
Chapter 2. Bridging the Two Worlds—Managed and Unmanaged Code
In This Chapter
• Managed Code Versus Unmanaged Code
• How Unmanaged Code Interacts with Managed Code
• Unmanaged Code Isn’t Always the Answer
This chapter explains how and why managed code and unmanaged code interact, and introduces the interoperability technologies that are the subject of this book. It also provides an overview of COM, relating it to the .NET Framework and highlighting important differences between the two programming models.
Managed Code Versus Unmanaged Code
Throughout this book (and much documentation), the terms unmanaged code and managed code are used. See the following “Frequently Asked Question” sidebars for an explanation of what is meant by these terms. C#, Visual Basic .NET, and C++ with Managed Extensions all produce managed code. Visual Basic 6 and plain C++, on the other hand, produce unmanaged code.
Goals of Unmanaged Code Interaction
The .NET Framework enables interaction with unmanaged code in a few different ways. Using the features described in this chapter, you don’t have to build managed applications from scratch. Instead, you can still build applications using all the great functionality that current software components provide. Because .NET is a new technology, a lot of functionality doesn’t exist natively. Examples of this are voice recognition, advanced 3D graphics, and an endless number of other areas. This isn’t a problem for .NET applications, however, because any previous unmanaged implementations can still be used by managed code.
Besides enabling numerous components to be a part of a .NET developer’s toolbox, interoperability is great news for anyone who has written such software components using pre-.NET technology. Unmanaged components aren’t suddenly obsolete with the arrival of .NET because managed clients can still use them. There’s often no need to port existing software because it still functions in this new world of .NET, but interoperability services also enable gradual migration of unmanaged components into the managed world if you do wish to migrate unmanaged code to take advantage of new .NET features.
How Can Using Unmanaged Code Be Secure?
Because managed code can interact with unmanaged code (which, by definition, is outside the control of the .NET Framework’s security system), there must be a restriction on calling unmanaged code. Otherwise, a malicious assembly can simply call out to unmanaged code to do its dirty work. This restriction is in the form of an unmanaged code permission. Thus, no managed components can execute unmanaged code unless they are granted this permission. Although technically not the same as full trust, permission to run unmanaged code is really the same thing in practice because unmanaged code’s capabilities are only limited by forces outside the .NET Framework (such as the security provided by the operating system).
How Unmanaged Code Interacts with Managed Code
Four technologies exist that enable the interaction between unmanaged and managed code:
• Platform Invocation Services (PInvoke)
• Mixed-Mode Programming Using Managed Extensions to C++
• Java User Migration Path to .NET (JUMP to .NET)
• COM Interoperability
Platform Invocation Services (PInvoke)
Many programs expose APIs as static entry points in a dynamic link library (DLL). For example, the Win32 API consists of static entry points in modules such as KERNEL32.DLL, USER32.DLL, GDI32.DLL, and ADVAPI32.DLL. To continue using such APIs in managed code, the Common Language Runtime has a feature called Platform Invocation Services, or PInvoke for short. PInvoke enables the following two actions:
• Calling entry points in unmanaged DLLs
• Passing function pointers to unmanaged code for callbacks
Unmanaged C++ code accomplishes this functionality using the LoadLibrary and GetProcAddress APIs. Visual Basic 6 exposes this using the Declare statement.
PInvoke works by having a method declaration in managed code marked with a special custom attribute (System.Runtime.InteropServices.DllImportAttribute). This attribute contains a string with the name of the DLL that contains the exported function. Visual Basic .NET supports the same Declare syntax as Visual Basic 6, but uses PInvoke as the underlying mechanism.
Here is the canonical example of C# code that uses PInvoke to access a commonly used method in the Win32 API:

Often, there isn’t a need to call the common Win32 APIs in managed code because there are equivalent managed APIs in the .NET Framework that you can call without the security restrictions associated with calling unmanaged code. In this example, you can call the managed System.Windows.Forms.MessageBox.Show method, defined in the System.Windows.Forms assembly, instead.
Using the Win32 API might be handy when porting existing code to a managed language, or necessary if wanted features aren’t exposed in the equivalent managed APIs. PInvoke is also useful for your own DLLs, or for DLLs that don’t already have equivalent functionality available in managed APIs. PInvoke is covered in Part VI, “Platform Invocation Services.”
Mixed-Mode Programming Using Managed Extensions to C++
Unlike Visual Basic .NET, which changed from Visual Basic 6 to fit solely into the .NET Framework, Visual C++ .NET hasn’t removed or changed anything in the language. Instead, managed extensions have been added. The result is a pretty slick and powerful way to write interacting managed and unmanaged code—even in the same source file! If you compile any existing C++ code with the Visual C++ .NET compiler’s /CLR switch, MSIL is produced instead of all native code and the program still works the same way at run time. There’s no good reason to do this unless you change or add to the code, but at this point you can reference assemblies and call any managed APIs. The following code is an update to the “Hello, World” C++ example in Chapter 1, combining the worlds of managed and unmanaged code:

This is sometimes called mixed-mode programming, referring to the mixing of managed and unmanaged code. Using the language’s new keywords (such as __gc), existing code can gradually take advantage of more and more features from the .NET Framework. The price of the power to mix managed and unmanaged code is that the Visual C++ .NET compiler produces code that is not verifiably type safe (checked by the Common Language Runtime), so additional security constraints apply.
