
Chapter 5. Software Development Security
This chapter covers the following topics:
• System development life cycle: Covers development steps, including Initiate, Acquire/Develop, Implement, Operate/Maintain, and Dispose
• Software development life cycle: Describes the steps in the software development lifecycle, including Gather requirements, Design, Develop, Test/Validate, Release/Maintain, and Change Management/Configuration Management
• Software development security best practices: Includes a survey of industry approaches to ensuring best practices in securing software development
• Software development methods: Explains common software development methods and terms important to understanding their application
• Programming concepts: Discusses software architectures and languages used to implement them
• Database concepts and security: Surveys database concepts and security
• Knowledge-based systems: Covers artificial intelligence (AI) and its use in knowledge-based or expert systems
• Software threats: Describes common security issues presented by insecure code and malware
• Software security effectiveness: Describes methods of validating and certifying software security
Software is at the heart of all functionality in computer systems. Various types of software, including operating systems, applications, and utilities, work together to deliver instructions from the human to his hardware. All of these instructions are created with the intent of making some operation possible.
When software is written and developed the focus can be placed on its functionality and ease of use or on its security. In many cases the two goals might work at cross purposes. Giving inadequate attention to the security of a piece of software results in software that can introduce security issues to both the application and the systems on which it is run.
Moreover, some types of software are intentionally developed to create security openings in a network or system. This chapter discusses software development methodology, best practices for secure development, and types of malware and methods of mitigating the effects of malware.
Foundation Topics

System Development Life Cycle
When an organization defines new functionality that must be provided either to its customers or internally, it must create systems to deliver that functionality. Many decisions have to be made, and a logical process should be followed in making those decisions. This process is called the System Development Life Cycle. Rather than being a haphazard approach, a System Development Life Cycle provides clear and logical steps to follow to ensure that the system that emerges at the end of the development process provides the intended functionality with an acceptable level of security.
System Development Life Cycle
1. Initiate
3. Implement
5. Dispose
This section explains the five steps in the System Development Life Cycle.
Initiate
In the Initiate phase, the realization is made that a new feature or functionality is desired or required in an existing piece of software. This new feature might constitute an upgrade to an existing product or the development of a whole new piece of software. In either case the Initiate phase includes making a decision on whether to purchase or develop the product internally.
In this stage an organization must also give thought to the security requirements of the solution. Creating a preliminary risk assessment can be used to detail the confidentiality, integrity, and availability requirement and concerns. Identifying these issues at the outset is important so these considerations can guide the purchase or development of the solution. The earlier in the System Development Life Cycle that the security requirements are identified, the more likely that the issues will be successfully addressed in the final product.
Note
Chapter 4, “Information Security Governance and Risk Management” covers risk assessment in depth.
Acquire/Develop
In the Acquire/Develop stage of the System Development Life Cycle, a series of activities take place that provide input to facilitate making a decision about acquiring or developing the solution; the organization then makes a decision on the solution. The activities are designed to get answers to the following questions:
What functions does the system need to perform?
What are the potential risks to CIA exposed by the solution?
What protection levels must be provided to satisfy legal and regulatory requirements?
What tests are required to ensure that security concerns have been mitigated?
How do various third-party solutions address these concerns?
How do the security controls required by the solution affect other parts of the company security policy?
What metrics will be used to evaluate the success of the security controls?
The answers to these questions should guide the acquisition/develop decision as well as the steps that follow this stage of the System Development Life Cycle.
Implement
In the Implement stage the solution is introduced to the live environment but not without its completing both certification and accreditation. Certification is the process of technically verifying the solution’s effectiveness and security. The Accreditation process involves a formal authorization to introduce the solution into the production environment by management.
Operate/Maintain
After the system is operating in the environment the process does not end. Doing a performance baseline is important so that continuous monitoring can take place. The baseline ensures that performance issues can be quickly determined. Any changes over time (addition of new features, patches to the solution, and so on) should be closely monitored with respect to the effects on the baseline.
Instituting a formal change management process ensures that all changes are both approved and documented. Because any changes can affect both security and performance, special attention should be given to monitoring the solution after any changes.
Finally, vulnerability assessments and penetration testing after the solution is implemented can help discover any security or performance problems that might either be introduced by a change or arise as a result of a new threat.
Dispose
The Dispose stage consists of removing the solution from the environment when it reaches the end of its usefulness. When this occurs an organization must consider certain issues. They include:
1. Does removal or replacement of the solution introduce any security holes in the network?
2. How can the system be terminated in an orderly fashion so as not to disrupt business continuity?
3. How should any residual data left on any systems be removed?
4. How should any physical systems that were a part of the solution be disposed of safely?
5. Are there any legal or regulatory issues that would guide the destruction of data?
Software Development Life Cycle
The Software Development Life Cycle can be seen as a subset of the System Development Life Cycle in that any system under development could (but not necessarily) include the development of software to support the solution. The goal of the Software Development Life Cycle is to provide a predictable framework of procedures designed to identify all requirements with regard to functionality, cost, reliability, and delivery schedule and ensure that each are met in the final solution. This section breaks down the steps in the Software Development Life Cycle and describes how each step contributes to this ultimate goal. Keep in mind that steps in the SDLC can vary based on the provider and this is but one popular example. The following sections flesh out the Software Development Life Cycle steps in detail:
2. Design
3. Develop
5. Change Management and Configuration Management
Gather Requirements
In the Gather Requirements phase of the Software Development Life Cycle, both the functionality and the security requirements of the solution are identified. These requirements could be derived from a variety of sources such as evaluating competitor products for a commercial product to surveying the needs of the users for an internal solution. In some cases these requirements could come from a direct request from a current customer.
From a security perspective, an organization must identify potential vulnerabilities and threats. When this assessment is performed the intended purpose of the software and the expected environment must be considered. Moreover the data that will be generated or handled by the solution must be assessed for its sensitivity. Assigning a privacy impact rating to the data to help guide measures intended to protect the data from exposure might be useful.
Design
In the Design phase of the Software Development Life Cycle, an organization develops a detailed description of how the software will satisfy all functional and security goals. It attempts to map the internal behavior and operations of the software to specific requirements in an attempt to identify any requirements that have not been met prior to implementation and testing.
During this process the state of the application is determined in every phase of its activities. The state of the application refers to its functional and security posture during each operation it performs. Therefore all possible operations must be identified. This is done to ensure that at no time does the software enter an insecure state or act in an unpredictable way.
Identifying the attack surface is also a part of this analysis. The attack surface describes what is available to be leveraged by an attacker. The amount of attack surface might change at various states of the application but at no time should the attack surface provided violate the security needs identified in the Gather Requirements stage.
