
5. User-Defined Types and Aggregates
SQL SERVER PROVIDES types for scalars like FLOAT and CHAR. These can be represented by a single value, such as a number or a string. Some scalars, such as a date, require more than one value to be represented. A date has a month, day, and year value in its representation. SQL Server provides the DATETIME scalar type for dates. There are other scalars that require more than one value to represent them for which SQL Server does not provide a scalar type. Dimensions in a mechanical drawing, for example, have quantity value and unit value, like “12 in.” SQL Server 2005 allows a Common Language Runtime, CLR, language to be used to add scalar types and aggregates to SQL Server that can be used in the same way that any built-in scalar type or aggregate is.
Why Do We Need User-Defined Types?
User-defined types in SQL Server 2005 are used to extend its scalar type system. A column in a table is meant to hold a scalar. If you were given a sample set of data that looked like 12 4 9, 13 5 2, 9 14 11, you would say, “Those are triples of numbers, so each must be a vector, and I will need three columns to represent each one.” You would know from experience and the first normal form that trying to squeeze each triple into a single column would be a false economy.
But not all triples are vectors. Consider this set of data: 10 13 1966, 6 15 1915, 7 3 1996. Writing this set as follows might make it clearer that these are dates: 10/13/1966, 6/15/1915, 7/3/1996. Again, from experience, you would know that storing a date in three columns would make it difficult to work with. The triple, in this case, would use a single column. The reason you would want to use a single column is that storing a date in three columns makes no more sense or utility than storing the number 123 in three single-digit columns. The reason you can do this is that the SQL-92 specification realized how important it was to have a scalar type for a date, so it included a number of types for it, including DATETIME, which SQL Server implements.
There are other multifield values that are scalars. Angles, such as latitude and longitude, are written as having four fields: degrees, minutes, seconds, and direction. Geographic Information Systems (GIS) often have values that look like 34°6′12″N, 61° 35′ 19″W. Unfortunately, the SQL Server scalar type system is missing the Latitude and Longitude data types. User-defined types allow you to make your own Latitude and Longitude types and use them in the same convenient way you use the DATETIME type.
Scalars often have type-specific functions associated with them. Numerous functions, for example, such as ASIN and CEILING, are associated with numerical scalars. A user-defined type may also implement functions specifically associated with it. In some cases, it may be useful to implement a user-defined type that is based on a built-in scalar type so that you may encapsulate some functionality with it.
Overview of User-Defined Types
A user-defined type is implemented by a public CLR class that meets a set of requirements discussed later in this chapter. There is no way to implement a user-defined type using Transact-SQL (T-SQL). This class must implement the three key features of a user-defined type: a string representation, a binary representation, and a null representation. The string representation is the form of the user-defined type that a user will see. One string representation of a Date, for example, is “2/5/1988”. The binary representation
is the form of the user-defined type that SQL Server will use to persist its value on disk. Last, a scalar in SQL Server must be able to have a null value, so the user-defined type must implement this too. See “A Few Words About Null Values” in Chapter 3 for a discussion of null values and their syntax and usage in various languages.
The class that implements the user-defined type must be in an assembly that has been catalogued, as described in Chapter 2, into any database that uses it. The CREATE TYPE command, shown in Figure 5-20 later in this chapter, is used to add the user-defined type in the class to the scalar type system for a database, much as CREATE PROCEDURE, FUNCTION, and TRIGGER are used to add procedures, functions, and triggers based on CLR methods to a database.
User-defined types are similar to the DATETIME type in that they are inserted into a column as a string but stored as a stream of bytes—that is, they are entered using their string representation but stored using their binary representation. Figure 5-1 shows a table, Dates, that has a single column (1) of type DATETIME. A single row is inserted (2) into it. A SELECT statement (3) selects the date in two forms: as a string and as a binary number.
Figure 5-1. Date as binary number
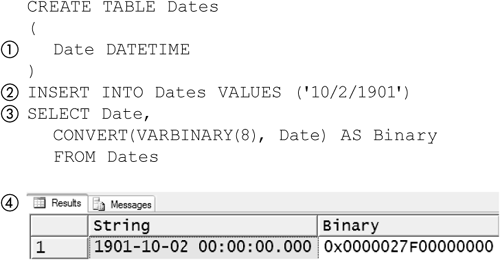
The result (4) of the select shows the date as a 16-byte binary number. This gives us the best of both worlds. We can write and read dates in a familiar notation and conveniently write predicates like (WHERE '1/1/1997' < InstallDate). User-defined types can also support this convenient comparison feature if their binary representation is appropriately designed, though they are not required to.
SQL Server 2005 provides a number of aggregate functions, such as MAX and AVG, for many of its scalar types. Likewise, in SQL Server 2005, you can create user-defined aggregates for the user-defined types that you create and for the built-in SQL Server 2005 scalar types. You can also create used-defined aggregates for SQL Server 2005 built-in scalar types.
To illustrate a user-defined type, we will implement one that supports a simple linear dimension that might be used in a mechanical drawing. It is called LDim. An instance of this type will contain a numeric value and units. The units can be any of “in,” “ft,” or “yd.” A typical LDim we might write would look like “1.34 ft” or “7.9 yd”. We want to be able to treat LDim as we would any other scalar variable, so we will also implement an aggregate function, SumLDim, for it.
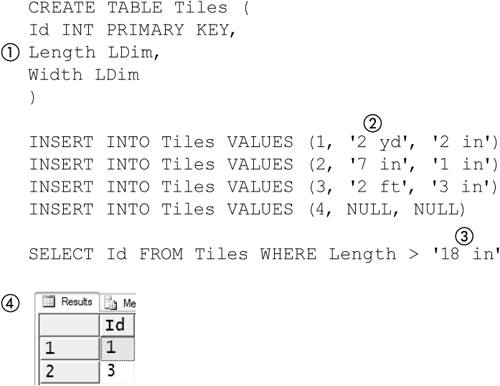
Figure 5-2 shows that a user-defined type, LDim, can be used in the same way as any other scalar. It is used as the data type for the Length and Width columns (1) in a table named Tiles. The string representation (2) of an LDim can be inserted into the Tiles table and can be used as part of a predicate (3) in a query. The results of the query show that tiles 1 and 3 have a Length greater than 18 in. Note that the comparison was done on the actual dimension, not its string representation; tile 1 has a Length of 2 yd, which is, of course, greater than 18 in.
Figure 5-2. Using a user-defined type
Creating a User-Defined Type
Now we will look at how to create the LDim user-defined type used in the previous example in this chapter. It has two parts: value and units. The value is a numeric, and the units can be one of “in” for inches, “ft” for feet, and “yd” for yard. We are going to add a couple of real-world constraints to it, though.
It is often tempting to say, “There is something we have to measure, so let’s just use a double to represent it; that way, we can be sure it will have enough range and accuracy.” It is important to determine the range and accuracy of any value you want to store before you select the data type you will use to represent it. In the case of LDim, we want to be able to measure a distance of up to about ten miles with an accuracy of a thousandth of an inch. We also want accurate arithmetic calculation, so we will not want to use either float or double. Any calculation can become inaccurate if it goes though enough operations, of course, but with floats or doubles, the operations that produce inaccurate results can be deceptively simple.
Figure 5-3 shows a comparison of simple arithmetic results using the C# double and decimal data type. Two double types (1) are added, and their nominal sum is subtracted. The result (2) is sent to standard out. The same operation is repeated (3) using the decimal data type, and its result (4) is sent to standard out. Running this program (5) shows that the simple addition operation using double has introduced a small error, but the one using decimal has not.
Figure 5-3. Comparison of numeric results

Does this mean you should always use decimal for arithmetic operations? Definitely not. A CLR decimal data type is larger and operations on it in general are slower than for doubles. It’s a matter of deciding what is appropriate for the calculations that will be done with the data.
Note that we have also put limits on both the accuracy—one thousandth of an inch—and range—ten miles—for LDim, because those are the requirements we have. Later, the fact that we have limited LDim to a given range and accuracy will be very useful to us.
The basis of a user-defined type is a public class. In general, any public class, with some limitations, can be the basis of a user-defined type. In practice, the class should represent a scalar value. We will cover the specific limitations and what it means to be a scalar as we go through this chapter.
Figure 5-4 shows a C# struct, which is a class that can be used as the basis of a user-defined type. Note that C# uses the keyword struct to define a value type, which is a class that derives from System.ValueType. See the MSDN documentation for a discussion of the tradeoffs between value types and reference types—that is, classes that do not derive from System.ValueType.
Figure 5-4. Basis for LDim

There are no strict rules for choosing a value or reference type as the basis for a user-defined type. Value types do not allocate any memory from the heap, so in general, they do not require any resources to be cleaned up. On the other hand, value types must be copied when passed as a parameter or returned as a value, where reference types are not copied. Unfortunately, you cannot start with a value type as the basis for the user-defined type and later change it to a reference type, as that change would quite likely break the code using the user-defined type.
The struct, named LDim, is public (1) and contains two fields. One is value (2), which will hold the numeric part of the dimension. The other is units (3), which will hold the name of the units for the dimension.
Three things must be supported by a user-defined type: a null value representation, a string representation, and a binary representation. The null value representation is supported by implementing the INullable interface and the well-known (a defined requirement rather than inherited from a base class) static property named Null. The string representation is supported by overriding System.Object.ToString method and implementing the wellknown method Parse. The binary representation can be implemented by SQL Server 2005 to the CLR or by implementing the IBinarySerialize interface. The size of the binary representation is limited to 8,000 bytes regardless of the implementation. Note that all classes in the CLR ultimately derive from System.Object and can override the ToString method.
Figure 5-5 shows a skeleton of the class we will use to implement LDim. The SqlUserDefinedType attribute (1) decorates the class; this is a requirement of any class that implements a user-defined type. The NULL implementation (2) is the static property Null and the instance property IsNull. The string implementation (3) is the methods ToString and Parse. The binary implementation (4) is the Read and Write methods.
Figure 5-5. Skeleton of LDim implementation

One thing to note about this skeleton is that except for the INullable interface, no base class or interface defines what you must implement—just a number of well-known methods and properties.
Null Value Implementation
Figure 5-6 shows a T-SQL batch that uses NULL in conjunction with a user-defined type, a variable named @ldim of type LDim. SQL Server 2005 uses the static Null property shown in the skeleton in Figure 5-5 to make an instance of LDIM that is a null value, and it assigns (1) to @ldim. SQL Server 2005 uses the IsNull instance property shown in Figure 5-5 to test @ldim (2) to see if it is a null value.
Figure 5-6. Using NULL

