
CHAPTER FIFTEEN
Data Integration and Interfaces1
The core purpose of WFM data integration is to share data between the WFM system and support systems (human resources [HR], payroll, etc.) in such a way that they appear synchronous while also reducing manual process errors and certainly increasing performance of the overall system. The next pages will detail what data integration is, the core interfaces in a WFM implementation, what pitfalls to be aware and wary of, the project flow of an integration project, some detailed components of what is involved, and some insight to the type of developer you might need for the complexity of your project.
WFM systems will likely interface with other business systems as well such as enterprise resource planning (ERP), point of sale (POS), clinical and production applications as well as data warehouse systems. The same principles and concerns can be applied to these integration points.
- Define data integration and data interface, as well as what each accomplishes in a workforce management (WFM) system.
- Identify the primary interfaces for WFM systems and explain the functionality of each.
- Recognize integration readiness and avoid the common pitfalls during WFM system integration.
- Define the two facets of interface timing and why they are important.
- Understand the importance of selecting the right data source interfaces.
- Identify which interfaces can be automated and what tools and utilities can help enhance functionality and usefulness of automation.
15.1 GETTING DATA IN AND OUT
Data integration in a WFM system relieves the payroll department of manual and redundant entry of data. The prospect of manually keying and maintaining employee information is daunting; for large enterprise businesses it is outright impossible. Imagine entering 20 pieces of data for 20,000 employees and then maintaining dozens of changes each day. Even for small businesses with only a handful of employees, the task is time-consuming. Once demographic information (i.e., employee information such as identification [ID], address, phone number, pay grade, position, etc.) is in the system and being used for its intended purpose (e.g., collecting time punches and calculating total pay period time), the collected and computed data has to be moved to other systems such as payroll, HR, general ledger and accounting systems, and business information systems. Again, manually keying this information into multiple systems is time-consuming and in many cases unrealistic.
Quality software applications offer import/export utilities, usually integral to the application, that can and should be leveraged to exchange data between systems. Not only does electronic data interchange (EDI) dramatically decrease the amount of time it takes to exchange, load, or extract data, it virtually eliminates errors, simplifies and accelerates updates, offers a “set it and forget it” method of operation for many of the exchanges, and reduces staff count needed for the equivalent manual process. The return on investment (ROI) from automated integration includes reduction in support staff that becomes significant in large enterprise environments, decreases the margin of error in data exchange, and increases throughput (the time it takes data to get from point A to point B) manyfold. These efficiencies have allowed the amount, type, and timing of data shared among systems to increase, and it is expected things will continue to expand.
There can potentially be many sources of data that are fed into a WFM system. For example, a corporation's accounting system may contain labor allocation information (i.e., department, division, facility, job, etc.), while the HR system contains employee demographic data (name, address, hire/seniority/benefit dates, accrual balances, etc.), and another system containing schedule information. Many destinations for data originating from within the WFM system are also possible: accounting systems receive information for payroll; HR for accrual takings; and enterprise resource planning (ERP) systems for actual hours reporting and forecasting.
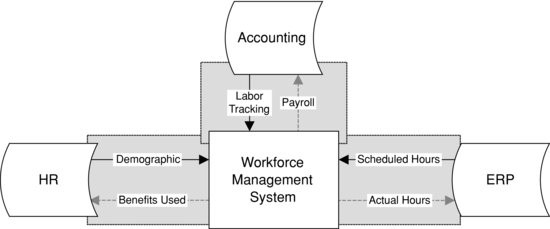
In Figure 15.1, systems are bridged together. This is known as data integration: making disparate systems work together in an apparent symmetrical fashion. In Figure 15.1, the shaded areas indicate where this virtual integration takes place. The bridging components that make systems understand each other are known as interfaces.
Figure 15.1 Data Integration
The purpose of an interface is to take data from system A and make it compatible and usable within system B. In a very basic interface, data from system A is retrieved, reformatted, and delivered to system B. A more complex interface may calculate values, make decisions, build values, or qualify records (collectively referred to as massaging data) with regard to other source information, existing destination information, external file or database consultation, or any combination thereof.
The reference loop depicted in Figure 15.2 shows this type of complex interaction: The interface may be configured to make determinations by mediating communication between the two.
Figure 15.2 Complex Interface Flow

There is no hard-and-fastt rule for what is used to create an interface—various data manipulation techniques may be employed provided it yields the proper result. Tools such as Excel or Access; Structured Query Language (SQL); a programming language such as Visual Basic, C++, or Java; or even workforce vendor-specific tools may be used to accomplish the task. The key is to determine what tool is most appropriate for the job (it may be a combination of tools) with regard to source and destination formats and systems, performance metrics, and the amount of data massaging that needs to take place.
Before launching into the primary interfaces common among WFM systems there are some points to consider when deciding on the tool, developer, or both.
15.2 GENERAL PRACTICES
When designing and implementing data interfaces there are a few general practices that should be considered. These represent guidelines for interface configuration and application.
(a) Modularity
Interfaces should be efficient yet have flexibility in application. Each distinct function or data set should utilize a separate interface component for transfer of the data. This method allows the option of sequencing each component together to create the overall data transfer while giving the flexibility of running just one component to affect a small change to the overall data set.
For example, loading a workforce timekeeping database requires certain configuration and employee-related data to be preloaded, such as:
- Labor structures
- Governing pay definitions (overtime rules, punch capture parameters, rounding, wage type)
- Distribution
- Manager identity
- Predefined schedules (generally used for exempt employees)
- Benefit time
- Other required information
Each of these should have its own interface to allow individual execution while maintaining the ability to run in sequential fashion as needed.
Labor levels may include entity, process level, division, department, job, and so on. (For more on labor levels, see Section 8.7 on the general ledger in Chapter 8.) It is recommended practice to break labor structure design down and create a separate component for each meaningful labor grouping. The breakdown becomes a labor hierarchy component of the timekeeping system and is commonly used within interfaces to sort, group, manipulate, and direct data to the proper calculation and final destination.
(b) Portability
Good practice in implementing WFM systems dictates having (at minimum) both a test and a production system. Depending on complexities of the implementation, size of the employee database, cross-section of groups using the system, and many other factors, multiple test systems may be implemented to analyze different facets in simultaneous development and perhaps one or more acceptance and/or training systems may be put in place as well. With so many potential systems to keep in sync, it is vital that dependent references (i.e., database name, source/destination filenames, etc.) be easily altered for portability between environments so when it comes time to deploy a test version to production it is not a monumental task in changing references within the interfaces to point to the correct database and application servers.
