
1. Introduction
SQL SERVER 2005 contains features that constitute the biggest change since the internal server rewrite of SQL Server 7. This is true from both programmability and data model viewpoints. This chapter describes SQL Server 2005 in terms of .NET Framework programmability, SQL:1999 compliance, user-defined types (UDTs), and XML integration to present a picture of holistic data storage, manipulation, and access.
The .NET Framework and the Microsoft Platform
The .NET Framework is Microsoft’s latest environment for running program code. The concept of managed code, running under control of an execution engine, has quickly permeated all major operating systems, including those from Microsoft. The .NET Framework is one of the core technologies in Windows 2003 Server, Microsoft’s latest collection of server platforms. Handheld devices and computer-based mobile phones have quickly acquired .NET Framework-based development environments. The .NET Framework is an integral part of both Internet Information Server (IIS) and Internet Explorer (IE). ASP.NET runs on the Windows 2000 version and up of IIS 5.0. Internet Explorer 5.5, and can load and run .NET Framework code referenced by <object> tags embedded in Web pages. Rich .NET Framework–based Windows applications, based on the WinForms library that comes with the .NET Framework, may be deployed directly from the Internet and run on Windows-based desktops. So what is it about the .NET Framework that has caused it to catch on?
Managed code has made the .NET Framework so compelling. Development tools produce managed code using .NET Framework classes. Managed code is so named because it runs in an environment produced by mscoree.dll, the Microsoft common object runtime execution engine, which manages all facets of code execution. These include memory allocation and disposal, and class loading, which in traditional execution environments are major sources of programming errors. The .NET Framework also manages error recovery, and because it has complete information about the runtime environment, it need not always terminate an entire application in the face of an error such as an out-of-memory condition, but can instead terminate just a part of an application without affecting the rest of it.
.NET Framework code makes use of code access security that applies a security policy based on the principal running the code, the code itself, and the location from which the code was loaded. The policy determines the permissions the code has. In the .NET Framework, by default, code that is loaded from the machine on which it runs is given full access to the machine. Code loaded from anywhere else, even if run by an administrator, is run in a sandbox that can access almost nothing on the machine. Prior to the .NET Framework, code run by an administrator would generally be given access to the entire machine regardless of its source. The application of policies is controlled by a system administrator and can be very fine grained.
Multiple versions of the .NET Framework, based on different versions of user-written classes or different versions of the .NET base class libraries (BCL), can execute side by side on the same machine. This makes versioning and deployment of revised and fixed classes easier. The .NET Framework kernel or execution engine and the BCL can be written to work with different hardware. A common .NET Framework programming model is usable in x86-based 32-bit processors, like those that currently run versions of Windows 9x, Windows NT, Windows 2000, and Windows XP, as well as mobile computers like the iPaq running on radically different processors. The development libraries are independent of chipset. Because .NET Framework classes can be Just-in-Time compiled (JIT compiled), optimization based on processor type can be deferred until runtime. This allows the .NET Framework to integrate more easily with the new versions of 64-bit processors.
.NET Framework tools compile code into an intermediate language (IL) that is the same regardless of the programming language used to author the program. Microsoft provides C#; Visual Basic .NET; Managed C++; JavaScript; and J#, a variant of the Java language that emits IL. Non-Microsoft languages such as COBOL.NET and Eiffel.NET are also first-class citizens. Code written in different languages can interoperate completely if written to the Common Language Specification (CLS). Even though language features might be radically different—as in Managed C++, where managed and unmanaged code can be mixed in the same program—the feature sets are similar enough that an organization can choose the language that makes the most sense without losing features. In addition, .NET Framework code can interoperate with existing COM (Component Object Model) code (via COM-callable wrappers and runtime-callable wrappers) and arbitrary Windows Dynamic Link Libraries (DLLs) through a mechanism known as Platform Invoke (PInvoke).
The .NET Framework’s Effects on SQL Server
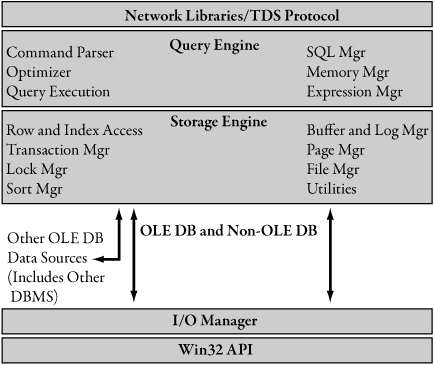
So the .NET Framework with managed code is so compelling because it improves developer productivity and the reliability and security of applications, provides interoperability among a wide variety of languages, and supports use of legacy Windows code not written using the .NET Framework. What does this mean with respect to SQL Server, Microsoft’s flagship database management system (DBMS)? Originally, SQL Server shared ancestry with the Sybase relational database management system (RDBMS). SQL Server version 7 was split off from this common ancestry and rewritten using component-based programming. This makes adding new features at any level of functionality easier. Prior to version 7, SQL Server was a monolithic application. SQL Server version 7 factored code into layers, with communication between the relational and storage engines accessible through OLE DB. The SQL Server 7 component-based architecture is shown in Figure 1-1. In addition to easing accommodation of new features in future versions, such as SQL Server 2005, the new component-based model offered a variety of form factors, from the SQL Server Enterprise Edition, that provided a data store for an entire enterprise to the Microsoft Data Engine (MSDE), which provided a data store for a single application. Separation of the relational engine from the storage engine in SQL Server 7 made it easier to accommodate other data sources, such as Exchange or WebDav, which are traditionally not thought of as databases. SQL Server’s relational engine can load OLE DB rowsets from an Exchange or WebDav store just as though it were processing data managed by the storage engine.