Note that this language-specific feature differs from the language-neutral PInvoke and the soon-to-be-introduced COM Interoperability features because it involves recompiling and updating source code. However, developers might find this an easy way of introducing managed interfaces to existing C++ components (which helps cross-language interoperability if they don’t already expose COM interfaces). You’ll see some mixed-mode programming in action in Chapter 20, “Custom Marshaling.”
Java User Migration Path to .NET (JUMP to .NET)
JUMP to .NET is the preferred migration path for Java (and Visual J++) programs to enter the .NET world. The first part of JUMP to .NET is Microsoft Visual J# .NET, a Java-language development tool that plugs into Visual Studio .NET and includes upgrade tools for Visual J++ 6.0 projects. Visual J# .NET is in a beta release at the time of writing. The second part of JUMP to .NET is a utility that converts Java source code into C# source code.
COM Interoperability
I’ve saved COM Interoperability for last because it’s the most complicated of the technologies presented, and because it’s the main focus of this book. Commonly referred to as COM Interop, it provides a bridge between COM and the .NET Framework. More concretely, it enables the use of COM components from managed code and the use of .NET components from COM.
So, what exactly is COM Interoperability? It’s made up of three parts:
• Core services provided by the Common Language Runtime. The CLR provides the infrastructure that enables .NET components to communicate with COM components, and vice-versa. This core functionality is at the root of other features in the .NET Framework, such as support for ActiveX controls and support for COM+ services.
• A handful of APIs. Many features of COM Interoperability work without any additional COM-specific coding in .NET applications. However, there is an Interop API (classes, custom attributes, and so on) in the mscorlib assembly with the namespace System.Runtime.InteropServices. The Runtime portion of the namespace indicates that these APIs interact with services provided by the Common Language Runtime. There are other COM-specific types and methods in other namespaces, such as: System, System.Windows.Forms (for APIs related to ActiveX controls), and System.EnterpriseServices (for APIs related to COM+ services).
• Tool support. In order for COM Interoperability to work, certain tasks often need to be performed to produce type information, or to ensure proper registration. The .NET Framework SDK provides some essential programs (tools) that can be used from the command line to carry out the necessary tasks. These tools are described throughout the book and summarized in Appendix B, “SDK Tools Reference.” In addition to the tools provided by the SDK, you can think of Visual Studio .NET as the ultimate tool for pulling together tons of functionality, and combining it into one seamless experience. Visual Studio .NET has built-in support for making COM Interoperability so seamless that you might not even realize COM is involved (if you’re lucky). One good example is that ActiveX controls can be dropped onto a Windows Form or an ASP.NET page just as if they were managed controls.
Goals of COM Interoperability
The goals of unmanaged code interaction (described earlier) also apply to COM Interoperability, which has another important goal worth mentioning: programming model consistency.
As described later in this chapter, the programming models of COM and the .NET Framework differ greatly. To simplify communication between COM objects and .NET objects, the Common Language Runtime masks these differences. Thus, a COM object is not only usable from managed code, but often usable the same way you would use a .NET object. Rather than calling CoCreateInstance and checking for HRESULTs, you can use the new operator and catch exceptions. Similarly, COM clients don’t need to learn any new tricks to use .NET components. They can be used just like COM objects—calling CoCreateInstance, QueryInterface, and so forth. Therefore, COM components don’t need to be redesigned to avoid appearing antiquated or hard-to-use in the .NET world, and .NET components can be used by unmodified COM components written well before .NET came along.
Note that COM Interoperability works at the binary level. This ensures the capability to expose .NET types that are compatible with COM’s expectations, and vice-versa. This does not mean that the source code involved in creating such types looks anything like it does in unmanaged languages. Much of that capability depends on the programming language you use.
About COM
This section contains the obligatory overview of COM. If you’re familiar with COM, you should still read the comparisons to the .NET Framework to get a clear picture of the hurdles COM Interoperability overcomes. If your exposure to COM is only through pre-.NET versions of Visual Basic, don’t worry too much about these details. Throughout the book, necessary COM concepts are explained in both VB terms and in “raw” terms.
COM, which made its debut in the early 1990s as the technology powering OLE 2.0, is described in Microsoft’s documentation as follows: “COM is a platform-independent, distributed, object-oriented system for creating binary software components that can interact. COM is the foundation technology for Microsoft’s OLE (compound documents) and ActiveX (Internet-enabled components) technologies, as well as others.” Like the .NET Framework, COM is not a programming language, but a language-independent framework for creating components. More specifically, COM is a specification for a binary standard that defines how objects can interact, and is also a library containing low-level APIs.
Distributed COM (DCOM), introduced in 1996, enhanced COM by enabling components on different computers to communicate. With Windows 2000 came the arrival of COM+, the evolution of Microsoft Transaction Server (MTS) and COM. COM+ provides built-in services (such as security, object pooling, and transaction management) so that it becomes much easier to write scalable enterprise applications.