(c) Maintenance and Scalability
Because of changing data, added facilities, jobs, pay definitions, pay distributions, and so forth, periodic maintenance will be required to keep these interfaces up to date once deployed. Hard coding of values should be avoided (preferably removed) in deference to externally accessible data stores (such as ASCII2 files or temporary database tables) that are easily modified and contain information the interface may refer to for assigning values. For example, configuration profiles may be driven by the pay definition, in which case a single pay definition (i.e., exempt) might be used as a key for assigning any number of system access, pay, or scheduling profiles. Using such methodology increases scalability of the interfaces that employ it. Scalability denotes the ability to increase usefulness and grow along with an expanding employee population while minimizing the effort to do so. For growing enterprises, scalability plays an important role in the ROI factor of an implementation and the full system cycle. Systems that cannot easily scale suffer performance degradation, difficulty in handling additional load, and problematic breakdowns due to stress.
15.3 INTERFACE PROJECT FLOW: MILESTONES
The following is a typical progression in the life span of an integration project. It is somewhat of a café approach—not all steps will apply to all projects—and complex projects may find it necessary to add additional facets. In general the main salient milestones are:
- Specification. A document is created describing what the interface(s) will do, the environment, source and destination paths/files/specifications, methodology (where applicable), and other project-related items. This may be termed as a detailed work statement as it is intended to contain everything pertinent to the successful implementation of the interface(s).
- Development. The interface is core coded. Some alpha testing (basic developer-level, on-the-fly functional validation) occurs at this stage.
- Alpha testing. A developer tests a subset of the data to fix any bugs. Many operational anomalies are discovered and addressed here.
- Beta testing. Once alpha testing has demonstrated that it is relatively stable, a full load of data is processed against the interface. Known scenarios are tested for accuracy (“known scenarios” are specific scenarios that the developer has been asked to address and stress test). Generating a list of known scenarios with specific test criteria is highly recommended. Testing at this level generally ferrets out bugs and reveals special case scenarios previously missed.
- Automation. This process involves the creating, testing, and installing of external scripts3 and data handling that encompass or enhance the interface functionality. This can include scheduling automatic processes and implementing third-party utilities to augment the core interface functionality (e.g., a third-party e-mail utility might be implemented for notification purposes). Utilities might be sprinkled throughout the process for a variety of reasons. As such, an automation process might span the entire interface process.
- Operator training (as needed). Many interfaces do not require a lot of training unless they are extremely interactive or have a large degree of required maintenance. Minimum training should include how to launch interfaces manually and edit/modify files containing supporting data.
- Certification testing. Interfaces are delivered for detailed testing and evaluation. It is recommended that someone be dedicated to developing test scenarios and running them through to make the most of the time and efficiency of this step. That is sometimes unrealistic given workloads and responsibilities, but it will yield greater results in the smallest time frame. During the certification phase, the developer should not be actively engaged unless a bug is reported or the tester has questions. This methodology is by design to promote impartiality in the certification process. Making sure that the interfaces perform correctly and achieve desired results is the responsibility of the system owners.
- Documentation. Once the interface is certified, interface operations, support, and maintenance documentation is prudent to have because at some point the interface will need to be modified, upgraded, or both, and insight to how the interface is crafted will make it easier for whomever is charged with this task. In some cases, particularly with complex implementations, having technical documentation is desired. Standard, primary interfaces—in many cases—stand on their own and are easily understood and managed, making the additional expense of documentation a frill and unjustified. This is especially true for interfaces that have no interaction or maintenance requirements.
- Knowledge transfer (as needed/desired). This is usually an extension of documentation; an interactive training where the developer briefs the administrator or information technology (IT) personnel responsible for the support of the interfaces and answers any questions. Depth of knowledge transfer is largely a function of interface complexity; for standard implementations documentation is acceptable.
15.4 PRIMARY INTERFACES FOR WORKFORCE MANAGEMENT SYSTEMS
WFM systems utilize a plethora of interfaces ranging from data loads to very specific needs of individual groups or data items. Each installation is different and may have unique requirements, but typically each has at least a handful of interfaces in common, generally in the area of populating and retrieving key employee data to determine proper pay period processing.
This section introduces the primary interfaces used in a WFM system that in some cases is considered the bare minimum of data exchange.
(a) Employee Demographics
As WFM systems have evolved, the demographic data accommodated and/or needed has grown in a significant fashion: added application and device functionality require additional information, and this is an area that has grown as far as integration is concerned.
With continuing product evolution comes the need to adequately and periodically evaluate and predefine what information is required, what is necessary, and what is simply desired.
- Required information is the minimum data set the system must have: the information that is nonnegotiable and without which the system will not operate.
- Necessary information is that which is required to achieve the business objectives. This is generally an extension of the required information but may overlap.
- Desired information includes the niceties that end users, operators, or managers may like to have but are not vital to the operation or end result. Desired information may also reside in similar systems and be requested inside WFM systems for convenience or to expand the availability of information to a larger user community. WFM systems often are used by a much broader group of employees and managers than related systems such as payroll, HR, and ERP. Including desired information may increase productivity and/or performance and therefore could be acceptable. Yet, the desired information should be weighed against the ROI, privacy concerns, maintainability, and organizational benefit to justify inclusion.
i. The Chicken or the Egg
One of the common mistakes in integration design is losing sight of or paying little or no attention to which data must come first.
To load an employee into the WFM system, certain components must already exist—which means that they have already been loaded before the employee. Labor accounting structures and pay policies usually must preexist in order to assign employees to them, so the first order of business is to populate the database with those. In general, required information falls into this category, but can easily extend to necessary information, say, in regard to assigning managers that are bound (exist themselves as an employee record) in the database. The manager set should then be loaded before the employees, or proper steps taken to update or augment the employees in a latter step once all are loaded.
ii. Components
Early WFM systems simply required a name, employee ID number, and some kind of registration ID (personal identification number [PIN], badge number, card ID), but today's systems may require a great deal more information to enforce pay policies, pay distributions, segment employee populations, assign security and proper operational governances, and so on.
- Employee details. May include employee ID, registration ID (PIN, badge, etc.), address, phone, company e-mail, dates (hire, rehire, termination, leave of absence, birthday, etc.), full-time equivalency (FTE) status, standard hours, bargaining agreement or contract information, time-off benefit plan, and so forth.
- Profile assignments. May include pay governances, benefits governances, group memberships (scheduling, availability, shift templates, etc.), management functions (departments authorized, editing authorizations/groups, etc.).
- Access assignments. System functions (edit and view capability) that a given employee or manager has access to.
- Security. System access parameters.
- Licensing. Type of access an employee has (employee, manager) to the WFM system and what modules affect them (scheduling, leave, accruals, etc.).
- Custom data. Tag-along data useful for reference in lookup or reporting and/or for information otherwise not accommodated that the integration project requires (alternate ID number, concatenated account information, function override flags, employee total hours to date, etc.).
(b) Payroll Export
The payroll export of hours interface is one of the most prevalent data exchanges, second only to the demographics interface and just as necessary. In an ideal world, systems would have a standard exchange paradigm that would allow the payroll export to just grab the data from the workforce database, stick it in a file, and ship it off to the host system. This is rarely the case.
- Translations. Pay codes (regular, overtime, vacation, sick, etc.) may or may not be an apples-to-apples transfer to the host payroll system. The pay code in a WFM system may need to be translated to something else for the payroll system. Regular might translate to 100, OT to 200, Vacation (VAC) to 400, and so on. In this case a translation table is needed to facilitate maintenance and future additions of data. A translation table is an external, easily accessible and maintainable list of information that the interface uses to substitute one value for another. It may take the form of a text file with values separated by some delimiter (comma being most common) or perhaps a temporary database translation table (see Figure 15.3).
- Divisions of time. Each host payroll system has its own particular requirement for importing data. Aside from the format of import (discussed in a later section), there is the division of time that the host expects. In many cases this will coincide with the pay period length (weekly, biweekly, semimonthly), but some require subdivisions within the period. The need for daily records data is not uncommon, nor is splitting a biweekly period into two individual weeks. When this type of subdivision is performed, the data also needs to have some kind of indicator to show where in the period it falls. Date is predominantly used, but it is also possible that day number or week number (or a week code) may be employed. The interface will have to take into account the necessary requirements and parse (break apart) the data accordingly.
- Analyzing totals. As a check and balance, it is good practice to balance interface totals (amounts generated outside of the WFM system by the interface) against the WFM system's internal totals report. A host payroll system's import totals audit is better because it shows that the data has made the entire transition from workforce to payroll (including import into the payroll system itself) correctly, but if one does not exist then it is wise to have the interface generate one for review.
- Posting transfers. Employees are assigned default values for demographic data such as pay rule, job, or department. Under certain conditions the employee may transfer to different cost centers, be governed by different pay policies for different jobs or functions, engage in activities that have special pay considerations, or potentially any mix of these. When deviating from the default values for these items, it may be necessary to transmit that data to the payroll host as well. In many cases governing pay policy or activity transfers are configured such that the hours are distributed inside the WFM system to the appropriate pay buckets and transmitting the transfer information in the payroll expert is unnecessary. However, cost center transfers are widely used and are a common type of transfer data in the payroll interface. Translation of the information may also be necessary as the host system may use a different nomenclature or break down certain cost centers in the WFM system, subcategorized to increase reporting granularity, for values posted as a single item in the host payroll system. This is known as a many-to-one translation as shown in Table 15.1.
An infrequent requirement with translations is the scenario in which one workforce value needs to equate to two or more payroll values. This type of relationship is called one-to-many and can be very problematic if not dutifully analyzed and implemented carefully. - Posting temporary wages. Wage rates may vary by cost center, time of day (i.e., differential pay for evening, night, or weekend shifts), job performed, or a combination of factors. If the adjusted rate is needed by the host system and the WFM system does not provide a sum total, the interface needs to intervene and calculate the value. This may involve a litany of calculations depending on the implementation and is something the developer will have to analyze and craft. Many contemporary systems simply pass the hours, cost center transfer information, and/or shift flags and the host payroll system applies the math. The key is to be aware of the requirements to determine if the interface component applies the correct logic, preferably utilizing external references to discard the need for interface hard-coding or modification.
Table 15.1 Sample Many-to-One Translation

Figure 15.3 Basic Translation Table

(c) Labor Data Import
Accounting structure is a required component of a WFM system and usually one of the first interfaces constructed as no employees can be loaded without reference to it.
Keep the following in mind when working with the developer to define this interface:
- Multilevel data requirements. Workforce management systems will typically have more than one level of accounting in the hierarchy. Multilocation corporations may have a structure like this:

- Combination values. Combining components into a single value is common to save resources or because the components are normally referenced together:

- Values must be unique. Duplication of values is taboo and commonly rears its ugly head when merging two or more disparate systems together into one database. Less frequently, but just as legitimately, duplicates arise from reused account numbers. Analyze the data carefully to avoid collision. Using combination values sometimes alleviates this issue, but the leading practice is to clean it up by reassigning duplicates to unique values. Doing so will likely incur additional labor up front, but in the long run it will serve to avoid complications.
- Maintaining current lists. Once values are initially loaded into the WFM system, a regular update schedule is usually implemented to keep the information current. This schedule is generally driven by the frequency of update in the host system. For large manufacturing firms updates might be performed hourly to keep up with production while a service company may only perform weekly updates. Most common is daily.
- Removing unused account information from use. Deleting accounting information that has been used taints or destroys the integrity of the data, so when labor data is no longer needed, the leading practice is to inactivate and hide it so it cannot be used while maintaining its historical relevance. How this is flagged for removal is system dependent, but more times than not it will simply be removed from the source, leaving it up to the interface to mitigate the process by comparing it to the active data in the WFM system.
(d) Balance Imports
Common in WFM systems are benefits accruals totals (e.g. vacation hours). Some WFM systems calculate them and inform the host system how much is available (via integration interfacing), but it is standard practice for the system of record to provide balance totals for import into the WFM system.
Accruals balance reset, therefore, takes position 4 in the most common workforce interface listing. It has been asked why this is not included in the employee demographic interface. Some have done so, but generally the frequency of this import and the frequency of the demographics import do not match, so common practice is to separate them.
As an example, balance resets in a WFM system for vacation or PTO (paid time off) and sick or EIB (extended illness benefits) are typically performed after the end of a pay period and payroll has been completed. This confirms that all time taken has been accounted for before resetting the balance in the WFM system. The new balance may be posted three days into the new period, but referenced to the first day of the new pay period.
Due to the nature of accruals, it is important to reconcile the decimal precision of the host system with the capabilities of the WFM system during the specification phase. If the system calculating a balance floats the value to six-digit precision but the system loading the balance has two-digit precision, there will be a disparity in totals between the systems.
Similar to accruals balances are leave balances. These balances are tied with the Family Medical Leave Act (FMLA) policies and are usually less frequently updated (annually being very common). While the process of import may be functionally identical to accruals balances, a separate interface component should be employed.
In addition to the permanently recurring balance import interfaces, it is prudent for balance imports to be able to stage data and run the import at will. At-will execution is particularly useful in a test environment. In the test environment, balance amounts can be loaded in excess of reality for each employee. This can allow for the assessment of a process or an import of data that affects the balances. This type of preload may be called a blast. Giving everyone 200 PTO hours, then, would be an accruals blast. When the intended test process is completed, one can either load actual balances or blast everyone with a zero balance.
(e) Schedule Imports
Importing employee work schedules ranges from simple to monstrously complex and is a subject of interest because it touches on so many aspects of a WFM system (schedules, timecards, accruals). There are critical issues that should be considered when creating an import of schedule data.
i. Productive and Nonproductive Time
Scheduling shifts (productive time) and time-off (nonproductive) seems simple enough on the surface, but when one takes it from paper to the electronic format things get a little more complicated. Scheduling is largely a multilayered, subjective, personal relationship-based process and interface software is not. Care should be given to these factors when designing schedule import:
- Source of data. Because both productive (scheduled shifts) and nonproductive (scheduled pay code edits such as a day off (8 hours of vacation) time occupy the same schedule area, the source of the data should be the same. Trying to merge productive data from one source and nonproductive from another is possible but extremely complex. Also, if there is a need to examine existing schedules first to apply different rules (e.g., existing schedules trump incoming schedules under x, y, or z conditions but not a, b, or c conditions) or if any kind of transfers are implemented (and also have trumping rules), it can create difficulties down the road.
- Application of data. How are successive schedules applied? Are all existing schedules in the defined period removed and replaced with newly imported data? Are just new records posted? How do you know if it's new? What if a new record replaces an old record? What if something overlaps? Or doubles (e.g., sick time changes to vacation time and both are posted)? Are lunches included in the scheduled time? Do they need to be added? Are they all the same length? Does the item to be posted in the WFM system affect accruals balances? What if the available balance of hours is insufficient?
- Work rule transfers. When a work rule transfer is imported into a schedule, it is imperative that the rule is valid or the assignment will fail. To synchronize this data with the external scheduling system, it is advisable to create an interface export from the system of record—the WFM system—to populate the valid work rule names in the external scheduling system.
- Labor account transfers. Similar to work rule transfers, these are a little more forgiving in some WFM systems as they can be flagged to import regardless of validity (not recommended). It is prudent to determine whether the external scheduling system is populated with this information from the system of record as well (usually HR).
- Accruals. Nonproductive schedule items will affect accrual balances (if used). Items such as vacation and sick generally debit the respective balances when posted to a schedule. If the source system is unaware of the balances, these could be converted to an overdraw when the import is performed. Depending on the configuration of the WFM system, overdraws may or may not be allowed to post. Errors will likely ensue, so proper notification or interface review should be performed to mitigate the result. Also possible is that scheduled pay code edits that are deleted may affect accrual balances as well. For example, if a nonproductive pay type counts toward an accrual grant, then deleting it negates that grant, dropping the overall balance. Consider a PTO hour type that is granted 0.1 hours per hour. If 40 hours PTO is scheduled, this grants an additional 4 hours, which are then also scheduled. When the schedule refresh (delete/re-add) occurs, the 4 accrued hours are negated until the system regrants based on the new scheduled pay code entries, leaving a net of 40 available but 44 scheduled, which then causes an overdraft. Additionally, if the system does not tie things together referentially, pay code edits may double (e.g., PTO and PTO Eve might get posted simultaneously).
These are the types of questions that need to be asked to properly analyze the design process of a schedule import. The simplest way to import schedules is to use a single data source, delete all existing schedules, and refresh the entire data set for the period imported. This means that users in the WFM scheduling module cannot make changes in the schedule module and must input new or changed data in the outside data source and wait for the import. This is why many organizations may choose to go with the complicated interface solution or a WFM product that includes an integrated scheduling module that eliminates the need for an interface between two separate systems.
ii. Returning Hours
Schedule host systems may sometimes want actual hours reported back to them for coverage reporting and other analytics after the pay period is over. These return-trip interfaces are usually very similar to payroll export interfaces ranging from basic, hours-only exports to exports, including account and/or work rule transfers, differential pay codes, and so on, dictated by scheduling system requirements and intended use of the data in that system.
(f) Other Interfaces
While interfaces are principally viewed as exchanging data between systems, there are other creative uses as well:
- Report preparation exports. A well-crafted export can be used as the basis for a custom report. WFM systems have standard reports but sometimes there is a need for something that the system just does not offer. Perhaps a listing of managers and their direct reports and the direct reports' direct reports if they are managers themselves.
- Loopback. This is an interface that extracts data from the WFM system, massages it, and puts it back in. Loopback interfaces are extremely useful for data manipulation that the system cannot perform natively but is needed to be in the system as part of the historical data. For example, let's say a company allows employees who work holidays to discretionarily bank their paid holiday time as vacation time for later use. A loopback would scan for worked holiday time, consult the list of employees who opted for banked time, perhaps compare the number of hours worked versus holiday time granted and adjust accordingly, then cancel the holiday grant, and post the hours to their vacation bucket.
- Support table creation (DB tables). Not an interface proper, but an important part of the process is having a central repository of code used in the generation of support tables for the interfaces. This repository would contain SQL code for creating/refreshing temporary database or tracking tables as well as assigning proper access permissions or aliases, and so on. This facilitates the porting of interfaces between environments and serves as pseudodocumentation for maintenance purposes. Other support items may include simple interfaces to generate translation tables from raw data or reformatting existing files.
15.5 INTERFACE TIMING
There are two facets to interface timing: sequence of events and preventing collisions. Sequencing is important to confirm that data is properly formatted, massaged, and/or referenced to preceding processes for validity and integrity purposes. Preventing collisions demonstrates that data is able to be written without being locked out by another process or without causing itself or another process to fail.
(a) Sequence of Events
The Workforce Asset Management Professional (WAM-Pro) considers and plans for the proper order of work to be done so that important steps are not missed. This is especially important for new interface deployments and upgrades to existing systems.
i. New Installations
For a new installation the sequence of events is critical to confirm that cascading required data is present. For example, in an employee demographic import the cost center information must preexist in order to assign an employee to it; a supervisor ID must exist in order to assign the employee's supervisor; a pay governance structure must exist before the employee can be assigned to it; and so on.
When designing the interfaces and consulting with the host system vendor or champion, the developer obtains the prerequisite data first (also referred to as dependent data) and populates the WFM system with it (if an interface is to be used) before attempting to import records that depend on it.
A common concession is populating the WFM system with bogus temporary data to try to rush the demographic data in. While this accomplishes the short-term, instant gratification paradigm, it rarely is a good idea to do so. It puts garbage data in the system, and the developer will generally have to readdress several areas of the interface once the real data is in place. It is far better to plan ahead and obtain the required data in the sequence needed to promote a smooth-flowing development cycle.
ii. Upgrades
The principal difference between new installations and upgrades is that required data already exists—but that data may be changing so the rules are the same. Preload the required data in the necessary order to promote smooth development flow.
Upgrades may also require that the old values be inactivated and/or deleted to finish the process. Deletion should be considered carefully with respect to maintaining historical information and applied as a separate process after observing that the changed data is correct.
Keep in mind that when changing data in a system, a trickle-down effect may or may not occur. A changed cost center included in a manager grouping of cost centers may not automatically update. Automatic updates to references of the core piece of data are dependent on the WFM system. When core data is changed and the related grouping updates, the data is termed as being bound or having referential integrity.
Upgrading an interface suite to accommodate a new host system will entail inspecting all input and output formats and likely changing them. Depending on the tool used to create the interfaces the core will be sound; it is just the front and back ends that will need to be modified.
Upgrading to accommodate a new WFM system is generally much easier, unless there has been a major change like a modification to the application programming interface (API). API is a set of data structures and commands written specifically for interaction with the application or database that the interfaces depend on.
