
2
Exploring Key AWS Machine Learning Services for Healthcare and Life Sciences
AWS is the leader in cloud computing technology. According to the Gartner report published in July 2021 that covers cloud infrastructure and platform services, they recognize AWS as a leader placed highest in the Magic Quadrant, a mechanism used by Gartner to categorize candidates in their evaluation report. They rank it highest in both axes of measurement, the ability to execute and the completeness of vision. AWS also provides one of the most complete and feature-rich lists of services for ML.
The vast number of services on AWS might be confusing for someone just starting to build with AWS. Specifically, healthcare and life sciences organizations that have requirements that cater only to the domain may find it difficult to operate with domain agnostic services that AWS provides. To facilitate healthcare and life sciences organizations running ML workloads on AWS, AWS has created a set of services that are specifically designed for solving business problems in the healthcare and life sciences industry. In other cases, there are features that are available in domain-agnostic services such as Amazon SageMaker that can be easily tailored for specific healthcare and life science workflows. These services provide the necessary controls for security, privacy, and regulatory requirements that are a prerequisite for any healthcare and life sciences organization.
In this chapter, we will get into the details of why ML is needed in healthcare and life sciences and learn about some of the key ML use cases that healthcare and life sciences organizations are building today to create a positive impact in the industry. Then, we will revisit the AWS ML stack and dive deeper into some key AWS AI/ML services designed specifically for the healthcare and life sciences domain. We will also look at some domain-agnostic AI/ML services that can be used for healthcare and life sciences workloads because of the capability they provide to end users.
By the end of this chapter, you will get a deeper understanding of some key AWS services such as Amazon Comprehend Medical, Amazon Transcribe Medical, and Amazon HealthLake. We will cover the following topics:
- Applying ML in healthcare and life sciences
- Introducing AWS AI/ML services for healthcare and life sciences
- Introducing Amazon HealthLake
Applying ML in healthcare and life sciences
In the first chapter, we went over the introductory concepts of ML and how it differs from typical software. We also covered the ML life cycle and the different steps involved in an ML project. Let us now apply this understanding to healthcare and life sciences and look at some examples of how ML is impacting the healthcare and life sciences industry.
The healthcare and life sciences industry can be divided into multiple subsegments that organizations help support. It starts from research that allows for the discovery of new therapeutics and drugs and helps understand the human body by mapping the genetic code. It includes the process of taking drugs into clinical trials and tracking their progress and regulatory reporting through various stages of testing to ascertain whether the drug is safe. It involves manufacturing the drugs at scale for fast global distribution and matching that with targeted sales and commercial campaigns to ensure the maximum success of the drug. It involves making sure care providers have all the necessary tools to provide the best possible care and prescribe the right medications to targeted populations. Finally, it involves the reimbursement of care providers, taking into account the goal of reducing the cost of healthcare while increasing care quality.
Machine learning has a big part to play in each of these areas and has allowed healthcare and life sciences organizations to improve the way they run their businesses. We will cover some specific examples in each of these areas in detail in the subsequent chapters of this book. For now, let us get an overview of some use cases for each segment.
Healthcare providers
Healthcare providers are licensed to diagnose and treat medical conditions. It can be an individual physician or a facility such as a clinic or a hospital. The performance of a healthcare provider is determined by their ability to provide high care quality while keeping costs low. These performance metrics determine how healthcare providers are paid for their services and hence play a very important role in the overall success of the provider’s business.
One area in that ML has had a huge impact on care quality is by identifying patients in the population that are at a high risk of a negative outcome. This could be a risk of mortality or a risk of a worsening medical condition. Another common risk for healthcare providers is the risk of readmission. It occurs when a patient discharged from the facility is admitted again to the hospital within a set number of days (typically 30 days). Healthcare providers are tracked for their rate of readmissions. ML can identify at-risk patients early so that necessary interventions can be done while the patient is in the hospital, which will help prevent readmission and keep the rate of readmission low.
Another common area of the application of ML for healthcare providers is operational efficiency. Healthcare providers are under a lot of pressure, which causes provider burnout and results in a negative impact on their ability to provide critical care. Providers spend considerable time taking notes and doing back-office work that takes time away from patient care and results in poor efficiency. ML can help automate manual steps that result in better operational efficiency and improved care quality for healthcare providers.
Healthcare payors
Healthcare payors are in charge of paying the providers for the services they offer and processing their claims. Healthcare payors design health plans containing service rates for healthcare services that subscribers in the plan can claim. For example, in the US, Medicare is a national health insurance service for people over 65 years of age. Healthcare payors need to process claims fast and efficiently to ensure they are able to meet their volumetric requirements and maintain their profit margins. At the same time, they need to ensure they process claims correctly to avoid any waste of money and resources.
