
Everything is vague to a degree you do not realize till you have tried to make it precise.
—Bertrand Russell
British author, mathematician, and philosopher (1872–1970)
Code generation can be regarded as a form of semantics. It specifies how the source language should be interpreted. This chapter, much of it based on work I did with Jos Warmer (Ordina, Netherlands), focuses on the specifics of code generation.
Why should a software language engineer be interested in code generation? Is not creating the language itself a task with enough challenges and complexity without having to consider code generation? These are valid questions, but as explained in Chapters 4 and 9, defining the semantics is part of the language engineer’s job, and providing a code generator is exactly that: providing a semantics.
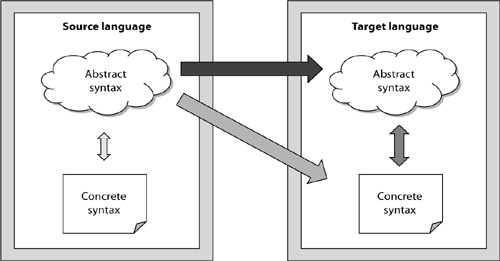
Code generation takes a mogram in one language, the source language, and generates one or more mograms in another language, the target language. Thus, code generation defines a translational form of semantics. Code generation provides semantics to the source language in terms of the target language. The target language is assumed to be known by the audience of the semantics description. Code generation is a specific form of model transformations.
In code generation, the target language is usually at a lower level of abstraction than the source language. The same holds for any compiler. Java, C#, and all the other languages for which compilers exist are translated to assembler or bytecode. Definitely, assembler or bytecode is at a lower level of abstraction than Java, C#, and so on.
A strange twist here is caused by the difference in abstraction between the source and target languages of a compiler. In Section 9.2, I mentioned that any semantics description should be targeted toward a certain audience. Therefore, you could argue that the target audience for a semantics that is provided by means of a compiler consists of people who are familiar with bytecode. However, collectively, we have been putting bytecode under the virtual zero line (see Section 3.2.2). This means that currently, not many computer scientists are able to understand this form of semantics. Instead, most people rely on the explanation of Java given in English: for example, Gosling et al. [2005].
But when you create a code generator, the target language of your code generator will very likely be above the virtual zero line. A large proportion of your audience is very well able to understand the generated code and will be very critical about it. They will prefer their handwritten code over the generated code, unless it works well and the generation saves them a lot of time.
Having both a compiler and a written explanation of what the compiler should do is a case of having two semantics that may conflict with each other. For many people, the compiler provides the ultimate semantics. If the Java program does not work as explained in the English text, the English text is regarded as incorrect. Other people regard the explanation to be leading and therefore regard the compiler as buggy if the program does not execute as expected. The same situation exists when multiple code generators for the same source language are available—for instance, translating a UML model to both Java and C#.
As a language engineer, you will encounter this situation many times. It is part of your job to decide which semantics is leading: in other words, which is the defining semantics and which only explains to other audiences what the first is defining.
By now, you should know that a code generator translates one language to another. What we have not yet addressed is how you go about creating a code generator. This section gives details on a number of issues concerning the creation of a code generator. These issues are interrelated, but are described separately here so you can better understand them.
When making decisions on these issues, keep in mind that the life span of a code generator is usually short. Changes will need to be made regarding the source language, the target language, and the translation itself. Only very flexible code generators will be able to keep up with the high pace of incoming change requests.
A code generator can be described by a model transformation from one abstract form to another (see Section 5.2.2). There is a standard formalism, called QVT (short for Query/View/Transformation [OMG-QVT 2007]), and a number of other formalisms for writing model transformations. Each of these formalisms relies on a generic tool that takes as input a set of model-transformation rules next to the mogram in the source language and produces a mogram in the target language. This generic tool is able to execute a variety of model transformations. Figure 10-1 gives an example of a QVT rule.
Figure 10-1. A rule-based transformation written in QVT
relation ClassToTable /* map each persistent class to a table */ |
On the other hand, when you implement a code generator using another type of language, the transformation is hard coded. The tool you create in this manner can execute only one transformation. A hard-coded tool is obviously less flexible but may also be more efficient, which poses another choice for the language engineer.
