
In the previous chapters, I demonstrated how to load data from ADLS Gen2 and then into a Synapse Analytics dedicated SQL pool using Data Factory. In this chapter, I will demonstrate how to leverage the pipelines that have been built to implement a process for tracking the log activity for pipelines that run and persist the data.
- 1.
Option 1 – Create a Stored Procedure activity: Updating pipeline status and datetime columns in a static pipeline parameter table using ADF can be achieved by using a Stored Procedure activity.
- 2.
Option 2 – Create a CSV log file in Data Lake Storage Gen2: Generating a metadata CSV file for every parquet file that is created and storing the logs as CSV files in hierarchical folders in ADLS Gen2 can be achieved using a Copy data activity.
- 3.
Option 3 – Create a log table in Azure SQL Database: Creating a pipeline log table in Azure SQL Database and storing the pipeline activity as records in the table can be achieved by using a Copy data activity.

ADF options for logging custom pipeline data
Option 1: Create a Stored Procedure Activity
The Stored Procedure activity will be used to invoke a stored procedure in a Synapse Analytics dedicated SQL pool.
For this scenario, you might want to maintain your pipeline_status and pipeline_date details as columns in your adf_db.dbo.pipeline_parameter table rather than having a separate log table. The downside to this method is that it will not retain historical log data but will simply update the values in the original pipeline_parameter table based on a lookup of the incoming files to records in the pipeline_parameter table. This gives a quick, yet not necessarily robust, method of viewing the status and load date across all items in the pipeline parameter table. Specific use cases for this approach might be to log the max folder date based on the incoming folder and file names and timestamps.

