
C H A P T E R 1
Principles and Method
Modern large-scale web sites are amazingly complex feats of engineering. Partly as a result of this, many sites run into significant performance and scalability problems as they grow. In fact, it’s not unusual for large sites to be reengineered almost from scratch at some point in order to handle their growth. Fortunately, consistently following a few basic principles can make sites faster while they’re still small, while minimizing the problems you will encounter as they grow.
This book will explore those principles and show how and why you should apply them.
I’m basing the ideas presented here on my work developing network-oriented software over the past 30+ years. I started working with the Internet in 1974 and with Unix and C in 1979 and later moved to C++ and then Java and C#. I learned about ASP.NET and SQL Server in depth while working at Microsoft, where I helped architect and develop a large-scale web site for MSN TV. I polished that knowledge over the next few years while I was an architect at the Microsoft Technology Center (MTC) in Silicon Valley. During that time, I helped run two- to three-day architectural design sessions once or twice each week for some of Microsoft’s largest and most sophisticated customers. Other MTC architects and I would work to first understand customer issues and problems and then help architect solutions that would address them.
It didn’t take long before I discovered that a lot of people had the same questions, many of which were focused around performance and scalability. For example:
- “How can we make our HTML display faster?” (Chapter 2)
- “What’s the best way to do caching?” (Chapter 3)
- “How can we use IIS to make our site faster?” (Chapter 4)
- “How should we handle session state?” (Chapter 5)
- “How can we improve our ASP.NET code?” (Chapters 5 to 7)
- “Why is our database slow?” (Chapters 8 and 9)
- “How can we optimize our infrastructure and operations?” (Chapter 10)
- “How do we put the pieces together?” (Chapter 11)
One of the themes of this book is to present high-impact solutions to questions like these.
One aspect of the approach I’ve taken is to look at a web site not just as an application running on a remote server but rather as a distributed collection of components that need to work well together as a system.
In this chapter, I’ll start with a description of performance and scalability, along with what I mean by ultra-fast and ultra-scalable. Then I’ll present a high-level overview of the end-to-end process that’s involved in generating a web page, and I’ll describe the core principles upon which I base this approach to performance. I’ll conclude with a description of the environment and tools that I used in developing the examples that I present later in the book.
The Difference Between Performance and Scalability
Whenever someone tells me that they want their system to be fast, the first question I ask is, “What do you mean by fast?” A typical answer might be “It needs to support thousands of users.” A site can be slow and still support thousands of users.
Scalability and performance are distinctly different. In the context of this book, when I talk about improving a site’s performance, what I mean is decreasing the time it takes for a particular page to load or for a particular user-visible action to complete. What a single user sees while sitting at their computer is “performance.”
Scalability, on the other hand, has to do with how many users a site can support. A scalable site is one that can easily support additional users by adding more hardware and network bandwidth (no significant software changes), with little or no difference in overall performance. If adding more users causes the site to slow down significantly and adding more hardware or bandwidth won’t solve the problem, then the site has reached its scalability threshold. One of the goals in designing for scalability is to increase that threshold; it will never go away.
Why Ultra-fast and Ultra-scalable?
Speed and scalability should apply to more than just your web servers. Many aspects of web development can and should be fast and scalable. All of your code should be fast, whether it runs at the client, in the web tier, or in the data tier. All of your pages should be fast, not just a few of them. On the development side, being fast means being agile: fast changes and fixes, and deployments.
A definite synergy happens when you apply speed and scalability deeply in a project. Not only will your customers and users be happier, but engineers too will be happier and will feel more challenged. Surprisingly, less hardware is often required, and quality assurance and operations teams can often be smaller. That’s what I mean by ultra-fast and ultra-scalable (which I will often refer to as just ultra-fast for short, even though scalability is always implied).
The ultra-fast approach is very different from an impulsive, “do-it-now” type of programming. The architectural problems that inevitably arise when you don’t approach development in a methodical way tend to significantly offset whatever short-term benefits you might realize from taking shortcuts. Most large-scale software development projects are marathons, not sprints; advance planning and preparation pay huge long-term benefits.
I’ve summarized the goals of the ultra-fast and ultra-scalable approach in Table 1-1.
