
Match-Merging
Merging with a BY Statement
Merging with a BY statement
enables you to match observations according to the values of the BY
variables that you specify. Before you can perform a match-merge,
all data sets must be sorted by the variables that you want to use
for the merge.
In order to understand
match-merging, you must understand three key concepts:
BY group
specifies the set of
all observations with the same value for the BY variable (if there
is only one BY variable). If you use more than one variable in a BY
statement, then a BY group is the set of observations with a unique
combination of values for those variables. In discussions of match-merging,
BY groups commonly span more than one data set.
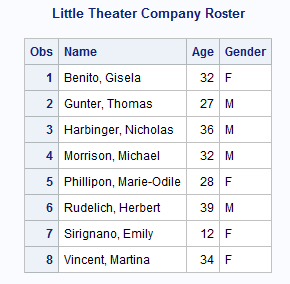
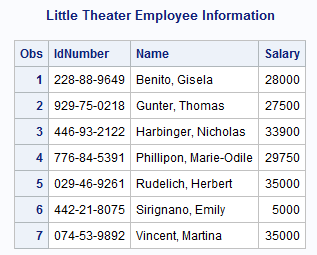
Input SAS Data Set for Examples
The director of a small
repertory theater company, the Little Theater, maintains company records
in two SAS data sets, COMPANY and FINANCE.
data company;input Name $ 1-25 Age 27-28 Gender $ 30; datalines; Vincent, Martina 34 F Phillipon, Marie-Odile 28 F Gunter, Thomas 27 M Harbinger, Nicholas 36 M Benito, Gisela 32 F Rudelich, Herbert 39 M Sirignano, Emily 12 F Morrison, Michael 32 M ; run;proc sort data=company;by Name;run;data finance;input IdNumber $ 1-11 Name $ 13-37 Salary; datalines; 074-53-9892 Vincent, Martina 35000 776-84-5391 Phillipon, Marie-Odile 29750 929-75-0218 Gunter, Thomas 27500 446-93-2122 Harbinger, Nicholas 33900 228-88-9649 Benito, Gisela 28000 029-46-9261 Rudelich, Herbert 35000 442-21-8075 Sirignano, Emily 5000 ; run;proc sort data=finance;by Name;run; proc printdata=company;title 'Little Theater Company Roster'; run; proc printdata=finance;title 'Little Theater Employee Information'; run;
The Program
To avoid having to maintain
two separate data sets, the director wants to merge the records for
each player from both data sets into a new data set that contains
all of the variables. The variable that is common to both data sets
is Name. Therefore, Name is the appropriate BY variable.
The data sets are already
sorted by Name, so no further sorting is required. The following
program merges them by Name:
Explanation
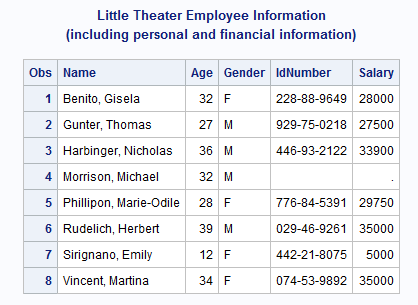
The new data set contains
one observation for each player in the company. Each observation contains
all the variables from both data sets. Notice in particular the fourth
observation. The data set FINANCE does not have an observation for
Michael Morrison. In this case, the values of the variables that
are unique to FINANCE (IdNumber and Salary) are missing.
Match-Merging Data Sets with Multiple Observations in a BY Group
Input SAS Data Set for Examples
The Little Theater has a third data set, REPERTORY,
that tracks the casting assignments in each of the season's plays.
