In Chapter 6, you learned how to load data lake files into a Synapse Analytics dedicated SQL pool using Data Factory by using the COPY INTO command as one such load option. Now that you have designed and developed a dynamic process to auto-create and load the ETL schema tables into a Synapse Analytics dedicated SQL pool with snappy compressed parquet files, let’s explore options for creating and loading tables into a curated schema, where you can dynamically define schemas and distribution types at runtime to create curated schema tables. Note that in many modern cloud-based data architectural patterns, the staging and curation is happening more within the data lake. However, this chapter will demonstrate the vast capabilities of persisting large volumes of tables into a data warehouse by using a few simple ADF pipelines. Despite all of the benefits of Delta Lake, which we will cover in greater detail in Chapter 15, customers are still interested in persisting their final production-ready, trusted, and curated data into a SQL data warehouse for a number of reasons, including ease of analytical querying, ease of connectivity to Power BI and other reporting tools, and more.
In Chapter 4, I introduced the concept of a pipeline parameter table to track and control all SQL Server tables, servers, schemas, and more. Essentially, this pipeline parameter table is set up to drive the Data Factory orchestration process. To solve for dynamically being able to define distribution types along with curated schemas, I will introduce a few new columns to this pipeline parameter table: [distribution_type], [dst_schema], and [dst_name]. These new columns can be used within the Data Factory pipeline to dynamically create and load curated tables from the ETL schema.
Dynamically Create and Load New Tables Using an ADF Pre-copy Script
The ADF pipeline process to load tables from the source Data Lake Storage account into Synapse Analytics DW tables will begin with a Lookup activity to the pipeline parameter table shown in Figure 7-1 using a query in which you can specify your flags and filters appropriately.
Figure 7-1
ADF Lookup settings showing query to select from pipeline_parameter table
Note that Figure 7-1 adds the source SQL select statement as a query for the purpose of this exercise. As a best practice, I would recommend considering converting this SQL statement to a stored procedure instead and then calling the code through the ADF pipeline by setting the source query to Stored Procedure. This will allow for easier maintenance of the code outside of the ADF environment.
Once you add the source lookup query, the filter pipeline_status = 'success' allows for tracking if the files successfully made it to the lake, and this is done via a SQL stored procedure. Also, it is important to note that there are quite a few columns in this pipeline parameter that help track steps throughout the end-to-end process. For the purpose of this exercise, there is an interest in columns [dst_schema], [dst_schema], and [distribution_type].
Add the following code to the source query section of the ADF Lookup activity shown in Figure 7-1:
SELECT [id],
[server_name],
[src_type],
[src_schema],
[src_db],
[src_name],
[dst_type],
[dst_name],
[include_pipeline_flag],
[partition_field],
[process_type],
[priority_lane],
[pipeline_date],
[pipeline_status],
[load_synapse],
[load_frequency],
[dst_folder],
[file_type],
[lake_dst_folder],
[spark_flag],
[data_sources_id],
[dst_schema],
[distribution_type],
[load_sqldw_etl_pipeline_date],
[load_sqldw_etl_pipeline_status],
[load_sqldw_curated_pipeline_date],
[load_sqldw_curated_pipeline_status],
[load_delta_pipeline_date],
[load_delta_pipeline_status]
FROM [dbo].[pipeline_parameter]
WHERE load_synapse = 1
AND pipeline_status = 'success'
AND include_pipeline_flag = 1
AND process_type = 'full'
AND load_frequency = 'daily'
As an example, the dst_schema and distribution_type in the pipeline_ parameter table may look like the following illustration in Figure 7-2.
Figure 7-2
dst_schema and distribution_type in the pipeline_parameter table
As you move on to the ForEach loop activity shown in Figure 7-3, ensure that the Items field within the Settings tab is filled in correctly to get the output of the Lookup activity.
Figure 7-3
ADF ForEach settings for the pipeline
Here is the code that you will need to add to the Items field within the ForEach loop activity in Figure 7-3:
@activity('L_Get_Tables').output.value
Drill into the ForEach activities. There is the Copy data activity shown in Figure 7-4 along with the required dataset properties.
