
Chapter 10
Electronic Mail Security: PGP, S/MIME
Pretty Good Privacy (PGP) was invented by Philip Zimmermann who released version 1.0 in 1991. Subsequent versions 2.6.x and 5.x (or 3.0) of PGP have been implemented by an all-volunteer collaboration under the design guidance of Zimmermann. PGP is widely used in the individual and commercial versions that run on a variety of platforms throughout the computer community. PGP uses a combination of symmetric secret-key and asymmetric public-key encryption to provide security services for electronic mail and data files. It also provides data integrity services for messages and data files by using digital signature, encryption, compression (zip), and radix-64 conversion (ASCII Armor). With the explosively growing reliance on e-mail and file storage, authentication and confidentiality services have become increasing demands.
MIME is an extension to the RFC 2822 framework which defines a format for text messages being sent using e-mail. MIME is actually intended to address some of the problems and limitations of the use of SMTP. Secure/Multipurpose Internet Mail Extension (S/MIME) is a security enhancement to the MIME Internet e-mail format standard, based on technology from RSA Data Security.
Although both PGP and S/MIME are on an IETF standards track, it appears likely that PGP will remain the choice for personnel e-mail security for many users, while S/MIME will emerge as the industry standard for commercial and organizational use. Two schemes of PGP and S/MIME are discussed in this chapter.
10.1 PGP
Before looking at the operation of PGP in detail, it is convenient to confirm the notation. In the forthcoming analyses for security and data integrity services, the following symbols are generally used:
10.1.1 Confidentiality via Encryption
PGP provides confidentiality by encrypting messages to be transmitted or data files to be stored locally using a conventional encryption algorithm such as IDEA, 3DES, or CAST-128. In PGP, each symmetric key, known as a session key, is used only once. A new session key is generated as a random 128-bit number for each message. Since it is used only once, the session key is bound to the message and transmitted with it. To protect the key, it is encrypted with the receiver's public key. Figure 10.1 illustrates the sequence, which is described as follows:
Figure 10.1 PGP confidentiality computation scheme with compression/decompression Algorithms.

- The sender creates a message.
- The sending PGP generates a random 128-bit number to be used as a session key for this message only.
- The session key is encrypted with RSA, using the recipient's public key.
- The sending PGP encrypts the message, using CAST-128 or IDEA or 3DES, with the session key. Note that the message is also usually compressed.
- The receiving PGP uses RSA with its private key to decrypt and recover the session key.
- The receiving PGP decrypts the message using the session key. If the message was compressed, it will be decompressed.
Instead of using RSA for key encryption, PGP may use a variant of Diffie–Hellman (known as ElGamal) that does provide encryption/decryption. In order for the encryption time to reduce, the combination of conventional and public-key encryption is used in preference to simply using RSA or ElGamal to encrypt the message directly. In fact, CAST-128 and other conventional algorithms are substantially faster than RSA or ElGamal. Since the recipient is able to recover the session key that is bound to the message, the use of the public-key algorithms solves the session key exchange problem. Finally, to the extent that the entire scheme is secure, PGP should provide the user with a range of key size options from 768 to 3072 bits.
Both digital signature and confidentiality services may be applied to the same message. First, a signature is generated from the message and attached to the message. Then the message plus signature are encrypted using a symmetric session key. Finally, the session key is encrypted using public-key encryption and prefixed to the encrypted block.
10.1.2 Authentication via Digital Signature
The digital signature uses a hash code of the message digest algorithm and a public-key signature algorithm. Figure 10.2 illustrates the digital signature service provided by PGP. The sequence is as follows:
Figure 10.2 PGP authentication computation scheme using compression algorithm.
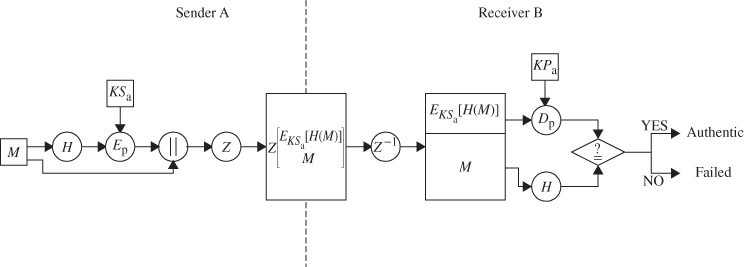
- The sender creates a message.
- SHA-1 is used to generate a 160-bit hash code of the message.
- The hash code is encrypted with RSA using the sender's private key and a digital signature is produced.
- The binary signature is attached to the message.
- The receiver uses RSA with the sender's public key to decrypt and recover the hash code.
- The receiver generates a new hash code for the received message and compares it with the decrypted hash code. If the two match, the message is accepted as authentic.
The combination of SHA-1 and RSA provides an effective digital signature scheme. As an alternative, signatures can be generated using DSS/SHA-1. The National Institute of Standards and Technology (NIST) has published FIPS PUB 186, known as the Digital Signature Standard (DSS). The DSS uses an algorithm that is designed to provide only the digital signature function. Although DSS is a public-key technique, it cannot be used for encryption or key exchange. The DSS approach for generating digital signatures was fully discussed in Chapter 5. The DSS makes use of the secure hash algorithm (SHA-1) described in Chapter 4 and presents a new digital signature algorithm (DSA).
10.1.3 Compression
As a default, PGP compresses the message after applying the signature but before encryption. The placement of Z for compression and ![]() for decompression is shown in Figures 10.1 and 10.2. This compression algorithm has the benefit of saving space both for e-mail transmission and for file storage. However, PGP compression technique will present a difficulty.
for decompression is shown in Figures 10.1 and 10.2. This compression algorithm has the benefit of saving space both for e-mail transmission and for file storage. However, PGP compression technique will present a difficulty.
Referring to Figure 10.1, message encryption is applied after compression to strengthen cryptographic security. In reality, cryptanalysis will be more difficult because the compressed message has less redundancy than the original message.
Referring to Figure 10.2, signing an uncompressed original message is preferable because the uncompressed message together with the signature are directly used for future verification. On the other hand, for a compressed message, one may consider two cases, either to store a compressed message for later verification or to recompress the message when verification is required. Even if a recompressed message were recovered, PGP's compression algorithm would present a difficulty due to the fact that different trade-offs in running speed versus compression ratio produce different compressed forms.
PGP makes use of a compression package called ZIP which is functionally equivalent to PKZIP developed by PKWARE, Inc. The zip algorithm is perhaps the most commonly used cross-platform compression technique.
Two main compression schemes, named after Abraham Lempel and Jakob Ziv, were first proposed by them in 1977 and 1978, respectively. These two schemes for text compression (generally referred to as lossless compression) are broadly used because they are easy to implement and also fast.
In 1982 James Storer and Thomas Szymanski presented their scheme, LZSS, based on the work of Lempel and Ziv. In LZSS, the compressor maintains a window of size N bytes and a lookahead buffer. Sliding-window-based schemes can be simplified by numbering the input text characters mod N, in effect creating a circular buffer. Variants of sliding-window schemes can be applied for additional compression to the output of the LZSS compressor, which include a simple variable-length code (LZB), dynamic Huffman coding (LZH), and Shannon–Fano coding (ZIP 1.x). All of them result in a certain degree of improvement over the basic scheme, especially when the data is rather random and the LZSS compressor has little effect.
Recently an algorithm was developed which combines the idea behind LZ77 and LZ78 to produce a hybrid called LZFG . LZFG uses the standard sliding window, but stores the data in a modified tree data structure and produces as output the position of the text in the tree. Since LZFG only inserts complete phrases into the dictionary, it should run faster than other LZ77-based compressors.
