
While working with Azure Data Lake Storage Gen2 and Apache Spark, users have learned about both the limitations of Apache Spark and the many data lake implementation challenges. The need for an ACID-compliant feature set is critical within the data lake landscape, and Delta Lake offers many solutions to the current limitations of the standard Azure Data Lake Storage Gen2 accounts.
Delta Lake is an open source storage layer that guarantees data atomicity, consistency, isolation, and durability in the lake. In short, a Delta Lake is ACID compliant. In addition to providing ACID transactions, scalable metadata handling, and more, Delta Lake runs on an existing data lake and is compatible with Apache Spark APIs. There are a few methods of getting started with Delta Lake. Databricks offers notebooks along with compatible Apache Spark APIs to create and manage Delta Lakes. Alternatively, Azure Data Factory’s Mapping Data Flows, which uses scaled-out Apache Spark clusters, can be used to perform ACID-compliant CRUD operations through GUI-designed ETL pipelines. This chapter will demonstrate how to get started with Delta Lake using Azure Data Factory’s Delta Lake connector through examples of how to create, insert, update, and delete in a Delta Lake.
Why an ACID Delta Lake
- 1.
Atomicity: Write either all data or nothing. Apache Spark save modes do not utilize any locking and are not atomic. With this, a failed job may leave an incomplete file and may corrupt data. Additionally, a failing job may remove the old file and corrupt the new file. While this seems concerning, Spark does have built-in data frame writer APIs that are not atomic but behave so for append operations. This however does come with performance overhead for use with cloud storage. The currently available Apache Spark save modes include ErrorIfExists, Append, Overwrite, and Ignore.
- 2.
Consistency: Data is always in a valid state. If the Spark API writer deletes an old file and creates a new one and the operation is not transactional, then there will always be a period of time when the file does not exist between the deletion of the old file and creation of the new. In that scenario, if the overwrite operation fails, this will result in data loss of the old file. Additionally, the new file may not be created. This is a typical Spark overwrite operation issue related to consistency.
- 3.
Isolation: Multiple transactions occur independently without interference. This means that when writing to a dataset, other concurrent reads or writes on the same dataset should not be impacted by the write operation. Typical transactional databases offer multiple isolation levels, such as read uncommitted, read committed, repeatable read, snapshot, and serializable. While Spark has task- and job-level commits, since it lacks atomicity, it does not have isolation types.
- 4.
Durability: Committed data is never lost. When Spark does not correctly implement a commit, then it overwrites all the great durability features offered by cloud storage options and either corrupts and/or loses the data. This violates data durability.
Prerequisites
Now that you have an understanding of the current data lake and Spark challenges along with benefits of an ACID-compliant Delta Lake, let’s get started with the exercise.
- 1.
Create a Data Factory V2: Data Factory will be used to perform the ELT orchestrations. Additionally, ADF’s Mapping Data Flows Delta Lake connector will be used to create and manage the Delta Lake.
- 2.
Create a Data Lake Storage Gen2: ADLS Gen2 will be the data lake storage, on top of which the Delta Lake will be created.
- 3.
Create Data Lake Storage Gen2 container and zones: Once your Data Lake Storage Gen2 account is created, also create the appropriate containers and zones. Revisit Chapter 3 for more information on designing ADLS Gen2 zones where I discuss how to design an ADLS Gen2 storage account. This exercise will use the Raw zone to store a sample source parquet file. Additionally, the Staging zone will be used for Delta Updates, Inserts, and Deletes and additional transformations. Though the Curated zone will not be used in this exercise, it is important to mention that this zone may contain the final ETL, advanced analytics, or data science models that are further transformed and curated from the Staging zone. Once the various zones are created in your ADLS Gen2 account, they would look similar to the illustration in Figure 15-1.
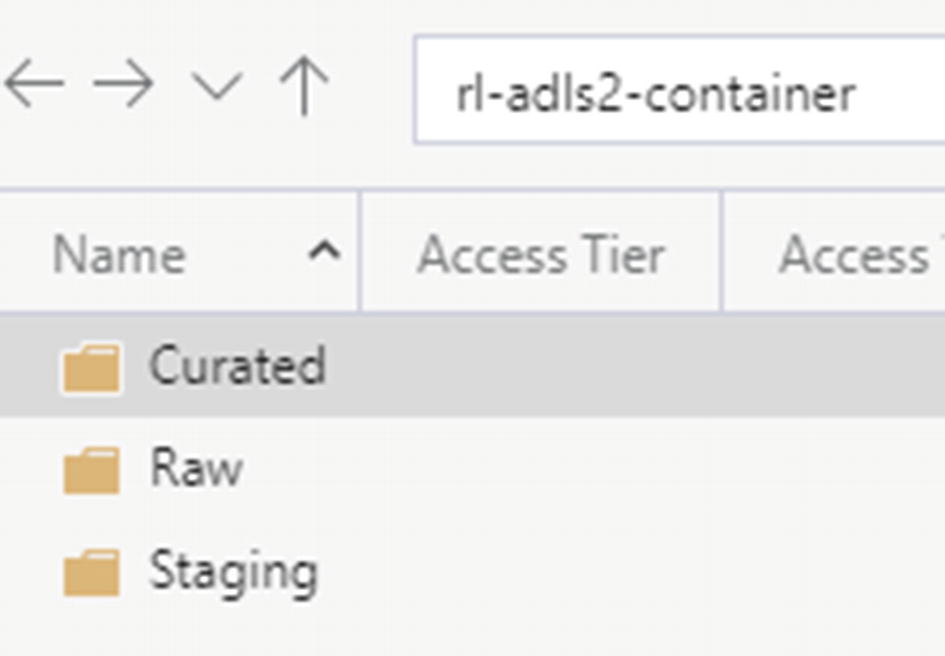
ADLS Gen2 zones/folders
- 4.
Upload data to the Raw zone: Finally, you’ll need some data for this exercise. By searching for “sample parquet files” online or within publicly available datasets, you’ll obtain access to a number of free sample parquet files. For this exercise, you could download the sample parquet files within the following GitHub repo (https://github.com/Teradata/kylo/tree/master/samples/sample-data/parquet) and then upload it to your ADLS Gen2 storage account, as shown in Figure 15-2.
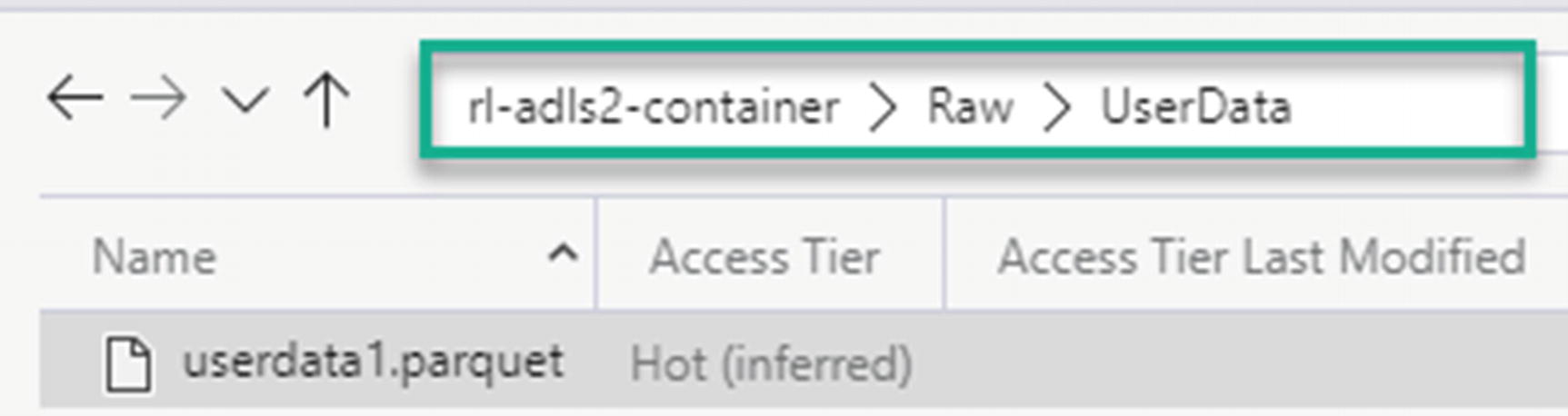
Sample userdata1.parquet file
- 5.
Create a Data Factory parquet dataset pointing to the Raw zone: The final prerequisite would be to create a Parquet format dataset in the newly created instance of ADF V2, as shown in Figure 15-3, pointing to the sample parquet file stored in the Raw zone.
