
Chapter 3. Consuming the Sent Data
In this chapter
▪ 3.1 Document-Centric Approaches
▪ 3.3 How to Decide on a Request Type
There are two main ways you can use the data you receive from XMLHttpRequest or one of the fallback methods: the document-centric approach, and the other is remote scripting. In this chapter, we look at different ways to implement these techniques and use the data we learned to send in the previous chapter.
3.1 Document-Centric Approaches
A document-centric approach to AJAX simply means that your main interaction with the server is pulling down pages of content. This doesn’t mean that the pages aren’t dynamically generated, but it does mean you’re pulling down the content in a ready-to-use or parse format. The simplest use case is to download a chunk of HTML from your server and insert it into the page using innerHTML.
The biggest differentiator between document-centric approaches and remote scripting is how the design relates with the server. Remote scripting-style AJAX is tightly coupled to the server and gives you a direct interface to the server-side code, using a standardized system to transfer the call and request between the client and the server. Document-centric approaches are loosely tied to the server; the only requirement is that the data be in the usable format, allowing you to generate plain text, HTML, or XML in whatever manner you want. One advantage that document-centric approaches have is that they are highly scalable because more of the work happens on the client. Document-centric approaches are not a magic bullet for scalability or performance, because dynamically generated content can have many bottlenecks; however, they do closely resemble current Web models, which allow the same optimization strategies to be used.
3.1.1 Adding New HTML Content to a Page with AJAX
One of the basic actions performed on every Web page is the displaying of new content when a user clicks a link. In many circumstances, this works fine, but when you want to keep the original content, you have a problem. HTML offers two solutions to the problem: frames and IFrames. Both allow multiple pages to be embedded into a single page. The problem with frame-based solutions is that you’re still stuck loading entire pages; that being said, you can easily use frame-based solutions to add a new row to a table or provide a status message. AJAX offers an easy way out: load the HTML directly using XMLHttpRequest and add it to your page by replacing the content of a DIV using innerHTML. An example of using the HttpClient.js XMLHttpRequest wrapper we built earlier (Listing 2-3) is shown in Listing 3-1. The pages that are being loaded, content1.html and content2.html, are also shown; they can be any fragment of HTML or other text you want to load into the DIV.
Listing 3-1. Adding HTML Content.html

Line 4 includes the XMLHttpRequest wrapper, HttpClient, which is instantiated on line 7. Because we want to make an asynchronous request, we turn that mode on at line 8 and then create our callback function (lines 10–12). This callback will take the result from the load and set the innerHTML of the target element to it. Lines 14–16 create a JavaScript function that we can call from HTML links. This function, replaceContent, takes a single parameter, page, which is the URL we want to load. Line 15 makes the remote request. The second parameter is null because we have no POST data that we want to send as a payload.
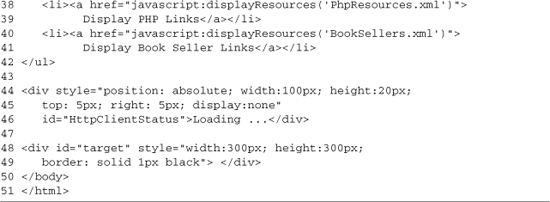
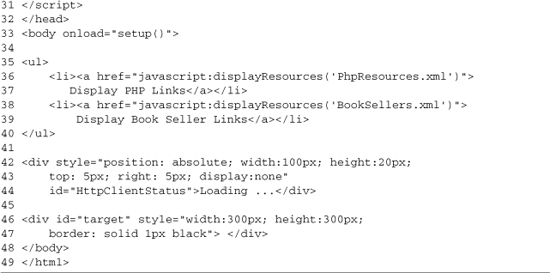
The rest of the example is a list of test calls to replaceContent and the user interface (UI) elements used by the JavaScript code. Lines 22–23 load Content1.html, and lines 24–25 load Content2.html. Lines 28–30 create a DIV element with an ID of HttpClientStatus. Whenever you are using HttpClient.js, you need to provide an element with this ID. The element should be hidden by default; this is accomplished by setting display:none in the style attribute. When the XMLHttpRequest object downloads content from the server, the HttpClientStatus element will be shown by setting the style.display attribute to block. Lines 32–33 provide a DIV with an ID of target; this is where the downloaded content is displayed. The results of Listing 3-1 loading content1.html are shown in Figure 3-1.

Figure 3-1. Using AJAX to perform basic content replacement
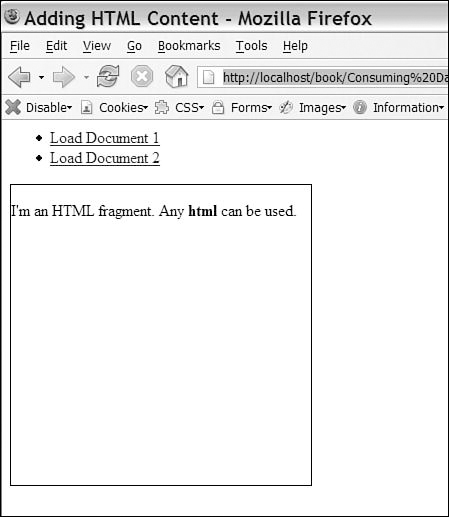
In Listing 3-1, we took a normal HTML document and used AJAX to load in new content at will. This basic technique can be accomplished through the use of frames, but AJAX gives you a lot more flexibility. We can divide the page in any way we choose, dynamically updating something as small as a single word or as large as the majority of the page. Dynamically updating a page with content is powerful, and it fits well into any server-side development model, because you’re simply increasing the number of pages you generate while decreasing their size and scope.
3.1.2 Consuming XML Using DOM
Another popular way to load new data is to use XML. XML is useful when you want abstraction between the code on the server that produces the data and the JavaScript client code that uses it. This allows you to change out the back end without affecting the front end. It also allows you to expose data for other clients through the same generic API. The XML Document Object Model (DOM) is similar to the HTML one that we’ve used in other examples.
An easy way to visualize the DOM is to picture a tree of objects, one for each XML element on the page. For example, the following sample XML document will make DOM with four nodes: the root Document node, an Element node for the rootTag, and an Element node for the childTag. The childTag has a Text node containing Some Text.

