
1 The amazing world of TensorFlow
- What TensorFlow is
- Hardware in machine learning: GPUs and CPUs
- When and when not to use TensorFlow
- What this book teaches
- Who this book is for
- Why we should care about TensorFlow
More than 5 million gigabytes—that’s how much data is predicted to be generated a second by 2025 (https://www.weforum.org). Those tiny contributions we make using Google search queries, tweets, Facebook photos, and voice commands to Alexa will add up to unprecedented amounts of data. Therefore, there’s no better time than the present to fight on the frontier of artificial intelligence, to make sense of and most importantly leverage the ever-growing universe of digital data. It is a no-brainer that data itself is not very useful until we elicit information from it. For example, an image is more useful if the machine knows what’s in that image; a voice command is more useful if the machine can articulate/transcribe what was said. Machine learning is the gatekeeper that lets you cross from the world of data into the realm of information (e.g., actionable insights, useful patterns) by allowing machines to learn from data. Machine learning, particularly deep learning methods, deliver unparalleled performance in the presence of abundant data. With the explosive growth of data, more and more use cases will emerge for deep learning to be applied in. Of course, we cannot ignore the possibility of a better technique drowning the popular deep learning methods. However, it is an irrefutable reality that, to date, deep learning has been constantly outperforming other algorithms, particularly when ample data is present.
Deep learning models can easily exceed millions (and recently billions) of parameters (i.e., weights and biases), and they have a large appetite for data. This signifies the need for frameworks that allow us to train and infer from deep learning models efficiently while utilizing optimized hardware such as graphical processing units (GPUs) or tensor processing units (TPUs) (http://mng.bz/4j0g). One aspect of achieving this is to develop highly scalable data pipelines that can read and process data efficiently.
1.1 What is TensorFlow?
TensorFlow is a machine learning framework and has been making its mark in the community of machine learning for almost five years. It is an end-to-end machine learning framework that is designed to run faster on optimized hardware (e.g., GPUs and TPUs). A machine learning framework provides the tools and operations needed to implement machine learning solutions easily. Though TensorFlow is not limited to implementing deep neural networks, that has been its main use. TensorFlow also supports the following:
-
Implementing probabilistic machine learning models (https://www.tensorflow.org/probability)
-
Computer graphics-related computations (https://www.tensorflow.org/graphics)
-
Reusing (pretrained) models (https://www.tensorflow.org/hub)
-
Visualizing/debugging TensorFlow models (https://www.tensorflow.org/tensorboard)
TensorFlow was one of the earliest frameworks to enter the bustling market of machine learning. Developed and maintained by Google, TensorFlow has released more than 100 versions with around 2,500 contributors, making the product bigger and better every day. It has evolved to become a holistic ecosystem that moves from the early prototyping stage to productionizing the model. Between these stages, TensorFlow supports a range of functionalities:
-
Model development—Building deep learning models easily by stacking predefined layers or creating custom layers
-
Performance monitoring—Monitoring performance of the model as it is trained
-
Model debugging—Debugging any issues, such as numerical errors, that occur during model training/prediction
-
Model serving—Once the model is trained, deploying the model to the wider public so that it can be used in the real world
As you can see, TensorFlow supports almost all the stages of building your machine learning solutions and eventually serving it to users in the real world. All these services are made into and shipped in a single convenient package, which will be at your disposal with a single line of installation instructions.
The various components that come together to solve an ML problem will be discussed in detail in the coming sections.
Next, we will discuss different components of TensorFlow. These components will go from raw data all the way to deploying models to be accessed by customers.
1.1.1 An overview of popular components of TensorFlow
As previously mentioned, TensorFlow is an end-to-end machine learning framework. This means TensorFlow needs to support many different capabilities and stages of a machine learning project. After a business problem is identified, any machine learning project starts with data. An important step is to perform exploratory data analysis. Typically, this is done using a mix of TensorFlow and other data manipulating libraries (e.g., pandas, NumPy). In this step, we try to understand our data because that will determine how well we can use it to solve the problem. With a solid understanding of the data (e.g., data types, data-specific attributes, various cleaning/processing that needs to be done before feeding data to the model), the next step is to find an efficient way to consume data. TensorFlow provides a comprehensive API (application programming interface), known as the tf.data API (or tensorflow.data API) (https://www.tensorflow.org/guide/data), that enables you to harness the data found in the wild. Specifically, this API provides various objects and functions to develop highly flexible custom-input data pipelines. Depending on your needs, you have several other options for retrieving data in TensorFlow:
-
tensorflow-datasets—Provides access to a collection of popular machine learning data sets that can be downloaded with a single line of code.