Huffman compression is a statistical data compression technique which reduces the average code length used to represent the symbols of an alphabet. Huffman code is an example of a code which is optimal when all symbols probabilities are integral powers of 1/2. A technique related to Huffman coding is Shannon–Fano coding. This coding divides the set of symbols into two equal or almost equal subsets based on the probability of occurrence of characters in each subset. The first subset is assigned a binary 0, the second a binary 1. Huffman encoding always generates optimal codes, but Shannon–Fano sometimes uses a few more bits.
Decompression of LZ77-compressed text is simple and fast. Whenever a (position, length) pair is encountered, one goes to that position in that window and copies length bytes to the output.
10.1.4 Radix-64 Conversion
When PGP is used, usually part of the block to be transmitted is encrypted. If only the signature service is used, then the message digest is encrypted (with the sender's private key). If the confidentiality service is used, the message plus signature (if present) are encrypted (with a one-time symmetric key). Thus, part or all of the resulting block consists of a stream of arbitrary 8-bit octets. However, many electronic mail systems only permit the use of blocks consisting of ASCII text. To accommodate this restriction, PGP provides the service of converting the raw 8-bit binary octets to a stream of printable 7-bit ASCII characters, called radix-64 encoding or ASCII Armor. Therefore, to transport PGP's raw binary octets through unreliable channels, a printable encoding of these binary octets is needed.
The scheme used for this purpose is radix-64 conversion. Each group of 3 octets of binary data is mapped into four ASCII characters. This format also appends a Cyclic Redundancy Check (CRC) to detect transmission errors. This radix-64 conversion is a wrapper around the binary PGP messages and is used to protect the binary messages during transmission over nonbinary channels, such as Internet e-mail.
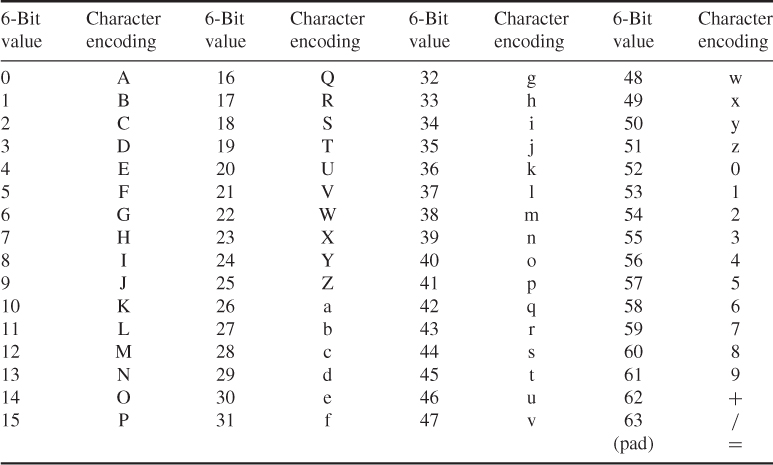
Table 10.1 shows the mapping of 6-bit input values to characters. The character set consists of the upper- and lower-case letters, the digits 0–9, and the characters ‘![]() ’ and ‘
’ and ‘![]() ’. The ‘
’. The ‘![]() ’ character is used as the padding character. The hyphen “-” character is not used.
’ character is used as the padding character. The hyphen “-” character is not used.
Table 10.1 Radix-64 encoding
Thus, a PGP text file resulting from ASCII characters will be immune to the modifications inflicted by mail systems. It is possible to use PGP to convert any arbitrary file to ASCII Armor. When this is done, PGP tries to compress the data before it is converted to radix-64.
![]()
The hexadecimal representation of this text sequence is b2 63 29.
![]()
The extracted 6-bit decimal values are 44, 38, 12, and 41.
![]()
If these characters are stored in 8-bit ASCII format with zero parity, we have them in hexadecimal as follows:
![]()
In binary representation, this becomes:
![]()
ASCII Armor Format
When PGP encodes data into ASCII Armor, it puts specific headers around the data, so PGP can construct the data later. PGP informs the user about what kind of data is encoded in ASCII Armor through the use of the headers.
Concatenating the following data creates ASCII Armor: an Armor head line, Armor headers, a blank line, ASCII-Armored data, Armor checksum, and Armor tail. Specifically, an explanation for each item is as follows:
- An Armor head line. This consists of the appropriate header line text surrounded by five dashes (“-”, 0x2D) on either side of the header line text. The header line text is chosen based upon the type of data that is being encoded in Armor, and how it is being encoded. Header line texts include the following strings:
- BEGIN PGP MESSAGE—used for signed, encrypted, or compressed files.
- BEGIN PGP PUBLIC KEY BLOCK—used for armoring public keys.
- BEGIN PGP PRIVATE KEY BLOCK—used for armoring private keys.
- BEGIN PGP MESSAGE, PART X/Y—used for multipart messages, where the armour is divided among Y parts, and this is the Xth part out of Y.
- BEGIN PGP MESSAGE, PART X—used for multipart messages, where this is the Xth part of an unspecified number of parts and requires the MESSAGE-ID Armor header to be used.
- BEGIN PGP SIGNATURE—used for detached signatures, PGP/MIME signatures, and natures following clear-signed messages. Note that PGP 2.xs BEGIN PGP MESSAGE is used for detached signatures.
- Armor headers. There are pairs of strings that can give the user or the receiving PGP implementation some information about how to decode or use the message. The Armor headers are a part of the armor, not a part of the message, and hence are not protected by any signatures applied to the message. The format of an Armor header is that of a (key, value) pair. A colon (“:” 0x38) and a single space (0x20) separate the key and value. PGP should consider improperly formatted Armor headers to be corruptions of ASCII Armor. Unknown keys should be reported to the user, but PGP should continue to process the message.
Currently defined Armor header keys include:
- Version. This states the PGP version used to encode the message.
- Comment. This is a user-defined comment.
- MessageID. This defines a 32-character string of printable characters. The string must be the same for all parts of a multipart message that uses the “PART X” Armor header. MessageID string should be unique enough that the recipient of the mail can associate all the parts of a message with each other. A good checksum or cryptographic hash function is sufficient.
- Hash. This is a comma-separated list of hash algorithms used in the message. This is used only in clear-signed messages.
- Charset. This is a description of the character set that the plaintext is in. PGP defines text to be in UTF-8 by default. An implementation will get the best results by translating into and out of UTF-8 (see RFC 2279). However, there are many instance where this is easier said than done. Also, there are communities of users who have no need for UTF-8 because they are all satisfied with a character set like ISO Latin-5 or a Japanese one. In such instances, an implementation may override the UTF-8 default by using this header key.
- A blank line. This indicates zero length or contains only white space.
- ASCII-Armored data. An arbitrary file can be converted to ASCII-Armored data by using Table 10.1.
- Armor checksum. This is a 24-bit CRC converted to four characters of radix-64 encoding by the same MIME base 64 transformation, preceded by an equals sign (
 ). The CRC is computed by using the generator 0x864cfb and an initialization of 0xb704ce. The accumulation is done on the data before it is converted to radix-64, rather than on the converted data. The checksum with its leading equals sign may appear on the first line after the base 64 encoded data.
). The CRC is computed by using the generator 0x864cfb and an initialization of 0xb704ce. The accumulation is done on the data before it is converted to radix-64, rather than on the converted data. The checksum with its leading equals sign may appear on the first line after the base 64 encoded data. - Armor tail. The Armor tail line is composed in the same manner as the Armor header line, except the string “BEGIN” is replaced by the string “END”.
