
All parts should go together without forcing. You must remember that the parts you are reassembling were disassembled by you. Therefore, if you can’t get them together again, there must be a reason. By all means, do not use a hammer.
—IBM maintenance manual, 1925
This chapter identifies what elements should be in a language specification, explains how to create a language specification, and describes what a language specification has to do with model transformations.
When you want to know how to create languages, you need to know how to describe a language. What is your result: a document, a set of tools, both? I think that we need both, but the language-specification document is the most important element. It should be written in such a way that it supports the creation of the tool set. Preferably, the tool set should be generated from the language specification, just as a parser can be generated from a grammar. But first, we need a definition of what a language specification is.
Definition 4-1 (Language Specification) A language specification of language L is the set of rules according to which the linguistic utterances of L are structured, optionally combined with a description of the intended meaning of the linguistic utterances.
A language specification should at least make clear what is and is not a syntactically valid mogram in that language. In my opinion, a language description should also include a description of what a mogram means or is supposed to do, that is, its semantics. After all, what’s the use of speaking a syntactically perfect Russian sentence if you do not know what it means? Most humans prefer to speak sentences that both speaker and listener can understand, even if the sentences are syntactically flawed. However, I know that some people, even experts, think that the semantics need not be part of a language specification. To accommodate some flexibility on this subject, the preceding definition states that the semantics description is optional.
A language specification can be compared to the constitution of a country. Every citizen should abide the law, but because a certain citizen might not, law abidance must be checked (Figure 4-1). Likewise, every mogram should be checked for its structure according to the given set of rules. This check needs to be implemented in the tool set that is to be created for the language.
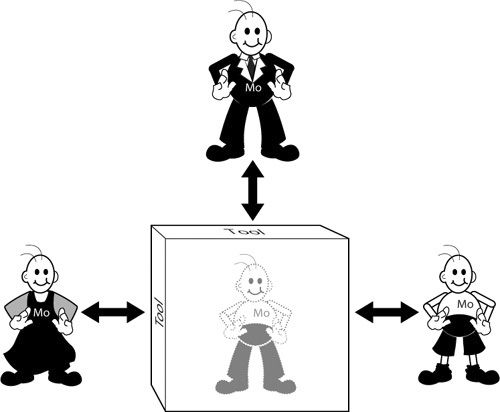
A language specification is a set of rules to structure mograms. So what are these rules? To explain this clearly, we need to take into account the fact that a mogram has several representations. A mogram presents itself to the language user in a concrete form: for instance, as a piece of text or a diagram. A mogram also has a representation that is hidden in the tool(s) that handle it. This in-memory representation is the abstract form of the mogram, or abstract syntax graph, or abstract syntax tree.
The essence of abstract syntax is that a mogram cannot be experienced in its abstract form. Whenever you see or read a mogram, it has (again obtained) a concrete form (Figure 4-2). From Chapter 1, you might recall that languages can have multiple syntaxes. Actually, languages can have multiple concrete syntaxes. But no matter how the mogram is represented to a language user, its abstract form is the same. The abstract form is the unification of several concrete forms, as detailed in Chapter 6.
Taking the concrete/abstract distinction into account, a language specification exists of the following six parts:
-
An abstract syntax model (ASM) that specifies the abstract form of the mograms in the language
-
One or more concrete syntax models (CSMs), each describing one of the concrete forms of the mograms in the language
-
For each concrete syntax model, a model transformation that defines how the concrete form of a mogram is transformed into its abstract form (syntax mapping)
-
Optionally, a description of the meaning of the mograms, including a model of the semantic domain
-
Optionally, a definition of what the language’s mograms need from other mograms written in another language or languages: the required language interfaces
-
Optionally, a definition of what parts of the language’s mograms are available to mograms written in another language or languages: the offered language interfaces
Parts 5 and 6 are especially important for DSLs, which by definition have a small focus. Therefore, you often need to combine the use of a number of DSLs in order to create a complete application. For instance, you might use a DSL dedicated to the design of Web-based user interfaces with a DSL for the design of services in a service-oriented architecture.
