
Chapter 8. Weaknesses and Strengths
Recognizing and Handling Difficult Cases
No one can guarantee success in war, but only deserve it.
—Sir Winston Churchill (1874–1965)
There are a number of cases when one has either to fight on unfavorable ground, or to attack a formidable amount of data with feeble weapons. In this chapter, I am going to try to describe a number of these difficult cases; first to try to sketch some tactics to disentangle oneself with honor from a perilous situation, and, perhaps more importantly, to be able to recognize as soon as possible those options that may just lead us into a trap. In mechanics, the larger the number of moving parts, the greater the odds that something will break. This is an observation that applies to complex architectures as well. Unfortunately, snappy, exciting new techniques—or indeed revamped, dull old ones—often make us forget this important principle: keep things simple. Simpler often means faster and always means more robust. But simpler for the database doesn’t always mean simpler for the developer, and simplicity often requires more skills than complexity.
In this chapter, we shall first consider a case when a criterion that looks efficient proves rather weak but can be reinvigorated, and then we shall consider the dangers of abstract “persistency” layers and distributed systems. We shall finally look in some detail at a PHP/MySQL example showing the subtleties of combining flexibility with efficiency when a degree of freedom is left to the program user for the choice of search criteria.
Deceiving Criteria
I already mentioned in Chapter 6 that in some queries we have a very selective combination of criteria that individually are not very selective. I noted that this was a rather difficult situation from which to achieve good performance.
Another interesting case, but one in which we are not totally helpless, is a criterion that at first sight looks efficient, that has the potential for becoming an efficient criterion, but that requires some attention to fulfill its potential. Credit card validation procedures provide a good example of such a criterion. As you may know, a credit card number encodes several pieces of information, including credit card type, issuer, and so on. By way of example, let’s look at the problem of achieving a first level of control for payments made at a toll road in one of the most visited Western European countries. This means checking a very large number of credit cards, supplied by a large number of international issuers, each with its own unique method of encoding.
Credit card numbers can have a maximum of 19 digits, with some exceptions, such as the cards issued by MasterCard (16 digits), Visa (16 or 13), and American Express (15 digits), to mention just three well-known issuers. The first six digits in all cases indicate who the issuer is, and the last digit is a kind of checksum to spot any mistyping. A first, coarse level of control could be to check that the issuer is known, and that the checksum is correct. However the checksum algorithm is public knowledge (it can be found on the Internet) and can easily be faked. A more refined level of control also checks that the prefix of the card number belongs, for one given issuer, to a valid range of values for this issuer, together with an additional control on the number of digits in the card. In our case, we are provided with a list of about 200,000 valid prefixes of varying lengths.
How do we write the query to test a given card number against the valid ranges of values for the card’s issuer? The following is easy enough:
select count(*)
from credit_card_check
where ? like prefix + '%'
The where ? indicates the card
number to check and here + denotes
string concatenation, often done via || or concat(
). We just have to index the prefix column, and we will get a full table
scan each time.
Why is a full table scan happening? Haven’t we seen that an index was usable when we were addressing only the leftmost part of the key? True enough, but saying that the value we want to check is the leftmost part of the full key is not the same as saying, as here, that the full key is the leftmost part of the value we want to check. The difference may seem subtle, but the two cases are mirror images of each other.
Suppose that the credit card number to verify is 4000 0012 3456
7899[*] Now imagine that our credit_card_checks table holds values such as
312345, 3456 and 40001. We can see those three values as
prefixes and, more or less implicitly, we see them as being in sorted
order. First of all, they are in ascending order if they are stored as
strings of characters, but not if they are stored as numbers. But there
is yet more to worry about.
When we descend a tree (our index), we have a value to compare to the keys stored in the tree. If the value is equal to the key stored into the current node, we are done. Otherwise, we have to search a subtree that depends on whether our value is smaller or greater than that key. If we had a prefix of fixed length, we would have no difficulty: we should only take the suitable number of digits from our card number (the current prefix), and compare it to the prefixes stored in the index. But when the length of the prefix varies, which is our case, we must compare a different number of characters each time. This is not a task that a regular SQL index search knows how to perform.
