
A different language is a different vision of life.
—Federico Fellini
Italian movie director (1920–1993)
A single software language is usually not capable of specifying an application completely. In almost every case, multiple languages are used during the development of a single application. This means that software languages must relate to each other. This chapter describes how software languages can be designed to work together. Part of the content of this chapter was developed in cooperation with Jos Warmer (Ordina, Netherlands).
When developing one of today’s complex applications (see Sections 1.4 and 3.2.3 on the complexity crisis), multiple software languages are used: one language for Web pages, one language for database access, one language for the interchange format, on so on. No application’s code is written in only one language. The burden on the language engineer is to design each software language in such a way that its mograms can easily be combined with mograms written in a different language. But let’s first examine why you should be interested in this topic.
I always have doubts when I explain the advantages of multiple mograms to create one application. Do I really need to explain this? When you think of a program, it is all so obvious, but in the modeling world, these ideas have not yet been embraced. So let’s start by looking at the characteristics of using multiple source code files to build one application, all of which are taken for granted but are nevertheless very important for the process of creating software.
The source code for one application is divided into separate files because (1) a single source file would be too large to handle and (2) doing so enables the following features:
• Multiple programmers working on one application
• Version control per source file
• Compilation per source file
• Increased understandability of the application (you don’t have to understand it all)
• Increased reusability of (parts of) the application (e.g., by creating libraries)
I don’t think that any programmer would want to work with one single source file containing all the code for one application. The days are long gone when programmers were creating a single main program in a single file, but this is what we continue to do in the modeling world. One huge (main) model file contains all we need to specify about the application. In practice, this file often becomes too large to handle. It takes minutes to load and when you want to generate code from it (read: compile it), it takes a large part of an hour. No wonder most programmers prefer programs over models.
If you want your DSLs to be used, your IDE should offer your language users at least the same features their programming environment offers them. The users will reject anything less from what they are currently used to.
The arguments for working with multiple files apply when all mograms are written in a single language. Therefore, the remainder of this chapter should be of interest to you, whether you will be creating a large set of coordinated software languages or only one simple language.
Keep in mind that the number of applications written in a single language is extremely small. Most commonly, one application is created using multiple mograms in multiple languages. Language engineers will need to address this. The rest of this chapter explains how the preceding advantages can be realized in such a complex situation. Using this knowledge in the simpler situation of a single language is up to you.
References are a key element in designing a software language so that its mograms can easily be combined with other mograms written either in the same language or in a different language. References are the links between the mograms and keep the application together, like mortar between bricks.
Combining mograms from different languages means that one mogram can hold references to things defined in another mogram; for example, one class file can hold references to other classes and operations. Here, two different types of references are of importance: the soft reference, which is also known as referencing by name, and the hard reference, which is also known as referencing by address.
Hard referencing (by address) means that you know exactly where the element that you are referencing is positioned in the other mogram. You use this position to indicate which element in the second mogram your mogram is referring to. This makes the two mograms closely connected. When the mogram to which your mogram holds a reference changes, your mogram needs to be changed as well. An example of hard referencing is an IP address, such as 101.92.85.100.
Soft referencing (by name) depends on identifiers. It means that the first mogram holds an identifier that unambiguously identifies an element in another mogram. This identifier can be a name, but it can also have another form: for instance, a path name in which the (file) name of the mogram containing the element occurs. An example of a soft reference is a Web site address, such as www.mycompany.com.
When you are as bad at remembering names as I am, you often encounter the problems of hard referencing. For instance, I know that I recently spoke to an interesting person whose office was in the second room on the left on the third floor. Now that I want to renew this contact, it appears that higher management decided to make some office changes. The room in which I was expecting to find this interesting person is now occupied by someone else, someone who does not know where the previous resident is located. The only thing I can hope for is to remember some distinguishing mark so that I will be able to ask the secretary something like, “Do you know where the tall guy with the large mustache is?” On the other hand, the problem with soft referencing is that every time you want to contact this interesting person, you have to somehow determine where he is located. You always need to visit the secretary first.
We know from past experience that in software, the close connection of hard referencing is unwanted. General knowledge in software engineering says that parts of a software system should be loosely coupled. So to avoid strongly coupled mograms, our new software languages should cater to soft referencing.
Soft referencing has two sides—or even or three, as discussed in Section 11.4.1. First, you must be able to identify elements in the mogram to be referenced. Let’s call this mogram the passive one. Second, a way to specify outgoing references in the referencing mogram must be provided. Let’s call this second mogram the active one.
