
Chapter 4 Analyzing Data with Random Effects
4.2.1 Analysis of Variance for Nested Classifications
4.2.2 Computing Variances of Means from Nested Classifications and Deriving Optimum Sampling Plans
4.2.4 Variance Component Estimation for Nested Classifications: Analysis Using PROC MIXED
4.3 Blocked Designs with Random Blocks
4.3.1 Random-Blocks Analysis Using PROC MIXED
4.4.2 Standard Errors for the Two-Way Mixed Model: GLM versus MIXED
4.5 A Classification with Both Crossed and Nested Effects
4.5.1 Analysis of Variance for Crossed-Nested Classification
4.5.3 Satterthwaite’s Formula for Approximate Degrees of Freedom
4.5.4 PROC MIXED Analysis of Crossed-Nested Classification
4.6.1 A Standard Split-Plot Experiment
4.6.1.1 Analysis of Variance Using PROC GLM 137
4.6.1.2 Analysis with PROC MIXED
4.1 Introduction
Chapter 3 looked at factors whose levels were chosen intentionally. Typically, the objective of a particular study dictates that a specific set of treatments, or treatment factor levels, be included. The effects corresponding to factors chosen in this way are called fixed effects.
On the other hand, many studies use factors whose levels represent a larger population. Many studies incorporate blocking factors to provide replication over a selection of different conditions. Investigators are not normally interested in the specific performance of individual blocks, but rather in what the average across blocks reveals. For example, you might want to test chemical compounds at several laboratories to compare the compounds averaged across all laboratories. Laboratories are selected to represent some broader possible set of laboratories. Other studies employ experimental factors in which the levels of the factors are a sample of a much larger population of possible levels. If you work in industry, you probably have seen experiments that use a selection of batches of a raw material, or a sample of workers on an assembly line, or a subset of machines out of a much larger set of machines that are used in a production process. Such factors (laboratories, batches, workers, machines, or whatever) are called random effects. Theoretically, the levels of a factor that are in the experiment are considered to be a random sample from a broader population of possible levels of the factor.
Traditionally, one criterion used to distinguish fixed and random effects was the type of inference. If you were interested in specific treatments, or laboratories, or machines—for example, you wanted to estimate means or test treatment differences—then by definition that effect was fixed. If, instead, your interest was in what happened across the broader collection of laboratories or batches or workers or machines, rather than in what happened with a particular laboratory or batch or worker or machine, and the only parameter to be estimated was the variance associated with that factor, then your effect was random.
With contemporary linear model theory for fixed and random effects, the distinction is more subtle. Fixed effects remain defined as they have been. However, for random effects, while interest always focuses on estimating the variance, in some applications you may also be interested in specific levels. For example, your laboratories may be a sample of a larger population, and for certain purposes you want a population-wide average, but you may also want to look at certain laboratories. Workers may represent a population for certain purposes, but the supervisor may also want to use the data for performance evaluations of individual workers. Animal breeding pioneered this approach: randomly sampled sires were used to estimate variance among sires for genetic evaluation, but individual “sire breeding values” were also determined to identify valuable sires. You can do this with random effects as long as you take into account the distribution among the random effect levels, a method called best linear unbiased prediction.
In contemporary linear model theory, there is only one truly meaningful distinction between fixed and random effects. If the effect level can reasonably be assumed to represent a probability distribution, then the effect is random. If it does not represent a probability distribution, then the effect is fixed. Period. Treatments are almost invariably fixed effects, because interest focuses almost exclusively on mean differences and, most importantly, the treatment levels result from deliberate choice, not sampling a distribution. On the other hand, blocks, laboratories, workers, sires, machines, and so forth, typically (but not always!) represent a sample (although often an imperfect sample) of a population with a probability distribution. Random effects raise two issues in analyzing linear models. First is how you construct test statistics and confidence intervals. Second, if you are interested in specific levels, you need to use best linear unbiased prediction rather than simply calculating sample means.
With balanced data, random factors do not present a major issue for the estimation of treatment means or differences between treatment means. You simply compute means or differences between means, averaged across the levels of random factors in the experiment. However, the presence of random effects has a major impact on the construction of test statistics and standard errors of estimates, and hence on appropriate methods for testing hypotheses and constructing confidence intervals. It is safe to say that improper attention to the presence of random effects is one of the most common and serious mistakes in statistical analysis of data.
Random effects probably occur in one form or another in the majority of statistical studies. The RANDOM statement in the GLM procedure can help you determine correct methods in many common applications. The MIXED procedure provides an even more comprehensive set of tools for working with random effects. In many common applications, methods that are essential are available in MIXED but not in GLM.
4.2 Nested Classifications
Data may be organized into two types of classification patterns, crossed (Figure 4.1) or nested (Figure 4.2).
Figure 4.1 Crossed Classification

Figure 4.2 Nested Classification
Nested classifications of data have sampling units that are classified in a hierarchical manner. Typically, these samples are taken in several stages:
1. selection of main units (analogous to level A in Figure 4.2)
2. selection of subunits from each main unit (analogous to level B in Figure 4.2)
3. selection of sub-subunits from the subunits, and so on.
Normally, the classification factors at each stage are considered random effects, but in some cases a classification factor may be considered fixed, especially one corresponding to level A in Figure 4.2, that is, the first stage of sampling.
Here is an example of a nested classification. Microbial counts are made on samples of ground beef in a study whose objective is to assess sources of variation in numbers of microbes. Twenty packages of ground beef (PACKAGE) are purchased and taken to a laboratory. Three samples (SAMPLE) are drawn from each package, and two replicate counts are made on each sample. Output 4.1 shows the raw data.
Output 4.1 Microbial Counts in Ground Beef
| Obs | package | ct11 | ct12 | ct21 | ct22 | ct31 | ct32 |
| 1 | 1 | 527 | 821 | 107 | 299 | 1382 | 3524 |
| 2 | 2 | 2813 | 2322 | 3901 | 4422 | 383 | 479 |
| 3 | 3 | 703 | 652 | 745 | 995 | 2202 | 1298 |
| 4 | 4 | 1617 | 2629 | 103 | 96 | 2103 | 8814 |
| 5 | 5 | 4169 | 2907 | 4018 | 882 | 768 | 271 |
| 6 | 6 | 67 | 28 | 68 | 111 | 277 | 199 |
| 7 | 7 | 1612 | 1680 | 6619 | 4028 | 5625 | 6507 |
| 8 | 8 | 195 | 127 | 591 | 399 | 275 | 152 |
| 9 | 9 | 619 | 520 | 813 | 956 | 1219 | 923 |
| 10 | 10 | 436 | 555 | 58 | 54 | 236 | 188 |
| 11 | 11 | 1682 | 3235 | 2963 | 2249 | 457 | 2950 |
| 12 | 12 | 6050 | 3956 | 2782 | 7501 | 1952 | 1299 |
| 13 | 13 | 1330 | 758 | 132 | 93 | 1116 | 3186 |
| 14 | 14 | 1834 | 1200 | 18248 | 9496 | 252 | 433 |
| 15 | 15 | 2339 | 4057 | 106 | 146 | 430 | 442 |
| 16 | 16 | 31229 | 84451 | 6806 | 9156 | 12715 | 12011 |
| 17 | 17 | 1147 | 3437 | 132 | 175 | 719 | 1243 |
| 18 | 18 | 3440 | 3185 | 712 | 467 | 680 | 205 |
| 19 | 19 | 8196 | 4565 | 1459 | 1292 | 9707 | 8138 |
| 20 | 20 | 1090 | 1037 | 4188 | 1859 | 8464 | 14073 |
The data are plotted in Output 4.2, with points identified according to their SAMPLE number.
Output 4.2 Plots of Count versus Package Number
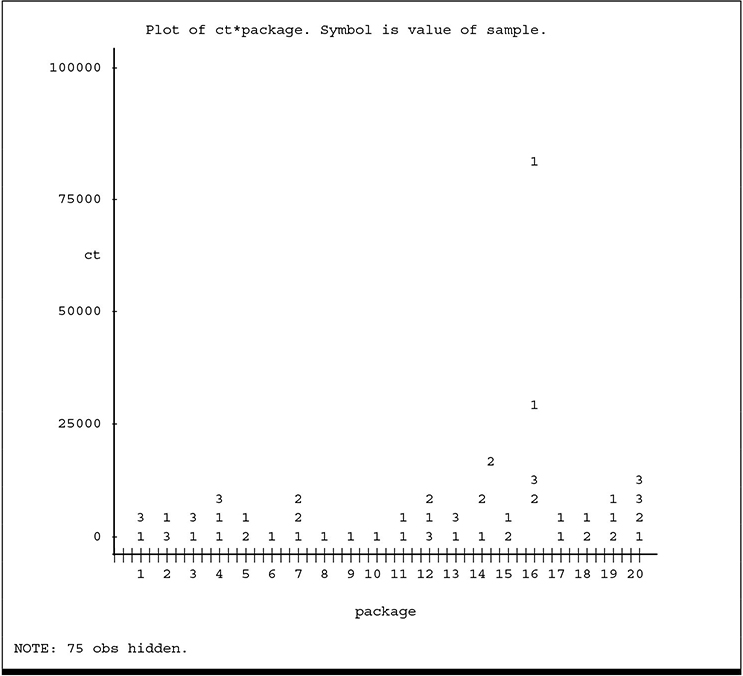
You can see the larger variation among larger counts. In order to stabilize the variance, the logarithm (base 10) of the counts (LOGCT) was computed and serves as the response variable to be analyzed. The plot of LOGCT, which appears in Output 4.3, indicates the transformation was successful in stabilizing the variance.
Output 4.3 Plot of Log Count versus Package Number
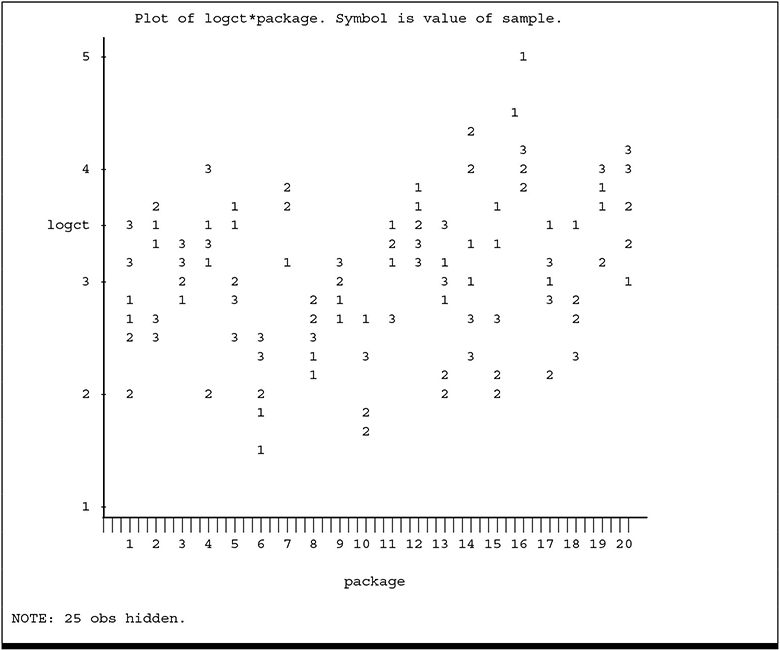
Logarithms are commonly computed for microbial data for the additional reason that interest is in differences in the order of magnitude rather than in interval differences.
A model for the data is
yijk = μ + ai + b(a)ij + eijk (4.1)
where
| yijk | is the log10 count for the kth replicate of the jth sample from the ith package. |
| μ | is the overall mean of the sampled population. |
| ai | are the effects of packages, that is, random variables representing differences between packages, with variance σ2p |
| b(a)ij | are random variables representing differences between samples in the same package, with variance σ2s |
| eijk | are random variables representing differences between replicate counts in the same sample, with variance σ2, i = 1, . . . ,20, j = 1, 2, 3 and k = 1, 2. |
The random variables ai, b(a)ij, and eijk are assumed to be normal distributed and independent with means equal to 0. Note several conventions used in this text for denoting fixed versus random effects. Greek symbols denote fixed effects, as they have for all models in previous chapters, and for μ in this model. Latin symbols denote random effects. If you consider packages to be fixed, instead of random, you would denote the package effects as αi instead of αai. The notation b(a) is used for nested factors, in this case factor B (samples) nested within factor A (packages). You could denote the effects of replicates within samples as c(ab)ijk, but by convention the smallest subunit in the model is generally denoted as eijk.
The variance (V) of the log counts can be expressed as
V(yijk) = σ2y
= σ2p
Expressing the equation with words, the variance of the logarithms of microbial count is equal to the sum of the variances due to differences among packages, among samples in the same package, and between replicates in the same sample. These individual variances are therefore called components of variance. The first objective is to estimate the variance components, and there are several statistical techniques for doing so, including analysis of variance (ANOVA) and maximum likelihood (or, more commonly, restricted maximum likelihood, or REML). In this chapter, both ANOVA and REML methods are used. For balanced data, ANOVA and REML produce identical results. The first examples in this chapter use ANOVA because it is easier to see how the method works. PROC MIXED, introduced later in this chapter, uses REML because it is easier to generalize to more complex models.
4.2.1 Analysis of Variance for Nested Classifications
An analysis-of-variance table for the ground beef microbial counts has the following form:
| Source of Variation | DF |
|---|---|
| packages | 19 |
| samples in packages | 40 |
| replicates in samples | 60 |
You can produce this table by using the GLM procedure (see Chapter 3, “Analysis of Variance for Balanced Data”). You can also use the ANOVA, NESTED, and VARCOMP procedures to produce this table. The MIXED procedure does not compute the analysis of variance table per se, but it computes statistics that are typical end points for the analysis of data with random effects. Which procedure is best to use depends on your objectives.