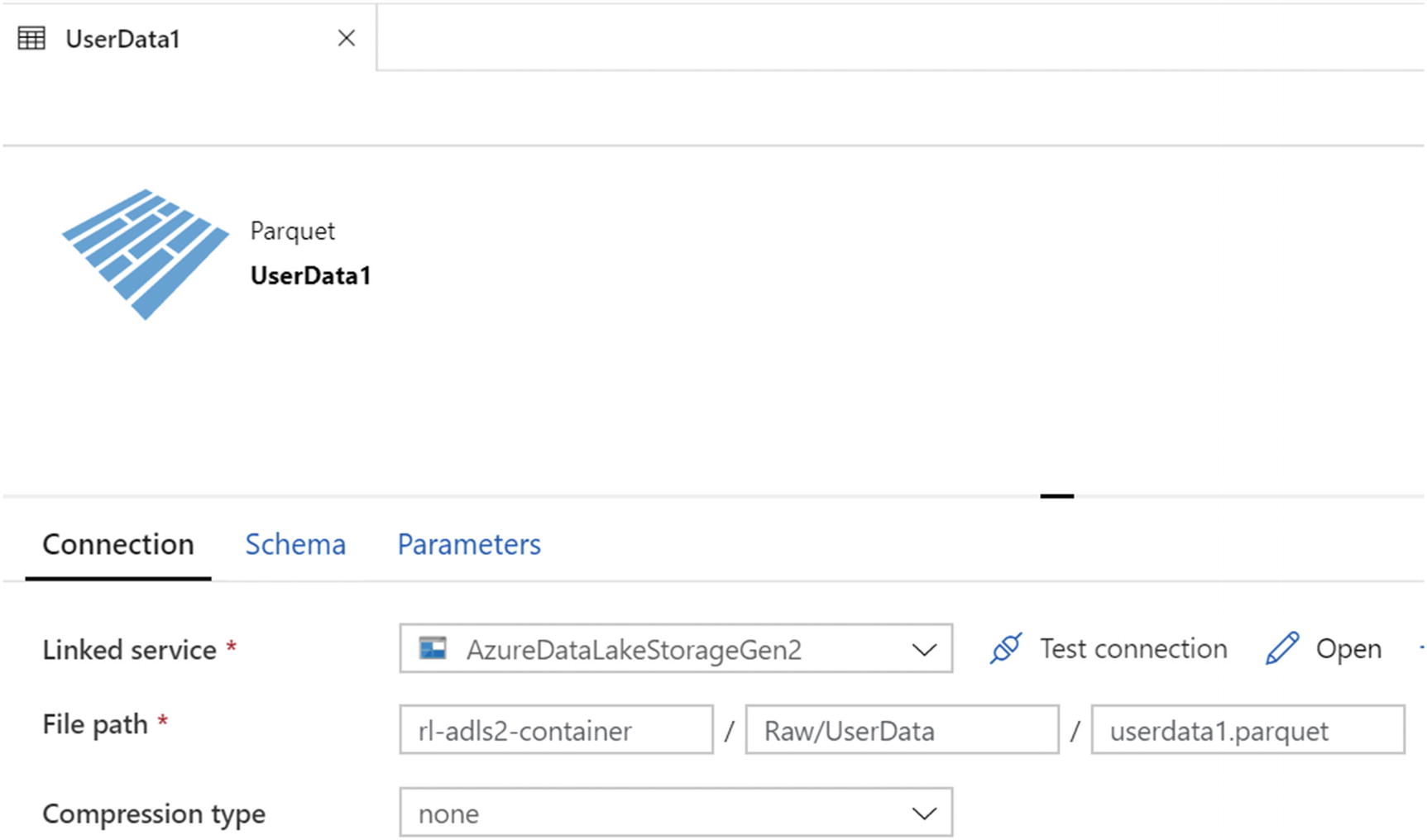
userData1 connection setting in ADF
Create and Insert into Delta Lake
Now that all prerequisites are in place, you are ready to create the initial delta tables and insert data from your Raw zone into the delta tables.
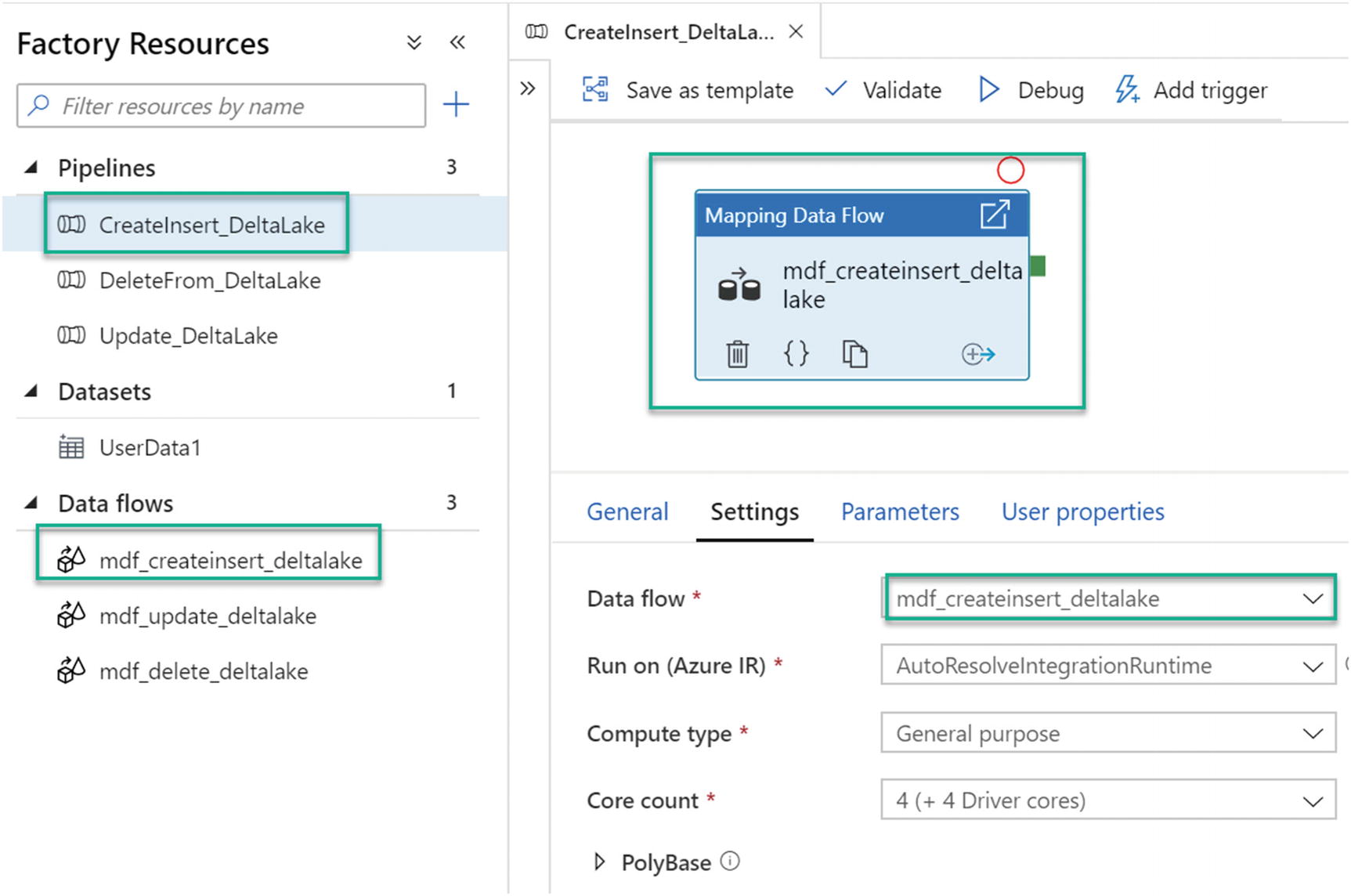
Mapping Data Flow canvas for insert
Within the data flow, add a source with the configuration settings shown in Figure 15-5. Also, check the option to “Allow schema drift.” When metadata related to fields, columns, and types change frequently, this is referred to as schema drift. Without a proper process to handle schema drift, an ETL pipeline might fail. ADF supports flexible schemas that change often. ADF treats schema drift as late binding. Therefore, the drifted schemas will not be available for you to view in the data flow.
When schema drift is enabled, all of the incoming fields are read from your source during execution and passed through the entire flow to the sink. All newly detected columns arrive as a string data type by default. If you need to automatically infer data types of your drifted columns, then you’ll need to enable Infer drifted column types in your source settings.