Is there any way out? Fortunately, there is one. An operator such
as like actually selects a range of
values. If we want to check, say, that a 16-digit Visa card number is
like 4000%, it
actually means that we expect to find it between 4000000000000000 and 400099999999999. If we had a composite index on
these lower and upper boundary numbers, then we could very easily check
the card number by checking the index. That is, if all card numbers had
16 digits. But a varying number of digits is a problem that is easy to
solve. All cards have a maximum number of 19 digits. If we right-pad our
Visa card number with three more 0s, thus bringing its total number of
digits to 19, we can as validly check whether
4000001234567899000 is between
4000000000000000000 and
400099999999999999.
Instead of storing prefixes, we need to have two columns: lower_bound and upper_bound. The first one, the lower_bound, is obtained by right-padding our
prefix to the maximum length of 19 with 0s, and upper_bound is obtained by right-padding with
9s. Granted, this is denormalization of a sort. However, this is a real
read-only reference table, which makes our sin slightly more forgivable.
We just have to index (lower_bound,
upper_bound) and write our condition
as the following to see our query fly:
where substring(? + '0000000000000000000', 1, 19) between lower_bound
and upper_bound
Many products directly implement an rpad(
) function for right-padding. When we have a variable-length
prefix to check, the solution is to get back to a common access case—the
index range scan.
Abstract Layers
It is a common practice to create a succession of abstract layers over a suite of software primitives, ostensibly for maintenance reasons and software reuse. This is a worthy practice and provides superb material for exciting management presentations. Unfortunately, this approach can very easily be abused, especially when the software primitives consist of database accesses. Of course, such an industrial aspect of software engineering is usually associated with modern, object-oriented languages.
I am going to illustrate how not to encapsulate database accesses with some lines from a real-life program. Interestingly for a book entitled The Art of SQL, the following fragment of C# code (of questionable sharpness...) contains only bits of an SQL statement. It is nevertheless extremely relevant to our topic, for deplorable reasons.
1 public string Info_ReturnValueUS(DataTable dt,
2 string codeForm,
3 string infoTxt)
4 {
5 string returnValue = String.Empty ;
6 try
7 {
8 infoTxt = infoTxt.Replace("'","''");
9 string expression = ComparisonDataSet.FRM_CD
10 + " = '" + codeForm
11 + "' and " + ComparisonDataSet.TXT_US
12 + " = '" + infoTxt + "'" ;
13 DataRow[] drsAttr = dt.Select(expression);
14
15 foreach (DataRow dr in drsAttr)
16 {
17 if (dr[ComparisonDataSet.VALUE_US].ToString().ToUpper().Trim( )
18 != String.Empty)
19 {
20 returnValue = dr[ComparisonDataSet.VALUE_US].ToString( ) ;
21 break;
22 }
23 }
24 }
25 catch (MyException myex)
26 {
27 throw myex ;
28 }
29 catch (Exception ex)
30 {
31 throw new MyException("Info_ReturnValueUS " + ex.Message) ;
32 }
33 return returnValue ;
34 }
There is no need to be a C# expert to grasp the purpose of the
above method, at least in general terms. The objective is to return the
text associated with a message code. That text is to be returned in a
given language (in this case American English, as US suggests). This code is from a multilingual
system, and there is a second, identical function, in which two other
letters replace the letters U and
S. No doubt when other languages will
be required, the same lines of code will be copied as many times as we
have different languages, and the suitable ISO code substituted for
US each time. Will it ease
maintenance, when each change to the program has to be replicated to
umpteen identical functions (...but for the ISO code)? I may be forgiven
for doubting it, in spite of my legendary faith in what exciting
management presentations promise modern languages to deliver.
