
A. .NET Framework 101
The .NET Framework is the latest component platform from Microsoft and probably is one of the biggest changes for software developers since the move from the 16-bit MS-DOS platform to the 32-bit Windows NT platform.
This appendix gives a brief introduction to the .NET Framework and the CLR for those of you who haven't done any development using the .NET Framework.
The Common Language Runtime
One of the biggest changes in the .NET Framework is that there is an execution engine: the CLR (Common Language Runtime), which handles many of the tasks you had to do previously. The runtime is responsible for (among other things):
• Memory management
• Lifetime management (garbage collection)
• Field layout
• Thread management
• Type safety
• IO management
These are things that you, as a developer, had to handle before the CLR and the .NET Framework, and there were errors in the applications you wrote if you did not handle them correctly. You are giving up control ideally to become more productive and ensure that your coding is less error prone.
This situation, in which you as a developer give up control, is very much like when you went from MS-DOS to Windows NT. In MS-DOS, you were used to handling physical memory and dealing with interrupts. You gave up control over this in favor of virtual memory and threads. Now you give up control over memory management, among other things, in favor of using types. A type is declared as a class; later in this appendix, we cover how to create them.
Figure A-1 shows a simplified picture of the new programming model, and as you see, your code now executes inside the CLR.
Figure A-1. The CLR programming model

Having the code execute inside the CLR raises an interesting question: What do I do if I want to code against Windows, databases, or anything else outside the CLR? Most of the resources we know and use in our applications are outside the CLR.
You can access the underlying platform features from your application; Microsoft has put down a lot of work on making it possible to interoperate between managed and native code. Microsoft discourages this, however, and ships with the CLR a family of runtime libraries that provides a language-neutral way to write Web programs, database access programs, XMLprograms, and Windows programs. Most of these libraries/routines reside in a DLL, mscorlib.dll, that also contains the metadata for the CLR type system. The runtime is an environment that is being initialized by various host environments: It is being hosted. Windows in itself acts as a host; ASP.NET acts as a host; and yes, SQL Server Yukon acts as a host.
What makes it possible to host the runtime from native code is a COM DLL, mscoree.dll. This DLL exposes several API functions that are used to initialize and host the CLR. But mscoree.dll is just a thin layer over the runtime. As soon as it is initialized, it loads either mscorwks.dll or mscorsvr.dll, dependent on certain rules. These two DLLs are the “real” runtime, and we discuss them in more detail in Chapter 2. Because mscoree.dll is needed by every .NET Framework application, you do not need to link to it explicitly, but the .NET Framework compilers reference it implicitly as well as mscorlib.dll.
Development Languages
As opposed to other, competing frameworks, the CLR allows you to choose what development language you want to use. The only requirement is that the language has a compiler that produces CLR executables. This also means that the features of the CLR are available to all languages. If the CLR allows implementation inheritance (which it does), for example, all languages can use that feature. Therefore, the choice of which development language to use can be based on what you feel comfortable with, not what restrictions the language puts on you. Microsoft ships compilers for five languages together with the CLR:
• C# (C-Sharp)
• Viusal Basic .NET
• MC++ (Managed C++)
• J Script
• MSIL (Microsoft Intermediate Language)
Compilers for other development languages also are available, ranging from Python to COBOL.
Looking at the list of languages above, you may wonder what MSIL (IL) is. IL is the CLR's assembly language. It turns out that when you compile your code, the code is not compiled to machine code but, as you can see in Figure A-2, to IL code, which can be seen as interpreted code.
Figure A-2. Compilation of code into IL
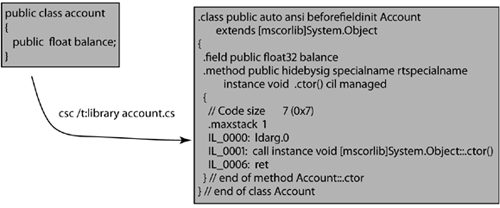
Does this mean, then, that when your CLR application executes, it executes interpreted code? No, because when you run the application, the IL code will be compiled into machine code as needed through the Just-in-Time Compiler(JIT Compiler, also called JITter). After the application has been loaded, it is the JITter's responsibility to compile the IL code to machine code (native CPU instructions) when a function is first executed. The native code is saved, and for each subsequent time that particular function is called, the native code is executed without the JITter's being called. From a performance perspective, there is a slight delay for the first call into a particular function, whereas subsequent calls are executed at optimal speed.
