
An invasion of armies can be resisted, but not an idea whose time has come.
—Victor Hugo
French dramatist, novelist, and poet (1802–1885)
This chapter explains why languages are becoming more and more important in computer science and why language engineering, the art of creating languages, is an important topic for computer scientists. This chapter also gives some background knowledge on several theories regarding languages and language engineering.
In the past few years, an increasing number of languages used for designing and creating software have been created. Along with that has come an increasing interest in language engineering: in other words, the act of creating languages.
First, domain-specific languages (DSLs) have become more and more dominant. DSLs—languages for describing software—are focused on describing either a certain aspect of a software system or that software system from a particular viewpoint. One can compare a DSL to a certain jargon, for example, in stockmarket jargon terms like “going short” and “bear market” have specific meaning.
Second, modeling languages, specifically domain-specific modeling languages (DSMLs)—a special type of DSL—have become very important within the field of model-driven development (MDD), also known as model-driven architecture (MDA). Each model is written in a specific language, and the model is transformed into another model written in (in most cases) yet another language. Without the existence of multiple modeling and programming languages, model-driven development would be certainly less relevant. However, multiple languages do exist and, judging by the number of (programming) language debates on the Internet, many people are very happy with that. They are glad that they can use their favorite language because, in their opinion, the other languages are all so very worthless.
Another driving force behind the increase in the number of languages used in software development is the recognition of various categories of software systems. Each category of software systems, or architecture type, defines its own set of languages. For example, Service Oriented Architecture (SOA) has brought a large number of languages into being:
• Semantic Web Services Language (SWSL)
• Web Services Business Process Execution Language (WS-BPEL)
• Web Services Choreography Description Language (WS-CDL)
• Web Services Description Language (WSDL)
• Web Services Flow Language (WSFL, from IBM)
• Web Services Modeling Language (WSML, from ESSI WSMO group)
The coming years will bring more and more languages describing software into this world. Without a doubt, there will be developments similar to the ones we have witnessed in the creation of programming languages. Some languages will be defined and owned by private companies, never to be used outside that company. Some languages will be defined by standardization committees (e.g., OMG, CCITT, DOD, ISO); others will be created by private companies and standardized later on. Some languages will become popular, and some will find an early death in oblivion. But the one thing we can be certain of is that information technology (IT) professionals will be spending their time and efforts on creating languages and the tooling to support their use.
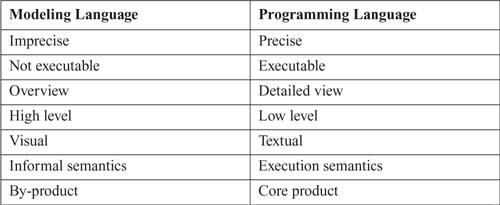
What is the type of the languages that are we talking about? For instance, the acts of modeling software and programming are traditionally viewed to be different. Likewise, the characteristics of the languages used for either modeling or programming are perceived to be different, as shown in Table 1-1. However, the similarities between modeling and programming languages are larger than the differences. In essence, both describe software, and ultimately—after transformation and/or compilation—both need to be executable. Differences between modeling and programming that traditionally seemed very important are becoming less and less distinctive. Models are becoming precise and executable—see, for instance, Executable UML [Mellor and Balcer 2002]—and graphical; high-level syntaxes for programming languages are becoming popular—see, for example, the UML profile for Java [OMG-Java Profile 2004]. Furthermore, model-driven development has taught us that models must not be regarded as rather inconsequential artifacts of software development but instead as the core products.
Table 1-1. Perceived Differences between Modeling and Programming Languages
In the remainder of this book, I use the term software language to indicate any language that is created to describe and create software systems. Note that many different languages target software development: programming and modeling languages, as well as query, data-definition, and process languages. In fact, all the languages mentioned in Section 1.1 are software languages.
But how should the product written in a software language be named? Should it be called model, program, query, or data definition or any other word that is currently in use for an artifact created with a software language? To avoid any form of bias, I introduce the term mogram (Figure 1-1), which can be a model or a program, a database schema or a query, an XML file, or any other thing written in a software language (see Section 3.1.1).

