
Chapter 9. Business Continuity and Disaster Recovery
This chapter covers the following topics:
• Business continuity and disaster recovery concepts: This section explains disasters, disaster recovery and the disaster recovery plan, continuity planning and the business continuity plan, business impact analysis, contingency plan, availability, reliability, recoverability, and fault tolerance.
• Business continuity scope and plan: This includes a discussion of personnel components, project scope, and business continuity steps.
• Business impact analysis development: This section describes the process for performing a business impact analysis, including identifying the critical functions and systems, prioritizing functions and systems, identifying threats and vulnerabilities, and calculating risks.
• Preventive controls: This includes fault-tolerant technologies, insurance, data backup, and fire detection and suppression.
• Recovery strategies: This section covers categorizing asset recovery priorities, business process recovery, facility recovery, supply and technology recovery, user environment recovery, data recovery, and training personnel.
• Critical teams and duties: This includes the damage assessment team, legal team, media relations team, recovery team, relocation team, restoration team, salvage team, and security team.
• Contingency plan: This section discusses the development, usage, and maintenance of the contingency plan.
• BCP testing: This includes a checklist test, structured walk-through test, simulation test, parallel test, full-interruption test, and BCP maintenance.
Organizations should never view business continuity and disaster recovery as a discretionary expense. Organizations must include business continuity and disaster recovery as part of any comprehensive security plan. No matter how diligent you are, your organization will be the victim of security breaches and disasters. If your organization appropriately plans for business continuity and disaster recovery, it will be able to recover from a breach or disaster in a timely and efficient manner. Without proper planning in this area, your organization could suffer irreparable damage.
This chapter explains the business continuity and disaster recovery concepts that you need to understand for the CISSP exam. The business continuity scope and plan and business impact analysis are vital parts of business continuity and disaster recovery. Preventive controls can be implemented but only provide a limited level of protection against disasters. An organization must develop recovery strategies to ensure that all assets can be recovered to the state they were in prior to the disaster. Organizations must also consider the teams involved in any disaster recovery and assign the appropriate duties to these teams. Contingency plans should also be developed to ensure that an organization’s recovery occurs as planned. Finally, all aspects of the business continuity plan must be fully tested to ensure that the plan actually works. The plan should be maintained and kept current through a regular revision cycle.
Foundation Topics
Business Continuity and Disaster Recovery Concepts
Security professionals must be involved in the development of any business continuity and disaster recovery processes.

As a result, security professionals must understand the basic concepts involved in business continuity and disaster recovery planning, including the following:
• Manmade
• Natural
• Disaster Recovery and the Disaster Recovery Plan (DRP)
• Continuity Planning and the Business Continuity Plan (BCP)
• Business Impact Analysis (BIA)
Disruptions
A disruption is any unplanned event that results in the temporary interruption of any organizational asset, including processes, functions, and devices. Disruptions are grouped into three main categories: non-disaster, disaster, and catastrophe.
Non-disasters are temporary interruptions that occur due to malfunction or failure. Non-disasters might or might not require public notification and are must easier to recover from than disasters or catastrophes.
A disaster is a suddenly occurring event that has a long-term negative impact on life. Disasters require that the organization publicly acknowledge the event and provide the public with information on how the organization will recover. Disasters require more effort for recovery than non-disasters but less than catastrophes.
A catastrophe is a disaster that has a much wider and much longer impact. In most cases, a disaster is considered a catastrophe if facilities are destroyed, thereby resulting in the need for the rebuilding of the facilities and the use of a temporary offsite facility.
Disasters
A disaster is an emergency that goes beyond the normal response of resources. A disaster usually affects a wide geographical area and results in severe damage, injury, loss of life, and loss of property. Any disaster has negative financial and reputational effects on the organization. The severity of the financial and reputational damage is also affected by the amount of time the organization takes to recover from the disaster.
The causes of disasters are categorized into three main areas according to origin: technological disasters, manmade disasters, and natural disasters. A disaster is officially over when all business elements have returned to normal function at the original site. The primary concern during any disaster is personnel safety.
Technological Disasters
Technological disasters occur when a device fails. This failure can be the result of device defects, incorrect implementation, incorrect monitoring, or human error. Technological disasters are not usually intentional. If a technological disaster is not recovered from in a timely manner, an organization might suffer a financial collapse.
If a disaster occurs because of a deliberate attack against an organization’s infrastructure, the disaster is considered a man-made disaster even if the attack is against a specific device or technology. In the past, all technological disasters were actually considered man-made disasters because technological disasters are usually due to human error or negligence. However, in recent years, experts have started categorizing technological disasters separately from man-made disasters, although the two are closely related.
Man-made Disasters
Man-made disasters occur through human intent or error. Man-made disasters include enemy attacks, bombings, sabotage, arson, terrorism, strikes or other job actions, infrastructure failures, personnel unavailability due to emergency evacuation, and mass hysteria. In most cases, man-made disasters are intentional.
Natural Disasters
Natural disasters occur because of a natural hazard. Natural disasters include flood, tsunami, earthquake, hurricane, tornado, and other such natural events. A fire that is not the result of arson is also considered a natural disaster.
Disaster Recovery and the Disaster Recovery Plan (DRP)
Disaster recovery minimizes the effect of a disaster and includes the steps necessary to resume normal operation. Disaster recovery must take into consideration all organizational resources, functions, and personnel. Efficient disaster recovery will sustain an organization during and after a disruption due to a disaster.
Each organizational function or system will have its own disaster recovery plan (DRP). The DRP for each function or system is created as a direct result of that function or system being identified as part of the business continuity plan. The DRP is implemented when the emergency occurs and includes the steps to restore functions and systems. The goal of DRP is to minimize or prevent property damage and prevent loss of life. More details on disaster recovery are given later in this chapter in the “Recovery Strategies” section.
Continuity Planning and the Business Continuity Plan (BCP)
Continuity planning deals with identifying the impact of any disaster and ensuring that a viable recovery plan for each function and system is implemented. Its primary focus is how to carry out the organizational functions when a disruption occurs.
The business continuity plan (BCP) considers all aspects that are affected by a disaster, including functions, systems, personnel, and facilities. It lists and prioritizes the services that are needed, particularly the telecommunications and IT functions. More details on continuity planning are given later in this chapter in the “Business Continuity Scope and Plan” section.
