
Chapter 9. Multiple Fronts
Tackling Concurrency
Yet to their General’s Voice they soon obey’d Innumerable. Paradise Lost, Book I
—John Milton (1608–1674)
When we have a lot of sessions running concurrently, all accessing one database, we may encounter difficulties that can remain hidden when running single-user tests. Contention occurs, and locks may be held for unpredictable periods of time. This chapter discusses how to face the situation when users advance in overwhelming numbers.
There are several different issues associated with a large number of concurrent users. One of the most obvious is contention when updating (sometimes reading) data and the consequent requirement for locks at one level or another. But users are not only fighting for the right to modify bytes at one place in the system without any interference from others; they are also competing for processing power, access to disks, workspace in memory, and network bandwidth. Very often difficulties that are latent with a few users become blatant with many. Increases in the number of users are not always as smooth as one might expect them to be. Sudden increases can come through the meteoritic success of your company, but fast-paced increases more often happen through the gradual deployment of applications—or sometimes as a result of mergers or buyouts.
The Database Engine as a Service Provider
You might be tempted to consider the DBMS as an intelligent and dedicated servant that rushes to forestall your slightest desire and bring data at the exact time when you need it. Reality is slightly less exalted than the intelligent servant model, and at times a DBMS looks closer to a waiter in a very busy restaurant. If you take your time to choose from the menu, chances are that the waiter will tell you “I’ll let you choose, and I’ll come back later to take your order” before disappearing for a long time. A DBMS is a service provider or, perhaps more precisely, a collection of service providers. The service is simply to execute some operation against the data, fetching it or updating it—and the service may be requested by many concurrent sessions at the same time. It is only when each session queries efficiently that the DBMS can perform efficiently.
The Virtues of Indexes
Let’s execute some fairly basic tests against a very simple
table with three columns. The first two are integer columns (each
populated with distinct values from 1 to 50,000), one being declared
as the primary key and the second without an index. The third column
(named label) is a text column
consisting of random strings thirty to fifty characters long. If we
generate random numbers between 1 and 50,000 and use these random
numbers as query identifiers to return the label column, you might be
surprised to discover that on any reasonably powerful machine, the
following query:
select label
from test_table
where indexed_column = random value
as well as this one:
select label
from test_table
where unindexed_column = random value
provide virtually instant results. How is this possible? A query using an unindexed column should be much slower, surely? Actually, a 50,000-row table is rather small, and if it has as few columns as is the case in our example, the number of bytes to scan is not that enormous, and a modern machine can perform the full scan very rapidly. We indeed have, on one hand, a primary key index search, and on the other hand, a full-table scan. What’s happening is that the difference between indexed and unindexed access is too small for a human to perceive.
To really test the benefit of an index, I have run our queries continuously for one minute, and then I have checked on how many queries I was able to process by unit of time. The result is reassuringly familiar: on the machine on which I ran the test, the query using the indexed column can be performed 5,000 times per second, while the query using the unindexed column can only be performed 25 times per second. A developer running single user tests may not really notice a difference, but there is one, and it is truly massive.
A Just-So Story
Continuing with the example from the preceding section,
let’s have a look at what may very well happen in practice. Suppose
that instead of being a number, the key of our table happens to be a
string of characters. During development, somebody notices that a
query has unexpectedly returned the wrong result. A quick
investigation shows that the key column contains both uppercase and
lowercase characters. Under pressure to make a quick fix, a developer
modifies the where clause in the
query and applies an upper( )
function to the key column—thus forfeiting the index. The developer
runs the query, the correct result set is returned, and anyone other
than a native of the planet Krypton cannot possibly notice any
significant difference in response time. All appears to be for the
best, and we can ship the code to production.
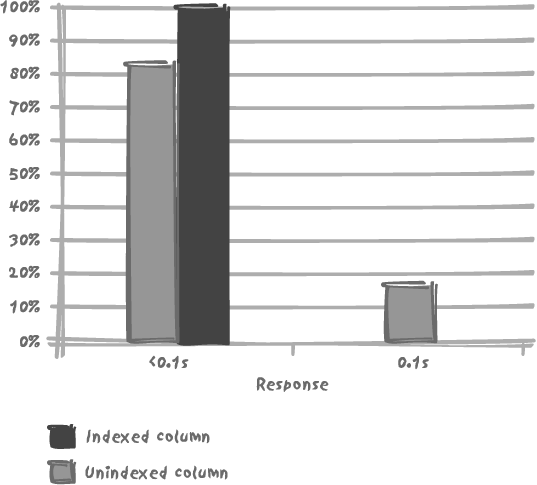
Now we have hordes of users, all running our query again, again and again. Chapter 2 makes the point that in our programs we should not execute queries inside loops, whether they are cursor loops or the more traditional for or while constructs. Sadly, we very often find queries nested inside loops on the result set of other queries, and as a result, our query can be run at a pretty high rate, even without having tens of thousands of concurrent users. Let’s see now what happens to our test table when we run the query at a high rate, with a set number of executions per unit of time, occurring at random intervals. When we execute our query at the relatively low rate of 500 per minute, everything appears normal whether we use the index or not, as you can see in Figure 9-1. All our queries complete in under 0.2 seconds, and nobody will complain.
