
She got her looks from her father. He’s a plastic surgeon.
—Groucho Marx
U.S. comedian (1890–1977)
This chapter focuses on the concrete syntax of textual languages. We investigate the generation of a textual concrete syntax from an abstract syntax model. Large parts of this chapter were published in Kleppe [2007].
Following the writings of Frederick P. Brooks in “No Silver Bullet” [Brooks 1986], I distinguish between the essential part and accidental part of software construction. In 1995, Brooks wrote a response to critics of the original article, and a review of the silver bullets, that missed the mark over the intervening decade, called “‘No Silver Bullet’ Refired” [Brooks 1995]. In this response, he comments that the essential part of software building is the “mental crafting of the conceptual construct,” and that accidental does not “mean occuring by change, nor misfortunate, but incidental, or appurtenant.” Instead, the accidental part simply refers to the implementation of the conceptual construct.
Both essential and accidental parts of software construction carry with them their own complexity. Essential complexity is inherent to the problem to be solved. If, for instance, a complex interest calculation for a new type of mortgage needs to be programmed, the essential complexity arises from the interest calculation, not from the fact that it needs to be implemented. Accidental complexity comes from the act of software building itself, dealing with the limitations of the software languages used, the boundaries set by the chosen architecture, the configuration-management system, and so on.
In 1986, Brooks claimed that we have cleaned up much of the accidental complexity because of the use of high-level languages. But as I have found (contrary to Brooks’s claims, the amount of accidental complexity has been growing over the last two decades (see Section 1.4). The hopes for model-driven software development are that it will relieve us from most of this accidental complexity by means of code generators. Whenever the similarities between applications become large enough, a code generator can be built to produce these applications more quickly, thus freeing programmers from accidental complexity.
If cleaning up accidental complexity is not enough reason for you, another argument for using the generation approach in language engineering is a reduced time to market of the language’s IDE. Using generation, the language engineer is able to play around with the abstract syntax model and, for each change in the model, will be able to generate a working IDE with a single push of a button. Testing the changes in the language definition thus takes the least effort possible.
I followed the code-generation approach when I was faced with creating a parser and static semantic analyzer for yet another textual language. A static semantic analyzer (SSA) is the name for (part of) the tool that implements the recognition phases of binding and checking (see Section 7.1.1 and Background on Compiler Technology on p. 96). Currently, there are many parser generators, but as far as I know, no generators for static semantic analyzers. Thus, I decided to put my efforts into creating an SSA generator that would do this job for me. I have used an existing parser generator and combined its results with the output of the newly created SSA generator. The generator is named the Grasland generator in accordance with the project I was working on at the time. The rest of the chapter describes the various parts of the Grasland generator and how they fit together.
Traditionally, when a new textual language is created, the main activity is to produce the set of BNF rules (BNFset) (see again the Background on Compiler Technology, p. 96). Next, a parser is created using a parser generator, such as Antlr, JavaCC, or Yacc [Johnson 1974, Antlr 2008, JavaCC 2008]. The other parts of the language’s compiler are implemented by hand, often by creating treewalkers that traverse the parse tree generated by the parser. In the process overview shown in Figure 8-1, the gray parts are created by the language engineer. In most cases, there is no explicit definition of the set of possible parse trees, the textual concrete syntax model, or the abstract syntax model, although one can always extract the set of pure BNF rules from the parser-generator input. This set might serve as a textual concrete syntax model description.
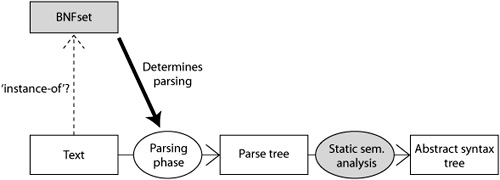
In contrast, using the Grasland generator, the main manual activity is to create the abstract syntax model, that is, a metamodel and its invariants. Figure 8-2 shows the various elements in the Grasland approach; again, the manually created elements are gray. From the abstract syntax model (ASM), you generate a textual concrete syntax model (TCSM), which upholds certain requirements explained in Section 8.2. This transformation, called asm2tcsm, implements the abstraction phase in the recognition process. From the TCSM, we generate a BNFset. This transformation is called tcsm2bnf. The BNFset can be generated in a format that is processable by the JavaCC parser generator [JavaCC 2008]. Next, JavaCC generates a parser, which is able to produce a parse tree that is an instance of the TCSM in the sense that the nodes in the parse tree are instances of the Java classes that correspond to the classes in the TCSM. To implement the static semantic analysis, a tool is generated that transforms a parse tree into an abstract syntax graph (ASG). This tool implements a model transformation from a textual concrete syntax model to an abstract syntax model, which is in the terminology of Section 5.2.2 called a syntax mapping.

