
Chapter 13. Mashups with public web services
| This chapter covers |
|
In the previous chapter, we looked at some of the more general web service components of Zend Framework and explored both client and server roles. In this chapter, we’re going to take on the client role and use some of the publicly available web services to make significant additions to our Places site. It would also be fair to say that this chapter should be easier and, if it’s possible, even a bit more exciting than the last. Chapter 12 demonstrated the use of one such public web service, the Akismet spam-filtering service, using the more general components Zend_Http_Client and Zend_Rest. While doing so, we also mentioned that Zend Framework has a prebuilt component for doing this: Zend_Service_Akismet. Of course, this chapter wouldn’t exist if there weren’t more of these components, and we’ll start off with an overview of many of the currently available web service components.
We’ll then demonstrate some of those components. Our aim in doing so is not only to show how they can be used but also how they can be integrated into a Zend Framework-based application. In the process, we’ll also give you an early introduction to the use of Zend_Cache to cache the results and avoid the inevitable slowness of including content from remote web services.
13.1. Accessing Public Web Services
Constructing our own API to allow desktop blog editors to access our Places web application in the last chapter should have left you quite comfortable with the concept of APIs. That knowledge will be very useful when dealing with the public web service APIs. However, one of the great things about the Zend_Service_* components is that you don’t always need to get too involved in the APIs to get them working.
The number of Zend_Service_* components is growing at quite a rate, attesting to the importance and attention given to including web services in Zend Framework. Aside from the components we’ll shortly introduce, there are many in various stages of proposal as the number of web services increase. The following list includes those in the Zend Framework core at the time of writing and some that were in development and which may be in a public offering as you read this. It’s inspiring to see that the variety of companies offering web services ranges from the very large to the comparatively small:
- Zend_Gdata
- Zend_Service_Akismet
- Zend_Service_Amazon
- Zend_Service_Audioscrobbler
- Zend_Service_Delicious
- Zend_Service_Flickr
- Zend_Service_Gravatar
- Zend_Service_Nirvanix
- Zend_Service_RememberTheMilk
- Zend_Service_Simpy
- Zend_Service_SlideShare
- Zend_Service_StrikeIron
- Zend_Service_Technorati
- Zend_Service_Yahoo
Before we get into demonstrating the use of some of some of these components, we’ll describe each briefly and give some indication of its possible uses in relation to the Places application we have been building, in the hope that this will help indicate the potential of these services.
13.1.1. Zend_Gdata
While you’d expect this Google Data client to be called Zend_Service_Gdata, Zend_Gdata breaks the naming scheme of the other components for historical reasons. Google’s own team of developers was responsible for putting together what has become the official PHP5 client for the Google Data APIs. The fact that it’s available as a separate standalone download indicates the standing the Gdata component has as part of the framework.
Later in this chapter, we’ll give an example of the use of Zend_Gdata with one of Google’s services, but before we do, let’s take a quick look at Google’s mission statement:
Google’s mission is to organize the world’s information and make it universally accessible and useful.
That doesn’t really tell us, the potential users of Google’s APIs, much about what the services might provide. If we look at table 13.1, we can see that this is because Google provides a large number of services accessible via the Google Data API.
Table 13.1. The services available via Google’s Data API
|
Service |
Purpose |
|---|---|
| Google Calendar | Manages an online calendar application |
| Google Spreadsheets | Manages an online spreadsheet application |
| Google Documents List | Manages word-processing documents, spreadsheets, and presentations; otherwise known as Google Docs |
| Google Provisioning | Manages user accounts, nicknames, and email lists on a Google Appshosted domain |
| Google Base | Manages an online database application |
| YouTube | Manages an online video application |
| Picasa Web Albums | Manages an online photo application |
| Google Blogger | Manages a blogging application; the current incarnation of the Blogger API that we covered in Chapter 12 |
| Google CodeSearch | Searches the source code of public projects |
| Google Notebook | Views public notes and clippings |
The Google Data API is a collective name for the services based on the Atom syndication format and publishing protocol (APP). This explains why services like Google Maps, which embeds maps in your web application using JavaScript, are not included in this selection.
Note
Because the Zend_Gdata components are extended versions of Atom, they could theoretically also be used as generic Atom components to access services not provided by Google.
13.1.2. Zend_Service_Akismet
We’re already familiar with this service from Akismet because we used it in Chapter 12 to filter user reviews for potential spam:
Automatic Kismet (Akismet for short) is a collaborative effort to make comment and trackback spam a nonissue and restore innocence to blogging, so you never have to worry about spam again.
The service, which originated with the WordPress blogging system, provided a spam-filtering service for reader comments, but it can be used for any kind of data. Zend_Service_Akismet also allows you to send back to Akismet spam that gets through the filter, as well as false positives. Of course, having covered the use of Akismet in Chapter 12, we have to demonstrate how we could have done it with Zend_Service_Akismet. Listing 13.1 does just that.
Listing 13.1. Using Zend_Service_Akismet to filter a review for possible spam