For the example shown in Figure 5-6 to work, the LDim class will need some way to keep track of whether or not an instance is a null value. There are two ways it can do this: One is to have a Boolean field that indicates whether the instance is a null value, and the other is to store values in the value and units fields that are not possible when an instance of LDim is not a null value. LDim uses the latter technique and sets the units field to null to indicate that the instance is a null value.
Figure 5-7 shows how LDim implements the null value representation. The indicator that an instance is a null value is that the units field is null. The IsNull instance property just returns (1) the results of testing the units field to see if it is null.
Figure 5-7. Implementation of Null

The static Null property returns a newly created instance of LDim (2). The CLR guarantees that contents of the units field will be null and that the value field will be initialized with zeros.
String Implementation
Figure 5-8 shows a T-SQL batch that uses the string representation of a user-defined type in conjunction with a variable named @ldim of type LDIM. SQL Server 2005 uses the Parse method from the skeleton shown in Figure 5-5 to convert the ‘1 ft’ string to an instance of an LDIM and assign it (1) to @ldim. It uses the ToString() method shown in Figure 5-5 to cast (2) @ldim to a VARCHAR.
Figure 5-8. Using string

The implementation of ToString is less involved than that of Parse, so we will look at that first; it’s shown in Figure 5-9. The implementation overrides (1) the ToString method from System.Object, which all classes in the CLR ultimately derive from. See the MSDN documentation for a complete description of the class hierarchy in the CLR.
Figure 5-9. Implementation of ToString

The ToString implementation first tests (2) to see if the instance of LDIM is a null value. Note that it uses the IsNull property that is part of the null representation implementation. If the instance is not a null value, it returns (3) a string, which is the string representation of the value field concatenated with a space and the units field.
The implementation of the Parse method is a bit more involved, because it has to extract the value and units from a string in a reliable manner. Parse takes a SqlString as an input parameter and returns an instance of an LDim. As with any string passed into a SQL Server stored procedure or function, it is very important that its format be verified before it is used. For example, what would happen if the string “10 light years” was passed in? If its format was not validated, the units field of the LDim struct could be set to an invalid value. In addition, the Parse implementation will have to parse the numeric part of the string and if it is not properly formatted this will throw an exception which the Parse implementation will not be able to control.
An instance of the Regex class, named vu, is initialized with a string, as shown in Figure 5-10. The string that initializes vu is a regular expression that can be used to both validate and parse the input to the Parse method. For convenience, the string that is used to initialize the vu is the concatenation of two strings. The parts of the initialization string enclosed in parentheses are called groups; later, we will see that they can be used to extract the parts of a string that matches regular expression. The first group (1) matches a floating-point number—a sequence of digits with at most a single decimal point. The second group (2) matches the possible units strings that may be used in a LDim.
Figure 5-10. Regular expression for validation

Figure 5-11 shows the implementation of Parse (1). If the SqlString is null, it returns a LDim (2) that is a null value. Note that the static Null property that is part of the null representation implementation is used to make a null instance of LDim.
Figure 5-11. Implementation of parse

The input string is validated (3) by using a regular expression in vu discussed previously. It is beyond the scope of this book to explain the details of regular expressions, but they are the preferred way to validate and parse strings in the CLR. See Chapter 3 for some references to learn about regular expressions.
In Figure 5-11, the IsMatch method of a Regex class tests (3) an input string against the regular expression and returns false if the input string does not match. If it does not match, Parse throws an exception. The “Bad format” string thrown in the exception should be more descriptive, but for simplicity of the example, it is not.
The Match method of the Regex class is used to extract (4) the parts of the strings that match groups in a regular expression. It produces a Match object. The Result method of a Match object can be used to extract the groups by name.
A new instance of an LDim is created and will be returned at the end of the method, as shown in Figure 5-11. The string for the units is in the “${u}” group (5), is extracted using the Result method of Match object, and is then assigned to the units field of the new LDim. Likewise, the string for the value is the “${v}” group (6), is extracted using the Result method again, and is then converted to a decimal using the static Parse method of the decimal class. Note that these strings can be processed further without checking because the overall format was validated by the IsMatch method (3).
The last thing Parse has to do is check to be sure that the value of the LDim meets our range and accuracy requirements. If it does not (7), the Parse method throws an exception to indicate this. SQL Server 2005 will send this to the client as a RAISERROR with an error number of 6522. Part of the error message will include the string “Out of range or accuracy” that was part of the exception. Likewise, the exception thrown when the Parse method finds the string not properly formatted results in a 6522 error, but in this case, the error message will have “Bad format” embedded in it.
Figure 5-12 shows the CheckRangeAndAccurcy method that is used to check an LDim to see if it meets our requirement of being no more accurate than one-thousandth of an inch with a range of ten miles.
Figure 5-12. Checking range and accuracy
static bool CheckRangeAndAccurcy(LDim d)
{
decimal value = d.value;
// check overall range
if (d.units == "in")
{
if ((value > (52800M * 12M)) ||
(value < -(52800M * 12M)))
{
return false;
}
}
if (d.units == "ft")
{
if ((value > 52800M) ||
(value < -52800M))
{
return false;
}
}
if (d.units == "yd")
{
if ((value > (52800M / 3M)) ||
(value < -(52800M) / 3M))
{
return false;
}
}
// check accuracy to 0.001 inches
if (d.units == "ft")
{
value *= 12M;
}
if (d.units == "yd")
{
value *= 36M;
}
decimal norm = value * 1000M;
norm = decimal.Round(norm);
if ((norm - (value * 1000M)) != 0M)
{
return false;
}
return true;
}
Binary Implementation
One of the requirements of a user-defined type is that the class that implements it must be decorated with a SqlUserDefinedType attribute, as shown in the skeleton in Figure 5-5 earlier in this chapter. The SqlUserDefinedType attribute is used to specify how the binary representation will be implemented. There are two choices for implementing the binary representation: SQL Server 2005 can do the implementation, or the class itself can do the implementation.
The Format property of the SqlUserDefinedType attribute indicates how the binary representation will be implemented. SqlUserDefinedType. Format=UserDefined indicates that the class will implement IBinary Serialize to implement the binary representation.
SqlUserDefinedType.Format=Format.Native indicates that SQL Server will implement the binary representation. SQL Server can implement the binary representation only if all the fields in the class, even private ones, come from a restricted set of data types. The acceptable data types are listed in Figure 5-13. There is no default value for SqlUserDefinedType.Format; it must be specified. We will look at using Format.Native later in this chapter, in the section on user-defined aggregates. User-defined aggregates have the same serialization issues as user-defined types.
Figure 5-13. Format=Native data types
System.Boolean
System.Byte
System.SByte
System.Int16
System.Int32
System.Int64
System.UInt16
System.UInt32
System.UInt64
System.Single
System.Double
System.Data.SqlTypes.SqlBoolean
System.Data.SqlTypes.SqlByte
System.Data.SqlTypes.Int16
System.Data.SqlTypes.SqlInt32
System.Data.SqlTypes.DateTime
System.Data.SqlTypes.SqlMoney
System.Data.SqlTypes.SqlDouble
System.Data.SqlTypes.SqlSingle
System.Data.SqlTypes.SqlInt64
LDim has member fields of type string and decimal, neither of which is listed in Figure 5-13, so LDim must use SqlUserDefinedType.Format= Format. UserDefined. When Format.UserDefined is used, SQL Server 2005 requires other pieces of information.
SQL Server will store the binary representation of LDim in a stream, and it needs to know how much space to allocate in that stream for it. The MaxByteSize property (2), shown in Figure 5-14, is the maximum number of bytes that the binary representation might require. As noted earlier, MaxByteSize may not be greater than 8,000. If SqlFormatUserDefined-Type.Format=Format.UserDefined, MaxByteSize must be specified; otherwise, it may not be specified.
Figure 5-14. SqlUserDefinedType for LDim

Just as there is a tradeoff between fixed and variable sized strings in TSQL, there is one for SqlUserDefinedType.Format=Format.UserDefined. If the length of the stream required to store the binary representation is fixed, SQL Server 2005 can store it more efficiently if it knows this. The SqlUserDefinedType.IsFixedLength=true (3) indicates that this is the case for LDim. The default value for SqlUserDefinedType.IsFixedLength is false.
When SqlUserDefinedType.Format=Format.UserDefined is used, the SqlUserDefinedType.IsByteOrdered property indicates whether an instance of the type can be sorted; true indicates it can be sorted, and false indicates that it cannot be sorted. Sorting is not automatically provided for user-defined types; the implementation has to take this into account, which we will see shortly. LDim will be sortable (4). The default value for SqlUserDefinedType.IsByteOrdered is false, and it must be false when SqlUserDefinedType.Format=Format.Native.
Figure 5-14 shows the SqlUserDefined attribute used to decorate the LDim class.
SQL Server 2005 sorts user-defined types with SqlUserDefinedType. Format=Format.UserDefined by the byte, from high-order byte to loworder byte. Figure 5-15 shows a table, named BOrder, that contains a single column (1) of type VARBINARY. BOrder is filled (2) with four rows. The rows are selected (3) and sorted. The results (4) show that the byte, starting with the high-order byte, of the binary data is sorted, then the next, and so on. Binary data is byte ordered, and user-defined types are sorted as binary data based on their binary representation, if SqlUserDefinedType.IsByteOrdered=true.
Figure 5-15. Sort by byte

IBinarySerialize.Read/Write
The IBinarySerialize interface has two methods in it: Write and Read. The Write method has a single parameter: a BinaryWriter that is used to write the binary representation. A trivial implementation of the Write method (1) is shown in Figure 5-16. It uses the built-in serialization capability of the CLR to write the value (2) and units (3) into the stream passed into the Write method.
Figure 5-16. Trivial implementation of write

The trivial Write implementation shown in Figure 5-16 is not suitable for LDim, because one of the requirements of LDim is that it be sortable. The implementation of the binary representation must ensure that it is byte ordered. The binary representation of CLR numeric types are not byte ordered. Figure 5-17 shows a numeric sort of decimal numbers minus one, zero, and one compared with a byte-order sort of the same numbers. To the right of each number is its binary representation when serialized by the CLR. Note that the high-order byte of the number zero is zero, so it will come before the number minus one and one because the value of their high-order byte is one.
Figure 5-17. Comparison of numeric and byte-ordered sort

One way to force the binary representation is to encode the value of the user-defined type so that it is byte ordered. In general, making a byte-ordered encoding is a bit of work. LDim encodes the value and units into 5 bytes. It makes use of the fact that unsigned integers are, in fact, byte ordered.
Figure 5-18 shows the implementation of Write and Read for IBinarySerialize. Some helper methods that we will look at later in this chapter are involved. The Write method uses the ToBytes helper method to convert the value of LDim to an array (1) of 5 bytes. It writes (2) those bytes into the stream provided by SQL Server 2005.
Figure 5-18. Implementation of write and read

