
Language is the most important of all the instruments of civilization.
—Charles Kay Ogden (1889–1957) and Ivor Armstrong Richards (1893–1979), British philosophers and linguists
In this chapter, you will learn what a language and a linguistic utterance are. The chapter explains that a DSL must be treated the same as any other software language and what the abstraction level of a language is.
When you want to become a language engineer, you need to answer one fundamental question: What is a language? Luckily for us, formal language theory uses an excellent, simple definition of what a language is. (See, for instance, Hopcroft and Ullman 1979.) I adhere to this definition, although stated a little differently (Figure 3-1).
Obviously, this definition does not make sense until I define the concept of linguistic utterance. This term stems from natural-language research, where it represents any expression in a certain language—for instance a word, a sentence, or a conversation—[Fromkin et al. 2002, Tserdanelis and Wong 2004]. It is also a more formal term for mogram, as explained in the next section.
The concept of linguistic utterance exists in not only natural language but also computer science. This concept is often called expression, statement, or sentence. All these rather confusing terms, however, are understood differently by different people. The word expression is confusing because of the mathematical interpretation of this word, which, according to Wikipedia, is “a combination of numbers, operators, grouping symbols (such as brackets and parentheses) and/or free variables and bound variables arranged in a meaningful way which can be evaluated.” Thus, the term expression seems to exclude the nonexecutable aspects of a software system, such as the ones specified in class diagrams, XML schemas, or database schemas.
The word statement is confusing because it has so many meanings. In linguistics, for instance, a statement is a sentence that is intended to assert something. In programming, a statement is an instruction to execute something that will not return a value. In mathematical logic, a statement is a proposition.
The word sentence in most cases indicates a sequence of words or tokens. In this book, we consider not only textual languages, whose elements might be considered sentences, but also graphical languages, whose elements cannot be characterized as sequences.
Last but not least, we should consider the use of the words model and program. In Section 1.2, I mentioned the useless debate going on about the difference between a model and a program. Because of this debate, these two words are not good candidates either. Certainly, we cannot use words with more specific meaning, such as query or diagram, because we want to include in this study all types of software languages. In this book, I therefore refrain from using any of the preceding words.
The best alternative would be to use the term linguistic utterance (LU), but both are unpleasant to the ears and eyes, and LU is a bit too similar to the word loo. So I use linguistic utterance only in definitions and other texts where I want to be formal and use mogram in other cases. A mogram can be either a model or a program, a database schema, or an XML file, a business-process model or a solid CAD model, something written in a domain-specific language or in a general-purpose language. Any artifact of software development can be considered a mogram, as long as it is a valid linguistic utterance by the standards of its language. If you do not like the word, you can always use it as a template and substitute whatever phrase you prefer.
The rules that specify whether a mogram is part of a language are written down in the language specification. Chapter 4 provides more information on the language specification. The remainder of this chapter looks at some characteristics of languages.
Often, a language provides a number of predefined elements, or primitives, that cannot be changed by the user. For instance, the Java primitive types int and boolean are provided and can be used but not changed by a programmer; nor can the programmer add other primitive types.
Note that primitive elements are more than syntax (keywords). These primitive elements are linguistic utterances of that language, as are the elements defined by the language user. For instance, the Java int type can be used in the same way as a type that has been defined by the user as a Java class. This is different from the keyword class, which in itself is not an element that can be used. The keyword is merely an indication of how to interpret the text that follows.
The abstract syntax specification of the language must always contain the construct of which the predefined element is an instance. The following definition states this more formally.
Definition 3-2 (Primitive Linguistic Utterance) A primitive linguistic utterance of a language L is a linguistic utterance that is provided together with the definition of language L and that cannot be created by a language user.
A synonym for primative linguistic utterances is primitive language element. Note that primitive linguistic utterances themselves may be either types or instances, such as class Object in Java or Smalltalk’s true and false instances.
Most software languages come packed with one or more libraries of predefined elements. In fact, languages that provide extensive libraries appear to be more successful than ones that do not provide a large number of predefined constructs. I define a library to be a set of linguistic utterances of language L, some of which may be primitive linguistic utterances. A library containing only primitive linguistic utterances is called a primitive library. A library containing all predefined linguistic utterances is usually called a standard library. An example of a standard library is given in Sections 6.4.4 and 6.5.