A visual representation of this tree is shown here:

To turn this DOM model into HTML, we will need to use a couple basic methods and properties:
• getElementsByTagName(tagName). Gets an array of tags of the specified name as a result
• getAttribute(attributeName). Gives you the value of one of the tag’s attributes
• firstChild(). Returns the first child node of any node
The other step we need to take is to get the XML document result from XMLHttpRequest instead of the plain text. To do this, set the Content-type of the downloaded page to text/xml. This causes the responseXML property of XMLHttpRequest to create a DOM document from the contents.
In the following examples, we take an XML list of resource links about a subject and turn them into a simple HTML list. The two test lists contain PHP resource links and a list of book sellers. Listing 3-2 contains the list of PHP resources, whereas Listing 3-3 contains the list of sellers. These files are used by Listing 3-4, which uses the DOM to update the current page and build the list.




The JavaScript HttpClient class (from Chapter 2, “Getting Started”) gives us cross-browser XMLHttpRequest support. On line 4, we include the library, and on line 7, we create an instance of the client. Then, on line 8, we set isAsync to true because we want to make an asynchronous request for the XML data file. Next, on lines 10–28, we add our callback function; this function takes the downloaded XML document, creates an HTML list, and then shows the list using innerHTML.
On line 11, we grab the XML DOM document from response XML. We have to use the XMLHttpRequest object directly because HttpClient doesn’t wrap this. Depending on the complexity of the HTML page, updating a node with innerHTML can be an expensive operation. To keep this to a minimum, we use a variable to hold our HTML content and then update it all at once at the end of the function. On lines 13–15, we read the type attribute from the site’s tag and use it to make a title for our list. Then on line 17, we get an array of all the site nodes in our XML document, which is looped through on lines 18–23. In each iteration of the site’s array, we build one list element. This is a pretty straightforward process; the only item of note is the use of firstChild() and nodeValue() to get to the text content of the site tag. These calls are needed because text content exists in its own node in the DOM, and there is no innerHTML attribute to read from the text content and its markup, as is the case with the HTML DOM.
The rest of the page gives you a basic UI for testing. Lines 30–32 provide a helper function that requests the download of new XML files. When the download is done, the callback function that builds the output will be called. Lines 37–42 contain a list with links to process the sample XML files, and lines 44–46 contain a basic loading DIV that is shown while waiting for the XML documents to be downloaded. Finally, we have a target DIV that is used by the callback function as a place to display the generated list. The output of Listing 3-4, showing the PHP resources list, is shown in Figure 3-2.
Figure 3-2. Updating an HTML page by consuming XML documents using the DOM
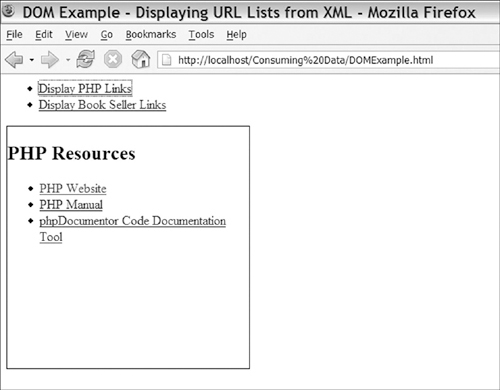
When tied with dynamically updates, DOM-based consumption of XML can be an efficient way to dynamically display data on the browser. Using the DOM manipulation function can make for tedious programming, so it isn’t usually the best approach for generating a large amount of content from nonstructured data.
3.1.3 Consuming XML Using XSLT
eXtensible Stylesheet Language Transformations (XSLT) is another popular way to take a DOM document and generate new output. The advantage it has over DOM is that the transformation and the data are in an XML file. XSLT has been used by many successful AJAX applications, such as Google Maps, but it does have a number of drawbacks. XSLT browser support is uneven, and even when two browsers, such as Internet Explorer 6 and Firefox 1.0, support the same main features, the application programming interfaces (APIs) for controlling the transformations from JavaScript are completely different. This difference is large enough that you can’t just write a simple wrapper like you can for XMLHttpRequest. If you need cross-browser support, you’ll need to rely on a library like Sarissa instead. (The Sarissa library is explained in detail in Chapter 8, “Libraries Used in Part II: Sarissa, Scriptaculous.”)
XSLT can also be problematic simply due to its complexity. Not only will you need to learn how to write the XSLT style sheets that drive the actual transformation, but you’ll also need to learn XPath, which is used to refer to XML nodes inside the style sheet. Because XSLT is a World Wide Web Consortium standard, there are tools and documentation out there to help, but in many cases, the added effort required over a DOM approach isn’t worth the effort.
Although the purpose of this book isn’t to teach you how to write an XSLT style, I will explain the basics of the one used. Listing 3-5 replaces the JavaScript DOM code in Listing 3-4 with an XSLT transformation. The same XML data files (PhpResources.xml and Booksellers.xml) that are used in the DOM example are used here. The Mozilla XSLT API is used in these examples because it’s easier to understand, and all you have to do to make it work in IE is include the Sarissa library.
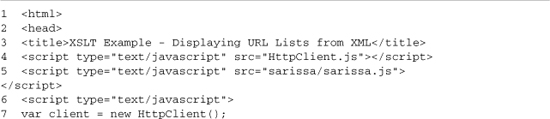

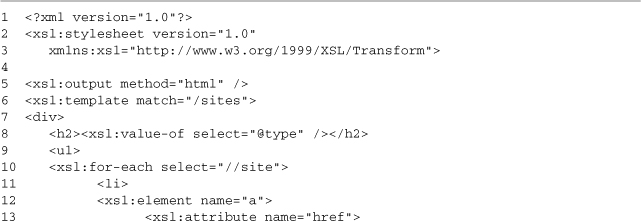
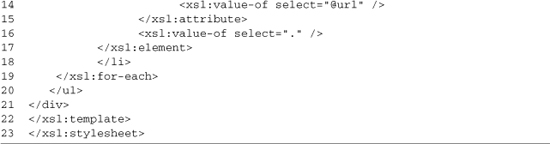
The first 18 lines cover the basic setup; we include our HttpClient XMLHttpRequest wrapper and the Sarissa XML compatibility library. On line 7, we create an HttpClient instance; this will be used to load both the style sheet and the XML files we’re going to transform; on line 8, we set isAsync to true because we will be making only asynchronous requests. On line 9, we create a new xsltProcessor instance; this will be loaded with a style sheet in the setup function (lines 11–18) and then used to transform XML files loaded by the displayResources function (lines 20–30). On lines 13–16, we create a callback to run when the style sheet is loaded. It grabs the new XML DOM from the client (line 14) and then adds it to the xsltProcessor using its importStylesheet method (line 15); this style sheet is shown in Listing 3-6. The setup function completes by making the actual request (line 17) and is run by an onload handler (line 33).
The displayResources function is called by links in the HTML page; it loads new XML files and then transforms them. Lines 21–27 add a callback method that processes the downloaded XML document. Line 23 uses the processor we created to generate a new DOM document formatted by the style sheet we imported on line 15. Line 24 clears the target element on the HTML page, and then on lines 25–26, we append the content of the transformed DOM document. document.importNode has to be used for this process to work in a cross-browser manner. The rest of the HTML page (lines 34–49) has no changes from the DOM example. It’s just a basic list of actions to be performed and a target to display the results.
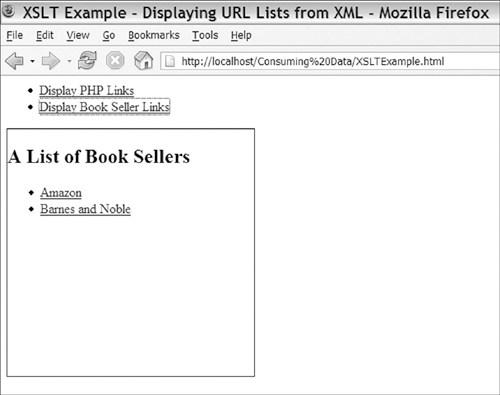
Listing 3-6 finishes up the process; it is run on each XML file to produce HTML that is similar to the DOM example. Line 8 creates the list title using value-of to output the type attribute. Lines 10–19 loop over each site tag in the file, outputting a list item with the link inside it. You can see the output of this script showing the PHP resource list in Figure 3-3.
Figure 3-3. Using XSLT to transform XML documents loaded using AJAX
XSLT is an extremely powerful technique for managing AJAX transformation, and because it’s supported by most browsers, it’s easy to see how it could be paired with AJAX. XSLT’s strength lies in its ability to create rules that will work against nonstructured or structured schemas. This trait allows it to easily transform any type of XML document and generate new content to add to the current HTML page. If you are already dealing with XML on the server side, XSLT makes a great choice because there is a good chance you’re already familiar with its basics.
3.2 Remote Scripting
Remote scripting is a technique in which you make a request to the server that directly maps to a function on the server. In most environments, this is usually referred to as a Remote Procedure Call (RPC). Remote scripting approaches differ from document-centric ones mainly in how tightly coupled the server side is to the JavaScript client side. The data formats used are of a more generic nature and are designed to move standard data types, such as arrays or strings, and are not application-specific, such as the schema used by our data XML files in the DOM or XSLT examples.
The general RPC pattern is shown in Figure 3-4 and is as follows:
1. The JavaScript client code serializes the request data into a standard format.
2. The serialized data is sent to the server.
3. The data is userialized to a native data type.
4. The data in native format is used to perform an action, usually calling a preregistered function or method.
5. The results of the server action are serialized back to the standard format.
6. The serialized data is returned to the JavaScript client.
7. The JavaScript client unserializes the data to a native JavaScript type.
8. An action is performed on the result.
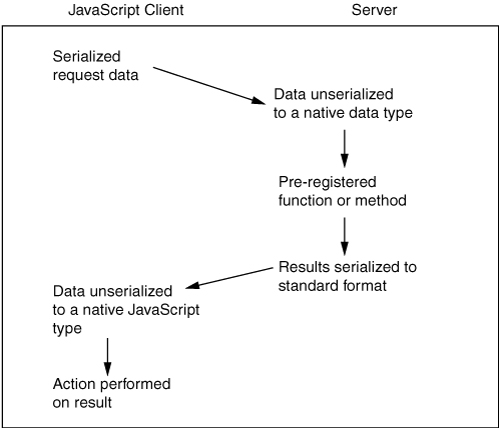
Any approach that follows this basic pattern can be considered an RPC approach. This can be anything from a simple technique that passes plain strings back and forth to something as complex as an entire Simple Object Access Protocol (SOAP) stack.
RPC approaches fit into four main subgroups:
• Approaches that use plain text or basic serialization such as URL encoding
• Approaches that use standardized XML schemas, such as SOAP or XML-RPC
• Approaches that use custom XML schemas
• Approaches that send JavaScript or its subset, JavaScript Object Notation (JSON)
All these approaches are used in various AJAX implementations and, in many cases, are even combined; this is especially prevalent with approaches that generate JavaScript because few server-side languages have the ability to natively parse it.
3.2.1 Basic RPC
The simplest RPC approaches send plain text between the client and the server. What distinguishes them from document-centric approaches is that they usually call only a single page on the server, and the results come directly from what a function on the server returns. Like any remote scripting approach, there is a server component and a client component. The server component has a list of functions that can be called by the client (for security reasons, any RPC server should allow calls only to preregistered functions), and it manages dispatching client requests to a function and returning its results. The application flow is this: The JavaScript client makes a call using XMLHttpRequest to the server, sending the function to call and a payload. The server calls the requested functions and outputs the results, and the JavaScript client does something useful with the result. The process is shown in Listings 3-7 and 3-8; Listing 3-7 shows the server side written in PHP, and Listing 3-8 shows the client-side HTML and JavaScript.
Listing 3-7. rpc-basic-plain.php

