
6. Auditing Software
“There will always be engineering failures. But the worst kind of failures are those that could readily be prevented if only people stayed alert and took reasonable precautions. Engineers, being human, are susceptible to the drowsiness that comes in the absence of crisis. Perhaps one characteristic of a professional is the ability and willingness to stay alert while others doze. Engineering responsibility should not require the stimulation that comes in the wake of catastrophe.”
—SAMUEL C. FLORMAN
THE CIVILIZED ENGINEER
When we discussed the impact of source availability on security in Chapter 4, we argued that having people stare at your code is a necessary but not sufficient means for assessing security. As it turns out, there is much more to security analysis than code review. This chapter is all about auditing software systems. We discuss when to audit, how to audit, and what tools to use.
In a majority of software houses, security is considered only once or twice during the development life cycle (if at all). The main motivator in these organizations appears to be fear. That is, a security audit is performed only when the vendor becomes scared about the security of the product. A few companies become concerned during the design phase; most others wait until potential customers start to ask hard questions.
At design time, software teams are likely to believe that whatever they have done for security is probably fine, and if it isn’t, then they can go back and fix things later. So in practice, what happens mirrors this logic. Some cursory thinking is devoted to security, but the majority of design focuses on features. After all, you can show new functionality to investors. They can see progress and get a good, warm, fuzzy feeling. This focus on features makes security lose out, mostly because security doesn’t manifest itself as interesting functionality. You can spend two months improving your security and have nothing visible to show for it. Then, to top things off, despite your hard work you can still have your product broken a week after launch!
Companies usually don’t start getting concerned about security until potential customers start to ask hard questions about the security of a product. This means that when security is most commonly invoked, analysis tends to focus on the finished product and not on the design. Unfortunately, by the time you have a finished product, it’s generally way too late to start thinking about security. At this stage of the game, design problems are usually deeply ingrained in the implementation, and are both costly and time-consuming to fix. Security audits that focus on code can find problems, but they do not tend to find the major flaws that only an architectural analysis can find.
Of course, there are plenty of implementation flaws that can be coded right in to a sound design. Some such flaws are reasonably easy to fix when they are identified (such as buffer overflows). This means that a code review is sometimes productive. Usually, it’s not worth anyone’s time to look for implementation-level problems though. That’s because if you haven’t thought about analyzing what you’re doing before the implementation stage, an attacker can usually find significant design flaws that have been present since the software was designed.
We like to use an analogy to understand the importance of architectural and implementation analysis. Auditing implementations by inspecting code is much like checking for high-quality locks on your windows and doors. A useful activity to be sure, but only when the building in question has four walls and a roof. When you’re missing a wall, it doesn’t do much good to make sure the front door locks properly. Who cares about specific details when the entire architecture is fundamentally unsound?
We believe in beginning risk management early in the software life cycle, and continuing the risk management regimen throughout the entire life cycle. This is the only way to ensure that a system’s security reflects all changes ever made to the system. Recall that one of the major problems of the penetrate-and-patch approach is that patches that are intended to address a known security problem often introduce new problems of their own. The same sort of thing can happen when software is being created. Systems that are being modified to address previously identified security risks sometimes end up replacing one security problem with another. Only a continual recycling of risks can help address this problem.
A good time to perform an initial security analysis of a system is after completing a preliminary iteration of a system design. At this point, you expect that you may find problems in your design and fix them, yet you probably have a firm handle on the basic functionality you wish to have, as well as the most important requirements you are trying to address. Waiting until you’re done with design is probably not a good idea, because if you consider yourself “done” with design, then that implies you’re going to be less inclined to fix design problems that come up during a security audit. If your design process is lengthy, you should periodically go back and see how changes impact your level of security risk.
Only when you’re confident about your basic design should you begin to worry about security bugs that may be added during implementation. Per-module security reviews can be worthwhile, because the all-at-once approach can sometimes be overwhelming for a team of security analysts.
Who should perform a security analysis on a project? A risk analysis tends only to be as good as the security knowledge of the team performing the analysis. There are no checkbox solutions for auditing that are highly effective. Although a good set of auditing guidelines can be used to help jog the memory of experts, and can also be an effective training tool for novices, there is no match for experience. It takes expertise to understand security requirements, especially in the context of an entire system. It also takes expertise to validate that security requirements are actually met, just as it takes expertise on the part of developers to translate requirements into a functional system that meets those requirements. This variety of expertise can only be approximated in guidelines, and poorly at that.