Business Impact Analysis (BIA)
A business impact analysis (BIA) is a functional analysis that occurs as part of business continuity and disaster recovery. Performing a thorough BIA will help business units understand the impact of a disaster. The resulting document that is produced from a BIA lists the critical and necessary business functions, their resource dependencies, and their level of criticality to the overall organization. More details on the BIA are given later in this chapter in the “Business Impact Analysis (BIA) Development” section.
Contingency Plan
The contingency plan is part of an organization’s overall BCP. Although the BCP defines the organizational aspects that can be affected and the DRP defines how to recover functions and systems, the contingency plan provides instruction on what personnel should do until the functions and systems are restored to full functionality. Think of the contingency plan as a guideline for operation at a reduced state. It usually includes contact information for all personnel, vendor contract information, and equipment and system requirements.
Failure of the contingency plan is usually considered a management failure. A contingency plan, along with the BCP and DRP, should be reviewed at least once a year. As with all such plans, version control should be maintained. Copies should be provided to personnel for storage both onsite and offsite to ensure that personnel can access the plan in the event of the destruction of the organization’s main facility.
Availability
As you already know, availability is one of the key principles of the CIA triad and has been discussed in almost every defined CISSP domain. Availability is a main component of business continuity planning. The organization must determine the acceptable level of availability for each function or system. If the availability of a resource falls below this defined level, then specific actions must be followed to ensure that availability is restored.
In regard to availability, most of the unplanned downtime of functions and systems is attributed to hardware failure. Availability places emphasis on technology.
Reliability
Reliability is the ability of a function or system to consistently perform according to specifications. It is vital in business continuity to ensure that the organization’s processes can continue to operate. Reliability places emphasis on processes.
Business Impact Analysis (BIA) Development
The BCP development depends most on the development of the business impact analysis (BIA). The BIA helps the organization to understand what impact a disruptive event would have on the organization. It is a management-level analysis that identifies the impact of losing an organization’s resources.
The four main steps of the BIA are as follow:
1. Identify critical processes and resources.
2. Identify outage impacts, and estimate downtime.
3. Identify resource requirements.
4. Identify recovery priorities.
The BIA relies heavily on any vulnerability analysis and risk assessment that is completed. The vulnerability analysis and risk assessment may be performed by the BCP committee or by a separately appointed risk assessment team. The risk assessment process is discussed in detail in the “Risk Assessment” section in Chapter 4, “Information Security Governance and Risk Management.”
Identify Critical Processes and Resources
When identifying the critical processes and resources of an organization, the BCP committee must first identify all the business units or functional areas within the organization. After all units have been identified, the BCP team should select which individuals will be responsible for gathering all the needed data and select how to obtain the data.
These individuals will gather the data using a variety of techniques, including questionnaires, interviews, and surveys. They might also actually perform a vulnerability analysis and risk assessment or use the results of these tests as input for the BIA.
During the data gathering, the organization’s business processes and functions and the resources upon which these processes and functions depend should be documented. This list should include all business assets, including physical and financial assets that are owned by the organization, and any assets that provide competitive advantage or credibility.
Identify Outage Impacts, and Estimate Downtime
After determining all the business processes, functions, and resources, the organization should then determine the criticality level of each resource.
As part of determining how critical an asset is, you need to understand the following terms:
• Maximum tolerable downtime (MTD): The maximum amount of time that an organization can tolerate a single resource or function being down. This is also referred to as maximum period time of disruption (MPTD).
• Mean time to repair (MTTR): The average time required to repair a single resource or function when a disaster or disruption occurs.
• Mean time between failure (MTBF): The estimated amount of time a device will operate before a failure occurs. This amount is calculated by the device vendor. System reliability is increased by a higher MTBF and lower MTTR.
• Recovery time objective (RTO): The shortest time period after a disaster or disruptive event within which a resource or function must be restored to avoid unacceptable consequences. RTO assumes that an acceptable period of downtime exists. RTO should be smaller than MTD.
• Work recovery time (WRT): The difference between RTO and MTD, which is the remaining time that is left over after the RTO before reaching the maximum tolerable.
• Recovery point objective (RPO): The point in time to which the disrupted resource or function must be returned.
Each organization must develop its own documented criticality levels. A good example of organizational resource and function criticality levels include critical, urgent, important, normal, and nonessential. Critical resources are those resources that are most vital to the organization’s operation and should be restored within minutes or hours of the disaster or disruptive event. Urgent resources should be restored in 24 hours but are not considered as important as critical resources. Important resources should be restored in 72 hours but are not considered as important as critical or urgent resources. Normal resources should be restored in 7 days but are not considered as important as critical, urgent, or important resources. Nonessential resources should be restored within 30 days.
Each process, function, and resource must have its criticality level defined to act as an input into the disaster recovery plan. If critical priority levels are not defined, a disaster recovery plan might not be operational within the timeframe the organization needs to recover.
Identify Resource Requirements
After the criticality level of each function and resource is determined, you need to determine all the resource requirements for each function and resource. For example, an organization’s accounting system might rely on a server that stores the accounting application, another server that holds the database, various client systems that perform the accounting tasks over the network, and the network devices and infrastructure that support the system. Resource requirements should also consider any human resources requirements. When human resources are unavailable, the organization can be just as negatively impacted as when technological resources are unavailable.
Note
Keep in mind that the priority for any CISSP should be the safety of human life. Consider and protect all other organizational resources only after personnel are safe.
The organization must document the resource requirements for every resource that would need to be restored when the disruptive event occurs. This includes device name, operating system or platform version, hardware requirements, and device interrelationships.
Identify Recovery Priorities
After all the resource requirements have been identified, the organization must identify the recovery priorities. Establish recovery priorities by taking into consideration process criticality, outage impacts, tolerable downtime, and system resources. After all this information is compiled, the result is an information system recovery priority hierarchy.
Three main levels of recovery priorities should be used: high, medium, and low. The BIA stipulates the recovery priorities but does not provide the recovery solutions. Those are given in the disaster recovery plan.
Recoverability
Recoverability is the ability of a function or system to be recovered in the event of a disaster or disruptive event. As part of recoverability, downtime must be minimized. Recoverability places emphasis on the personnel and resources used for recovery.
Fault Tolerance
Fault tolerance is provided when a backup component begins operation when the primary component fails. One of the key aspects of fault tolerance is the lack of service interruption.