-
Keras data generators—Keras is a submodule in TensorFlow and provides various high-level functionality built on top of the TensorFlow’s low-level API. The data generators provide ways to load specific types of data (e.g., images or time series data) from various sources (e.g., disk).
Using any of these elements (or a combination of them), you can write a data-processing pipeline (e.g., a Python script). Data would vary depending on the problem you are trying to solve. For example, in an image recognition task, data would be images and their respective classes (e.g., dog/cat). For a sentiment analysis task, the data would be movie reviews and their respective sentiments (e.g., positive/negative/neutral). The purpose of this pipeline is to produce a batch of data from these data sets. The data sets typically fed to deep learning models can have tens of thousands (if not more) data points and would never fit fully in limited computer memory, so we feed a small batch of data (e.g., few hundred data points) at a time and iterate through the full data set in batches.
Next up is the model-building phase. Deep learning models come in many flavors and sizes. There are four main types of deep networks: fully connected, convolutional neural, recurrent neural, and Transformer. These models have different capabilities, strengths, and weaknesses, as you will see in later chapters. TensorFlow also offers different APIs that have varying degrees of control for building models. First, in its most raw form, TensorFlow provides various primitive operations (e.g., matrix multiplication) and data structures to store inputs and outputs of the models (e.g., n-dimensional tensors). These can be used as building blocks to implement any deep learning models from the ground up.
However, it can be quite cumbersome to build models using the low-level TensorFlow API, as you need to repetitively use various low-level operations in TensorFlow and ensure the correctness of the computations happening in the model. This is where Keras comes in. Keras (now a submodule in TensorFlow) offers several advantages over the TensorFlow API:
-
It provides Layer objects that encapsulate various common functionality that repeatedly happens in neural networks. We will learn what layers are available to us in more detail in the coming chapters.
-
It provides several high-level model-building APIs (e.g., Sequential, functional, and subclassing). For example, the Sequential API is great for building simple models that go from an input to an output through a series of layers, whereas the functional API is better if you are working with more complex models. We will discuss these APIs in more detail in chapter 3.
As you can imagine, these features drastically lower the barriers for using TensorFlow. For example, if you need to implement a standard neural network, all you need to do is stack a few standard Keras layers, which, if you were to do the same with the low-level TensorFlow API, would cost you hundreds of lines of code. But, if you need the flexibility to go wild and implement complicated models, you still have the freedom to do so.
Finally, TensorFlow offers its most abstract API known as the Estimator API (https://www.tensorflow.org/guide/estimator). This API is designed to be very robust against any user-induced errors. The robustness is guaranteed by a very restricted API, exposing the user to the bare minimum functionality to train, predict from, and evaluate models.
When you build the model, TensorFlow creates what’s known as a data-flow graph. This graph is a representation of what your model looks like and the operations it executes. Then, if you have optimized hardware (e.g., a GPU), TensorFlow will identify those devices and place parts of this graph on that special hardware so that any operations you run on the model are executed as quickly as possible. Appendix A provides detailed instructions for setting up TensorFlow and other required dependencies to run the code.
1.1.2 Building and deploying a machine learning model
After you build the model, you can train it with the data you prepared using the tf.data API. The model’s training process is critical, as for deep learning models, it is quite time-consuming, so you need a way to periodically monitor the progress of the model and make sure the performance stays at a reasonable level during the course of training. For that we write the loss value, the evaluation metric for performance on both training and validation data, so if something goes wrong, you can intervene as soon as possible. There are more advanced tools in TensorFlow that will allow you to monitor the performance and health of your model with more options and convenience. TensorBoard (https://www.tensorflow.org/tensorboard) is a visualization tool that comes with TensorFlow and can be used to visualize various model metrics (e.g., accuracy, precision, etc.) while the model is trained. All you need to do is log the metrics you’d like to visualize to a directory and then start the TensorBoard server, providing the directory as an argument. TensorBoard will automatically visualize the logged metrics on a dashboard. This way, if something goes wrong, you’ll quickly notice it, and the logged metrics will help pinpoint any issues with the model.
