, the code is almost as straightforward as the Java code, but not quite, because an interface is not a native concept in C++. There are two common approaches to implement interfaces in C++. The first, shown in Code Listing 2-4, is to create an abstract base class by declaring the interface operations as pure virtual. The other common approach is to use the Interface or Façade pattern. This involves creating the interface class as an instantiable class that associates to a separate implementation class.
Example 2-4. Class Diagram in C++
class SensorClient {
protected:
iSensor* myISensor;
public:
void displayValue(void) {
int sensedValue = iSensor.getValue();
cout << value << endl;
};
};
class iSensor { // abstract class
public :
virtual int acquire(void)=0; // pure virtual
virtual int getValue(void)=0; // pure virtual
virtual void setCalibrationConstant(long
newCalibrationConstant)=0;
};
class Sensor : public iSensor {
protected :
iFilter* myIFilter;
int value;
long calibrationConstant;
public :
int acquire(void);
int getValue(void){
return myIFilter->filterValue(value);
};
void setCalibrationConstant(long
newCalibrationConstant) {
calibrationConstant = newCalibrationConstant;
};
};
class iFilter {
public :
virtual int filterValue(int value)=0; // pure virtual
};
class Filter : public iFilter {
public :
int filterValue(int value) {
lowPass = newLowPass;
highPass = newHighPass;
};
};
In summary, an object is one of many possible instances of a class. A class has two notable features—attributes (which store data values) and methods (which provide services to clients of the class). Interfaces are named collections of operations that are realized by classes. Interfaces need not be explicitly modeled. Many useful systems have been designed solely with classes, but there are times when the addition level of abstraction is useful, particularly when more than a single implementation of an interface will be provided.
Classes, objects, and interfaces are usually little things. It takes collaborations of many of them to achieve system-wide behavior. Because of the complexity of today's systems, it is unusual to find a system that can be effectively developed and managed without thinking about larger-scale structures. The UML does provide a number of concepts to manage systems in the large scale (all based on the concept of a class), although most of the literature has not effectively explained or demonstrated the use of these features.
“Big things” come in two primary flavors to reflect the two common scalability problems in building real systems. The first is the issue of organizing a model, keeping track of hundreds or thousands of classes, and effectively sharing the work among many different developers, possibly geographically separated. The model management question is primarily addressed with the UML concept of packages, as we will see in the next section.
The other scalability concept is for large runtime things. If I'm building a spacecraft, I need to think at many different levels of abstraction. I might have a use case (system capability) like “Go get a rock on Mars” and this will involve potentially millions of things at the most primitive scale. I would like to think about the roles of the deep space network, the launch vehicle, the orbiter, the lander, Mission Control, and so on. These elements are BIG, each containing thousands of parts. In the design of the spacecraft, I may want to consider large-scale things such as the navigation system, attitude control, the communications system, hydraulics, power control, life support, thermal management, and so on. Each of these things is likewise BIG (although only a piece of the largest-scale things in the system to be considered), also containing potentially thousands of simple parts. And so on until we get down to the level of simple individual sensors, switches, messages, waypoints, batteries, and the like. We need some way to think about large-scale elements that exist at runtime that are composed of parts, which may themselves contain smaller parts. The UML 2.0 specification refines the concepts of component and subsystem, and even class, for this purpose. These concepts will be discussed after we discuss the easier issue of packages and model management.
Packages are (design-time) model elements that can contain other model elements, including other packages. Packages are used to sub divide models to permit teams of developers to manipulate and work effectively together. Packages cannot be instantiated and can only be used to organize models. They do define a namespace for the model elements that they contain, but no other semantics. The UML does not provide any criterion as to whether a class should go in this package or that—it merely provides packages as model-building blocks to aid in whatever organizational purpose the developer desires.
The ROPES process recommends that packages be used with a specific criterion—“common subject matter or common vocabulary.” This is similar to the Shaler and Mellor concept of a domain, and the ROPES process uses the stereotype «domain» to indicate this particular usage of packages. However, packages can be used to organize the application model in just about any desired way.