Varying levels of fault tolerance can be achieved at most levels of the organization based on how much an organization is willing to spend. However, the backup component often does not provide the same level of service as the primary component. For example, an organization might implement a high-speed T1 connection to the Internet. However, the backup connection to the Internet that is used in the event of the failure of the T1 line might be much slower but at a much lower cost of implementation than the primary T1 connection.
Business Continuity Scope and Plan
As you already know, creating the business continuity plan is vital to ensure that the organization can recover from a disaster or disruptive event. Several groups have established standards and best practices for business continuity. These standards and best practices include many common components and steps.
This section covers the personnel components, the project scope, and the business continuity steps that must be completed.
Personnel Components
The most important personnel in the development of the BCP is senior management. Senior management support of business continuity and disaster recovery drives the overall organizational view of the process. Without senior management support, this process will fail.
Senior management sets the overall goals of business continuity and disaster recovery. A business continuity coordinator should be named by senior management and leads the BCP committee. The committee develops, implements, and tests the BCP and DRP. The BCP committee should contain a representative from each business unit. At least one member of senior management should be part of this committee. In addition, the organization should ensure that the IT department, legal department, security department, and communications department are represented because of the vital role that these departments play during and after a disaster.
With management direction, the BCP committee must work with business units to ultimately determine the business continuity and disaster recovery priorities. Senior business unit managers are responsible for identifying and prioritizing time-critical systems. After all aspects of the plans have been determined, the BCP committee should be tasked with regularly reviewing the plans to ensure they remain current and viable. Senior management should closely monitor and control all business continuity efforts and publicly praise any successes.
After an organization gets into disaster recovery planning, other teams are involved. These teams are discussed in the “Critical Teams and Duties” section later in this chapter.
Project Scope
To ensure that the development of the business continuity plan is successful, senior management must define the business continuity plan scope. A business continuity project with an unlimited scope can often become too large for the BCP committee to handle correctly. For this reason, senior management might need to split the business continuity project into smaller, more manageable pieces.
When considering the splitting of the business continuity plan into pieces, an organization might want to split the pieces based on geographic location or facility. However, an enterprise-wide BCP should be developed that ensures compatibility of the individual plans.
Business Continuity Steps
Many organizations have developed standards and guidelines for performing business continuity and disaster recovery planning. One of the most popular standards is Special Publication 800-34 Revision 1 from the National Institute of Standards and Technology (NIST).
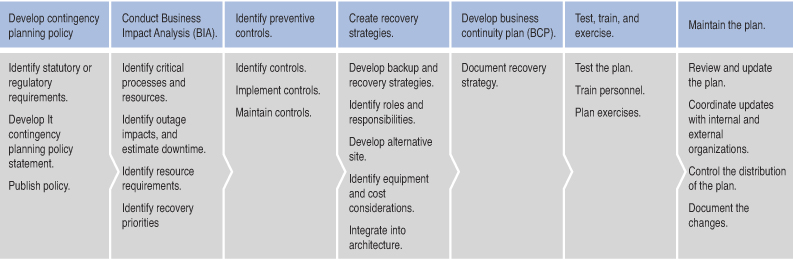
The following list summarizes the steps of SP 800-34 R1:
1. Develop contingency planning policy.
2. Conduct business impact analysis (BIA).
3. Identify preventive controls.
4. Create recovery strategies.
5. Develop business continuity plan (BCP).
6. Test, train, and exercise.
7. Maintain the plan.
Figure 9-1 shows a more detailed listing of the tasks included in SP 800-34 R1.
Figure 9-1. NIST Special Publication 800-34 Revision 1
Preventive Controls
Identifying the preventive controls is the third step of the business continuity steps as outlined in NIST SP 800-34 R1. If preventive controls are identified in the BIA, disasters or disruptive events might be mitigated or eliminated. These preventive measures deter, detect, and/or reduce impacts to the system. Preventive methods are preferable to actions that might be necessary to recover the system after a disruption if the preventative controls are feasible and cost effective.
The following sections discuss the primary preventive controls that organizations can implement as part of business continuity and disaster recovery, including redundant systems, facilities, and power; fault-tolerant technologies; insurance; data backup; and fire detection and suppression.
Redundant Systems, Facilities, and Power
In anticipation of disasters and disruptive events, organizations should implement redundancy for critical systems, facilities, and power and assess any systems that have been identified as critical to determine whether implementing redundant systems is cost effective. Implementing redundant systems at an alternate location often ensures that services are uninterrupted. Redundant systems include redundant servers, redundant routers, redundant internal hardware, and even redundant backbones. Redundancy occurs when an organization has a secondary component, system, or device that takes over when the primary unit fails.
Redundant facilities ensure that the organization maintains a facility at whatever level it chooses to ensure that the organizational services can continue when a disruptive event occurs. Redundant facilities are discussed in more depth later in this chapter.
Power redundancy is implemented using uninterruptible power supplies (UPSs) and power generators.
Fault-Tolerant Technologies
Fault tolerance enables a system to continue operation in the event of the failure of one or more components. Fault tolerance within a system can include fault-tolerant adapter cards and fault-tolerant storage drives. One of the most well-known fault tolerance systems is Redundant Array of Independent Disks (RAID). Chapter 8, “Operations Security” discusses RAID.
By implementing fault-tolerant technologies, an organization can ensure that normal operation occurs if a single fault-tolerant component fails.
Insurance
Although redundancy and fault tolerance can actually act as preventative measures against failures, insurance is not really a preventive measure. If an organization purchases insurance to provide protection in the event of a disruptive event, the insurance has no power to protect against the event itself. The purpose of the insurance is to ensure that the organization will have access to additional financial resources to help in the recovery.
Keep in mind that recovery efforts from a disruptive event can often incur large financial costs. Even some of the best estimates might still fall short when the actual recovery must take place. By purchasing insurance, the organization can ensure that key financial transactions, including payroll, accounts payable, and any recovery costs, are covered.
Insurance actual cost valuation (ACV) compensates property based on the value of the item on the date of loss plus 10 percent. However, keep in mind that insurance on any printed materials only covers inscribed, printed, or written documents, manuscripts, or records. It does not cover money and securities. A special type of insurance called business interruption insurance provides monetary protection for expenses and lost earnings.
Organizations should annually review insurance policies and update them as necessary.
Data Backup
Data backup provides prevention against data loss but not prevention against the disruptive event. All organizations should ensure that all systems that store important files are backed up in a timely manner. Users should also be encouraged to back up personal files that they might need. In addition, periodic testing of the restoration process should occur to ensure that the files can be restored.