COM classes, also known as coclasses (the “co” is short for COM), must implement interfaces to expose functionality. The interface that every COM object must implement, and the root of all COM interfaces, is IUnknown. The types that COM exposes are typically written or presented in Interface Definition Language (IDL), whose syntax is based on an older language called Object Definition Language (ODL). The IDL representation of IUnknown is the following:

IUnknown’s methods enable clients to manipulate the object’s reference count and ask the object what interfaces it implements.
Many objects implement IDispatch to enable dynamic method invocation (also referred to as late binding), whose IDL definition is shown here:

Clients can call the methods of IDispatch to get type information and invoke members by name. COM components typically store and deploy type information in the form of type libraries. Type libraries are explained in more detail in the upcoming “Type Information” section.
Useful COM Utilities
The following utilities, included in the Windows Platform SDK, are widely used in COM development. If you have Visual Studio, you have these tools. Otherwise, they can be downloaded from MSDN Online (http://msdn.microsoft.com). It’s a good idea to familiarize yourself with these tools if you haven’t already.
• OLE/COM Object Viewer (OLEVIEW.EXE). This tool can, among other things, display the contents of a type library in IDL notation. This capability can be very useful and is used throughout the book. Visual Studio .NET lists this utility on its Tools menu. To view a type library, you can pass the name of the file containing it as a command-line parameter, for example:
oleview stdole2.tlb
A type library can also be selected by clicking View TypeLib on the File menu or toolbar. Figure 2.1 shows what viewing a type library looks like using OLEVIEW.EXE.
Figure 2.1. The OLE/COM Object Viewer (OLEVIEW.EXE) displaying the contents of a type library.
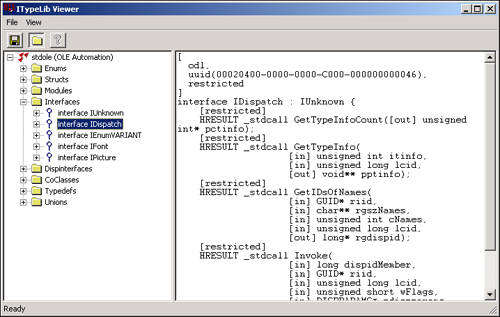
• MIDL.EXE and MKTYPLIB.EXE. These two utilities can compile an IDL or ODL text file to a binary type library. MIDL.EXE is preferred, and considered a replacement for MKTYPLIB.EXE.
• REGSVR32.EXE. This necessary utility registers and unregisters COM components in the Windows Registry. Because registration needs to be done on any computer (not just a developer’s machine), this tool is shipped with the Windows operating system.
• REGEDIT.EXE and REGEDT32.EXE. These utilities, which enable viewing and editing of the Windows Registry, are also shipped with Windows. Figures that display the registry throughout this chapter use REGEDIT.EXE.
Differences Between COM and the .NET Framework
The .NET Framework can be considered an evolution of COM—taking the same high-level goals, but making them easier to accomplish and better suited for an Internet-centric world. Both of these frameworks focus on building reusable components that can communicate regardless of the programming language used to create them. Despite the similarities, the details of the two technologies are quite different. We’ll now examine some of these differences, focusing on the following:
• Programming Model
• Type Information
• Identity
• Locating Components
• Type Compatibility
• Versioning
• Type Safety
• Error Handling
• Object Lifetime
Another important difference—threading models—is discussed in Chapter 6, “Advanced Topics for Using COM Components.” The result of all these differences is that the .NET Framework is simpler than COM. Although simplicity is in the eye of the beholder, I believe that if a survey were conducted using developers who were forced to become proficient in both COM programming and .NET programming, the results would clearly favor the .NET Framework.
Programming Model
The .NET Framework and COM are both object-oriented models. COM’s status of being truly object oriented has been the subject of debates, due to its lack of implementation inheritance. However you define what it means to be object oriented, I think it’s safe to say that COM is object oriented enough for practical purposes. The .NET Framework model is much richer, however.
COM deals primarily with interfaces, although Visual Basic 6 makes the exact opposite seem true. It is only through interfaces that you can invoke methods and properties of COM objects. Coclasses are non-descript entities that you create just to ask for certain interfaces. COM supports single interface inheritance, but not implementation inheritance (that is, class inheritance). Instead, COM enables implementation reuse via aggregation and containment. Containment is an easy concept, in which one object simply delegates work to a second object contained inside. Aggregation is a powerful and more complex mechanism, which enables an outer object to expose the implementation of an inner object without delegating to the inner object on a call-by-call basis.
