
Chapter 16. COM Design Guidelines for Components Used by .NET Clients
In This Chapter
• General Guidelines
• Using Array Parameters
• Issues with VARIANT Parameters
• Reporting Errors
• Adjusting Certain COM-Specific Idioms
• Managing Limited Resources
• Threading and Apartment Guidelines
• Providing Self-Describing Type Information
• Naming Guidelines
• Performance Considerations
This chapter focuses on developing new software using COM. With the arrival of .NET, the recommendations for designing COM APIs have changed, assuming you care about .NET clients using your COM components (either now or in the future). Most existing COM components have a disadvantage of being designed before .NET existed, so their authors did not know what COM Interoperability handles well and what it doesn’t. Today, however, it would be foolish to design new COM components or add new functionality to existing COM components without considering how this functionality gets exposed to .NET.
Don’t worry too much if you must use a technique that conflicts with the guidelines in this chapter. These guidelines point out what works best so you can avoid a suboptimal design when you have no constraints. (Although, if you have no constraints, why are you developing the new object as a COM object rather than a .NET object?) Many of the techniques advised against can still work for .NET clients—it just may involve extra work on your behalf in customizing your Primary Interop Assembly, or extra work for clients attempting to work around the quirks of your APIs.
Many of the IDL and type library guidelines given in the previous chapter apply to new COM applications as well, so you should refer to the previous chapter as well as this one when designing new COM components.
General Guidelines
Before examining a few major areas in detail, here’s a laundry list of guidelines that you should follow when designing COM objects that will work well for .NET clients. The effects of not following these guidelines were examined in Part II.
• Don’t define a struct with a SAFEARRAY field because the Interop Marshaler doesn’t support it.
• Don’t define a struct with a VARIANT_BOOL field because the type library importer transforms it into a 16-bit integer, unless you plan on manually modifying the corresponding metadata.
• Don’t use struct parameters in a dispinterface method (such as a source interface), because it necessitates late binding and structs passed inside VARIANTs aren’t automatically supported.
• Don’t use parameter types that lose their meaning in a type library, such as the Win32 BOOL type.
• Don’t define properties with both a Let and a Set accessor (propput and propputref) because this doesn’t transform naturally into properties supported by .NET languages.
• Avoid typedefs of primitive types, because they don’t naturally translate to metadata.
• Avoid optional parameters because C# clients can’t treat them as optional. Unfortunately, overloaded methods aren’t an alternative in COM.
• Use dual interfaces wherever possible because they match the .NET expectations of being able to early bind or late bind, and because Type.InvokeMember doesn’t work without an underlying IDispatch implementation—even if invoking on a strongly-typed Runtime-Callable Wrapper (RCW).
• Avoid unions, especially if they contain types that become reference types in .NET (such as BSTR or VARIANT) because the type library importer can’t import them naturally.
• As when creating COM components for use by Visual Basic 6, it’s best when a coclass lists a single implemented interface and single source interface. Although multiples of either can work without problems for .NET clients, it can cause name collisions when multiple interface members are added to the class type, and it causes .NET clients to cast to the non-intuitive importer-generated event interfaces when hooking up event handlers to non-default source interfaces.
• Expose events in the natural COM way (using connection points) and expose enumerators in the natural COM way (using DISPID_NEWENUM and IEnumVARIANT) because they are both mapped naturally to .NET events and .NET enumeration functionality.
Using Array Parameters
Arrays are often used as COM parameters, and there are many different options for expressing them. The guidelines for defining array parameters that work well for .NET clients can be summarized in once sentence: Use single-dimensional SAFEARRAYs with a lower bound of zero. Let’s discuss the three different parts of this recommendation:
• Use SAFEARRAYs
• Use Zero Lower Bounds
• Use Single-Dimensional Arrays
Use SAFEARRAYs
When exposing array parameters, you should stick to SAFEARRAYs (normal arrays in Visual Basic 6). C-style arrays don’t get imported as arrays because they look like simple pointers in a type library without any size_is information. So, the following transformation occurs:
IDL:
HRESULT SetBytes(
[in, size_is(dwDataInLen)] byte *pbDataIn, [in] long dwDataInLen);
![]()
C# Representation of Imported Method:
public void SetBytes([In] ref byte pbDataIn, [In] int dwDataInLen);
This is unusable from managed code unless the user wants to pass a single element. As you saw in Chapter 7, “Modifying Interop Assemblies,” the .NET signature can be (and should be) hand-tuned to be marshaled as an array instead:
public void SetBytes([MarshalAs(UnmanagedType.LPArray, SizeParamIndex=1)]
byte [] pbDataIn, int dwDataInLen);
However, having to pass an array’s length as a separate parameter still looks bizarre to .NET clients because .NET arrays are self-describing. The Interop Marshaler doesn’t use the dwDataInLen length parameter when marshaling the array from managed code to unmanaged code; it decides how many elements need to be marshaled by checking the array’s Length property. The length parameter (and the SizeParamIndex marking) is needed when marshaling from unmanaged code to managed code, as is the case if a .NET object implements a COM interface with such a method.