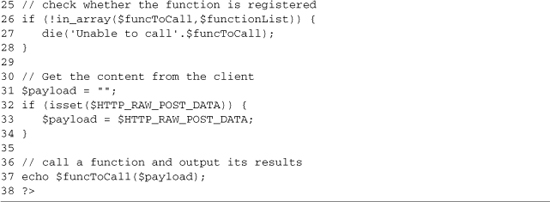
The server-side component of this basic RPC arrangement is as simple as it could be; this works for small pages, but to build a full site, you would want to move to a more feature-rich solution, like one of the toolkits listed in Appendix A, “JavaScript AJAX Libraries.” In Listing 3-7, lines 2–8 define two small string-processing functions; these could just as easily contain calls to a database or code that builds HTML. Lines 11–15 provide an array of functions that can be called remotely; this provides security, locking remote access to a small set of functions that expect input from JavaScript. On line 23, we set the Content-type header. text/plain is used because we’re merely sending back string data. Lines 25–28 show the security check; it uses the $functionList array we built on lines 12–15; it also uses $funcToCall, which we read on line 19. The function we’re trying to call isn’t in this array; we end the script execution using the die command. The script ends by reading in the POST data that was sent from the form and then calling the requested function with that data as its only parameter.
The HTML page contains an input box and some links to perform some remote actions on the contents of the box. The actions run the two functions registered on the PHP page, reverse and rot13, against the content in the input box. The reverse function returns a string in reverse order, whereas rot13 replaces each character with the one that is 13 characters ahead of it in the alphabet. Now that we have a server to call, we need to build our client HTML and JavaScript page. We will reuse the same HttpClient class, adding in a helper function to allow us to make remote function calls. An HTML page that makes RPCs to the PHP script we built in Listing 3-7 is shown in Listing 3-8.
Listing 3-8. rpc-basic-plan.html
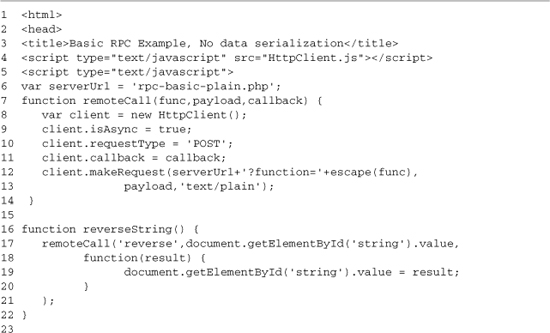
Like the earlier example pages, this one is broken into two main sections. The JavaScript code is at the top, followed by the HTML interface that calls it. Lines 7–14 contain the remoteCall function, which creates a new HttpClient. It sets up this new client to make an asynchronous POST request, and it uses the callback parameter as the callback function for the request. The function finishes by sending the request to the server. Each request is made to the same PHP page; we just change the query string, setting function to the PHP function we want to call. A new HttpClient instance is created for each request. If you didn’t do this, you would need to add in extra logic to keep a new request from being made before an earlier one had finished, because each HttpClient instance can have only a single outstanding request.
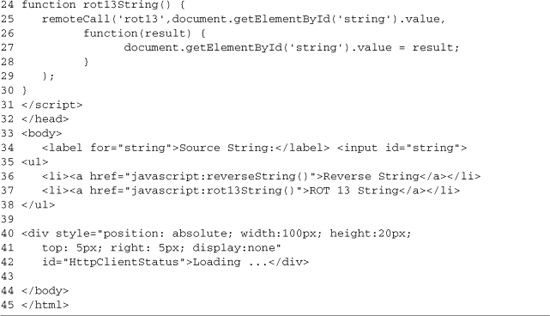
Lines 16–30 provide the two helper functions that initiate the remote function calls. The first is for reverse, and the second is for rot13. The two functions are nearly identical; they both call remoteCall, passing in the remote function to run, the value of the input box as the payload, and a callback to handle the results. The callback functions get the result from the PHP server and set the value of the input box to it.
The rest of the page is the basic UI. Line 34 contains the input box we’re reading from to make remote calls; the input box also gets updated with the results of the calls. Lines 36–37 contain links to run the JavaScript functions that make the remote calls. The script ends with a DIV (lines 40–42), which is shown while we wait for the server to respond. Figure 3-5 illustrates example output showing a reversed string.
Figure 3-5. Using a basic RPC example to reverse a string
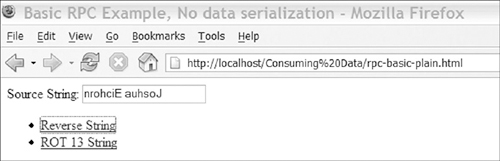
A simple RPC system is quick to build and has little overhead, but it lacks enough functionality that it’s not usually used in larger projects. Normally, you want the ability to pass multiple arguments to the functions on the server side and an easy way to get back something besides a string on the client.
3.2.1.1 Mimicking a Form POST
Another option for performing AJAX-based RPC is to mimic a form POST. This entails URL encoding the data. URL encoding is the format used in the query string of a GET request; key value pairs are separated by an ampersand, and a basic example is shown here:
ajax=asynchronous+javascript+and+xml&hello=world
As you can see in this example, spaces are encoded as + characters. In addition, =, &, and other non-ASCII characters are escaped as hexadecimal entities. Knowing the actual details of the encoding isn’t that important because JavaScript contains the encodeURIComponent() to handle the encoding of each key and value, and PHP will automatically handle the decoding for you. URL encoding can be used to perform basic RPC, allowing multiple variables to be passed, or to submit a form over AJAX. The form submission method is especially useful because you can easily fall back to normal form submission for users who don’t have JavaScript enabled.
The example of this takes an HTML form and uses a drop-down element to decide how it’s submitted. One mode does a submission to a slightly modified version of Listing 3-8; another submits the form using AJAX, and one mode does a normal form submission. The AJAX and normal form submission submit to the same page, showing you how you can detect an AJAX form submission. Because the AJAX code mimics a normal form submission, the server side can treat the data sent from either input method identically. You’ll generally create different output from an AJAX form submission because you need to return only that content that needs to be updated (instead of generating an entire page). The fake form submission example is shown in Listing 3-9, starting with the HTML page and finishing with the two back ends.
![]()

