

CHAPTER 10
Reusable Content
In Chapter 9, “Adaptable Content,” we learned about different considerations for content in responsive and adaptive websites. But that’s just one way your content might need to shift. Like the oft-touted NPR example, you may also need to get content out across lots of very different products or destinations. Or, you might not really be dealing with publishing content all at once, but rather creating a repository of information that can be used in the future, however it’s needed—or even selected and arranged by your users, creating their own personalized collections of your content to suit whatever their needs happen to be.
This is the world of reusable and reconfigurable content: content that can be pushed out lots of places at once, assembled and associated with other relevant bits on the fly, displayed in different combinations for different purposes, or connected and combined by users themselves.
In this chapter, we’ll explore the ways that reuse might be useful for whatever it is your content is facing, discuss things to consider when prepping content for reuse, and, of course, see how structured content will help you at every step of the way. We’ll also look at an unexpected example of content reuse and see why you don’t need to have the perfect plan in place to start making your content more reusable, useful, and efficient now.
Revisiting Content Reuse
Reusable content has been a rallying cry of the technical communications crowd for a couple decades now, and for good reason. As we touched on in Chapter 2, “Building a Way Forward,” large organizations have long needed ways to make things like help content, specifications, instructions, and other technical documentation easily reusable and translatable for everything from product manuals to customer-facing websites to intranets.
For example, Ann Rockley, the CEO of consulting firm the Rockley Group, wrote the first edition of her book Managing Enterprise Content, which focuses heavily on content reusability, way back in 2002. In those days, there was no need for a chapter about mobile content, nor to think about responsive and adaptive experiences. But there was still plenty of practical information on how to manage content across distributed organizations by structuring it, storing it in a central database, and considering how it could be reused.
Back then, pretty much everyone talking about content structure and reuse, though, was focusing on a couple of very specific technologies: XML and DITA, which we touched on in Chapter 6, “Understanding Markup.” Today, the need for reusable, reconfigurable content is no longer limited to those in huge enterprises or with strict technical requirements—and that means that as reuse goes mainstream, people are developing all sorts of new ways to make it happen, ranging from the semi-manual to the completely automated. And they’re doing it in all kinds of places, even some spots where you might not expect coordinated efforts at efficiency and innovation, like the federal government.
Let’s take a look at a few of them and start seeing why reusable content needn’t be a pipe dream—nor is it the answer to every content problem.
Building a Central Content Store
The documentation and knowledge management industry was probably the first to embrace reusable content, often in the form of central content stores or repositories. Content stores have long made sense for things like documentation, which might be used by everyone from customers to customer service reps to the IT team, all operating in different countries and speaking a multitude of languages.
A central content store helps by allowing authors to write information in a structured environment, and then make that information accessible to a variety of people who use it to publish a variety of different content products.
For example, consider a major electronics producer that sells personal computers and related items in countries around the world—and requires technical documentation for all of those products, in several dozen different languages.
In the past, all that work would have been done by technical writers crafting manuals in Microsoft Word, which would then make their way through the production and translation/localization process and come out the other side as final printed pieces. While these documents served their purpose well, all that content was essentially locked up: because it was created in large, single documents, it couldn’t be used any other way except for in its printed or PDF format.
As a result, customers who needed to find information about their specific product—such as how to install a new battery—were forced to not just dig around the website to find their model’s documentation, but also to then download the complete manual to access that tidbit of knowledge.
Today the company is investing in a better, more reusable way: a single repository of technical content written in chunks called “topics” and arranged using DITA, the XML schema designed for technical documentation we touched on in Chapter 6.
The approach is designed to give users access to technical documentation on demand—that is, just the topic module a customer needs, when he needs it, delivered online in a searchable format—while also streamlining the process for producing the printed pieces the company must ship with its products, all using the same reusable store of content.
You might think the hardest part of a project like this would be understanding DITA or doing the technical implementation, but that’s often not the case. Many organizations that undertake a project like this find that it’s actually most difficult to help the people involved change how they operate: the technical writers who are used to creating Word documents for their manuals, not crafting short little nuggets that answer a single question and saving them in a CMS module.
To cope with this challenge, enterprises that launch these sorts of content repositories need to invest in ongoing training and guidance—and also figure out where to start. For example, this company first focused on updating its print manual creation process to use the new structured, component-based system, because despite the importance of digital content, it still has to ship each product with printed materials for compliance reasons. By first training writers to craft DITA topic modules that culminate in printed documents, the project team was able to make writers feel more at home, increasing their confidence in the new method. From there, beginning to use the topic modules for other purposes was much easier.
