
10. XML Query Languages: XQuery and XPath
XML BRINGS WITH it some powerful query languages for dealing with the hierarchical format that is typical of an XML document. This chapter covers XQuery from the perspective of its definition in a series of W3C standards. After looking at the standards, we describe the SQL Server 2005–specific implementation of the XQuery standards. The implementation consists of five SQL Server–specific methods on the XML data type that use XQuery to allow you to query or mutate XML data.
What Is XQuery?
In Chapter 1, we describe the components and uses of XML, and in Chapter 9, we cover the XML native data type in SQL Server 2005. The XML data type typically is a complex type—that is, a type that almost always contains more than one data value. We can use XML data type columns in two distinct ways:
• Query the data and perform actions on it as though it were a simple data type. This is analogous to the way we would treat an XML file in the file system; we read the entire file or write the entire file.
• Run queries and actions on the XML data in the column, using the fact that the XML Infoset model allows the concrete data to be exposed as a sequence of data values or nodes. For this, we need an XML query language.
Currently, the most-used query language in XML is XPath. XPath 1.0 is a mature W3C recommendation. XPath uses a syntax for queries that is similar to the syntax you’d use to locate files on a file system (using forward slashes to indicate levels of hierarchy). XPath queries are used to select data from an XML document in XSLT, the XML stylesheet language. XSLT 1.0 is also a mature W3C recommendation. XSLT operates on a data model defined in the XPath recommendation, which is a somewhat different view of XML than that provided by the Infoset. XPath 1.0 and XSLT 1.0 are supported in the .NET Framework base class libraries as part of the System.Xml namespace.1
XQuery 1.0, XPath 2.0, and XSLT 2.0 are in the midst of the W3C standardization process. As of late 2005, they are at “Candidate Recommendation,” which is the last step before becoming a final Recommendation. Both XQuery 1.0 and XSLT 2.0 use XPath 2.0 to select subsets of data to operate on. XQuery is a query language designed to be SQL-like in its appearance and to be optimizable. A native XQuery 1.0 engine and XPath 2.0 parser live inside the SQL Server 2005 and work in conjunction with the relational engine. This will change the diagram of SQL Server internals presented in Chapter 1 to look like Figure 10-1.
Figure 10-1. SQL Server 2005 internals
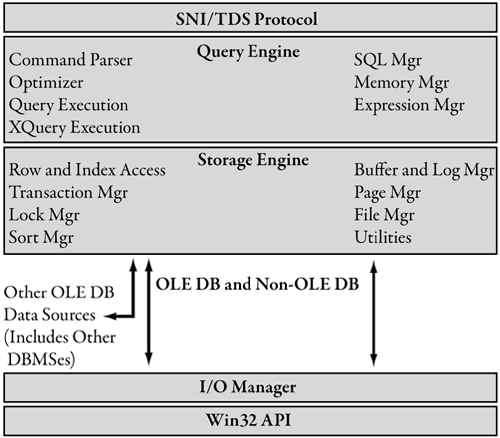
Because you can load .NET Framework classes from the System.Xml.dll assembly inside SQL Server 2005, it is also possible to use the client-side XML APIs inside the server.
The SQL Server 2005 internal implementation of XQuery implements a stable subset of the entire XQuery 1.0 language specification. It differs from most other implementations of XQuery in where it gets it data. In the most common implementations of XQuery, the data comes from one or more instances in one or more files, perhaps by using the SAX (Simple API for XML) or DOM (Document Object Model)2 API to produce an XML Infoset. In SQL Server’s implementation, the query is tied to an instance of an XML data type or an XML type variable with the option of using SQL columns or variables as well.
We’ll start by describing XQuery from the latest W3C standards documents without making direct reference to the implementation inside SQL Server. Note that SQL Server 2005 does not implement the entire specification; we’ll have more to say about this later. Remember as we go that SQL Server implements a useful subset of the specification. We’ll continue by comparing XQuery with SQL, the language used by every SQL Server developer. After you are comfortable with the XQuery language, we’ll look at the implementation of XQuery in SQL Server 2005, pointing out differences from the spec whenever they are relevant. SQL Server implements some XQuery extension functions to allow integration of SQL and XML data inside the XQuery query itself.
An Introduction to XQuery
The XQuery specification consists of a series of specification documents and some related documents. The specification describes not only the query language semantics, but also the underlying data model, the XPath 2.0 path expression language used in XQuery expressions, a formal algebra, and a way to represent XQuery queries in an XML format. The names of the specifications follow. To see the most current versions of these specifications, browse to http://www.w3.org/XML/Query.
• XML Query Requirements
• XML Query Use Cases
• XQuery 1.0 and XPath 2.0 Data Model
• XSLT 2.0 and XQuery 1.0 Serialization
• XQuery 1.0 and XPath 2.0 Formal Semantics
• XQuery 1.0, an XML Query Language
• XQuery 1.0 and XPath 2.0 Functions and Operators
• XML Syntax for XQuery 1.0 (XQueryX)
• XPath Requirements Version 2.0
• XML Path Language (XPath) 2.0
• XML Query and XPath Full-Text Requirements
• XML Query and XPath Full-Text Use Cases
• XML Query and XPath 2.0 Full-Text
• XQuery Update Facility Requirements
• Building a Tokenizer for XPath or XQuery
The documents that you may be going back to most often if you use them for reference will probably be “XQuery 1.0, an XML Query Language” and “XQuery 1.0 and XPath 2.0 Functions and Operators,” but the key concept document is “XQuery 1.0 and XPath 2.0 Data Model,” because you can’t understand how to use XQuery if you don’t understand the model of the data you are querying. The data model used by SQL Server 2005 (and the ISO/ANSI SQL:2003 specification) is slightly different from the XQuery Data Model. The next version of the ISO/ANSI SQL spec may align with the XQuery 1.0/XPath 2.0 data model.
The main building block of the XQuery Data Model is the sequence. A sequence is an ordered collection of zero or more items. Items in a sequence are either nodes or atomic values. There are seven types of XML nodes: document, element, attribute, text, namespace, processing instruction, and comment.
Atomic values are instances of values of XML Schema or XQuery 1.0/XPath 2.0 atomic data types. This model includes types defined in the XML Schema specification, Part 2, Datatypes, and some additional types (including xdt:untyped, xdt:untypedAtomic and xdt:anyAtomicType) that are specific to the XQuery 1.0/XPath 2.0 data model.
Another way to say this is that XQuery language uses the XML Schema type system; instances of XML Schema types are recognized as first-class items in XQuery sequences. XQuery sequences can consist of only items that are nodes, only items that are atomic values, or a combination of both. To demonstrate quickly, here is an XML fragment that consists of two element nodes, each with an attribute node and a text node:
<hello color="green">world</hello>
<hello color="red">world</hello>
And here are a few atomic values:
42 (an instance of the value of an xs:integer)
hello world (an instance of the value of an xs:string)
2003-08-06 (an instance of the value of an xs:date)
One thing to notice here is that world in the node example is a text node of type string and the hello world in the atomic value example is an atomic value, not a node. The difference is subtle. Input sequences in queries are represented using comma-separated values surrounded by parentheses, like this:
(1,2,3)
(4,5,<root/>)
Sequences are serialized as space-separated values, without the parentheses, like this:
1 2 3
4 5 <root/>
The XQuery Data Model is a closed data model, meaning that the value of every expression is guaranteed to be an instance of the data model. In other words, each expression will yield a sequence, even if it is a sequence containing no items or only a single item. Sequences are flat, not nested; a sequence cannot contain another sequence. In SQL Server 2005’s implementation, sequences must be homogeneous (that is, all nodes or all atomic values); the (4,5,<root/>) sequence above would be disallowed.
According to the specification, the data model, like XML itself, is a node-labeled, tree-structured graph, although sequences are flat. Two main concepts of the data model are node identity and document order. Nodes (but not atomic values or sequences) have a unique identity that is assigned when the node constructor is used to construct a node or when data containing nodes is parsed by the query. No two nodes share the same node identity. In the XQuery Data Model, order is significant, and an algorithm for determining the order of nodes in an XML document or fragment is defined in the specification. Here is the document order algorithm defined in the XPath 2.0 specification, which is illustrated in Figure 10-2:
Figure 10-2. XML document illustrating document order

- The root node is the first node.
- The relative order of siblings is determined by their order in the XML representation of the tree. A node N1 occurs before a node N2 in document order if, and only if, the start tag node of N1 occurs before the start of N2 in the XML representation.
- Attribute nodes immediately follow the namespace nodes of the element with which they are associated. The relative order of attribute nodes is stable but implementation dependent.
- Element nodes occur before their children; children occur before following siblings.