The Read method works in a complementary fashion. It reads 5 bytes (3) from the stream provided by SQL Server 2005 and then uses the FromBytes helper method to convert the array to an LDim.
All implementations of IBinarySerialize work this way; they convert the value they represent to or from a stream of bytes. The real effort, of course, is in those helper methods.
The basic algorithm to convert an LDim to a stream of bytes is to normalize the LDim to inches and break it into four parts. The top of Figure 5-19 shows how the normalized LDim is broken into its constituent parts, which are a sign, a normalized whole number of inches, the number of thousandths, and the units. The bottom shows how the parts are mapped into 5 bytes, which in turn are written and read by the Write and Read functions shown in Figure 5-18.
Figure 5-19. Encoding of LDim
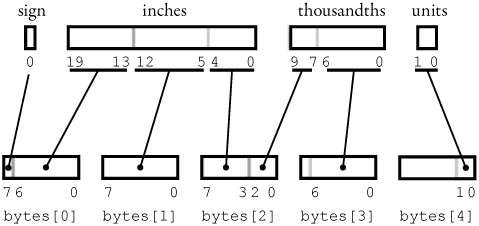
The actual mapping is done by several helper methods that are in the source for the LDim class shown in Listing 5-1 later in this chapter. The MoveBitsFromIntToByte method masks bits from and maps them into a byte. MoveBitsFromIntToByte (i, 3, 5, ref b, 1), for example, will copy bits 3 though 7 from int i into bits 1 through 4 in byte b. The MoveBitsFromByteToInt complements this method by moving bits from a byte into an int. The FromBytes and ToBytes methods are used by the MoveBitsFromIntToByte and MoveBitsFromByteToInt to encode LDim into/from bytes, as shown in Figure 5-19.
Creating User-Defined Types
The CREATE TYPE statement in T-SQL is used to create a user-defined type that is implemented by the CLR. Figure 5-20 shows a user-defined type being loaded prior to use. Before the user-defined type can be loaded, the assembly that contains it must be catalogued (1), as with any type of CLR extension to SQL Server 2005 and as discussed in Chapter 2. The CREATE TYPE statement names the type (3) and, in a way similar to CLR-based functions and stored procedures, identifies the class that implements the user-defined type with a two-part (2) EXTERNAL NAME. The parts are separated by a period. The CREATE TYPE statement in Figure 5-20 adds a new type to SQL Server 2005: LDim, which is implemented by the class Dimensions.LDim in the assembly named Geo.
Figure 5-20. Creating a user-defined type

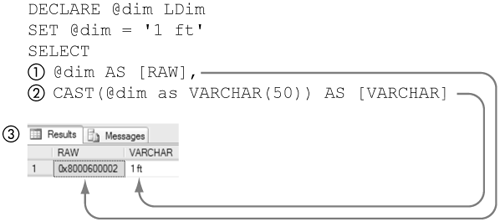
Figure 5-21 shows LDim being used in a T-SQL batch. A variable of type LDim is set to '1 ft'. It is selected both in its raw form (1) and cast (2) to an VARCHAR. The results (3) show that the raw representation is a binary number, not the string representation of an LDim. It might seem strange that selecting an LDim does not automatically produce its string representation, but the code required to do this is part of the class that implements LDim. SQL Server 2005 streams the binary representation of a user-defined type to the client, not the string representation.
Figure 5-21. Casting LDim to VARCHAR
The results shown in Figure 5-21 were produced by SQL Server Management Studio, but any client application would have the same results. As Chapter 13 shows, a client application could use the LDim class to convert the binary representation to the string representation. Both SQL Server Management Studio and SQLCMD, however, prevent the use of the class that implements a user-defined type to minimize the security surface area of those products.
SQL Server Management Studio and SQLCMD must convert a user-defined type to a string representation on the server if they want the string representation. Both disallow the use of the assemblies that implement user-defined types to minimize their surface area for security purposes. The examples in the rest of this chapter use the CAST function to do this. Later, we will see that T-SQL can access the public methods of a user-defined type, so the ToString method could also be used to convert a user-defined type to a string on the server.
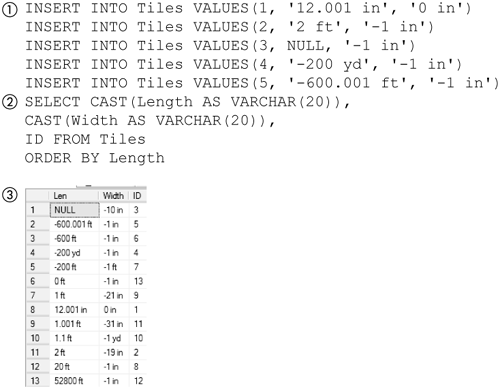
Figure 5-22 shows LDim in use. The Tiles table shown in Figure 5-2 earlier in this chapter has been loaded with different data (1). The rows are selected from the Tiles table ordered by Length (2). The results (3) show that NULL is sorted first. The figure also shows that negative dimensions are sorted before zero, which in turn is sorted before the positive dimensions. Also note that 12.001 in is sorted before 1.001 ft, as it should be.
Figure 5-22. Selecting and sorting user-defined types
User-defined types like LDim can be used in comparison predicates. too. Figure 5-23 shows a SELECT statement (1) that selects tiles whose length is greater than 1.02 ft and less than 3 yd. The results (2) show that only two of the tiles in this table meet the criteria expressed in the predicate.
Figure 5-23. UDT and comparison

Typically, it is a fair amount of work to get a byte-ordered representation of a user-defined type. It is worth the effort, though, because when completed, that value can easily be treated the same way as any other scalar in SQL Server 2005.
SQL Server 2005 will not use the IComparable interface if a user-defined type implements it. Implementing it, however, is good practice so that client code that uses the user-defined type has access to it. IComparable is the CLR interface that by convention implements comparison. The System.Array.Sort method in the CLR uses it, for example. See “IComparable” in the MSDN documentation for a discussion of it.
Public Properties, Fields, and Methods
A user-defined type is a class. It is common to encapsulate into a class methods that can be used on instances of that class. SQL Server 2005 supports this programming technique for user-defined types. Every public field, method, and read–write property in the class that implements a user-defined type can be accessed with T-SQL as long as it involves data types that T-SQL understands. In some cases, a dotted syntax is used; in others, a double-colon syntax is used.
Any public-instance property or field in the class that implements a user-defined type can be accessed by T-SQL through a dotted syntax. Figure 5-24 shows the Inches property that is part of the class that implements LDim. The Inches property is public and of type SqlDecimal (1). The SqlFacet attribute is used to specify the precision and scale of the returned value. The get (2) method of the property converts the value to inches, if needed, and returns it. The set method of the property will not set a null instance of an LDim to a value; because nulls are immutable, they may not be changed into a concrete value.
Figure 5-24. Inches property

The SqlFacet attribute is used by SQL Server 2005 to determine characteristics of values returned from methods, parameters, properties, and fields. The SqlFacet attribute can be used to specify the maximum length of a returned SqlString. Figure 5-25 shows the usage of SqlFacet in a C# method and the equivalent type usage in a T-SQL function. See “SqlFacetAttribute” in the MSDN documentation for a more detailed discussion.
Figure 5-25. Using SqlFacet

Figure 5-26 shows the Inches property being used in a SELECT (1) expression. A SELECT uses the get method of a property. The Length column from the Tiles tables, used in the previous example, has a period and the name of the property, Length, appended to it. This produces (2) a column with the dimension converted to inches.
Figure 5-26. Selecting the inches property

A property of a user-defined type can also be used to update or set it. Figure 5-27 shows an UPDATE expression being used to set (1) the Length column of the Tiles table to 10 inches. The SELECT statement that follows (2) shows (3) that the column was set to 10 inches.
Figure 5-27. Updating the property

A common object-oriented technique is to encapsulate the methods used to manipulate an object with the class for the object; these are sometimes called instance methods because you call them on an instance of the class. SQL Server 2005 supports this in user-defined types by allowing any public method or property to be accessed by appending a period and its name to a column or variable that is of that user-defined type.
Figure 5-28 shows the LDim class in skeleton form (Listing 5-1 later in this chapter shows the complete source code for LDim), the public members of the LDim class being accessed from T-SQL, and the results of the T-SQL usage. Note that a C# struct is a class in the CLR.
Figure 5-28. Using methods, fields, and properties
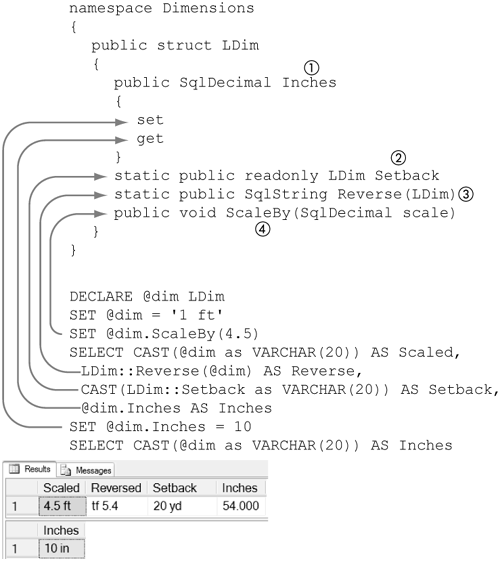
Inches (1) is a public-instance property—that is, a property that can be accessed though an instance of the LDim class. The Inches property represents the value of the LDim instance in inches. In the CLR, a property may have a get and a set method. The set method modifies the value of the property and is accessed in T-SQL by appending a period and the name of the property to a T-SQL variable or column and using it in a statement that modifies a value—in this example, SET @dim.Inches='1 ft'.
The get method of a property is accessed with the same syntax as the set method but is used in a statement that returns a value—in this example, SELECT @dim.Inches. Note that a public field in a class is accessed the same way as a public property.
A static field in the CLR is a field that is marked as static and that may be accessed without using an instance of the class. Setback (2) is a public, static field in LDim. Note that Setback is also marked as read-only, as it is meant to be a source of a constant. There is no requirement for a static field to be marked as read-only, but if it is not marked read-only, the assembly that contains it must be catalogued with PERMISSION_SET=UNSAFE, which in practice greatly limits its utility.
T-SQL can access a static field by prefacing it with the name of the user-defined type and two colons. When used in a statement that returns a value—in this example, SELECT LDim::Setback—the value of the static field is returned. It is possible to modify a static field in T-SQL if it is not marked as read-only in the CLR, but again, this practice is not recommended.
Reverse (3) is a static-instance method in the LDim class that returns the reversed string representation of the instance of LDim passed into it. T-SQLcan access a static method in a class by prefacing the method name with the name of the user-defined type and two colons—LDim::Reverse, in this example.
T-SQL can access a public-instance method of a class (a method that is not marked as static) by appending a period and the name of the method to a variable or column. ScaleBy (4) is a public-instance method—in this example, the LDim class that modifies the value of the instance by scaling it by the parameter passed into it. In this example, T-SQL accesses it as SET @dim.ScaleBy(4.5).
Figure 5-28 and the explanation accompanying it show the usage of member of a class that defines a user-defined type but do not show the metadata SQL Server 2005 needs to manage the usage of these members. The ScaleBy instance method, for example, changes the value of a variable or column and so may not be used in a SELECT statement. A method that changes the value of an instance of a user-defined type is said to be a mutator.
ToString is an example of one of the public-instance methods in LDim. One of the public properties in LDim is IsNull. Note that a property in the CLR is just shorthand for creating a related pair of set and get methods, so it also is an instance method. Both of these can be accessed by T-SQL.
T-SQL can access any public method of a user-defined type if its return value and parameters can be mapped to T-SQL types. There are in essence two kinds of methods: those that can change the value of the instance of the user-defined type they are associated with and those that can’t. A method that can change the value of an instance of a user-defined type is said to be a mutator. The SqlMethod attribute is used to specify this.
Methods that are mutators must set the IsMutator property of the SqlMethod attribute to true and return a void. Those that can’t change the value set the IsMutator property of the SqlMethod to false and return a scalar value.
The SqlMethod attribute derives from the SqlFunction attribute and in usage is much like a SqlFunction. All the parameters for a SqlMethod must be input parameters; no out or ref parameters are allowed. SqlMethod adds three properties to SqlFunction: IsMutator, OnNullCall, and InvokeIfReceiverIsNull. A SqlMethod may not use the Table Definition or FillRowMethodName properties, because a SqlMethod may not return a table—only a scalar or user-defined type.
Figure 5-29 shows an instance method, ScaleBy, that is part of the LDim user-defined type. Its purpose is to scale the LDim it is associated with by the scale factor passed in to it. The SqlMethod attribute has the IsMutator property (1) set to true. The IsMutator property indicates to SQL Server 2005 that this method may change the value of the LDim and will limit its use to those places where side effects are allowed—that is, not in a SELECT statement. It is important to set the value of IsMutator properly to reflect what the method actually does, because if it is incorrectly set, it may lead to hard-to-diagnose bugs or corrupted data in a database.
Figure 5-29. User-defined-type mutator method