We start by setting up our connection with Akismet and our required API key. We then compile an array of data to be checked, including the required user_ip and user_agent and also some other information that may be useful in determining the nature of the content. Finally, we send the data to Akismet to check whether it’s spam and then act accordingly.
13.1.3. Zend_Service_Amazon
Amazon is probably the largest and most well-known store on the internet. As Google is to search, so Amazon is to e-commerce, and its vision is only slightly less broad:
Our vision is to be earth’s most customer-centric company; to build a place where people can come to find and discover anything they might want to buy online.
—http://phx.corporate-ir.net/phoenix.zhtml?c=97664&p=irol-faq)
Zend_Service_Amazon gives developers access to store item information, including images, prices, descriptions, reviews, and related products via the Amazon web services API. We’ll demonstrate its capabilities later when we use it to find a selection of books that may be useful to users of our Places web application.
13.1.4. Zend_Service_Audioscrobbler
Audioscrobbler is the engine behind the social music site last.fm, which tracks and learns your musical tastes and connects you to new music. The engine is described like so:
The Audioscrobbler system is a massive database that tracks listening habits and calculates relationships and recommendations based on the music people listen to.
The Audioscrobbler web service API allows access to user, artist, album, track, tag, group, and forum data. For our Places application, we could use this service to find music the kids might like to take on trips.
13.1.5. Zend_Service_Delicious
Along with a fairly recent update to its previously unpronounceable Web 2.0 name, Yahoo!-owned Delicious’s description of itself has also been simplified:
Delicious is a social bookmarking service that allows users to tag, save, manage and share web pages from a centralized source.
Zend_Service_Delicious provides read-write access to Delicious posts as well as read-only access to public data. Aside from the obvious personal uses for such an application API, we could use it for accessing statistical information about users bookmarking our Places website.
13.1.6. Zend_Service_Flickr
Flickr, owned by Yahoo!, has an equally simple and self-confident description:
Flickr—almost certainly the best online photo management and sharing application in the world
In section 13.3, we’ll use the Flickr data API’s read-only access to lists of images matching specific tags, user information, and more, to display a selection of images that match keywords in our Places articles.
13.1.7. Zend_Service_Gravatar
Gravatar is now owned by Automattic, which is responsible for the Akismet service. This may partly explain the grand description for what is currently a way to centralize users’ identification icons, otherwise known as avatars:
Gravatar aims to put a face behind the name. This is the beginning of trust. In the future, Gravatar will be a way to establish trust between producers and consumers on the internet.
The component is currently in the incubator, but it looks to provide access to users’ avatars and could be used to put a face to the name in our Places reviews.
13.1.8. Zend_Service_Nirvanix
Nirvanix provides read-write access to its online storage service:
Nirvanix is the premier “Cloud Storage” platform provider. Nirvanix has built a global cluster of storage nodes collectively referred to as the Storage Delivery Network (SDN), powered by the Nirvanix Internet Media File System (IMFS).
Places could use this exactly as described for online storage of media that we may not want to store and serve from our own hosting service, such as video or other large files.
13.1.9. Zend_Service_RememberTheMilk
Remember The Milk, is, as the name suggests,
The best way to manage your tasks. Never forget the milk (or anything else) again.
The Places developers could use this with the support tracker we put together in Chapter 10 to track tasks we have to do. Another idea would be to use it to help parents organize their trips on Places.
13.1.10. Zend_Service_Simpy
Like Delicious, Simpy is a social bookmarking service:
Simpy is a social bookmarking service that lets you save, tag, search and share your bookmarks, notes, groups and more.
Choosing whether to use this or the Delicious service is largely a matter of taste, but either way its potential use is similar.
13.1.11. Zend_Service_SlideShare
SlideShare hosts and displays PowerPoint, Open Office, and PDF presentations for worldwide distribution, or as the company puts it,
SlideShare is the best way to share your presentations with the world.
Using Zend_Service_SlideShare, we could embed SlideShare-hosted slideshows in Places and also upload our own presentations for potential Places investors or presentations of our great web application for the next developers conference!