To cater to the passive side, the language of the passive mogram should provide a form of identification for the elements defined in a mogram. The language developer can use several identification schemes: for instance, model name followed by the type of the element in the abstract syntax model followed by the name of the element. Instead of using the name of an element, the language engineer may decide to use a specially added attribute, representing a unique identifier within a mogram, to each concept (class) in the abstract syntax model.
To cater to the active side, the language engineer must design a way to reference an element in another mogram. Certain elements in the active mogram are references to elements in the passive mogram. Still, the active mogram needs to be an instance of its abstract syntax model. So the question is: What is a reference in terms of the abstract syntax model?
Because every concept is represented in the abstract syntax model as a class, references must also be represented as one or more classes. You can choose one class to represent all references. In that case, it is practical to have a number of attributes in this class that hold metadata: that is, data on the reference, such as the language of the passive mogram, the version number, and so on. This simplifies resolving the reference. You can also decide to use several classes: for instance, one for every passive language that a language user is allowed to access or even one for every type of element (read: abstract syntax class) you want to reference.
All reference classes must be aware of the identification scheme of the passive language. A reference class usually holds attributes that correspond to the elements of the identification scheme. For instance, the class OperationRef in Figure 11-1 implements a reference to an operation of a class in a UML model. Each instance of this class holds as metadata the version of the UML language. The actual reference is divided into four elements: the model-id, the diagram-id, the class-name, and the operation-name. The diagram-id is present because the UML model can have multiple diagrams, each of which could hold the definition of the requested class. Note that the two classes in Figure 11-1 are not part of the abstract syntax model of UML but instead are part of the abstract syntax model of another (active) language. The UML is the passive language in this case.
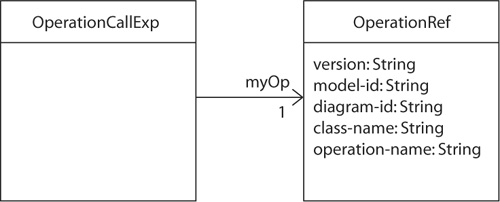
The language engineer has full control over the identification scheme used in the passive language. Thus, the language engineer can also decide to hide some elements from being referenced by any active mogram. For instance, in most object-oriented programming languages, you can write a class that contains references to other classes, operations (methods), and attributes (fields). But you cannot reference a parameter of an operation, a statement, or the initial value expression of an attribute. These (and more) are hidden.
Note that this kind of hiding is different from that indicated by the use of public and private markers. According to the language specification, there is a way to reference a private attribute or operation; thus, language users are able to make a reference, but the compiler will tell you that it is illegal. In other words, the private marker operates in the same manner as a constraint: When your mogram contains an illegal reference to a private element, the mogram is still an instance of the abstract syntax model, but a constraint is violated, and so it is not a valid instance.
By hiding elements, the language engineer makes it impossible for a language user to refer to them. For example, in an object-oriented programming language, there is no way to reference the first assignment in an operation. No language user is able to do that. In our terminology, you can say that the mogram is not an instance of the abstract syntax model, not even an invalid instance. The notion of information hiding by the language engineer can be brought to an extreme when you define a language interface.
A language interface is similar to an application interface but holds for all mograms of that language. The language interface determines what is and is not visible from the outside. For instance, in a simple database application you may decide to build an API to enable other applications to extract the records from a certain table, yet you do not include reading of other tables. In the same way, a language interface determines what elements can and cannot be referenced by mograms of another language. The following definition states this more formally.
Definition 11-1 (Language Interface) A language interface of a language L is a model of the information in linguistic utterances of L that is available to linguistic utterances of languages other than L.
The simplest way of defining a language interface is to take the complete abstract syntax model as the language interface. In this case, everything in a mogram is available for referencing, provided that an identification scheme is available. The next step is to select a subset of the abstract syntax model and thus create a true language interface. Some elements in a mogram are available and some are not, depending on what is in the subset.
Yet another way to create a language interface is to define a model that is different from the abstract syntax model, together with a transformation from the abstract syntax model to this new model. A good reason to do this is when you want to combine information from a rather complex model into a more simple model. For instance, Figure 11-2 shows you an extended version of the reference to a UML operation. The right-hand side shows some of the UML metamodel concerned with operations and parameters. This structure is much more complex than necessary for any active language that wants to reference an operation. Therefore, the language interface between our active language and UML has a different, simpler structure. Yet there is an unambiguous translation of the interface to the actual UML model: the paramTypes of an OperationRef are the types of all the ownedParameters of the referred Operation.