Each part of a language specification is so important that it deserves separate treatment. More on abstract syntax models can be found in Chapter 6. Chapter 7 explains concrete syntax models, as well as the concrete-to-abstract transformation. Chapter 8 gives an example of a textual concrete syntax and its transformation. The meaning of mograms is discussed in Chapters 9 and 10. The language interfaces are described in Chapter 11.
Traditionally, the approaches for defining languages with a textual syntax and those with a visual or graphical syntax are different. To a large extent, this difference has resulted from the tools that support language design. For textual languages, the supporting tools—namely parser generators—focus on the concrete syntax, helping the language engineer with specifying scanning and parsing rules. A language user will use a free-format editor in combination with the generated scanner/parser. For graphical languages, many of the supporting tools focus on the abstract syntax, helping the language engineer to create structure editors, which allow a user to enter only syntactically valid mograms.
The differences between these approaches pose a problem because of the growing demand for languages with multiple concrete syntaxes: some graphical, some textual, some in which text and graphical symbols are intermixed. Therefore, using an approach to language design that focuses on concrete syntax is not the right way to go. Instead, the abstract syntax model should be central. Note that this does not mean that all editors created should take the form of a structure editor. Free-format editors combined with parsers are still an option, even when the abstract syntax plays a central role in the language specification.
As explained earlier, this book does not provide a step-by-step plan of how to create a new software language but instead shows you what the ingredients of a language specification are and how each of these can be best expressed. However, a general outline of such a plan can be drawn.
-
Create an abstract syntax model, taking into account references to other languages.
-
Generate a concrete syntax model, and experiment with some example mograms.
-
Revise the abstract syntax model and reiterate.
-
Create a semantics.
-
Revise the abstract syntax model and reiterate, possibly changing the concrete syntax model(s) as well.
-
Create the tools that support the language user.
-
Devise a way to handle different versions of the language, because many enthusiastic users will demand changes, and some will want to stick to older versions.
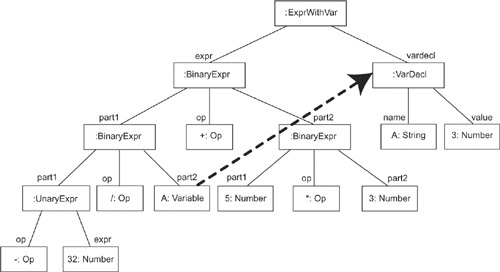
To illustrate the various elements in a language specification, let’s take a look at an example that will be familiar to many people: the language of mathematical expressions. The model in Figure 4-3 is a specification of the abstract syntax of this language. The model contains no hints on what a mathematical expression should look like; that is, it does not contain information on the concrete syntax.
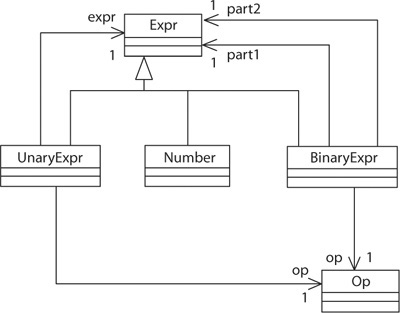
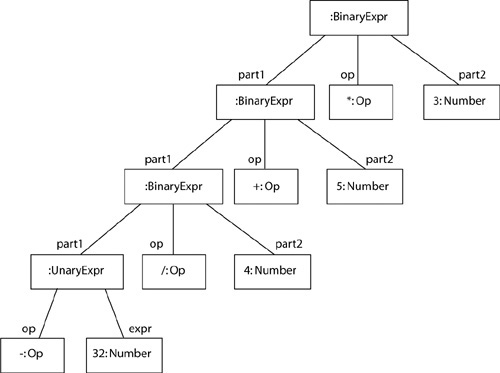
Figure 4-4(a) shows various concrete forms of a mathematical expression—a mogram of this language. They are all textual but differ with regard to the position of the operator. Figure 4-4(b) shows the abstract form of this mogram as a tree of instances of the classes in the ASM.