13.1.12. Zend_Service_StrikeIron
StrikeIron’s service is a little harder to describe because it’s actually a collection of smaller services:
StrikeIron’s Data Services give you access to live data to use now, integrate into applications or build into websites.
Three out of the hundreds of available services—ZIP Code Information, U.S. Address Verification, and Sales & Use Tax Basic—have supported wrappers in Zend_Service_StrikeIron, but the API can be used with many of the other services too. Most, if not all, of the services are subscription-based, with costs being relative to the number of hits to the service.
13.1.13. Zend_Service_Technorati
WordPress users may already be familiar with the integration of Technorati in Word-Press’s dashboard to show incoming links, but Technorati’s own description suggests greater things:
Technorati is the recognized authority on what’s happening on the World Live Web, right now. The Live Web is the dynamic and always-updating portion of the Web. We search, surface, and organize blogs and the other forms of independent, user-generated content (photos, videos, voting, etc.) increasingly referred to as “citizen media.”
We can use Zend_Service_Technorati to search and retrieve blog information, and for Places we’d likely use it the same way WordPress does—to track incoming links and find out what people are saying about us. Listing 13.2 shows an example of how this could be done.
Listing 13.2. Checking incoming links to Places!
require_once 'Zend/Service/Technorati.php';
$technorati = new Zend_Service_Technorati('PLACES_API_KEY'),
$results = $technorati->cosmos('http://www.placestotakethekids.com/'),
This quick but effective example fetches the results of a search of blogs linking to our Places URL.
13.1.14. Zend_Service_Yahoo
Yahoo! is another company whose scale and ubiquity make it hard to define:
Yahoo! powers and delights our communities of users, advertisers, and publishers—all of us united in creating indispensable experiences, and fueled by trust.
Zend_Service_Yahoo focuses on search through Yahoo! Web Search, Yahoo! News, Yahoo! Local, and Yahoo! Images. A useful feature for our Places application would be checking the indexing of our site with the kind of code that listing 13.3 demonstrates.
Listing 13.3. Checking indexing of our site
require_once 'Zend/Service/Yahoo.php';
$yahoo = new Zend_Service_Yahoo('PLACES_YAHOO_APPLICATION_ID'),
$results = $yahoo->pageDataSearch('http://www.placestotakethekids.com/'),
You may have noticed how similar the code in this Yahoo! example is to the previous Technorati one. While that is somewhat coincidental, it does begin to demonstrate how the web services components simplify and make available a broad range of services with a relatively simple approach.
With that in mind, and having completed our overview of some of the web services available in Zend Framework, it’s time to go a little deeper with some more detailed examples of the components in use. We’ll start by retrieving some items from Amazon using Amazon’s web services API.
13.2. Displaying ads with Amazon Web Services
You may have noticed in previous chapters that we’ve left a noticeable blank space on the right side of our Places application, waiting for some advertising. Having gone through the available web services, it is obvious that we have a candidate for that space with Zend_Service_Amazon.
Since that space is in the layout file, we’re going to make use of a view helper whose purpose, as stated in the manual, is to “perform certain complex functions over and over.” This is well-suited to our need to show the same view data repeatedly from outside of any controller. Dealing with the data retrieval, however, is a job for a model class, and we’ll do that first.
13.2.1. The Amazon Model Class
The first thing we need to do is establish some settings before querying Amazon. The model class we’re setting up here is quite specific to the needs of our Places application but it could, if needed, be made more generic. The point of our examples is to demonstrate the separation of responsibilities, with the model class being responsible for the data retrieval, which will be used by the view helper.
We’ve decided that all we really need in order to fill our advertising space is a small selection of books matching some keywords that will be passed to the view helper in the layout file. A thumbnail image of the cover and a title linked back to its parent page on Amazon UK is all we need for each book.
After having provided the required Amazon API key, our code in listing 13.4 uses the fluent interface of Zend_Service_Amazon_Query to pass in some of our requirements. Information about obtaining an API key and more is available through the Amazon Web Services website at http://www.amazon.com/gp/aws/landing.html.
Listing 13.4. The Amazon model class that will be used for data retrieval