Figure 1-1. SQL Server architecture, version 7 and above
In versions of SQL Server prior to 2005, there were two ways to write programs that ran in SQL Server: Transact-SQL (T-SQL) and extended stored procedures. T-SQL is Microsoft’s proprietary implementation of persistent stored modules (SQL-PSM) as defined in SQL standards.
T-SQL code is highly integrated into SQL Server and uses data types that have the same representation in the storage engine as they do in T-SQL. Instances of these data types are passed between T-SQL and the storage engine without marshaling or conversion between representations. This makes T-SQL code as efficient in its use of data types as the compiled code that runs in the storage engine.
On the other hand, SQL Server interprets T-SQL code; it does not compile it prior to use. This is not as efficient an execution technique as is used by the compiled code in the storage engine but typically does not affect the performance of data access operations. It does affect, however, the performance of numeric and string-oriented operations. Prior to SQL Server version 7, T-SQL code was preparsed and precompiled into a tree format to alleviate some of this effect. Starting with SQL Server version 7, this is no longer done. An example of a simple T-SQL stored procedure is shown in Listing 1-1. Note that even though procedural code is interspersed with SQL statements, T-SQL variables passed between T-SQL and the storage engine are not converted.
Listing 1-1. A simple stored procedure
CREATE PROCEDURE dbo.find_expensive (
@category
@price MONEY,
@verdict VARCHAR(20) OUTPUT
)
AS
IF (SELECT AVG(cost)
FROM dbo.products WHERE cat = @category) > @price
SET @verdict = 'Expensive'
ELSE
SET @verdict = 'Good Buy'
Extended stored procedures are an alternative to interpreted T-SQL code and prior to SQL Server 2005 were the only alternative to T-SQL. Extended stored procedures written in a complied language, such as C++, do numeric and string operations more efficiently than T-SQL. They also have access to system resources such as files, the Internet, and timers that T-SQL does not. Extended stored procedures integrate with SQL Server through the Open Data Services API. Writing extended stored procedures requires a detailed understanding of the underlying operating system that is not required when writing T-SQL. Typically, more testing and debugging are needed to establish the reliability of an extended stored procedure than are needed for T-SQL stored procedures.
In addition, data access operations by an extended stored procedure are not as efficient as T-SQL. Data accessed using ODBC or OLE DB requires data type conversion that T-SQL does not. An extended stored procedure that does data access also requires a separate connection to the database even though it runs inside SQL Server itself. T-SQL directly accesses data in the storage engine and does not require a separate connection. Listing 1-2 shows a simple extended stored procedure written in C++.
Listing 1-2. A simple extended stored procedure
ULONG __GetXpVersion()
{ return ODS_VERSION; }
SRVRETCODE xp_sayhello(SRV_PROC* pSrvProc)
{
char szText[15] = "Hello World!";
// error handling elided for clarity
// describe the output column
srv_describe(pSrvProc, 1, "Column 1",
SRV_NULLTERM, SRVVARCHAR,
strlen(szText), SRVVARCHAR, 0, NULL);
// set column length and data
srv_setcollen(pSrvProc, 1, strlen(szText));
srv_setcoldata(pSrvProc, 1, szText);
// send row
srv_sendrow(pSrvProc);
// send done message
srv_senddone(pSrvProc,
(SRV_DONE_COUNT | SRV_DONE_MORE),
0, 1);
return (XP_NOERROR);
}
SQL Server uses structured exception handling to wrap all calls to extended stored procedures. This prevents unhandled exceptions from damaging or shutting down SQL Server. There is, however, no way for SQL Server to prevent an extended stored procedure from misusing system resources. A rogue extended stored procedure could call the exit() function in the Windows runtime library and shut down SQL Server. Likewise, SQL Server cannot prevent a poorly coded extended stored procedure from writing over the memory SQL Server is using. This direct access to system resources is the reason that extended stored procedures are more efficient than T-SQL for non–data access operations but is also the reason that a stored procedure must undergo much more scrutiny before it is added to SQL Server.
Under SQL Server 2005, T-SQL code continues to operate mostly as before. In addition to providing complete compatibility with existing code, this enables the millions of current T-SQL programmers to continue to write high-performance data access code for the SQL Server relational engine. For these programmers, T-SQL is still their language of choice.
SQL Server 2005 adds the ability to write stored procedures, user-defined functions, and triggers in any .NET Framework–compatible language. This enables .NET Framework programmers to use their language of choice, such as C# or Visual Basic .NET, to write SQL Server procedural code.
