
It is important that you get the architecture correct. If you follow the approach described in earlier chapters, you will approach a resilient architecture quickly. But you must continually evaluate and improve the architecture. This necessitates viewing the architecture from various perspectives, which allows you to evaluate if the use cases are indeed kept separate and whether systemwide concerns such as maintainability, extensibility, portability, reusability, performance, and reliability are met. If necessary, you make some improvements. The techniques we describe in this chapter constitute what is commonly known as refactoring. Martin Fowler and his colleagues list a number of such techniques [Fowler et al. 1999]. The refactoring we discuss has an essential difference. Since use-case slices cut across the element structure, refactoring is conducted along two dimensions—along the element structure and along the use-case structure.
Before we conduct the evaluation, let us summarize what you have learned so far. From the discussion in the preceding chapters, you probably notice there is a general approach to analyzing and designing use cases and through them different kinds of crosscutting concerns.
Identify Classes or Parameters. You identify classes that are involved in the use case. If you are analyzing use cases generically, then instead of identifying classes, you identify parameterized classes. These parameterized classes subsequently are substituted with actual classes.
Identify Pointcuts. If the use case is an extension use case—whether an application-extension use case, infrastructure use case, or just platform specifics—you must identify pointcuts and operation-extension declarations. The pointcuts and operation-extension declarations define where the extension will be executed. They can be derived from the use-case specifications.
Allocate Use-Case Behavior to Classes. You consider how the classes or parameterized classes interact to realize the use case. At this point, you do not worry which parts of the interaction are specific to the use-case realization and which are not. The focus is on understanding the interaction and finding responsibilities of classes or parameters.
Separate the Use-Case Specifics. With a good understanding of the interaction, you determine which classes or features of classes are specific to the use case and which are not. You collate the use-case specific parts into use-case slices and the common parts into non-use-case-specific slices.
Bind Parameters. If you have been analyzing and designing the use cases generically (i.e., you are using class parameters instead of actual classes), you must define these class parameters. This can be achieved through pointcut expressions or by binding template parameters. Once you understand this general approach, understanding each special case is much simpler.
In the remainder of this section, we compare and contrast ways to analyze and design the different kinds of use cases you have encountered in preceding chapters.
Application Peer Use Cases (Chapter 12, “Separating Functional Requirements with Application Peer Use Cases”)
Application peer use cases provide end-user functionality on top of the element structure that defines the problem domain. The emphasis when analyzing peers is on distinguishing what is common and what is specific to a use case. The Reserve Room use case is an example of an application peer use case. Its use-case slice is depicted in Figure 17-1. The aspects within application peer use-case slices contain primarily intertype declarations (additional and complete operations) to be added to existing elements.
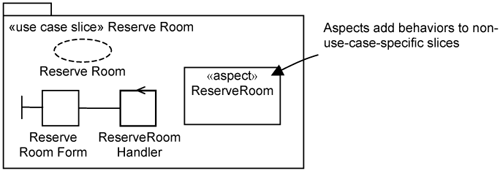
Peer use cases do not extend other use cases and do not have extension flows and pointcuts. Thus, you do not identify pointcuts during analysis. However, aspects in peer use-case slices have operation extensions to list services they offer and to allow actors to initiate the appropriate ones.
Application-Extension Use Cases (Chapter 13, “Separating Functional Requirements with Application-Extension Use Cases”)
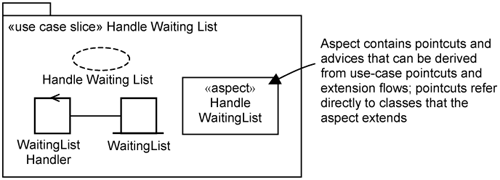
Application-extension use cases add additional behaviors on top of the use cases they extend. They may have basic flows through which actors can initiate them directly. They also have extension flows that are executed in the context of an extended use case. The Handle Waiting List is an example of an application-extension use case. It has an extension flow that puts the customer into a waiting list when there are no rooms available during a reservation. It typically also has basic flows to view who are in the waiting list and their waiting status. Thus, application-extension use cases are a special case of application use cases.