Figure 7-4
ADF Copy activity source settings and dataset properties
The names and values of the source dataset properties as shown in Figure 7-4 can be found in the following:
Name
Value
dst_name
@{item().dst_name}
src_schema
@{item().src_schema}
distribution_type
@{item().distribution_type}
load_sqldw_etl_pipeline_date
@{item().load_sqldw_etl_pipeline_date}
load_sqldw_etl_pipeline_status
@{item().load_sqldw_etl_pipeline_status}
load_sqldw_curated_pipeline_date
@{item().load_sqldw_curated_pipeline_date}
load_sqldw_curated_pipeline_status
@{item().load_sqldw_curated_pipeline_status}
dst_schema
@{item().dst_schema}
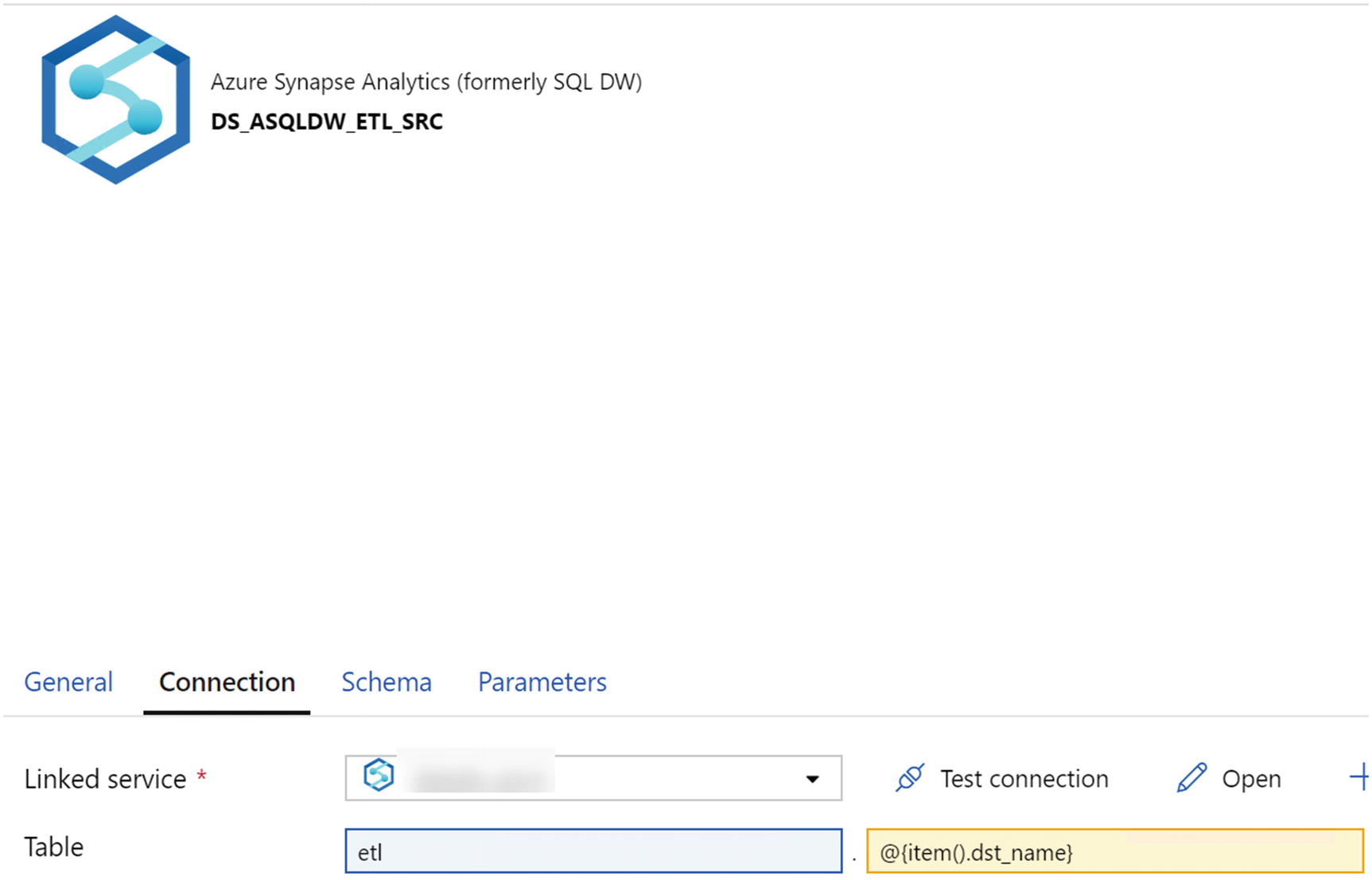
Configure the source dataset connection for the Synapse Analytics dedicated SQL pool ETL schema as shown in Figure 7-5. Notice that the etl schema is hard-coded. However, the table name is coming from the pipeline_parameter table.