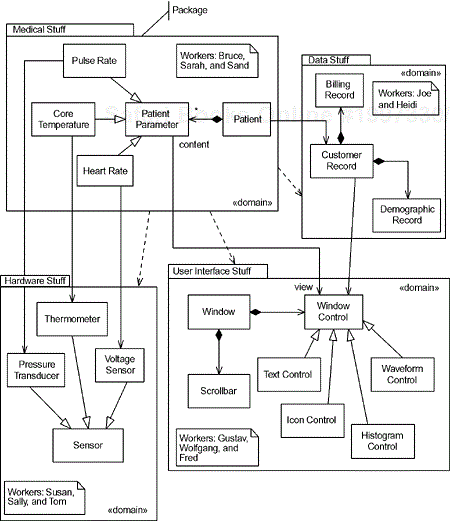
A package normally contains elements that exist only at design-time—classes and data types—but may also contain use cases and various diagrams, such as sequence and class diagrams. These design pieces are then used to construct collaborations that realize system-wide functionality. Packages are normally the basic configuration items for a configuration management tool, rather than the individual classes. Figure 2-11 shows that packages are drawn to look like a tabbed folder and may optionally show elements that they semantically contain. In this figure, there are four packages—Medical Stuff, Data Stuff, User Interface Stuff, and Hardware Stuff. Each class in the system resides in a single package, although it may be referenced by elements of other packages. In fact, we see many associations from elements in one package to elements in another, such as PatientParameter associating with WindowControl. This association allows the two classes to collaborate so that a WindowControl may display information held within the PatientParameter. A domain is organized around a single subject matter and vocabulary, such as user interface or hardware. All the classes that are within that subject matter are defined in the appropriate domain. Generalization taxonomies almost always fall within a single domain (a subclass of a window class is always a kind of window). If a class seems to fit in multiple domains, then it has too broad a scope and should be broken down into a set of collaborating classes, each of which fits in a single domain. Other strategies use packages with different rules about the elements they contain. Several different strategies are given in Chapter 1.
It is important to remember that packages have very little in the way of semantics. They define an enclosing namespace for the elements contained within them but that's all. They are not instantiable—you can't point to a running system and point to an instance of a package. Packages are used to organize models for model management and are, therefore, design-time organizational concepts only.
So far, we've considered classes only at the small end of the scale—simple, primitive, and easy to implement. If only life could be so easy! However, it is necessary to concern ourselves as well with “designing in the large” and construct and manipulate classes that are not simple, primitive, and directly implemented.
When we talk about nonprimitive things, we mean things that are defined in terms of smaller pieces. Structured classes (or more properly structured classifiers) are exactly that—classes that contain an internal collaboration structure of Parts. Parts are instance roles linked together with Connectors (similar to links, but connect parts rather than objects). Structured classes are not any different than ordinary classes really, it's just that classes may be specified in terms of smaller, contained parts which themselves are typed by classes. There are a couple of special kinds of structured classifiers—components and subsystems—that carry particular meaning, but really it's all just classes.
The concept of a structured class is based on both decomposition and encapsulation. The decomposition aspect is provided by the part objects contained within the structured class. In this case, we mean that the Smart Arm in Figure 2-12 is “rich” in the sense that it is internally implemented by the collaboration of its internal parts, including instances of CommandQueue, CommandController, ForceSensors, PositionSensors, Lamps, and so on. The structured class is not relegated to be a simple runtime container of these parts. Not only does it have the responsibility to create and destroy the part instances, it may also coordinate the activities and collaboration of these various part objects; when this is done, a statechart is normally created for the structured class to control and mediate the interaction of the parts.

The structured class itself is a class that owns its parts via the composition relation already discussed. For example, Figure 2-12 presents a structured class called Smart Arm. This robotic arm provides some set of services via the collaboration of its internal parts, such as instances of classes Controller, DCMotor, or Lamp. This use of the composition relation between the structured class and its parts implies several things. First, only a single structured class may own a specific part (instance of a contained class). Further, the structured class is responsible for the creation, destruction, and linking together of its parts. The number of instances of a Part held within a structured class is specified by its instance multiplicity.