- Namespace nodes immediately follow the element node with which they are associated. The relative order of namespace nodes is stable but implementation dependent.3
Finally, the XQuery Data Model extends the XML Information Set (Infoset) after schema validation, known as the Post Schema Validation Infoset (PSVI). Some of the items defined in the PSVI definition are not used in the XQuery Data Model, however, and the XQuery language itself does not use all the information yielded by schema validation either. The data model supports well-formed XML documents defined in terms of the XML 1.0 and Namespaces specification, as well as the following types of XML documents:
• Well-formed documents conforming to the Namespaces and XML specs
• DTD-valid documents conforming to the Namespaces and XML specs
• XML Schema validated documents
The data model goes beyond the XML Infoset to support data that does not conform to the Infoset as well. As we showed in the examples earlier, this data can consist of the following:
• Well-formed document fragments (XML with multiple top-level nodes)
• Sequences of document nodes
• Sequences of atomic values
• Top-level atomic values (top-level text, for example)
• Sequences mixing nodes and atomic values
Now that we know what we are querying, let’s look at the structure of the query itself. XQuery, like XML itself, is case sensitive. Keywords are all lowercase. The query consists of two parts: an optional query prolog, followed by the query body.
The XQuery Prolog
The query prolog sets up part of the “environment" in which to query. A simple example of this environment would be the default XML Namespace to which elements without a namespace prefix belong, as shown here:
(: This is an XQuery comment. Query Prolog begins here :)
declare default element namespace = http://example.org;
(: XQuery body begins here :)
(: looking for somelement in namespace "http://example.org" :)
//somelement
Items that can be declared in the XQuery prolog include the following, though this is not an exhaustive list:
• Default element namespace
• Default namespace for functions
• Namespace declarations with a corresponding namespace prefix
• XML Schema import statements
• XMLSpace declarative (that is, whether boundary whitespace is preserved)
• Default collation
• User-defined function definitions
SQL Server 2005’s implementation allows only namespace mappings in the prolog. Note also that if you do not define a default element, attribute, or function namespace, the default is “no namespace.” In addition to the namespace prefixes that you define yourself, there are five namespace prefix/namespace pairs that are built in and never need to be declared in the query prolog:
• xml = http://www.w3.org/XML/1998/namespace
• xs = http://www.w3.org/2001/XMLSchema
• xsi = http://www.w3.org/2001/XMLSchema-instance
• fn = http://www.w3.org/2004/07/xpath-functions
• xdt = http://www.w3.org/2004/07/xpath-datatypes
SQL Server’s implementation also includes:
• (no prefix) = urn:schemas-microsoft-com:xml-sql
• (no prefix) = http://schemas.microsoft.com/sqlserver/2004/SOAP
• sqltypes = http://schemas.microsoft.com/sqlserver/2004/sqltypes
Finally, XQuery has a rich set of built-in functions and operators, defined in the “XQuery 1.0 and XPath 2.0 Functions and Operators Version 1.0” document. In addition, you can define user-defined functions in the query prolog. We’ll look at system-defined and user-defined functions in the context of SQL Server’s implementation later in the chapter.
The XQuery Body
Now we’ll move on to the query body—the part of the query that actually produces the output that we want. An XQuery query consists of expressions; expressions can contain data and variables. There are many different types of expressions, the simplest being the literal expression, which is a simple string or numeric literal. The expression 'Hello World' is an example of a valid (though fairly useless) XQuery query. The query result consists of that same string, Hello World. XQuery variables are named by variable name. The let expression assigns a value to a variable. The following query declares a variable, $a (XQuery variables begin with a dollar sign), assigns the value of a string literal to it, and returns the variable’s value as the result of the query:4
let $a := 'Hello World'
return $a
You can also declare variables in the prolog.
Because you’ll probably want to do something more with your query than emit “Hello World,” you’ll need to provide some XML input to the query. XQuery has the concept of an execution context for its queries, and part of the execution context is the input sequence. In general, the way that the input sequence is provided is implementation defined, but XQuery defines some functions that can be used in conjunction with input: fn:doc and fn:collection. fn:doc, in its simplest form, can be used to return a document node, given a string URI that references an XML document. It also may be used to address multiple documents or document fragments. fn:collection returns a sequence of nodes pointed to by a collection that is named by a URI. Note that you can always implicitly set the context node or provide data via externally bound variables. Now we have input! The following query echoes the content of a file containing an XML document using the fn:doc function:5
let $a := doc("data/test/items.xml")
return $a
Notice that this query illustrates two items that are implementation dependent. The parser that uses this query allows the use of the document function without the namespace prefix, because it is a built-in system function. Also, the parser allows the use of a relative pathname rather than strictly requiring a URI; the current part used to resolve the relative pathname is part of the environment. This is just an example of possible parser implementation-dependent behavior.
Two of the most important constructs of the XQuery language are path expressions and FLWOR expressions. Path expressions refer to XPath, the selection language portion of XQuery. XPath expressions consist of a series of evaluation steps, separated by forward slashes. Each evaluation step selects a sequence of nodes, each item of which is input to the next evaluation step. The result of the final evaluation step in the output is the final result of the XPath expression. If any location step returns an empty sequence, the XPath expression stops (because there are no items for the next step to process) and returns an empty sequence. XPath expressions can be used as stand-alone queries. In fact, if all you want to do is simply select a sequence of nodes in document order, this may be all you need. Let’s assume we have a simple document that looks like the following:
<items>
<item status="sold">
<itemno>1234</itemno>
<seller>Fanning</seller>
<description>Antique Lamp</description>
<reserve-price>200</reserve-price>
<end-date>12-31-2002</end-date>
</item>
<item status="sold">
<itemno>1235</itemno>
<seller>Smith</seller>
<description>Rugs</description>
<reserve-price>1000</reserve-price>
<end-date>2-1-2002</end-date>
</item>
</items>
The XQuery
doc("data/test/items.xml")/items/item/itemno
produces the following output, a sequence of nodes:
<itemno>1234</itemno>
<itemno>1235</itemno>
Because XML documents are hierarchical, XPath expression steps can operate on different axes of data. Although the XPath specification defines 13 different axes, an XQuery implementation has to support only 6 of them, though implementations may choose to support more:
• The child axis contains the children of the context node.
• The descendant axis contains the descendants of the context node. A descendant is a child or a child of a child and so on; thus, the descendant axis never contains attribute or namespace nodes.
• The parent axis contains the parent of the context node, if there is one.
• The attribute axis contains the attributes of the context node; the axis will be empty unless the context node is an element.
• The self axis contains just the context node itself.
• The descendant-or-self axis contains the context node and the descendants of the context node.
Figure 10-3 shows the nodes that make up the main XPath axes for a particular document, given a particular context node.
Figure 10-3. XPath axes

The context node that we are referring to here is the starting point of the evaluation step. In our earlier simple XPath expression, the starting point of the first evaluation step, the document node, is a concrete node. In the XQuery Data Model, this is the root node. The root node is the parent items node in this example document. In the second evaluation step, the items node would be the context node; in the third evaluation step, each item node would be the context node in turn; and so on. Each evaluation step can also filter the resulting sequence using a node test that can filter by name or by node type. In the last evaluation step, for example, only children of item named itemno will be selected. If we wanted to select all the children of item nodes, including seller nodes, description nodes, and all others, we could change the path expression to the following:
doc("data/test/items.xml")/items/item/*
Each evaluation step has an axis; in our simple query, we have let the axis default to “child” by leaving it out. The same query could be expressed this way:
doc("data/test/items.xml")/child::items/child::item/child::*
Any other valid axis could also be used. Another common abbreviation is to abbreviate the attribute axis to @. The evaluation step /attribute: :status in a query against the document above could be abbreviated to/@status.
Although XPath has much more functionality and a function library of its own (that can be used in path expressions in XQuery), in addition to being able to use the XPath and XQuery operators and functions, we’ll finish by discussing XPath predicates. After you filter any evaluation step by using a node test, you can filter the results further by using a query predicate. Query predicates follow the node test in square brackets. This predicate filters item elements whose itemno subelement has a text subelement with a value less than 1,000:
doc("data/test/items.xml")/items/item[itemno/text() < 1000]
A predicate can be as simple or complex as you want, but it must evaluate to a boolean value. More exactly, it is evaluated using the Effective Boolean Value (essentially, the rules for fn:Boolean). /a[1], for example, would evaluate to true for the first node named "a" in no namespace at the root; other nodes named "a" would evaluate to false. You can even have multiple predicates on the same evaluation step, if you want.
The heart of XQuery expressions—what forms most of the “selection logic” in an XQuery query—is called the FLWOR expressions. FLWOR (pronounced “flower”) is an acronym for the five main expression keywords: for, let, where, order by, and return. We’ve already seen the let expression, used to assign a value to a variable, and the return expression, for returning the value of a variable in the query:
let $a := doc("data/test/items.xml")
return $a
We’ll briefly define the use of each expression.
The for and let keywords are used to set up a stream of tuples, each tuple containing one or more bound variables. The for keyword is used for iteration. In the following query,
for $p in doc("mydocument.xml")/people/person
let $a := $p/age
where $a > 50
return $p/name/firstName/text()
the for statement uses an XPath expression to select a sequence of items. The for statement iterates over all the items that match the XPath expression, assigning a different item to the variable $p, one value for each time around the loop. If the sequence produced is (<person name='joe'/> <person name='bob'/>, <person name='phil'/>), the loop is executed three times, with $p assigned to one node for each iteration. The let keyword performs an assignment. The expression on the right side of the assignment is assigned to the variable in its entirety. The assignment takes place whether the value is a single item (as in the let $a := $p/age statement in the preceding query) or an entire sequence. To show the difference between iteration and assignment, consider the following two queries:
for $p in (1,2), $q in (A,B)
let $a := (7,8,9)
return ($p, $q, $a)
(: this returns: 1 A 7 8 9 1 B 7 8 9 2 A 7 8 9 2 B 7 8 9 :)
for $p in (1,2)
let $a := (7,8,9), $q := (A,B)
return ($p, $q, $a)
(: this returns: 1 A B 7 8 9 2 A B 7 8 9 :)
You can use the where keyword to filter the resulting tuples. You can filter based on the value based on any XQuery expression. Interestingly, in many situations you could use an XPath predicate in the for statement to achieve the same effect as using a where keyword. The earlier query that looks for people using the FLWOR where clause could be expressed just as easily like this:
for $p in doc("mydocument.xml")/people/person[age > 50]
return $p/name/firstName/text()
XQuery supports five types of comparison operators in the where clause:
- General (existential) comparison
- Value comparison
- Node comparison
- Type comparison
- Document position comparison
General comparison can compare a sequence with another sequence or with a value. If any of the items in the sequence match using the comparison operator (the general comparison operators are symbols like =, >, and <), the comparison is true. For example:
(1,2,3) = 1 (: this is true :)
(1,2,3) != 1 (: this is also true :)
(1,2,3) = (4,5,6) (: this is not true, none of the values compare :)
Value comparison compares an expression to an atomic value, and the expression must resolve to an atomic value, or the comparison produces an error. The value comparison operators are letter abbreviations like eq, gt, and lt. Here are some value comparisons:
given the sequence: <doc num="1"/>
number(/doc/@num) lt 2 (: this is true :)
number(/doc/@num) lt "2" (: this will work too :)
count(/doc) eq 4 (: this is false :)
(1,2,3) ne (4,5,6) (: this is an error, sequences are not comparable :)
Node comparison compares node identity; this is accomplished by using the XQuery is operator. Each node (including a constructed node) has a unique identity. The is operator compares two expressions that return a node for equality. is cannot be used with sequences. Type comparison looks at the data type of a node or atomic value. Document position comparison operators test whether one node is before or after another node in document order.
The order by keyword changes the order of the returned tuples. Usually, tuples are returned in the order of the input, which often is the document order (which we defined earlier in this chapter). The expression after the order by clause must resolve to a single atomic value; node sets and sequences are not orderable. The following query orders the returned items by the text of the givenName subelement of the name:
for $p in doc("mydocument.xml")/people/person[age > 50]
order by $p/name/givenName/text() descending
return $p/name/firstName/text()
The return keyword defines what the sequence that constitutes the return value will look like. In the last few queries, we have been returning only information derived from tuples as simple items. But items can be composed from scratch or from existing tuple information using node constructors. Node constructors can use simple literal strings with individual items separated by commas, but they can also use calculated values enclosed in curly braces. An example follows:
<descriptive-catalog>
{
for $i in doc("catalog.xml")//item,
$p in doc("parts.xml")//part[partno = $i/partno],
$s in doc("suppliers.xml")//supplier[suppno = $i/suppno]
order by $p/description, $s/suppname
return
<item>
{
$p/description,
$s/suppname,
$i/price
}
</item>
}
</descriptive-catalog>
Notice that this example uses construction twice. The <descriptive-catalog> element is constructed by simply using it as a literal. The <item>s in the return clause are constructed with a literal, but all <item> subelements are constructed by evaluation of the expressions between the curly braces; this is called a direct constructor. In addition to literal constructors and direct constructors, you can use computed constructors; these begin with the name of the node type to be constructed, followed by the content in curly braces. Here’s an example of computed constructors:
element person
{
attribute name
{$p/name[1]/givenName[1]/text()[1])}
}
That’s a brief introduction, and here’s a list of some of the other types of expressions available in XQuery:
• Function calls
• Expressions combining sequences
• Arithmetic and logic expressions
• Comparisons—content, identity, and order based
• Quantified expressions—where one element satisfies a condition
• Expressions involving types—cast, instance of, treat, and typeswitch
Finally, let’s explore the question “With what types of data [XML can represent many different data models] is XQuery useful?” Some authors have attempted to make a distinction between XQuery and XSLT based on the premise that although XSLT and XQuery can be used for almost all the same functions (at least if you compare XSLT 2.0 and XQuery 1.0), XSLT, with its template mechanism, is better for data-driven transformations, whereas XQuery is better suited for queries. We find it instructive to look at the XQuery use-cases document to see what the inventors of XQuery had in mind. The use cases mention many different kinds of data:
• Experiences and exemplars—general XML
• Tree—queries that preserve hierarchy
• Sequence—queries based on document ordering
• Relational—relational data (representing tables as XML documents)
• SGML—queries against SGML data
• String—string search (aka full-text search)
• Queries using namespaces
• Parts explosion—usually done well by object and CODASYL databases
• Strong types—queries that exploit strongly typed data
• Full-text use cases (separate specification)
So it appears that XQuery can be useful with all kinds of data; particular implementations, however, may not implement certain features that their data types cannot take advantage of. We’ll see this point when we look at the XQuery implementation inside SQL Server.
Comparing and Contrasting XQuery and SQL
SQL is the native language of SQL Server. SQL Server programmers have used it exclusively with Transact-SQL (T-SQL) until the CLR language became available in SQL Server 2005. These same programmers probably were not familiar with XQuery, and it is instructive to compare the two languages to make SQL programmers more at home.
SQL currently is a more complete language than XQuery with regard to its capabilities. SQL can be used for data definition (DDL), data manipulation (INSERT, UPDATE, and DELETE), and queries (SELECT). XQuery delegates its DDL to XML Schema, and the rest of XQuery equates to the SQL SELECT statement. Microsoft and others have proposed data manipulation extensions to XQuery, and the W3C has begun research and produced the “XQuery Update Facility Requirements” document. XQuery-based data manipulation is part of SQL Server 2005. But for now, we’ll just compare SQL’s SELECT and XQuery’s FLWOR expressions.
The clauses of a SQL SELECT statement have an almost one-to-one correspondence in function to the clauses of a FLWOR statement, as shown in Figure 10-4.
Figure 10-4. SQL SELECT and FLWOR

Both SQL’s SELECT clause and XQuery FLWOR’s return clause enumerate data to be returned from the query. SELECT names columns in a resultset to be returned, whereas return names a sequence of items to be returned. Fairly complex nodes can be returned using, for example, element constructors and nested elements, but items in a sequence are what are being returned nevertheless. Another similarity is that both return and SELECT can be nested in a single statement.
SQL’s FROM clause lists the tables from which the data will be selected. Each row in each table is combined with each row in other tables to yield a Cartesian product of tuples, which make up the candidate rows in the resultset. XQuery FLWOR’s for clause works exactly the same way by defining variables. Multiple clauses in a for statement, separated by commas, produce a Cartesian product of candidate tuples as well. Because a for clause in XQuery can contain a selection using XPath, for also has some of the functionality of a SQL WHERE clause; this is especially noticeable when the XPath predicate is used. Both SQL and XQuery do support WHERE and ORDER BY, although the XQuery WHERE clause can be based on general (this is known as existential comparison), value comparison, and other types of comparison, whereas SQL is based on value comparison.
Both XQuery FLWOR’s let clause and SQL’s SET clause can be used for assignment, though let brings variables into scope inside an XQuery FLWOR expression like for does. SET in SQL is often a clause in a SQL UPDATE statement, or a stand-alone statement in a SQL batch or a stored procedure. In fact, in T-SQL, SELECT can also be used for assignment.
Though some of the matches are not 100 percent exact, it should not be a big stretch for SQL users to learn XQuery. The ease of adoption by SQL programmers, rather than data models served, is probably the reason for relational database vendors (or, for that matter, OODBMS (Object Oriented Database Management System) vendors, because XQuery also resembles OQL, the Object Query Language in object-oriented databases) to embrace XQuery over the functionally equivalent XSLT language.
SQL and XQuery differ with respect to their data models. Attributes (column values) in SQL usually have two possible value spaces: an atomic value or NULL. Having NULL complicates some of the SQL operations; NULLs are not included by default in aggregate operations, for example. XQuery has the NULL sequence (a sequence with zero items), which has some of the same semantics (and complications) as the SQL NULL, as well as the xsi:nil = true attribute that denotes a nil value. In addition, XQuery has to deal with complications of nodes versus atomic values, as well as the complications of possibly hierarchical nodes or multivalue sequences. This makes some of the rules for XQuery quite complex. As an example, value comparisons between unlike data types in SQL are not possible without casting (although SQL Server performs implicit casting in some cases). Comparing a value with NULL (including NULL) is always undefined. This rule could be stated in two sentences with two cases. Contrast this with the rules for value comparison in XQuery:
- Atomization is applied to each operand. If the result is not an empty sequence or a single atomic value, a type error is raised.
- If either operand is an empty sequence, the result is an empty sequence.
- If either operand has the most specific type
xdt:untypedAtomic, that operand is cast to a required type, which is determined as follows: - If the type of the other operand is numeric, the required type is
xs:double.
• If the most specific type of the other operand is
xdt:untyped Atomic, the required type isxs:string.• Otherwise, the required type is the type of the other operand.
- If the cast fails, a dynamic error is raised.
- The result of the comparison is true if the value of the first operand is (equal, not equal, less than, less than or equal, greater than, or greater than or equal) to the value of the second operand; otherwise, the result of the comparison is false. The “B.2 Operator Mapping” section of the specifications describes which combinations of atomic types are comparable and how comparisons are performed on values of various types. If the value of the first operand is not comparable with the value of the second operand, a type error is raised.
Quite a bit more complex, don’t you agree? This rule is not presented here for your memorization—only to point out that the XQuery rules are more complex than the equivalent SQL rules.
Both SQL and XQuery are strongly typed languages. Strong typing refers to the fact that all of the functions and operators require the correct data type, although a language is allowed to do implicit typecasting and type promotion. SQL implementations do static type checking; in XQuery, static type checking is optional, although SQL Server’s implementation of XQuery implements it. Static type checking refers to the fact that a language has a type-checking phase of the query in which the expressions are checked for type-correctness and cardinality; this type checking does not use the data. When static type checking is used, having schemas assists optimization. Both SQL and XQuery are declarative languages; T-SQL is a procedural extension, however, especially considering modules like stored procedures that can contain SQL statements and procedural logic.
While we’re mentioning stored procedures, the XQuery equivalents to SQL’s stored procedures and user-defined functions (Persistent Stored Modules, as they are called in ANSI SQL) are user-defined functions. These can either be defined in the query prolog or in separate modules. XQuery allows for implementation-dependent extensions to store and access modules in libraries. XQuery’s functions are supposed to be side effect free. SQL stored procedures and triggers are not guaranteed to be side effect free, although SQL user-defined functions can make this guarantee.
In conclusion, the SQL SELECT statement has a lot in common with the XQuery language, though XQuery is more complex because of the underlying data model. XQuery has some of the functionality of data manipulation through the use of constructors but no way to affect the underlying data. It more reflects the querying and reporting functionality of SQL SELECT and stored procedures.
Using XQuery with the XML Data Type
SQL Server 2005’s implementation of XQuery is aligned with the July 2004 version of the XQuery specification. It’s an implementation of a stable subset of the specification.
SQL Server supports XQuery on the XML data type directly. It does this through four of the XML data type’s methods:
• xml.query takes an XQuery query as input and returns an XML data type as a result.
• xml.value takes an XQuery query as input and returns a SQL type as a scalar value.
• xml.exist takes an XQuery query as input and returns zero or one, depending on whether the query returns an empty sequence (zero) or a sequence with at least one item (one).
• xml.nodes takes an XQuery query as input and returns a one-column rowset that contains references to XML documents with the XQuery context set at the matching node.
Any of these accessor functions can also return NULL if the input value is NULL. XQuery usually gets its input from the XQuery function doc or collection in dealing with documents from the file system or input from a stream. XQuery can also use a user-defined context document. In SQL Server 2005, though, the XML functions refer to a specific instance of the XML data type, and input will come from that instance’s value; this is the context document.
Although the XQuery language itself can be used to produce complex documents, as we’ve seen, this functionality is really used to a great extent in SQL Server only in the xml.query function. When using xml.value and xml.exist, we’ll almost always be using simple XPath 2.0 expressions rather than complex XQuery with sequences, constructors, formatting information, and so on. Although we could use more complex XQuery, the reason for this is that xml.value can return only a sequence containing a single scalar value (it cannot return an XML data type), and xml.exist is used to check for existence. So let’s cover them first.
xml.exist(string xquery-text)
The xml.exist function applies an XQuery query to an instance of the XML data type. If the query returns an empty sequence, xml.exist returns false (0); if the query returns anything other than an empty sequence, xml.exist returns true (1). Null input returns a NULL answer. Here’s a simple example using an untyped XML variable:
DECLARE @x XML
SELECT @x.exist('/people/person') -- returns NULL
SET @x = '<people><person>fred</person></people>'
SELECT @x.exist('/people/person') -- returns 1
SET @x = '<person>sam</person>'
SELECT @x.exist('/people/person') -- returns 0
You can also use a SQL SELECT statement that uses the xml.exist function on an XML data type column in a table. If we define the following table,
CREATE TABLE xml_tab(
the_id INTEGER PRIMARY KEY IDENTITY,
xml_col XML)
and fill the table with some rows, using the xml.exist function in the column list of a SQL SELECT statement will search the xml_col value in each row, looking for data that matches the given XQuery expression. For each row, if the row contains matching data in the specified column, the function returns true (1). If the rows inserted look like this,
INSERT xml_tab VALUES('<people><person name="curly"/></people>')
INSERT xml_tab VALUES('<people><person name="larry"/></people>')
INSERT xml_tab VALUES('<people><person name="moe"/></people>')
GO
the XQuery xml.exist expression to see if any row in the table contains a person named "moe" would look like this:
SELECT xml_col.exist('/people/person[@name="moe"]') AS is_there_moe
FROM xml_tab
The result will be a three-row rowset containing the values, 0 (“False”), 0 (“False”), and 1 (“True”) in the is_there_moe column. Notice that if we add just a single row containing a single XML document with multiple <person> elements,
-- insert one row containing an XML document with 3 persons
-- rather than 3 rows each containing an XML document with 1 person
INSERT xml_tab VALUES(
'<people>
<person name="curly"/>
<person name="larry"/>
<person name="moe"/>
</people>')
the result of the SELECT statement above is a one-row rowset containing the value 1 (“True”), not one row for each person in the XML document. The rows are the rows of a SQL rowset, rather than XML results.
Because the xml.exist function returns bit, a SQL data type, it could also be used as a predicate in a SQL statement—that is, in a SQL WHERE clause. This SQL statement would select only rows that had an XML document containing a person named "moe":
SELECT the_id FROM xml_tab
WHERE xml_col.exist('/people/person[@name="moe"]') = 1
A good use for xml.exist is in a selection predicate in a query that then produces complex XML for the same or another XML column by using the xml.query function. In this case, the xml.query function operates only on the subset of rows selected by xml.exist, rather than on all the rows in the table. We’ll come back to this when we discuss xml.query.
xml.value(string xquery-text, string SQLType)
The xml.value function takes a textual XQuery query as a string and returns a single scalar value. The SQL Server type of the value returned is specified as the second argument, and the value is cast to that data type. The data type can be any SQL Server type except the following:
• XML data type
• TIMESTAMP data type
• UNIQUEIDENTIFIER data type
• SQL_VARIANT data type
• IMAGE, TEXT, or NTEXT data type
• A CLR UDT
You wouldn’t need to have xml.value to return a single XML data type, because a different method, xml.query, does exactly that. The xml.value function must be guaranteed to return a single scalar value, or else an error is thrown. SQL Server’s implementation of XQuery static type checking works according to the specification: Query execution is divided into a static type-checking phase and a dynamic execution phase. Static type checking does not use the data to determine if the query is guaranteed to return a singleton value. If the query fails static type checking, it’s as though you misspelled the word SELECT (as, for example, SELEC) in a SQL query. The query is not executed, and an error is thrown. If this static-type-checking error occurs in a stored procedure definition, CREATE PROCEDURE fails.
Using our overly simple document from the xml.exist section,
CREATE TABLE xml_tab(
the_id INTEGER PRIMARY KEY IDENTITY,
xml_col XML)
GO
INSERT xml_tab VALUES('<people><person name="curly"/></people>')
INSERT xml_tab VALUES('<people><person name="larry"/></people>')
INSERT xml_tab VALUES('<people><person name="moe"/></people>')
GO
the following SQL query using xml.value
SELECT the_id,
xml_col.value('/people[1]/person[1]/@name', 'varchar(50)') AS name
FROM xml_tab
would produce a single row containing the_id and name columns for each row. The result would look like this:
the_id name
------ ------------------------------
1 curly
2 larry
3 moe
Note that we’ve had to use the subscript [1] in every XPath evaluation step to ensure that we’re getting a singleton answer (strictly speaking, the cardinality must be zero-or-one). This is because of SQL Server XQuery’s static type checking. If we didn’t use the subscript, the engine would have to assume that the document permits multiple person elements and would fail with this error message: XQuery [value()]: 'value()' requires a singleton (or empty sequence), found operand of type 'xdt:untypedAtomic *'. Using the subscript predicate ensures that the query returns 'xdt:untypedAtomic ?'.