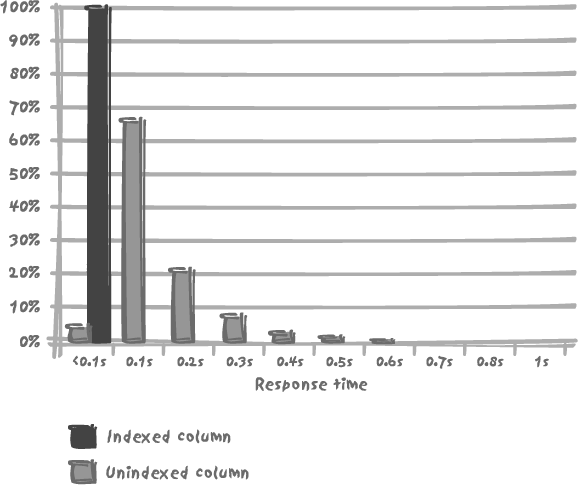
We actually have to increase our execution rate 10 times, to a relatively high rate of 5,000 executions per minute, to notice in Figure 9-2 that we may occasionally have a slow response when we use the unindexed column as key. This, however, affects only a very low percentage of our queries. In fact, 97% of them perform in 0.3 seconds or less.
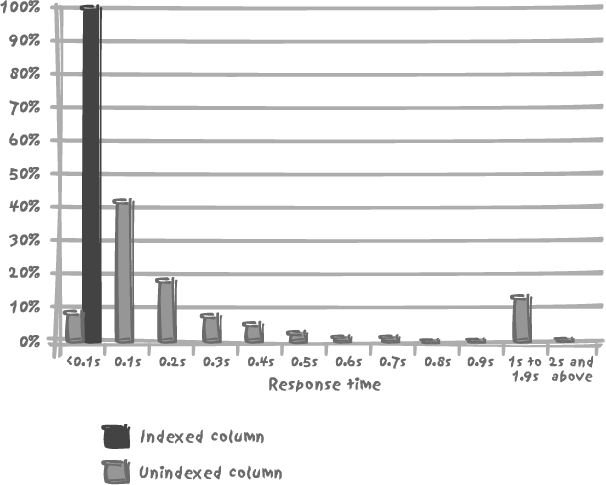
But at 5,000 queries per minute, we are unaware that we are tottering on the brink of catastrophe. If we push the rate up to a very high 10,000 executions per minute, you can see in Figure 9-3 that a very significant proportion of the queries will execute noticeably more slowly, some taking as long as 4 seconds to complete. If in another test we run the queries that use the index at the same high rate, all queries execute imperturbably in 0.1 seconds or less.
Of course, when some queries that used to run fast start to take much longer, users are going to complain; and other users who, unprompted, would otherwise have noticed nothing will probably grumble as well, out of sympathy. The database is slow—can’t it be tuned? Database administrators and system engineers will tweak parameters, gaining a few weeks of relief, until the evidence will finally impose itself, in all its glorious simplicity: we need a more powerful server.
Get in Line
One can take a fairly realistic view of a DBMS engine by imagining it to be like a post office staffed by a number of clerks serving customers with a wide array of requests—our queries. Obviously, a very big post office will have many counters open at the same time and will be able to serve several customers all at the same time. We may also imagine that young hypercaffeinated clerks will work faster than older, sedate, herbal-tea types. But we all know that what will make the biggest difference, especially at peak hours, is the requests actually presented by each customer. These will vary between the individual who has prepared the exact change to buy a stamp book and the one who inquires at length about the various rates at which to send a parcel to a remote country, involving the completion of customs forms, and so on. What is most irritating is of course when someone with a mildly complicated request spends several minutes looking for a purse when the moment for payment arrives. But fortunately, in post offices, you never encounter the case that is so frequent in real database applications: the man with 20 letters who joins the queue on 20 separate successive occasions, buying only one stamp in each visit to the counter. It is important to understand that there are two components that determine how quickly one is served at the counter:
The performance of, in our example, the clerk. In the case of a database application, this equates to a combination of database engine, hardware, and I/O subsystems .
The degree of complexity of the request itself, and to a large extent how the request is presented, its lucidity and clarity, such that the clerk can easily understand the request, and accordingly make a quick and complete answer.
In the database world, the first component is the domain of system engineers and database administrators. The second component belongs squarely within the business requirements and development arena. The more complicated the overall system, the more important becomes the collaboration between the different parties involved when you want to get the best out of your hardware and software investment.