Figure 7-5
ADF source dataset connection properties
Here is the code that you will need to enter in the Table connection setting in Figure 7-5:
etl.@{item().dst_name}
The sink dataset shown in Figure 7-6 is defined as the curated schema where you will need to parametrize the destination schema and name. Note that the source dataset contains parameters that will be needed from the source schema. However, the sink dataset does not contain any parameters.
Figure 7-6
ADF sink dataset connection properties
Here is the code that you will need to enter into the Table connection setting in Figure 7-6:
@{item().dst_schema}.@{item().dst_name}
After creating the datasets, take a closer look at the pre-copy script. Note that Bulk insert is being used as the copy method since the data currently exists in the ETL schema in a Synapse Analytics dedicated SQL pool and must be loaded to a curated schema.
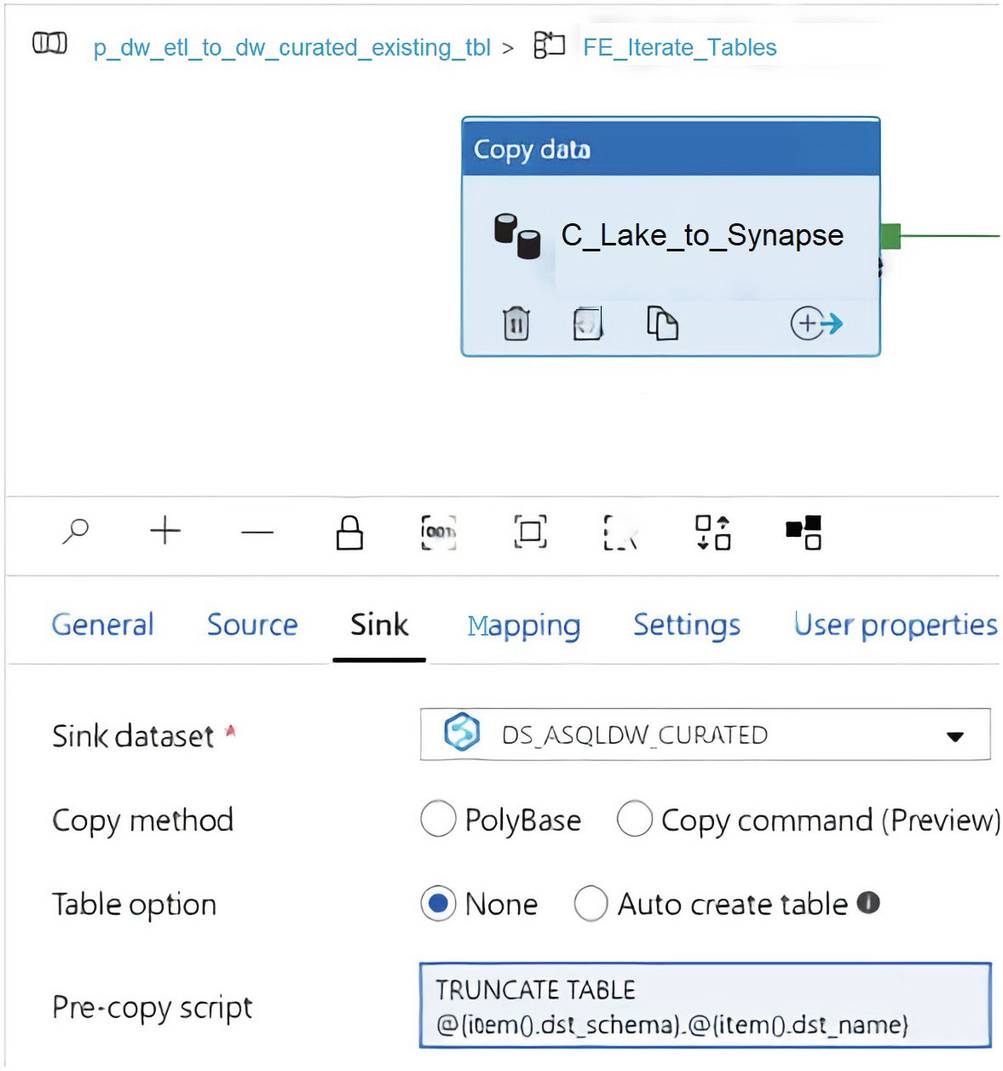
Also set the table option to “None” as shown in Figure 7-7, since the tables will be created using the following pre-copy script, which is basically a dynamic Create Table as Select (CTAS) syntax that references the destination schema and name along with the distribution type from the pipeline_parameter table, specifically the sections shown in Figure 7-2. Additionally, SELECT TOP (0) is being used in the script because we only want to create the tables using this step and load them using the ADF Copy activity.
