
In the preceding chapters, we've seen how architectural design defines the largest-scale strategic design decisions and that mechanistic design specifies exactly how groups of objects collaborate together. Now it is time to peer inside the objects themselves and learn how to design their internal structure. Detailed design specifies details such as the storage format used for attributes, the implementation of associations, the set of operations the object provides, the selection of internal algorithms, and the specification of exception handling within the object.
Notation and Concepts Discussed | ||
|---|---|---|
Data Collections | Visibility | Data Structure |
Realizing Associations | Algorithms | Derived Attributes |
Operations | Exceptions | |
You're just about at the point where you can actually run code on that pile of wires and chips cluttering up your Geekosphere,[1] so if you're like me, you're getting pretty excited. If architectural design is deciding which planet to fly to and mechanistic design is the flight path to the selected planet, then detailed design is deciding on which rock you want to eat your “tube of salami” sandwich once you arrive.[2] It is the smallest level of decomposition before you start pounding code.
The fundamental unit of decomposition in object-oriented systems is the object. As we have seen, the object is a natural unit from which systems can be specified and implemented. We have also seen that it is necessary but insufficient for large-scale design. Mechanistic design deals with mechanisms (groups of collaborating objects) and architectural design is concerned with an even larger scale—domains, tasks, and subsystems. At the root of it all remains the object itself, the atom from which the complex chemistry of systems is built.
Although most objects are structurally and behaviorally simple, this is certainly not universal. Every nontrivial system contains a significant proportional of “interesting” objects that require further examination and specification. The detailed design of these objects allows the objects to be correctly implemented, of course, but also permits designers to make tradeoff decisions to optimize the system.
One definition of an object is “data tightly bound to its operations forming a cohesive entity.” Detailed design must consider both the structure of information and its manipulation. In general, the decisions made in detailed design will be these:
Data structure
Class refactoring
Implementation of associations
Set of operations defined on the data
Visibility of data and operations
Algorithms used to implement those operations
Exceptions handled and thrown
Data format in objects is generally simple because if it were not, a separate object would be constructed to hold just the data. However, not only must the structure of the data be defined, the valid ranges of data, accuracy, preconditions, and initial values must also be specified during detailed design. This is part of what Bertrand Meyer calls “design by contract” [7]. Detailed data design applies to “simple” numeric data just as much as of user-defined data types. After all, aircraft, spacecraft, and missile systems must perform significant numeric computation without introducing round-off and accuracy errors or bad things are likely to happen.[3] Consider a simple complex number class. Complex numbers may be stored in polar coordinates, but let's stick to rectilinear coordinates for now. Most of the applications using complex numbers require fractional values, so that using ints for the real and imaginary parts wouldn't meet the need. What about using floats, as in
class complex_1 {
public:
float iPart, rPart;
// operations omitted
};
That looks like a reasonable start. Is the range sufficient? Most floating-point implementations have a range of 10-40 to 10+40 or more, so that is probably OK. What about round-off error? Because the infinite continuous set of possible values are stored and manipulated as a finite set of machine numbers, just representing a continuous value using floating-point format incurs some error. Numerical analysis identifies two forms of numerical error—absolute error and relative error [1]. For example, consider adding two numbers, 123456 and 4.567891, using six-digit-precision floating-point arithmetic:
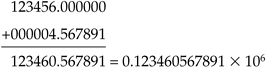
Because this must be stored in six-digit precision, the value will be stored as 0.123460 × 106, which is an absolute error of 0.567891. Relative error is computed as
where m(x) is the machine number representation of the value x. This gives us a relative error of 4.59977 × 10-8 for this calculation. Although this error is tiny, errors can propagate and build during repeated calculation to the point of making your computations meaningless.
