
It has been traditional to mix cinema soundtracks in large mixing theatres in order that the many variables involved in transposing a mix from the studios to the public cinemas could be minimised. However, the more recent needs for compatibility with smaller theatres and subsequent DVD releases have again highlighted the problems of the compatibility of playback in rooms of different sizes. The X-curve, used for cinema loudspeaker playback, has long recognised the need for different high-frequency roll-offs depending on room size and decay time, but another room-size related problem–that of the perceived level of the dialogue varying relative to the music and effects–has led many people to ask whether a further compensation needs to be defined and applied. To date, many discussions and internet forums have alluded to the existence of a perceived problem, but no thorough investigation appears to have taken place.
A.4.1 Hypothesis
In general, as rooms become larger they tend to exhibit a decay time which rises at low frequencies. They also tend towards their first reflexions arriving later than those in small rooms, and the subsequent reflexions are more separated in time. It has been noted by many people that the relative level of the dialogue in a film soundtrack which has been mixed in a large room can seem excessively loud when reproduced in a small room, although no definitive proof has so far been published. Allen,1 in his 2006 paper, demonstrated how the reverberation in a room would develop in response to pink noise, and three figures from his paper are reproduced as Figures A.4.1(a), (b) and (c). Given a reverberation characteristic as shown in Figures A.4.1(a), it can be seen from (b) and (c) how the first arriving signal, having a flat response, is subsequently subjected to a reverberant build-up which is moderate at mid frequencies but greater at low frequencies and less at high frequencies.
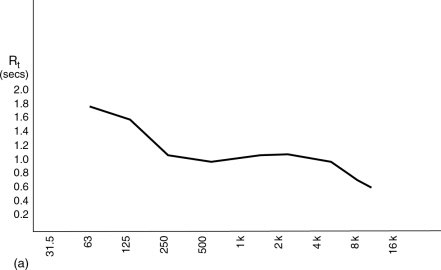
Figure A.4.1a Typical medium to large size theatre reverberation characteristic
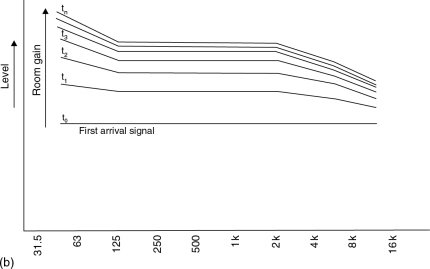
Figure A.4.1b Pink noise build-up over time in medium to large size theatres
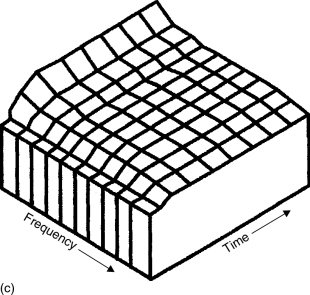
Figure A.4.1c Frequency response changes with duration of signal
The short sounds of the spoken word are essentially in the range of 100 Hz–2 kHz, but their duration is too short to exhibit signs of reverberant build-up. They are also above the frequency band which would suffer the greatest reverberation in a complex, wide-band soundtrack. Consequently, in a complex soundtrack, the low frequency build-up would tend to mask the short sounds of dialogue and reduce the intelligibility as compared to dialogue at the same level but with less ambient or musical accompaniment. The natural tendency, therefore, is for the person making a mix for a soundtrack to elevate the dialogue levels when mixing in a room with a longer and low-frequency-dominant reverberation time, as compared to mixing in a less reverberant room with less low frequency build-up, because despite the large and small rooms both being equalised flat, the time-smeared reverberant response exhibits a greater masking effect. As a result of this, when such a soundtrack is played back in a smaller, drier room, the dialogue levels may seem to be excessively high in terms of their relative balance with the rest of the soundtrack.
When a room is equalised to be flat in response to a pink noise signal, with the equalisation of the loudspeaker system compensating for the reverberant build-up at low frequencies, the time-history of the response would tend to be as shown in Figure A.4.2, also taken from Allen’s paper. The tendency would be for a direct signal to be reduced in bass and increased above around 2 kHz, leading to a generally thinner, harsher sound, which is exactly what is being reported by many people as being the nature of the dialogue when auditioned in small rooms after being mixed in larger, more reverberant rooms.
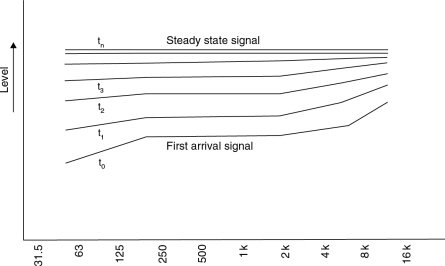
Figure A.4.2 What would happen to first arrival signal if pink noise was tuned for a flat steady-state response
In real life, if a human being were to speak in rooms of different sizes, the characteristics of the direct sound would not change. It is probable that the direct sound (in all but highly reverberant conditions which would not be suitable for cinema use) forms a significant part of what a listener would deem to be the ‘natural’ sound of the voice. Therefore, to linearly distort the direct sound in order to compensate for room effects, which although affecting more steady-state sounds do not make a significant change to the perception of the spoken word, would seem to be detrimental to the uniformity of its perception in different rooms. That is to say, once a large room has been equalised to the X-curve with pink noise, such that the direct response from the loudspeakers is similar to that shown for the first arrival in Figure A.4.2, the re-recording mixers will probably equalise the dialogue to give it a more natural characteristic–in effect adding the inverse of the first-arrival response. When the soundtrack is played back in a smaller or drier room, in which the loudspeakers have been equalised with a flatter general characteristic, then the dialogue may tend to be perceived with a much ‘heavier’ sound. The concept is described more fully in Section 11.5.