Within the hard-coded category, you have a choice between the use of a template language—for example, Velocity, JET, eXpand from openArchitectureWare, Microsoft T4—and a programming language. Figure 10-2 gives an example of the use of a template language, and Figure 10-3 gives an example of the use of a programming language. The choice between these two is closely related to the choices described in the next two sections.
Figure 10-2. A target-driven transformation written in a template language
package <%=jClass.getPackageName()%>; |
Figure 10-3. A target-driven transformation written in a programming language
System.out.println("import java.util.*; "); |
Any code generator must make a match between source and target language concepts. Often, a single source language concept is matched to a number of concepts of the target language. For instance, one UML class can be matched to a number of Java classes that are part of the user interface: one for selecting, one for displaying details, and one for displaying an overview. In this case, the transformation is most efficient when you search for the source language concept in the input mogram, and for each of these you create the complete set of target language elements, more or less according to the following pseudocode (Figure 10-4). We call this a source-driven transformation.
Figure 10-4. A hard-coded, source-driven, abstract target transformation
|
for each class in model.classes do |
In other cases, a single target language concept is matched against many source language concepts. For instance, a Hibernate mapping file references a number of UML classes. In these cases, it is better to structure the transformation in a target-driven style. Both Figures 10-2 and 10-3 give examples of a target-driven transformation. Note that when you use a template language, you are always working in a target-directed style.
When you create a code generator, you must decide on the form of the target: Are you targeting the concrete form or the abstract form? Recall from Section 5.2.2 that there are structure transformations and hybrid syntax transformations. The target of a structure transformation is the abstract form of the target language. The target of a hybrid syntax transformation is one of the concrete forms. Figure 10-4 gives an example of a transformation that creates the abstract form of the target. This transformation creates a new instance of a Java class and fills it with the necessary fields and methods. Figure 10-3 is an example of a transformation targeting the concrete form. This transformation produces a set of strings.
The advantage of targeting the abstract form is that the abstract form of a mogram will remain available in memory for further processing. You can apply another transformation to it, thus building a larger transformation from (a series of) smaller ones. This means that your transformation need not simultaneously do everything that is needed. Instead, you will be able to rearrange the target during or directly after the transformation.
For instance, when you transform a UML class model to Java, you need not create all fields in a Java class at once. You may create the class and add the fields that correspond to the attributes later. In yet another phase, you can introduce fields for outgoing associations, after which you reorder the fields according to the alphabet or to the lengths of their names. You can even remove a field that you have earlier created, thus fine-tuning an initial coarse transformation. I have found the latter option very useful when implementing OCL-derived attributes in our Octopus tool [Octopus 2008]. (A derived attribute is one whose value completely depends on other values. A derivation rule is given to specify how to calculate the value.) The transformation that handles derived attributes removes the corresponding field and adds a getter method that executes the derivation rule.
All this is not possible—or only with considerable effort—when you target the concrete form, even when it is not printed directly but kept in memory as a string. For instance, ordering the fields in the textual string that represents a Java class is much harder than ordering a list of Field objects that are part of a JavaClass object. A consequence of targeting the abstract form is that you will also need an abstract-to-concrete-form transformation (model-to-text) for the target language, as illustrated in Figure 10-5. In most cases, however, this transformation is already available or is very easy to create.
The advantage of targeting the concrete form is that you do not need the abstract syntax model of your target language. A concrete syntax description suffices. Obviously, because the concrete syntax description of a graphical language is so much like the abstract syntax model, targeting the concrete form is much more interesting when your target language is textual.
An interesting mix of both advantages is to use a simplified abstract syntax model of the target language. For instance, you could use a Java abstract syntax model that includes packages, classes, fields, and methods but does not model expressions completely. A Java expression could be represented by a string. Thus, method bodies and field initial values are strings. This means that you can add or change methods and fields to classes and classes to packages in any stage of the transformation, but you cannot alter a method body or field initial value once it has been created.
However, take care that the concrete parts do not contain any reference to things that might be changed later on. For instance, the first of the following two Java fragments is more robust than the second. The underlined parts are represented as instances of abstract syntax classes, the italics are the parts introduced by the abstract-to-concrete-form transformation, and the other parts are created as string representations during the transformation. Moving class SomeType to another package would break the second example but not the first one.
/* example 1 */
package mypackage1
import mypackage2/SomeType;
....
methodA ( ... ) {
SomeType var = ....;
...