Subtraction of two values is a common source of significant error. For example,
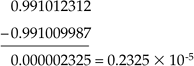
But truncating these numbers to six digits of precision yields
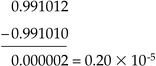
which is an absolute error of 0.325 × 10-6 and a relative error of 14%. This means that we may have to change our format to include more significant digits, change our format entirely to use infinite precision arithmetic,[4] or change our algorithms to equivalent forms when a loss of precision is likely, such as computing 1–cos(x) when the angle close to zero can result in the loss of precision. You can use the trigonometric relation
to avoid round-off error.[5]
Data is often constrained beyond its representation limit by the problem domain. Planes shouldn't pull a 7g acceleration curve, array indices shouldn't be negative, ECG patients rarely weigh 500 Kg, and automobiles don't go 300 miles per hour. Attributes have a range of valid values and when they are set unreasonably, these faults must be detected and corrective actions must be taken. Mutator operations (operations that set attribute values) should ensure that the values are within range. These constraints on the data can be specified on class diagrams using the standard UML constraint syntax, such as { range 0..15}.
Subclasses may constrain their data ranges differently than their superclasses. Many designers feel that data constraints should be monotonically decreasing with subclass depth, that is, that a subclass might constrain a data range further than its superclass. Although system can be built this way, this violates the Liskov Substitution Principle (LSP):
An instance of a subclass must be freely substitutable for an instance of its superclass.
If a superclass declares a color attribute with a range of { white, yellow, blue, green, red, black} and a subclass restricts it to { white, black} then what happens if the client has a superclass pointer and sets the color to red, as in
enum color {white, yellow, blue, green, red, black};
class super {
protected:
color c;
public:
virtual void setColor(color temp); // all colors valid
};
class sub: public super {
public:
virtual void setColor(color temp); // only white and black now valid
};
Increasing constraints down the superclass hierarchy is a dangerous policy if the subclass will be used in a polymorphic fashion.
Aside from normal attributes identified in the analysis model, detailed design may add derived attributes as well. Derived attributes are values that can in principle be reconstructed from other attributes within the class, but are added to optimize performance. They can be indicated on class diagrams with a «derived» stereotype, and defining the derivation formula within an associated constraint, such as { age = currentDate–startDate}.
For example, a sensor class may provide a 10-sample history, with a get(index) accessor method. If the clients often want to know the average measurement value, they can compute this from the history, but it is more convenient to add an average( ) operation like so:
class sensor {
float value[10];
int nMeasurements, currentMeasurment;
public:
sensor(void): nMeasurements(0),
currentMeasurement(0) {
for (int j = 0; j<10; j++) value[10] = 0;
};
void accept(float tValue) {
value[currentMeasurement] = tValue;
currentMeasurement = (++currentMeasurement)
10;
if (nMeasurements < 10) ++nMeasurements;
};
float get(int index=0) {
int cIndex;
if (nMeasurements > index) {
cIndex = currentMeasurement-index-1; //
last valid one
if (cIndex < 0) cIndex += 10;
return value[cIndex];
else
throw "No valid measurement at that
index";
};
float average(void) {
float sum = 0.0;
if (nMeasurements > 0) {
for (int j=0; j < nMeasurements-1; j++)
sum += value[j];
return sum / nMeasurements;
}
else
throw "No measurements to average";
};
};
The average() operation only exists to optimize the computational path. If the average value was needed more frequently than the data was monitored, the average could be computed as the data was read:
class sensor {
float value[10];
float averageValue;
int nMeasurements, currentMeasurment;
public:
sensor(void): averageValue(0), nMeasurements(0),
currentMeasurement(0) {
for (int j = 0; j<10; j++) value[10] = 0;
};
void accept(float tValue) {
value[currentMeasurement] = tValue;
currentMeasurement = (++currentMeasurement)
10;
if (nMeasurements < 10) ++nMeasurements;
// compute average
averageValue = 0;
for (int j=0; j < nMeasurements-1; j++)
averageValue += value[j];
averageValue /= nMeasurements;
};
float get(int index=0) {
int cIndex;
if (nMeasurements > index) {
cIndex = currentMeasurement-index-1; // last valid one
if (cIndex < 0) cIndex += 10;
return value[cIndex];
else
throw "No valid measurement at that index";
};
float average(void) {
if (nMeasurements > 0)
return averageValue;
else
throw "No measurements to average";
};
};
In this case, the derived attribute averageValue is added to minimize the required computation when the average value is needed frequently.