After (or even during) the training process, you need to save the model; otherwise, it will be destroyed right after you exit the Python program. Also, if your training process gets interrupted during training, you can restore the model and continue training (if you saved it). In TensorFlow you can save models in several ways. You can simply save a model in HDF5 format (i.e., a format for large file storage). Another recommended method is saving it as a SavedModel (https://www.tensorflow.org/guide/saved_model), the standard way to save models adopted by TensorFlow. We will see how to save different formats in the coming chapters.
All the great work you’ve done has paid off. Now you want to joyfully tell the world about the very smart machine learning model you built. You want users to use the model and be amazed by it and for it to find its way into a news headline on artificial intelligence. To take the model to users, you need to provide an API. For this, TensorFlow has what is known as TensorFlow serving (https://www.tensorflow.org/tfx/guide/serving). TensorFlow serving helps you to deploy the trained models and implement an API for users and customers to use. It is a complex topic and involves many different subtopics, and we’ll discuss it in a separate chapter.
We have gone on a long journey from mere data to deploying and serving models to customers. Next, let’s compare several popular hardware choices used in machine learning.
1.2 GPU vs. CPU
If you have implemented simple computer programs (e.g., a commercial website) or worked with standard data science tools like NumPy, pandas, or scikit-learn, you would have heard the term GPU. To reap real benefits, TensorFlow relies on special hardware, such as GPUs. In fact, the progress we have achieved so far in deep neural networks can be heavily attributed to the advancement of GPUs in the last few years. What is so special about GPUs? How are they different from the brains of the computer, the central processing unit (CPU)?
Let’s understand this with an analogy. Remind yourself of how you commute to work. If you get ready early and have some time to spare, you might take the bus. However, if you only have 10 minutes to spare for the important meeting happening at 9:00 a.m., you might decide to take your car. What is the difference between these two types of transportation? What different purposes do they serve? A car is designed to get a few people (e.g., four) quickly to a destination (i.e., low latency). On the other hand, a bus is slow but carries more people (e.g., 60) in a single trip (i.e., high throughput). Additionally, a car is fitted with various sensors and equipment that will make your drive/ride comfortable (e.g., parking sensors, lane detection, seat heaters, etc.). But the design of a bus would focus more on providing basic needs (e.g., seats, stop buttons, etc.) for a lot of people with limited options to make your ride joyful (figure 1.1).

Figure 1.1 Comparing a CPU, a GPU, and a TPU. A CPU is like a car, which is designed to transport a few people quickly. A GPU is like a bus, which transports many people slowly. A TPU is also like a bus, but it operates well in only specific scenarios.
A CPU is like a car, and a GPU is like a bus. A typical CPU has a handful of cores (e.g., eight). A CPU core does many things (I/O operations, coordinating communications between different devices, etc.) fast, but at a small scale. To support a variety of operations, CPUs need to support a large set of instructions. And to make these run fast, a CPU relies on expensive infrastructure (e.g., more transistors, different levels of caches, etc.). To summarize, CPUs execute a large set of instructions very fast at a small scale. In contrast, a typical GPU has many cores (e.g., more than a thousand). But a GPU core supports a limited set of instructions and focuses less on running them fast.
In the context of machine learning, particularly in deep learning, we mostly need to perform lots of matrix multiplications repeatedly to train and infer from models. Matrix multiplication is a functionality GPUs are highly optimized for, which makes GPUs desirable.
We shouldn’t forget our friends, TPUs, which are the latest well-known addition to an optimized hardware list. TPUs were invented by Google and can be thought of as stripped-down GPUs. They are application-specific integrated circuits (ASICs) targeted for machine learning and AI applications. They were designed for low-precision high-volume operations. For example, a GPU typically uses 32-bit precision, whereas a TPU uses a special data type known as bfloat16 (which uses 16 bits) (http://mng.bz/QWAe). Furthermore, TPUs lack graphic-processing capabilities such as rasterizing/ texture mapping. Another differentiating characteristic of TPUs is that they are much smaller compared to GPUs, meaning more TPUs can be fit in a smaller physical space.