If you follow the advice we provide in Chapter 2, then you will have a person on the project whose job is software security. In a strange twist of logic, this person is not the right one to do an architectural security audit. For that matter, neither is anyone else working on the project. People who have put a lot of effort into a project often can’t see the forest for the trees when it comes to problems they may have accidentally created. It is much better to get someone with no vested interest in the project who is able to stay objective. This extra pair of eyes almost always pays off. Security experts working on other projects within the same company are okay, but they may tend to have some of the same biases as the designer (especially in a small organization). If you can afford it, bringing in objective experts from outside is the best way to go.
When it comes to doing implementation analysis, the same general principles apply. People who have been directly involved with the implementation are not the right people to be performing an audit. If you have a security architect who designs systems but does not build them, then this person may be a good candidate to review an implementation (although there may still be a project or corporate bias that causes this person to miss flaws). The additional skill that an implementation analyst must have is a solid understanding of programming. Sometimes, excellent security architects are not the greatest programmers. In such a case, you may pair a highly skilled programmer with the analyst. The analyst can tell the programmer what sorts of things to look for in code, and the programmer can dig through the code to see if the right and wrong things are there.
Even if your security architect is very well rounded, groups of people tend to work best for any kind of analysis. In particular, having multiple people with a variety of diverse backgrounds always increases the effectiveness of a security audit. Different analysts tend to see different things, and understand things differently. For example, systems engineers tend to think differently than computer scientists. If you unite multiple people and have them discuss their findings after independent review, they tend to find even more things than if they each work independently.
By the same logic, it can be helpful when bringing in outside experts to bring in multiple sets of outside experts. Of course, different groups are likely to find largely the same things, yet each group can be expected to notice a few things the other group does not. Major financial companies often take this approach when assessing high-risk products. It’s also a good technique for figuring out whether a particular analysis team is good. If an outside team is not finding the more “obvious” things that other teams are finding, then the quality of their work may be suspect.
Architectural Security Analysis
During an architectural security analysis, you can use the techniques of your favorite software engineering methodology for performing a risk analysis on a product design. In this section we divulge our preferred strategy. There are three basic phases: information gathering, analysis, and reporting.
During the information-gathering phase, the goal of the security analyst is not to break the system so much as it is to learn everything about a system that may be important from the point of view of security. The information-gathering phase has several general aspects. First, the analyst strives to understand the requirements of a system. Second, the analyst attempts to understand the proposed architecture at a high level. At this point, the analyst should identify the areas of the system that seem to be most important in terms of security, and research those parts of the system thoroughly. Ultimately, the analyst will have a number of questions about the system and the environment in which it operates. When all these questions are answered, it’s time to move into the analysis phase.
Of course the analysis phase frequently raises all sorts of new questions about the system that need to be answered. There is no harm in this. The phases or our approach tend to overlap somewhat, but are distinct in terms of their basic focus. When in the information-gathering phase, we may break a system, but we’re actually more worried about ensuring that we have a good overall understanding of the system than we are about breaking it. This highlights a critical difference between our approach and a more ad hoc “red-teaming” approach. During the analysis phase, we’re more interested in exploring attacks that one could launch against a system, but will go out and get more information if necessary to aid in our understanding of how likely or how costly it will be to launch an attack.
It is unrealistic to think that an analyst won’t be trying to think of possible attacks on the system during the information-gathering phase. Any good analyst will, and that’s to be expected (and is perfectly acceptable). In fact, such critical thinking is important, because it helps the analyst determine which areas of the system are not understood deeply enough. Although the analyst should be taking notes on possible attacks, formal analysis should be put off until the second phase.
Let’s delve more deeply into the information-gathering phase. First, there are requirements to examine. This implies that a system should have a complete, well-documented set of requirements that address security. This is important, because the requirements encode the security policy of the system at a high level. Without the notion of what a security breach consists of, an analyst’s job becomes much harder. What tends to happen is that the analyst is forced to make assumptions about security requirements, which often leads to a defensive stance from management when the analyst errs on the side of security. For example, an analyst may complain that a large company doesn’t encrypt data from its application servers to its databases. Although the application server is behind a firewall, firewalls tend to be easy to circumvent, especially as the number of computers behind a firewall grows. However, when this finding is presented to management, management may get defensive and say that this is an acceptable risk. If the fact that the company is willing to rely on corporate network security is documented in the requirements, then this misunderstanding can be avoided.
