
Chapter 4 showed you how to create a dynamic, parameterized, and metadata-driven process to fully load data from an on-premises SQL Server to Azure Data Lake Storage Gen2. This chapter will demonstrate how to fully load all of the snappy compressed parquet data files from ADLS Gen2 into an Azure dedicated SQL pool.
- 1)
PolyBase
- 2)
Copy command
- 3)
Bulk insert
First, there is some prep work to do by creating the datasets and the pipelines demonstrated in the first few sections of the chapter. Toward the end of the chapter, the three methods for loading data that have been listed previously will be discussed and demonstrated.
Recreate the Pipeline Parameter Table
Begin by recreating the pipeline_parameter table in the ADF_DB that you had created in Chapter 4 to make it much more robust in preparation for the ADF pipeline that will be built in this chapter.
Notice from the columns listed in the code that there are quite a few new metadata fields that have been added and can be captured within the ADF pipelines by creating dynamic datasets and pipelines.
Create the Datasets
In this next section, create a source dataset for the ADLS Gen2 snappy compressed parquet files and a sink dataset for the Azure dedicated SQL pool.
- 1)
DS_ADLS_TO_SYNAPSE
- 2)
DS_ADLS_TO_SYNAPSE_MI
- 3)
DS_SYNAPSE_ANALYTICS_DW
Then the following subsections will show how to create each one.
DS_ADLS_TO_SYNAPSE
Start by creating a source ADLS Gen2 dataset with parameterized paths. Remember that the pipeline_date has been added to the pipeline_parameter table that you had created in Chapter 4 since the pipeline_date captures the date when the data was loaded to ADLS Gen2. In this step, you are loading data from ADLS Gen2 into a Synapse Analytics dedicated SQL pool. You could either rerun the pipeline from Chapter 4 or manually enter a date in this pipeline_date column , which would ideally contain the latest folder date. Chapter 8 will