ADF option 1 for logging data using a stored procedure

SSMS view showing stored procedure used by ADF option 1
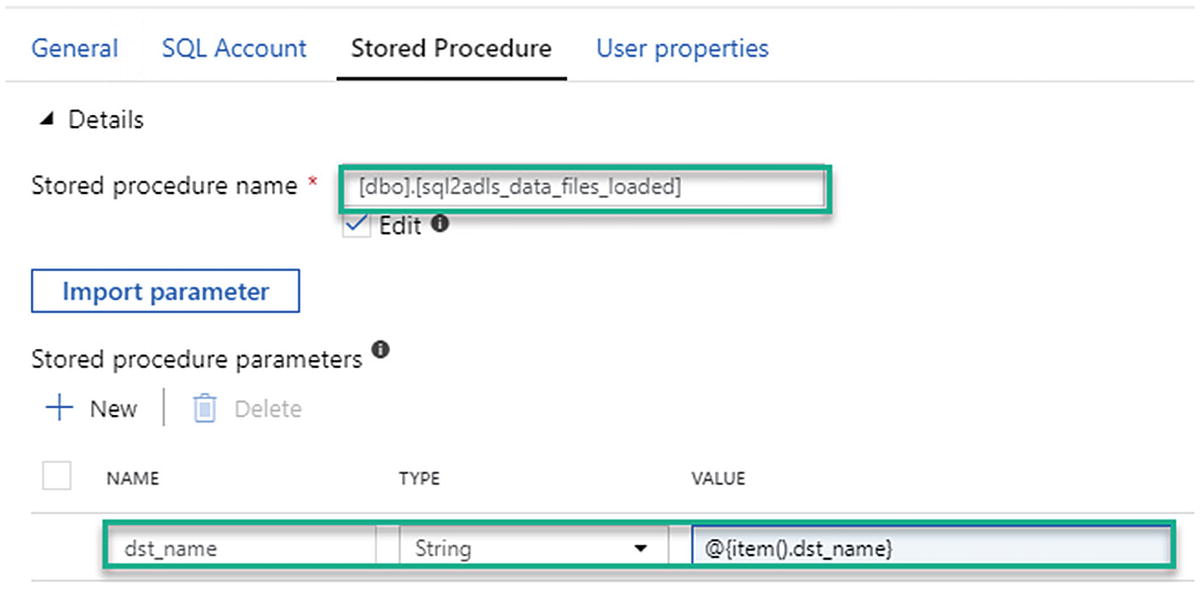
ADF stored procedure details and parameters
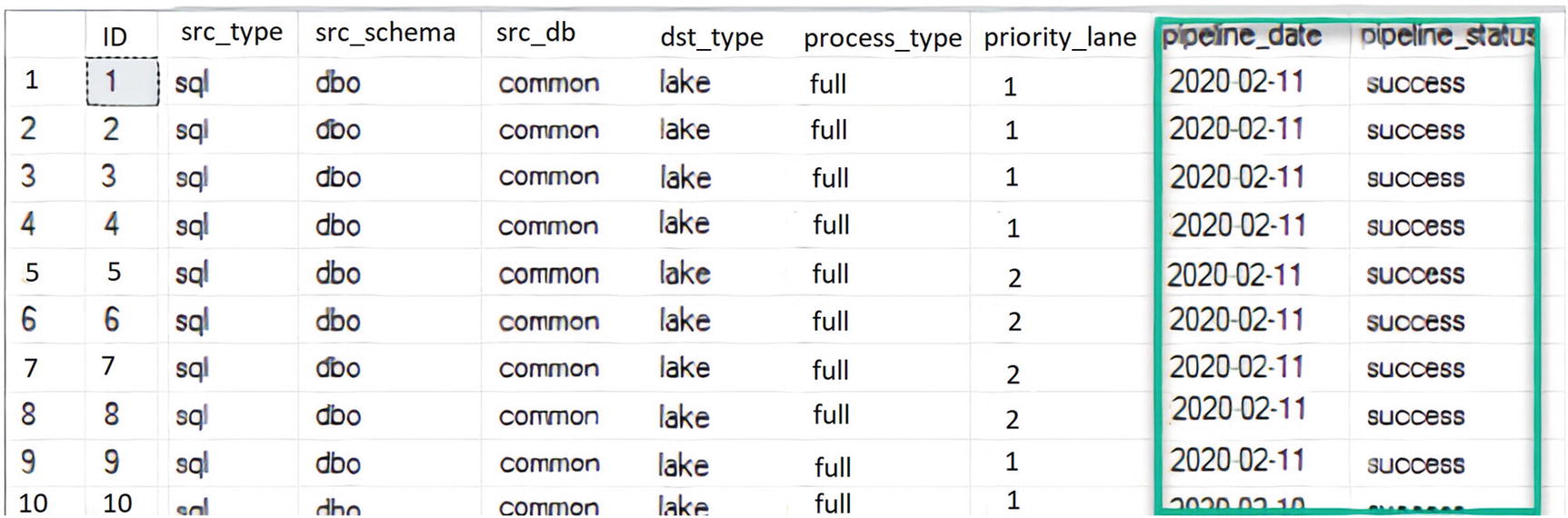
SSMS view of updated pipeline_date and pipeline_status columns from ADF stored procedure
Option 2: Create a CSV Log File in Data Lake Storage Gen2
Since your Copy-Table activity is generating snappy parquet files into hierarchical ADLS Gen2 folders, you may also want to create a CSV file containing pipeline run details for every parquet file in your ADLS Gen2 account. For this scenario, you could set up a Data Factory Event Grid trigger to listen for metadata files and then trigger a process to transform the source table and load it into a curated zone to somewhat replicate a near-real-time ELT process.

ADF option 2 for logging data using a Copy data activity to create a CSV file

ADF option 2 source query to extract pipeline activity metrics
Recall the notes from previous chapters that call out the embedding of source queries as code into the ADF pipeline merely for visual demonstration purposes. It is always a better and more efficient process to add the source query as a stored procedure and then call the stored procedure. This will help with ease of maintenance of the code in a centralized location.