Develop
The Develop phase is where the code or instructions that make the software work is written. The emphasis of this phase is strict adherence to secure coding practices. Some models that can help promote secure coding are covered later in this chapter in the section “Software Development Security Best Practices.”
Many security issues with software are created through insecure coding practices such as lack of input validation or data type checks. Identifying these issues in a code review that attempts to assume all possible attack scenarios and their impact on the code is needed. Not identifying these issues can lead to attacks such as buffer overflows and injection and to other error conditions, which are covered later in this chapter in the section “Source Code Issues.”
Test/Validate
In the Test/Validate phase several types of testing should occur, including ways to identify both functional errors and security issues. The auditing method that assesses the extent of the system testing and identifies specific program logic that has not been tested is called the test data method. This method tests not only expected or valid input but also invalid and unexpected values to assess the behavior of the software in both instances. An active attempt should be made to attack the software, including attempts at buffer overflows and DOS attacks. Some goals of testing performed at this time are
• Verification testing: Determines whether the original design specifications have been met
• Validation testing: Takes a higher level view and determines whether the original purpose of the software has been achieved
Software is typically developed in pieces or modules of code that are later assembled to yield the final product. Each module should be tested separately in a procedure called unit testing. Having development staff carry out this testing is critical, but using a different group of engineers than the ones who wrote the code can ensure an impartial process occurs. This is a good example of the concept of separation of duties.
The following should be characteristics of the unit testing:
• The test data is part of the specifications.
• Testing should check for out-of-range values and out-of bounds conditions.
• Correct test output results should be developed and known beforehand.
Live or actual field data is not recommended for use in the unit testing procedures.
Additional testing that is recommended includes:
• Integration testing: Assesses the way in which the modules work together and determines whether functional and security specifications have been met
• Acceptance testing: Ensures that the customer (either internal or external) is satisfied with the functionality of the software
• Regression testing: Takes places after changes are made to the code to ensure the changes have neither reduced functionality or security
Release/Maintain
Also called the release/maintenance phase in some documentation, this phase includes the implementation of the software into the live environment and the continued monitoring of its operation. Finding additional functional and security problems at this point as the software begins to interface with other element of the network is not unusual.
In many cases vulnerabilities are discovered in the live environments for which no current fix or patch exists. In that case it is referred to as zero-day vulnerability. Having the supporting development staff discover these rather than those looking to exploit the vulnerability is best.
Change Management and Configuration Management
After the solution is deployed in the live environment there will inevitably be additional changes that must be made to the software due to security issues. In some cases the software might be altered to enhance or increase its functionality. In either case changes must be handled through a formal change and configuration management process.
The purpose of this process is to ensure that all changes to the configuration of and to the source code itself are approved by the proper personnel and are implemented in a safe and logical manner. This process should always ensure continued functionality in the live environment and changes should be documented fully, including all changes to hardware and software.
Software Development Security Best Practices
To support the goal of ensuring that software is soundly developed with regard to both functionality and security, a number of organizations have attempted to assemble a set of software development best practices. In this section we’ll look at some of those organizations and in the section that follows lists a number of their most important recommendations.
WASC
The Web Application Security Consortium (WASC) is an organization that provides best practices for web-based applications along with a variety of resources, tools, and information that organizations can make use of in developing web applications.
One of the functions undertaken by WASC is continual monitoring of attacks leading to the development of a list of top attack methods in use. This list can aid in ensuring that organizations are not only aware of the latest attack methods and how widespread these attacks are but also can assist them in making the proper changes to their web applications to mitigate these attack types.
OWASP
The Open Web Application Security Project (OWASP) is another group that monitors attacks, specifically web attacks. OWASP maintains a list of top 10 attacks on an ongoing basis. This group also holds regular meetings at chapters throughout the world, providing resources and tools including testing procedures, code review steps, and development guidelines.
BSI
The Department of Homeland Security (DHS) also has become involved in promoting software security best practices. The Build Security In (BSI) initiative promotes a process-agnostic approach that makes security recommendations with regard to architectures, testing methods, code reviews, and management processes. The DHS Software Assurance program addresses ways to reduce vulnerabilities, mitigate exploitations, and improve the routine development and delivery of software solutions.
ISO/IEC 27000
The International Organization for Standardization (ISO) and the International Electrotechnical Commission (IEC) created the 27034 standard, which is part of a larger body of standards called the ISO/IEC 27000 series. These standards provide guidance to organizations in integrating security into the development and maintenance of software applications. These suggestions are relevant not only to the development of in-house applications but also to the safe deployment and management of third-party solutions in the enterprise.
Note
All the standards that are part of ISO/IEC 27000 are discussed in more depth in Chapter 4, “Information Security Governance and Risk Management.”
Software Development Methods
In the course of creating software over the last 30 years, developers have learned many things about the development process. As development projects have grown from a single developer to small teams to now large development teams working on massive projects with many modules that must securely interact, development models have been created to increase the efficiency and success of these projects. Lessons learned have been incorporated into these models and methods. This section covers some of the more common models along with concepts and practices that must be understood to implement them.
This section discusses the following software development methods:
• V-shaped
• Spiral
• Rapid Application Development
• Agile
• JAD
• CMMI
Build and Fix
Although it’s not a formal model, the Build and Fix approach describes a method that while certainly used in the past has been largely discredited and is now used as a template for how not to manage a development project. Simply put, in this method, the software is developed as quickly as possible and released.
No formal control mechanisms are used to provide feedback during the process. The product is rushed to market, and problems are fixed on an as-discovered basis with patches and service packs. Although this approach gets the product to market faster and cheaper, in the long run, the costs involved in addressing problems and the collateral damage to the product in the marketplace outweigh any initial cost savings.
Despite the fact that this model still seems to be in use today, most successful developers have learned to implement one of the other models discussed in this section so that the initial product, though not necessarily perfect, comes much closer to meeting all the functional and security requirements of the design. Moreover using these models helps to identify and eliminate as many bugs as possible without using the customer as “quality control.”
In this simplistic model of the software development process, certain unrealistic assumptions are made, including:
• Each step can be completed and finalized without any effect from the later stages that might require rework.
• Iteration (reworking and repeating) among the steps in the process that is typically called for in other models is not stressed in this model.
• Phases are not seen as individual milestones as in some other models discussed here.
Waterfall
The original Waterfall model breaks the process into distinct phases. Although this model is somewhat of a rigid approach, the basic process is as a sequential series of steps that are followed without going back to earlier steps. This approach is called incremental development. Figure 5-1 is a representation of the Waterfall process.