The .NET Framework code that SQL Server runs is completely isolated from SQL Server itself. SQL Server uses a construct in the .NET Framework called an AppDomain. It completely isolates all resources that the .NET Framework code uses from the resources that SQL Server uses, even though SQL Server and the AppDomain are part of the same process. Unlike the technique used to isolate stored procedures, the AppDomain protects SQL Server from all misuse or malicious use of system resources.
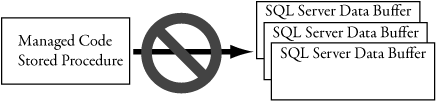
.NET Framework code shares the advantage of compilation with extended stored procedures. .NET Framework code is Just-In-Time compiled into machine instructions at execution time. .NET Framework classes are objects that enable usage of object-oriented programming techniques. The execution engine controls storage allocation and memory management. This ensures that short of a bug in the engine itself, .NET Framework procedural code will never step on random memory buffers. In case of severe programmer error, the execution engine can always dispose of the offending thread or even an AppDomain while SQL Server continues to run without interruption. This is shown in Figure 1-2. Writing SQL Server procedural code is examined in detail in Chapters 3 and 4.
Figure 1-2. Preventing managed code from interfering with SQL Server processing or writing over buffers
SQL Server 2005 ships with an in-memory .NET Framework data provider to optimize data access from managed procedural code. When using this provider, programmers have a choice of using vanilla .NET Framework types or SQL types. Some vanilla .NET Framework types, like System.Int32, require no conversion or marshaling, but some, such as System.Decimal, are not exact matches. The .NET Framework classes in System.Data.SqlTypes correspond exactly to the corresponding SQL Server types. Using these types in .NET Framework procedures means no type conversion or marshaling is required, and that means faster execution. Enhancements to SQL Server 2005’s ADO.NET provider, known as System.Data.SqlClient, also contains optimizations that permit .NET Framework procedural code to share an execution environment (including Connection and Transaction) with its caller. .NET Framework procedures can run in the security context of the user who cataloged the procedure or of the current user. Using the SqlClient data provider in .NET Framework procedures, triggers, and functions is discussed in Chapter 4.
The SQL:1999 Standard: Extending the Relational Model
Many of the interesting changes to the programmability and data type extensions in SQL Server 2005 are related to ongoing changes to the SQL standard, so it is instructive here to take a look at that standard. SQL:1999 is the latest version of ANSI standard SQL, although at this writing a newer version yet, known as SQL:2003, is in progress. Some of the features added to standard SQL in SQL:1999, such as triggers, have always been part of SQL Server. The more interesting features of SQL:1999 have to do with extending the type system to support extended scalar types, distinct types, and even complex types. In SQL Server 2005, you can add a new scalar type to the relational type system yourself without waiting for Microsoft to implement it in the engine. The most common use for SQL Server 2005 user-defined types will be to add new scalar types.
A distinct type extends simple data types (such as integer or varchar) with special semantics. A JPEG data type may be defined, for example. This type is stored as an IMAGE data type in SQL Server, but the IMAGE type is extended with user-defined functions such as get_background_color and get_foreground_color. Extending a simple type by adding behaviors was inspired by object-relational databases of the mid-1990s. Adding functions to the simple IMAGE type enables SQL queries that accomplish a task, such as “Select all the rows in the database where the JPEG column x has a background color of red.” Without the user-defined functions to extend the type, the IMAGE would have to be decomposed into one or more relational tables for storage. As an alternative, the background color could be stored separately from the IMAGE, but this could introduce update anomalies if the IMAGE were updated but the background color was not. SQL:1999 codified the definition of the distinct type and defined some rules for its use. As an example, if the JPEG type and the GIF type are both distinct types that use an underlying storage type of IMAGE, JPEG types and GIF types cannot be compared (or otherwise operated on) without using the SQL CAST operator. CAST indicates that the programmer is aware that two distinct types are being compared. Using the JPEG type’s get_background_color is likely to get incorrect results against a GIF column.
Complex types contain multiple data values, also called attributes. Including these data types in the SQL standard was inspired by the popularity of object-oriented databases in the early and mid-1990s. An example of a complex type is a person type that consists of a name, an address, and a phone number. Although these data types violate the first normal form of the relational data model and can be easily represented as a discrete table in a properly normalized database, these types have a few unique features. A diagram representing the data structures involved is shown in Figure 1-3.
Figure 1-3. Complex types in otherwise-relational tables

The person type could be used in multiple tables while maintaining its “personness”—that is, the same attributes and functions are usable against the person type even when the person column is used in three unrelated tables. In addition to allowing complex types, SQL:1999 defined types that could be references to complex types. A person type could contain a reference (similar to a pointer) to an address type in a different table, as shown in Listing 1-3.1
Listing 1-3. Using SQL:1999 structured data types
CREATE TYPE PERSON (
pers_first_name VARCHAR(30),
pers_last_name VARCHAR(30),
-- other fields omitted
pers_address REF(ADDRESS) SCOPE ADDR_TAB)
)
CREATE TYPE ADDRESS (
addr_street VARCHAR(20),
addr_city VARCHAR(30),
addr_state_province VARCHAR(10),
addr_postal_code VARCHAR(10)
)
CREATE TABLE ADDR_TAB (
addr_oid BIGINT,
addr_address ADDRESS
)
In addition, complex type–specific methods could be defined, and the SQL language was extended to support using attributes of a complex type in queries. An example of a complex type and a SELECT statement that uses it would look like the following:
SELECT pers.address FROM ADDR_TAB
WHERE ADDR.addr_city like 'Sea%'
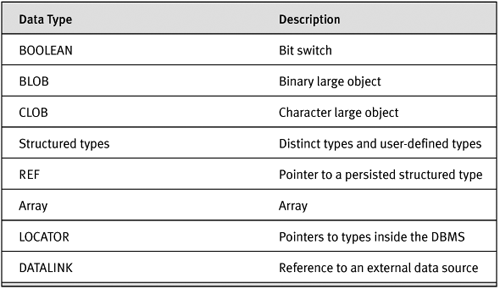
SQL:1999 expanded the type system to add some less revolutionary types, such as the BOOLEAN data type (which can contain TRUE, FALSE, or NULL) and the LOCATOR and DATALINK data types, which point to other storage inside or outside the database. A complete list of the new types is shown in Table 1-1.