Figure 7-7
ADF Copy data sink settings
Here is the code that is used in the sink pre-copy script in Figure 7-7:
Note that the pre-copy script shown in Figure 7-7 is merely an example that shows you the range of capabilities that can be used for a pre-copy script. In this scenario, I have demonstrated how to add dynamic string interpolation functions that use metadata-driven pipeline parameters all within a pre-copy SQL statement. As a best practice, try to avoid embedding code directly into the ADF pipeline activities and only consider such options when there may be noticeable limitations with the product’s features, which may warrant the use of such custom configurations.
After running the pipeline, all the curated tables will be created in the Synapse Analytics dedicated SQL pool with the appropriate destination schema, name, and distribution type.
Dynamically Truncate and Load Existing Tables Using an ADF Pre-copy Script
In a scenario where you may need to dynamically truncate and load existing tables rather than recreate the tables, approach that task by simply truncating the destination table as shown in Figure 7-8. This approach would be the only notable change from the previous pipeline.
Figure 7-8
ADF Copy data sink settings with pre-copy script changed to TRUNCATE
Here is the code that is used in the sink pre-copy script in Figure 7-8:
Dynamically Drop, Create, and Load Tables Using a Stored Procedure
Finally, let’s explore an option to use stored procedures from the Synapse Analytics dedicated SQL pool to drop and create the curated tables.
The pipeline design will be very similar to the previous pipelines by starting with a lookup and then flowing into a ForEach loop activity, shown in Figure 7-9.
Figure 7-9
ADF pipeline flow containing Lookup and ForEach activities
Within the ForEach loop activity, there is one Stored Procedure activity called CTAS from the pipeline parameter shown in Figure 7-10. This stored procedure has been created within the Synapse Analytics dedicated SQL pool and is based on a dynamic Create Table as Select (CTAS) statement for which I will provide the code further in this section. Additionally, the destination name and schema have been defined as stored procedure parameters whose values are coming from the pipeline parameter table and are being passed to the stored procedure, shown in Figure 7-10.
Figure 7-10
ADF stored procedure details and parameters
It uses dynamic parameters that can be passed from the pipeline_parameter table to the stored procedure, which will be called by the ADF pipeline. Here is the source code that has been used in the [etl].[Ctas_from_pipeline_parameter] ADF stored procedure that is being called in the ForEach loop activity as shown in Figure 7-10.
After heading over to SSMS and then scripting the stored procedure, notice that the preceding script is doing the following
Declaring and setting the distribution_type along with ETL, curated, and schema/table names dynamically
Dropping the curated_stage table if it exists
Setting the SQL syntax to create the stage table as selecting all data from the etl table with the distribution type dynamically set
Dropping the actual/original curated table
Renaming the curated_stage to the actual/original curated table
In a scenario where you might be interested in renaming the original curated table, rather than dropping the original curated table, use this script in the Stored Procedure activity within the ADF pipeline:
+ @table_stage + ' TO ' + @name + '; if object_id ('''
+ @schematable_drop
+ ''',''U'') is not null drop table '
+ @schematable_drop + ';'
EXEC(@sql)
END
go
Lastly, it is important to note that within the Synapse Analytics dedicated SQL pool, if you are attempting to drop or rename a table that has dependencies linked to a materialized view that has been created, then the drop and rename script might fail.
Summary
In this chapter, I have outlined steps on how to dynamically create and load new tables into a Synapse Analytics dedicated SQL pool by using ADF’s pre-copy script within the Copy activity. Additionally, I covered how to dynamically truncate and load existing tables by using ADF’s pre-copy script, and finally I demonstrated how to dynamically drop, create, and load Synapse Analytics dedicated SQL pool tables by using a SQL stored procedure stored in a Synapse Analytics dedicated SQL pool.
Some of the examples that I have demonstrated in this chapter might not be fully applicable to your specific scenario or use case, but may help with further deepening your understanding of the capabilities of ADF and how to build and leverage customized and dynamic SQL scripts and stored procedures to fit specific use cases that might not be available through the out-of-the-box features within ADF. I hope you will find some of these examples helpful. In the next two chapters, you will learn more about how to make these ADF pipelines that you have learned about and built more robust by building custom audit and error logging processes to capture and persist the pipeline-related metrics within your SQL database tables after the ADF pipeline completes running.