In the modified Waterfall model each phase in the development process is considered its own milestone in the project management process. Unlimited backward iteration (returning to earlier stages to address problems) is not allowed in this model. However, product verification and validation are performed in this model. Problems that are discovered during the project do not initiate a return to earlier stages, but rather are dealt with after the project is complete.
V-Shaped
The V-shaped model is also somewhat rigid but differs primary from the Waterfall method in that verification and validation are performed at each step. Although this model can work when all requirements are well understood upfront (frequently not the case) and potential scope changes are small, it does not provide for handling events concurrently because it is also a sequential process like the Waterfall. It does build in a higher likelihood of success because it performs testing at every stage. Figure 5-2 is a representation of this process.

Prototyping
Although it’s not a formal model unto itself, prototyping is the use of a sample of code to explore a specific approach to solving a problem before extensive time and cost have been invested in the approach. This allows the team to both identify the utility of the sample code as well as identify design problems with the approach. Prototype systems can provide significant time and cost savings because you don’t have to make the whole final product to begin testing it.
Incremental
A refinement to the basic Waterfall model that states that software should be developed in increments of functional capability is called the Incremental model. In this model a working version or iteration of the solution is produced, tested, and redone until the final product is completed. You could think of it as a series of waterfalls. After each iteration or version of the software is completed testing occurs to identify gaps in functionality and security from the original design. Then the gaps are addressed by proceeding through the same analysis, design, code, and test stages again. When the product is deemed to be acceptable with respect to the original design it is released. Figure 5-3 is a representation of this process.

Spiral
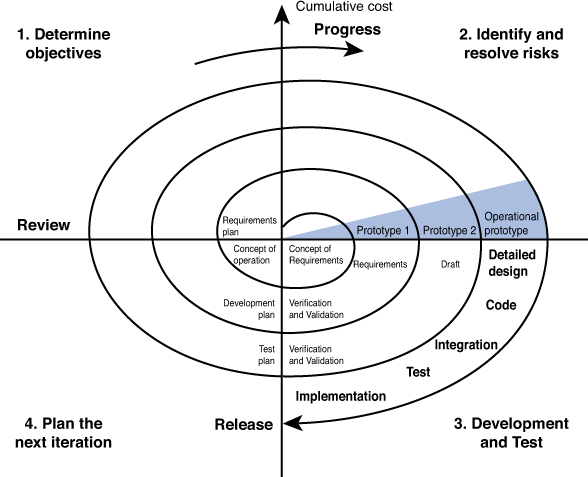
The Spiral model is actually a meta-model that incorporates a number of the software development models. It is also an iterative approach but places more emphasis on risk analysis at each stage. Prototypes are produced at each stage, and the process can be seen as a loop that keeps circling back to take a critical look at risks that have been addressed while still allowing visibility into new risks that might been created in the last iteration.
This model assumes that knowledge will be gained at each iteration and should be incorporated into the design as it evolves. Some cases even involve the customer making comments and observations at each iteration as well. Figure 5-4 is a representation of this process. The radial dimension of the diagram represents cumulative cost, and the angular dimension represents progress made in completing each cycle.
Rapid Application Development (RAD)
In the Rapid Application Development (RAD) model, less time is spent upfront on design while emphasis is placed on rapidly producing prototypes with the assumption that crucial knowledge can only be gained through trial and error. This model is especially helpful when requirements are not well understood at the outset and are developed as issues and challenges arise during the building of prototypes. Figure 5-5 is a comparison of the RAD model to traditional models where the project is completed fully and then verified and validated.
Figure 5-5. Traditional and RAD Model

Agile
Many of the processes discussed thus far rely on a rigid adherence to process-oriented models. In many cases the focus is more on following procedural steps than on reacting to changes quickly and increasing efficiency. The Agile model puts more emphasis on continuous feedback and cross-functional teamwork.
It attempts to be nimble enough to react to situations that arise during development. Less time is spent on the upfront analysis and more emphasis is placed on learning from the process and incorporating lessons learned in real time. There is also more interaction with the customer throughout the process. Figure 5-6 is a comparison of the Agile model with the Waterfall model.
Figure 5-6. Agile and Waterfall Comparison Model

JAD
The Joint Analyses Development or Joint Application Development (JAD) model is one that uses a team approach. It uses workshops to both agree on requirements and to resolve differences. The theory is that by bringing all parties together at all stages that a more satisfying product will emerge at the end of the process.
Cleanroom
In contrast to the JAD model, the Cleanroom model strictly adheres to formal steps and a more structured method. It attempts to prevent errors and mistakes through extensive testing. This method works well in situations where high quality is a must, the application is mission critical, or the solution must undergo a strict certification process.
CMMI
The Capability Maturity Model Integration (CMMI) is a comprehensive set of guidelines that addresses all phases of the software development life cycle. It describes a series of stages or maturity levels that a development process can advance through as it goes from the ad hoc (Build and Fix) model to one that incorporates a budgeted plan for continuous improvement. Figure 5-7 shows its five maturity levels along with an explanation of each.
Figure 5-7. CMMI Maturity Levels

Programming Concepts
Software comprises the written instructions that allow humans to communicate with the computer hardware. These instructions are written in various programming languages. As programming has evolved over the years, each successive language has delivered more functionality to programmers. Programming languages can be classified in categories based on the type of instructions they create and to which part of the system they speak. This section covers the main categories.
Machine Languages
Machine languages are those that deliver instructions directly to the processor. This was the only type of programming done in the 1950s and uses basic binary instructions using no complier or interpreter (programs that convert higher language types to a form that can be executed by the processor). This type of programming is both time consuming and prone to errors. Most of these programs were very rudimentary due to the need to keep a tight rein on their length.
Assembly Languages and Assemblers
Considered to be “one step above” machine languages, assembly languages use symbols or mnemonics to represent sections of complicated binary code. Consequently, these languages use an assembler to convert the code to machine level. Although this greatly simplifies and shortens the code, it still requires extensive knowledge of the computer’s architecture. It also means that any code written in these languages will be hardware specific. Although assembly language is simpler to write than machine language, it is not as easy to create as the high-level languages discussed next.
High-level Languages, Compilers, and Interpreters
In the 1960s a third level of language emerged called high-level languages. These instructions use abstract statements (for example, IF-THEN-ELSE) and are processor independent. They are easier to work with, and their syntax is more similar to human language. This code uses either assemblers or compilers to convert the instructions into machine code. The end result is a decrease in the total amount of code writers required for a particular project.