Listing 3-9 makes a form submission perform different actions; this basic setup leads us to a different layout in our JavaScript code than most of the RPC examples. Instead of having a number of smaller helper functions, we end up with a large form handler function that performs many of the same actions, no matter how we submitted the form. In its definition, this function handle Form, which starts on line 6 and continues to line 43, expects the form to be submitted as a parameter. Lines 7–18 decide how we’re going to submit the form. To do this, we create a switch statement around the value of a select element. If we do a normal form submission, we return true, which allows normal form submission to take place. For AJAX or RPC form submission, we set the URL to submit content, too. The rest of the logic is the same because the data is formatted the same—whether we’re treating it as a normal form POST or a URL-encoded RPC submission.
Lines 20–23 set up an HttpClient instance to make an asynchronous POST submission; HttpClient is the XMLHttpRequest we built earlier and included on line 4. After that, we prepare a payload to send as the POST body. This is done on lines 26–34. We loop over each element in the form, and if name is set on it, we add it to the form as the string name=value. Both name and value are escaped using encodeURIComponent, with each form element’s value being separated from the next by an ampersand (&). Then a callback handler (lines 36–38) is created to perform an action on the results of our remote calls; in this case, it just updates the contents of a DIV using innerHTML. The form handler finishes by making a remote request and returning false. When making a request (lines 40–41), it’s important to include the correct Content-type, because $_POST will be automatically populated in PHP only when the content-type is application/x-www-form-urlencoded. The final action of returning false is also important. Without it, the form would submit over our HttpClient and then as a normal form.
The rest of the file creates a basic user interface: an HTML form, an output target, and an element to show while we’re waiting for the server to respond. Lines 48–49 define the form, and the action attribute sets the page that will handle normal form submission requests. onsubmit ties our form-handling function to this form, and the value from this function is returned, allowing it to cancel the normal form submission. Line 51 creates the source string; this will be the payload sent to our RPC functions when doing an RPC submission. Lines 55–59 define the select element that lets us select how the form will be submitted; the value of each option matches up with the switch statement in the handler function. Lines 63–65 define a select element that lets us pick an RPC function to call on the string payload, and the values of these options match functions registered on the PHP RPC page. The page finishes with a submit button (line 68), a DIV with an ID of target that is used to show the output of our calls (line 71), and a status DIV (lines 73–75).
The output from ajax-form.html can be sent to one of two pages: rpc-basic-urlencoded.php or ajax-form.php. Each page interacts with the data in the same way because our encoding works in the form submission handler, which makes each POST request look like a normal form submission. ajax-form.php is shown in Listing 3-10; it’s a simple page that checks if this is an AJAX submission or a normal submission and then shows the value of $_POST using var_dump. The check for an AJAX submission is done by looking for the ajax element in the $_POST being set. Unless you set a marker like this, there is no way to tell that XMLHttpRequest was used instead of a normal form submission.