So far, we have looked at language interfaces from the passive side. We have determined that a language interface can hide elements from active mograms. This type of language interface, called the offered language interface, defines what is available to other languages, without knowing the other languages that might make use of this.
We can also look at language interfaces from the active side: What would an active mogram want to reference from another language? In other words, on what information from passive mograms does the active mogram depend? The language of the active mogram may define that its mograms depend on certain information in mograms of a certain language. The active mogram’s language specification should in that case define a required language interface, which defines what is needed from the other language or languages.
OCL is an example of a language that needs another language. Expressions written in OCL require information from a UML model. Figure 11-3 shows part of the OCL abstract syntax model [OMG-OCL 2005]. The gray classes belong to OCL; the white classes, to UML. When we were working on this model, we had no idea of separating the two languages by a language interface. But already, our intuition was to provide a small and clean way to link them. Thus, the number of classes from the UML used in the OCL model is relatively small, and all associations between OCL classes and UML classes are one-way: from OCL to UML. Because of this neat interface to UML, OCL is easily combined with other languages. All that needs to be done is to provide the right classes to substitute for the UML classes.
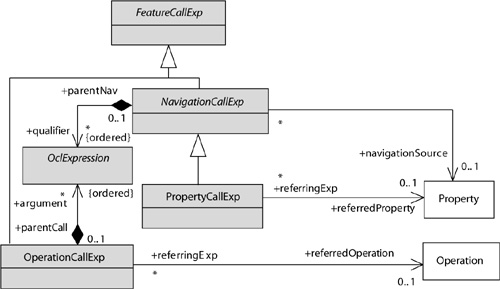
Note that not every mogram needs to use the elements in a required interface. For instance, I could write perfectly legal OCL expressions without making any references to properties or operations. In this example, however, the expressions would be very simple indeed, such as “23 – 11 = 12” or “true or false implies true.”
The use of language interfaces has consequences for the tool support of the language user. A complicating factor is that the IDE is no longer dedicated to a single language, but instead needs to at least provide multiple editors—one for each language—and probably should also provide multiple transformers, code generators, and the like. Clearly, the stress on the I (integrated) of IDE is large. For instance, the language user will be asking for code completion (intellisense) not only for elements written in one language but also for those written in any language available in the IDE. Some form of coordination will need to be in the IDE.
The most obvious task of a multilanguage IDE is to resolve and check references. You could implement a reference resolver per language, but it is probably wiser to implement a single resolver that is able to resolve references to all the languages supported by the IDE. Having similar identification schemes in all languages makes this easier.
I know of two examples of multilanguage IDEs that offer this type of support. One is xText, which is part of Open Architecture Ware [openArchitectureWare 2008]; the other was created using Microsoft DSL tools by my longtime colleague and writing partner, Jos Warmer. Present in this environment are four DSLs corresponding to the layers of the application architecture, which is a common architecture for Web-based, service-oriented administrative applications:
-
The Web Scenario DSL for the presentation layer
-
The Business Class DSL for the business classes
-
The Services DSL for the service interface and business processes
-
The Data Contract DSL for the data contract
On Save, each mogram will write to file (an easy-to-access XML format) the information on its elements that are part of its language’s offered interface. At the moment this export file becomes available in the environment, a special broker component reads it. When a reference needs to be resolved, the editor or other component that needs it requests the information from the broker. For instance, when an editor needs a list of elements of a certain type to be used for code completion, it asks the broker for a list of names. The broker then selects this list from all the elements known based on the required language, required type of element, and possibly other things, such as the first characters of the name of the element. In fact, the broker is a rather simple database that stores and retrieves the information in all the export files of all mograms.
Checking references, of course, also involves the broker. In this case, the broker is asked whether a certain element still exists. If the broker cannot find this element in its database, the reference is faulty, and an error message is presented to the language user. You can find more information in Warmer and Kleppe [2006].
How should the IDE support changes? If a language user changes a name of an element in a passive mogram and this element is being referred to (by name) in a number of active mograms, what should happen? What if the element is completely removed?
There are a number of ways to do this. The choice depends on the time and budget for the development of the IDE and on what you think your users will and will not accept.
• No support at all. When references are checked after an element is changed or removed, an error message is given, and the language user has the responsibility to “repair” the reference.