As noted in Chapter 3, PROC ANOVA computes analysis of variance for balanced data only. PROC GLM computes the same analysis of variance but can be used for unbalanced data as well (see Chapter 5). In the early days of computing, limited capacity often forced users to use PROC ANOVA for large data sets. However, with contemporary computers this is rarely an issue and hence there is rarely any reason to use PROC ANOVA instead of PROC GLM. PROC NESTED is a specialized procedure that is useful only for nested classifications. It provides estimates of the components of variance using the analysis-of-variance method of estimation. Because PROC NESTED is so specialized, it is easy to use. However, PROC GLM can compute the same analysis of variance as PROC NESTED, but it does so within the framework of a much broader range of applications. Finally, PROC MIXED and PROC VARCOMP compute the variance component estimates. The MIXED procedure can also compute a variety of statistics not available with any other procedure. Many of these statistics have become increasingly important in the analysis of data with random effects. For these reasons, this chapter focuses on using PROC GLM to compute the analysis of variance, and later sections introduce PROC MIXED to compute additional statistics typically of interest.
The program statements for PROC GLM are similar to those introduced in Chapter 3. You add a RANDOM statement to compute the expected values of the mean squares—that is, what is being estimated by the individual mean squares. Here are the proper SAS statements:
proc glm;
class package sample;
model logct=package sample(package);
random package sample(package);
You can see that the syntax for a nested effect, in this case SAMPLE nested within PACKAGE, follows from the notation used for nested effects in model (4.1). The RANDOM statement is simply a list of effects in the model to be considered random. In most practical situations, you add a TEST option to the RANDOM statement in order to compute the proper test statistics. Section 4.2.3 illustrates the TEST option. However, you should first understand the analysis-of-variance statistics that PROC GLM computes by default.
The analysis-of-variance results appear in Output 4.4, and the expected mean square coefficients are given in Output 4.5.
Output 4.4 GLM Analysis of Variance of Log Count
| Sum of | |||||
| Source | DF | Squares | Mean Square | F Value | Pr > F |
| Model | 59 | 50.46346700 | 0.85531300 | 22.23 | <.0001 |
| Error | 60 | 2.30863144 | 0.03847719 | ||
| Corrected Total | 119 | 52.77209844 | |||
| R-Square | Coeff Var | Root MSE | logct Mean |
| 0.956253 | 6.432487 | 0.196156 | 3.049459 |
| Source | DF | Type I SS | Mean Square | F Value | Pr > F |
| package | 19 | 30.52915506 | 1.60679763 | 41.76 | <.0001 |
| sample(package) | 40 | 19.93431194 | 0.49835780 | 12.95 | <.0001 |
| Source | DF | Type III SS | Mean Square | F Value | Pr > F |
| package | 19 | 30.52915506 | 1.60679763 | 41.76 | <.0001 |
| sample (package) | 40 | 19.93431194 | 0.49835780 | 12.95 | <.0001 |
Note: The F-statistics computed by PROC GLM for the basic analysis of variance of models with random effects are not necessarily correct. For the basic F-statistics shown above, GLM always uses MS(ERROR) for the denominator. For example, the F-statistic for PACKAGE is incorrect because MS(ERROR) is not the correct denominator mean square. Section 4.2.3, in conjunction with Table 4.1, shows you how to use the expected mean squares to determine the correct F-statistics.
Output 4.5 Expected Mean Squares for Log Count Data
| Type III Expected Mean Square | |
| Source | |
| package | Var(Error) + 2 Var(sample(package)) + 6 Var(package) |
| sample(package) | Var(Error) + 2 Var(sample(package)) |
Now consider the output labeled “Type III Expected Mean Square.” This part of the output gives you the expressions for the expected values of the mean squares. Table 4.1 shows you how to interpret the coefficients of expected mean squares.
Table 4.1 Coefficients of Expected Mean Squares
| Variance Source | Source of Variation | DF | Expected Mean Squares | This Tells You: |
|---|---|---|---|---|
| PACKAGE | packages | 19 | σ2 |
MS(PACKAGE) estimates |
| σ2 |
||||
| SAMPLE | samples in packages | 40 | σ2 |
MS(SAMPLE) estimates |
| σ2 |
||||
| ERROR | replicates in samples | 60 | σ2 |
MS(ERROR) estimates |
| σ2 |
From the table of coefficients of expected mean squares you get the estimates of variance components. These estimates are
❏ ˆσ2
❏ ˆσ2s
❏ ˆσ2p
The variance of a single microbial count is
ˆσ2y
= ˆσ2
= 0.0385 + 0.2299 + 0.1847
= 0.4532
Note: The expression TOTAL Variance Estimate does not refer to MS(TOTAL) = 0.4435,
although the values are similar. From these estimates, you see that
❏ 8.49% of TOTAL variance is attributable to ERROR variance
❏ 50.74% of TOTAL variance is attributable to SAMPLE variance
❏ 40.77% of TOTAL variance is attributable to PACKAGE variance.
4.2.2 Computing Variances of Means from Nested Classifications and Deriving Optimum Sampling Plans
The variance of a mean can also be partitioned into portions attributable to individual sources of variation. The variance of a mean ˉY⋅⋅⋅
ˆσ2y...
Output 4.4 showed that the overall mean is 3.0494. Its standard error can be determined from the square root of the formula for the variance of the mean. For these data, the standard error is
ˆσ2y...
The formula for the variance of a mean can also be used to derive an optimum sampling plan, subject to certain cost constraints. Suppose you are planning a study, for which you have a budget of $500. Each package costs $5, each sample costs $3, and each replicate count costs $1. The total cost is
cost = $5 * np+ $3 * np * ns+ $1 * np * ns * n
You can create a SAS data set by taking various combinations of nP, nS, and n for which the cost is $500, and compute the variance estimate for the mean. Then you can choose the combination of nP, nS, and n that minimizes ˆσ2y...
4.2.3 Analysis of Variance for Nested Classifications: Using Expected Mean Squares to Obtain Valid Tests of Hypotheses
Expected mean squares tell you how to set up appropriate tests of a hypothesis regarding the variance components. Suppose you want to test the null hypothesis H0: σ2p=0
Formally, you do this with an F-statistic: divide MS(PACKAGE) by MS(SAMPLE). The result has an F-distribution with np –1 DF in the numerator and np(ns–1) DF in the denominator. For the microbial count data, F=1.607/0.498=3.224, with numerator DF=19 and denominator DF=40, which is significant at the p=0.0009 level. Therefore, you reject H0: σ2p=0
You can go through the same process of using the table of expected mean squares to set up a test of the null hypothesis H0: σ2s=0
You can compute the test statistics for H0: σ2p=0
proc glm;
class package sample;
model logct=package sample(package);
random package sample(package)/test;
test h=package e=sample(package);
Notice that you only need to use either the TEST option in the RANDOM statement or the TEST statement, but not both. The former uses the expected mean squares determined by the RANDOM statement to define the appropriate F-statistics. The latter requires you to know what ratio needs to be computed. In the TEST statement, H= refers to the numerator MS, and E= specifies the denominator MS to be used for the F-statistic. For the balanced data sets presented in this chapter, the F-statistics computed by the RANDOM statement’s TEST option and by the TEST statement are the same. This is not always true for unbalanced data, which is discussed in Chapters 5 and 6. Note that you do not need a TEST statement for H0: σ2s=0
Output 4.6 RANDOM TEST Option and TEST Statement Results in PROC GLM for Log Count Data
| Output from RANDOM statement TEST option: | |||||
| Tests of Hypotheses for Random Model Analysis of Variance | |||||
| Dependent Variable: logct | |||||
| Source | DF | Type III SS | Mean Square | F Value | Pr > F |
| package | 19 | 30.529155 | 1.606798 | 3.22 | 0.0009 |
| Error | 40 | 19.934312 | 0.498358 | ||
| Error: MS(sample(package)) | |||||
| Source | DF | Type III SS | Mean Square | F Value | Pr > F |
| sample(package) | 40 | 19.934312 | 0.498358 | 12.95 | <.0001 |
| Error: MS(Error) | 60 | 2.308631 | 0.038477 | ||
| Output from TEST H=PACKAGE E=SAMPLE(PACKAGE) statement: | |||||
| Tests of Hypotheses Using the Type III MS for sample(package) as an Error Term | |||||
| Source | DF | Type III SS | Mean Square | F Value | Pr > F |
| package | 19 | 30.52915506 | 1.60679763 | 3.22 | 0.0009 |
4.2.4 Variance Component Estimation for Nested Classifications: Analysis Using PROC MIXED
PROC MIXED is SAS’ most sophisticated and versatile procedure for working with models with random effects. You can duplicate the tests and estimates discussed in previous sections. In addition, there are several linear models statistics that only PROC MIXED can compute. This section introduces the basic features of PROC MIXED for random-effects models. The required statements for model (4.1) are
proc mixed;
class package sample;
model logct= ;
random package sample(package);
In some respects, the statements for PROC GLM and PROC MIXED are the same—the CLASS statement, the MODEL statement up to the left-hand side, and the RANDOM statement are all identical to the statements used above for PROC GLM. The MODEL statement contains the big difference. In PROC GLM, you list all the effects in the model other than the intercept and error, regardless of whether they are fixed or random. In PROC MIXED, you list ONLY the fixed effects, if there are any, other than the intercept. For this model, the only fixed effect is ?, so nothing appears to the right of the equal sign except a space and a semicolon. Output 4.7 shows the results for these statements.
Output 4.7 Basic PROC MIXED Results for Log Count Data
| Iteration History | |||
| Iteration | Evaluations | -2 Res Log Like | Criterion |
| 0 | 1 | 245.73109785 | |
| 1 | 1 | 128.18662316 | 0.00000000 |
| Convergence criteria met. | |
| Covariance Parameter | |
| Estimates | |
| Cov Parm | Estimate |
| package | 0.1847 |
| sample(package) | 0.2299 |
| Residual | 0.03848 |
| Fit Statistics | |
| -2 Res Log Likelihood | 128.2 |
| AIC (smaller is better) | 134.2 |
| AICC (smaller is better) | 134.4 |
| BIC (smaller is better) | 137.2 |
The essential part of this output appears under “Covariance Parameter Estimates.” These are the estimates of σ2p, σ2s, and σ2
The REML procedure requires numerical iteration. The “Iteration History” appears immediately before the variance component estimates. You should look for the expression “Convergence Criteria Met.” If it appears, fine. For the types of data sets in this book, convergence problems are extremely rare. If you do get a failure to converge, it is probably because the data are being misread, or the CLASS, MODEL, or RANDOM statements are mistyped.
The basic MIXED output does not contain an analysis-of-variance table. If you want to test hypotheses about the variance components, you can use PROC GLM to compute the F-tests as shown previously. PROC MIXED does allow you two ways to test the variance components—the Wald test and the likelihood ratio test. Of the two, the likelihood ratio test is preferable for most applications.
The likelihood ratio test uses the residual log likelihood—more precisely, –2 times the residual log likelihood, that is, “–2 Res Log Likelihood” in Output 4.7—to construct a test statistic that has an approximate χ2 distribution. For the model that contains both effects, PACKAGE and SAMPLE(PACKAGE), the –2 residual log likelihood is 128.2. If you drop SAMPLE(PACKAGE) from the RANDOM statement and rerun the analysis, you can test H0: σ2s=0
proc mixed;
class package sample;
model logct= ;
random package;
You get the “Fit Statistics” shown in Output 4.8.
Output 4.8 Statistics for Fit of Model without SAMPLE (PACKAGE) for Log Count Data
| Fit Statistics | |
| -2 Res Log Likelihood | 201.2 |
| AIC (smaller is better) | 205.2 |
| AICC (smaller is better) | 205.3 |
| BIC (smaller is better) | 207.2 |
The –2 residual log likelihood for this model is 201.2. The difference between this and the value of the full model is 201.2–128.2 = 73.0. This is the likelihood ratio statistic. It has an approximate χ2 distribution with 1 DF. The 1 DF is because one variance component has been removed from the model. The α=0.05 critical value for χ2 is 3.84, the p-value for χ2=73.0 is <0.0001. Therefore, you reject H0: σ2s=0
You can then drop PACKAGE from the model to test H0: σ2p=0
proc mixed;
class package sample;
model logct= ;
yield a –2 residual log likelihood of 245.7. The likelihood ratio test statistic for H0: σ2p=0
You can also obtain Wald statistics. You use the option COVTEST in the PROC MIXED statement to compute approximate standard errors for the variance components. The Wald statistic is the ratio Z=variance estimatestandard error
proc mixed covtest;
class package sample;
model logct= ;
random package sample(package);
Output 4.9 shows the results.
Output 4.9 PROC MIXED Variance Component Estimates Using the COVTEST Option
| Covariance Parameter Estimates | ||||
| Standard | Z | |||
| Cov Parm | Estimate | Error | Value | Pr Z |
| package | 0.1847 | 0.08885 | 2.08 | 0.0188 |
| sample(package) | 0.2299 | 0.05583 | 4.12 | <.0001 |
| Residual | 0.03848 | 0.007025 | 5.48 | <.0001 |
Using H0: σ2p=0
Important Note: For tests of variance components, the normal approximation is very poor unless the sample size (in this case the number of packages) is in the hundreds or, preferably, thousands. For this reason, use of the Wald statistic to test variance components is strongly discouraged unless your sample size is very large. The ANOVA F-tests using PROC GLM are preferable. Alternatively, you can construct likelihood ratio tests using PROC MIXED, although doing so requires multiple runs and is therefore less convenient. See Littell et al. (1996) for more about likelihood ratio tests.
4.2.5 Additional Analysis of Nested Classifications Using PROC MIXED: Overall Mean and Best Linear Unbiased Prediction
Section 4.2.2 presented the estimate and standard error of the overall mean. The PROC GLM output provides the estimate y̅…, but not the variance component estimates. You have to calculate these from the mean squares and then hand-calculate the standard error of the mean. PROC MIXED does not compute these numbers by default, but you can obtain them either with the SOLUTION option in the MODEL statement or with an ESTIMATE statement. The SAS statements are
model logct= / solution;
random package sample(package);
estimate 'overall mean' intercept 1;
Output 4.10 shows the results.