REPERTORY contains these variables:
data repertory;
input Play $ 1-23 Role $ 25-48 IdNumber $ 50-60;
datalines;
No Exit Estelle 074-53-9892
No Exit Inez 776-84-5391
No Exit Valet 929-75-0218
No Exit Garcin 446-93-2122
Happy Days Winnie 074-53-9892
Happy Days Willie 446-93-2122
The Glass Menagerie Amanda Wingfield 228-88-9649
The Glass Menagerie Laura Wingfield 776-84-5391
The Glass Menagerie Tom Wingfield 929-75-0218
The Glass Menagerie Jim O'Connor 029-46-9261
The Dear Departed Mrs. Slater 228-88-9649
The Dear Departed Mrs. Jordan 074-53-9892
The Dear Departed Henry Slater 029-46-9261
The Dear Departed Ben Jordan 446-93-2122
The Dear Departed Victoria Slater 442-21-8075
The Dear Departed Abel Merryweather 929-75-0218
;
run;
proc print data=repertory;
title 'Little Theater Season Casting Assignments';
run;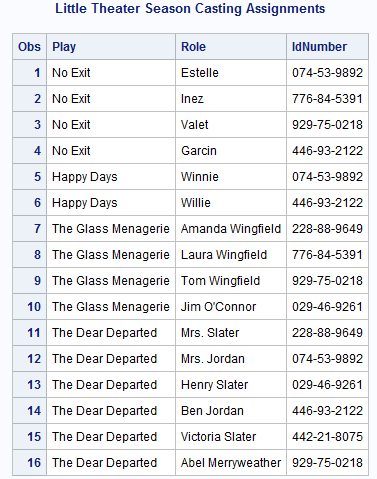
To maintain confidentiality
during preliminary casting, this data set identifies players by employee
ID number. However, casting decisions are now final, and the manager
wants to replace each employee ID number with the player's name. Of
course, it is possible to re-create the data set, entering each player's
name instead of the employee ID number in the raw data. However, it
is more efficient to make use of the FINANCE data set, which already
contains the name and employee ID number of all players.
When the data sets are
merged, SAS adds the players' names to the data set. Of course, before
you can merge the data sets, you must sort them by IdNumber.
proc sort data=finance;by IdNumber;run;proc sort data=repertory;by IdNumber;run; proc printdata=finance;title 'Little Theater Employee Information'; title2 '(sorted by employee ID number)'; run; proc printdata=repertory;title 'Little Theater Season Casting Assignments'; title2 '(sorted by employee ID number)'; run;
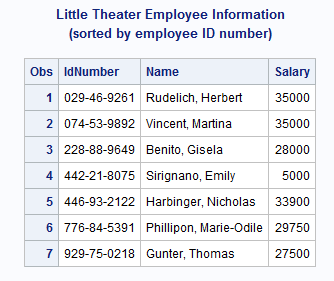
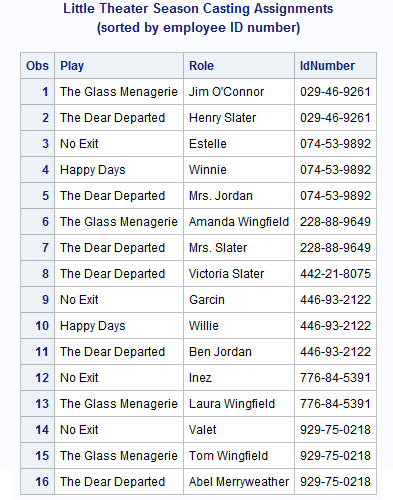
These two data sets
contain seven BY groups. That is, among the 23 observations are seven
different values for the BY variable, IdNumber. The first BY group
has a value of 029-46-9261 for IdNumber. FINANCE has one observation
in this BY group; REPERTORY has two. The last BY group has a value
of 929-75-0218 for IdNumber. FINANCE has one observation in this BY
group; REPERTORY has three.
The Program
The following program
merges the data sets FINANCE and REPERTORY. It also illustrates what
happens when a BY group in one data set has more observations in it
than the same BY group in the other data set.
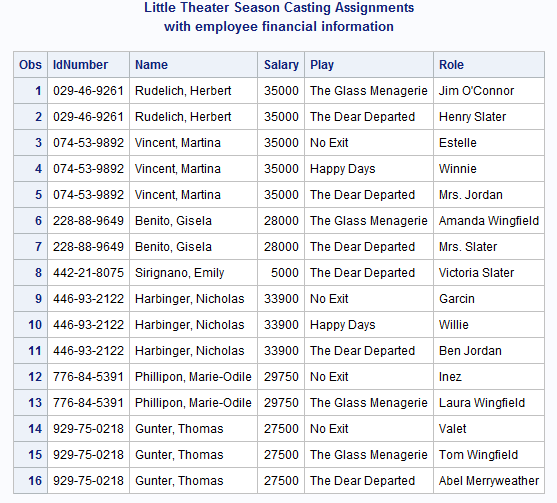
Explanation
-
Before executing the DATA step, SAS reads the descriptor portion of the two data sets and creates a program data vector that contains all variables from both data sets: IdNumber is already in the program data vector because it is in the FINANCE data set. SAS sets the values of all variables to missing, as the following figure illustrates.
-
SAS looks for a second observation in the BY group in each data set. REPERTORY has one; FINANCE does not. The MERGE statement reads the second observation in the BY group from REPERTORY. Because FINANCE has only one observation in the BY group, the statement uses the values of Name (
Rudelich,Herbert) and Salary (35000) that were retained in the program data vector for the second observation in the new data set. The next figure illustrates this behavior. -
SAS writes the observation to the new data set. Neither data set contains any more observations in this BY group. Therefore, as the final figure illustrates, SAS sets all values in the program data vector to missing and begins processing the next BY group. It continues processing observations until it exhausts all observations in both data sets.