Encoding Binary in Radix-64
The encoding process represents three 8-bit input groups as output strings of four encoded characters. These 24 bits are then treated as four concatenated 6-bit groups, each of which is translated into a single character in the radix-64 alphabet. Each 6-bit group is used as an index. The character referenced by the index is placed in the output string.
Special processing is performed if fewer than 24 bits are available at the end of the data being encoded. There are three possibilities:
Radix-64 printable encoding of binary data is shown in Figure 10.3.
Figure 10.3 Radix-64 printable encoding of binary data.

| 8-bit octets: | 00010101 11010000 00101111 10011110 10110111 01001100 |
| 6-bit index: | 000101 011101 000000 101111 100111 101011 011101 001100 |
| Decimal: | 5 29 0 47 39 43 29 12 |
| Output character: | F d A v n r d M |
| (radix-64 encoding) | |
| ASCII format (0x): | 46 64 41 76 6e 72 64 4d |
| Binary: | 01000110 01100100 01000001 01110110 |
| 01101110 01110010 01100100 01001101 |
| 8-bit octets: | 00010101 11010000 00101111 10011110 10110111 |
| 6-bit index: | 000101 011101 000000 101111 100111 101011 011100 |
| Pad with 00 ( | |
| Decimal: | 5 29 0 47 39 43 28 |
| Output character: | F d A v n r c |
| 8-bit octets: | 00010101 11010000 00101111 10011110 |
| 6-bit index: | 000101 011101 000000 101111 100111 100000 |
| Pad with 0000 ( | |
| Decimal: | 5 29 0 47 39 32 |
| Output character: | F d A v n g |
10.1.5 Packet Headers
A PGP message is constructed from a number of packets. A packet is a chunk of data which has a tag specifying its meaning. Each packet consists of a packet header of variable length, followed by the packet body.
The first octet of the packet header is called the packet tag as shown in Figure 10.4.The MSB is “bit 7” (the leftmost bit) whose mask is 0x80 (10000000) in hexadecimal. PGP 2.6.x only uses old format packets. Hence, software that interoperates with PGP 2.6.x must only use old format packets. These packets have 4 bits of content tags, but new format packets have 6 bits of content tags.
Figure 10.4 Packet header.

Packet Tags
The packet tag denotes what type of packet the body holds. The defined tags (in decimal) are:
Old-format Packet Lengths
The meaning of the length type in old-format packets is:
New-format Packet Lengths
New-format packets have four possible ways of encoding length.
- One-octet lengths.
A 1-octet body length header encodes packet lengths from 0 to 191 octets. This type of length header is recognized because the 1-octet value is less than 192. The body length is equal to:
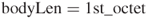
- Two-octet lengths.
A 2-octet body length header encodes a length from 192 to 8383 octets. It is recognized because its first octet is in the range 192–223. The body length is equal to:

- Five-octet lengths.
A 5-octet body length header encodes packet lengths of up to
 (0xffffffff) octets in length. This header consists of a single octet holding the value 255, followed by a 4-octet scalar. The body length is equal to:
(0xffffffff) octets in length. This header consists of a single octet holding the value 255, followed by a 4-octet scalar. The body length is equal to:
- Partial body lengths.
A partial body length header is 1 octet long and encodes the length of only part of the data packet. This length is a power of 2, from 1 to
 (2 to the 30th power). It is recognized by its 1-octet value that is greater than or equal to 224 and less than 255. The partial body length is equal to:
(2 to the 30th power). It is recognized by its 1-octet value that is greater than or equal to 224 and less than 255. The partial body length is equal to: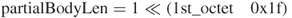
Each partial body length header is followed by a portion of the packet body data. The header specifies this portion's length. Another length header (of one of the three types: 1 octet, 2 octet, or partial) follows that portion. The last length header in the packet must not be a partial body length header. The latter headers may only be used for the nonfinal parts of the packet.
![]()
Thus, a packet with length 100 may have its length encoded in 1 octet: 0x64. This header is followed by 100 octets of data. Similarly, a packet with length 1723 may have its length encoded in 2 octets: 0xc5 and 0xfb. This header is followed by the 1723 octets of data. A packet with length 100 000 may have its length encoded in 5 octets: 0xff, 0x00, 0x01, 0x86, and 0xa0.
10.1.6 PGP Packet Structure
A PGP file consists of a message packet, a signature packet, and a session key packet.
Message Packet
This packet includes the actual data to be transmitted or stored as well as a header that includes control information generated by PGP such as a filename and a timestamp. A timestamp specifies the time of creation. The message component consists of a single literal data packet.
Signature Packet (Tag 2)
This packet describes a binding between some public key and some data. The most common signatures are a signature of a file or a block of text and a signature that is a certification of a user ID.
Two versions of signature packets are defined. PGP 2.6.x only accepts version 3 signature. Version 3 provides basic signature information, while version 4 provides an expandable format with subpackets that can specify more information about the signature. It is reasonable to create a v3 signature if an implementation is creating an encrypted and signed message that is encrypted with a v3 key.
At first, version 3 for basic signature information will be presented in the following. The signature packet is the signature of the message component, formed using a hash code of the message component and sender a's public key. The signature component consists of single signature packet.
The signature includes the following components:
- Timestamp. This is the time at which the signature was created.
- Message digest (or hash code). A hash code represents the 160-bit SHA-1 digest, encrypted with sender a's private key. The hash code is calculated over the signature timestamp concatenated with the data portion of the message component. The inclusion of the signature timestamp in the digest protects against replay attacks. The exclusion of the filename and timestamp portion of the message component ensures that detached signatures are exactly the same as attached signatures prefixed to the message. Detached signatures are calculated on a separate file that has none of the message component header fields.
If the default option of compression is chosen, then the block consisting of the literal data packet and the signature packet is compressed to form a compressed data packet:
- Leading 2 octets of hash code. These enable the recipient to determine if the correct public key was used to decrypt the hash code for authentication, by comparing the plaintext copy of the first 2 octets with the first 2 octets of the decrypted digest. Two octets also serve as a 16-bit frame-check sequence for the message.
- Key ID of sender's public key. This identifies the public key that should be used to decrypt the hash code and hence identifies the private key that was used to encrypt the hash code.
The message component and signature component (optional) may be compressed using ZIP and may be encrypted using a session key.
There are a number of possible meanings of a signature, which are specified in signature-type octets as shown below:
The contents of the signature packets of version 3 (v3) and version 4 (v4) are illustrated in Table 10.2.
Table 10.2 Signature packet format of version 3 and version 4
| Content | Length in octets | |
| v3 | v4 | |
| Version number: v3(3), v4(4) | 1 | 1 |
| Signature type | 1 | 1 |
| Creation time | 4 | — |
| Signer's key ID | 8 | — |
| Public-key algorithm | 1 | 1 |
| Hash algorithm | 1 | 1 |
| Field holding left 16 bits of signed hash value | 2 | 2 |
| One or more MPIs comprising the signature | Algorithm specific2* | Algorithm specific |
| Scalar octet count for hashed subpacket data | — | 2 |
| Hashed subpacket data | — | Zero or more subpackets |
| Scalar octet count for all of the unhashed subpackets | — | 2 |
| Unhashed subpacket data | — | Zero or more subpackets |
*Algorithm-specific fields for RSA signature: MPI of RSA signature value ![]() ; algorithm-specific fields for DSA signature: MPI of DSA value r, MPI of DSA value s. (
; algorithm-specific fields for DSA signature: MPI of DSA value r, MPI of DSA value s. (![]() Integer)
Integer)
The signature calculation for version 4 signature is based on a hash of the signed data. The data being signed is hashed, and then the signature data from the version number to the hashed subpacket data is hashed. The resulting hash value is what is signed. The left 16 bits of the hash are included in the signature packet to provide a quick test to reject some invalid signatures.
Session Key Packets (Tag 1)
This component includes the session key and the identifier of the receiver's public key that was used by the sender to encrypt the session key. A public-key-encrypted session key packet, ![]() (
(![]() ), holds the session key used to encrypt a message. The symmetrically encrypted data packets are preceded by one public-key-encrypted session key packet for each PGP 5.x key to which the message is encrypted. The message is encrypted with the session key, and the session key is itself encrypted and stored in the encrypted session key packet. The recipient of the message finds a session key that is encrypted to its public key, decrypts the session key, and then uses the session key to decrypt the message.
), holds the session key used to encrypt a message. The symmetrically encrypted data packets are preceded by one public-key-encrypted session key packet for each PGP 5.x key to which the message is encrypted. The message is encrypted with the session key, and the session key is itself encrypted and stored in the encrypted session key packet. The recipient of the message finds a session key that is encrypted to its public key, decrypts the session key, and then uses the session key to decrypt the message.
The body of this session key component consists of:
- A 1-octet version number which is 3.
- An 8-octet key ID of the public key that the session key is encrypted to.
- A 1-octet number giving the public key algorithm used.
- A string of octets that is the encrypted session key. This string's contents are dependent on the public-key algorithm used:
- Algorithm-specific fields for RSA encryption: multiprecision integer (MPI) of RSA encrypted value
 -mod n.
-mod n. - Algorithm-specific fields for ElGamal encryption: MPI of ElGamal value
 mod p; MIP of ElGamal value my
mod p; MIP of ElGamal value my mod p. The value ‘m’ is derived from the session key.
mod p. The value ‘m’ is derived from the session key.
- Algorithm-specific fields for RSA encryption: multiprecision integer (MPI) of RSA encrypted value
If compression has been used, then conventional encryption is applied to the compressed data packet format from the compression of the signature packet and the literal data packet. Otherwise, conventional encryption is applied to the block consisting of the signature packet and the literal data packet. In either case, the ciphertext is referred to as a conventional-key-encrypted data packet.
As shown in Figure 10.5, the entire block of PGP message is usually encoded with radix-64 encoding.
Figure 10.5 PGP message format.

10.1.7 Key Material Packet
A key material packet contains all the information about a public or private key. There are four variants of this packet type and two versions.
Key Packet Variants
There are:
- Public-key packet (tag 6). This packet starts a series of packets that forms a PGP 5.x key.
- Public subkey packet (tag 14). This packet has exactly the same format as a public-key packet, but denotes a subkey. One or more subkeys may be associated with a top-level key. The top-level key provides signature services, and the subkeys provide encryption services. PGP 2.6.x ignores public-subkey packets.
- Secret-key packet (tag 5). This packet contains all the information that is found in a public-key packet, including not only the public-key materials but also the secret-key material after all the public-key fields.
- Secret-subkey packet (tag 7). A secret-subkey packet is the subkey analogous to the secret-key packet and has exactly the same format.
Public-key Packet Formats
There are two variants of version 3 packets and version 2 packets. Version 3 packets were originally generated by PGP 2.6. Version 2 packets are identical in format to version 3 packets, but are generated by PGP 2.5. However, v2 keys are deprecated and they must not be generated. PGP 5.0 introduced version 4 packets, with new fields and semantics. PGP 2.6.x will not accept key-material packets with versions greater than 3. PGP 5.x (or PGP3) implementation should create keys with version 4 format, but v4 keys correct some security deficiencies in v3 keys.
A v3 key packet contains:
- A 1-octet version number (3).
- A 4-octet number denoting the time that the key was created.
- A 2-octet number denoting the time in days that this key is valid.
- A 1-octet number denoting the public-key algorithm of this key.
- A series of MPIs comprising the key material: an MPI of RSA public module n and an MPI of RSA public encryption exponent e.
A key ID is an 8-octet scalar that identifies a key. For a v3 key, the 8-octet key ID consists of the low 64 bits of the public modulus of the RSA key. The fingerprint of a v3 key is formed by hashing the body (excluding the 2-octet length) of the MPIs that form the key material with MD5.
Note that MPIs are unsigned integers. An MPI consists of two parts: a 2-octet scalar that is the length of the MPI in bits followed by a string of octets that contain the actual integer.
![]()
The MPI size is:
![]()
which checks the given size of the MPI string.
A v4 key packet contains:
- A 1-octet version number (4).
- A 4-octet number denoting the time that the key was created.
- A 1-octet number denoting the public-key algorithm of this key.
- A series of MPIs comprising the key material:
- Algorithm-specific fields for RSA public keys: MPI of RSA public modulus n and MPI of RSA public encryption exponent e.
- Algorithm-specific fields for DSA public keys: MPI of DSA prime p; MPI of DSA group order q (q is a prime divisor of
 ); MPI of DSA group generator g; and MPI of DSA public key value
); MPI of DSA group generator g; and MPI of DSA public key value  where x is secret.
where x is secret. - Algorithm-specific fields for ElGamal public keys: MPI of ElGamal prime p; MPI of ElGamal group generator g; and MPI of ElGamal public key value
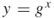 where x is secret.
where x is secret.
Secret-key Packet Formats
The secret-key and secret-subkey packets contain all the data of public-key and public-subkey packets in encrypted form, with additional algorithm-specific key data appended.
The secret-key packet contains:
- A public-key or public-subkey packet, as described above.
- One octet indicating string-to-key (S2K) usage conventions: 0 indicates that the secret-key data is not encrypted; 255 indicates that an S2K specifier is being given. Any other value specifies a symmetric-key encryption algorithm.
- If the S2K usage octet was 255, a 1-octet symmetric encryption algorithm (optional).
- If the S2K usage octet was 255, an S2K specifier (optional). The length of the S2K specifier is implied by its type, as described above.
- If secret data is encrypted, an 8-octet IV (optional).
- Encrypted MPIs comprising the secret-key data. These algorithm-specific fields are as described below.
- A 2-octet checksum of the plaintext of the algorithm-specific portion (sum of all octets,
 ):
):
- Algorithm-specific fields for RSA secret keys: MPI of RSA secret exponent d; MPI of RSA secret prime value p; MPI of RSA secret prime value q (
 ); and MPI of u, the multiplicative inverse of p, mod q.
); and MPI of u, the multiplicative inverse of p, mod q. - Algorithm-specific fields for DSA secret keys: MPI of DSA secret exponent x.
- Algorithm-specific fields for ElGamal secret keys: MPI of ElGamal secret exponent x.
- Algorithm-specific fields for RSA secret keys: MPI of RSA secret exponent d; MPI of RSA secret prime value p; MPI of RSA secret prime value q (
Simple S2K directly hashes the string to produce the key data:
It also hashes the passphrase to produce the session key. The hashing process to be done depends on the size of the session key and the size of the hash algorithm's output. If the hash size is greater than or equal to the session key size, the higher-order (leftmost) octets of the hash are used as the key. If the hash size is less than the key size, multiple instances are preloaded with 0, 1, 2, ![]() octets of zeros in order to produce the required key data.
octets of zeros in order to produce the required key data.