A fourth generation of languages called very-high-level languages focus on abstract algorithms that hide some of the complexity from the programmer. This frees the programmer to focus on the real world problems they are trying to solve rather than the details that go on behind the scenes.
Finally, in the 1990s, a fifth generation of languages began to emerge called natural languages. The goal is to use these languages to create software that can solve problems on its own rather than require a programmer to create code to deal with the problem. Although this goal is not fully realized, using knowledge-based processing and artificial intelligence is worth pursuing.
A significant distinction exists with respect to security between compiled code and interpreted code. Because compiled code has already been translated to binary language, detecting malicious code inside an application is very difficult. Interpreted code, on the other hand, uses a language interpreter that is a piece of software that allows the end user to write a program in some human-readable language and have this program executed directly by the interpreter. In this case spotting malicious code is somewhat easier because the code is a bit more readable by humans.
Object-Oriented Programming
In classic software development, data is input into a program, the program manages the data from beginning to end, and a result is returned. Object-Oriented Programming (OOP) supplies the same functionality but it is more efficiently introduced through different techniques. In OOP, objects are organized in a hierarchy of classes with characteristics called attributes attached to each. OOP emphasizes the employment of objects and methods rather than types or transformations as in other software approaches.
The programmer creates the classes of objects but not all the objects themselves. Software in the program allows for objects to be created on demand when needed through requests. When a request comes in, usually from an existing object for a new object to carry out some function, it is built (instantiated) with necessary code. It does not matter if objects are written in a different programming languages as long as the objects have the ability to communicate with one another, a process usually made possible through an application programming interface (API).
Moreover, because objects are organized in hierarchical classes, object methods (a functionality or procedure) can be passed from a class to a subclass through a process called inheritance. The objects contain or encapsulate attribute values. Objects communicate with messages sent to another object’s API. Different objects might react differently to the same message, which is called the object’s behavior. The code that defines how an object will behave with respect to a message is called its method.
Some parts of an object may be private, which means its internal data and operation is not visible by other objects. This privacy is provided through the encapsulation process and is sometimes called data hiding. Abstraction is the ability to suppress these unnecessary internal details. Other objects, subjects, and applications can make use of objects’ functionality through standardized interfaces without worrying about the details of the functionality.
Examples of OOP languages are C++, Simula 67, and Smalltalk. The many advantages to this approach include:
• Modularity in design through autonomous objects
• Definition of internal components without impacting other parts of the system
• Reusability of components
• More readily maps to business needs
Polymorphism
In an object-oriented system, polymorphism denotes objects of many different classes that are related by some common superclass; thus, any object denoted by this name can respond to some common set of operations in a different way. Polymorphism is the ability of different objects with a common name to react to the same message or input with different output. For example, three objects might receive the input “Dodge Dart.” One object’s output might be “subcompact,” another’s might be “uses unleaded fuel,” and another’s might be “costs 35,000.” In some cases these differences derive from the fact that the objects have inherited different characteristics from their parent classes.
Cohesion
Cohesion is a term used to describe how many different tasks a module can carry out. If it is limited to a small number or a single function it is said to have high cohesion. High cohesion is good in that changes can be made to the model without affecting other modules. It also makes reusing the module easier to do. The highest cohesion is provided by limiting the scope of a module’s operation.
Coupling
Coupling describes how much interaction one module requires from another module to do its job. Low or loose coupling indicates a module does not need much help from other modules, whereas high coupling indicates the opposite. If Module A needs to wait on results from messages it sent to three other modules before it can proceed, it is said to have high coupling. To sum up these last two sections, the best programming provides high cohesion and low coupling.
Data Structures
Data structure refers to the logical relationship between elements of data. It describes the extent to which elements, methods of access, and processing alternatives are associated and the organization of data elements. These relationships can be simple or complex. From a security standpoint these relationships or the way in which various software components communicate and the data formats that they use must be well understood to understand the vulnerabilities that might be exposed by these data structures.
Distributed Object-Oriented Systems
When an application operates in a client/server framework as many do, the solution is performing distributed computing. This means that components on different systems must be able to both locate each other and communicate on a network. Typically, the bulk of the solution is on the server, and a smaller piece is located on the client. This requires some architecture to support this process-to-process communication. There are several that can be used as discussed shortly.
CORBA
Common Object Request Broker Architecture (CORBA) is an open object-oriented standard developed by the Object Management Group (OMG). This standard uses a component called the Object Request Broker (ORB) to implement exchanges among objects in a heterogeneous, distributed environment.
The ORB manages all communication between components. It accepts requests for service from the client application, directs the request to the server, and then relays the response back to the client application. The ORB makes communication possible locally or remotely. This is even possible between components that are written in different languages because they use a standard interface to communicate with the ORB.
COM and DCOM
Component Object Model (COM) is a model for communication between processes on the same computer, whereas as its name implies, the Distributed Component Object Model (DCOM) is a model for communication between processes in different parts of the network. DCOM works as the middleware between these remote processes (called interprocess communication or IPC).
DCOM provides the same services as those provided by the ORB in the CORBA framework; that is, data connectivity, message service, and distributed transaction service. All of these functions are integrated into one technology that uses the same interface as COM.
OLE
Object Linking and Embedding (OLE) is a method for sharing objects on a local computer that uses COM as its foundation. In fact, OLE is sometimes described as the predecessor of COM. It allows objects to be embedded in documents (spreadsheets, graphics, and so on). The term linking refers to the relationship between one program and another, and the term embedding refers to the placement of data into a foreign program or document.
Java
Java Platform, Enterprise Edition (Java EE) is another distributed component model that relies on the Java programming language. It is a framework used to develop software that provides APIs for networking services and uses an interprocess communication process that is based on CORBA. Its goal is to provide a standardized method of providing back-end code that carries out business logic for enterprise applications.
SOA
A newer approach to providing a distributed computing model is the Service-Oriented Architecture (SOA). It operates on the theory of providing web-based communication functionality without each application requiring redundant code to be written per application. It uses standardized interfaces and components called service brokers to facilitate communication among web-based applications.
Mobile Code
Mobile code is a type that can be transferred across a network and then executed on a remote system or device. The security concerns with mobile code revolve around the prevention of the execution of malicious code without the knowledge of the user. This section covers the two main types of mobile code, Java applets and ActiveX applets, and the way they operate.
Java Applets
A Java applet is a small component created using Java that runs in a web browser. It is platform independent and creates intermediate code called byte code that is not processor-specific. When the applet downloads to the computer, the Java virtual machine (JVM), which must be present on the destination computer, converts the byte code to machine code.
The JVM executes the applet in a protected environment called a sandbox. This critical security feature, called the Java Security Model (JSM), helps to mitigate the extent of damage that could be caused by malicious code. However, it does not eliminate the problem with hostile applets (also called active content modules) so Java applets should still be regarded with suspicion because they might launch an intentional attack after being downloaded from the Internet.
ActiveX
ActiveX is a Microsoft technology that uses Object-Oriented Programming (OOP) and is based on the COM and DCOM. These self-sufficient programs, called controls, become a part of the operating system after they’re downloaded. The problem is that these controls execute under the security context of the current user, which in many cases has administrator rights. This means that a malicious ActiveX control could do some serious damage.
ActiveX uses Authenticode technology to digitally sign the controls. This system has been shown to have significant flaws, and ActiveX controls are generally regarded with more suspicion than Java applets.
Database Concepts and Security
Databases have become the technology of choice for storing, organizing, and analyzing large sets of data. Users generally access a database though a client interface. As the need arises to provide access to entities outside the enterprise, the opportunities for misuse increase. In this section concepts necessary to discuss database security are covered as well as the security concerns surrounding database management.
DBMS Architecture and Models
Databases contain data and the main difference in database models is how that information is stored and organized. The model describes the relationships between the data elements, how the data is accessed, how integrity is ensured, and acceptable operations. The five models or architectures we will discuss are:
• Relational
• Hierarchical
• Network
• Object oriented
• Object relational
The relational model uses attributes (columns) and tuples (rows) to organize the data in two-dimensional tables. Each cell in the table, representing the intersection of an attribute and a tuple, represents a record.
When working with relational database management systems, you should understand the following terms:
• Relation: Fundamental entity in a relational database in the form of a table.
• Tuple: A row in a table.
• Attribute: A column in a table.
• Schema: Description of a relational database.
• Record: Collection of related data items.
• Base relation: In SQL, a relation that is actually existent in the database.
• View: The set of data available to a given user. Security is enforced through the use of these.
• Degree: The number of columns in a table.
• Cardinality: The number of rows in a relation.
• Domain: The set of allowable values that an attribute can take.
• Primary key: Columns that make each row unique.
• Foreign key: An attribute in one relation that has values matching the primary key in another relation. Matches between the foreign key to the primary key are important because they represent references from one relation to another and establish the connection among these relations.
• Candidate key: An attribute in one relation that has values matching the primary key in another relation.
• Referential integrity: Requires that for any foreign key attribute, the referenced relation must have a tuple with the same value for its primary key.
An important element of database design that ensures that the attributes in a table depend only on the primary key is a process called normalization. Normalization includes
• Eliminating repeating groups by putting them into separate tables
• Eliminating redundant data (occurring in more than one table)
• Eliminating attributes in a table that are not dependent on the primary key of that table
In the hierarchical model data is organized into a hierarchy. An object can have one child (an object that is a subset of the parent object), multiple children, or no children. To navigate this hierarchy, you must know the branch in which the object is located. An example of the use of this system is the Windows registry and a Lightweight Directory Access Protocol (LDAP) directory.
In the network model, like in the hierarchical model, data is organized into a hierarchy but unlike the hierarchical model, objects can have multiple parents. Because of this, knowing which branch to find a data element in is not necessary because there will typically be multiple paths to it.
The object-oriented model has the ability to handle a variety of data types and is more dynamic than a relational database. Object-Oriented Database (OODB) systems are useful in storing and manipulating complex data, such as images and graphics. Consequently, complex applications involving multimedia, computer-aided design, video, graphics, and expert systems are more suited to it. It also has the characteristics of ease of reusing code and analysis and reduced maintenance.
Objects can be created as needed, and the data and the procedure (or methods) go with the object when it is requested. A method is the code defining the actions that the object performs in response to a message. This model uses some of the same concepts of a relational model. In the object-oriented model, a relation, column, and tuple (relational terms) are referred to as class, attribute, and instance objects.
The object-relational model is the marriage of object-oriented and relational technologies, combining the attributes of both. This is a relational database with a software interface that is written in an object-oriented programming language. The logic and procedures are derived from the front-end software rather than the database. This means each front-end application can have its own specific procedures.
Database Interface Languages
Access to information in a database is facilitated by an application that allows you to obtain and interact with data. These interfaces can be written in several different languages. This section discusses some of the more important data programming languages.
ODBC
Open Database Connectivity (ODBC) is an API that allows communication with databases either locally or remotely. An API on the client sends requests to the ODBC API. The ODBC API locates the database and a specific driver converts the request into a database command that the specific database will understand.
JDBC
As one might expect from the title, Java Database Connectivity (JDBC) makes it possible for Java applications to communicate with a database. A Java API is what allows Java programs to execute SQL statements. It is database agnostic and allows communication with various types of databases. It provides the same functionality as the ODBC.
XML
Data can now be created in XML format, but the XML:DB API allows XML applications to interact with more traditional databases, such as relational databases. It requires that the database have a database-specific driver that encapsulates all the database access logic.
OLE DB
Object Linking and Embedding Database (OLE DB) is a replacement for ODBC, extending its functionality to non-relational databases. Although it is COM-based and limited to Microsoft Windows-based tools, it provides applications with uniform access to a variety of data sources, including service through ActiveX objects.
Data Warehouses and Data Mining
Data warehousing is the process of combining data from multiple databases or data sources in a central location called a warehouse. The warehouse is used to carry out analysis. The data is not simply combined but is processed and presented in a more useful and understandable way. Data warehouses require stringent security because the data is not dispersed but located in a central location.
Data mining is the process of using special tools to organize the data into a format that makes it easier to make business decisions based on the content. It analyzes large data sets in a data warehouse to find non-obvious patterns These tools locate associations between data and correlate theses associations into metadata. It allows for more sophisticated inferences (sometimes called business intelligence) to be made about the data. Three measures should be taken when using data warehousing applications:
• Control metadata from being used interactively.
• Monitor the data purging plan.
• Reconcile data moved between the operations environment and data warehouse.
Database Threats
Security threats to databases usually revolve around unwanted access to data. Two security threats that exist in managing databases involve the processes of aggregation and inference. Aggregation is the act of combining information from various sources. The way this can become a security issue with databases is when a user does not have access to a given set of date objects, but does have access to them individually or least some of them and is able to piece together the information to which he should not have access. The process of piecing the information together is called inference. Two types of access measures can be put in place to help prevent access to inferable information:
Content-dependent access control bases access on the sensitivity of the data. For example, a department manager might have access to the salaries of the employees in his/her department but not to the salaries of employees in other departments. The cost of this measure is an increased processing overhead.