The use-case slice for the Handle Waiting List is shown in Figure 17-2. Application-extension use cases contain pointcuts from which you identify corresponding pointcuts in extension use-case slices. Since you normally analyze the extension use case with reference to the use case it extends, the pointcuts refer to the classes in the base slice directly. This differs from infrastructure use cases (discussed below) that are analyzed with reference to a generic application use case.
Infrastructure Use Cases (Chapter 14, “Separating Nonfunctional Requirements with Infrastructure Use Cases”)
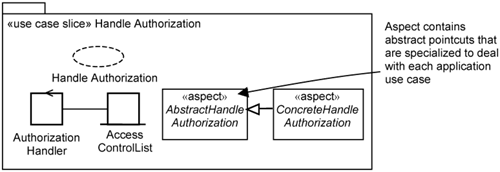
The infrastructure use cases keep nonfunctional requirements separate from the application. The analysis and design of infrastructure use cases follows a two-step approach. In the first step, you attempt to extend a generic Perform Transaction use case to yield an abstract use-case slice. This use-case slice is abstract because the pointcuts are identified with reference to a generic application use case. Therefore, you cannot have a precise pointcut expression defined, so the aspects are usually abstract. In the second step, you specialize the abstract aspect by defining pointcut expressions for the specific application use case you want to extend. This two-step approach is exemplified by the Handle Authorization use case, whose use-case slice is depicted in 17-3.
Platform-Specific Extension Use Case (Chapter 15, “Separating Platform Specifics with Platform-Specific Use-Case Slices”)
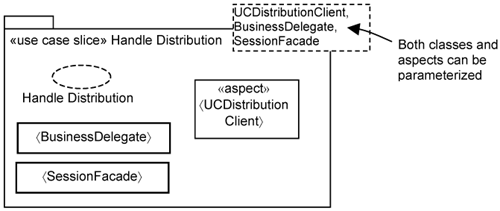
Platform-specific extension use cases are special infrastructure use cases that require additional classes on a per-use-case basis. You still use the same two-step approach as in the case of normal infrastructure use cases. This is exemplified by the Handle Distribution use case, which requires a BusinessDelegate and a Session Facade be added to each application use case (e.g., Reserve Room).
The design of the platform-specific use-case slice is conducted in two steps. You first define the additional behavior and pointcuts on top of a generic base behavior. This results in a parameterized use-case slice, illustrated in Figure 17-4, which shows the parameterized use-case slice for Handle Distribution.
In the second step, you bind the parameters with the actual classes and aspects for a particular application use-case slice. It is common practice to explore the possibilities of automatically generating parameters. For example, BusinessDelegate and SessionFacade can usually be generated based on some code templates.
Test Cases (Chapter 16, “Separating Tests with Use-Case Test Slices”)
Test-case slices are very much like extension use-case slices, but instead of adding more functionality, they provide additional code to support test-case execution. Figure 17-5 depicts the test slice for the Reserve Room test case.
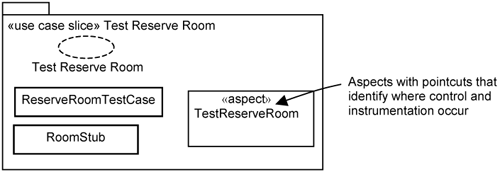
In the test slice, you need test case, a class that drives the test, and possibly some test stubs. The aspects in the test slice provide control and instrumentation capability to force the use case under test to adhere to the desired execution path and to check if the execution path is indeed correct.
We have highlighted the use of abstract and concrete aspects, parameterized use-case slices, and so on. Although these concepts are discussed with reference to specific examples dealing with particular concerns, the techniques themselves are general. You can apply any of these techniques to any kind of use-case slice. For example, you might want to parameterize an application use-case slice.
Evaluating the separation of concerns across elements and slices occurs all throughout the project. It is not a separate activity from use-case modeling, use-case analysis, and use-case design. You do them as an integral part of these activities.
Recall that the analysis model and the design model each have an element structure and use-case structure. Consequently, you must evaluate along both structures. In this section, we discuss how to evaluate the element structure. Whether it is the analysis element structure or the design element structure, the same principle of separation applies. In this section, we assume that you are evaluating the design element structure.