The xml.value function is good for mixing data extracted from the XML data type in the same query with columns returned from SQL Server, which by definition contain a single value. In addition, it can be used as a predicate in a SQL JOIN clause or in a SQL WHERE clause, as in the following query:
SELECT the_id
FROM xml_tab
WHERE xml_col.value(
'/people[1]/person[1]/@name', 'VARCHAR(50)') = 'curly'
xml.query(string xquery-text)
Although all the functions of the XML data type do invoke the internal XQuery engine, the function that returns an instance of the XML data type is xml.query. This function takes the XQuery text, which can be as simple or complex as you like, as an input string and returns an instance of XML data type. The result is always an XQuery sequence as the specification indicates, except when your input instance is NULL; then the result is NULL. The resulting instance of XML data type can be returned as a SQL variable, used as input to an INSERT statement that expects an XML type, or returned as an output parameter from a stored procedure. The instance is always untyped XML. To check for schema-validity, you can assign the returned XML to an XML variable typed with an XML SCHEMA COLLECTION. SQL Server’s XQuery does not implement the XQuery validate function.
The simplest XQuery query might be one that consists only of an XPath 2.0 expression. This would return a sequence containing zero or more nodes or atomic values. Given our previous document, a simple XQuery query like this
SELECT xml_col.query('/people/person') AS persons
FROM xml_tab
would return an XML instance with a value that is a sequence containing a single node for each row:
persons
-----------------------
<person name="curly"/>
<person name="larry"/>
<person name="moe"/>
The query does not have to return a single node or a well-formed document, however. If the following row is added to the table, the results are different:
INSERT xml_tab VALUES(
'<people>
<person name="laurel"/>
<person name="hardy"/>
</people>')
GO
SELECT xml_col.query('/people/person') AS persons
FROM xml_tab
These are the results:
persons
----------------------------------------------
<person name="curly"/>
<person name="larry"/>
<person name="moe"/>
<person name="laurel"/><person name="hardy"/>
Note that the result from the last row is a multinode sequence, and though it is not a well-formed XML document, it does adhere to the XQuery 1.0 Data Model.
In addition to simple XQuery statements consisting of a simple XPath expression, you can use the FLWOR expressions that we saw at the beginning of this chapter. (Note that at this time, SQL Server’s implementation of XQuery does not support the let FLWOR operator.) This query uses FLWOR expressions and produces the same result as the previous query:
SELECT xml_col.query('
for $b in /people/person
return ($b)
')
FROM xml_tab
You can subset the results with an XQuery predicate and the WHERE clause, as well as with an XPath predicate. For example, these two queries return the same results.
-- XQuery WHERE clause
SELECT the_id, xml_col.query('
for $b in /people/person
where $b/@name = "moe"
return ($b)
') AS persons
FROM xml_tab
-- XPath predicate
SELECT the_id, xml_col.query('/people/person[@name="moe"]') AS persons
FROM xml_tab
Note that for the columns in which "moe" did not occur, the result is an empty sequence rather than an empty string or a NULL value. That’s because the output from xml.query is an XML data type. If you cast or convert the XML empty sequence to a VARCHAR data type, it is an empty string, not the value NULL:
the_id persons
-----------------------------
1
2
3 <person name="moe"/>
4
You can also return literal content interspersed with query data by using the XQuery standard curly brace notation. The following query returns a series of results surrounded by XHTML list tags (<li>). Note that this uses an element normal form version of the XML in the table, rather than the attribute normal form we’ve been using thus far:
CREATE TABLE xml_tab(
the_id INTEGER PRIMARY KEY IDENTITY,
xml_col XML)
GO
INSERT xml_tab
VALUES('<people><person><name>curly</name></person></people>')
INSERT xml_tab
VALUES('<people><person><name>larry</name></person></people>')
INSERT xml_tab
VALUES('<people><person><name>moe</name></person></people>')
INSERT xml_tab VALUES(
'<people>
<person><name>curly</name></person>
<person><name>larry</name></person>
<person><name>moe</name></person>
<person><name>moe</name></person>
</people>')
GO
-- literal result element and
-- constructor with curly braces
SELECT xml_col.query('
for $b in //person
where $b/name="moe"
return <li>{ string($b/name[1]) }</li>
') as query_for_moe
FROM xml_tab
GO
This returns
query_for_moe
--------------
<li>moe</li>
<li>moe</li><li>moe</li>
This query also uses the XQuery string function, which leads us to talking about XQuery standard functions. We’ll talk about XQuery standard functions and operators later in this chapter.
xml.nodes(string xquery-text)
The xml.nodes XML data type function produces a single-column rowset from the contents of an XML data type column or variable. This function takes an XQuery expression and produces zero or more rows that contain a single column that is an opaque reference to a special type of XML document. This reference is special because the context node for future XQuery functions is set at the node that matches the XQuery statement in the xml.nodes clause. This document must be used with other XQuery functions, like query or value, and can even be used as input to another nodes function.
Because xml.nodes produces a context node other than the root node, relative path expressions can be used with the resultant document reference. Because the column in the table produced by xml.nodes is of data type XML, you can use XML functions on it to extract pieces of its content. Here’s a simple example that uses an XML variable containing a small document:
DECLARE @x XML
SET @x = '
<customers>
<customer>
<givenName>Jill</givenName><givenName>Rodgers</givenName>
<country>US</country>
</customer>
<customer>
<givenName>Juan</givenName><givenName>Rodriguez</givenName>
<country>Costa Rica</country>
</customer>
</customers>'
SELECT
tab.col.value('givenName[1]', 'VARCHAR(20)') AS FirstName,
tab.col.value('givenName[1]', 'VARCHAR(20)') AS GivenName,
tab.col.value('country[1]', 'VARCHAR(20)') AS Country,
tab.col.exist('country/text()[.="US"]') AS Local
FROM
@x.nodes('//customer') tab(col)
That produces this output:
LastName FirstName Country Local
---------------------------------------
Jill Rodgers US 1
Juan Rodriguez Costa Rica 0
Note that the table produced by xml.nodes must be aliased in the form tablename(columnname). In this example, we call it tab(col) though the names themselves are irrelevant. Note also that the table produced by xml.nodes cannot be returned directly to the caller, because there isn’t a good way to visualize what it contains.
If you use xml.nodes with an instance of a column in a table, the function must be used in conjunction with the CROSS APPLY or OUTER APPLY clause of a SELECT statement, because the table that contains the XML data type column must be part of the left side of an APPLY clause. Here’s a simple example that shows its usage. Starting with the simple XML data type table of people,
CREATE TABLE xml_tab(
the_id INTEGER PRIMARY KEY IDENTITY,
xml_col XML)
GO
INSERT xml_tab
VALUES('<people><person><name>curly</name></person></people>')
INSERT xml_tab
VALUES('<people><person><name>larry</name></person></people>')
INSERT xml_tab
VALUES('<people><person><name>moe</name></person></people>')
INSERT xml_tab values('
<people>
<person><name>laurel</name></person>
<person><name>hardy</name></person>
</people>')
GO
we can use the xml.nodes method to extract a series of rows, one for each person’s name:
xml_col.nodes('/people/person[1]') AS result(a)
This produces a four-row, one-column rowset of abstract document references (meaning that the entire document in the table-valued function does not take up the same amount of memory as the original document in the table), with each abstract document pointing at a different XML context node. Then we can use the xml.value function to extract values:6
SELECT the_id, tab.col.value('text()[1]', 'VARCHAR(20)') AS name
FROM xml_tab
CROSS APPLY
xml_col.nodes('/people/person/name') AS tab(col)
This produces a rowset that looks like this:
the_id name
------- ---------
1 curly
2 larry
3 moe
4 laurel
4 hardy
Notice that we could not have produced the same result by using either the xml.value function or the xml.query function alone. The xml.value function would produce an error, because it needs to return a scalar value. The xml.query function would return only four rows, a single row for the “laurel and hardy” person.
There are a few interesting features to note about this syntax:
• The xml.nodes method produces a table, which must be given an alias in the form tablename(columnname).
• The xml.value method on the left side of the CROSS APPLY keyword refers to the table and column from the xml.nodes method.
• The xml.nodes statement on the right side of the CROSS APPLY keyword refers to the xml_col column from the xml_tab table. The xml_tab table appears on the left side of the CROSS APPLY keyword.
• The SELECT statement can also refer to the other columns in the xml_tab table—in this case, the the_id column.
You could use OUTER APPLY instead of CROSS APPLY. In this case, because all the row values contain a matching <name> node, the result will be the same, but if we added a “nameless person” as follows,
INSERT xml_tab VALUES('<people><person></person></people>')
the CROSS APPLY version would produce five rows, and the OUTER APPLY version would produce six rows with the name as a NULL value. A similar condition occurs even if the part of the query that uses the value method against the noderefs returns NULL. Suppose that we look for a node in the xml.value portion (l_name) that doesn’t exist in any of the noderefs:
SELECT the_id,
tab.col.value('l_name[1]/text()[1]', 'varchar(20)') AS l_name
FROM xml_tab
CROSS APPLY
xml_col.nodes('/people/person/name') AS tab(col)
CROSS APPLY still produces five rows, and OUTER APPLY produces six rows, all with NULL values for l_name.