}
/* example 2 */
package mypackage1
....
methodA ( ... ) {
mypackage2/SomeType var = ....;
...
}
I have never seen this approach anywhere else, but something worth mentioning is the experiments that we did during the development of the Octopus tool for UML/OCL [Octopus 2008]. Octopus is capable of generating a Java application from a UML/OCL model. This code generator is hard coded in Java, for the most part is source driven, and is always targeted toward the abstract form.
From the preceding, you will have learned that it is not possible to target the abstract form of a mogram using a standard template language. Therefore, we have developed a template language especially for this purpose. This language is called Octel, and you can find it on SourceForge together with the Octopus tool.
Octel works like a preprocessor. You create a template of what you want the code generator to produce. Next, Octel reads this template and produces the code that implements this code generator. Don’t be confused: Code created by Octel does not produce the target mogram but instead produces the code that is able to generate the target mogram. Figure 10-6 shows an example of a template, and Figure 10-7 shows the code produced by Octel that is part of the code generator.
Figure 10-6. An example of the use of Octel
<field type="%ATT.getType()%" name="%ATT.getName()%" visibility="private"/> |
Figure 10-7. Implementation of the code generator produced by Octel
|
JavaField field1 = new JavaField(); |
As yet, not many generic ways of building a code generator have been recognized. Generic ways are patterns that you would see over and over again in many code generators. Here are few of the patterns that do exist and have proved their value.
In an abstract syntax form of a mogram, you can always recognize a containment tree: a tree of objects connected by containment (composite) relationships. This tree is very useful. Most code generators use treewalkers that go over the containment tree to visit the objects in the abstract form of a mogram. In this context, the objects are also called nodes. The Visitor pattern is another name for this pattern. The essence of the pattern is that the manner and order in which the nodes are traversed is separated from the code that does something with the nodes.
Traversals can be implemented in a number of ways. The traversal algorithm can be implemented either as part of the abstract syntax classes or separately. The latter is called a noninvasive algorithm. In fact, because code generators usually need more than one way to traverse a containment tree, noninvasive algorithms are to be preferred. If each of these traversal algorithms is implemented in the way the Visitor pattern is described in Gamma et al. [1995], all abstract syntax classes would need one accept method per different traversal. For instance, in the simple case of having only a depth-first and a breadth-first traversal, each abstract syntax class would need to implement the following two methods (written in Java):
public void accept(IDepthFirstVisitor vis) { ... }
public void accept(IBreadthFirstVisitor vis) { ... }
It is much more convenient to have a number of separate classes that take as input both the tree to visit and the visitor. In general, we call such classes walkers, or treewalkers. The following code gives an example:
public class DepthFirstWalker {
public void travers(ITopOfTree tree, IVisitor vis) { ... }
}
One thing the language engineer has to decide is how many times to traverse the tree. An advantage of many traversals is that you can separate various aspects of the transformation. For instance, in one traversal, you create Java fields; in the next, you create the methods. This makes your generator more flexible and easier to change. You could take out a complete phase and replace it with something else. A disadvantage of many traversals is, of course, that they take time. When the source language mograms are expected to be very large, you should seek to combine aspects of the transformation and have fewer traversals. Another show of your excellent trade-off skills as language engineer is required.
Another pattern that often occurs in code generators is CreateOrFind. The background for this pattern is that most code generators have different phases, and during each you might have to search for an element in the target mogram. Upfront, you do not know whether the element has already been created, so if it is not found, the pattern creates the element.
A prerequisite for this pattern is that the elements must be identifiable. For instance, in Java, two fields may have the same name as long as they are in a different class. This means that the search algorithm needs to take into account the name of the class that holds the field and probably also the package in which the class resides. Identifiable does not necessarily mean that all elements need to have a name or identifying number. You can also identify an element based on the fact that it is, for instance, the first or last in a sequence.
When the element needs to be created, it is created based on the identification. This means that, for instance, when the search is based on the name of a Java field together with the name of the class, the field is created, given the right name, and linked to the right class, which also has to be created or found, but no info on the type and initial value are available. Either your generator needs to be able to deal with incomplete elements or you have to complete the element right after the create or find action.