Once you have a content repository in place for one purpose, you can also start looking at how you might be able to extend its value beyond a single application. For example, you might find that your customer service team also uses similar content for its own internal documentation. You could then hook their versions of the same content into the central system as well. That way, customer service can update the content with any customizations it needs, while still keeping all the content, in all its versions, in one centralized location, and eliminating the inefficiency of re-creating content.
Not ready for totally automating your content’s publication across platforms? That doesn’t mean a content store won’t work for you. Done right, a content repository can manage multiple versions of the same content at any given time, each with different metadata associated with it. That way, different groups can repurpose different versions of the same basic chunk of content in many ways—some more manually, some more automatically.
As long as your content is structured based on its meaning and stored in a central place, you can build systems based on that structure to make finding and retrieving the content item you want to use simple and quick—and to ensure you’re always starting from the latest, most updated source content, even if you’re then going to manipulate it manually for certain circumstances.
Content Across Products
The need for content that can cross devices and applications isn’t limited to major media outlets like NPR, nor to enterprises publishing technical content. In fact, online retailers may be the ones who are most ahead of the game on delivering content—that is, their product information—from one database to many device-specific destinations.
Just look at Amazon.com, the online purveyor of books and, well, pretty much everything else. In addition to its desktop site, Amazon offers a wide range of mobile-optimized and device-specific products: a mobile site; shopping apps for iPhone, Android, BlackBerry, Windows 7, and iPad; barcode-scanning apps for iPhone and Android; a book-browsing app for iPad; and others with even more niche purposes.
What do all these distinct experiences have in common? Their content, of course. Using a private API, like those we talked about in Chapter 7, “Making Sense of Content APIs,” Amazon can easily transport any or all of its millions of product listings it chooses—each full of descriptions, specs, images, reviews, and more structured content—to any or all of these apps and sites.
But Amazon doesn’t use all product content in the same way across all these destinations. For example, the browsing iPad app, Windowshop, is designed for users who want to sit back and leaf through categories like bestsellers or baby gear. When you select a product, as I’ve done with Cheryl Strayed’s book Wild in Figure 10.1, it puts visual content front and center, while tucking away descriptions and reviews in tabs along the left.
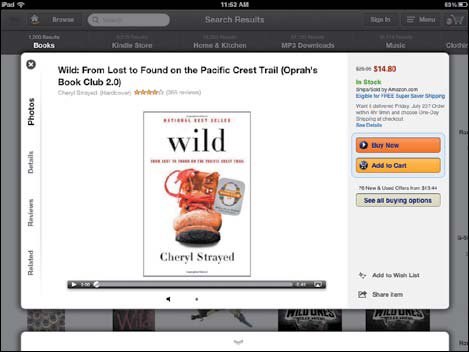
FIGURE 10.1
Windowshop for iPad, an app from Amazon designed around browsing books and other merchandise, prioritizes images over descriptions. Yet all of Amazon’s digital products rely on the same set of content, reused across platforms via an API.
Meanwhile, PriceCheck, the iPhone barcode scanner, emphasizes much more straightforward content: the product’s name and price, as shown in Figure 10.2. After all, if you’ve picked up a product and bothered to scan its barcode, odds are good you already know a bit about it and primarily want to assess whether you should buy it in store or order it. But if needed, additional content—including professional and customer reviews, ratings, publisher information, and more—are all tucked one swipe away.
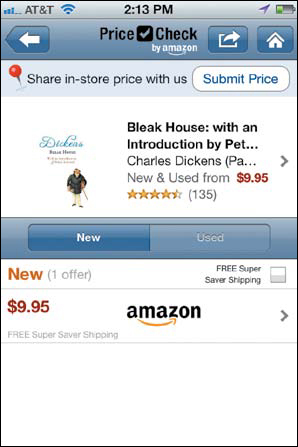
FIGURE 10.2
PriceCheck, another app from Amazon—this one for iPhone. PriceCheck emphasizes content related specifically to purchasing products, but it still pulls from the same set of content as other Amazon experiences.
While Amazon’s API has enabled the company to more easily share the same content base across products, it’s not without its issues. For example, as Karen McGrane has noted, content often truncates on smaller screens, leaving off important parts of a book’s title or cutting a review before it’s communicated much of anything, like it does in Figure 10.3 with Amazon’s own review of one of Dickens’ well-known works.
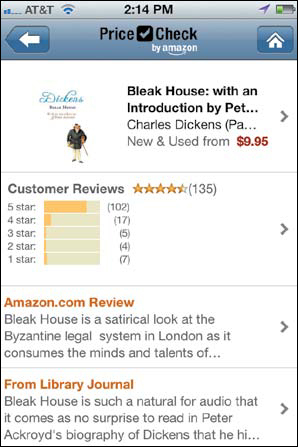
FIGURE 10.3
“Bleak House is a satirical look at the byzantine legal system in England as it consumes the minds and talents of...” Damn. It was just getting good, wasn’t it?
And that’s the trouble: Only the first three lines of copy are displayed for each content element, regardless of what that element is—meaning that the most important information, such as the product description or features, has exactly the same amount of information revealed as the details about the publication date and publisher: around 120 characters. But the people producing that content weren’t thinking about it displaying in such a short space, so their prose often takes that much space just to get warmed up. As a result, these content chunks often fail to provide anything useful, thus making the content difficult to do much with at a glance.
It would be easy to say that Amazon’s problem is content reuse—that the company is causing usability and experience flaws by trying to force-fit the same content to all these different products. But I’d argue the real problem isn’t that they’re reusing content—no one’s about to write custom content for each product for each of the millions of products Amazon sells, after all, so what other option is there? The underlying issue is structure: Amazon’s content—structured as it is—isn’t chunked in parts small enough to be exposed, layered, combined, or prioritized effectively on all those screen sizes.
While reusing content has allowed Amazon to quickly and efficiently build new digital products to meet user and business needs, the company could have made these experiences even stronger if it had considered what each piece of content was communicating, how the various chunks needed to work together, and how much of which sorts of content should be revealed when making decisions about the API’s structure and substance, as we learned in Chapter 7. If it had, perhaps important content, like product names, would get a bit more room to breathe—and less important content, like publisher information, would get truncated.
And as we learned in Chapter 9, “Adaptable Content,” if you’re the one making these decisions, this is also the perfect time to take a step back and assess: Do you really need all this content in the first place? Could you tighten it up, cut some crap, and get to the good stuff more quickly—without sacrificing sales or frustrating customers? You’ll never have a better opportunity to find out.
Personalized Content
Content reuse isn’t just about repurposing the same content to different platforms. It’s also about repurposing and reorganizing it for different people, based on their personal requirements and desires.
This approach to personalized content, where a user can select the information she needs and create her own unique set of dashboards, reports, or other content collections, is becoming increasingly important in areas like healthcare, government, and education—places where users require different information depending on their needs, and where they tend to return regularly for news and updates.
As we touched on briefly in Chapter 7, the FCC launched just such a personalized content project in late 2011: my.fcc.gov. Unlike fcc.gov, which is geared toward consumers who have a problem that they need FCC information to solve, MyFCC is a beta site designed for frequent visitors, such as the telecommunications industry and the legal community that serves it, to create personal collections of FCC content.
This content—the same content that’s available on the FCC’s main site—is reused on MyFCC via the agency’s API, and can be displayed in any order and priority the user chooses. For example, a telecoms attorney in the accessibility field may need to always stay abreast of the latest official documents and filings the FCC publishes about accessibility. With the MyFCC site, she can establish a dashboard that just includes those desired content modules, as shown in Figure 10.4, which are updated on the fly whenever new content arrives via the API.
While designed primarily for those users with frequent FCC business, everyone who wants to—from government officials down to interested citizens—can create and save their own MyFCC dashboards, dragging and dropping as many of the site’s two dozen or so content widgets as they please wherever they want, and easily adding new ones or changing up the configuration anytime.
In addition to allowing users to create personalized content centers, this approach also lets the FCC’s audiences take that content with them—that is, to mash up their MyFCC content with other organizations’ information, and plug those modules into other sites as needed.
As we talked about in Chapter 7, when you open your content up by establishing an API, you can make this kind of reuse—across different sites, users, and needs—possible, efficiently. And, once you have an API in place that powers content personalization or reuse, you may well identify new purposes for that API in the future, giving your content even more places it can go.
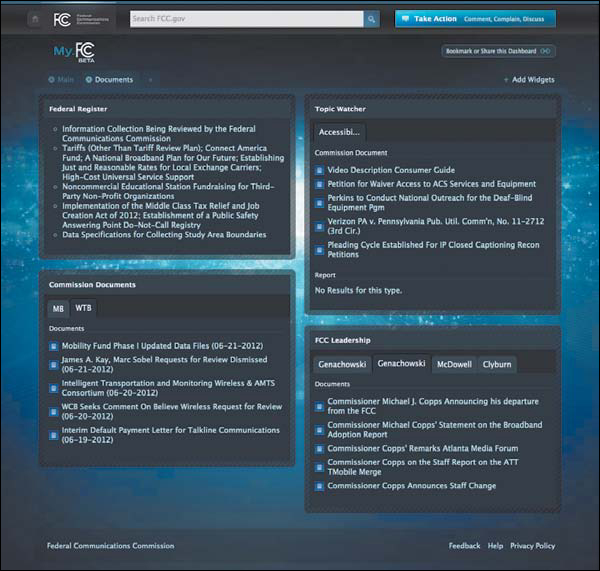
FIGURE 10.4
A sample MyFCC dashboard, where a content API powers a personalized experience that allows you to quickly access just the reports, news, and other content you want.
A Reuse Imperative
If you think reuse is taking off now, just wait. Pretty soon, you’ll see not just the FCC, but all of the federal government’s many entities get on the bandwagon. That’s right: What could be the largest content producer in the United States is embracing reusable content.
Often seen as complex, bureaucratic, and slow moving, the U.S. government is now actively changing how it operates by adopting more flexible, future-ready strategies and technologies for content.
This shift has been underway for a while, and lots of agencies are already experimenting with projects similar to the FCC’s API. But the effort became a coordinated, government-wide mandate in May 2012 with the White House’s release of “Digital Government: Building a 21st Century Platform to Better Serve the American People”—a new strategic initiative which includes, as one of its four main pillars, the goal of developing “an information-centric approach”—one that “moves us from managing ‘documents’ to managing discrete pieces of open data and content which can be tagged, shared, secured, mashed up and presented in the way that is most useful for the consumer of that information.”1
Wowza. That’s a lot to bite off—but it’s exactly the sort of future-friendly approach we’ve been talking so much about, right?
In this new model, government is tasked with operating in a “customer-centric” way, rather than a bureaucratic, agency-oriented manner—meaning they’ll not only be creating and sharing content using APIs, but they’ll also be using and reusing that content in multiagency, multichannel ways, putting the experience of the customer who needs the content—you and I, that is—ahead of the specific agency that’s producing it.
According to the report, this new approach to digital government also “influences how we create, manage, and present data through websites, mobile applications, raw data sets, and other modes of delivery, and allows customers to shape, share and consume information, whenever and however they want it”—in other words, providing personalized content, structured and organized in whatever way a user needs.
Why’s this initiative such a big deal? Well, if you think you’ve got problems with duplicative, redundant, or hard-to-sort content, just imagine what the U.S. government is dealing with: 450 million pages of digital content, according to Todd Parks, a longtime Silicon Valley entrepreneur who joined the Obama administration in 2009 and became the CTO of the United States in 2012.2
For example, when the digital government initiative launched, Parks noted that the government was running 14 separate websites for students seeking information about federal financial aid—one for applying, one for managing loans, one for consolidating student loans, and so on—each operating independently, and each producing its own content (just a few of those sites are shown here in Figures 10.5–10.7).
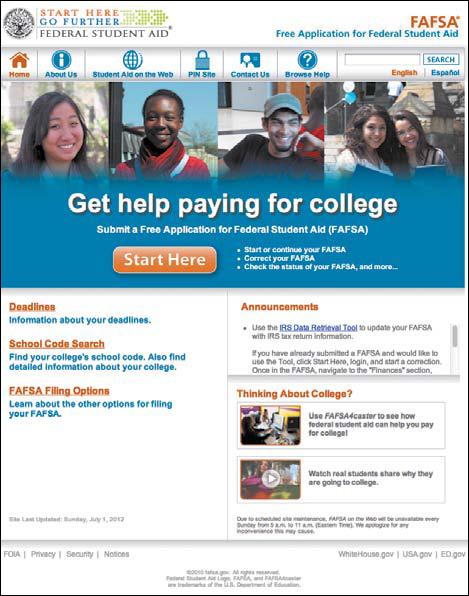
FIGURE 10.5
The Free Application for Federal Student Aid site, fafsa.ed.gov, one of more than a dozen websites related to federal student aid.

FIGURE 10.6
Another of the federal government’s student aid sites, the National Student Loan Data System at nslds.ed.gov. Here borrowers can manage their federal loans.

FIGURE 10.7
And yet another separate federal student aid site, loanconsolidation. ed.gov, where those same borrowers must go to find out how to consolidate their student loans.
What the government realized is that all these siloed sites with variations on the same information were taking lots of time and money to manage—time and money that wasn’t actually serving the government’s customer: the constituents who need to get things done, and don’t care whether they’re supposed to visit the NSLDS or the FAFSA (or the Small Business Association or the Federal Trade Commission, for that matter) to do it.
As part of the solution, the initiative effectively bans establishing new .gov domains—so the days of building a website for every new initiative are effectively over. But the broader goal is so much bigger: To end this era of thousands of government websites and millions of pages of locked-down, hard-to-find content, and replace it with one built on open data, machine-readable content, and APIs that transmit information wherever it needs to go.
What will it take? Well, transforming government is no small task. A huge number of those 450 million pages of content are locked into fixed, hard-to-adapt documents like PDFs. To get there, the government is pulling content out of fixed objects like these, and into clean databases that are separated from their display, readying them for both public and private APIs.
What’ll happen with all this data? Take an example like flu.gov, shown in Figure 10.8—a federal site run by the Department of Health & Human Services to help the public prevent, prepare for, identify, and treat the flu.
While flu.gov seeks to be the resource for Americans who need flu information, “Flu” isn’t the name of a government agency, of course. Instead, it’s a site that uses content and data from myriad government agencies: the Centers for Disease Control, the National Institutes of Health, and the Federal Drug Administration, just to name a few.
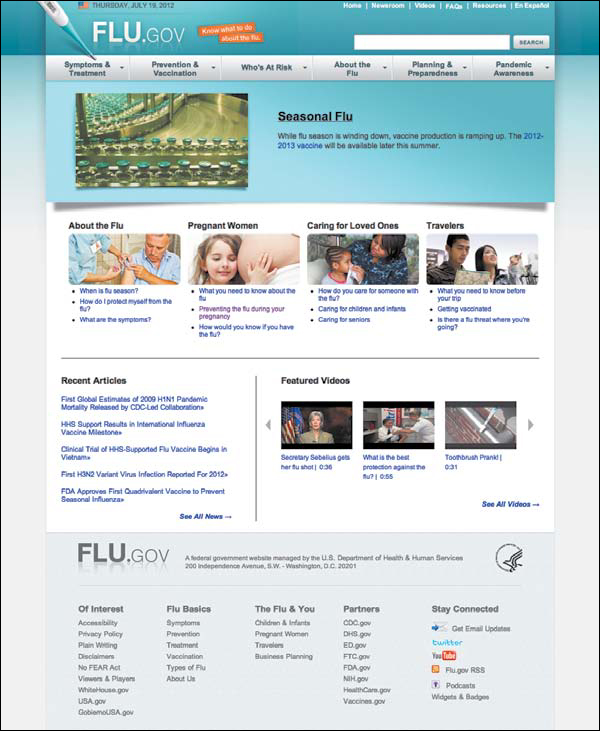
FIGURE 10.8
Flu.gov, which reuses content from across multiple agencies like the CDC, NIH, and FDA to create a user-centered, useful site for the American people—instead of for a specific agency.
Each of these agencies is tasked with performing different research and producing its own specific reports, but none of that matters much to the American people, who just want to find accurate, up-to-date information about the flu and any current outbreaks, affected communities, symptoms, and treatment methods.
What better way to present all that flu-related content than to collect it in one place, rather than expect the public to find it when scattered across multiple sites? And that’s exactly what the government is working toward, with some content—including that of the CDC, for example—already being accessed via API and reused by flu.gov automatically, and more to come as the digital government initiative grows.
And Now for Something Completely Different
Serving up different content combinations across different platforms or to different users is relatively easy when you have a well-structured database and content-focused API behind you. But what if you’re trying to reuse content that wasn’t created under such ideal terms? What can you do with content that’s deeply rooted in a print production process, besides start over from scratch?
Where there’s a will, there’s a way. Just as many organizations are experimenting with ways to get more mileage out of each piece of digital content they produce, others are also doing interesting things in order to make the most of print material—and their existing print production practices.
Take the Guardian, a major daily newspaper with a large online presence in the UK. In publication for nearly two centuries, the Guardian has spent its recent years embracing social media and mobile wholeheartedly, launching apps and sites for everything from iOS and Android to Kindle, Nokia, and even Facebook.
In 2011, the Guardian decided to try something different than the standard mobile fare of up-to-the-minute news stories: It launched a tablet edition of the daily paper. Unlike its other digital products, which provide readers with an ever-changing experience, the design team built this particular product to deliver “a reflective once-a-day Guardian, designed and edited for iPad,” noted editor-in-chief Alan Rusbridger shortly after the app’s launch. By following the concept of the Guardian’s print edition, the organization sought to bring those readers who enjoy the daily snapshot of news the print edition provides with a way to have that experience in a digital format.
But putting the paper online as a PDF wouldn’t cut it design- or usability-wise, and the Guardian, like all papers, has to continually operate under tight deadlines to get the next day’s edition out the door and ready for readers. So how was the organization going to deliver a tablet edition without hiring a bunch of extra hands to import the stories and design each day’s iPad layout from scratch?
Rather than running their designers ragged by essentially creating a PDF-like version of the print newspaper specifically for iPad (or worse yet, creating two PDFs—one in portrait and the other in landscape), the team opted for something a bit more content-focused and a lot less time-consuming to perform on a daily basis. It decided to start analyzing its print content’s structure in order to re-create that same sense of priority, hierarchy, and importance on the iPad—while simultaneously taking advantage of the new form factor and functionality. You can see the result in Figure 10.9.

FIGURE 10.9
Rather than dismantling its daily paper production process, the Guardian takes its print edition and mechanically analyzes the way stories are prioritized; it then uses business rules to keep those same relationships in place for this daily iPad edition.
How does it work? Well, the Guardian team built a script that can (nearly) automatically read the InDesign files for the print version of the paper, assess them according to predetermined criteria—such as page number, amount of space devoted to the story, positioning on the page, headline and image sizing, and the like—and then assign them a score. That value is then carried into a new InDesign template for the app, and the stories are rebuilt automatically based on their score. Effectively, this means that the editorial eye and manual art direction that went into the print edition are automatically taken into account for the iPad version, rather than investing that same level of human care all over again for the new platform.
The automation isn’t perfect, but it gives the Guardian a solid first draft. From there, editors and designers can easily go through the iPad edition each night, ensuring everything’s as it should be and making tweaks to keep the experience polished and usable. But, in comparison to crafting the iPad edition from scratch, this manual investment is miniscule.
Chasing Perfection
Once you start working with reusable content, it’s easy to start obsessing over a dream: a world where all content can be perfectly reused everywhere you need it, and where content production becomes as set-it-and-forget-it as a Ronco Rotisserie Oven.
Alas, that’s not to be. Content is work. Content takes people. And content certainly doesn’t do well when it’s treated like a factory-produced commodity (see also: content farms, SEO spammers, and low-rent link aggregators). While reusing and establishing systems for centralized content stores can be incredibly effective, nothing good will come from getting obsessed over it working perfectly, without human intervention, for every single output in the world.
Instead, relax. Making your content more reusable isn’t about mechanizing your entire process. While some reuse evangelists might make it seem otherwise, there are likely plenty of good reasons to handcraft some of your content—to carefully, manually, painstakingly make your content sing for one specific output, rather than pull from a generic listing.
Sometimes.
Fact is, you have to make choices: choices about what’s important enough to invest your limited time and budget and sleepless nights on, and what isn’t. And those choices come down to understanding what you’re trying to accomplish and whether repurposing content will help you do it or not.
Of course, even if you choose to handcraft quite a lot of your content, there’s still something to be said for building a central content repository or asset library—one place from which all critical content assets can be managed and maintained, updated and archived—and using it as your source content. Because from there, whoever is responsible for crafting custom content for a specific purpose or destination can be confident he’s working from the latest and greatest source material—without spending endless time hunting down information or asking people in multiple departments to provide material.
Making Reuse Meaningful
Whether your organization wants to allow customers to develop their own personalized collections of content, provide internal teams with access to up-to-date source material, automate publishing across multiple platforms and devices, or even try something more experimental, structured content will help you get there—gracefully.
By breaking your content down along the lines that matter, you’ve done what it takes to make your content ready for reuse—and, just as critically, to know whether or not it makes sense for reuse in the first place.
Now that we’ve covered content that’s reusable and reconfigurable across all the systems and channels under your purview, it’s time for something weirder—how content travels outside your control. In Chapter 11, “Transportable Content,” we’ll tackle content that goes beyond your bounds, transported by your users to places you may not even be able to imagine yet.