Output 4.10 PROC MIXED Estimates of Overall Mean for Log Count Data
| Solution for Fixed Effects | |||||
| Standard | |||||
| Effect | Estimate | Error | DF | t Value | Pr > |t| |
| Intercept | 3.0495 | 0.1157 | 19 | 26.35 | <.0001 |
| Estimates | |||||
| Standard | |||||
| Label | Estimate | Error | DF | t Value | Pr > |t| |
| overall mean | 3.0495 | 0.1157 | 19 | 26.35 | <.0001 |
You can see that the SOLUTION option and the ESTIMATE statement produce identical results. In this case, they are simply different ways of including μ̂ in the output.
In some applications with random-effects models, the equivalent of treatment means may be of interest. Henderson (1963,1975) first developed this procedure in the context of animal breeding. Random sires were used to estimate variance components that had genetic interpretations. At the same time, breeders wanted to assess the “breeding value” of each sire, conceptually similar to the mean sire performance. However, because sire effects are random, and there is information about their probability distribution, this affects how you estimate breeding value. The mixed-model procedure called best linear unbiased prediction, or BLUP, was developed for this purpose. In addition to animal breeding, there are many other applications of BLUP. In clinical trials, random samples of patients provide estimates of the mean performance of a treatment for the population of inference, but BLUPs are essential for physicians to monitor individual patients. In quality assurance, a sample of workers can provide estimates of the mean performance of a machine, but BLUPs can help supervisors monitor the performance of individual employees.
To illustrate using the log count data, suppose you want to know the “mean” log count of the first package (PACKAGE=1 in the SAS data set). In terms of model (4.1) you want to estimate μ+a1, that is, the overall mean plus the effect of package 1. If PACKAGE were a fixed effect, you would simply calculate the sample mean for package 1, ˉy1⋅⋅=2.8048
The best linear predictor of μ+a1 is equal to the estimate of μ + E(a1|y), the expected value of the effects of package 1 given the data. Because μ is a fixed effect, its estimate, as you have seen, is its sample mean. The conditional expectation of a1 turns out to be E(a1)+cov(ˆa1,ˉy1⋅⋅)[var(ˉy1⋅⋅)]-1(ˉy1⋅⋅−ˉy⋅⋅⋅)
(ˆσ2pˆσ2p+ˆσ2sns+ˆσ2nsn)(ˉy1⋅⋅ˉy⋅⋅⋅)=(0.18470.1847+0.22993+0.038483*2)(2.8048−3.0495)=−0.1688
This expression is often called an “EBLUP” because it uses estimated variance components. A “true” BLUP assumes the variance components are known. Note that the “usual” fixed effects estimate of the package effect, ˉy1⋅⋅−ˉy⋅⋅⋅
You can obtain EBLUPs for the random effects, such as ˆa1
proc mixed;
class package sample;
model logct= / solution;
random package sample(package)/solution;
estimate 'pkg 1 blup' intercept 1 | package 1 0;
Output 4.11 gives the results for the PACKAGE random effects and PKG 1 BLUP, the EBLUP analog of the PACKAGE 1 mean. The SOLUTION statement also causes the SAMPLE(PACKAGE) EBLUPs to be printed, but these are not shown. Note: When random effects are involved, the ESTIMATE statement requires a vertical bar (|). Fixed effects (for example, μ) go before the bar; random effects (for example, ai) go after the bar. Otherwise, you use the same syntax as in any other ESTIMATE statement.
Output 4.11 EBLUPs of Package Effects and Package “Mean” for Log Count Data
| Solution for Random Effects | |||||||
| Std Err | |||||||
| Effect | package | sample | Estimate | Pred | DF | t Value | Pr > |t| |
| package | 1 | -0.1688 | 0.2523 | 60 | -0.67 | 0.5061 | |
| package | 2 | 0.1171 | 0.2523 | 60 | 0.46 | 0.6442 | |
| package | 3 | -0.03558 | 0.2523 | 60 | -0.14 | 0.8883 | |
| package | 4 | -0.04658 | 0.2523 | 60 | -0.18 | 0.8542 | |
| package | 5 | 0.07525 | 0.2523 | 60 | 0.30 | 0.7666 | |
| package | 6 | -0.7363 | 0.2523 | 60 | -2.92 | 0.0049 | |
| package | 7 | 0.3593 | 0.2523 | 60 | 1.42 | 0.1596 | |
| package | 8 | -0.4495 | 0.2523 | 60 | -1.78 | 0.0799 | |
| package | 9 | -0.09742 | 0.2523 | 60 | -0.39 | 0.7008 | |
| package | 10 | -0.5484 | 0.2523 | 60 | -2.17 | 0.0337 | |
| package | 11 | 0.1601 | 0.2523 | 60 | 0.63 | 0.5282 | |
| package | 12 | 0.3226 | 0.2523 | 60 | 1.28 | 0.2060 | |
| package | 13 | -0.1901 | 0.2523 | 60 | -0.75 | 0.4542 | |
| package | 14 | 0.1521 | 0.2523 | 60 | 0.60 | 0.5491 | |
| package | 15 | -0.2128 | 0.2523 | 60 | -0.84 | 0.4024 | |
| package | 16 | 0.8166 | 0.2523 | 60 | 3.24 | 0.0020 | |
| package | 17 | -0.1594 | 0.2523 | 60 | -0.63 | 0.5300 | |
| package | 18 | -0.06795 | 0.2523 | 60 | -0.27 | 0.7886 | |
| package | 19 | 0.3966 | 0.2523 | 60 | 1.57 | 0.1213 | |
| package | 20 | 0.3132 | 0.2523 | 60 | 1.24 | 0.2194 | |
| Estimates | |||||
| Standard | |||||
| Label | Estimate | Error | DF | t Value | Pr > |t| |
| pkg 1 blup | 2.8807 | 0.2420 | 19 | 11.90 | <.0001 |
Note that the PKG 1 BLUP is ˆμ+ˆa1
4.3 Blocked Designs with Random Blocks
Chapter 3 presented the analysis of variance for randomized-complete-blocks designs. The analysis implicitly assumed fixed blocks. In many cases, it is more reasonable to assume that blocks are random. Technically, the question of fixed versus random blocks depends on whether the blocks observed constitute the entire population of possible blocks—if so, they are fixed. Also considered is whether it is reasonable to assume there is a larger population of blocks with some probability distribution of block effects and the blocks observed are representatives of that population—if so, blocks are random. Seen from this perspective, it is hard to imagine a fixed-block experiment of any inferentially interesting consequence. From a practical viewpoint, however, many experiments do not represent the population of blocks well enough to make use of the additional inference possible with random blocks. Furthermore, with complete-blocks designs, inference for treatment differences is identical for fixed-blocks and random-blocks models. As you will see in Chapters 5 and 6, even when you have missing data or use an incomplete blocks design, fixed versus random typically has only a trivial effect on inference about treatment differences. Thus, for experiments whose exclusive goal is to estimate treatment effects, there is often little point in fulfilling the extra design requirements for random-blocks inference.
On the other hand, if estimating treatments means is important, especially obtaining confidence intervals for means, then the choice of a fixed- or random-blocks model matters a great deal.
The purpose of this section is to present the random-blocks analysis of the randomized-complete-blocks design, and to compare it with fixed-blocks ANOVA. Section 4.3.1 takes the data first presented in Output 3.17 and shows how to use PROC MIXED to do the random-blocks analysis. Section 4.3.2 discusses differences and similarities between the random-blocks analysis and fixed-blocks ANOVA. Section 4.3.2 also presents general guidelines for deciding whether fixed- or random-blocks analysis is more appropriate.
4.3.1 Random-Blocks Analysis Using PROC MIXED
The analysis of variance for the randomized-blocks design uses the model equation
yij=μ+τi+βj+eij
where
| yij | is the observation on treatment i and block j. |
| μ | is the intercept. |
| τi | is the ith treatment effect. |
| μj | is the jth block effect. |
| eij | is the residual, or error, for the ijth observation, assumed i.i.d. N(0,σ2). |
The Valencia orange data set presented in Output 3.17 was an example. The τi’s were the IRRIG method effects.
The analysis of variance presented in Section 3.5 implicitly assumes that treatments are fixed effects, but it does not depend on any assumptions about the block effects. However, additional features of the analysis of variance using PROC GLM reveals GLM computations assume fixed blocks. Although fixed treatments is usually a reasonable assumption, fixed blocks may not be.
Model (4.2) can be modified for random blocks. Usually, blocks are assumed i.i.d. N(0, σ2b
You use the following PROC MIXED statements to compute the mixed-model random-blocks analysis:
proc mixed;
class bloc irrig;
model fruitwt=irrig;
random bloc;
Compared to the GLM statements in Section 3.5, you delete BLOC from the MODEL statement and add a RANDOM statement for the BLOC effect. Output 4.12 shows the results.
Output 4.12 Random-Blocks Analysis of Valencia Orange Data Using PROC MIXED
| Covariance Parameter | |
| Estimates | |
| Cov Parm | Estimate |
| bloc | 10793 |
| Residual | 3362.38 |
| Fit Statistics | |
| -2 Res Log Likelihood | 413.8 |
| AIC (smaller is better) | 417.8 |
| AICC (smaller is better) | 418.2 |
| BIC (smaller is better) | 417.9 |
| Type 3 Tests of Fixed Effects | ||||
| Num | Den | |||
| Effect | DF | DF | F Value | Pr > F |
| irrig | 4 | 28 | 3.27 | 0.0254 |
The output contains the essential information contained in the analysis of variance, but in different form. Instead of sums of squares and mean squares for the various sources of variation, the output provides variance estimates for random-effects sources of variation and F-statistics and associated degrees of freedom and p-values for fixed-effects sources of variation. Note that F=3.27 and p=0.0254 are identical to the results for IRRIG in the analysis of variance (Output 3.18).
You can compute least-squares means (LS means) and estimated treatment differences by adding the statement
lsmeans irrig / diff;
to the above PROC MIXED program. Output 4.13 shows the results.
Output 4.13 Estimated Least-Squares Means and Treatment Differences Using PROC MIXED
| Least Squares Means | ||||||
| Effect | irrig | Estimate | Standard Error |
DF | t Value | Pr > |t| |
| irrig | basin | 290.37 | 42.0652 | 28 | 6.90 | <.0001 |
| irrig | flood | 229.62 | 42.0652 | 28 | 5.46 | <.0001 |
| irrig | spray | 223.75 | 42.0652 | 28 | 5.32 | <.0001 |
| irrig | sprnkler | 292.00 | 42.0652 | 28 | 6.94 | <.0001 |
| irrig | trickle | 299.62 | 42.0652 | 28 | 7.12 | <.0001 |
| Differences of Least Squares Means | |||||||
| Standard | |||||||
| Effect | irrig | _irrig | Estimate | Error | DF | t Value | Pr > |t| |
| irrig | basin | flood | 60.7500 | 28.9930 | 28 | 2.10 | 0.0453 |
| irrig | basin | spray | 66.6250 | 28.9930 | 28 | 2.30 | 0.0292 |
| irrig | basin | sprnkler | -1.6250 | 28.9930 | 28 | -0.06 | 0.9557 |
| irrig | basin | trickle | -9.2500 | 28.9930 | 28 | -0.32 | 0.7521 |
| irrig | flood | spray | 5.8750 | 28.9930 | 28 | 0.20 | 0.8409 |
| irrig | flood | sprnkler | -62.3750 | 28.9930 | 28 | -2.15 | 0.0402 |
| irrig | flood | trickle | -70.0000 | 28.9930 | 28 | -2.41 | 0.0225 |
| irrig | spray | sprnkler | -68.2500 | 28.9930 | 28 | -2.35 | 0.0258 |
| irrig | spray | trickle | -75.8750 | 28.9930 | 28 | -2.62 | 0.0141 |
| irrig | sprnkler | trickle | -7.6250 | 28.9930 | 28 | -0.26 | 0.7945 |
For balanced data, LS means for treatments are identical to sample treatment means obtained from the MEANS statement in PROC GLM. Note that the values in the “Estimate” column for the LS means are the same as the IRRIG means in Output 3.19. The output from PROC MIXED gives the standard error of the estimated treatment means by default. Here, the standard error is 42.0652. The standard error of a treatment mean in the random-blocks analysis of a randomized-complete-blocks design is √ˆσ2b+ˆσ2r
As with the MEANS statement in PROC GLM, you can specify mean comparisons other than the LSD test. The ADJUST= option with the LSMEANS statement in PROC MIXED allows you to adjust the p-value to correspond to different procedures. For example, use these statements to compute p-values for Dunnett’s test:
proc mixed order=data;
class bloc irrig;
model fruitwt=irrig;
random bloc;
lsmeans irrig/diff adjust=dunnett;
Ordinarily, you do not need to use the ORDER=DATA option in the PROC MIXED statement; it is a special requirement for Dunnett’s test with this example. From the description of the problem in Chapter 3, the FLOOD method was intended to be the reference. As with PROC GLM, the default control or reference treatment for the DUNNETT test is the first treatment in alphameric order. In Section 3.5, you used an option with the MEANS statement in PROC GLM to override this default. However, there is no corresponding option in the LSMEANS statements in GLM or MIXED. In order to obtain the desired test, you have to rearrange the data as they are entered in the DATA step so that the FLOOD level of IRRIG appears first, then use the ORDER=DATA option. This changes the order of the treatments for assigning CONTRAST and ESTIMATE coefficients as well as for Dunnett’s test. You can look at the “Class Level Information” (not shown) or the order in which the LS means are printed (shown below) to see the order of the treatments MIXED will use. The results appear in Output 4.14.