When you evaluate a design element, you must consider it in a composed manner: a design class (e.g., the Room class) may have several features (attributes, operations, and relationships) from one use-case slice (e.g., the Reserve Room use-case slice) and several features from another use-case slice (e.g., the Check In Customer use-case slice). The total composed number of features for this class (i.e., the Room class) is the total number of features from all use-case slices.
To evaluate the goodness of a design class, you compose the class and consider the following:
Does the design class represent a meaningful abstraction with respect to the system?
Does the class obey the responsibilities hinted at by its name or stereotype?
Does the class own a cohesive set of responsibilities?
Can the responsibilities of the design class be delegated to another class, perhaps a child class, or parent class, or even some helper classes?
Considering each design class individually is not enough. You need to consider the design class as part of a design package in some design layers. We take this opportunity to depict the design element structure after composing the minimal design package with the platform-specific design elements based on the principles discussed in Chapter 15.
Figure 17-6 depicts the design elements that participate in the Reserve Room use case. It shows the classes separated into packages, which are in turn separated into other packages or layers.
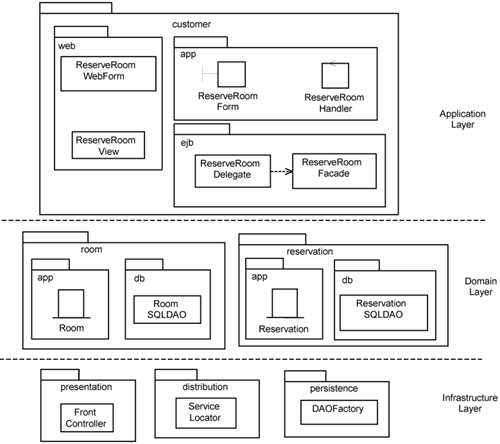
Details of the classes in Figure 17-6 are described in Chapter 15. Basically, Figure 17-6 shows the three design element layers: application layer, domain layer, and infrastructure layer. Within them are packages such as customer, room, and so on. Each of these may have nested packages named app, web, ejb, and db.
The app package contains boundary, control, and entity classes that are derived from the analysis model. The Web package contains design classes that are needed to provide a Web user interface. The ejb package contains design classes needed to provide EJB-based distribution. Finally, the db package contains classes that provide relational persistency. We have discussed them earlier in Chapter 15.
The following questions help you evaluate the goodness of the design element structure:
Is there a clear separation of responsibilities across the packages in the respective layers?
Does each package contain classes that are functionally related to each other? Is there loose coupling across packages and tight cohesion between classes within the package?
What if the user interfaces change? What if the object structure changes? What if the deployment structure of the system changes? Would the impact of such changes be limited to only a few slices in the use-case structure and only a few packages in the element structure?
There are several rules you can use to enforce the separation defined in the design element structure:
Design classes in the app package should contain no platform-specific operations. They are minimal design packages. Their operations may have extensions that are platform-specific (these are added by platform-specific use-case slices), but the operations themselves must be platform-independent.
Design classes in the app package cannot make calls to classes in the infrastructure services layer.
The above checkpoints help you to evaluate the architecture you have established so far. Additional checkpoints can be added to the list as you continue with your project.
After evaluation, what kinds of improvements do you make? Generally, you relocate responsibilities from one class to another, or relocate classes from one package to another, or even repackage the classes. As you relocate responsibilities across classes, remember that you have to preserve the semantics of the analysis stereotypes. For example, you should never relocate a responsibility to retrieve some data elements to a boundary class or relocate a responsibility to display some data to an entity class.
The use-case structure represents another dimension of the model. It is used to preserve separation of use cases from requirements to code. As you may recall, use-case slices are used to keep crosscutting concerns of various kinds separate—separating functional requirements, nonfunctional requirements, platform specifics, and so forth.
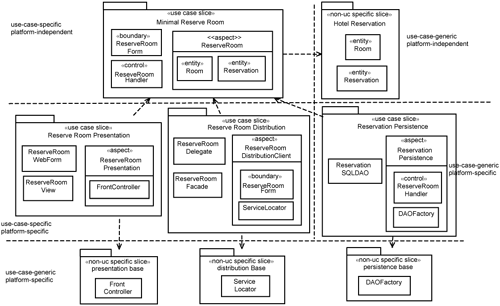
To make our discussion concrete, let’s consider the slices involved in the Reserve Room use-case design. Figure 17-7 depicts the slices that are relevant to the Reserve Room use case. We do not show the features (attributes, operations and relationships) within the class extensions—if we did, Figure 17-7 will be very large indeed. The intent of Figure 17-7 is to provide an overview of the contents in the various use-case slices.