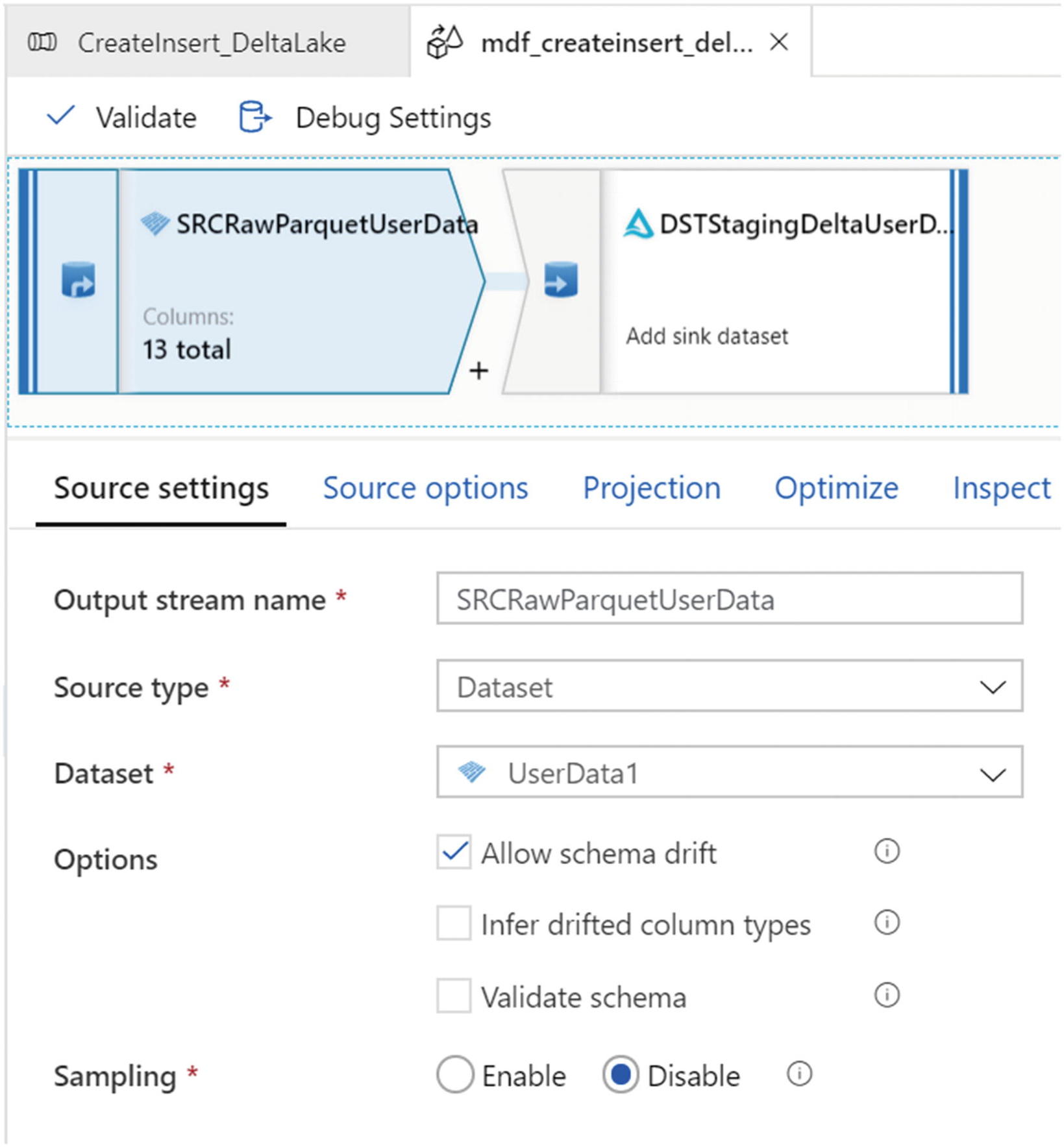
Mapping Data Flows ETL flow source settings for inserts
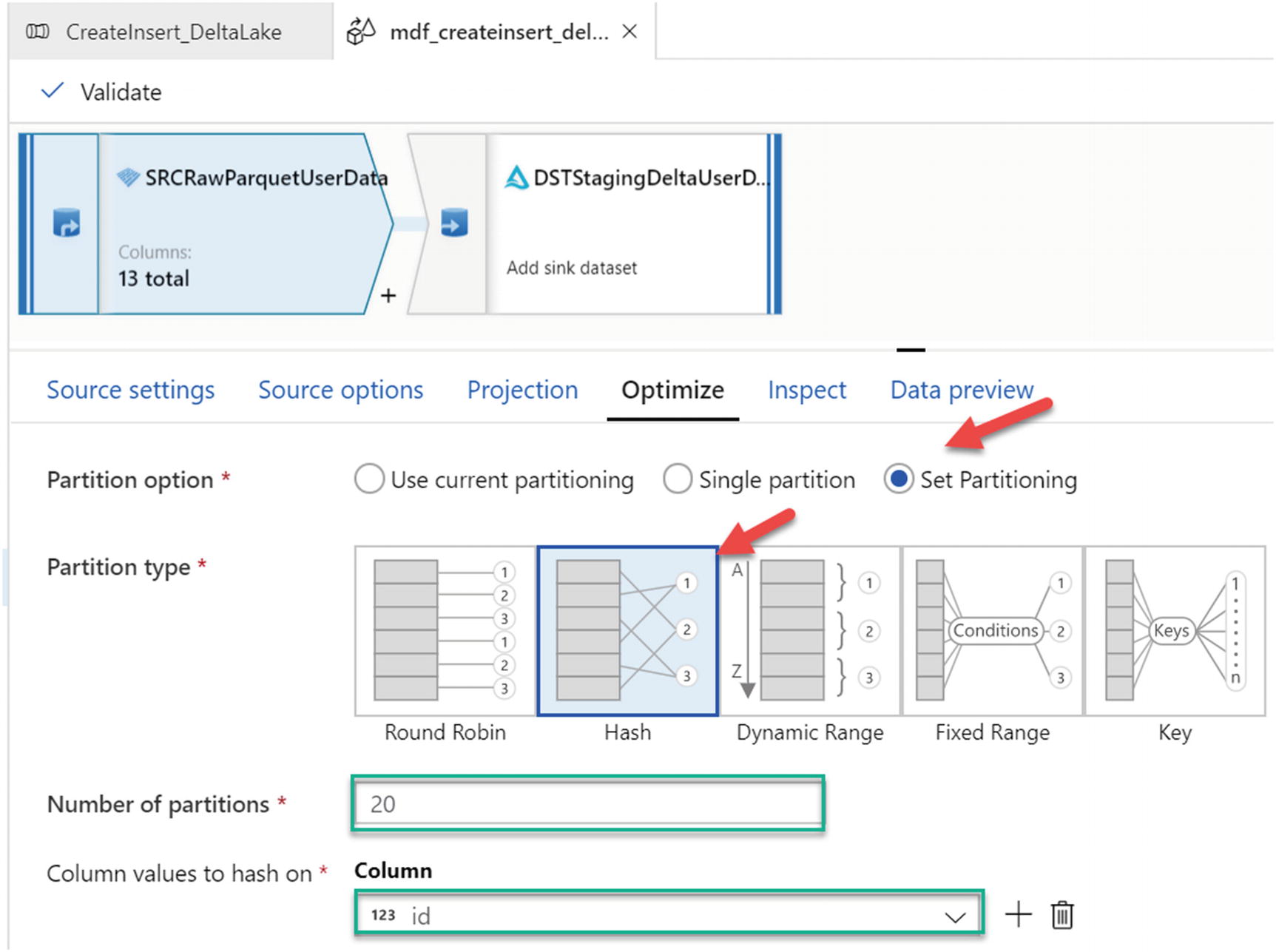
Optimize settings for MDF partitioning

MDF sink settings
Under the Settings tab shown in Figure 15-8, ensure that the Staging folder is selected and select Allow insert for the update method. Also, select the Truncate table option if there is a need to truncate the delta table before loading it.