The .NET Framework type system has interfaces, but COM has three kinds of interfaces:
• IUnknown-only interfaces—Interfaces that don’t support IDispatch (sometimes called custom interfaces)
• Dispinterfaces—Interfaces whose members can only be called through the IDispatch interface
• Dual interfaces—Interfaces can be both called directly and accessed through IDispatch
The .NET Framework is object-based, so implementing interfaces is no longer a requirement for cross-component communication. Unlike COM, multiple interface inheritance and single implementation inheritance are supported. Classes can have all sorts of methods: static (Shared in VB .NET), instance, virtual (CanInherit in VB .NET), and even overloaded methods. Besides methods, classes can have properties, fields, events (all of which are first class members), and even constructors with any number of arguments. .NET classes and members can also have various levels of visibility (such as public, protected, and private). None of this is possible in COM. All these features have been available in programming languages (such as C++) for years, but the .NET Framework extends all these concepts to the component level. So, objects written in any .NET language can take advantage of these rich features.
Type Information
Type information—the description of classes, interfaces, and more—is an important part of both COM and the .NET Framework. In COM, type information can be stored in many forms. It’s commonly stored in a language-specific fashion (such as C++ header files or IDL files). More common, however, is the language-neutral representation of COM type information, known as a type library. Although type library viewers often present the information in IDL syntax, a type library contains binary information describing COM interfaces and coclasses that the author chooses to expose.
Creating a type library for a COM component is optional, and it might be a separate file (such as MSHTML.TLB), or it might be embedded in a DLL as a resource (as in MSXML.DLL). Coclasses state a subset of interfaces that they implement—not necessarily all of them. For example, although coclasses authored in Visual Basic 6 always implement ISupportErrorInfo, the type libraries produced by VB6 don’t bother listing this interface in coclass statements. COM components written in VB6 have predictable type information, but type libraries created from other sources (such as MIDL.EXE) can contain plenty of tricks because COM doesn’t enforce the correctness of the information. The result is that you can’t count on type information being correct, complete, or even available.
A COM object’s type information, if available, can be obtained programmatically via the ITypeInfo interface (or the ITypeInfo2 interface, which was later created to enable access to extended information). There are a host of other interfaces related to the discovery of type information (such as ITypeLib, ITypeLib2, ITypeComp, and IRecordInfo).
As introduced in the preceding chapter, type information has only one form in the .NET Framework: metadata. Unlike type information in COM, it is always available, complete, and accurate for every single component. It’s so complete that even private types and members are visible in metadata (something that makes a few people uneasy when they discover it for their own components). Any .NET compiler (even C++) must produce and consume metadata directly, so there’s no type information in separate files (like an IDL file) to mess around with.
The ubiquity and completeness of metadata is the source of much of the power in the .NET Framework. The CLR never has to ask an object if it supports an interface (as in COM’s IUnknown.QueryInterface), or ask an object to construct itself (as in COM’s class factories). Instead, it can consume and inspect the object’s metadata to provide these services without executing user-written code. Similarly, late binding can be performed without requiring objects to provide the functionality themselves (contrary to COM’s IDispatch interface).
Type information can be obtained and manipulated programmatically using System.Type, which can be considered the managed equivalent of COM’s ITypeInfo interface. The other classes and interfaces that are used to access type information live in the System.Reflection namespace.
Identity
It’s important to give a unique identity to classes and interfaces that you share with others. You could name a component “Brad’s Super-Fast Hashtable” and be reasonably sure that your users will never install another application that exposes something with the same name. However, there are probably a good number of software developers named Brad, and someday one of those people might ship a component with this exact name. COM and the .NET Framework have two different methods of providing developers with an easy way to give their components and types unique names.
In COM, classes and interfaces have human friendly names such as WebBrowser and ISupportErrorInfo, but their real names are 128-bit numbers known as UUIDs (Universally Unique Identifiers) or more often GUIDs (Globally Unique Identifiers) since it’s easier to pronounce. To make GUIDs as readable as possible (which isn’t easy for a 128-bit number!), they are typically shown in a segmented hexadecimal format known as registry format:
ECEBEC7C-C62F-4279-85E7-B799BACAA24A
COM developers can generate GUIDs using the CoCreateGuid API in OLE32.LIB to generate a number that, with a very high degree of certainty, is a unique value. Prior to Windows 2000, the CoCreateGuid algorithm used the current date and time plus the MAC address of the computer’s network card to generate the value. Nowadays, GUID generation is based on a cryptographic pseudo-random number generator. Rather than calling CoCreateGuid directly, developers often use the GUIDGEN.EXE graphical utility or the UUIDGEN.EXE command-line utility (which ship with the Windows Platform SDK), or they rely on Visual Studio to automatically generate GUIDs in COM-related projects.
GUIDs are given many other names, depending on what they are describing. These names are
• CLSID (Class Identifier)—Identifies a class
• IID (Interface Identifier)—Identifies an interface
• LIBID (Library Identifier)—Identifies a type library
• AppID (Application Identifier)—Identifies an application (used by DCOM)
In all cases, these identifiers are nothing more than 128-bit GUIDs.
Thus, when a COM client requests an instance of the “Brad’s Super-Fast Hashtable” class, it calls COM’s standard instantiation method (CoCreateInstance) to request an instance of the class with a CLSID of ECEBEC7C-C62F-4279-85E7-B799BACAA24A. Because referring to types by these ugly GUIDs isn’t very human friendly, classes often have another identifier known as a ProgID (Programmatic Identifier). A ProgID is simply a string that contains a nice name, which should be unique if everyone follows recommended conventions, but there’s no guarantee of uniqueness. ProgIDs are commonly seen in Visual Basic 6 code when calling VB’s CreateObject method:
Dim o as Object
Set o = CreateObject("BradCo.SuperFastHashtable")
In the .NET Framework, there are no separate identifiers tacked onto types. A type is uniquely identified by its name (usually including a namespace) plus the identity of the assembly containing the type.
