
7. SQL Engine Enhancements
SQL SERVER 2005 includes new SQL engine functionality. The enhancements span the range from an alternative mechanism for transaction isolation to a new way of using query hints. And statement-level recompilation even improves existing SQL applications that were written before 2005.
Improvements to the SQL Engine
Microsoft has continually improved the Transact-SQL (T-SQL) language and the infrastructure of SQL Server itself. In brief, the improvements in SQL Server 2005 include the following:
• SNAPSHOT isolation—Additional isolation level that does not use write locks
• Statement-level recompile—More efficient recompilation of stored procedures
• Event Notifications—Integration of Data Definition Language (DDL) and trace event operations with Service Broker
• Large data types—New data types that deprecate TEXT, NTEXT, and IMAGE
• DDL triggers—Triggers that fire on DDL operations
• Additional query hints
• Plan guides for deployment of query hints
SNAPSHOT Isolation
SQL Server changes the state of a database by performing a transaction on it. Each transaction is a unit of work consisting of one or more steps. A “perfect” transaction is ACID, meaning that it is atomic, consistent, isolated, and durable. In short, this means that the result of performing two transactions on a database, even if they are performed simultaneously by interleaving some of the steps that make them up, will not corrupt the database.
Atomic means that a transaction will perform all its steps or fail and perform none of its steps. Consistent means that the transaction must not leave the results of a partial calculation in the database; if a transaction is to move money from one account to another, for example, it must not terminate after having subtracted money from one account but not having added it to the other. Isolated means that none of the changes a transaction makes to a database becomes visible to other transactions until the transaction making the changes completes; then they all appear simultaneously. Durable means that changes made to the database by a transaction that completes are permanent, typically by being written to a medium like a disk.
A transaction need not always be perfect with respect to the ACID properties. The isolation level of a transaction determines how close to perfect it is. Prior to SQL Server 2005, SQL Server provided four levels of isolation: READ UNCOMMITTED, REPEATABLE READ, READ COMMITTED, and SERIALIZABLE.
A SERIALIZABLE transaction is a perfect transaction. Functionally, a database could always use SERIALIZABLE—that is, perfect—transactions, but doing so typically affected performance adversely. Judicious use of isolation levels other than SERIALIZABLE, when analysis of an application shows that it does not require perfect transactions, will improve performance.
SQL Server uses the isolation level of a transaction to control concurrent access to data through a set of read and write locks. It applies these locks pessimistically—that is, the locks prevent any access to data that might compromise the required isolation level. In some cases, this will delay a transaction as it waits for a lock to be freed or may even cause it to fail because of a timeout waiting for the lock.
SQL Server 2005 adds SNAPSHOT isolation that in effect provides alternative implementations of SERIALIZABLE and READ COMMITTED levels of isolation that use versioned concurrency control rather than pessimistic locking to control concurrent access. For some applications, SNAPSHOT isolation may provide better performance than pre–SQL Server 2005 implementations did. In addition, SNAPSHOT isolation makes it much easier to port database applications to SQL Server from database engines that make extensive use of SNAPSHOT isolation.
SQL Server 2005 has two kinds of SNAPSHOT isolation: transaction level and statement level. Transaction-level SNAPSHOT isolation makes transactions perfect, the same as SERIALIZABLE does. Statement-level SNAPSHOT isolation results in transactions that have the same degree of isolation as READ COMMITTED does. SNAPSHOT isolation just achieves these isolation levels differently.
Transaction-level SNAPSHOT isolation optimistically assumes that if a transaction operates on an image of that database’s committed data when the transaction started, the result will be the same as a transaction run at the SERIALIZABLE isolation level. Sometime before the transaction completes, the optimistic assumption is tested, and if it proves to be false, the transaction is rolled back.
Transaction-level SNAPSHOT isolation works by in effect making a virtual copy of the database by taking a snapshot of it when a transaction starts. Figure 7-1 shows this.
Figure 7-1. Snapshot versioning
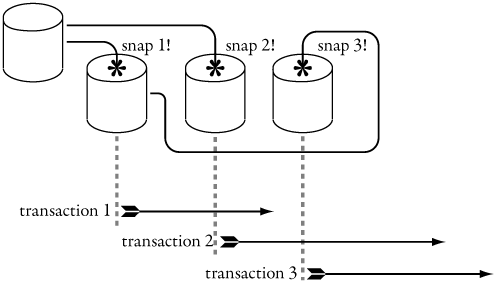
There are three transactions in Figure 7-1: transaction 1, transaction 2, and transaction 3. When transaction 1 starts, it is given a snapshot of the initial database. Transaction 2 starts before transaction 1 finishes, so it is also given a snapshot of the initial database. Transaction 3 starts after transaction 1 finishes but before transaction 2 does. Transaction 3 is given a snapshot of the initial database plus all the changes committed by transaction 1.
The result of using SERIALIZABLE or transaction-level SNAPSHOT isolation is the same; some transactions will fail and have to be retried, and may fail again, but the integrity of the database is always guaranteed.
SQL Server can’t actually make a snapshot of the entire database, of course, but it achieves the same effect by tracking all changes made to the database while one or more transactions are incomplete. This technique is called row versioning.
The row-versioning model is built upon having multiple copies of the data. When data is read, the read happens against the copy of the data, and no locks are held. When data is written, the write happens against the “real” data, and it is protected with a write lock. In a system implementing row versioning, for example, user A starts a transaction and updates a column in a row. Before the transaction is committed, user B wants to read the same column in the same row. He is allowed to do the read but will read an older value. This is not the value that user A is in the process of updating the column to, but the value user A originally read.
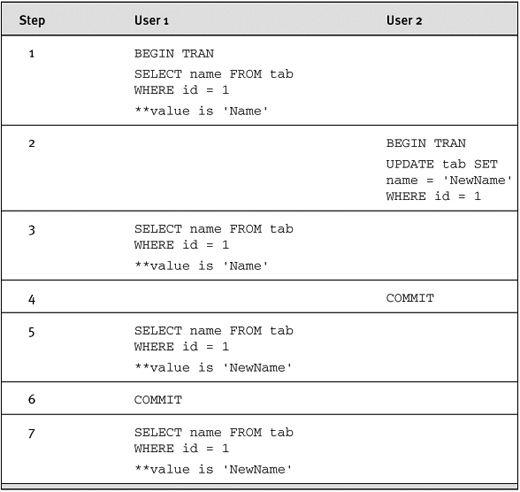
In statement-level SNAPSHOT isolation, the reader always reads the last committed value of a given row, just as READ COMMITTED does in a versioning database. Let’s say we have a single-row table (called tab) with two columns: ID and name. Table 7-1 shows a versioning database at READ COMMITTED isolation.
Table 7-1. Versioning Database at READ COMMITTED Isolation
The other transaction isolation level in a versioning database, SERIALIZABLE, is always implemented by the behavior that the reader always reads the row as of the beginning of the transaction, regardless of whether other users’ changes are committed during the duration of the transaction. Table 7-2 shows a specific example of how two transactions interoperate when the SERIALIZABLE isolation level of a versioning database is used.
Table 7-2. Versioning Database at SERIALIZABLE Isolation

The difference between this table and Table 7-1 occurs at step 5. Even though user 2 has updated a row and committed the update, user 1, using the SERIALIZABLE transaction isolation level, does not “see” the next value until user 1 commits his transaction. He sees the new value only in step 7. In SQL Server 2005, this is called transaction-level SNAPSHOT isolation.
Transaction-level SNAPSHOT isolation requires that SNAPSHOT be enabled by using the SNAPSHOT isolation option of the ALTER DATABASE command. The following SQL batch does this for the pubs database:
ALTER DATABASE pubs
SET ALLOW_SNAPSHOT_ISOLATION ON
SNAPSHOT isolation can be turned on or off as needed. If a session attempts to use SNAPSHOT isolation where it is not available, it receives an error message: “Snapshot isolation transaction failed accessing database ‘[Your database]’ because snapshot isolation is not allowed in this database.” For more information about the state transitions possible when changing the snapshot isolation setting, as well as the effects on DDL statements, reference the whitepaper “SQL Server 2005 Beta 2 Snapshot Isolation,” by Kimberly L. Tripp, on the MSDN Web site (http://msdn.microsoft.com).
When SNAPSHOT isolation has been enabled, transaction-level isolation is used by specifically setting the transaction isolation level to SNAPSHOT. The SQL batch in Listing 7-1 does this.
Listing 7-1. Setting and using the SNAPSHOT isolation level
ALTER DATABASE pubs
SET ALLOW_SNAPSHOT_ISOLATION ON
GO
USE pubs
GO
SET TRANSACTION ISOLATION LEVEL SNAPSHOT
BEGIN TRANS
-- SQL Expressions
COMMIT TRANS
The SQL expressions in the preceding batch will be executed, in effect, against a snapshot of the database that was taken when BEGIN TRANS was executed.
Statement-level SNAPSHOT isolation requires the use of a different database option, READ_COMMITTED_SNAPSHOT. If this database option is ON, all transactions done at the READ COMMITTED level will be executed as READ COMMITTED–level transactions using versioning instead of locking. The transaction shown in the SQL batch in Listing 7-2 will be executed as READ COMMITTED using versioning.
Listing 7-2. Setting and using the READ_COMMITTED_SNAPSHOT option
-- alter the database
ALTER DATABASE pubs SET READ_COMMITTED_SNAPSHOT ON
GO
USE pubs
GO
SET TRANSACTION ISOLATION LEVEL READ COMMITTED
BEGIN TRAN
-- SQL expression will be executed as READ COMMITTED using versioning
END TRAN
Whether or not READ_COMMITTED_SNAPSHOT or ALLOW_SNAPSHOT_ISOLATION is ON can be checked for a particular database by using the sys.databases metadata view. The columns to check are snapshot_isolation_state, snapshot_isolation_state_desc, and is_read_ committed_snapshot_on.
As stated earlier, SQL Server does not actually make a copy of a database when a SNAPSHOT transaction is started. Whenever a record is updated, SQL Server stores a copy (version) of the previously committed value in TEMPDB and maintains these changes in the database as usual. All the versions of a record are marked with the system change number when the change was made, and the versions are chained in TEMPDB using a linked list. The newest record value is stored in a database page and linked to the version store in TEMPDB. For read access in a SNAPSHOT isolation transaction, SQL Server first accesses from the data page the last committed record. Then it retrieves the record value from the version store by traversing the chain of pointers to the specific record version of the data.
The code in Table 7-3 shows an example of how SNAPSHOT isolation works. The example uses a table, snapTest, looking like this:
Table 7-3. Example of SNAPSHOT Isolation

--it is necessary to run
--SET ALLOW_SNAPSHOT_ISOLATION ON
--if that's not done already
CREATE TABLE snapTest ([id] INT IDENTITY,
col1 VARCHAR(15))
--insert some data
INSERT INTO snapTest VALUES(1,'Niels')
The steps in Table 7-3 do the following:
- User 1 starts a transaction under
SNAPSHOTisolation and updates one column in one row. This causes SQL Server to store a copy of the original value inTEMPDB. Notice that User 1 does not commit or roll back at this stage, so locks are held. If we were to runsp_lock, we would see an exclusive lock on the primary key. - User 2 starts a new transaction under a new session and tries to read from the same row that is currently being updated. This is the row with an exclusive lock. If this had been a previous version of SQL Server (running under at least
READ COMMITTED), we would be locked out. Running inSNAPSHOTmode, however, SQL Server looks in the version store inTEMPDBto retrieve the latest committed value and returns'Niels'. - User 1 commits the transaction, so the value is updated in the database, and another version of the row is put into the version store.
- User 2 does a new
SELECT(from within his original transaction) and will now receive the original value,'Niels'. - User 2 finally commits the transaction.
- User 2 does a new
SELECT(after his transaction commits) and will now receive the new value,"NewNiels".
SNAPSHOT isolation is useful for converting an application written for a versioning database like Oracle or Borland’s InterBase to SQL Server. When an application is developed for a versioning database, the developer does not need to be concerned with locking. Converting such an application to SQL Server may result in diminished performance because SQL Server does more locking than these other databases. Prior to SQL Server 2005, this sort of conversion may have required rewriting the application. In version 2005, in many cases the only thing that will have to be done is enable SNAPSHOT isolation and READ_COMMITTED_SNAPSHOT.
SNAPSHOT isolation is also beneficial for applications that mostly read and do few updates. It is also interesting to note that when SQL Server 2005 is installed, versioning is enabled in the MASTER and MSDB databases by default. This is because it is used for some internal features of SQL Server 2005, such as the online index rebuilding feature.
Drawbacks of Versioning
Versioning has the capability to increase concurrency but does come with a few drawbacks of its own. Before you write new applications to use versioning, you should be aware of these drawbacks. Then you can assess the value of locking against the convenience of versioning.