The OnNullCall property indicates how SQL Server 2005 should treat calls to this method if one of the input parameters is a null value. If OnNullCall = false, SQL Server 2005 will shortcut things by not calling this method if it is invoked with any null parameters and directly return a NULL. If OnNullCall = true, SQL Server 2005 will call this method even if some of the parameters are null values.
In the case of the ScaleBy method in Figure 5-29, OnNullCall = true (2). The ScaleBy method must check (3) to make sure that both its instance and input parameters are not null values and make no changes to the LDim if either is a null value. When it does make a change, it checks that change (4) to see whether the new value is in an acceptable range and accuracy. If not, the method reverts to the original value.
Figure 5-30 shows the use of the ScaleBy method. An LDim variable, @d1, is set (1) to 1.1 ft. Next, it is changed (2) by use of the ScaleBy instance method. The results (3) show the ScaleBy method multiplied @d1 to 2.2 ft, as expected.
Figure 5-30. Using ScaleBy

A user-defined type method that uses IsMutator=false may return a value and be used in a SELECT or similar statement. Figure 5-31 shows the GetScaled method. It returns a new LDim that is a scaled version of the LDim on which it was called. OnNullCall = false (1) for this method, which means that if the scale input parameter is a null value, SQL Server 2005 will not call this method but directly return a NULL. Unlike the ScaleBy method, this method will not be called by T-SQL if the scale parameter is a null value, but it does check it for null value for those cases where it is used outside T-SQL. Like ScaleBy, this method also checks to make sure that the new LDim is in the proper range and accuracy. If not, the method returns a copy of the original value.
Figure 5-31. User-defined-type nonmutator method

Note that SQL Server Management Studio (SSMS) treats null instances of a user-defined type as an error, which is different from the way it treats a built-in scalar type that is a null value, as shown in Figure 5-32.
Figure 5-32. NULL user-defined type

Figure 5-33 shows the use of the GetScaled method. An LDim variable, @dim, is set to 1 ft. Then a SELECT statement uses the return value of the GetScaled method (2). The result (3) shows that the value of the returned LDim is twice that of the original.
Figure 5-33. Using GetScaled

There is a difference between user-defined-type instance methods and those in object-oriented languages. An instance method may be invoked on a user-defined type if the method is marked IsMutator = false. Figure 5-34 shows an LDIM variable, @dim, being set to NULL (1). Next, the GetScaled method is called (2) on it. It succeeds and returns (3) a NULL instance of an LDIM.
Figure 5-34. Using method on null instance

Invoking an instance method of a user-defined type that is a null value and that is marked IsMutator = true will produce a runtime error.
The InvokeIfReceiverIsNull property of the SqlMethod attribute determines what SQL Server 2005 will do if an instance method is called on a null value. By default, InvokeIfReceiverIsNull is false, and SQL Server 2005 will not call the method but instead will directly return NULL. This is the case for the example in Figure 5-34.
If InvokeIfReceiverIsNull=true, the method will be called even if the instance is a null value. This means that SQL Server 2005 will make an instance of the user-defined type using the static Null property of the class that implements the user-defined type, call the method on that instance, and then not use that instance again.
The best practice for testing a variable or column to see if it is null is to use the IS NULL clause. This works for user-defined types in the same way as it does for built-in scalars, as shown (1) in Figure 5-35.
Figure 5-35. Comparing iS NULL to IsNull

Every user-defined type, however, implements the IsNull property that will return a true if the user-defined type is null. This may produce unexpected results when invoked from T-SQL. The IsNull property of a user-defined property will return NULL, not one, if the get method of the IsNull property is not attributed with [SqlUserDefinedType(InvokeIf ReceiverIsNull=true)]. The result, shown in Figure 5-35, is that a null value may appear not to be a null value (2) when in fact it is.
There is no way to prevent a T-SQL user from invoking the IsNull property of a user-defined type, which in turn will lead to unexpected results. Because of this, it is a best practice to include InvokeIfReceiverIs-Null=true on the get method of the IsNull property of a user-defined type, as shown in Figure 5-36, to force SQL Server 2005 to call the IsNull property in all cases and get the appropriate zero or one value.
Figure 5-36. Ensuring that IsNull works as expected

Helper Functions
Chapter 3 discusses using the static methods of a CLR class to make functions that T-SQL can use. These functions can return or use as parameters user-defined types. Table 3-3 in Chapter 3 lists the standard operators used in the CLR—for example, op_Addition. In general, it is a good idea to implement those operators that make sense for a user-defined type.
Figure 5-37 shows a static method that implements the + operator (2) for the LDim class. The + operator in C# is mapped to the op_Addition method. This method is decorated with the SqlFunction attribute. The Name property of the SqlFunction attribute is set to "LDimAdd" (1). SQL Server 2005 does not use this property, but Visual Studio 2005 does when it deploys this function. Even if Visual Studio 2005 is not going to be used to deploy this function, this is a good place to note what it should be named in SQL Server 2005.
Figure 5-37. Implementing add

There is no requirement that a function that uses a particular user-defined type as a parameter or return value be implemented in the same class as the user-defined type itself, but sometimes, as in this case, it is convenient to use this implementation.
The method in Figure 5-37 returns a null instance of LDim if (3) either of the input parameters is null. If both of the input parameters have the same units (4), those units are used for the return value. If the units are different, inches (5) are used for the units of the return value.
Figure 5-38 shows the LDimAdd (1) function being used by T-SQL. Note that T-SQL never uses any of the arithmetic operators for a user-defined type; it can use the function only by name. The results show (3) that the units were preserved and that the dimensions were added.
Figure 5-38. Using add

Why go to the trouble of implementing “operator +” and renaming it for SQL Server 2005 instead of just naming it LDimSum in the first place? There are a couple of reasons for this. In C# and most CLR languages, the actual name of “operator +” is always op_Addition for all data types. T-SQL cannot deal with method overloading, so it would be possible to implement “operator +” for only a single user-defined data type.
Figure 5-39 shows an example of a C# console application (1) that uses the LDim user-defined data type. Another reason to implement the “+” (2) is that it allows client-side applications that use user-defined types to use standard operator symbols to manipulate them.
Figure 5-39. Client program using LDimAdd

So the real reason to implement “operator +”, and all the other arithmetic operators in the CLR, is to make it easier to use the user-defined type in CLR languages. One of the strengths of a user-defined type is that it can be used in both T-SQL and CLR languages. Chapter 13 shows how to return an instance of a user-defined type to a client program.
User-Defined-Type Validation
It is possible to insert a value into any an instance of any SQL Server 2005 scalar data type just by inserting its binary representation. Figure 5-40 shows an LDim variable, @d1, being set (1) with a 5-byte binary number. Doing a SELECT (2) on @d1 and casting to a string shows (3) that its value is 52802.666666666666666666666667 ft.
Figure 5-40. Invalid LDim

This value is invalid according to the limits on both range and accuracy we specified for LDim at the beginning of this chapter. In fact, Figure 5-41 shows that if we try to SET an LDim variable (1) with the value 52802.666666666666666666666667 ft, it produces an “Out of range or accuracy” error (2) from the code that LDim uses to check range and accuracy.
Figure 5-41. Range error

Invalid direct binary input of data can be prevented by adding a validation method to the LDim implementation. We almost have one already: the static bool CheckRangeAndAccurcy(LDim d) in LDim that the Parse and other methods use to validate input, except that it does not have the correct signature. A validation method must be an instance method, return a Boolean, and take no parameters. A return value of false indicates that the LDim is not valid.
The CheckDirectInput method is shown in Figure 5-42. The ValidationMethodName property (1) of the SqlUserDefinedType attribute is used to indicate the method (2) that SQL Server 2005 should use to validate any binary input directly inserted into an LDim. SQL Server 2005 uses this method whenever it casts a value to a user-defined type, for example.
Figure 5-42. Validation method

The CheckDirectInput method delegates the actual checking to the CheckRangeAndAccurcy method (3) that LDim already uses to check input from the Parse method.
Figure 5-43 shows that if an out-of-range or -accuracy binary number is inserted into an LDim (1), it will produce an error that shows that the validate method (2) LDim class has failed.
Figure 5-43. Validation error