Instance multiplicity is the number of instances for a part within its context. There may be other instances that are parts of other structured classes (or even other instances of the same structured class), but they aren't considered in the multiplicity of a part within another class. There are two common forms for showing instance multiplicity. The first is to put the multiplicity in square brackets following the name of the class, as was done in Figure 2-12 for the DCMotor class. The other notation is to put the multiplicity in a corner of the part class as was done for the Controller class. If the multiplicity of a part is fixed, then those parts are made in the constructor of the structured class. For example, the seven DCMotors and the single Controller instances are made in the constructor of the SmartArm class. When the multiplicity of the part is variable (such as 0..4 or *) then the structured class typically does not create the parts in the structured class's constructor, but rather on as-needed basis during the execution of the structured class. Examples are the Command objects owned by the Command Queue.
The parts within a structured class are linked together with connectors. A connector is a link, owned not by the part objects (which is the usual case with association instances), but rather, owned by the structured class. Each connector has two or more connector ends, each terminating on a part. The actual location of the connector end points forms the part topology of the structured class. The connectors are created by the structured class and link together the parts so that they can collaborate in the context of the structured class.
The other key concept of structured classes is encapsulation of the class away from its environment. This is done through the use of ports, and offered and required interfaces. A structured class offers a set of services to its clients and in turn may levy requirements on its servers in the form of required interfaces. Some of these services are commands that can be sent to the Smart Arm via the iCommand interface, such as acceptCommand(c: Command) or reset(void). The acceptCommand (c: Command) operation is really defined on the part class called Command Scheduler. We would like this interface published across the encapsulation boundary defined by the Smart Arm, and we do this by defining a port to present that interface across this encapsulation boundary. Figure 2-12 provides a port that associates with an interface called iCommand. Note the use of the ball-and-socket notation for offered (ball) and required (socket) interfaces. This means that the client, Robot Planner, requires a specific set of services defined by iCommand to be met by a class, while the Smart Arm offers that same set of services. One can think of a port as a window placed on the boundary of a structured object to some specific internal feature that you want to make visible. The port delegates the operation on the edge of the structured class and redirects any message coming in to the internal part, or from that part out to an external object attached to the structured class via the port.
Most commonly, a port is associated with either an offered or required interface, but a port is more general than that. Ports may be associated with either, neither, or both offered and required interfaces. Ports are said to be typed by their interfaces.
It should be noted that ports, and even interfaces for that matter, are not required to build systems with structured classes. Using ports will usually introduce some runtime overhead and require additional memory. Since ports are not required, an operation of an internal part may be used directly by an external object (we call the structured class transparent in that case), although that tends to tightly couple the structured class internal structure with its environment. Ports and interfaces provide a convenient notation for specifying how a service offered from an internal part is published across the boundary of its enclosing structured class. As we will see in the next chapter, ports and interfaces may specify their behavior and sequencing constraints in protocol state machines so that we have the power to specify exactly how we want the operations published via the interfaces to work.
The real power of structured classes is to enable the containment hierarchy of systems. That is, classes may contain internal parts, each of which may be decomposed into smaller parts, ad infinitum. This is necessary to model and manipulate models of large-scale real-time and embedded systems, from medical devices and aircraft to C4ISR[6] systems.
Ports are different than interfaces in one important aspect—ports are instantiable while interfaces are not. A port instance is a connection slot into an instance of a class that either relays a message to a part internal to the class (called a relay port) or accepts the message and hands it off to the object for handling (called an end or behavioral port). Since ports are instantiable, they have identity so that the class can tell which port provided the message. Since ports themselves may have behavior, they can mediate the handling of messages in a state-based way.
An interface is a named collection of operations, but those operations are provided elsewhere. Interfaces have no behavior in and of themselves, they just allow a collection of services to be given a name. The required and offered aspects of the interface form a contract to which the client and server agree adhere. To get behavior, a class must realize the operations of the interface by providing matching methods that actually provide the services. An interface is like a phone book in that it names the services, while a port is like a telephone switchboard that handles the incoming messages and patches them through to where they need to go.
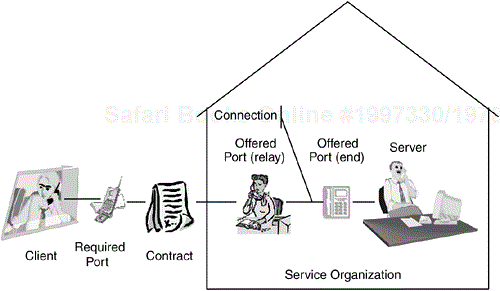
Figure 2-13a shows metaphorically how I, at least, think of ports, interfaces, and connections. The interface is the contract, the rules by which you agree to abide, while the ports actually connect the plays (client and server) to invoke the services specified in the contract. In the example, the server is in fact a part of a larger service organization so that services requests are mediated by a relay port (our metaphorical secretary) but ultimately services requests are sent via the end port to the server. The connection is the infrastructure used to convey the messages (the phone lines in the metaphor). Figure 2-13b shows the UML notational equivalent for the metaphor.