A consequence of building several phases in your code generator is that often one phase needs information on what another phase has generated. Let’s again look at the example of generating a Java application from a UML model. Suppose that you have decided that a UML attribute is translated into the combination of a Java field and a pair of setter and getter methods. Suppose also that your generator is producing a user interface that enables viewing and changing the value of each attribute. Furthermore, the generation of the field and methods, and the generation of the user interface are implemented in separate phases. How does the user interface generation know how to get and set the value of the attribute; in other words, which are the setter and the getter for this attribute?
You could address this question by using standard names for the getter and setter methods, but your code generator will be much more flexible when the user interface generation can simply ask for the names. In that way, you could change the creation of the getter and setter methods, and the user interface generation would still be working fine.
In my experience with building the code generation for the Octopus tool, I have found that a lot of information needs to be available to other phases of the code generation. It is best to dedicate a number of separate objects to this job. We decided to have one dedicated object per source language construct. We call these objects mappers. Thus, we have an AttributeMapper, a ClassMapper, an AssociationEndMapper, and so on. When a mapper instance is created, it takes a source mogram element as parameter and is able to tell you how this source element is mapped to one or more Java elements. The following code is part of the mapper for attributes:
public String fieldname(){
return "f_" + StringHelpers.firstCharToLower(feature.getName());
}
public String getter() {
String name = feature.getName();
if (name.indexOf("is") == 0) {
// usually an attribute of boolean type like 'isBoldFace'
return name; // getter name becomes 'isBoldFace'
}
return "get" + StringHelpers.firstCharToUpper(name);
}
public String setter() {
String name = feature.getName();
if (name.indexOf("is") == 0) {
// usually an attribute of boolean type like 'isBoldFace'
name = name.substring(2, name.length());
// setter name becomes 'boldFace'
}
return "set" + StringHelpers.firstCharToUpper(name);
}
public String adder(){
return "addTo" + StringHelpers.firstCharToUpper(feature.getName());
}
public String remover(){
return "removeFrom" + StringHelpers.firstCharToUpper(feature.getName());
}
Unfortunately, in many cases, we are not yet able to generate a complete application from a high-level mogram. Current-day code generators are not yet as strong as old-fashioned compilers. Of course, the truth of this statement depends very much on the source and target languages of your code generator. In some cases, you will be able to generate 100 percent; in other cases, you will be able to generate only 80 percent. Because the latter case is too common, I am addressing the issue of creating points in the generated code whereby a human programmer can add the nongenerated parts. However, do try to get this percentage up. Only 100 percent generation will be acceptable in the long run.
One thing to remember is that you must never allow your language users to change generated code. When generated code is changed by hand, it becomes more important than the mogram from which it was generated. The changed code contains handwritten parts that obviously were important enough to include. They must not be lost, and they will be lost as soon as the code is regenerated. Therefore, regeneration is first postponed and finally never done at all. Ergo, the generated and changed code has become the focus of development instead of the mogram that was input to the original generation. In this case, the software development process is similar to one in which you take a copy of an existing application (the first generated code) and hand build the application from that. None of the advantages of model-driven development will be realized.
What you may allow your users to do is extend or override the generated code. To realize this, you can use techniques that are also used in frameworks. After all, frameworks also combine basic, unchangeable code with user-created code. The following list gives some examples of the techniques that you may use.
• Notifications. You may allow user code to subscribe to notification of events in the generated code. The user code is then able to extend the generated code.
• Plug-in code. You may allow your users to create instances of generated interfaces that can be linked to parts of the generated code. For instance, the user code may extend the generated code when saved or when opened. The interface provides the fixed points at which the user can introduce handwritten code.
• Partial classes in C#. When your target language is C# or any other language that will in the future support partial classes, you may allow your user to create a partial class. This handwritten partial class can extend or override the generated partial class.
• Empty subclasses. When your target language supports inheritance, you can generate an empty subclass and allow your user to add handwritten code to it. Again, extension and overriding are possible. Take care that the generated code always creates instances of the subclass and never of the superclass, which would obfuscate the user’s additions.
• Guarded blocks. Some tools allow you to generate guarded blocks, which are uneditable by the language user. Put everything you generate in guarded blocks, and let the user extend or change the code outside them.
Note that all possible extensions must be documented for your language users. For example, you might generate ToDo comments that are picked up by the IDE using highlighting or lists.
A number of other issues at first glance do not have much to do with code generation. But when you look more closely, it makes sense to think about them before you build a code generator.