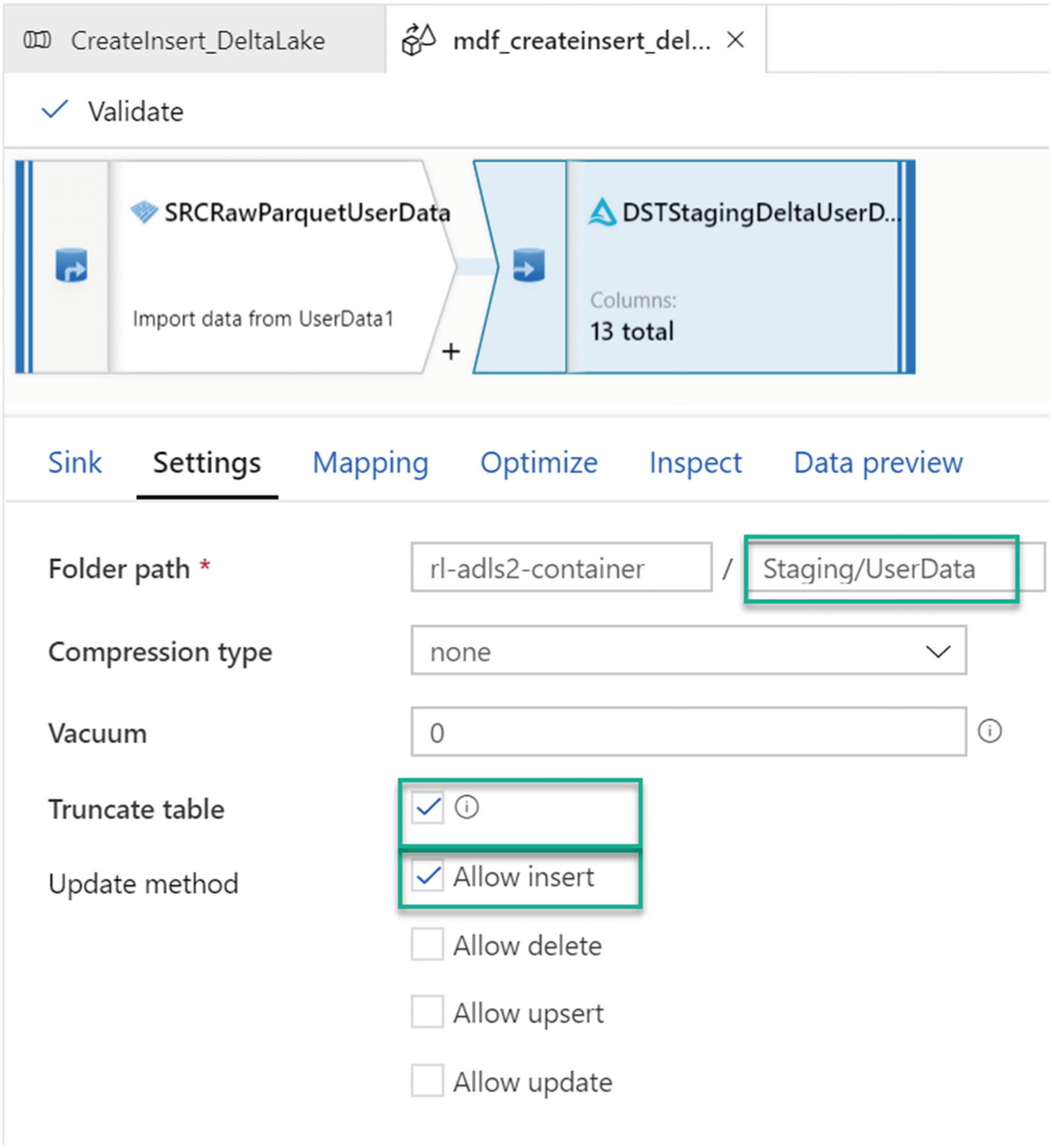
Settings for insert sink in MDF
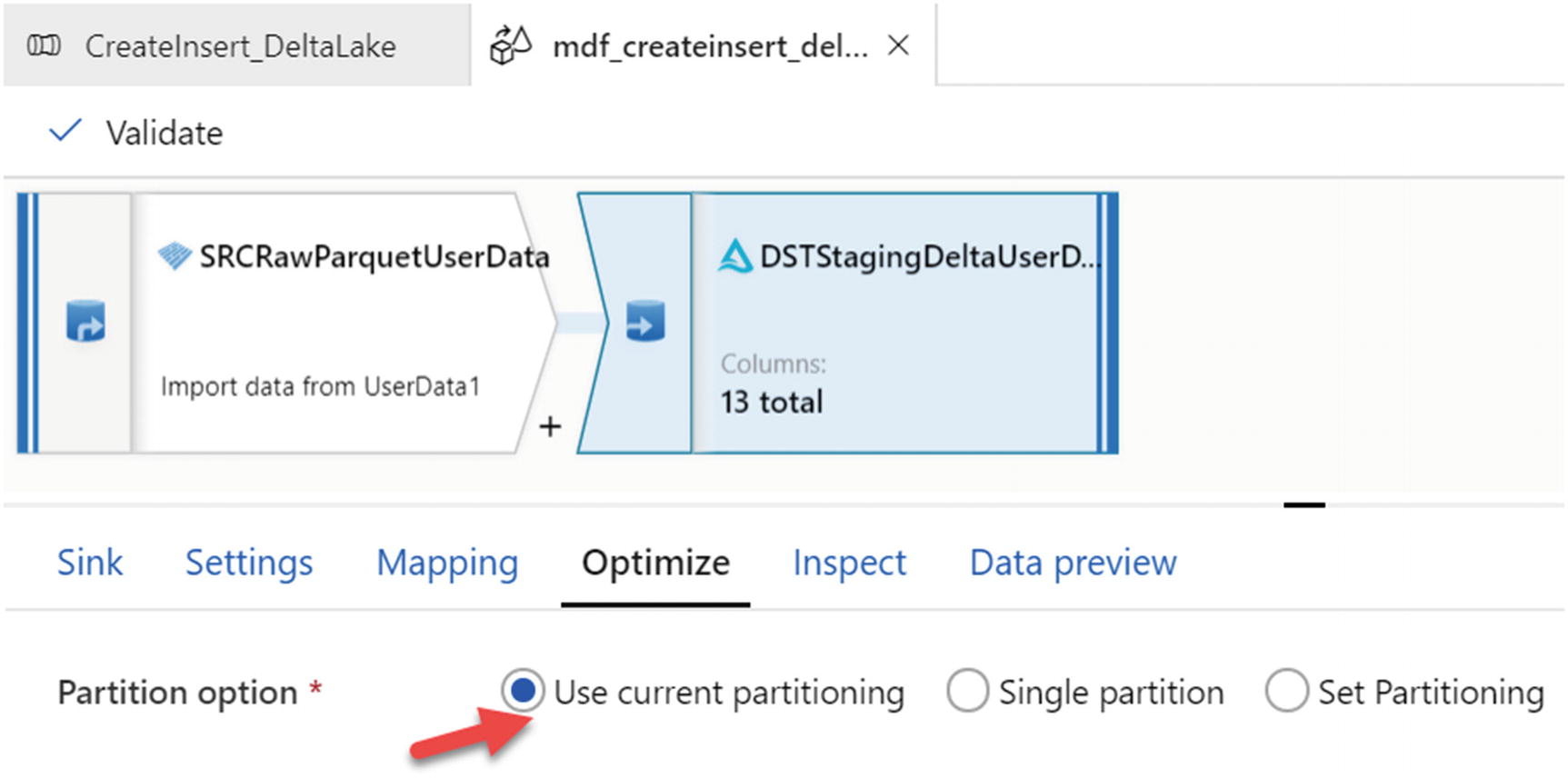
Partitioning options for optimizing sink
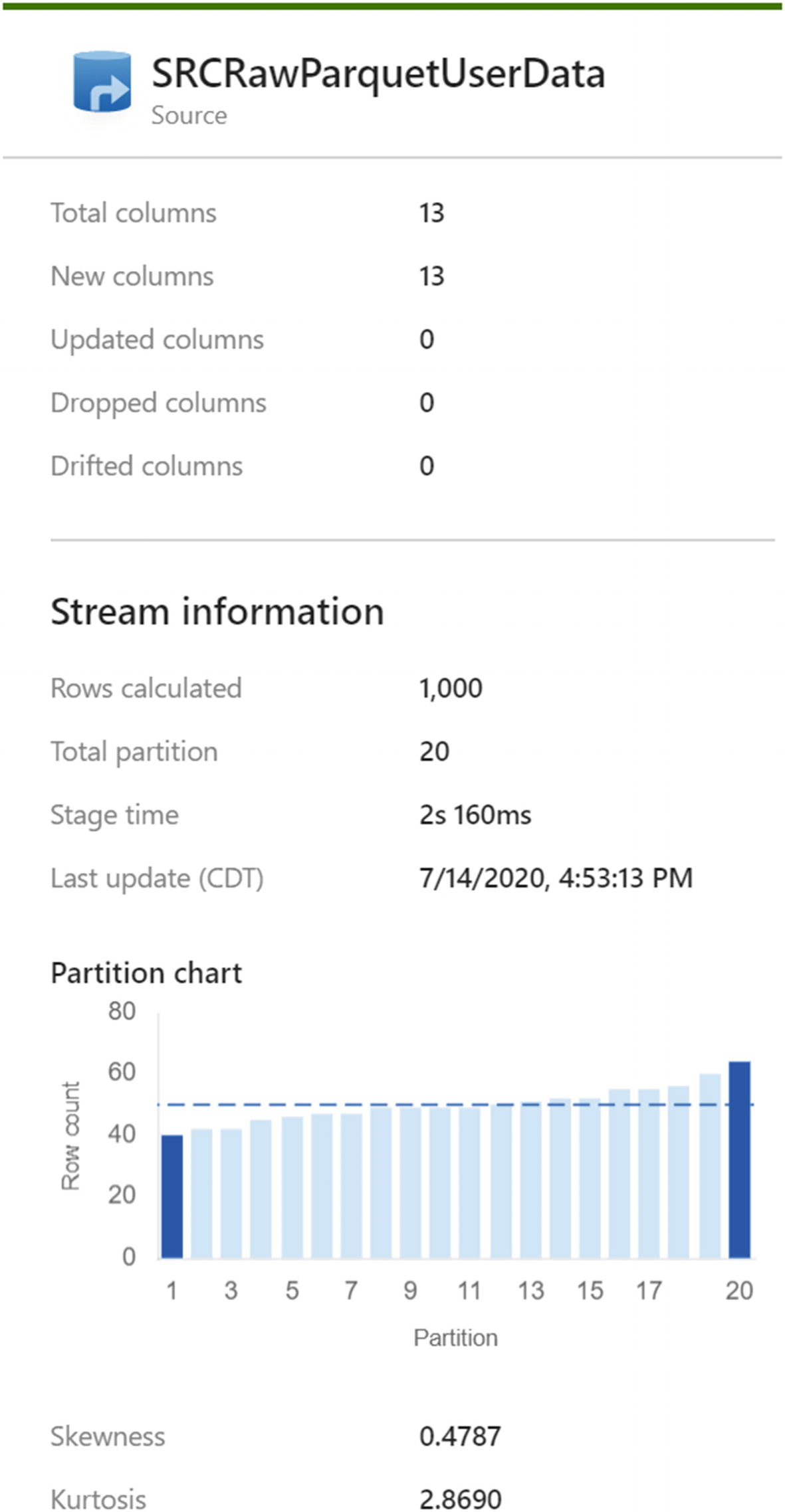
ADF MDF pipeline run details

Delta Lake partitioned files
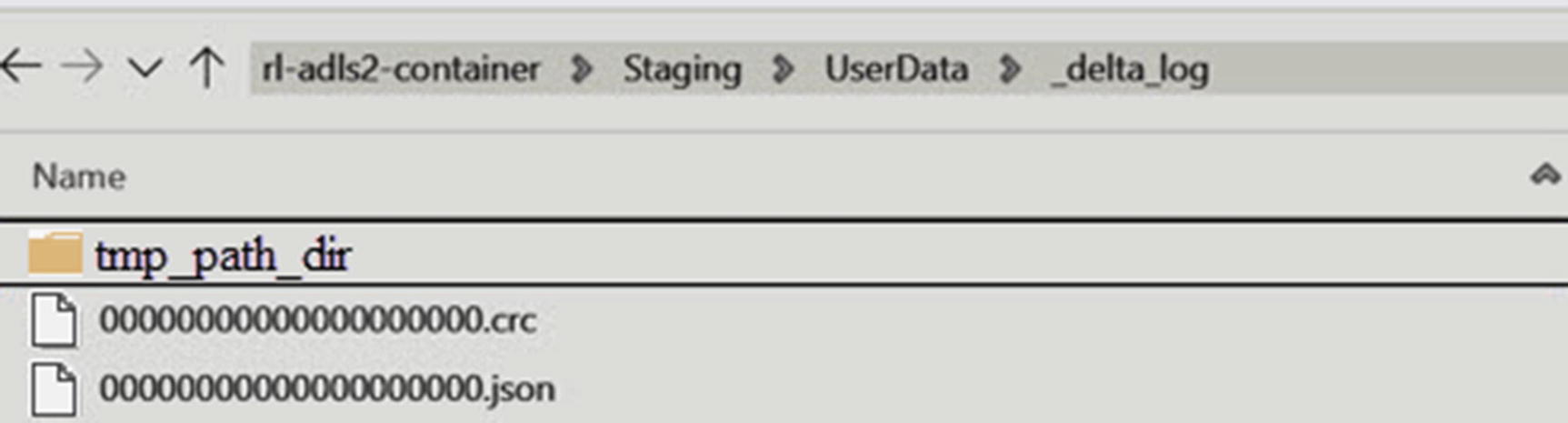
Delta log files
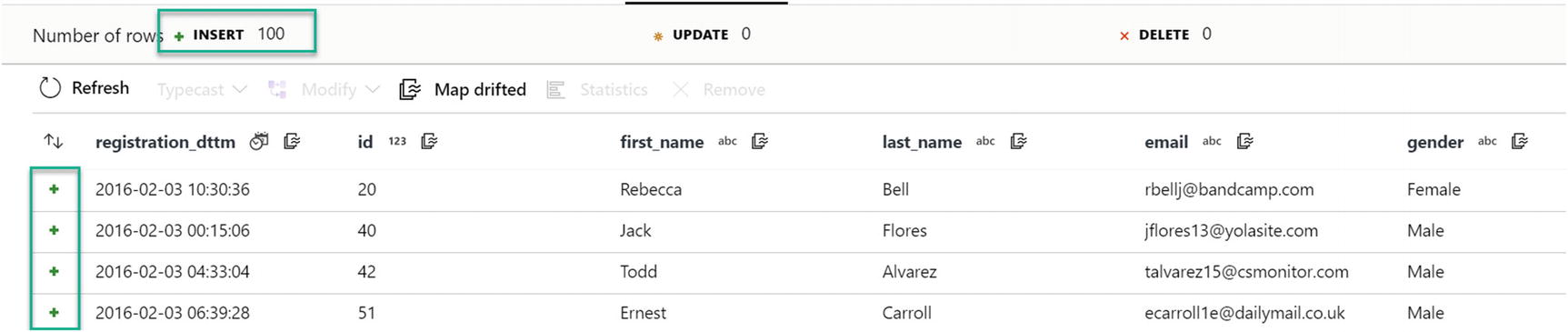
Insert data results reading from parquet file
Update Delta Lake

MDF update Delta Lake
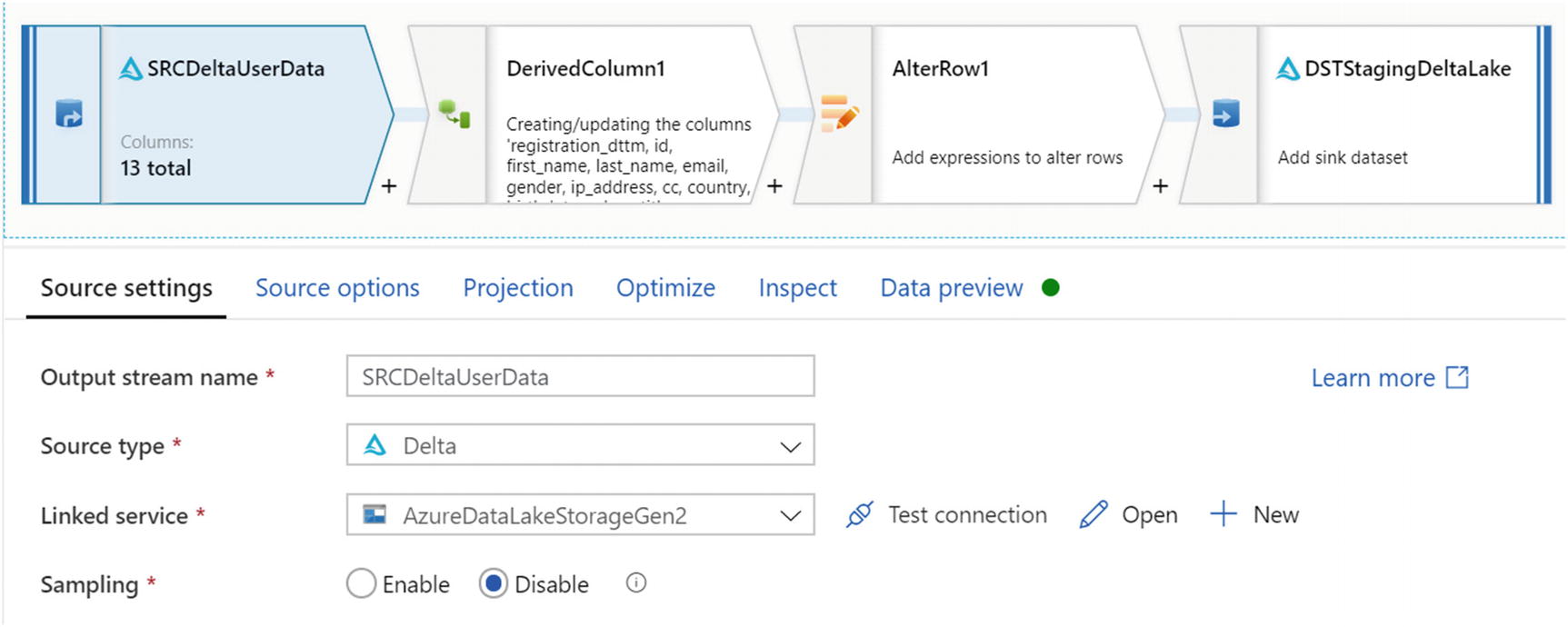
Source settings for updating Mapping Data Flows parquet
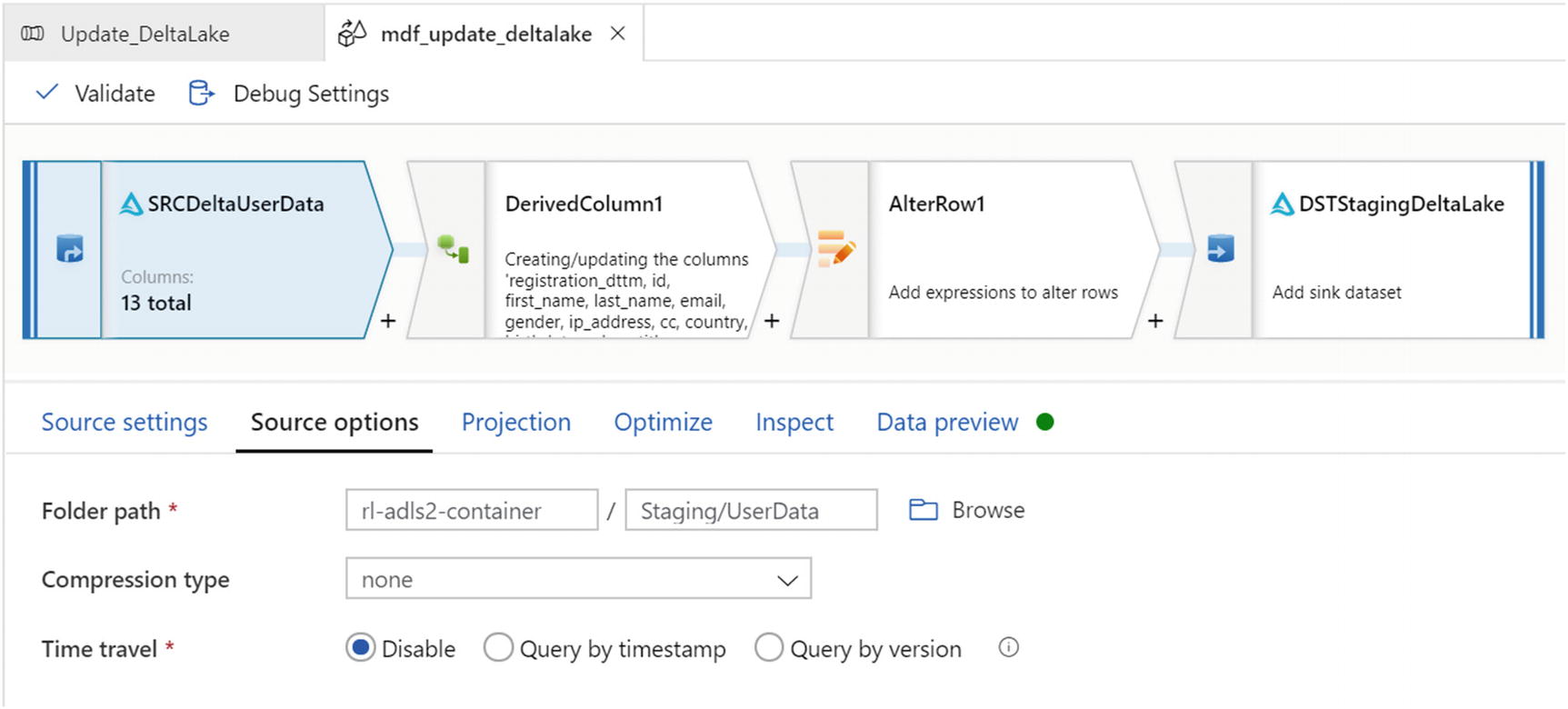
Update source options

Derived column settings for update