discuss how to automate the insertion of the max folder date into this pipeline_date column to ensure this column always has the latest and max folder date that can be passed into the parameterized ADF pipeline. This will be achieved by using a Stored Procedure activity that runs immediately following the success of a Copy activity.
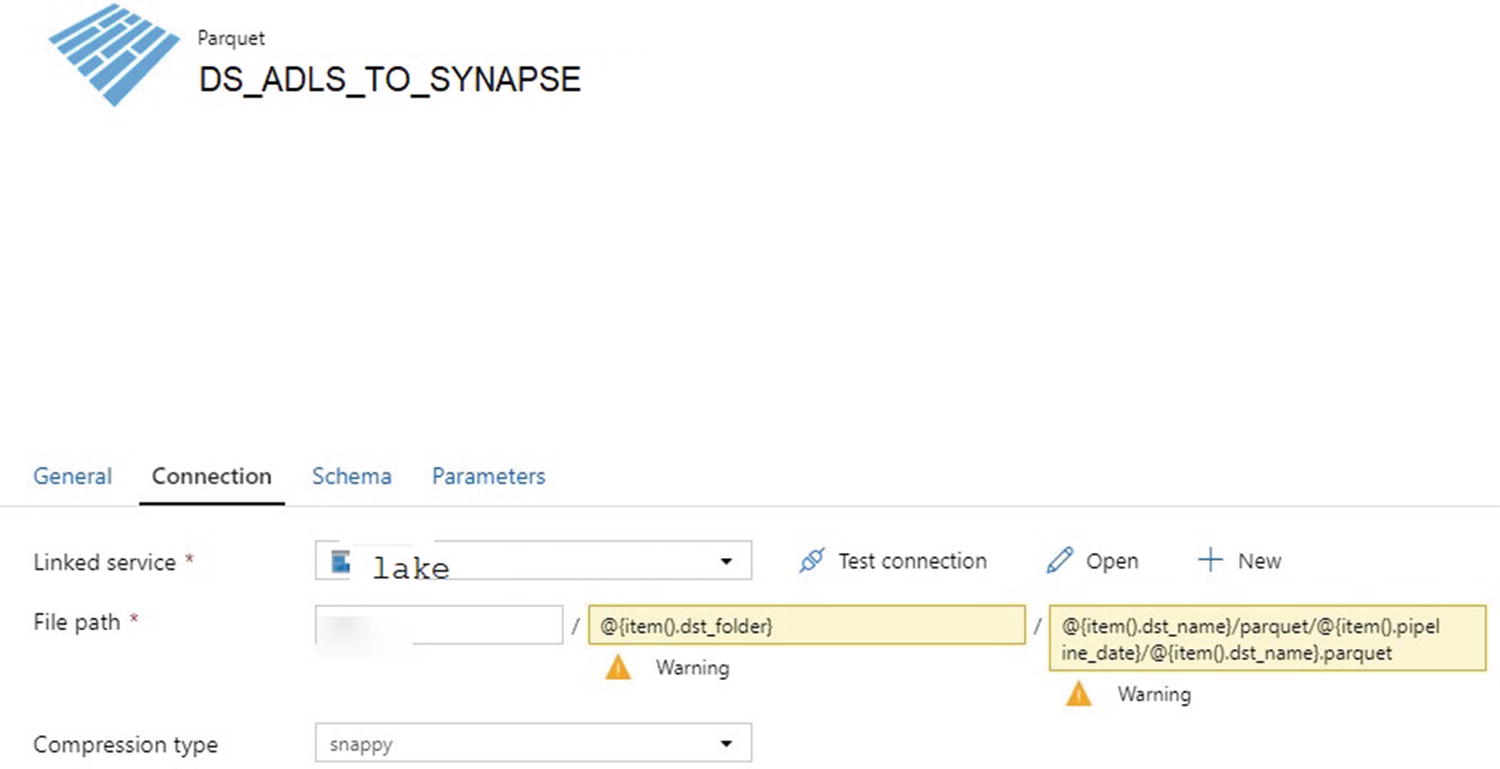
ADF parameterized connections for ADLS Gen2 parquet folders and files
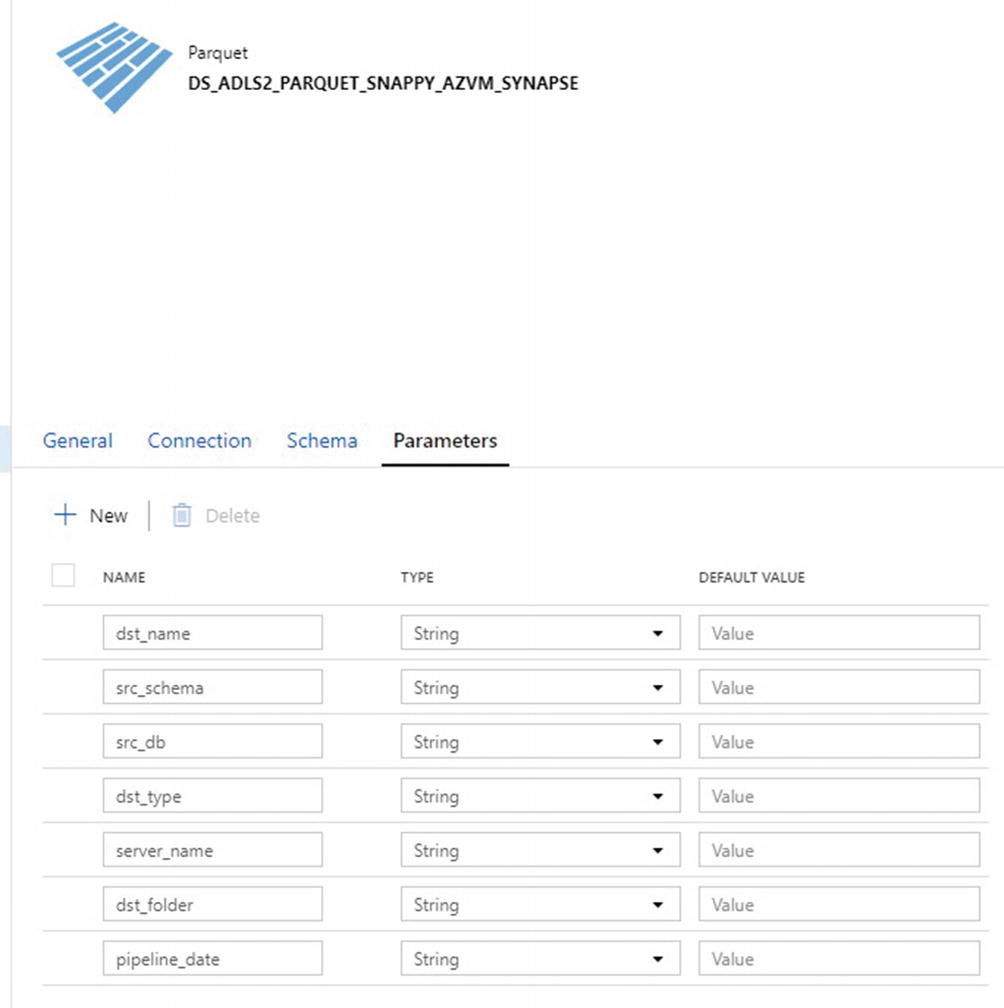
ADF parameters for ADLS Gen2 parquet folders and files
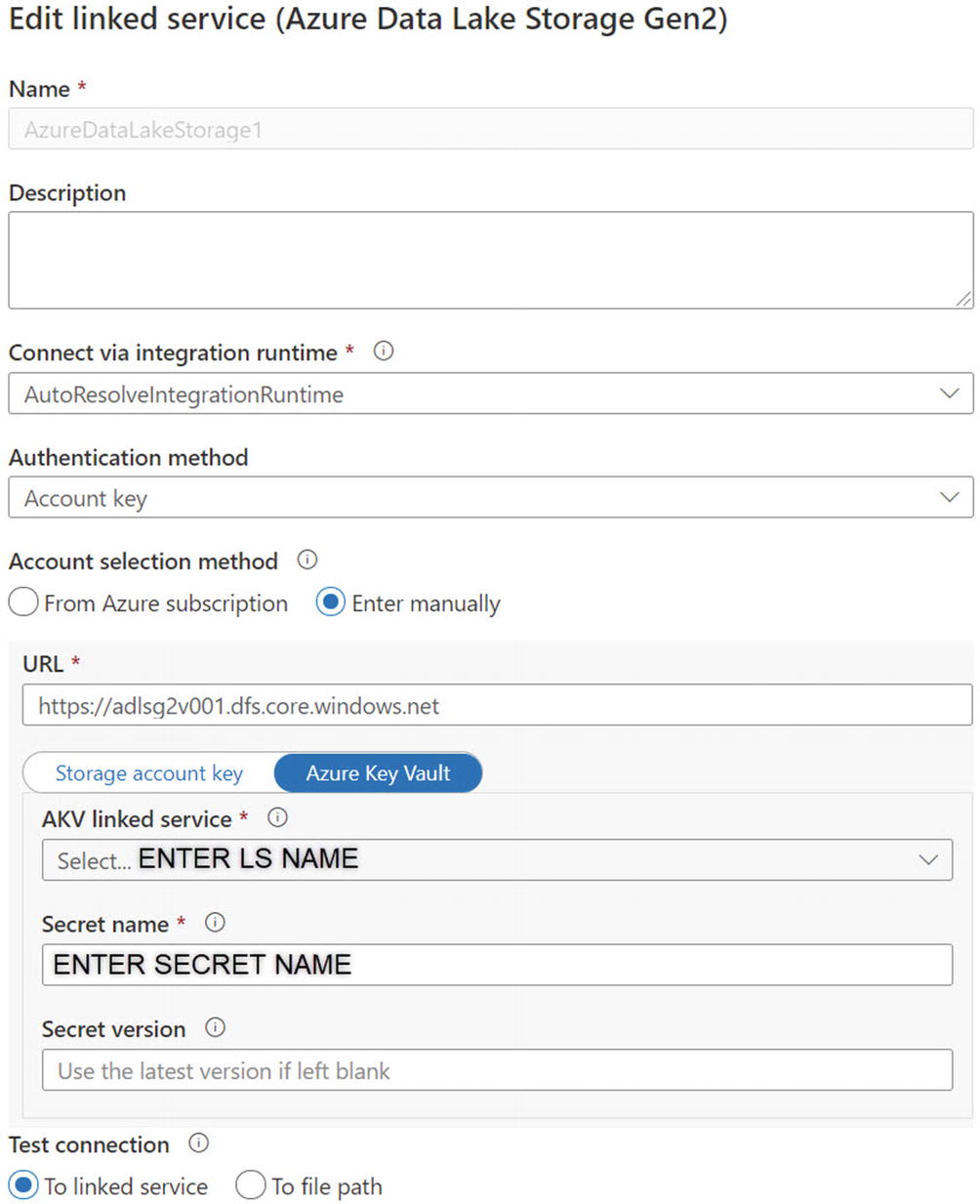
ADF linked service connection properties using Azure Key Vault
DS_ADLS_TO_SYNAPSE_MI
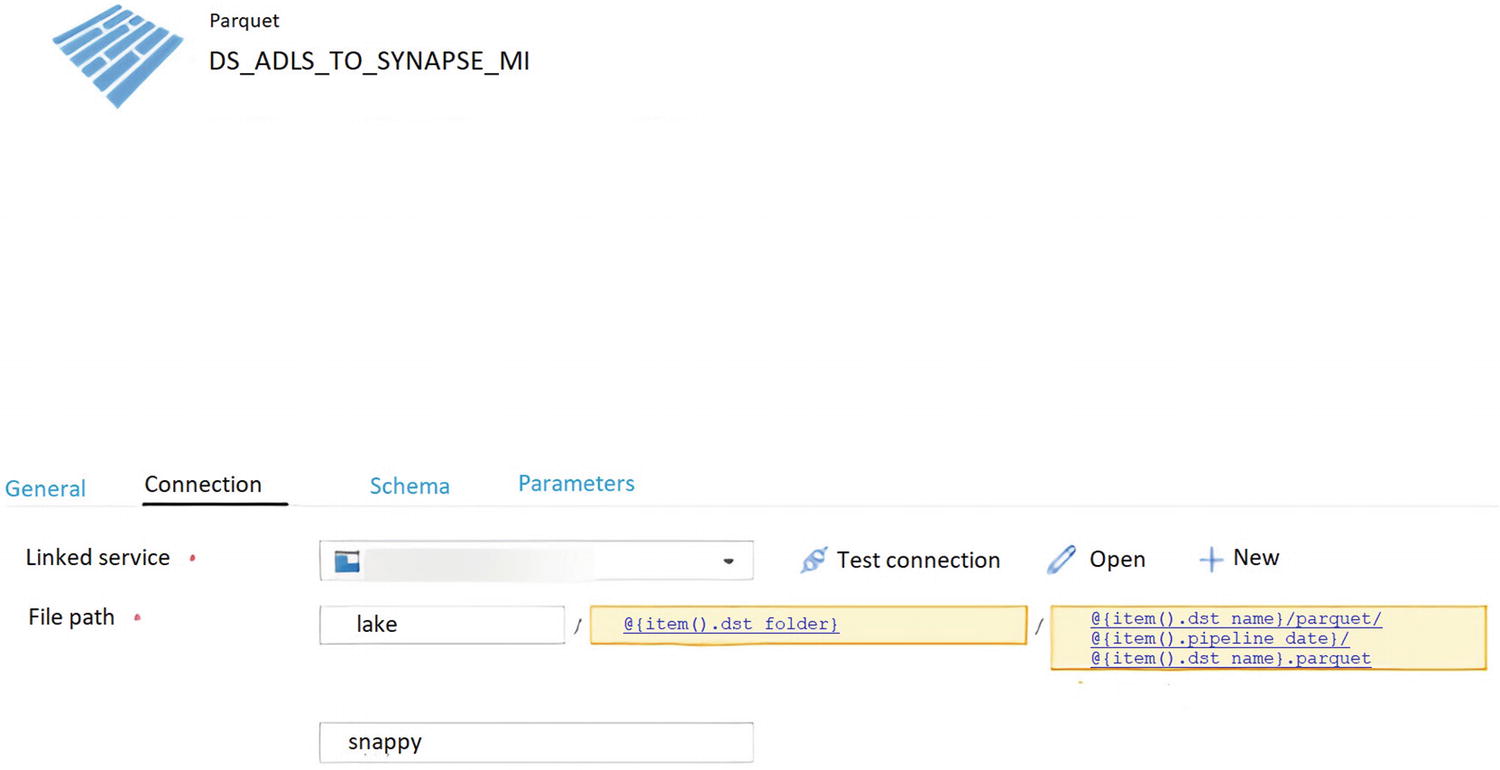
ADF dataset connection properties using Managed Identity

ADF parameters for ADLS Gen2 parquet folders and files – Managed Identity

ADF linked service connections
In this section, a new ADF linked service connection has been created using Managed Identity .