ML can help with both these tasks. Healthcare payors have been utilizing ML to identify fraudulent claims so they can be flagged and followed up on, saving them a lot of time dealing with unwarranted claims. Moreover, the adjudication of claims involves several manual steps such as processing the claim forms and checking subscriber coverage based on their enrolment in a plan. These are steps that ML models can automate. This helps healthcare payors process a larger volume of claims in the same amount of time. Lastly, ML models can learn from past claims data and identify areas of optimization in health plans that can save money. These include identification of costly procedures that can be avoided by proactive steps such as preventive care and also identification of individuals who may be at a high risk of a disease that could be very costly and deciding appropriate mechanisms to offset that cost such as higher premiums.
Medical devices and imaging
The term medical device is used to describe a large category of medical equipment and consumables that aid in activities such as treatment, diagnosis, and cure of certain diseases and chronic conditions. For example, a Magnetic Resonance Imaging (MRI) machine is a highly specialized medical device used by radiologists to generate pictures of human anatomy that can be used to help diagnose a variety of cancers. Contact lenses are also medical devices that are commonly worn to correct vision in lieu of prescription glasses. In the US, the Food and Drug Administration (FDA) classifies medical devices into three classes. Class 1 medical devices are low risk and include consumables such as bandages and some handheld surgical instruments. A class 2 medical device is an intermediate-risk device and includes devices such as pumps and scanners. A class 3 medical device is a high-risk device. It is critical to sustaining life and is highly regulated. Examples include pacemakers and defibrillators.
The application of ML in medical devices is a developing topic and is challenging due to a variety of regulations that go along with making any changes to the underlying operations of the device. A device needs to be validated for use by the FDA and any change in its operating process or design process needs a revalidation. Hence, using technologies such as ML is a difficult proposition. However, the FDA understands the value ML can bring to medical devices and created guidance for medical device organizations to create validated ML pipelines.
One common application of ML to medical devices is in the space of smart connected devices. For example, smart glucometers can take regular readings of blood glucose levels and stream that to the cloud for aggregation. You can then analyze the trends in glucose readings for an individual and forecast the onset of chronic diabetes or other diseases. You can also recommend and alert individuals to adhere to their medications and care plan so they can avoid serious medical conditions in the future. ML models can also run directly on these medical devices, also known as ML models on the edge. For example, ML models to segment parts of a tumor in an X-ray can be trained on AWS and then deployed on X-ray machines to run locally and highlight tumors in X-rays for easy identification and diagnosis.
Pharmaceutical organizations
Pharmaceutical organizations have licenses to develop, test, market, and distribute drugs to treat medical conditions. They also conduct research to develop new drugs and therapies. The pharmaceutical industry works with multiple partners who help them with conducting clinical trials, manufacturing drugs, and distributing them globally. For example, they work with Clinical Research Organizations (CROs) that conduct extensive clinical trials for the drugs. In fact, the process of taking a drug to market can take 10 years and require billions of dollars in investments. Hence, it’s really important to market the drugs appropriately to maximize the return on investment.
ML can help optimize the process of taking a drug to market and help save money in the process. For example, the process of drug discovery can involve searching across billions of molecules using trial and error. ML algorithms can dramatically reduce this search space by identifying probable targets. In the clinical trial process, ML can help with identifying the right trial participants based on the sites where the trials would be conducted and the inclusion and exclusion criteria of the trials defined in the trial protocol. It can help detect and report adverse drug reactions during the trial process. ML models can also help with predicting critical equipment failures before they happen to prevent any bottlenecks in the manufacturing of the drugs. It can help forecast demand and help with logistics and planning around the distribution of the drug in particular regions and target markets. It can also track drug reviews from healthcare providers and consumers (patients) to understand sentiments around the drug and take corrective action to address negative reviews that may jeopardize sales and profits.
Genomics
Genomics is the branch of biology that works in the area of understanding the function of genomes, the complete DNA of an organism. In the case of the human genome, we are still early in the journey of the understanding and full-scale adoption of genomics-driven clinical interventions. However, the successful mapping of the whole human genome in 2003 led to a slew of research that has fueled discoveries of novel genes. DNA is made up of four types of nucleic acids, namely: T (thymine), C (cytosine), G (guanine), and A (adenine), that occur in a particular sequence. It looks like a twisted ladder that forms the iconic double helix that is normally used to portray DNA graphically. A majority of genes (99.9%) in all humans are arranged in the same manner. The 0.1% variation in this order is enough to define the unique characteristics of an individual such as the color of your eyes or skin. These variations, known as genetic variants, sometimes can put an individual at a higher risk of certain diseases and decide their response to certain types of medications. The knowledge of these variants and how they correlate with certain diseases are the basis of the field of precision medicine. This field is centered around the design of drugs and therapies that are unique to an individual’s genetic code instead of mass-producing drugs that are the same for everyone. It is shown in research that individualized care plans and therapies driven by genomic data for the treatment of serious diseases such as cancer produce better outcomes for patients.