Table 1-1. New Data Types in SQL:1999
User-Defined Types and SQL Server
SQL Server has always supported its own concept of a user-defined data type. These data types are known as alias types and are defined by using the system stored procedure sp_addtype.2 These data types share some functionality with SQL:1999 distinct types. They must be derived from a SQL Server built-in data type. You can add integrity constraints by using SQL Server RULEs. You create a SQL Server RULE using CREATE RULE and associate a rule with a SQL Server user-defined type by using sp_bindrule. A single user-defined data type can be used in multiples tables, and a single SQL Server rule can be bound to more than one user-defined type. Creating two SQL Server data types, creating rules, and binding the rules to the types are shown in Listing 1-4.
Listing 1-4. Creating types and binding them to rules
-- define two user-defined types
EXEC sp_addtype iq, 'FLOAT', 'NULL'
EXEC sp_addtype shoesize, 'FLOAT', 'NULL'
-- specify constraints
CREATE RULE iq_range AS @range between 1 and 200
CREATE RULE shoesize_range AS @range between 1 and 20
-- bind constraint to type
EXEC sp_bindrule 'iq_range', 'iq'
EXEC sp_bindrule 'shoesize_range', 'shoesize'
SQL Server user-defined types have some things in common with SQL distinct types. Like distinct types, they extend the SQL types by adding user-defined behaviors, in that a rule can be considered a behavior. Unlike SQL distinct types, they may not have associated user-defined functions that are scoped to the type. Although we defined the shoesize type and limited its values to floating-point numbers from 1 to 20, for example, we cannot associate a function named derive_suit_size_from_shoesize with the type. This would be possible if shoesize were a SQL standard derived type. In addition, SQL Server user-defined types are comparable based on where the underlying built-in type is comparable, without using the SQL CAST operator. The SQL specification mandates that a user-defined type must be cast to a built-in or user-defined type before it can be used in a comparison operation, but attempting to apply the CAST operator to a user-defined type in SQL Server causes an error. Listing 1-5 shows this difference in behavior.
Listing 1-5. Comparing unlike user-defined types
-- use the type
CREATE TABLE dbo.people (
personid INTEGER,
iq iq,
shoe shoesize,
spouse_shoe shoesize
)
-- SQL Server syntax
SELECT * FROM dbo.people WHERE iq < shoe
-- SQL:1999 syntax
-- invalid in SQL Server
-- SELECT * FROM dbo.people
WHERE CAST(iq AS shoesize) < shoe
SQL Server 2005 goes beyond previous versions in support of SQL:1999 distinct and complex user-defined types. Extended data types must be defined as .NET Framework classes and cannot be defined in T-SQL, although they are accessible in T-SQL stored procedures, user-defined functions, and other procedural code. These classes (types) may have member functions that are accessible in T-SQL … la SQL distinct types, and in addition, they may have mutator functions that are usable in T-SQL UPDATE statements.
In addition to enabling users to define distinct types based on a single built-in data type, SQL Server 2005 allows user-defined types to have multiple storage items (attributes). Such a user-defined data type is considered a complex type in SQL:1999. Once defined to the SQL Server catalog, the new type may be used as a column in a table. Variables of the type may be used in stored procedures, and the type’s attributes and methods may be used in computed types and user-defined functions. Although we’ll see how to define user-defined distinct and complex types in Chapter 5, Listing 1-6 shows an example of defining a user-defined complex type, SecondsDelay, and using it as a column in a table.
Listing 1-6. Defining a user-defined type and using it in a table
CREATE TYPE SecondsDelay
AS EXTERNAL NAME SomeTypes.SecondsDelay
GO
CREATE TABLE Transforms(
transform_id BIGINT,
transform_input, SecondsDelay,
transform_result SecondsDelay)
GO
After even a fundamental description, we should immediately point out that SQL Server complex types extend relational data types. The most common usage will not be to define “object” data types that might be defined in an object-oriented database, but to define new scalar types that extend the relational type system, such as the SecondsDelay type shown in Listing 1-6. In SQL Server 2005, the server is unaware of the inheritance relationships among types (although inheritance may be used in the implementation) or polymorphic methods, however, as in traditional object-oriented systems.