ADF sink dataset for CSV
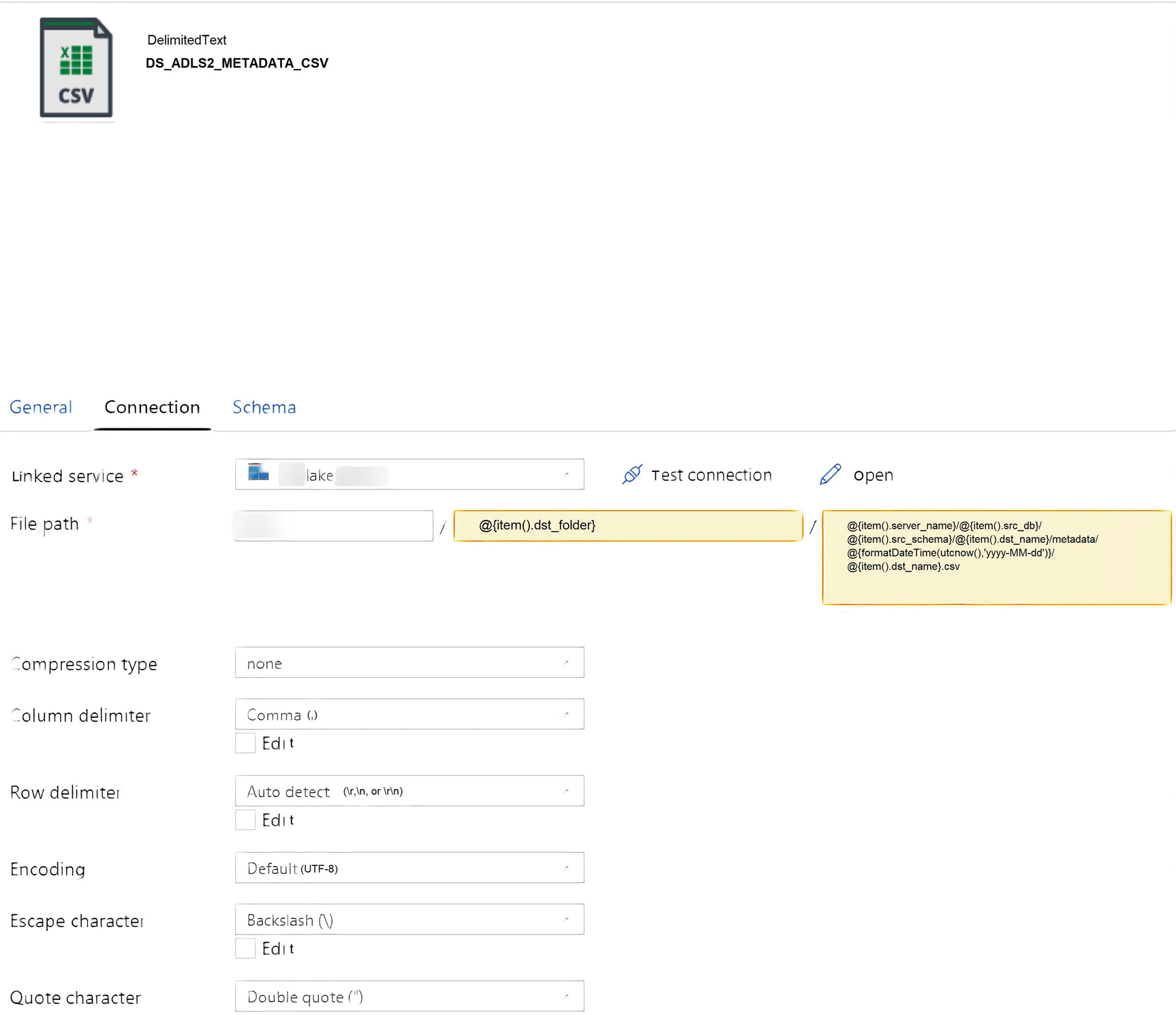
ADF sink dataset connection properties for CSV
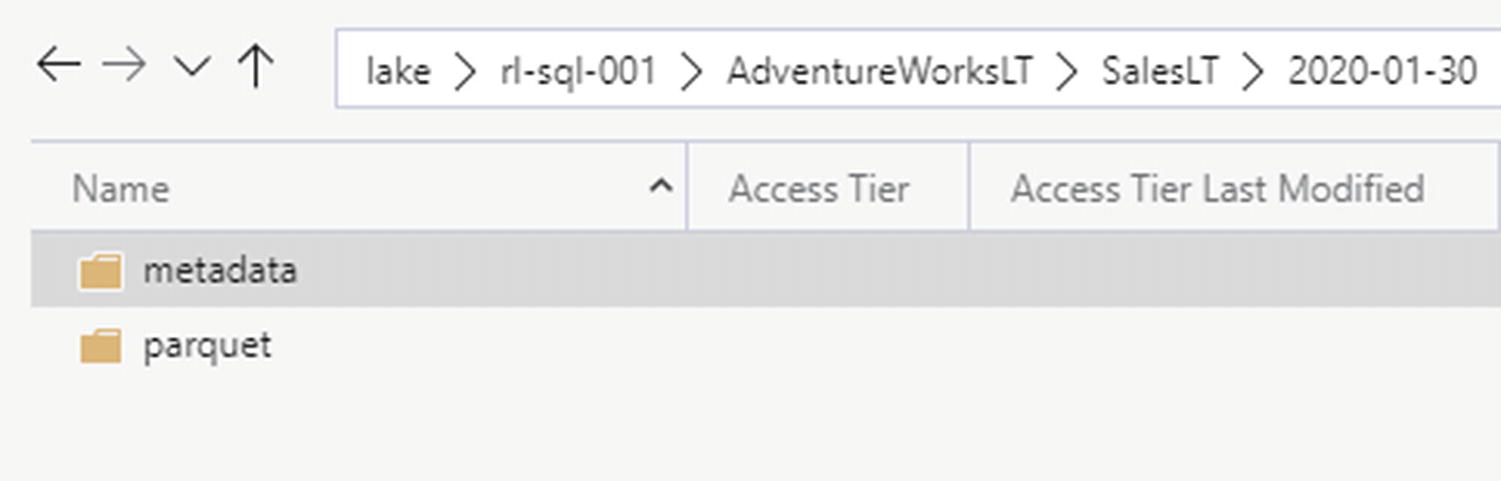
ADLS Gen2 folders generated by ADF pipeline option 2
ADLS Gen2 folders by timestamp created by ADF pipeline option 2