Building a fast and scalable web site has some high-level similarities to building a race car. You need to engineer and design the core performance aspects from the beginning in order for them to be effective. In racing, you need to decide what class or league you want to race in. Is it going to be Formula One, stock car, rallying, dragster, or maybe just kart? If you build a car for kart, not only will you be unable to compete in Formula One, but you will have to throw the whole design away and start again if you decide you want to change to a new class. With web sites, building a site for just yourself and a few friends is of course completely different from building eBay or Yahoo. A design that works for one would be completely inappropriate for the other.
A top-end race car doesn’t just go fast. You can also do things like change its wheels quickly, fill it with fuel quickly, and even quickly swap out the engine for a new one. In that way, race cars are fast in multiple dimensions. Your web site should also be fast in multiple dimensions.
In the same way that it’s a bad idea to design a race car to go fast without considering safety, it is also not a good idea to design a high-performance web site without keeping security in mind. In the chapters that follow, I will therefore make an occasional brief diversion into security in areas where there is significant overlap with performance, such as with cookies in Chapter 3.
Optimization
As many industry experts have rightly pointed out, optimization can be a deadly trap and time-waster. The key to building high-performance web sites is engineering them so that optimization is not required to get decent results. However, as with racing, if you want to compete with the best, then you need to integrate measuring, adjusting, tuning, tweaking, and innovating into your development process. There’s always something you can do better, provided you have the time, money, and motivation to do so.
The real trick is knowing where to look for performance and scalability problems and what kinds of changes are likely to have the biggest impact. Comparing the weight of wheel lugs to one another is probably a waste of time, but getting the fuel mixture just right can win the race. Improving the efficiency of an infrequently called function won’t improve the scalability of your site; switching to using asynchronous pages will.
I don’t mean that small things aren’t important. In fact, many small problems can quickly add up to be a big problem. However, when you’re prioritizing tasks and allocating time to them, be sure to focus on the high-impact tasks first. Putting a high polish on a race car is nice and might help it go a little faster, but if the transmission is no good, you should focus your efforts there first. Polishing some internal API just how you want it might be nice, but eliminating round-trips should be a much higher priority.
Process
Ultra-fast is a state of mind—a process. It begins with the architecture and the design, and it flows into all aspects of the system, from development to testing to deployment, maintenance, upgrades, and optimization. However, as with building a race car or any other complex project, there is usually a sense of urgency and a desire to get something done quickly that’s “good enough.” Understanding where the big impact points are is a critical part of being able to do that effectively, while still meeting your business goals. The approach I’ve taken in this book is to focus on the things you should do, rather than to explore everything that you could do. The goal is to help you focus on high-impact areas and to avoid getting lost in the weeds in the process.
I’ve worked with many software teams that have had difficulty getting management approval to work on performance. Often these same teams run into performance crises, and those crises sometimes lead to redesigning their sites from scratch. Management tends to focus inevitably on features, as long as performance is “good enough.” The problem is that performance is only good enough until it isn’t—and that’s when a crisis happens. In my experience, you can often avoid this slippery slope by not selling performance to management as a feature. It’s not a feature, any more than security or quality are features. Performance and the other aspects of the ultra-fast approach are an integral part of the application; they permeate every feature. If you’re building a racecar, making it go fast isn’t an extra feature that you can add at the end; it is part of the architecture, and you build it into every component and every procedure.
There’s no magic here. These are the keys to making this work:
- Developing a deep understanding of the full end-to-end system
- Building a solid architecture
- Focusing effort on high-impact areas, and knowing what’s safe to ignore or defer
- Understanding that a little extra up-front effort will have big benefits in the long term
- Using the right software development process and tools
You might have heard about something called the “eight-second rule for web performance. It’s a human-factors-derived guideline that says if a page takes longer than eight seconds to load, there’s a good chance users won’t wait and will click away to another page or site. Rather than focusing on rules like that, this book takes a completely different approach. Instead of targeting artificial performance metrics, the idea is to focus first on the architecture. That puts you in the right league. Then, build your site using a set of well-grounded guidelines. With the foundation in place, you shouldn’t need to spend a lot of effort on optimization. The idea is to set your sights high from the beginning by applying some high-end design techniques. You want to avoid building a racer for kart and then have to throw it away when your key competitors move up to Formula One before you do.