As explained in Chapter 1, an assembly is uniquely identified by a simple name, version, culture, and public key token. Thus, every single type has an associated version, culture, and public key token. The public key token is what ensures uniqueness. Whereas every other piece of assembly identity can easily conflict with other assemblies (much like with ProgIDs in COM), no two assemblies produced by different publishers should ever have the same public key token. As for conflicts between assembly or type names when the public key token is identical, it is the responsibility of the individual publisher that owns the public key to choose names wisely.
People often refer to a fully qualified type name as a name that includes its namespace; but the fully, fully qualified type name that guarantees uniqueness is called an assembly-qualified type name. Current .NET languages (excluding IL Assembler) don’t have syntax to declare assembly-qualified type names. The compilers find the assembly containing each type via referenced assemblies. (This means that you can’t declare and use two different type names that differ only in their assembly identities in the same compilation unit.) The relationship between fully qualified type names and assembly-qualified type names is reminiscent of the relationship between ProgIDs and CLSIDs. One noticeable difference is that the type names are the actual names rather than additional identifiers, and assembly identity is mostly human readable.
The following C# code demonstrates how to obtain a fully qualified name, as well as an assembly-qualified name, for a given type using System.Type’s AssemblyQualifiedName property:

This code gives the following output:
![]()
The format of an assembly-qualified name is TypeName, AssemblyName. As seen in the previous example, an assembly name is a comma-delimited list of its defining characteristics.
Locating Components
The identities for COM and .NET components contain no information about their physical location in the file system. A GUID is just a number, and an assembly name (although closely resembling a filename) is not a filename, nor does it provide location information. Thus, both COM and the .NET Framework have a mechanism for finding a component from a type’s identity.
COM components must be registered in the Windows Registry to be instantiated. The various identifiers described earlier can be listed under various keys of the HKEY_CLASSES_ROOT registry hive, as shown:

Rather than manually typing the appropriate registry entries, developers frequently use one of several tools available to register and unregister COM components. The most common means of registration and unregistration is the REGSVR32.EXE utility, described in the “Useful COM Utilities” section.
When a COM client wants to create an instance of a class by calling CoCreateInstance, COM checks the registry values under the key for the specified CLSID. These registry values tell COM the name and location of the executable or DLL that needs to be loaded to activate the class. Figure 2.2 shows typical registry entries found under a CLSID key.
Figure 2.2. Typical Windows Registry entries for a CLSID, displayed with REGEDIT.EXE.

Depending on the registry entries and on the client’s request, COM looks for the component one of the following ways:
• in the same process as the client (an inproc server)
• in an EXE running in a separate process (an outproc server)
• in an EXE running on a different machine (a remote server)
ProgIDs are stored in the Windows Registry as a means to look up the corresponding CLSID. This can be seen in Figure 2.3.
Figure 2.3. Typical Windows Registry entries for a ProgID.

Registered LIBIDs are used by Visual Basic 6 (and Visual Studio .NET) to provide a list of components that can be referenced in your project. The entries under the LIBID point to a file containing the type library, which is not necessarily the same file containing any implementation. In addition, interfaces are often registered with entries that point to special marshaling classes. These classes implement proxies that are used whenever interface pointers are marshaled across context boundaries. Chapter 6 describes these classes in more detail.
With all these registry entries (and more) pointing to files scattered around the file system, COM’s registration process is fairly brittle. If files are moved without updating the corresponding registry entries, programs break. It’s also easy to pollute the registry with entries for programs that no longer exist. I can’t tell you how many entries are in my computer’s registry for sample COM components that I’ve written and forgotten to unregister!
In the .NET Framework, the Windows Registry is not used for locating components. When a client needs to instantiate a class in a given assembly, the .NET Framework looks for the assembly in either the Global Assembly Cache (GAC), the local directory, or some other location specified by a configuration file. This means that if private applications don’t need to share components, they can simply place all the relevant files in the same directory, and everything works. This is refreshingly simple compared to COM, in which registration is always required.
When components need to be shared, they should be installed in the Global Assembly Cache. When COM programmers first hear this, they often think: Wait a minute! Isn’t this just the Windows Registry all over again? The answer is no. Just as the GAC is an improvement over a shared directory such as System32 for storing components, it’s also an improvement over the Windows Registry for locating components.
Type Compatibility
In the world of COM, programming languages have their own type systems and runtime environments. Communication between such components is accomplished through COM’s binary standard. It is this binary compatibility that enables COM to be language neutral. The downfall is that COM has its own type system—requiring either additional work for languages, or additional work for programmers, to transform data appropriately.