Our API key is stored in a Zend_Config object that is itself stored in a Zend_Registry object and is recovered in the constructor of our class ![]() . If no API key is available, our search method will immediately halt and return a null value
. If no API key is available, our search method will immediately halt and return a null value ![]() . Because we have no control over the availability of public web services, or over the network connections, our code needs
to allow for that. PHP5’s new exception model is particularly valuable in such circumstances, and in this case we’ve wrapped
the query in a try-catch block and allowed it to fail silently because its availability isn’t crucial to the operation of
our website
. Because we have no control over the availability of public web services, or over the network connections, our code needs
to allow for that. PHP5’s new exception model is particularly valuable in such circumstances, and in this case we’ve wrapped
the query in a try-catch block and allowed it to fail silently because its availability isn’t crucial to the operation of
our website ![]() .
.
If all is well, we first set up our Zend_Service_Amazon_Query object with our API key and specify Amazon UK as the service ![]() . Then we set options for the search, starting by specifying that we want only books to be searched
. Then we set options for the search, starting by specifying that we want only books to be searched ![]() . Next, we set the keywords
. Next, we set the keywords ![]() and the response group
and the response group ![]() , which “controls the data returned by the operation.” In this case, we have specified the Small group, which “provides global, item-level data (no pricing or availability), including the ASIN, product title, creator (author,
artist, composer, directory, manufacturer, etc.), product group, URL, and manufacturer,” and the Images group, so that we have some thumbnail images of the covers to show. If all isn’t well, we return a null value
, which “controls the data returned by the operation.” In this case, we have specified the Small group, which “provides global, item-level data (no pricing or availability), including the ASIN, product title, creator (author,
artist, composer, directory, manufacturer, etc.), product group, URL, and manufacturer,” and the Images group, so that we have some thumbnail images of the covers to show. If all isn’t well, we return a null value ![]() , but we could do something more adventurous if needed.
, but we could do something more adventurous if needed.
With our model class now ready to accept query requests, we can move on to the view helper that will prepare the view data.
13.2.2. The Amazon ads View Helper
Our view helper will take the data retrieved by our Amazon model class in listing 13.4 and format it into an unordered HTML list. It can then be included in the site layout file, like so:
<?php echo $this->amazonAds('kids, travel', 2); ?>
Here we’re specifying that the keywords to search for are “kids, travel” and that the number of books we want to show is 3 (when the foreach loop hits key 2). In listing 13.5, we can see that the amazonAds() method in our view helper code also takes a third parameter, which is an optional UL element ID. As with all view helpers, the naming of this method is important and must match the class name (aside from the lowercase first character) so that it can be automatically called when the object is used in view files.
Listing 13.5. Our AmazonAds view helper that composes the HTML for our view