The Full Experience
Performance should encompass the full user experience. For example, the time to load the full page is only one aspect of the overall user experience; perceived performance is even more important. If the useful content appears “instantly” and then some ads show up ten seconds later, most users won’t complain, and many won’t even notice. However, if you display the page in the opposite order, with the slow ads first and the content afterward, you might risk losing many of your users, even though the total page load time is the same.
Web sites that one person builds and maintains can benefit from this approach as much as larger web sites can (imagine a kart racer with some Formula One parts). A fast site will attract more traffic and more return visitors than a slow one. You might be able to get along with a smaller server or a less expensive hosting plan. Your users might visit more pages.
As an example of what’s possible with ASP.NET and SQL Server when you focus on architecture and performance, one software developer by himself built the site pof.com, and in 2009, it was one of the highest-traffic sites in Canada. The site serves more than 45 million visitors per month, with 1.2 billion page views per month, or 500 to 600 pages per second. Yet it only uses three load-balanced web servers, with dual quad-core CPUs and 8GB RAM, plus a few database servers, along with a content distribution network (CDN). The CPUs on the web servers average 30 percent busy. I don’t know many details about the internals of that site, but after looking at the HTML it generates, I’m confident that you could use the techniques I’m providing in this book to produce a comparable site that’s even faster.
Unfortunately, there’s no free lunch: building an ultra-fast site does take more thought and planning than a quick-and-dirty approach. It also takes more development effort, although usually only in the beginning. Over the long run, maintenance and development costs can actually be significantly less, and you should be able to avoid any costly ground-up rewrites. In the end, I hope you’ll agree that the benefits are worth the effort.
End-to-End Web Page Processing
A common way to think about the Web is that there is a browser on one end of a network connection and a web server with a database on the other end, as in Figure 1-1.
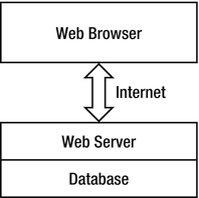
Figure 1-1. Simplified web architecture model
The simplified model is easy to explain and understand, and it works fine up to a point. However, quite a few other components are actually involved, and many of them can have an impact on performance and scalability. Figure 1-2 shows some of them for web sites based on ASP.NET and SQL Server.
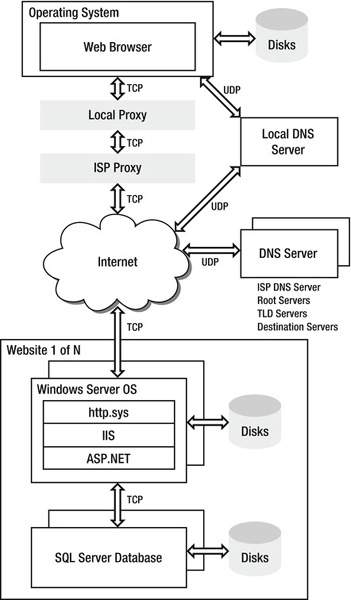
Figure 1-2. Web architecture components that can impact performance
All of the components in Figure 1-2 can introduce delay into the time it takes to load a page, but that delay is manageable to some degree. Additional infrastructure-oriented components such as routers, load balancers, and firewalls aren’t included because the delay they introduce is generally not very manageable from a software architecture perspective.
In the following list, I’ve summarized the process of loading a web page. Each of these steps offers opportunities for optimization that I’ll discuss in detail later in the book:
- First, the browser looks in its local cache to see whether it already has a copy of the page. See Chapter 2.
- If the page isn’t in the local cache, then the browser looks up the IP address of the web or proxy server using DNS. The browser and the operating system have each have separate DNS caches to store the results of previous queries. If the address isn’t already known or if the cache entry has timed out, then a nearby DNS server is usually consulted next (it’s often in a local router, for example). See Chapter 10.
- Next, the browser opens a network connectionto the web or proxy server. Proxy servers can be either visible or transparent. A visible proxy is one that the user’s browser or operating system is aware of. They are sometimes used at large companies, for example, to help improve web performance for their employees or sometimes for security or filtering purposes. A transparent proxy intercepts all outgoing TCP connections on port 80 (HTTP), regardless of local client settings. If the local proxy doesn’t have the desired content, then the HTTP request is forwarded to the target web server. See Chapters 2 and 3.