Maintaining User-Defined-Type Definitions
There are two ways to replace a user-defined type. One is to use DROP TYPE followed by CREATE TYPE. The other is to use the ALTER ASSEMBLY command to replace the assembly that contains the implementation of the user-defined type.
Changing a user-defined type is a fundamental change to a database. Think about how you would feel if Microsoft said it was going to change how the SQL DECIMAL data type works, even if Microsoft said it would just “improve the accuracy of decimal.” The fact that calculations you had done in the past might produce different, albeit more accurate, results could easily have an overwhelming impact on your database, because things that compared as equal in the past might not do so after the change. You must keep this level of impact in mind whenever you make a change to a user-defined type.
The safest way to change a user-defined type is to export tables that refer to the type to a text file using SQL Server Integration Services (SSIS), drop and re-create the type and everything that references it, and then reload the tables. You will not miss anything that refers to the user-defined type, because you cannot drop a type if any table, stored procedure, and so on references it. All UDTs, by definition, support conversion to and from a string, so SSIS will work with any UDT.
This is safest because it guarantees that any changes to the semantics of the type and how it is represented will be propagated to the entire database. Note that it may not be possible to reimport some of the data, because the new type definition may not allow it. What if one of the changes to the user-defined type was to the validation method, for example? It will, however, guarantee the integrity of the database, which is paramount in any change.
In many cases, you will not be changing something as fundamental as the semantics of the type or how it is represented. In these cases, you can use the ALTER ASSEMBLY command, described in Chapter 2. The ALTER ASSEMBLY expression can replace an existing assembly with user-defined types in it without dropping objects such as tables and stored procedures that reference those types.
ALTER ASSEMBLY is meant to be used to make bug changes or improve implementations, not semantic or operational changes. You cannot use ALTER ASSEMBLY, for example, to replace an assembly with one whose assembly name is different in anything other than the revision of the assembly. Note that the revision is the fourth of the dotted list of numbers that specifies an assembly version. In the assembly version “1.2.3.4,” “4” is the revision of the assembly.
It is your responsibility, however, when changing an assembly this way to ensure that the meaning, sorting, and so on of any data persisted by user-defined types is not changed by replacing the assembly. The ALTER ASSEMBLY expression can check for some of these issues, but not all. Keep this in mind when deciding between drop and re-create, and ALTER ASSEMBLY. Maintaining integrity of data should always be the most important factor when you are making this decision.
User-Defined Types and XML
XML has been tightly integrated into the CLR since its first release. Part of the support of XML is provided in the System.Xml.Serialization namespace, which provides support for the serialization of an instance of a CLR class to and from XML. Because a user-defined type is a CLR class, instances of it can be serialized to and from XML.
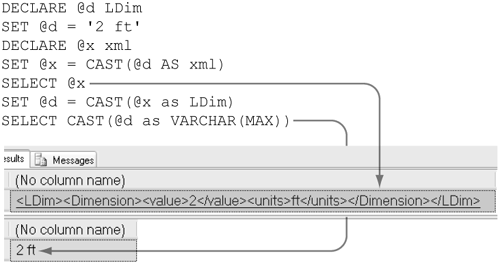
SQL Server 2005 also provides support for XML. The xml data type is supported, and so is the FOR XML phrase, which can be added to a SELECT expression. User-defined types, however, cannot be implicitly converted to or from XML; conversions must be explicit. Figure 5-44 shows an instance of the LDim user-defined type being cast to and from XML. It sets @d, an instance of an LDim, to 2 ft, and then casts it to XML and sets it into @x, an xml variable. Then it casts @x back to an LDim and shows the result.
Figure 5-44. Casting a user-defined type to and from XML
A user-defined type must be cast to xml if it is part of a SELECT expression that uses a FOR XML clause, as shown in Figure 5-45. A table, Lengths (1), has a column that is a user-defined type. A SELECT expression (2) selects that column, Value, using a FOR XML clause. As part of the SELECT expression, the Value column is cast to xml. The result (3) shows the xml serialized form of the user-defined type. If the Value column were selected directly, this SELECT statement would have produced an error when it was run.
Figure 5-45. Using FOR XML

By default, the CLR will build an assembly dynamically at runtime to serialize a CLR class to or from XML; SQL Server 2005 does not support this feature of the CLR, however. User-defined types must include the code that supports xml serialization with using this feature. The SGen utility is used to generate an assembly and optionally the source code that supports xml serialization from the assembly that implements a user-defined type.
Figure 5-46 shows SGen being used to create an assembly and C# source code that supports the xml serialization of LDim from Dimension.dll, the assembly that implements LDim. SGen is run (1) from the command line with the /K and /O switches. The /K switch keeps the source code for the assembly SGen creates. The /O switch is used to specify the directory the SGen should write its results to—in this example, the xml directory. The output of SGen is also shown, including the assembly it has created (2) and the source code for that assembly (3). Note also that the switches used to run the C# compiler are in the file with the .cmdline extension and that the output of running the C# compiler is in the file with the .out extension.
Figure 5-46. Using SGen

A full discussion of what is produced by SGen is beyond the scope of this book. One of the things in the assembly produced by SGen—Dimension.XmlSerializers.dll in Figure 5-46—is a class named XmlSerializerContract. This class in effect provides a method that SQL Server 2005 can use to look up the classes needed to support the xml serialization of the LDim class.
The last thing to do to tie everything together is to let SQL Server 2005 know which assembly contains the xml serialization support for a user-defined type. This is done by decorating the class that implements the user-defined type with a XmlSerializerAssembly attribute. The xml serialization support can be provided from the assembly generated by SGen, Dimension.XmlSerializers.dll (2) in Figure 5-46, or it can be provided by compiling the source code generated by SGen, hr5r4ovs.0.cs (3), into the assembly that contains the user-defined type.
To use the assembly created by SGen, the assembly must be catalogued into the same database as the user-defined type is. The logical name of the assembly doesn’t matter. In addition, the XmlSerializerAssembly attribute must be initialized with the full name of the assembly.
Figure 5-47 shows LDim (1), the class that implements the user-defined type, decorated with an XmlSerializerAssembly attribute. The AssemblyName property of the XmlSerializerAssemblyAttribute is set to the full name of the assembly that was created by SGen. Note that the full assembly name is broken into multiple lines for the convenience of the diagram. In actual usage, it must be a single line.
Figure 5-47. Using an assembly created by SGen

The assembly created by SGen is catalogued using a CREATE ASSEMBLY (2) statement. When SQL Server 2005 needs to convert an LDim to or from xml, as shown in Figure 5-44 earlier in this chapter, it will use the Dimension.XmlSerializers assembly to get the code it needs to do this conversion.
An alternative way to use the xml support generated by the SGen utility is to compile the source code it creates into the assembly that implements the user-defined type. An advantage to this technique is that there is no need for an extra step to catalog the assembly generated by SGen. When the user-defined type is catalogued, its xml serialization support will be catalogued along with it. When the code generated by SGen is compiled with the assembly that implements the user-defined type, the XmlSerializerAssemblyAttribute is used without any assembly name, as shown in Figure 5-48.
Figure 5-48. Built-in XML serialization
[XmlSerializerAssemblyAttribute]
public struct LDim …
{
The format of the XML produced by casting a user-defined type to xml is determined by the class that implements the user-defined type. By default, the values of all public properties and fields will output as content of elements named for the corresponding property or field. Note that the default format requires that all information included in the xml be in public fields and properties and that all other information be in nonpublic fields and properties.
In general, the requirement that information must be in a public field or property to be serialized into xml can be difficult to meet, so there are two ways to control the format of the output. One is to use attributes from the System.Xml.Serialization namespace. The XmlIgnore attribute, for example, can be used to prevent a field or property from being serialized to xml, as shown in Figure 5-49.
Figure 5-49. XmlIgnore attribute

Several of these attributes can be used to control xml serialization; search for “Introducing XML Serialization” in the MSDN documentation for a discussion of them. Note that there are attributes that can be used force a nonpublic member to be serialized.
The second way to control the serialization of a user-defined type into xml is to control it directly by implementing the IXmlSerializable interface. This interface has three methods: one named WriteXml, to serialize the user-defined type into xml; one named ReadXml, to serialize it from xml; and one named GetSchema, to provide the xml schema for the serialization format. The ReadXml and WriteXml methods completely override the default xml serialization and any attributes from the System.Xml.Serialization namespace.
A discussion of xml serialization and Xml Schema is beyond the scope of this book, but we will look briefly at the implementation of IXmlSerializable. Figure 5-50 shows the WriteXml method for the LDim user-defined type. An XmlWriter is passed into the method. The serialized form of the LDim is written into this stream. Note that the first write into an XmlWriter must be done with XmlWriter.StartDocument() and that the last write must be done with XmlWriter.EndDocument(); neither is done in this method. SQL Server 2005 has already called this method and inserted the open tag for an "LDim" element—an element whose name is the same as that of the class that implements the user-defined type. Likewise, when the WriteXml method returns, SQL Server 2005 will insert the closing tag for the "LDim" element and call the XmlWriter.EndDocument() method.
Figure 5-50. WriteXml

The format for a non-null (2) LDim is just a value and units element. The format for a null LDim uses the convention as an element that includes the xsi:nil attribute. The WriteXml method shown in Figure 5-50 produced the xml output shown in Figure 5-44 and Figure 5-45.
The IXmlSerializable.ReadXml method is used to serialize xml into an LDim. Figure 5-51 shows the implementation of ReadXml for the LDim user-defined type. An XmlReader is passed in to (1) this method. The method must extract the information it needs to initialize the user-defined type. An XPath-Navigator is used to do this. XPathNavigator is the CLR class that typically is used to extract information from xml and is discussed in the MSDN documentation. If the xml passed into ReadXml is for a null instance of an LDim, the value and units fields (2) are appropriately initialized. If the xml is for a nonnull instance of LDim, the value and units elements are extracted, and their string representation is parsed (3) using the Parse function. This is done both to convert the strings found in the xml to an LDim and to ensure that the range and precision meet the requirements we have set for LDim dimensions.
Figure 5-51. ReadXml

The IXmlSerializable.GetSchema method returns a schema that defines the format used by the ReadXml and WriteXml methods. SQL Server 2005 does not use this method during the serialization of user-defined types, and it is permissible for it to return null. The GetSchema method, however, is used by SQL Server 2005 when it generates a WSDL file for a Web Service that uses a user-defined type as an argument. Chapter 12 discusses Web Services and WSDL files. Best practice would be for GetSchema to return an appropriate XML Schema. A discussion of XML Schema is beyond the scope of this book, but many resources do discuss it. The primer on the www.w3.org site is a good place to start; it is at http://www.w3.org/TR/2004/REC-xmlschema-0-20041028/.
Should Objects Be Represented by User-Defined Types?
If the object represents a scalar and requires more than one field to be described, or if you want to encapsulate some methods with it, a user-defined type should be used to represent it; otherwise, it should not. By definition, a column in a row of a relational table holds a scalar, so it can hold any object that is a scalar. This definition is crucial to features we associate with a relational database—such as the ability to have efficient declarative referential integrity via foreign keys and to order rows when they are used rather than when they are inserted.
A scalar is a value that can be represented in a single dimension. A value that requires more than one dimension to be represented is not a scalar. Note that the number of fields required to represent a value does not determine whether it is a scalar; the date example at the beginning of this chapter had three fields but was still a scalar.
Is a geometric point a scalar? No, because its representation requires two dimensions, not just two numbers. But why is a date that has three numbers a scalar, whereas a point that has only two numbers associated with it is not a scalar? You can ask of any dates something like “Is date d2 between date d1 and date d3?” and get a consistent answer. But there is no way in general to answer consistently the question “Is point p2 between point p1 and point p3?” The reason you can’t get a consistent answer to this question for points is that each answer to a “between” question makes a commitment to the next. Consider the following questions and answers:
“Is date d2 between date d1 and date d3?” “Yes.”
“Is date d4 between date d1 and date d2?” “Yes.”
If someone then asks, “Is date d4 between date d1 and date d3?”, the answer must be “Yes.” This is because dates have an order; they in effect map onto the real number line. In fact, internally, SQL Server can use integer numbers to represent dates because of this. Figure 5-52 pictorially illustrates this.
Figure 5-52. Answering the “between” question for dates