Because most applications execute the same methods repeatedly, the performance hit is not significant. If you are worried about this, you can use a specific tool in the .NET Framework SDK: the NGen.exe, which compiles the IL code directly into native code.
Assemblies and Modules
When you read about the .NET Framework and the CLR, you are certain to come across the term assembly. Before we can define what an assembly is, we need to discuss briefly another term in the CLR: the module.
Modules
Programs written for the CLR reside in modules. A CLR module is a byte stream, typically stored as a file in the local file system or on a Web server. CLR modules contain code, metadata, and resources. The module's metadata describes the types defined in the module, including names, inheritance relationships, method signatures, and dependency information. The module's resources consist of static read-only data such as strings, bitmaps, and other aspects of the program that are not stored as executable code.
The compilers in .NET Framework translate source code into CLR modules. The compilers accept a common set of command-line switches to control which kind of module to produce. You normally choose between producing an executable (EXE) or a library module (DLL). Listing A-1 shows how to use the C# compiler from the command line. The first uncommented line of code creates an EXE, and the next uncommented code line creates a DLL. In both cases, the source-code file is called source.cs. It is the /target: switch that decides whether you want an EXE or a DLL. In Visual Studio .NET, you make the same decision by choosing an executable or a class library as the project type.
Listing A-1. Compiling from command line
//compiling an EXE
csc /target:exe source.cs
//compiling a dll
csc /target:library source.cs
Table A-1 shows what choices you have when deciding what you want to compile your C# application into.
Table A-1. Target Switches
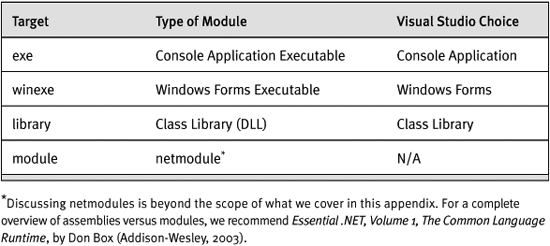
Notice that you can not compile netmodules from Visual Studio .NET. You have to do it from the command line.
In previous component model technologies, you had various ways of investigating the metadata of your component. In COM, you used the OLEView.EXE to get type information, and for non-COM components, you probably used DUMPBIN.EXE. In the .NET Framework, you have various tools if you want to inspect a module or assembly.
One such tool is ILDasm.EXE, which ships with the .NET Framework SDK. ILDasm stands for Intermediate Language Disassembler, and you use ILDasm to view the metadata and disassembled code of your application in a hierarchical tree view.
Figure A-3 shows the metadata for a component, which consists of a class called Person. Notice that you can see both private members and public members of the class. The figure also shows a method called SaySomething.
Figure A-3. Screenshot of ILDasm
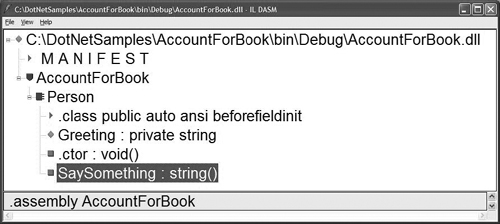
As you can see, the method is fully disassembled, and the code you see is the compiled IL code.
ILDasm is extremely useful, and we urge you to get to know it, as it will help you when you develop applications, as well as understand what code from other developers does.
Assemblies
An assembly is the essential building block of your application and consists of a collection of modules. You can think of an assembly as being the logical EXE or DLL. The assembly is also the fundamental unit for deployment and is used to package, load, distribute, and version CLR modules. The assembly consists of one or more modules, and the most common scenario is that your assembly has only one module. This is what you get when you compile a Visual Studio .NET Framework project.