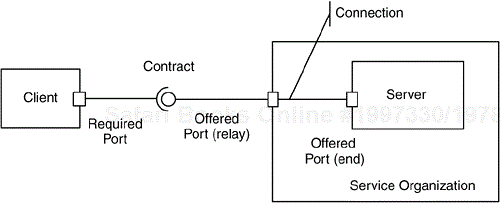
Now we understand the basic concepts of a structured class as having parts connected, publishing services via interfaces, and providing runtime connections via ports. Any class can do this in the UML 2.0, but these notions relate very significantly to the concept of a UML component.
In some sense, a UML component is merely a structured class with aspirations—it is meant to be the primary replaceable unit of software—a well-encapsulated piece of software that provides a coherent set of services, normally used and replaced together. There have been long and strenuous debates within the UML community over what constitutes a component versus a class, and how the specifically differ. The answer is that they don't, not really, but the term is so commonly used that relating concepts of structured classes to components used in the literature (and programming frameworks) is very helpful.
As structured classes, components usually (but needn't necessarily) have interfaces and ports. To optimize a component for replaceability, encapsulating them away from their external environment is important and ports and interface help in this. In the UML 2.0 the notation for a component changed slightly, as shown in Figure 2-14. In UML 2.0, a component uses a box, just like a class, but can use either the stereotype «component» or the component icon inside the box.
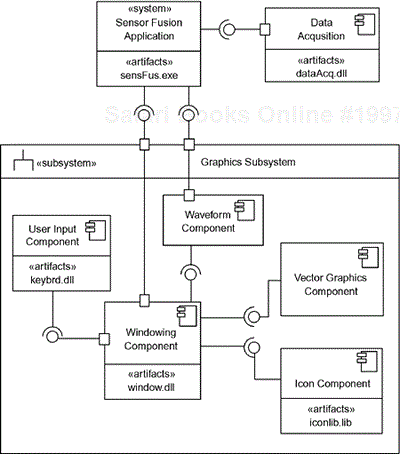
Note that some of the components have an «artifact» section. In UML 2.0, an artifact represents a piece of work created to deploy or represent information used in the systems or software development process. Documents, defect reports, Microsoft® Word documents, and computer files are all examples of artifacts. With components and other software entities on UML diagrams, the most common use for artifacts is to specify the unit of deployment of the software unit—usually, although not limited to, a disk file. The identification of the implementing artifact is optional.
In the example shown in Figure 2-14, the sensor fusion application consists of three primary pieces: the system (with the artifact senfus.exe), a data acquisition component (deployed in the artifact dataAcq.dll), and a graphics subsystem, which is further decomposed into several components. These components (and the subsystem) are all elements of the system structural architecture. These elements are each not primitive, but are internally decomposed into smaller pieces, and some of those may themselves be decomposed as well. In fact, it is common for components to contain (i.e., be composed of) smaller components just as structured classes may contain parts which are themselves structured classes. Just as a component is really nothing more than a class at the architectural level, this component diagram is nothing more than a class diagram that emphasizes the component architecture of the system.
Frequently, component-based systems are built on a commercial or at least standardized component framework, such as Enterprise Java Beans (EJB), COM+, .NET, or the CORBA Component Model (CCM). Such component frameworks provide a standardized set of services (such as COM+ iUnknown interface for component identification) and the ability to load, unload, and otherwise manage components at runtime. This is not required to use the UML component concept, but the UML is consistent with those infrastructures. It is also common to construct real-time and embedded systems with custom component frameworks.
