
2. Hosting the Runtime: SQL Server As a Runtime Host
THIS CHAPTER DISCUSSES what it means to be a .NET Framework runtime host. Topics include how SQL Server differs from other runtime hosts such as Internet Information Server (IIS) and Internet Explorer (IE) with respect to loading and running code. Finally, we’ll show how you would catalog and maintain user assemblies stored in SQL Server.
Why Care How Hosting Works?
If you are an SQL Server developer or database administrator, you might be inclined to use the new Common Language Runtime (CLR) hosting feature to write stored procedures in C# or Visual Basic .NET (or establish a company policy forbidding its use) without knowing how it works. But you should care. SQL Server is an enterprise application, perhaps one of the most important in your organization. When the CLR was added to SQL Server, there were three goals in the implementation, considered in this order:
- Security
- Reliability
- Performance
The reasons for this emphasis are apparent. Without a secure system, you have a system that can reliably run code, including code introduced by hackers, very quickly. It’s not what you’d want for an enterprise application (or any application). Reliability comes next. Critical applications, like a database management system (DBMS), are expected to be available 99.999 percent of the time. You don’t want to wait in a long line at the airport or the bank while the database restarts itself. Reliability, therefore, is considered over performance when the two clash; a decision might be whether to allow stack overflows potentially to bring down the main application or to slow processing to make sure they don’t. Applications that perform transactional processing using SQL Server must ensure data integrity and its transactional correctness, which is another facet of reliability.
Performance is extremely important in an enterprise application as well. DBMSes can be judged on benchmarks, such as the TPC-C (Transaction Processing Performance Council benchmark C) benchmark, as well as programmer-friendly features. So although having stored procedures and user-defined types written in high-level languages is a nice feature, it had to be implemented in such a way as to maximize performance.
SQL Server introduced hosting APIs as one of the features in a series of vast internal changes. The changes are meant to encapsulate operating system services and are known collectively as the SQL Server Operating System (SQLOS). Hosting the .NET Framework runtime is only one of the reasons for the SQLOS and perhaps not even the main reason. SQLOS is a user-mode operating system that abstracts different Windows operating system–level services. Among the features that are enabled by SQLOS are better support for extended hardware architectures such as NUMA (Non-Uniform Memory Access), better support for operating system features such as the ability for SQL Server to recognize dynamically “hot-added” memory and processors, increased server reliability and scalability, a dedicated administrator connection, and a set of hosting APIs for hosted components. The .NET Framework runtime is one of the hosted components and is a consumer of many of the OS-level services that SQLOS provides, as shown in Figure 2-1.
Figure 2-1. SQLOS services
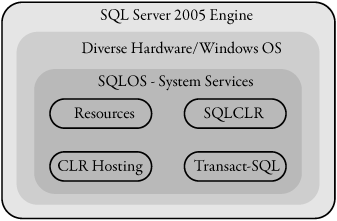
Because SQL Server 2005 introduces fundamental changes, we’ll first consider how SQLOS works as a .NET Framework runtime host; how it compares with other .NET Framework runtime hosts; and what special features of the runtime are used to ensure security, reliability, and performance.
You may already know that the latest version of the .NET Framework runtime, version 2.0, is required to use the .NET Framework in-process with SQL Server 2005. In this chapter, we’ll explain why.
What Is a .NET Framework Runtime Host?
A runtime host is defined as any process that loads the .NET Framework runtime and runs code in a managed environment. The most common scenario is that a runtime host is simply a bootstrap entry point that executes from the Windows shell, loads the runtime into memory, and then loads one or more managed assemblies. An assembly is the unit of deployment in the .NET Framework roughly analogous to an executable program or DLL in prior versions of Windows.
A runtime host begins loading the runtime by calling CorBindToRuntimeEx, an export from mscoree.dll that is a shim DLL whose only job is to load the runtime. Only a single copy of the .NET Framework CLR engine can ever be loaded into a process during the process’s lifetime. It is not possible to run multiple versions of the CLR within the same host. Four of CorBindToRuntimeEx’s parameters allow some customizing of runtime loading and behavior, namely the following:
• Server or workstation behavior
• Version of the CLR (for example, version 1.0.3705.0)
• Garbage-collection behavior
• Whether to share JIT compiled code across AppDomains (an AppDomain is a subdivision of the CLR runtime space)
In addition to these four parameters, three other parameters of CorBind-ToRuntimeEx request a pointer to an interface that provides methods to start and stop the runtime and that allows the host and runtime to communicate. In .NET Framework 1.1, hosts request the ICorRuntimeHost interface that allows limited host control of the runtime’s behavior, but in .NET Framework 2.0, hosts can also request the ICLRRuntimeHost interface. This interface provides two methods, GetCLRControl and SetHostControl, that allow deep delegation of control to the host program—SQL Server, in this case. A series that a manager interface sets allow hosts to control
• Assembly loading
• Host protection
• Failure policy
• Memory
• Threading
• Thread pool management
• Synchronization
• I/O completion
• Garbage collection
• Debugging
• CLR events
SQL Server, in its role as a runtime host, uses almost every one of these control mechanisms to provide security, reliability, and performance when hosting the .NET Framework. The CLR requests interfaces to talk to SQL Server by using IHostControl::GetHostManager, and SQL Server (through SQLOS) uses ICLRControl::GetCLRManager to talk back. The exact details of every interface and method are beyond the scope of this book. Refer to Customizing the Microsoft .NET Framework Common Language Runtime, by Steven Pratschner (Microsoft Press, 2005), for a complete description. This excellent treatise on hosting was published before SQL Server 2005 and .NET Framework 2.0 shipped, so a few SQL Server–related details have changed since its publication.
Two examples of specialized runtime hosts are the ASP.NET worker process and IE. The ASP.NET worker process differs from the norm in code location and in how the executable code, threads, and AppDomains are organized. (We’ll discuss AppDomains in the next section.) The ASP.NET worker process divides code into separate applications. Application is a term that is borrowed from IIS to denote code running in a virtual directory. Code is located in virtual directories, which are mapped to physical directories in the IIS metabase, a proprietary file maintained by IIS to store this and other configuration information. IE is another runtime host with behaviors that differ from the ASP.NET worker process or SQL Server 2005. IE loads code when it encounters a specific type of <object> tag in a Web page. The location of the code is obtained from an HTML attribute of the tag. SQL Server 2005 is an example of a specialized runtime host that goes far beyond ASP.NET or IE in specialization and control of CLR semantics.
SQL Server As a Runtime Host
SQL Server’s special requirements of utmost security, reliability, and performance have necessitated an overhaul of how the managed hosting APIs work, as well as of how the CLR works internally. SQL Server is a specialized host like ASP.NET and IE rather than a simple bootstrap mechanism. The runtime is lazy loaded; if you never catalog a user assembly, or use a managed stored procedure or user-defined type, the runtime is never loaded. This is useful because loading the runtime takes a one-time memory allocation of approximately 10MB to 15MB in addition to SQL Server’s buffers and unmanaged executable code. How SQL Server manages its resources and locates the code to load is unique as well. Figure 2-2 shows how SQL Server 2005 hosts the CLR.