Output 4.14 Dunnett-Adjusted p-values for PROC MIXED Analysis of Valencia Orange Data with FLOOD as the Control Irrigation Method
| Least Squares Means | ||||||
| Effect | irrig | Estimate | Standard Error |
DF | t Value | Pr > |t| |
| irrig | flood | 229.62 | 42.0652 | 28 | 5.46 | <.0001 |
| irrig | basin | 290.37 | 42.0652 | 28 | 6.90 | <.0001 |
| irrig | spray | 223.75 | 42.0652 | 28 | 5.32 | <.0001 |
| irrig | sprnkler | 292.00 | 42.0652 | 28 | 6.94 | <.0001 |
| irrig | trickle | 299.62 | 42.0652 | 28 | 7.12 | <.0001 |
| Differences of Least Squares Means | |||||||
| Standard | |||||||
| Effect | irrig | _irrig | Estimate | Error | DF | t Value | Pr > |t| |
| irrig | basin | flood | 60.7500 | 28.9930 | 28 | 2.10 | 0.0453 |
| irrig | spray | flood | -5.8750 | 28.9930 | 28 | -0.20 | 0.8409 |
| irrig | sprnkler | flood | 62.3750 | 28.9930 | 28 | 2.15 | 0.0402 |
| irrig | trickle | flood | 70.0000 | 28.9930 | 28 | 2.41 | 0.0225 |
| Effect | irrig | _irrig | Adjustment | Adj P |
| irrig | basin | flood | Dunnett-Hsu | 0.1389 |
| irrig | spray | flood | Dunnett-Hsu | 0.9988 |
| irrig | sprnkler | flood | Dunnett-Hsu | 0.1245 |
| irrig | trickle | flood | Dunnett-Hsu | 0.0728 |
Note the order that the IRRIG levels appear in the “Least Squares Means” table follows from the order the data were entered and the ORDER=DATA option in the PROC MIXED statement. FLOOD was entered first, then the other IRRIG levels in alphabetical order. The “Differences of Least Squares Means” shows only differences allowed by Dunnett’s test with FLOOD as the reference treatment. Two sets of p-values are shown. The first are the unadjusted t-test results, identical to what you would get in an LSD test. The “Dunnett-Hsu” adjustment are the appropriate p-values for Dunnett’s test.
In Section 3.5, standard errors were not discussed. Least-squares means and their standard errors can be obtained in conjunction with analysis of variance using the LSMEANS statement in PROC GLM. However, GLM does not allow you to compute standard errors of treatment differences, as you can with the DIFF option in MIXED. In addition, GLM and MIXED compute different standard errors for the LS means, revealing the primary distinction between fixed-blocks and random-blocks analysis. The next section discusses these differences.
4.3.2 Differences between GLM and MIXED Randomized-Complete-Blocks Analysis: Fixed versus Random Blocks
For randomized-complete-blocks designs, inference on treatment differences is entirely unaffected by whether blocks are fixed or random. This is not true with missing data or incomplete-blocks-designs (see Chapter 6). However, for inference on treatment means, standard errors, and hence how you interpret the data, can be substantially affected by fixed versus random blocks.
4.3.2.1 Treatment Means
You can obtain LS means and their standard errors in PROC GLM using the statement
lsmeans trt / stderr;
Unlike PROC MIXED, GLM does not compute the standard error by default. You must use the STDERR option. The results appear in Output 4.15.
Output 4.15 LS Means for Analysis of Randomized-Complete-Blocks Design Using PROC GLM
| The GLM Procedure | |||
| Least Squares Means | |||
| fruitwt | Standard | ||
| irrig | LSMEAN | Error | Pr > |t| |
| basin | 290.375000 | 20.501170 | <.0001 |
| flood | 229.625000 | 20.501170 | <.0001 |
| spray | 223.750000 | 20.501170 | <.0001 |
| sprnkler | 292.000000 | 20.501170 | <.0001 |
| trickle | 299.625000 | 20.501170 | <.0001 |
Note the return to the original order of the data. The LS means are the same as computed by MIXED (Output 4.13) and by the MEANS statement in PROC GLM (Output 3.19). However, whereas MIXED obtained a standard error of 42.0652, the standard error of the mean using GLM is 20.5012. Why the difference? PROC GLM uses the fixed-block formula for the standard error of the mean, √ˆσ2r=√MS(error)r=√3362.388=20.5012
With fixed blocks, the definition of a treatment LS mean for the randomized-blocks design is μ+τi+1r∑jβj
estimate 'irrig lsmean' intercept 1 irrig 1 0;
estimate 'irrig narrow lsm' intercept 8 irrig 8 0
| bloc 1 1 1 1 1 1 1 1/divisor=8;
The first ESTIMATE statement uses the coefficients from the definition of the LS mean for BASIN in a random-blocks model. The second uses the fixed-blocks definition of the LS mean for BASIN. Note that for the random-blocks model, the second ESTIMATE statement is actually a BLUP. More precisely, it is a BLUP limiting the estimate of the treatment mean to only those blocks actually observed. Hence, it is termed the “narrow” estimate, because it narrows the scope of inference from the entire population of blocks to only the blocks that were observed. Output 4.16 shows the results.
Output 4.16 BASIN LS Mean: Usual Definition and Narrow Inference Definition from the ESTIMATE Statement in Random-Blocks Analysis
| Estimates | |||||
| Label | Estimate | Standard Error |
DF | t Value | Pr > |t| |
| irrig lsmean | 290.37 | 42.0652 | 28 | 6.90 | <.0001 |
| irrig narrow lsm | 290.38 | 20.5012 | 28 | 14.16 | <.0001 |
The numbers in the “Estimate” column reflect a MIXED round-off idiosyncrasy—they are both 290.375, the same as the LS mean and the MEANS in PROC GLM. The standard error of the first estimate matches the MIXED LS mean; the second matches GLM.
To summarize, the standard error that PROC GLM obtains—that is, the fixed-blocks standard error of the mean—assumes that all uncertainty in the estimated treatment means results exclusively from experimental unit variability. The random-blocks standard error that PROC MIXED obtains assumes that there is additional variation among blocks, over and above experimental unit differences.
One way to view this is to assume you want to use the information from this study to anticipate the mean fruit weight yield you will get at your orchard. The estimated mean for the BASIN treatment is 290.375. You know you will not have a mean yield of exactly 290.375, so you want to put a confidence interval around this estimate. How wide should it be? If you use the fixed-blocks standard error for your confidence interval, you assume your orchard has the same expected yield as the orchards used in the experiment. Only variation among the plots contributes to uncertainty. If you use the random-blocks standard error, you assume your orchard is different from the orchards used in the experiment, and that there is likely to be variation among orchards in addition to variability within the orchard. The block variance is the best measure you have of the variance among orchards.
The validity of the random-blocks confidence interval depends on this last sentence. Does the block variance really provide an adequate estimate? Typically, if the blocks are in close proximity and intended mainly to account for local variation, the answer is probably no. On the other hand, if the blocks do a reasonably good job of representing variability in the population, then the block variance can provide the basis for a useful confidence interval for the mean. This latter condition occurs when the blocks are locations, operators, batches, or similar effects, and a plausible, even if not technically random, sampling scheme has been used.
4.3.2.2 Treatment Differences
For fixed blocks, the expected value of the treatment mean is μ+τi+1r∑jβj
estimate ‘trt diff’ irrig 1 –1 0;
to compute the estimate and standard error of the difference between the BASIN and FLOOD treatments. In a complete-blocks design, the standard errors for all pairwise differences are equal, so it is sufficient to compute just one. Output 4.17 shows the result.
Output 4.17 Estimate and Standard Error of Treatment Difference Using the GLM ESTIMATE Statement
| Estimates | |||||
| Standard | |||||
| Label | Estimate | Error | DF | t Value | Pr > |t| |
| trt diff | 60.7500 | 28.9930 | 28 | 2.10 | 0.0453 |
You see that the standard error of the difference is identical to that obtained using PROC MIXED for the random-blocks model.
For this reason, just because a design is not suitable for allowing a valid interval estimate of treatment means, this does not mean that it is necessarily unsuitable for obtaining valid interval estimates of treatment differences. Because treatment difference estimates do not depend on fixed versus random-blocks issues, well-conceived block designs can always provide valid estimates of treatment effects. However, the requirements for a blocked design to provide believable interval estimates of treatment means are more exacting. Specifically, if you want good interval estimates of the treatment means, ideally you need a random sample of the population of blocks. Failing that, you at least need a sample that plausibly represents variation among blocks in the population.
4.4 The Two-Way Mixed Model
Recall the discussion in Section 3.7, “A Two-Way Factorial Experiment.” Assume that you actually have sources of seed from many varieties, perhaps several hundred. Also, suppose the objective of the experiment is to compare the methods across all the varieties in the population of potential varieties. Because it is not feasible to include all varieties in the experiment, you randomly choose a manageable number of varieties—say, five, for the purposes of this example—from the population of varieties. Your interest is not specifically in these five varieties, but in the population from which they were drawn. This makes VARIETY a random effect. As a consequence, any effect involving VARIETY is also a random effect. In particular, METHOD*VARIETY is a random effect. Interest remains only in the three methods, so METHOD is still a fixed effect. Since both random and fixed effects are involved, the model is mixed.
The fact that VARIETY is a random effect alters how you should analyze METHOD differences. First of all, VARIETY being a random effect determines how you measure experimental error appropriate for comparing methods. Furthermore, in many applications, you are not interested in simple effects, but only in METHOD main effects. When the response of specific VARIETY levels or simple effects of METHOD given VARIETY are of interest, you must take into account the distribution of VARIETY and METHOD*VARIETY effects. As you saw in Section 4.2, the means you use are EBLUPs.
You can test the main effect of METHOD either by using PROC GLM with the RANDOM statement and TEST option to determine the appropriate F-statistics, or by using PROC MIXED. You can use both PROC MIXED and, up to a point, PROC GLM, to do mean comparison tests. Only PROC MIXED can compute correct standard errors for all the means and differences of potential interest. Also, PROC GLM cannot compute EBLUPs; when they are of interest, you must use PROC MIXED.
4.4.1 Analysis of Variance for the Two-Way Mixed Model: Working with Expected Mean Squares to Obtain Valid Tests
A model for the data is
yijk = μ + αi + bj + (ab)ij + eijk
where
| μ + αi= μi | is the mean for method i, averaged across all varieties in the population, i =1, 2, 3. |
| bj | are random variables representing differences between varieties, assumed i.i.d. N(0, σ2V |
| (ab)ij | are random variables representing interaction between methods and varieties, assumed i.i.d. N(0, σ2MV |
| eijk | are random variables representing differences in yields among plants of the same variety using the same method, assumed i.i.d. N(0,σ2), with k = 1,...,6. |
The random variables bj, (ab)ij, and eijk are all assumed to be mutually independent.
Note: This formulation of the model is not universally accepted. Other formulations specify other assumptions regarding terms in the model. See Hocking (1973). The main distinction in these formulations pertains to how you define VARIETY variance. This is discussed at greater length in Chapter 6, “Understanding Linear Models Concepts.” Here, the concern is comparing METHODs. All formulations of the model lead to the same techniques for comparing METHODs, so the issue of alternative model formulations is not of immediate concern.
The data contain the same sources of variation whether VARIETY is fixed or random, so you can compute the same analysis-of-variance table. But you should use computations from the table differently than when VARIETY was considered fixed. The main effect of differences between METHODs, rather than simple effects, even in the presence of interaction between METHOD and VARIETY, is tested here. Also tested is the comparison A vs B,C between the METHODs. Now, however, the focus is on the main effect of the contrast, even in the presence of interaction.
Run the following statements:
proc glm data=fctorial; class method variety;
model yield = method variety method*variety / ss3;
contrast 'A vs B,C' method 2 -1 -1;
The results appear in Output 4.18.
Output 4.18 Analysis of Variance for the Two-Way Mixed Model
| Sum of | |||||
| Source | DF | Squares | Mean Square | F Value | Pr > F |
| Model | 14 | 1339.024889 | 95.644635 | 4.87 | <.0001 |
| Error | 75 | 1473.766667 | 19.650222 | ||
| Corrected Total | 89 | 2812.791556 | |||
| R-Square | Coeff Var | Root MSE | yield Mean |
| 0.476048 | 24.04225 | 4.432857 | 18.43778 |
| Source | DF | Type III SS | Mean Square | F Value | Pr > F |
| method | 2 | 953.1562222 | 476.5781111 | 24.25 | <.0001 |
| variety | 4 | 11.3804444 | 2.8451111 | 0.14 | 0.9648 |
| method*variety | 8 | 374.4882222 | 46.8110278 | 2.38 | 0.0241 |
| Source | DF | Contrast SS | Mean Square | F Value | Pr > F |
| A vs B,C | 1 | 940.7347222 | 940.7347222 | 47.87 | <.0001 |
Add the RANDOM statement to specify that VARIETY and METHOD*VARIETY are random effects.
random variety method*variety;
The RANDOM statement specified here only causes expected mean squares to be computed. It does not affect any of the PROC GLM computations. Note that you must place the RANDOM statement after the CONTRAST statement in order to get the expected mean square for the contrast. If you want correct F-statistics, you have to specify them in a TEST statement or use the TEST option in the RANDOM statement.
Output 4.19 shows expected mean squares.
Output 4.19 Expected Mean Squares for Two-Way Mixed Models
| Source | Type III Expected Mean Square |
| method | Var(Error) + 6 Var(method*variety) + Q(method) |
| variety | Var(Error) + 6 Var(method*variety) + 18 Var(variety) |
| method*variety | Var(Error) + 6 Var(method*variety) |
| Contrast | Contrast Expected Mean Square |
| A vs B,C | Var(Error) + 6 Var(method*variety) + Q(method) |
In statistical notation, these expected mean squares are as follows:
| Source | Expected Mean Squares |
|---|---|
| METHOD | σ2+6σ2MV+30[∑i(αi−ˉα⋅)2/2] |
| VARIETY | σ2+6σ2MV+18σ2V |
| METHOD*VARIETY | σ2+6σ2MV |
| ERROR | σ2 |
You can probably see how all of these terms come from Output 4.19 except for the expression 30[∑i(αi−ˉα⋅)2/2]
The null hypothesis H0: μA=μB=μC is true when Q(METHOD)=0. Therefore, when H0 is true, the expected mean square for METHOD is the same as the expected mean square for METHOD*VARIETY. This tells you to use F=MS(METHOD)/MS(METHOD*VARIETY) to test the null hypothesis. You can obtain this either by adding the TEST option to the RANDOM statement or by using the following TEST statement:
test h=method e=method*variety;
At first glance, the expected mean square for the contrast A vs B,C in Output 4.19 appears to be the same as the expected mean square for METHOD, but Q(METHOD) has a different interpretation. For the contrast A vs B,C, Q(METHOD) stands for 30[μA − 0.5(μB + μC)]2. The form of the contrast expected mean square tells you to use F=MS (A vs B,C)/MS(METHOD*VARIETY) to test the null hypothesis H0: μA–0.5(μB+ μC)=0. You can do this with the E= option in the CONTRAST statement:
contrast 'A vs B,C' method 2 -1 -1 / e=method*variety;
Results of the TEST and CONTRAST statements appear in Output 4.20.