To extend our car-bus analogy to TPUs, you can think of a TPU as an economical bus that is designed to travel short distances in remote areas. It cannot be used as a normal bus to travel long distances comfortably or to suit a variety of road/weather conditions, but it gets you from point A to point B, so it gets the job done.
1.3 When and when not to use TensorFlow
A key component in knowing or learning TensorFlow is knowing what and what not to use TensorFlow for. Let’s look at this through a deep learning lens.
1.3.1 When to use TensorFlow
TensorFlow is not a silver bullet for any machine learning problem by any means. You will get the maximum output by knowing what TensorFlow is good for.
Prototyping deep learning models
TensorFlow is a great tool for prototyping models (e.g., fully connected networks, convolutional neural networks, long short-term memory networks), as it provides layer objects (in Keras), such as the following:
-
RNN (recurrent neural network)/LSTM (long short-term memory)/GRU (gated recurrent unit) layers for sequential models
(You do not need to know the underlying mechanics of these layers, as they will be discussed in depth in the chapters ahead.) TensorFlow even offers a suite of pretrained models, so you can develop a simple model with a few layers or a complex ensemble model that consists of many models with fewer lines of code.
Implementing models that can run faster on optimized hardware
TensorFlow contains kernels (implementations of various low-level operations; e.g., matrix multiplication) that are optimized to run faster on GPUs and TPUs. Therefore, if your model can take advantage of such optimized operations (e.g., linear regression), and you need to run the model on large amounts of data repetitively, TensorFlow will help to run your model faster.
Productionize models/serving on cloud
The most common goal of a machine learning model is to serve in solving a real-world problem; thus the model needs to be exposed for predictions to interested stakeholders via a dashboard or an API. A unique advantage of TensorFlow is that you do not need to leave it when your model reaches this stage. In other words, you can develop your model-serving API via TensorFlow. Additionally, if you have lavish hardware (e.g., GPUs/TPUs), TensorFlow will make use of that when making predictions.
Monitoring models during model training
During the training of the model, it is crucial that you keep tabs on model performance to prevent overfitting or underfitting. Training deep learning models can be tedious, even with access to GPUs, due to their high computational demand. This makes it more difficult to monitor these models than simpler ones that run in minutes. If you want to monitor a model that runs in a few minutes, you can print the metrics to the console and log to a file for reference.
However, due to the high number of training iterations deep learning models go through, it is easier to absorb information when these metrics are visualized in graphs. TensorBoard provides exactly this functionality. All you need to do is log and persist your performance metrics in TensorFlow and point TensorBoard to the log directory. TensorBoard will take care of the rest by automatically converting this information in the log directory to graphs, which we can use to analyze the quality of our model.
Creating heavy-duty data pipelines
We have stated several times that deep learning models have a big appetite for data. Typically, data sets that deep learning models sit on do not fit in memory. This means that we need to feed large amounts of data with low latency in smaller, more manageable batches of data. As we have already seen, TensorFlow provides rich APIs for streaming data to deep learning models. Most of the heavy lifting has been done for us. All we need to do is understand the syntax of the functions provided and use them appropriately. Some example scenarios of such data pipelines include the following:
-
A pipeline that consumes large amounts of images and preprocesses them
-
A pipeline that consumes large amounts of structured data in a standard format (e.g., CSV [comma separated value]) and performs standard preprocessing (e.g., normalization)
-
A pipeline that consumes large amounts of text data and performs only simple preprocessing (e.g., text lowering, removing punctuation)
1.3.2 When not to use TensorFlow
It’s important to know the don’ts as well as the do’s when it comes to mastering a tool or a framework. In this section, we will discuss some of the areas where other tools might make you more efficient than TensorFlow.
Implementing traditional machine learning models
Machine learning has a large portfolio of models (e.g., linear/logistic regression, supporting vector machines, decision trees, k-means) that fall under various categories (e.g., supervised versus unsupervised learning) and have different motivations, approaches, strengths, and weaknesses. There are many models used where you will not see much performance improvement using optimized hardware (e.g., decision trees, k-means, etc.) because these models aren’t inherently parallelizable. Sometimes you’ll need to run these algorithms as a benchmark for a new algorithm you developed or to get a quick ballpark figure as to how easy a machine learning problem is.