But let’s study the program a little more closely. The string expression in lines 9–12 is an example
of shameless hardcoding , before being passed in line 13 to a Select( ) method that can reasonably be
expected to perform a query. In fact, it would seem that two different
types of elements are hardcoded: column names (stored in attributes
ComparisonDataSet.FRM_CD and ComparisonDataSet.TXT_US--and here,
apparently, there is one column per supported language, which is a
somewhat dubious design) and actual values passed to the query (codeForm and infoTxt). Column names can only be hardcoded,
but there should not be a very great number of different combinations of
column names, so that the number of different queries that can be
generated will necessarily be small and we will have no reason to worry
about this. The same cannot be said of actual values: we may query as
many different values as we have rows in the table; in fact we may even
query more, generating queries that may return nothing. The mistake of
hard-coding values from codeForm and
infoTxt into the SQL statement is
serious because this type of “give me the associated label” query is
likely to be called a very high number of times. As it is written, each
call will trigger the full mechanism of parsing, determining the best
execution plan, and so on—for no advantage. The values should be passed
to the query as bind variables--just like arguments
are passed to a function.
The loop of lines 15–23 is no less interesting. The program is
looking for the first value that is not empty in the dataset just
returned—dare we say the first value that is not null? Why code into an external
application something that the SQL language can do perfectly well? Why
return from the server possibly many more rows than are required, just
to discard them afterwards? This is too much work. The database server
will do more work, because even if we exit the loop at the first
iteration, it is quite common to pre-fetch rows in order to optimize
network traffic. The server may well have already returned tens or
hundreds of rows before our application program begins its first loop.
The application server does more work too, because it has to filter out
most of what the database server painstakingly returned. Needless to
say, the developer has written more code than is required. It is
perfectly easy to add a suitable condition to expression, so that unneeded rows are not
returned. As the C# code generates the query, the server has no idea
that we are interested only in the first non-null value and will simply
do as instructed. If we were to try and check on the database side for a
clue indicating wrongly written code, the only thing that may possibly
hint at a problem in the code will be the multitude of nearly identical
hardcoded statements. This anomaly is, however, only a part of the
larger problem.
One can write very poor code in any language, from plain old COBOL down to the coolest object-oriented language. But the greater the degree of independence between each layer of software, the better written those layers must each be. The problem here is that a succession of software layers may be called. No matter how skilled the developer who assembles these layers into the overall module, the final performance will be constrained by the weakest layer.
The problem of the weakest layer is all the more perverse when you inherit bad libraries—as with inheriting bad genes, there is not much you can do about it. Rewriting inefficient low-level layers is rarely allowed by schedules or budgets. I once learned about a case in which a basic operator in a programming language had been “overloaded” (redefined) and was performing a database access each time it was used by unsuspecting developers! It is all the more complicated to correct such a situation, because it is quite likely that individual queries, as seen from the database server, will look like conspicuously plain queries, not like the bad sort of SQL query that scans millions of rows and attracts immediate attention.
Distributed Systems
Whether you refer to federated systems , a linked server , or a database link, the principle is the same: in distributed queries, you are querying data that is not physically managed inside the server (or database to the Oracle crowd) you are connected to. Distributed queries are executed through complex mechanisms, especially for remote updates, in which transaction integrity has to be preserved. Such complexity comes at a very heavy cost, of which many people are not fully aware.
By way of example, I have run a series of tests against an Oracle database, performing massive inserts and selects against a very simple local table, and then creating database links and timing the very same operations with each database link. I have created three different database links:
- Inter-process
A link made by connecting through inter-process communications—typically what one might do to query data located in another database[*] on the same host. No network was involved.
- Loop-back
A link connecting through TCP, but specifying the loop-back address (127.0.0.1) to limit our foray into the network layers.
- IP address
A link specifying the actual IP address of the machine—but once again without really using a network, so there is no network latency involved.