(b) Performance Considerations
The following is a list of performance considerations to take into account for data integration and interfacing:
- Schedule the resource-hungry interfaces to execute during low-usage time frames. Interfaces with extensive data exchanges or calls to the database can quickly rack up time resources. Additional server load during the execution of an interface will cause graduated delays, so it is recommended to run high-intensity, large volume processes when the load on the server is low. When interfaces are not scheduled properly, system performance may be poor, other critical server functionality may be sluggish or lagging, and the potential of collisions or dependent data being unavailable is increased. While the servers of today can handle multiple scheduled imports at a time, it is recommended to sequence them instead of stacking, simply to remove any question of collision or dependency should there be an issue.
- Avoid per-record, in-line SQL calls. Whenever possible, build temporary tables as a preexecution process to save overhead and network traffic. One call to the database to create a comprehensive reference listing of employee data from the workforce database might take 3 minutes to process but is far more efficient than an in-line call for each of the 13,000 employees at 5 milliseconds (a total of 65 minutes). As an example, optimizing a demographic interface by moving two of three in-line SQL calls to preprocess reference tables and eliminating the third redundant one entirely dropped the processing time from 8 hours to 8 minutes.
- Keep the electronic distance between the application, database, and interface servers as short as possible. The further away each server is from the other, the longer it takes for the information to travel back and forth—just like driving between cities. There was a situation, for example, on the West Coast where information was being sent from one machine to another in the same room, 10 feet apart from each other, and was taking an inordinate amount of time to reach the destination. After investigating the network path, they discovered that the information was being routed through New York and back.
- Dedicate a server to interface processing if possible. This off-loads any user volume for the application and gives flexibility in the scheduling of interface jobs.
- Monitor and average the time it takes for an interface to run, add 10 percent for system fluctuations and use that resulting time when scheduling interfaces in sequence so there is no overlap.
- For critical or complex interface sequences, it is advisable to implement a monitoring system that notifies and/or prevents succeeding interfaces from running if there is a failure in any preceding interface. Notification is a viable way of determining if the interfaces are well maintained. Preventing succeeding interfaces from running can reduce or eliminate the potential for incorrect, duplicated, or corrupted data due to dependency or referential integrity issues.
(c) Blocking Mechanisms
When certain steps or processes are dependent on the successful completion of a previous one, or when two or more processes share the same destination or source and must be prevented from operating at the same time, a blocking mechanism is a good mediator. In the following decision chart in Figure 15.4, the processes are all independent of each other but depend on execution order to maintain proper application.
Figure 15.4 Blocking Diagram

Figure 15.4 depicts a mechanism that waits for process A to complete before transferring control to process B and likewise that process B completes before transferring control to process C. A robust event scheduler or command file (.CMD) may be used to sequence and measure successful completion before allowing succeeding events to occur. This avoids collision (two or more processes operating on the same data at the same time), protecting data integrity.
Likewise, this scenario can be broken down further to confirm that a particular function within a process completes successfully before the next function is executed, and if it fails to take some intervening action (such as halting the process and sending an e-mail notification).
In mission-critical applications, identifying potential points of failure and mitigating each touchdown point (where the system obtains, creates, transfers data) is prudent and an excellent application of blocking.
The scheduling interface analysis (see Figure 15.5) identifies each touchdown point, the type of potential failure, severity, recommendation for resolution/recovery, and what additional resources (if any) are needed to implement the mitigation plan. Some junctures are critical requiring the operation be aborted. Analysis of this sort to implement corresponding mitigation procedures can save a lot of headaches once the process is in full swing in a production system; provides preventative failure measures; and facilitates administration and maintenance.
Figure 15.5 Mitigating Points of Failure

(d) Precedence/Priority
It has been mentioned before but bears repeating here. WFM systems have a litany of information that is required before one can populate employees, and these data elements need to be prioritized and sequenced such that the dependencies of each are satisfied. Cost center/labor account information needs to be imported before manager groupings that depend on those values are used; manager demographic information and configuration must exist before employees may be assigned to them; pay policies (and all their dependencies) must be configured before employees can be assigned to them; accrual balances must exist before the benefit may be scheduled or used.
Likewise, when operating in normal daily mode, some updates (such as cost center) need to take precedence over others (such as demographic data) because the latter relies on the changes in the former.
15.6 OBTAINING, TRANSFERRING, AND DELIVERING DATA
The condition, type, and format of data are important to accurate collection and use of data. Sometimes data has to be altered to match the type and format needed or to effectively talk to the system to which it is headed. When source systems cannot make these modifications, the interfaces take on the job of transforming the data without altering its meaning or usefulness.
(a) Data Massaging
When integrating data between systems, it is rare that the native data from the source system will perfectly match the destination system requirements without some type of manipulation. Interfaces are intended to make that square peg fit in the round hole.
Interfaces can do a plethora of work to this end, but the leading practice is to have data transforms or manipulations performed by the source system whenever possible. The fewer tasks the interface has to perform, the better. This keeps data tighter and more succinct.
(b) Source and Destination Medium Types
When designing an interface suite for integration, the developer must know what type of exchange format is available and analyze the leading uses for the interface at hand. Many factors can influence the decision on which to employ, but there are no rules as to which is preferred. In some cases there are no choices—there is one option and one option only and that is what has to be used.
When considering the format to use, the bottom line is to select that which strikes a balance between data integrity, performance, and security requirements.
i. Terminology
Data is known by its field name or record identifier.
- Field. Unique data chunk (i.e., employee ID)
- Record. Combination of fields on one line comprising a data set for a specific entity (i.e., employee demographic information)
ii. ASCII/Unicode
This is a standard text file that is viewable/editable using any text editor. Standard line terminator is a carriage-return/line feed or just a line feed. The two common ASCII file formats are:
iii. Database
Direct database access is an excellent choice for extracting or retrieving data as it is a nonintrusive, read-only function (cannot damage data), bypasses the middleman (i.e., an export file), increases performance, and delivery of the data is not dependent on any separate function (i.e., export process). This creates a just-in-time type of data collection that can be of particular importance in systems that need to approximate a real-time environment (such as a call center that collects and compiles statistical information hourly or even more frequently).
Sometimes, though, having the interim export process is advantageous because data massaging can be applied to the file being delivered from the database. It is recommended that data be massaged/modified as close to the source as possible, so in a situation where data cannot be used directly, this needs to be considered as a viable alternative to direct extraction and massaging by the interface. Many database applications have custom programming functionality to facilitate this. However, this, too, should be balanced against the resources available for the database programming versus interface programming when evaluating the preferred course of action. If the interface developer can accomplish the task, saving the need to hire a database developer, there could be a cost savings as well as knowledge compression; no need for a resource that knows the database programming language. As a side note, many interface developers have a good working knowledge of database development as well; it is when the application itself has a proprietary language that the resource issue is of great impact.