Although the syntax for producing the table may seem strange at first, this equates to the second parameter in the OpenXML function, which also produces one row for each node selected by the expression in the second parameter. You use each reference node produced by the xml.nodes function as a starting node (context node) for the XML data type accessor functions xml.query, xml.value, xml.nodes, and xml.exist. These functions are used to produce additional columns in the final rowset, analogous to the WITH clause in OpenXML. When used in conjunction with the XML data type functions, the xml.nodes function is a less-memory-intensive version of OpenXML. It uses less memory because the table contains references to data in the XML data type column; we get similar results to using OpenXML without the overhead of having a DOM in memory.
XQuery Standard Functions and Operators
The XQuery standard includes two companion specifications that describe the data model and its standard functions and operators. These standards apply not only to XQuery, but also to XPath 2.0 and indirectly to XSLT 2.0, which uses XPath 2.0 as its query language. The first specification, “XQuery 1.0 and XPath 2.0 Data Model,” lays the groundwork for both specifications and defines the data model as being based on the XML Information Set data model, with some extensions. It also describes functions that each XQuery processor should implement internally. Note that although these are described using functional notation, they are meant to be implemented inside the parser and should not be confused with the standard SQL function library. We discussed the data model in Chapter 9, along with its implementation in the SQL Server 2005 XML data type.
The second companion spec is more relevant to XQuery and XPath as query languages. It is called “XQuery 1.0 and XPath 2.0 Functions and Operators Version 1.0,” and it describes a standard function library and a standard set of operators for XQuery engine implementers. This would be similar to the standard function library in SQL:1999. The XQuery engine in SQL Server 2005 implements some of the standard functions, concentrating on the ones that make the most sense for a database or where the functionality is similar to a T-SQL function.
The functions and operators are grouped in the spec according to the data type that they operate on or their relationship to other functions and operators. The complete list of groups is as follows:
• Accessors
• Error function
• Trace function
• Constructors
• Functions and operators on numerics
• Functions on strings
• Functions and operators on boolean values
• Functions and operators on durations, dates, and times
• Functions related to QNames
• Functions and operators for anyURI
• Functions and operators on base64Binary and hexBinary
• Functions and operators on NOTATION
• Functions and operators on nodes
• Functions and operators on sequences
• Context functions
• Casting
Some of these categories require further explanation.
Accessors get information about a specific node. Examples include fn:node-kind, fn:node-name, and fn:data, which obtain the kind of node, the QName, and the data type.
The error function is called whenever a nonstatic error (that is, an error at query execution time) occurs. It can also be invoked from XQuery or XPath applications and is similar to a .NET Framework exception. SQL Server 2005 XQuery does not implement this function.
Constructors are provided for every built-in data type in the XML Schema, Part 2, Datatypes, specification. These are similar to constructors in .NET Framework classes and may be used to create nodes dynamically at runtime.
Context functions can get information about the current execution context—that is, the document, node, and number of items in the currentsequence being processed. These are similar to environment variables in a program or the current environment (SET variables) in a SQL query.
Casting functions are used to cast between different data types, similar to casting in a programming language, the CType function in Visual Basic .NET, or the CAST function in SQL:1999. A specific casting function is defined for each legal cast among the XML Schema primitive types.
SQL Server XQuery Functions and Operators
The SQL Server engine’s implementation of XQuery provides a subset of the XQuery and XPath functions and operators. The functions that are implemented are listed in the sidebar “XQuery Functions Supported by SQL Server.”
XQuery Functions Supported by SQL Server
Data Accessor Functions
string
data
Functions on Numeric Values
floor
ceiling
round
Functions on String Values
concat
contains
substring
string-length
Constructors and Functions on Booleans
not
Functions on Nodes
number
local-name
namespace-uri
Context Functions
position
last
Functions on Sequences
Aggregate Functions
count
avg
min
max
sum
Functions Related to QNames
expanded-QName
local-name-from-QName
namespace-uri-from-QName
Constructor Functions
To create instances of any of the XSD types (except QName, xs:NMTOKEN, xs:NOTATION, xdt:yearMonthDuration, xdt:dayTimeDuration, and subtypes of xs:duration)
The sidebar “XQuery Operators Supported by SQL Server” lists all the operators supported by SQL Server 2005’s implementation of XQuery.
XQuery Operators Supported by SQL Server
Numeric operators: +, -, *, div, mod
Value comparison operators: eq, ne, lt, gt, le, ge
General comparison operators: =, !=, <, >, <=, >=
Note also that although the specification defined that each function (including built-in functions) lives in a specific namespace, SQL Server’s XQuery engine does not require the namespace prefix for the built-in functions.
In addition to the fact that not all the functions and operators are implemented, there are some usage limits. Some of the limits you might run into are
• Use of a positional variable with the for clause of FLWOR using the at keyword is not supported.
• The context functions (last and position) are allowed only in predicates.
• Queries and some functions (like the data function) are not allowed over constructed sequences.
• You cannot use an ORDER BY clause that compares multiple iterators.
• You cannot construct the name of an element or attribute using expressions.
• Some filter expressions are not allowed in path expressions.
Here are examples of some of these constructs:
(: A query over a constructed sequence :)
for $i in (for $j in //a return <row>{ $j }</row>)
return $i
(: A filter expression with a filter in a path expression :)
/a/b/attribute()
(: This is allowed :)
/a/b/@*
(: Using order by with multiple iterators :)
for $x in //a
for $y in //b
order by $x > $y
return $x, $y
SQL Server’s implementation does not allow XQuery user-defined functions or modules, but some built-in extension functions permit using SQL variables and table data inside the XQuery statement. Let’s look at them now.
SQL Server XQuery Extended Functions
Because the XQuery engine is executing in the context of a relational database, it is convenient to provide a standard way to use non-XML data (that is, relational data) inside the XQuery query itself. SQL Server provides two extension functions for exactly this purpose: sql:column and sql:variable. These keywords allow you to refer to relational columns in tables and T-SQL variables, respectively, from inside an XQuery query. Because an XQuery eventually uses the relational query processor with some XQuery-specific functions and optimizations, you can use the sql:variable XQuery function to parameterize your XQuery queries in a way similar to parameterizing SQL queries.
These functions can be used anywhere an XQuery query can be used—namely, xml.exist, xml.value, xml.query, and xml.modify. xml.modify is discussed in the next section.
The functions can refer to any SQL data type, with the following exceptions:
• The XML data type
• User-defined data types
• TIMESTAMP
• UNIQUEIDENTIFIER
• TEXT and NTEXT
• IMAGE
sql:column
This function refers to a column in the current row of the current SQL query. The column can be in the same table as the XML data type column, or it can be included in the result as part of a join. The table must be in the same database and owned by the same schema owner, and is specified using a two-part name in the format Tablename.Columnname Here’s an example, using the table with name as a subelement that we’ve been using in the XQuery xml.nodes examples:
CREATE TABLE xml_tab(
the_id INTEGER PRIMARY KEY IDENTITY,
xml_col XML)
GO
INSERT xml_tab
VALUES('<people><person><name>curly</name></person></people>')
INSERT xml_tab
VALUES('<people><person><name>larry</name></person></people>')
INSERT xml_tab
VALUES('<people><person><name>moe</name></person></people>')
INSERT xml_tab VALUES(
'<people>
<person><name>curly</name></person>
<person><name>larry</name></person>
<person><name>moe</name></person>
<person><name>moe</name></person>
</people>')
GO
SELECT xml_col.query('
for $b in //person
where $b/name="moe"
return <li>{ $b/name/text() } in record number
{sql:column("xml_tab.the_id")}</li>
')
FROM xml_tab
This returns the following result. (Note: The first two rows in the result are empty, and some extra whitespace appears between the word number and the value of the id field because of the way the query text is formatted.)
-----------------------------------
<li>moe in record number 3</li>
<li>moe in record number 4</li><li>moe in record number 4</li>
sql:variable
The sql:variable function allows you to use any T-SQL variable that is in scope at the time the XQuery query is executed. This will be a single value for the entire query, as opposed to the sql:column, where the column value changes with every row of the result. This function is subject to the same data type limitations as sql:column. An example of using sql:variable in an XQuery query would look like this:
DECLARE @occupation VARCHAR(50)
SET @occupation = ' is a stooge'
SELECT xml_col.query('
for $b in //person
where $b/name="moe"
return <li>{ $b/name/text() } { sql:variable("@occupation") }</li>
')
FROM xml_tab
This statement uses the value of a T-SQL variable, @occupation, in the returned sequence in the XQuery query.
This returns the following result. (Note: The first two rows in the result are empty.)
----------------------------------------------------
<li>moe is a stooge</li>
<li>moe is a stooge</li><li>moe is a stooge</li>
Multiple-Document Query in SQL Server XQuery
As we saw in the XQuery specification discussion earlier in this chapter, queries can encompass more than one physical XML document by using the doc or collection function. In SQL Server’s implementation of XQuery, however, the functions that allow input are not implemented. This is because the XQuery functions are implemented as instance functions that apply to a specific instance of the XML data type. Using the instance functions (xml.query, xml.exist, and xml.value), the XQuery query is a single document only. So what if you want to combine more than one document—the XQuery equivalent of a SQL JOIN?