The idea of generating an IDE from a language specification is not new. In fact a number of metacase tools exist that perform this task: [Reps and Teitelbaum 1984, MetaEdit+ 2008]. What is new in this approach is that the focus of the language engineer is on the metamodel, not on the BNF grammar (see Background on Backus-Naur Format). Keeping the focus on the abstract syntax model instead of on the grammar is much more in line with the model-driven process, in which instances of the abstract syntax model are being transformed.
The algorithm for the asm2tcsm transformation implements the creation of the textual concrete syntax model and is outlined in List 8-1. Note that this algorithm is defined on the meta-meta level, which means that it is a transformation not of model to model, but of metamodel to metamodel.
An important issue in the asm2tcsm transformation is that the abstract syntax model by its nature describes a graph, whereas instances of the concrete syntax model should be trees (see Background on Graphs and Trees on p. 50). We must therefore find a way to transform some of the relationships between classes in the abstract syntax model to a representation in the concrete syntax model that basically holds the same information.
List 8-1. The algorithm for asm2tcsm
-
Every class in the abstract syntax model becomes a class in the textual concrete syntax model. The language engineer may indicate prefix and postfix strings that are used to name the classes in the concrete syntax model, in order to distinguish them from the classes in the abstract syntax model. For example, the abstract syntax model class named
VariableDeclarationbecomes the concrete syntax model class namedprefixVariableDeclarationpostfix. -
Every composite association is retained.
-
For every noncomposite association from class A to class B, a new class is introduced that represents a reference to an instance of class B. A new composite association is added from class A to this new reference class. The role name of the old association is copied to the new one, as well as the multiplicities.
-
Every attribute with nonprimitive type—that is, whose type is another class in the metamodel—is transformed into a composite association from the owner of the attribute to the class that is the attribute type. The name of the attribute becomes the role name. Any multiplicities are copied.
-
Enumerations and datatypes are retained.
-
Additionally, three attributes are added to every concrete syntax model class. They hold the line number, column number, and filename of the parsed instance of the class.
From past experience with textual languages, we already know how to handle references in BNF rules. To refer to the other element, you simply use a name or a name combined with something else. For example, when you write ClassA var1 in Java, you use the name ClassA to refer to the definition of ClassA, which is probably in another file. You do not use a direct link; you use a name-based reference.
In our situation, the occurrence of a name in a parse tree must be an instance of a class in the concrete syntax model. So, the names that are references should be instances of one or more special classes. For this purpose for each class to which a reference exists, the toolkit generates in the concrete syntax model a special reference class. For instance, in Alan, the abstract syntax model holds a class called Type, and the concrete syntax model contains a class called TypeREF.
To decide which associations in the abstract syntax model represent references and should therefore be handled like this, we make use of the composite/reference distinction in associations in the abstract syntax model. Our formal definition of metamodel in Section 5.1.5 ensures that in any instance of the abstract syntax model, the composite associations build a subgraph that is a tree or a set of unrelated trees (a forest). Thus, the composite relationships in the abstract syntax model are the perfect start for creating a concrete syntax model. If the subgraph formed by the composite associations is not a tree but rather a forest, the algorithm will produce a set of unrelated sets of grammar rules. It is up to the language engineer to decide whether this is desired.
Note that for each of the classes for which a reference class is created (step 3 of the algorithm), the language engineer must indicate which attribute of String type is used as identifier. This knowledge is used in the static semantic analyzer to implement the binding phase.
Figure 8-3 shows a small part of the abstract syntax model in Alan. Since this model does not contain any attributes with nonprimitive types, I have, for the sake of argument, regarded the relationship between an operation and its parameters as represented by an attribute in the class OperDecl. (In Figure 6-1, this relationship is shown as an association between the class OperDecl and the class VarDecl.)