Collections of primitive data attributes may be structured in myriad ways, including stacks, queues, lists, vectors, and a forest of trees. The layout of data collections is the subject of hundreds of volumes of research and practical applications. The UML provides a role constraint notation to indicate different kinds of collections that may be inherent in the analysis model. Common role constraints for multivalued roles include
{ordered} | Collection is maintained in a sorted manner. |
{bag} | Collection may have multiple copies of a single item. |
{set} | Collection may have at most a single copy of a given item. |
{hashed} | Collection is referenced via a keyed hash. |
Some constraints may be combined, such as { ordered set} . Another common design scheme is to use a key value to retrieve an item from a collection. This is called a qualified association and the key value is called a qualifier.
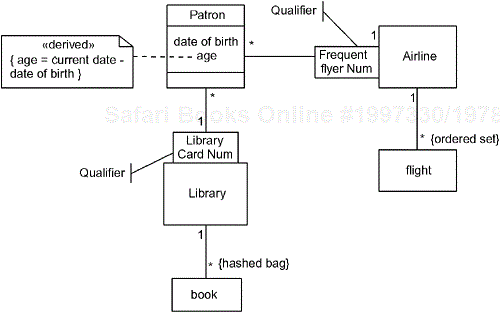
Figure 10-1 shows examples of constraints and qualified associations. The association between Patron and Airline is qualified with Frequent Flyer Num. This qualifier will be ultimately implemented as an attribute within the Patron class and will be used to identify the patron to the Airline class. Similarly, the Patron has a qualified association with Library using the qualifier Library Card Num. The associations between Airline and Flight and between Library and Book have constrained multivalued roles. The former set must be maintained as an ordered set while the latter is a hashed bag. Note also the use of a text note to constrain the Patron's age attribute. The stereotype indicates that it is a derived attribute and the constraint shows how it is computed. Other constraints can be added as necessary to indicate valid ranges of data and other representational invariants.
Selection of a collection structure depends on what characteristics should be optimized. Balanced trees, for example, can be searched quickly, but inserting new elements is complex and costly because of the need to rotate the tree to maintain balance. Linked lists are simple to maintain, but searching takes relatively long.
Associations among objects allow client objects to invoke the operations provided by server objects. There are many ways to implement associations, appropriate to the nature and locality of the objects and their association. Implementations appropriate for objects within the same thread will fail when used across thread or processor boundaries. Accessing objects with multivalued roles must be done differently than with a 1-to-1 association. Some implementation strategies that work for composition don't work for client-server associations. One of the purposes of detailed design is to resolve the management of associations within the objects.
The simplest cases are the 1-to-1 or 1-to-(0,1) association between objects within the same thread. The 1-to-(0,1) is best done with a pointer to the server object, since there are times when the role multiplicity will be zero (i.e., the pointer will be null). A 1-to-1 association may also be implemented with a reference (in the C++ sense) because the association link is always valid.[6] A 1-to-1 composition association may also be used in inline class declaration, which would be inappropriate for the more loosely coupled client-server association. Normal aggregation is implemented in exactly the same way as an association. The following class shows these simple approaches.
class testAssoc {
T myT; // appropriate only for 1-to-1
composition
T* myT2; // ok for 1-to-1 or 1-to-(0,1)
association or composition
T& myT3; // ok for 1-1 association or composition
};
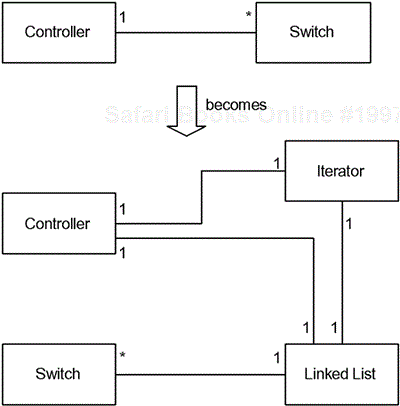
As discussed in Chapter 9, multivalued roles are most often resolved using the container pattern. This involves inserting a container class between the two classes with the multivalued role, and possibly iterators as well, as shown in Figure 10-2. Review Chapter 9 for more detail on the container pattern.
Crossing thread boundaries complicates the resolution of associations somewhat. Simply calling an operation across a thread boundary is not normally a good idea because of mutual exclusion and reentrancy problems. It can be done if sufficient care is taken: The target operation can implemented using mutual exclusion guards and both sides must agree on the appropriate behavior if access cannot be immediately granted. Should the caller be blocked? Should the caller be returned to immediately with an indication of failure? Should the caller be blocked, but only for a maximum specified period of time? All of these kinds of rendezvous are possible and appropriate in different circumstances.