Languages are at various levels of abstraction. In general, UML is considered to be more abstract than a programming language. But what exactly does this mean? The word abstraction comes from Latin, meaning to withdraw or remove something (ab means away from, trahere or tractum means to draw, and -ion indicates an action, process, or state). Often, people say that abstraction means leaving out details, but this is not correct. Abstraction is leaving out some details while retaining others. For instance, FIFA[1] specifies a ball as an air-filled sphere with a circumference of 68–70 cm (or 27–28 in.), a weight 410–450 gr (or 14–16 oz.), an inflated pressure of 8–12 psi, and a leather cover (see www.fifa.com—search for the pdf file called laws of the game; law 2 states the specifications). Abstracting this concept to a round leather ball means that you are no longer interested in information on circumference, weight, pressure, or what substance is used to inflate the thing, but you remain interested in the material and the fact that the ball is round. The key question with abstraction is what type of details are kept and what type of details are trashed.
[1] Federation Internationale de Football Association, of which the U.S. Soccer Federation is a member.
So what details are no longer in a mogram of a higher-level language compared to a mogram written in a language at a lower level of abstraction? In other words, what remains of interest for software languages at a higher level of abstraction, and what is not? To formulate an answer to this question, we need to realize that ultimately all software runs on a combination of memory and central processing unit, (CPU) power, a combination known as hardware. All software is executed by CPU instructions that act on binary numbers. However, specifying a mogram in terms of CPU instructions and binary numbers is cumbersome. Most computer scientists feel the need to abstract away from the hardware level. For software languages, a higher level of abstraction means that we include fewer details about the exact way a mogram is executed on the hardware. Abstraction with regard to software languages can therefore be defined as follows.
Definition 3-3 (Abstraction Level) The abstraction level of a concept present in a software language is the amount of detail required to either represent (for data) or execute (for processes) this concept in terms of computer hardware.
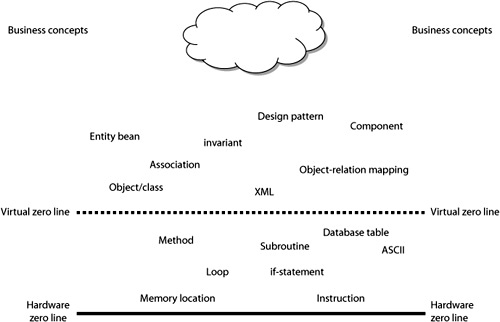
Loosely speaking, abstraction level is the distance between a concept and the computer hardware. The more effort you need to represent the concept in terms of hardware, the more abstract it is. For instance, the concept memory location is very close to the computer hardware and therefore at a very low level of abstraction. Object, as used in object-oriented programming languages, is at a much higher level of abstraction. Yet the concept is much closer to the computer hardware than a business concept, such as client or phone bill. In Figure 3-2, some typical IT concepts have been mapped relative to their abstraction level. As you can see, there is still a gap between the known IT concepts and business concepts.

As a property of a language, expressiveness has a close connection to the abstraction level. The term represents how easily a language user can express complicated things; with regard to software languages, complicated means difficult to realize in terms of computer hardware and thus at a higher level of abstraction.
Now that it is clear that the key issue to abstraction is which type of details to omit, we can shed some light on a common misconception. Many people think that when you include less detail in your mogram, it is by definition on a higher level of abstraction. But abstraction is not about leaving out every detail; it is about leaving out only the irrelevant bits (irrelevant from a certain point of view). Leaving out random details results only in vague and incomplete models and is, in my view, just plain stupid.
For instance, in the financial domain, the concept of payment instruction is an order to a bank to take some money from one account and put it into another. For every payment instruction, the amount needs to be known—including the two digits after the dot—as well as the currency, the bank account to credit the amount to, and the bank account to debit the amount from. Leaving out any of these elements in a payment-instruction mogram would result in an incomplete mogram, not in a more abstract one.
When creating a software language dedicated to payment instructions, the language engineer abstracts away only from how the payment instructions are stored/executed on a computer. The details about database tables and how the entries in these tables are stored in bits and bytes are considered irrelevant to the language user. But for the language engineer, these details are important. The language engineer is responsible for translating the mograms created by the user into executable software and thus needs to know these details. This knowledge is used to build a standard way of bridging abstraction levels.