Output 4.20 Tests Using the Proper Denominator in the F-Statistic
| Dependent Variable: yield | |||||
| Tests of Hypotheses Using the Type III MS for method*variety as an Error Term | |||||
| Source | DF | Type III SS | Mean Square | F Value | Pr > F |
| method | 2 | 953.1562222 | 476.5781111 | 10.18 | 0.0063 |
| Tests of Hypotheses Using the Type III MS for method*variety as an Error Term | |||||
| Contrast | DF | Type III SS | Mean Square | F Value | Pr > F |
| A vs B,C | 1 | 940.7347222 | 940.7347222 | 20.10 | 0.0020 |
The denominator MS(METHOD*VARIETY) of the F-values in Output 4.20 is larger than the denominator MS(ERROR) of the F-values in Output 4.18. The correct F-tests (Output 4.20) are therefore less significant than they appeared to be using Output 4.18 inappropriately. Using MS(METHOD*VARIETY) in the denominator makes inference from the tests valid for all varieties in the population, whereas use of MS(ERROR) in the denominator restricts inference to only the five varieties actually used in the experiment. MS(METHOD*VARIETY) is the experimental error for comparing methods across all varieties in the population, whereas MS(ERROR) is the experimental error for comparing methods across only those varieties used in the experiment.
4.4.2 Standard Errors for the Two-Way Mixed Model: GLM versus MIXED
While you can obtain valid F-tests for mixed models with PROC GLM, you cannot always obtain valid standard errors. The two-way mixed model is an example of when GLM cannot compute the correct standard errors. The statement
estimate ‘trt diff’ method 1 –1 0;
computes the estimate and standard error of μA– μB. The result appears in Output 4.21.
Output 4.21 Estimate and Standard Error for Method A-B Difference Computed by PROC GLM
| Parameter | Estimate | Error | t Value | Pr > |t| |
| A-B diff | 7.31333333 | 1.14455879 | 6.39 | <.0001 |
GLM computes the standard error of the difference as √2ˆσ25*6=√2*MSE30=√2*19.6530=1.14
Use the following statements to run the analysis with PROC MIXED:
proc mixed data=fctorial;
class method variety;
model yield = method;
random variety method*variety;
contrast 'A vs B,C' method 2 -1 -1;
Output 4.22 shows the results.
Output 4.22 Analysis of the Two-Way Mixed Model Using PROC MIXED
| Covariance Parameter | |
| Estimates | |
| Cov Parm | Estimate |
| variety | 0 |
| method*variety | 2.0842 |
| Residual | 19.6502 |
| Type 3 Tests of Fixed Effects | ||||
| Num | Den | |||
| Effect | DF | DF | F Value | Pr > F |
| method | 2 | 8 | 14.82 | 0.0020 |
| Contrasts | ||||
| Num | Den | |||
| Label | DF | DF | F Value | Pr > F |
| A vs B,C | 1 | 8 | 29.26 | 0.0006 |
Compare these results to Outputs 4.18 through 4.21 using PROC GLM. PROC MIXED provides variance component estimates rather than ANOVA sums of squares and mean squares. From the mean squares in Output 4.18 and the expected mean squares in Output 4.19, you can see that MS(VARIETY)=2.845 is less than MS(METHOD*VARIETY), resulting in a negative estimate of σ2V
Setting σ2V=0
Statisticians, quantitative geneticists, and others who use variance component estimates in their work have struggled with the question of how negative variance components should be reported. Some think that negative estimates should be reported as such, whereas others argue that because variance by definition cannot be negative, negative estimates have no meaning and they should be set to zero. Using variance components to construct test statistics adds another dimension to the problem. While you can debate the merits of reporting negative variance components, biased F-statistics and standard errors are clearly to be avoided.
PROC MIXED has a number of options that allow you to get the same variance component estimates and hence the same F-values that PROC GLM computes. The NOBOUND option uses REML computing algorithms, except that it allows negative variance component estimates to remain negative. The METHOD=TYPEn option (n =1, 2, or 3) computes ANOVA estimates based on the expected mean squares that result from TYPE I, II, or III sum of squares. For the balanced data sets presented in this chapter, all these options produce the same results. Chapters 5 and 6 discuss the differences between the various types of SS for unbalanced data. As an example, the following SAS statements use the Type III variance component estimates:
proc mixed method=type3 data=fctorial;
class method variety;
model yield = method;
random variety method*variety;
contrast 'A vs B,C' method 2 -1 -1;
Output 4.23 shows the results.
Output 4.23 PROC MIXED Analysis Using the METHOD= TYPE3 Option
| Type 3 Analysis of Variance | ||
| Source | Expected Mean Square | Error Term |
| method | Var(Residual) + 6 Var(method*variety) + Q(method) | MS(method*variety) |
| variety | Var(Residual) + 6 Var(method*variety) + 18 Var(variety) | MS(method*variety) |
| method*variety Residual | Var(Residual) + 6 Var(method*variety) Var(Residual) | MS(Residual) |
| Covariance Parameter | |
| Estimates | |
| Cov Parm | Estimate |
| variety | -2.4426 |
| method*variety | 4.5268 |
| Residual | 19.6502 |
| Type 3 Tests of Fixed Effects | ||||
| Num | Den | |||
| Effect | DF | DF | F Value | Pr > F |
| method | 2 | 8 | 10.18 | 0.0063 |
| Estimates | |||||
| Standard | |||||
| Label | Estimate | Error | DF | t Value | Pr > |t| |
| A-B diff | 7.3133 | 1.7666 | 8 | 4.14 | 0.0033 |
| Contrasts | ||||
| Num | Den | |||
| Label | DF | DF | F Value | Pr > F |
| A vs B,C | 1 | 8 | 29.26 | 0.0006 |
The output gives you the same expected mean squares obtained by the RANDOM statement in PROC GLM. When you use the METHOD=TYPEn option, the output also contains the ANOVA table: sum of squares, mean squares, and F-statistics. You can see that the “Covariance Parameter Estimates” correspond to the ANOVA estimates. Also, the F-tests for the METHOD main effect and the A vs B,C contrast are now the same as those obtained by using PROC GLM with the properly specified E= option. As mentioned above, for balanced data you can obtain the same variance component estimates and F-statistics with the NOBOUND option:
proc mixed nobound data=fctorial;
You can obtain the estimated treatment means and differences with their correct standard errors. In conjunction with the above PROC MIXED METHOD=TYPEn or NOBOUND option, use the following statement:
lsmeans method/diff;
Output 4.24 shows the results.
Output 4.24 Estimates of Treatment Means and Differences in the Two-Way Mixed Model Using PROC MIXED
| Least Squares Means | ||||||
| Standard | ||||||
| Effect | method | Estimate | Error | DF | t Value | Pr > |t| |
| method | A | 23.0100 | 1.0353 | 8 | 22.23 | <.0001 |
| method | B | 15.6967 | 1.0353 | 8 | 15.16 | <.0001 |
| method | C | 16.6067 | 1.0353 | 8 | 16.04 | <.0001 |
| Differences of Least Squares Means | |||||||
| Standard | |||||||
| Effect | method | _method | Estimate | Error | DF | t Value | Pr > |t| |
| method | A | B | 7.3133 | 1.7666 | 8 | 4.14 | 0.0033 |
| method | A | C | 6.4033 | 1.7666 | 8 | 3.62 | 0.0067 |
| method | B | C | -0.9100 | 1.7666 | 8 | -0.52 | 0.6204 |
Consistent with the formula for the standard error of a difference, √2(ˆσ2+6ˆσ2MV)30
4.4.3 More on Expected Mean Squares: Determining Quadratic Forms and Null Hypotheses for Fixed Effects
In some situations, you may want to obtain detailed information about the hypotheses tested by various F-statistics. In balanced cases, this is rarely an issue, because the hypotheses are obvious from the structure of the ANOVA table or the contrast coefficients. In unbalanced data sets, however, the hypotheses may depend on the type of SS you use and the order of the terms in the model. These are considered in Chapters 5 and 6. The purpose of this section is to show how to use optional PROC GLM output to use fixed-effects quadratic forms to determine what hypothesis a given F-statistic tests. Using balanced data makes it easier to follow the computations. This section is mainly of interest to graduate students who are learning to use quadratic forms and to readers who are familiar with matrix algebra and want to get a deeper insight into the distinctions among the types of SS.
When you obtain expected mean squares, the basic output gives you a “Q” term for the fixed effects. This “Q” stands for quadratic form. For example, Q(METHOD) is the quadratic form for the fixed-effect METHOD in Outputs 4.19 and 4.23. You can obtain detailed information about the meaning of Q(METHOD) by using the Q option at the end of the PROC GLM RANDOM statement. Output 4.25 shows the results of using the Q option.
random variety method*variety / q;
Output 4.25 Quadratic Forms for Method Effects from the Q Option
| Quadratic Forms of Fixed Effects in the Expected Mean Squares | |||
| Source: Type III Mean Square for method | |||
| method A | method B | method C | |
| method A | 20.00000000 | -10.00000000 | -10.00000000 |
| method B | -10.00000000 | 20.00000000 | -10.00000000 |
| method C | -10.00000000 | -10.00000000 | 20.00000000 |
| Source: Contrast Mean Square for A vs B,C | |||
| method A | method B | method C | |
| method A | 20.00000000 | -10.00000000 | -10.00000000 |
| method B | -10.00000000 | 5.00000000 | 5.00000000 |
| method C | -10.00000000 | 5.00000000 | 5.00000000 |
The Q option prints a matrix of the quadratic form for fixed effects, which tells you
Q(METHOD) = α΄AαDF
where α'=(αA, αB, αC) is a row vector containing the fixed-effects parameters in the model. A is the matrix of the quadratic form, and DF is the number of degrees of freedom for the effect. You see two matrices printed in Output 4.25, one for the METHOD effect in the analysis-of-variance table and one for the contrast A vs B,C. For the overall METHOD effect, the matrix is
A=[20−10−10−1020−10−10−1020]
This tells you the matrix algebraic expression for the quadratic form is
Q(METHOD)= (αA,αB,αC)[20−10−10−1020−10−10−1020][αAαBαC](12)
Some algebraic manipulation yields Q(METHOD) = 30∑i(αi−ˉα⋅)2/2
You can use the quadratic form expressions to indicate the null hypothesis tested by an F-statistic with the corresponding mean square as its numerator. To do this, determine the values of the fixed parameters that make Q(METHOD)=0. For the overall METHOD effect, you have already seen that Q(METHOD)=0 whenever αA = αB = αC, or equivalently, whenever μA = μB = μC.
4.5 A Classification with Both Crossed and Nested Effects
Some classifications involve both crossed and nested factors. The example in this section is typical of a study design that is common to many fields of investigation. As you will see by the end of this section, in practical situations, PROC MIXED is better suited to analyze these kinds of data sets. Nonetheless, in order to adequately present the linear model issues associated with these designs, the first part of this section uses PROC GLM.
Output 4.26 presents a data set that illustrates the essential features of designs with crossed and nested factors. An engineer in a semiconductor plant investigated the effect of several modes of a process condition (ET) on the resistance in computer chips. Twelve silicon wafers (WAFER) were drawn from a lot, and three wafers were randomly assigned to each of four modes of ET. Resistance in chips was measured in four positions (POS) on each wafer after processing. The measurement was recorded as the variable RESISTA in a SAS data set named CHIPS.
Output 4.26 Semiconductor Resistance Data
| Obs | resista | et | wafer | pos |
| 1 | 5.22 | 1 | 1 | 1 |
| 2 | 5.61 | 1 | 1 | 2 |
| 3 | 6.11 | 1 | 1 | 3 |
| 4 | 6.33 | 1 | 1 | 4 |
| 5 | 6.13 | 1 | 2 | 1 |
| 6 | 6.14 | 1 | 2 | 2 |
| 7 | 5.60 | 1 | 2 | 3 |
| 8 | 5.91 | 1 | 2 | 4 |
| 9 | 5.49 | 1 | 3 | 1 |
| 10 | 4.60 | 1 | 3 | 2 |
| 11 | 4.95 | 1 | 3 | 3 |
| 12 | 5.42 | 1 | 3 | 4 |
| 13 | 5.78 | 2 | 1 | 1 |
| 14 | 6.52 | 2 | 1 | 2 |
| 15 | 5.90 | 2 | 1 | 3 |
| 16 | 5.67 | 2 | 1 | 4 |
| 17 | 5.77 | 2 | 2 | 1 |
| 18 | 6.23 | 2 | 2 | 2 |
| 19 | 5.57 | 2 | 2 | 3 |
| 20 | 5.96 | 2 | 2 | 4 |
| 21 | 6.43 | 2 | 3 | 1 |
| 22 | 5.81 | 2 | 3 | 2 |
| 23 | 5.83 | 2 | 3 | 3 |
| 24 | 6.12 | 2 | 3 | 4 |
| 25 | 5.66 | 3 | 1 | 1 |
| 26 | 6.25 | 3 | 1 | 2 |
| 27 | 5.46 | 3 | 1 | 3 |
| 28 | 5.08 | 3 | 1 | 4 |
| 29 | 6.53 | 3 | 2 | 1 |
| 30 | 6.50 | 3 | 2 | 2 |
| 31 | 6.23 | 3 | 2 | 3 |
| 32 | 6.84 | 3 | 2 | 4 |
| 33 | 6.22 | 3 | 3 | 1 |
| 34 | 6.29 | 3 | 3 | 2 |
| 35 | 5.63 | 3 | 3 | 3 |
| 36 | 6.36 | 3 | 3 | 4 |
| 37 | 6.75 | 4 | 1 | 1 |
| 38 | 6.97 | 4 | 1 | 2 |
| 39 | 6.02 | 4 | 1 | 3 |
| 40 | 6.88 | 4 | 1 | 4 |
| 41 | 6.22 | 4 | 2 | 1 |
| 42 | 6.54 | 4 | 2 | 2 |
| 43 | 6.12 | 4 | 2 | 3 |
| 44 | 6.61 | 4 | 2 | 4 |
| 45 | 6.05 | 4 | 3 | 1 |
| 46 | 6.15 | 4 | 3 | 2 |
| 47 | 5.55 | 4 | 3 | 3 |
| 48 | 6.13 | 4 | 3 | 4 |
Here are some features of this experiment:
❏ There are two experimental factors, ET and POS, which appear together in all combinations. These factors are crossed because the POS labels 1, 2, 3, and 4 have the same meaning for all levels of ET; POS 1 refers to the same location on a wafer in ET 1 as it does on a wafer in ET 2. The engineer wants to compare mean resistance between levels of ET and between levels of POS. He also wants to determine if differences between levels of ET depend on the value of POS at which they are measured. The data are analyzed in terms of either simple effects or main effects of ET and POS, depending on the presence or absence of interaction between ET and POS. Section 4.5.2 discusses expected mean squares and how to use them to set up appropriate tests for several types of effects.