With the post-office image in mind, we can understand what happened in our query test. What matters is the ratio of the number of customers arriving (e.g., the rate of execution of queries), to the average time required to answer the query. As long as the rate of arrival is low enough to enable everyone to find a free counter, nobody will complain. However, as soon as customers arrive faster than they can be serviced, queues will start to lengthen, just as much for the fast queries as for the slow ones.
There is a threshold effect, very similar to what one of Charles Dickens’s characters says in David Copperfield:
Annual income twenty pounds, annual expenditure nineteen six, result happiness. Annual income twenty pounds, annual expenditure twenty pounds ought and six, result misery.
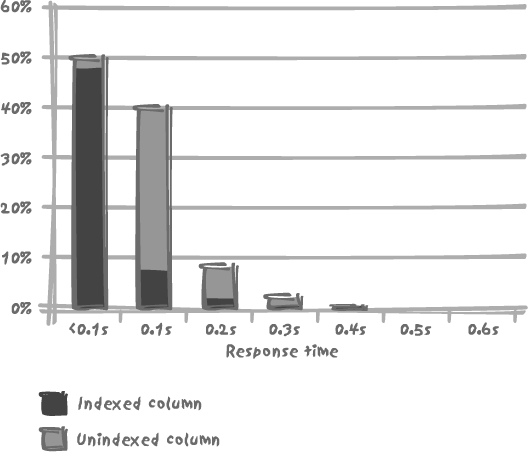
This can easily be demonstrated by running our two queries simultaneously, the one using the indexed column and the other using the unindexed column, at a rate of 5,000 times per second. The compound result of Figure 9-4 is noticeably different from Figure 9-2, in which results were shown for the two queries running separately, not concurrently. As appears clearly from Figure 9-4, the performance of the fast query has deteriorated because of the simultaneous presence of slow queries.
Concurrent Data Changes
When you change data, the task of maintaining a good level of performance becomes even more difficult as the level of activity increases. For one thing, any change is by essence a more costly operation than a mere query, since it involves both getting the data and then writing it back to the database. In the case of inserts, only the latter operation applies. Therefore, data modification, whether updates, deletes, or inserts, intrinsically requires a longer service time than the equivalent query-only task. This longer service time is made worse by one mechanism and one situation that are often confused. The mechanism is locking , and the situation is contention.
Locking
When several users want to modify the same data at once—for instance to book the very last seat on a flight—the only solution available to the DBMS is to block all but one user, who is usually the first person to present the request. The necessity of sequentializing access to critical resources is a problem that is as old as multiuser systems themselves. It existed with files and records long before database systems began to be adopted. One user acquires a lock over a resource, and the other users who also want to lock the same resource either have to queue up, waiting patiently for the lock to be released, or handle the error code that they will receive. In many ways, the situation is entirely analogous to our fictitious post office when several customers require the use of a single photocopier—people must wait patiently for their turn (or turn away and come back later).
Locking granularity
One of the most important practical questions to address when attempting to change the contents of the database will be to determine exactly where the locks will be applied. Locks can impact any or all of the following:
The entire database
The physical subset of the database where the table is stored
The table identified for modification
The particular block or page (unit of storage) containing the target data
The table row containing the affected data
The column(s) in the row
As you can see, how much users interfere with each other is a question that relates to the granularity of the locking procedures. The type of locking that can be applied varies with the DBMS. Locking granularity is an area where “big products,” designed for large information systems, are significantly different from “small products” that have more limited ambitions.
When locks apply to a restricted amount of data, several concurrent processes can happily change data in the very same table at the same time without much affecting each other. Instead of having to wait until another process has finished with its transaction to get ahold of a lock, there can be some overlap between the various processes—which means that from a hardware point of view you can have more processors working, thus making better use of your hardware resources. The benefit of a finer granularity can be seen quite clearly in Figure 9-5, which shows the contrast in the total throughput of a number of concurrent sessions updating a table, first in table-locking mode and then second in row-locking mode. In each case the DBMS server is the same one.
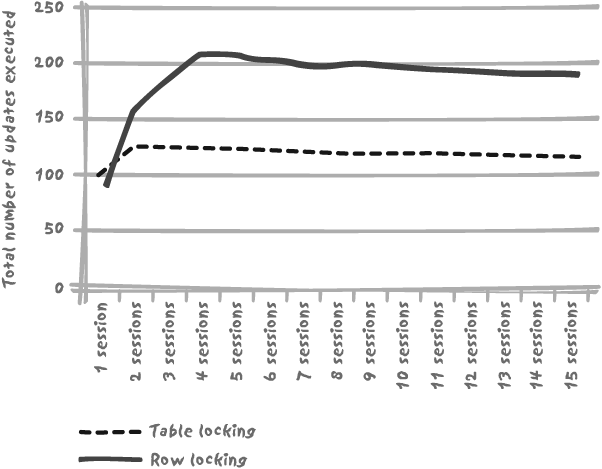
In the table-locking case, throughput increases slightly with two sessions, because the server, in the sense of service provider, is not saturated. But two sessions generate the maximum number of updates we can sequentially execute per unit of time, and from then on the curve is flat—actually, very slowly decreasing because system resources are required to handle more sessions, and this is detrimental to the system resources required to perform the updates. The situation of table locking can be contrasted with the situation of row locking, where changes applied to the same table can occur simultaneously as long as they do not affect identical rows. As in the case of table locking we will eventually reach a point where we saturate the server, but this point is reached both later and for a much higher number of concurrent updates.