There is no standard way to represent the concrete syntax model. However, when we look at the information that is required—note that since we already have the abstract syntax model, we do not need to identify Expr, BinaryExpr, and so on—we can see that we need answers to the following questions.
• What is the representation of an Op?
• What is the representation of a Number?
• What is the order of elements of a BinaryExpr?
• What is the order of elements of a UnaryExpr?
• What adornments (brackets) may be used in combination with an Expr?
Figure 4-5(a) shows the answers to these questions in an ad hoc notation that uses the association roles names from Figure 4-3; Figure 4-5(b) shows the library that is used for this language. Here we touch on a tough spot for every language: The very basic building blocks are always difficult to specify. We often need to refer to other formalisms, such as mathematical formulas, as in “for all x in R.” We could also have used the grammar in Figure 4-6 to specify the concrete syntax. However, the common interpretation of such a grammar is that it specifies not only concrete syntax but also abstract syntax.

The syntax mapping for this language is a simple one-to-one mapping, as long as we do not take operator precendence into account. Note that this issue is only for the concrete syntax that uses infix notation. For example, the value, or meaning, of the infix form of the expression in Figure 4-4(a)—simply evaluating it from left to right without operator precendence—would be quite different; compare ((((–32) / 4) + 3)*5) = –9 with ((–32) / 4) + (3*5) = 7. The syntax mapping that takes operator precendence into account would be a transformation that maps the tree in Figure 4-7 to the tree in Figure 4-4(b).
The description of the meaning of the mograms would in this case be a simple reference to calculus. The expression language does not have any required interface, but it could offer an interface consisting of the one class Expr, thus making it possible for users of other languages to refer to a mathematical expression that is a correct mogram of this expression language.
Many of the formalisms to define languages define only a single part of a language specification. Even when you take the advice to focus on the abstract syntax, you have to choose among them. We’ll compare them shortly.
Context-free grammars have long been the way to specify languages. When you create a context-free grammar, you build a specification of a concrete syntax. All keywords and other symbols that must be present in the concrete form of a mogram are specified by the grammar. For instance, the rule for the Java switch statement in Figure 4-8 contains the keywords “switch”, “case”, and “default”, as well as two types of brackets and a semicolon. All these elements determine how the mogram is presented to the language user; in other words, they are concrete syntax elements. They are not present in the abstract form of the mogram.
An advantage of context-free grammars is that they have been around for more than half a century. There is plenty of knowledge on grammars and many tools that support the creation of a grammar. Usually, Backus-Naur Form (BNF) or some dialect of BNF is used as input for these tools.
The context-free grammar’s underlying structure is a derivation tree, whereby each node represents either the application of a production rule during the recognition of a mogram or a basic symbol (a nonterminal). Some nodes in the derivation tree are names that are references to other nodes in the tree. A standard trick in compiler construction is to use, next to the tree, a symbol table that holds information on which name refers to which node. The fact that you need both the syntax tree and the symbol table means that the underlying structure is not a tree but a directed graph. An example can be found in Figure 4-9, in which a variable in a mathematical expression refers to a value that is defined elsewhere. Unfortunately, this is not commonly understood.
Another aspect of context-free grammars is that they allow you to specify only textual languages. You cannot create a graphical language using a simple context-free language, which brings us to an interesting extension of grammars: the attributed grammar.
An attributed grammar is a context-free grammar that has attributes associated with each of the nonterminals. The attributes may have any structure: trees, graphs, and even more complex things. In many cases, attributed grammars hide the real information on a mogram in their attributes. The complete abstract form of a mogram can be created as an attribute of a concrete element, such as a keyword. For instance, when processing a textual mogram specifying a C# class, an attributed grammar allows you to build an abstract syntax tree of the class and assign it to a grammar attribute of the terminal representing the keyword class.