Context-dependent access control bases the access to data on multiple factors to help prevent inference. Access control can be a function of factors such as location, time of day, and previous access history.
Database Views
Access to the information in a database is usually controlled through the use of database views. A view refers to the given set of data that a user or group of users can see when they access the database. Before a user is able to use a view, they must have both permission on the view and all dependent objects. Views enforce the concept of least privilege.
Database Locks
Database locks are used when one user is accessing a record that prevents another user from accessing the record at the same time to prevent edits until the first user is finished. Locking not only provides exclusivity to writes but also controls reading of unfinished modifications or uncommitted data.
Polyinstantiation
Polyinstantiation is a process used to prevent data inference violations like the ones discussed in the section “Database Threats.” It does this by enabling a relation to contain multiple tuples with the same primary keys with each instance distinguished by a security level. It prevents low-level database users from inferring the existence of higher level data.
OLTP ACID Test
An Online Transaction Processing (OLTP) system is used to monitor for problems such as processes that stop functioning. Its main goal is to prevent transactions that don’t happen properly or are not complete from taking effect. An ACID test ensures that each transaction has the following properties before it is committed:
• Atomicity: Either all operations are complete, or the database changes are rolled back.
• Consistency: The transaction follows an integrity process that ensures that data is consistent in all places where it exists.
• Isolation: A transaction does not interact with other transactions until completion.
• Durability: After it’s verified, the transaction is committed and cannot be rolled back.
Knowledge-Based Systems
Knowledge-based systems, also called expert systems, use artificial intelligence to emulate human logic when solving problems. They use rules-based programming to determine how to react through if-then statements and an inference engine to match patterns and facts to determine whether an operation should be allowed.
In an expert system, the process of beginning with a possible solution and using the knowledge in the knowledge base to justify the solution based on the raw input data is called backward chaining. This mode allows determining whether a given hypothesis is valid. Developing these systems requires the input of both a knowledge engineer and a domain expert.
An off-the-shelf software package that implements an inference engine, a mechanism for entering knowledge, a user interface, and a system to provide explanations of the reasoning used to generate a solution is called an expert system shell, which provides the fundamental building blocks of an expert system and supports the entering of domain knowledge.
A fuzzy expert system is an expert system that uses fuzzy membership functions and rules, instead of Boolean logic, to reason about data. Thus, fuzzy variables can have an approximate range of values instead of the binary True or False used in conventional expert systems
Software Threats
Software threats can also be created in the way software is coded or developed. Following development best practices can help prevent this inadvertent creation of security issues when creating software. Software threats also can be introduced through malware. In this section malware and software coding issues are discussed as well as options to mitigate the threat.
Malware
Malicious software (or malware) is a term that describes any software that harms a computer, deletes data, or takes actions the user did not authorize. It includes a wide array of malware types, including ones you have probably heard of such as viruses, and many you might not have heard of, but of which you should be aware.
The malware that you need to understand includes the following:
• Virus
• Boot sector virus
• Parasitic virus
• Stealth virus
• Polymorphic virus
• Macro virus
• Multipartite virus
• Worm
• Botnet
• rootkit
Virus
A virus is a self-replicating program that infects software. It uses a host application to reproduce and deliver its payload and typically attaches itself to a file. It differs from a worm in that it usually requires some action on the part of the user to help it spread to other computers.
The following list shows virus types along with a brief description of each.
• Boot sector: These infect the boot sector of a computer and either overwrite files or install code into the sector so the virus initiates at startup.
• Parasitic: This virus attaches itself to a file, usually an executable file, and then delivers the payload when the program is used.
• Stealth: This virus hides the modifications that it is making to the system to help avoid detection.
• Polymorphic: This virus makes copies of itself, and then makes changes to those copies. It does this in hopes of avoiding detection from antivirus software.
• Macro: These infect programs written in Word, Basic, Visual Basic, or VBScript that are used to automate functions. These viruses infect Microsoft office files. They are easy to create because the underlying language is simple and intuitive to apply. They are especially dangerous in that they infect the operating system itself. They also can be transported between different operating systems because the languages are platform independent.
• Multipartite: These viruses can infect both program files and boot sectors.
Worm
A worm is a type of malware that can spread without the assistance of the user. They are small programs that, like viruses, are used to deliver a payload. One way to help mitigate the effects of worms is to place limits on sharing, writing, and executing programs.
Trojan Horse
A Trojan horse is a program or rogue application that appears to or is purported to do one thing but it does another when executed. For example, it might appear to be a screensaver program when it is really a Trojan horse. When the user unwittingly uses the program, it executes its payload, which could be to delete files or create backdoors. Backdoors are alternative ways to access the computer undetected in the future.
One type of Trojan targets and attempts to access and make use of smart cards. A countermeasure to prevent this attack is to use “single-access device driver” architecture. Using this approach, the operating system allows only one application to have access to the serial device (and thus the smart card) at any given time. Another way to prevent the attack is by using a smart card that enforces a “one private key usage per PIN entry” policy model. In this model, the user must enter her PIN every single time the private key is used, and therefore the Trojan horse would not have access to the key.
Logic Bomb
A logic bomb is a type of malware that executes when a particular event talks place. For example, that event could be a time of day or a specific date or it could be the first time you open notepad.exe. Some logic bombs execute when forensics are being undertaken, and in that case the bomb might delete all digital evidence.
Spyware/Adware
Adware doesn’t actually steal anything, but tracks your Internet usage in an attempt to tailor ads and junk email to your interests. Spyware also tracks your activities and can also gather personal information that could lead to identity theft. In some cases, spyware can even direct the computer to install software and change settings.
Botnet
A bot is a type of malware that installs itself on large numbers of computers through infected emails, downloads from websites, Trojan horses and shared media. After it’s installed, the bot has the ability to connect back to the hacker’s computer. After that, his server controls all the bots located on these machines. At a set time, the hacker might direct the bots to take some action, such as direct all the machines to send out spam messages, mount a DoS attack, or perform phishing or any number of malicious acts. The collection of computers that act together is called a botnet, and the individual computers are called zombies. Figure 5-8 shows this relationship.

Rootkit
A rootkit is a set of tools that a hacker can use on a computer after he has managed to gain access and elevate his privileges to administrator. It gets its name from the root account, the most powerful account in UNIX-based operating systems. The rootkit tools might include a backdoor for the hacker to access. This is one of the hardest types of malware to remove, and in many cases only a format of the hard drive will completely remove it.
Some of the actions a rootkit can take are
• Installation of a backdoor.