Figure 2-2. Hosting the CLR
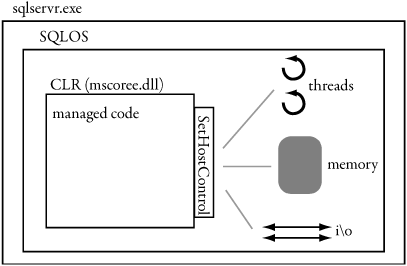
SQL Server Resource Management
As mentioned previously, SQL Server 2005 handles resource management using a user-mode operating system known as SQLOS. SQL Server 2005’s SQLOS provides management functionality such as:
• Nonpreemptive scheduling
• Memory management
• Resource monitoring
• Network and disk I/O
• Synchronization
• Hosting subsystems
Having all the features abstracted allows SQL Server to exploit different hardware configurations and different Windows operating system versions better. Note that there is almost a direct correlation between resources that the CLR allows the host to manage and those that SQLOS manages. SQLOS provides these features to manage all OS-level functions—not just those of the CLR—in an integrated and consistent manner. If SQL Server is running short on memory, for example, all subsystems are notified so that they can release memory to alleviate the shortage. The buffer pool may release some of its data buffers; the CLR might respond by performing eager garbage collection.
In .NET Framework runtime hosts, resources like memory and threads are usually managed by the CLR itself in conjunction with the underlying operating system. In SQLCLR (this is a term that is used for the functionality of the CLR running inside SQL Server), SQL Server controls these chores. SQL Server does this by informing, negotiating with, and layering over the CLR if needed by using the CLR hosting interfaces described previously, in conjunction with the SQLOS hosting interfaces. SQL Server uses its own memory allocation scheme, for example, managing real memory and mapping it to virtual memory as needed. The SQL Server buffer pool optimizes throughput by balancing memory usage among data and index buffers, plan caches, and other internal data structures. SQL Server can do a better job if it manages all the memory in its process. As an example, prior to SQL Server 2000, it was possible to specify that the TEMPDB database should be allocated in memory. In SQL Server 2000, that option was removed, because SQL Server can manage this better than the programmer or database administrator (DBA).
Clients of SQLOS in SQL Server 2005 (like the CLR) allocate memory using a SQLOS structure called a memory clerk. You can see all the memory clerks in a SQL Server instance by using the dynamic management view sys.dm_os_memory_clerks. Dynamic management views are new in SQL Server 2005 and allow administrators to look at much more of the inner workings of SQL Server than was possible in previous versions. These dynamic management views show real-time information. The dynamic views whose names begin with sys.dm_os display SQLOS internals, and those whose names begin with sys.dm_clr display information about SQLCLR internals.
SQL Server also uses its own thread scheduler, putting threads “to sleep” until it wants them to run. The DBA can configure SQL to use fibers rather than threads by adjusting the lightweight pooling configuration option, though this option is rarely used. In the Windows operating system, a thread represents an independent execution mechanism. A fiber is a lightweight thread that requires fewer resources; one Windows thread can be mapped to many fibers.1 In SQLOS, schedulers manage tasks, which can be threads or fibers, depending on which mode SQL Server is using. Within the Windows operating system, the CLR usually maintains its own thread pools and allows programmers to create new threads; within SQL Server 2005, however, SQLCLR delegates the responsibility of managing pooling and scheduling to SQLOS. The key difference is the way threads are scheduled. SQL Server uses cooperative thread scheduling; the CLR natively uses preemptive thread scheduling. When a thread is cooperatively scheduled, it voluntarily yields control back to the operating system when it has completed its task. When a thread is preemptively scheduled, the operating system interrupts the thread when it has executed for a given time slice. SQL Server uses cooperative thread scheduling to minimize thread context switches. The CLR hosting APIs also define units of execution and scheduling in terms of tasks. The SQL scheduler manages blocking points, and hooks PInvoke and COM interop calls out of the runtime (which still use preemptive scheduling) to control switching the scheduling mode. The CLR hosting interfaces provide the hooks.
SQLOS also manages thread synchronization and locking for SQLCLR, using a combination of locks and latches. The physical implementation in SQLOS, such as a spinlock, is used to provide the implementation that SQLCLR uses when you request a monitor, semaphore, reader-writer lock, or critical section. The CLR delegates that responsibility to SQLOS, as opposed to using the Win32 API primitives, by using the host manager interfaces. It does the same type of delegation for I/O completion ports and other services usually provided directly by the underlying operating system.
Exceptional Condition Handling
In .NET Framework 1.1, certain exceptional conditions, such as an out-of-memory condition or a stack overflow, could bring down a running process. This cannot be allowed to happen in SQL Server. Although transactional semantics might be preserved, reliability and performance would suffer dramatically. In addition, unconditionally stopping a thread (using Thread.Abort or other API calls) can conceivably leave some system resources in an indeterminate state. Although using garbage collection reduces the severity of memory leaks, leaving system resources in an indeterminate state can still cause memory leaks. A subset of the .NET Framework base class libraries (BCL) has gone through more extensive testing and instrumentation, and in some cases, the libraries have been rewritten for .NET Framework 2.0 to guarantee that they do not leak unmanaged operating system handles or other unmanaged resources under exceptional conditions. The way this was accomplished in .NET Framework 2.0 was to use some new APIs (Thread.BeginCriticalRegion and EndCriticalRegion) to mark the beginning and ending of sections of code that could not be protected against leaks. If a thread must be terminated in a critical region, it might leak, and SQLOS will take appropriate action, such as unloading the AppDomain. And as we just discussed, SQL Server itself manages the memory.
Different runtime hosts deal with these hard-to-handle conditions in different ways. In the ASP.NET worker process, for example, recycling both the AppDomain and the process itself is considered acceptable, because disconnected, short-running Web requests would hardly notice. With SQL Server, rolling back all the in-flight transactions might take a few minutes (or a few hours). Process recycling would ruin long-running batch jobs in progress. Therefore, changes to the CLR exceptional condition handling needed to be made through the hosting APIs’ exception escalation policy manager.