The main difference between a module and an assembly (between .netmodule and EXE/DLL) is that in an assembly, exactly one module holds not only the metadata for the particular module, but also a manifest. The manifest is metadata with information about what types the assembly consists of and in what files those types can be found. The module containing the assembly manifest will also have a list of externally referenced assemblies. This list consists of the dependencies of every module in the assembly, not just the dependencies of the current module.
In Listing A-2, you can see the manifest for the component we showed the ILDasm for in Figure A-2. Notice that the only externally referenced assembly is mscorlib.dll.
Listing A-2. Manifest for component
.assembly extern mscorlib
{
.publickeytoken = (B7 7A 5C 56 19 34 E0 89 )
// .zV.4..
.ver 1:0:5000:0
}
.assembly account
{
// --- The following custom attribute is added automatically, do not
uncomment -------
// .custom instance void
[mscorlib]System.Diagnostics.DebuggableAttribute::.ctor(bool,
//
bool) = ( 01 00 00 01 00 00 )
.hash algorithm 0x00008004
.ver 0:0:0:0
}
.module account.dll
// MVID: {6802C533-1DBF-4E78-A61E-9B883723E40B}
.imagebase 0x00400000
.subsystem 0x00000003
.file alignment 512
.corflags 0x00000001
// Image base: 0x06cf0000
In Listing A-2, you can also see the version number for the actual component, as well as the version number for the referenced mscorlib.dll. In the next section, we'll discuss assembly names and versioning.
Assembly Names and Versions
If you have a COM background, you probably remember that your components were uniquely identified by a Globally Unique Identifier (GUID). In the .NET Framework, Microsoft has done away with the GUIDs, and assemblies are identified by a four-part name. When the assembly is loaded by the runtime, this name is used to find the correct component. The name consists of:
• Friendly name
• Locale
• Developer
• Version
The Name property of the assembly name corresponds to the underlying filename of the assembly manifest without any extension, and this is the only part of the assembly name that is not optional. The name is needed in simple scenarios to locate the correct component at load time. When building an assembly, this part of the assembly name is selected by your compiler automatically based on the target filename. Although strictly speaking, the Name of the assembly does not need to match the underlying filename, keeping the two in sync makes the job of the assembly resolver (and system administrators) much simpler.
Assembly names can contain a CultureInfo (locale) that identifies the spoken language and country code that the component has been developed for.
An assembly name can contain a public key (token) that identifies the developer of the component. An assembly reference may use either the full 128-byte public key or the 8-byte public key token. The public key (token) is used to resolve filename collisions between organizations, allowing components with the same name to coexist in memory and on disk. This is if each component originates from a different developer, each of which is guaranteed to have a unique public key. When you give your components a public key, you give them a strong name.
All assembly names have a four-part version number (Version) of the form Major.Minor.Build.Revision. If you do not set this version number explicitly, its default value will be 0.0.0.0. The version number is set at build time using a custom attribute in the source code or using a commandline switch. The runtime is doing a version check during the loading of the respective assemblies, which means you can differentiate between two assemblies with the same name and publisher based upon version number. Notice that we said “name and publisher.” Publisher is the keyword here, as the runtime makes this version check only for strongly named assemblies.
The CLR Type System
The CLR is all about types, and some people go as far as to say that the CLR was developed to rectify previous models' shortcomings with regard to type and type information. Be that as it may, types are essential in the CLR, and there is a formal specification describing how to define types and how the types should behave. This formal specification is known as the Common Type System (CTS).
The CTS specifies, among other things:
• What members a type can contain
• The visibility of types and members
• How types are inherited, virtual functions, and so on
The CTS also specifies that all types within the CLR have to derive from a predefined type, which acts as the root of the type system. This type is System.Object, and because this type is the root, any member in the CLR can be assigned to variables of System.Object. This also means that every member in a class has a minimum set of behaviors (inherited from System.Object). Table A-2 shows the members of System.Object and what they do.