Had the COM method used a SAFEARRAY instead:
HRESULT SetBytes([in] SAFEARRAY(byte) bytes);
then the .NET signature would look natural in managed code:
public void SetBytes(byte [] bytes);
SAFEARRAYs can be much more difficult to use in unmanaged C++ code, but it spares you from having to modify the Interop Assembly produced by the type library importer. Having the importer do the right thing automatically saves a lot of effort, especially for an ever-changing type library under development.
For by-reference or out-only array parameters, defining an array as a C-style array makes its use even harder for .NET clients. The Interop Marshaler would need to know the rank and size of the array in order to marshal it to managed code, yet using MarshalAsAttribute’s SizeParamIndex and SizeConst values are not supported for anything other than by-value arrays and by-value length parameters. This means that an IDL signature such as:
HRESULT GetBytes(
[out, size_is(dwDataInLen)] byte **ppbDataOut, [out] long* dwDataOutLen);
![]()
would be translated by the type library importer into the following .NET signature (shown in C#):
public void GetBytes(IntPtr ppbDataOut, out int dwDataOutLen);
Then, as shown in Chapter 7, you’d likely want to change the signature to:
public void GetBytes(out IntPtr ppbDataOut, out int dwDataOutLen);
so that a client can process the array data using methods of the System.Runtime.InteropServices.Marshal class. Defining the COM method to return a SAFEARRAY instead:
HRESULT GetBytes([out, retval] SAFEARRAY(byte)* bytes);
would naturally produce a usable .NET signature:
public byte [] GetBytes();
Use Zero Lower Bounds
If you have a choice, always choose zero-bounded arrays. Choosing a bound other than zero means that the array can only ever be used as a System.Array type in managed code. The result is that clients must access its elements using the Array.GetValue and Array.SetValue methods that are much more awkward than using array indexing syntax. Also, .NET clients can only create instances of arrays with non-zero lower bounds using the Array.CreateInstance method. Using TLBIMP.EXE’s /sysarray option (used by Visual Studio .NET by default) imports all array parameters as System.Array types rather than single-dimensional zero-lower-bound arrays, in case you already use non-zero based arrays and it’s too difficult to change them.
Use Single-Dimensional Arrays
Prefer single-dimensional arrays over multi-dimensional because the type library importer automatically treats SAFEARRAYs as single-dimensional (when not using the /sysarray option).
For example, rather than exposing a method that requires a list of paired strings (such as an employee name with his or her social security number):
HRESULT GetEmployeeList([out, retval] SAFEARRAY(BSTR)* employees);
consider splitting the array into two one-dimensional arrays:
HRESULT GetEmployeeList([out] SAFEARRAY(BSTR)* employeeNames,
[out] SAFEARRAY(BSTR)* employeeNumbers);
Of course, this is not feasible for larger arrays or arrays with more dimensions.
If you must expose a multi-dimensional array, you have two options to properly expose it to .NET clients:
• Use TLBIMP.EXE’s /sysarray option to expose array parameters as System.Array types. If your array parameter doesn’t have a fixed rank (in other words, it’s sometimes a two-dimensional array and other times a three-dimensional array), this is the only option.
• Use the techniques discussed in Chapter 7 to change the array parameter in the .NET signature to be multi-dimensional. This only works for array parameters with a fixed rank.
Issues with VARIANT Parameters
Care should be used when exposing VARIANT parameters. Ask yourself why you aren’t defining the VARIANT as a more specific type. Exposing VARIANT parameters is fine as long as you don’t expect users to pass a type such as CURRENCY or a user-defined structure. For CURRENCY, .NET clients must use the non-intuitive CurrencyWrapper type. For user-defined structures, .NET clients must use a variety of workarounds, as seen in Chapter 6, “Advanced Topics for Using COM Components,” since the Interop Marshaler doesn’t support them inside VARIANTs.
For Visual Basic 6 COM components, don’t use public VARIANT fields because they get exposed as properties with all three accessors. Use a property instead or a more specific data type.
For C++ COM components manually inspecting the vt field of a passed-in VARIANT, you should be as lenient as possible when determining what is a legal value. For example, if you’re expecting an interface pointer inside the VARIANT, don’t check to see whether the type is VT_UNKNOWN and report an error if it is not. Most .NET objects appear as VT_DISPATCH when passed inside a VARIANT, so your code should be prepared to expect that type as well. In addition, don’t require the VT_BYREF flag to be set if it’s not necessary, because it can be difficult for .NET callers to set this flag. See Chapter 3, “The Essentials for Using COM in Managed Code,” for more details about how .NET types are exposed as VARIANTs to COM.
Reporting Errors
With any software, good error reporting is critical to keeping the frustration level of your consumers (and often yourself) low. Understanding how COM errors are converted to .NET errors is critical so your COM components can take advantage of this transformation.
As described in Chapter 3, when a COM member returns a failure HRESULT value, the CLR throws a .NET exception on the COM component’s behalf. The exception type depends on the HRESULT value, according to the table shown in Appendix C, “HRESULT to .NET Exception Transformations.” Any HRESULT values not in this list become a user-unfriendly COMException type.