- Some ISPs also use proxies to help improve performance for their customers and to reduce the bandwidth they use. As with the local proxy, if the content isn’t available in the ISP proxy cache, then the request is forwarded along. See Chapter 3.
- The next stop is a web server at the destination site. A large site will have a number of load-balanced web servers, any of which will be able to accept and process incoming requests. Each machine will have its own local disk and separate caches at the operating system driver level (
http.sys), in Internet Information Services (IIS), and in ASP.NET. See Chapters 3 through 7.- If the requested page needs data from the database, then the web server will open a connection to one or more database servers. It can then issue queries for the data it needs. The data might reside in RAM cache in the database, or it might need to be read in from disk. See Chapters 8 and 9.
- When the web server has the data it needs, it dynamically creates the requested page and sends it back to the user. If the results have appropriate HTTP response headers, they can be cached in multiple locations. See Chapters 3 and 4.
- When the response arrives at the client, the browser parses it and renders it to the screen. See Chapter 2.
Overview of Principles
The first and most important rule of building a high-performance site is that performance starts with the application itself. If you have a page with a loop counting to a gazillion, for example, nothing I’m describing will help.
Performance Principles
With the assumption of a sound implementation, the following are some high-impact core architectural principles for performance and scalability:
- Focus on perceived performance. Users are happier if they quickly see a response after they click. It’s even better if what they see first is the information they’re most interested in. See Chapter 2.
- Reduce round trips. Every round trip is expensive, whether it’s between the client and the web server or between the web server and the database. “Chattiness” is one of the most common killers of good site performance. You can eliminate these types of round trips by caching, combining requests (batching), combining source files or data, combining responses (multiple result sets), working with sets of data, and other similar techniques. See Chapters 2 through 8.
- Cache at all tiers. Caching is important at most steps of the page request process. You should leverage the browser’s cache, cookies, on-page data (hidden fields or
ViewState), proxies, the Windows kernel cache (http.sys), the IIS cache, the ASP.NET application cache, page and fragment output caching, the ASP.NET cache object, server-side per-request caching, database dependency caching, distributed caching, and caching in RAM at the database. See Chapters 3 and 8.- Minimize blocking calls. ASP.NET provides only a limited number of worker threads for processing web page requests. If they are all blocked because they are waiting for completion of long-running tasks, the runtime will queue up new incoming HTTP requests instead of executing them right away, and your web server throughput will decline dramatically. You could have a long queue of requests waiting to be processed, even though your server’s CPU utilization was very low. Minimizing the amount of time that worker threads are blocked is a cornerstone of building a scalable site. You can do this using features such as asynchronous pages, async
HttpModules, async I/O, async database requests, background worker threads, and Service Broker. Maximizing asynchronous activity in the browser is a key aspect of reducing browser page load times because it allows the browser to do multiple things at the same time. See Chapters 2 and Chapters 5 through 8.- Optimize disk I/O management. Disks are physical devices; they have platters that spin and read/write heads that move back and forth. Rotation and head movement (disk seeks) take time. Disks work much faster when you manage I/O to avoid excessive seeks. The difference in performance between sequential I/O and random I/O can easily be 40 to 1 or more. This is particularly important on database servers, where the database log is written sequentially. Proper hardware selection and configuration plays a big role here, too, including choosing the type and number of drives, using the best RAID level, using the right number of logical drives or LUNs, and so on. Solid State Disks (SSDs) have no moving parts, and can be much faster for certain I/O patterns. See Chapters 8 and 10.
Secondary Techniques
You can often apply a number of secondary techniques easily and quickly that will help improve system-level performance and scalability. As with most of the techniques described here, it’s easier to apply them effectively when you design them into your web site from the beginning. As with security and quality requirements, the later in the development process that you address performance and scalability requirements, the more difficult the problems tend to be. I’ve summarized a few examples of these techniques in the following list:
- Understand behavior. By understanding the way that the browser loads a web page, you can optimize HTML and HTTP to reduce download time and improve both total rendering speed and perceived speed. See Chapter 2.