The result of my tests, as it appears in Figure 8-1, is revealing. In my case, there is indeed a small difference linked to my using inter-process communications or TCP in loop-back or regular mode. But the big performance penalty comes from using a database link in the very first place. With inserts, the database link divides the number of rows inserted per second by five, and with selects it divides the number of rows returned per second by a factor of 2.5 (operating in each case on a row-by-row basis).
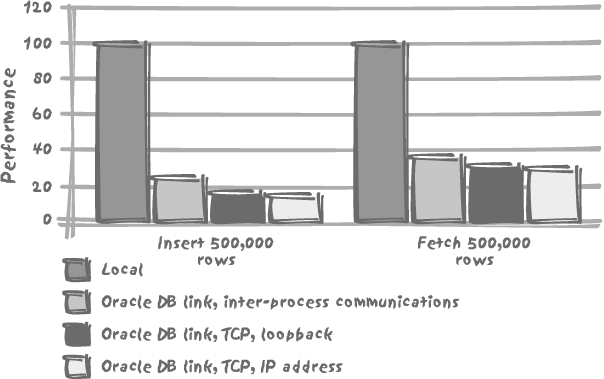
When we have to execute transactions across heterogeneous systems , we have no other choice than to use database links or their equivalent. If we want data integrity, then we need to use mechanisms that preserve data integrity, whatever the cost. There are, however, many cases when having a dedicated server is an architectural choice, typically for some reference data. The performance penalty is quite acceptable for the odd remote reference. It is quite likely that if at connection time some particular credentials are checked against a remote server, nobody will really notice, as long as the remote server is up. If, however, we are massively loading data into a local database and performing some validation check against a remote server for each row loaded locally, then you can be sure to experience extremely slow performance. Validating rows one by one is in itself a bad idea (in a properly designed database, all validation should be performed through integrity constraints): remote checks will be perhaps two or three times slower than the same checks being carried out on the same local server.
Distributed queries, involving data from several distinct servers, are also usually painful. First of all, when you send a query to a DBMS kernel, whatever that query is, the master of the game is the optimizer on that kernel. The optimizer will decide how to split the query, to distribute the various parts, to coordinate remote and local activity, and finally to put all the different pieces together. Finding the appropriate path is already a complicated-enough business when everything happens on the local server. We should take note that the notion of “distribution” is more logical than physical: part of the performance penalty comes from the unavailability of remote dictionary information in the local cache. The cost penalty will be considerably higher with two unrelated databases hosted by the same machine than with two databases hosted by two different servers but participating in a common federated database and sharing data dictionary information.
There is much in common between distributed and parallelized queries (when a query is split into a number of independent chunks that can be run in parallel) with, as you have seen, the additional difficulties of the network layers slowing down significantly some of the operations, and of the unavailability at one place of all dictionary information making the splitting slightly more hazardous. There is also an additional twist here: when sources are heterogeneous—for example when a query involves data coming from an Oracle database as well as data queried from an SQL Server database, all the information the optimizer usually relies on may not be available. Certainly, most products gather the same type of information in order to optimize queries. But for several reasons, they don’t work in a mutually cooperative fashion. First, the precise way each vendor’s optimizer works is a jealously guarded secret. Second, each optimizer evolves from version to version. Finally, the Oracle optimizer will never be able to take full advantage of SQL Server specifics and vice versa. Ultimately, only the greatest common denominator can be meaningfully shared between different product optimizers.
Even with homogeneous data sources, the course of action is narrowly limited. As we have seen, fetching one row across a network costs considerably more than when all processes are done locally. The logical inference for the optimizer is that it should not take a path which involves some kind of to and fro switching between two servers, but rather move as much filtering as close to the data as it can. The SQL engine should then either pull or push the resulting data set for the next step of processing. You have already seen in Chapters 4 and 6 that a correlated subquery was a dreadfully bad way to test for existence when there is no other search criterion, as in for instance, the following example:
select customer_name
from customers
where exists (select null
from orders,
orderdetails
where orders.customer_id = customers.customer_id
and orderdetails.order_id = orders.order_id
and orderdetails.article_id = 'ANVIL023')
Every row we scan from customers fires a subquery against orders and orderdetails.