Recall that security is not an end in itself; it is simply a means to an end. The business context is often clear from the requirements (or at least it should be). Requirements should clearly explain why something must be so. This tends to set the appropriate context.
If no security requirements exist, the analyst may consider helping to derive a set of security requirements for everyone’s benefit. This is likely to involve writing down what the analyst thinks the requirements should be, then soliciting the feedback of the people requesting the analysis. It is almost always better for everyone if there’s a firm understanding of a company’s security needs up front.
Attack Trees
The second goal of the information-gathering phase is getting to know the system. A good way to go about this is to get a brief, high-level overview of the architecture from the design team (from the security engineer in particular, should one exist). At this time, the analyst should read all available documentation about a system, noting any questions or inconsistencies. Sometimes, parts of the documentation can be skipped if they are not security relevant and do not contribute significantly to understanding the system as a whole (although figuring out what is okay to skip is much more of an art than a science). At this point, the documentation should be used mainly to get a high-level sense of the system. We can put off a thorough review with a fine-tooth comb until later.
If a system isn’t documented, or it is poorly documented, then a security analyst will have a hard time doing a solid job. Unfortunately, this often is the case when an analyst is called in to look at a design, and the implementation is done or is in progress. In these cases, the best way for an analyst to proceed is to get to know the system as deeply as possible up front, via extensive, focused conversations with the development team. This should take a day or two (depending on the size and complexity of the system, of course).
It is often a good idea to do this even when the system is well documented, because documentation does not always correlate with the actual implementation, or even the current thinking of the development staff! When conflicting information is found, the analyst should try to find the correct answer, and then document the findings. If no absolute answer is immediately forthcoming, any available evidence should be documented so that the development staff may resolve the issue on its own time. Inconsistency is a large source of software security risk.
When the analyst has a good overall understanding of the system, the next step is to create a battle plan. This can be as simple as creating a list of things to pursue next. The analyst needs to learn as much as possible about the system, and may need to do extensive research about the methods or tools used. However, the analyst could probably spend as much time learning about the first component as is available for the entire analysis. This will not do. Thus, the idea is to prioritize things to dig into based on probable risk, and to budget available time and staff appropriately.
The next step is to research parts of the system in order of priority. Remember to include parts of the system that were not created in-house. For example, shrink-wrapped software used as a part of a system tends to introduce real risk. The analyst should strive to learn as much as possible about the risks of any shrink-wrapped software. The analyst should scour the Internet for known bugs, pester the vendor for detailed information, check out Bugtraq archives, and so forth.
When researching parts of the system, questions inevitably arise. During this part of the analysis, providing access to the product development staff may seem to be a good idea, because it will produce mostly accurate information quickly. However, you may want to rethink giving this kind of full-bore access to the analyst, because the analyst can easily become a nuisance to developers. Instead, the analyst should interact only with a single contact (preferably the security architect, if one exists), and should batch questions to be delivered every few days. The contact can then be made responsible for getting the questions answered, and can buffer the rest of the development team.
The analysis phase begins when all the information is gathered. The main goal of the analysis phase is to take all of the gathered information, methodically assess the risks, rank the risks in order of severity, and identify countermeasures. In assessing risk, we like to identify not only what the risks are, but also the potential that a risk can actually be exploited, along with the cost of defending against the risk.
The most methodical way we know of achieving this goal is to build attack trees. Attack trees are a concept derived from “fault trees” in software safety [Leveson, 1995]. The idea is to build a graph to represent the decision-making process of well-informed attackers. The roots of the tree represent potential goals of an attacker. The leaves represent ways of achieving the goal. The nodes under the root node are high-level ways in which a goal may be achieved. The lower in the tree you go, the more specific the attacks get.
The way we use attack trees, there is a second kind of node called a pruning node. It specifies what conditions must be true for its child nodes to be relevant. These nodes are used to prune the tree in specific circumstances, and are most useful for constructing generic attack trees against a protocol or a package that can be reused even in the face of changing assumptions. For example, some people may decide not to consider insider attacks. In our approach, you can have nodes in which the children are only applicable if insider attacks are to be considered.