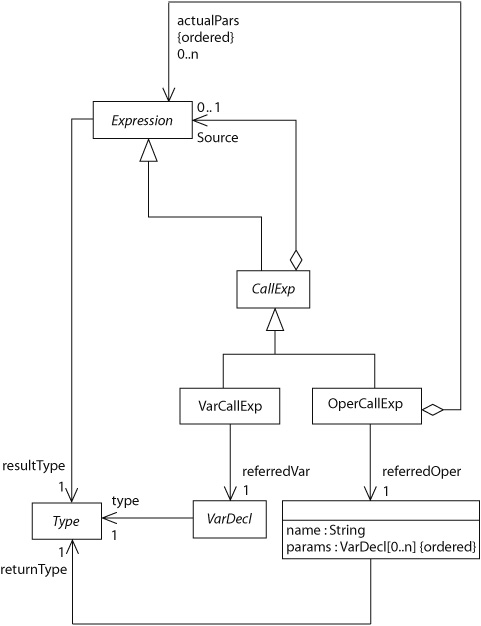
Figure 8-4 shows the concrete syntax model that is automatically generated from this part of the abstract syntax model. The differences are marked by the gray color of the classes and the font of the role names. You can see that VarCallExp and OperCallExp are no longer associated with VarDecl and OperDecl, respectively. Instead, they have an acyclic (see Section 5.1.3) constraint on their relationships with VarDeclREF and OperDeclREF, respectively. The same holds for the relationships of VarDecl and OperDecl with Type. Furthermore, as expected, the params attribute in class OperDecl has been replaced by an acyclic relationship between OperDecl and VarDecl. The result of all this is that the concrete syntax model specifies a tree and not a graph.
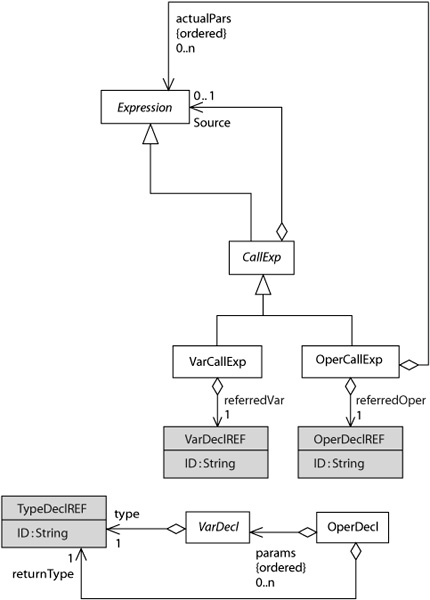
The Grasland toolkit implements the algorithm in List 8-1 in a fully automatic way and is able to produce a concrete syntax model without any extra user effort. However, if the algorithm for the asm2tcsm transformation is executed as is, the differences between the abstract syntax model and the concrete syntax model are minimal; only the references are represented differently. Often, the language engineer wants a larger difference between the two, so there are two options to tune the asm2tcsm transformation. Because the static semantic analyzer must be able to inverse the asm2tcsm transformation on the instance level, these options are taken into account in the generation of the static semantic analyser as well.
The first option is to indicate that certain metaclasses in the abstract syntax model should not appear at all in the concrete syntax model. Examples are the classes PrimitiveType and NullType (you may want to have another look at Figure 6-1). These types are present in the abstract syntax model only to provide for a number of predefined elements in the language, the ones that are part of the standard library, but the language user is not meant to create new instances of these meta-classes. The language engineer can indicate that these classes are hidden to the concrete syntax.
The second option is to indicate that certain attributes and outgoing associations of a metaclass need not be present in the input text file; instead, their value will be determined based on the values of other elements that are present. In fact, these elements are what is known in OCL [Warmer and Kleppe 2003, OMG-OCL 2005] as derived elements. The language engineer may indicate that if an OCL derivation rule for this element in the abstract syntax model is provided, a certain element need not be taken into account in the concrete syntax model. An example of a derived value is the resultType of an Expression, which is shown in Figure 8-3 but is absent in Figure 8-4.
The second meta-metatransformation—from metamodel to metamodel—is the tcsm2bnf transformation, which implements the creation of the BNF rules that a parser generator uses to produce the parser. Alanen and Porres [2004] present some algorithms for the relation between the concrete syntax model and BNFset, which I have used and extended.