That is, although we can define a complex user-defined type called SecondsDelay that contains multiple data fields (whole seconds, whole milliseconds) and instance methods, and define a complex type called MinutesDelay that inherits from SecondsDelay and adds a whole minutes field to it, we cannot invoke methods of the SecondsDelay type when using an MinutesDelay type or cast MinutesDelay to SecondsDelay.
In addition to supporting user-defined types, SQL Server 2005 supports user-defined aggregate functions. These types extend the concept of user-defined functions that return a single value and can be written in any .NET Framework language, but not T-SQL. The SQL specification defines five aggregates that databases must support (MAX, MIN, AVG, SUM, and COUNT). SQL Server implements a superset of the specification, including such aggregates as standard deviation and variance. By using SQL Server 2005 support for .NET Framework languages, users need not wait for the database engine to implement their particular domain-specific aggregate. User-defined aggregates can even be defined over user-defined types, as in the case of an aggregate that would perform aggregates over the SecondsDelay data type described earlier.
Support of user-defined types and aggregates moves SQL Server closer to SQL:1999 compliance, and it extends SQL:1999 in that SQL:1999 does not mention user-defined aggregates in the specification.
XML: Data and Document Storage
XML is a platform-independent data representation format based originally on Standard Generalized Markup Language (SGML). Since its popularization, it is becoming used as a data storage format. It has its own type system, based on the XML schema language (XSD). Both XML and XSD are W3C standards at the Recommendation level.3 An XML schema defines the format of an XML document as a SQL Server schema defines the layout of a SQL Server database.
The XML type system is quite rigorous, enabling definition in XML schema definition language of almost all the constructs available in a relational database. Because it was originally designed as a system that could represent documents with markup as well as what is traditionally thought of as “data,” the XML type system is somewhat bifurcated into attributes and elements. Attributes are represented in the XML serialization format as HTML attributes are, using the name='value' syntax. Attributes can hold only simple data types, like traditional relational attributes. Elements can represent simple or complex types. An element can have multiple levels of nested subelements, as in the following example:
<table>
<row>
<id>1</id>
<name>Tom</name>
</row>
<row>
<id>2</id>
<name>Maureen</name>
</row>
</table>
This means that an element can be used to represent a table in a relational database. Each tuple (row) would be represented as a child element, with relational attributes (columns) represented as either attributes or subelements. The two ways of representing relational column data in XML are known as element-centric mapping (where each column is a nested subelement) and attribute-centric mapping (where each column is an attribute on an element tuple). These are illustrated in Listing 1-7.
Listing 1-7. Element-centric mapping and attribute-centric mapping
<!-- element-centric mapping -->
<!-- all data values are element content -->
<table>
<row>
<id>1</id>
<name>Tom</name>
</row>
<row>
<id>2</id>
<name>Maureen</name>
</row>
</table>
<!-- same document in attribute-centric mapping-->
<!-- id and name are represented as attributes -->
<!-- and cannot themselves be complex types -->
<table>
<row id="1" name="Tom" />
<row id="2" name="Maureen" />
</table>
Because subelements can be nested in XML documents, a document more closely corresponds to a hierarchical form of data than to a relational form. This is reinforced by the fact that by definition, an XML document must have a single root element. Sets of elements that do not have a single root element are called document fragments. Although document fragments are not well-formed XML documents, multiple fragments can be composed together and wrapped with a root element, producing a well-formed document.
In addition to being able to represent relational and hierarchical data, XML schema definition language (XSD) can represent complex type relationships. XSD supports the notion of type derivation, including derivation by both restriction and extension. This means that XML can directly represent types in an object hierarchy.
A single XML schema document (which itself is defined in an XML form specified by the XML schema definition language) represents data types that scope a single XML namespace, although you can use XML namespaces in documents without having the corresponding XML schema. An XML namespace is a convenient grouping of types, similar to a schema in SQL Server. This is illustrated in Listing 1-8.
Listing 1-8. An XML namespace defining a set of types
<schema targetNamespace="http://www.MyCompany.com/order.xsd"
xmlns:po="http://www.MyCompany.com/order.xsd"
xmlns="http://www.w3.org/2001/XMLSchema"
elementFormDefault="qualified">
<!-- define a new type -->
<complexType name="PurchaseOrderType">
<sequence>
<element name="PONum" type="decimal"/>
<element name="Company" type="string"/>
<element name="Item" maxOccurs="1000">
<!-- a nested anonymous type -->
<complexType>
<sequence>
<element name="Part" type="string"/>
<element name="Price" type="float"/>
</sequence>
</complexType>
</element>
</sequence>
</complexType>
<!-- global element definition using type above -->
<element name="PurchaseOrder" type="po:PurchaseOrderType"/>
</schema>
An XML schema defines the namespace that its types belong to by specifying the targetNamespace attribute on the schema element. An XML document that uses types from a namespace can indicate this by using a default namespace or explicitly using a namespace prefix on each element or attribute of a particular type. Namespace prefixes are arbitrary; the xmlns attribute established the correspondence between namespace prefix and namespace. This is illustrated in Listing 1-9. This is analogous to using SQL Server two-part or three-part names in SQL statements.