Versioning can be costly because row versions need to be maintained even if no read operations are executing. This has the potential to cause contention in TEMPDB or even fill up TEMPDB. If a database is set up for versioning, versions are kept in TEMPDB whether or not anyone is running a SNAPSHOT isolation-level transaction. Although a garbage-collector algorithm will analyze the older versioning transaction and clean up TEMPDB eventually, you have no control over how often that cleanup is done. Plan the size of TEMPDB accordingly; it is used to keep versions for all databases with SNAPSHOT enabled. If you run out of space in TEMPDB, long-running transactions may fail.
In addition, reading data sometimes costs more because of the need to traverse the version list. If you are doing versioning at the READ COMMITTED isolation level, the database may have to start at the beginning of the version list and read through it to attempt to read the last committed version.
There is also the possibility of update concurrency problems. Let’s suppose that in Table 7-1, User 1 decides to update the row also. Table 7-4 shows how this would look.
Table 7-4. Versioning Database at SNAPSHOT Isolation, Concurrent Updates

In this scenario, User 1 reads the value 'Name' and may base his update on that value. If User 2 commits his transaction before User 1 commits his, and User 1 tries to update, he bases his update on possibly bad data (the old value he read in step 1). Rather than allow this to happen, SQL Server raises an error. The error message in this case is as follows:
Msg 3960, Level 16, State 1, Line 1. Cannot use snapshot isolation to
access table 'tab' in database 'pubs'. Snapshot transaction aborted due to
update conflict. Retry transaction.
Obviously, retrying transactions often enough will slow the overall throughput of the application. In addition, the window of time for a concurrency violation to occur increases the longer a transaction reads old values. Because at the SNAPSHOT isolation level the user always reads the old value until he commits the transaction, the window is much bigger—that is, concurrency violations are statistically more likely to occur. In fact, vendors of versioning databases recommend against using SNAPSHOT isolation in most cases. READ COMMITTED is a better choice with versioning.
Finally, as we said before, in versioning databases readers don’t block writers, which might be what we want. In a versioning database, there must be a way, when it is needed to ensure consistency, to insist on a lock on read that lasts for the duration the transaction. Ordinarily, this is done by doing a SQL SELECT FOR UPDATE. But SQL Server does not support SELECT FOR UPDATE with the appropriate semantic. There is a solution, however. Even when READ_COMMITTED_SNAPSHOT is on, you can ensure a read lock by using SQL Server’s REPEATABLE READ isolation level, which never does versioning. The SQL Server equivalent of ANSI’s SELECT FOR UPDATE is SELECT with (REPEATABLEREAD). This is one place where programs written for versioning databases may have to change their code in porting code from a versioning database to SQL Server 2005.
Monitoring Versioning
Allowing versioning to achieve concurrency is a major change. We’ve already seen how it can affect monitoring and capacity planning for TEMPDB. Therefore, all the tools and techniques that we’ve used in the past must be updated to account for this new concurrency style. Here are some of the enhancements that make this possible.
The following is a list of some new T-SQL system metadata views and dynamic management views that assist in this area:
• sys.databases—Contains information about the state of snapshot isolation and whether read-committed SNAPSHOT is on
• sys.dm_tran_top_version_generators—Tables with most versions
• sys.dm_tran_transactions_snapshot—Transaction and SNAPSHOT sequence numbers when a SNAPSHOT transaction started
• sys.dm_tran_active_snapshot_database_transactions—Includes information about SNAPSHOT transaction (or not), if SNAPSHOT includes information about version chains and SNAPSHOT timestamps
• sys.dm_tran_version_store—Displays information about all records in the version store
There are new performance-monitor counters for the following:
• Average version store data-generation rate (kilobytes per minute)
• Size of current version store (kilobytes)
• Free space in TEMPDB (kilobytes)—this is not new but is more important now
• Space used in the version store for each database (kilobytes)
• Longest running time in any SNAPSHOT transaction (seconds)
By using the new dynamic management views for versioning in conjunction with the views for locking and blocking, and the new performance-monitor counter, you should be able to minimize SNAPSHOT isolation-related problems, as well as diagnose any that do occur.
Data Definition Language Triggers
A trigger is a block of SQL statements that is executed based on the fact that there has been a change (INSERT, UPDATE, or DELETE) to a row in a table or view. In previous versions of SQL Server, the statements had to be written in T-SQL, but in version 2005, as we saw in Chapter 3, they can also be written using .NET Framework languages. As we mentioned, the triggers are fired based on action statements (Data Manipulation Language, or DML, statements) in the database.
What about changes based on DDL statements—changes to the schema of a database or database server? It has not been possible to use triggers for that purpose—until SQL Server 2005. In SQL Server 2005, you can create triggers for DDL statements as well as DML.
The syntax for creating a trigger for a DDL statement is shown in Listing 7-3. As with a DML trigger, DDL triggers can be written using .NET Framework languages.
Listing 7-3. Syntax for a DDL trigger
CREATE TRIGGER trigger_name
ON { ALL SERVER | DATABASE }
[ WITH <ddl_trigger_option> [ ,...n ] ]
{ FOR | AFTER } { event_type | event_group } [ ,...n ]
AS {
sql_statement [ ; ] [ ,...n ] |
EXTERNAL NAME < method specifier > [ ; ] }
<ddl_trigger_option> ::=
[ ENCRYPTION ]
[ EXECUTE AS Clause ]
< method_specifier > ::=
assembly_name.class_name.method_name
The syntax for a DML trigger is almost identical to that for a DDL trigger. There are, however, some differences:
• The ON clause in a DDL trigger refers to either the scope of the whole database server (ALL SERVER) or the current database (DATABASE).
• A DDL trigger cannot be an INSTEAD OF trigger.
• The event for which the trigger fires is defined in the event_type argument, which for several events is a comma-delimited list. You can also use event_groups.
As an alternative to specifying a particular event_type, you can use the blanket argument DDL_DATABASE_LEVEL_EVENTS or any defined level of subevents from the DDL_DATABASE_LEVEL_EVENTS hierarchy. This hierarchy is the same one used by the WMI (Windows Management Interface) provider for server events. SQL Server Books Online has more information about the event hierarchy, as well as the full list of DDL statements that can be used in the event_type argument and also are included in the DDL_DATABASE_LEVEL_EVENTS by default. A typical use of DDL triggers is for auditing and logging. Listing 7-4 shows a simple example where we create a trigger that writes to a log table.