DS_SYNAPSE_ANALYTICS_DW

ADF Synapse DW linked service connection properties
Create the Pipeline
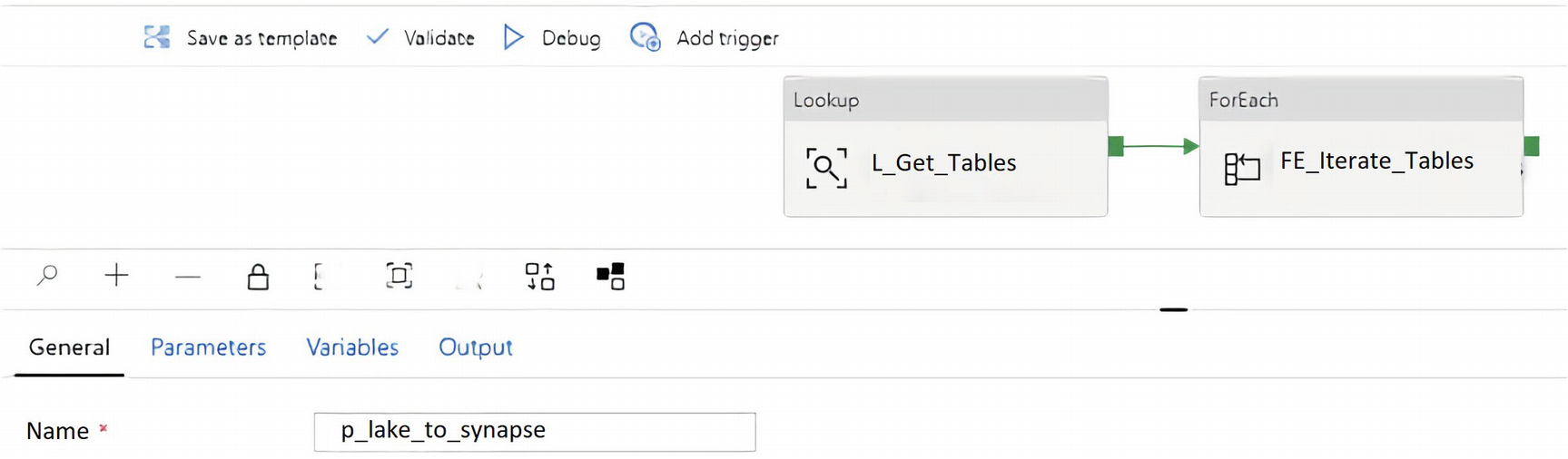
ADF pipeline canvas containing Lookup and ForEach loop activities
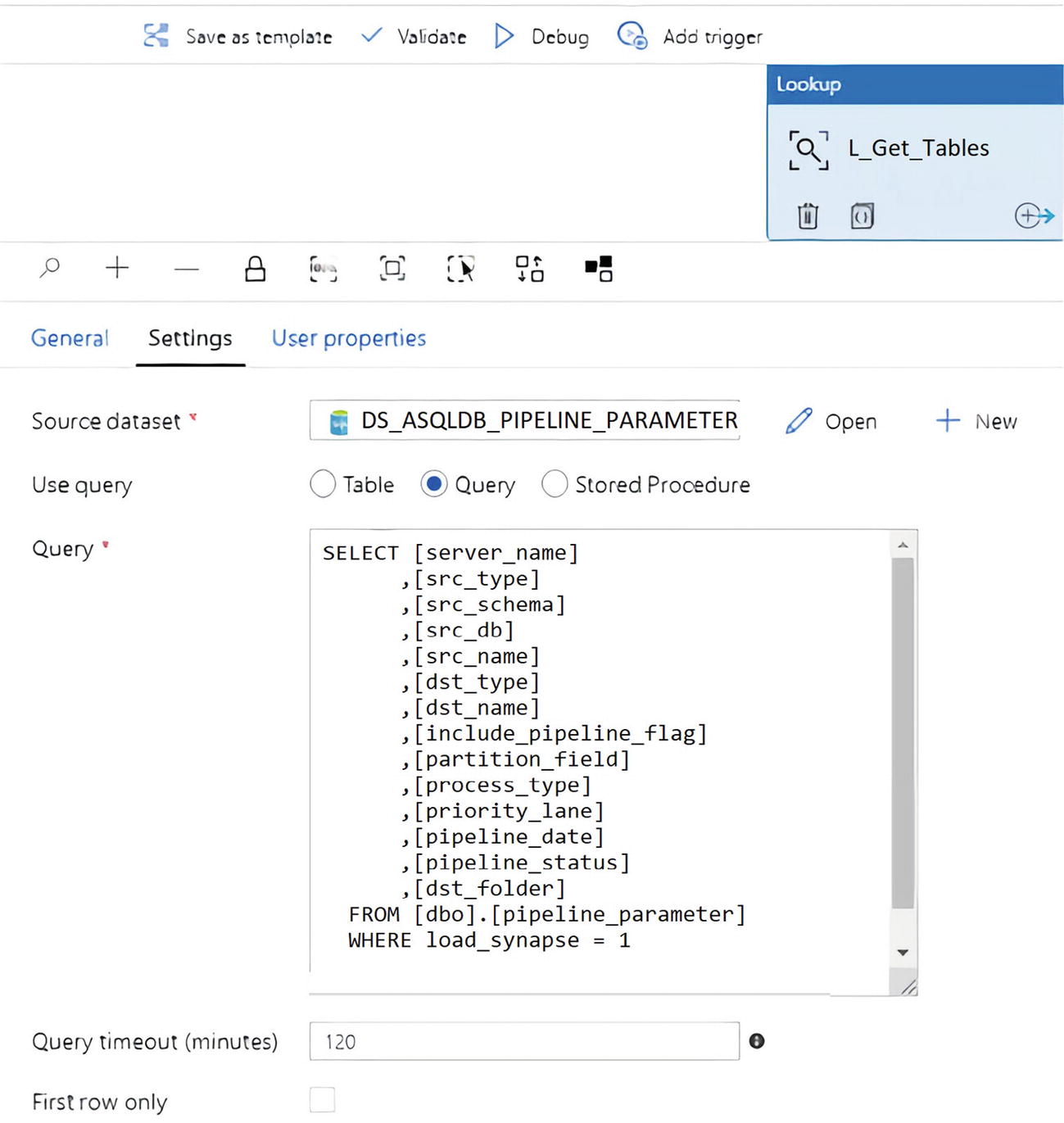
ADF Lookup activity query setting
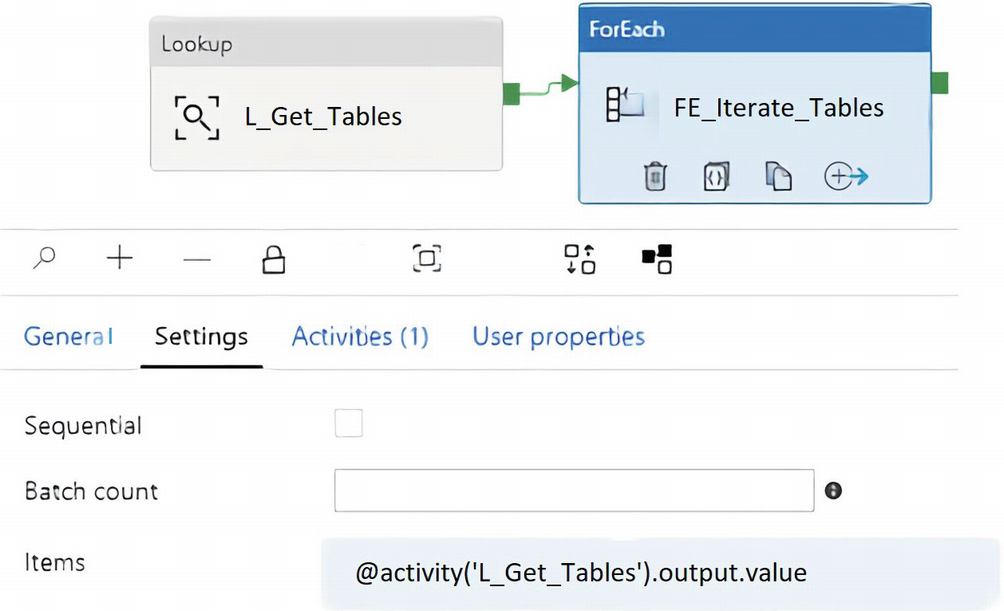
ADF ForEach activity settings
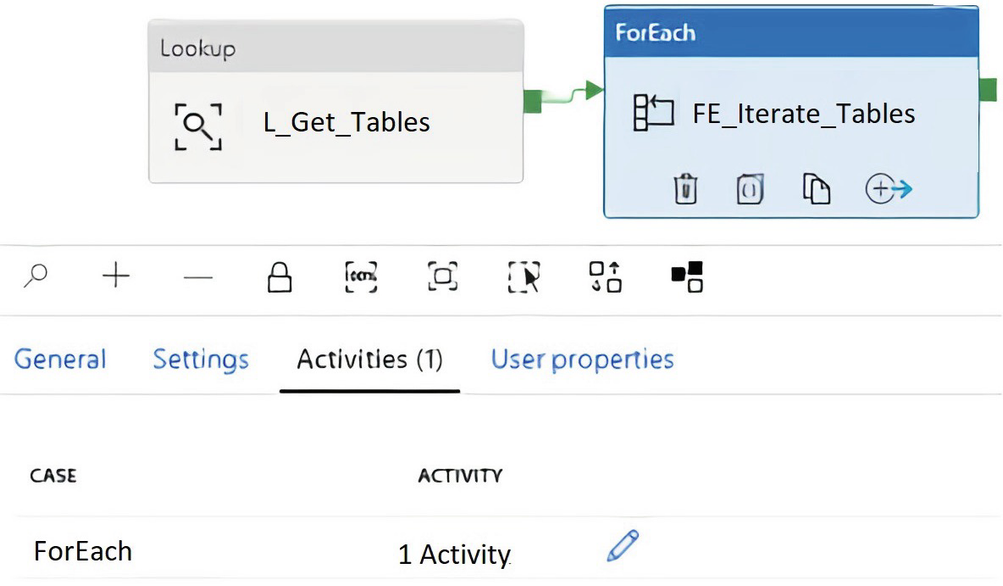
ADF ForEach activities
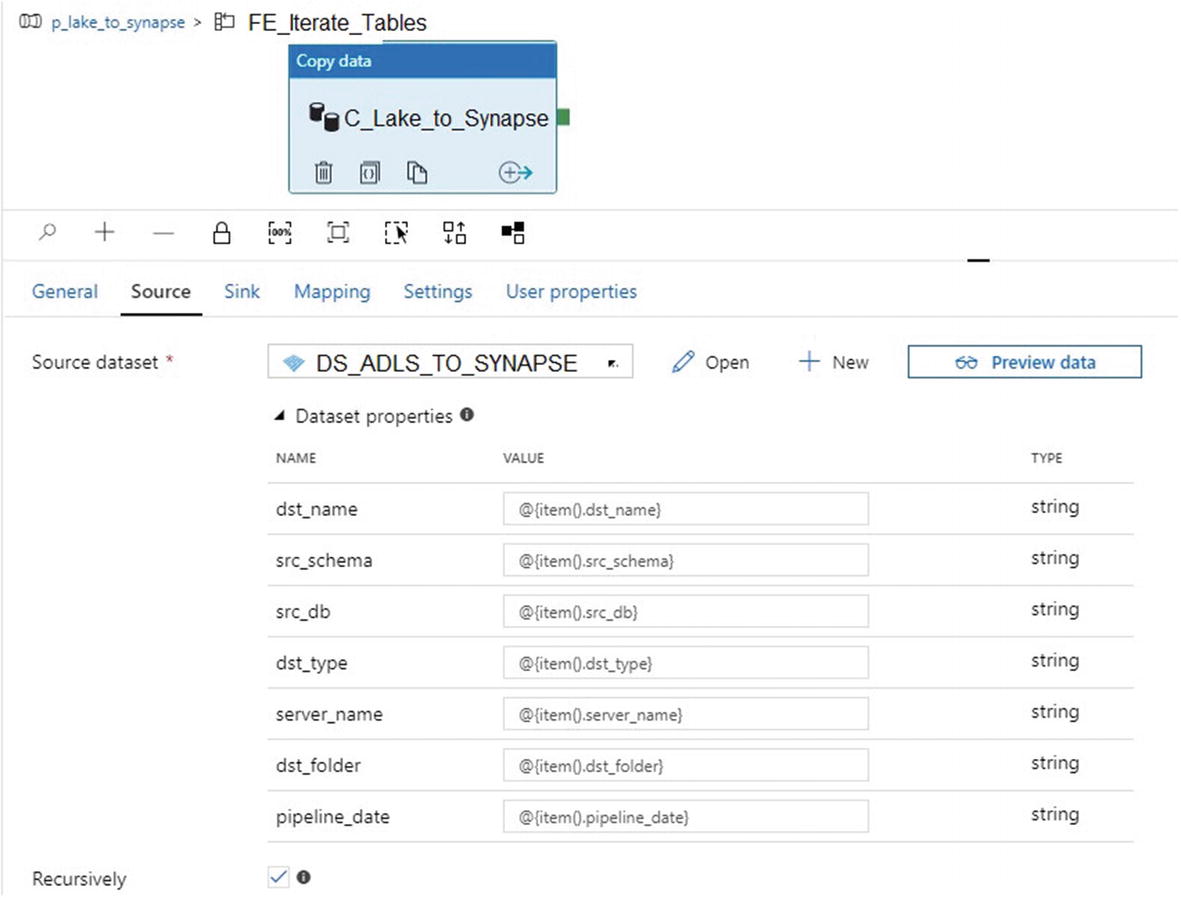
ADF Copy activity source dataset properties
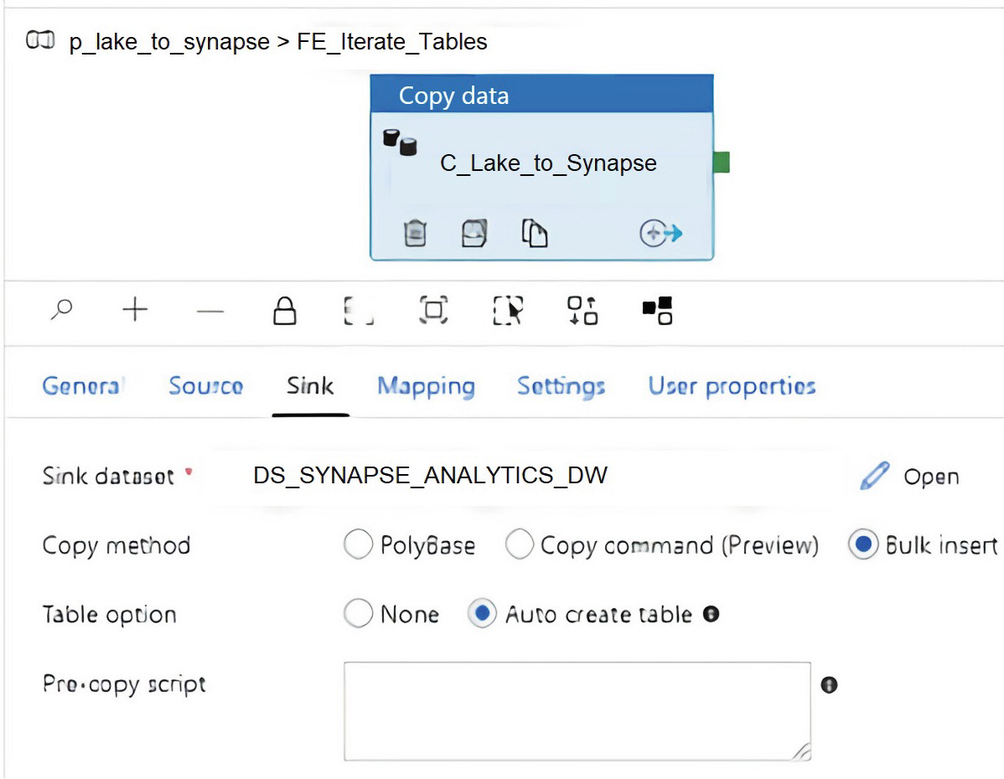
ADF Copy activity sink dataset properties
Based on the current configurations of the pipeline, since it is driven by the pipeline_parameter table, when (n) number of tables/records are added to the pipeline parameter table and the load_synapse flag is set to 1, then the pipeline will execute and load all tables to Azure Synapse Analytics dedicated SQL pools in parallel based on the copy method that is selected.
Choose the Copy Method
Now, finally, we have arrived at the choice of copy method. There are three options for the sink copy method. Bulk insert, PolyBase, and Copy command are all options that you will learn to use in this section.
BULK INSERT
SQL Server provides the BULK INSERT statement to perform large imports of data into SQL Server using T-SQL efficiently, quickly, and with minimal logging operations.
Within the Sink tab of the ADF Copy activity, set the copy method to Bulk insert. “Auto create table” automatically creates the table if it does not exist using the schema from the source file. This isn’t supported when the sink specifies a stored procedure or the Copy activity is equipped with the staging settings. For this scenario, the source file is a parquet snappy compressed file that does not contain incompatible data types such as VARCHAR(MAX), so there should be no issues with the “Auto create table” option.

ADF Copy activity sink pre-copy script
If the default Auto create table option does not meet the distribution needs for custom distributions based on tables, then there is “Add dynamic content” that can be leveraged to use a distribution method specified in the pipeline parameter table per table.