Out-of-memory conditions are particularly difficult to handle correctly, even when you leave a safety buffer of memory to respond to them. SQL Server attempts to use all memory available to it to maximize throughput. SQL Server 2005 works through the hosting interfaces to maintain a very small safety net and to handle out-of-memory conditions by providing memory for the CLR just-in-time. The .NET Framework 2.0 runtime and hosting APIs permit handling these conditions more robustly—that is, they guarantee availability and reliability after out-of-memory conditions without requiring a large safety net, letting SQL Server tune memory usage to the amount of physical memory. The CLR notifies SQL Server about the repercussions of failing each memory request. SQLOS monitors and responds to operating system memory pressure by using the QueryMemoryResourceNotification API, and it monitors and responds to CLR memory pressure by using the CLR host manager event infrastructure. Low-memory conditions may be handled by permitting the garbage collector to run more frequently, unloading AppDomains that are no longer being used, waiting for other procedural code to finish before invoking additional procedures, or even aborting running threads if needed.
There is also a failure escalation policy implemented via the hosting interfaces that allows SQL Server to determine how to deal with exceptions. SQL Server can decide to abort the thread that causes an exception and, if necessary, unload the AppDomain (we’ll discuss AppDomains shortly). On resource failures, the CLR will unwind the entire managed stack of the session that takes the resource failure. If that session has any locks, the entire AppDomain in which the session is running is unloaded. The entire AppDomain must be unloaded, because having locks indicates that there is some shared state to synchronize and, thus, that shared state is not likely to be consistent if just the session was aborted. In certain cases, this might mean that finally blocks in CLR code may not run. In addition, finalizers—hooks that programmers can use to do necessary but not time-critical resource cleanup—might not get run. Except in UNSAFE mode (discussed later in the chapter), finalizers are not permitted in CLR user libraries that run in SQL Server.
Stack overflow conditions cannot be entirely prevented and are usually handled by implementing exceptional condition handling in the program. If the program does not handle these conditions, the CLR will catch these exceptions, unwind the stack, and abort the thread if needed. In exceptional circumstances, such as when memory allocation during a stack overflow causes an out-of-memory condition, recycling the AppDomain may be necessary.
In addition to exceptions that the programmer does not catch, there is the possibility that the database administrator can issue the Transact-SQL (T-SQL) KILL command. This command terminates a running SQL Server session or SPID (system process identifier). SQLCLR has an exception escalation policy, implemented through the hosting APIs that were mentioned at the beginning of the chapter and enforced by SQLOS. This is shown in Figure 2-3. To reiterate:
Figure 2-3. SQL Server 2005 unhandled exception escalation policy
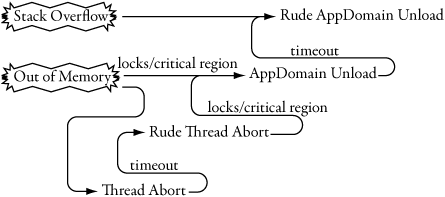
- An unhandled exception or SQL
KILLstatement can cause a thread abort. The CLR has a certain amount of time to respond, configured through the hosting APIs. - If the CLR does not respond, this is escalated to a rude thread abort. In a rude thread abort,
finallyblocks may not run. - If the CLR does not respond to rude thread abort, this is escalated to AppDomain unload.
- Finally, SQLOS will escalate to rude AppDomain unload.
In all the cases just mentioned, SQL Server will maintain transactional semantics. If the session is running SQLCLR code, how do the .NET Framework base class libraries guarantee that they clean up all unmanaged resources after a thread abort or an AppDomain unload?
In .NET Framework 2.0, a new set of classes was introduced to allow the CLR libraries to wrap operating system handles in a more robust manner. These classes all derive from the SafeHandle class. In implementations of SafeHandle, classes provide finalizers that are guaranteed to be run during rude thread abort or during AppDomain unload. This is because the SafeHandle class itself is derived from the CriticalFinalizerObject class. In this way, the base class libraries can provide guarantees to SQL Server that they will not leak handles over time.
Code Loading
SQL Server does not allow users to run arbitrary programs, because doing so might threaten the reliability of the server environment. Therefore, SQLCLR assemblies are loaded differently within SQLOS than CLR assemblies are loaded within Windows. The user or DBA must preload the code into the database and define which portions are invocable from T-SQL. Preloading and defining code uses ordinary SQL Server Data Definition Language (DDL) statements. Loading code as a stream of bytes from the database rather than from the file system makes SQL Server’s class loader unique. Later in this chapter, we’ll look at the exact DDL that is used to “create” an assembly in SQL Server (that is, load or refresh the bytes of code in the database) and manage the behavior of the assemblies.
The special subset of base class libraries that makes up the .NET Framework and has been approved for loading in SQL Server 2005 is treated differently from ordinary user .NET Framework assemblies in that the libraries are loaded from the global assembly cache (GAC) and are not defined to SQL Server or stored in SQL Server. Base class libraries that are not approved for loading must be treated as ordinary user assemblies—that is, stored in the database and loaded from the database. Most of the base class libraries are not on the approved list. Some portions of the base class libraries may have no usefulness in a SQL Server environment (for example, System.Windows.Forms); some may be dangerous to the health of the service process when used incorrectly (System.Threading) or may be a security risk (portions of System.Security). The architects of SQL Server 2005 have reviewed the class libraries that make up the .NET Framework, and only those deemed relevant are enabled for loading. This is accomplished by providing the CLR a list of libraries that are OK to load. Providing a list of libraries that are OK to load from the GAC, as well as overriding the .NET Framework’s ordinary class loading mechanism, is accomplished through the CLR host management APIs described at the beginning of this chapter. The current list of libraries enabled for loading from the GAC is
• CustomMarshallers.dll
• Microsoft.VisualBasic.dll
• Microsoft.VisualC.dll
• mscorlib.dll
• System.dll
• System.Configuration.dll
• System.Data.dll
• System.Data.OracleClient.dll
• System.Data.SqlXml.dll
• System.Security.dll
• System.Web.Services.dll
• System.Xml.dll
SQL Server will take responsibility for validating all user libraries and FX libraries that are not on the approved list, to determine that they are suitable for use within SQL Server. It will examine them, for example, to determine that they don’t contain updatable static variables unless specially allowed because the assembly is registered as PERMISSION_SET = UNSAFE. SQL Server does not allow sharing state between user libraries and registers through the new CLR hosting APIs for notification of all interassembly calls. In addition, user libraries are divided into three categories for security purposes; two of these categories have similar reliability guarantees. Assemblies must be assigned to a category and use only the appropriate libraries for that category. We’ll discuss this further after we’ve looked at the syntax involved in assembly definition.
Because code in SQL Server must be reliable, SQL Server will load only the latest version of the Framework class libraries it supports. This is analogous to shipping a particular tested version of ADO with SQL Server. Multiple versions of your code cannot run side by side in SQL Server 2005, although this is permitted by other .NET Framework runtime hosts.
Security
You may have noticed that we started this chapter by asserting that security is the most important consideration in an enterprise application, but in this discussion, we have saved it for last. This is because an entire chapter of this book is devoted to the subject of .NET Framework code access security (CAS), assembly security, user security, and other security enhancements in SQL Server 2005 (see Chapter 6). We’ll talk about XML namespace security in Chapter 9, which discusses the XML data type.