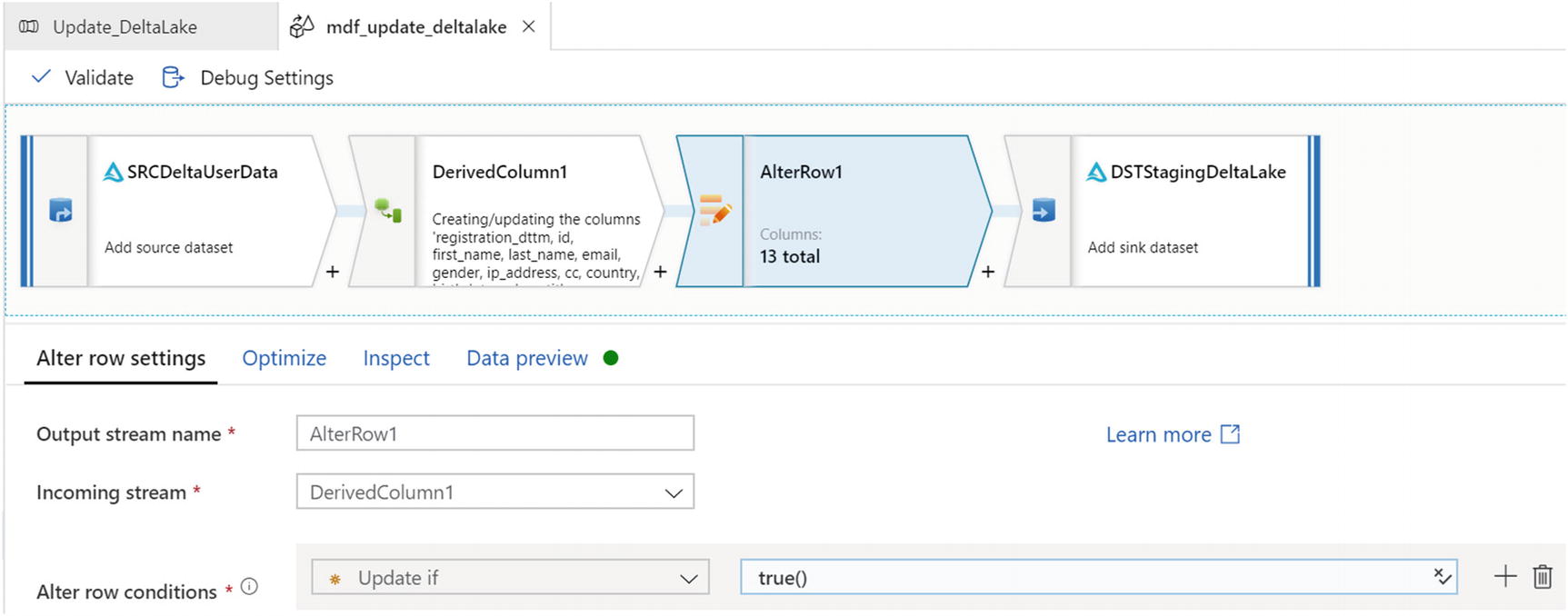
Settings for the AlterRow updates
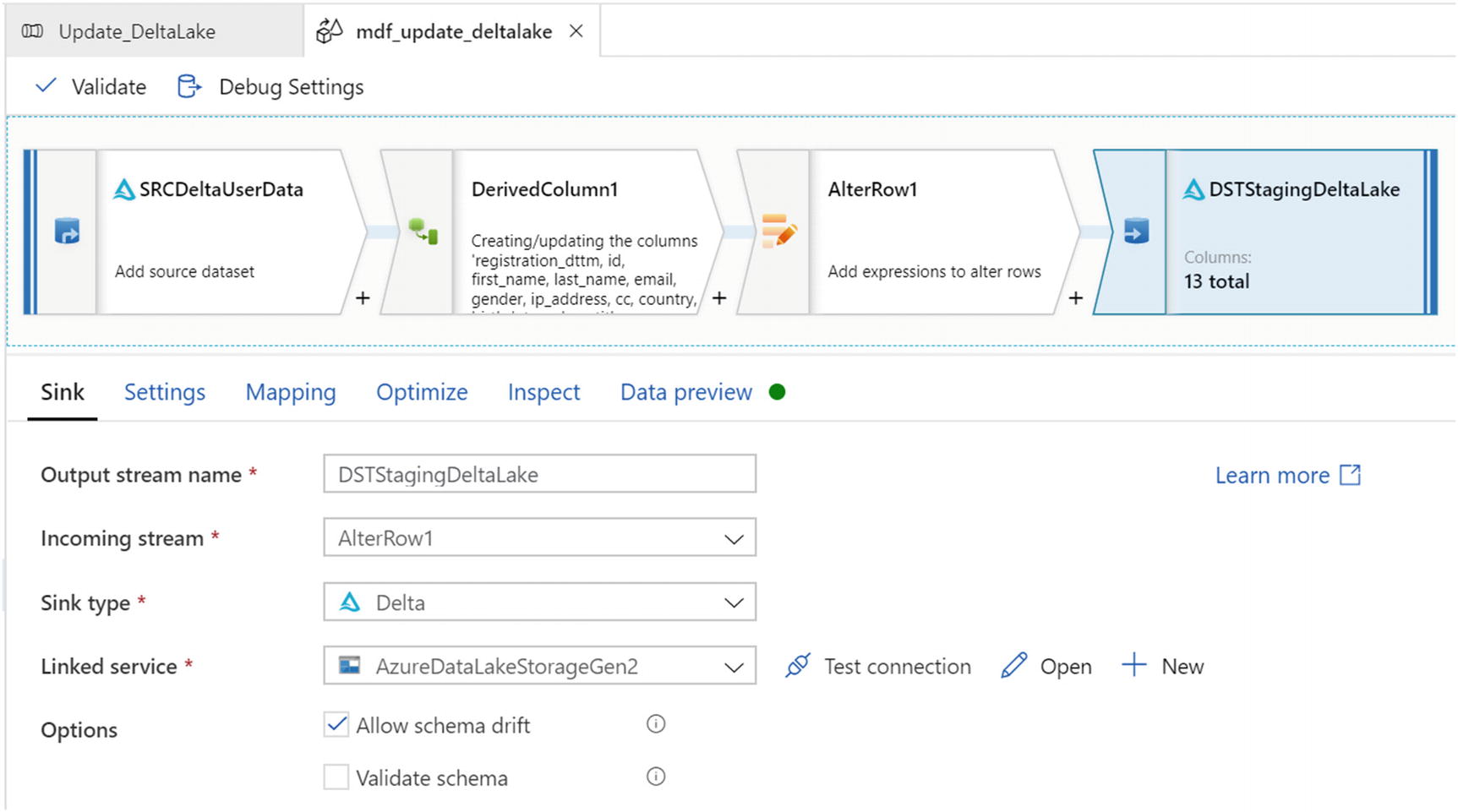
Sink settings for update MDF

Update method settings for MDF sink
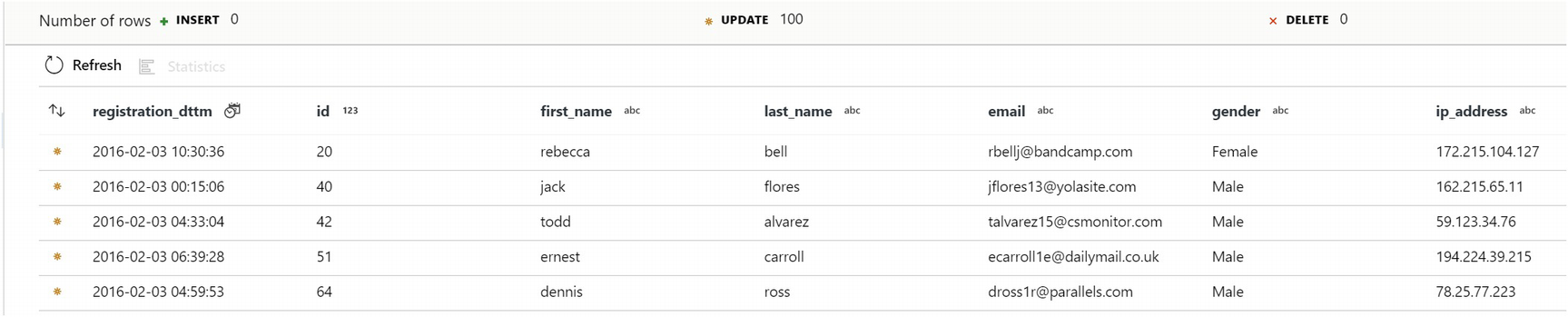
Data showing updates as expected
Delete from Delta Lake

MDF for deleting from Delta Lake

Source settings for mdf_delete_deltalake
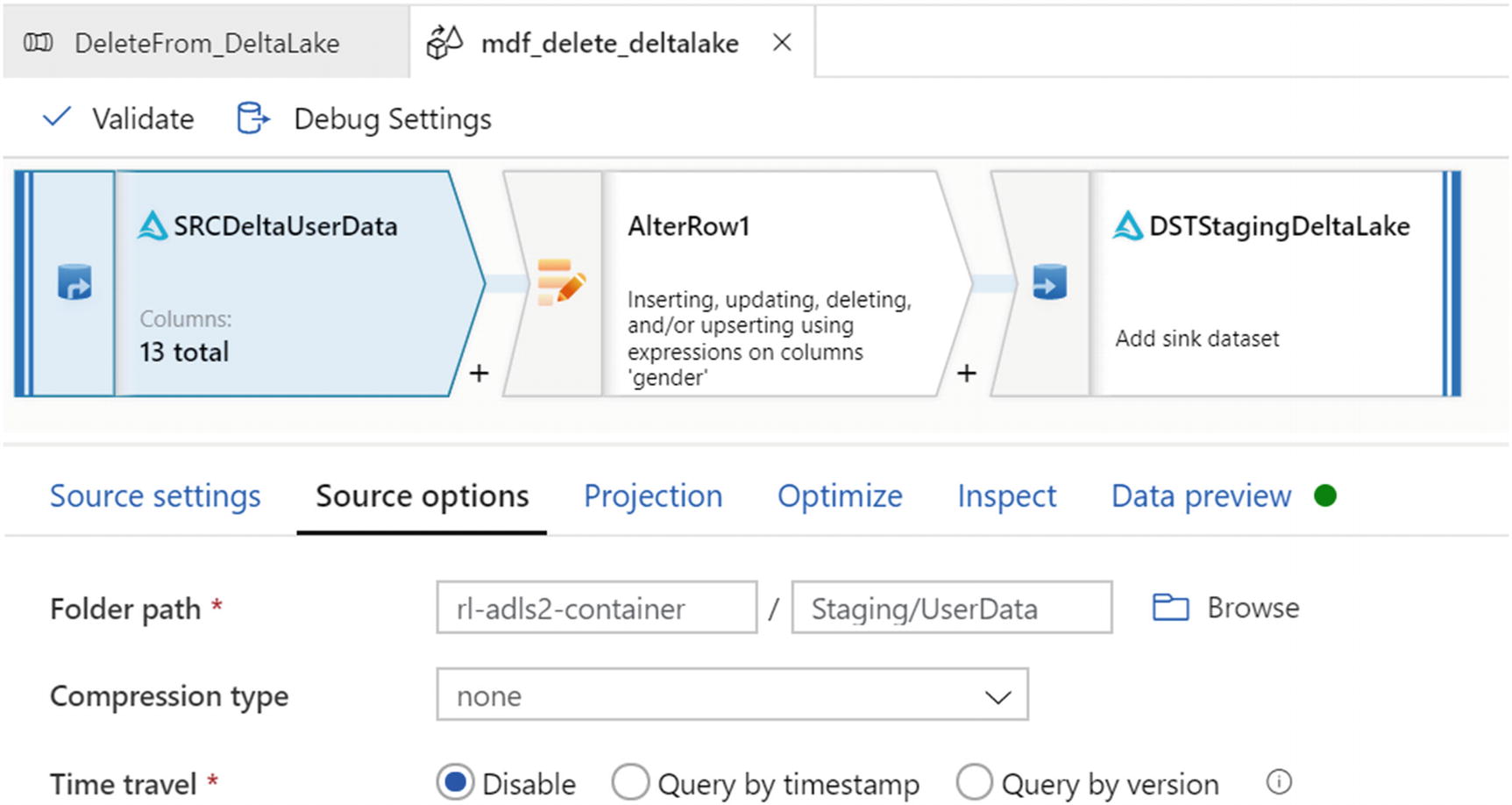
Source options for mdf_delete_deltalake
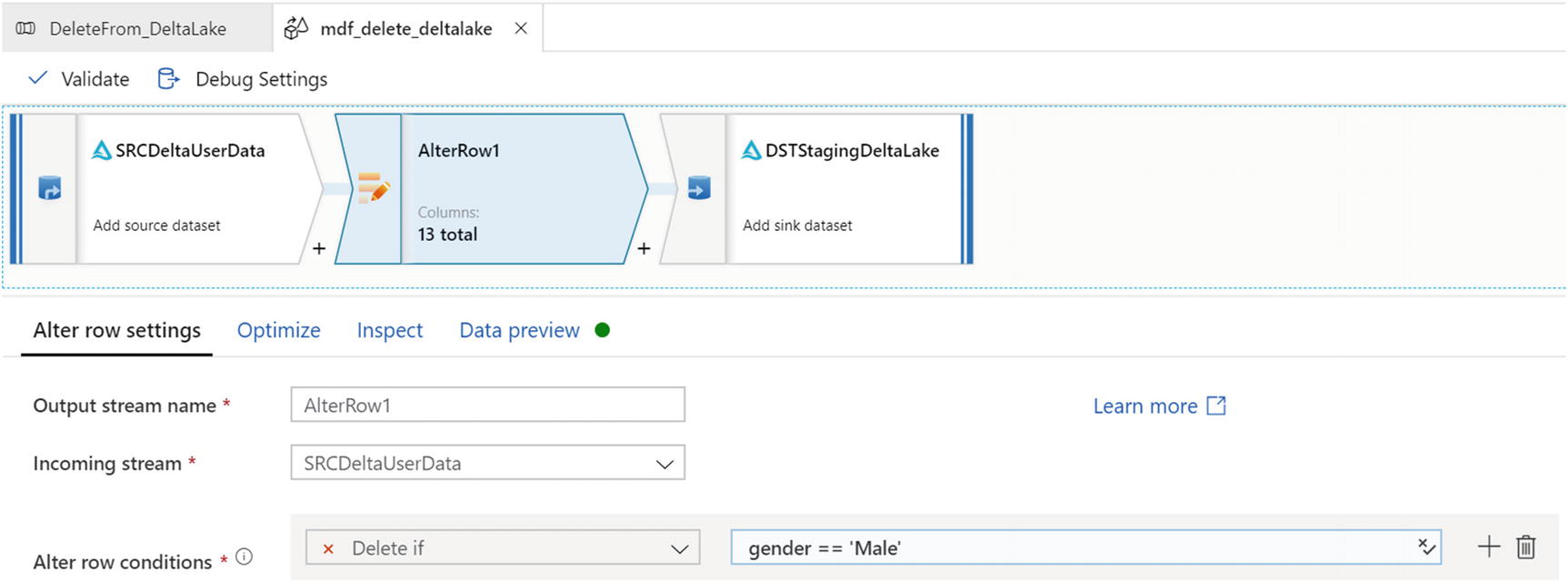
Alter row settings for mdf_delete_deltalake delta
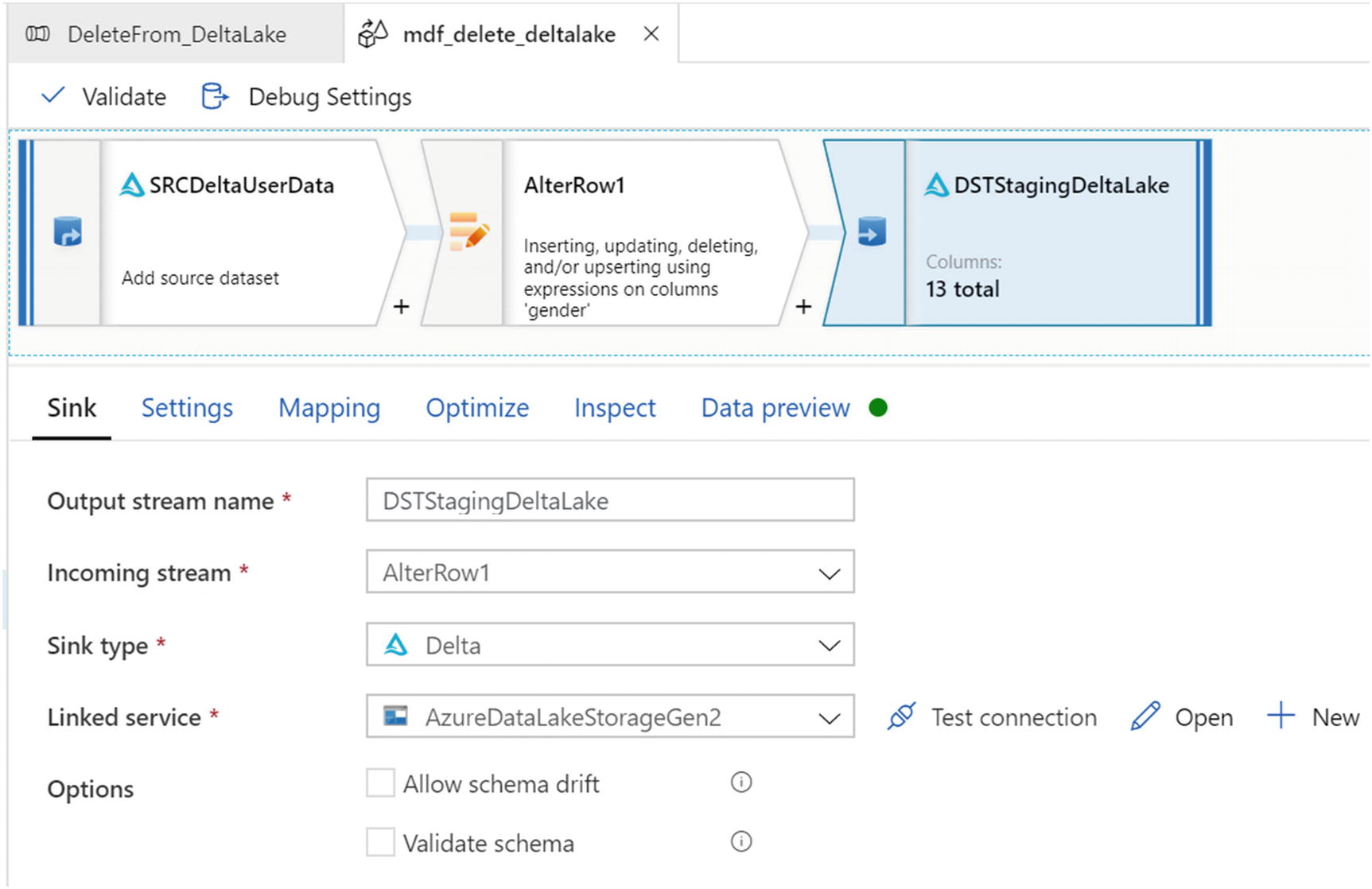
Sink settings for mdf_delete_deltalake
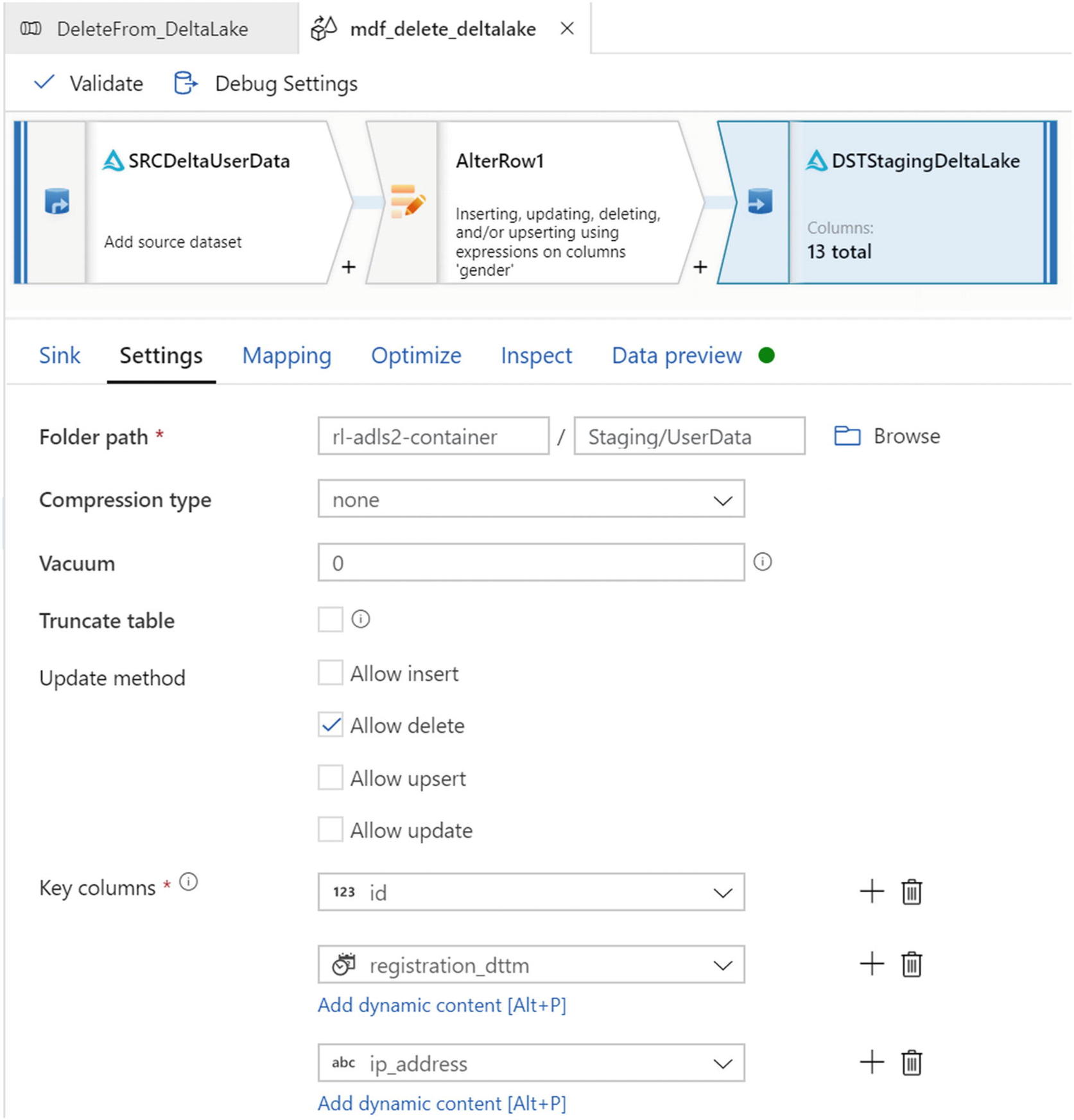