3.2.1.2 URL-Encoded AJAX RPC
The RPC handler, rpc-basic-urlencoded.php, is the same code as rpc-basic-plain.php, except for a change to how the payload is read. Lines 31–34 of rpc-basic-plain.php are replaced with the code shown next. This code sets $payload with the value of the payload index in $_POST:

You can experiment with the example by loading Listing 3-9. Figure 3-6 shows what the listing’s output should look like. Notice how easy it is to move between a normal form submission and an AJAX form submission. AJAX form submissions can be used with document-based approaches as well as with remote scripting approaches.
Figure 3-6. URL-encoded AJAX RPC
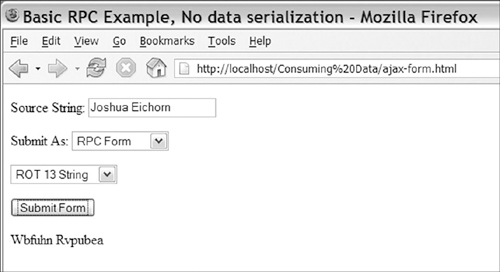
Adding some basic data encoding to our AJAX requests adds a lot of power and flexibility to AJAX-based RPC. It’s a great way to send multiple parameters to the server, and it is a great fit for form type data. The same encoding technique can also be used with non-RPC-based approaches when you want to emulate a normal form submission.
3.2.2 SOAP and XML-RPC
SOAP and XML-RPC are standardized XML protocols for doing remote requests. Many people who have used them before will wonder why they are not used more often. There are a variety of reasons for this, but the mains ones are as follows:
• The standards are complex and require large client libraries.
• Their encodings are verbose, making for slower interaction.
• The biggest benefits of talking to any Web service are negated by the fact that XMLHttpRequest’s security model limits you to talking to the same server that sent the HTML page.
At present, there are no successful cross-browser implementations in JavaScript for either SOAP or XML-RPC. There don’t seem to be technical issues stopping SOAP or XML-RPC from being implemented, except that any implementation will be much larger than the RPC options. SOAP or XML-RPC may become more popular in the future if browsers add native clients, but, so far, any implementations such as the SOAP client in Mozilla have been restricted to signed code or custom browsers built from the Mozilla base.
3.2.3 Custom XML
Some AJAX implementations use various custom XML schemas for transferring data. Although these formats suffer from some of the same data-bloat problems as SOAP or XML-RPC, they are generally much simpler and make a better fit because of this. One advantage of custom XML formats is that a format can be constructed to drive actions on the client side instead of just transferring data. Custom XML schemas based off the current schemas in your application’s workflow might also be useful, but these generally fit a document-centric approach better because most of the schemas will be data-specific and don’t fit into a generic RPC approach.
The XML example server pages, Rpc-xml.html and Rpc-xml.php, build off the RPC plain-encoded example. One advantage of using this approach over the basic RPC code is that it makes your client code more dynamic, because you can use a set of generic content-replacement functions that are put into action as needed from the server. You can use these generic functions instead of coding lots of custom callbacks. Depending on your needs, you may want to use a different XML schema in each direction, but for this example, we use the same one. It’s a basic schema that tells which function to call and the parameters to pass to the function. An example of the schema is shown in Listing 3-11.
Listing 3-11. Example Call XML

On the JavaScript side, we can use the DOM to read the XML, turning it into a string that can be run through the eval function to make the actual call. This works well from a security standpoint because the browser security sandbox keeps any remote requests on the same server, so you can trust any new content just as much as you trusted the original page load. On the PHP side, you don’t have that same level of trust, because a request can come from anywhere on the Internet. Instead, you’ll want to compare the function to call against a white list and use a method like call_user_func instead of eval. XML processing is also slightly harder than in JavaScript, because versions older than 5.0 don’t have DOM support by default. An easy way to support PHP 4 and 5 is to use a library from PEAR called XML_Serializer. XML_Serializer has the capability to take an XML file and turn it into a native PHP array. Most recent PHP installs come with the PEAR package manager, allowing you to install the library by running pear install XML_Serializer. (Detailed installation instructions are available at http://pear.php.net.) An example using XML to build an AJAX RPC system is shown in Listing 3-12.