Data recovery, including backup types and schemes and electronic backup, is covered in more detail later in this chapter.
Fire Detection and Suppression
Organizations should implement fire detection and suppression systems as part of any business continuity plans. Fire detection and suppressions vary based on the method of detection/suppression used and are discussed in greater detail in the “Environmental Security” section of Chapter 11, “Physical and Environmental Security.”
Create Recovery Strategies
The next step in the business continuity process is to create recovery strategies. Higher level recovery strategies identify the order in which processes and functions are restored. System-level recovery strategies define how a particular system is to be restored. Keep in mind those individuals who best understand the system should define system recovery strategies. Although the BCP committee probably can develop the prioritized recovery lists and high-level recovery strategies, system administrators and other IT personnel need to be involved in the development of recovery strategies for IT assets.
Disaster recovery tasks include recovery procedures, personnel safety procedures, and restoration procedures. The overall business recovery plan should require a committee to be formed to decide the best course of action. This recovery plan committee receives its direction from the BCP committee and senior management. All decisions regarding recovery should be made in advance and incorporated into the disaster recovery plan. Any plans and procedures that are developed should refer to functions or processes, not specific individuals. As part of the disaster recovery planning, the recovery plan committee should contact critical vendors ahead of time to ensure that any equipment or supplies can be replaced in a timely manner.
When a disaster or disruptive event has occurred, the organization’s spokesperson should report the bad news in an emergency press conference before the press learns of the news through another channel. The disaster recovery plan should detail any guidelines for handling the press. The emergency press conference site should be planned ahead of time.
When resuming normal operations after a disruptive event, the organization should conduct a thorough investigation if the cause of the event is unknown. Personnel should account for all damage-related costs that occur as a result of the event. In addition, appropriate steps should be taken to prevent further damage to property.
The commonality between all recovery plans is that they all become obsolete. For this reason, they require testing and updating.
This section includes a discussion of categorizing asset recovery priorities, business process recovery, facility recovery, supply and technology recovery, user environment recovery, data recovery, and training personnel.
Categorize Asset Recovery Priorities
Discussed in the “Identify Outage Impacts, and Estimate Downtime” section earlier in this chapter, the RTO, WRT, and RPO values affect the recovery solutions that will be selected. An RTO stipulates the amount of time an organization will need to recover from a disaster, and an RPO stipulates the amount of data an organization can lose when a disaster occurs. The RTO, WRT, and RPO values are derived during the BIA process.
In developing the recovery strategy, the recovery plan committee takes the RTO, WRT, and RPO value and determines the recovery strategies that should be used to ensure that the organization meets these BIA goals.
Critical devices, systems, and applications need to be restored earlier than devices, systems, or applications that do not fall into this category. Keep in mind when classifying systems that most critical systems cannot be restored using manual methods. The recovery plan committee must understand the backup/restore solutions that are available and implement the system that will provide recovery within the BIA values and cost constraints. The window of time for recovery of data processing capabilities is based on the criticality of the operations affected.
Business Process Recovery
As part of the disaster recovery plan, the recovery plan committee must understand the interrelationships between the processes and systems. A business process is a collection of tasks that produce a specific service or product for a particular customer or customers.
For example, if the organization determines that an accounting system is a critical application and the accounting system relies on a database server farm, the disaster recovery plan needs to include the database server as a critical asset. Although restoring the entire database server farm to restore the critical accounting system might not be necessary, at least one of the servers in the farm is necessary for proper operation.
Workflow documents should be provided to the recovery plan committee for each business process. As part of recovering the business processes, the recovery plan committee must also understand the process’s required roles and resources, input and output tools, and interfaces with other business processes.
Facility Recovery
When dealing with an event that either partially or fully destroys the primary facility, the organization will need an alternate location from which to operate until the primary facility is restored. The disaster recovery plan should define the alternate location and its recovery procedures.
The disaster recovery plan should include not only how to bring the alternate location to full operation, but also how the organization will return from the alternate location to the primary facility after it is restored. Also, for security purposes, the disaster recovery plan should include details on the security controls that were used at the primary facility and guidelines on how to implement these same controls at the alternate location.
The most important factor in locating an alternate location during the development of the disaster recovery plan is to ensure that the alternate location is not affected by the same disaster. This might mean that the organization must select an alternate location that is in another city or geographic region. The main factors that affect the selection of an alternate location include the following:
• Geographic location
• Organizational needs
• Location’s cost
• Location’s restoration effort
Testing an alternate location is a vital part of any disaster recovery plan. Some locations are easier to test than others. The disaster recovery plan should include instructions on when and how to periodically test alternate facilities to ensure that the contingency facility is compatible with the primary facility.
The alternate locations that security professionals should understand for the CISSP exam include the following:
• Hot site
Hot Site
A hot site is a leased facility that contains all the resources needed for full operation. This environment includes computers, raised flooring, full utilities, electrical and communications wiring, networking equipment, and uninterruptible power supplies (UPSs). The only resource that must be restored at a hot site is the organization’s data, often only partially. It should only take a few hours to bring a hot site to full operation.
Although a hot site provides the quickest recovery, it is the most expensive to maintain. In addition, it can be administratively hard to manage if the organization requires proprietary hardware or software. A hot site requires the same security controls as the primary facility and full redundancy, including hardware, software, and communication wiring.
Cold Site
A cold site is a leased facility that contains only electrical and communications wiring, air conditioning, plumbing, and raised flooring. No communications equipment, networking hardware, or computers are installed at a cold site until it is necessary to bring the site to full operation. For this reason, a cold site takes much longer to restore than a hot or warm site.
Although a cold site provides a slowest recovery, it is the least expensive to maintain. It is also the most difficult to test.
Warm Site
A warm site is a leased facility that contains electrical and communications wiring, full utilities, and networking equipment. In most cases, the only devices that are not included in a warm site are the computers. A warm site takes longer to restore than a hot site but less than a cold site.
A warm site is somewhere between the restoration time and cost of a hot site and cold site. It is the most widely implemented alternate leased location. Although testing a warm site is easier than testing a cold site, a warm site requires much more effort for testing than a hot site.
Figure 9-2 is a chart that compares the components deployed in these three sites.