At this point, suffice it to say that there are three categories of access security for managed code. These are SAFE, EXTERNAL_ACCESS, and UNSAFE, which we mentioned previously with respect to class loading. They allow the DBA to grant certain privileges to an assembly after (s)he has weighed the risks and benefits of doing so. SAFE and EXTERNAL_ACCESS assemblies have similar reliability guarantees; they are different only with respect to security. These categories equate to SQL Server–specific permission sets using CAS concepts. For ensuring the integrity of userpermissions defined in the database, we depend on the principal execution context of the stored procedure or user-defined function in combination with database roles. See Chapter 6 for the specifics of security enhancements.
Loading the Runtime: Processes and AppDomains
We’ve spoken of AppDomains quite a bit in previous paragraphs. It’s time to describe exactly what they are and how SQL Server uses them. In the .NET Framework, processes can be subdivided into pieces known as application domains, or AppDomains. Loading the runtime creates a default AppDomain; user or system code can create other AppDomains. AppDomains are like lightweight processes themselves with respect to code isolation and marshaling. This means that object instances in one AppDomain are not directly available to other AppDomains by means of memory references; the parameters must be marshaled up and shipped across. In the .NET Framework, the default is not to marshal at all. If marshaling is allowed by specifying the Serializable attribute, the default is marshal-by-value; a copy of the instance data is made and shipped to the caller. Another choice is marshal-by-reference, in which the caller gets a locator or “logical pointer” to the data in the callee’s AppDomain, and subsequent use of that instance involves a cross-AppDomain trip. This isolates one AppDomain’s state from others and is shown graphically in Figure 2-4.
Figure 2-4. .NET Framework marshaling choices. The default is to not allow marshaling.
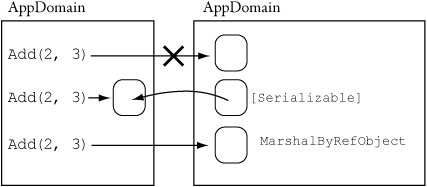
Each process that loads the .NET Framework creates a default AppDomain.2 From this AppDomain, you can create additional AppDomains programmatically, as shown in Listing 2-1.
Listing 2-1. Creating AppDomains programmatically
public static int Main(string[] argv) {
// create domain
AppDomain child = AppDomain.CreateDomain("dom2");
// execute yourapp.exe
int r = child.ExecuteAssembly("yourapp.exe",null,argv);
// unload domain
AppDomain.Unload(child);
return r;
}
Although there may be many AppDomains in a process, AppDomains cannot share class instances without marshaling.
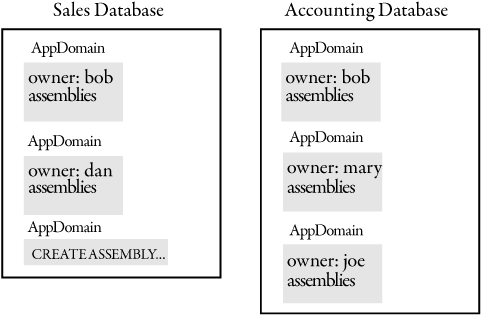
SQL Server does not use the default AppDomain for database processing, although it is used to load the runtime. Exactly how AppDomains are allocated in SQL Server 2005 is not controllable by the user or DBA; AppDomains are scoped to the database, and a separate AppDomain is created for each assembly owner in a database. In the current implementation, there are two reasons that new AppDomains are created: to run DDL that creates assemblies and other database objects, and to run .NET Framework code. The DDL-AppDomains are transient and are destroyed as soon as the DDL completes. The AppDomains that run code are created when new .NET Framework code or updated .NET Framework code runs for the first time. The system dynamic management view sys.dm_clr_appdomains shows the code running AppDomains in the SQL Server process. Creation and destruction of AppDomains that run code produce messages in the SQL Server log. AppDomains are allocated based on the owner of the assembly. This isolates each assembly owner’s code. This effectively prevents using code that is not type-safe to circumvent SQL Server permissions without the overhead of intercepting each call. The relationship among the SQL Server process, databases, and AppDomains is shown in Figure 2-5.
Figure 2-5. AppDomains in SQL Server databases
The runtime-hosting APIs also support the concept of domain-neutral code. Domain-neutral code means that one copy of the JIT compiled code is shared across multiple AppDomains. Although this reduces the working set of the process because only one copy of the code and supported structures exists in memory, it is a bit slower to access static variables, because each AppDomain must have its own copy of static variables, and this requires the runtime to add a level of indirection. There are four domain-neutral code settings:
- No assemblies are domain neutral.
- All assemblies are domain neutral.
- Only strongly named assemblies are domain neutral.
- The host can specify a list of assemblies that are domain neutral.
SQL Server 2005 uses the fourth option; it will share only a set of Framework assemblies. Strongly named assemblies cannot be shared, because these shared assemblies could never be unloaded.
AppDomains do not have a concept of thread affinity—that is, all AppDomains share the common CLR thread pool. This means that although object instances must be marshaled across AppDomains, the marshaling is more lightweight than COM marshaling because not every marshal requires a thread switch. This also means it is possible to delegate the management of all threads to SQL Server while retaining the existing marshaling behavior with respect to threads.
Safe Code: How the Runtime Makes It Safer to Run “Foreign” Code
If you’ve used SQL Server for a while, you might be thinking at this point, “We’ve always been able to run code other than T-SQL inside the SQL Server process. OLE DB providers can be defined to load into memory. Extended stored procedures are written in C++ and other languages. What makes this scenario different?” The difference is that managed code is safe code. Except in the special UNSAFE mode, code is verified by the runtime to ensure that it is type-safe and validated to ensure that it contains no code that accesses memory locations directly. This all but eliminates buffer overruns, pointers that point to the wrong storage location, and so on.
The unmanaged extended stored procedure code does run under structured exception handling. You cannot bring down a SQL Server process by branching to location zero, for example. Because an extended stored procedure runs directly in memory shared with SQL Server, however, it is possible for the procedure to access or change memory that it does not own. This can cause memory corruption and violate security, which is potentially more insidious.
Because managed code runs in its own AppDomain and is prevented from accessing memory except through the runtime, it is an order of magnitude safer than the extended stored procedures of the past. Note that it is possible to run unsafe .NET Framework code inside SQL Server, but this code must be defined using the UNSAFE option in the CREATE ASSEMBLY DDL statement. It is worth noting that UNSAFE assemblies may be catalogued only by SQL Server administrators that are granted UNSAFE ASSEMBLY permission. .NET Framework code in the Managed C++ compiler without the /safe compile switch and C# code that uses the unsafe keyword must use the UNSAFE declaration in the DDL. In addition to analyzing your code when it is catalogued to SQL Server, SQL Server also performs safety checks at runtime.