S2K specifiers are used to convert passphrase strings into symmetric-key encryption/decryption keys. They are currently used in two ways: to encrypt the secret part of private keys in the private keyring and to convert passphrases to encryption keys for symmetrically encrypted messages.
Secret MPI values can be encrypted using a passphrase. If an S2K specifier is given, it describes the algorithm for converting the passphrase to a key, otherwise a simple MD5 hash of the passphrase is used. The cipher for encrypting the MPIs is specified in the secret-key packet.
Encryption/decryption of the secret data is done in CFB (Cipher Feedback) mode using the key created from the passphrase and IV from the packet. A different mode is used with v3 keys (which are only RSA) than with other key formats. With v3 keys, the prefix data (the first two octets) of the MPI is not encrypted; only the MPI nonprefix data is encrypted. Furthermore, the CFB state is resynchronized at the beginning of each new MPI value, so that the CFB block boundary is aligned with the start of the MPI data. With v4 keys, a simpler method is used: all secret MPI values are encrypted in CFB mode, including the MPI bitcount prefix.
The 16-bit checksum that follows the algorithm-specific portion is the algebraic sum, mod ![]() , of the plaintext of all the algorithm-specific octets (including the MPI prefix and data). With v4 keys, the checksum is encrypted like the algorithm-specific data. This value is used to check that the passphrase was correct.
, of the plaintext of all the algorithm-specific octets (including the MPI prefix and data). With v4 keys, the checksum is encrypted like the algorithm-specific data. This value is used to check that the passphrase was correct.
Besides simple S2K, there are two more S2K specifiers currently supported:
- Salted S2K. This includes a salt value in the simple S2K specifier that hashes the passphrase to help prevent dictionary attacks:
Octet 0: 0x01Octet 1: hash algorithmOctets 2–9: 8-octet salt valueSalted S2K is exactly like simple S2K, except that the input to the hash function consists of the 8 octets of salt from the S2K specifier, followed by the passphrase.
- Iterated and salted S2K.
This includes both a salt and an octet count. The salt is combined with the passphrase and the resulting value is hashed repeatedly. This further increases the amount of work an attacker would have to do.Octet 0: 0x03Octet 1: hash algorithmOctets 2–9: 8-octet salt valueOctet 10: count, a 1-octet, coded value. (The count is coded into a 1-octet number.)Iterated–salted S2K hashes the passphrase and salt data multiple times. The total number of octets to be hashed is given in the encoded count in the S2K specifier. But the resulting count value is an octet count of how many octets will be hashed, not an iteration count. The salt followed by the passphrase data is repeatedly hashed until the number of octets specified by the octet count has been hashed. Implementations should use salted or iterated–salted S2K specifiers because simple S2K specifiers are more vulnerable to dictionary attacks.
10.1.8 Algorithms for PGP 5.x
This section describes the algorithms used in PGP 5.x.
Public-key Algorithms
| ID | Algorithm |
| 1 | RSA (encrypt or sign) |
| 2 | RSA encryption only |
| 3 | RSA sign only |
| 16 | ElGamal (encrypt only) |
| 17 | DSA (DSS) |
| 18 | Reserved for elliptic curve |
| 19 | Reserved for ECDSA |
| 20 | ElGamal (encrypt or sign) |
| 21 | Reserved for Diffie–Hellman |
| 100–110 | Private/experimental algorithm |
Symmetric-key Algorithms
| ID | Algorithm |
| 0 | Plaintext or unencrypted data |
| 1 | IDEA |
| 2 | Triple DES (DES–EDE) |
| 3 | CAST 5 (128-bit key) |
| 4 | Blowfish (128-bit key, 16 rounds) |
| 5 | SAFER-SK128 (13 rounds) |
| 6 | Reserved for DES/SK |
| ID | Algorithm |
| 7 | Reserved for AES (128-bit key) |
| 8 | Reserved for AES (192-bit key) |
| 9 | Reserved for ASE (256-bit key) |
| 100–110 | Private/experimental algorithm |
Compression Algorithm
| ID | Algorithm |
| 0 | Uncompressed |
| 1 | ZIP (RFC 1951) |
| 2 | ZLIB (RFC 1950) |
| 100–110 | Private/experimental algorithm |
Hash Algorithms
| ID | Algorithm |
| 1 | MD5 |
| 2 | SHA-1 |
| 3 | RIPE-MD/160 |
| 4 | Reserved for double-width SAH (experimental) |
| 5 | MD2 |
| 6 | Reserved for TIGER/192 |
| 7 | Reserved for HAVAL (5 pass, 160-bit) |
| 100–110 | Private/experimental algorithm |
These tables are not an exhaustive list. An implementation may utilize an algorithm not on these lists.
10.2 S/MIME
S/MIME provides a consistent means to send and receive secure MIME data. S/MIME, based on the Internet MIME standard, is a security enhancement to cryptographic electronic messaging. Further, S/MIME not only is restricted to e-mail, but can be used with any transport mechanism that carries MIME data, such as HTTP. As such, S/MIME takes advantage of allowing secure messages to be exchanged in mixed-transport systems. Therefore, it appears likely that S/MIME will emerge as the industry standard for commercial and organizational use. This section describes a protocol for adding digital signature and encryption services to MIME data.
10.2.1 MIME
SMTP is a simple mail transfer protocol by which messages are sent only in NVT (Network Virtual Terminal) 7-bit ASCII format. NVT normally uses what is called NVT ASCII. This is an 8-bit character set in which the seven lowest-order bits are the same as ASCII and the highest-order bit is zero.
MIME was defined to allow transmission of non-ASCII data through e-mail. MIME allows arbitrary data to be encoded in ASCII and then transmitted in a standard e-mail message. It is a supplementary protocol that allows non-ASCII data to be sent through SMTP. However, MIME is not a mail protocol and cannot replace SMTP; it is only an extension to SMTP. In fact, MIME does not change SMTP or POP3, neither does it replace them.
The MIME standard provides a general structure for the content type of Internet messages and allows extensions for new content-type applications. To accommodate arbitrary data types and representations, each MIME message includes information that tells the recipient the type of the data and the encoding used. The MIME standard specifies that a content-type declaration must contain two identifiers, a content type and a subtype, separated by a slash.
MIME Description
MIME transforms non-ASCII data at the sender's site to NVT ASCII data and delivers it to the client SMTP to be sent through the Internet. The server SMTP at the receiver's site receives the NVT ASCII data and delivers it to MIME to be transformed back to the original non-ASCII data. Figure 10.6 illustrates a set of software functions that transforms non-ASCII data to ASCII data and vice versa.
Figure 10.6 MIME showing a set of transforming functions.

MIME Header
MIME defines five headers that can be added to the original SMTP header section:
- MIME_Version
- Content_Type
- Content_Transfer_Encoding
- Content_Id
- Content_Description.
The MIMI header is shown in Figure 10.7 and described below.
Figure 10.7 MIME header.

MIME_Version
This header defines the version of MIME used. The current version is 1.0.
Content_Type
This header defines the type of data used in the message body. The content type and the content subtype are separated by a slash. MIME allows seven different types of data:
- Text. The original message is in 7-bit ASCII format.
- Multipart. The body contains multiple, independent parts. The multipart header needs to define the boundary between each part. Each part has a separate content type and encoding.
The multipart/signed content type specifies how to support authentication and integrity services via digital signature.Definition of multipart/signed:
- MIME type name: multipart
- MIME subtype name: signed
- Required parameters: boundary, protocol, and micalg
- Optional parameters: none
- Security considerations: must be treated as opaque while in transit.