• Removal of all entries from the security log (log scrubbing)
• Replacement of default tools with compromised version (Trojaned programs)
• Malicious kernel changes
Source Code Issues
Many security issues with software find their basis in poor development practices. A number of threats can be minimized by following certain coding principles. In this section source code issues are discussed along with some guidelines for secure development processes.
Buffer Overflow
A buffer is an area of memory where commands and data are placed until they can be processed by the CPU. A buffer overflow occurs when too much data is accepted as input to a specific process. Hackers can take advantage of this phenomenon by submitting too much data, which can cause an error or in some cases execute commands on the machine if he can locate an area where commands can be executed. Not all attacks are designed to execute commands. Some just lock up the computer and are used as a DoS attack.
A packet containing a long string of no-operation instructions (NOPs) followed by a command is usually indicative of a type of buffer overflow attack called a NOP slide. The purpose is to get the CPU to locate where a command can be executed. The following is an example of a packet as seen from a sniffer where you can see a long string of 90s in the middle of the packet that pads the packet and causes it to overrun the buffer.
TCP Connection Request
---- 14/03/2004 15:40:57.910
68.144.193.124 : 4560 TCP Connected ID = 1
---- 14/03/2004 15:40:57.910
Status Code: 0 OK
68.144.193.124 : 4560 TCP Data In Length 697 bytes
MD5 = 19323C2EA6F5FCEE2382690100455C17
---- 14/03/2004 15:40:57.920
0000 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 ................
0010 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 ................
0020 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 ................
0030 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 ................
0040 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 ................
0050 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 ................
0060 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 ................
0070 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 ................
0080 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 ................
0090 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 ................
00A0 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 ................
00B0 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 ................
00C0 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 ................
00D0 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 ................
00E0 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 ................
00F0 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 ................
0100 90 90 90 90 90 90 90 90 90 90 90 90 4D 3F E3 77 ............M?.w
0110 90 90 90 90 FF 63 64 90 90 90 90 90 90 90 90 90 .....cd.........
0120 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 ................
0130 90 90 90 90 90 90 90 90 EB 10 5A 4A 33 C9 66 B9 ..........ZJ3.f.
0140 66 01 80 34 0A 99 E2 FA EB 05 E8 EB FF FF FF 70 f..4...........p
0150 99 98 99 99 C3 21 95 69 64 E6 12 99 12 E9 85 34 .....!.id......4
0160 12 D9 91 12 41 12 EA A5 9A 6A 12 EF E1 9A 6A 12 ....A....j....j.
0170 E7 B9 9A 62 12 D7 8D AA 74 CF CE C8 12 A6 9A 62 ...b....t......b
0180 12 6B F3 97 C0 6A 3F ED 91 C0 C6 1A 5E 9D DC 7B .k...j?.....^..{
0190 70 C0 C6 C7 12 54 12 DF BD 9A 5A 48 78 9A 58 AA p....T....ZHx.X.
01A0 50 FF 12 91 12 DF 85 9A 5A 58 78 9B 9A 58 12 99 P.......ZXx..X..
01B0 9A 5A 12 63 12 6E 1A 5F 97 12 49 F3 9A C0 71 E5 .Z.c.n._..I...q.
01C0 99 99 99 1A 5F 94 CB CF 66 CE 65 C3 12 41 F3 9D ...._...f.e..A..
01D0 C0 71 F0 99 99 99 C9 C9 C9 C9 F3 98 F3 9B 66 CE .q............f.
01E0 69 12 41 5E 9E 9B 99 9E 24 AA 59 10 DE 9D F3 89 i.A^....$.Y.....
01F0 CE CA 66 CE 6D F3 98 CA 66 CE 61 C9 C9 CA 66 CE ..f.m...f.a...f.
0200 65 1A 75 DD 12 6D AA 42 F3 89 C0 10 85 17 7B 62 e.u..m.B......{b
0210 10 DF A1 10 DF A5 10 DF D9 5E DF B5 98 98 99 99 .........^......
0220 14 DE 89 C9 CF CA CA CA F3 98 CA CA 5E DE A5 FA ............^...
0230 F4 FD 99 14 DE A5 C9 CA 66 CE 7D C9 66 CE 71 AA ........f.}.f.q.
0240 59 35 1C 59 EC 60 C8 CB CF CA 66 4B C3 C0 32 7B Y5.Y.`....fK..2{
0250 77 AA 59 5A 71 62 67 66 66 DE FC ED C9 EB F6 FA w.YZqbgff.......
0260 D8 FD FD EB FC EA EA 99 DA EB FC F8 ED FC C9 EB ................
0270 F6 FA FC EA EA D8 99 DC E1 F0 ED C9 EB F6 FA FC ................
0280 EA EA 99 D5 F6 F8 FD D5 F0 FB EB F8 EB E0 D8 99 ................
0290 EE EA AB C6 AA AB 99 CE CA D8 CA F6 FA F2 FC ED ................
02A0 D8 99 FB F0 F7 FD 99 F5 F0 EA ED FC F7 99 F8 FA ................
The key to preventing many buffer overflow attacks is input validation. This method requires that any input be checked for format and length before it is used. Buffer overflows and boundary errors (when input exceeds the boundaries allotted for the input) are considered to be a family of error conditions called input validation errors.
Escalation of Privileges
Privilege escalation is the process of exploiting a bug or weakness in an operating system to allow a user to receive privileges to which they are not entitled. These privileges can be used to delete files, view private information, or install unwanted programs such as viruses.
Backdoor
Backdoors have been mentioned in passing several times here already. A backdoor is a piece of software installed by a hacker using one of the delivery mechanisms previously discussed that allows her to return later and connect to the computer without going through the normal authentication process. Some commercial applications inadvertently include backdoors because programmers forget to remove them before release to market. In many cases the program is listening on a specific port number and when the attacker attempts to connect to that port she is allowed to connect without authentication. An example is Back Orifice 2000 (BO2K), an application-level Trojan horse used to give an attacker backdoor network access.
Malware Protection
We are not totally helpless in the fight against malware. Programs and practices can help to mitigate the damage malware can cause. This section discusses some of the ways to protect a network from malware.
Antivirus Software
The first line of defense is antivirus software. This software is designed to identify viruses, Trojans, and worms and delete them or at least quarantine them until they can be removed. This identification process requires that you frequently update the software’s definition files, the files that make it possible for the software to identify the latest viruses. If a new virus is created that has not yet been identified in the list, you will not be protected until the virus definition is added and the new definition file is downloaded.
Antimalware Software
Closely related to and in some cases part of the same software package, antimalware software focuses on other types of malware, such as adware and spyware. A way to help prevent malware infection is training the user on appropriate behavior when using the Internet. For that reason, user education in safe practices is a necessary part of preventing malware. This should be a part of security policies, covered in the next section.