Listing 7-4. Creating and using a DDL trigger
--first create a table to log to
CREATE TABLE dbo.ddlLog (id INT PRIMARY KEY IDENTITY,
logTxt XML)
GO
--create our test table
CREATE TABLE dbo.triTest (id INT PRIMARY KEY)
GO
-- create the trigger
CREATE TRIGGER ddlTri
ON DATABASE
AFTER DROP_TABLE
AS
INSERT INTO dbo.ddlLog VALUES('table dropped')
You may wonder what the XML is all about in creating the first table. We cover the XML data type in detail in Chapter 9; for now, it’s enough to realize that XML is a new built-in data type in SQL Server 2005. The trigger is created with a scope of the local database (ON DATABASE), and it fires as soon as a table is dropped in that database (ON DROP_TABLE). Run the following code to see the trigger in action:
-- cause the trigger to fire
DROP TABLE triTest
-- check the trigger output
SELECT * FROM dbo.ddlLog
The DROP TABLE command fires the trigger and inserts one record into the ddlLog table. The record is later retrieved by the SELECT command.
As mentioned previously, DDL triggers can be very useful for logging and auditing. We do not get very much information from the trigger we just created, however. In DML triggers, we have the inserted and deleted tables, which allow us to get information about the data affected by the trigger. So clearly, we need a way to get more information about events when a DDL trigger fires. The way to do that is through the EVENTDATA function.
The EVENTDATA system function returns information about what event fired a specific DDL trigger. The return value of the function is XML, and the XML is typed to a particular XML schema. Depending on the event type, the XML instance includes different information. The following four items, however, are included for any event type:
• The time of the event
• The server process ID (SPID) of the connection that caused the trigger to fire
• The login name and user name of the user who executed the statement
• The type of the event
The additional information included in the result from EVENTDATA is covered in SQL Server Books Online, so we will not go through each item here. For our trigger, however, which fires on the DROP TABLE command, the additional information items are as follows:
• Database
• Schema
• Object
• ObjectType
• TSQLCommand
In Listing 7-5, we change the trigger to insert the information from the EVENTDATA function into the ddlLog table. Additionally, we change the trigger to fire on all DDL events.
Listing 7-5. Alter trigger to use EVENTDATA
-- alter the trigger
ALTER TRIGGER ddlTri
ON DATABASE
AFTER DDL_DATABASE_LEVEL_EVENTS
AS
INSERT INTO ddlLog VALUES(EVENTDATA())
From the following code, we get the output in Listing 7-6:
--delete all entries in ddlLog
DELETE ddlLog
--create a new table
CREATE TABLE evtTest (id INT PRIMARY KEY)
--select the logTxt column with the XML
SELECT logTxt
FROM ddlLog
Listing 7-6. Output from EVENTDATA
<EVENT_INSTANCE>
<EventType>CREATE_TABLE</EventType>
<PostTime>2005-11-17T09:35:04.617</PostTime>
<SPID>56</SPID>
<ServerName>ZMV03</ServerName>
<LoginName>ZMV03Administrator</LoginName>
<UserName>dbo</UserName>
<DatabaseName>pubs</DatabaseName>
<SchemaName>dbo</SchemaName>
<ObjectName>evtTest</ObjectName>
<ObjectType>TABLE</ObjectType>
<TSQLCommand>
<SetOptions ANSI_NULLS="ON" ANSI_NULL_DEFAULT="ON"
ANSI_PADDING="ON" QUOTED_IDENTIFIER="ON" ENCRYPTED="FALSE" />
<CommandText>CREATE TABLE evtTest (id int primary key)
</CommandText>
</TSQLCommand>
</EVENT_INSTANCE>
Because the data returned from the function is XML, we can use XQuery queries to retrieve specific item information. This can be done both in the trigger and from the table where we store the data. Listing 7-7 illustrates how to retrieve information about the EventType, Object, and CommandText items in the EVENTDATA information stored in the table ddlLog. Notice that we store it in an XML data type variable before we execute the XQuery statement against it.
Listing 7-7. Using XQuery to SELECT items in the EVENTDATA
DECLARE @data XML
SELECT @data = logTxt FROM ddlLog
WHERE id = 11
SELECT
@data.value('(EVENT_INSTANCE/EventType)[1]','NVARCHAR(50)')
AS 'EventType',
@data.value('(EVENT_INSTANCE/ObjectName)[1]','NVARCHAR(128)')
AS 'Object',
@data.value('
(EVENT_INSTANCE/TSQLCommand/CommandText)[1]','NVARCHAR(4000)')
AS 'CommandText'
If the syntax in the previous code snippet seems strange, that’s because it is using XML and XQuery; read Chapters 9 and 10, where the XML data type and XQuery are covered in detail. If you don’t want to use inline XQuery to pick pieces out of the EVENTDATA XML each time you use it, Listing 7-8 produces a rowset from the EVENTDATA document. Bear in mind that not every instance of EVENTDATA contains the same elements as every other instance. Missing elements will result in NULL values in the rowset.
Listing 7-8. Using XQuery to create a rowset from EVENTDATA information
DECLARE @x XML
SET @x = EVENTDATA()
SELECT Tab.Col.value('./EventType[1]','NVARCHAR(50)') AS 'EventType',
Tab.Col.value('./PostTime[1]','datetime') AS 'PostTime',
Tab.Col.value('./SPID[1]','NVARCHAR(50)') AS 'SPID',
Tab.Col.value('./ServerName[1]','NVARCHAR(50)') AS 'ServerName',
Tab.Col.value('./LoginName[1]','NVARCHAR(50)') AS 'LoginName',
Tab.Col.value('./UserName[1]','NVARCHAR(50)') AS 'UserName',
Tab.Col.value('./DatabaseName[1]','NVARCHAR(128)') AS 'DatabaseName',
Tab.Col.value('./SchemaName[1]','NVARCHAR(128)') AS 'SchemaName',
Tab.Col.value('./ObjectName[1]','NVARCHAR(128)') AS 'ObjectName',
Tab.Col.value('./ObjectType[1]','NVARCHAR(50)') AS 'ObjectType',
Tab.Col.value('./TSQLCommand[1]/CommandText[1]','NVARCHAR(4000)')
AS 'CommandText',
Tab.Col.value('./TSQLCommand[1]/SetOptions[1]/@ANSI_NULLS',
'NVARCHAR(3)') AS 'ANSI_NULLS_OPTION',
Tab.Col.value('./TSQLCommand[1]/SetOptions[1]/@ANSI_NULL_DEFAULT',
'NVARCHAR(3)') AS 'ANSI_NULL_DEFAULT_OPTION',
Tab.Col.value('./TSQLCommand[1]/SetOptions[1]/@ANSI_PADDING',
'NVARCHAR(3)') AS 'ANSI_PADDING_OPTION',
Tab.Col.value('./TSQLCommand[1]/SetOptions[1]/@QUOTED_IDENTIFIER',
'NVARCHAR(3)') AS 'QUOTED_IDENTIFIER_OPTION',
Tab.Col.value('./TSQLCommand[1]/SetOptions[1]/@ENCRYPTED_OPTION',
'NVARCHAR(4)') AS 'ENCRYPTED_OPTION'
FROM @x.nodes('/EVENT_INSTANCE') AS Tab(Col)
The programming model for both DML and DDL triggers is a synchronous model, which serves well when the processing that the trigger does is relatively short running. This is necessary because DDL and DML triggers can be used to enforce rules and can roll back transactions if these rules are violated. If the trigger needs to do longer-running processing tasks, the scalability inevitably suffers. Bearing this in mind, we can see that for certain tasks, it would be beneficial to have an asynchronous event model. Therefore, in SQL Server 2005, Microsoft has included a new asynchronous Event Notification model that works asynchronously: Event Notifications.