Writing data directly to the database requires significantly more consideration. Databases are a complex set of data storage areas (called tables) that are interconnected with each other—many with multiple connections, indexed, subindexed—and have requirements for the format and type of data each field in each table can contain. When writing directly to a database table, the developer must have an intimate knowledge of what other tables, indexes, procedures, and/or triggers the table in use affects and how to determine that those items are also updated to maintain referential integrity of the database. Referential integrity refers to the interconnections between tables, uniqueness of the data, indexing, and overall general health of the database, without which records may become corrupt (unusable) or orphaned (floating around without purpose or connection). It is generally better not to write directly to a database table unless it is designated as a staging table. Staging tables are less-restricted, generally open-format tables designed specifically for loading data that an application function or database stored procedure operates on to bring data in to the system.
Database Access and Use—Options and Methods
- SQL query. SQL command that operates on the database. Used to extract data from one or more tables. The following sample would return employee ID, name, and employment status for each person in the Employee table:
SELECT ID, Name, Status FROM EMPLOYEE
There are several different SQL databases available for use but the syntax of each is largely uniform; there will be some nuances in function syntax, generally in the way data is formatted. Once a WAM-Pro has a handle on one style, she can use any style with a little adaptation and access to the syntax documentation. For example, Oracle and Microsoft are the SQL databases that have been predominantly used in enterprise WFM systems over the past decade. In each, the overall syntax is the same. - Tables versus views. Tables store data in row and column format, similar to what is seen on a spreadsheet, having one column (field) be different and (optionally) indexed on one or more fields. In the previous sample, the employee ID would be the visibly different value (database internal numerical identifiers are usually generated for each row to maintain required uniqueness as well). Tables will be designated by what they hold: Employee will hold employee demographic data; Department will hold accounting and cost center data; Job will hold job function data, and so on. One or more tables may be tied together in a complex SQL query to produce a desired result. Many workforce applications will come installed with a set of these complex queries packaged as “views”—predefined SQL queries tapping multiple tables to produce a standard output. This query would produce the same information as presented earlier but also include the cost center and job information by leveraging the V_EMPDATA view:
The equivalent complex query might look like this:
This very simple example, the mechanics of which is beyond the scope of this guide, is included to demonstrate the power of views. Here, three tables and five columns of information can be compressed into a single statement. In fact, if that were all that was in the table it could be compressed even further using the universal give-me-everything asterisk:
Whenever possible, use a vendor-defined view instead of a table. When applications are upgraded, augmented, or otherwise modified, the underlying tables may undergo restructuring, renaming, reorganization, or any combination thereof rendering table access queries ineffective or nonfunctional. Since views are an accumulation of tables and interconnections, most application developers will rewrite them to maintain that the data returned from a view remains the same. In this manner, as an analogy, it does not matter if they have changed the engine of the car; it still drives the same.
- Stored procedures. Similar to a view, stored procedures operate on multiple tables to affect a result, may perform some programmatic operations or complex table merging, and perhaps write data to a temporary table or outbound staging table. Stored procedures are infrequently used but have their place, particularly if the query takes a long time to process—a stored procedure may be scheduled to run automatically to pregenerate data that an interface picks up later. Stored procedures are used primarily in custom report generation to compile data ahead of time that the report writer cannot, or to duplicate and modify existing vendor-supplied stored procedures to augment custom reports. The duplicate-and-modify method may be preferable because service pack updates to the database sometimes modify the stored procedures that in turn can render custom reports inoperable; using a copy of the stored procedure terminates this possibility as the vendor will not overwrite it (provided, of course, it is uniquely named). The disadvantage to this method is that it must be manually generated in a new database space (i.e., promoting it from a test to production environment) or when the database is restored with a version that did not contain it.
- XML. Many applications implement and support the XML (eXtensible Markup Language) data interchange format as a standard data exchange. Because it is ubiquitous, if the vendor supports it and there is good documentation, this is a viable way of exchanging information between applications. It is generally bidirectional in functionality (import and export) and is a Web-based protocol so it can be very portable.
- API. Application programming interface functionality is a defined set of functions and procedures that the developer may use to interact directly with the application that it supports. An API may actually leverage other functionality (such as XML) by being the driver of the underlying technology (i.e., an API function might generate the XML code needed to perform a particular function) making the interaction with the application more developer and reader friendly. APIs usually provide the most functionality of any interchange format and promote performance gains due to their direct interaction with the application. Using an API facilitates adherence to the rules for the database when posting data to the system (or at least puts the onus on the vendor to ensure data integrity) and is probably the leading option for posting data to a system given the functionality, performance, and referential integrity factors.
(c) Cross-Platform Data/File Transfer
In addition to exchanging data between the applications proper, there stands the possibility that the applications run and reside on different operating system (OS) machines (platforms)—Windows and Linux, for example. This introduces yet another echelon of complexity, and when present is usually a good candidate for enhanced point-of-failure mitigation. Like traveling between countries, it is critical to carry a passport, otherwise cross-country travels can turn into a one-way ticket. Likewise, depending on the transfer method (border crossing), a smooth data transition is preferred.
It is also important to carefully examine the nuances between systems. For example, standard line terminators vary between platforms: Linux uses the line feed (LF) character; Mac uses the carriage return (CR); Windows/DOS uses both (CRLF).
Common Data Transfer Methods
- FTP. File transfer protocol is such a common transfer protocol that the major operating systems include it as a standard utility. There are two components: the FTP client (the program that sends the file) and the FTP server (the program that receives the file on the other end). The FTP server component, residing on the receiving machine, applies the proper line terminators and other formatting characteristics to the received file to match the requirements of the operating system. This (or SFTP) is an excellent choice for exchanging data between platforms, especially when the platforms are not on the same physical network.
- SFTP. Secure file transfer protocol is the same as FTP but is encrypted using SSH (secure shell) encryption technology. This is an excellent choice for sensitive information transfer between platforms but usually requires a third-party utility (many are free).
- SMB. Server message block (a.k.a. CIFS, or common Internet file system) is a direct transfer protocol supported by many OSs. Use of this protocol provides immediate access between platforms but may be unsuitable for security reasons if the machines are not on the same physical network.
(d) Selecting Source/Destination Systems
The following is a list of considerations that should be taken into account when determining the source for and the definition of the WFM systems:
- Define systems needed for each import/export. Usually it is fairly straightforward and obvious which systems are to be used when integrating data. In large implementations, with a mix of different systems that need to be synchronized together, a good developer will investigate and pencil out each interface requirement and each host/destination option taking into account cross-platform traversals, performance, database considerations, available tools and resources, and particularly shared data. In many cases, the obvious selections will win out, but there are occasions when the HR system, for example, might be a better choice than the payroll system for employee demographic data because of the way HR and Payroll are integrated with each other themselves, or the HR database might offer more available required information.