There are three guidelines to keep in mind when reporting errors from COM:
• Reserve Failure HRESULTs for Exceptional Circumstances
• Don’t Use Success HRESULTs Other than S_OK
• Set Additional Error Information
All three of these guidelines were already considered good practice for COM components that may be used from Visual Basic 6, so hopefully your existing COM components follow them anyway.
Tip
There are two more guidelines worth mentioning, both of which also apply when .NET isn’t in the picture. The first is to document all your HRESULTs clearly in your help files. This includes documenting every HRESULT that every member might return. The second is to never return an HRESULT with the value E_FAIL. This value is too generic to convey meaningful information to the caller.
Reserve Failure HRESULTs for Exceptional Circumstances
In COM, there’s no performance penalty inherent to returning a failure HRESULT value; regardless of success or failure, a 32-bit integer is returned to the caller. When .NET clients are involved, however, the transformation from returning a failure HRESULT to throwing a .NET exception incurs a significant performance penalty that is inherent to throwing an exception. This is similar to returning a failure HRESULT value to a Visual Basic 6 client; the VB6 runtime does more work to raise an error, therefore making failures slightly slower than successes. The difference in performance between error versus no error is much greater in .NET however. Exception handling is optimized such that .NET clients that are prepared to handle exceptions incur almost no performance penalty for the common case of no exception being thrown.
Therefore, the same .NET design guideline of “reserve exceptions for exceptional situations” applies to failure HRESULTs. Only return failure HRESULTs (or, in Visual Basic 6, only raise an error) in important and sufficiently rare cases. Don’t use different failure values to signal different program states that are useful in normal program operation.
Don’t Return Success HRESULTs Other than S_OK
This section doesn’t apply to COM members implemented in Visual Basic 6, because they cannot return success HRESULT values.
You’ve seen in Part II how much of a nuisance a COM component can be in .NET if it returns multiple success HRESULTs that need to be seen by the client. Because any success HRESULT values (values for which the most significant bit is not set) are swallowed by the Runtime-Callable Wrapper, the values are unattainable from .NET clients unless the managed signature corresponding to the member returning the HRESULT is marked with the PreserveSigAttribute pseudo-custom attribute.
Technically, it doesn’t matter which success HRESULT you return, just so you don’t require that the caller needs the ability to distinguish between different success HRESULT values. The S_OK HRESULT (with value 0), however, is the conventional success HRESULT that should always be used for success to avoid potential confusion for any COM clients.
You might now be saying to yourself, “I’m not supposed to use failure HRESULTs in non-exceptional situations, and I’m never supposed to use multiple success HRESULTs, so how can I communicate informational status?” You should use an [out, retval] parameter (or in Visual Basic 6, a return type) that’s a boolean value or an enumeration value instead. Save the “real” HRESULT return value for exception transport only.
Set Additional Error Information
There’s not much that’s more annoying than using a COM object in a .NET program and seeing an exception thrown with the message, “Exception from HRESULT: 0x80090324.” To spare your users from this aggravation, you should always set additional error information when returning a failure HRESULT in unmanaged C++ or raising an error in Visual Basic 6. If nothing else, set a descriptive message.
To make exceptions caused by failure HRESULTs more user-friendly, the CLR fills in an exception’s properties with data from a COM error object if one exists. An error object implements the IErrorInfo COM interface, and the mechanism for making it available to clients such as the CLR is discussed in the following sections. If no error object has been made available by the COM member, the resultant exception contains less helpful information.
The following text summarizes how the CLR fills in an exception object’s properties:
• Message—The string returned from IErrorInfo.GetDescription (Err.Description in VB6). If no error object is available, the CLR attempts to use the FormatMessage Windows API to see if the operating system recognizes the HRESULT and returns a descriptive message. Otherwise, the message is the generic “Exception from HRESULT: HRESULT displayed in hexadecimal.”
• ErrorCode—The failure HRESULT value.
• Source—The string returned from IErrorInfo.GetSource (Err.Source in VB6). If no error object is available, then the string is either set to the name of the Interop Assembly defining the RCW that threw the exception, or an empty string if the RCW is System.__ComObject.
• TargetSite—A System.Reflection.MethodBase instance that corresponds to the method (or property accessor) that returned the failure HRESULT. More precisely, it’s the top-most member in the call stack with a .NET definition (which could be Type.InvokeMember when late-binding to a COM component with no metadata).
• StackTrace—Because there’s no stack information for the COM component, the bottom of the stack trace is the method where the exception is caught, and the top is the call into unmanaged code (the same member corresponding to the TargetSite property). Even if the failure HRESULT returned from the COM object originated as an exception thrown from a .NET object (managed code calling into COM which calls into managed code), the top of the stack trace is still the first transition into unmanaged code.
• InnerException—The IErrorInfo interface doesn’t have the notion of an “inner error,” so this property is null (Nothing in VB .NET). If the failure HRESULT returned from the COM object originated as an exception thrown from a .NET object, the InnerException property is set to the original exception’s InnerException object.