Event Notifications
Event Notifications differ from triggers in that the actual notification does not execute any code. Instead, information about the event is posted to a SQL Server Service Broker (SSB) service and is placed on a message queue where it can be read by other processes.1 Another difference between triggers and Event Notifications is that the Event Notifications execute in response not only to DDL statements, but also to many trace events. This is a superset of the events that can be specified in DDL triggers.
Listing 7-9 shows the syntax for creating an Event Notification.
Listing 7-9. Syntax for an EVENT NOTIFICATION
CREATE EVENT NOTIFICATION event_notification_name
ON { SERVER | DATABASE | QUEUE queue_name }
[ WITH FAN IN ]
FOR { event_type | event_group } [ ,...n ]
TO 'broker_service', { broker_instance | 'current database' }
The syntax looks a little like the syntax for creating a DDL trigger, and the arguments are as follows:
• event_notification_name—This is the name of the Event Notification. It must be a valid SQL identifier.
• SERVER—The scope of the Event Notification is the current server.
• DATABASE—The scope of the Event Notification is the current database.
• QUEUE—Using an EVENT NOTIFICATION on a Service Broker QUEUE is used for external activation. See Chapter 11 for more information.
• WITH FAN IN—This reduces the number of events sent if the same event is specified with multiple EVENT NOTIFICATIONs.
• event_type or event_group—This is the name of an event that, after execution, causes the Event Notification to execute. SQL Server Books Online has the full list of events included in event_type and event_groups.
• broker_service—This is the SSB service to which SQL Server posts the data about an event. You must also specify whether the service exists on the current database or specify a Service Broker SERVICE ID. Service Broker IDs are unique even across databases and SQL Servers. You can find the ID for a particular database in the sys.databases table; it’s the value in service_broker_guid column for the appropriate database.
The Event Notification contains the same information received from the EVENTDATA function mentioned previously. When the Event Notification fires, the notification mechanism executes the EVENTDATA function and posts the information to a Service Broker SERVICE. For an Event Notification to be created, an existing SQL Server Service Broker instance needs to be located either locally or remotely. The steps to create the SQL Server Service Broker are shown in Listing 7-10. Chapter 11 covers SSB in detail.
Listing 7-10. Steps to create a service broker SERVICE
--first we need a queue
CREATE QUEUE evtDdlNotif
WITH STATUS = ON
--then we can create the service
CREATE SERVICE evtDdlService
ON QUEUE evtDdlNotif
--this is a built-in contract
--which uses an existing message type
--http://schemas.microsoft.com/SQL/Notifications/EventNotification
([http://schemas.microsoft.com/SQL/Notifications/PostEventNotification]
)
First, the message queue that will hold the EVENTDATA information is created. Typically, another process listens for incoming messages on this queue, or another process will kick off when a message arrives. Then a service is built on the queue. When a SQL Server Service Broker service is created, there needs to be a contract to indicate what types of messages this service understands. In a SQL Server Service Broker application, the developer usually defines message types and contracts based on the application’s requirements. For Event Notifications, however, Microsoft has a predefined message type, http://schemas.microsoft.com/SQL/Notifications/EventNotification and a contract, http://schemas.microsoft.com/SQL/Notifications/PostEventNotification.
The following code shows how to create an Event Notification for DDL events scoped to the local database, sending the notifications to the evtDdlService:
CREATE EVENT NOTIFICATION ddlEvents
ON DATABASE
FOR DDL_DATABASE_LEVEL_EVENTS
TO SERVICE 'evtDdlService', 'current database'
With both the Event Notification and the service in place, a new process can be started in SQL Server Management Studio, using the WAITFOR and RECEIVE statements (more about this in Chapter 11) as in the following code:
WAITFOR(
RECEIVE * FROM evtDdlNotif
)
Now you can execute a DDL statement, switch to the process with the WAITFOR statement, and view the result. Running CREATE TABLE evt NotifTbl (id INT) shows in the WAITFOR process a one-row resultset, where the row has a message_type_id of 20. This is the http://schemas.microsoft.com/SQL/Notifications/EventNotification message type. The EVENTDATA information is stored as a binary value in the message_body column. To see the actual data, we need to change the WAITFOR statement a little bit, as shown in Listing 7-11.
Listing 7-11. Reading EVENT NOTIFICATION information from the QUEUE
DECLARE @msgtypeid INT
DECLARE @msg XML
WAITFOR(
RECEIVE TOP(1)
@msgtypeid = message_type_id,
@msg = CONVERT(XML, message_body)
FROM evtDdlNotif
)
--check if this is the correct message type
IF @msgtypeid = 4
--do something useful WITH the message
--here we just select it as a result
SELECT @msg
You may wonder what happens if the transaction that caused the notification is rolled back. In that case, the posting of the notification is rolled back as well. If for some reason the delivery of a notification fails, the original transaction is not affected.
Large Value Data Types
In SQL Server 2000 (and 7), the maximum size for VARCHAR and VARBINARY was 8,000, and for NVARCHAR, 4,000. If you had data that potentially exceeded that size, you needed to use the TEXT, NTEXT, or IMAGE data type (known as large object data types, or LOBs). These data types were more challenging to use because they required special retrieval and manipulation statements.
This situation changes in SQL Server 2005 with the introduction of three new data types that use the MAX specifier. This specifier allows storage of up to 231 bytes—that is, 231 single-byte ASCII characters or 230 double-byte ASCII characters. When you use the VARCHAR(MAX) or NVARCHAR(MAX) data type, the data is stored as character strings, whereas for VARBINARY(MAX), it is stored as bytes. These three data types are commonly known as large value data types or the MAX data types. Listing 7-12 shows how you can use these types to store large values in a table. Note that in SQL Server 2005, all these columns can be used together in a single row; we’ll get back to this point later in this chapter.
Listing 7-12. Table using the large value types
CREATE TABLE largeValues (
id INT IDENTITY,
long_document VARCHAR(MAX),
long_unicode_document NVARCHAR(MAX),
large_picture VARBINARY(MAX)
)
We mentioned earlier that LOBs are challenging to use. Additionally, they cannot, for example, be used as variables in a procedure or a function. The large value data types do not have these restrictions, as we can see in Listing 7-13, which shows a large value data type being used as function parameter. It also shows how a VARCHAR literal can be concatenated with a variable of type VARCHAR(MAX), creating a larger VARCHAR (max) value.
Listing 7-13. (N)VARCHAR supports most T-SQL string handling functions
CREATE FUNCTION dovmax(@in VARCHAR(MAX))
RETURNS VARCHAR(MAX)
AS
BEGIN
--supports concatenation
RETURN @in + '12345'
END
SQL Server’s string handling functions can be used on VARCHAR(MAX) and NVARCHAR(MAX) columns. So instead of having to read in and parse an entire large value string, SUBSTRING can be used. By storing the data as character strings (or bytes), the large value data types are similar in behavior to their smaller counterparts VARCHAR, NVARCHAR, and VARBINARY, and offer a consistent programming model. Using the large value data types instead of LOBs is recommended; in fact, the LOBs are deprecated in this release.
It should be noted that the MAX data types are distinct from the existing varying character and binary data types that specify a length. The VARCHAR( MAX) data type, for example, is not the same type as VARCHAR(n) but a different data type. When you use string functions with the MAX data types, all input variables must be MAX data types or must be explicitly CAST/CONVERTed to the appropriate data type. Listing 7-14 shows an example using the REPLICATE function.
Listing 7-14. Using large value types with the REPLICATE function
DECLARE @x VARCHAR(MAX)
SET @x = REPLICATE('a', 9000) -- first operand is only VARCHAR
PRINT DATALENGTH(@x) -- prints 8000
SET @x = REPLICATE(CAST('a' as VARCHAR(MAX)), 9000)
PRINT DATALENGTH(@x) -- prints 9000
The MAX data types are stored differently from the way the old LOB data types TEXT, NTEXT, and IMAGE are. The MAX data types are stored in row by default. The exact number of characters that can be stored in row is determined by the length of the fixed-length columns in the same table, up to 8,000 bytes; after 8,000 bytes, the data is stored in separate data pages. This behavior can be changed by using sp_tableoption and setting the 'large value types out of row' option on. The older LOB data types are stored out of row by default; you can change this by using the 'text in row' option with sp_tableoption. When the old or new LOB types are stored out of row, a 16-byte reference to their storage location is stored in row. Fetching and updating the data through the reference is managed by SQL Server.
The MAX character and binary data types have a WRITE method that allows you to update the data partially or to extend the data. The syntax used for this method is instance.WRITE. Although this is the same syntax used in invoked methods on a .NET Framework UDT, the MAX data types are not implemented using .NET Framework. Because WRITE is a distinct data type method rather than a function, however, attempting to invoke the method on a NULL instance of the type will raise an error. This is consistent with the SQL:1999/SQL:2003 standard behavior. You invoke the method and specify a starting character index and number of characters/bytes to be written. If the starting character/byte number is equal to the length of the instance, or if the value would cause the instance to be extended, additional characters/bytes are appended to the instance. Specifying a length greater than the number of characters/bytes in the value is not an error, but attempting to specify an offset greater than the length of the instance raises an error. Listing 7-15 shows an example.
Listing 7-15. Using the WRITE method
DECLARE @x NVARCHAR(MAX)
DECLARE @y NVARCHAR(MAX)
SET @y = REPLICATE(cast('b' as NVARCHAR(MAX)), 500)
SET @x.WRITE(@y, 0, 500) -- error, can't write to NULL instance
SET @x = REPLICATE(cast('a' as NVARCHAR(MAX)), 5000)
PRINT LEN(@x) -- prints 5000
SET @x.WRITE(@y, 5000, 500)
PRINT LEN(@x) -- prints 5500
SET @x.WRITE(@y, 5000, 995) -- not an error, replaces 500
PRINT LEN(@x) -- prints 5500
SET @x.WRITE(@y, 5200, 995) -- not an error, replaces 300, appends 200
PRINT LEN(@x) -- prints 5700
SET @x.WRITE(@y, 5800, 500) -- error, offset larger than last character
GO
In addition to the introduction of the three new large object data types, the restrictions on having a table that contains rows longer than 8,060 bytes (the amount of data that can be stored on a single data page) have been relaxed. In previous versions of SQL Server, if you had a table with rows of greater than 8,060 bytes, you would receive a warning at table-creation time, and attempting to store data longer than 8,060 bytes would succeed but silently truncate the data. You can have rows in which the total size of variable-length columns is greater than 8,060 types, and all of the data will be stored. If the size of the fixed-length columns exceeds 8,060 bytes, an error is raised. The example in Listing 7-16 illustrates this.
Listing 7-16. A table's fixed-length fields must total 8,060 characters or less
CREATE TABLE largeValues2 (
COLUMN1 VARCHAR(MAX), COLUMN2 VARCHAR(MAX) -- OK
)
GO
CREATE TABLE largeFixedLengthValues (
COLUMN1 CHAR(80), COLUMN2 CHAR(8000)) -- error
GO
Loading Data with the New BULK Provider
SQL Server 2005 provides an alternative to the BULK INSERT statement for loading data from a file. The new functionality is accessed by using a new OLE DB BULK rowset provider with the INSERT INTO SELECT ... FROM OPENROWSET syntax. This provider allows a more flexible syntax than BULK INSERT because all the flexibility of the SQL SELECT statement is available while loading from a file. Using the BULK provider allows you to select a subset of columns in the input file and permits data conversion using the CONVERT function within the SELECT statement.