If your DBMS is rather heavy-handed when locking resources, your only hope to cope with a sudden increase of activity, optimistically assuming that everything else has been tried, is to buy better hardware. “Better hardware” must of course be qualified. If locking is the bottleneck, more processors will not help, because the critical resource is access to the data. However, faster processors may speed up execution, reduce the time locks are actually held, and therefore allow the processing of more changes per unit of time. Processing still remains strictly sequential, of course, and the same number of locks is still applied.
Lock handling
Locking mechanisms are an integral part of the implementation of a DBMS and there is not much that we can do about them. We are limited to just two directions in dealing with locks:
- Try not to lock tables in a haphazard way.
It goes without saying that we should not run a program that massively updates rows in a table by the million at the same time as many users are trying to execute very short update transactions against the same table.
- Try to hold locks for as short a time as possible.
When we are in a situation where several users are concurrently attempting to access a resource that cannot be shared, speed matters not to one, but to all transactions. There is little benefit in running a fast update that has to wait for a slow one to release a lock before it can do its work. Everything must be fast, or else everything will be slow: “A chain is only as strong as its weakest link.”
The overwhelming majority of update and delete statements contain a where clause, and so any rewrite of the
where clause that speeds up a
select statement will have the
same effect on a data manipulation statement with the very same
where clause. If a delete statement has no where clause (in other words the entire
table is being deleted!), then it is likely that we would be better
off using a truncate statement,
which empties a table (or a partition) much more efficiently.
We mustn’t forget, though, that indexes also have to be
maintained, and that updating an indexed column is costly; we may
have to arbitrate between the speed of fetches and the speed of
changes. The index that might be helpful in the where clause may prove to be a nuisance
when rows are changed. Concerning insert statements, a number of them may
actually be insert...select
constructs in which the link between select performance and insert performance is naturally
obvious.
You’ve seen in Chapter 2
that impeccable statement performance doesn’t necessarily rhyme with
good program performance. When changing data, we have a particular
scope to consider: the transaction or, in other
words, the duration of a logical unit of work. We shall have to
retain locks on a particular part of the database for most if not
all of the transaction. Everything that need not be done within the
transaction, especially if it is a slow activity, should be excluded
from that transaction. The start of a transaction may sometimes be
implicit with the first data manipulation language (DML) statement
issued. The end of a transaction is always obvious, as it is marked
by a commit or rollback statement. With this background,
some practices are just common sense. Inside a transaction:
Avoid looping on SQL statements as much as possible.
Keep round-trips between the program and the database, whether running as an application server or as a mere client, to a minimum, since these add network latency to the overall elapsed time.
Exploit to the full whatever mechanisms the DBMS offers to minimize the number of round-trips (e.g., take advantage of stored procedures or array fetching).
Keep any nonessential SQL statements that are not strictly necessary within the logical unit of work outside of it. For instance, it is quite common to fetch error messages from a table, especially in localized applications. If we encounter an error, we should end our transaction with a
rollbackfirst, and then query the error message table, not the reverse: doing so will release locks earlier, and therefore help to maximize throughput.
As simple a transaction as one that inserts a new row in both
a master table and a slave table provides ample ground for mistakes.
An example for this type of transaction is typically the creation of
a new customer order (in the master table) and of the first item in
our shopping basket (held in an order_detail table). The difficulty
usually comes as a result of using system-generated identifiers for
the orders.
The primary mistake to avoid is to store into a table the
“next value to use.” Such a table is mercilessly locked by all
concurrent processes updating it, thus becoming the major bottleneck
in the whole application. Depending on the DBMS you are using, a
system-generated identifier is either the value of an
auto-incremented column, which will take for each new row inserted the
value of the previous row plus one, or the next value of a database
object such as a sequence, which is in essence very similar to an
auto-incremented column but without the explicit reference to a
column in an existing table. We have nothing to do to generate a new
identifier for each new order other than to grab the value generated
by the system. The snag is that we must know this value to be able
to link the items in the basket to a particular order. In other
words, we have to insert this value into table order_detail as well as the master
table.
Some DBMS products that use auto-incremented columns provide either a system variable (as @@IDENTITY with Transact-SQL), or a
function (such as MySQL’s last_insert_id(
)) to retrieve the value that was last generated by the
session. Fail to use facilities provided by your DBMS, and you are
condemned to run useless queries to perform the same task in the
middle of a transaction, thus wasting resources and slowing down
your transaction. Using functions or variables referring implicitly
to the last generated value requires a little discipline in
executing statements in the proper order, particularly if one is
juggling several auto-incremented columns simultaneously.