Destination for mdf_delete_deltalake
Delete data file as expected
Explore Delta Logs

Delta logs after insert, update, and delete
Insert

Delta log insert
Update

Delta log update
Delete

Delta log delete
Summary
In this chapter, I have demonstrated how to get started with Delta Lake using Azure Data Factory’s Delta Lake connector through examples of how to create, insert, update, and delete in a Delta Lake by using Azure Data Lake Storage Gen2 as the storage account. Since Delta Lake is an open source project that is meant to enable building a lakehouse architecture on top of existing storage systems, it can certainly be used with other storage systems such as Amazon S3, Google Cloud Storage, HDFS, and others. Additionally, you could just as easily work with Delta Lake by writing Spark, Python, and/or Scala code within Databricks notebooks.
With such flexibility, the lakehouse data management paradigm is gaining momentum with a vision of becoming an industry standard and the evolution of both the data lake and data warehouse. The low-cost storage of data lakes makes this option very attractive for organizations that embrace a cost-sensitive and growth mindset. Additional advantages of data lakehouse include reduced data redundancy, elimination of simple ETL jobs, decoupled compute from storage, real-time streaming support, ease of data governance, and the capability to connect directly to modern-day BI tools. While still in their infancy, data lakehouse and Delta Lake do have certain limitations that prevent them from being a full-fledged replacement of traditional data warehousing appliances such as SQL Server databases and warehouses. Nevertheless, this chapter demonstrates the capability of working directly with Delta Lake in a code-free manner and shows how to easily work with Delta Lake to begin exploring the building blocks of a data lakehouse.