Using the provider gives you the flexibility of loading a single large data value into either a data column or a SQL variable by using the SINGLE_BLOB, SINGLE_CLOB, or SINGLE_NCLOB keyword. Here’s a simple example:
DECLARE @d VARCHAR(MAX)
SET @d = (SELECT * FROM OPENROWSET
(BULK 'c:mylargedocument.txt', SINGLE_CLOB) AS A
PRINT @d
GO
We’ll have more to say about the BULK provider in Chapter 9, because you can also use the BULK provider to load XML into the database from a file.
Statement-Level Recompilation
SQL Server must compile an execution plan for a query before it can be executed. The execution plan is cached for later use so that the overhead of compiling it will not be incurred when the query is executed in the future. The execution plan is compiled the first time the query is used, and its optimization is based on information available to SQL Server at that time. Indexes available, table schema, and even the amount of data in a table can affect what kind of plan is compiled.
Several things can cause a cached execution plan to become nonoptimal. An index useful to the execution of the query may have been added since the execution plan was compiled and cached, for example. SQL Server detects these kinds of changes to a database and marks any queries that could be affected by the change to be recompiled the next time the query is executed.
This change detection and marking for recompilation is automatic and keeps the execution plan up to date with the current state of the database, but sometimes, it is a mixed blessing because of the overhead of compiling the execution plan. SQL Server 2005 has improved the efficiency of the recompilation process by recompiling only those parts of the query that will likely be improved by the recompilation. You need not do anything to enable this; even your existing stored procedures will take advantage of this feature when they are run on SQL Server 2005.
Figure 7-2 shows an example of where SQL Server would recompile a stored procedure. It shows a stored procedure (1), GetPubAuth, being created. This stored procedure accesses two different tables: the Publishers and Authors tables in the pubs database.
Figure 7-2. Recompile

The execution plan is compiled the first time GetPubAuth is executed (2). The execution plan is based on the tables accessed by GetPubAuth and the value of the @state parameter—in this case, 'UT'.
After the execution of the GetPubAuth stored procedure, an index is added (3) that indexes the State column of the Publishers table. This causes SQL Server to mark the GetPubAuth stored procedure for recompilation because it accesses the Publishers table.
The GetPubAuth stored procedure is executed again (4), but this time with 'CA' as a parameter. The recompilation appears in the SQL Server Profiler tool (5) as two events. One event, which was in previous versions of SQL Server, is SP:Recompile. The second event, added to SQL Server 2005, is SQL:StmtRecompile.
Only one line of the GetPubAuth stored procedure is recompiled: the one that accesses the Publishers table instead of the entire stored procedure. The execution plan for this line is optimized for a @state value equal to 'CA'. Note that this does not change the fact that the execution plan for the statement that accesses the Authors table is optimized for a @state value equal to 'UT'. If you need more fine-tuned or direct control over the compilation of execution plans, you may need to use query hints or even force SQL Server 2005 to use a specific plan.
Query Hints, Plan Guides, and Plan Forcing
One of the biggest advances of the relational database was the declarative SQLlanguage. Rather than write code to navigate the database directly, you describe your query in SQL, and the query processor determines how to execute the query for best performance. As the query processor and engine get “smarter,” your queries run faster without major programmatic rewrites. On the other hand, programmers now spend a great deal of time trying to understand exactly how the query engine works and sometimes even second-guess the query processor on a rare occasion when it picks a suboptimal plan. Although you should rarely need to use them, query hints permit you to instruct the query engine how to execute your query. I’ve actually needed to use query hints only a few times in my career: once because the same query was used for two use cases that needed different plans, and once when a Service Pack changed a query’s plan to one that I thought was suboptimal. SQL Server will cache only one query plan per query, and improvements in the query engine that make 99 percent of the queries run faster may make 1 percent of queries run slower.
SQL Server 2005 comes with three major improvements that make query hints easier to use and manage:
• Enhanced presentation of query plans for review
• New query hints
• A new feature called plan guides that makes query hints easier to use and to remove when they are no longer needed
Before we launch into describing these improvements, we’re required to include the following disclaimer: “Query hints are generally evil, because you’re telling the query processor what to do rather than allowing it to decide what to do. This could negate the work of over 20 years of query optimization and means you might as well be using imperative programming. Using hints makes your system more cumbersome to maintain, because you must retest all your previous query assumptions each time you make a change. Overhinting will be likely to make your system run slower overall.”
Now that we’ve gotten that out of the way, let’s describe the new plan-reading and -hinting features and how they work.
The way that you figure out what the query processor is doing to process your query and exactly how many rows are being processed is to turn on showplan and showplan statistics. In SQL Server 2000, there are two styles of showplan; they capture mostly the same data but present it differently. With the Query Analyzer utility, you can turn on the ability to show the actual or estimated execution plan. You receive the information in a nice graphical format; the statistics and specifics are available by hovering over the relevant plan step. Even the thicknesses of the lines between the graphics convey information. The only drawback to looking at query plans this way is that you can’t bundle up this information and send it to a friend (or to tech support) for assistance. The interactive graphics don’t even lend themselves well to screenshots. After a few screenshots, everyone reverts to the tried-and-true method of analyzing this information: the text-based showplan. Although the information is not formatted as nicely, it is text format, so you can send it in e-mail without information loss. You can even write string-parsing code to automate analysis of the plan, though this is fairly complex to write.
SQL Server 2005 introduces XML-based showplan. The text-based showplan is still there to support programmers who use it. The XML-based showplan is a bit wordy but has some additional capabilities. First, the graphic showplan in SQL Server Management Studio (SSMS) is now (most likely) an XML stylesheet. You can capture your XML showplan output in either SSMS or in SQL Profiler, save the XML to a file, and send it to a friend. You must save the XML itself with the .sqlplan extension, but double-clicking or loading this file into either utility produces a graphical showplan, hover-over statistics and all. Also, because lots of tools are available (including SQL Server 2005) that deal with XML queries, it is easier to write code that analyzes an XML showplan than to write code that performs string parsing of a textual showplan. There’s even an XML schema for the showplan provided in a subdirectory of the Tools directory. Finally, XML showplan output can be used to do plan forcing. We’ll discuss plan forcing later in this chapter.
Many query hints are available for SQL Server. You specify them using an OPTION keyword and the hint in parentheses at the end of the query. Listing 7-17 shows an example of the syntax, forcing the query processor to use a MERGE JOIN to accomplish the join between the Store and Sales OrderHeader tables.