These phenomena give rise to perceptual differences in the balance of the different components of a soundtrack, dependent upon the sizes of the rooms in which they were either mixed or reproduced, but there may also be other mechanisms at work. The level of early reflexions in a room can reinforce the short sounds of dialogue, if they arrive with a delay of less than about 40 ms relative to the direct signal. The reflexions will tend to reinforce dialogue levels in smaller rooms more than in larger rooms, where the reflexion density will be less, and where the reflexions will tend to be at a lower relative level due to the fact that they have travelled greater distances than in small rooms. They would also suffer a high frequency roll-off due to air absorption, at the rate of about 1 dB for every 5 m travelled at 10 kHz. Where the direct and reflected paths differ significantly, say by more than 10 m, the roll-off of the high frequencies may become noticeable in the reflected sound.
Therefore, taking a mix from a large room, with a reverberation characteristic similar to that shown in Figure A.4.1(a), and playing it back in a smaller room with a drier, flatter decay characteristic, we could observe the following:
- The overall response of a large, more reverberant room with a significant rise at low frequencies (in the RT will consist of a direct signal which is bass light and, perhaps, slightly treble heavy. People mixing in such a room will probably compensate for this effect by adding equalisation to the dialogue which will restore the natural frequency balance of the direct signal. Subsequently, on playback in a smaller room which has been equalised with a flatter direct response, the dialogue will sound to have been boosted by the applied equalisation, which would not have been necessary in the flatter direct monitoring conditions of the smaller, drier room, and which therefore sounds excessive. Perhaps consideration should be given to equalising the centre loudspeaker, carrying most of the dialogue, to be flat (or to the X-curve) in the close-field rather than in the far-field. For example, 1/3 distance from the screen to the mixing position.
- The dialogue will receive no significant reverberant support in either a large or a small room, so the effect of reverberation can be largely discounted when considering the dialogue only. However, the music and low frequency ambience would not receive as much reverberant support in a small, dry room as in a larger, more reverberant room, and so many sound weaker. Note that even if the levels of these signals had been boosted at low frequencies by the flatter direct signal from the loudspeakers in the smaller room, the faster overall decay may well still leave the dialogue more exposed.
- The dialogue may receive more support from early reflexions in the smaller room due to the close proximity of reflective surfaces, because the reflexions arriving within 40 ms of the direct sound will reinforce its level. This would perhaps be noticed more on the short sounds of the dialogue than on the longer sounds of the music and ambience, because the latter two had received reverberant support during the mix whilst the dialogue had not.
- Air absorption at high frequencies would be less in the smaller room, so any reflexions would tend to be brighter than in a larger room, once again giving a boost to signals which were being supported by the higher reflexion density.
A further complication arises from the interrelation of our senses of hearing and seeing. That is, we expect different sound levels from different sizes of objects at different distances. Imagine that we are looking at a full-screen picture of a tank, firing its gun, on a screen 12 m wide and 20 m away. A peak SPL of 115 dBC would be impressive, and also very realistic. Now imagine that we are seeing the same picture, subtending the same angle of vision, but on a television screen of 50 cm wide and at a distance of only about 85 cm. In each case the picture would fill the same field of vision from the viewer, as shown in Figure A.4.3, but 115 dBC would be grossly excessive, if heard in relation to the picture on a nearby television screen. Conversely, a soundtrack at an appropriate level for television viewing, even in the same room as the big screen, would be much too quiet for viewing at 20 m distance. Notwithstanding the fact that the television would essentially be heard from within the critical distance, whereas the big screen would be heard from a position in the reverberant field of the room, similar level difference needs would be apparent even in a very dry, low decay-time room.

Figure A.4.3 Change of viewing distance whilst maintaining the same angle of vision and relative picture size
There are therefore a number of characteristics of perception in rooms of different sizes and decay times which all lead to different level and equalisation requirements in order to sound most natural and appropriate. Work is currently in progress to try to qualify and quantify these differences in order to facilitate the realistic compatibility of mixes in different listening and viewing environments.
Reference
1 Allen, Ioan, ‘The X-Curve: Its Origins and History’, SMPTE Journal, Vol. 115, Nos 7 & 8, pp. 264–275 (2006)
Bibliography
Newell, P., Holland, K., Neskov, B., Castro, S., Desborough, M., Pena, A., Torres, M.,Valdigem, E., Suarez, D., ‘The Perception of Dialogue Loudness Levels within Complex Soundtracks
Newell, P. R. Holland, K. R. Neskov, B., Castro, S., Desborough, M., Torres Guijarro, S., Pena, A., Valdigêm, E., Suarez Staub, D., Newell, J. P. Harris, L., Beusch, C. “The Effect of Visual at Similar Overall Sound Pressure Levels in Rooms of Different Sizes’, Proceedings of the Stimuli on the Perception of ‘Natural’ Loudness and Equalisation”, Proceedings of the Institute of Acoustics, Vol. 30, Part 6, pp 15–26, Reproduced Sound 24 conference, Institute of Acoustics, Vol. 29, Part 7, pp. 125–139 (November 2007). Brighton, UK (2008).