Listing 1-9. Referring to a type via namespace and namespace prefixes
<pre:PurchaseOrder
xmlns:pre="http://www.MyCompany.com/order.xsd"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.MyCompany.com/order.xsd
http://www.MyCompany.com/schemas/order.xsd">
<pre:PONum>1001</pre:PONum>
<pre:Company>SQL Traders</pre:Company>
<pre:Item>
<pre:Part>Dons Boxers</pre:Part>
<pre:Price>11.95</pre:Price>
</pre:Item>
<pre:Item>
<pre:Part>Essential ADO.NET</pre:Part>
<pre:Price>49.95</pre:Price>
</pre:Item>
</ pre:PurchaseOrder>
Only when an XML document contains types defined by XML schemas is it possible to determine the exact data types of elements or attributes. XML elements and attributes are data type "string" by definition, although the encoding used in the document can be defined in the XML document element. A predecessor of XML schemas, known as Document Type Definition (DTD), was primarily concerned with defining document structure and allowed only limited information about data types. XSD is a superset of the aforementioned type systems, including all the DTD structure types. Using an XSD schema or schemas to determine whether a document is “correct” is known as schema validation. Schema validation can be thought of as applying type constraints and declarative integrity constraints to ensure that an XML document is correct. A nonvalidated XML schema still must conform to XML “well-formedness” rules, and a single XML document adheres to a set of rules known as the XML Infoset, consisting of structure and some content information. Validating an XML document against one or more XML schemas produces what is called a Post Schema Validation Infoset (PSVI). The PSVI information makes it possible to determine a strong, well-defined type for each XML element and attribute.
SQL Server 2005 introduces an XML data type. This data type can be used in table definitions to type a column, as a variable type in T-SQL procedural code, and as procedure parameters. A definition of a simple table containing an XML type would look like a “normal” CREATE TABLE statement:
CREATE TABLE dbo.xml_tab(
id INTEGER PRIMARY KEY,
xml_col XML)
In addition, columns, variables, and parameters of the XML data type can be constrained by an XML schema. XML schemas are defined in the SQL Server catalog.
XML, like relational databases, has its own query language optimized for the data format. Because XML data is hierarchical, it’s reminiscent of a hierarchical file system. The archetypical query language for XML documents is known as XPath. Queries in XPath reflect the hierarchical nature of XML, because nodesets are selected by using syntax similar to that used to specify files in the UNIX file system. As an example, when a typical XML document is queried using a hierarchical XPath query, the result is a nodeset containing all the nodes at that level of hierarchy. Listing 1-10 shows an example of an XPath query that, when run against the purchase-order document in Listing 1-9, produces a nodeset result containing all the item elements. Think of an XPath query as analogous to a SQL query.
Listing 1-10. Simple XPath query
<!-- this query -->
//pre:Item
<!-- produces this nodeset -->
<!-- two Item nodes -->
<pre:Item>
<pre:Part>Dons Boxers</pre:Part>
<pre:Price>11.95</pre:Price>
</pre:Item>
<pre:Item>
<pre:Part>Essential ADO.NET</pre:Part>
<pre:Price>49.95</pre:Price>
</pre:Item>
Like a SQL query, an XPath query simply produces a resultset consisting of possibly multiple instances of items; unlike in SQL, these results are not always rectangular. XPath results can consist of nodesets of any shape or even scalar values. In SQL, database vendors can implement a variation of SQL-PSM that composes possibly multiple SQL queries and some procedural code to produce a more complex result. SQL Server’s variation of SQL-PSM is known as T-SQL. XML processing libraries implement an analogous concept by using an XML-based nonprocedural language called XSLT (Extensible Stylesheet Language Transformations). Originally meant to produce nice-looking HTML pages from XML input, XSLT has evolved into an almost full-fledged programming language. Vendors have even added proprietary extensions to XSLT to allow it to execute code routines in procedural programming languages like Visual Basic and C#.
Because XPath and XSLT were not originally developed to process large amounts of data, a new programming language for XML, known as XQuery, has been developed under the auspices of the W3C. XQuery implements many of the best features of XPath and XSLT, is developed from the ground up to handle large documents, and is also designed specifically to be optimizable. In addition, it adds some of the syntax features of SQL. XQuery’s data can be strongly typed; this also assists in query optimization. XQuery includes a query language, the equivalent of SQL Server SELECT, but does not define a standard implementation of the equivalent of SQL Server’s INSERT, UPDATE, and DELETE statements.
SQL Server 2000 allows users to define mapping schemas (normal XML schemas with extra annotations that mapped XML items and concepts to SQL items and concepts) that represented all or a portion of the database as a virtual XML document, and to issue XPath queries against the resulting data structure. In addition, SQL Server 2000 extended T-SQL to enable relational resultsets to be returned as XML. This consists of support for a FOR XML clause; three different subcategories of FOR XML are supported. The SQL Server 2000 support allows XML document composition from relational data and XML document decomposition into multiple relational tables; this will be discussed further in Chapter 8.