The multipart/signed content type contains exactly two body parts. The first body part is the one over which the digital signature was created, including its MIME headers. The second body part contains the control information necessary to verify the digital signature.Definition of multipart/encrypted:- MIME type name: multipart
- MIME subtype name: encrypted
- Required parameters: boundary and protocol
- Optional parameters: none
- Security considerations: none.
The multipart/encrypted content type contains exactly two body parts. The first body part contains the control information necessary to decrypt the data in the second body part and is labeled according to the value of the protocol parameter. The second body part contains the data which was encrypted and is always labeled application/octet-stream. - Message. In the message type, the body is itself a whole mail message, a part of a mail message, or a pointer to the message. Three subtypes are currently used: RFC 2822, partial body, or external body. The subtype RFC 2822 is used if the body is encapsulating another message. The subtype partial is used if the original message has been fragmented into different mail messages and this mail message is one of the fragments. The fragments must be reassembled at the destination by MIME. Three parameters must be added: ID, number, and total. The id identifies the message and is present in all the fragments. The number defines the sequence order of the fragment. The total defines the number of fragments that comprise the original message.
- Image. The original message is a stationary image, indicating that there is no animation. The two subtypes currently used are Joint Photographic Experts Group (JPEG), which uses image compression, and Graphics Interchange Format (GIF).
- Video. The original message is a time-varying image (animation). The only subtype is Motion Picture Experts Group (MPEG). If the animated image contains sound, it must be sent separately using the audio content type.
- Audio. The original message contains sound. The only subtype is basic, which uses 8-kHz standard audio data.
- Application. The original message is a type of data not previously defined. There are only two subtypes used currently: octet-stream and PostScript. Octet-stream is used when the data represents a sequence of binary data consisting of 8-bit bytes. PostScript is used when the data is in Adobe PostScript format for printers that support PostScript.
Content_Transfer_Encoding
This header defines the method to encode the messages into ones and zeros for transport. There are the five types of encoding: 7 bit, 8 bit, binary, Base64, and Quoted-printable. Table 10.3 describes the Content_Transfer_Encoding by the five types.
Table 10.3 Five types of encoding
| Type | Description |
| 7 Bit | NVT ASCII characters and short lines |
| 8 Bit | Non-ASCII characters and short lines |
| Binary | Non-ASCII characters with unlimited-length lines |
| Base64 | 6-Bit blocks of data encoded into 8-bit ASCII characters |
| Quoted-printable | Non-ASCII characters encoded as an equals sign followed by an ASCII code |
Note that lines in the header identify the type of the data as well as the encoding used.
- 7 Bit. This is 7-bit NVT ASCII encoding. Although no special transformation is needed, the length of the line should not exceed 1000 characters.
- 8 Bit. This is 8-bit encoding. Non-ASCII characters can be sent, but the length of the line still should not exceed 1000 characters. Since the underlying SMTP is able to transfer 8-bit non-ASCII characters, MIME does not do any encoding here. Base64 (or radix-64) and quoted-printable types are preferable.
- Binary. This is 8-bit encoding. Non-ASCII characters can be sent, and the length of the line can exceed 1000 characters. MIME does not do any encoding here; the underlying SMTP must be able to transfer binary data. Therefore, it is not recommended. Base64 (or radix-64) and quoted-printable types are preferable.
- Base64. This is a solution for sending data made of bytes when the highest bit is not necessarily zero. Base64 transforms this type of data of printable characters which can be sent as ASCII characters.
- Quoted-printable. Base64 is a redundant encoding scheme. The 24-bit non-ASCII data becomes four characters consisting of 32 bits. We have an overhead of 25%. If the data consists of mostly ASCII characters with a small non-ASCII portion, we can use quoted-printable encoding. If a character is ASCII, it is sent as it is; if a character is not ASCII it is sent as three characters.
Content_Id
This header uniquely identifies the whole message in a multiple message environment:
![]()
Content_Description
This header defines whether the body is image, audio, or video:
Content_Description: ![]() description
description![]()
In this example, MIME_Version declares that the message was composed using version 1.1 of the MIME protocol. The MIME standard specifies that a Content_Type declaration must contain two identifiers, a content type and a subtype, separated by a slash. In this example, image is the content type, and gif is the subtype. Therefore, the Content_Type declares that the data is a GIF image. For the Content_Transfer_Encoding, the header declares that Base64 encoding was used to convert the image to ASCII. To view the image, a receiver's mail system must first convert from Base64 encoding back to binary, and then run an application that displays a GIF image on the user's screen.
MIME Security Multiparts
An Internet e-mail message consists of two parts: the headers and the body. The headers form a collection of field/value pairs, while the body is defined according to the MIME format. The basic MIME by itself does not specify security protection. Accordingly, a MIME agent must provide security services by employing a security protocol mechanism, by defining two security subtypes of the MIME multipartcontent type: signed and encrypted. In each of the security subtypes, there are exactly two related body parts: one for the protected data and one for the control information. The type and contents of the control information body parts are determined by the value of the protocol parameter of the enclosing multipart/signed or multipart/encrypted content type. A MIME agent should be able to recognize a security multipart body part and to identify its protected data and control information body part.
The multipart/signed content type specifies how to support authentication and integrity services via digital signature. The multipart/singed content type contains exactly two body parts. The first body part is the one over which the digital signature was created, including its MIME headers. The second body part contains the control information necessary to verify the digital signature. The Message Integrity Check (MIC) is the quantity computed over the body part with a message digest or hash function, in support of the digital signature service. The multipart/encrypted content type specifies how to support confidentiality via encryption. The multipart/encrypted content type contains exactly two body parts. The first body part contains the control information necessary to decrypt the data in the second body part. The second body part contains the data which was encrypted and is always labeled application/octet-stream.
MIME Security with OpenPGP
This subsection describes how the OpenPGP message format can be used to provide privacy and authentication using the MIME security content type. The integrating work on PGP with MIME suffered from a number of problems, the most significant of which was the inability to recover signed message bodies without parsing data structures specific to PGP. RFC 1847 defines security multipart formats for MIME. The security multiparts clearly separate the signed message body from the signature.
PGP can generate either ASCII Armor or a stream of arbitrary 8-bit octets when encrypting data, generating a digital signature, or extracting public-key data. The ASCII Armor output is the required method for data transfer. When the data is to be transmitted in many parts, the MIME message/partial mechanism should be used rather than the multipart ASCII Armor OpenPGP format.
Agents treat and interpret multipart/signed and multipart/encrypted as opaque, which means that the data is not to be altered in any way. However, many existing mail gateways will detect if the next hop does not support MIME or 8-bit data and perform conversion to either quoted-printable or Base64. This presents serious problems for multipart/signed where the signature is invalidated when such an operation occurs. For this reason all data signed according to this protocol must be constrained to 7 bits.
Before OpenPGP encryption, the data is written in MIME canonical format(body and headers). OpenPGP encrypted data is denoted by the multipart/encrypted content type, described in the Section MIME Security Multiparts, and must have a protocol parameter value of “application/pgp-encrypted”. The multipart/encrypted MIME body must consist of exactly two body parts, the first with content type “application/pgp-encrypted.” This body contains the control information. The second MIME body part must contain the actual encrypted data. It must be labeled with a content type of “application/octet-stream.”