Although directly calling an operation across a thread boundary is lightweight, it is not always the best way. If the underlying operating system or hardware enforces segmented address spaces for threads, it may not even be possible. Operating systems provide additional means for inter-task communication, such as OS message queues and OS pipes.
An OS message queue is the most dominant approach for requesting services across a thread boundary. The receiver thread's active object reads the message queue and dispatches the message to the appropriate component object. This approach has a fairly heavy runtime cost, but maintains the inherent asychronicity of the threads.
OS pipes are an alternative to message queues. They are opened by both client and server objects and are a slightly more direct way for the client to invoke the services of the server.
When the service request must cross processor boundaries, the objects must be more decoupled. Common operating services to meet intra-processor communications include sockets and remote procedure calls (RPCs). Sockets usually implement a specified TCP/IP protocol across a network. The common protocols are the Transmission Control Protocol (TCP) and User Datagram Protocol (UDP). The TCP/IP protocol suite does not make any guarantees about timing, but it can be placed on top of a data link layer that does. TCP supports reliable transmission using acknowledgements; it also supports what are called stream sockets. UDP is simpler and makes no guarantees about reliable transmission.
Lastly, some systems use RPCs. Normally, RPCs are implemented using a blocking protocol so that the client is blocked until the remote procedure completes. This maintains the function call–like semantics of the RPC, but may be inappropriate in some cases.
Using any of the approaches that cross the thread boundary (with the exception of the direct guarded call), requires a different implementation in the client class. The client must now know the thread ID and a logical object ID to invoke the services. So rather than a C++ pointer or reference, ad hoc operating system–dependent means must be used.
These methods can be implemented using the broker pattern from [9] or the observer pattern described in Chapter 9. The observer pattern allows the server to be remote from the client, but requires that the client know the location of the server. The broker pattern adds one more level of indirection, requiring only that the client know a logical name for the target object, which allows the Broker to identify and locate the server.
Note that this discussion has been independent of the underlying physical medium of inter-processor communication. It can be implemented using shared memory, Ethernet networks, or various kinds of buses, as appropriate. Reusable protocols are built using the layered architecture pattern, so that the data link layer can be replaced with one suitable for the physical medium with a minimum of fuss.
The operations defined by a class specify how the data may be manipulated. Generally speaking, a complete set of primitive operations maximizes reusability. A set class template typically provides operators such as add item or set, remove item or subset, and test for item or subset membership. Even if the current application doesn't use all these operations, adding the complete list of primitives makes it more likely to meet the needs of the next system.
Analysis models abstract class operations into object messages (class, object, sequence, and collaboration diagrams), state event acceptors (statecharts), and state actions (statecharts). The great majority of the time, these messages will be directly implemented as operations in the server class using the implementation strategy for the association supporting the message passing (see the previous section).
Analysis and early design models only specify the public operations. Detailed design often adds operations that are only used internally. These operations are due to the functional decomposition of the public operations. For example, a queue might provide the following set of public operations:
template <class T, int size>
class queue {
protected:
T q[size];
int head, tail;
public:
queue(void): head(0), tail(0);
virtual void put(T myT);
virtual T get(void);
};
A cached queue caches data locally but stores most of it on a more remote, but larger data store, such as a hard disk. Operations can be added to implement the caching so that it is invisible to the client, maintaining LSP:
template <class T, int size>
class cachedQueue : public queue<T, size> {
protected:
void writeToDisk(void);
void readFromDisk(void);
public:
cachedQueue(void): head(0), tail(0);
virtual void put(T myT); // new version uses
// writeToDisk
// when cache fills
virtual T get(void); // new version uses
// readFromDisk
// when data is not
cached
};
These operations are added to support the additional functionality of the cachedQueue subclass.
Functional decomposition of operations is shown in structured methods using structure charts. Since the UML does not provide structure charts, activity diagrams should be used instead.
Visibility in the UML refers to accessibility of internal object elements by other objects. Visibility is always a design concern. There are four general guidelines of visibility:
If clients need it, make it visible, otherwise make it inaccessible. This first guideline is pretty obvious. Once you are down in the depths of detailed design, you should have a pretty good idea which messages are being sent to an object. If other clients are depending on the service, then they must be able to call it. This is none other than the old data-hiding principle in vogue since the 1970s.