The Host Protection Attribute was invented in .NET Framework 2.0 to allow the host to have a say in running certain classes and methods based on information the author of the class or method provides. The System.Security.Permissions.HostProtectionAttribute class is applied to assemblies, classes, constructors, delegates, or methods to indicate that the item contains functionality that could cause instability in the host when invoked by user code. HostProtectionAttribute has a series of properties that can be set to indicate different potentially dangerous functionality types. The current set of properties is as follows:
• ExternalProcessMgmt3
• ExternalThreading
• SelfAffectingProcessMgmt
• SelfAffectingThreading
• MayLeakOnAbort
• Resources (this is a bitswitch of all the other properties of type HostProtectionResource)
• SecurityInfrastructure
• SharedState
• Synchronization
• UI
Applying the HostProtectionAttribute to a class or method creates a LinkDemand—that is, a demand that the immediate caller have the permission required to execute the method. The LinkDemand is checked against the permission set of the assembly and/or the procedural code. Setting permission sets on assemblies is shown in the section on CREATE ASSEMBLY later in the chapter. A HostProtectionAttribute differs from a normal security LinkDemand in that it is applied at the discretion of the host—in this case, SQL Server. Some hosts, such as IE, can choose to ignore the attribute, while others, such as SQL Server, can choose to enforce it. If the host chooses to ignore the HostProtectionAttribute, the LinkDemand evaporates—that is, it’s not executed at all.
All the Framework class libraries permitted to load in SQL Server have been decorated with HostProtectionAttributes. In conjunction with CAS (discussed in Chapter 6), HostProtectionAttributes produce a SQL Server–specific sandbox based on a permission set that ensures that the code running with any permission set other than UNSAFE cannot cause instability or lack of scalability in SQL Server.
In addition to the usage of HostProtectionAttribute, there is a set of attributes that is disallowed in all SQL Server user assemblies. These attributes are deemed dangerous because they affect thread management or security. A few additional attributes are disallowed in SAFE and EXTERNAL_ACCESS assemblies but allowed in UNSAFE assemblies. The dangerous attributes are listed below:
• System.ContextStaticAttribute
• System.MTAThreadAttribute
• System.Runtime.CompilerServices.MethodImplAttribute
• System.Runtime.CompilerServices.CompilationRelaxations Attribute
• System.Runtime.Remoting.Contexts.ContextAttribute
• System.Runtime.Remoting.Contexts.Synchronization Attribute
• System.Runtime.InteropServices.DllImportAttribute
• System.Security.Permissions.CodeAccessSecurity Attribute
• System.STAThreadAttribute
• System.ThreadStaticAttribute
• System.Security.SuppressUnmanagedCodeSecurityAttribute
• System.Security.UnverifiableCodeAttribute
Where the Code Lives: Storing .NET Framework Assemblies (CREATE ASSEMBLY)
A .NET Framework assembly is catalogued in a SQL Server database by using the CREATE ASSEMBLY statement. The following lines of code define an assembly to SQL Server and assign it the symbolic name SomeTypes:
CREATE ASSEMBLY SomeTypes
FROM 'C: ypesSomeTypes.dll'
This not only loads the code from the file, but also assigns a symbolic name to it—in this case, SomeTypes. The code can be loaded from a network share or from a local file system directory, and it must be a library (DLL) rather than directly executable from the command line (EXE). No special processing of the code is needed beyond normal compilation; SomeTypes.dll is a normal .NET Framework assembly. SomeTypes.dll must contain an assembly manifest, and although a .NET Framework assembly can contain multiple physical files, SQL Server does not currently support multifile assemblies. The complete syntax for CREATE ASSEMBLY follows:
CREATE ASSEMBLY assembly_name
[ AUTHORIZATION owner_name ]
FROM { < client_assembly_specifier > | < assembly_bits > [,...n] }
[ WITH PERMISSION_SET = { SAFE | EXTERNAL_ACCESS | UNSAFE } ]
< client_assembly_specifier > :: =
'\machine_nameshare_name[path]manifest_file_name'
< assembly_bits > :: =
{ varbinary_literal | varbinary_expression }
where:
• assembly_name—Is the name of the assembly; the name should be a valid SQL Server identifier.
• client_assembly_specifier—Specifies the local path or the network location (as UNC Path) of the assembly being loaded, including the filename of the assembly.
• manifest_file_name—Specifies the name of the file that contains the manifest of the assembly. SQL Server will also look for the dependent assemblies of this assembly, if any, in the same location—that is, the directory specified by client_assembly_specifier.
• PERMISSION_SET = { SAFE | EXTERNAL_ACCESS | UNSAFE }—Changes the .NET Framework Code Access Permission Set property granted to the assembly. We’ll have more to say about this later in the chapter and in Chapter 6.
• assembly_bits—Supplies the list of binary values that constitute the assembly and its dependent assemblies. If assembly_bits is specified, the first value in the list should correspond to the rootlevel assembly—that is, the name of the assembly as recorded in its manifest should match the assembly_name. The values corresponding to the dependent assemblies can be supplied in any order.
• varbinary_literal—Is a varbinary(max) literal of the form 0x . . .
• varbinary_expression—Is an expression of type varbinary(max).
When you catalog an assembly using CREATE ASSEMBLY, the symbolic name you assign to the assembly need not agree with the name in the assembly manifest. This allows you to catalog assemblies with the same name that differ in culture specifier. Multiple versions of an assembly that differ by version number are not permitted in SQL Server 2005.
The current user’s identity is used (via impersonation) to read the assembly file from the appropriate directory. Therefore, the user must have permission to access the directory where the assembly is located. If you are logged into SQL Server using an SQL login, the credentials of the SQL Server service account are used to attempt to access the file. Note that using CREATE ASSEMBLY copies the assembly’s bits into the database and stores them physically in a system table (sys.assembly_files). There is no need for SQL Server to have access to the file system directory to load the bits the next time SQL Server is started; when the CREATE ASSEMBLY statement completes, SQL Server never again accesses the location from which it loaded the assembly. If the file or bits that CREATE ASSEMBLY points to do not contain an assembly manifest, or if the manifest indicates that this is a multifile assembly, CREATE ASSEMBLY will fail.
SQL Server will verify that the assembly code is type-safe (except if PERMISSION_SET = UNSAFE) and validate the code when it is catalogued.This not only saves time, because this is usually done by the runtime during the Just-in-Time (JIT) compilation process (at first load), but also ensures that only verifiable code is catalogued into SQL Server. Unverifiable code will cause CREATE ASSEMBLY to fail. What happens during validation depends on the value of the PERMISSION_SET specified. The default PERMISSION_SET is SAFE. Permission sets control CAS permissions when the code executes but also enforce semantics with respect to what kind of calls can be made. CREATE ASSEMBLY uses reflection4 to ensure that you are following the rules.