When you want to create software languages, you need to have a clear picture of their character. Over the past two decades, the nature of software languages has changed in at least two important ways. First, software is increasingly being built using graphical (visual) languages instead of textual ones. Second, more and more languages have multiple syntaxes.
There is an important difference between graphical and textual languages. In the area of sound, a parallel to this difference is clearly expressed in the following quote contrasting the use of spoken word with music.
It is helpful to compare the linear structure of text with the flow of musical sounds. The mouth as the organ of speech has rather limited abilities. It can utter only one sound at a time, and the flow of these sounds can be additionally modulated only in a very restricted manner, e.g., by stress, intonation, etc. On the contrary, a set of musical instruments can produce several sounds synchronously, forming harmonies or several melodies going in parallel. This parallelism can be considered as nonlinear structuring. The human had to be satisfied with the instrument of speech given to him by nature. This is why we use while speaking a linear and rather slow method of acoustic coding of the information we want to communicate to somebody else. [Bolshakov and Gelbukh 2004]
In the same manner, we can distinguish between textual and graphical software languages. An expression in a textual language has a linear structure, whereas an expression in a graphical language has a more complex, parallel, nonlinear structure. Each sentence in a textual language is a series of symbols—or tokens as they are called in the field of parser design—juxtaposed. In graphical languages, symbols, such as a rectangle or an arrow, also are the basic building blocks of a graphical expression. The essential difference between textual and graphical languages is that in graphical languages, the symbols can be connected in more than one way.
To exemplify this, I have recreated a typical nonlinear expression in a linear manner. Figure 1-2(a) shows what a Unified Modeling Language (UML) class diagram would need to look like when being expressed in a linear fashion. The normal, nonlinear way of expressing the same meaning is shown in Figure 1-2(b). The problem with the linear expression is that the same object (Company) needs to appear twice because it cannot be connected to more than one other element at the same time. This means that you need to reconcile the two occurrences of that object, because both occurrences represent the same thing.

Note that many languages have a hybrid textual/graphical syntax. For instance, the notation for attributes and operations in a UML class diagram is a textual syntax embedded in a graphical one.
The traditional theory of computer languages—compiler technology—is focused on textual languages. Therefore, without losing the valuable knowledge gained in this area, we need to explore other paths that lead toward the creation of graphical languages.
Another aspect of current-day software languages is the fact that they often have multiple (concrete) syntaxes. The mere fact that many languages have a separate interchange format (often XML based) means that they have both a normal syntax and an interchange syntax. At the same time, there is a growing need for languages that have both a graphical and a textual syntax, as shown by such tools as TogetherJ, which uses UML as a graphical notation for Java. The UML itself is a good example of multisyntax language. There is the well-known UML diagram notation [OMG-UML Superstructure 2005], which is combined with the Human-readable UML Textual Notation (HUTN) [OMG-HUTN 2004] and the interchange format called XMI [OMG-XMI 2005].
A natural consequence of multiple syntaxes is that (concrete) syntax cannot be the focus of language design. Every language must have a common representation of a language expression independent of the outward appearance in which it is entered by or shown to the language user. The focus of language design should be on this common representation, which we call abstract syntax.
One reason to invest in software language engineering is that over the past decades, the nature of not only software languages but also software development has changed. In fact, it is the nature of the software applications that has changed and with it, software development.
Software applications are becoming more and more complex. As Grady Booch once mentioned in a presentation on UML 1.1, computer scientists today do not create the type of application from the 1960s or 1970s in less time and with less effort. Instead, they create far more complex applications.
The number of languages, frameworks, and so on, that an ordinary programmer nowadays needs to deal with is exceedingly large. For example, in the development of an average Web application based on Java, one needs to have knowledge of the Java language and some of its APIs, XML, XSD, XSLT, JSP, Struts or JSF, Enterprise JavaBeans or Hibernate/Spring, SQL, UML, Web Services, and, lately, Ajax. All these bring with them their own complexity, not to mention the complexity that arises from the combination. The time when printing “Hello, World” on a screen was a simple exercise for novices is long gone. Nowadays, you need to know how the graphical user interface (GUI) library works, because this text needs to be shown in a separate window with fitting fonts and colors. Furthermore, user demands are such that the sentence must be personalized into “Hello Mrs. Kleppe,” for which data must be retrieved from the database. Even better would be to print the text “Goodmorning, Mrs. Kleppe,” for which you have to find out what time of day it is at the user’s site. In short, building software is becoming more and more challenging for all of us, not only for novices.