❏ ET levels are assigned to wafers in a completely randomized design, making WAFER the experimental unit for comparing levels of ET. Wafers are nested within levels of ET.
❏ Levels of POS change between chips on the same wafer, whereas levels of ET change between wafers. So a different measure of experimental error is required to compare positions than is used to compare levels of ET. This is the primary feature that distinguishes this experiment from a standard factorial.
This data set has features of both crossed and nested classification, so it is referred to as crossed-nested. It is similar to a split-plot experiment, with wafer taken as the main-plot unit and chips on a wafer as the sub-plot unit. It also has features in common with repeated-measures experiments, which are discussed in Chapter 9.
A model for the data is
yijk = μ + αi + wij + βk + (αβ)ik + eijk
where yijk is the measured resistance at the kth position on the jth wafer in the ith level of ET, i = 1, 2, 3, 4; j = 1, 2, 3; k = 1, 2, 3, 4; μ+αi+βk+(αβ)ik = μik is the mean resistance at position k with ET level i. wij are random variables representing differences among wafers assigned to the same level of ET. The wij are assumed i.i.d. N(0, σ2W
eijk are random variables representing differences among chips on the same wafer. The eijk are assumed i.i.d. N(0,α2) and independent of the wij. The former is a potentially flawed assumption because correlation between chips could depend on their relative proximity on the wafer. If so, then the data should be analyzed using methods appropriate for repeated-measures experiments (see Chapter 9).
4.5.1 Analysis of Variance for Crossed-Nested Classification
An analysis-of-variance table has the form
| Source of Variation | DF |
|---|---|
| ET | 3 |
| WAFER(ET) | 8 |
| POS | 3 |
| ET*POS | 9 |
| ERROR = POS*WAFER(ET) | 24 |
4.5.2 Using Expected Mean Squares to Set Up Several Tests of Hypotheses for Crossed-Nested Classification
This section illustrates how to set up several types of tests of hypothesis for an experiment of this type. These include tests of the following null hypotheses:
❏ overall main effect of ET H0: μ1⋅ =μ2⋅ = μ3⋅ = μ4⋅
❏ overall main effect of POS H0: μ⋅1 = μ⋅2 = μ⋅3 = μ⋅4
❏ main effect contrast of ET (ET1 vs ET2) H0: μ1⋅ = μ2⋅
❏ main effect contrast of POS (POS1 vs POS2) H0: μ⋅1 = μ⋅2
❏ simple effect contrast of POS (POS1 vs POS2 in ET1) H0: μ11 = μ12
❏ simple effect contrast of ET (ET1 vs ET2 in POS1) H0: μ11 = μ21
You can use the CONTRAST and RANDOM statements in PROC GLM or PROC MIXED to obtain appropriate tests for these effects. Both allow a high degree of flexibility. GLM is better suited for illustrating key features of linear model theory and methods. Primarily because of standard error considerations discussed in Section 4.5.3, MIXED is better suited to the actual analysis of data. For now, we focus on linear model issues via GLM.
The following SAS statements produce the analysis-of-variance table and contrasts:
proc glm data=chips;
class et wafer pos;
model resista = et wafer(et) pos et*pos / ss3;
contrast 'ET1 vs ET2' et 1 -1 0 0;
contrast 'POS1 vs POS2' pos 1 -1 0 0;
contrast 'POS1 vs POS2 in ET1' pos 1 -1 0 0 et*pos 1 -1;
contrast 'ET1 vs ET2 in POS1' et 1 -1 0 0 et*pos 1 0 0 0 -1;
Note that the simple effect contrasts POS1 vs POS2 in ET1 and ET1 vs ET2 in POS1 use coefficients of ET*POS in addition to their respective main effects. Table 4.2 and the explanation immediately following detail why these terms are necessary. The analysis-of-variance table and CONTRAST statement results appear in Output 4.27.
Output 4.27 Analysis of Variance for Semiconductor Resistance Data
| The GLM Procedure | |||||
| Dependent Variable: resista | |||||
| Sum of | |||||
| Source | DF | Squares | Mean Square | F Value | Pr > F |
| Model | 23 | 9.32500833 | 0.40543514 | 3.65 | 0.0013 |
| Error | 24 | 2.66758333 | 0.11114931 | ||
| Corrected Total | 47 | 11.99259167 | |||
| R-Square | Coeff Var | Root MSE | resista Mean |
| 0.777564 | 5.553811 | 0.333391 | 6.002917 |
| Source | DF | Type III SS | Mean Square | F Value | Pr > F |
| et | 3 | 3.11215833 | 1.03738611 | 9.33 | 0.0003 |
| wafer(et) | 8 | 4.27448333 | 0.53431042 | 4.81 | 0.0013 |
| pos | 3 | 1.12889167 | 0.37629722 | 3.39 | 0.0345 |
| et*pos | 9 | 0.80947500 | 0.08994167 | 0.81 | 0.6125 |
| Contrast | DF | Contrast SS | Mean Square | F Value | Pr > F |
| ET1 vs ET2 | 1 | 0.69360000 | 0.69360000 | 6.24 | 0.0197 |
| POS1 vs POS2 | 1 | 0.07706667 | 0.07706667 | 0.69 | 0.4132 |
| POS1 vs POS2 in ET1 | 1 | 0.04001667 | 0.04001667 | 0.36 | 0.5541 |
| ET1 vs ET2 in POS1 | 1 | 0.21660000 | 0.21660000 | 1.95 | 0.1755 |
The output contains F-statistics for all effects in the MODEL statement as well as for all of the effects in the CONTRAST statements. Note: These F-statistics use the default MS(ERROR) in the denominator. Remember that in PROC GLM, the RANDOM statement does not override the default use of MS(ERROR). You must examine the expected mean squares to determine which of these automatically computed F-statistics are valid. For all other tests, you must specify an appropriate error term. As with previous examples in this chapter, you can specify appropriate error terms with a TEST statement or by using the TEST option with the RANDOM statement. For CONTRAST statements, use the E= option.
Now, obtain tests for the fixed effects of ET, POS, and ET*POS in the analysis-of-variance table and tests for the effects specified in the CONTRAST statements. Start by obtaining the expected mean squares for all effects. The following statement gives the results in Output 4.28. Recall that this statement must be placed after the CONTRAST statements in the PROC GLM program given above:
random wafer(et);
Output 4.28 Expected Mean Squares for Semiconductor Data
| Source | Type III Expected Mean Square |
| et | Var(Error) + 4 Var(wafer(et)) + Q(et,et*pos) |
| wafer(et) | Var(Error) + 4 Var(wafer(et)) |
| pos | Var(Error) + Q(pos,et*pos) |
| et*pos | Var(Error) + Q(et*pos) |
| Contrast | Contrast Expected Mean Square |
| ET1 vs ET2 | Var(Error) + 4 Var(wafer(et)) + Q(et,et*pos) |
| POS1 vs POS2 | Var(Error) + Q(pos,et*pos) |
| POS1 vs POS2 in ET1 | Var(Error) + Q(pos,et*pos) |
| ET1 vs ET2 in POS1 | Var(Error) + Var(wafer(et)) + Q(et,et*pos) |
You could use the Q option at the end of the RANDOM statement to get an interpretation of Q(effect) in the expected mean squares. Table 4.2 relates the Q(effect) with the corresponding algebraic expressions in terms of model parameters and means model.
Table 4.2 Q(effect) in Expected Mean Squares
| Effect Name |
Expression in Output |
Algebraic Expression for Q(effect) |
|---|---|---|
| ET | Q(ET,ET*POS) | 12∑i[αi+(̅αβ)i⋅−ˉα⋅−(̅αβ)⋅⋅]2 |
| POS | Q(POS,ET*POS) | 12∑j[βj+(̅αβ)⋅j−ˉβ⋅−(̅αβ)⋅⋅]2=4[μ⋅j−ˉμ⋅⋅]2 |
| ET*POS | Q(ET*POS) | 12∑ij[(αβ)ij−(¯αβ)i⋅−(¯αβ)⋅j+(¯αβ)⋅⋅]2 = 12∑ij[μij−μi⋅−μ⋅j+μ⋅⋅]2 |
| ET1 vs ET2 | Q(ET,ET*POS) | 12[α1+(̅αβ)1⋅−α2+(̅αβ)2⋅]2=4[ˉμ1⋅−ˉμ2⋅]2 |
| POS1 vs POS2 | Q(POS,ET*POS) | 12[β1+(̅αβ)⋅1−β2+(̅αβ)⋅2]2=4[ˉμ⋅1−ˉμ⋅2]2 |
| POS1 vs POS2 IN ET1 | Q(POS,ET*POS) | 12[β1+(̅αβ)11−β2+(̅αβ)12]2=4[ˉμ11−ˉμ12]2 |
| ET1 vs ET2 IN POS1 | Q(ET,ET*POS) | 12[α1+(̅αβ)11−α2+(̅αβ)12]2=4[ˉμ11−ˉμ12]2 |
It may seem strange that the Q(effect) for ET main effects contains the expression ET*POS within the parentheses. The ET*POS expression is present because the quadratic form is a function of the (αβ) parameters as well as the α parameters. This is because PROC GLM imposes no assumptions on the model parameters, so that ˉμi⋅=μ+αi+ˉβ⋅+(̅αβ)i⋅
In each case, you see from the algebraic expression for Q(effect) that the null hypothesis you want to test is H0: Q(effect)=0. The expected mean squares tell you to use the denominators in the F-statistics as indicated in this table:
Table 4.3 Required Denominator MS for Tests of Effects
| Effect | Appropriate Denominator for F-Statistic |
|---|---|
| ET | MS(WAFER(ET)) |
| POS | MS(ERROR) |
| ET*POS | MS(ERROR) |
| ET1 vs ET2 | MS(WAFER(ET)) |
| POS1 vs POS2 | MS(ERROR) |
| POS1 vs POS2 in ET1 | MS(ERR0R) |
| ET1 vs ET2 in POS1 | Not directly available |
For any tests that use MS(ERROR) the F-statistics PROC GLM automatically computes are correct. All others require additional attention. Note that you cannot compute the appropriate test for the ET1 vs ET2 in POS1 contrast using PROC GLM. In fact, you cannot get the correct standard error for the estimate of ET differences for a given POS with PROC GLM either. The method for getting the right test and standard error are explained later in this section and in Section 4.5.3. The correct statistics are easily obtained using PROC MIXED. Section 4.5.4 shows you how to do this. This is the main reason why PROC MIXED is preferred in actual data analysis.
Appropriate F-tests for ET main effect and ET1 vs ET2 contrast are obtained with the statements
test h=et e=wafer(et);
contrast 'ET1 vs ET2' et 1 -1 0 0 / e=wafer(et);
Results appear in Output 4.29.
Output 4.29 F-Tests for ET Effects
| Tests of Hypotheses Using the Type III MS for wafer(et) as an Error Term | |||||
| Source | DF | Type III SS | Mean Square | F Value | Pr > F |
| et | 3 | 3.11215833 | 1.03738611 | 1.94 | 0.2015 |
| Tests of Hypotheses Using the Type III MS for wafer(et) as an Error Term | |||||
| Contrast | DF | Contrast SS | Mean Square | F Value | Pr > F |
| ET1 vs ET2 | 1 | 0.69360000 | 0.69360000 | 1.30 | 0.2875 |
Compare F-statistics in Output 4.29 with those in Output 4.27 for these effects.
Alternatively, you can obtain test statistics for effects in the analysis-of-variance table with the TEST option in the RANDOM statement, as follows:
random wafer(et)/test;
Output 4.30 shows the results.
Output 4.30 F-Tests from the TEST Option
| Tests of Hypotheses for Mixed Model Analysis of Variance | ||||||
| Dependent Variable: resista | ||||||
| Source | DF | Type III SS | Mean Square | F Value | Pr > F | |
| * | et | 3 | 3.11215833 | 1.03738611 | 1.94 | 0.2015 |
| Error: MS(wafer(et)) | 8 | 4.274483 | 0.534310 | |||
| * | This test assumes one or more other fixed effects are zero. | |||||
| Source | DF | Type III SS | Mean Square | F Value | Pr > F | |
| wafer(et) | 8 | 4.274483 | 0.534310 | 4.81 | 0.0013 | |
| * | pos | 3 | 1.128892 | 0.376297 | 3.39 | 0.0345 |
| et*pos | 9 | 0.809475 | 0.089942 | 0.81 | 0.6125 | |
| Error: MS(Error) | 24 | 2.667583 | 0.111149 | |||
| * | This test assumes one or more other fixed effects are zero. | |||||
Compare results in Output 4.30 with those in Outputs 4.27 and 4.29. Unfortunately, the TEST option does not compute appropriate tests for effects in CONTRAST statements.