Our method starts by instantiating our Amazon model object from listing 13.4. Then we use it to make the query with the requested keywords. If the search gives no results, we return a null value; otherwise we set up the HTML, which will be returned and displayed in our view file.
Since you’re reading this book, you’re obviously sharp-witted enough to have noticed, even without trying out this code, that it has a few notable flaws. The first problem is that if it fails, it returns a null value, which will leave a blank space on our page. The second problem is that if it succeeds, it may still cause a noticeable delay, because the information is retrieved from Amazon every time a page on our site is requested.
The first problem isn’t too hard to deal with. We could, for example, simply call another view helper to show a banner ad if our Amazon query fails. The second problem is not only out of our control, but is also more important, because annoying page delays can turn users away from our site. What we need is a way to reduce our vulnerability to network delays.
The way to do this is to cache the view helper result, which we’ll do using the Zend_Cache component.
13.2.3. Caching the View Helper
This section will introduce the use of caching to reduce the number of query calls we need make to Amazon, but it isn’t intended as a detailed introduction to caching, because that’s the subject of the next chapter. Nevertheless, we’ll take a bit of time to explain the example shown in listing 13.6.
Listing 13.6. Our AmazonAds view helper with added caching using Zend_Cache

Our cached version of our view helper will store a copy of the HTML output in a file that is set to update every two hours. Each view helper call is preceded by a check to see if there is an up-to-date cache file that can be used as the output of the view helper. If a current cache file isn’t available, we make the request to Amazon and, before out-putting, save the HTML to the cache file to be used in the next request.
The benefit of all this is that we need to make a request to Amazon only every two hours, at most, rather than on every page request. Because we’re only showing a selection of books we think might interest our readers, the two-hour delay between data refreshment is insignificant. If we needed more recent data, we’d just reduce the lifetime in the frontend options.
In figure 13.1, you can see that what was previously a blank space is now filled with a selection of books linked back to Amazon, from which we could earn a percentage of sales through the Amazon affiliate program. It is cached to avoid unnecessary delays in page loading, but it isn’t perfect because the images themselves still need to be retrieved from Amazon. For our needs, this is acceptable. The HTML will allow the page to render, and users are generally accepting of some delay in image loading. If demand got high enough, we could cache the images as well, but we’d need to check the Amazon Web Services terms of use before doing so.
Figure 13.1. Our new Amazon ads shown on the right, and a similar search on Amazon on the left

An unfortunate side effect of adding the Amazon thumbnail images is that our site content, particularly the article content, now looks quite bare. In the next section, we’ll remedy that by using images from Flickr to complement the articles.
13.3. Displaying Pictures from Flickr
Before we get into our example, it’s important to note that what we’ll be showing here is for demonstration purposes only. For actual use, we’d need to be careful that our use of images from Flickr complied with its terms of use, which includes licensing limitations on individual images as well as limitations on what Flickr considers commercial use.
Our intention is to display relevant images from Flickr within our articles, but the main purpose of our example is to demonstrate the use of a public web service within an action controller rather than to suggest a particular use of Flickr’s service. With that disclaimer in mind, we can move on to our example.
The methods available in Zend_Service_Flickr are a relatively small set of those available in Flickr’s API, limited basically to finding images by tag, user information, or specific image details. While this could be used to retrieve a specific user’s images from Flickr for use in an article submitted by that user, we’re going to use the more general tag search for our example. Our starting point will be the same as for our Amazon example—a model class responsible for retrieving the data from Flickr.
13.3.1. The Flickr Model Class
The model class we’re about to cover for Flickr is very similar to the one we developed for our Amazon example. Like Amazon, Flickr also requires an API key, available via the API documentation page at http://www.flickr.com/services/api/, which is used for tracking use of the API. Listing 13.7 shows that once again we’re developing a model responsible for data retrieval, but this time it will be used within the article action controller.
Listing 13.7. Our Flickr model class
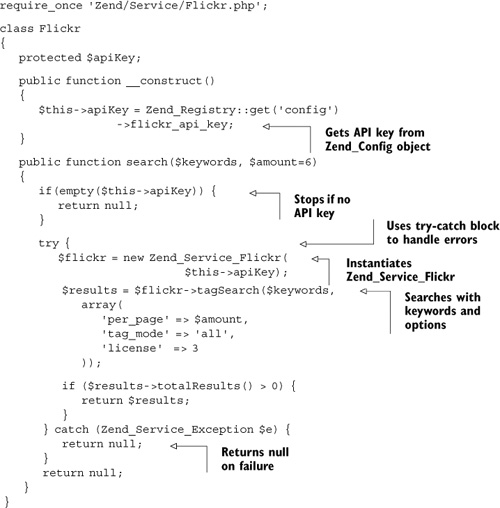
In listing 13.7 our API key is recovered from the config object and passed to the Zend_Service_Flickr object. Next, we use the tagSearch() method, which is a wrapper for the flickr.photos.search Flickr method, passing it a few option settings.
It’s worth checking out the API documentation, because the list of available options is huge and allows a great variation in the type of results returned. We could limit our search to different date settings, a specific user, a geographical area, a group and more. In our case, we’re specifying a per-page limit, that the search uses all the tags we specify when searching, and that the license for images returned is suitable for our use. In this case, the license value 3 indicates the No Derivative Works Creative Commons license, which is defined like so:
No Derivative Works. You let others copy, distribute, display, and perform only verbatim copies of your work, not derivative works based upon it.
Limiting the results by group would be particularly useful, as it would allow us to work with groups of images that we had some control over, but for the sake of our example we’ve kept things simple.
On that note, our example model class is now complete enough to move on to its integration in the action controller.
13.3.2. Using Flickr in an Action Controller
Our Amazon example used a view helper, because we were going to use it repeatedly across pages and it wasn’t specific to any single page. In this case, we’re only going to use the Flickr images with articles, so calling our model from the article controller action is quite sufficient.
Since we’re doing a search for images based on their tags, we’re going to need a way of getting words to search for. We’ll do this by adding a keywords column to the articles table in our Places database, and as shown in listing 13.8, passing those keywords to the Flickr object from the previous section.
Listing 13.8. Using our Flickr model class in our article controller action