SQL Server 2005 extends this support by adding direct support for XQuery. The XQuery engine runs directly inside SQL Server, as opposed to XPath support in SQL Server 2000. XPath support in SQL Server 2000 is accomplished by a portion of the SQL Server OLE DB provider (SQLOLEDB) that took a mapping schema and an XPath query, produced a SELECT ... FOR XML query, and sent that query to SQL Server. Native support for XQuery, combined with XQuery’s design for optimization, and support for multiple documents (a series of XML columns) should improve on the already-good support for querying XML data.
Web Services: XML As a Marshaling Format
Marshaling data to unlike platforms has always been a problem. In the past, vendors could not even agree on a marshaling format, let alone a common type system. Microsoft used COM (component object model) for its distributed object model and marshaling format; it did not support CORBA (common object request broker architecture). Processor differences such as endianness (byte ordering), floating-point representation, and character set were considered in both these models. Marshaling between systems required a “reader–make right” approach—that is, the receiver of a message had to determine the format and convert it to something understandable to his processor. In addition, the distributed programming models were plagued by the requirement to have a specific naming model or security system. As an example, porting COM to the Solaris platform required installing the equivalent of a Windows Registry and an NTLM security service. But the biggest problems were network protocol and access to specific ports on network servers. COM not only used a proprietary protocol and network ports when run over TCP/IP, but also required opening port 135 for the naming service to operate correctly—something that few systems administrators would permit for security reasons. By contrast, most systems administrators gladly opened port 80 and allowed the HTTP protocol, even setting up special proxy servers rather than deny internal users access to the World Wide Web. Systems such as DCOM over HTTP and Java RMI over HTTP were the first steps away from a proprietary distributed programming system.
Vendors such as Microsoft, IBM, Oracle, and Sun are moving toward supporting distributed computing over HTTP using a framing protocol known as SOAP and using XML as a marshaling format. SOAP itself uses XML to frame XML-based payloads; elements and attributes used in SOAP are defined in two XSD schemas. SOAP also defines a portable way of representing parameters to remote procedure calls (RPCs), but since the completion and adaptation of XML schemas, a schema-centric format has been used. Using XML as a marshaling format, framed by SOAP, possibly over HTTP, is known as Web Services.
The popularity of XML and Web Services, like the popularity of SQL, is fairly easy to explain. Managers of computer systems have learned over time to shy away from proprietary solutions, mostly because companies often change hardware and operating system (and other) software over time. In addition, a company may have to communicate with other companies that use an unlike architecture. Therefore, protocols like HTTP; formats like XML and CSV (comma-separated value) files; and languages like SQL, XPath, XSLT, and XQuery tend to be used for a single reason: They are available on every hardware and software platform.
Consider as an example the RDS (remote data services) architecture used by Microsoft to marshal resultsets (known as recordsets) over HTTP in a compact binary format, as opposed to XML, a rather verbose text-based format. Because Microsoft invented the RDS marshaling format (known as Advanced Data Tablegrams, or ADTG), other vendors (such as Netscape) refused to support it. This is known as NIH (not invented here) syndrome. On the other hand, visit any large software or hardware manufacturer on the planet, and ask, “Who invented XML?” The answer is always the same: “We did.” Because XML (or SQL, to expand the analogy) cannot possibly be perceived as “a Microsoft thing” or “an Oracle thing,” support is almost universal.
SQL Server 2005 supports creating Web Services and storing data to be used in Web Services at a few different levels. The XML data type and XQuery support mentioned previously are a good start. Data can be stored in XML format inside SQL Server and used directly with XQuery to produce or consume Web Services. With the addition of direct support in SQL Server for HTTP, we could think of SQL Server 2005 as a “Web Services server.” This reduces the three-tier architecture usually required to support Web Services (database, middle tier, and client) to a two-tier architecture, with stored procedures or XQuery/XSLT programs being used as a middle tier.
Client Access . . . And Then There Are Clients
Database programmers, especially those who specialize in procedural dialects of SQL, tend to forget that without client access libraries, a database is just a place to keep data. Although the SQL language itself was supposed to ensure that ordinary clients could access the data, performance issues and the complexity of SQL queries (and XPath and XQuery queries, for that matter) ensure that very few (if any) users actually go right to SQL Server Management Studio or Query Analyzer for the data they need, and no enterprise applications that we know of use SQL Server Management Studio as a front end to the database. Applications, both rich Windows applications and Web applications, are written using high-level programming languages like C++, Visual Basic, and the .NET Framework family of languages.
Client-Side Database APIs and SQL Server 2005
With all the new features in SQL Server 2005, client libraries such as OLE DB have quite a lot of work to do just to keep up. Although the designers of OLE DB and ADO designed support for user-defined types into the model, the intricacies of supporting them weren’t made clear until support for these types was added to popular mainstream databases like SQL Server 2005. OLE DB and ADO are very Rowset/Recordset-centric and have limited support for user-defined types, invoking methods on database types and extending the type system. The next version of these libraries adds support for fetching complex types in a couple of different ways: as a data type Object or as a nested resultset (Rowset or Recordset). Most of the support in OLE DB and ADO leverages existing objects and methods, and extends them to support the new types. Support for the SQL:1999 information schema rowsets is another new feature in data access.