For some unknown reason, there is a marked tendency among
developers who are using sequences to first issue a
<sequence name> .nextval call to the database to get a new
value, and then to store it in a program variable for future
reference. There is actually a <sequence
name> .currval
call (or previous value for
<sequence name> with DB2), and as
its name implies its purpose is to return the last value that was
generated for the given sequence. In most cases, there is no need to
use a program variable to store the current value, and even less to
precede true action with a special get a new sequence
value call. In the worst case, some DBMS extensions can
prove useful. For instance, Oracle (and PL/SQL) users can use the
returning ... into ... clause of
insert and update statements to return
system-generated values without requiring a new round-trip to the
server. Running one special statement to get the next sequence value
and adding one more round-trip to the database generates overhead
that can globally amount to a very significant percentage for simple
and often executed transactions.
Locking and committing
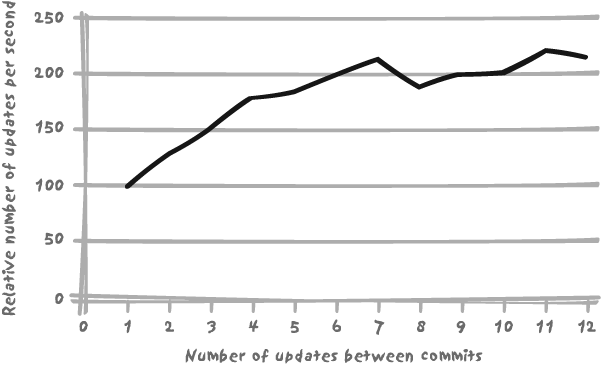
If we try and hold locks for the minimum possible time, we are bound to have to make frequent commits. Committing is a very costly process, since it means writing to persistent memory (journal files), and therefore initiating physical I/O operations. If we commit changes after absolutely every logical unit of work, we add a lot of overhead as can be seen in Figure 9-6. The figure shows the performance impact of committing every 1, 2, 3...12 rows in the case of a very fast update executed by a single user process running on an empty test machine. Depending on the statement and the number of rows affected, figures may of course vary but the trend is always the same. If a batch update program commits every transaction, it can easily take two to three times as long to complete as when it commits less frequently.
In the case of batch programs in which concurrency control is not an issue, it is advisable to avoid committing changes too often. The snag with not committing zillions of changes, besides the impact of holding the inevitable locks, is that the system has to record the pre-change data image for a hypothetical undo operation, which will put some serious strain on resources. If the process fails for any reason, rolling back the changes may take a considerable amount of time. There are two schools of thought on this topic. One favors committing changes at regular intervals so as to moderate demands on the system in terms of resources, as well as reduce the amount of work which might have to be done in case of a database change failure. The other school is frankly more gung ho and argues,
not without some reason, that system resources are here to sustain business processes, not the other way around. For the disciples of this school, if higher throughput can be achieved by less frequent commits—and if they can afford the occasional failure and still have processes completed properly and faster—then there is benefit in less frequent commits. Their case is further strengthened if the DBMS features some “pass or break” mode that shuns the generation of undo data. The commit-once-when-we’re-done approach implicitly assumes that redoing everything from scratch when something has totally failed is often simpler than trying to fix something that only partially worked. Both schemes have advantages and disadvantages, and the final choice may often be linked to operational constraints—or perhaps even to politics.
In any case, a batch program committing once in a while may block interactive users. Likewise, it is possible for interactive users to block batch programs. Even when the locking granularity is at the row level, a mechanism such as lock escalation that is applied by some database systems (in which many fine-grain locks are automatically replaced by a coarser-grain lock) may lead to a hung system. Even without lock escalation, a single uncommitted change may block a massive update. One thing is clear: concurrency and batch programs are not a happy match, and we must think about our transactions in a different way according to whether they are interactive or batch.
Locking and scalability
When comparing table and row locking , you have seen that the latter facilitates a much better throughput. However, just as with table locking, the performance curve quickly reaches its ceiling (the point at which performance refuses to improve), and from then on the curve is rather flat. Do all products behave in the same way? As a matter of fact, they don’t, as Figure 9-7 shows.
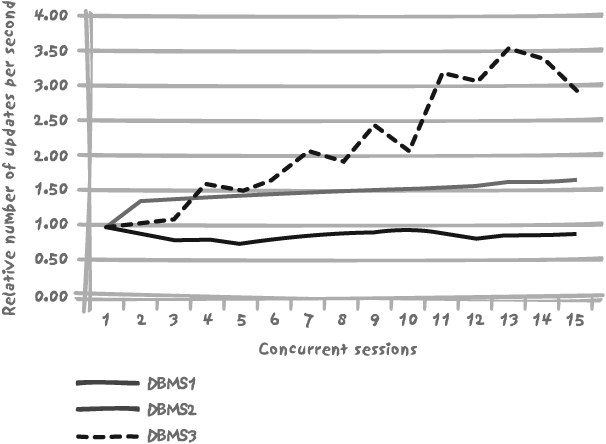
To really compare how the various systems were behaving under increased concurrency, irrespective of speed on a particular example, I performed two series of updates against a large table: first, fast updates with a condition on the primary key, and second, slow updates with a condition on an unindexed column. These updates were repeated with a varying number of sessions, and the total number of updates performed was recorded each time.