• HelpLink—The string returned from IErrorInfo.GetHelpFile (Err.HelpFile in VB6), or an empty string if no error object is available. If IErrorInfo.GetHelpContext returns a non-zero number, a “#” symbol and this number are appended to the end of the HelpLink string, because in .NET the HelpLink is supposed to represent a URL, and in COM the HelpContext is supposed to represent a section of the HelpFile.
The mechanism for setting this additional error information is different in unmanaged C++ than in Visual Basic 6, and, of course, the Visual Basic mechanism is much easier to use. Each of these mechanisms is discussed in more detail in the following sections.
Setting Additional Error Information in Visual Basic 6
Returning an error without any additional information is done as follows in Visual Basic 6:
Err.Raise 5640
If a member that raised this error were called by a .NET client, it would receive the following exception:
System.Runtime.InteropServices.COMException (0x800A1608): Application-defined or object-defined error
at Project1.Class1Class.FindUser(String name)
at client.Main()
Notice that the message isn’t the default “Exception from HRESULT” message. That’s because the Visual Basic 6 runtime always makes a COM error object available and sets “Application-defined or object-defined error” as its default message for any error codes it doesn’t recognize.
Adding the additional information is simply a matter of passing values for Err.Raise’s optional parameters. These are, in order, Source, Description, HelpFile, HelpContext, and can be set as follows:
Err.Raise 5640, "My Component", _
"The name 'Sue' does not match any existing records.", _
"http://www.samspublishing.com/help.html", 44444
This would result in a .NET exception thrown that looks like the following, which is much more helpful than in the previous case:
System.Runtime.InteropServices.COMException (0x800A1608): The name 'Sue' does not match any existing records.
at Project1.Class1Class.FindUser(String name)
at Client.Main()
Setting Additional Error Information in Unmanaged Visual C++
Setting additional error information in unmanaged Visual C++ is significantly more involved than in Visual Basic 6, and requires dealing with the IErrorInfo interface directly. First, any COM object that wants to return additional error information via IErrorInfo must implement the ISupportErrorInfo interface. This interface is used by the CLR (as well as other COM clients) to determine whether or not to bother attempting to retrieve an error object via the GetLastError Windows API.
As discussed in Chapter 14, “Implementing COM Interfaces for Binary Compatibility,” ISupportErrorInfo has a single method—InterfaceSupportsErrorInfo—with a single parameter containing an IID. This method’s implementation must return S_OK if the interface identified by the passed-in IID uses IErrorInfo to report additional error information, or S_FALSE otherwise. All COM classes authored in Visual Basic 6 implicitly have an implementation of ISupportErrorInfo that returns S_OK from InterfaceSupportsErrorInfo for any interfaces implemented by the class.
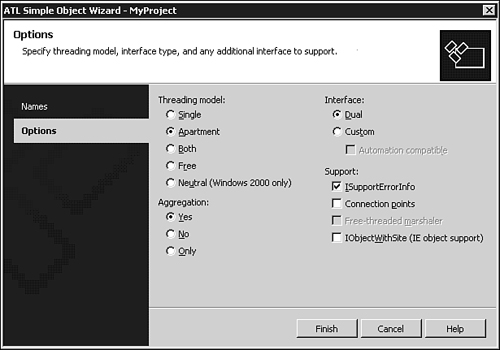
When using the Visual C++ 6 ATL COM Wizard to create a COM object, it does not implement ISupportErrorInfo by default. However, by checking the Support ISupportErrorInfo check box on the Attributes tab, an appropriate implementation is filled in by the wizard. This is pictured in Figure 16.1. Using the Visual C++ .NET ATL Simple Object Wizard, you can check the ISupportErrorInfo check box to enable the same behavior. This is pictured in Figure 16.2.
Figure 16.1. Telling the Visual C++ 6 ATL COM Wizard to generate an implementation of ISupportErrorInfo.

Figure 16.2. Telling the Visual C++ .NET ATL Simple Object Wizard to generate an implementation of ISupportErrorInfo.
The filled-in implementation of ISupportErrorInfo.InterfaceSupportsErrorInfo looks like the following (in Visual C++ 6), returning S_OK for every interface whose IID is listed in the arr array:
STDMETHODIMP CMyObject::InterfaceSupportsErrorInfo(REFIID riid)
{
static const IID* arr[] =
{
&IID_IMyObject
...other interfaces implemented by the class
};
for (int i=0; i < sizeof(arr) / sizeof(arr[0]); i++)
{
if (InlineIsEqualGUID(*arr[i],riid))
return S_OK;
}
return S_FALSE;
}
Caution
Don’t forget to make your COM objects implement ISupportErrorInfo and ensure that all the necessary IIDs are accounted for in the InterfaceSupportsErrorInfo implementation. Otherwise, any effort spent setting rich error information will be ignored by the CLR and not visible to .NET users.
The code in Listing 16.1, when used by a COM object that appropriately implements ISupportErrorInfo, has the exact same result as the following Visual Basic 6 code from the previous section:
Err.Raise 5640, "My Component", _
"The name 'Sue' does not match any existing records.", _
"http://www.samspublishing.com/help.html", 44444
Listing 16.1. Unmanaged C++ Code That Sets Rich Error Information to be Used by the CLR When Constructing a .NET Exception

Lines 5–9 define the four aspects of the rich error information that we’ll be setting. The first step in setting this information is to obtain an object implementing ICreateErrorInfo. This is obtained in Line 11 by calling the CreateErrorInfo Windows API. CreateErrorInfo can return E_OUTOFMEMORY if there’s not enough memory to allocate an error object, but if the call succeeds, Lines 14–17 call the methods of ICreateErrorInfo to set the information initialized in Lines 5–9.
ICreateErrorInfo has a method that’s not used in this code listing: SetGUID. This is skipped because an error object’s GUID value is not used by the CLR when constructing a .NET exception; there’s no corresponding property in a .NET exception. Because COM clients may use an error object’s GUID value to interpret HRESULTs in an interface-specific yet object-independent manner, a proper COM object should call ICreateErrorInfo.SetGUID.
After setting the error information, Line 19 queries for the IErrorInfo interface from the error object. This is the interface type that we must pass to the SetErrorInfo Windows API on Line 22. Its first parameter is reserved and must always be set to zero, and the second parameter is the IErrorInfo type. After releasing the two interface pointers in Lines 23 and 26, the only thing left to do is to return the failure HRESULT. Notice that the code is structured such that if the process of setting rich error information fails, we silently fall back to simply returning the HRESULT. This is desirable so the client can see the original error rather than getting confused by an HRESULT that doesn’t directly apply to the original error we’re trying to communicate to the user.
Adjusting Certain COM-Specific Idioms
Just as defining a method with an array parameter and a length parameter looks unusual in .NET, there are other common idioms used in COM methods that betray their COM heritage when used in managed code. To provide as seamless of an experience as possible, this section outlines some minor changes that can be made to COM members to make them work more seamlessly for .NET clients (and still be reasonable to use from COM).
We’ll look at three common patterns:
• Passing a Pointer to Anything
• Passing Type Information
• Passing Error Information
Passing a Pointer to Anything
The following COM method, shown in IDL, uses a common pattern of returning an interface pointer that corresponds to a passed-in IID:
HRESULT GetSite(
[in] REFIID riid,
[out, iid_is(riid)] void **ppvObject
);
This gets imported as the following .NET signature (shown in C#), which is not very user-friendly:
void GetSite([In] ref Guid riid, IntPtr ppvObject);
If the item returned via the second parameter is always an interface pointer (as the IDL signature with iid_is implies) then the metadata can be legally changed so the second parameter is a System.Object marked with MarshalAs(UnmanagedType.Interface). However, the IDL source for the type library can also be changed instead, which is more maintainable. For example, GetSite could be changed to the following:
HRESULT GetSite(
[in] REFIID riid,
[out, retval, iid_is(riid)] IUnknown **ppvObject
);
Notice both changes—IUnknown** instead of void** and the addition of the retval attribute. Both of these have zero effect on the method’s implementation, but make a huge difference in the imported signature. The .NET signature for the updated GetSite would be (in C#):
[return:MarshalAs(UnmanagedType.IUnknown)] object GetSite([In] ref Guid riid);
The returned object could then be naturally cast to the desired interface.
Passing Type Information
Despite the changes made to GetSite in the previous section, the method still doesn’t look very .NET-like, does it? Even with our .NET-ifications to change the [out] to an [out, retval] and the void to IUnknown, the use of the method is still unnatural for .NET clients because of the GUID parameter. The point of this method is to enable clients to request an object implementing a certain interface. Because the interface is identified by a GUID, a .NET client would need code like the following to call this (in VB .NET):
Dim g As Guid = GetType(IDesired).GUID
Dim returnedObj As Object = obj.GetSite(g)
Ideally, .NET clients could use a Type instance directly, for example:
Dim returnedObj As Object = obj.GetSite(GetType(IDesired))
Such a method wouldn’t betray its COM roots as the existing GetSite definition does.
The GetSite definition could instead require a _Type interface as its first parameter (the class interface for System.Type), but using such a method from COM would be even more unnatural than using a GUID in .NET. Fortunately, the automatic bridging of the COM ITypeInfo interface and the .NET System.Type class provides a way to satisfy both COM and .NET clients simultaneously. The GetSite method can be defined as follows:
HRESULT GetSite(
[in] ITypeInfo* desiredType,
[out, retval] IUnknown** ppvObject
);
Such a method is imported as follows (shown in VB .NET syntax):
Public Function GetSite( _
<MarshalAs(UnmanagedType.CustomMarshaler, _
MarshalTypeRef:=GetType(TypeToTypeInfoMarshaler))> _
desiredType As Type) As <MarshalAs(UnmanagedType.IUnknown)> Object
Although the custom attributes clutter the definition almost to the point of unreadability, from a client’s perspective this signature is used no differently than a signature like:
Public Function GetSite(desiredType As Type) As Object
So .NET clients can use this definition of GetSite in a natural way. There’s some work to be done by the COM client that implements this method, however. Rather than getting an IID value directly, it now has to extract it from the ITypeInfo interface passed in by calling ITypeInfo.GetTypeAttr and checking the guid field of the returned TYPEATTR structure.