Listing 3-12 follows the normal pattern of a JavaScript section at the top and then a small UI to interact with it below. The JavaScript starts on line 4 by including the standard XMLHttpRequest wrapper. After that, we define the remoteCall method. This method is based on remoteCall in rpc-basic-plain.html; the biggest different is that instead of a callback being passed in, it is built from the XML. Lines 8–10 create an HttpClient instance and set it up for an asynchronous POST request. Lines 11–24 build the callback handler that handles this result; this code uses the DOM representation of the resulting XML file to perform an action.
The basic process is to build a string and evaluate it. This process starts on line 13 by grabbing the root node of the XML document (the call tag) and putting it into callNode. Next, we append the function name and an "(" to the call string. After that, we use getElementsByTagName() (line 15) to get an array of all the param tags. We loop through these tags, appending each one inside single quotes to the string (lines 17–19). Each value is also run through the escape function in case it contains a single quote or another character that would cause our eval() to fail. At the end of this process, we will get a string like “functionName (‘param1’, ’param2’,”. To finish up the process of building our call string, we remove the extra "," from the end and append the closing ")" on line 21. Finally, the string is run through eval() on line 23, calling the function.
Lines 26–27 prepare the XML payload to be sent to the server. Because this is just a simple example with one parameter, it is just a matter of escaping the input and putting it together with the XML tags using string concatenation. Line 26 finishes remoteCall() by making the actual server request.
Next, the file contains a couple of generic callback functions and a helper function for making the remote calls. Lines 32–34 contain a generic function that replaces the content of an HTML element using innerHTML. This method takes two parameters: the ID of the element and the content to use for innerHTML. Lines 36–38 contain an append() function that follows the same pattern as the replace() function on lines 32–34; the only difference is that append() appends to innerHTML. The remote() function on lines 40–42 grabs the input value from the string input box and calls remoteCall() with it, passing it the function in the func variable.
The rest of the file (lines 46–57) contains the basic HTML UI. Line 47 contains our source input box, and lines 48–50 contain a list of action links that call the JavaScript remote() function. Line 52 contains our target DIV, which can be used by the append and replace functions. The file is finished by a status DIV on lines 53–55. The back end for this page is shown in Listing 3-13.
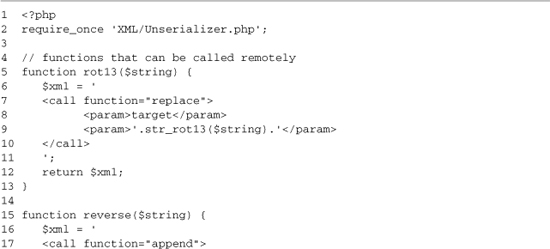

The first section of the file contains the same small function wrappers around basic PHP string handling functions as the plain example. The difference is that returned small chunks of XML define what to do with the results instead of just sending the results back. The rot13 function on lines 5–13 returns XML to replace the content of the element with an ID of target with a rot13 of the input string. The reverse() function on lines 15–23 returns XML to append to the contents of the target element with the reverse output of the input string. These two functions are then added to our function white list on lines 27–30.
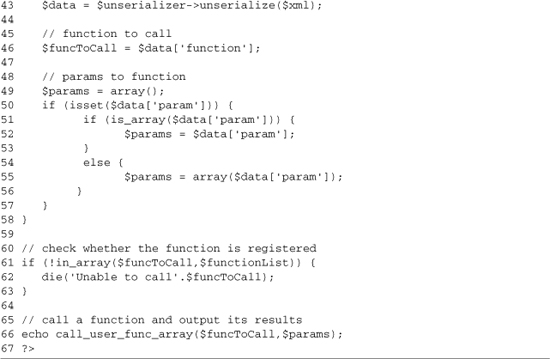
The latter half of the file (lines 33–66) takes an incoming request and prepares the results. Line 34 sets the content-type; if it’s not set to text/xml, then responseXML will never be populated on the client without this header being set. Lines 37–58 parse the XML, getting the function to call and building an array of parameters to call it with. Lines 41–42 create a new XML_Unserializer instance. Options are set to parse XML attributes (line 42) and to return the parsed data form unserialized instead of using an extra method call to get it. Line 43 parses the actual XML and sets its output array to the $data variable. Line 46 uses this array to get the function we’re calling, and then lines 49–57 grab the array of parameters. We first check whether the param index is set (line 50), allowing us to call functions without input. If it is set, we check whether it’s an array (line 51). If it is, we just set that to $params; if it’s not, we wrap it in an array as we set it to $params. This is done because XML_Serializer makes $data['param'] an array when multiple param tags exist, but if just one exists, XML_Serializer makes $data['param'] index string. Lines 60–63 do a basic security check, canceling script execution if the function isn’t in our white list of AJAX-callable functions. Finally on line 66, we use call_user_func_array to call the function and echo its results to the client. This example is shown in Figure 3-7.
Figure 3-7. XML-based AJAX RPC
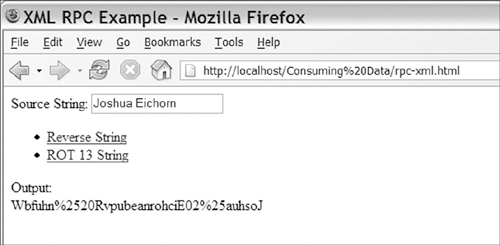
Using XML to move the data in our AJAX RPC system, we can build a system that can transfer any type of data. Using the concepts of standard XML-based RPC systems, we can encode any type of data and get the flexibility needed to build complex applications. If we optimize the schema for the server-side language that is being used, we can also limit the overhead created by the XML tags needed to describe the data. XML is used in many AJAX RPC libraries and provides everything you need to make a complete RPC solution.
3.2.4 JavaScript and JSON
Generating JavaScript and sending it to the client where it is run through eval() is a popular way to move data in object implementations. This process is popular because JavaScript has compact notations available for data types, such as arrays, and it allows for very flexible operations. Some AJAX frameworks use this ability to generate new client code from the server as needed, allowing the framework to provide a more centralized view of the development instead of the normal client/server dichotomy.
A mixed XML/JavaScript example could easily be built for the RPC XML in Listings 3-12 and 3-13. On the client side, you would send XML to the server, as is the case with the current code, but for the results, the server would return JavaScript and the client would eval it directly. To accomplish this, we need to make some small edits to Listings 3-12 and 3-13. For Listing 3-12, we need to replace lines 12–24 with a simple three-line callback that will run eval on the results from the server. This new callback is shown in Listing 3-14. The server URL on line 6 is updated to point to a new PHP script, which will be an edited version of Listing 3-13. This update is shown here:
var serverUrl = 'rpc-xml-javascript.php';
On the server side, lines 4–23 of Listing 3-13 are removed and replaced with the eight lines shown in Listing 3-15. The content type on line 34 of Listing 3-13 was also changed to text/plain.
Listing 3-14. Changes to Make Rpc-xml-javascript.html