There is no definite upper limit to the notion of abstraction level, although business or user concepts are usually considered to be at the high end of the scale. On the other hand, the hardware imposes a clear zero line. Over time, there has been a continued struggle from the zero line toward the realm of business concepts. Evidence of this battle goes back to 1959, when the famous programming language COBOL (COmmon Business-Oriented Language) appeared. Even then, computer scientists were reaching for the upper side of the abstraction scale.
Furthermore, the average software developer has forgotten the original zero line. Relying fully on their compilers, debuggers, and such, programmers have more or less stopped thinking about the concepts to which their programs are translated. Who cares about memory locations when using C#? Collectively, we have been raising the zero line because we have tools that can reliably generate all concepts below this line.
The dotted line in Figure 3-3 shows roughly where the thinking of most software developers resides today. Since object-relational mappers, such as Hibernate, are in use, database tables are no longer of interest, but we still need to write our objects, use our design patterns, and deal with the import/export of XML files. Unfortunately, when dealing with performance issues, we are not yet capable of completely abstracting away from the underlying level, which only shows how arbitrary the position of the virtual zero line is.
We should be aware that this new zero line is indeed a virtual one and that it is moving upward all the time. In my opinion, a breakthrough tool, method, or language is such a breakthrough simply because it raises this virtual line.
What might prove to be the biggest challenge in the coming years is that while IT people are trying to reach for the level of business concepts, business is raising its expectations. I have no hard data to back this up, but it appears that the gap between business and IT is growing (Figure 3-4). While humble computer scientists are struggling to support work-flow and business processes, business demands that we create systems that can autonomously interact with their environment and with each other. Examples of these systems are robots that can identify and dismantle explosive devices, be it terrorists’ bombs or land mines. Another example can be found in electrical networks, in which so-called agents negotiate price and quantity. The agents serve individual customers that deploy solar or wind generators, buying and selling electricity to the network operator on the basis of demand by the customer and the total network.
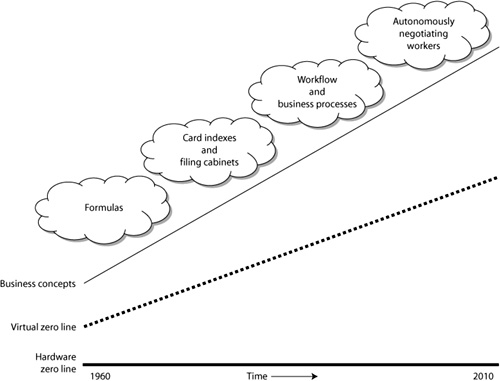
Despite the fact that previous projects have not delivered all that was asked for, business clients return to the software builders and require even smarter software than before. I cannot see any rational reason for this; I simple notice that this is the case. So, software engineer, beware. You will very likely be unable to fully satisfy your next customer.
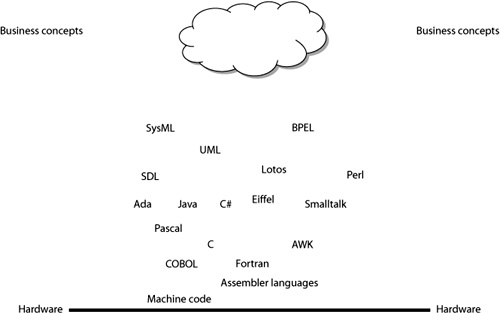
Because it contains a multitude of concepts, a language does not occupy a single point on the abstraction scale but rather is always characterized by a range. We can consider a language to be at a certain level of abstraction when most of its concepts are at that level of abstraction. Figure 3-5 shows some software languages on the abstraction-level scale.
Frederick Brooks argues in his book The Mythical Man Month [Brooks 1995] that a software developer’s productivity is constant in terms of the number of statements produced per time unit. He states: “Programming productivity may be increased by a much as five times when a suitable high-level language is used” (p. 94). In other words, the use of a high-level language could bring us increased productivity: one of the benefits that our field has long sought and one that was recently claimed by model-driven development. Future language developments should therefore be aimed at a high level of abstraction.
Recently, the subject of domain-specific languages has received much attention. This section explains why we must treat a DSL like any other software language.
DSLs are special because of their focus on a certain domain. Unfortunately, a truly satisfactory definition of domain remains elusive. Most authors and presenters use examples to explain what a domain is, such as insurance or telecom, but do not define the term. The line between domain-specific and general-purpose (or domain-independent?!) appears to be very vague.