Only make semantically appropriate operations visible. This guideline seeks to avoid pathological coupling among classes. For example, suppose a class is using a container class. Should the operations be GetLeft() and GetRight() or Prev() and Next()? The first pair makes the implementation visible (binary tree) while the latter pair captures the essential semantics (ordered list).
Attributes should never be directly visible to clients. This guideline is similar to the previous one in that it wants to avoid tight coupling whenever possible. If clients have direct access to attributes, they fundamentally depend on the structure of that attribute. Should the structure change, the clients all become instantly broken and must be modified as well. Additionally, accessor and mutator operations applied to that attribute can ensure that preconditions are met, such as valid ranges or consistency with other class attributes. Direct access to the attribute circumvents these safeguards. The “Hungarian” naming convention uses the type of the variable or attribute in the name. I recommend that this highly questionable practice be avoided precisely because it introduces an artificial and unnecessary tight coupling attribute and its type.
When different levels of visibility are required to support various levels of coupling, use the interface pattern to provide the sets of interfaces. Sometimes a class must present different levels of access to different clients. When this is true, the interface pattern is an obvious solution. A class can have many interfaces, each semantically appropriate to its clients.
The UML provides a simple, if peculiar, syntax for specifying visibility on the class diagram: A visibility attribute is prepended to the class member. The UML defines the following visibility attributes:
# | Private—. accessible only within the class itself |
– | Protected—. accessible only by the class and its subclasses |
+ | Public—. generally accessible by other classes |
~ | Package—. accessible to other member of the same package |
Some theorists are adamant that attributes should be private (as opposed to protected) and even subclasses should go through accessor methods to manipulate them. Personally, I find that view somewhat draconian because subclasses are already tightly coupled with their superclasses, but to each his or her own.
Another approach to providing different levels of access is through the use of friend classes.[7] Friend classes are often used as iterators in the container pattern, discussed in Chapter 9. Another use is the facilitation of unit testing by making unit testing objects friends of the class under test.
An algorithm is a step-by-step procedure for computing a desired result. The complexity of algorithms may be defined in many ways, but the most common is time complexity, the amount of execution time required to compute the desired result. Algorithmic complexity is expressed using the “order of” notation. Common algorithmic complexities are
O(c)
O(log2n)
O(n)
O(n log2n)
O(n2)
O(n3)
where c is a constant and n is the number of elements participating in the algorithmic computation.
All algorithms with the same complexity differ from each other only by a multiplicative and additive constant. Thus, it is possible for one O(n) algorithm to perform 100 times faster than another O(n) algorithm and be considered of equal time complexity. It is even possible for an O(n2) algorithm to outperform an O(c) algorithm for sufficiently small n. The algorithmic complexity is most useful when the number of entities being manipulated is large (as in “asymptomatically approaching infinity”) because then these constants become insignificant and the complexity order dictates performance. For small n, they can only given rules of thumb.
Execution time is not the only optimization criteria applied to systems. Objects may be designed to optimize
Runtime performance
Average performance
Worst-case performance
Deterministic (predictable) performance
Runtime memory requirements
Simplicity and correctness
Development time and effort
Reusability
Extensibility
Reliability
Safety
Security
Of course, to some degree these are conflicting goals.[8] For example, some objects must maintain their elements in sorted order. A Bubble sort is very simple, so it requires a minimum of development time. Although it has a worst-case runtime performance of O(n2), it can actually have better performance than more efficient algorithms if n is small. Quicksort is generally much faster—O(log2n) in the normal case, and O(n2) in the worst case—but is more complicated to implement. It is not always best to use a Quicksort and it is not always worst to use a Bubble sort even if the Quicksort is demonstrably faster for the data set. Most systems spend most of their time executing a small portion of the code. If the sorting effort is tiny compared to other system functions, the additional time necessary to correctly implement the Quicksort might be more profitably spent elsewhere.
Some algorithms have good average performance but their worst-case performance may be unacceptable. In real-time systems, raw performance is usually not an appropriate criterion—deterministic performance is more crucial. Often, embedded systems must run in a minimum of memory, so that efficient use of existing resources may be very important. The job of the designer is to make the set of design choices that results in the best overall system, and this includes its overall characteristics.