Figure 9-2. Hot Site, Warm Site, and Cold Site Comparison

Tertiary Site
A tertiary site is a secondary backup site that provides an alternate in case the hot site, warm site, or cold site is unavailable. Many large companies implement tertiary sites to protect against catastrophes that affect large geographic areas.
For example, if an organization requires a data center that is located on the coast, the organization might have its primary location in New Orleans, Louisiana and its hot site in Mobile, Alabama. This organization might consider locating a tertiary site in Miami, Florida, because a hurricane can affect both the Louisiana and Alabama Gulf coast.
Reciprocal Agreements
A reciprocal agreement is an agreement between two organizations that have similar technological needs and infrastructures. In the agreement, both organizations agree to act as an alternate location for the other if either of the organization’s primary facilities are rendered unusable. Unfortunately in most cases, these agreements cannot be legally enforced.
A disadvantage of this site is that it might not be capable of handling the required workload and operations of the other organization.
Note
A mutual-aid agreement is a pre-arranged agreement between two organizations in which each organization agrees to provide assistance to the other in the event of a disaster.
Redundant Sites
A redundant or mirrored site is a site that is identically configured as the primary site. A redundant or mirrored site is not a leased site but is usually owned by the same organization as the primary site. The organization is responsible for maintaining the redundant site.
Although redundant sites are expensive to maintain, many organizations today see them as a necessary expense to ensure that uninterrupted service can be provided.
Supply and Technology Recovery
Although facility recovery is not often a concern with smaller disasters or disruptive events, almost all recovery efforts usually involve the recovery of supplies and technology. Organizations must ensure that any disaster recovery plans include guidelines and procedures for recovering supplies and technology. As part of supply and technology recovery, the disaster recovery plan should include all pertinent vendor contact information in the event that new supplies and technological assets must be purchased.
The disaster recovery plan must include recovery information on the following assets that must be restored:
• Heating, ventilation, and air conditioning (HVAC)
• Supplies
Hardware Backup
Hardware that must be included as part of the disaster recovery plan includes client computers, server computers, routers, switches, firewalls, and any other hardware that is running on the organization’s network. The disaster recovery plan must include not only guidelines and procedures for restoring all the data on each of these devices, but also information regarding restoring these systems manually if the systems are damaged or completely destroyed. Legacy devices that are no longer unavailable in the retail market should also be identified.
Note
Data recovery is covered later in this chapter.
As part of preparation of the disaster recovery plan, the recovery plan team must determine the amount of time that it will take the hardware vendors to provide replacements for any damaged or destroyed hardware. Without this information documented, any recovery plans might be ineffective due to lack of resources. Organizations might need to explore other options, including purchasing redundant systems and storing them at an alternate location, if vendors are unable to provide replacement hardware in a timely manner. When replacement of legacy devices is possible, organizations should take measures to replace them before the disaster occurs.
Software Backup
Even if an organization has every device needed to restore its infrastructure, those devices are useless if the applications and software that run on the devices is not available. The applications and software includes any operating systems, databases, and utilities that need to be running on the device.
Many organizations might think that this requirement is fulfilled if they have a backup on either tape, DVD, or other media of all their software. But all software that is backed up usually requires at least an operating system to be running on the device on which it is restored. These data backups often also require that the backup management software is running on the backup device, whether that is a server or dedicated device.
All software installation media, service packs, and other necessary updates should be stored at an alternate location. In addition, all license information should be documented as part of the disaster recovery plan. Finally, frequent backups of applications should be taken, whether this is through the application’s internal backup system or through some other organizational backup. A backup is only useful if it can be restored so the disaster recovery plan should fully document all the steps involved.
In many cases, applications are purchased from a software vendor, and only the software vendor understands the coding that occurs in the applications. Because there are no guarantees in today’s market, some organizations might decide that they need to ensure that they are protected against a software vendor’s demise. A software escrow is an agreement whereby a third party is given the source code of the software to ensure that the customer has access to the source code if certain conditions for the software vendor occur, including bankruptcy and disaster.
Human Resources
No organization is capable of operating without personnel. An occupant emergency plan specifically addresses procedures for minimizing loss of life or injury when a threat occurs. The human resources team is responsible for contacting all personnel in the event of a disaster. Contact information for all personnel should be stored onsite and offsite. Multiple members of the HR team should have access to the personnel contact information. Remember that personnel safety is always the primary concern. All other resources should be protected only after the personnel is safe.
After the initial event is over, the HR team should monitor personnel morale and guard against employee stress and burnout during the recovery period. If proper cross-training has occurred, multiple personnel can be rotated in during the recovery process. Any disaster recovery plan should take into consideration the need to provide adequate periods of rest for any personnel involved in the disaster recovery process. It should also include guidelines on how to replace any personnel who is a victim of the disaster.
The organization must ensure that salaries and other funding to personnel continue during and after the disaster. Because funding can be critical both for personnel and for resource purchases, authorized, signed checks should be securely stored offsite. Lower-level management with the appropriate access controls should have the ability to disperse funds using these checks in the event that senior management is unavailable.
An executive succession plan should also be created to ensure that the organization follows the appropriate steps to protect itself and continue operation.
Supplies
Often disasters affect the ability to supply an organization with its needed resources, including paper, cabling, and even water. The organization should document any resources that are vital to its daily operations and the vendors from which these resources can be obtained. Because supply vendors can also be affected by the disaster, alternative suppliers should be identified.
Documentation
For disaster recovery to be success, the personnel involved must be able to complete the appropriate recovery procedures. Although the documentation of all these procedures might be tedious, it is necessary to ensure that recovery occurs. In addition, each department within the organization should be asked to decide what departmental documentation is needed to carry out day-to-day operations. This documentation should be stored in a central location onsite, and a copy should be retained offsite as well. Specific personnel should be tasked with ensuring that this documentation is created, stored, and updated as appropriate.
User Environment Recovery
All aspects of the end user environment recovery must be included as part of the disaster recovery plan to ensure that the end users can return to work as quickly as possible. As part of this user environment recovery, end user notification must occur. Users must be notified of where and when to report after a disaster occurs.
The actual user environment recovery should occur in stages, with the most critical functions being restored first. User requirements should be documented to ensure that all aspects of the user environment are restored. For example, users in a critical department might all need their own client computer. These same users might also need to access an application that is located on a server. If the server is not restored, the users will be unable to perform their job duties even if their client computers are available.