In listing 13.8, we can see the original code for retrieving a requested article inside the ArticleController::indexAction() method, and underneath that our code to get the complementary images from Flickr. Having retrieved the article based on the ID passed to the action controller, we then pass that article’s keywords to our Flickr class. Finally, we pass the results to the view, which is shown in listing 13.9.
Listing 13.9. The article view with the added Flickr images

The additional code in the view is quite straightforward. It comprises a simple test to make sure we have some results before looping over them and setting up a linked image element and image title within an unordered list. With a little bit of CSS magic, we can float those images and achieve a gallery effect, as shown in figure 13.2. You can see the original images from the tag search in Flickr now appearing with our article on Edinburgh Zoo.
Figure 13.2. On the right, Flickr images based on article keywords displayed with the article; on the left, the original images on the Flickr site

You may have noticed that we didn’t use any caching in this example. That was partly to keep the focus on the web service component, but, also, as we mentioned in the Amazon section, the presence of the HTML means that the whole page won’t be overly delayed by network delays. In practice, it would probably be a good idea to implement some caching, taking note that the Flickr API terms warn us not to “cache or store any Flickr user photos other than for reasonable periods in order to provide the service you are providing to Flickr users.”
Having seen the improvement that the Amazon ads made to that blank right side of our site and now how the addition of images from Flickr have improved our articles, we’re up for a bigger and more visually dynamic challenge: adding video. In the next section, we’ll do that using what’s undoubtedly the biggest web service component in Zend Framework: Zend_Gdata.
13.4. Using Zend_Gdata for Google Access
In our earlier introduction to Gdata, we gave a brief overview of the different services available through the Google Data API. Our site, Places to take the kids, is one that would clearly benefit from some videos from one of those services: the YouTube API.
Adding video to your site isn’t an easy undertaking. Not only does it require proper preparation of the video for internet delivery; it can also stress your hosting space and bandwidth requirements. The success of YouTube and, in particular, its embedded video, is clearly a reflection of the benefits of outsourcing your video.
Of course, any video you add and use from YouTube is going to be carrying the YouTube branding, which makes it unsuitable for some needs. In such cases, solutions like Zend_Service_Nirvanix could be a possible option for dealing with hosting and bandwidth demands. We aren’t worried about the YouTube connection on Places, and in fact could use it as a way to draw traffic to our site.
As when using any public services, the first step is to find out what the terms of use allow you to do. Our intention is to add a video section to Places that will first show a list of video categories, then a list of videos in a selected category, and finally a selected video, and this seems to comply with the YouTube terms of service. With that check out of the way, we can start building the video categories page. As with the Flickr example in section 13.3, we’ll use an action controller.
13.4.1. The YouTube API in an Action Controller
What’s interesting about the example in this section is just how little actual coding is needed to achieve a significant addition to the Places site. We’re going to cover each page of our video section in detail shortly, but let’s pause and look at how concise our controller action in listing 13.10 is. After all, we can’t leave all the gloating over code brevity to the Ruby on Rails developers!
Listing 13.10. Our videos controller action