- Define one system to serve as master and commander. Each interface should have a designated system that serves as the system of record where all changes to data are made. Editing data in the applications on both sides of an integration will cause data integrity issues. For example, if someone changes the employee address in the WFM system, the next time the demographic information is imported it will be overwritten. Alternatively, someone may also change the information in the HR system. In this case, it would be double entry, or possibly even triple entry if the data is required in three areas (HR, payroll, and workforce). The recommended solution is to select one system, do all edits there, and use it as the reference (source) for the others.
- Exception accommodation through interface process. Even in such a setup there may arise the need to modify certain pieces of information in the destination system (i.e., workforce) that will be and should be different than what the source system (i.e., HR) has defined. This typically occurs for new employees or newly transferred employees and can generally be accommodated by the interface once determined so as not to overwrite existing data. Each situation can be different, and determining whether it should be written to the system or not may depend on several factors. For example, does the employee already exist? If not, post all data. If so, does the data already exist? If not, post it, otherwise leave it alone. Perhaps the change is conditional—only post the incoming data if it is on a list of acceptable updates, or if the employee has transferred to a new home cost center or if the home address has changed. Overwrite need and/or qualification can be very difficult to unearth and usually comes to the surface in application—when the operation is under way and it actually happens. Despite any great efforts of the developer(s), project manager(s), administrator(s), and operator(s) of the system, overwrite issues are an elusive beast that even the most diligent design can miss. This also extends to complex logic and multisystem usage for data import and is where testing of the interfaces becomes so important. It is usually at the certification testing stage that the cracks these data fall through become evident.
- Avoid mixing sources. The most complicated, problematic, expensive, and resource-hungry interfaces will be those that rely on different sources of data for a single destination. Take scheduling for example. There are two facets: scheduled shifts and scheduled time off. If the two facets come from the same source system, they are already aware of each other, accommodate each other when changes are made to the schedule, and may be imported into a WFM system as a single function, and if the entire schedule picture is provided (i.e., all information), overwriting of the existing schedule is a snap. But consider the challenge if the scheduled shifts come from source A and the scheduled time off comes from source B. Neither know of each other's existence, so the first thing that needs to happen is an interrogation of overlapping data—does A collide with B? If so, which takes precedence over the other? Or are they both valid and the start time of one or the other needs to be altered to accommodate both and link them together? If no collision but A and B are scheduled for the same day, does one trump the other, or are they both valid (e.g., a four-hour scheduled shift and four hours scheduled off)? Is there a minimum amount of time between schedule items that determines whether or not it is a linked shift? Do accruals of time-off benefits need to be taken into account to differentiate items from B? These questions do not even get into the issue of the source data being in differing formats or data sets. For example, B may be scheduled and delivered in bulk—40 hours PTO for a week, say—but the WFM system needs it in 8 hours per day, Monday–Friday, or perhaps 10 hours a day, Thursday–Sunday, or whatever the employees regular schedule might be, and needs to know what time of day to post each of these chunks, particularly when the scheduled time off is only a portion of a day and may have scheduled shift data (from A) to consider as well. This calls for preprocessing of the source data to reformat and ensure the data is presented in the correct format before the previous comparisons can even be initiated.
(e) Selecting Data to Share
WFM systems will have a required set of data necessary to operate—employee ID, cost accounting information, pay governances and codes, hire date, and so on—and then there will be information that is not required but may be included such as employee address, phone number, and so forth.
What to include should be broken down into these three levels:
- Is it available somewhere else?
- Is it required for or needed for export from the WFM system?
Do not bring it in if it is unnecessary, especially if there is any sensitivity to it (wages, Social Security number, etc.). Not only will the interface be cleaner, there is less likelihood for redundant information floating around in multiple systems.
When deciding what data to bring in, remember: Modify or formulate data as close to the source as possible.
15.7 WORKING ENVIRONMENTS AND RAW DATA ARCHIVING
When working with data, the storage and application environments should be considered. Enterprise WFM systems typically use a two-component approach: application and database. Depending on the size of the implementation there may be multiple application servers, sharing the load of work, communicating with the one database. The layout in Figure 15.6 shows an enterprise environment with three distinct test servers/databases, two acceptance servers sharing a database, and five production application servers attached to a single database. The production and test database servers are physically different machines. The database space for test databases (one database space for each test application and one shared database space for the acceptance application) reside on the same physical server. The production system in this example is completely separate, having its own database server and five application servers in a load balancer configuration.
Figure 15.6 Enterprise Environment

Smaller systems may use integrated or proprietary databases. The WFM system selected will influence the type of environment to be built. It is typically recommended that there be, at minimum, a test application/database in addition to the production system.
- Test. One or more test systems are recommended for developing, updating, and deploying configuration changes as well as interface modifications and what-if scenarios. Generally it is preferred that the individual test applications reside on different physical servers and point to the same database server. The DBA (database administrator) will fresh the data in the test environment from data copied from the productivity environment periodically to discover if the data is in synchronization for any implementation scenarios that may need developing or testing.
- Acceptance. Usually one application server containing the configuration designated for production that a group of testers may use to evaluate and validate the system. Certification testing will likely occur on an acceptance server if it exists. It is optional but highly advisable to have one in enterprise implementations.
- Production. The end of the road for configuration and interface deployments. This is the system of record, in use corporate-wide. Production systems should only contain configurations and utilize interfaces that are certified in the test and/or acceptance environments. The production application should reside on separate servers from the test applications.
- Test. At least one test database should be employed and reside on a different physical server if possible. This is not a hard-and-fast rule though. If resources are tight, a separate database space on the same server is acceptable.
- Acceptance. Usually either shares a test database directly (when there is more than one) or has a separate database space on the same server. The disadvantage of sharing a test database is that the developer(s) lose the ability to use that database for testing.
- Production. A separate machine and database server is recommended if possible, particularly in enterprise implementations to affirm viability and hedge against downtime under machine failure conditions.
(a) Defining Source/Output Archive Requirements
Archiving source and output data for a period of time is critical in some applications. Archiving allows for review and potentially even reprocessing in the event there is an issue requiring historical data be reprocessed (e.g., a hard-disk crash).
This section covers the basics of space allocation and methodology for storing vital data.
- Allocating storage. Depending on the nature of the data an interface operates on, archiving the source of the data for a period of time may be a prudent move, particularly if a scenario arises that needs said data to troubleshoot or reproduce. Generally a two-week period of data is sufficient for an archive of a daily interface; the balance may be purged at the end of that period. A good and safe allocation formula is:
2 × avg size × frequency × days
A two-week archive of a 5M file once daily would be 140MB (2 × 5 × 1 × 14) and should be located in an archive folder in an easily accessible location.