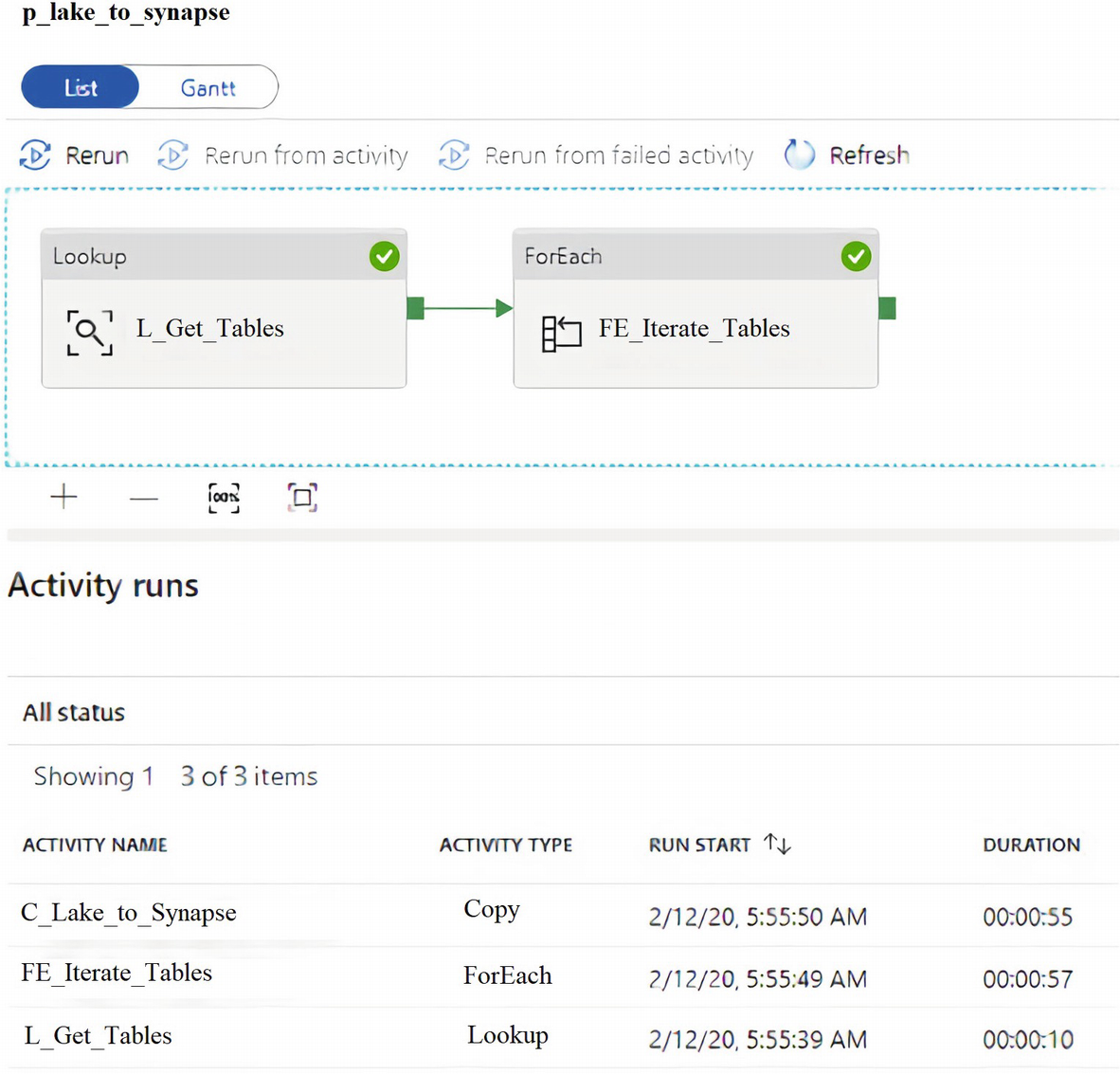
ADF pipeline success for Bulk insert

ADF pipeline run details for Bulk insert
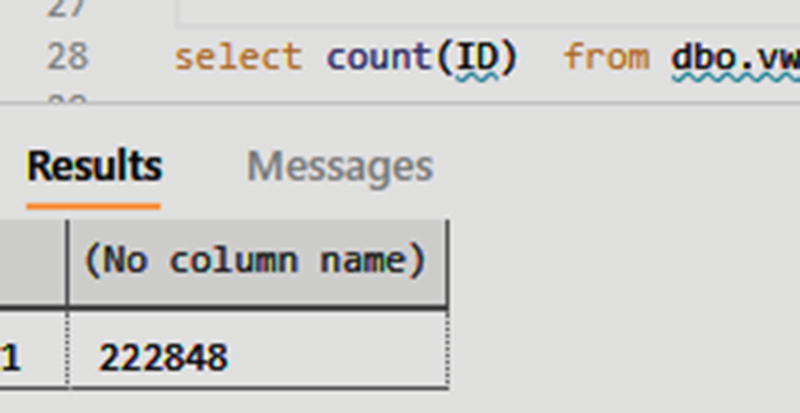
Query Synapse Analytics dedicated SQL pool tables to verify Bulk insert ADF pipeline results
The Bulk insert method also works for an on-premises SQL Server as the source with a Synapse Analytics dedicated SQL pool being the sink .
PolyBase
Using PolyBase is an efficient way to load a large amount of data into Azure Synapse Analytics with high throughput. You'll see a large gain in throughput by using PolyBase instead of the default Bulk insert mechanism.
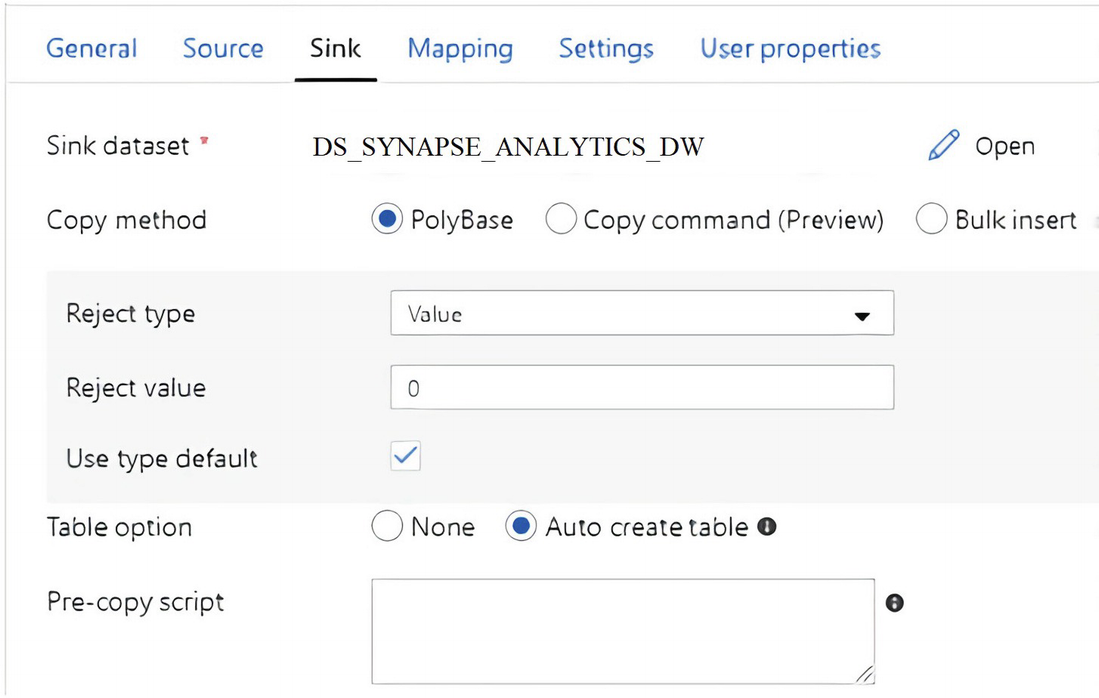
ADF pipeline sink dataset properties to select PolyBase
PolyBase will need Managed Identity credentials to provision Azure AD and grant Data Factory full access to the database.