Unfortunately, all this means that the problem, which was called the software crisis by Bauer in 1968 and Dijkstra in 1972 [Dijkstra 1972], has grown worse: Many software projects take more time and budget than planned. However, this is not because of the fact that there has been no progress in computer science. Rather, there has been so much progress that we are able to take up increasingly complex assignments. This means that time and again, we are facing a new, unknown, and uncertain task, which in its turn leads to an inability to take full control over the development process.
An interesting and worrying consequence of the increasing size and complexity of software applications is that it is no longer possible to know an application inside out. Much expert knowledge from various areas is needed to create an application. In many projects, experts on one topic—say, XML—are creating parts of the application without intimate knowledge of what other experts—for instance, on user interface design—produce. It is no longer humanly possible to know all the things that need to be known about an application.
A common way to tackle the complexity is to revert to using frameworks and patterns. And although in the short term this approach does help, in the long term we need our software languages to be at a higher level of abstraction if we want to be able to keep understanding what it is that we are producing. A higher level of abstraction means that we keep manual control over the parts of the development process in which new problems are tackled (variability), while relying on automation for the simpler parts (standardization). The stuff that we have created time and again and thus know thoroughly can be created automatically by mapping the higher-level mogram to a lower-level target language. This is the essence of model-driven development.
Furthermore, we are faced with an increase of interest in creating domain-specific languages. When these are not well designed, the applications created with these languages will not be of good quality.
The challenge for language engineers is that the software languages that we need to create must be at a higher level of abstraction, a level we are not yet familiar with. They must be well designed, and software developers must be able to intermix the use of multiple languages. Here too, we are facing a new, unknown, and uncertain task.
Luckily, a large amount of existing knowledge is helpful in the creation of software languages. In this book, I draw mainly from three sources: natural-language studies, traditional computer language theories, and graph grammars. And although this field does not have a great influence in this book, I also include a short description of the work from the visual languages community, because it is rather similar to traditional computer language theories but aimed at graphical, or visual, languages.
When someone who is not a computer scientist hears the word language, the first thing that comes to mind is a natural language, such as the person’s mother tongue. Although software languages are artificially created and natural languages are not, we can still learn a lot from the studies of natural languages. (See Background on Natural-Language Studies.) Of course, we cannot use every part of it. For example, software languages do not have a sound structure, so there is no need to study phonology.[1] However, all other fields of study are as relevant to software languages as they are to natural languages. It must be noted that these fields of study are, of course, interrelated. One cannot reasonably study one aspect of a language, such as morphology, without being at least aware of the other aspects, such as syntaxis.
[1] However, it is interesting to know that the graphical language UML has been adapted for use by blind people and that this adaptation does use some form of sound [Petrie et al. 2002].
It is interesting to see that with the advent of mobile phones, the phenomenon of multiple syntaxes is also emerging in natural language. A second morphological and syntactical structuring of natural language expressions has developed; for example, everybody understands the next two phrases as being the same: 4u and for you.
In the late 1950s, the fundamentals of current-day theory for textual software languages were laid down by such people as Chomsky [1965] and Greibach [1965, 1969]. In the 1970s and 1980s, these fundamentals were used by, among others, Aho and Ullman to develop the theory of compiler construction [Hopcroft and Ullman 1979, Aho et al. 1985]. In this research, grammars were used to specify textual languages.
The original motivation for the study of grammars was the description of natural languages. While linguists were studying certain types of grammars, computer scientists began to describe programming languages by using a special notation for grammars: Backus-Naur Form (BNF). This field has brought us a lot of knowledge about compiler technology. For more information, see Background on Grammars (p. 48), Background on Compiler Technology (p. 96), and Background on Backus-Naur Format (p. 116).
Graphs have long been known as mathematical constructs consisting of objects—called nodes or vertices—and links—called edges or arcs—between them. Over the ages, mathematicians have built up a large body of theory about graphs: for instance, algorithms to traverse all nodes, connectivity theorems, isomorphisms between two graphs. All this has been brought to use in graph grammars.