This is not true for points, because they are not scalars. One of the problems with asking a “between” question of points is that our conventional notion of “between” would require all three of the points involved to be on the same line. If we use this kind of definition of “between” for points, there are many points for which we cannot answer the “between” question, because it makes no sense.
But if we can just come up with an alternate definition of “between” that works consistently, we can still consider points to be scalars. Let’s try to make up something that is similar to the way “between” works for dates. For dates, we can say that d2 is between d1 and d3 if both abs(d2-d1) < abs(d1-d3) and abs(d2-d3) < abs(d1-d3) are true. The abs() function means absolute value, which we can think of as a distance or a number with any associated minus sign removed.
The date d3 is between the dates d2 and d4 because both the distance between d3 and d2 and the distance between d3 and d4 are less than the distance between d2 and d4. Likewise, d1 is not between d2 and d4, because the distance between d1 and d4 is greater than the distance between d2 and d4.
We can try to apply a similar rule for points. Figure 5-53 shows four points and their relationships to one another in terms of distance.
Figure 5-53. Answering the “between” question for points
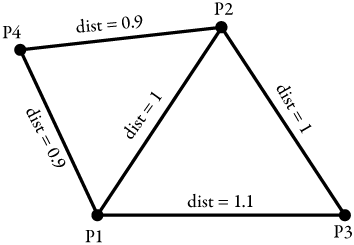
Because the distance between p1 and p2 and between p2 and p3 is less than the distance between p1 and p3, p2 is between p1 and p3, by our definition of “between.” Also, the distance between p4 and p1 and between p4 and p2 is less than the distance between p1 and p2, so p4 is between p1 and p2, by our definition of “between.” If our “between” definition is consistent, P4 is then between p1 and p3. But it is obvious that the distance between p4 and p3 is greater than the distance between p1 and p3, so p4 could not be considered to be between p1 and p3, even though it is between p1 and p2. So it is not behaving like a scalar.
If you could find a set of rules for answering the “between” question consistently for points, you could consider a point to be a scalar. No such set of rules exists, however, so a point is not a scalar, even though it has fewer fields than a date does.
User-defined types should be used only for objects that represent scalars, even though it is physically possible to use user-defined types to represent any object whose state is less than 8,000 bytes, just by implementing IBinarySerialize.
Just because an application uses objects to represent things that are not scalars does not mean that the database has to. Chapter 8 covers the XML data type. SQL Server 2005 also still supports SQLXML. These technologies, and simple object-relational mappings, are much more efficient for persisting objects in a relational database than user-defined types are.
Listing 5-1 puts together the things we have been discussing to implement the LDim user-defined type in one place. Note that it includes a lot of arithmetic calculations that have very few comments. The purpose of this example is to show the structure of a user-defined type and the things that must be done so that it can be sorted and validated, not to cover the specifics of how this is done.
Listing 5-1. LDim source code
using System;
using System.Data.SqlClient;
using System.Data.SqlTypes;
using System.Text.RegularExpressions;
using System.IO;
using Microsoft.SqlServer.Server;
using System.Xml.Serialization;
using System.Xml.Schema;
using System.Xml;
using System.Xml.XPath;
namespace Dimensions
{
[SqlUserDefinedType(Format.UserDefined,
MaxByteSize = 5,
IsFixedLength = true,
IsByteOrdered = true,
ValidationMethodName = "CheckDirectInput"
)]
[XmlSerializerAssemblyAttribute]
// source code modules produced by SGen /K
// also compile in this assembly
public struct LDim : INullable,
IBinarySerialize, IXmlSerializable
{
private decimal value;
private string units;
public override string ToString()
{
if (IsNull)
{
return null;
}
// Put your code here
return String.Format("{0} {1}", value, units);
}
public bool IsNull
{
[SqlMethod(InvokeIfReceiverIsNull = true)]
get
{
return units == null;
}
}
public static LDim Null
{
get
{
return new LDim();
}
}
[SqlFacet(Precision = 9, Scale = 3)]
// Prevents this property from being
// xml serialized if default serialization used
[XmlIgnore]
public SqlDecimal Inches
{
get
{
SqlDecimal d;
if (IsNull) return SqlDecimal.Null;
if (units == "in")
{
return this.value;
}
if (units == "ft")
{
d = this.value * 12.0M;
return this.value * 12.0M;
}
return 36.0M * this.value;
}
set
{
if (units != null)
{
this.value = value.Value;
units = "in";
}
}
}
[SqlFunction(Name = "LDimAdd")]
static public LDim operator +(LDim d1, LDim d2)
{
if (d1.IsNull || d2.IsNull)
{
return Null;
}
if (d1.units == d2.units)
{
LDim dim = new LDim();
dim.units = d1.units;
dim.value = d1.value + d2.value;
return dim;
}
LDim dim1 = new LDim();
dim1.units = "in";
dim1.value = d1.Inches.Value + d2.Inches.Value;
return dim1;
}
bool CheckDirectInput()
{
return CheckRangeAndAccurcy(this);
}
static bool CheckRangeAndAccurcy(LDim d)
{
decimal value = d.value;
// check overall range
if (d.units == "in")
{
if ((value > (52800M * 12M)) ||
(value < -(52800M * 12M)))
{
return false;
}
}
if (d.units == "ft")
{
if ((value > 52800M) ||
(value < -52800M))
{
return false;
}
}
if (d.units == "yd")
{
if ((value > (52800M / 3M)) ||
(value < -(52800M) / 3M))
{
return false;
}
}
// check accuracy to 0.001 inches
if (d.units == "ft")
{
value *= 12M;
}
if (d.units == "yd")
{
value *= 36M;
}
decimal norm = value * 1000M;
norm = decimal.Round(norm);
if ((norm - (value * 1000M)) != 0M)
{
return false;
}
return true;
}
static void MoveBitsFromIntToByte(
// source int
uint i1,
// start at this bit
int start1,
// take this many bits
int width,
// insert into this byte
ref byte b2,
// starting here
int start2)
{
uint mask = 0xFFFFFFFF;
mask = 1U << start1 + 1;
mask -= 1;
uint mask2 = 1U << (start1 - (width - 1));
mask2 -= 1;
mask2 ^= 0xFFFFFFFF;
mask &= mask2;
i1 &= mask;
int shift = start2 - start1;
if (shift < 0)
{
i1 >>= -shift;
}
if (shift > 0)
{
i1 <<= shift;
}
mask = 1U << start2 + 1;
mask -= 1U;
mask2 = 1U << (start2 - (width - 1));
mask2 -= 1;
mask2 ^= 0xFFFFFFFF;
mask &= mask2;
b2 |= (byte)(i1 & mask);
}
static void MoveBitsFromByteToInt(
// source byte
byte b1,
// start at this bit
int start1,
// take this many bits
int width,
// insert bits into this int
ref uint i2,
// starting at this bit
int start2)
{
uint bvalue = b1;
uint mask = 1U << (1 + start1);
mask -= 1U;
uint mask2 = 1U << (start1 - (width - 1));
mask2 -= 1;
mask ^= mask2;
bvalue &= mask;
mask = 1U << (1 + start2);
mask -= 1U;
mask2 = 1U << (1 + start2 - width);
mask2 -= 1;
mask ^= mask2;
mask ^= 0xFFFFFFFF;
i2 &= mask;
int shift = start2 - start1;
if (shift < 0)
{
bvalue >>= -shift;
}
if (shift > 0)
{
bvalue <<= shift;
}
i2 |= bvalue;
}
public static LDim Parse(SqlString s)
{
if (s.IsNull)
return Null;
// regular expression to test, extract
string fp = @"-?([0-9]+(.[0-9]*)?|.[0-9]+)";
Regex vu = new Regex(@"(?<v>" + fp + @") (?<u>in|ft|yd)");
if (!vu.IsMatch(s.Value))
{
throw new Exception("Bad format", null);
}
Match m = vu.Match(s.Value);
LDim d = new LDim();
d.units = m.Result("${u}");
d.value = decimal.Parse(m.Result("${v}"));
if (!CheckRangeAndAccurcy(d))
{
throw new Exception("Out of range or accuracy", null);
}
return d;
}
[SqlMethod(IsMutator = true, OnNullCall = true)]
public void ScaleBy(
[SqlFacet(Precision = 10, Scale = 15)]
SqlDecimal scale)
{
if (!IsNull && !scale.IsNull)
{
Decimal oldValue = this.value;
this.value *= scale.Value;
if (!CheckRangeAndAccurcy(this))
{
this.value = oldValue;
}
}
}
[SqlMethod(IsMutator = false, OnNullCall = false)]
public LDim GetScaled(SqlDecimal scale)
{
LDim ldim = new LDim();
if (!IsNull)
{
ldim.value = this.value;
ldim.units = this.units;
ldim.value *= scale.Value;
if (!CheckRangeAndAccurcy(ldim))
{
ldim = this;
}
}
return ldim;
}
[SqlMethod(IsMutator = true, OnNullCall = false)]
public void ToIn()
{
if (units == "ft")
{
value *= 12M;
}
if (units == "yd")
{
value *= 36M;
}
units = "in";
}
public void Write(System.IO.BinaryWriter w)
{
byte[] bytes = ToBytes();
foreach (byte b in bytes)
{
w.Write(b);
};
}
public byte[] ToBytes()
{
byte[] bytes = new byte[5];
if (IsNull)
{
bytes[0] = bytes[1] = bytes[2] = bytes[3] = bytes[4] = 0;
}
else
{
// store as inches and thousandths of an inch
int thousandths;
uint sign = 1;
Decimal floor = 0M;
Decimal d = this.Inches.Value;
int inches;
if (d < 0M)
{
floor = Decimal.Floor(-d);
thousandths = (int)((-d - floor) * 1000M);
sign = 0;
}
else
{
floor = Decimal.Floor(d);
thousandths = (int)((d - floor) * 1000M);
}
inches = (int)floor;
if (sign == 0)
{
// this is negative dim
inches = 10 * 5280 * 12 - inches;
thousandths = 1000 - thousandths;
}
// max number of inches is 633600 or 0x9AB00
// this fits in about 2.5 bytes or 20 bits
// thousandths (0-999) fits about 1.5 bytes or 10 bits
// sign takes 1 bit
// units takes 2 bits
// store as inches. note as calculated inches is never negative
// total bits needed is 20 + 10 + 1 + 2 or 33
// storage then will be 5 bytes
byte b = 0;
MoveBitsFromIntToByte(sign, 0, 1, ref b, 7);
// move bit 19 to position 6
MoveBitsFromIntToByte((uint)inches, 19, 7, ref b, 6);
//w.Write(b); //1
bytes[0] = b;
// move bit 11 to position 7
b = 0;
MoveBitsFromIntToByte((uint)inches, 12, 8, ref b, 7);
//w.Write(b); //2
bytes[1] = b;
// move bit 4 to position 7
b = 0;
MoveBitsFromIntToByte((uint)inches, 4, 5, ref b, 7);
// move bit 10 to position 2
MoveBitsFromIntToByte((uint)thousandths, 9, 3, ref b, 2);
//w.Write(b); //3
bytes[2] = b;
// move bit 7 to position 7
b = 0;
MoveBitsFromIntToByte((uint)thousandths, 6, 7, ref b, 6);
//w.Write(b); //4
bytes[3] = b;
// no add units 1=in, 2=ft, 3=yd
if (units == "in")
{
b = 1;
}
if (units == "ft")
{
b = 2;
}
if (units == "yd")
{
b = 3;
}
//w.Write(b); //5
bytes[4] = b;
}
return bytes;
}
public void Read(System.IO.BinaryReader r)
{
byte[] bytes = r.ReadBytes(5);
FromBytes(bytes);
}
public void FromBytes(byte[] bytes)
{
// if all bytes are zero this is null instance
if (
(bytes[0] == 0)
&& (bytes[1] == 0)
&& (bytes[2] == 0)
&& (bytes[3] == 0)
&& (bytes[4] == 0)
)
{
units = null;
value = 0M;
return;
}
uint sign = 0;
MoveBitsFromByteToInt(bytes[0], 7, 1, ref sign, 0);
uint inches = 0;
MoveBitsFromByteToInt(bytes[0], 6, 7, ref inches, 19);
MoveBitsFromByteToInt(bytes[1], 7, 8, ref inches, 12);
MoveBitsFromByteToInt(bytes[2], 7, 5, ref inches, 4);
uint thousandths = 0;
MoveBitsFromByteToInt(bytes[2], 2, 3, ref thousandths, 9);
MoveBitsFromByteToInt(bytes[3], 6, 7, ref thousandths, 6);
uint u = 0;
MoveBitsFromByteToInt(bytes[4], 1, 2, ref u, 1);
if (sign == 0)
{
inches = 10 * 5280 * 12 - inches;
thousandths = 1000 - thousandths;
}
value = thousandths;
value /= 1000M;
value += inches;
switch (u)
{
case 1: units = "in"; break;
case 2:
units = "ft";
value /= 12;
break;
case 3:
units = "yd";
value /= 36;
break;
}
if (sign == 0)
{
value = -value;
}
}
#region IXmlSerializable Members
System.Xml.Schema.XmlSchema IXmlSerializable.GetSchema()
{
System.IO.StringReader sr = new StringReader(@"
<xsd:schema xmlns:xsd='http://www.w3.org/2001/XMLSchema'>
<xsd:element name='LDim'>
<xsd:complexType>
<xsd:sequence>
<xsd:element name='Dimension'>
<xsd:element name='value' type='xsd:float'/>
<xsd:element name='units:'>
<xsd:simpleType>
<xsd:restriction>
<xsd:enumeration value='ft'/>
<xsd:enumeration value='in'/>
<xsd:enumeration value='yd'/>
</xsd:restriction>
</xsd:simpleType>
</xsd:element>
</xsd:element>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
</xsd:schema>");
XmlSchema schema = XmlSchema.Read(sr, null);
return null;
}
void IXmlSerializable.ReadXml(System.Xml.XmlReader reader)
{
XPathDocument xdoc = new XPathDocument(reader);
XPathNavigator nav = xdoc.CreateNavigator();
XmlNamespaceManager nm = new XmlNamespaceManager(nav.NameTable);
nm.AddNamespace("xsi", "http://www.w3.org/2001/XMLSchema-instance");
if ((bool)(nav.Evaluate("boolean(//@xsi:nil = 'true')", nm)))
{
value = 0;
units = null;
}
else
{
LDim dim = Parse((string)(nav.Evaluate(
"concat(//value, ' ', //units)")));
units = dim.units;
value = dim.value;
}
}
void IXmlSerializable.WriteXml(System.Xml.XmlWriter writer)
{
if (!IsNull)
{
writer.WriteStartElement("Dimension");
writer.WriteElementString("value", value.ToString());
writer.WriteElementString("units", units);
writer.WriteEndElement();
}
else
{
writer.WriteStartElement("Dimension");
writer.WriteAttributeString("nil",
"http://www.w3.org/2001/XMLSchema-instance", "true");
writer.WriteEndElement();
}
}
#endregion
}
}
User-Defined Aggregates
An aggregate function operates on a set and produces a scalar. The SUM function in SQL Server is an example of an aggregate. A SELECT statement is used to produce a set of rows, and the SUM function produces the arithmetic sum of some column in the rows produced by the SELECT statement. Figure 5-54 shows an example of a SQL batch using the SUM function.
Figure 5-54. Using the SUM aggregate function

The SELECT statement made a set of all the rows (1) from the Items table where the size=3; then the SUM function added each of the price columns from those rows to produce 15 (2).
This ability to do operations that produce a scalar result on sets of data is a key feature of a relational database. In fact, the SQL-92 specification requires that a database implement the COUNT, SUM, AVG, MAX, and MIN aggregate functions for compliance. SQL Server includes these aggregate functions and several others—for example, COUNT and COUNT_BIG, plus a number of statistical aggregates, such as STDEV and VAR, for standard deviation and variance.
You can create your own user-defined aggregates with SQL Server 2005. One reason you might want to do this is if you have created your own user-defined type and need to be able to aggregate it. None of the built-in aggregates in SQL Server will work with a user-defined type, so you may have to create your own in this case.
A second reason is performance. You do not need the SUM aggregate to calculate the sum of a column. Figure 5-55 shows a SQL batch that calculates the sum of prices that the example in Figure 5-54 does, but it does not use the SUM aggregate function.
Figure 5-55. Calculating a sum without an aggregate
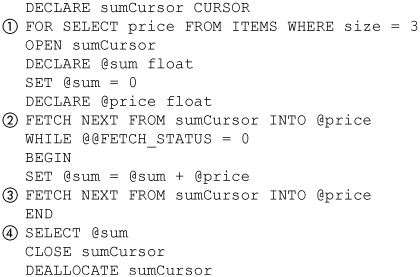
The sum technique shown in Figure 5-55 uses a CURSOR (1) to iterate through the results of a query and add up the prices. The first row is read (2); then all the rest of the rows are read (3). At each step along the way, the @sum variable is incremented by the price that is read and then selected (4). It typically is orders of magnitude slower than using the built-in SUM aggregate and uses a lot more resources on the server because of the CURSOR. Prior to SQL Server 2005, if you needed an aggregate other than one of the built-in ones provided by SQL Server, you might have used this technique to create your own aggregation.
Note that it is possible to build fairly complicated aggregates out of the ones built into SQL Server 2005. Figure 5-56 shows, in effect, a product aggregate; it calculates the product of all the numbers passed into it. A simple table (1) named Measurements has some floating-point distances in it. Some distances are inserted (2) into Measurements. The product aggregate is calculated (3) by summing the logarithms of the distances and raising ten to that sum that is produced (4). As a point of interest, this is how an old analog calculator known as a slide rule did multiplication, and using this technique to calculate the product of signed numbers has the same issues it did with a slide rule.
Figure 5-56. Product aggregate
In many cases, combining existing T-SQL scalar and aggregate functions is a better choice than a user-defined aggregate when possible. The example shown in Figure 5-56 would not work, however, if the dist column of the Measurements table were of type DECIMAL, because the LOG and EXP functions require a float as input.
The example in Figure 5-56, of course, could be made to work by casting the dist to a float before computing the logarithm, but a float is not big enough to hold all possible decimal values; besides, we saw at the beginning of this chapter that floats can easily lead to inaccurate results.
Prior to SQL Server 2005, if you wanted to make an aggregate like the one shown in Figure 5-56 but maintain the accuracy of the DECIMAL type, you would have to use the CURSOR technique shown in Figure 5-55. In SQL Server 2005, you can write your own aggregate, and its performance will be on the order of the built-in aggregates instead of orders of magnitude slower, as the CURSOR-based technique would be.
In the end, if we are going to have a user-defined type, we should be able to aggregate it just as we can a built-in scalar type, and that is what we are looking at in the next section.
Implementing a User-Defined Aggregate
In this section, we look at creating a user-defined aggregate that is the equivalent of SUM for the LDim user-defined type. Note that even though you can create a new aggregate function, there is no way to extend an existing aggregate function to support additional data types—that is, there is no way to extend the SUM aggregate to support user-defined types such as LDim.
We will call this new aggregate SumLDim, and it will produce an LDim that represents the arithmetic sum of the LDims that it processes. Figure 5-57 shows a SQL batch that makes use of the SumLDim aggregate function. Note that a user-defined aggregate function must be referenced with a two-part name.
Figure 5-57. Using a user-defined aggregate
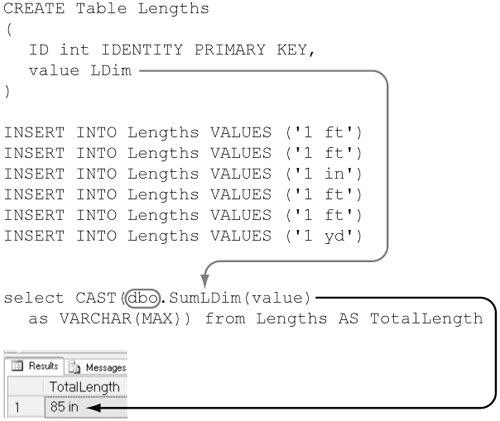
A user-defined aggregate is implemented by a public class, decorated with the SqlUserDefinedAggregate attribute, that implements four wellknown methods: Init, Aggregate, Merge, and Terminate. User-defined aggregates must be serialized, and the serialization can be done by either SQL Server 2005 itself or via IBinarySerialize, just as is done with user-defined functions.
Figure 5-58 shows a skeleton of the implementation of the SumLDim aggregate. This aggregate uses Format.Native (2) serialization, meaning that it is going to let SQL Server do the serialization. SQL Server is going to use the CLR to do the actual serialization, and because of this, the class that implements LDim must be marked with the Serializable attribute. The CLR will not serialize classes that are not marked with this attribute.
Figure 5-58. SumLDim implementation skeleton