After researching the error, the reason is because the original Azure Data Lake Storage linked service from source dataset DS_ADLS_TO_SYNAPSE is using an Azure Key Vault to store authentication credentials, which is an unsupported Managed Identity authentication method at this time for using PolyBase and Copy command .
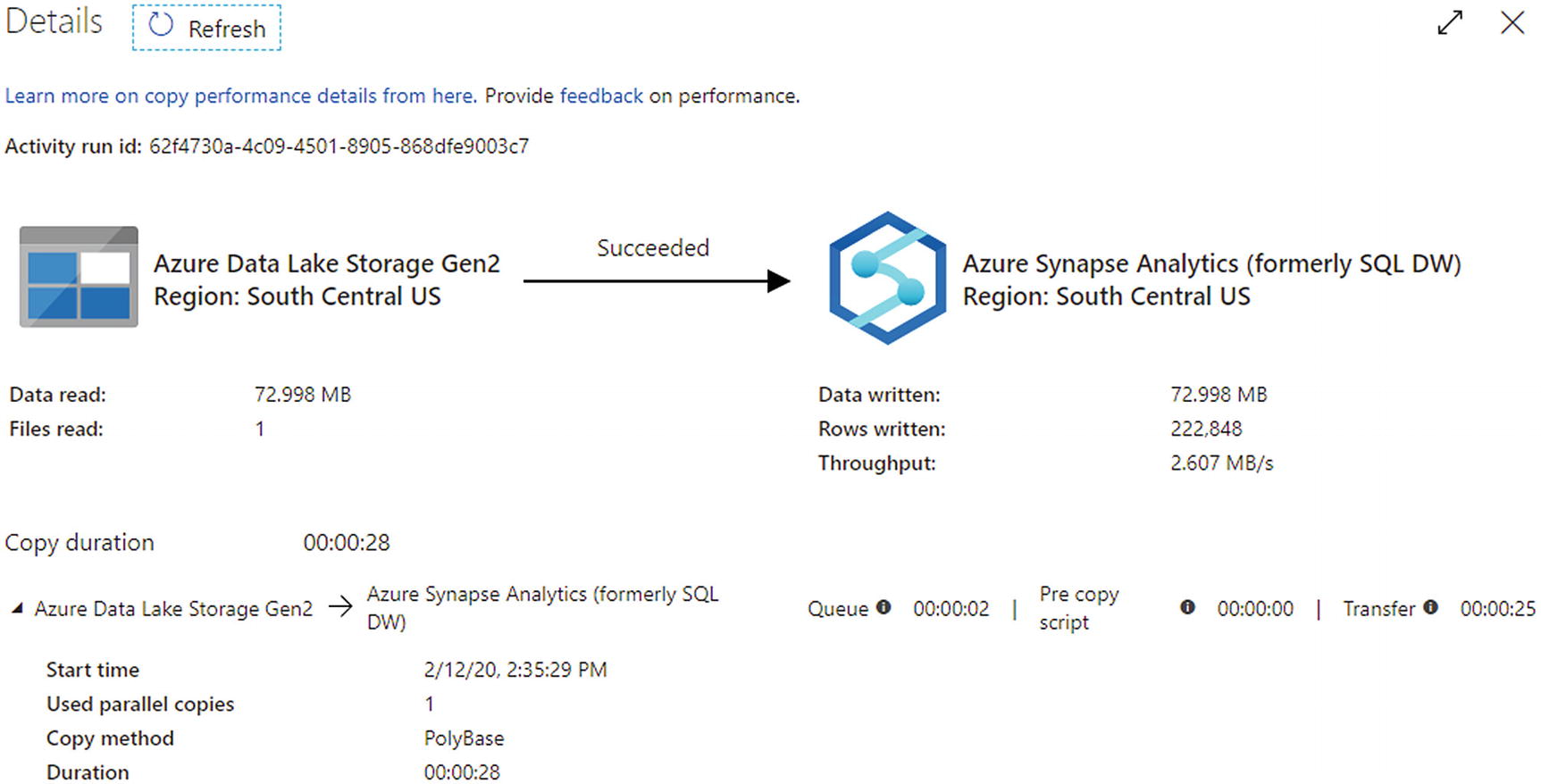
ADF pipeline execution showing success after changing to Managed Identity
Copy Command

Configure Copy command in ADF sink

ADF pipeline execution results
Note that it is important to consider scheduling and triggering your ADF pipelines once they have been created and tested. Triggers determine when the pipeline execution will be fired, based on the trigger type and criteria defined in the trigger. There are three main types of Azure Data Factory triggers: the Schedule trigger that executes the pipeline on a wall-clock schedule, the Tumbling window trigger that executes the pipeline on a periodic interval and retains the pipeline state, and the event-based trigger that responds to a blob-related event. Additionally, ADF features alerts to monitor pipeline and trigger failures and send notifications via email, text and more.
Summary
In this chapter, I showed you how to create a source Azure Data Lake Storage Gen2 dataset and a sink Synapse Analytics dedicated SQL pool dataset along with an Azure Data Factory pipeline driven by a parameter table. You also learned how to load snappy compressed parquet files into a Synapse Analytics dedicated SQL pool by using three copy methods: Bulk insert, PolyBase, and Copy command. This chapter taught you about the various ingestion options that are available in Azure Data Factory.