Graphs grammars specify languages, usually graphical (visual) languages, by a set of rules that describe how an existing graph can be changed and added to. Most graph grammars start with an empty graph, and the rules specify how the expressions in your language can be generated. For more information, see Background on Graphs and Trees (p. 50).
Visual-language design is our last background area. Although it started later than textual languages, the advance of visual languages has also been investigated for a few decades now. This area can be roughly divided into two parts: one in which grammars are based on graphs and one that does not use graph grammars.
In this book, I do not use visual language, the term commonly used in this community. Instead, I use graphical language, a phrase I find more appropriate because textual languages are also visual, while at the same time most nontextual languages are denoted by some sort of nodes with edges or connectors between them: in other words, denoted like a graph.
The non-graph-grammar-based research is concerned mostly with scanning and parsing visual-language expressions: in other words, diagrams. Several formalisms for denoting the rules associated with scanning and parsing have been proposed: Relational Grammars [Weitzman and Wittenburg 1993], Constrained Set Grammars [Marriott 1995], and (Extended) Positional Grammars [Costagliola and Polese 2000]. For a more extensive overview, see Marriott and Meyer [1997] or Costagliola et al. [2004].
Virtually all work in this area focuses on the recognition of basic graphical symbols and grouping them into more meaningful elements, although some researchers stress the fact that more attention needs to be paid to language concepts, which in this field is often called semantics. Often, these semantics are added in the form of attributes to the graphical symbols. This is very different from the metamodeling point of view. For instance, although UML is a visual language, its metamodel does not contain the notions of box, line, and arrow.
Common to all formalisms is the use of an alphabet of graphical symbols. These graphical symbols hold information on how to materialize the symbol to our senses, such as rendering info, position, color, and border style. Next to the alphabet, various types of spatial relationships are commonly defined, based on position (left to, above), attaching points (end point of a line touches corner of rhombus), or attaching areas by using the coordinates of the symbol’s bounding box or perimeter (surrounds, overlaps). Both the alphabet and the spatial relationships are used to state the grammar rules that define groupings of graphical symbols.
Although the work in this area does not use graph grammars, the notion of graphs is used. The spatial relationships can be represented in the form of a graph, a so-called spatial-relationship graph [Bardohl et al. 1999], in which the graphical symbols are the nodes, and an edge between two nodes represents a spatial relationship between the two symbols.
The graph-grammar community has also paid attention to visual-language design, most likely because the graph formalism itself is a visual one. In this field, more attention is paid to language concepts. In fact, the graph-grammar handbook states that the graphical symbols needed to materialize the language concepts to the user are attached as attribute values to the graph nodes representing the language concepts, an approach that is certainly different from the non-graph-grammar-based field.
Another distinctive difference is that the non-graph-grammar-based approach uses grammar rules with only one nonterminal on the left-hand side: that is, grammar rules in a context-free format. Graph grammars, on the other hand, may contain rules that have a graph as the left-hand side: that is, grammar rules in a context-sensitive format.
A large number of tools are able to create development environments for visual languages. These include, among others, DiaGen [Minas and Viehstaedt 1995], GenGed [Bardohl 1999], AToM3 [de Lara and Vangheluwe 2002], and VL-Eli [Kastens and Schmidt 2002].
More and more languages are used for building software. Almost always, multiple languages are needed to create one single application. I use the name software language to indicate any of them: a modeling language, a query language, a programming language, or any other kind of language.
The nature of software languages has changed over the years. The most important software languages used to be textual, but currently many software languages have a graphical syntax. Furthermore, many languages today have two or more syntaxes: for instance, both a textual and a graphical, or a normal and an interchange syntax.
Because the applications that we create are becoming more and more complex, the languages that we use must reside at a higher level of abstraction. Otherwise, we will never be able to meet the ever-rising demands and expectations of our customers.
All software languages must be artificially created. Therefore, language specification—both the act and the result of the act—becomes very important. Luckily, this is not a completely new field. We can draw on the knowledge gained in natural-language research, compiler technology, graph theory, and visual languages.