None of the products displays a strong dependency of throughput on the number of sessions with fast updates, probably because of a saturation of hardware resources. What is interesting, though, is checking whether there is a benefit attached to running a larger number of sessions in parallel. Can increased concurrency somewhat compensate for speed? This is exactly the same type of question as asking “is it better to have a server machine with few fast processors or a higher number of slower processors?”
Figure 9-7 shows how the ratio of the number of slow updates to the number of fast updates evolves as we increase the number of sessions. The DBMS1 product stands out for two reasons:
Slow updates are not that slow relatively to fast ones (hence a higher ratio than the other products).
As the steep decrease between 1 and 3 concurrent sessions shows, slow updates also suffer relatively more of increased concurrency.
The product to watch, though, is not DBMS1. Even if row locking were in use in all systems, we see that one of the products, DBMS3 on the figure, will scale much better than the others, because the ratio slowly but significantly improves as more and more concurrent sessions enter the fray. This observation may have a significant impact on hardware choices and architectures; products such as DBMS1 and DBMS2 would probably get the most benefit from faster processors, not more numerous ones. From a software point of view, they would also benefit from query pooling on a small number of sessions. On the other hand, a product such as DBMS3 would better profit from additional processors at the same speed and, to some extent, from a higher number of concurrent sessions.
How can I explain such differences between DBMS3 and the other products? Mostly by two factors:
- Saturation of hardware resources
This probably partly explains what occurs in the case of DBMS1, which achieves excellent overall results in terms of global throughput, but that simply cannot do better on this particular hardware.
- Contention
Remember that we have the same locking granularity in all three cases (row-level locks). Exactly the same statements where executed and committed. There is in fact more than data locking that limits the amount of work that several sessions can perform in parallel. To take a mechanical analogy, we could say that there is more friction in the case of DBMS1 and DBMS2 than in the case of DBMS3. This friction can also be called contention.
Contention
Rows in tables are not the only resources that cannot be shared. For instance, when one updates a value, the prior or original value (undo data) must be saved somewhere in case the user decides to roll back the change. On a loaded system, there may actually be some kind of competition between two or more processes trying to write undo data into the same physical location, even if these processes are operating on totally unrelated rows in different tables. Such a situation requires some kind of serialization to control events. Likewise, when changes are committed and written to transaction logfiles or in-memory buffers before being flushed to a file, there must be some means of preventing processes from overwriting each other’s bytes.
The examples I’ve just given are examples of contention . More than contention, locking is a mechanism that tends to be a defining characteristic of particular DBMS architectures, leaving us little choice other than to try and keep to an absolute minimum the time that the lock is held. Contention, however, is linked to low-level implementation, and there are several actions that can be undertaken to tune contention. Some of these actions can be performed by systems engineers, for example by carefully locating transaction log files on disks. Database administrators can also help to improve the situation by playing with database parameters and storage options. Finally we can, as developers, address these problems in the way we build our applications. To show how we can try to code so as to limit contention, I shall walk you through a case in which contention is usually at its most visible: during multiple, concurrent inserts.
Insertion and contention
Let’s take as an example a 14-column table with two unique indexes. The primary key constraint is defined on a system-generated number (a surrogate key), and a unique constraint (enforced by a unique index of course) is applied to a “natural” compound key, the combination of some short string of characters and a datetime value. We can now proceed to run a series of insert operations for an increasing number of simultaneous sessions.
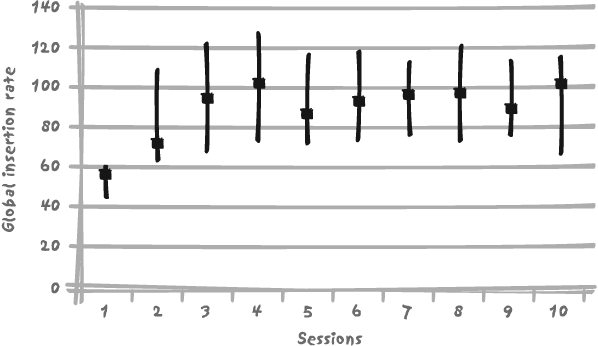
As Figure 9-8 shows, although we are operating in row-locking mode, adding more processes inserting in parallel doesn’t do much to improve the number of rows inserted by unit time. The figure displays the median and the minimum and maximum values for 10 one-minute runs for each of the different numbers of concurrent processes. As you can see, there is much variability in the results—but the best result is obtained for four concurrent processes (which, by some happy coincidence, is not totally unrelated to the number of processors on the machine).