The .NET Framework isn’t considered a binary standard, but rather a type standard, because components communicate using the Common Language Runtime’s type system. Each .NET language’s type system is the CLR type system. This means that regardless of which managed language you use, a String is a String, an Object is an Object, and so on.
Versioning
Versioning is the process of evolving the contract exposed by a component. As future versions are released, you might want to add (or even remove/rename) members of classes, interfaces, and more. Making these changes without causing grief to your clients can be tricky, but the .NET Framework was designed with these needs in mind.
In COM, type libraries are associated with a two-part version number (Major.Minor). This allows for side-by-side versions of a type library to be listed in the registry. Figure 2.4 shows registry entries for multiple versions of the Visual Basic for Applications (VBA) type library (2.1, 4.0, 5.0, and 6.0).
Figure 2.4. Typical Windows Registry entries for multiple versions of the same type library.

There’s nothing very dynamic about type libraries and version numbers—this is just a way of organizing them. In fact, COM developers often assign brand new LIBIDs to later versions of the same component’s type library.
ProgIDs also have a versioning scheme. There are actually two types of ProgIDs: version-dependent and version-independent. Version-dependent ProgIDs look just like version-independent ProgIDs with an extra period and a version number. Clients can use a version-dependent ProgID (if it exists) to obtain a specific version, or use the version-independent ProgID to get the current version, as defined by a key in the registry. In Visual Basic 6 code, this looks like the following:
' Give me the current version of the Word.Application object
Set o = CreateObject("Word.Application")
' Give me version 8
Set o = CreateObject("Word.Application.8")
' Give me version 9
Set o = CreateObject("Word.Application.9")
Figure 2.5 shows how multiple ProgIDs are organized in the registry.
Figure 2.5. Typical Windows Registry entries for version-dependent and version-independent ProgIDs.

Versioning does not apply to a COM interface. Interfaces, when defined, must always stay the same. Removing or changing members obviously breaks clients that invoke or implement such members. Adding members breaks clients that implement the interface. Therefore, any updates to an interface must be done to a new interface with a different IID, so it has a completely different identity as far as COM is concerned. As for coclasses, they can safely be modified to implement additional interfaces.
Unlike the situation in COM, versioning is one of the central themes of the .NET Framework. As you’ve seen in the preceding chapter, multiple versions of an assembly can live side-by-side in the Global Assembly Cache (much like multiple versions of a type library can live side-by-side in the registry). One big difference is that an administrator can specify a versioning policy on a machine-wide or application-by-application basis, deciding which applications should use which versions of components. Because of this, it’s fairly painless to install a new version of a shared .NET component, tell all your applications to switch to the new version, and roll back the change for any application that breaks because of unexpected incompatibilities.
Thanks to the dynamic binding performed by the Common Language Runtime, classes can add and rearrange members without breaking clients. Interfaces still can’t be changed without breaking clients, although an interface’s members can safely be rearranged (unlike interfaces in COM).
Type Safety
Type-safe code, as defined in .NET Framework documentation, is well-behaved code that can only access memory it is allowed to access. Unmanaged code is not type safe, and there are no general mechanisms to prove that unmanaged code never accesses memory it shouldn’t inside a given process. Managed code, on the other hand, is often type safe. As mentioned in the preceding chapter, the .NET Framework security system is capable of giving code guaranteed to be type safe a higher level of trust. For example, type safety is the key to carefully executing downloaded code—ensuring that malicious activity cannot be performed by playing tricks with memory. Besides preventing malicious activity, type safety in programming languages can increase developer productivity by catching a broader class of bogus operations at compile time rather than run time.
Error Handling
Reporting and receiving errors is a programming fact of life. COM and the .NET Framework have standard methods of reporting errors, and these methods are significantly different.
The COM way of error handling is checking integral status codes, called HRESULTs (also called SCODEs in “ancient” times), returned by members. These status codes are 32 bits long and segmented into 4 portions, detailed in the following list:
• The most significant bit is called the severity bit. Failure is indicated by a “1” and success or a non-fatal warning is indicated by a “0”.
• There are 4 reserved bits following the severity bit.
• Next, there are 11 bits comprising the facility code, which represents the source responsible for the failure. The facility code acts like a category that determines the meaning of the remaining bits.
• The remaining 16 bits describe the warning or error.
HRESULT values are typically called failure HRESULTs or success HRESULTs based on the value of the severity bit. Components that define new HRESULTs should document them so that clients can interpret the codes they might receive.
A proper unmanaged C++ client should check the value of the returned HRESULT after every method call, which can be cumbersome. On the other hand, Visual Basic 6 provides a nice abstraction for an HRESULT in its global Err object. When a failure HRESULT is returned, Visual Basic 6 raises an error, eliminating the need to check for failure after every action. Another nice thing about the Err object is that it has several properties (such as Description), which can give user-friendly information about the cause of the error rather than just a cryptic number. This extra information, when available, can also be obtained in unmanaged C++ via the IErrorInfo interface, demonstrated in Chapter 8, “The Essentials for Using .NET Components from COM.” Checking to see if COM objects support this interface and using this extra information is significantly more work than simply checking the HRESULT value, so C++ clients often don’t bother and instead suffer with the lack of rich error information.