In essence, when you evaluate whether you have a good use-case structure, you are asking if you have good use-case slices, good aspects, and good operation extensions (i.e., advices). So, you ask questions like these:
Is the separation between what is use-case-specific and what is use-case-generic appropriate? We draw dashed lines in Figure 17-7 to help you consider if there is appropriate separation between what is Reserve Room–specific and Reserve Room–generic, what is platform-specific and what is platform-independent. If it is not appropriate, you may need to relocate extensions across slices.
If a use-case slice extends more than one other slice, is it sufficient to use only one aspect, or should you split the aspect to make individual aspects more resilient to changes?
Is the behavioral and structural context of each operation extension clearly defined? Otherwise, you may add behaviors to places where they are not needed and thereby cause unwanted side effects.
Again, what we have above is a small checklist. As aspect-oriented software development matures, this list will be more comprehensive.
The system grows as you start to add more use cases into it. This makes it increasingly more difficult for you to conduct the evaluation because you have more use cases to consider, more classes to consider, and so on. Finding errors is more difficult if you must find them manually. You want to spend more time improving the architecture than hunting for errors. Naturally, you look for ways to automatically hunt possible errors. We explore two ways for automation: through metrics and access rules.
You can formulate some measurements on the various system attributes, such as size, complexity, and dependency of each element within the system, to determine which areas need more attention. These measurements should preferably be automated so that you can quickly scan through the architecture.
Size refers to the number of classes in a package, the number of features in a class, and so on.
Complexity refers to the number of paths through a class. So, if a responsibility of a class has many conditions, then it is considered complex.
Dependency refers to the number of classes a class depends on, the number of packages a package depends on, and so on.
In addition, you must consider the three attributes from several perspectives:
From the perspective of one use case—that is, from one use-case realization.
From the perspective of the system—that is, after the composition of multiple use-case realizations.
A class that is simple in the eyes of one use-case realization may in reality be quite complex after adding all the responsibilities from various use-case realizations.
In general any element that is big in terms of size, complexity, and dependency is difficult to understand, and you will have to retry to make it smaller. If the system is comprised of only a few classes, then each of these classes will be complex. Since there are few classes, the dependencies between them will be few.. The degenerate case occurs when the entire system has only one class. In this case, the dependency is zero, but the complexity of each class is huge. If you have many small classes, each individual class may be simple, but there will be a large number of classes in a package. So, refinement is a tradeoff between size, complexity, and dependencies.
However, numbers are just numbers. They serve only to highlight potential problems in the system. You must do some structuring work (discussed above) to determine where best to locate classes and their features.
During analysis and design, you define the permitted relationships between classes belonging to different packages. For example, classes in package A cannot access classes in package B. In a team with many people, there are bound to be developers who break such rules for some reason—lack of training, lack of understanding, convenience, and so on. This is illustrated in Figure 17-8.
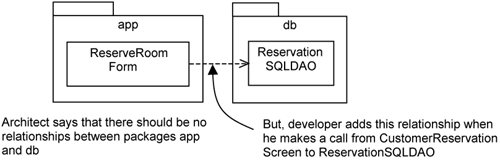
Figure 17-8 contains no modeled dependencies between the app package and the db package. This is because the architect does not want any classes within the two accessing each other (i.e., making calls to each other) or any kind of dependencies between them. First, the app package is supposed to be free from any platform specifics that are in the db package. Second, the db package should not make calls to classes in the app package, since there should be no calls from the domain layer to the application layer.
However, during implementation, a developer for some reason makes a call from the ReserveRoomForm class to the ReservationSQLDAO. This is a violation of the access policies defined by the architect. Although such errors are obvious, finding them is laborious work.
AspectJ provides facilities to detect such access errors, illustrated in Listing 17-1.