Must we conclude that we are saturating the hardware resources? The answer of course is yes, but the real question is “can’t we make better use of these resources?” There is, in a
case like this, not much we can do about locking, because we
never have two processes trying to access the same row. However, we
do have contention when trying to access the data
containers. In this situation contention can
occur at two places within the database: in the table and in the
index. There may be other contention issues at the system level, but
these often derive from choices made at the database level.
Contention consumes CPU, because there is the execution of code that
is required for handling that very same contention issue, with
possibly some active waits involved or idle loops while waiting for
a resource held by a process running on another processor to be
released. Can we try to lower contention and divert some of the CPU
cycles to our inserts
proper?
I have run my example to generate Figure 9-8 on Oracle, one of the database systems that provides the widest range of possible options to try to limit contention. Basically, database-centric solutions to a contention issue will fall into one or more of the following three categories:
DBA solutions
Architectural solutions
Development solutions
The following sections review each of these categories.
DBA solutions
A database administrator often has scant knowledge of business processes. What we call DBA solutions are changes that are applied to the containers themselves. They are application-neutral (as it is near impossible to be absolutely application-neutral, it would probably be more exact to say that the impact is minimal on processes other than the insertion process we are trying to improve).
There are two main zones in which Oracle DBAs can try and improve a contention issue with a minimum of fuss:
- Transaction space
The first weapon is playing with the number of transaction entry slots reserved in the blocks that constitute the actual physical storage of tables and indexes. A transaction entry slot can be understood as the embodiment of a low-level lock. Without going into arcane detail, let me say that competition for these slots usually figures prominently among the reasons for contention when several sessions are competing for write access to the same block. A DBA can try to improve the situation by allocating more space for transaction management. The only impact on the rest of the application is that less space will be available for data in table or index blocks; the direct consequence of such a situation is that more blocks will be required to store the same amount of data, and operations such as full scans and, to a much lesser degree, index searches will have to access more blocks.
- Free lists
The second weapon is trying to force insertions to be directed to different blocks, something that can be done if some degree of control is retained on storage management. For each table, Oracle maintains one or several lists of blocks where new rows can be inserted. By default, there is only one list, but if there are several such lists, then insertions are assigned in a round-robin fashion to blocks coming from the various lists. This solution is not as neutral as allocating more space to transaction management; remember that the clustering of data has a significant impact on the performance of queries, and therefore while we may improve insertion performance, we may degrade some other queries.
Architectural solutions
Architectural solutions are those based on a modification of the physical disposition of data using the facilities of the DBMS. They may have a much more profound impact, to the disadvantage of our other processes. The three most obvious architectural solutions are:
- Partitioning
Range partitioning will of course defeat our purpose if our goal is to spread update activity over the table—unless, for instance, each process is inserting data for one particular month, and we could assign one process to one partition, but this is not the situation in our current example. Hash partitioning, however, might help. If we compute a hash value from our system-generated (sequence) value, successive values will be arbitrarily assigned to different partitions. Unfortunately, there are limitations to what we can do to an index used to enforce a constraint, and therefore it’s only contention at the table level that we can hope to improve. Moreover, this is a solution that unclusters data, which may impact on the performance of other queries.
- Reverse index
Chapter 3 shows that reversing the bytes in index keys can disperse the entries of keys that would otherwise have been in close proximity to one another, into unrelated leaves of the index, and that is a good way to minimize index contention (although it will do nothing for table contention). The disadvantage is that using a reverse index will prevent us from performing range scans on the index, which can be a very serious hindrance.
- Index organized table
Organizing our table as an index will allow us to get rid of one of the sources of contention. It will do nothing for the second one by itself, but instead of stumbling from one point of contention—the table block—to a second point of contention—the index block—we will have everybody fighting in one place.
Development solutions
Development solutions are in the sole hands of the developer and require no change to the physical structure of the database. Here are two examples where the developer can influence matters:
- Adjusting parallelization
The attempt at varying the number of concurrent processes shows clearly that there is a peak at 4 concurrent sessions and that adding more sessions doesn’t help. There is no benefit in assigning 10 people to a task that 4 people can handle perfectly well; it makes coordination more complicated, and some simple subtasks are sooner performed than assigned. Figure 9-8 showed that the effect of adding extra sessions beyond a hardware-dependent number is, in the best of cases, worthless. Removing them would put less strain on the system.
- Not using system-generated values
Do we really need sequential values for a surrogate key? This is not always the case. Sequential values are of interest if we want to process ranges of values, because they allow us to use operators such as
>orbetween. But if all we need is a unique identifier that can be used as a foreign key value in some other tables, why should it belong to a particular range? Let’s consider a possible alternative—namely to simply use a random number—and regenerate a new one if we hit a value we have already used.
Results
Figure 9-9 shows the insertion rates we obtained with 10 concurrent sessions, using each of the methods just described.
Once again there is a significant variability of results (each test was run 10 times, as before). We cannot conclude that a technique that works well in this case will behave as well in any other one, nor, conversely, that a technique which gives disappointing results here will not one day surpass all expectations. But the result is nevertheless interesting.