Table A-2. Members of system.Object
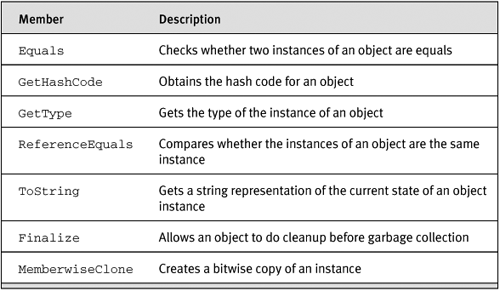
Because the CLR has a defined type system with System.Object as root, the runtime can make sure that the code we write is type safe. Figure A-4 illustrates the CLR type system. Notice that the type system is logically divided into two subsystems: reference types and value types.
Figure A-4. The CLR type system

Programming languages in general have a set of built-in types, referred to as simple or primitive types. Normally, they are int, float, bool, char, and so on. You find in the CLR a rich set of these types, which Listing A-3 illustrates.
Listing A-3. Types in the CLR type system
struct Point
{
bool outside;
int X;
int Y;
float density;
}
In Figure A-4, you see some boxes that illustrate various user-defined types based on the primitive types. In the following section, we cover how to create these user-defined types.
Classes and Types
When you create a type in the CLR, you ultimately derive from System. Object, System.ValueType, or System.Enum. Suppose that you want to create a new reference type called Person. The C# code for that would look something like Listing A-4. Because it is required that you ultimately derive from System.Object, however, you can write your code as shown in Listing A-5.
Listing A-4. Create person class by explicitly deriving from System.Object
class Person : System.Object {
}
Listing A-5. Create person class by implicitly deriving from System.Object
class Person {
}
You indicate that you want to inherit from a type by using the colon after your class name, followed by the type you want to derive from: class YourType : TypeToDeriveFrom.
Looking at the code in Listing A-4, you may think that to create a value type, you would write code something like class MyValueType : System. ValueType. That is not the case if you code in C#, Visual Basic .NET, or some of the other programming languages in the CLR. The programming languages use their own concepts of types: class, interfaces, structures, enumerations, and so on. The runtime sees these ultimately as type definitions, and it distinguishes among the various types based on base class or attributes in the metadata.
When you use C#, you indicate what kind of type you want to create by using the syntax in Table A-3.
Table A-3. Syntax for Type Definitions in C#

The keyword struct may be somewhat misleading when creating a value type, and you may believe that the value type is only a data structure, nothing more. That is not the case at all; a value type can have fields, methods, properties and so on, exactly like a class. The value type can also support interfaces.
Visibility
When you create your types, you may want to decide how they should be accessible and whether they should be visible to the outside world. For this reason (as we mentioned earlier), the CTS defines rules for visibility and access to types, as well as members within a type. You decide what visibility and access you want by using access modifiers. These access modifiers are
keywords that you mark your type or member with. Table A-4 shows the access modifiers for both types, as well as members. We cover type members later in this appendix.
Table A-4. Access Modifiers

Listing A-6 shows some code that uses these access modifiers.
Listing A-6. C# Code making use of access modifiers
public class Person { //this class is visible to anyone
private int age; //this is private
string name; //this is also private
public string address; //this field is visible to anyone
//this method is visible from anywhere inside the assembly
internal void DoSomethingInternally() {}
//this method is visible from anywhere
public void DoSomethingPublicly() {}
//this method is visible only within the type
//as the default is private
void DoSomethingPrivately() {}
}
Instances
You access your types through instance variables. In Listing A-7, we see that the type system is divided into reference types and value types.
A reference type variable contains the memory address of the particular object it refers to and is not the actual type instance. Before a reference type variable can be used, it must be initialized to point to a valid object. Value types, on the other hand, are the instances themselves, not references. This means that a value type variable is useful immediately upon declaration.
In C#, you initialize reference type by using the new keyword, which will be translated into an IL newobj instruction. The corresponding keyword in Visual Basic .NET is New. The code in Listing A-6 shows how you initialize a reference type and a value type.
Listing A-7. Initialization of reference types and value types
class RefPerson {
public int age;
public string name;
}
struct ValPerson {
public int age;
public string name;
}
class App {
static void Main(string[] args) {
//initilize the reference type
RefPerson p = new RefPerson();
p.age = 33;
//initialize the value type
ValPerson vp;
vp.age = 33;
//the following code will not compile as it is a reference type
//there will be an error: 'Use of unassigned local variable 'p1''
//RefPerson p1;
//p1.age = 33;
}
}
Notice that we get an error when we try to use an instance of the reference type without having initialized it with new. A value type can be initialized using new as well. The difference from a reference type is that the IL instruction will be initobj instead of newobj. Listing A-8 shows how a value type is initialized with the new keyword.