Figure 6-1 shows a partial attack tree for the SSH protocol. The leaves could be expanded into many, far more specific attacks. We certainly would not claim that this attack tree covers every attack against SSH! Part of the difficulty of security analysis of this sort is getting the confidence that your analysis is even reasonably complete.
Figure 6-1 Partial attack tree for the SSH protocol.

Attack trees tend to be very large. They’re thus better represented in outline format than in picture format.
Note that most child nodes represent logical ORs. Sometimes we may also need to use logical ANDs. For example, in the attack tree shown in Figure 6-1, we can attack the system by obtaining an encrypted private key AND the pass phrase used to encrypt it.
Now that we have an attack tree, we need to make it more useful by assigning some sort of value to each node for perceived risk. Here we must consider how feasible the attack is in terms of time (effort), cost, and risk to the attacker.
We may, for example, believe that breaking the encryption is incredibly hard, both in terms of the amount of effort and the cost. Many attacks that allow us to obtain a key are often pretty easy in comparison, such as physically compelling someone to give us what we need. However, physically compelling someone probably puts the attacker at much greater risk, and is therefore less likely.
Man-in-the-middle attacks tend to be a very high risk for SSH users. The conditionals in that section of the tree are often true, the cost of launching such an attack is relatively low (tools like dsniff can automate the process very well), and there is very little risk to the attacker. This is an excellent area to concentrate on during an analysis.
Looking at the attack tree we can determine that our two biggest risks are probably man-in-the-middle attacks and attacks on a user’s password or pass phrase (in each case, attacks can be automated). In fact, this attack tree suggests that most users of SSH could be successfully attacked with relative simplicity, which may come as a surprise to many SSH users.
The best thing about attack trees is that data get organized in a way that is easy to analyze. In this way, it is easy to determine the cheapest attack. The same goes for the most likely attack. How do we do all these things? We come up with the criteria we’re interested in enforcing, and walk the tree, determining at each node whether something violates the criteria. If so, we prune away that node and keep going. This is simple, as long as you know enough to be able to make valid judgments.
Making valid judgments requires a good understanding of potential attackers. It is important to know an attacker’s motivations, what risks the system operator considers acceptable, how much money an attacker may be willing to spend to break the system, and so on. If you’re worried about governments attacking you, then much more of the attack tree will be relevant than if you’re simply worried about script kiddies.
Unfortunately, building attack trees isn’t much of a science. Nor is using them. Not surprisingly, attack trees can thus be put to more effective use by experts than by novices. Expertise is needed to figure out how to organize a tree. A broad knowledge of attacks against software systems is required to come up with a tree that even begins to be complete. For example, attacks discovered against the SSH protocol, version 1, in 2000 only get covered at a high level in the tree shown in Figure 6-1 (see level 1.3). If we know about a problem, it is easy to add it to the tree. Otherwise, a security expert would be unlikely to find a previously unknown cryptographic problem simply by looking at an attack tree, but it is a good tool for determining the kinds of possible weaknesses to pursue.
Putting exact numbers on the nodes is nontrivial and error prone. Again, experience helps. In any case, it is always a good idea to have supporting evidence for any decisions made when constructing the tree (or at least be able to find supporting evidence when pressed).
The way we build attack trees is as follows. First we identify the data and resources of a system that may be targeted. These are the goals in the attack tree. Then we identify all the modules, all the communication points between the modules, and all the classes of users of the system. Together, these tend to encompass the most likely failure points. We make sure to include not just the software written in-house, but any shrink-wrapped components used by the software. We also consider the computers on which the software runs, the networks on which they participate, and so on.
Next we get the entire analysis team together in a room with a big white board (assuming, of course, that they’re all familiar with the system at this point). One person “owns” the white board, while everyone starts brainstorming possible attacks. Often, people have thought of attacks before coming into the room. This is the time to discuss their feasibility. Almost without fail, people get new ideas on the spot, sparked by the conversation, and thus new attacks may surface.
All possible attacks should make it up onto the white board, even if you don’t think they’re going to be interesting to anyone. For example, you may point out that someone from behind a firewall could easily intercept the unencrypted traffic between an application server and a database, even though the system requirements clearly state that this risk is acceptable. So why note this down? Because we’re not worried about reporting results yet, it is a good idea to be complete, especially because assessing risk is such an inexact art. Give everyone involved access to everything, even though they may only be producing a high-level report in the end.