In the interest of full disclosure, there is a bit of logic that takes place in the view files, so before we get too self indulgent, we should take a look through them, starting with the video categories page.
Note that because we have only read-only access, the YouTube API does not require an API key, but we have established a YouTube user account to work with.
13.4.2. The Video Categories Page
This page is a selection of video categories. Our users can click on one to see the list of videos that it contains. Our controller action file in listing 13.10 has an index-Action() method, which is responsible for this page. It simply gets a playlist feed for our “ZFinAction” user account and passes it to the view:
public function indexAction()
{
$this->view->playlistListFeed =
$this->_youTube- >getPlaylistListFeed('ZFinAction'),
}
YouTube refers to playlists as “collections of videos that can be watched on YouTube, shared with other people, or embedded into websites or blogs.” In figure 13.3, you can see the YouTube account page, which we used to set up the playlists. Those playlists then appear in the view file shown in listing 13.11 as our video categories. Notice that we can also set a description for each one that we can use on our page.
Figure 13.3. Our video category page on the right, and the YouTube playlist management page on the left

Listing 13.11. Our video categories view code

The view file simply loops over the playlist feed, filters out the playlist entry feed ID from its URL, then uses that ID and a description in a link to our next page—the video list page.
13.4.3. The Video List Page
The video list page shows the videos in the playlist that the user selected. Figure 13.4 shows the YouTube account we used to add video selections to each playlist and their appearance on our video list page.
Figure 13.4. Our video list page on the right, and the YouTube video list management page on the left

Looking at the listAction() action controller method in listing 13.10, we can see that it takes the ID that we previously filtered out of the playlist entry URL and uses it in a query that gets the video feed for the chosen playlist:
public function listAction()
{
$playlistId = $this->_request->getParam('id'),
$query = $this->_youTube->newVideoQuery(
'http://gdata.youtube.com/feeds/playlists/' . $playlistId);
$this->view->videoFeed = $this->_youTube->getVideoFeed($query);
}
That video feed is then passed to the view file in listing 13.12.
Listing 13.12. Our video list view file

This view file is much the same as the video categories page. It loops over the video feed, filters out the video ID from its URL, and uses that ID along with a description in a link to our next page, the video page. Note that there are further options available, such as thumbnail images, which you could also display. You can find more information about these options on Google’s YouTube API pages at http://code.google.com/apis/youtube/overview.html.
13.4.4. The Video Page
The video page is the simplest of them all because it just needs to show the video itself. In figure 13.5, you can see the selected video from YouTube now showing on our video page.
Figure 13.5. Our video page on the right, and the original video on YouTube on the left

The controller action code in the viewAction() method that does this is equally simple. It uses the video ID passed to it to get the video from YouTube and sets that up as a view variable.
public function viewAction()
{
$videoId = $this->_request->getParam('id'),
$this->view->videoId = $videoId;
$this->view->videoEntry = $this->_youTube->getVideoEntry($videoId);
}
Note that we also pass that video ID as a view variable of its own, because this will be used in the view, shown in listing 13.13, to construct the URLs needed to retrieve the data from YouTube.
Listing 13.13. Our video view file

In our view file in listing 13.13, the videoEntry data is used to get the title and the video ID, included in the URL, which allows our video to appear on the final page.
The end result of what’s actually very little work is that you can add quite a considerable amount of value to your site with a video section that can be fully controlled through your YouTube account. That means that you can not only use public video but also upload and feature your own video. Anyone who has been doing internet work for a while or who has ever wished he could control his own TV station will recognize that this has quite exciting possibilities.
13.5. Summary
In the previous chapter, we covered a lot of the theory and practice of working with web services using Zend Framework from both the client and server sides. This chapter should have felt a lot easier, not only because it worked only with the client side, but also because the Zend_Service_* and Zend_Gdata components wrap a lot of the complexities of each service in a more digestible form. This was evident in how little we needed to mention any of the technologies behind the services.
You now should have a good idea of some of the Zend Framework web service components that are available and are aware that more are on their way. Even better, you may be inspired to add some of your own.
Our brief examples were meant to give an idea of how you could use the components in your own projects, and our more detailed examples should have provided some indication of how the components can work within the MVC structure of Zend Framework. In a chapter that had to cover so many components, there were clearly limits to how much detail we could go into. Nevertheless, we hope that we did cover the main points, including checking the service’s terms of use, taking care to code defensively, particularly in dealing with the very real issue of network delays, and using caching to reduce the number of service requests.
Caching is a topic that requires its own chapter, and it’s the topic of our next chapter.