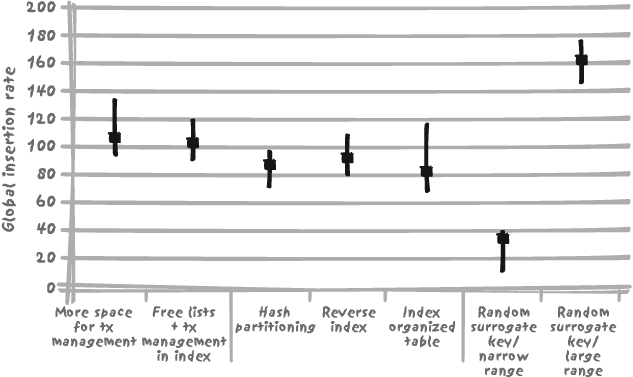
First, the DBA techniques gave results that were positive, but not particularly remarkable. Architectural choices are, in this example, rather inefficient. It is worth mentioning that our two indexes are enforcing constraints, a situation that limits the number of options applicable to them. Therefore, some of the techniques may improve contention at the table level when most of the contention occurs within indexes. This is typically the case with the index organized table, in which table contention is eliminated by the simple expedient of removing the table; unfortunately, because we now have more data to store inside the index, index contention increases and offsets the benefit of no longer having the table. This is also a situation in which we find that the system resource most in demand happens to be the CPU. This situation puts at a disadvantage all the techniques that use extra CPU—such as computing hash values or reversing index keys.
Finally, random values provided both the worst and the best results. In the worst case, the (integer) random value was generated between 1 and a number equal to about twice the number of rows we were expecting to insert during the test. As a result, a significant number of values were generated more than once, causing primary key constraint violation and the necessity to generate a new random number. This was of course a waste of time, resulting in excessive consumption of resources—plus, since violation is detected when inserting the primary key index, and since this index stores the physical address, violation is detected after the row has been inserted into the table, so an operation must then be undone, again at additional cost.
In the best case, the random number was generated out of an interval 100 times greater than in the worst case. The improvement is striking. But since having 10 concurrent sessions is no more efficient than having 4 concurrent sessions, what would have been the result with only 4 sessions? Figure 9-10 provides the answer.
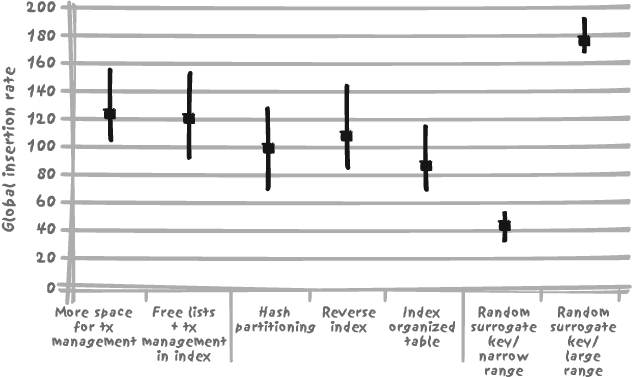
Very interestingly, all techniques give significantly better results, even if they rank identically in terms of improved throughput (e.g., their relative performances remain largely similar). The comparison of the results between Figures 9-9 and 9-10 teaches some interesting lessons:
In our case study, the bottleneck is the primary key index. Techniques that should strongly limit contention at the table level (hash partitioning, IOT) bring no benefit; actually, the IOT provides worse performance on this example than does the combination of a regular table and a primary key index. On the contrary, techniques that reduce contention on both table and index (such as allowing more room for transaction management) or only improve the situation at the index level (reverse index, random surrogate key) all bring benefits.
The comparison of 10 sessions with 4 sessions shows that some of the techniques require additional (and scarce) CPU resources from a machine already running flat out and consequentially show no improvement.
The best way to avoid contention is not to use a sequentially generated surrogate key! Instead of considering how much performance we can gain by adopting various measures, let’s consider how much performance loss is (inadvertently?) introduced by the use of a sequential key with the resulting contention on the primary key index. Solely because of contention on the primary key index, our insertion rate drops from a rate of 180 to 100 insertions per unit of time; in other words, it is divided by a factor of almost 2! The lesson is clear: we are better off without auto-incremented columns where they are not required, such as for tables that are not referenced by other tables or that do not have a very long natural primary key.
Can we recommend randomly generated surrogate keys? The difference in performance between a key generated out of a very large interval of values and a key generated out of too narrow a range of values shows that it can be dangerous and not really efficient if we expect a final number of rows greater than perhaps one hundredth of the total possible number of values. Generating random integer values between 1 and 2 billion (a common range for integer values) can prove hazardous for a large table; unfortunately, tables that are subject to heavy insertion traffic have a tendency to grow big rather quickly. However, if your system supports “long long integers,” they can be a good solution—if you really need a surrogate key.