As the brainstorming session winds down, work on organizing attacks into categories. A rough attack tree can be created on the spot from the board. At this point, divide up the parts of the attack tree between team members, and have the team go off and flesh out their branches independently. Also, have them “decorate” the branches with any information deemed important for this analysis (usually estimated cost, estimated risk, and estimated attack effort).
Finally, when everyone has fleshed out their part of the tree, someone assembles the full tree, and another meeting is held to review it. Usually, some minor tweaking occurs at this time. Sometimes, there will be a major revision.
Reporting Analysis Findings
Although an attack tree usually contains all the critical security risk information, it should not be the final product of an analysis. This is not the kind of thing that anyone would want to see as a report. First, attack trees don’t make for a good read. Second, they don’t tell others the entire story. Instead, they only present risks (and usually don’t present risks in too much detail). It’s good to assume that a development team and its manager are destined to pick over your report with a fine-tooth comb.
The organization of risks can come directly from the attack tree. This helps the report flow well. However, you shouldn’t expect that people will want to read the report straight through. There are those who are interested in knowing the biggest risks, who then read only about these. For this reason, the risks should be ranked in terms of perceived risk for your audience. In the beginning of the report, place a list of critically high risks, along with forward references detailing where they are described. This kind of material is great for an executive summary, which you should definitely provide. Many times there are readers who don’t benefit from reading any further than the executive summary anyway.
Within each section of the report, try to order risks from most significant to least. At the beginning of your discussion of each risk, give a one-line summary of how serious you think the risk is, including the estimated cost of attack, estimated risk to the attacker, and estimated effort. Doing so helps readers determine the parts of the report that are most important for them to read.
For each identified risk, we like to provide three pieces of information. The first is an overview of the attack. It describes the attack in sufficient detail that someone without a security background can understand it. This piece should also include information such as what resources an attacker needs to launch a successful attack, the conditions under which an attack will fail, and so forth. The second piece should be a discussion of the consequences of a successful attack. It’s okay to project here. What is the potential impact on the bottom line? Will there be brand damage? Will end users be placed at unnecessary risk? Will data that should remain private get out? What will the consequences be if so? The third piece should cover mitigation techniques that discuss how a risk should be averted. Get as specific as possible. Suggest specific changes to the architecture. Don’t simply name a library that can help, describe how it can be used, and where it could be integrated into the current design.
Implementation Security Analysis
As we have discussed, an architectural analysis should almost always precede an implementation analysis. The results of an architectural risk assessment can be used to guide and focus an implementation analysis.
There are two major foci of an implementation analysis. First we must validate whether the implementation actually meets the design. The only reliable way to get this done is by picking through the code by hand, and trying to ensure that things are really implemented as in the design. This task alone can be quite difficult and time-consuming because programs tend to be vast and complex. It’s often a reasonable shortcut to ask the developers specific questions about the implementation, and to make judgments from there. This is a good time to perform a code review as part of the validation effort.
The second focus of implementation analysis involves looking for implementation-specific vulnerabilities. In particular, we search for flaws that are not present in the design. For example, things like buffer overflows never show up in design (race conditions, on the other hand, may, but only rarely).
In many respects, implementation analysis is more difficult than design analysis because code tends to be complex, and security problems in code can be subtle. The large amount of expertise required for a design analysis pales in comparison with that necessary for an implementation analysis. Not only does the analyst need to be well versed in the kinds of problems that may crop up, he or she needs to be able to follow how data flow through code.
Auditing Source Code
Trying to understand and analyze an entire program is more work than most people are willing to undertake. Although a thorough review is possible, most people are willing to settle for a “good-enough” source code audit that looks for common problems.
With this in mind, our strategy for auditing source code is as follows: First, identify all points in the source code where the program may take input from a user, be it a local user or a remote user. Similarly, look for any places where the program may take input from another program or any other potentially untrusted source. By “untrusted,” we mean a source that an attacker may control the input that the piece in question sends us. Most security problems in software require an attacker to pass specific input to a weak part of a program. Therefore, it’s important that we know all the sources from which input can enter the program. We look for network reads, reads from a file, and any input from GUIs.