The generation of the BNFset from the concrete syntax model is implemented in a single algorithm. Yet the language engineer may choose between two different output formats: either BNF or a grammar that can directly be used as input to the JavaCC parser generator [JavaCC 2008]. The BNF grammar that is produced is an extension of EBNF that uses labeling of nonterminals in the right-hand side of a grammar rule. (Not to be confused with Labeled BNF [Forsberg and Ranta 2003], which uses labels on the nonterminals at the left-hand side of each rule.) The labels correspond to the names of the attributes and association roles in the concrete syntax model. List 8-3 shows an example in which the labels are called out in boldface.
The input for the JavaCC parser generator is such that the generated parser produces instances of the Java implementations of the classes in the concrete syntax model. The algorithm that implements tcsm2bnf is given in List 8-2. List 8-3 shows the BNF rules generated from the concrete syntax model in Figure 8-4. Note that terminals in the right-hand side of the grammar rules are surrounded by angle brackets (< and >).
Like the algorithm for the asm2tcsm transformation, the Grasland toolkit implements the algorithm in List 8-2 in a fully automatic way. A grammar can be produced without any extra effort from the language engineer. However, there are a number of differences between the metamodel formalism used for the concrete syntax model and the BNF formalism, and the language engineer is able to influence how these differences appear in the generated grammar, thus tuning the tcsm2bnf generation.
List 8-2. The algorithm for tcsm2bnf
-
Every class in the textual concrete syntax model becomes a nonterminal in the grammar. The BNF rules for these nonterminals are formed according to the following rules.
-
If a class has subclasses, the BNF rule becomes a choice between the rules for the subclasses. All attributes and navigations of the superclass are handled in the subclass rules.
-
For every composite association from A to B, B will appear in the right-hand side of the grammar rule for A. The multiplicity is the same as in the association (for 0..1, 1, 0..*, 1..*; multiplicities of the form 3..7 are considered to be specified using invariants). Using an extension of BNF, we associate the rolename with the nonterminal in the right-hand side of the rule.
-
Every attribute, all of which have a primitive type, is transformed into an occurrence of a predefined nonterminal for that primitive type in the right-hand side of the rule for its owner. (We support the primitive types
String,Integer,Real.) -
Every attribute that has
Booleantype is transformed into an optional keyword. If present, the attribute has value true; if not, the attribute’s value is false.
List 8-3. The resulting BNF rules
Expression = (CreateExp
| CallExp
| LiteralExp )
CallExp = (VarCallExp
| OperCallExp
| ObserveExp
| LoopExp
| DisobserveExp )
OperCallExp =
referredOper:OperDeclREF
<BRACKET_OPEN> [ actualPars:Expression ( <COMMA>
actualPars:Expression )* ] <BRACKET_CLOSE>
[ <ONKW> source:Expression ]
VarCallExp =
referredVar:VarDeclREF [ <ONKW> source:Expression ]
OperDeclREF =
ID:<IDENTIFIER>
OperDecl =
name:<IDENTIFIER>
<BRACKET_OPEN> [ params:VarDecl ( <COMMA> params:VarDecl )* ]
<BRACKET_CLOSE>
<COLON> returnType:TypeREF
body:BlockStat
TypeREF =
ID:<IDENTIFIER>
Type = (ActualType
| GenericType )
VarDeclREF =
ID:<IDENTIFIER>
VarDecl = (LocalVarDecl
| AttributeDecl )
LocalVarDecl =
name:<IDENTIFIER> <COLON> type:TypeREF
[ <EQUALS> initExp:Expression ]
The most apparent difference is the lack of ordering in navigation—attributes and outgoing association—from a metaclass versus the ordering of the elements in the right-hand side of a BNF rule for a nonterminal. To indicate a certain ordering in the BNF rules, the language engineer can associate an index to all navigations. This is done in a so-called properties file. An example can be found in List 8-4, where, among other things, the order of the navigations from the metaclass OperCallExp in Figure 8-3 is given. The first element to be included in the right-hand side of the corresponding BNF rule is the attribute called name, the second element is the list of actual parameters, and the third is the object on which to call the operation.[1] Without directions from the language engineer, the Grasland toolkit will randomly assign an ordering.
[1] You may notice that the source of the operation call expression is the last in this order. This does not conform to the explanation of Alan in Section 6.4. A grammar in which the order would be different has a left-recusion problem. To make the example understandable without intimate knowledge of the notion of left-recursion, I have chosen to stick to the given ordering.