- Avoid full page loads by using Ajax and plain JavaScript. You can use client-side field validation and other types of request gating with JavaScript to completely avoid some page requests. You can use Ajax to request small amounts of data that can be dynamically inserted into the page or into a rich user interface. See Chapter 2.
- Avoid synchronous database writes on every request. Heavy database writes are a common cause of scalability problems. Incorrect use of session state is a frequent source of problems in this area, since it has to be both read and written (and deserialized and reserialized) with every request. You may be able to use cookies to reduce or eliminate the need for server-side session state storage. See Chapters 5 and 8.
- Monitoring and instrumentation. As your site grows in terms of both content and users, instrumentation can provide valuable insights into performance and scalability issues, while also helping to improve agility and maintainability. You can time off-box calls and compare the results against performance thresholds. You can use Windows performance counters to expose those measurements to a rich set of tools. Centralized monitoring can provide trend analysis to support capacity planning and to help identify problems early. See Chapter 10.
- Understand how SQL Server manages memory. For example, when a T-SQL command modifies a database, the server does a synchronous (and sequential) write to the database log. Only after the write has finished will the server return to the requestor. The modified data pages are still in memory. They will stay there until SQL Server needs the memory for other requests; they will be written to the data file by the background lazy writer thread. This means that SQL Server can process subsequent read requests for the same data quickly from cache. It also means that the speed of the log disk has a direct impact on your database’s write throughput. See Chapter 8.
- Effective use of partitioning at the data tier. One of the keys to addressing database scalability is to partition your data. You might replicate read-only data to a group of load-balanced servers running SQL Express, or you might partition writable data among several severs based on a particular key. You might split up data in a single large table into multiple partitions to avoid performance problems when the data is pruned or archived. See Chapter 8.
I will discuss these and other similar techniques at length in the chapters ahead.
What this book is not about is low-level code optimization; my focus here is mostly on the high-impact aspects of your application architecture and development process.
Environment and Tools Used in This Book
Although cross-browser compatibility is important, in keeping with the point I made earlier about focusing on the high-impact aspects of your system, I’ve found that focusing development and tuning efforts on the browsers that comprise the top 90 percent or so in use will bring most of the rest for free. You should be able to manage whatever quirkiness might be left afterward on an exception basis, unless you’re building a site specifically oriented toward one of the minority browsers.
I also don’t consider the case of browsers without JavaScript or cookies enabled to be realistic anymore. Without those features, the Web becomes a fairly barren place, so I think of them as being a given for real users; search engines and other bots are an entirely different story, of course.
As of April 2012, the most popular browsers according to Net Applications were Internet Explorer with 54 percent, Firefox with 21 percent, and Chrome with 19 percent. The remaining 6 percent was split between Safari, Opera, and others.
Software Tools and Versions
The specific tools that I’ve used for the code examples and figures are listed in Table 1-2, including a rough indication of cost. A single $ indicates a price under US$100, $$ is between $100 and $1,000, and $$$ is more than $1,000.

Most of the code that I discuss and demonstrate will also work in Visual Studio Web Express, which is a free download.
Terminology
See the glossary for definitions of business intelligence (BI)-specific terminology.
Typographic Conventions
I am using the following typographic conventions:
- Italics: Term definitions and emphasis
- Bold: Text as you would see it on the screen
Monospace: Code, URLs, file names, and other text as you would type it
Author’s Web Site
My web site at http://www.12titans.net/ has online versions of many of the web pages used as samples or demonstrations, along with code downloads and links to related resources.
Summary
In this chapter, I covered the following:
- Performance relates to how quickly something happens from your end user’s perspective, while scalability involves how many users your site can support and how easily it can support more.
- Ultra-fast and Ultra-scalable include more than just the performance of your web server. You should apply speed and scalability principles at all tiers in your architecture. In addition, your development process should be agile, with the ability to change and deploy quickly.
- Processing a request for a web page involves a number of discrete steps, many of which present opportunities for performance improvements.
- You should apply several key performance and scalability principles throughout your site: focus on perceived performance, reduce round trips, cache at all tiers, minimize blocking calls, and optimize disk I/O management.
In the next chapter, I’ll cover the client-side processing of a web page, including how you can improve the performance of your site by structuring your content so that a browser can download and display it quickly