OpenPGP signed messages are denoted by the multipart/signed content type, described in the Section MIME Security Multiparts, with a protocol parameter which must have a value of “application/pgp-signature”. The micalg parameter for the “application/pgp-signature” protocol must contain exactly one hash symbol of the format “pgp-![]() hash-identifier
hash-identifier![]() ” where
” where ![]() hash-identifier
hash-identifier![]() identifies the MIC algorithm used to generate the signature. Hash symbols are contracted from text names or by converting the text name to lower case and prefixing it with the four characters “pgp-”. Currently defined values are “pgp-md5,” “pgp-sha1.” “pgp-ripemd160,” “pgp-tiger192,” and “pgp-haval-5-160.” The multipart/signed body must consist of exactly two parts. The first part contains the signed data in MIME canonical format, including a set of appropriate content headers describing the data. The second part must contain the OpenPGP digital signature. It must be labeled with a content type of ‘application/pgp-signature.’
identifies the MIC algorithm used to generate the signature. Hash symbols are contracted from text names or by converting the text name to lower case and prefixing it with the four characters “pgp-”. Currently defined values are “pgp-md5,” “pgp-sha1.” “pgp-ripemd160,” “pgp-tiger192,” and “pgp-haval-5-160.” The multipart/signed body must consist of exactly two parts. The first part contains the signed data in MIME canonical format, including a set of appropriate content headers describing the data. The second part must contain the OpenPGP digital signature. It must be labeled with a content type of ‘application/pgp-signature.’
When the OpenPGP digital signature is generated:
- The data to be signed must first be converted to its content-type specific canonical form.
- An appropriate Content_Transfer_Encoding is applied. In particular, line endings in the encoded data must use the canonical
 CR
CR LF
LF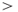 sequence where appropriate.
sequence where appropriate. - MIME content headers are then added to the body, each ending with the canonical
 CR
CR LF
LF sequence.
sequence. - Any trailing white space must be removed from the signed material.
- The digital signature must be calculated over both the data to be signed and its set of content headers.
- The signature must be generated as detached from the signed data so that the process does not alter the signed data in any way.
Note that the accepted OpenPGP convention is for signed data to end with a ![]() CR
CR![]() LF
LF![]() sequence.
sequence.
Upon receipt of a signed message, an application must:
- Convert line endings to the canonical
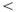 CR
CR LF
LF sequence before the signature can be verified.
sequence before the signature can be verified. - Pass both the signed data and its associated content headers along with the OpenPGP signature to the signature verification service.
Sometimes it is desirable both to digitally sign and then to encrypt a message to be sent. This encrypted and signed data protocol allows for two ways of accomplishing this task:
- The data is first signed as a multipart/signature body, and then encrypted to form the final multipart/encrypted body. This is most useful for standard MIME-compliant message forwarding.
- The OpenPGP packet format describes a method for signing and encrypting data in a single OpenPGP message. This method is allowed in order to reduce processing overheads and increase compatibility with non-MIME implementations of OpenPGP. The resulting data is formatted as a “multipart/encrypted” object. Messages which are encrypted and signed in this combined fashion are required to follow the same canonicalization rules as multipart/singed object. It is explicitly allowed for an agent to decrypt a combined message and rewrite it as a multipart/signed object using the signature data embedded in the encrypted version.
A MIME body part of the content type “application/pgp-keys” contains ASCII-Armoured transferable public-key packets as defined in RFC 2440.
Signatures of a canonical text document as defined in RFC 2440 ignore trailing white space in signed material. Implementations which choose to use signatures of canonical text documents will not be able to detect the addition of white space in transit.
10.2.2 S/MIME
S/MIME provides a way to send and receive 7-bit MIME data. S/MIME can be used with any system that transports MIME data. It can also be used by traditional mail user agents (MUAs) to add cryptographic security services to mail that is sent, and to interpret cryptographic security services in mail that is received. In order to create S/MIME messages, an S/MIME agent has to follow the specifications discussed in this section, as well as the specifications listed in the cryptographic message syntax (CMS).
The S/MIME agent represents user software that is a receiving agent, a sending agent, or both. S/MIME version 3 agents should attempt to have the greatest interoperability possible with S/MIME version 2 agents. S/MIME version 2 is described in RFC 2311 to RFC 2315 inclusively.
Before using a public key to provide security services, the S/MIME agent must certify that the public key is valid. S/MIME agents must use the Internet X.509 Public-Key Infrastructure (PKIX) certificates to validate public keys as described in the PKIX certificate and CRL profile.
Definitions
The following definitions are to be applied:
- ASN.1. Abstract Syntax Notation One, as defined in ITU-T X.680–689.
- BER. Basic Encoding Rules for ASN.1, as defined in ITU-T X.690.
- DER. Distinguished Encoding Rules for ASN.1, as defined in ITU-T X.690.
- Certificate. A type that binds an entity's distinguished name to a public key with a digital signature. This type is defined in the PKIX certificate and CRL profile. The certificate also contains the distinguished name of the certificate issuer (the signer), an issuer-specific serial number, the issuer's signature algorithm identifier, a validity period, and extensions also defined in that certificate.
- CRL. The Certificate Revocation List that contains information about certificates whose validity the issuer has prematurely revoked. The information consists of an issuer name, the time of issue, the next scheduled time of issue, a list of certificate serial numbers and their associated revocation times, and extensions as defined in Chapter 6. The CRL is signed by the issuer.
- Attribute certificate. An X.509 AC is a separate structure from a subject's PKIX certificate. A subject may have multiple X.509 ACs associated with each of its PKIX certificates. Each X.509 AC binds one or more attributes with one of the subject's PKIXs.
- Sending agent. Software that creates S/MIME CMS objects, MIME body parts that contains CMS objects, or both.
- Receiving agent. Software that interprets and processes S/MIME CMS objects, MIME parts that contain CMS objects, or both.
- S/MIME agent. User software that is a receiving agent, a sending agent, or both.
Cryptographic Message Syntax (CMS) Options
CMS allows for a wide variety of options in content and algorithm support. This subsection puts forth a number of support requirements and recommendations in order to achieve a base level of interoperability among all S/MIME implementations. CMS provides additional details regarding the use of the cryptographic algorithms.
DigestAlgorithmIdentifier
This type identifies a message digest algorithm which maps the message to the message digest. Sending and receiving agents must support SHA-1. Receiving agents should support MD5 for the purpose of providing backward compatibility with MD5-digested S/MIME v2 SignedData objects.
SignatureAlgorithmIdentifier
Sending and receiving agents must support id-dsa defined in DSS. Receiving agents should support rsaEncryption, defined in PRCS-1.
KeyEncryptionAlgorithmIdentifier
This type identifies a key encryption algorithm under which a content encryption key can be encrypted. A key-encryption algorithm supports encryption and decryption operations. The encryption operation maps a key string to another encrypted key string under the control of a key encryption key.
Sending and receiving agents must support Diffie–Hellman key exchange. Receiving agents should support rsaEncryption. Incoming encrypted messages contain symmetric keys which are to be decrypted with a user's private key. The size of the private key is determined during key generation. Sending agents should support rsaEncryption.
General syntax
The syntax is to support six different content types: data, signed data, enveloped data, signed-and-enveloped data, digested data, and encrypted data. There are two classes of content types: base and enhanced. Content types in the base class contain just data with no cryptographic enhancement, categorized as the data content type. Content types in the enhanced class contain content of some type (possibly encrypted), and other cryptographic enhancements. These types employ encapsulation, giving rise to the terms outer content containing the enhancements and inner content being enhanced.
CMS defines multiple content types. Of these, only the data, signed data and enveloped data types are currently used for S/MIME.
- Data content type. This type is arbitrary octet strings, such as ASCII text files. Such strings need not have any internal structure.
The data content type should have ASN.1 type Data:
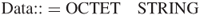 Sending agents must use the id-data content-type identifier to indicate the message content which has had security services applied to it.