Also, be aware that whereas every COM interface has an IID, not every COM interface necessarily has a corresponding ITypeInfo implementation that describes it. But any interfaces defined in a type library do, so the client would likely want to ensure that all the interface types it expects are defined in a type library.
Passing Error Information
COM components sometimes pass error information as a parameter. For example, the Microsoft Direct Animation type library defines an IDASite interface with the following method (in IDL):
HRESULT ReportError([in] HRESULT hr, [in] BSTR ErrorText);
Such a method can be called fairly naturally from managed code with an exception object by using the ErrorWrapper type, for example (in C#):
obj.ReportError(new ErrorWrapper(myException), myException.Message);
Although passing an error as a parameter is kind of bizarre anyway, it would be more natural if the .NET client could simply pass the exception type rather than wrapping it with ErrorWrapper and extracting its message to pass as a separate parameter:
obj.ReportError(myException);
When a .NET exception object is exposed to COM, clients can successfully query for the IErrorInfo interface and get the error information in a way that’s natural for COM. However, if the parameter type were changed to IErrorInfo, it would be imported as a .NET IErrorInfo interface type rather than being transformed to an exception object. Using such a method from .NET would be pretty awkward. The client would have to define a class that implements IErrorInfo, instantiate it, then set its various properties with information (perhaps from an Exception object), then pass that.
On the other hand, if the parameter were defined as an IUnknown pointer, then the .NET client would be able to pass a .NET exception object (circumventing strong type checking because the parameter is just a System.Object) and the COM client can call QueryInterface to get an IErrorInfo pointer from the object. Such a method would look like the following:
HRESULT ReportError([in] IUnknown* errorInformation);
The IErrorInfo interface doesn’t contain an HRESULT value, however, so using it isn’t necessarily a suitable replacement for an HRESULT parameter.
Managing Limited Resources
Besides memory, COM objects often use other kinds of limited resources, such as database connections, Windows graphics objects, file handles, and so on. Because these system-wide resources can be scarce, components should ensure that they are released as soon as possible. In COM, releasing such resources is often done at the same time the object’s memory is released during object destruction.
This scheme of releasing resources on an object’s destruction works well in COM because objects can be deterministically destroyed when users are finished with them. In .NET, however, tying the use of a limited resource to an object’s lifetime does not work well. The .NET garbage collector decides when it’s time to free memory, and if there is an abundance of available memory on the computer, it can choose not to waste processor cycles on such a task.
From the standpoint of memory usage alone, it’s fine if memory isn’t freed immediately if there’s no demand for it. But by tying the release of other resources to the release of memory, you’re effectively marking some memory as more important than other memory in a way that the garbage collector doesn’t understand. That’s because garbage collection handles one type of resource for you—memory in a GC heap—but not any other types of resources. (The .NET garbage collector is also aware of the total amount of unmanaged memory being consumed on a computer, which can affect when collection occurs, but it cannot attribute the memory to individual COM objects.)
As demonstrated in Chapter 6, COM components that continue the practice of only releasing resources on destruction can cause quite a bit of subtle problems for .NET clients that aren’t familiar with garbage collection and its interactions with RCWs. The solution for this is to expose a method with a name like Close or Dispose that enables clients to dispose resources independently of the object’s lifetime. Besides adding such a method, this entails guarding any uses of these resources with a check that they’re still “alive” because the resources may have been destroyed while the object is still active. The class’s destructor can still release the resources, but only if they haven’t been released already (for example, a client forgot to call the Dispose method). This is the same design pattern used in .NET with IDisposable and a finalizer that releases resources if they haven’t been already.
Tip
The best way to expose a method that clients can call to free non-memory resources is to have the COM class implement the .NET IDisposable interface. This works well when freeing resources both in the implementation of IDisposable.Dispose and also in the object’s destructor if Dispose is never called, because COM clients that are oblivious to IDisposable can still use the object as it always has (releasing it immediately to dispose the resources) whereas .NET clients can naturally use the IDisposable interface (such as with the C# using construct).
Implementing .NET interfaces in COM is discussed and an example of implementing IDisposable is shown in Chapter 17.
If you don’t want to change your existing source code to add such an explicit disposing method, at least clearly document which classes encapsulate limited non-memory resources, and warn users if instances of these classes should be destroyed as soon as possible.
Threading and Apartment Guidelines
There are two basic guidelines regarding threading and apartments:
• Favor giving all COM objects the Both threading model, so they can run on either an STA or MTA thread.
• Follow the rules of COM.
Except for Visual Basic .NET programs, .NET programs run in a multithreaded apartment (MTA) by default (although Windows Forms applications are usually marked with the STAThreadAttribute so they run in an STA). COM objects that can’t be used from either type of thread can cause performance problems due to COM marshaling, or can impose restrictions for .NET clients if not all interfaces are marshalable. Web services always run in an MTA with no way to change the apartment state (other than manually starting a new thread), so STA COM objects can be particularly troublesome for them. Unfortunately, components authored in Visual Basic 6 don’t have a choice and are always STA components.