Example 17-1. Dependency Checks with AspectJ
1. public aspect DependencyCheck { 2. declare error : within(app.*) && call(* db.*.*(..)) 3. : "app class should not access db classes directly"; 4. }
Lines 2 and 3 declare an error. The error occurs when any class within the app package makes a call to any operation in any class in the db package. If such a call is made, the AspectJ compiler displays an error message defined in Line 3: “app class should not access db classes directly.”
The advantage of doing such checks as part of compilation is that the developer is notified of the error and must fix it immediately. This is much better than a separate code review, which usually occurs many days and even months after implementation, if it is ever done at all. Errors are usually detected too late in the project. The result is schedule slippage. This follows the principle of the test-first approach—you want quality from the beginning, not as an afterthought.
We do not model errors, so we do not have a UML notation for Listing 17-1. You model what is allowed and thus define permitted dependencies between packages. If no such dependency exists in the model and such calls are in the code, there is an access error, and you have to declare an error check in AspectJ for every unmodeled dependency between packages. Usually, quite a large number of error declarations are needed. Therefore, you might create a utility to generate all these AspectJ error declarations. In addition, you should always strive to detect such errors even earlier, for instance, during analysis.
It is important to keep use cases and concerns separate. However, there are a number of system qualities that are not restricted to a single use case but span the entire system. Such qualities include maintainability, extensibility, portability, configurability, reusability, reliability, and performance. We discuss each of these qualities and how to evaluate whether your system has such qualities. More importantly, we demonstrate how to achieve these qualities. As you read this section, you will notice a key theme: By keeping concerns separate, you naturally achieve these architectural qualities.
Maintainability is about whether a system is easy to understand and modify. When a requirement changes, you want to be able to quickly identify which parts of the system are affected, and as far as possible, the parts affected should be few.
Separation of concerns is key to maintainability. In this part of the book, we discuss how to keep concerns of different kinds separate. By following the approach discussed throughout the book, you should have systematically arrived at a system that is easy to understand and maintain.
To evaluate if your system is indeed maintainable, you must evaluate the element structure and the use-case structure. We discussed this in the preceding sections (see Section 17.2).
Extensibility is about whether you can easily incorporate enhancements to the system. To evaluate extensibility, you must first think about what kind of enhancements you want and what kinds of changes you might have. These are called change cases. Change cases attempt to predict possible changes that you will encounter in the near future. For example, you might foresee that the Hotel Management System will need to handle new kinds of reservation schemes or manage hotel chains rather than individual hotels.
In Chapter 7, “Capturing Concerns with Use Cases,” we highlighted the identifications of variables during use-case modeling. These variables give a systematic basis for considering potential variations (changes). You will evaluate extensibility with respect to each variation or change case for your system.
In this book, we go a step further. We show how you can achieve extensibility. In essence, we treat each change case as an extension use case. So, you identify these extension use cases at the beginning of the project and analyze and design the system to realize them. A large part of Chapter 13 deals with the design of such extension use cases.
Configurability is about changing the behavior of the system by changing some settings instead of changing its design or implementation. This system quality is closely related to extensibility. In essence, your system must be able to read some configuration parameters and use them during execution. These configuration files and related elements can be easily incorporated as part of your extensibility mechanism.
Portability is being able to run a system on different execution platforms. To evaluate portability, you need to identify change cases for porting scenarios as well. You consider the potential parts of the system that you will port and evaluate the system accordingly.
Portability is largely about changing the infrastructure and platform specifics, discussed extensively in Chapters 14 and 15. You model portability change cases as extension use cases. Thus, you can have extension use cases for authorization, distribution, presentation, persistence, and so on. So, if you want to change from a browser client to a thick client, you just need to consider the Handle Presentation extension use case (see Chapter 15) and determine how you can perform the port.
This book goes further by showing how you can design the infrastructure and platform as an extension use case. You can have different realizations for each of these extension use cases. Thus, porting would simply mean replacing an existing extension use-case slice with a new extension use-case slice.
Reusability is about using the same design element under different contexts. In a system, some parts are reusable, and some are project-specific and not so reusable. To evaluate reusability of a system, you evaluate how well the reusable parts are modularized and kept separate from the parts that are project-specific—how the design elements are organized in separate layers. Thus, you look for reusable elements in lower layers or lower packages in each layer. For example, in the application layer, you find lower packages that are application-generic. These packages are utilized by application-specific packages. Likewise, you find domain-generic packages that are used by domain-specific packages. Use-case slices and extension use-case slices are potentially reusable elements as well. Each of these realizes a specific stakeholder concern. You can pick the appropriate ones to compose the desired system.