Finally, manual steps that can be used for any function should be documented. Because we are so dependent on technology today, we often overlook the manual methods of performing our job tasks. Documenting these manual methods might ensure that operations can still occur, even if they occur at a decreased rate.
Data Recovery
In most organizations, the data is one of the most critical assets when recovering from a disaster. The business continuity and disaster recovery plans must include guidelines and procedures for recovering data. However, the operations teams must determine which data is backed up, how often the data is backed up, and the method of backup used. So while this section discusses data backup, remember that the BCP teams do not actually make any data backup decisions. The BCP teams are primarily concerned with ensuring that the data that is backed up can be restored in a timely manner.
This section discusses the data backup types and schemes that are used as well as electronic backup methods that organizations can implement.
Data Backup Types and Schemes
To design an appropriate data recovery solution, security professionals must understand the different types of data backups that can occur and how these backups are used together to restore the live environments.
For the CISSP exam, security professionals must understand the following data backup types and schemes:
• Full backup
• Differential backup
• Incremental backup
• Copy backup
• Daily backup
• Transaction log backup
• First in, first out rotation scheme
• Grandfather/father/son rotation scheme
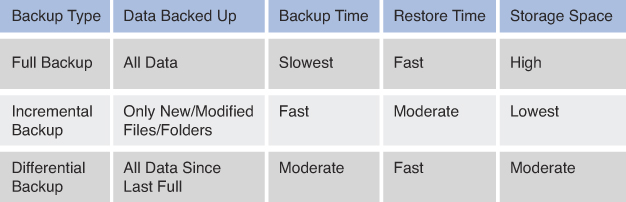
The three main data backups are full backups, differential backups, and incremental backups. To understand these three data backup types, you must understand the concept of archive bits. When a file is created or updated, the archive bit for the file is enabled. If the archive bit is cleared, the file will not be archived during the next backup. If the archive bit is enabled, the file will be archived during the next backup.
With a full backup, all data is backed up. During the full backup process, the archive bit for each file is cleared. A full backup takes the longest time and the most space to complete. However, if an organization only uses full backups, then only the latest full backup needs to be restored. Any backup that uses a differential or incremental backup will first start with a full backup as its baseline. A full backup is the most appropriate for off-site archiving.
In a differential backup, all files that have been changed since the last full backup will be backed up. During the differential backup process, the archive bit for each file is not cleared. A differential backup might vary from taking a short time and a small amount of space to growing in both the backup time and amount of space it needs over time. Each differential backup will back up all the files in the previous differential backup if a full backup has not occurred since that time. In an organization that uses a full/differential scheme, the full and the only the most recent differential backup must be restored, meaning only two backups are needed.
An incremental backup backs up all files that have been changed since the last full or incremental backup. During the incremental backup process, the archive bit for each file is cleared. An incremental backup usually takes the least amount of time and space to complete. In an organization that uses a full/incremental scheme, the full backup and each subsequent incremental backup must be restored. The incremental backups must be restored in order. If your organization completes a full backup on Sunday and an incremental backup daily Monday through Saturday, up to seven backups could be needed to restore the data.
Figure 9-3 shows a comparison of the three main backup types.
Figure 9-3. Backup Types Comparison
Copy and daily backups are two special backup types that are not considered part of any regularly scheduled backup scheme because they do not require any other backup type for restoration. Copy backups are similar to normal backups but do not reset the file’s archive bit. Daily backups use a file’s time stamp to determine whether it needs archiving. Daily backups are popular in mission-critical environments where multiple daily backups are required because files are updated constantly.
Transaction log backups are only used in environments where capturing all transactions that have occurred since the last backup is important. Transaction logs backups help organizations to recover to a particular point in time and are most commonly used in database environments.
Although magnetic tape drives are still in use today and used to back up data, many organizations today back up their data to optical discs, including CD-ROMs, DVDs, and Blu-ray discs; high-capacity, high-speed magnetic drives; or other media. No matter the media used, retaining backups both onsite and offsite is important. Store onsite backup copies in a waterproof, heat-resistant, fire-resistant safe or vault.
As part of any backup plan, an organization should also consider the backup rotation scheme that it will use. Cost considerations and storage considerations often dictate that backup media is reused after a period of time. If this reuse is not planned in advance, media can become unreliable due to overuse. Two of the most popular backup rotation schemes are first in, first out and grandfather/father/son.
In the first in, first out (FIFO) scheme, the newest backup is saved to the oldest media. Although this is the simplest rotation scheme, it does not protect against data errors. If an error in data exists, the organization might not have a version of the data that does not contain the error.
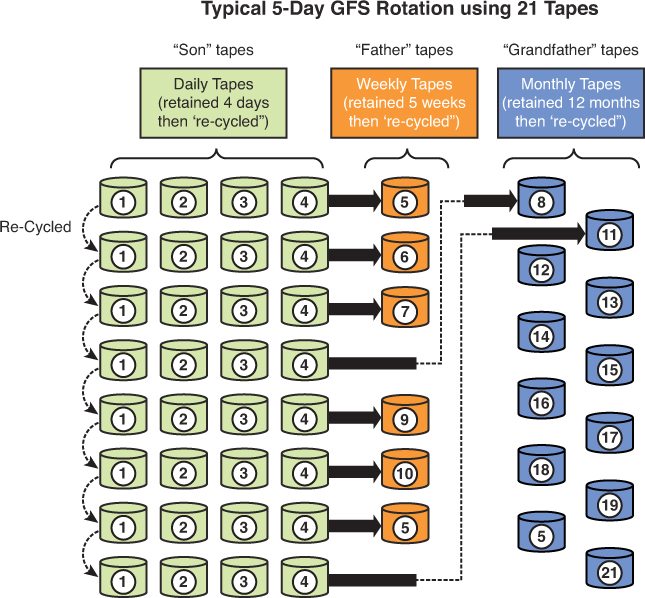
In the grandfather/father/son scheme (GFS), three sets of backups are defined. Most often these three definitions are daily, weekly, and monthly. The daily backups are the sons, the weekly backups are the fathers, and the monthly backups are the grandfathers. Each week, one son advances to the father set. Each month, one father advances to the grandfather set.
Figure 9-4 displays a typical 5-day GFS rotation using 21 tapes. The daily tapes are usually differential or incremental backups. The weekly and monthly tapes must be a full backup.
Figure 9-4. Grandfather/Father/Son Backup Rotation Scheme
Electronic Backup
Electronic backup solutions back up data quicker and more accurately than the normal data backups and are best implemented when information changes often.