Listing A-8. Initialize a value type with new
//the definition for RefPerson and ValPerson is the same as in
// A–6
class App {
static void Main(string[] args) {
//initilize the reference type
RefPerson rp = new RefPerson();
rp.age = 33;
//get a new variable for RefPerson
RefPerson rp1 = rp;
rp1.age = 35;
//here you will see the same age (35) for both rp as well as rp1
System.Console.WriteLine("Reference Types:
rp's age is:
{0}
rp1's age is: {1}", rp.age, rp1.age);
//initialize the value type
ValPerson vp = new ValPerson();
vp.age = 33;
//get a new variable for ValPerson
ValPerson vp1 = vp;
vp1.age = 35;
//vp's age is 33, vp1's age is 35
System.Console.WriteLine("
Value Types:
vp's age is:
{0}
vp1's age is: {1}", vp.age, vp1.age);
}
}
Listing A-8 also shows how assignment of variables works differently depending on the type. For reference types, the assignment results in a duplicate variable pointing to the same address space as the first. Subsequently, when you change the state from one variable, that change is visible through the second variable as well.
The assignment for a value type results in a copy of the instance, which is completely unrelated to the first instance. Any change of state from one variable does not affect the other.
The main differences between reference types and value types are
• Reference types inherit from System.Object or a type that in its root of the inheritance chain has System.Object. A value type inherits from either System.ValueType or System.Enum1 and from those two types only. In other words, you can derive from a reference type but not from a value type.
• A reference type is created on the garbage-collected heap, whereas a value type normally is created on the stack. A value type can be allocated on the heap, however. This happens when the value type is a member of a reference type, for example.
• Another difference is that a reference type always is accessed via a strongly typed reference. A value type, on the other hand, can be accessed directly or via a reference.
From the perspective of the developer, there is not much difference between a reference type and a value type. A value type can have fields, methods, properties and so on, exactly like a reference type.
Namespaces
When you develop your projects, the likelihood that you will have types related to one another is fairly big. These types may be located in different assemblies, for example, and you want to group them. You accomplish this by using namespaces.
Namespaces provide a way to group types logically. You use them both within your application to organize your types and in an external organization system. When you look through the helper libraries in the CLR, you find that namespaces are used everywhere. An example is the System.Data namespace, which defines types that have to do with data access. It is further divided into namespaces for certain providers, such as the System.Data. SqlClient namespace and the System.Data.OleDb namespace.
You indicate that your type(s) belong to a namespace by using the Namespace keyword, as the code in Listing A-9 shows.
Listing A-9. Creating a namespace
namespace People {
public class Person {
}
public class Instructor {
}
}
public class Calculator {
}
In the code in Listing A-9, the Person and Instructor class both belong to the People namespace. The Calculator class, however, does not belong to any namespace.
The CLR has no knowledge about namespaces and sees the Person type in Listing A-9 as being of the type People.Person. Subsequently, when you want to create an instance of this type, you create an instance of People.Person.
With namespaces, the code to create an instance of a type can become fairly verbose, as the code in Listing A-10 shows. Therefore, most compilers have mechanisms to make it easier for the programmer and reduce the typing the programmer has to do. Listing A-11 shows how the C# developer can use the using directive.
Listing A-10. Explicitly typing full type names
public class DataStuff {
public void Main() {
//from the compiler's perspective as well as the CLR the type
//is the full name including namespace
System.Data.SqlClient.SqlConnection conn;
conn = new System.Data.SqlClient.SqlConnection();
//code to connect etc follows but not shown
}
}
Listing A-11. Use of the using directive in C#
using System.Data.SqlClient;
public class DataStuff {
public void Main() {
SqlConnection conn;
conn = new SqlConnection();
//code to connect etc follows but not shown
}
}
The directive for the Visual Basic .NET developer is Imports instead of using.