It is of course even worse when customers happens to be hosted by one machine
and orders and orderdetails by another. In such a case, given
the high cost of fetching a single row, the reasonable solution looks
like a transformation (in the ideal case, by the optimizer) of the above
correlated subquery into an uncorrelated one, to produce the following
instead:
select customer_name
from customers
where customer_id in (select orders.customer_id
from orders,
orderdetails
where orderdetails.article_id = 'ANVIL023'
and orderdetails.order_id = orders.order_id)
Furthermore, the subquery should be run at the remote site. Note that this is also what should be performed even if you write the query as like this:
select distinct customer_name
from customers,
orders,
orderdetails
where orders.customer_id = customers.customer_id
and orderdetails.article_id = 'ANVIL023'
and orders.order_id = orderdetails.order_id
Now will the optimizer choose to do it properly? This is another question, and it is better not to take the chance. But obviously the introduction of remote data sources narrows the options we have in trying to find the most efficient query. Also, remember that the subquery must be fully executed and all the data returned before the outer query can kick in. Execution times will, so to speak, add up, since no operation can be executed concurrently with another one.
The safest way to ensure that joins of two remote tables actually take place at the remote site is probably to
create, at this remote site, a view defined as this join and to query
the view. For instance, in the previous case, it would be a good idea to
define a view vorders as:
select orders.customer_id, orderdetails.article_id
from orders,
orderdetails
where orderdetails.order_id = orders.order_id
By querying vorders we limit
the risks of seeing the DBMS separately fetching data from all the
remote tables involved in the query, and then joining everything
locally. Needless to say, if in the previous case, customers and orderdetails were located on the same server
and orders were located elsewhere, we would indeed be in a very perilous
position.
Dynamically Defined Search Criteria
One of the most common causes for awful visible performance (as opposed to the common dismal performance of batch programs, which can often be hidden for a while) is the use of dynamically defined search criteria. In practice, such criteria are a consequence of the dreaded requirement to “let the user enter the search criteria as well as the sort order via a screen interface.”
The usual symptoms displayed by this type of application is that many queries perform reasonably well, but that unfortunately from time to time a query that seems to be almost the same as a well-performing query happens to be very, very slow. And of course the problem is difficult to fix, since everything is so dynamic.
Dynamic-search applications are often designed as a two-step
drill-down query, as in Figure
8-2. Basically, a first screen is displayed to the user with a
large choice of criteria and an array of possible conditions such as
exclude or date between ... and .... These criteria are
used to dynamically build a query that returns a list with some
identifier and description, from which you can view all the associated
details by selecting one particular item in the list.
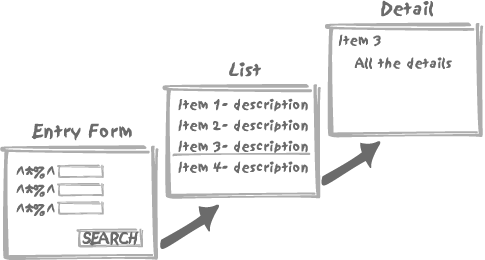
When the same columns from the same tables are queried with varying search criteria, the key to success usually lays in a clever generation of SQL queries by the program that accesses the database. I am going to illustrate my point in detail with a very simple example, a movie database , and we shall only be concerned with returning a list of movie titles that satisfy a number of criteria. The environment used in this example is a widely popular combination, namely PHP and MySQL. Needless to say, the techniques shown in this chapter are in no way specific to PHP or to MySQL—or to movie databases.
Designing a Simple Movie Database and the Main Query
Our central table will be something such as the following:
Table MOVIES
movie_id int(10) (auto-increment)
movie_title varchar(50)
movie_country char(2)
movie_year year(4)
movie_category int(10)
movie_summary varchar(250)
We certainly need a categories table (referenced by a foreign
key on movie_category) to hold the
different genres, such as Action,
Drama, Comedy,
Musical, and so forth. It can be argued that some
movies sometimes span several categories, and a better design would
involve an additional table representing a many-to-many relationship
(meaning that one genre can be associated with several movies and that
each movie can be associated with several genres as well), but for the
sake of simplicity we shall admit that a single, main genre is enough
for our needs in this example.
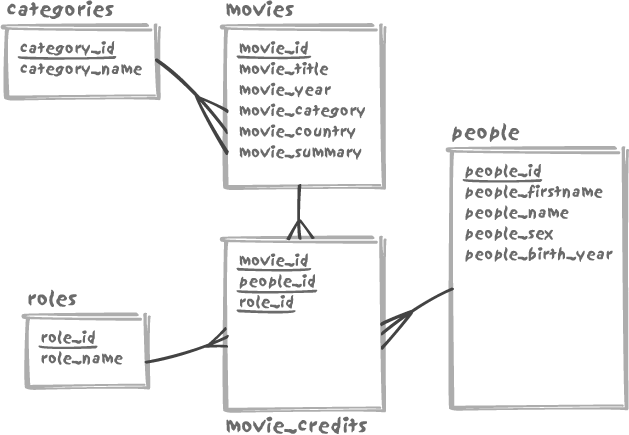
Do we need one table for actors and another for directors? Creating two tables would be a design mistake, because it is quite common to see actors-turned-directors, and there is no need to duplicate personal information. From time to time one even finds a movie directed by one of the lead actors.
We therefore need three more tables: people to store information such as name,
first name, sex, year of birth, and so on; roles to define how people may contribute to
a movie (actor, director, but also composer, director of photography,
and the like); and movie_credits to
state who was doing what in which movie. Figure 8-3 shows our complete
movie schema.
Let’s suppose now that we want to let people search movies in our database by specifying either: words from the title, the name of the director, or up to three names of any of the actors. Following is the source of our prototype page, which I have built in HTML to act as our screen display:
<html>
<head>
<title>Movie Database</title>
</head>
<body>
<CENTER>
<HR>
<BR>
Please fill the form to query our database and click on <b>Search</b> when you are done...
<BR>
<HR>
<BR>
<form action="display_query.php" method="post">
<TABLE WIDTH="75%">
<TR>
<TD>Movie Title :</TD>
<TD><input type="text" name="title"></TD>
</TR>
<TR>
<TD>Director :</TD>
<TD><input type="text" name="director"></TD>
</TR>
<TR>
<TD>Actor :</TD>
<TD><input type="text" name="actor1"></TD>
</TR>
<TR>
<TD>Actor :</TD>
<TD><input type="text" name="actor2"></TD>
</TR>
<TR>
<TD>Actor :</TD>
<TD><input type="text" name="actor3"></TD>
</TR>
<TR>
<TD COLSPAN="2" ALIGN="CENTER">
<HR>
<input type="Submit" value="Search">
<HR>
</TD>
</TR>
</TABLE>
</form>
</CENTER>
</body>
</html>
This prototype page shows on screen as in Figure 8-4.
First, let me make a few remarks:
Although we want to store the first and last names separately in our database (definitely more convenient if we want to generate a listing ordered by last name), we don’t want our entry form to look like a passport renewal form: we just want a single entry field for each individual.
We want our query input values to be case-insensitive.
Certainly the thing not to do is to generate a query containing a criterion such as:
and upper(<value entered for actor1>) =
concat(upper(people_firstname), ' ', upper(people_name))
As shown in Chapter 3, the right part of the equality in such a criterion would prevent us from using any regular index we might have logically created on the name. Several products allow the creation of functional indexes and index the result of expressions, but the simplest and therefore best solution is probably as follows:
Systematically store in uppercase any character column that is likely to be queried (we can always write a function to beautify it before output).