There are three distinct PERMISSION_SETs:
SAFE—This is the default permission set. An assembly catalogued with the SAFE permission set cannot compromise the security, reliability, or performance of SQL Server. SAFE code cannot access external system resources such as the Registry, network, file system, or environment variables; the only CLR permission that SAFE code has is execution permission. SAFE code cannot access unmanaged code through runtime-callable wrappers or use PInvoke to invoke a native Windows DLL. SAFE code can make data access calls using the current context but cannot access external data through the SqlClient or other data providers. SAFE code cannot create threads or otherwise do any thread or process management. Attempting to use forbidden methods within a SAFE assembly will result in a security exception. The following example shows the security exception produced when a method in a SAFE assembly tries to connect to the Web using System.Net.WebRequest:
Msg 6522, Level 16, State 1, Procedure GetFromWeb, Line 0
A .NET Framework error occurred during execution of user defined routine
or aggregate 'GetFromWeb':
System.Security.SecurityException:
Request for the permission of type
System.Net.WebPermission,
System, Version=2.0.0.0,
Culture=neutral,
PublicKeyToken=b77a5c561934e089 failed.
at System.Security.CodeAccessSecurityEngine.Check(Object demand,
StackCrawlMark& stackMark, Boolean isPermSet)
at System.Security.CodeAccessPermission.Demand()...
EXTERNAL_ACCESS—Specifying EXTERNAL_ACCESS gives code the ability to access external system resources. As with SAFE, an assembly catalogued with the EXTERNAL_ACCESS permission set cannot compromise the reliability or performance of SQL Server. Unlike SAFE assemblies, EXTERNAL_ACCESS assemblies can pose a threat to security because they access resources outside the database process. The Registry, network file system, external databases, and environment variables are available through the managed code APIs, but EXTERNAL_ACCESS code cannot use COM-callable wrappers or PInvoke, or create threads. An administrator must have EXTERNAL ACCESS ASSEMBLY permission to catalog an EXTERNAL_ACCESS assembly with CREATE ASSEMBLY.
UNSAFE—UNSAFE code is not restricted in any way, including using unmanaged code. Because using UNSAFE could compromise SQL Server, only users with UNSAFE ASSEMBLY permission can catalog UNSAFE code. Usage permissions are described in Chapter 6. Although it seems unwise even to permit UNSAFE code to execute, UNSAFE code is really no more unsafe than an extended stored procedure.
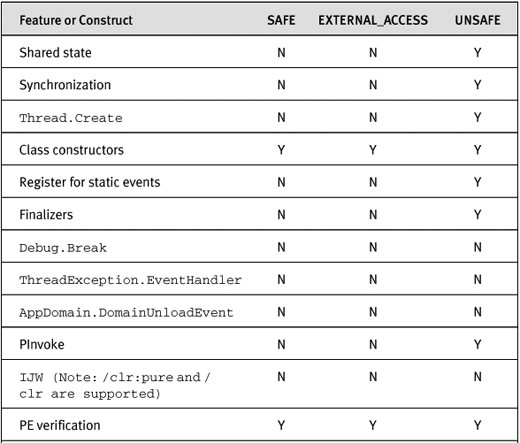
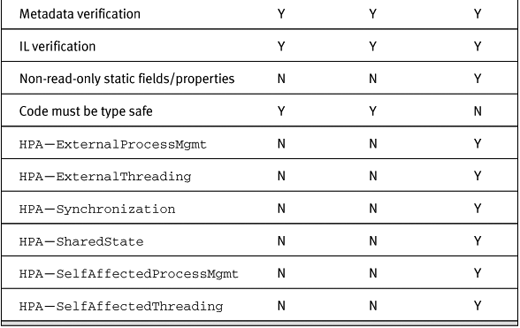
In addition to CAS permission sets, which will be discussed in Chapter 6, there is a series of .NET Framework code requirements and coding constructs that can be used based on the PERMISSION_SET applied to the code. Table 2-1 shows a list of .NET Framework constructs and their permitted usage in the three permission sets.
Table 2-1. Code Requirements and Constructs, and SQL Server Permission Sets
Assembly Dependencies: When Your Assemblies Use Other Assemblies
Assemblies have a database-level scope. Because each database has its own set of AppDomains, as mentioned previously, and assemblies may not be shared among AppDomains, each assembly owner by a distinct owner must be loaded in a distinct AppDomain. However, you might want to share an assembly within a single database if the assemblies are owned by the same owner. Examples would be statistical packages or spatial data types that are referenced by many user-defined assemblies in multiple databases. System utilities, such as collection classes, and user-defined class libraries can be used in this manner.
To ensure that a library that’s being referenced by multiple assemblies is not dropped when a single library that references it is dropped, SQL Server will reflect on the assembly when CREATE ASSEMBLY is executed, to determine the dependencies. It automatically catalogs these dependencies in the SQL metadata tables. As an example, let’s assume that both the Payroll department and the HR department reference a common set of formulas to calculate an employee’s years of service. This library is called EmployeeRoutines.
When Payroll routines and HR routines are declared (in assemblies of analogous names), they each reference EmployeeRoutines as follows:
-- SQL Server reflection determines
-- that PayrollRoutines references EmployeeRoutines
-- EmployeeRoutines is cataloged too
CREATE ASSEMBLY PayrollRoutines FROM
'C: ypesPayrollRoutines.DLL'
GO
-- SQL Server reflection determines
-- that HRRoutines references EmployeeRoutines
-- this sets up another reference to EmployeeRoutines
CREATE ASSEMBLY HRRoutines FROM
'C: ypesHRRoutines.DLL'
GO
With the previous declarations, neither the Payroll programmers nor the HR programmers can change or drop the EmployeeRoutines without the consent of the other. We’ll look at how you’d set up the permissions for this in Chapter 6, the security chapter.
Assemblies and SQL Schemas: Who Owns Assemblies (Information Schema)
Assemblies, like other SQL Server database objects, are the property of the user who catalogs them using CREATE ASSEMBLY: the owner. This has security repercussions for the users who wish to use the procedures, triggers, and types within an assembly. Though we’ll go over all the security details in Chapter 6, we’d like to discuss execution context here. In addition, we’ll see exactly where in the system tables information about assemblies is stored.
System Metadata Tables and INFORMATION_SCHEMA
Information about assemblies, assembly code, and code dependencies is stored in the system metadata tables, which in general store information about SQL Server database objects, such as tables and indexes. Some metadata tables store information for the entire database instance and exist only in the MASTER database; some are replicated in every database, user databases as well as MASTER. The names of the tables and the information they contain are proprietary. System metadata tables are better performing, however, because they reflect the internal data structures of SQL Server. In the big rewrite that took place in SQL Server 7, the system metadata tables remained intact. In SQL Server 2005, the metadata tables have been overhauled, revising the layout of the metadata information and adding metadata for new database objects. In addition, programmers and DBAs can no longer write to a system metadata table. It is really a read-only view.