When we have these things identified, we look to see what the internal API is like for getting input. Sometimes developers build up their own helper API for getting input. We look to make sure it’s sound, and then treat the API as if it were a standard set of input calls.
Next we look for symptoms of problems. This is where experience comes into play. When you’ve read the back half of this book, you will probably have plenty of ideas when it comes to the things you should be looking for. Enumerating them all is difficult. For example, in most languages, you can look for calls that are symptomatic of time-of-check/time-of-use (TOCTOU) race conditions (see Chapter 9). The names of these calls change from language to language, but such problems are universal. Much of what we look for consists of function calls to standard libraries that are frequently misused.
When we identify places of interest in the code, we must analyze things manually to determine whether there is a vulnerability. Doing this can be a challenge. (Sometimes it turns out to be better to rewrite any code that shows symptoms of being vulnerable, regardless of whether it is. This is true because it is rare to be able to determine with absolute certainty that a vulnerability exists just from looking at the source code, because validation generally takes quite a lot of work.)
Occasionally, highly suspicious locations turn out not to be problems. Often, the intricacies of code may end up preventing an attack, even if accidentally! This may sound weird, but we’ve seen it happen. In our own work we are only willing to state positively that we’ve found a vulnerability if we can directly show that it exists. Usually, it’s not worth the time to go through the chore of actually building an exploit (something that is incredibly time-consuming). Instead, we say that we’ve found a “probable” vulnerability, then move on. The only time we’re likely to build an exploit is if some skeptic refuses to change the code without absolute proof (which does happen).
This is the extent of our general guidelines for implementation audits. It is worth noting that this strategy should be supplemented with thorough code reviews. Scrutinize the system to whatever degree you can afford. Our approach tends to do a very good job of finding common flaws, and doesn’t take too long to carry out, but there are no guarantees of completeness.
Source-level Security Auditing Tools
One of the worst things about design analysis is that there are no tools available to automate the process or to encode some of the necessary expertise. Building large numbers of attack trees and organizing them in a knowledge base can help alleviate the problem in the long term. Fortunately, when auditing source code, there are tools that statically scan source code for function calls and constructs that are known to be “bad.” That is, these tools search for language elements that are commonly involved in security-related implementation flaws, such as instances of the strcpy function, which is susceptible to buffer overflows (see Chapter 7).
Currently, there are three such tools available:
• RATS (Rough Auditing Tool for Security) is an open source tool that can locate potential vulnerabilities in C, C++, Python, PHP, and Perl programs. The RATS database currently has about 200 items in it. RATS is available from http://www.securesw.com/rats/.
• Flawfinder is an open source tool for scanning C and C++ code. Flawfinder is written in Python. At the time of this writing, the database has only 40 entries. It is available from http://www.dwheeler.com/flawfinder/.
• ITS4 (It’s The Software, Stupid! [Security Scanner]) is a tool for scanning C and C++ programs, and is the original source auditing tool for security. It currently has 145 items in its database. ITS4 is available from http://www.cigital.com/its4/.
The goal of source-level security auditing tools is to focus the person doing an implementation analysis. Instead of having an analyst search through an entire program, these tools provide an analyst with a list of potential trouble spots on which to focus. Something similar can be done with grep. However, with grep, you need to remember what to look for every single time. The advantage of using a scanning tool is that it encodes a fair amount of knowledge about what to look for. RATS, for example, knows about more than 200 potential problems from multiple programming languages. Additionally, these tools perform some basic analysis to try to rule out conditions that are obviously not problems. For example, though sprintf() is a frequently misused function, if the format string is constant, and contains no “%s”, then it probably isn’t worth examining. These tools know this, and discount such calls.
These tools not only point out potential problem spots, but also describe the problem, and potentially suggest remedies. They also provide a relative assessment of the potential severity of each problem, to help the auditor prioritize. Such a feature is necessary, because these tools tend to give a lot of output . . . more than most people would be willing to wade through.
One problem with all of these tools is that the databases currently are composed largely of UNIX vulnerabilities. In the future, we expect to see more Windows vulnerabilities added. In addition, it would be nice if these tools were a lot smarter. Currently, they point you at a function (or some other language construct), and it’s the responsibility of the auditor to determine whether that function is used properly or not. It would be nice if a tool could automate the real analysis of source that a programmer has to do. Such tools do exist, but currently only in the research lab.