In the .NET Framework, on the other hand, errors are communicated to clients via exceptions. Of course, nothing prevents a die-hard HRESULT fan from returning error codes rather than throwing exceptions in methods that he defines and implements. Typically, this is not done, however, due to the ease and built-in support for throwing and catching exceptions. There is no standard mechanism for the same kind of nonerror notifications that success HRESULTs provide in COM.
The great thing about exceptions is that rich error information is easy to obtain. Like VB6’s Err object, exceptions contain many properties, which in turn contain the extra information. Unlike the Err object, however, exceptions are extensible. By deriving from System.Exception, you can define your own exception class with any number of properties, methods, and so forth. Another great aspect of exception handling is that different types of errors are distinguished by the type name of the exception object (something human readable, such as System.OutOfMemoryException), instead of an error code. The one unfortunate aspect of exceptions is that throwing one is expensive in terms of performance. As the name implies, they should be reserved for exceptional situations. Thus, managed APIs often indicate failure by returning a null object where a valid instance is expected. An example of this is the System.Type.GetType method. If this method can’t obtain the type specified in the string parameter, it fails by returning a null Type. (If you don’t like this behavior, it also has an overload with a boolean throwOnError parameter that makes it throw an exception to indicate failure instead.) Another example is C#’s as keyword, which (besides confusing VB programmers who use As completely differently) enables you to perform a cast operation and not throw an InvalidCastException on failure. Instead, failure causes the target object to be null.
Object Lifetime
The lifetime of an object refers to the time it remains in memory—from creation to destruction. The rules of object lifetime are another major difference between COM and the .NET Framework.
In COM, an object is responsible for managing its own lifetime and determining when to delete itself. An object is able to determine this through its reference count. Because all objects must implement the IUnknown interface, clients of any COM object call IUnknown.AddRef to increment the reference count when obtaining an interface pointer. Likewise, clients call IUnknown.Release to decrement the reference count when finished with an interface pointer. When the object’s reference count reaches zero, it is free to self-destruct. Because an object is typically destroyed as soon as a user is finished with it, COM objects are typically written to release any resources at the time of destruction (such as files or database connections).
Because Visual Basic 6 hides IUnknown and its methods from programmers, the Visual Basic runtime handles reference counting for you, based on the scope of the variable containing an interface pointer. If waiting for Visual Basic to call IUnknown.Release is problematic, you can tell VB to call it at a specific time by setting the object’s reference equal to Nothing.
In the .NET Framework, programmers no longer need to perform the mundane and error-prone task of reference counting, nor do they need to deal with the hard problems it can cause (such as breaking cycles). That’s because the .NET Framework uses garbage collection to manage object lifetime. Rather than requiring each object to maintain a reference count and destroy itself, the Common Language Runtime tracks the usage of an object and frees it when it is no longer in use. The important difference, of course, is that the object isn’t always freed as soon as the last client is finished using it. It’s freed at some undetermined point afterward when the garbage (i.e. memory) is collected. This means that setting an object reference equal to Nothing in VB .NET no longer immediately releases the object, as it did in VB6.
Because an object might not be released soon after a client is finished with it, the practice of releasing resources at destruction time is not a good idea in the .NET Framework. Instead, resource-holding classes typically implement System.IDisposable, which has a Dispose method that clients should call explicitly when finished with the object. Such classes also typically call Dispose in their finalizers (just in case the user forgot to call it).
How COM Interoperability Works
You’ve now seen the multitude of differences in the details of these two technologies, and might be wondering how COM Interoperability is able to bridge these two worlds. The answer lies in wrapper objects, which give COM objects the illusion that they’re interacting with other COM objects and give .NET objects the illusion that they’re interacting with other .NET objects. A wrapper object produced for a COM object and consumed by .NET clients is called a Runtime-Callable Wrapper (RCW), where runtime refers to the Common Language Runtime. The wrapper object produced for a .NET object and consumed by COM clients is called a COM-Callable Wrapper (CCW).
To maintain object identity, each COM instance is wrapped by a single RCW, and each .NET instance is wrapped by a single CCW. These wrappers are responsible for handling the transitions between COM and .NET (such as data marshaling, exception handling, object lifetime, and much more). Most of the time, all this works without additional coding. You can create an instance of a wrapper using familiar object-creation syntax, and the wrapper internally creates the real object. You can call members on a wrapper and the real object’s members get called appropriately. The .NET Framework SDK provides utilities that generate type information for the wrappers (either a type library describing CCWs, or an assembly with metadata describing RCWs) and a utility that handles registration of either kind of wrappers. These utilities are discussed throughout the book, and listed in Appendix B, “SDK Tools Reference.” Let’s now take a closer look at these two types of wrappers.
Runtime-Callable Wrapper (RCW)
When using a COM object in managed code, you aren’t talking to the object directly. Instead, you’re interacting with an RCW. An RCW acts as a proxy to the COM object, and looks just like any other .NET object. The wrapper forwards calls to the original object through its exposed interfaces. This enables managed code to be written that uses COM objects in a seamless way, as pictured in Figure 2.6. In this figure, you can see that IUnknown and IDispatch are not exposed to the .NET clients. The result is that these clients never need to know about the COM way of reference counting and late binding. They can stick to the world of garbage collection and reflection that they’re used to.