The SQL INFORMATION_SCHEMA, on the other hand, is a series of metadata views defined by the ANSI SQL specification as a standard way to expose metadata. The views evolve with the ANSI SQL specification; SQL:1999 standard INFORMATION_SCHEMA views are a superset of the SQL-92 views. SQL Server 2000 supports the INFORMATION_SCHEMA views at the SQL-92 standard level; there are few changes to this support in SQL Server 2005. Listing 2-2 shows code that can be used to retrieve the list of tables in a specific database. The sample uses the system metadata tables, followed by analogous code using the INFORMATION_SCHEMA views. Note that neither query (in SQL Server, the SQL:1999 spec seems to indicate otherwise) includes the system tables in the list of tables.
Listing 2-2. Getting metadata from SQL Server
-- this uses the old system metadata tables, supported for compatibility
SELECT * FROM sysobjects
WHERE type = 'U'
-- this uses the INFORMATION_SCHEMA
SELECT * FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_TYPE = 'BASE TABLE'
SQL Server 2005 includes a reorganization of the system metadata tables. This includes renaming the tables to use an arbitrary schema (named SYS) as well as table renames and reorganization of some of the information. The goal, once again, is speed and naming consistency. The equivalent query to the previous two using the new system metadata tables would be as follows:
SELECT * FROM sys.tables
Note that the information returned by all three queries differs in the number of columns returned, the column names used, and the information in the rowset. Although a complete description of all the new metadata tables is beyond the scope of this book, we’ll discuss the metadata information that is stored when CREATE ASSEMBLY is executed and explain assembly properties.
Assembly Metadata
Information about assemblies and the assembly code itself is stored in three metadata tables. These tables exist in each database, because assemblies are scoped to the database.
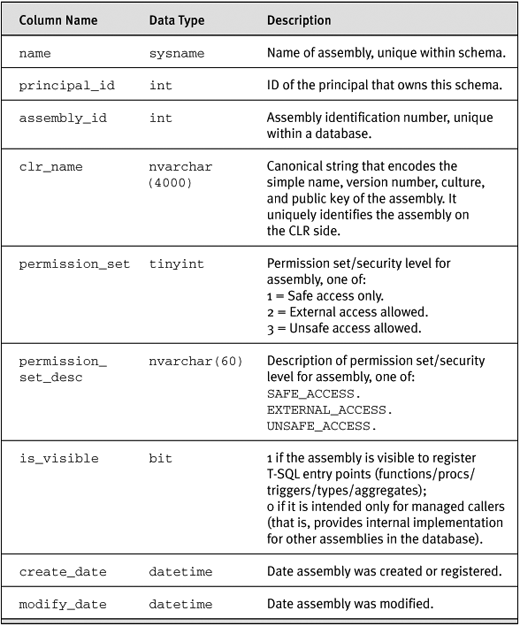
sys.assemblies stores information about the assembly itself as well as schema_id, assembly_id, and the .NET Framework version number. The complete list of columns in sys.assemblies is shown in Table 2-2.
Table 2-2. Contents of sys.assemblies
The assembly dependencies are stored in sys.assembly_references, one row per assembly-reference pair. Table 2-3 shows the columns in sys.assembly_references. Note that this table does not contain information about which base class libraries an assembly references.
Table 2-3. Contents of sys.assembly_references

Finally, the assembly code itself is catalogued in sys.assembly_files. In all cases, this table contains the actual code rather than the name of the file where the code resided when it was catalogued. The original file location is not even kept as metadata. In addition, if you have added a debugger file, using a DDL statement such as ALTER ASSEMBLY ADD FILE, the debug information will appear as an additional entry in the sys.assembly_files table. Table 2-4 shows the contents of the sys.assembly_files table.
Table 2-4. Contents of sys.assembly_files
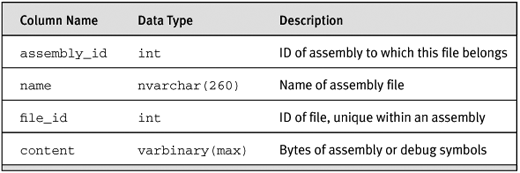
We’ll further discuss declaring routines and types in the CREATE ASSEMBLY DDL statement in Chapters 3 and 4. Notice that you can define an assembly that is “invisible” with respect to defining routines and types to the runtime. Lack of visibility is the default when SQL Server loads
dependent assemblies of an assembly defined using CREATE ASSEMBLY. You might do this, for example, to define a set of utility routines to be invoked internally only. If you specify VISIBILITY=ON (the default), this means that methods and types in this assembly can be declared as SQL Server stored procedures, user-defined functions, triggers, and types through DDL.
Maintaining User Assemblies (ALTER ASSEMBLY, DROP ASSEMBLY)
Although we stated earlier in this chapter that SQL Server loads only a single version of the .NET Framework runtime and base class libraries on the approved list, assemblies may be updated, their code reloaded, and properties (including the set of dependent assemblies) altered via DDL. Assemblies may also be dropped via DDL, subject to whether they are currently used by other system objects. An example of dropping the SomeTypes assembly defined earlier follows:
DROP ASSEMBLY SomeTypes
The complete syntax for dropping a defined assembly follows:
DROP ASSEMBLY assembly_name
[WITH NO DEPENDENTS]
Note that the DROP ASSEMBLY statement will fail if any existing database objects reference the assembly. We’ll get back to dependent assemblies in a moment.
You may change the properties of an assembly or even modify the assembly code in place using the ALTER ASSEMBLY statement. Let’s assume that we have decided that the SomeTypes assembly mentioned earlier needs to be present in SQL Server, but it need not be visible (for example, it is accessed only by other assemblies and not from the outside). To prevent routines in this assembly from inadvertently being declared publicly via DDL, we can alter its visibility like this:
ALTER ASSEMBLY SomeTypes
WITH VISIBILITY=OFF
To reload the SomeTypes assembly, as long as it is not currently being referenced, we can use the following syntax:
ALTER ASSEMBLY SomeTypes
FROM 'C: ypesSomeTypes.dll'
The complete syntax for ALTER ASSEMBLY follows. We’ll discuss uses of some of the more esoteric options in Chapter 5 and the security options in Chapter 6.