The identification of these unique genes and variants requires sequencing of the human genome and processing the resulting data. This process is known as Next-Generation Sequencing (NGS). The cost of whole genome sequencing has reduced considerably in the last decade, from thousands of dollars to a few hundred now. This has led to large population-level sequencing initiatives by several countries. For example, the UK biobank project consists of genetic sequences and health information for half a million participants from the UK. These types of large-scale sequencing studies aim to identify genetic variation and answer evolutionary questions at a population level. The resulting data produced is in the petabyte scale and needs specialized technology to store, process, and interpret it for clinical relevance.
One common area where ML has been applied successfully in genomics is the area of correlation studies. When it comes to genetic variants, it is important to understand their effects on certain types of diseases and other observable characteristics of an individual, known as phenotypes. For example, ML can help identify patients with a high risk of breast cancer by analyzing their gene expressions. It can also identify individuals with lactose intolerance or other types of allergies.
Now that we have seen the applications of ML in different healthcare and life sciences segments, let us look at some key AWS offerings that allow you to build these applications.
Introducing AWS AI/ML services for healthcare and life sciences
The AWS AI/ML stack consists of purpose-built services that can help organizations develop ML applications for a variety of use cases. Some of these services are unique to healthcare and life sciences and are designed to solve specific industry problems. Others are not designed specifically for healthcare and life sciences but are a great building block for ML applications in healthcare and life sciences. Let us look at some of these services in more detail.
Introducing Amazon Comprehend Medical
Amazon Comprehend Medical is the first healthcare-specific ML service from AWS. It falls in the category of Natural Language Processing (NLP), a branch of ML that allows models to understand the nuances of human language. Amazon Comprehend Medical extends this concept to the healthcare domain, by helping understand medically relevant information from unstructured clinical text. The service performs Named Entity Extraction (NEE) of key medical entities from texts, such as discharge summaries, progress notes, visit summaries, and a variety of other unstructured clinical notes. The service provides pre-trained models that are accessible using the AWS SDK via APIs, the AWS Command Line Interface (CLI), and the AWS console. It is a stateless service, which means it does not store any end-user information passed to it. It also falls under the category of AWS HIPAA Eligible Services. These services allow you to store, process, and transmit Protected Health Information (PHI) information.
Amazon Comprehend Medical provides easy-to-use APIs. These APIs provide an output in JSON format that is easy to process and integrate with downstream applications or even store in a database. These APIs can be called in a synchronous manner or an asynchronous manner. You can choose between synchronous or asynchronous processing based on your overall application architecture. The functionalities that the service provides include the following:
- Extract clinical entities by performing NER on unstructured clinical notes. There are various categories of entities that the services can recognize. The entities are automatically detected from unstructured clinical text using ML models. The following are the categories of entities that the service recognizes:
- Anatomy: References to parts of a body and their location
- Medical condition: For example, signs, symptoms, and diagnosis
- Medication: Medicine names and dosage information
- Test treatment procedure: Procedures that determine medical conditions
- Time expression: Detects time elements in the notes when associated with an entity.
- Protected health information: Detects PHI elements in the notes
Amazon Comprehend Medical also provides a dedicated PHI detection functionality, which is a subset of the larger entity extraction capability. This alternative is ideal for anyone looking to just detect sensitive information in medical notes and who does not want to get visibility into the full list of entities. The PHI detection feature can be used for the de-identification of medical notes, a process of removing or masking PHI information.
In addition to identifying entities, the service also detects attributes and their relationships to the entities. For example, the dosage is an attribute of medication and is related to it automatically by the service. It also recognizes traits of an entity. Traits contain information about the entity that Amazon Comprehend Medical detects from context. For example, NEGATION is a trait that can be detected by Comprehend Medical and attached to the medication entity when the patient is not taking the medication.
For each of the entities, the output provides a confidence score, which is a measure of how sure the model is of the prediction being made. It also provides the beginning and end offset of the text, which denotes the position where the text occurs.
- Amazon Comprehend Medical can detect the 2021 version of the international classification of diseases, 10th revision, clinical modification (ICD-10-CM) codes provide by the Centers for Disease Control and Prevention (CDC). ICD-10-CM codes are associated with medical conditions and are used extensively for a variety of medical processes such as ordering procedures and making reimbursements. For each medical condition detected by Amazon Comprehend Medical, there are five ICD-10-CM codes provided in decreasing order of confidence.
- Amazon Comprehend Medical can detect the concept identifiers (RxCUI) from the RxNorm database from the National Library of Medicine. The source for each RxCUI is the UMLS Metathesaurus 2020AB. The RxNorm codes are used for identifying medications and standardizing their representations across different healthcare systems such as billing and ordering systems. It is also used in filling and ordering prescriptions.
- Amazon Comprehend Medical can detect concepts from the 2021-03 version of the Systematized Nomenclature of Medicine, Clinical Terms (SNOMED CT). SNOMED codes are widely used for standardizing medical information and provide a comprehensive vocabulary of medical information. It covers entities such as medical conditions, tests, treatments, procedures, and anatomy. Just like in the case of ICD-10-CM and the RxNorm ontology, Amazon Comprehend Medical provides the top five SNOMED codes for the detected medical concept in decreasing order of confidence. The codes can be used to standardize medical information and automate the process of manual coding. Let us look at an example of the SNOMED code detection feature of Amazon Comprehend Medical.
Amazon Comprehend Medical can be used as a building block for a variety of healthcare and life sciences applications that depend on processing unstructured information. The APIs of Comprehend Medical described in this section can also be combined with other AWS services to create a workflow for use cases such as population health management, medical billing and claims processing, and medical coding. You can refer to the developer guide of Amazon Comprehend Medical for more details on how to use these APIs for your applications.
A very common workflow is to integrate Amazon Transcribe Medical with Amazon Comprehend Medical for medical transcription and conversation analysis. Let us now look at Amazon Transcribe Medical in more detail.
Introducing Amazon Transcribe Medical
Amazon Transcribe Medical is an automatic speech recognition (ASR) service specifically designed for the medical domain. Just like Amazon Transcribe, which is a generic version of the service, Amazon Transcribe Medical covers speech-to-text and transcribes a variety of clinical terminology such as medication names, disease names, and medical procedures. The service covers primary care and also specializations such as cardiology, neurology, obstetrics-gynecology, pediatrics, oncology, radiology, and urology.
Amazon Transcribe Medical is a HIPAA-eligible service and provides a pretrained model that can be accessed via different APIs available in multiple programming languages. When combined with Amazon Comprehend Medical, you can create an end-to-end workflow for a variety of applications in healthcare such as analyzing doctor-patient exchanges, detecting medical entities in real time during a telehealth visit, or summarizing patient visit information for recording into the Electronic Medical Record (EMR) system.
Amazon Transcribe Medical can be used to transcribe audio in conversation format or dictation format:
- Conversation: The conversation option allows you to transcribe interactions between different individuals. For example, an interaction between a doctor and a patient. In this mode, the service allows you to identify and label each speaker in the conversation. This is useful when trying to identify what was said by the doctor and what was said by the patient in the conversation.
- Dictation: In this mode, the service assumes that there is a single person narrating in the audio. This option is useful for clinicians dictating at the end of a patient visit.
Amazon Transcribe Medical provides APIs that work for both synchronous batch workflows and asynchronous streaming workflows.
Streaming
In streaming transcription, the text output from the service is generated in real time by taking in a stream of audio. You can also use an audio file and generate a stream of text from it. The service supports HTTP/2 and WebSocket protocols using which real-time transcriptions can be generated. You can also set up the streaming transcription using the AWS SDK or go to the AWS console to try it out. The following screenshot shows the options available under the real-time streaming option for Transcribe Medical.

Figure 2.1 – The AWS console for Amazon Transcribe Medical real-time transcription
As shown in Figure 2.1, the service provides you with the ability to choose your medical specialty. It also provides options for choosing between conversation and dictation. The service supports the US English language and also recognizes different accents spoken by non-native English speakers. The output is generated in JSON format and supports word-level timestamps and confidence scores.
Batch
You can use Transcribe Medical to start a batch transcription job. You provide the location of the audio file that you want to transcribe. It supports multiple audio file formats such as FLAC and WAV. Once you start a transcription job, you can track its status and progress. The results of all batch transcription jobs are stored on S3, the object store from AWS. It provides the output in JSON format, which makes it easy to integrate with other AWS AI services and also within downstream applications. Let us look at the various options that Transcribe Medical provides for batch transcription in the AWS console.

Figure 2.2 – The AWS console for Amazon Transcribe Medical batch transcription
As shown in the screenshot, you can select between conversation and dictation audio format. You can then provide the S3 location of your audio file that you want to transcribe and the output location where Transcribe Medical can store the output JSON file.
Custom vocabulary
Custom vocabulary allows you to improve the accuracy of Transcribe Medical output. This is useful for terms that the default Transcribe Medical models are not able to accurately convert to text from its pronunciation in the audio. It is also useful for synonyms or terminology that is specific to an organization that may be present in the audio. These help you to design a custom version of Transcribe Medical that is unique to your organization’s use case.
Custom vocabulary is created using user input that is provided to Transcribe Medical via a tab-delimited text file. The text file provides the columns that the user needs to fill. These columns include the original phrase, how it should sound, and how it should be displayed. This provides the users an intuitive way to provide vocabulary to the service. Once the text file is created, it can be used to create a custom vocabulary in Transcribe Medical. The following screenshot shows the Create vocabulary screen that can be used in the AWS Management Console to create a custom vocabulary in Transcribe Medical.

Figure 2.3 – The AWS console for Amazon Transcribe Medical custom vocabulary
As shown in the preceding screenshot, the custom vocabulary creation process requires the location of the input text file created by you. You can upload the text file on S3 and provide its location for Transcribe Medical to automatically create a custom vocabulary. Once the custom vocabulary is created, it can be used in both the real-time streaming transcriptions and batch transcription jobs by choosing the custom vocabulary option.
Amazon Transcribe Medical makes it simple for users to create workflows that involve voice-enabled inputs. Once the audio is transcribed, it can be fed into Amazon Comprehend Medical to detect key medical entities for analysis. You can refer to the developer guide of Amazon Transcribe Medical for a deeper understanding of the service and the APIs it provides.
Let us now look at Amazon HealthLake and how it helps you store, transform, and query healthcare data while adhering to healthcare interoperability standards using Health Language International (HL7) Fast Healthcare Interoperability Resources (FHIR).
Introducing Amazon HealthLake
Amazon HealthLake is the latest addition to healthcare-specific AI services provided by AWS. It is a HIPAA-eligible service that allows you to ingest healthcare data in FHIR format. It then stores that data in a fully managed FHIR data store. During the ingestion process, it transforms the data by automatically extracting key medical entities from unstructured records in your healthcare data, thereby giving you a complete view of a patient’s record. You can then query your records using both the structured portion of your patient records and also the entities extracted from the unstructured portions of your healthcare records.
Before we look into the details of HealthLake, let us understand the FHIR format better. FHIR is a healthcare interoperability standard created by HL7 with the aim of standardizing how healthcare information is represented and exchanged. It uses the JSON format to represent healthcare entities known as FHIR resources. The FHIR resource definition contains attributes that fully describe the healthcare entity. These FHIR resources are stored in a FHIR data store and can be connected together through natural keys in a query to get a full view of the patient. FHIR released multiple versions of FHIR standards and HealthLake supports the R4 version of FHIR. You can find more information about the FHIR R4 standard in their resource guide.
To begin using HealthLake, you will need FHIR R4-compliant data. This is a common healthcare interoperability standard and a large number of healthcare systems support FHIR-enabled interfaces that can provide FHIR resources to ingest into a HealthLake data store. There are AWS partners who can help if you do not have FHIR R4-compliant data. Once you have data in FHIR R4 format, you can create a data store and ingest data into it.
Creating and importing data into a data store
HealthLake allows you to create fully managed FHIR data stores. The data store is the repository where you store your FHIR resources. You can create the data store using the AWS CLI, the console, or APIs available via the AWS SDK. Here is an example of creating the FHIR data store in HealthLake using the AWS console.
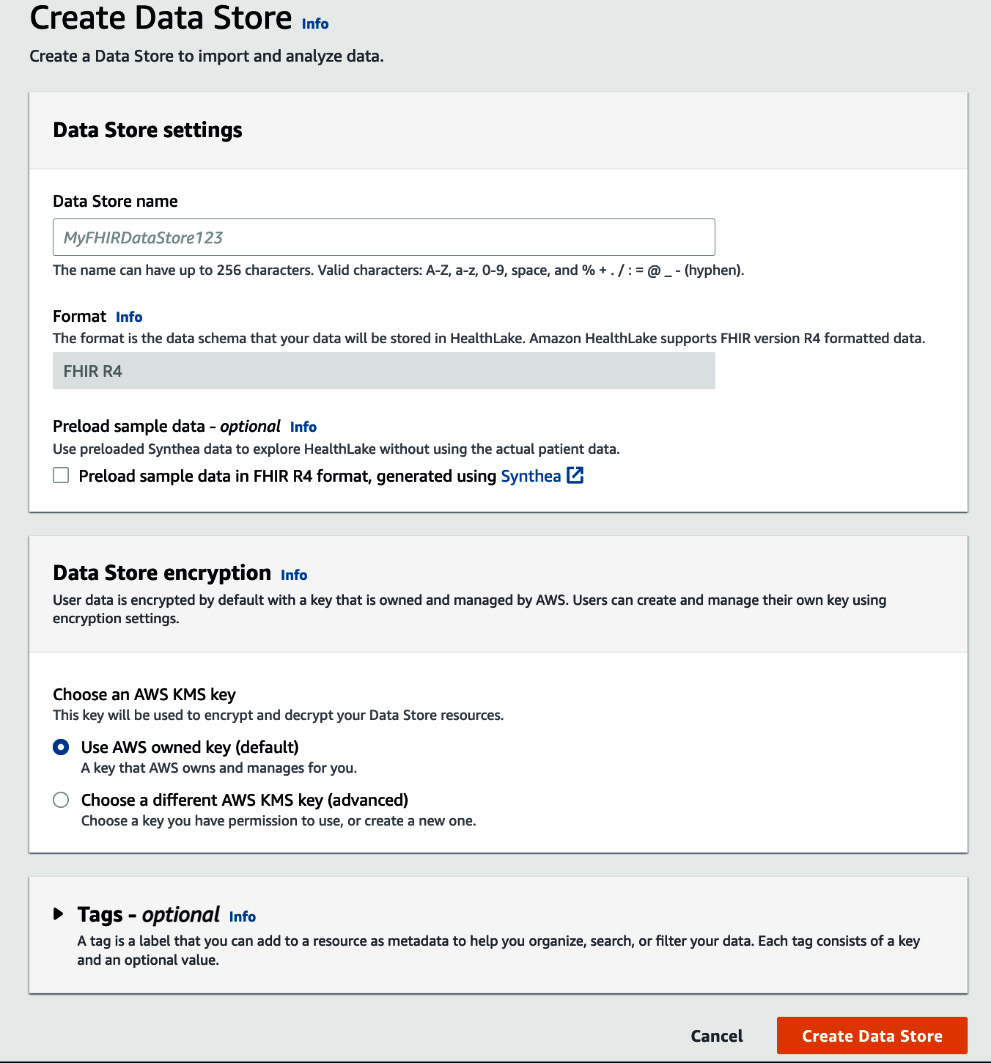
Figure 2.4 – The AWS console for Amazon HealthLake Create Data Store
As shown in the preceding screenshot, you can provide the name of your data store while creating it. During the creating process, you can choose to preload the data store with some artificially generated patient data using Synthea, which is a synthetic patient data generator. This allows you to experiment with the service without loading it with real-world patient data. The service also supports encryption using AWS Key Management Service (KMS) keys.
Once the data store has been created, you can import data into it using the AWS console, CLI, or API available via the AWS SDK. You can also interact with the records in the data store using a Hypertext Transfer Protocol (HTTP) client using methods such as POST, PUT, and GET.
If there are unstructured records in your medical data, Amazon HealthLake automatically detects clinical entities in it. The unstructured information is stored in the DocumentReference resource in FHIR. These entities are added as extensions in your DocumentReference FHIR resource and are available for search and query operations downstream. This is an automatic behind-the-scenes operation that HealthLake carries out on your behalf. The extensions are immediately available for search and query after ingesting into HealthLake.
Querying and exporting data from Amazon HealthLake
Amazon HealthLake data store supports FHIR-based search or query operations. You can also search using the GET or POST HTTP methods. It is highly recommended to use the POST operation to search when the attributes include PHI information. You can use the GET operation to search from the Management Console. Here is an example of performing the query operation from the AWS Management Console.
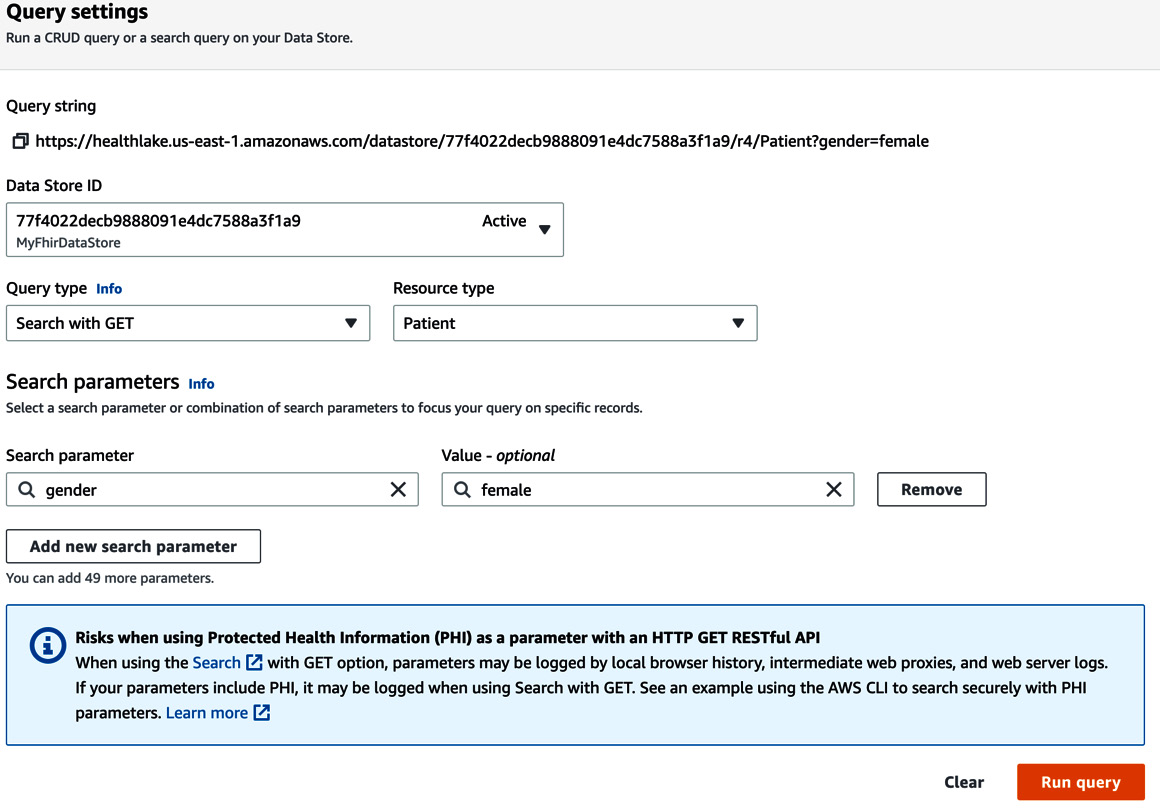
Figure 2.5 – The AWS console for Amazon HealthLake Run query
As you can see in the screenshot, the HealthLake query feature allows you to select the Data Store ID, Query type, Resource type, and the Search parameters on which you want to query. In this case, I have chosen to use the GET operation by selecting Search with GET to fetch all female patients in my data store. The results of this query are fetched from the underlying patient resource. As mentioned earlier, I am using synthetic patient data in this query that is generated by Synthea. If I had real-world patient data, I would have used the POST operation. As described earlier, this query functionality automatically extends into the unstructured part of your clinical data in HealthLake, which is stored in the DocumentReference resource. Here is an example of such a query from the AWS Management Console.