For the CISSP exam, you should be familiar with the following electronic backup terms and solutions:
• Electronic vaulting: Copies files as modifications occur. This method occurs in real time.
• Remote journaling: Copies the journal or transaction log offsite on a regular schedule. This method occurs in batches.
• Tape vaulting: Creates backups over a direct communication line on a backup system at an offsite facility.
• Hierarchical storage management (HSM): Stores frequently accessed data on faster media and less frequently accessed data on slower media.
• Optical jukebox: Stores data on optical disks and uses robotics to load and unload the optical disks as needed. This method is ideal when 24/7 availability is required.
• Replication: Copies data from one storage location to another. Synchronous replication uses constant data updates to ensure that the locations are close to the same, whereas asynchronous replication delays updates to a predefined schedule.
High Availability
High availability in data recovery is a concept that ensures that data is always available using redundancy and fault tolerance. Most organizations implement high-availability solutions as part of any disaster recovery plan.
High-availability terms and techniques that you must understand include the following:
• Redundant Array of Independent Disks (RAID): A hard drive technology in which data is written across multiple disks in such a way that a disk can fail and the data can be quickly made available from remaking disks in the array without restoring a backup tape.
• Storage area network (SAN): High-capacity storage devices that are connected by a high-speed private network using storage-specific switches.
• Failover: The capacity of a system to switch over to a backup system if a failure in the primary system occurs.
• Failsoft: The capability of a system to terminate non-critical processes when a failure occurs.
• Clustering: Refers to a software product that provides load-balancing services. With clustering, one instance of an application server acts as a master controller and distributes requests to multiple instances using round-robin, weighted round-robin or least-connections algorithms.
• Load balancing: Refers to a hardware product that provides load-balancing services. Application delivery controllers (ADCs) support the same algorithms, but also use complex number-crunching processes, such as per-server CPU and memory utilization, fastest response times, and so on, to adjust the balance of the load. Load-balancing solutions are also referred to as farms or pools.
Training Personnel
Even if an organization takes the steps to develop the most thorough business continuity and disaster recovery plans, these plans are useless if the organization’s personnel do not have the skills to completely recover the organization’s assets when a disaster occurs. Personnel should be given the appropriate time and monetary resources to ensure that adequate training occurs. This includes allowing personnel to test any disaster recovery plans.
Training should be obtained from both internal and external sources. When job duties change or new personnel are hired, policies should be in place to ensure the appropriate transfer of knowledge occurs.
Critical Teams and Duties
Although the number one and number two priorities when a disaster occurs are personnel safety and health and damage mitigation, respectively, recovering from a disaster quickly becomes an organization’s priority after these two are handled. However, no organization can recover from a disaster if the personnel are not properly trained and prepared. To ensure that personnel can perform their duties during disaster recovery, they must know and understand their job tasks.
During any disaster recovery, financial management is important. Financial management usually includes the chief financial officer and any other key accounting personnel. This group must track the recovery costs and assess the cash flow projections. They formally notify any insurers of claims that will be made. Finally this group is responsible for establishing payroll continuance guidelines, procurement procedures, and emergency costs tracking procedures.
Organizations must decide which teams are needed during a disaster recovery and ensure that the appropriate personnel are placed on each of these teams. The disaster recovery manager directs the short-term recovery actions immediately following a disaster.
Organizations might need to implement the following teams to provide the appropriate support for the disaster recovery plan:
Damage Assessment Team
The damage assessment team is responsible for determining the disaster’s cause and the amount of damage that has occurred to organizational assets. It identifies all affected assets and the critical assets’ functionality after the disaster. The damage assessment team determines which assets will need to be restored and replaced and contacts the appropriate teams that need to be activated.
Legal Team
The legal team deals with all legal issues immediately following the disaster and during the disaster recovery. The legal team oversees any public relations events that are held to address the disaster, although the media relations team will actually deliver the message. The legal team should be consulted to ensure that all recovery operations adhere to federal and state laws and regulations.
Media Relations Team
The media relations team informs the public and media whenever emergencies extend beyond the organization’s facilities according to the guidelines given in the disaster recovery plan. The emergency press conference site should be planned ahead. When issuing public statements, the media relations team should be honest and accurate about what is known about the event and its effects. The organization’s response to the media during and after the event should be unified.
A credible, informed spokesperson should deliver the organization’s response. When dealing with the media after a disaster, the spokesperson should report bad news before the media discovers it through another channel. Anyone making disaster announcements to the public should understand that the audience for such announcements includes the media, unions, stakeholders, neighbors, employees, contractors, and even competitors.
Recovery Team
The recovery team’s primary task is recovering the critical business functions at the alternate facility. This mostly involves ensuring that the physical assets are in place, including computers and other devices, wiring, and so on. The recovery team usually oversees the relocation and restoration teams.
Relocation Team
The relocation team oversees the actual transfer of assets between locations. This includes moving assets from the primary site to the alternate site and then returning those assets when the primary site is ready for operation.
Restoration Team
The restoration team actually ensures that the assets and data are restored to operations. The restoration team needs access to the backup media.
Salvage Team
The salvage team recovers all assets at the disaster location and ensures that the primary site returns to normal. The salvage team manages the cleaning of equipment, the rebuilding of the original facility, and identifies any experts to employ in the recovery process. In most cases, the salvage team declares when operations at the disaster site can resume.
Security Team
The security team is responsible for managing the security at both the disaster site and any alternate location that the organization uses during the recovery. Because the geographic area that the security team must manage after the disaster is often much larger, the security team might need to hire outside contractors to aid in this process. Using these outside contractors to guard the physical access to the sites and using internal resources to provide security inside the facilities is always better because the reduced state might make issuing the appropriate access credential to contractors hard.
BCP Testing
After the BCP is fully documented, an organization must take measures to ensure that the plan is maintained and kept up to date. At a minimum, an organization must evaluate and modify the BCP and DRP on an annual basis. This evaluation usually involves some sort of test to ensure that the plans are accurate and thorough. Testing frequently is important because any plan is not viable unless testing has occurred. Through testing, inaccuracies, deficiencies, and omissions are detected.
Testing the BCP and DRP prepares and trains personnel to perform their duties. It also ensures that the alternate backup site can perform as needed. When testing occurs, the test is probably flawed if no issues with the plan are found.