ALTER ASSEMBLY assembly_name
[ FROM { < client_assembly_specifier > | < assembly_bits > [ ,...n ] ]
[ WITH < assembly_option > [ ,...n ] ]
[ DROP FILE { file_name [ ,...n ] | ALL } ]
[ ADD FILE FROM { client_file_specifier
[ AS file_name ] | file_bits AS file_name } [,...n ]
< client_assembly_specifier > :: =
'\computer_nameshare-name[path]manifest_file_name'
< assembly_bits > :: =
{ varbinary_literal | varbinary_expression }
< assembly_option > :: =
PERMISSION_SET { SAFE | EXTERNAL_ACCESS | UNSAFE }
| VISIBILITY { ON | OFF }
| UNCHECKED DATA
In order to change the permission set with ALTER ASSEMBLY, you must have analogous permissions as with CREATE ASSEMBLY—that is, you need EXTERNAL ACCESS ASSEMBLY permission to alter an assembly to the EXTERNAL_ACCESS safety level, and you must have UNSAFE ASSEMBLY permission to alter an assembly to UNSAFE. You also must have analogous file access permissions as with CREATE ASSEMBLY if you are going to load any new code from a file.
You can use ALTER ASSEMBLY not only to change individual metadata properties, but to update or reload the code as well. Reloading the code (by using the FROM clause) not only reloads, but revalidates code as well. Of course, this code must be built against the same version of the runtime and the same base class libraries as the original.
If there are references to the assembly, none of the method signatures of the methods defined as stored procedures, triggers, and user-defined functions is allowed to change. If your new version contains user-defined types, ALTER ASSEMBLY not only checks all the methods’ signatures, but also, if the serialization format is Native, all the data members must be the same so that the user-defined type instances that have been persisted (as column values in tables) will still be usable. Other types of persisted data will be checked, too, if your assembly contains the following:
• Persisted computed columns that reference assembly methods
• Indexes on computed columns that reference assembly methods
• Computed columns with expressions that reference assembly user-defined functions
• Columns with check constraints that reference assembly user-defined functions (UDFs)
You can bypass checking persisted data by specifying the UNCHECKED DATA option; you must be db_owner or db_ddlowner or must have equivalent permissions to use this option. The metadata will indicate that the data is unchecked until you use the command DBCC CHECKTABLE to check the data in each table manually. You must be sure that the formulas (content) of UDFs have not changed before you use the UNCHECKED DATA option, or else corrupted data could result.
When you use ALTER ASSEMBLY, there may be user sessions using the old version of the assembly. In order not to disrupt those sessions, SQL Server will create a new AppDomain to load your new code. Existing sessions continue to use the old code in the original AppDomain until logoff; new sessions will be routed to the new AppDomain. When all the existing sessions finish, the old AppDomain is shut down. This is the only (transient) case where two different versions of your code can be running at the same time but is not the same as side-by-side execution.
One common requirement for programmers will be to add debugging information to use during development. A.NET Framework assembly can be debugged inside SQL Server with any of the usual .NET Framework debuggers—for example, Visual Studio 2005. You may have noticed that one of the metadata tables (sys.assembly_files) contains an additional entry if you have added the .NET Framework debugging symbols for the assembly. This file usually has a .pdb extension when it is produced by the compiler. To add a debug symbols file for the assembly that we defined earlier, we can execute the following statement:
ALTER ASSEMBLY SomeTypes
ADD FILE FROM 'C: ypesSomeTypes.pdb'
GO
The Database Project in Visual Studio 2005 will perform this step automatically when you use the Deploy menu entry.
Specification Compliance
The ANSI SQL specification attempts to standardize all issues related to relational databases, not just the SQL language. Although some databases allow external code to run inside the database (SQL Server permits this through extended stored procedures), this was not part of the SQL specification until recently. Two specifications that appeared at the end of the SQL:1999 standardization process relate to the concepts we’re going to be covering in the SQL Server–.NET Framework integration portion of this book. The specifications related to the concept of managed code running inside the database and the interoperation of managed types and unmanaged types are called SQL/J part 1 and SQL/J part 2. There are two interesting features of these specs:
• They were added as addenda to SQL:1999 after the specification was submitted. SQL/J part 1 became SQL:1999 part 12, and SQL/J part 2 became SQL:1999 part 13. This specification was consolidated as part 13 of SQL:2003 and is there known as SQL-Part 13: Java Routines and Types (SQL/JRT).
• Although the specs are part of the ANSI SQL specification, the only managed language they address is Java, which is itself not a standard. Java was withdrawn from the ECMA (European Computer Manufacturers Association) standardization process. On the other hand, the .NET Framework CLR is an ECMA standard.5
Nevertheless, it is interesting at least to draw parallels.
The closest equivalents to SQL Server 2005’s CREATE ASSEMBLY/ALTER ASSEMBLY/DROP ASSEMBLY statements are SQL/J’s SQLJ.INSTALL_JAR, SQLJ.REMOVE_JAR, and SQLJ.REPLACE_JAR procedures. These procedures are not implemented by all the implementers of the standard. Because the SQL/J standard does not state that the actual code needs to be stored in the database, you can also change the defined path where the jar file6 resides with SQLJ.ALTER_JAR_PATH. Because SQL Server assemblies are stored inside the database, an equivalent function is unnecessary.
Some of the ancillary concepts are analogous with respect to deploying the items that an assembly or jar file contains. The specification includes a bit to indicate whether a deployment descriptor included in the jar file should be read; an analogous concept would be the list of publicly declared methods and types in the CREATE ASSEMBLY or ALTER ASSEMBLY statement. Visibility of classes and methods is defined by using the public or private keywords, as it is in SQL Server 2005, but no notion of visibility at the jar level exists in the SQL specification to correspond to the SQL Server 2005 notion of assembly visibility. References are defined in the ANSI specification only with respect to pathnames; there is no concept of keeping references in the schema. The ANSI specification contains no notion of CAS level and execution context. Database permissions for managed code within an assembly are part of SQL Server 2005 and, to an extent, the code within a SQL/JRT file as well. We’ll discuss this in Chapter 6, which covers security.
Conclusions
If your assembly is SAFE or EXTERNAL_ACCESS, nothing you can do will affect SQL security, reliability, or performance. You’ll have to work hard to make your app itself unreliable and nonscalable at these safety levels. SAFE or EXTERNAL_ACCESS levels enforce the general principles of no-shared-state and no multithreaded programming. Writing secure, reliable, and performant code that doesn’t follow these tenets is harder, and such assemblies must be catalogued as UNSAFE.
Where Are We?
We’ve seen that SQL Server 2005 is a full-fledged runtime host and can run your managed code. SQL Server’s choices as a runtime host are geared to security and reliability, with an eye to performance.
We’ve seen how to define an assembly (managed DLL) to SQL Server for storage inside the server and how to specify the execution context (identity) and degree of safety with which the code runs. The CLR’s class libraries are even categorized by degree of safety; this should ameliorate some of the DBA’s concerns.
In the next chapter, we’ll look at some of the specific code you’d write as managed—stored procedures, user-defined functions, and triggers—and see how this code is defined to SQL Server so that it’s indistinguishable from T-SQL procedures to the caller.