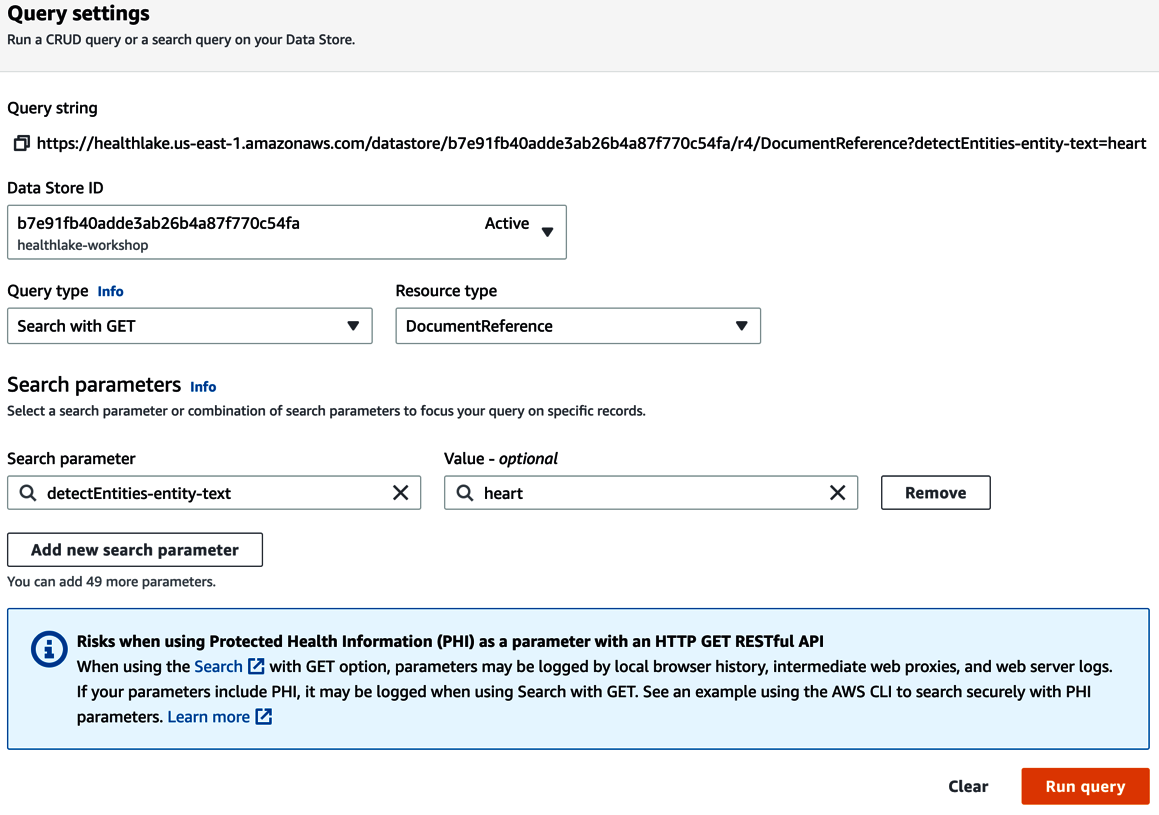
Figure 2.6 – The AWS console for Amazon HealthLake Run query with DocumentReference resource
As shown in the preceding figure, I can search the DocumentReference FHIR resource and select the detectEntities-entity-text parameter. I then provide the value heart for my query. This will allow me to filter for clinical notes that mention “heart.” I can also select other parameters such as Medical Conditions, Protected Health Information, and Medications.
The query operation allows you to slice and dice data in HealthLake and integrate it with downstream applications for analytics or ML. You can also export your data store into S3. The export API from HealthLake exports data in newline delimited JSON (ndjson) format. Each line in the export file consists of a valid FHIR resource. You can perform the export operation from the CLI, AWS Console, or the API provided via the AWS SDK. For more details about Amazon HealthLake and its APIs, you can refer to the Developer Guide of Amazon HealthLake.
Amazon Comprehend Medical, Amazon Transcribe Medical, and Amazon HealthLake are three AI services from AWS that are specific to healthcare and life sciences. However, there are some other services from AWS that are highly utilized in healthcare and life sciences use cases even though they are not designed specifically for the domain. Next, let us look at some of these services.