Subsystems are used to decompose the physical organization of large-scale systems at the highest level of abstraction. Figure 2-14 included an example of a subsystem, shown using both the stereotype «subsystem» and the icon (an inverted two-pronged fork). Like components, subsystems are architectural-level structured classes, and as such may have ports, and interfaces, and are decomposed into smaller parts. In the UML 2.0, in fact, a subsystem is a specialized kind of component (formally speaking, a stereotype), one that also includes a packaging name space. In actual usage, there is little to distinguish subsystems from components.
Various notations for subsystems are shown in Figure 2-15. The Power Subsystem is shown with a stereotype and two subdivisions, one for specification (containing the specifying use cases) and one for realization (containing the parts that implement the subsystem specification). Either or both of these compartments may be suppressed as desired. The Power Source subsystem uses a subsystem stereotype icon (the inverted fork) rather than the textual stereotype and doesn't show any of its contents. In the figure, subsystems have both ports and interfaces, and while the use of interfaces is strongly encouraged, they are not required.

The next figure, Figure 2-16, provides an example of a subsystem diagram. In this diagram, a system object (the spacecraft) is shown with its internal subsystem parts. Of course, these subsystems are large and complex and are, no doubt, decomposed at least one or two more levels, if not more. In addition, exposed interfaces and ports are shown, along with the actors that interact with the system. However, this diagram shows the high-level system architecture. The connections among the subsystems support their collaboration to collectively realize the system's use cases.
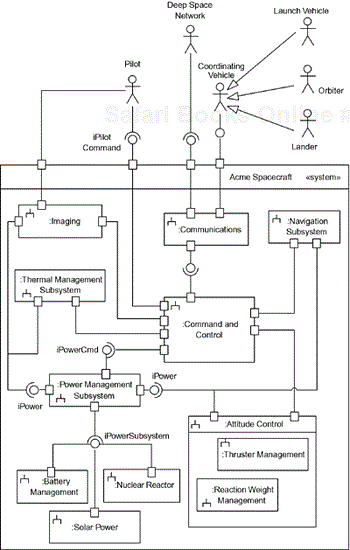
Subsystems need not be constrained to be only composed of software elements. In systems engineering environments, it is common to use the UML notion of subsystem to represent things that are internally decomposed into parts of various kinds, including software, electronic, mechanical and chemical.
As mentioned earlier, artifacts such as files implement software elements such as components, subsystems, and classes. Artifacts are useful for describing processes, and the UML can be used to model development processes and document flow, but primarily we'll be concerned here about artifacts that deploy executable software elements. While we don't normally think of executing documents, we do think of executing .exe, .dll, and .lib files, and we think of these artifacts as being the implementation of components and other objects. In the UML, the thing onto which an artifact is deployed is called a node. A node executes the implementation of these software elements. So it is with UML 2.0. While in UML 1.x, it was common to nest a component within a node, in UML 2.0, we nest artifacts that implement them instead.
In UML 2.0, the two primary kinds of nodes are devices and execution environments. Devices are commonly further stereotyped into «processors» and «simple devices», a «processor» being a device that executes the software that you write, while a «simple device» is one that does not (such as a printer, display, keyboard, or sensor). It is very common to use iconic stereotypes for various kinds of «simple devices» such as DC motors, stepper motors, IR sensors, thermometers, force sensors, pressure transducers, and so on. The other kind of node, an execution environment, is a kind of virtualized device, such as the Java Virtual Machine.
Nodes connect to other nodes via connections, which represent the physical media through which the artifacts executing on the nodes send and receive messages. As with UML 1.x, a node is the only three-dimensional icon used, and artifacts may optionally be shown on them. While perhaps not strictly proper, it is still nevertheless perfectly reasonable to nest components in the nodes as well with the understanding that we are, in fact, executing the implementing artifact on the node.
Figure 2-17 shows a typical deployment diagram. The three-dimensional boxes are nodes—you can see that both textual stereotypes are used as well as icons, so you may use whichever you prefer. Several kinds of connections are shown, including Ethernet, RS485, RS232, and a digital line of exchanging messages and control information as well as a power bus. The artifacts inside the nodes may be indicated with the textual stereotype «artifact», or they may be shown with the more common artifact stereotype icon (a rectangle with a folded corner). These artifacts implement components which may also be shown within a constraint, as is done for a number of the artifacts. The artifacts shown are java files, .jar Java repositories, dynamic link libraries, and executable .exe files.