Background on Graphs and Trees
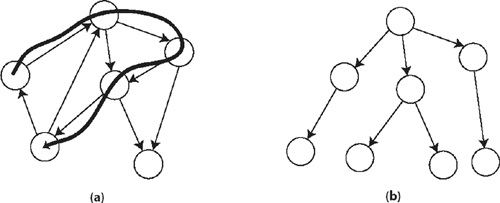
A directed graph, denoted by G = (N, E, src, tgt), is a mathematical construct that consists of a finite set of nodes N and a finite set of edges E, plus two mappings: src and tgt. Each mapping associates a node to an edge. The node src(e) is called the source of edge e, and the node tgt (e) is called the target of e. In other words, an edge goes from its source node to its target node. An example graph is shown in figure (a).
A graph may also be undirected, in which case an edge is usually regarded to be a pair of nodes.
A path in a graph is a sequence of edges e1, e2, ..., ek, such that the source of one edge is the target of its predecessor; that is, for each i, 1 < i <= k, src(ei) = tgt (ei −1). An example is figure (a), where a path is drawn between five nodes. A path is said to go from the source of its first edge to the target of its last edge.
A cycle is a path whereby the source of the first edge is the target of the last; that is, src(e1) = tgt(ek).
A tree is a directed graph with the following two properties.
1. One node, called the root, that is not the target of any edge and has a path to every other node.
2. For each node other than the root, there is exactly one edge with this node as target.
An example can be found in figure (b).
A forest is a set of trees, or a tree in which the root does not have a path to all other nodes.
The visual-languages community, which uses attributed grammars to be able to deal with graphical languages, is concerned mostly with scanning and parsing visual-language expressions, or diagrams. Virtually all work in this area focuses on the recognition of basic graphical symbols and grouping them into more meaningful elements, although some researchers stress the fact that more attention needs to be paid to language concepts, which in this field is often—wrongly—called semantics. Often, these so-called semantics are added in the form of attributes to the graphical symbols. For instance, an attributed grammar may have a nonterminal compartmented box. An attribute to this nonterminal may hold the information that this element represents a use case and that the top compartment is to be considered its name. This is very different from the metamodeling point of view. For instance, although UML is a visual language, its metamodel does not contain the notions of box, line, and arrow.
Common to all formalisms of this type is the use of an alphabet of graphical symbols. These graphical symbols hold information on how to materialize the symbol to our senses: rendering info, position, color, border style. Next to the alphabet, various types of spatial relationships are commonly defined, based on position (left to, above), attaching points (endpoint of a line touches corner of rhombus), or attaching areas using the coordinates of the symbol’s bounding box or perimeter (surrounds, overlaps). Both the alphabet and the spatial relationships are used to state the grammar rules that define groupings of graphical symbols.
Although the work in this area does not use graph grammars, the notion of graphs is used. The spatial relationships can be represented in the form of a so-called spatial-relationship graph [Bardohl et al. 1999], in which the graphical symbols are the nodes, and an edge between two nodes represents a spatial relationship between the two symbols.
Since the 1970s, graph grammars have been used to tackle the problem of specifying graphical languages [Shaw 1969]. Graph grammars are rather complex, since two structuring mechanisms collide.
First, the diagrams themselves are represented as directed graphs in which the edges represent relationship between the parts of the diagram. Either attributes or labels to the edges and/or nodes represent the concrete representation of the element. Compared to the structure of a textual mogram, which is a simple sequence of characters, this is a rather complex structure. Second, the application of the grammar rules in the creation or recognition of a certain diagram forms a structure that is also represented as a graph. Compared to context-free grammars, in which the underlying structure is a tree, this representation is again much more complex.