One way to combine multiple documents to produce a single XQuery sequence as a result is to perform the query over each document separately and concatenate the results. This can be easily accomplished using the SELECT...FOR XML...TYPE syntax, although this is an XML data type instance subject to the XML data type size limit (at least 2GB). This may not always be what you want, however. Some multidocument queries are based on using one document to “join” another in a nested for loop. These types of queries cannot be accomplished by using sequence concatenation. Another way to accomplish multidocument queries is to use the xml.query function on different types, combined with the SQL JOIN syntax. This doesn’t deal with the nested-tuple problem, either.
XML DML:7 Updating XML Columns
The XQuery 1.0 specification does not currently include an XQuery syntax for mutating XML instances or documents in place. A data manipulation language (DML) is not planned for the first version of XQuery, but a working draft is under development. A working draft of the first specification in the series, “XQuery Update Facility Requirements,” was released in April 2005.
Because SQL Server 2005 will use XQuery as the native mechanism for querying the XML data type inside the server, it is required to have some sort of manipulation language. The alternative would be replacing the instance of the XML data type only as an entire entity. Because changes to XML data type instances should participate in the current transaction context, this would be equivalent to using SELECT and INSERT in SQL without having a corresponding UPDATE statement. Therefore, SQL Server 2005 introduces an implementation of XML DML.
XML DML is implemented using XQuery-like syntax with SQL-like extensions. This emphasizes the fact that manipulating an XML instance inside SQL Server is equivalent to manipulating a complex type or, more accurately, a graph of complex types. You invoke XML DML by using the xml.modify mutator function on a single XML data type column, variable, or procedure parameter. You use XML DML within the context of a SQL SET statement, using either UPDATE...SET on an XML data type column or using SET on an XML variable or parameter. As a general rule, it would look like this:
-- change the value of XML data type column instance
-- note: the string 'some XML DML' is NOT valid XML DML
UPDATE some_table
SET xml_col.modify('some XML DML')
WHERE id = 1
-- change the value of an XML variable
DECLARE @x XML
-- initialize it
SET @x = '<some>initial XML</some>'
-- now, mutate it
-- in this case delete all of the some nodes at the root
SET @x.modify('delete /some')
As with the VARCHAR(MAX).WRITE mutator, attempting to call modify() on a NULL XML instance will cause a SQL exception. Note that this syntax is used only to modify the XML nodes contained in an existing instance of an XML data type. To change a value to or from NULL, you must use the normal XML data type construction syntax. With the xml.modify function, you can use XQuery syntax with the addition of three keywords: insert, delete, and replace value of. Only one of these keywords may be used in a single XML DML statement.
xml.modify(‘insert . . .’)
You use the XML DML insert statement to insert a single node or an ordered sequence of nodes into the XML data type instance as children or siblings of another node. The node or sequence to be inserted can be an XML or XQuery expression, as can the “target node” that defines the position of the insert. The general format of the insert statement is as follows,
insert
Expression1
{as first | as last} into | after | before
Expression2
where Expression1 is the node or sequence to be inserted and Expression2 is the insert target. Any of the seven node types and sequences of those types may be inserted as long as they do not result in an instance that is malformed XML. Remember that well-formed document fragments are permitted in XML data types.
The keywords as first, as last, and into are used to specify inserting child nodes. Using the into keyword inserts the node or sequence specified in Expression1 as a direct descendant, without regard for position. It usually is used to insert child nodes into an instance where no children currently exist. Using as first or as last ensures that the nodes will be inserted at the beginning or end of a sequence of siblings. These usually are used when you know that the node already contains child nodes. These keyword are ignored and do not cause an error when attribute nodes are being inserted. When processing-instruction or comment nodes are being inserted, “child” refers to the position in the document rather than a real parent–child relationship.
Let’s start with an instance of an XML invoice and mutate the invoice.
Here’s our starting point:
-- declare XML variable and set its initial value
DECLARE @x xml
SET @x =
'<Invoice>
<InvoiceID>1000</InvoiceID>
<CustomerName>Jane Smith</CustomerName>
<LineItems>
<LineItem>
<Sku>134</Sku>
<Quantity>10</Quantity>
<Description>Chicken Patties</Description>
<UnitPrice>9.95</UnitPrice>
</LineItem>
<LineItem>
<Sku>153</Sku>
<Quantity>5</Quantity>
<Description>Vanilla Ice Cream</Description>
<UnitPrice>1.50</UnitPrice>
</LineItem>
</LineItems>
</Invoice>'
You could insert a new InvoiceDate element as a child of the Invoice element by using the following statement:
SET @x.modify('insert <InvoiceDate>2002-06-15</InvoiceDate>
into /Invoice[1]')
SELECT @x
This statement would insert the InvoiceDate element as the last child of Invoice, after LineItems. To insert it as the first child of Invoice, simply change the statement to the following:
SET @x.modify('insert <InvoiceDate>2002-06-15</InvoiceDate>
as first
into /Invoice[1]')
SELECT @x
Here’s an example of inserting an attribute, status="backorder", on the Invoice element:
SET @x.modify('insert attribute status{"backorder"}
into /Invoice[1]')
SELECT @x
Notice that this uses the constructor evaluation syntax (curly braces) to define the value of the attribute (backorder). You can also insert an entire series of elements using the insert statement. If you wanted to add a new LineItem, you would do the following:
SET @x.modify('insert
(
<LineItem>
<Sku>154</Sku>
<Quantity>20</Quantity>
<Description>Chocolate Ice Cream</Description>
<UnitPrice>1.50</UnitPrice>
</LineItem>
)
into /Invoice[1]/LineItems[1]')
SELECT @x
The after and before keywords are used to insert siblings at the same level of hierarchy in the document. These keywords cannot be used in the same statement as into; this produces an error. It is also an error to use the after and before keywords when inserting attributes.
Following our earlier example, if you want to set the InvoiceDate at a specific position in the Invoice element’s set of children, you need to use the before or after keyword and have an XPath expression that points to the appropriate sibling:
SET @x.modify('insert <InvoiceDate>2002-06-15</InvoiceDate>
before /Invoice[1]/CustomerName[1]')
— this works too, and equates to the same position
SET @x.modify('insert <InvoiceDate>2002-06-15</InvoiceDate>
after /Invoice[1]/InvoiceID[1]')
The key to understanding the insert statement is that although Expression1 can be any of the seven node types and can contain multiple nodes in a sequence or even hierarchical XML, Expression2 must evaluate to a single node. If Expression2 evaluates to a sequence of nodes and no node, the insert statement will fail. In addition, Expression2 cannot refer to a node that has been constructed earlier in the query; it must refer to a node in the original XML instance. This is what the variable looks like after all the previous modifications. Although InvoiceDate was used multiple times in multiple examples, we’ve chosen to show only the insert position from the last example (ignoring the first two examples, where InvoiceDate was inserted in a different position):
-- value in the variable @x after modifications
'<Invoice status="backorder">
<InvoiceID>1000</InvoiceID>
<InvoiceDate>2002-06-15</InvoiceDate>
<CustomerName>Jane Smith</CustomerName>
<LineItems>
<LineItem>
<Sku>134</Sku>
<Quantity>10</Quantity>
<Description>Chicken Patties</Description>
<UnitPrice>9.95</UnitPrice>
</LineItem>
<LineItem>
<Sku>153</Sku>
<Quantity>5</Quantity>
<Description>Vanilla Ice Cream</Description>
<UnitPrice>1.50</UnitPrice>
</LineItem>
<LineItem>
<Sku>154</Sku>
<Quantity>20</Quantity>
<Description>Chocolate Ice Cream</Description>
<UnitPrice>1.50</UnitPrice>
</LineItem>
</LineItems>
</Invoice>'
go
xml.modify(‘delete . . .’)
The delete XML DML command, as input to the modify function, deletes zero or more nodes that are identified by the output sequence of the XQuery query following the keyword delete. As in SQL, you can qualify the delete statement with a where clause. The general syntax of delete is
delete Expression
Each node returned by Expression is deleted. Returning a sequence of zero nodes just deletes zero nodes; it is not an error. As with the insert command, attempting to delete a constructed node (a node that was produced earlier in the query, rather than a node in the original document) will cause an error. Attempting to delete a value rather than a node will result in an error. Also, attempting to delete a metadata attribute, such as a namespace declaration, will result in an error. To delete all the LineItem elements in our example, you could execute the following statement:
SET @x.modify('delete /Invoice/LineItems/LineItem')
xml.modify(‘replace value of . . .’)
Unlike a searched UPDATE in SQL and also unlike xml.modify ('delete...'), xml.modify('replace value of...') modifies the value of a single node. It is not a searched UPDATE that uses a WHERE clause to select a sequence of nodes. The general syntax for replace value of follows:
replace value of
Expression1
with
Expression2
Expression1 must return a single node; if a sequence of zero nodes or multiple nodes is returned, an error is produced. Note that again, this is unlike a searched UPDATE statement in SQL, where returning zero rows to update is not an error. It is more similar to UPDATE WHERE CURRENT OF in SQL when using a cursor. Expression1 is used to find the current node.