In this book, we discussed such layering, packaging, and modularizing concepts and guidelines extensively. Following the approach discussed in this book will help you achieve reusability.
To evaluate the performance and reliability characteristics of a system, you have to execute it. A system executes in a composed manner that involves several use-case slices, including the platform-specifics, at once.
We use the Reserve Room use case as an example. Figure 17-9 shows the participating elements within the Reserve Room use-case realization. These elements execute within two processes: the Web container and the EJB container.
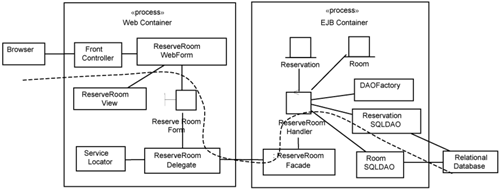
The Web container is responsible for serving HTML pages to the browser. It contains the ReserveRoomForm, which is a boundary class, and also a number of elements to provide Web-presentation support. Since the control class (ReserveRoomHandler) is distributed over the EJB container, the Web container must have elements to support making remote calls.
The EJB container includes elements that perform the actual processing. It comprises control classes (e.g., ReserveRoomHandler) and entity classes (e.g., Room and Reservation). It also has elements to provide distribution and elements to provide access to the relational database.
You can determine the response time to handle an actor request by tracing how the request is processed and passed between the elements. As you trace the request, you sum up how long each element takes. The total time will be the response time. To be really sure about the performance characteristics of the system, tracing request flows is not sufficient. You need to conduct performance tests in which you measure turnaround time, throughput, and other performance attributes of the requests.
There are many different kinds of application use cases. Some involve short user requests, while others involve batch computations and similar tasks. You must evaluate each different type.
If there are more requests coming into the system than can be processed, you probably need to consider buffers to queue up the requests, or you may consider load balancing or other request-handling methods. It should be easy to add these additional capabilities. For example, you might extend the Service Locator with the ability to schedule between different processing nodes, and so on. Because you have been keeping infrastructure and platform specifics separate, you can make such changes easily.
It is important to emphasize that the architectural qualities (e.g., extensibility, performance, reliability) cannot be evaluated and achieved in total isolation. There are tradeoffs. Frequently, these architectural qualities conflict with one another. For example, extensibility implies that you add new elements to the system. As can be seen in Figure 17-9, new elements introduce additional delay, increasing the total response time of the entire system and degrading performance quality. You must also bear in mind that not all systems require all architectural qualities. For example, a system might not need to have a rich extensibility mechanism. There is also a question of time and resources, neither of which is unlimited. The goal when building the whole system, then, is to find the correct balance. The architect must be able to distinguish between what is important and what is not.
In this chapter, we discussed how to evaluate and achieve system qualities such as maintainability, extensibility, performance, and reliability. Key to achieving these qualities is the concept of separation of concerns. By following the approach outlined in Part IV, you can achieve effective separation of concerns and these qualities.
You probably noticed as you read preceding chapters in this part of the book that there is a general approach for dealing with concerns of different kinds—you model them with use cases; you analyze them and start separating use-case specific from use-case-generic; and you proceed in this manner all the way to code. Once you understand this general approach, aspect-oriented software development with use cases us easy.
It is important that you have an architecture that is of some minimum quality to start with. If you follow our approach, you will have a good candidate architecture to begin with, and you can commence evaluations and refinements iteratively. If you have a poor architecture to start with, the refinements you do will not give you the desired benefits. Your work will be time consuming. If your system is poorly organized in the first place, we strongly suggest that you take a step back and begin from analysis to establish a good candidate architecture of sufficient quality. Then consider how you can migrate the elements from the disorganized structure into this new candidate structure. Remember, it is architecture first.
Remember, too, that architectural evaluation is not a task that you do at the end of certain milestones. No—you evaluate the architecture continually in a project. If there are necessary improvements to be made, you make them immediately. Thus, achieving that an effective architecture and evaluation occur in parallel.