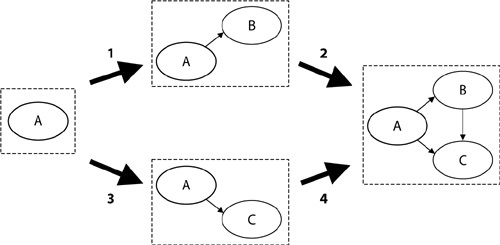
The graph that represents the application of grammar rules is called the derivation graph. In this type of graph, the nodes themselves are graphs representing the diagram. For instance, suppose that we want to find the derivation of the A-B-C graph on the right-hand side of Figure 4-10. Two rules could apply: the rule that adds a C node to an AB graph (2), or the rule that adds a B node to an AC graph (4). Much interesting theoretical work has been carried out with regard to the derivation graph. For instance, some theories state whether a set of grammar rules always have the same result, regardless of the order of application of the rules.
With a context-free grammar, there is only one structure to deal with: the derivation tree, which makes things easier. Furthermore, the tree derived from a BNF grammar helps us to understand the structure of the mogram, whereas the derivation graph from a graph grammar does not help us in this respect. This graph of graphs is—at least for now—too complex a structure to be of practical use in the definition of languages. The fact that you may not even understand all this only illustrates my point.
Creating a UML profile is a very popular way to create a new language, even though many people don’t even realize that they are creating a language by extending an existing one. When you create a UML profile, you take the UML specification as base and change little bits by adding stereotypes. That is, you stick to the UML concrete syntax using stereotyped names to adorn the concrete symbols. The abstract syntax also follows the path set by UML, but because you can create your own classes and associations between them, you have some freedom in creating the abstract syntax model.
There is also freedom in setting the semantics of your new language. The UML defines only the general outlines of what your language’s concepts mean. For instance, when you define a new construct based on the UML Class concept, you know that the systems specified by your mograms will contain some sort of instance entity. When you define a new association, you know that the systems specified by your mograms will contain some sort of relationship between these entities. When your stereotype is based on the UML state, you known that your entities will have states. Whatever else you want your new language to mean is up to you. You can specify this in some natural-language text, in a tool, or in any other format of your choice.
Note that the profile itself is only the abstract syntax model of your language. The concrete syntax model and the mapping to the abstract syntax model are given by the stereotypes and the UML specification. Your language still has undefined semantics and must be specified by you in some other manner.
The creation of the Unified Modeling Language in the 1990s not only provided us with a modeling language but also popularized metamodeling as a means to specify languages. A metamodel is a model, usually some form of class diagram, that describes—models—the mograms that are part of the language.
It is recognized by some [Greenfield et al. 2004] that metamodels are more powerful for specifying languages than traditional (BNF) grammars are, but this fact is not yet commonly known (see Figure 4-11). The mogram in Figure 4-11(c) can be described by the metamodel in Figure 4-11(a) but cannot be described by the grammar in Figure 4-11(b).

In the remainder of this book, I use metamodeling as the formalism to specify software languages. The reason I choose metamodeling as the basis to define software languages is that it is the most practical of the possible choices. Because its underlying structure is a tree and not a graph, an ordinary context-free grammar is not able to express everything we need in a language specification. An attributed grammar simply obscures the true structure of the mogram. A graph grammar is too complex, and a UML profile is too restrictive.
A language specification is the set of rules according to which the mograms of L are structured, optionally combined with a description of the intended meaning of the linguistic utterances. A mogram has two forms: a concrete form, which is the way it is experienced by humans, and an abstract form, which is the way it is represented internally in the tools that handle it. Both forms have rules associated with them. A mogram must be structured according to the rules of both concrete syntax and abstract syntax. Therefore, a language specification exists of the following six parts:
-
An abstract syntax model (ASM) that specifies the abstract form of the mograms in the language
-
One or more concrete syntax models (CSMs), each describing one of the concrete forms of the monograms in the language
-
A syntax mapping, for each concrete syntax model, that defines how the concrete form of a mogram is transformed into its abstract form
-
Optionally, a list of required language interfaces, which define what the language’s mograms need from other mograms written in another language or languages
-
Optionally, a list of offered language interfaces, which define what parts of the language’s mograms are available to mograms written in another language or languages
Although a number of formalisms can be used to specify languages, this book uses metamodeling.