Other AI services for healthcare and life sciences
As we saw in Chapter 1, the AWS AI/ML stack provides a wide array of services for ML use cases. Here are some key services from the stack that are useful for healthcare and life sciences use cases – we will be utilizing some of them in the subsequent chapters:
- Amazon Textract: Amazon Textract is an ML service from AWS that automatically extracts text and handwritten data from scanned documents. It automates the process of extracting and understanding data in PDFs and images. With Amazon Textract APIs, you can detect text in the document, key-value pairs in a form, and also detect the presence of a table and extract individual cell values from it. You can also ask questions to Textract about data in the document and Textract will provide a value from the document corresponding to the question. For example, you can analyze the patient intake form using Amazon Textract and ask what is the patient’s name? and Textract will provide a response with the name of the patient.
Amazon Textract provides both asynchronous APIs and synchronous APIs that you can integrate with your downstream applications. To learn more about Amazon Textract, you can refer to its developer guide.
- Amazon SageMaker: Amazon SageMaker allows data scientists to build, train, and deploy ML models at scale. While the AI services provide pre-trained models in most cases and require minimal knowledge of ML, SageMaker provides tools for data scientists to customize their ML models as needed. SageMaker is a feature-rich ML development environment and provides tools to label and prepare your data, build your models, train and tune your models, and deploy and manage your models. Each of these areas comes with multiple tools and options that you can choose from depending on your use case and the type of data.
SageMaker also provides an Integrated Development Environment (IDE) for ML called SageMaker Studio. The IDE provides an easy-to-use interface for accessing all the features of SageMaker and also provides Jupyter notebooks for writing ML scripts. You also have the option of running AutoML on SageMaker using AutoPilot. For citizen data scientists, SageMaker Canvas provides an easy-to-use intuitive UI that takes you through the process of creating high-quality ML models. For more about Amazon SageMaker, you can refer to its developer guide.
Now that we have a high-level understanding of the key AI/ML services from AWS, you can start thinking about how to map them to particular use cases and address specific capabilities. Then, you can dive deeper into that service by referring to the corresponding developer guide. For example, you can check whether your use case involves any unstructured clinical text that can be processed using Amazon Comprehend Medical, whether you have to process and store FHIR format data that Amazon HealthLake can be utilized for, or whether you have to process and analyze multiple documents as part of your use case that Amazon Textract can help with. These building blocks of capabilities are unique in their own way, but when used together can create powerful intelligent applications. We will see examples of such use cases in future chapters of this book.
Summary
In this chapter, we went through the different segments of the healthcare and life sciences industry. These include healthcare providers, healthcare payors, pharmaceutical organizations, medical devices, and genomics. In each of these segments, we went over some important applications of ML. We then got an introduction to some key AI services from AWS specific to healthcare and life sciences, such as Amazon Comprehend Medical, Amazon HealthLake, and Amazon Transcribe Medical. We also touched upon other services such as Amazon Textract and SageMaker that are not specifically designed for the healthcare and life sciences domain but address specific problems in the industry.
In Chapter 3, Machine Learning for Patient Risk Stratification, we will learn about how ML can help identify at-risk patients for various types of clinical conditions or medical events. Timely identification of these patients helps avoid negative healthcare outcomes and improves the overall quality of care.
Further reading
- Magic Quadrant for Cloud Infrastructure and Platform Services by Raj Bala, Bob Gill, Dennis Smith, David Wright, Kevin Ji in Gartner (2021): https://www.gartner.com/doc/reprints?id=1-271OE4VR&ct=210802&st=sb
- Solution Scorecard for Amazon SageMaker by Daniel Cota, Su En Goh in Gartner (2021): https://www.gartner.com/en/documents/4002618
- AWS Healthcare & Life Sciences Case Studies: https://aws.amazon.com/health/case-studies/?nc=sn&loc=5&refid=ar_card&case-studies-health-cards.sort-by=item.additionalFields.publishedDate&case-studies-health-cards.sort-order=desc&awsf.case-studies-filter-area=*all
- UK Biobank: https://www.ukbiobank.ac.uk/
- Centers for Medicare & Medicaid Services: https://www.cms.gov/medicare/icd-10/2021-icd-10-cm
- RxNorm Files: https://www.nlm.nih.gov/research/umls/rxnorm/docs/rxnormfiles.html
- SNOMED: https://www.snomed.org/snomed-ct/why-snomed-ct
- Amazon Comprehend Medical: https://docs.aws.amazon.com/comprehend-medical/latest/dev/comprehendmedical-welcome.html
- Amazon Transcribe Medical: https://docs.aws.amazon.com/transcribe/latest/dg/transcribe-medical.html
- FHIR resources: https://www.hl7.org/fhir/resourcelist.html
- Synthea: https://synthetichealth.github.io/synthea/
- Amazon HealthLake: https://docs.aws.amazon.com/healthlake/latest/devguide/what-is-amazon-health-lake.html
- Amazon Textract: https://docs.aws.amazon.com/textract/latest/dg/what-is.html