We expect to see these tools evolve, and to see better tools than these in the near future. (In fact, we’ll keep pointers to the latest and greatest tools on this book’s Web site.) Even if these tools aren’t perfect, though, they are all useful for auditing. Additionally, these tools can even be integrated easily with development environments such as Microsoft Visual Studio, so that developers can get feedback while they code, not after.
Using RATS in an Analysis
Any of these above tools can be used to streamline our approach to implementation analysis. In this section, we’ll discuss RATS. Most of the features of RATS we discuss in this section exist in some form in other tools.
First, we can use RATS to help us find input points to a program. RATS has a special mode called input mode that picks out all input routines in the standard C libraries. To run RATS in input mode on a directory of C files, type
rats -i *.c
This mode doesn’t know anything about inputs via a GUI, so we need to find such places via manual inspection.
When we determine the internal input API of a program, we configure RATS to scan for this API as well. We can either add database entries of our own to our local copy of the RATS database or we can pass in function names at the command line during future scans. Let’s say we found a function read_line_from_socket and read_line_from_user. In a subsequent scan we can add these functions to our search list as follows:
rats -a read_line_from_socket -a read_line_from_user *.c
Running RATS in this mode (the default mode) should produce a lot of output. By default, the output is ordered by severity, then function name. The following shows a small piece of code:
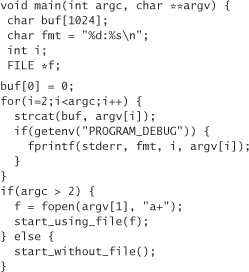

In the output above, we first see that the code contains a stack-allocated variable, which means that any buffer overflow that happens to be in the code is likely to be exploitable (see Chapter 7).
Next in the output, we see two calls commonly associated with buffer overflows: strcat and getenv. Here, strcat is used improperly, but the call to getenv is not exploitable.
Finally, we see an stdio call where format strings are variables and are not string constants. The general construct is at risk for format string attacks (see Chapter 12). In this instance, though, the format string is completely uninfluenced by user input, and thus is not a problem. RATS doesn’t know any of this; all it knows is that an stdio function has been used where a variable was passed as the format parameter.
The default mode only shows reasonably likely vulnerabilities. If we pass the “-w 3” flag to RATS to show all warnings, we will see a call to fopen that may be involved in a race condition. However, because this is not reported in the default output, RATS couldn’t find a file check that might match up to it, so it decides that there is a significant chance of this call is not actually a problem (it’s hard to determine; there may need to be checks around the fopen that aren’t performed. It depends on the context of the program).
On a real program, RATS may produce hundreds of lines of output. We can’t emphasize enough how important it is not to skim the output too lightly, even when it seems like you’re only getting false hits. False hits are common, but real vulnerabilities often lie buried in the list. Go as far through the output as you have the time to go.
Also, if you don’t understand the issue a tool is raising, be sure to learn as much as you can about the problem before you dismiss it. This book should be a good resource for that.
The Effectiveness of Security Scanning of Software
Here are some initial conclusions based on our experiences using software security scanners:
• They still require a significant level of expert knowledge. Although security scanners encode a fair amount of knowledge on vulnerabilities that no longer must be kept in the analyst’s head, we have found that an expert still does a much better job than a novice at taking a potential vulnerability location and manually performing the static analysis necessary to determine whether an exploit is possible. Experts tend to be far more efficient and far more accurate at this process.
• Even for experts, analysis is still time-consuming. In general, this type of scanner only eliminates one quarter to one third of the time it takes to perform a source code analysis because the manual analysis still required is so time-consuming. Code inspection takes a long time.
• Every little bit helps. These tools help significantly with fighting the “get-done go-home” effect. In the case where a tool prioritizes one instance of a function call over another, we tend to be more careful about analysis of the more severe problem.
• They can help find real bugs. These tools have been used to find security problems in real applications. It is often possible to find problems within the first 10 minutes of analysis that would not otherwise have been found as quickly [Viega, 2000].
Conclusion
Performing a security audit is an essential part of any software security solution. Simply put, you can’t build secure software without thinking hard about security risks. Our expertise-driven approach has been used successfully in the field for years and has resulted in much more secure software for our clients. By leveraging source-code scanning tools, an architectural analysis can be enhanced with an in-depth scan of the code. As the field of software security matures, we expect to see even better tools become available.