Classes with rich behavior must not only perform correctly, they must also be optimal in some sense. Most often, average execution speed is the criterion used for algorithm selection, but as we saw in Section 10.1, many other criteria may be used. Once the appropriate algorithm is selected, the operations and attributes of the class must be designed to implement the algorithm. This will often result in new attributes and operations that assist in the execution of the algorithm.
For example, suppose you are using the container pattern and decide that a balanced AVL tree container is best.[9] An AVL tree, named after its inventors Adelson, Velskii, and Landis, takes advantage of the fact that the search performance of a balanced tree is O(log2n). A balanced binary tree is one in which all subtrees are the same height ±1. Each node in an AVL tree has a balance attribute,[10] which must be in the range [–1, 0, +1] for the tree to be balanced. The problem with simple trees is that their balance depends on the order in which elements are added. In fact, adding items in a sorted order to an ordinary binary tree results in a linked list, with search properties of O(n). By balancing the tree during the addition and removal of items, we can improve its balance and optimize its search performance.
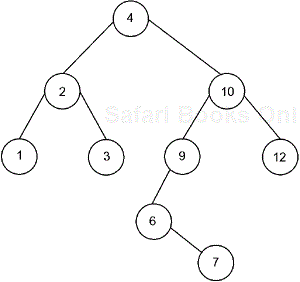
Let's assume that we want an in-order tree—that is a tree in which a node is always “greater than” its left child and “less than” its right child, such as the one shown in Figure 10-3. Note that node 10 is greater than its left child (6) and less than its right child (12). If we now add a 9 to the tree, we could make it the left child of node 10 and the parent of node 6. But this would unbalance the tree, as shown in Figure 10-4. If we then balance the tree we might end up with a tree such as the one in Figure 10-5.


AVL trees remain balanced because whenever a node is inserted or removed that unbalances the tree, nodes are moved around using techniques called tree rotations to regain balance. The algorithm for adding a node to an AVL tree looks like this:
Create the new node with NULL child pointers, set the attribute Balance to 0.
If the tree is empty, set the root to point to this new node and return.
Locate the proper place for the node insertion and insert.
Recompute the balance attribute for each node from the root to the newly inserted node.
Locate an unbalanced node (balance factor is ±2). This is called the pivot node. If there is no unbalanced node, then return.
Rebalance the tree so that it is now balanced. There are several situations:
Pivot has a balance of +2. Rotate the subtree based at the Pivot left.
Pivot has a balance of –2. Rotate the subtree based at the Pivot right.
Continue balancing subtrees on the search path until they are all in the set [-1, 0 +1].
Rotating left means replacing the right child of the pivot as the root of the subtree, as shown in Figure 10-6. Right rotations work similarly and are applied when the balance of the pivot is –2. Many times, double rotations are required to achieve a balanced tree, such as a left-right or a right-left rotation set.

The set of operations necessary to meet this algorithm are
typedef class node {
public:
data d; // whatever data is held in the tree nodes
int balance; // valid values are –1, 0 , 1
node* leftPtr;
node* rightPtr;
} * nodePtr;
class avlTree {
nodePtr root;
void rotateLeft(nodePtr n);
void rotateRight(nodePtr n);
public:
void add(data a);
void delete(data a);
nodePtr find(data a);
};
Structured English and pseudocode, as shown above, work perfectly well in most circumstances to capture the essential semantics of algorithms. The UML does define a special kind of state diagram, called an activity diagram, which may be helpful in some cases.
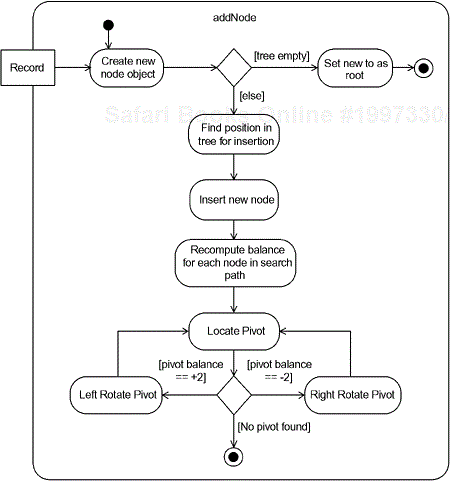
Activity diagrams depict systems that may be decomposed into activities—roughly corresponding to states that mostly terminate upon completion of the activity rather than as a result of an externally generated event. Activity diagrams may be thought of as a kind of flowchart where diagrammatic elements are member function calls. Figure 10-7 shows the activity diagram for the addNode() operation of our AVL tree class.
In reactive classes, exception handling is straightforward—exceptions are signals (associated with events) specified in the class state model that result in transitions being taken and actions being executed. In nonreactive classes, the specification means is less clear. The minimum requirements are to identify the exceptions raised by the class and the exceptions handled by the class.
Exception handling is a powerful addition to programming languages. Language-based exception handling provides two primary benefits. The first is that exceptions cannot be ignored. The C idiom for exception handling is to pass back a return value from a function, but this is generally ignored by the clients of the service. When was the last time you saw the return value for print checked?
The correct usage for the C fopen function is something like this
FILE *fp;
if ( (fp = fopen("filename", "w")) == NULL) {
/* do some corrective action */
exit(1); /* pass error indicator up a level */
};
Many programmers, to their credit, always do just that. However, there is no enforcement that the errors be identified or handled. It is up to the programmer and the code peer review process to ensure this is done. With exceptions, the error condition cannot be ignored. Unhandled exceptions are passed to each preceding caller until they are handled—a process called unwinding the stack. The terminate-on-exception approach has been successfully applied to programs in Ada and C++ for many years.
The other benefit of exception handling is that it separates the exception handling itself from the normal execution path. This simplifies both the normal processing code and the exception handling code. For example, consider the following standard C code segment:
if ( (fp = ftest1(x,y,z))) == NULL) {
/* do some corrective action */
printf("Failure on ftest1");
exit(1); /* pass error indicator up a level */
};
if (!ftest2()) {
/* do some corrective action */
printf("failure on ftest2");
exit(1);
};
if (ftest3() == 0) {
/* do some corrective action */
printf("failure on ftest3");
exit(1);
};
This is arguably more difficult to understand than the following code:
// main code is simplified
try {
ftest1(x,y,z);
ftest2();
ftest3();
}
// exception handling code is simplified
catch (test1Failure& t1) {
cout << "Failure on test1";
throw; // rethrow same exception as in code
above
}
catch (test2Failure& t2) {
cout << "Failure on test2";
throw;
};
catch (test3Failure& t3) {
cout << Failure on test3";
throw;
};
The second code segment separates the normal code processing from the exception processing, making both clearer.
Each operation should define the exceptions that it throws as well as the exceptions that it handles. There are reasons to avoid using formal C++ exceptions specifications [2] but the information should be captured nonetheless. Exceptions should never be used as an alternative way to terminate a function, in much the same way that a crowbar should not be used as an alternative key for your front door. Exceptions indicate that a serious fault requiring explicit handling has occurred.
Throwing exceptions is computationally expensive because the stack must be unwound and objects destroyed. The presence of exception handling in your code adds a small overhead to your executing code (usually around 3%) even when exceptions are not thrown. Most compiler vendors offer nonstandard library versions that don't throw exceptions and so this overhead can be avoided if exceptions are not used. Destructors should never throw exceptions or call operations that can throw exceptions nor should the constructors of exception classes throw exceptions.[11]
Exception handling applies to operations (i.e., functions) and is a complicating factor in the design of algorithms. In my experience, writing correct programs (i.e., those that include complete and proper exception handling) is two to three times more difficult than writing code that merely “is supposed to work.”[12]
Capturing the exception handling is fundamentally a part of the algorithm design and so can be represented along with the “normal” aspects of the algorithms. Exceptions can be explicitly shown as events on either statecharts or activity diagrams.
That still leaves two unanswered questions:
What exceptions should I catch?
What exceptions should I throw?
The general answer to the first question is that an operation should catch all exceptions that it has enough context to handle or that will make no sense to the current operation's caller.
The answer to the second is “all others.” If an object does not have enough context to decide how to handle an exception, then its caller might. Perhaps the caller can retry a set of operations or execute an alternative algorithm.