Using TensorFlow to implement such methods would cost you more time than it should. In such situations, scikit-learn (https://scikit-learn.org/stable/) is a better alternative, as the library provides a vast number of models readily implemented. TensorFlow does support some algorithms, such as boosted-tree-based models (http://mng.bz/KxPn). But from my experience, using XGBoost (extreme gradient boosting) (https://xgboost.readthedocs.io/en/latest/) to implement boosted trees has been more convenient, as it is more widely supported by other libraries than the TensorFlow alternative. Furthermore, should you need GPU-optimized versions of scikit-learn algorithms, NVIDIA also provides some of these algorithms that are adapted and optimized for GPUs (https://rapids.ai/).
Manipulating and analyzing small-scale structured data
Sometimes we will work with relatively small-structure data sets (e.g., 10,000 samples) that can easily fit in memory. If the data can be loaded into memory fully, pandas and NumPy are much better alternatives for exploring and analyzing data. These are libraries that are equipped with highly optimized C/C++ implementations of various data manipulation (e.g., indexing, filtering, grouping) and statistics-related operations (e.g., mean, sum). For a small data set, TensorFlow can cause significant overhead (transferring data between the CPU and the GPU, launching computational kernels on the GPU), especially if a high volume of smaller, less expensive operations is run. Additionally, pandas/NumPy would be much more expressive in terms of how you can manipulate the data, as it’s their primary focus.
Creating complex natural language processing pipelines
If you are developing a natural language processing (NLP) model, you would rarely pass data to the model without doing at least simple preprocessing on the data (e.g., text lowering, removing punctuation). But the actual steps that dictate your preprocessing pipeline will depend on your use case and your model. For example, there will be instances where you will have a handful of simple steps (e.g., case lowering, removing punctuation), or you might have a fully blown preprocessing pipeline that requires complex tasks (e.g., stemming, lemmatizing, correcting spelling). In the former case, TensorFlow is a good choice as it provides some simple text preprocessing functionality (e.g., case lowering, replacing text, string splitting, etc.). However, in the latter case, where costly steps such as lemmatization, stemming, spelling correction, and so on dominate the preprocessing pipeline, TensorFlow will hinder your progress. For this, spaCy (https://spacy.io/) is a much stronger candidate, as it provides an intuitive interface and readily available models to perform standard NLP processing tasks.
spaCy does support including TensorFlow models (through a special wrapper) when defining pipelines. But as a rule of thumb, try to avoid this when possible. Integrations between different libraries are generally time-consuming and can even be error prone in complex setups.
Table 1.1 summarizes various strengths and weaknesses of TensorFlow.
Table 1.1 Summary of TensorFlow benefits and drawbacks
|
Implementing models (including non-deep learning) that can run faster on optimized hardware | ||
1.4 What will this book teach you?
In the coming chapters, this book will teach you some vital skills that will help you use TensorFlow principally and effectively for research problems.
1.4.1 TensorFlow fundamentals
First, we will learn the basics of TensorFlow. We will learn the different execution styles it provides, primary building blocks that are used to implement any TensorFlow solution (e.g., tf.Variable, tf.Operation), and various functionalities as low-level operations. Then we will explore various model-building APIs exposed by Keras (a submodule in TensorFlow) to users and their benefits and limitations, which will help with making decisions such as when to use a certain model-building API. We will also study various ways we can retrieve data for TensorFlow models. Unlike traditional methods, deep learning models consume large amounts of data, so having an efficient and scalable data ingestion pipeline (i.e., input pipeline) is of paramount importance.
1.4.2 Deep learning algorithms
Implementing efficient deep learning models is one of the primary purposes of TensorFlow. Therefore, we will be discussing the architectural details of various deep learning algorithms such as full connected neural networks, convolutional neural networks (CNNs), and recurrent neural networks (RNNs). Note that investigating theories of these models is not an objective of this book. We will only be discussing these models at a level that helps us understand how to implement them comfortably with TensorFlow/Keras.
We will further hone our understanding of these models by implementing and applying these models to popular computer vision and NLP applications such as image classification, image segmentation, sentiment analysis, and machine translation. It will be interesting to see how well these models do when it comes to such tasks, with no human-engineered features.