- Retention guidelines. Retention of archived files is purely subjective. One should balance the frequency of the archive with the frequency of data review that it affects and also consider whether or not the source system can re-create the file in its entirety. Some files will have no need for archive because it could be identical to the source; others may change so frequently that an archive is necessary to keep for multiple pay periods—at least until the period in question is locked. A basic guideline is to retain the files for a long enough period of time to where they are no longer useful, and that is something that is dependent on what the data is, what it is used for, how frequently it is used, how long it is valid for, how frequently it changes, and so on.
- Copying/moving data. The principal time to archive a file is promptly before it is used by the interface. Make a copy in the designated archive folder before the operation begins. This preserves the content of the file should there be an issue with the system physically crashing in the middle of processing and destroying the file as well as removing any question of whether or not the file got modified by the interface process (this is rare, but sometimes an interface will modify the source file itself in a preprocess scenario, thus changing the original contents). In certain cases, the source file may need to be removed from its place of residence (e.g., to ensure that it is not double processed), in which case it should be copied to the archive first, then moved to the place it will be operated on. Adding a date/time stamp (DTS) to the archived file name is also a good measure (prefixing a DTS format of YYYYMMDDHHMMSS_ to the filename might yield the archive file 20120518080050_EMPDATA.CSV making it easily identifiable for retrieval, sorting, and purging purposes) and is imperative for operations that run more than once a day.
- Purging. This is an important step and one that gets forgotten frequently . . . until the hard drive is saturated with data and operations come to a screeching halt. Determine if a process is put into place to periodically purge the old data so this disk space is not fully consumed. This may be done manually or automatically (recommended) using a script file or third-party utility (e.g., a system called PurgeIt operates on the embedded DTS in the file name).
(b) Backing Up Interfaces and Support Files/Redundancy
Keep a copy of interfaces, support files and tables, documentation, and archived files on a server separate from the operational server (the one where the interfaces run and the aforementioned data is stored) and determine if the daily backup is picking up the same information. If the copy operation is performed by or before the daily back-up process, it will have a readily available redundant copy of everything if a quick restore is needed while maintaining the long-term storage of the regular backup.
15.8 AUTOMATION/UNATTENDED OPERATION
Many interfaces that bring information into a WFM system require no operator intervention. The employee demographic, benefits updates, labor account updates, job updates, and so on generally have a hands-off approach and are therefore excellent candidates for automating their operation.
Other interfaces may require the operator to enter some data at a prompt or simply need to be at will because of a sliding schedule time dependency (e.g., payroll closure).
Lastly, whether the former or the latter, multiple-step interfaces may leverage automation to streamline operations. For example, an interface gets data from a Linux server that needs preprocessing and archiving before being handed off to the interface proper on the Windows side. FTP, custom utility, OS copy and/or move commands, and executing the interface engine may all enter into this equation. Sequencing these steps together is a form of automation that is well received.
(a) Command File
Operating systems (OS) offer the ability to script functions and/or commands together in a line-by-line, procedural fashion that execute in the order listed. This is useful when tying several components together and needing to pass information from one to the next (provided the applications used support it). These may vary from being simple to lengthy and complex, depending upon what they do. They can be used in implementing points-of-failure mitigation processes, monitoring processes for multi-interface environments, multistep interface sequencing, interface priority processing, notification processing, and others.
(b) Operating System Event Scheduler
Operating Systems (OS) provide a native event scheduler that interfaces may be scheduled to run through automatically. This is very convenient and widely used for automating interface processes but comes with a bit of a caveat. When the event managers run an event, they do it in the background—there is no display on the screen. Consequently, if an error occurs that throws a message box onto the screen, the interface appears to have frozen; it is actually waiting for someone to respond to a message box that will rarely be seen. It is important then that functionality be built into automated interfaces that will prevent this from happening (my preference is to provide a “quiet mode” of operation that writes everything to a log file while leaving the flexibility of screen display by simply turning the quiet mode off).
(c) Internal App Scheduler
Some WFM systems provide an event manager inside the application itself that may either leverage the OS version or be a proprietary process. The same issues regarding background processing apply here, and in many cases take on additional security issues when there are multiple servers to consider. In a multiserver environment, the account that runs scheduled events must be able to talk to the servers for the process to work and share files and so on. From the OS level, this is easier to manage as the account is defined when one schedules the event. From the application it is a little trickier as the account being used needs to be determined in order to run the scheduled events and then ensure that the account has access to the other servers in the environment. Sometimes this entails changing the account running services on the server or adding the account to the network security schema. An advantage to going through this configuration is that once it is accomplished, the interface(s) are ready to run on the scheduler as well as available manually to run at will through the application.
(d) Utilities
Third-party utilities may be used to enhance the functionality and usefulness of automated processes:
- SMTP. Simple mail transport protocol (e-mail) notifications are extremely helpful in an automated environment. Leading practice is to review each interface process upon its conclusion to support that everything ran successfully and there were no errors, or to address the errors that were there to prevent a repeat of them in the future. This can be a daunting task when there are multiple interfaces, especially if the majority of them run error free. Script files can be crafted to determine whether or not eyes are needed on a certain interface result and to send SMTP notifications to intended recipients only when necessary. For more real-time responsiveness, consider sending the SMTP notifications to a specific e-mail account that can even send text alerts if a process fails.
- Automated notifications. Similar to the SMTP notifications previously discussed, and leveraging SMTP as well, these types of notifications are useful when an error is detected to let end users know that the error was detected and is being investigated. A copy would go to the administrator and developer as well so the investigation can commence, and the end user saves having to call and ask if something went wrong. This can also be applied as a more generic notification, simply letting end users know, for example, that an interface ran without error so they are certain the information is up to date.
- Pruning. Mentioned previously as purging, this process would follow a formula to keep excessive data from accumulating on the server. Each instance may be different and require different pruning parameters, with the key element being that it needs to be done to prevent server deadlock.
- Preprocessing Conversions/Massaging. Source data not fitting the proper format that cannot be formatted correctly by the source or is impractical to be formatted by the interface proper may require a custom preprocessing data conversion or massaging.
The scheduling preprocess mentioned earlier is an excellent example. Figure 15.7 (extract from support documentation) shows what it does.


Figure 15.7 describes what the preprocess custom utility (Tsplit.exe) does, but it has dependencies itself as it is an integral part of an interface tied into the WFM system to get vital data it needs to operate on.
Combining, transferring, and storing data is a highly technical and elaborate process. The business requirements that govern the movement and activity of the data between systems are fundamental functions. Data interfacing and integrations require not just programming and architecture, but also a clear understanding of the intent of and impact to the data when two or more events converge. These functions should be designed for performance, quality, and scalability. While the WAM-Pro may not necessarily be an interface programmer, an appreciation of how subtle complexities can manifest into unworkable collisions, or how prerequisites and storage must be understood early on in the development process helps lead to better design and improved technical operations.
NOTES
1. ASCII—American Standard Code for Information Interchange; text readable characters.
2. Scripts—a file containing a list of events to be executed in sequence by the operating system or application.
3. This chapter was contributed by Dan Freeman.