The second guideline, “follow the rules of COM,” should be a no-brainer. However, several COM components exist that don’t follow COM rules yet haven’t run into problems until being used from .NET applications due to forgiving COM clients. Such problems often arise in COM components authored in unmanaged C++ that are primarily used from Visual Basic 6.
For example, COM clients need to be able to handle the fact that they may be called from a different apartment. The previous chapter discussed the importance of registering an interface marshaler, whether you use type library marshaling or your own proxy/stub DLL. When registering your COM component, make sure that the threading model value accurately represents the COM component’s capabilities. COM components have been known to register themselves with the Both threading model value to get increased performance over using the Apartment value, but do not have the necessary logic to cope with multiple threads. This may work from clients running in an STA or clients running in an MTA that don’t use the objects in a multithreaded fashion, but can cause problems when used by .NET clients.
Caution
If your COM component is registered with the Both threading model value, you can count on the component being called on multiple threads when used from .NET. The Runtime-Callable Wrapper’s finalizer runs on a finalizer thread separate from the thread on which the object was created.
Providing Self-Describing Type Information
In some cases, the CLR doesn’t know the class type of a COM object when wrapping it in a Runtime-Callable Wrapper, so it must wrap it in the generic System.__ComObject type. For example, this can occur when a COM member returns an interface pointer to an anonymous COM object (when the interface type isn’t the coclass interface). .NET clients that use System.__ComObject instances run into the following difficulties:
• Confusion if examining the object’s type in a debugger or when printing the result of calling GetType.
• Inability to call members of the COM object using reflection unless using Type.InvokeMember. Reflecting on the type provides information about System.__ComObject rather than the expected COM type.
• Inability to cast the object to a COM class type.
To prevent these problems from happening, a COM object can implement the IProvideClassInfo interface to provide information about its class type. But the CLR can only get the class’s CLSID from IProvideClassInfo; not the .NET class type that should wrap the COM object. The way to give the CLR this information is to register your (Primary) Interop Assembly with REGASM.EXE. When doing this, the .NET class and assembly information is registered under the CLSID key in the registry. The CLR can then use this information to map a CLSID to the appropriate .NET class type.
Naming Guidelines
When designing new COM APIs, try to follow the .NET naming conventions discussed in the .NET Framework SDK documentation and touched on in Chapter 11, “.NET Design Guidelines for Components Used by COM Clients.” Failure to do so makes the APIs seem antiquated, and COM clients have little reason to complain about the .NET naming conventions. These include suggestions such as:
• Give public type and members pascal casing (PascalCasing) and parameters camel casing (camelCasing).
• Avoid abbreviations.
• Avoid expressing type information in parameter names. Instead, focus on the meaning (like using name instead of bstrName).
• Avoid keywords in .NET languages or classes with common namespace or class names (such as System, Form, and so on).
• Don’t give enum names an Enum suffix, and choose a sensible name because .NET languages like C# require full qualification of enum members.
In addition, avoid the unmanaged convention of prefixing pointer parameters with p (or pp for pointers to pointers), although the parameter name of an [out, retval] parameter doesn’t matter because its name is not preserved in metadata under normal circumstances.
Another thing to avoid is choosing member names that conflict with members of a Runtime-Callable Wrapper’s base classes. An RCW either derives from or is a System.__ComObject type, which derives from System.MarshalByRefObject, which derives from System.Object. These classes have the following public members:
• CreateObjRef
• Equals
• GetHashCode
• GetLifetimeService
• GetType
• InitializeLifetimeService
• ReferenceEquals
• ToString
Reusing these names as COM interface members isn’t an error; they are emitted as “new slot” members, which translates to new in C# (when specified on a signature) and Shadows in VB .NET. However, this can easily cause confusion for .NET clients that may be expecting different functionality when calling one of these methods.
Performance Considerations
Bridging the world of COM with the world of .NET is not a trivial task. Because of this, every transition from managed code to unmanaged code and vice-versa involves some overhead. Besides marshaling non-blittable parameters from one representation to another (and besides pinning blittable parameters), the CLR needs to do additional tasks. For example, the CLR does the following when transitioning from managed to unmanaged code:
• Ensures that the garbage collector won’t block unmanaged threads during the call
• Protects callee-saved registers
• Handles the calling convention appropriately
• Handles unmanaged exceptions
• Converts the RCW being called on into a COM interface pointer appropriate for the current context (COM Interoperability only)
This extra work is done with as little as 8 processor instructions for a PInvoke call that doesn’t require marshaling, or 31 instructions if marshaling is required (not including the marshaling itself). For COM Interoperability, the work typically equates to around 65 instructions, not counting marshaling. (These figures don’t include security stack walking for unmanaged code permission, which is done unless SuppressUnmanagedCodeSecurityAttribute is used.)