This implementation makes use of some optimizations. Many aggregates will ignore a null value—that is, they will not include it in the aggregate calculation. The IsInvariantToNulls property of the SqlUserDefinedAggregate is used to indicate this. If the aggregate is going to ignore null, the IsInvariant-ToNulls property should be set to true. When this is set to true, SQL Server 2005 may skip passing NULLs to the aggregate as an optimization. Note that the implementation of the aggregate must still be able to process null values, as IsInvariantToNulls is only a hint and is used only if the query processor finds it will be helpful.
In general, and specifically in the case of LDim, aggregates don’t care about the order in which rows are processed. Some interesting aggregates could be implemented, however, if the order in which rows were processed could be controlled. In Figure 5-58, the IsInvariantToOrder property of the SqlUserDefinedAggregate attribute is used to indicate whether the aggregate expects the rows to be processed in some particular order. IsInvariantToOrder=true indicates that the aggregate does not care in what order the rows are processed; IsInvariantToOrder=false indicates that the aggregate requires rows to be processed in the order in which they are sorted.
SQL Server 2005 ignores the value of IsInvariantToOrder, but some future version of SQL Server may respect this setting. To respect this setting, SQL Server 2005 would have to either use or build an index when processing the aggregate function, which it never does. Best practice is to set this property to true so that if this aggregate is used with a version of SQL Server that supports IsInvariantToOrder, its performance will not be compromised by SQL Server’s sorting rows before they are processed by the user-defined aggregate.
Two other properties of the SqlUserDefinedAggregate attribute should also be considered: IsInvariantToDuplicates and IsNullIfEmpty. Some aggregates can ignore duplicate values; the MIN and MAX aggregate functions are examples of these. Auser-defined aggregate can, as an optimization hint, set IsInvariantToDuplicates=true if it is like MAX and MIN in that it need not have the same value passed in to it multiple times to make a correct calculation. The default value for IsInvariantToDuplicates is false, and this is the case for SumLDim, so it need not be specified.
The IsNullIfEmpty property is used to indicate that the aggregate function will return NULL if there are no rows to process. The SUM aggregate function returns a NULL if no rows are passed to it, for example. If NullIfEmpty = true, SQL Server 2005 may skip using the user-defined aggregate and directly return a NULL if there are no rows for the aggregate to process.
Both IsInvariantToDuplicates and IsNullIfEmpty are only hints; even if they are set to true, the user-defined aggregate must work property if they are ignored.
The underlying data type for an LDim is decimal; that was chosen to maintain the accuracy of arithmetic calculations as much as possible. The SumLDim should likewise use decimal for its calculations so that it can also preserve arithmetic accuracy as much as possible. One of the issues we ran into in the implementation of LDim was that the CLR decimal type must be serialized using Format.UserDefined.
A user-defined aggregate must store some kind of accumulator to build up the final result as rows are passed in to it. In the case of SumLDim, this accumulator will in effect be an LDim. In fact, the accumulator will accumulate inches and be a decimal.
It is possible to use Format.Native to serialize the internal representation of a decimal data type. Internally, a decimal data type is made up of four ints, which can be obtained by the decimal.GetBits method. Given the internal representation, a new decimal data type can be instantiated from these four ints. So by representing a decimal data type as four ints, we can serialize it using Format.Native.
Figure 5-59 shows how SumLDim stores a decimal type (1) as four ints. Two helper methods save and restore a decimal from these four ints. The SaveSum method (2) takes a decimal as an input parameter and then uses the decimal.GetBits method to extract the four ints that make it up. The GetSum method (3) returns a decimal by using the constructor for a decimal that takes as input an array of four ints.
Figure 5-59. Representing decimal

The well-known method Init in the class that implements a user-defined type is used to initialize the accumulator for the aggregate. Init is guaranteed to be called once for an aggregate calculation, and it will be called before any of the other well-known methods are. Figure 5-60 shows the implementation of the Init method. It uses the SaveSum method (1) to save a zero. It might seem to be a better idea to have initialization for a class done in its constructor. Initialization for a user-defined aggregate, however, must be done in the Init method. SQL Server 2005 may, as an optimization, reuse an instance of the class that implements a user-defined aggregate rather than construct a new one.
Figure 5-60. Implementation of init

The well-known method Accumulate is the method that does the actual aggregation. SumLDim aggregates LDims so that its input parameter type is LDim. Figure 5-61 shows the implementation of the Accumulate method. This method is called by SQL Server 2005 once for each row that is aggregated in a query. Note that it does check (1) the value passed in and does not process it if it is null, even though IsInvariantToNulls = true, because IsInvariantToNulls is only a hint. The input value is processed (2) by converting the LDim input value to inches, adding the current sum to it, and then saving the result in the four ints used to save the decimal value.
Figure 5-61. Implementation of accumulate

SQL Server 2005 may, in some cases, use more than one instance of a user-defined aggregate while doing an aggregate calculation. The well-known method Merge is called by SQL Server when it needs to combine two instances of a user-defined aggregate. The Merge method may be called zero or more times. Figure 5-62 shows the implementation of Merge. It simply adds (1) the current sum in the instance with the sum from the other instance and saves the result into the four ints used to save the decimal value.
Figure 5-62. Implementation of merge

At the end of an aggregate calculation, SQL Server 2005 will call the well-known Terminate method to get the results of the aggregate calculation. The Terminate method will be called only once. Figure 5-63 shows the implementation of the Terminate method. It creates a new instance of an LDim (1) initialized to zero. Next, it uses the Inches property of LDim instance to set (2) it directly to the sum that was accumulated. Last, the new instance of LDim is returned (3).
Figure 5-63. Implementation of terminate

Creating User-Defined Aggregate
A CREATE AGGREGATE statement is used to add an aggregate to SQL Server 2005, as shown in Figure 5-64. The assembly must already be loaded (1) into SQL Server. The syntax for CREATE AGGREGATE is similar to that for a function. The type of the input parameter (2) and return value (3) must be specified.
Figure 5-64. Loading a user-defined aggregate

There is no requirement that a user-defined aggregate return the same type that it takes as an input. The SumLDim, for example, could have returned a float that by convention was the number of inches accumulated.
Format.Native vs. Format.UserDefined
You can also see in the SumLDim that implementing Format.Native is very simple, and the implementation of the user-defined type LDim would have been much easier if this technique had been used.
There were two reasons for using Format.UserDefined in the implementation of LDim. One was simply to provide an example of an implementation that used Format.UserDefined. The second reason was so that we could control the sorting order. Implementations that use Format.Native will be sorted according to the order of the fields in their class definition. Ordering in this case will be done numerically, not by byte order.
Unfortunately, that leaves us between a rock and a hard place with respect to controlling the sort order of the decimal type. If LDim used the four ints technique that SumLDim does, the order would not reflect the numeric order of decimal numbers.
In addition, the units would have to be taken into account. They could be represented as the numbers 0, 1, 2 and 3, but that would just compound the ordering problem.
To control the sort order of a Format.Native type closely, you can add a field that precedes all other fields in the class and have that field be maintained with a number that represents the order. You could add a float field and cast the decimal into it, for example, but this would lead to range problems and accuracy.
In the end, if your implementation of a user-defined type is based on a type that cannot be serialized by Format.Native, you probably will find that techniques similar to those shown in the LDim implementation will be required to achieve both accuracy and a desired sort order. Listing 5-2 shows source code for the SumLDim aggregate.
Listing 5-2. Source code for SumLDim
using System;
using System.Data;
using System.Data.SqlClient;
using System.Data.SqlTypes;
using Microsoft.SqlServer.Server;
using Dimensions;
[Serializable]
[Microsoft.SqlServer.Server.SqlUserDefinedAggregate(
Format.Native,
IsInvariantToNulls = true,
IsInvariantToOrder = true
)]
public struct SumLDim
{
int int0;
int int1;
int int2;
int int3;
void SaveSum(decimal d)
{
int[] ints = decimal.GetBits(d);
int0 = ints[0];
int1 = ints[1];
int2 = ints[2];
int3 = ints[3];
}
decimal GetSum()
{
int[] ints = new int[4];
ints[0] = int0;
ints[1] = int1;
ints[2] = int2;
ints[3] = int3;
return new decimal(ints);
}
public void Init()
{
SaveSum(0M);
}
public void Accumulate(LDim Value)
{
if (!Value.IsNull)
{
SaveSum((Value.Inches.Value + GetSum()));
}
}
public void Merge(SumLDim Group)
{
SaveSum(GetSum() + Group.GetSum());
}
public LDim Terminate()
{
LDim ldim = LDim.Parse("0 ft");
ldim.Inches = GetSum();
return ldim;
}
}
Where Are We?
User-defined types are extensions to the SQL Server built-in scalar types. They are used in the same way and for the same purpose. They allow us to use an application-specific format for the string representation of a value—for example, “1 ft”—in much the same way that we use a string representation of a date—such as “12/1/1998”—for a DATETIME built-in data type. They also allow us to encapsulate functionality for a type with the type itself.
A user-defined type is implemented by a CLR class that implements a number of well-known methods and is decorated with the SqlUserDefinedType attribute. It can be accessed from within SQL Server when its assembly has been added to a database and CREATE TYPE has been used to create the user-defined type.
The user-defined type can be used in the definition of a column type for a table, a variable type, or a parameter type in a stored procedure or function. It is often useful to add user-defined-type-specific methods that can manipulate or extract information from an instance of that type. It is often useful also to add utility functions that can create initialized instances of a user-defined type.
User-defined types can also expose their properties and fields. This is useful when one of the fields of a user-defined type must be accessed or manipulated.
A user-defined aggregate is implemented using a CLR language. There is no way to create an aggregate function using T-SQL. Aggregate functions are often created for use with user-defined types. They may also be created for built-in types.
Both user-defined type and user-defined aggregate implementations must always be aware that they are manipulating data in SQL Server at a very low level and will often require extra code beyond the function they are implementing, to ensure that the data is not corrupted.
We’ve covered most of the new features of SQL Server 2005 that directly relate to .NET Framework, finishing with user-defined types and user-defined aggregates. Chapter 2 pointed out that no matter how flexible or powerful a database is, a database without security is less than useful. The next chapter talks about how security has been considered at every level when the new functionality was designed. In addition, we’ll see how permissions work with the .NET Framework features.