Split the entry field into first name and (last) name before passing it to the query.
The first point simply means inserting upper( string ) instead of string,
which is easy enough. Keep the second point in mind for the time
being: I’ll come back to it in just a bit.
If users were to fill all entry fields, all the time, then our resulting main query could be something such as:
select movie_title, movie_year
from movies
inner join movie_credits mc1
on mc1.movie_id = movies.movie_id
inner join people actor1
on mc1.people_id = actor1.people_id
inner join roles actor_role
on mc1.role_id = actor_role.role_id
and mc2.role_id = actor_role.role_id
and mc3.role_id = actor_role.role_id
inner join movie_credits mc2
on mc2.movie_id = movies.movie_id
inner join people actor2
on mc2.people_id = actor2.people_id
inner join movie_credits mc3
on mc3.movie_id = movies.movie_id
inner join people actor3
on mc3.people_id = actor3.people_id
inner join movie_credits mc4
on mc4.movie_id = movies.movie_id
inner join people director
on mc4.people_id = director.people_id
inner join roles director_role
on mc4.role_id = director_role.role_id
where actor_role.role_name = 'ACTOR'
and director_role.role_name = 'DIRECTOR'
and movies.movie_title like 'CHARULATA%'
and actor1.people_firstname = 'SOUMITRA'
and actor1.people_name = 'CHATTERJEE'
and actor2.people_firstname = 'MADHABI'
and actor2.people_name = 'MUKHERJEE'
and actor3.people_firstname = 'SAILEN'
and actor3.people_name = 'MUKHERJEE'
and director.people_name = 'RAY'
and director.people_firstname = 'SATYAJIT'
Unfortunately, will somebody who can name the title, director and the three main actors of a film (most typically a movie buff) really need to use our database? This is very unlikely. The most likely search will probably be when a single field or possibly two, at most, will be populated. We must therefore anticipate blank fields, asking the question: what will we do when no value is passed?
A common way of coding one’s way out of a problematic situation like this is to keep the select list unchanged; then to join together all the tables that may intervene in one way or another, using suitable join conditions; and then to replace the straightforward conditions from the preceding example with a long series of:
andcolumn_name= coalesce(?,column_name)
where ? will be associated
with the value from an entry field, and coalesce( ) is the function that returns the
first one of its arguments that is non null. If a value is provided,
then a filter is applied; otherwise, all values in the column pass the
test.
All values? Not really; if a column contains a NULL, the condition for that column will
evaluate to false. We cannot say that something we don’t know is equal
to something we don’t know, even if it is the same something
(nothing?). If one condition in our long series of conditions linked
by and evaluates to false, the query will return nothing, which
is certainly not what we want. There is a solution though, which is to
write:
and coalesce(column_name,constant) = coalesce(?,column_name,constant)
This solution would be absolutely perfect if only it did not
mean forfeiting the use of any index on
column_name when a parameter is specified.
Must we sacrifice the correctness of results to performance, or
performance to the correctness of results? The latter solution is
probably preferable, but unfortunately both of them might also mean
sacrificing our job, a rather unpleasant prospect.
A query that works in all cases, whatever happens, is quite
difficult to write. The commonly adopted solution is to build such a
query dynamically. What we can do in this example scenario is to store
in a string everything up to the where and the fixed conditions on role
names, and then to concatenate to this string the conditions which
have been input by our program user—and only those conditions.