Bidirectionality is an aspect of model transformations in general. Bidirectional model transformations can be executed in two ways: (1) to produce a target language mogram from a source language mogram, and (2) to produce a source language mogram from a target language mogram. Bidirectional transformations in general are capable of maintaining the link between source language mogram and target language mogram such that whenever one changes, the other changes accordingly.
Maintaining a permanent link between source language mogram and target language mogram in a code generator is very complex. Considering its short lifespan, this investment is often not worthwhile.
Taking one step back by offering bidirectionality in the form of round-trip engineering is already a more practical approach. In round-trip engineering, the source can be created from the target and the other way around, but no permanent links are kept. The problem with round-trip engineering is that in most cases, a source mogram is not transformed to simply one target mogram but to a set of target mograms. For instance, one UML class is transformed into (parts of) the following elements:
• C# business class
• DTO class
• Hibernate mapping file
• Database create script
• DTO to C# business class methods
• Edit screen for the business class
• Search and list screen for the business class
When one of these elements changes, it is often very difficult to decide what this change means for the source mogram and, more important, for the other elements in the list. Thus, when you can figure out how to adjust the source mogram, you have to regenerate all the other elements. Only when there is a one-to-one relationship between source and target mogram is round-tripping usable. In this case, it is very important to mark either source or target mogram as leading. Whatever changes are made in the other should be of minor importance. Major changes should always be made in the leading mogram.
In my opinion, it is usually best to forget about round-trip engineering and implement a unidirectional transformation from source to target language(s). Try to aim for as much generation as possible and to provide extension points to the user of your tool. When you do this, the need for round-trip engineering will be reduced to zero, and a much simpler code-generation tool will suffice.
Still, a simple form of bidirectionality can be useful: traceability. When the generated code is executed, all reporting on errors and warnings to the language user should be done in source language terminology. After all, the language user is a user of the source language and knows its terminology best. This means that for every element in the target mogram, the tool must know from which source mogram element(s) it originated.
Code generation becomes simpler in the same degree that the target platform becomes more complex, or at least more similar to the source language. Recall from Section 5.2.1 that a platform is the language specification combined with predefined types and instances and patterns. Some platforms include a high-level framework, consisting of predefined types and instances, that implements some of the more complex constructs that are needed in the generated application. In this case, less code needs to generated. You might say that this is a huge advantage, but there are also disadvantages to the use of frameworks, especially ones that are made specifically for the purpose of code generation.
Frameworks add more complex structures to an existing language, as explained in Section 3.3.5. This means that they are more difficult to understand than the original language. So when a code generator is targeted toward a framework, it is more difficult to understand the workings of the generated code. You must also understand what the frameworks does. An example is the EMF (Eclipse Modeling Framework), which generates toward a framework that was newly created for the purpose of implementing UML class diagrams in Java. The framework implements, for instance, the coordination between the ends of an association. With version 1.0, no one had previous knowledge of the work, yet to understand EMF’s view on associations, you needed to understand the workings of the framework. Thus, a steep learning curve was introduced.
You can say that there is a trade-off between the complexity of the code generator itself and the target platform. When the target platform is less complex, the generated code will be easier to understand. This might be exactly what you want, because it could cause a much higher acceptance rate of your code generator. On the other hand, the code generator is much easier to build when the target platform is more complex. This might result in a code generator with fewer bugs. Again, it is the job of the language engineer to find the middle ground that is most acceptable to all people involved.
A huge difference between using a framework together with code from a generator and using a framework with handwritten code is that there is a different purpose for using the framework. If the extra code needs to be handwritten, as much as possible must be put in the framework to minimize the handwritten code. Repetitions of handwritten code parts that are very similar must be avoided. Therefore, the framework will make extensive use of abstraction. On the other hand, when the code to go together with the framework is generated, repetition of similar code parts is not a problem.
Take, for instance, the following code, which contains two almost identical statements (the differences are in boldface type). When this code is generated, the repetition is absolutely no problem, but when you have to handwrite it, it becomes a bore.