List 8-4. Part of the properties file for tcsm2bnf
OPERCALLEXP_ORDER=referredOper actualPars source
OPERCALLEXP_ACTUALPARS_BEGIN=BRACKET_OPEN <MANDATORY>
OPERCALLEXP_ACTUALPARS_SEPARATOR=COMMA
OPERCALLEXP_ACTUALPARS_END=BRACKET_CLOSE <MANDATORY>
OPERCALLEXP_SOURCE_BEGIN=ONKW
#
VARCALLEXP_ORDER=referredVar source
VARCALLEXP_SOURCE_BEGIN=ONKW
#
OPERDECL_ORDER=name params returnType body
OPERDECL_PARAMS_BEGIN=BRACKET_OPEN <MANDATORY>
OPERDECL_PARAMS_SEPARATOR=COMMA
OPERDECL_PARAMS_END=BRACKET_CLOSE <MANDATORY>
OPERDECL_RETURNTYPE_BEGIN=COLON
#
ATTRIBUTEDECL_ORDER=name type initExp otherEnd
ATTRIBUTEDECL_TYPE_BEGIN=COLON
ATTRIBUTEDECL_INITEXP_BEGIN=EQUALS
ATTRIBUTEDECL_OTHEREND_BEGIN=OTHERSIDE
#
LOCALVARDECL_ORDER=name type initExp
LOCALVARDECL_TYPE_BEGIN=COLON
LOCALVARDECL_INITEXP_BEGIN=EQUALS
#
CREATEEXP_BEGIN=NEW
Another difference between a metamodel and a grammar is that most grammar rules contain one or more keywords, whereas the metamodel does not. These keywords are relevant in the parser because they enable it to differentiate between language elements (rules). For instance, the difference between a class and an interface is indicated by either the keyword class or interface. Therefore, the Grasland toolkit provides the option for the language engineer to indicate which keywords should be used in the grammar rule corresponding to a metaclass instance. Without keyword directions, the Grasland toolkit will generate keywords based on the class and association role names.
For each metaclass that is used in the right-hand side of a BNF rule, there are two options to use a keyword: (1) before the occurrence of the metaclass, and (2) after the occurrence of the metaclass. An example is the keyword new, indicated by CREATEEXP_BEGIN, that should appear at the start of a CreateExp instance.
For each navigation—attributes and outgoing associations—that appears in the right-hand side of a BNF rule, there are three possibilities: (1) a keyword before the navigated element, (2) a keyword after the element, and (3) a keyword that separates the elements in a list. The last is sensible only when the multiplicity of the association is larger than 1. If the element is optional—that is, the lower bound of multiplicity is 0—the language engineer is able to indicate whether the keyword should still appear even if the element is not present. This is useful, for instance, to indicate that the opening and closing brackets of a parameter list should be present even if there are no parameters. In List 8-4, for example, the brackets are mandatory for the navigation OPERCALLEXP_ACTUALPARS. Note that a keyword in this approach can be any string, including brackets.
A third difference between a metamodel and a grammar is that the parsing algorithm used poses a number of requirements on the rules. For instance, the JavaCC parser generator creates LL(n) parsers, and its input should be an LL(n) grammar, where n indicates the number of look-ahead tokens used. If the language engineer decides to create a grammar with too few keywords, the parser generator will produce errors and/or warnings. As the Grasland toolkit is a prototype, resolving these issues is the responsibility of the language engineer. By adding more keywords or by adding (by hand) look-aheads to the generated grammar, the language engineer will always be able to generate a grammar that is correct. Even so, the Grasland toolkit provides a minimal support in the form of the generation of lookaheads in the rule for a class with subclasses, where choice conflicts are likely because the attributes and navigations of the superclass appear in the rules for each subclass.
The two aspects of static semantic analysis are binding and checking. This section describes how the Grasland toolkit implements these issues.
Binding is the general term for the binding of names to their definitions. These names may refer to types—for instance, in a variable declaration—or to variables or operation/functions—for instance, in assignments or operation calls. Binding is often context sensitive in the sense that not all occurrences of the same name are bound to the same definition; depending on the context of the name, it may be bound to a different definition, sometimes even to a definition of a different kind of element. For instance, in one context, “message” may be bound to a variable, in another to a type, and in yet another to an operation. Such a context is usually called a namespace.