A node is a kind of structured class in the UML 2.0, so it has all the richness of classes—it may have behavior and state machines. This is important in systems engineering when these software and hardware elements must be executed, simulated, and/or analyzed for performance. This work can be done by representing all the elements—both hardware and software—as classes and then generating VHDL or SystemC for the ones that are realized in hardware and C, C++, or Ada for the ones that are realized in software. It is most likely more work to manually change nodes to classes and vice versa within design tools, so when different hardware/software breakdowns are to be evaluated, it probably is less work to just model everything as classes. Note that this applies for systems engineering (rather than software engineering) work primarily. If your project uses COTS (commercial off-the-shelf) hardware or the hardware is not being codesigned, the decomposition of the system can be made more obvious by making the hardware pieces nodes and the software pieces classes. However, it really can be done either way.
While the concepts of system, subsystem, and component are sufficiently flexible to support most any runtime organizational schema you would like to employ, I generally find it useful to use these concepts in a particular way. The system (shown with the «system» class stereotype) represents the entire system under development. The largest scale pieces of the system are «subsystem» objects (which, in systems engineering environments may contain hardware and software elements). Subsystems may in turn contain software (and other kinds of) components. Components may contain multiple threads, modeled with «active» objects. And the passive or semantic objects, which do the real work of the system, run within the «active» objects. For really large projects, you may have all of these levels and perhaps even multiples at one or more levels—for example, a large system might have subsystems decomposed into subsubsystems before you get to the component level. For simpler systems, you may not require all of these levels—you might skip the subsystem level and just have components. You may even find that, for very simple systems, you only need the system, «active» objects, and semantic objects. Your mileage may vary in terms of how you apply these concepts, but I have found this a useful way to use the organizational concepts in practice. This size hierarchy is shown in Figure 2-18.

This set of levels is a recommendation only and is not mandated (or even discussed) in the UML specification. In my experience, using the UML concepts in this way maps well to engineers' expectations.
Note: Here be dragons....[7]
We've talked about the UML concepts quite a bit in this chapter. In this section, we discuss the UML internals in just a bit more detail. Models done in UML are done in what is called a four-layer metamodel architecture, as shown in Table 2-1.
Table 2-1. Metamodel Language Architecture
Layer | Description | Examples |
|---|---|---|
M3 Meta-metamodel | Provides a language for specifying metamodels, such as UML | Metaclass, meta-attribute, meta-association, meta-operation |
M2 Metamodel | An instance of a modeling language, such as UML | Class, interface, attribute, association, operation, state, component |
M1 User Model | Model of the user application or system done in the metamodel language | Sensor, DC motor, Gaussian filter, window, direction, speed, inertia, waveform, text display |
M0 User Objects | Instances of the specification elements of the user model | Sensor [1], myMotor:Motor, MAF:Filter, mainWindow:Window |
The idea is that each layer is built using the elements specified in the layer above. The UML at the M2 level is constructed from a basis defined by the meta-metamodel at level M3, while user model elements (M1) are constructed using UML elements, such as classes, associations, and so on. The runtime model (M0) executes instances of the classes defined in the user model.
That having been said, we've thrown around some UML metamodel elements such as classifier, class, component, subsystem, interface, and so on. The UML 2.0 specification is the ultimate arbitrator of what is or is not UML, and is a maintained (i.e., managed, updated, and revised) standard, so the particulars at any point in time might differ slightly from what is presented here. Nevertheless, it is useful to understand the metarelations between the meta-elements in the UML. Figure 2-19 shows the relation of the primary structural elements in the UML that we have discussed in this chapter.

The UML metamodel is, of course, (far) more complex than this. I have not shown all the relations among the elements, nor all the more abstract metasuperclasses, the most central metaclass being Classifier. Common Classifiers include Class, DataType, Association, StructuredClassifier, Component, Subsystem, Node, and Use Case. The fact that they have a common ancestry allows the common aspects to be captured in a single place. Classifers associate with Features, which may be either BehavioralFeatures (such as operations) or StructuralFeatures. In addition, BehavioredClassifiers may have Behaviors, such as Statemachines or Activities.