Listing 7-17. Using a query hint on the SELECT statement
USE AdventureWorks;
GO
SELECT Name, SalesOrderNumber, OrderDate, TotalDue
FROM Sales.Store AS S
JOIN Sales.SalesOrderHeader AS SO ON S.CustomerID = SO.CustomerID
ORDER BY Name, OrderDate
OPTION (MERGE JOIN);
GO
Query hints exist to override many query processor behaviors. Some examples are
• Degrees of parallelism
• Query recompilation
• Join styles and join order
• Optimization for first N rows
There are a few new query hints in SQL Server 2005. One of them, OPTIMIZE FOR, allows you to tell the optimizer the value of a parameter to use in optimization for a parameterized query. This value will override the value actually submitted to the query in the current statement. If we knew, for example, that most of the rows had a state value of 'CA', we could have the optimizer use 'CA' as the parameter value, even though it is not the current parameter. Listing 7-18 shows an example.
Listing 7-18. Using the OPTIMIZE FOR query hint
DECLARE @state_name CHAR(2)
SET @state_name = 'CA'
SELECT * FROM Person.Address AS A
JOIN Person.StateProvince AS S
ON A.StateProvinceID = S.StateProvinceID
WHERE S.StateProvinceCode = @state_name
OPTION ( OPTIMIZE FOR (@state_name = 'CA') )
Another new query hint, MAXRECURSION, is used to set the maximum number of times the recursive portion of a recursive common table expression will be executed. We’ll discuss this in Chapter 8.
The final new hint is the most interesting one. It’s called plan forcing. If you had a query that worked differently in a previous release of SQL Server, or even a query plan (within limits) that you’d like the query processor to try because you believe it will be faster, you can force SQL Server to use that plan by providing a USE PLAN query hint along with an XML-format plan. You can get the XML plan by using XML showplan as described above or even hand-edit the plan within some tightly enforced limits. This plan exactly directs the query processor how to proceed. The query processor now has no role in deciding how the query is to be executed. This might be necessary in certain well-defined situations.
There is a potential problem with using XML plans as query hints; in SQL Server, if the entire text of the query exceeds 8,000 bytes, the query hint will not be used. Because the XML plan is quite wordy, we will likely be exceeding this limit. Enter plan guides.
A plan guide is a SQL Server 2005 database object that associates a query hint with a SQL statement. The statement can be either part of a stored procedure or a stand-alone statement. When you have defined a plan guide, you can turn the hint to which the plan guide refers on or off with a system stored procedure. In addition, the DBA can turn off all plan guides for a specific database with an ALTER DATABASE statement. Creating a plan guide for the statement in Listing 7-19 and using it would look like this.
Listing 7-19. Creating and enabling a plan guide
-- create plan guide for our query hint
sp_create_plan_guide
@name = N'PortlandGuide',
@stmt = N'SELECT * FROM Person.Address WHERE City = @city_name',
@type = N'SQL',
@module_or_batch = NULL,
@params = N'@city_name NVARCHAR(30)',
@hints = N'OPTION (OPTIMIZE FOR (@city_name = N''Portland''))'
GO
sp_control_plan_guide N'ENABLE', N'PortlandGuide'
GO
A plan guide dissociates the query hint from the query text itself. One key advantage of using plan guides is that you can force a plan in a query that you don’t have access to. You can change the way a query in a third-party packaged application works, for example, even though you have no way to add a hint to the text. Plan guides also make it unnecessary to track all the places where a hint has been used. If a hotfix (or, more likely, the next Service Pack or release of SQL Server) makes your hint unnecessary, just turn the plan guide off. In previous releases, you’d have to search through all your T-SQL source code or application for every occurrence of the hint and replace the code—a time-consuming and potentially error-prone process. You can create a plan guide for any SQL statement, including server cursor processing. Plan guides can also be used in conjunction with plan forcing, discussed earlier in this chapter. This solves the 8,000-byte-limit problem described earlier. To use plan guides together with plan forcing, you would
- Run the query or stored procedure in SQL Server Management Studio after selecting the Include Actual Execution Plan option from the Query menu. This produces a graphical execution plan.
- Capture to XML showplan to a file by using the Save Execution Plan As context-menu item.
- Construct a plan guide with the last parameter (the query hint) being set to
"OPTION (USE PLAN '[your XML showplan from step 1 here]')". Don’t forget to escape any single quotes in the XML showplan text.
Figure 7-3 shows the steps in this procedure using a fairly simple query. Bear in mind that this is just one method that you can use to capture an execution plan as an XML file in XML showplan format. You can also use "SET SHOWPLAN_XML ON" from the query window directly, use the option in SQL Profiler that allows you to save all XML showplan output to a single file, or save each query’s showplan output to a separate file. In addition, if the XML showplan output is saved in a file with the .sqlplan extension, it can be opened in SQL Server Management Studio in graphical mode. This is a very handy option, because it allows you to share an XML showplan with a colleague or e-mail it to technical support. The recipient of the file still has the ability to view it in graphical mode.
Figure 7-3. Capturing an XML showplan for use with plan forcing

Where Are We?
Transaction isolation is one of the features that define a database product. SQL Server has supported all the transaction isolation levels in the ANSI standard by using locking; SQL Server 2005 adds support for transaction isolation by using versioning as well. This extends the reach of SQL Server to behaviors that are possible only when using a versioning database while retaining locking of its default transaction isolation mechanism.
New large value data types make writing T-SQL code that handles large data easier, because they act in a manner consistent with the rest of the data types in SQL Server. In addition, the restriction that data rows cannot span pages has been relaxed, making it easier to use these multiple long variable-length columns in a single row without worrying about page overflow. This makes the logical structure of the database less dependent on the physical structure.
Database triggers and Event Notifications make SQL Server 2005 a more active database by allowing synchronous control over DDL and asynchronous ability to react to DDL events or even control reaction to trace events. Event notifications use SQL Server Service Broker; we’ll be discussing this feature in depth in Chapter 11.
Procedure-level recompiles take CPU cycles; this has always affected how programmers write stored procedures. SQL Server 2005 increases a programmer’s choices by doing recompiles at a statement level rather than a procedure level. In addition, there are new plan hints and the ability to force a particular plan for a particular SQL statement. This is useful if the query processor isn’t choosing the right plan but should be used with caution. With plan guides, there is also the ability to separate hints from statements in programs and to provide hints in situations where the programmer can’t change package source code.
In addition to internal engine features like the ones we’ve seen in this chapter, there are a plethora of enhancements to the T-SQL language itself. We’ll discuss these enhancements in Chapter 8.