Then, we will discuss a new family of models that have emerged, known as Transformers. Transformers are very different from both convolutional and recurrent neural networks. Unlike CNNs and RNNs, which can only see part of a time-series sequence at a time, Transformers can see the full sequence of data, leading to better performance. In fact, Transformers have been surpassing the previously recorded state-of-the-art models in many NLP tasks. We will learn how we can incorporate such models in TensorFlow to improve the performance of various downstream tasks.
1.4.3 Monitoring and optimization
It is not enough to know how to implement a model in TensorFlow. Close inspection and monitoring of model performance are vital steps in creating a reliable machine learning model. Using visualization tools such as TensorBoard to visualize performance metrics and feature representations is an important skill to have. Model explainability has also emerged as an important topic, as black-box models like neural networks are becoming commodities in machine learning. TensorBoard has certain tools for interpreting models or explaining why a model made a certain decision.
Next, we will investigate ways we can make models train faster. The training time is one of the most prominent bottlenecks in using deep learning models, so we will discuss some techniques to make the models train faster!
1.5 Who is this book for?
This book is written for a broader audience in the machine learning community to provide a somewhat easy entry for novices, as well as machine learning practitioners with basic to medium knowledge/experience, to push their TensorFlow skills further. In order to get the most out of this book, you need the following:
-
Experience in the model development life cycle (through a research/industry project)
-
Moderate knowledge of Python and object-oriented programming (OOP) (e.g., classes/generators/list comprehension)
-
Basic knowledge of NumPy/pandas libraries (e.g., computing summary statistics, what pandas series DataFrame objects are)
-
Basic knowledge of linear algebra (e.g., basic mathematics, vectors, matrices, n-dimensional tensors, tensor operations, etc.)
-
Basic familiarity with the different deep neural networks available
You will greatly benefit from this book if you are someone who has
-
At least several months of experience as a machine learning researcher, data scientist, machine learning engineer, or even as a student during a university/ school project in which you used machine learning
-
Worked closely with other machine learning libraries (e.g., scikit-learn) and has heard of amazing feats of deep learning and is keen to learn more about how to implement them
-
Experience with basic TensorFlow functionality but wants to write better TensorFlow code
You might be thinking, with the plethora of resources available (e.g., TensorFlow documentation, StackOverFlow.com, etc.), isn’t it easy (and free) to learn TensorFlow? Yes and no. If you just need “some” solution to a problem you’re working on, you might be able to hack one using the resources out there. But chances are that it will be a suboptimal solution, because to come up with an effective one, you need to build a strong mental image of how TensorFlow executes code, understand the functionality provided in the API, understand limitations, and so on. It is also important to understand TensorFlow and gain knowledge in an incremental and structured manner, which is very difficult to do by simply reading freely available resources at random. A strong mental image and solid knowledge come with many years of experience (while keeping a close eye on new features available, GitHub issues, and stackoverflow.com questions) or from a book written by a person with many years of experience. The million-dollar question here is not “How do I use TensorFlow to solve my problem?” but “How do I use TensorFlow effectively to solve my problem?” Coming up with an effective solution requires a solid grokking of TensorFlow. An effective solution, in my mind, can be one that does (but is not limited to) the following:
-
Keeps the code relatively concise without sacrificing readability too much (e.g., avoiding redundant operations, aggregating operations when possible)
-
Uses the latest and greatest features available in the API to avoid reinventing the wheel and to save time
-
Utilizes optimizations whenever possible (e.g., avoiding loops and using vectorized operations)
If you asked me to summarize this book into a few words, I would say “enabling the reader to write effective TensorFlow solutions.”
1.6 Should we really care about Python and TensorFlow 2?
Here we will get to know about the two most important technologies you’ll be studying heavily: Python and TensorFlow. Python is the foundational programming language we will be using to implement various TensorFlow solutions. But it is important to know that TensorFlow supports many different languages, such as C++, Go, JavaScript, and so on.
The first question we should try to answer is “Why are we picking Python as our choice of programming language?” Python’s popularity has recently increased, especially in the scientific community, due to the vast number of libraries that have fortified Python (e.g., pandas, NumPy, scikit-learn), which has made conducting a scientific experiment/simulation and logging/visualizing/reporting the results much easier. In figure 1.2, you can see how Python has become the most popular search term (at least in the Google search engine). If you narrow the results to just the machine learning community, you will see an even higher margin.