Security Policies
Security policies are covered in detail in Chapter 4, “Information Security Governance and Risk Management,” but it is important to mention here that encouraging or requiring safe browsing and data handling practices should be formalized into the security policy of the organization. Some of the items that to stress in this policy and perhaps include in training for the users are the importance of the following:
• Antivirus and antimalware updates
• Reporting any error message concerning an update failure on the user machine
• Reporting any strange computer behavior that might indicate a virus infection
Software Security Effectiveness
Regardless of whether a software program is purchased from a third party or developed in-house, being able to verify and prove how secure the application is can be useful. The two ways to approach this are auditing the program’s actions and determining whether it performs any insecure actions, or assessing it through a formal process. This section covers the two formal approaches.
Certification and Accreditation
In Chapter 7, “Security Architecture and Design,” you will learn about rating systems for both operating systems and applications. Although third-party ratings are an input to the process, the terms certification and accreditation do not simply refer to the use of these ratings.
Certification is the process of evaluating the software for its security effectiveness with regard to the customer’s needs. Ratings can certainly be an input to this but are not the only consideration.
Accreditation is the formal acceptance of the adequacy of a system’s overall security by the management.
Auditing
Another approach and a practice that should continue after the software has been introduced to the environment is continual auditing of its actions and regular reviewing of the audit data. By monitoring the audit logs, security weaknesses that might not have been apparent in the beginning or that might have gone unreported until now can be identified. Auditing is discussed in more depth in Chapter 2, “Access Control.”
Exam Preparation Tasks
Review All Key Topics
Review the most important topics in this chapter, noted with the Key Topics icon in the outer margin of the page. Table 5-1 lists a reference of these key topics and the page numbers on which each is found.

Define Key Terms
Define the following key terms from this chapter and check your answers in the glossary:
System Development Life Cycle
Software Development Life Cycle
Web Application Security Consortium (WASC)
Open Web Application Security Project (OWASP)
Build Security In (BSI)
ISO/IEC 27000
build and fix
waterfall
V-shaped
prototyping
incremental
spiral
Rapid Application Development (RAD)
agile
Joint Analyses Development Model
cleanroom
Capability Maturity Model Integration (CMMI)
high-level languages
very-high-level languages
natural languages
object-oriented programming
polymorphism
coupling
distributed object-oriented systems
Common Object Request Broker Architecture (CORBA)
Component Object Model (COM)
Distributed Component Object Model (DCOM)
Object Linking and Embedding (OLE)
Java Platform
Enterprise Edition (J2EE)
Service-Oriented Architecture (SOA)
mobile code
ActiveX
relational database
row or tuple
column or attribute
hierarchical database
network database
object-oriented database
object-relational database
Open Database Connectivity (ODBC)
Java Database Connectivity (JDBC)
XML:DB API
Object Linking and Embedding Database (OLE DB)
content-dependent access control
context-dependent access control
database views
database locks
polyinstantiation
OLTP ACID test
knowledge-based systems
data warehousing
data mining
malware
virus
boot sector virus
parasitic virus
stealth virus
polymorphic virus
macro virus
multipartite virus
worm
Trojan horse
logic bomb
adware
spyware
rootkit
buffer overflow
privilege
backdoor
accreditation
Complete the Tables and Lists from Memory
Print a copy of the CD Appendix A, “Memory Tables,” or at least the section for this chapter, and complete the tables and lists from memory. The CD Appendix B, “Memory Tables Answer Key,” includes completed tables and lists to check your work.
Review Questions
1. Which of the following is the last step in the System Development Lifecycle?
a. Operate/Maintain
b. Dispose
c. Acquire Develop
d. Initiate
2. In which of the following stages of the Software Development Lifecycle is the software actually coded?
a. Gather requirements
b. Design
c. Develop
d. Test/Validate
3. Which of the following initiatives was developed by the Department of Homeland Security?
a. WASC
b. BSI
c. OWASP
d. ISO
4. Which of the following development models provides no formal control mechanisms to provide feedback?
a. Waterfall
b. V-Shaped
c. Build and Fix
d. Spiral
5. Which language type delivers instructions directly to the processor?
a. Assembly Languages
b. High-level Languages
c. Machine Languages
d. Natural languages
6. Which term describes how many different tasks a module can carry out?
a. Polymorphism
b. Cohesion
c. Coupling
d. Data structures
7. Which term describes a standard for communication between processes on the same computer?
a. CORBA
b. DCOM
c. COM
d. SOA
8. Which of the following is a Microsoft technology?
a. ActiveX
b. Java
c. SOA
d. CORBA
9. Which of the following is the number or rows in a relation?
a. Tuple
b. Schema
c. Cardinality
d. Degree
10. In which database model can an object have multiple parents?
a. Hierarchical
b. Object oriented
c. Network
d. Object-relational
Answers and Explanations
1. b. The five steps, in order, are as follows:
1. Initiate
2. Acquire/Develop
3. Implement
4. Operate/Maintain
5. Dispose
2. c. In the Develop stage the code or instructions that make the software work is written. The emphasis of this phase is strict adherence to secure coding practice.
3. b. The Department of Homeland Security (DHS) also has become involved in promoting software security best practices. The Build Security In (BSI) initiative promotes a process-agnostic approach that makes security recommendations with regard to architectures, testing methods, code reviews, and management processes.
4. c. Though it’s not a formal model, the Build and Fix approach describes a method that while certainly used in the past has been largely discredited and is now used as a template for how not to manage a development project. Simply put, using this method, the software is developed as quickly as possible and released.
5. c. Machine languages are those that deliver instructions directly to the processor. This was the only type of programming done in the 1950s and uses basic binary instructions using no complier or interpreter (these are programs that convert higher language types to a form that can be executed by the processor).
6. b. Cohesion is a term used to describe how many different tasks a module can carry out. If it is limited to a small number or a single function it is said to have high cohesion. Coupling describes how much interaction one module requires from another module to do its job. Low or loose coupling indicates a module does not need much help from other modules whereas high coupling indicates the opposite.
7. c. Component Object Model (COM) is a model for communication between processes on the same computer, while as the name implies, the Distributed Component Object Model (DCOM) is a model for communication between processes in different parts of the network.
8. a. ActiveX is a Microsoft technology that uses Object-Oriented Programming (OOP) and is based on the COM and DCOM.
9. c. The number of rows in a relation describes its cardinality.
10. c. Like the hierarchical model, data is organized into a hierarchy but unlike the hierarchical model objects can have multiple parents.