Members of Types
For a type to be useful, it has to contain something. This something is member declarations, which describe the state or behavior of the type. The CLR supports six types of members; you can see them and their definitions in Table A-5.
Table A-5. Type Members

Listing A-12 shows code for a type containing the six members.
Listing A-12. A type with members
using System;
class MyType {
//field
int _age;
//field
public string name;
//constructor
public MyType() {
name = "Jim";
}
//method
public void SayHello() {
Console.WriteLine("hello");
}
//property
public int Age {
set { _age = value;}
get {return _age;}
}
//this event doesn't do anything
public event EventHandler MyEvent;
//nested type
class NestedType {
//some members
}
}
Each member in a type is of a certain data type. The data type can be some of the built-in types or a type that the developer has defined. Methods and properties may not necessarily have a particular return type. You declare this in C# with the keyword void. In Visual Basic .NET, you declare the method as a Sub.
Notice that the event MyEvent is not fully functional, as it is not implemented through any methods. We do not intend to cover events in this appendix; see Essential .NET,Volume 1, The Common Language Runtime, by Don Box, for a full coverage of events.
Fields and Properties
In Listing A-12, we have declared two fields: _age and name. _age is private, and name is public. Declaring a field as public is not considered to be good coding practice, as you should not allow direct access to the state of a type. Instead, fields should be accessed through properties. The property Age is an example of this.
Members can either be static members or instance members. The difference is that a static member is part of the type, whereas an instance member is part of the object. A popular definition of static members is that they are global. Static members are accessed by the syntax: type. member, as opposed to the instance member, which is accessed through variable.member.
As we mentioned in Table A-5 earlier in this chapter, a property is a special type of method that allows fieldlike syntax to retrieve or set state values. To the CLR, a property is a binding of a name to one or two method declarations, one of which is the “getter” and the other of which is the “setter.” A property also has a type, which applies to the return type of the “getter” method and the last parameter to the “setter” method.
In C#, you define a property as a special method that consists of a get part and a set part. Listing A-13 shows the code for a class with a property called Name. You make the property read-only by omitting the set part. For a write-only property, you omit the get part.
Listing A-13. Property declaration
public class Person {
string _name;
public string Name {
set { _name = value;}
get {return _name;}
}
}
Note that when you assign a value to a property, the value is passed in through an intrinsic parameter called value. Listing A-14 shows how to access the Name property in Person.
Listing A-14. Accessing a property
public class App {
string _name;
static void Main() {
Person p = new Person();
//set the property this uses the value parameter
p.Name = "Jim";
//get the property
System.Console.WriteLine(p.Name);
}
}
Parameters and Methods
When you pass parameters to a method, the method's declaration determines whether the parameters will be passed by reference or by value. Passing parameters by value (the default) results in the method's getting its own private copy of the parameter values. If the parameter is a value type, the method gets its own private copy of the instance. If the parameter is a reference type, it is the reference that is passed by value. The object the reference points to is not copied. Rather, both the caller and method wind up with private references to a shared object.
When the parameters are passed by reference, the method gets a managed pointer pointing back to the caller's variables. Any changes the method makes to the value type or the reference type will be visible to the caller. Furthermore, if the method overwrites an object reference parameter to redirect it to another object in memory, this change affects the caller's variable as well. In C#, you indicate that you want to pass a parameter by reference by using the ref or out modifier. Listing A-15 shows a method that takes three parameters and how it is called. When you pass parameters by reference, you need to indicate that in the calling code with the ref or out modifier.
Listing A-15. Parameter passing
public class Person {
public int DoSomething(int x, ref string y, out int z) {
//do something
z = 100;
//return a value
return 99;
}
}
public class App {
static void Main() {
int a = 99;
string b = "Jim";
int c;
Person p = new Person();
p.DoSomething(a, ref b, out c);
}
}
The difference between the ref and out modifiers is that the out marked variable does not need to be initialized before calling. Subsequently, it cannot be used in the method before it has been assigned a value from within the method.