• Refactoring support. The language user may explicitly perform a name change of a model element as a refactoring. The IDE will find all references to the element and change them to refer to the new name.
• Automatic support. When the user changes the name of a referred element, all references will change automatically.
Having no support at all does work but is cumbersome for the language users. The problem with automatic support is that the language users do not know where automatic changes take place and may encounter unexpected results. This might lead to the need to retest the whole system, because the changes were not controlled.
The best option seems to be refactoring support. Note that in this case, renaming a model element works exactly as renaming a class in C# or Java code. The user either changes the name, which results in dangling references, or requests an explicit refactoring and is offered the possibility of reviewing the resulting changes and applying them. The reference broker holds all the information needed to implement refactoring support.
In both automatic and refactoring support, the following problem may occur. Especially in large projects, there will be many dozens of mograms, each of which can be edited simultaneously by different users. To allow for automatic change propagation or refactoring, the user performing the change needs to have change control over all affected mograms. The use of the merge feature of a version control system solves this problem. However, most version-control systems work only with textual mograms and cannot handle graphical mograms very well.
The use of multiple languages also has consequences for code generation. Similar to compilation in programming language IDEs, we want to provide code generation per mogram whenever possible. In the scenario of multiple mograms per application, both a mogram and the code generated from that mogram are partial descriptions of the application. For the process of code generation, it is important to determine when the parts need to be brought together. In the extreme, there are two possibilities.
-
Link all mograms together to form the complete description of the application. Transform the complete description into code.
-
Transform every single mogram into code. Link the generated code.
Again, the programming language world offers a good example. In C#, the notion of partial classes exists. A partial class is part of a class description saved in a separate file. Thus, one single class description is scattered over a number of files. When this class needs to be compiled, every partial class must be known, as in option 1. On the other hand, the compilation of a number of different classes is completely independent of each other, as in option 2.
As this example shows, the two options are extremes. In most cases, a mixture of both is used. The language designer should focus on option 2 and use option 1 only if the information in two or more mograms needs to be transformed into a single source code file. For example, when the class and state diagrams belonging to one UML model are saved in separate files, you need to combine a class with the state chart defined for it before you can generate code. In my experience, such situations are rare. Most often, you will generate multiple source code files from one mogram. Remember that when you take option 2, the mapper pattern (Section 10.3) can be of help, especially for references to other mograms.
Any piece of software should be designed with the future is mind. What changes in requirements are likely, and how difficult will it be to realize them? Of course, you can never predict the future, but often, you can already see trends. Software languages should also be designed this way. If your language never changes, it will soon become obsolete.
Designing for the future is always difficult and depends on the situation you are in at the moment, so I cannot give you rock-solid advice on what to do and what not to do. But I can offer you the following list of questions, things you should think about sooner or later.
• Do the language interfaces that you offer or require support change? Are you able to change the abstract syntax model without changing the language interfaces?
• How difficult is it to change the target technology of your code generator? Does your code generator shield your language user from the underlying technology, or do concepts from the target language invade your language?
• Have you set up a procedure for new releases? Is it clear to your users when and how a new release will become available? How do users report bugs and send in change requests? Do you allow people to keep using older versions, and if so, what support do you offer them?
• When you are building a new release, what do you offer your users for the transition of their old mograms? Will you offer an update manual? Are you going to build a transformer that takes an old abstract syntax graph and produces an instance of the new abstract syntax model?
At the end of this book, I that hope you have gained a better understanding of the nature of software languages. You should understand that the task of a software language engineer is a very challenging process, especially because the field is still maturing. New insights are to be gained and shared. One important remaining challenge for us all is the generation of the language user’s IDE based on a language specification.
Every application is a combination of multiple mograms. These mograms can all be part of one language, but they are more commonly of multiple languages. In both cases, there are references between the mograms. Past experience teaches us that these references can best be soft coded, based on some form of identity, such as a name.
The active language(s)—the language whose mograms contain the references—should support these references by explicit constructs in the abstract syntax model, such as separate metaclasses. The passive language—the language with the mograms that are referred to—should supply an identification scheme for all elements that may be referenced.
A passive language can provide an extreme form of information hiding by offering a language interface, a metamodel that describes exactly which parts of the language’s mogram may be referenced and which may not. An active language may require certain language interfaces.
Support for multiple mograms must be implemented in the language user’s tool set. References need to be resolved and checked. A separate entity in the tool set is a good way to implement this. You must also decide how to deal with changes in the mograms that regard references. With regard to code generation, it is best to aim for generation per mogram.