Expression2 must be a sequence of atomic values. If it returns nodes, they are atomized. The sequence in Expression2 completely replaces the node in Expression1. Here’s an example that updates the CustomerName element’s text child element from “Jane Smith” to “John Smith”:
SET @x.modify('replace value of
/Invoice[1]/CustomerName[1]/text()[1]
to "John Smith"
')
General Conclusions and Best Practices
XML DML can be used to update portions of an XML data instance in place. The insert, update, and delete can be composed as part of a transaction. This is a unique ability for XML; although XML is often compared to databases and complex types, the usual pattern was to retrieve the XML, update the corresponding XML DOM (or, in .NET Framework’s XPathNavigator), and then write the entire document back to the file system. XML DML treats XML more like a complex type or a database and as similar to functionality found in XML-specific databases.
When you use XML DML to update a small piece of a large instance of an XML data type, it is a “sparse update” as far as the database is concerned—that is, usually, only the portion of the XML that is changed is actually updated in the database and written to the transaction log. In the best-case scenario, only the page containing the individual value replaced by a replace value of DML statement is logged. In the worst case, if you insert a node as the leftmost sibling of the root, most of the document may have to be logged.
There are a few general rules to remember when using XML DML:
• The nodes referenced by modify operations must be nodes in the original document.
• XML DML is not analogous to SQL DML. Although insert and delete are similar, position is all important. For SQL programmers, it is the equivalent of using an updatable cursor. Multiple insert or replace value of operations can be accomplished by invoking the modify function within a T-SQL loop, once for each node to be inserted/replaced.
• The resulting XML document or fragment cannot be malformed, or the xml.modify operation will fail.
• If the XML instance is validated by an XML schema, the xml.modify operation cannot interfere with schema validation.
Special Considerations When Using XQuery Inside SQL Server
XML Schemas and SQL Server 2005 XQuery
Unlike XPath 1.0, XPath 2.0 and XQuery 1.0 are strongly typed query languages. This is quite evident in the wide range of constructors and casting functions for different data types. The reasoning behind this is that XQuery is built to be optimized, and using strong types rather than using every element and attribute as type string or inferring/converting between types allows the query engine to do a better job of optimizing and executing the query. Imagine that the T-SQL query parser had to infer the coercion of every piece of data or deal with everything as a single data type!
Every XML data type column, XML variable, and XML procedure parameter can be strongly typed by reference to an XML schema or can be untyped. When typed XML is used in an XQuery, the query parser has more information to work with, and this prevents unnecessary type conversions. If untyped XML is used, the query engine must start with the premise that every piece of data is type string; infer the data type required by the query, based on the rules of the language; and convert to the appropriate type. As an example, the following query
SELECT invoice_id FROM xml_invoice
WHERE invoice.value('sum(//amount)', 'decimal(9,2)') > 150.00
must convert amount element content to decimal before doing the summarization if the XML column named invoice is untyped. When this XQuery is integrated into the relational query plan, this is the equivalent of a non-SARGable query (a query in SQL that doesn’t use a search argument)—that is, it can’t use indexes on the content, if you’ve created them, because each value must be converted first by using a type conversion function. This is one instance where the effect of having a typed column is observable.
XQuery supports static type checking, meaning that every expression will be checked at parse time. In addition, strong typing permits the XQuery language to syntax-check the input based on types at parse time, as T-SQL can, so fewer runtime errors occur. XQuery also allows the query processor to reorder the queries; although this is a performance optimization, this could lead to runtime errors on occasion.
You’ve seen a very noticeable example of SQL Server XQuery’s static type checking in almost all the example queries in this chapter. In these queries, whenever a function or return value requires a singleton, we must use the [1] subscript to ensure that it’s really a singleton; otherwise, a parse-time error results. Almost all other XQuery processors (without static type checking) will execute the query and produce a runtime error if the value is not actually a singleton. If we had a strongly typed XML column instead, in which the schema defined the elements we’re referring to as maxOccurs=1 minOccurs=1 (the default), a query without the subscript would succeed, because the parser “knows” that the element in question is a singleton. Having a schema-validated column permits you to do the type checking at column insert/update time, rather than take the extra measure of requiring a subscript to enforce it at XQuery parse time.
Even though the XML instance that is input to an XML function can be typed or untyped, remember that the result of an xml.query function is always an untyped XML instance. Typed XML should always be used, if possible, to give the XQuery engine a chance to use its knowledge of the data type involved. This also makes the resulting query run faster, as well as producing more accurate results and fewer runtime errors.
XML Indexes Usage in XQuery
As we mentioned in Chapter 9, you can create four different types of XML indexes on the XML data type, these are used to speed XQuery processing.
The index types are:
• XML PRIMARY INDEX—that is, node table and its associated clustered index
• PATH index
• PROPERTY index
• VALUE index
The PRIMARY XML INDEX is almost always useful when you’re using the XQuery functions; the three possible secondary indexes are useful for different types of queries. A key point to remember is that when the query processor evaluates the SQL query, it uses the SQL (relational) query engine. This applies to the XML portion of the query as well as the SQL portion. Because the same query processor is used for the entire query, the query produces a single query plan, as SQL queries always do. And that’s where indexes come in.
Data in an XML data type column is always stored in a special binary format. Although the query engine could work by fetching the entire BLOB into an internal buffer and processing the content, SQL Server benefits by having as little data in memory as possible at a given time. That’s where the node table and indexes come in. The node table is an alternative representation, similar in concept to a materialized view, of the XML document. It contains 12 columns; the primary XML index actually refers to an index over a column in the node table and the primary key of the base table. Table 10-1 lists the columns in the node table.
Table 10-1. Columns in the Node Table

The PRIMARY XML INDEX is a relational index on the columns pk1 and id. The three other indexes are indexes on other columns in the node table. For more information about XML Indexes, reference the paper “XQuery Indexes in a Relational Database System,” by Shankar Pal, et al., at http://www.vldb2005.org/program/paper/thu/p1175-pal.pdf.
The execution plan of a SQL query that uses XQuery inside the XML data type functions looks for the most part like a “normal” relational execution plan. There are a few XML-specific operations, but one of the indexes is almost always used if they exist. Just as in SQL, different types of indexes are useful for different styles of XML queries.
XML PATH index is useful for indexes involving paths. It may not always be the index selected for every expression involving a path (most XQuery queries will use at least one path expression), but the XML PATH index is useful when you’re using explicit paths (no // in the path) and most useful when the XML is highly nested and the path is long.
XML VALUE index is useful when you are using inexact paths (// somewhere in the path) or attribute wildcards (@*) or if your values are different in each text node. Having many different values (rather than some repeating values) would make the XML VALUE index highly selective.
XML PROPERTY index is most useful when you are using many XML data type methods (that use XQuery) in the same SQL expression, and each function selects a different property from the same set of XML instances. Remember that the entire SQL query (which may contain multiple XML data type methods) is evaluated and optimized into a single query plan. Another use for XML PROPERTY index is when the data is semi-structured, and the same values and elements may appear at different levels of hierarchy.
The PRIMARY XML INDEX is the fallback index; it’s used if none of the other indexes is selective enough. The SQL query engine will look at the statistics distributions for an XQuery index just as it will with a SQL index. This is totally unrelated to the XQuery (or SQL) static type checking, so that the general order of events, given a SQL query with one or more XML data type methods using XQuery, is
- Static analysis and object resolution of the SQL query
- Static type checking of all XQuery code in
XMLdata type functions - Consultation of node table and other SQL table statistics to choose the optimum overall query plan
For more information on XQuery in SQL query plans, consult the paper “XML Indexes in SQL Server 2005,” by Bob Beauchemin, at http://msdn.microsoft.com/library/default.asp?url=/library/enus/dnsql90/html/xmlindexes.asp.
Early SQL parsers were unoptimized; this was one of the reasons that early relational databases ran slowly. The performance improvement in relational databases since their inception is due, in no small way, to the optimization of SQL query processors, including static type analysis as well as to other, physical optimizations, such as types of indexes. With an XML data type, indexing and strong typing through XML schemas, and a query language that allows optimizations based on strong typing, XQuery users will most likely experience the same improvements in performance as the data type and query language mature. Programmers (and especially data center managers) like the idea of the same code running faster as vendors improve their parser engines, with minimal changes to the query code itself.
Where Are We?
SQL Server 2005 not only introduces XML as a new scalar data type, but also introduces a query language and a data manipulation language to operate on it. The query language selected for operation inside SQL Server is XQuery, a new query language that is still in standardization. (At this writing, XQuery is in W3C Working Draft at Candidate Recommendation status.) The XQuery implementation inside the database makes some simplifications and optimizations when compared with the entire specification. The subsetting is done to allow the queries to be optimizable and fast. This is a goal of XQuery itself, although the specification does not define implementable subsets.
Because XQuery does not specify a data manipulation language, SQL Server provides a proprietary language that uses XQuery expressions to produce sequences to mutate, known as XML DML. The standardization of XML DML is being considered, because every implementation by relational or XML database vendors is different. This is reminiscent of the early days of SQL.