
Once, I was in Lima, Peru, heading an AWS architecting course. During their first practice, the students started to complain about their labs issuing 500 errors, timeouts, and general inconsistencies. After a closer look, I realized that something uncommon was happening. I opened my personal production web console and navigated directly to the alerts center, and I found a large number of events involving S3, and many other systems, in northern Virginia. In the media, you could read messages like the following:
- No, you're not crazy. Part of the internet broke (https://www.cnet.com/news/amazon-web-services-aws-s3-service-problem/)
- How a typo took down S3, the backbone of the internet (https://www.theverge.com/2017/3/2/14792442/amazon-s3-outage-cause-typo-internet-server)
- Amazon S3 Outage Has Broken a Large Chunk of the Internet (https://www.forbes.com/sites/ryanwhitwam/2017/02/28/amazon-s3-outage-has-broken-a-large-chunk-of-the-internet/#51ebb502c467)
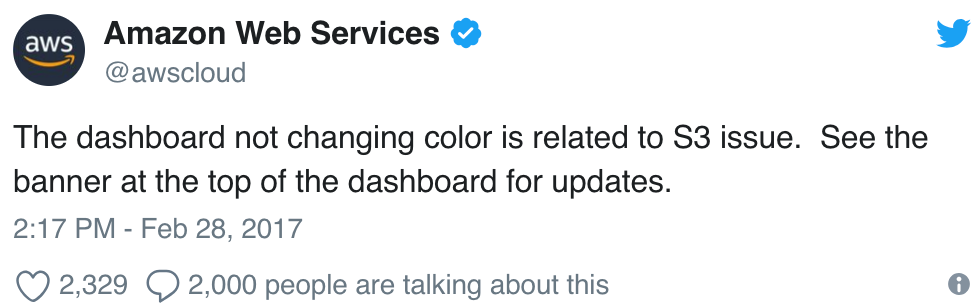
The @awscloud Twitter account disclosed the information in the following screenshot:

The Personal Health Dashboard in AWS was affected, too:
So many systems are dependent on S3, which is a central part of AWS operations. Simple Storage Service (S3) was designed to provide high levels of availability, and it had never had an outage like this before; at that moment, Moore's law was made present to teach us valuable lessons.