For instance, some arguments state that graphical user interface design is a separate domain, because only user interfaces contain buttons and windows. On the other hand, a graphical user interface is part of almost every software system, in the form of either traditional windows and subwindows or Web pages and frames.
It is difficult to find well-known examples of DSLs. Because a DSL targets a specific area of use, its success does not easily cross over to other areas, and thus it remains relatively unknown. A good example of what can be called a domain-specific language is the RISLA textual language [van den Brand et al. 1996], which is used to describe interest-rate products.
Some people argue that DSLs are languages in which the domain experts themselves can develop mograms, without the help of computer science specialists. But this way of thinking has disapointed us on other occasions. When Fortran (short for Formula Translating System) came into being in 1957, some people thought that (assembler) programmers would become obsolete because the formulas could be written by mathematicians, who at that time were the domain experts. History proved them wrong. Very likely, the same will happen to current-day claims of domain experts writing their own programs.
Other people even take an extra step by stating that domain-specific languages can be developed by the domain experts themselves. Surprisingly, something of the kind is indeed happening. Many companies in many domains depend on computer systems. A growing trend is that these companies decide to join forces to develop an interchange format. For instance, the Dutch government supported the creation of an interchange standard for geographical data [NEN 2005] in order to ease the interchange among city councils, engineering firms, and other government offices. Likewise, the German automobile industry launched AUTOSAR (www.autosar.org) to standardize a data exchange format. (Interestingly, the people doing the modeling in AUTOSAR are computer experts, not domain experts.) What is happening is that industries in various domains agree on a common vocabulary, defining their jargon. I do not yet call this a language; it is more like a library or a framework, but it is certainly a starting point for developing a language.
Another way to characterize DSLs is to claim that they are languages with a small, dedicated user group: the experts in a certain domain. However, the efforts to produce a new language justify the wish that the language be used by a large audience. Tool development for domain-specific languages is at least as complex as for general-purpose languages. When the potential number of users of these tools is small, one has to weigh the advances of using a DSL against the effort of creating that DSL. One might say that for economic reasons, it is a bad thing to have DSLs.
On the other hand, there will always be a demand for languages that will be used for a relatively small period of time by a small group of people. For instance, in large, long-running projects, small (scripting) languages are often built to automate specific, recurring tasks in that project. But even in this case, the effort of defining a new language must be less than that of executing the automated tasks by hand. If generation of the language user tools is possible, the scales will more often favor the creation of a new language.
Recalling the examples of industry putting effort into creating an interchange format, it is easy to see that characterizing DSLs by the size of the user group gives us an unclear criterion. If (hypothetically) all parties involved with geographical data used a DSL, a large user group certainly exists, yet the language is very specific to the domain of geographical data.
Perhaps because the term domain is not clearly defined, people have been making distinctions between types of domains: broad versus in-house, technically oriented versus business-oriented, horizontal versus vertical. Broad, technically oriented, and horizontal mean more or less the same thing, which is that the DSL can be applied to a large group of applications that share the same technical characteristic, for instance “any Web application.” Characterizing a DSL as in-house, business oriented, or vertical usually indicates that the concepts in the DSL are not computer science concepts but instead come from the business in which computer science is applied. For instance, the concepts of Web page and database table come from computer science, whereas downcoming tray, hifi tray, and manhole are concepts used in oil distilleries, an industry in which computer science is applied [van Leeuwen and Kleppe 2005].
In large part, I agree with MetaCase CTO Steven Kelly, who thinks that the greatest productivity increases come from in-house DSLs: “because the language can be made to precisely fit the needs of just one company. More importantly, the company is in control of the language and generators, so they can evolve as the problem domain evolves” (from www.ddj.com/dept/architect/199500627). On the other hand, this means that every company must try to create a language and user tools. In many cases, closing the gap between business concepts and computer languages that are suitable to translate the business concepts to, requires too large an effort.
Far more likely, we will see an increase of technically oriented DSLs, each tailored toward a certain application architecture. Each of these DSLs will raise the level of abstraction at which applications are being developed. This in its turn will diminish the gap between computer science concepts and business concepts, which will decrease the effort of individual companies or consortia to develop business-oriented DSLs. Any business-oriented DSL lands on, and finds its foundation in, a technically oriented DSL. It will be far easier to create language B from Figure 3-6 than language A.