At some point exception handling will run out of stack to unwind, so at some global level, an exception policy must be implemented. The actions at this level will depend on the severity of the exception, its impact on system safety, and the context of the system. In some cases, a severe error with safety ramifications should result in a system shutdown, because the system has a fail-safe state. Drill presses or robotic assembly systems normally shut down in the presence of faults because that is their fail-safe state. Other systems, such as medical monitoring systems, may continue by providing diminished functionality or reset and retry, because that is their safest course of action. Of course, some systems have no fail-safe state. For such systems, architectural means must be provided as an alternative to in-line fault correction.
Exceptions can be modeled in several ways in the UML. In the absence of state machines and activity diagrams, throw, try, and catch statements are simply added to the methods directly. This works well within a single thread, but fails thread boundaries. For reactive objects—those with state machines—the best way is simply to model the exceptions as events. If the event handling is asynchronous, then this approach will work across thread boundaries. However, virtually all state machines use FIFO queues for unhandled events. Since the UML does not assign priorities to events, exception events are treated as normal events and will be handled in a FIFO way. This may not be what is desired.
For activities, exceptions are modeled as interrupting edges applied to an interruptible segment of an activity diagram. This causes the activity to terminate and control flow proceeds along the interrupting edge.
One definition of an object is “a set of tightly coupled attributes and the operations that act on them.” Detailed design takes this microscopic view to fully specify the characteristics of objects than have been hitherto abstracted away and ignored. These characteristics include the structuring of the attributes and identification of their representational invariants, resolution of abstract message passing into object operations, selection and definition of algorithms, including the handling of exceptional conditions.
Attributes are the data values subsumed within the objects. They must be represented in some fashion supported by the implementation language, but that is not enough. Most often, the underlying representation is larger than the valid ranges of the attribute, so the valid set of values of the attributes must be defined. Operations can then include checking the representational invariants to ensure that the object remains in a valid state.
Analysis models use the concept of message-passing to represent the myriad of ways that objects can communicate. Detailed design must decide the exact implementation of each message. Most often, messages are isomorphic with operations, but that is only true when the message source is always in the same thread of execution. When this is not true, other means, such as OS message queues, must be employed to provide inter-object communication.
Many objects are themselves algorithmically trivial and do not require a detailed specification of the interaction of the operations and attributes. However, in every system, a significant proportion of objects have “rich” behavior. Although this requires additional work, it also provides the designer with an opportunity to optimize the system performance along some set of criteria. Algorithms include the handling of exceptions and this is usually at least as complex as the primary algorithm itself. Algorithms can be expressed using state charts or activity diagrams. Other representations, such as mathematical equations, pseudocode, or text can be used as well.
[1] Geekosphere (n): the area surrounding one's computer (“Jargon Watch,” Hardwired, 1997)
[2] My personal choice would be the Yogi rock on Mars (see http://www.jpl.nasa.gov, a public mirror site for the Mars Pathfinder mission).
[3] Having one's F-16 flip upside down when crossing the equator is an example of such a “bad thing.” Fortunately, this defect was discovered during simulation and not during actual flight.
[4] Infinite precision arithmetic is available in some Lisp-based symbolic mathematics systems, such as Derive and MacSyma.
[5] Widely different computational results of algebraically equivalent formulations can lead to hazardous situations. See [5].
[6] C++ requires that references always be valid; that is, a null reference is semantically illegal.
[7] The use of friend classes results in a kind of “clothing-optional” design, which, although it can be fun, may make some designers nervous.
[8] Which is why they are called tradeoffs.
[9] An AVL tree is not a specifically real-time example, but the algorithm is well known in the computer science literature and is quite straightforward. Thus, we will use it here for our discussion.
[10] This is a derived attribute. It can be explicitly stored and maintained during addition and deletion, or it can be recomputed as necessary.
[11] In C++, if an exception is thrown while an unhandled exception is active, the program calls the internal function terminate() to exit the program. As the stack is unwound during exception handling, local objects are destroyed by calling their destructors. Thus destructors are called as part of the exception handling process. If a destructor is called because its object is being destroyed due to an exception, any exception it throws will terminate the program immediately.
[12] In contrast to prevailing opinion, I don't think this is solely due to my recently hitting 40 and the associated loss of neural cells.