UML is has a rich set of notations and semantics. This richness makes it applicable to a wide set of modeling applications and domains. In this chapter, we have only discussed the primary structural modeling facilities of UML. In the coming chapters, new notations within UML will be presented when the context requires them. A concise overview of the notation is provided in Appendix A. Some notational elements we wish to present here include the text note, the constraint, and the stereotype because they will be used in a variety of places throughout the book.
A text note is a diagrammatic element with no semantic impact. It is visually represented as a rectangle with the upper righthand corner folded down (similar to the icon used to indicate an artifact). Text notes are used to provide textual annotations to diagrams in order to improve understanding.
A constraint is some additional restriction (above the normal UML well-formedness rules) applied against a modeling element. Timing and other QoS constraints can be shown on any kind of diagram, but are commonly used in both structural and behavioral diagrams. Constraints are usually shown inside curly brackets, and may appear inside of text notes.
Figure 2-20 shows text notes and constraints used together in a class diagram. In the model shown in the figure, two active classes (i.e., classes that own the threads in which they execute) collaborate via a Waveform class resource. The Sensor class monitors the external environment and executes periodically at a rate of 100Hz (10 ms period), with a worst-case execution time of 3 ms. These quantitative properties of the Sensor class are captured in the curly braces commonly used to identify constraints. The constraints themselves are put into a note. As can be seen in the ordering constraint on the WaveformSample class, constraints don't have to be put inside of notes, but since it helps to visually set such annotations off, it is common to do so. The active classes are shown by the double-bordered box indicating that they are classes of the «active» stereotype (the text indication could have been used just as easily). The active classes are further stereotyped; specifically, they are stereotyped «SASchedulable» and «SAAction» from the UML Profile for Schedulability, Performance, and Time, the so-called “Real-Time Profile”[3]. These stereotypes define the specific tags that are used in the constraints, such as isPeriodic, SAPriority, and so on. The tags are called tagged values in the UML and their values are commonly specified inside constraints, just as they are here.
A stereotype is a particular kind of a standard modeling element, such as an «active» class, a «SAAction» kind of action (which is also applied to «active» classes in this model). A «SAResource» is a kind of classifier but has some additional properties, captured as tags, assigned to it. In this case, the capacity of the resource—the number of clients it can simultaneously service—is set to 1. The tags defined for a stereotype are assigned particular values in constraints. This allows developers to annotate quantitative, schedulability, and performance properties of their models. This is such an important topic, we will devote Chapter 4 to how to use these stereotypes, tagged values, and constraints effectively to model the concurrency and performance aspects of systems later in this book.
In this chapter, we've discussed the elements (metaclasses) available within UML for modeling system and software structure—things like classes, interfaces, ports, and objects at the small scale, and packages, components, subsystems, and nodes at the large scale. We've also identified the ways in which these elements may be linked together to form collaborations. What we have not yet discussed is how to model the behavior of these elements. The UML allows us to model the behavior of individual elements as well as to model the emergent behavior of interacting collaborations of elements. That is the subject of Chapter 3.
Chapter 4 focuses on concurrency and resource modeling, and techniques that are commonly used to model them. Special attention will be given to the “RT Profile” and how to apply it.
[1] I don't mean to imply that merely the adoption of UML will improve productivity. There have been some notable failures in the adoption of UML. The successful adoption of any new technology requires willingness, thoughtfulness, and perseverance on the part of the adopter.
[2] RapidRMA is a schedulability analysis tool available from Tri-Pacific Corporation, www.tripac.com.
[3] The management of “point” releases of the UML is done by a revision task force (RTF) whose mandate is to fix defects and which is not allowed to introduce fundamentally new concepts to the UML. Thus, UML 1.x versions are all highly similar and have no significant semantic differences.
[4] Well, almost anyway—but that's a programming, rather than a modeling, issue.
[5] Which occurred sometime in the late sixties, I believe ;-).
[6] Command, Control, Communication, Computers and Intelligence, Surveillance, and Reconnaissance systems, such as the C4ISR Architecture Framework developed by the U.S. Department of Defense and in use in the Future Combat Systems (FCS) and similar projects. A C4ISR-UML mapping is provided in Chapter 11.
[7] These particular dragons are the most likely thing in this book to be wrong as the internals of the metamodel are reworked during the finalization process of the UML 2.0. However, their semantic meaning will be stable even if the details of the metarelations change, so for the average UML modeler, such changes will be largely irrelevant.