Memory Management
Memory is allocated on the heap/stack by creating an instance of a type. The allocation is handled by the runtime, and the developer does not need to care explicitly about memory management, field layout, and so on. The same is true of reclaiming memory. The CLR is wholly responsible for reclaiming (deallocating) memory. Memory management is one of the primary benefits of the CLR's managed execution mode. So how does the CLR know when to reclaim memory?
When an object is created, the CLR tracks the reference to this object (and all other objects referenced in the system). Because the CLR has this knowledge about the object references, it also knows when an object is no longer referenced. The memory allocated for the object can be reclaimed at this stage. The memory reclamation is done through garbage collection. Doing garbage collection affects performance. Because of this, garbage collection does not necessarily happen as soon as the object is no longer referenced. Instead, the CLR performs garbage collection when certain resource thresholds are exceeded.
Normally, the developer does not care about garbage collection, but if he wants explicit control, the System.GC class exposes the garbage collector programmatically. The Collect method tells the CLR to perform garbage collection as soon as the method is called. Be aware, however, that calling GC.Collect frequently can have a negative impact on performance.
Finalization and Destructors
Generally, the objects do not need to know when they are garbage-collected. Objects referenced by the one that is garbage-collected will themselves be collected as part of the normal garbage-collection run. Sometimes, however, there may be situations where an object holds references to resources that will not be garbage-collected or references to scarce resources. Examples are file handles, database connections, and so on. In a situation like that, the object may want to get a notification saying that it is about to be collected.
This can be achieved by something called object finalization. System. Object exposes Finalize, which is a method that can be overridden in derived types. Finalization, however, is a technique that adds complexity. Because of this, you cannot implement Finalize directly in C#. Instead, you implement a destructor, which causes the compiler to emit your destructor code inside a Finalize method. Listing A-15 shows this. The compiler also makes sure that the Finalize method in your base class is called. As you see in Listing A-16, the destructor looks like a constructor, but it is prepended with ~.
Listing A-16. Use of destructor
public class Person {
//other methods not shown
~Person() {
//call your cleanup code
CleanUp();
}
void CleanUp() {
//code to free scarce resources
}
}
One thing to bear in mind about finalizers is that the Finalize method may be called long after the object has been identified by the garbage collector. When the garbage collector tries to reclaim an object that has a finalizer, the reclamation is postponed until the finalizer can be called. Rather than reclaim the memory, the garbage collector puts the object onto a specific finalization queue. A dedicated garbage-collector thread eventually will call the object's finalizer, and when the finalizer has completed execution, the object's memory is available for reclamation.
Disposing
If your objects have scarce resources, finalization may not be ideal, based on the discussion in the preceding paragraph. Because of this, Microsoft has introduced a standard idiom in the CLR that provides an explicit method and that can be called when the user is done with the object. The method is Dispose, and it is part of the System.IDisposable interface. In fact, it is the only method in that interface.
Implementing this interface indicates that the specific class requires explicit cleanup. It also indicates that it is the client programmer's responsibility to invoke the IDisposable.Dispose method as soon as the referenced object is no longer needed. Listing A-17 shows a class that implements the IDisposable interface. Listing A-18 shows a client using the class in Listing A-16.
Listing A-17. Implementing IDisposable
using System;
public class Person :IDisposable {
//other methods not shown
~Person() {
//call your cleanup code
CleanUp();
}
void CleanUp() {
//code to free scarce resources
}
public void Dispose() {
GC.SuppressFinalize(this);
CleanUp();
}
}
You may wonder what the GC.SuppressFinalize(this) call does. As the Dispose method probably performs the same operations as your finalizer, you may not want the finalizer to run. The GC.SuppressFinalize (this) tells the runtime not to run the finalizer.
Listing A-18. Using an I Disposable class
class App {
static void Main() {
Person per = new Person();
try {
//do something with per
}
finally {
per.Dispose();
}
}
}
As a C# developer, you have the opportunity to let the compiler call Dispose automatically. The using statement (this is different from using for namespaces) does this. It allows the developer to declare one or more variables whose IDisposable.Dispose method will be called automatically. Listing A-19 shows client code utilizing using.
Listing A-19. C# using
class App {
static void Main() {
using(Person per = new Person()) {
//do something with per
} //Dispose is called here
}
}