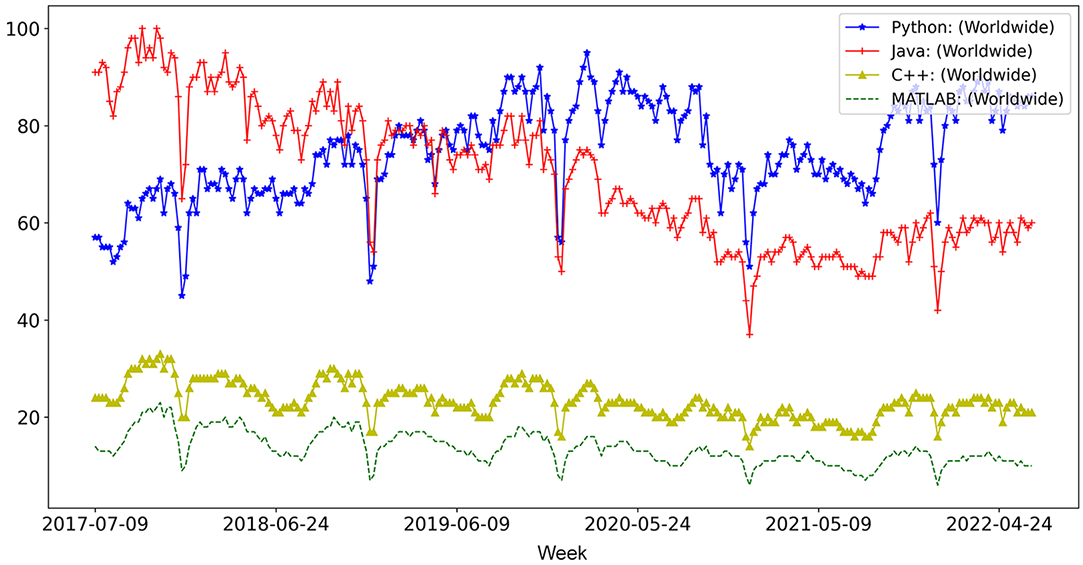
Figure 1.2 Popularity of different programming languages (2015-2020)
The next question to answer is “Why did we pick TensorFlow?” TensorFlow has been there almost since deep learning became popular (http://mng.bz/95P8). TensorFlow has been refined and revised over roughly five years, becoming more and more stable over time. Furthermore, unlike other counterpart libraries, TensorFlow provides an ecosystem of tools to satisfy your machine learning needs, from prototyping to model training to models. In figure 1.3, you can see how TensorFlow compares to one of its popular competitors, PyTorch.

Figure 1.3 Popularity of TensorFlow and PyTorch (2015-2020)
It’s also worth inspecting how much of a performance increase we gain as the size of the data grows. Figure 1.4 compares a popular scientific computation library (NumPy) to TensorFlow in a matrix multiplication task. This was tested on an Intel i5 ninth-generation processor and an NVIDIA 2070 RTX 8 GB GPU. Here, we are multiplying two randomly initialized matrices (each having size n × n). We have recorded the time taken for n = 100, 1000, 5000, 7500, 1000. On the left side of the graph, you can see the difference in time growth. NumPy shows an exponential growth of time taken as the size of the matrix grows. However, TensorFlow shows approximately linear growth. On the right side you can see how many seconds it takes if a TensorFlow operation takes one second. The message is clear: TensorFlow does much better than NumPy as the amount of data grows.

Figure 1.4 Comparing NumPy and TensorFlow computing libraries in a matrix multiplication task
Summary
-
Deep learning has become a hot topic due to the unprecedented performance it delivers when provided ample amounts of data.
-
TensorFlow is an end-to-end machine learning framework that provides ecosystem-facilitating model prototyping, model building, model monitoring, model serving, and more.
-
TensorFlow, just like any other tool, has strengths and weaknesses. Therefore, it is up to the user to weigh these against the problem they are trying to solve.
-
TensorFlow is a great tool to quickly prototype deep learning models with a vast range of complexities.
-
TensorFlow is not suited to analyzing/manipulating a small-structure data set or developing complex text-processing data pipelines.
-
This book goes beyond teaching the reader to implement some TensorFlow solution and teaches the reader to implement effective solutions with minimal effort while reducing the chance of errors.