When a single unmanaged method does a large amount of work, the overhead involved in calling it from managed code is a small percentage of the total amount of time occupied, and therefore barely noticeable or undetectable. If an unmanaged method does a small amount of work, however, the overhead could occupy a significant percentage of the total amount of time, and could noticeably diminish performance if such a method is called many times.
Therefore, it is recommended that COM objects exposed to .NET have a small number of members that each performs a significant amount of work when called. This is sometimes called a “chunky” interface. The opposite is called a “chatty” interface, which requires numerous transitions between managed and unmanaged code to do small amounts of work. An interface with several property accessors is often a “chatty” interface because it involves separate calls usually just to set the value of a single private field. Figure 16.3 illustrates the difference between a “chatty” COM object being called from .NET versus a “chunky” COM object being called from .NET.
Figure 16.3. A chunky COM object can realize a significant performance boost over a chatty COM object doing the same tasks.
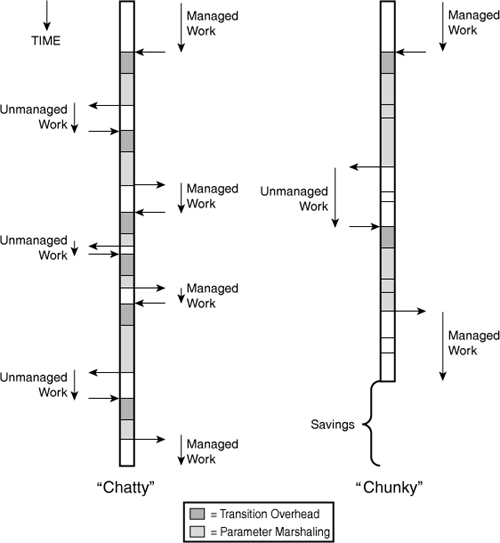
In both cases, this diagram shows the same amount of unmanaged work, the same amount of managed work, and the same amount of marshaling done by the Interop Marshaler. The only difference between the two programs is making three transitions versus one, and that’s where the time savings comes from. This concept is nothing new; it also applies to remote objects, for which the overhead of calling across a network encourages the use of chunky calls.
Although the diagram assumes that the same amount of marshaling is involved in both cases, the consolidation of method calls can often result in a savings of marshaling because you don’t have to pass the same data to the COM object multiple times. A good example is a COM method that is invoked from .NET inside a loop with a large number of iterations. By creating a larger COM method that does all the work of the loop, a significant savings can be realized, eliminating n-1 transitions and potentially a lot of marshaling for a loop whose body executes n times.
Of course, whether or not you can make a COM interface chunky highly depends on what the COM object is doing, and in many cases it can involve doing more work on the managed side than before, so there’s a tradeoff. The goal simply is to minimize the number of unmanaged/managed transitions as much as possible.
Besides minimizing transitions, cutting down on marshaling results in big savings if it’s possible to do, because marshaling takes much longer than the standard transition overhead. You should stick to blittable types as much as possible, because they don’t require complex marshaling. See Chapter 3 for a list of blittable types.
Unmanaged ANSI strings should also be avoided at all costs because .NET strings are Unicode internally, and the transformation from Unicode to ANSI and back can take a lot of time.
Therefore, the combination of a chunky API and blittable types shrinks transition overhead and parameter marshaling, the two items specific to managed/unmanaged interoperability that can diminish performance.
Finally, as mentioned in the “Threading and Apartment Guidelines” section, STA COM objects should be avoided because .NET clients may not be aware that they should use STAThreadAttribute (or use AspCompat=true in ASP.NET). If you have no other choice besides single-threaded apartments (because you’re developing in Visual Basic 6, for example), clearly document that .NET clients should use STAThreadAttribute to avoid the performance hit of COM apartment marshaling. For the most lightweight transitions, you may even consider exposing unmanaged entry points and using PInvoke (discussed in Chapters 18 and 19) to access them from managed code. You could then wrap these flat APIs in an object model that can provide .NET clients with the same or better usability of COM APIs plus better performance.
Conclusion
We began the chapter by listing many general design guidelines, array guidelines, and VARIANT guidelines that should have been obvious after reading Chapters 3–7 and seeing how .NET clients must use a variety of workarounds when attempting to use COM objects that don’t follow these guidelines. We then looked at the details of reporting good error information. The importance of setting an appropriate error message can’t be emphasized enough. C++ COM programmers may be used to receiving a failure HRESULT and looking up what the error code means, but .NET programmers have higher expectations!
We looked at a handful of common COM idioms and examined how they might get a facelift to avoid looking outdated to .NET clients while still looking reasonable to COM clients. Finally, after examining a handful of miscellaneous guidelines, we took a look at the performance of .NET’s interoperability services and strategies for avoiding unnecessary performance penalties.
If you follow the guidelines in this chapter when designing new COM APIs, you just may succeed in making COM an implementation detail that’s not noticeable to users, rather than presenting a design that is clearly meant for unmanaged clients. Plus, the more .NET-like your COM APIs are, the more likely you’ll be able to remain compatible if you ever decide to migrate any pieces to managed code.