There is no appropriate F-test for the contrast ET1 vs ET2 in POS1 directly available. An appropriate denominator for this F-statistic would be an estimate of σ2+σ2W
ˆσ2+ˆσ2W
=.75(0.111).25(0.534)
= 0.217
An appropriate F-statistic for testing H0: μ11 – μ21= 0 is then
F =MS(ET1 vs ET2 in POS1)/(ˆσ2+ˆσ2W
=0.2166/0.217
Here, F is essentially equal to 1.0, indicating that it is nonsignificant. You do not need to refer it to an F-distribution to calculate a p-value to determine its significance, because F must be substantially larger than 1.0 in order to be significant at any meaningful level. Thus, you do not need to know degrees of freedom for the denominator mean square. Normally, however, you would need degrees of freedom in order to assess the level of significance. They can be approximated using Satterthwaite’s formula, which is demonstrated in Section 4.5.3, “Satterthwaite's Formula for Approximate Degrees of Freedom.”
But first, Table 4.4 gives a summary of all the appropriate F-tests from the analysis-of-variance table and CONTRAST statements:
Table 4.4 Summary of F-Test Results from CONTRAST Statements
| Effect | Appropriate F-Statistic |
Level of Significance |
|---|---|---|
| ET | 1.037/0.534 = 1.94 | 0.202 |
| POS | 0.376/0.111 = 3.39 | 0.034 |
| ET*POS | 0.090/0.111 = 0.81 | 0.612 |
| ET1 vs ET2 | 0.694/0.534 = 1.30 | 0.287 |
| POS1 vs POS2 | 0.077/0.111 = 0.69 | 0.413 |
| POS1 vs POS2 in ET1 | 0.040/0.111 = 0.36 | 0.554 |
| ET1 vs ET2 in POS1 | 0.217/0.217 = 1.00 | NS |
4.5.3 Satterthwaite’s Formula for Approximate Degrees of Freedom
The denominator of the F-statistic for the contrast ET1 vs ET2 in POS1 is a linear combination of mean squares from the analysis-of-variance table. In general, such a linear combination has properties that approximate those of actual mean squares. The number of degrees of freedom for the linear combination of mean squares can be approximated by using a formula attributed to Satterthwaite (1946). This is the subject of the following discussion.
Let MS1, . . . ,MSk be a set of independent mean squares with respective degrees of freedom DF1, . . . ,DFk, and let a1, . . . ,ak be a set of known constants. Then the linear combination
MS=a1 MS1 + a2 MS2 + . . . + ak MSk
is a synthetic mean square with approximate degrees of freedom equal to
DF = (MS)2(MS1)2DF1+…+(MS2)2DF2
Applying Satterthwaite's formula, you get
ˆσ2+ˆσ2W=0.75MS(ERROR) + .25MS[WAFER(ET)]
The data used here yield
| MS1 = MS(ERROR) = 0.111 | DF1 = 24 | a1 = .75 |
| MS2 = MS(WAFER(ET)) = 0.534 | DF2 = 8 | a2 = .25 |
so
DF = (0.217)2(0.083)224+(0.134)28
= 0.04710.000287+0.002245
SAS has an internal function that can evaluate DF with fractional values. For use with published tables, round down to DF=18. This synthetic mean square with DF=18 is useful for several applications. It is an appropriate denominator for any contrast among levels of ET in a given level of POS, such as the comparison ET1 vs ET2 in POS1 shown in Table 4.3. Other examples include the CONTRAST statement
contrast 'ET1,ET2 vs ET3,ET4 at POS2'
et 1 1 -1 -1 et*pos 0 0 0 0 1 1 -1 -1;
In addition to providing appropriate denominators for F-statistics, it is equally important to use appropriate mean squares when you compute confidence intervals for means or differences between means. Suppose you wanted a confidence interval on the overall mean for ET1, averaged across WAFER and POS. This mean is
y̅1⋅⋅ = μ + α1 + w̅1⋅ + β1 + (α̅β̅)1⋅ + e̅1⋅⋅
The random parts are w̅1⋅ and e̅1⋅. Now w̅1⋅ is the mean of three w1j’s (w11, w12, and w13), so V(w̅1⋅) = σ2w
Additionally, e1.. is the mean of twelve e1jk’s, so V(e̅1⋅⋅) = α2/12. Therefore, the variance of y̅1⋅⋅ is
V(ˉy1..)=V(ˉw1.)+V(ˉe1..) =σ2w/3+σ2/12 =(σ2+4σ2w)/12
From the table of expected mean squares you have seen that an estimate of V(ˉy1⋅⋅
ˉy1..± t8,0.025×√MS[WAFER(ET)]12=5.632 ± 2.30(0.210)=(5.14, 6.12)
Similarly, the mean for POS1 averaged across POS and WAFER is
ˉy..1=μ+ˉα.+ˉw..+β1+(¯αβ)+ˉe..1
The variance of y̅⋅⋅1 is
V(ˉy..1)=V(ˉw..)+V(ˉe..1)
=σ2w/12+σ2/12
=(σ2w+σ2)/12
If you look back at the synthetic mean square we computed, you see that the estimate of V(y̅⋅⋅1 is {.75MS(ERROR) + .25 MS[WAFER(ET)]}/12. So an approximate 95% confidence interval for y̅⋅⋅1 is
ˉy..1± t18,0.025×√.75MS(ERROR) + .25MS[WAFER(ET)]12
= 6.02 ± 2.10(0.134)
= (5.74,6.30)
4.5.4 PROC MIXED Analysis of Crossed-Nested Classification
The previous sections used PROC GLM to develop the concepts underlying the analysis of models with multiple error terms. As you have seen, several default statistics PROC GLM computes are inappropriate and must be overridden. Other statistics are simply not available. These limitations occur because the underlying programming for PROC GLM is based entirely on fixed-effects-only linear model theory. Its mixed-model features are limited to options that allow you to determine expected mean squares and to certain tests using other than MS(ERROR). On the other hand, PROC MIXED uses more general linear mixed-model theory, meaning that when an effect is defined as random, it is handled as such throughout the entire computational process. Chapter 6 discusses the theory underlying the GLM and MIXED procedures.
Provided you correctly specify the model, MIXED automatically computes the correct test statistics and standard errors. Therefore, when you actually do data analysis, you should use PROC MIXED. This section shows the program statements needed to reproduce the essentials of the analysis developed in Sections 4.5.1 through 4.5.3. Note that MIXED does not, by default, compute an analysis-of-variance table nor the expected mean squares (although you can obtain both using the METHOD=TYPES option). Its focus is on the statistics relevant to analyzing the data.
The needed SAS statements for a PROC MIXED analysis are
proc mixed data=chips;
class et wafer pos;
model resista = et|pos/ddfm=satterth;
random wafer(et);
contrast ′ET1 vs ET2′ et 1 -1 0 0;
contrast ′POS1 vs POS2′ pos 1 -1 0 0;
contrast ′POS1 vs POS2 in ET1′ pos 1 -1 0 0 et*pos 1 -1;
contrast ′ET1 vs ET2 in POS1′ et 1 -1 0 0 et*pos 1 0 0 0 -1;
The results appear in Output 4.31. Several features of the MIXED program deserve attention. First, recall that you include ONLY fixed effects in the MODEL statement; the whole-plot error effect WAFER(ET) must not be included. All error terms are random effects and hence appear in the RANDOM statement. The vertical bar between ET and POS in the MODEL statement is SAS shorthand to obtain all main effects and interactions involving the terms connected by the bar. This syntax also works in PROC GLM, PROC GENMOD (see Chapter 10), and several other procedures in SAS that use MODEL statements (but not all of them—check the SAS/STAT® User’s Guide, Version 8, Volumes 1, 2, and 3, to be sure). The DDFM=SATTERTH option in the MODEL statement causes Satterthwaite’s approximation to be used to determine degrees of freedom. A more general degree-of-freedom procedure is the Kenward-Roger option, DDFM=KR. Because Satterthwaite’s procedure is a special case of Kenward and Roger’s procedure, you will get the same results for the designs discussed in this section. For designs with missing data, the Kenward-Roger option is recommended. The CONTRAST statements are identical for GLM and MIXED, except that the E= option is not needed in PROC MIXED.
Output 4.31 PROC MIXED Analysis of Semiconductor Data
| Covariance Parameter | |
| Estimates | |
| Cov Parm | Estimate |
| wafer(et) | 0.1058 |
| Residual | 0.1111 |
| Type 3 Tests of Fixed Effects | ||||
| Num | Den | |||
| Effect | DF | DF | F Value | Pr > F |
| et | 3 | 8 | 1.94 | 0.2015 |
| pos | 3 | 24 | 3.39 | 0.0345 |
| et*pos | 9 | 24 | 0.81 | 0.6125 |
| Contrasts | ||||
| Num | Den | |||
| Label | DF | DF | F Value | Pr > F |
| ET1 vs ET2 | 1 | 8 | 1.30 | 0.2875 |
| POS1 vs POS2 | 1 | 24 | 0.69 | 0.4132 |
| POS1 vs POS2 in ET1 | 1 | 24 | 0.36 | 0.5541 |
| ET1 vs ET2 in POS1 | 1 | 18.7 | 1.00 | 0.3305 |
Note that all the F-statistics and p-values are identical to the appropriate statistics for the corresponding effects computed in PROC GLM. In addition, PROC MIXED computes the correct F-statistic, denominator degrees of freedom, and p-value for the ET1 vs ET2 in POS1 contrast, which was unavailable with PROC GLM and would require considerable hand-calculation unless you use MIXED.
You can also obtain standard errors using either ESTIMATE statements or, for means and pairwise differences, the LSMEANS statement with the DIFF option. For example, the following statement computes the estimate and standard error of the ET1 vs ET2 in POS1 simple-effects difference:
estimate ‘ET1 vs ET2 in POS1’ et 1 -1 0 0 et*pos 1 0 0 0 -1;
The results appear in Output 4.32. Note that the coefficients for the ESTMATE statement are identical to those you use in the CONTRAST statement. Output 4.32 also shows the result you would get if you used PROC GLM. The GLM result is wrong, and there is no option GLM to correct the problem.
Output 4.32 Estimate of ET Simple Effect for POS 1
| ESTIMATE results using PROC MIXED: | |||||
| Estimates | |||||
| Standard | |||||
| Label | Estimate | Error | DF | t Value | Pr > |t| |
| ET1 vs ET2 in POS1 | -0.3800 | 0.3803 | 18.7 | -1.00 | 0.3305 |
| ESTIMATE results using PROC GLM: | |||||
| Estimates | |||||
| Standard | |||||
| Label | Estimate | Error | DF | t Value | Pr > |t| |
| ET1 vs ET2 in POS1 | -0.38000000 | 0.27221230 | -1.40 | 0.1755 | |
You can see that the two standard errors are different. MIXED uses the correct formula √2(ˆσ2W+ˆσ2)3
Using CONTRAST and ESTIMATE statements for treatment differences can be tedious, especially for simple-effects difference, such as ET1 vs ET2 in POS1 that required you to determine which ET and which ET*POS coefficients you need. PROC MIXED allows you to bypass the CONTRAST and ESTIMATE statements. Instead, use the following statement immediately after the RANDOM statement in the MIXED program:
lsmeans et|pos/diff;
The output contains all means and all possible main effect and simple-effect differences, so it can be quite lengthy. Output 4.33 shows only the results corresponding to the CONTRAST statements discussed above.
Output 4.33 Selected LSMEAN and Treatment Difference Estimates
| Least Squares Means | |||||||
| Standard | |||||||
| Effect | et | pos | Estimate | Error | DF | t Value | Pr > |t| |
| et | 1 | 5.6258 | 0.2110 | 8 | 26.66 | <.0001 | |
| et | 2 | 5.9658 | 0.2110 | 8 | 28.27 | <.0001 | |
| pos | 1 | 6.0208 | 0.1345 | 18.7 | 44.78 | <.0001 | |
| pos | 2 | 6.1342 | 0.1345 | 18.7 | 45.62 | <.0001 | |
| et*pos | 1 | 1 | 5.6133 | 0.2689 | 18.7 | 20.87 | <.0001 |
| et*pos | 1 | 2 | 5.4500 | 0.2689 | 18.7 | 20.27 | <.0001 |
| et*pos | 2 | 1 | 5.9933 | 0.2689 | 18.7 | 22.29 | <.0001 |
| Differences of Least Squares Means | |||||||||
| Standard | |||||||||
| Effect | et | pos | _et | _pos | Estimate | Error | DF | t Value | Pr > |t| |
| et | 1 | 2 | -0.3400 | 0.2984 | 8 | -1.14 | 0.2875 | ||
| pos | 1 | 2 | -0.1133 | 0.1361 | 24 | -0.83 | 0.4132 | ||
| et*pos | 1 | 1 | 1 | 2 | 0.1633 | 0.2722 | 24 | 0.60 | 0.5541 |
| et*pos | 1 | 1 | 2 | 1 | -0.3800 | 0.3803 | 18.7 | -1.00 | 0.3305 |
You can see that the standard errors of LS means also require Satterthwaite’s approximation to get the appropriate degrees of freedom for tests of the null hypothesis that LSMEAN = 0. The output for the differences gives you the same information provided by the ESTIMATE statement. Note that you can get the F-statistic for the corresponding CONTRAST by squaring the t-statistic. For example, F for ET1 vs ET2 contrast is 1.30, which is equal to (1.14)2, the t-value squared. For this reason, there is no real need to use the CONTRAST statement unless you want to test linear combinations other than pairwise differences.