/* The generation option */
public List<InvariantError> checkMultiplicities() {
List<InvariantError> result = new ArrayList<InvariantError>();
if ( getName() == null ) {
String message = "Mandatory feature 'name' in object '";
message = message + this.getIdString();
message = message + "' of type '" + this.getClass().getName()
+ "' has no value.";
result.add(new InvariantError(this, message));
}
if ( getReturnType() == null ) {
String message = "Mandatory feature 'returnType' in object '";
message = message + this.getIdString();
message = message + "' of type '" + this.getClass().getName()
+ "' has no value.";
result.add(new InvariantError(this, message));
}
return result;
}
When everything is handwritten, you would much rather write the following code for the checkMultiplicities method and have a framework implement the abstractTest method.
/* The framework option */
public List<InvariantError> checkMultiplicities() {
List<InvariantError> result = new ArrayList<InvariantError>();
abstractTest(result, getName(), "name");
abstractTest(result, getReturnType(), "returnType");
return result;
}
public void abstractTest(List<InvariantError> result, Object in,
String name) {
if ( in == null ) {
String message = "Mandatory feature '" + name + "' in object '";
message = message + this.getIdString();
message = message + "' of type '" + this.getClass().getName()
+ "' has no value.";
result.add(new InvariantError(this, message));
}
}
The first example is easier to understand and keeps all related code together. In the second example, less code needs to be generated. Again, your judgment has to provide the answer: Do you generate the code that is easier to understand but repetitive, or do you invest in creating a framework in order to generate less, but more obscure, code?
A code generator is a piece of software and therefore should be built in a modular fashion, especially because real code generators can become large. Of course, how you divide your code generator into modules is up to you. If you have to generate multiple targets, one possibility is to make a separate module for every target language. Another possibility is to use the following, very coarse division: First do some in-model transformations on the source mogram, then do a model-to-model transformation from source to target mogram, and then perform an in-model transformation on the target mogram. The last step could, for instance, be an optimalization step. Modules can be combined by using a programming language or a makefile or Ant file.
Modularization is an important argument for targeting the abstract syntax. The code in Figure 10-8 works only because the output is an abstract form of the mogram and can be adjusted by every module.
Figure 10-8. An example of modularization of a code generator
// step 1: create the skeleton java model |
In all software development, there is a certain amount of friction between confection software—commercial off the shelf (COTS)—and tailor-made software. Although a choice for COTS does in general reduce overall costs and development time compared to tailor-made software, often it does not always completely meet the demands. Modifications are necessary, and the software needs to be integrated with other installed software. In other words, maximizing flexibility (tailor-made) costs, but the rigidity of COTS makes it difficult to work with.
When language users first get acquainted with code generation, the same friction arises. People are glad that so much is generated, because it saves them time and money, but the code generated is almost never exactly want they would have produced by hand. Therefore, the language engineer must create code generators with built-in flexibility options: in other words, code generators that are configurable.
There are many ways in which you can make your code generator configurable. For example, you can work with parameters and defaults that can be overwritten by the users. But here I want to draw your attention to the flexibility that modularization of the code generator can bring to the language user.
When you have divided your code generator into a number of modules that each add to the same structure, the same abstract form of the generated mogram, you have created a built-in flexibility to be opened up to your language users directly. For instance, when you have a separate module for generating attributes, you can offer your users the possibility not to include generation of attributes, or maybe you could provide two ways of generating attributes and let your users choose between them.
Code generation takes a mogram in the source language and generates one or more mograms in the target language; thus, code generation defines a translational form of semantics. Code generation provides semantics to the source language in terms of the target language. In most cases, the source language is a newly defined software language, whereas the target language is a well-known programming language.
Code generation can be characterized through three dimensions: (1) rule-based versus hard-coded, (2) source driven versus target driven, and (3) target in abstract form versus target in concrete form. Current-day template languages allow only hard-coded, target-driven, concrete-form target code generation. The Octel template language allows hard-coded, source or target driven, abstract form target generators.
In many code generators, the following patterns occur:
• Treewalkers, which defines how the abstract form of the input can be traversed
• Create or Find, which takes care of creating target elements when they are not yet present
• Mappers, which takes care of distributing information of parts of the generation to other parts
Extension points offer the language user possibilities for adding handwritten code to the generated code. Other questions need to be answered when you create a code generator.
• How much bidirectionality do you implement?
• Do you create a framework in the target language and generate the code that uses the framework, or do you generate all the code?
• How do you modularize the code generation?
• What flexibility can you offer the language user?