ADLS Gen2 metadata file containing ADF pipeline metrics from option 2

ADLS Gen2 metadata file containing details for ADF pipeline metrics from option 2
Option 3: Create a Log Table in Azure SQL Database

ADF option 3 for logging data using a Copy data activity written to a log table

ADF option 3 source query to extract pipeline activity metrics
The sink will be a connection to the SQL database pipeline log table that was created earlier.
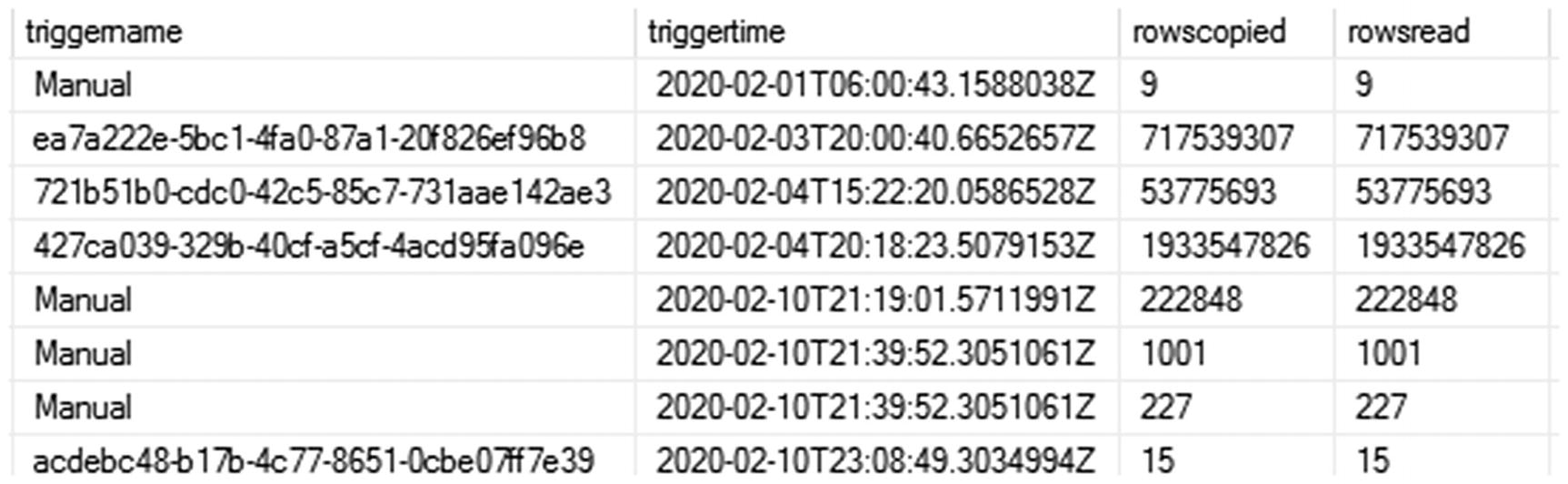
SSMS view of pipeline_log table results, which logged ADF option 3 pipeline data to SQL DW
Summary
In this chapter, I demonstrated how to log ADF pipeline data using a custom approach of extracting metrics for each table or file from the ADF pipeline and then either writing the results to the pipeline_parameter table, pipeline_log table, or a CSV file in ADLS Gen2. This custom logging process can be added to multiple ADF pipeline activity steps for a robust and reusable logging and auditing process that can be easily queried in SSMS through custom SQL queries and even linked to Power BI dashboards and reports to promote robust reporting on logged data. In the next chapter, I will demonstrate how to log error details from your ADF pipeline into an Azure SQL table.