Match-Merging Data Sets with Dropped Variables
Now
that casting decisions are final, the director wants to post the casting
list, but does not want to include salary or employee ID information.
As the next program illustrates, Salary and IdNumber can be eliminated
by using the DROP= data set option when creating the new data set.
data newrep(drop=IdNumber);merge finance(drop=Salary)repertory; by IdNumber; run; proc print data=newrep; title 'Final Little Theater Season Casting Assignments'; run;
Note: The difference in placement
of the two DROP= data set options is crucial. Dropping IdNumber in
the DATA statement means that the variable is available to the MERGE
and BY statements (to which it is essential), but that it does not
go into the new data set. Dropping Salary in the MERGE statement means
that the MERGE statement does not even read this variable, so Salary
is unavailable to the program statements. Because the variable Salary
is not needed for processing, it is more efficient to prevent it from
being read into the PDV in the first place.
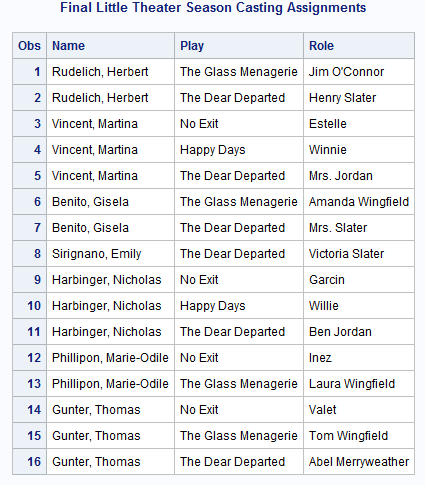
Match-Merging Data Sets with the Same Variables
You can match-merge data
sets that contain the same variables (variables with the same name)
by using the RENAME= data set option, just as you would when performing
a one-to-one merge (see Performing a One-to-One Merge on Data Sets with the Same Variables).
Match-Merging Data Sets That Lack a Common Variable
You
can name any number of data sets in the MERGE statement. However,
if you are match-merging the data sets, then you must be sure they
all have a common variable and are sorted by that variable. If the
data sets do not have a common variable, then you might be able to
use another data set that has variables common to the original data
sets to merge them.
For example, consider
the data sets that are used in the match-merge examples. The following
table displays the names of the data sets and the names of the variables
in each data set.
These data sets do not
share a common variable. However, COMPANY and FINANCE share the variable
Name. Similarly, FINANCE and REPERTORY share the variable IdNumber.
Therefore, as the next program shows, you can merge the data sets
into one with two separate DATA steps. As usual, you must sort the
data sets by the appropriate BY variable. (REPERTORY is already sorted
by IdNumber.)
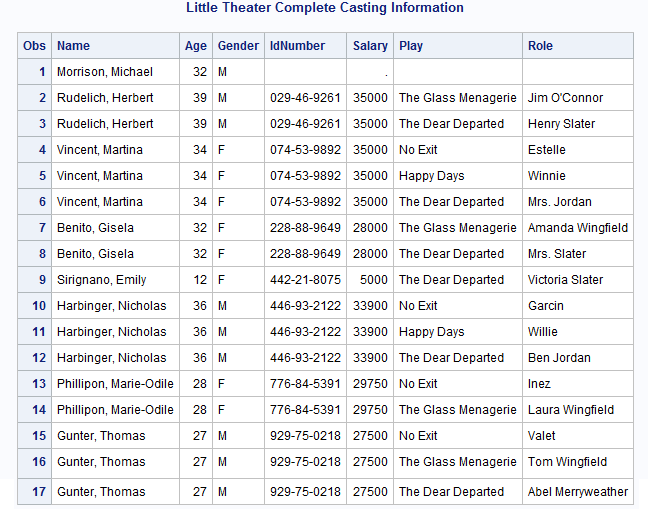
/* Sort FINANCE and COMPANY by Name */proc sort data=finance;by Name;run;proc sort data=company;by Name;run; /* Merge COMPANY and FINANCE into a */ /* temporary data set. */data temp;merge company finance;by Name;run;proc sort data=temp;by IdNumber;run; /* Merge the temporary data set with REPERTORY */data all;merge temp repertory;by IdNumber;run; proc print data=all; title 'Little Theater Complete Casting Information'; run;
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.