Figure 2.6. .NET clients calling methods on a wrapper object that hides the complexity of COM.
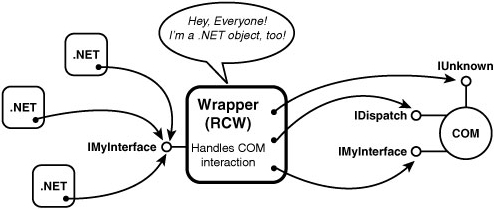
The bridging of data marshaling, exception handling, and more is covered in subsequent chapters. Right now let’s look at how object lifetime is handled when the two worlds interact. To prevent managed clients of a COM object from engaging in reference counting, an RCW’s lifetime is controlled by garbage collection (just like any other managed object). Each RCW caches interface pointers for the COM object it wraps, and internally performs reference counting on these interface pointers. When an RCW is collected, its finalizer calls IUnknown.Release on all its cached interface pointers. Thus, a COM object is guaranteed to be alive as long as its RCW is alive. The .NET Framework also provides an API that can be used to force the Release calls at a specific time, rather than waiting for garbage collection to occur. This is described in the following chapter.
If the RCW has associated metadata available, the RCW looks much like the original coclass. It has a similar type name and contains members of its implemented interfaces. But if no metadata exists for an RCW, it looks like a generic RCW type with the odd name System.__ComObject (an internal class in the mscorlib assembly). Chapter 6, “Advanced Topics for Using COM Components,” contains more information about how this happens and what you can do about it.
COM-Callable Wrapper (CCW)
When using a .NET object in COM, you aren’t talking to the object directly. Instead, you’re interacting with a CCW. A CCW acts as a proxy to the managed object and looks just like any other COM object. The wrapper forwards calls to the original object through its exposed members. This enables managed components to be written that can plug into existing COM applications that don’t know anything about .NET, as pictured in Figure 2.7. In this figure, you can see that a CCW implements standard COM interfaces such as IDispatch, IProvideClassInfo, and many more (besides the required IUnknown interface). The result is that the objects are easier to use for COM clients that take advantage of these interfaces.
Figure 2.7. COM clients calling methods on a wrapper object that looks just like another COM object.

Again, focusing on object lifetime, the CCW is not a managed class and thus is not controlled by garbage collection. It is reference counted just like any other COM object. Each CCW holds a reference to the .NET object it wraps. When the CCW’s reference count reaches zero, it destroys itself and releases the inner reference, making the managed object eligible for garbage collection. Thus, a .NET object is guaranteed to be alive as long as its CCW is alive.
Everything that a .NET component exposes to .NET clients might not be available to COM clients. Besides the fact that certain functionality is always off-limits to COM clients (such as parameterized constructors), authors of .NET components can pick and choose any subset of functionality to make off-limits for COM clients. This is discussed further in Part III, “Using .NET Components in COM Applications,” but the short story is that the usefulness of a CCW varies greatly depending on the design of the .NET component.
Unmanaged Code Isn’t Always the Answer
Although interaction with unmanaged code can work fairly seamlessly, in this book you see that it’s not always as easy as interaction with managed code. Besides trickier deployment, security constraints, and possible performance penalties; APIs that were designed specifically for the pre-.NET environment don’t always work as cleanly in the managed world. Thus, keep in mind that managed APIs might already exist for the functionality provided by COM components you want to use. The downside is that there’s usually a learning curve for any new APIs. The choice is yours, thanks to unmanaged code interoperability. If you don’t want to learn the new data access model in the .NET Framework, go ahead and use the exact same ADO model you’re familiar with. Table 2.1 (which is by no means an exhaustive list) displays some commonly used unmanaged technologies, along with the namespaces and physical modules (each of which happens to be a single-file assembly) containing .NET APIs with similar functionality.
Table 2.1. Some Common Unmanaged Technologies, and Where to Find Managed APIs with Similar Functionality

Conclusion
This chapter ends Part I, “Background,” with an overview of how unmanaged code can be utilized in the .NET Framework and the importance of this interaction. After all, without the capability to interact with unmanaged code, it’s unlikely that the .NET Framework would catch on very quickly. Again, the technologies enabling this are:
• Platform Invocation Services (PInvoke)
• Mixed-Mode Programming Using Managed Extensions to C++
• Java User Migration Path to .NET (JUMP to .NET)
• COM Interoperability
You should now understand the main ways in which COM differs from the .NET Framework, and how wrappers are used to bridge these differences.
The following chapter begins Part II, “Using COM Components in .NET Applications,” which delves into the specifics of using COM objects in managed code. Because Visual Basic 6 hides many details of COM, the way managed code is written to interact with COM components is similar to the way VB6 code is written. Due to underlying differences (such as garbage collection versus reference counting), however, the similar syntax can be misleading. Programmers need to learn some new tricks to use COM objects effectively, and that’s what Part II of this book is all about.