Some good examples of business-oriented DSLs can be found in [Kelly and Tolvanen 2008]. They include among others IP telephony, insurance, and home automation. Other business-oriented examples are DSLs for pension plan schemes and the configuration of mortgage products. Examples of technically oriented DSLs are languages to specify data contracts, work flows, and service-oriented architectures.
Although I have not done any research on this, my hypothesis is that there is a limit to the number of concepts that can successfully be put into a software language.[2] There is probably some psychology at work here. In the same way that most humans know only about 30,000 words of their native language, even though that language’s vocabulary is much larger, most software developers do not use more than a certain number of concepts from their software language. In natural languages, unused words and phrases become archaic, although the language lives on. In software, those languages that contain many unused concepts tend to fall out of favor and die in oblivion. An example is Ada, which at first appeared to be a powerful language but was hardly ever fully put to use.
[2] I started to think about this when Jan Heering mentioned during a presentation (http://swerl.tudelft.nl/twiki/pub/MoDSE/Colloquium/MoDSE-JanHeering.pdf) that his gut feeling was that, probably, the domain size times its expressiveness is constant. Well, we clearly have relatively large (UML) and small (SQL) languages, so the result of this equation is certainly not constant, but it might very well be bound to an upper limit.
If my hypothesis is true, software languages should be designed in such a way that they contain either a limited number of concepts at the same level of abstraction or a limited number of concepts of different levels. Such languages are either broad and not very high or are high and not very broad. I think that the first is more acceptable than the second. For example, C++ combined objects and classes with pointer arithmetic, concepts with very different levels of abstraction. Some people hated the objects and classes and would rather have programmed in C. Others hated the pointer arithmetic and were glad to switch to Java, which did not offer that concept.
It is often said that frameworks and APIs are the same as domain-specific languages, letting the developer work with a different set of concepts. This is partly true, in that language and tool are difficult to separate. The developer using frameworks or application programming interfaces (APIs) seems to be working with different concepts, often at a higher level of abstraction. But at the same time, the output—the mogram that the developer is creating—is written in the good old-fashioned programming language the developer used before. A DSL would offer its user not only more abstract concepts but also a new syntax.
Think back to your school days. A student learning a language finds it far easier to fill in the blanks, as in The boy ... toward the building (to run), than to produce the complete sentence. Yet in both cases, the student is working with the same language.
Frameworks and APIs only add more complex, and often more abstract, structures to an existing language. They do not create a new one.
Summarizing the criteria that distinguish a DSL from another software language, I must conclude that no specific characteristics make DSLs different from any other software language. All characteristics that are often mentioned, such as being targeted toward a specific domain or used by a small group of domain experts, are not true discriminators but form a sliding scale by which to measure a language.
The only difference lies in the economics. It can be worthwhile to handcraft a compiler for C#, but for most DSLs, this kind of effort would not be worth the advantages of using the language. We need to rely on generative tools to produce the language user’s tool set for a DSL.
In the remainder of this book, I treat DSLs like any other software language. However, a relevant distinction is that between vertical and horizontal DSLs. In Section 6.3, I explain the consequences of this difference on the specification of the abstract syntax of the language.
In this book, I define a language as nothing more or less than a set of linguistic utterances. A linguistic utterance is any expression in a language: a word, a statement, a sentence, an expression, a model, a program, a query, a diagram. Although I use the formal term linguistic utterance in definitions and such, I use the word mogram in all other cases. They represent exactly the same notion.
Within the context of software languages, the abstraction level of a concept is the distance between this concept and the elements present in the computer hardware. The abstraction level of a language cannot be pinpointed precisely, because a language is a combination of a number of concepts, each of which may be at a different level of abstraction.
Next to the hard zero line of abstraction, which is the one posed by the hardware, is a virtual zero line, which separates the concepts that reside in the average software developer’s mind from those in common use by software developers of earlier decades but that are now taken for granted. Examples are memory location and stack frame pointer.
Domain-specific languages are not very different from other software languages. All characteristics that are often mentioned, such as being targeted toward a specific domain or used by a small group of domain experts, are not true discriminators but form a sliding scale by which to measure a language. One relevant distinction is that between vertical and horizontal DSLs. A vertical DSL is a language whose concepts are not computer science concepts but instead come from the business in which computer science is applied. A horizontal DSL is a language to describe a group of applications that share the same technical characteristics.