The client-side .NET Framework data provider for SQL Server, known as SqlClient, has an easier time of it. Because user-defined types are .NET Framework types, code to process these types might be downloaded to a client from a SQL Server or stored on a network share. It’s possible to coerce a column in a DataReader from type Object to type Person and use it directly in a .NET Framework program. Techniques such as network-based code make this work. Handling complex data in situ or storing complex types in a .NET Framework DataSet presents a different set of problems. Bob Beauchemin’s first book, Essential ADO.NET (Addison-Wesley, 2002), describes many of these problems and theoretical solutions to them based on the existing .NET Framework libraries. Now that SQL Server supports columns that are classes or columns that are XML, this becomes an interesting area.
One limitation of SQL Server clients was that only a single Rowset or Recordset could be active at a time in the default cursorless mode of SQL Server data access. Different APIs solved this problem in different ways, and we’ll talk about the repercussions of this in Chapter 11. SQL Server 2005 breaks through the one-active-rowset barrier by allowing the user APIs to multiplex active results on a single connection. This empowering feature is known as MARS (multiple active resultsets).
Client-Side XML-Based APIs and SQL Server 2005 Integration
XML is ubiquitous in the SQL Server 2005–era client APIs. User-defined types use .NET Framework XML Serialization to be able to be marshaled or persisted as XML directly. The FOR XML syntax has been extended to allow a user to fetch data in an XML type. In addition, SQL Server Analysis Services can directly consume queries in XML format and produce XML results. This is called XML for Analysis and has been around for a while; in SQL Server 2005, it becomes a first-class API directly supported and on a par with OLE DB for Analysis. If you’ve gotten used to OLE DB for Analysis (or its automation equivalent, ADOMD), don’t fret; XML for Analysis uses an OLE DB–style syntax for both queries and properties.
The XML data type and XQuery engine inside SQL Server 2005 are complemented by a rich middle-tier or client-side model for XML. This model exposes XML data outside the server using a variety of data models. These models include the XML Document Object Model (DOM) and abstract XmlNavigator model, in addition to streaming models known as XmlReader and XmlWriter. The standard XML query and transformation models, XPath and XSLT, have been part of the .NET Framework platform since its inception.
Extending SQL Server into the Platform: Service Broker and Notification Services
Finally, SQL Server 2005 adds two more pieces of data access and application programming functionality that bear mention. SQL Server Service Broker allows you to use T-SQL to send asynchronous messages. These messages can be exchanged only with SQL Server 2005, but the messages can be sent to the same database, between databases in the same instance, or to a different instance on the same machine or different machines. The asynchronous messages work similarly to a message queuing system (they even use queues), but because SQL Server is controlling both the database data and the messages, messages can participate in a local database transaction. The T-SQL language is being extended to support the handling of queued messages that can be retrieved asynchronously.
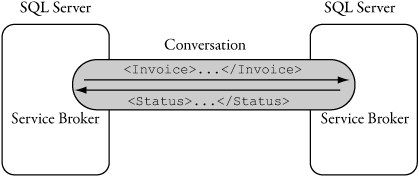
SQL Server Service Broker uses dialogs to achieve coordinated messaging with multimessage correlation semantics. A dialog is a bidirectional series of messages between two endpoints, in which each message contains a conversation ID to enable the other side to correlate messages, as shown in Figure 1-4.
Figure 1-4. Messages and dialogs
One of the main advantages of a dialog is that it maintains message order across transactions, threads, applications, and database restarts—something no other messaging system does. A dialog also allows guaranteed delivery of messages to a number of different subscribers. Multiple dialogs can be grouped into a single “application” known as a Conversation Group. A Conversation Group can maintain its state and share state among multiple dialogs. This goes beyond the concept of simple correlation ID message queuing systems, and it’s handled automatically by Service Broker rather than manually by the application programmer.
Using asynchronous messaging inside the database enables building scalable systems, because work that had to be handled serially in the past can now be multiplexed in the same transaction. In addition, Service Broker guarantees that the messages will arrive in order, even across transactions, and guarantees once-only delivery.
SQL Server Notification Services is an easy-to-use but powerful framework around which you can build scalable “notification applications” that can notify millions of users about millions of interesting events, using standard notification protocols like SMS (Simple Message Service) and programs like MSN Messenger. The unique pieces, such as an application, are defined using XML and integrated with the framework (which runs as a series of stored procedures over a mostly system-defined schema).
We’ll discuss Service Broker in Chapter 11 and Notification Services in Chapter 16. In addition, SQL Server 2005 adds a set of reporting tools to extend further the data-related platform. The Reporting Services feature is outside the scope of this book, but it does, among other things, allow users to get parameterized reports and to make a restricted set of ad hoc queries without the need to develop an application. Reporting Services continues the .NET Framework theme in SQL Server by allowing the use of .NET Framework classes to assist in building and displaying reports.
Where Are We?
In this chapter, we’ve had a whirlwind tour of the plethora of new technologies in SQL Server 2005; the problems they are intended to solve; and, in some cases, the entirely new data models they represent. SQL Server 2005 supports .NET Framework programming, user-defined data types and aggregates, and an XML data type. The support for these alternative data types extends from the server out to the client.
In the rest of the book, we’re going to explore the implementation and best practices when using these new data models, and see that SQL Server 2005 and improvements to the client libraries truly represent the integration of relational data, object-oriented data and concepts, and XML data.