Recent versions of both PROC GLM and PROC MIXED provide a SLICE option with the LSMEANS statement for means of factorial combinations. This option provides tests of one factor conditional on a single level of the other factor. For example, a SLICE on POS would test the equality of the ET means for a given level of POS, that is, H0: μ1j = μ2j = μ3j = μ4j for the jth level of POS. Use the following statement:
lsmeans et*pos/slice=pos;
You can use the DIFF option and multiple SLICE= statements in the same LSMEANS statement. For example, you could use the following statement
lsmeans et*pos/diff slice=(et pos);
to do a thorough analysis of the ET*POS effects. Although you can use this statement in both GLM and MIXED, be wary of the GLM results as they may use the wrong error term. Output 4.34 shows the results for the SLICE=POS option.
Output 4.34 Tests of Simple Effects of ET Given POS Using the SLICE Option in PROC MIXED and PROC GLM
| SLICE results using PROC MIXED: | ||
| Tests of Effect Slices | |||||
| Num | Den | ||||
| Effect | pos | DF | DF | F Value | Pr > F |
| et*pos | 1 | 3 | 18.7 | 1.30 | 0.3038 |
| et*pos | 2 | 3 | 18.7 | 3.19 | 0.0477 |
| et*pos | 3 | 3 | 18.7 | 0.28 | 0.8383 |
| et*pos | 4 | 3 | 18.7 | 1.26 | 0.3181 |
| SLICE results using PROC GLM: | |
| et*pos Effect Sliced by pos for resista | |||||
| Sum of | |||||
| pos | DF | Squares | Mean Square | F Value | Pr > F |
| 1 | 3 | 0.846292 | 0.282097 | 2.54 | 0.0805 |
| 2 | 3 | 2.075092 | 0.691697 | 6.22 | 0.0028 |
| 3 | 3 | 0.182958 | 0.060986 | 0.55 | 0.6539 |
| 4 | 3 | 0.817292 | 0.272431 | 2.45 | 0.0880 |
The GLM F-statistics use MS(ERROR), which is incorrect. The appropriate error term, as derived in Section 4.5.2, is 0.75MS(ERROR) + 0.25MS[WAFER(ET)]. You can see that PROC MIXED does this correctly, and uses the Satterthwaite approximation defined by the DDFM=SATTERTH (or DDFM=KR) option in the MODEL statement. In this case, the difference in potential inference is stark: an unwitting GLM user would conclude ET effects, at least at, say, α=0.10, for all positions except POS=3. Using the correct statistics, plausible evidence exists only at POS=2, with a p-value of 0.0477, not 0.0028.
The main point of this section is that several crucial statistics are either not computed by PROC GLM or, worse, are computed but not correctly. Therefore, we repeat our recommendation that PROC MIXED be used to analyze all models with multiple error terms.
4.6 Split-Plot Experiments
The split-plot design results from a specialized randomization scheme for a factorial experiment. It is often used when one factor is more readily applied to large experimental units, or main plots, and when another factor can be applied to smaller units, or subplots, within the larger unit. A split-plot design is also useful when more information is needed for comparing the levels of one factor than for comparing the levels of the other factor. In this case, the factor for which more information is needed should be the subplot factor.
A classic example of a split plot is an irrigation experiment where irrigation levels are applied to large areas, and factors such as varieties and fertilizers are assigned to smaller areas within a particular irrigation treatment. Split-plot designs are useful in many other contexts as well. For example, a teaching method may be applied to an entire class, but sections of the class may be assigned to different treatments. It is important to realize that split-plot experiments come in many forms. The whole-plot design may use randomized complete-blocks, as shown in Output 4.35. The semiconductor example in Section 4.5, is a type of split-plot experiment that uses a completely randomized whole-plot design. Incomplete-blocks designs, Latin squares, and other types of row-column designs may also be used for the whole plot. Whenever you analyze a factorial experiment, you should examine the design structure carefully for split-plot features regardless of a researcher’s intentions; they are frequently introduced inadvertently.
The proper analysis of a split-plot design must account for the fact that treatments applied to main plots are subject to larger experimental error than those applied to subplots. Hence, different mean squares must be used as denominators for the corresponding F-ratios. Also, many mean comparisons of potential interest have error terms that are linear combinations of mean squares. While PROC GLM is useful for determining expected mean squares, PROC MIXED is better suited to analyze split-plot data.
4.6.1 A Standard Split-Plot Experiment
The split-plot example below analyzes the effect on dry weight yields of three bacterial inoculation treatments applied to two cultivars of grasses (A and B). The experiment is a split-plot design with CULT (cultivar) as the main-plot factor and INOC (inoculi) as the subplot factor. INOC has the values CON for control, LIV for live, and DEA for dead. This provides more information for comparing levels of INOC than for comparing levels of CULT. This is desirable because INOC is the factor of primary interest in the experiment. Data for the experiment appear in Output 4.35.
Output 4.35 Data for Split-Plot Experiment
| Obs | rep | cult | inoc | drywt |
| 1 | 1 | A | CON | 27.4 |
| 2 | 1 | A | DEA | 29.7 |
| 3 | 1 | A | LIV | 34.5 |
| 4 | 1 | B | CON | 29.4 |
| 5 | 1 | B | DEA | 32.5 |
| 6 | 1 | B | LIV | 34.4 |
| 7 | 2 | A | CON | 28.9 |
| 8 | 2 | A | DEA | 28.7 |
| 9 | 2 | A | LIV | 33.4 |
| 10 | 2 | B | CON | 28.7 |
| 11 | 2 | B | DEA | 32.4 |
| 12 | 2 | B | LIV | 36.4 |
| 13 | 3 | A | CON | 28.6 |
| 14 | 3 | A | DEA | 29.7 |
| 15 | 3 | A | LIV | 32.9 |
| 16 | 3 | B | CON | 27.2 |
| 17 | 3 | B | DEA | 29.1 |
| 18 | 3 | B | LIV | 32.6 |
| 19 | 4 | A | CON | 26.7 |
| 20 | 4 | A | DEA | 28.9 |
| 21 | 4 | A | LIV | 31.8 |
| 22 | 4 | B | CON | 26.8 |
| 23 | 4 | B | DEA | 28.6 |
| 24 | 4 | B | LIV | 30.7 |
Table 4.5 shows the standard analysis of variance for this experiment.
Table 4.5 Split-Plot Analysis-of-Variance Table
| Source | DF |
|---|---|
| replication | 3 |
| cultivar | 1 |
| replication × cultivar (Error A or whole-plot error) | 3 |
| inoculi | 2 |
| cultivar × inoculi | |
| replication × | |
| inoculi + | |
| replication × | |
| inoculi × cultivar | |
| (Error B or split-plot error) |
|
Note that Table 4.5 contains two error terms. These correspond to the two sizes of experimental units in the design. The experimental unit for cultivar is the replicationμcultivar combination. For inoculi, and hence for cultivarμinoculi treatment combinations, the experimental unit is the replicationμcultivarμinoculi combination. Usually, determining the experimental units in this fashion is the best way to determine the error terms and hence the random effects that need to be in the mixed model. Also note that no replication×inoculi term appears separately in the model or as an error term in the ANOVA table. This is because, unlike replication×cultivar or replication×cultivar×inoculi, there is no physical unit that corresponds to replication inoculi. No physical unit means no corresponding term in the model or ANOVA table.
Defining the error terms by their corresponding experimental units also tells you what model term is computationally equivalent, and hence how to write the SAS statements. For example, the whole-plot error (called Error A in many texts), the appropriate error term in testing for differences among cultivars, is computationally equivalent to the replication×cultivar interaction. The split-plot error (also known as Error B) is computationally equivalent to the replication×inoculi + replication×inoculi×cultivar interaction. The Error B mean square is the appropriate error term for testing for inoculi and cultivar×inoculi effects. Note that Error B includes the replication×inoculi. Whenever a term does not appear in the model, its sum of squares is pooled with (that is, added to) the simplest term in the model of which it is a subset, in this case replication×inoculi×cultivar.
4.6.1.1 Analysis of Variance Using PROC GLM
The following SAS statements are needed to compute the analysis of variance:
proc glm;
class rep cult inoc;
model drywt=rep cult rep*cult inoc cult*inoc/ss3;
test h=cult e=rep*cult;
run;
The data are classified according to REP, CULT, and INOC, so these variables are specified in the CLASS statement. The response variable DRYWT appears on the left side of the equation in the MODEL statement, and the terms corresponding to lines in the analysis-of-variance table (Table 4.3) appear on the right side. You can see the similarity to the model used for the semiconductor data. The only difference is that the treatment applied to the larger experimental unit, CULT, was assigned using a randomized-blocks design, whereas ET was assigned to WAFER using a completely randomized design in the semiconductor example. Thus the block effect, REP, appears in this model but not in the semiconductor model. The rationale for the TEST statement follows from the expected mean squares shown in Output 4.36.
Note: You can add the following RANDOM statement to obtain expected mean squares to verify the appropriate tests:
random rep rep*cult/test;
Results of the analysis of variance and the expected mean squares appear in Output 4.36.
Output 4.36 Expected Mean Squares for a Split-Plot Experiment
| Source | Type III Expected Mean Square |
| rep | Var(Error) + 3 Var(rep*cult) + 6 Var(rep) |
| cult | Var(Error) + 3 Var(rep*cult) + Q(cult,cult*inoc) |
| rep*cult | Var(Error) + 3 Var(rep*cult) |
| inoc | Var(Error) + Q(inoc,cult*inoc) |
| cult*inoc | Var(Error) + Q(cult*inoc) |
You can see that the hypothesis concerning cultivars (H=CULT) should be tested using REP*CULT as the error term (E=REP*CULT). The TEST statement causes the required F=MS(CULT)/MS(REP*CULT) to be computed. As with the semiconductor example, you need either the TEST statement or the TEST option with the RANDOM statement to compute the correct F-statistics, because the F-statistic for CULT in the default is statistically invalid. The default F-values for INOC and CULT*INOC are valid, because the expected mean squares indicate that MS(ERROR) is their proper error term.
Output 4.37 Analysis of Variance for a Split-Plot Experiment
| Sum of | |||||
| Source | DF | Squares | Mean Square | F Value | Pr > F |
| Model | 11 | 157.2083333 | 14.2916667 | 20.26 | <.0001 |
| Error | 12 | 8.4650000 | 0.7054167 | ||
| Corrected Total | 23 | 165.6733333 | |||
| R-Square | Coeff Var | Root MSE | drywt Mean |
| 0.948905 | 2.761285 | 0.839891 | 30.41667 |
| Source | DF | Type III SS | Mean Square | F Value | Pr > F |
| rep | 3 | 25.3200000 | 8.4400000 | 11.96 | 0.0006 |
| cult | 1 | 2.4066667 | 2.4066667 | 3.41 | 0.0895 |
| rep*cult | 3 | 9.4800000 | 3.1600000 | 4.48 | 0.0249 |
| inoc | 2 | 118.1758333 | 59.0879167 | 83.76 | <.0001 |
| cult*inoc | 2 | 1.8258333 | 0.9129167 | 1.29 | 0.3098 |
| Tests of Hypotheses Using the Type III MS for rep*cult as an Error Term | |||||
| Source | DF | Type III SS | Mean Square | F Value | Pr > F |
| cult | 1 | 2.40666667 | 2.40666667 | 0.76 | 0.4471 |
These F-values indicate no significant CULT*INOC interaction (F=1.29, p=0.3098). The INOC main effect (F=83.76, p=0.0001) indicates highly significant differences between INOC means. The appropriate F-value, that is, the one printed below the main ANOVA table that uses REP*CULT as the error term, shows no evidence of differences between CULT means (F=0.76, p=0.4471). Do not use the inappropriate F-value for CULT of 3.41 from the ANOVA table, which declares differences among CULT means significant at the p=0.0895 level.
Note that the same set of valid F-statistics would be computed if you use the TEST option of the RANDOM statement in PROC GLM.
4.6.1.2 Analysis with PROC MIXED
Use the following SAS statements for the analysis with PROC MIXED:
proc mixed;
class rep cult inoc;
model drywt=cult inoc cult*inoc/ddfm=satterth
random rep rep*cult;
run;
To determine what effects to include in the MODEL statement and what effects to include in the RANDOM statement, use the following guidelines:
❏ Treatment main effects and interactions are generally fixed and thus belong in the MODEL statement.
❏ Error terms go in the RANDOM statement. Error terms correspond to the experimental unit with respect to a given model effect.
• REP*CULT is the experimental unit for CULT.
• The experimental unit for INOC and for CULTμINOC combinations is a replicationμcultivarμinoculi combination.
❏ The smallest experimental unit corresponds to residual error and thus does not appear in either the MODEL or the RANDOM statement.
❏ The specifics of a given design should determine whether to consider the blocking criterion as fixed or random. See Section 4.3 for guidelines. For this example, assume the blocking criterion REP is random.
The results of the basic MIXED analysis appear in Output 4.38.
Output 4.38 PROC MIXED Analysis of Split-Plot Data
| Covariance Parameter | |
| Estimates | |
| Cov Parm | Estimate |
| rep | 0.8800 |
| rep*cult | 0.8182 |
| Residual | 0.7054 |
| Type 3 Tests of Fixed Effects | ||||
| Num | Den | |||
| Effect | DF | DF | F Value | Pr > F |
| cult | 1 | 3 | 0.76 | 0.4471 |
| inoc | 2 | 12 | 83.76 | <.0001 |
| cult*inoc | 2 | 12 | 1.29 | 0.3098 |
You can see that the F-statistics and their associated p-values are identical to those obtained using PROC GLM, assuming the proper TEST options. The ANOVA lines for REP and REP*CULT are replaced by their respective variance component estimates. The variance component estimate for RESIDUAL is equal to the MS(ERROR) from the ANOVA table.
You can add CONTRAST or ESTIMATE statements as needed, as well as the LSMEANS statement, with DIFF and SLICE= options if called for by the objectives. These are subject to the same test statistic and standard error considerations as the semiconductor data in Section 4.5. For example, PROC MIXED computes the appropriate statistics for a CULT difference given a particular INOC, whereas PROC GLM has no option to permit this. To repeat the conclusion of Section 4.5, PROC MIXED is the recommended procedure to analyze split-plot experiments.