Because the concrete syntax model is generated, we can be sure that all elements that need to be bound are instances of reference metaclasses (see List 8-1, rule 3). For each reference metaclass, we know the metaclass from which it is derived. We call this metaclass the target metaclass.
The most primitive way of binding these elements is by searching the parse tree for all instances of the target metaclass and comparing their names with the name of the element to be bound. This is the default implementation of binding.
However, it is possible for the language engineer to indicate that certain metaclasses in the abstract syntax model act as namespaces. In our example, for instance, the classes Type, OperDecl, and Program all act as namespaces. If a class is labeled as namespace, the asm2tcsm algorithm will produce a metamodel in which every class has the operation findNamespace, which will return the element’s surrounding namespace. An INamespace interface is added to the metaclass(es) that act as namespaces for this purpose. The implementation of each of the findNamespace operations is specified by an OCL body expression.
In this case, the binding algorithm is implemented as follows. First, find the surrounding namespace of the instance of the reference metaclass; then search this namespace for occurrences of the target metaclass, and compare their names with the name of the reference element. If a match is found, the reference is bound to the found instance of the target metaclass. If no match is found, the surrounding namespace of the searched namespace is searched in the same manner, and so on, until the outermost namespace has been searched. If no match was found, an error message is given. The search of a namespace goes down the parse tree to the leaves of the tree, unless one of the nodes is itself a namespace, in which case the search stops at this node.
A more complex way of binding is based on not only the name of the reference element but also the occurrence of surrounding elements. For instance, the binding of an operation call is usually determined not only by the name of the operation but also by the number and types of the parameters. In our example, the link called referredOper between an OperCallExp instance and an instance of the reference class OperDeclREF is an example of such a complex binding.
The language engineer may indicate the use of a complex binding by stating an abstract syntax model invariant that must hold after the reference element is bound. In the example from Figure 8-3, the following entry in the properties file indicates the use of complex binding:
OperCallExp.referredOper=paramsCheck
In this case, the invariant called paramsCheck must be present for the class OperCallExp. It is specified by the following OCL expression. (Note that the use of names for invariants is a standard OCL feature.)
context OperCallExp
inv paramsCheck: referredOper.params.type = actualPars.type
Having this in place, the Grasland toolkit implements complex binding more or less in the same manner as simple binding. First, a list of possible matches is found, based on the name only; then the invariant is checked for each element in this list. If no correct element is found, the search continues in the next namespace, and so on.
An advantage of this approach is that, normally, these invariants need to be part of the abstract syntax model anyhow, so no extra effort is needed from the language engineer. Another advantage is that all the information that the language engineer must provide is based on the abstract syntax model. The abstract syntax model is truly the focus of the language-design process, even though a text-based language is being specified. This leaves room for the creation of multiple views, each based on a different concrete syntax, with the possibility of combining textual and graphical views all working together on the same abstract form of the mogram.
Note that this algorithm implements part of the static semantic analysis. This means that dynamic binding and dynamic scoping are, by definition, not covered.
An important observation about static checking is that the rules that are checked during this phase are easily specified by OCL invariants on the abstract syntax model. These are the so called well-formedness rules. For instance, in our (simple) example, the following rule provides enough information to perform type checking:
context VariableDecl
inv: self.type = initExp.type
Static checking is therefore implemented in the generated static semantic checker as the checking of invariants on the abstract form of the mogram. Whenever an invariant is broken, an error message is given to the language user.
Even more complex forms of type checking involving type conformance can be handled in this manner. For instance, given the existence of an operation in the Type class that implements the type conformance rules, the following invariant allows for type checking with type conformance. The type-conformance operation itself is also specified using OCL.
context VariableDecl
inv: self.type.conformsTo(initExp.type)
context Type::conformsTo( actualType: Type) : Boolean
body: if ( actualType = self)
then true
else if not actualType.superType.oclIsUndefined()
then self.conformsTo( actualType.superType)
else false
endif
endif
The advantage of this approach is that the invariants can be used for all concrete syntaxes that may be defined for the abstract syntax model. Thus, checking becomes a common functionality instead of a functionality that needs to be implemented for each concrete syntax.
It is possible to create a textual concrete syntax without first creating a grammar. The algorithms explained in this chapter make it possible to keep the focus on the central element in the language specification: the abstract syntax model. From this model, we can create a textual concrete syntax model and a grammar, while giving the language engineer the flexibility to determine the look and feel of the language.