Sending agents must use the id-data content-type identifier to indicate the message content which has had security services applied to it. - Signed-data content type. This type consists of any type and encrypted message digests of the content for zero or more signers. Any type of content can be signed by any number of signers in parallel. The encrypted digest for a signer is a digital signature on the content for that signer. Sending agents must use the signed-data content type to apply a digital signature to a message or in a degenerate case where there is no signature information to convey certificates. The syntax has a degenerate case in which there are no signers on the content. This degenerate case provides a means to disseminate certificates and certificate-revocation lists.
The process to construct signed data is as follows. A message digest is computed on the content with a signer-specific message digest algorithm. A digital signature is formed by taking the message digest of the content to be signed and then encrypting it with the private key of the signer. The content plus signature are then encoded using Base64 encoding. A recipient verifies the signed-data message by decrypting the encrypted message digest for each signer with the signer's public key, then comparing the recovered message digest to an independently computed message digest. The signer's public key is either contained in a certificate included in the signer information, or referenced by an issuer distinguished name and an issuer-specific serial number that uniquely identify the certificate for the public key.
- Enveloped-data content type. An application/prcs7-mime subtype is used for the enveloped-data content type. This content type is used to apply privacy protection to a message. The type consists of encrypted content of any type and encrypted-content encryption keys for one or more recipients. The combination of encrypted content and encrypted content-encryption key for a recipient is called a digital envelope for that recipient. Any type of content can be enveloped for any number of recipients in parallel. If a sending agent is composing an encrypted message to a group of recipients, that agent is forced to send more than one message.
The process by which enveloped data is constructed involves the following:
- A content-encryption key (a pseudorandom session key) is generated at random and is encrypted with the recipient's public key for each recipient.
- The content is encrypted with the content-encryption key. Content encryption may require that the content be padded to a multiple of some block size.
- The recipient-specific information values for all the recipients are combined with the encrypted content into an EnvelopedData value. This information is then encoded into Base64.
To cover the encrypted message, the recipient first strips off the Base64 encoding. The recipient opens the envelope by decrypting one of the encrypted content-encryption keys with the recipient's private key and decrypting the encrypted content with the recovered content-encryption key (the session key).A sender needs to have access to a public key for each intended message recipient to use this service. This content type does not provide authentication.
- Digested-data content type. This type consists of content of any type and a message digest of the content. A typical application of the digested-data content type is to add integrity to content of the data content type, and the result becomes the content input to the enveloped-data content type. A message digest is computed on the content with a message digest algorithm. The message digest algorithm and the message digest are combined with the content into a DigestedData value.
A recipient verifies the message digest by comparing the message digest to an independently computed message digest.
- Encrypted-data content type. This type consists of encrypted content of any type. Unlike the enveloped-data content type, the encrypted-data content type has neither recipients nor encrypted content-encryption keys. Keys are assumed to be managed by other means.
It is expected that a typical application of the encrypted-data content type will be to encrypt content of the data content type for local storage, perhaps where the encryption key is a password.
10.2.3 Enhanced Security Services for S/MIME
The security services described in this section are extensions to S/MIME version 3. Some of the features of each service use the concept of a triple wrapped message. A triple wrapped message is one that has been signed, then encrypted, and then signed again. The signers of the inner and outer signatures may be different entities or the same entity. The S/MIME specification does not limit the number of nested encapsulations, so there may be more than three wrappings.
The inside signature is used for content integrity, nonrepudiation with proof of origin, and binding attributes to the original content. These attributes go from the originator to the recipient, regardless of the number of intermediate entities such as mail list agents that process the message. Signed attributes can be used for access control to the inner body. The encrypted body provides confidentiality, including confidentiality of the attributes that are carried in the inside signature.
The outside signature provides authentication and integrity for information that is processed hop by hop, where each hop is an intermediate entity such as a mail list agent. The outer signature binds attributes to the encrypted body. These attributes can be used for access control and routing decisions.
Triple Wrapped Message
The steps to create a triple wrapped message are as follows:
- If it is signed using multipart/signed, the MIME construct added consists of a content type of multipart/signed with parameters, the boundary, the step 2 result, a content type of application/pkcs7-signature, optional MIME headers, and a body part that is the result of step 3.
- If it is instead signed using application/pkcs7-mime, the MIME construct added consists of a content type of application/pkcs7-mime with parameters, optional MIME headers, and the result of step 3.
A triple wrapped message has many layers of encapsulation. The structure differs depending on the choice of format for the signed portions of the message. Because of the way that MIME encapsulates data, the layers do not appear in order, and the notion of layers becomes vague.
There is no need to use the multipart/signed format in an inner signature because it is known that the recipient is able to process S/MIME messages. A sending agent might choose to use the multipart/signed format in the outer layer so that a non-S/MIME agent could see that the next inner layer is encrypted. Because many sending agents always use multipart/signed structures, all receiving agents must be able to interpret either multipart/signed or application/pkcs7-mime signature structures.
Security Services with Triple Wrapping
This subsection briefly describes the relationship of each service with triple wrapping. If a signed receipt is requested for a triple wrapped message, the receipt request must be in the inside signature, not in the outside signature. A secure mailing list agent may change the receipt policy in the outside signature of a triple wrapped message when the message is processed by the mailing list.
A security label is included in the signed attributes of any SignedData object. A security label attribute may be included in either the inner signature or the outer signature, or both.
The inner security label is used for access control decisions related to the original plaintext content. The inner signature provides authentication and cryptographically protects the integrity of the original signer's security label that is in the inside body. The confidentiality security service can be applied to the inner security label by encrypting the entire inner SignedData block within an EnvelopedData block. The outer security label is used for access control and routing decisions related to the encrypted message.
Secure mail list message processing depends on the structure of S/MIME layers present in the message sent to the mail list agent. The agent never changes the data that was hashed to form the inner signature, if such a signature is present. If an outer signature is present, then the agent will modify the data that was hashed to form that outer signature.
Contain attributes should be placed in the inner or outer SignedData message. Some attributes must be signed, while signing is optional for others, and some attributes must not be signed.
Some security gateways sign messages that pass through them. If the message is of any type other than a SignedData type, the gateway has only one way to sign the message by wrapping it with a SignedData block and MIME headers. If the message to be signed by the gateway is a SignedData message already, the gateway can sign the message by inserting SignerInfo into the SignedData block.
Signed Receipts
Returning a signed receipt provides to the originator proof of delivery of a message and allows the originator to demonstrate to a third party that the recipient was able to verify the signature of the original message. This receipt is bound to the original message through the signature. Consequently, this service may be requested only if a message is signed. The receipt sender may optionally also encrypt a receipt to provide confidentiality between the sender and the recipient of the receipt.
The originator of a message may request a signed receipt from the message's recipients. The request is indicated by adding a receiptRequest attribute to the signedAttributes field of the SignerInfo object for which the receipt is requested. The receiving user agent software should automatically create a signed receipt when requested to do so, and return the receipt in accordance with mailing list expansion options, local security policies, and configuration options.
Receipts involve the interaction of two parties: the sender and the receiver. The sender is the agent that sent the original message that includes a request for a receipt. The receiver is the party that received that message and generated the receipt.
The interaction steps in a typical transaction are:
Receipt Request Creation
Multilayer S/MIME messages may contain multiple SignedData layers. Receipts are requested only for the innermost SignedData layer in a multilayer S/MIME message such as a triple wrapped message. Only one receipt request attribute can be included in the signedAttributes of SignerInfo.