Listing 3-15. More changes to Make Rpc-xml-javascript.html

These small changes give you a simpler code base with which to work, and their use entails sending a much smaller amount of data back to the client. It also allows for simpler, more flexible coding because you can send back any JavaScript instead of only what your XML schema allows.
Taking this approach one step further and sending JavaScript in both directions would be nice because of the data savings, but that’s a much harder task to do for a couple reasons. Most server languages don’t contain a JavaScript interpreter, so they can’t evaluate JavaScript code, but even if they did, you wouldn’t want to allow arbitrary client-created code to run on your server. Running code from the client on the server would be a huge security problem. The solution to both of these problems is a subset of JavaScript called JSON, which is the literal syntax for JavaScript objects. It can be run by eval() on the JavaScript side. This allows for any JavaScript data types to be transferred, and it’s much faster than an XML-based solution because the compact encoding allows for a much smaller amount of data to be transferred. On the server side, JSON is simple enough for a small parser to be built to serialize native data types into JSON and to create native data types from JSON.
While JSON is powerful and supports all JavaScript data types, it also has the drawback of being a more complex solution. A library is needed on the server to handle moving to and from the JSON strings, and a library is needed on the JavaScript side to create JSON strings—although eval() can be used to turn JSON into JavaScript objects. This makes a JSON example more complex than the examples shown in the other sections, which means if you want to use JSON, you’ll need to find some external libraries to do the actual parsing. Appendix A contains a list of libraries that provide JSON processing. In Chapter 9, “Libraries Used in Part II: HTML_AJAX,” a complete JSON RPC library for PHP HTML_AJAX is shown.
3.3 How to Decide on a Request Type
There are two main request types used in AJAX communication: POST and GET. These are the identical choices you have with forms in HTML, and the same rules apply. GET requests can be used when the URL performs no action. (For example, a URL such as index.php?section=main that displays the main section of a Web site is a good use for GET.) A URL such as index.php?action=delete&id=1 should never be used with GET. The main reasons for this go back to the HTTP standard, which suggests that GET requests should not perform permanent actions and are not allowed to be cached by proxies and other infrastructure. Some Web accelerator products also prefetch GET URLs from pages, which causes huge problems when they hit a URL that deletes a record. GET requests also have the drawback of potentially limiting the amount of data that the client can send to the server; current HTTP specs don’t limit size, but many servers and browsers limit the size to around 2,000 characters. POST requests aren’t allowed to be cached by proxies or prefetched, and thus are much safer than GET requests.
In most AJAX setups, especially any using an RPC approach, only POST requests should be used. While some of the requests might be just to load new data, it’s generally too hard to keep track of which type of request is which. In a document-centric approach, GET requests might be useful, especially when you’re using AJAX to load in chunks of static HTML or XML content. If you go with an approach like that, you’ll want to use a good naming convention to help keep track of which type of request is needed for each URL.
3.4 Summary
The examples in this chapter cover the basic ways to consume the data we learned to transfer in Chapter 2. Although fully working, their simple implementation is not the best choice for most production environments, because their simple style does not provide the robustness and feature set that a larger library would provide. In Chapters 9–12, many of these same patterns will be implemented using various libraries. These libraries offer better error handling and various helper functions to remove some of the repetitive code in the example. The more complex libraries also allow you to mix and match RPC serialization types, letting you use whatever serialization format is most efficient for the data in question.
You have two main choices when working with AJAX data:
• Document-centric approaches easily fit into current server-side modules and allow for a loose coupling between the client and the server.
• RPC-based approaches produce a tight coupling with the server side but offer the ability to write simpler server-side code.
Either approach will allow you to successfully build AJAX applications, but neither choice will guarantee it. Successful AJAX applications are not created because of implementation choices (although a good implementation always helps). They are created by good, user-centered design; the AJAX addition improves usability and gives the user the ability to do things he or she never imagined.