The types of tests that are commonly used to assess the BCP and DRP include the following:
• Structured walk-through test
Checklist Test
The checklist test occurs when managers of each department or functional area review the BCP. These managers make note of any modifications to the plan. The BCP committee then uses all the management notes to make changes to the BCP.
Table-top Exercise
A table-top exercise is the most cost-effective and efficient way to identify areas of overlap in the plan before conducting higher-level testing. A table-top exercise is an informal brainstorming session that encourages participation from business leaders and other key employees. In a table-top exercise, the participants agree to a particular disaster scenario upon which they will focus.
Structured Walk-Through Test
The structured walk-through test involves representatives of each department or functional area thoroughly reviewing the BCP’s accuracy. This type of test is the most important test to perform prior to a live disaster.
Simulation Test
In a simulation test, the operations and support personnel execute the DRP in a role-playing scenario. This test identifies omitted steps and threats.
Parallel Test
A parallel test validates the operation of a new system against its predecessor. The performance of the replacement system is compared to the primary system. If performance deficiencies are found, the BCP team researches ways to prevent these deficiencies from occurring.
Full-Interruption Test
A full-interruption test involves shutting down the primary facility and bringing the alternate facility up to full operation. This is a hard switch-over in which all processing occurs at the primary facility until the “switch” is thrown. This type of test requires full coordination between all the parties and includes notifying users in advance of the planned test. An organization should perform this type of test only when all other tests have been implemented and are successful.
Functional Drill
A functionality drill tests a single function or department to see whether the function’s DRP is complete. This type of drill requires the participation of the personnel that perform the function.
Evacuation Drill
In an evaluation drill, personnel follow the evacuation or shelter-in-place guidelines for a particular disaster type. In this type of drill, personnel must understand the area to which they are to report when the evacuation occurs. All personnel should be accounted for at that time.
BCP Maintenance
After a test is complete, all test results should be documented, and the plans should be modified to reflect those results. The list of successful and unsuccessful activities from the tests will be the most useful to management when maintaining the BCP. All obsolete information in the plans should be deleted, and any new information should be added. In addition, modifying current information based on new regulations, laws, or protocols might be necessary.
Version control of the plans should be managed to ensure that the organization always uses the most recent version. In addition, the BCP should be stored in multiple locations to ensure that it is available if a location is destroyed by the disaster. Multiple personnel should have the latest version of the plans to ensure that the plans can be retrieved if primary personnel are unavailable when the plan is needed.
Exam Preparation Tasks
Review All Key Topics
Review the most important topics in this chapter, noted with the Key Topics icon in the outer margin of the page. Table 9-1 lists a reference of these key topics and the page numbers on which each is found.
Table 9-1. Key Topics for Chapter 9
Define Key Terms
Define the following key terms from this chapter and check your answers in the glossary:
disruption
non-disaster disruption
technological disasters
manmade disasters
natural disasters
reliability
maximum tolerable downtime (MTD)
mean time to repair (MTTR)
mean time between failure (MTBF)
recovery time objective (RTO)
recovery point objective (RPO)
hot site
cold site
warm site
tertiary site
reciprocal agreement
mutual aid agreement
redundant site
mirrored site
full backup
differential backup
incremental backup
copy backup
daily backups
transaction log backup
failsoft.
Review Questions
1. What is a catastrophe?
a. a temporary interruption that occurs due to malfunction or failure
b. a suddenly occurring event that has a long-term negative impact on life
c. a disaster that has a much wider and much longer impact than other disasters
d. a disaster that occurs when a device fails
2. What is the first step in a business impact analysis (BIA)?
a. Identify recovery priorities.
b. Identify outage impacts, and estimate downtime.
c. Identify resource requirements.
d. Identify critical processes and resources.
3. What is recovery time objective (RTO)?
a. the shortest time period after a disaster or disruptive event within which a resource or function must be restored to avoid unacceptable consequences
b. the point in time to which the disrupted resource or function must be returned
c. the maximum amount of time that an organization can tolerate a single resource or function being down
d. the average time required to repair a single resource or function when a disaster or disruption occurs
4. Which term is used for a leased facility that contains all the resources needed for full operation?
a. cold site
b. hot site
c. warm site
d. tertiary site
5. Which of the following is NOT a backup type?
a. full
b. incremental
c. grandfatherfatherson
d. transaction log
6. Which electronic backup type stores data on optical disks and uses robotics to load and unload the optical disks as needed?
a. optical jukebox
b. hierarchical storage management
c. tape vaulting
d. replication
7. What is failsoft?
a. the capacity of a system to switch over to a backup system if a failure in the primary system occurs
b. the capability of a system to terminate non-critical processes when a failure occurs
c. a software product that provides load-balancing services
d. high capacity storage devices that are connected by a high-speed private network using storage-specific switches
8. Which team is NOT defined as part of the business continuity plan?
a. media relations team
b. security team
c. recovery team
d. human resources team
9. Which test is the most cost-effective and efficient way to identify areas of overlap in the plan before conducting higher-level testing?
a. table-top exercise
b. checklist test
c. parallel test
d. simulation test
10. What is the first step in business continuity planning according to NIST SP 800-34 R1?
a. Conduct Business Impact Analysis (BIA).
b. Develop contingency planning policy.
c. Identify preventive controls.
d. Create recovery strategies.
Answers and Explanations
1. c. A catastrophe is a disaster that has a much wider and much longer impact than other disasters. A non-disaster disruption is a temporary interruption that occurs due to malfunction or failure. A disaster is a suddenly occurring event that has a long-term negative impact on life. A technological disaster is a disaster that occurs when a device fails.
2. d. The first step in a BIA is to identify critical processes and resources.
3. a. Recovery time objective (RTO) is the shortest time period after a disaster and disruptive event within which a resource or function must be restored to avoid unacceptable consequences.
4. b. A hot site is a leased facility that contains all the resources needed for full operation.
5. c. Grandfatherfatherson is NOT a backup type. It is a backup rotation scheme.
6. a. An optical jukebox stores data on optical disks and uses robotics to load and unload the optical disks as needed.
7. b. Failsoft is the capability of a system to terminate non-critical processes when a failure occurs.
8. d. The human resources team is NOT defined as part of the business continuity plan.
9. a. A table-top exercise is the most cost-effective and efficient way to identify areas of overlap in the plan before conducting higher-level testing.
10. b. The first step in business continuity planning according to NIST SP 800-34 R1 is developing a contingency planning policy.