Logstash is a data processing pipeline, capable of collecting data from a huge variety of sources simultaneously, performing transformations on it, and then sending it to an underlying store for indexing and retrieval. The underlying store can be anything. The natural contender is Elastic Search, as Logstash integrates very nicely with it.
The following architecture provides insight into the internals of Logstash:

Beats sends the data to the Logstash input component, whose primary responsibility is to quickly receive the data and send it to the underlying queue for the next phase to pick up.
Next in line is a set of filters that perform some basic data transformation on the incoming data. For example, you may define Grok patterns to parse the incoming logs. Once the transformation has happened, the data is sent back to a queue from where it is picked up by the output components responsible for writing transformed data out to the data store.
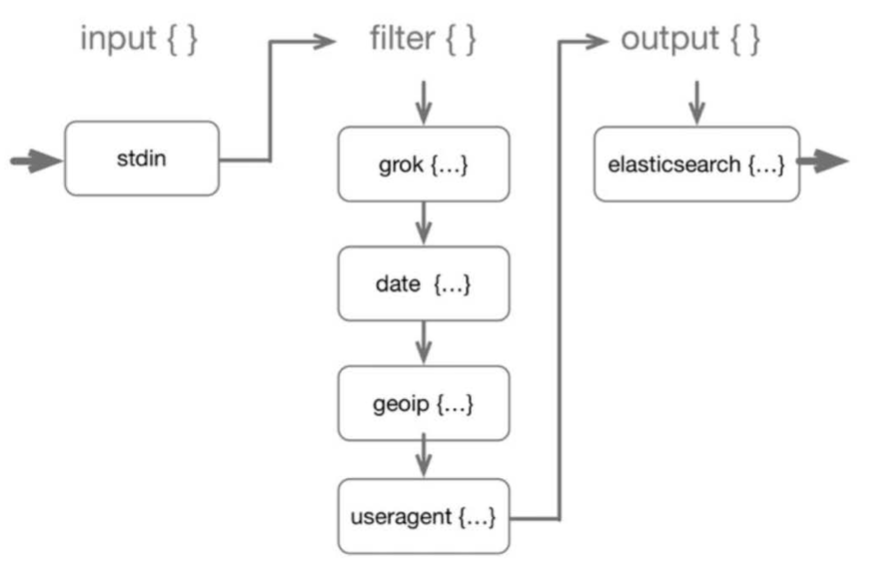
The following figure zooms into the filters process and depicts how the filter chain is applied: