
- Rendering variables at runtime with templating
- Variable templating with the
PythonOperatorversus other operators - Rendering templated variables for debugging purposes
- Performing operations on external systems
In the previous chapters, we touched the surface of how DAGs and operators work together and how to schedule a workflow in Airflow. In this chapter, we look in-depth at what operators represent, what they are, how they function, and when and how they are executed. We also demonstrate how operators can be used to communicate with remote systems via hooks, which allows you to perform tasks such as loading data into a database, running a command in a remote environment, and performing workloads outside of Airflow.
4.1 Inspecting data for processing with Airflow
Throughout this chapter, we will work out several components of operators with the help of a (fictitious) stock market prediction tool that applies sentiment analysis, which we’ll call StockSense. Wikipedia is one the largest public information resources on the internet. Besides the wiki pages, other items such as pageview counts are also publicly available. For the purposes of this example, we will apply the axiom that an increase in a company’s pageviews shows a positive sentiment, and the company’s stock is likely to increase. On the other hand, a decrease in pageviews tells us a loss in interest, and the stock price is likely to decrease.
4.1.1 Determining how to load incremental data
The Wikimedia Foundation (the organization behind Wikipedia) provides all pageviews since 2015 in machine-readable format.1 The pageviews can be downloaded in gzip format and are aggregated per hour per page. Each hourly dump is approximately 50 MB in gzipped text files and is somewhere between 200 and 250 MB in size unzipped.
Whenever working with any sort of data, these are essential details. Any data, both small and big, can be complex, and it is important to have a technical plan of approach before building a pipeline. The solution is always dependent on what you, or other users, want to do with the data, so ask yourself and others questions such as “Do we want to process the data again at some other time in the future?”; “How do I receive the data (e.g., frequency, size, format, source type)?”; and “What are we going to build with the data?” After knowing the answers to such questions, we can address the technical details.
Let’s download one single hourly dump and inspect the data by hand. In order to develop a data pipeline, we must understand how to load it in an incremental fashion and how to work the data (figure 4.1).

Figure 4.1 Downloading and inspecting Wikimedia pageviews data
We see the URLs follow a fixed pattern, which we can use when downloading the data in batch fashion (briefly touched on in chapter 3). As a thought experiment and to validate the data, let’s see what the most commonly used domain codes are for July 7, 10:00–11:00 (figure 4.2).

Figure 4.2 First simple analysis on Wikimedia pageviews data
Seeing the top results, 1061202 en and 995600 en.m, tells us the most viewed domains between July 7 10:00 and 11:00 are “en” and “en.m” (the mobile version of .en), which makes sense given English is the most used language in the world. Also, results are returned as we expect to see them, which confirms there are no unexpected characters or misalignment of columns, meaning we don’t have to perform any additional processing to clean up the data. Oftentimes, cleaning and transforming data into a consistent state is a large part of the work.
4.2 Task context and Jinja templating
Now let’s put all this together and create the first version of a DAG pulling in the Wikipedia pageview counts. Let’s start simple by downloading, extracting, and reading the data. We’ve selected five companies (Amazon, Apple, Facebook, Google, and Microsoft) to initially track and validate the hypothesis (figure 4.3).

Figure 4.3 First version of the StockSense workflow
The first step is to download the .zip file for every interval. The URL is constructed of various date and time components:
https://dumps.wikimedia.org/other/pageviews/
{year}/{year}-{month}/pageviews-{year}{month}{day}-{hour}0000.gz
For every interval, we’ll have to insert the date and time for that specific interval in the URL. In chapter 3, we briefly touched on scheduling and how to use the execution date in our code for it to execute one specific interval. Let’s dive a bit deeper into how that works. There are many ways to download the pageviews; however, let’s focus on the BashOperator and PythonOperator. The method to insert variables at runtime in those operators can be generalized to all other operator types.
4.2.1 Templating operator arguments
To start, let’s download the Wikipedia pageviews using the BashOperator, which takes an argument, bash_command, to which we provide a Bash command to execute—all components of the URL where we need to insert a variable at runtime start and end with double curly braces.
Listing 4.1 Downloading Wikipedia pageviews with the BashOperator
import airflow.utils.dates
from airflow import DAG
from airflow.operators.bash import BashOperator
dag = DAG(
dag_id="chapter4_stocksense_bashoperator",
start_date=airflow.utils.dates.days_ago(3),
schedule_interval="@hourly",
)
get_data = BashOperator(
task_id="get_data",
bash_command=(
"curl -o /tmp/wikipageviews.gz "
"https://dumps.wikimedia.org/other/pageviews/"
"{{ execution_date.year }}/" ❶
"{{ execution_date.year }}-"
"{{ '{:02}'.format(execution_date.month) }}/"
"pageviews-{{ execution_date.year }}"
"{{ '{:02}'.format(execution_date.month) }}"
"{{ '{:02}'.format(execution_date.day) }}-"
"{{ '{:02}'.format(execution_date.hour) }}0000.gz" ❷
),
dag=dag,
)
❶ Double curly braces denote a variable inserted at runtime.
❷ Any Python variable or expression can be provided.
As briefly touched on in chapter 3, the execution_date is one of the variables that is “magically” available in the runtime of a task. The double curly braces denote a Jinja-templated string. Jinja is a templating engine, which replaces variables and/or expressions in a templated string at runtime. Templating is used when you, as a programmer, don’t know the value of something at the time of writing, but do know the value of something at runtime. An example is when you have a form in which you can insert your name, and the code prints the inserted name (figure 4.4).

Figure 4.4 Not all variables are known upfront when writing code, for example, when using interactive elements such as forms.
The value of name is not known when programming because the user will enter their name in the form at runtime. What we do know is that the inserted value is assigned to a variable called name, and we can then provide a templated string, "Hello {{ name }}!", to render and insert the value of name at runtime.
In Airflow, you have a number of variables available at runtime from the task context. One of these variables is execution_date. Airflow uses the Pendulum (https://pendulum.eustace.io) library for datetimes, and execution_date is such a Pendulum datetime object. It is a drop-in replacement for native Python datetime, so all methods that can be applied to Python can also be applied to Pendulum. Just like you can do datetime.now().year, you get the same result with pendulum.now().year.
Listing 4.2 Pendulum behavior equal to native Python datetime
>>> from datetime import datetime >>> import pendulum >>> datetime.now().year 2020 >>> pendulum.now().year 2020
The Wikipedia pageviews URL requires zero-padded months, days, and hours (e.g., “07” for hour 7). Within the Jinja-templated string we therefore apply string formatting for padding:
{{ '{:02}'.format(execution_date.hour) }}
4.2.2 What is available for templating?
Now that we understand which arguments of an operator can be templated, which variables do we have at our disposal for templating? We’ve seen execution_date used before in a number of examples, but more variables are available. With the help of the PythonOperator, we can print the full task context and inspect it.
Listing 4.3 Printing the task context
import airflow.utils.dates from airflow import DAG from airflow.operators.python import PythonOperator dag = DAG( dag_id="chapter4_print_context", start_date=airflow.utils.dates.days_ago(3), schedule_interval="@daily", ) def _print_context(**kwargs): print(kwargs) print_context = PythonOperator( task_id="print_context", python_callable=_print_context, dag=dag, )
Running this task prints a dict of all available variables in the task context.
Listing 4.4 All context variables for the given execution date
{
'dag': <DAG: print_context>,
'ds': '2019-07-04',
'next_ds': '2019-07-04',
'next_ds_nodash': '20190704',
'prev_ds': '2019-07-03',
'prev_ds_nodash': '20190703',
...
}
All variables are captured in **kwargs and passed to the print() function. All these variables are available at runtime. Table 4.1 provides a description of all available task context variables.
Table 4.1 All task context variables
4.2.3 Templating the PythonOperator
The PythonOperator is an exception to the templating shown in section 4.2.1. With the BashOperator (and all other operators in Airflow), you provide a string to the bash_command argument (or whatever the argument is named in other operators), which is automatically templated at runtime. The PythonOperator is an exception to this standard, because it doesn’t take arguments that can be templated with the runtime context, but instead a python_callable argument in which the runtime context can be applied.
Let’s inspect the code downloading the Wikipedia pageviews as shown in listing 4.1 with the BashOperator, but now implemented with the PythonOperator. Functionally, this results in the same behavior.
Listing 4.5 Downloading Wikipedia pageviews with the PythonOperator
from urllib import request
import airflow
from airflow import DAG
from airflow.operators.python import PythonOperator
dag = DAG(
dag_id="stocksense",
start_date=airflow.utils.dates.days_ago(1),
schedule_interval="@hourly",
)
def _get_data(execution_date): ❶
year, month, day, hour, *_ = execution_date.timetuple()
url = (
"https://dumps.wikimedia.org/other/pageviews/"
f"{year}/{year}-{month:0>2}/"
f”pageviews-{year}{month:0>2}{day:0>2}-{hour:0>2}0000.gz"
)
output_path = "/tmp/wikipageviews.gz"
request.urlretrieve(url, output_path)
get_data = PythonOperator(
task_id="get_data",
python_callable=_get_data, ❶
dag=dag,
)
❶ The PythonOperator takes a Python function, whereas the BashOperator takes a Bash command as a string to execute.
Functions are first-class citizens in Python, and we provide a callable 2 (a function is a callable object) to the python_callable argument of the PythonOperator. On execution, the PythonOperator executes the provided callable, which could be any function. Since it is a function, and not a string as with all other operators, the code within the function cannot be automatically templated. Instead, the task context variables can be provided and used in the given function, as shown in figure 4.5.

Figure 4.5 Providing task context with a PythonOperator
Python allows capturing keyword arguments in a function. This has various use cases, mainly for if you don’t know the keyword arguments supplied upfront and to avoid having to explicitly write out all expected keyword argument names.
Listing 4.6 Keyword arguments stored in kwargs
def _print_context(**kwargs): ❶
print(kwargs)
❶ Keyword arguments can be captured with two asterisks (**). A convention is to name the capturing argument kwargs.
To indicate to your future self and to other readers of your Airflow code about your intentions of capturing the Airflow task context variables in the keyword arguments, a good practice is to name this argument appropriately (e.g., “context”).
Listing 4.7 Renaming kwargs to context for expressing intent to store task context
def _print_context(**context): ❶
print(context)
print_context = PythonOperator(
task_id="print_context",
python_callable=_print_context,
dag=dag,
)
❶ Naming this argument context indicates we expect Airflow task context.
The context variable is a dict of all context variables, which allows us to give our task different behavior for the interval it runs in, for example, to print the start and end datetime of the current interval:
Listing 4.8 Printing start and end date of interval
def _print_context(**context):
start = context["execution_date"] ❶
end = context["next_execution_date"]
print(f"Start: {start}, end: {end}")
print_context = PythonOperator(
task_id="print_context", python_callable=_print_context, dag=dag
)
# Prints e.g.:
# Start: 2019-07-13T14:00:00+00:00, end: 2019-07-13T15:00:00+00:00
❶ Extract the execution_date from the context.
Now that we’ve seen a few basic examples, let’s dissect the PythonOperator downloading the hourly Wikipedia pageviews as seen in listing 4.5 (figure 4.6).

Figure 4.6 The PythonOperator takes a function instead of string arguments and thus cannot be Jinja-templated. In this called function, we extract datetime components from the execution_date to dynamically construct the URL.
The _get_data function called by the PythonOperator takes one argument: **context. As we’ve seen before, we could accept all keyword arguments in a single argument named **kwargs (the double asterisk indicates all keyword arguments, and kwargs is the actual variable’s name). For indicating we expect task context variables, we could rename it to **context. There is yet another way in Python to accept keywords arguments, though.
Listing 4.9 Explicitly expecting variable execution_date
def _get_data(execution_date, **context): ❶
year, month, day, hour, *_ = execution_date.timetuple()
# ...
❶ This tells Python we expect to receive an argument named execution_date. It will not be captured in the context argument.
What happens under the hood is that the _get_data function is called with all context variables as keyword arguments:
Listing 4.10 All context variables are passed as keyword arguments
_get_data(conf=..., dag=..., dag_run=..., execution_date=..., ...)
Python will then check if any of the given arguments is expected in the function signature (figure 4.7).

Figure 4.7 Python determines if a given keyword argument is passed to one specific argument in the function, or to the ** argument if no matching name was found.
The first argument conf is checked and not found in the signature (expected arguments) of _get_data and thus added to **context. This is repeated for dag and dag_run since both arguments are not in the function’s expected arguments. Next is execution_date, which we expect to receive, and thus its value is passed to the execution_date argument in _get_data() (figure 4.8).

Figure 4.8 _get_data expects an argument named execution_date. No default value is set, so it will fail if not provided.
The end result with this example is that a keyword with the name execution_date is passed along to the execution_date argument and all other variables are passed along to **context since they are not explicitly expected in the function signature (figure 4.9).

Figure 4.9 Any named argument can be given to _get_data(). execution_date must be provided explicitly because it’s listed as an argument, all other arguments are captured by **context.
Now, we can directly use the execution_date variable instead of having to extract it from **context with context["execution_date"]. In addition, your code will be more self-explanatory and tools such as linters and type hinting will benefit by the explicit argument definition.
4.2.4 Providing variables to the PythonOperator
Now that we’ve seen how the task context works in operators and how Python deals with keywords arguments, imagine we want to download data from more than one data source. The _get_data() function could be duplicated and slightly altered to support a second data source. The PythonOperator, however, also supports supplying additional arguments to the callable function. For example, say we start by making the output_path configurable, so that, depending on the task, we can configure the output _path instead of having to duplicate the entire function just to change the output path (figure 4.10).

Figure 4.10 The output_path is now configurable via an argument.
The value for output_path can be provided in two ways. The first is via an argument: op_args.
Listing 4.11 Providing user-defined variables to the PythonOperator callable
get_data = PythonOperator(
task_id="get_data",
python_callable=_get_data,
op_args=["/tmp/wikipageviews.gz"], ❶
dag=dag,
)
❶ Provide additional variables to the callable with op_args.
On execution of the operator, each value in the list provided to op_args is passed along to the callable function (i.e., the same effect as calling the function as such directly: _get_data("/tmp/wikipageviews.gz")).
Since output_path in figure 4.10 is the first argument in the _get_data function, the value of it will be set to /tmp/wikipageviews.gz when run (we call these non-keyword arguments). A second approach is to use the op_kwargs argument, shown in the following listing.
Listing 4.12 Providing user-defined kwargs to callable
get_data = PythonOperator(
task_id="get_data",
python_callable=_get_data,
op_kwargs={"output_path": "/tmp/wikipageviews.gz"}, ❶
dag=dag,
)
❶ A dict given to op_kwargs will be passed as keyword arguments to the callable.
Similar to op_args, all values in op_kwargs are passed along to the callable function, but this time as keyword arguments. The equivalent call to _get_data would be
_get_data(output_path="/tmp/wikipageviews.gz")
Note that these values can contain strings and thus can be templated. That means we could avoid extracting the datetime components inside the callable function itself and instead pass templated strings to our callable function.
Listing 4.13 Providing templated strings as input for the callable function
def _get_data(year, month, day, hour, output_path, **_):
url = (
"https://dumps.wikimedia.org/other/pageviews/"
f"{year}/{year}-{month:0>2}/”
f"pageviews-{year}{month:0>2}{day:0>2}-{hour:0>2}0000.gz"
)
request.urlretrieve(url, output_path)
get_data = PythonOperator(
task_id="get_data",
python_callable=_get_data,
op_kwargs={
"year": "{{ execution_date.year }}", ❶
"month": "{{ execution_date.month }}",
"day": "{{ execution_date.day }}",
"hour": "{{ execution_date.hour }}",
"output_path": "/tmp/wikipageviews.gz",
},
dag=dag,
)
❶ User-defined keyword arguments are templated before passing to the callable.
4.2.5 Inspecting templated arguments
A useful tool to debug issues with templated arguments is the Airflow UI. You can inspect the templated argument values after running a task by selecting it in either the graph or tree view and clicking the Rendered Template button (figure 4.11).
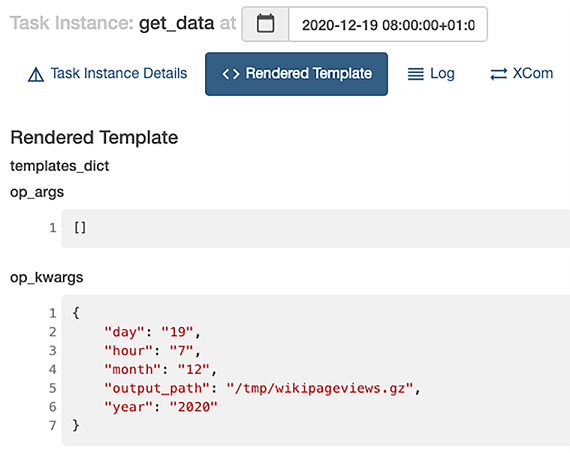
Figure 4.11 Inspecting the rendered template values after running a task
The rendered template view displays all attributes of the given operator that are render-able and their values. This view is visible per task instance. Consequently, a task must be scheduled by Airflow before being able to inspect the rendered attributes for the given task instance (i.e., you have to wait for Airflow to schedule the next task instance). During development, this can be impractical. The Airflow Command Line Interface (CLI) allows us to render templated values for any given datetime.
Listing 4.14 Rendering templated values for any given execution date
# airflow tasks render stocksense get_data 2019-07-19T00:00:00
# ----------------------------------------------------------
# property: templates_dict
# ----------------------------------------------------------
None
# ----------------------------------------------------------
# property: op_args
# ----------------------------------------------------------
[]
# ----------------------------------------------------------
# property: op_kwargs
# ----------------------------------------------------------
{'year': '2019', 'month': '7', 'day': '19', 'hour': '0', 'output_path': '/tmp/wikipageviews.gz'}
The CLI provides us with exactly the same information as shown in the Airflow UI, without having to run a task, which makes it easier to inspect the result. The command to render templates using the CLI is
airflow tasks render [dag id] [task id] [desired execution date]
You can enter any datetime and the Airflow CLI will render all templated attributes as if the task would run for the desired datetime. Using the CLI does not register anything in the metastore and is thus a more lightweight and flexible action.
4.3 Hooking up other systems
Now that we’ve worked out how templating works, let’s continue the use case by processing the hourly Wikipedia pageviews. The following two operators will extract the archive and process the extracted file by scanning over it and selecting the pageview counts for the given page names. The result is then printed in the logs.
Listing 4.15 Reading pageviews for given page names
extract_gz = BashOperator(
task_id="extract_gz",
bash_command="gunzip --force /tmp/wikipageviews.gz",
dag=dag,
)
def _fetch_pageviews(pagenames):
result = dict.fromkeys(pagenames, 0)
with open(f"/tmp/wikipageviews", "r") as f: ❶
for line in f:
domain_code, page_title, view_counts, _ = line.split(" ") ❷
if domain_code == "en" and page_title in pagenames: ❸ ❹
result[page_title] = view_counts
print(result)
# Prints e.g. "{'Facebook': '778', 'Apple': '20', 'Google': '451', 'Amazon': '9', 'Microsoft': '119'}"
fetch_pageviews = PythonOperator(
task_id="fetch_pageviews",
python_callable=_fetch_pageviews,
op_kwargs={
"pagenames": {
"Google",
"Amazon",
"Apple",
"Microsoft",
"Facebook",
}
},
dag=dag,
)
❶ Open the file written in previous task.
❷ Extract the elements on a line.
❹ Check if page_title is in given pagenames.
This prints, for example, {'Apple': '31', 'Microsoft': '87', 'Amazon': '7', 'Facebook': '228', 'Google': '275'}. As a first improvement, we’d like to write these counts to our own database, which allow us to query it with SQL and ask questions such as, “What is the average hourly pageview count on the Google Wikipedia page?” (figure 4.12).

Figure 4.12 Conceptual idea of workflow. After extracting the pageviews, write the pageview counts to a SQL database.
We have a Postgres database to store the hourly pageviews. The table to keep the data contains three columns, shown in listing 4.16.
Listing 4.16 CREATE TABLE statement for storing output
CREATE TABLE pageview_counts ( pagename VARCHAR(50) NOT NULL, pageviewcount INT NOT NULL, datetime TIMESTAMP NOT NULL );
The pagename and pageviewcount columns respectively hold the name of the Wikipedia page and the number of pageviews for that page for a given hour. The datetime column will hold the date and time for the count, which equals Airflow’s execution _date for an interval. An example INSERT query would look as follows.
Listing 4.17 INSERT statement storing output in the pageview_counts table
INSERT INTO pageview_counts VALUES ('Google', 333, '2019-07-17T00:00:00');
This code currently prints the found pageview count, and now we want to connect the dots by writing those results to the Postgres table. The PythonOperator currently prints the results but does not write to the database, so we’ll need a second task to write the results. In Airflow, there are two ways of passing data between tasks:
-
By using the Airflow metastore to write and read results between tasks. This is called XCom and covered in chapter 5.
-
By writing results to and from a persistent location (e.g., disk or database) between tasks.
Airflow tasks run independently of each other, possibly on different physical machines depending on your setup, and therefore cannot share objects in memory. Data between tasks must therefore be persisted elsewhere, where it resides after a task finishes and can be read by another task.
Airflow provides one mechanism out of the box called XCom, which allows storing and later reading any picklable object in the Airflow metastore. Pickle is Python’s serialization protocol, and serialization means converting an object in memory to a format that can be stored on disk to be read again later, possibly by another process. By default, all objects built from basic Python types (e.g., string, int, dict, list) can be pickled. Examples of non-picklable objects are database connections and file handlers. Using XComs for storing pickled objects is only suitable for smaller objects. Since Airflow’s metastore (typically a MySQL or Postgres database) is finite in size and pickled objects are stored in blobs in the metastore, it’s typically advised to apply XComs only for transferring small pieces of data such as a handful of strings (e.g., a list of names).
The alternative for transferring data between tasks is to keep the data outside Airflow. The number of ways to store data are limitless, but typically a file on disk is created. In the use case, we’ve fetched a few strings and integers, which in itself are not space-consuming. With the idea in mind that more pages might be added, and thus data size might grow in the future, we’ll think ahead and persist the results on disk instead of using XComs.
In order to decide how to store the intermediate data, we must know where and how the data will be used again. Since the target database is a Postgres, we’ll use the PostgresOperator to insert data. First, we must install an additional package to import the PostgresOperator class in our project:
pip install apache-airflow-providers-postgres
The PostgresOperator will run any query you provide it. Since the PostgresOperator does not support inserts from CSV data, we will first write SQL queries as our intermediate data first.
Listing 4.18 Writing INSERT statements to feed to the PostgresOperator
def _fetch_pageviews(pagenames, execution_date, **_): result = dict.fromkeys(pagenames, 0) ❶ with open("/tmp/wikipageviews", "r") as f: for line in f: domain_code, page_title, view_counts, _ = line.split(" ") if domain_code == "en" and page_title in pagenames: result[page_title] = view_counts ❷ with open("/tmp/postgres_query.sql", "w") as f: for pagename, pageviewcount in result.items(): ❸ f.write( "INSERT INTO pageview_counts VALUES (" f"'{pagename}', {pageviewcount}, '{execution_date}'" "); " ) fetch_pageviews = PythonOperator( task_id="fetch_pageviews", python_callable=_fetch_pageviews, op_kwargs={"pagenames": {"Google", "Amazon", "Apple", "Microsoft", "Facebook"}}, dag=dag, )
❶ Initialize result for all pageviews with zero
❸ For each result, write SQL query.
Running this task will produce a file (/tmp/postgres_query.sql) for the given interval, containing all the SQL queries to be run by the PostgresOperator. See the following example.
Listing 4.19 Multiple INSERT queries to feed to the PostgresOperator
INSERT INTO pageview_counts VALUES ('Facebook', 275, '2019-07-18T02:00:00+00:00');
INSERT INTO pageview_counts VALUES ('Apple', 35, '2019-07-18T02:00:00+00:00');
INSERT INTO pageview_counts VALUES ('Microsoft', 136, '2019-07-18T02:00:00+00:00');
INSERT INTO pageview_counts VALUES ('Amazon', 17, '2019-07-18T02:00:00+00:00');
INSERT INTO pageview_counts VALUES ('Google', 399, '2019-07-18T02:00:00+00:00');
Now that we’ve generated the queries, it’s time to connect the last piece of the puzzle.
Listing 4.20 Calling the PostgresOperator
from airflow.providers.postgres.operators.postgres import PostgresOperator dag = DAG(..., template_searchpath="/tmp") ❶ write_to_postgres = PostgresOperator( task_id="write_to_postgres", postgres_conn_id="my_postgres", ❷ sql="postgres_query.sql", ❸ dag=dag, )
❷ Identifier to credentials to use for connection
❸ SQL query or path to file containing SQL queries
The corresponding graph view will look like figure 4.13.

Figure 4.13 DAG fetching hourly Wikipedia pageviews and writing results to Postgres
The PostgresOperator requires filling in only two arguments to run a query against a Postgres database. Intricate operations such as setting up a connection to the database and closing it after completion are handled under the hood. The postgres_conn_id argument points to an identifier holding the credentials to the Postgres database. Airflow can manage such credentials (stored encrypted in the metastore), and operators can fetch one of the credentials when required. Without going into detail, we can add the my_postgres connection in Airflow with the help of the CLI.
Listing 4.21 Storing credentials in Airflow with the CLI
airflow connections add
--conn-type postgres
--conn-host localhost
--conn-login postgres
--conn-password mysecretpassword
my_postgres ❶
The connection is then visible in the UI (it can also be created from there). Go to Admin > Connections to view all connections stored in Airflow (figure 4.14).
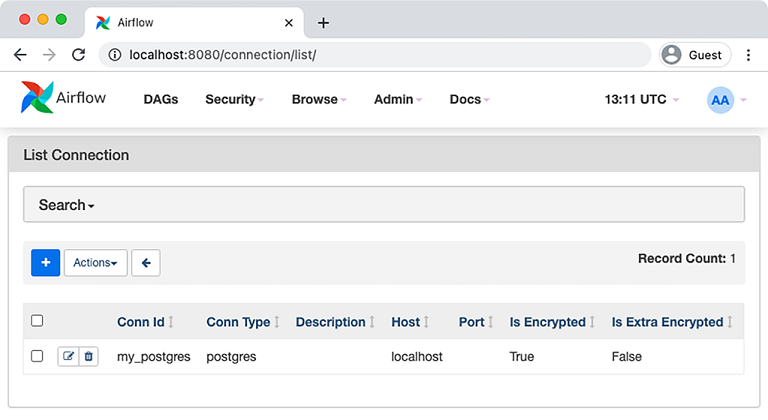
Figure 4.14 Connection listed in Airflow UI
Once a number of DAG runs have completed, the Postgres database will hold a few counts:
"Amazon",12,"2019-07-17 00:00:00" "Amazon",11,"2019-07-17 01:00:00" "Amazon",19,"2019-07-17 02:00:00" "Amazon",13,"2019-07-17 03:00:00" "Amazon",12,"2019-07-17 04:00:00" "Amazon",12,"2019-07-17 05:00:00" "Amazon",11,"2019-07-17 06:00:00" "Amazon",14,"2019-07-17 07:00:00" "Amazon",15,"2019-07-17 08:00:00" "Amazon",17,"2019-07-17 09:00:00"
There’s a number of things to point out in this last step. The DAG has an additional argument: template_searchpath. Besides a string INSERT INTO ..., the content of files can also be templated. Each operator can read and template files with specific extensions by providing the file path to the operator. In the case of the PostgresOperator, the argument SQL can be templated and thus a path to a file holding a SQL query can also be provided. Any filepath ending in .sql will be read, templates in the file will be rendered, and the queries in the file will be executed by the PostgresOperator. Again, refer to the documentation of the operators and check the field template_ext, which holds the file extensions that can be templated by the operator.
NOTE Jinja requires you to provide the path to search for files that can be templated. By default, only the path of the DAG file is searched for, but since we’ve stored it in /tmp, Jinja won’t find it. To add paths for Jinja to search, set the argument template_searchpath on the DAG and Jinja will traverse the default path plus additional provided paths to search for.
Postgres is an external system and Airflow supports connecting to a wide range of external systems with the help of many operators in its ecosystem. This does have an implication: connecting to an external system often requires specific dependencies to be installed, which allow connecting and communicating with the external system. This also holds for Postgres; we must install the package apache-airflow-providers-postgres to install additional Postgres dependencies in our Airflow installation. The many dependencies is one of the characteristics of any orchestration system—in order to communicate with many external systems it is inevitable to install many dependencies.

Figure 4.15 Running a SQL script against a Postgres database involves several components. Provide the correct settings to the PostgresOperator, and the PostgresHook will do the work under the hood.
Upon execution of the PostgresOperator, a number of things happen (figure 4.15). The PostgresOperator will instantiate a so-called hook to communicate with Postgres. The hook deals with creating a connection, sending queries to Postgres and closing the connection afterward. The operator is merely passing through the request from the user to the hook in this situation.
NOTE An operator determines what has to be done; a hook determines how to do something.
When building pipelines like these, you will only deal with operators and have no notion of any hooks, because hooks are used internally in operators.
After a number of DAG runs, the Postgres database will contain a few records extracted from the Wikipedia pageviews. Once an hour, Airflow now automatically downloads the new hourly pageviews data set, unzips it, extracts the desired counts, and writes these to the Postgres database. We can now ask questions such as “At which hour is each page most popular?”
Listing 4.22 SQL query asking which hour is most popular per page
SELECT x.pagename, x.hr AS "hour", x.average AS "average pageviews"
FROM (
SELECT
pagename,
date_part('hour', datetime) AS hr,
AVG(pageviewcount) AS average,
ROW_NUMBER() OVER (PARTITION BY pagename ORDER BY AVG(pageviewcount) DESC)
FROM pageview_counts
GROUP BY pagename, hr
) AS x
WHERE row_number=1;
This listing gives us the most popular time to view given pages is between 16:00 and 21:00, shown in table 4.2.
Table 4.2 Query results showing which hour is most popular per page
With this query, we have now completed the envisioned Wikipedia workflow, which performs a full cycle of downloading the hourly pageview data, processing the data, and writing results to a Postgres database for future analysis. Airflow is responsible for orchestrating the correct time and order of starting tasks. With the help of the task runtime context and templating, code is executed for a given interval, using the datetime values that come with that interval. If all is set up correctly, the workflow can now run until infinity.
Summary
-
Templating the
PythonOperatorworks different from other operators; variables are passed to the provided callable. -
The result of templated arguments can be checked with
airflowtasksrender. -
Operators describe what to do; hooks determine how to do work.
1.https://dumps.wikimedia.org/other/pageviews. The structure and technical details of Wikipedia pageviews data is documented here: https://meta.wikimedia.org/wiki/Research:Page_view and https://wikitech.wikimedia .org/wiki/Analytics/Data_Lake/Traffic/Pageviews.
2.In Python, any object implementing __call__() is considered a callable (e.g., functions/methods).