Assuming that a user searched our database for movies starring Amitabh Bachchan, the resulting, dynamically written query might be something like the following:
select distinct movie_title, movie_year
from movies
inner join movie_credits mc1
on mc1.movie_id = movies.movie_id
inner join people actor1
on mc1.people_id = actor1.people_id
inner join roles actor_role
on mc1.role_id = actor_role.role_id
and mc2.role_id = actor_role.role_id
and mc3.role_id = actor_role.role_id
inner join movie_credits mc2
on mc2.movie_id = movies.movie_id
inner join people actor2
on mc2.people_id = actor2.people_id
inner join movie_credits mc3
on mc3.movie_id = movies.movie_id
inner join people actor3
on mc3.people_id = actor3.people_id
inner join movie_credits mc4
on mc4.movie_id = movies.movie_id
inner join people director
on mc4.people_id = director.people_id
inner join roles director_role
on mc4.role_id = director_role.role_id
where actor_role.role_name = 'ACTOR'
and director_role.role_name = 'DIRECTOR'
and actor1.people_firstname = 'AMITABH'
and actor1.people_name = 'BACHCHAN'
order by movie_title, movie_year
First, let me make two remarks:
We have to make our
selectaselect distinct. We do this because we keep the joins without any additional condition. Otherwise, as many rows would be returned for each movie as we have actors and directors recorded for the movie.It is very tempting when building the query to concatenate the values that we receive to the SQL text under construction proper, thus obtaining a query exactly as above. This is not, in fact, what we should do. I have already mentioned the subject of bind variables; it is now time to explain how they work. The proper course is indeed to build the query with placeholders such as
?(it depends on the language), and then to call a special function to bind the actual values to the placeholders. It may seem more work for the developer, but in fact it will mean less work for the DBMS engine. Even if we rebuild the query each time, the DBMS usually caches the statements it executes as a part of its standard optimization routines. If the SQL engine is given a query to process that it finds in its cache, the DBMS has already parsed the SQL text and the optimizer has already determined the best execution path. If we use placeholders, all queries that are built on the same pattern (such as searches for movies starring one particular actor) will use the same SQL text, irrespective of the actor’s name. All the setup is done, the query can be run immediately, and the end user gets the response faster.
Besides performance, there is also a very serious concern
associated with dynamically built hardcoded queries, a security
concern: such queries present a wide-open door to the technique known
as SQL injection. What is SQL injection? Let’s
say that we run a commercial operation, and that only subscribers are
allowed to query the full database while access to movies older than
1960 is free to everybody. Suppose that a malicious non-subscriber
enters into the movie_title field
something such as:
X' or 1=1 or 'X' like 'X
When we simply concatenate entry fields to our query text we shall end up with a condition such as:
where movie_title like 'X' or 1=1 or 'X' like 'X%'
and movie_year < 1960
which is always true and will obviously filter nothing at all! Concatenating the entry field to the SQL statement means that in practice anybody will be able to download our full database without any subscription. And of course some information is more sensitive than movie databases. Binding variables protects from SQL injection. SQL injection is a very real security matter for anyone running an on-line database, and great care should be taken to protect against its malicious use.
Important
When using dynamically built queries, use parameter markers and pass values as bind variables, for both performance and security (SQL injection) reasons.
A query with prepared joins and dynamically concatenated filtering conditions executes very quickly when the tables are properly indexed. But there is nevertheless something that is worrisome. The preceding example query is a very complicated query, particularly when we consider the simplicity of both the output result and of what we provided as input.
Right-Sizing Queries
In fact, the complexity of the query is just one part of
the issue. What happens, in the case of the final query in the
preceding section, if we have not recorded the name of the director in
our database, or if we know only the names of the two lead actors? The
query will return no rows. All right, can we not use outer joins then,
which return matching values when there is one and NULL when there is none?
Using outer joins might be a solution, except that we don’t know
what exactly will be queried. What if we only have the name of the
director in our database? In fact, we would need outer joins
everywhere—and putting them everywhere is often, logically,
impossible. We therefore have an interesting case, in which we are
annoyed by missing information even if all of our attributes are
defined as mandatory and we have absolutely no NULL values in the database, simply because
our query so far assumes joins that may be impossible to
satisfy.
In fact, in the particular case when only one actor name is provided, we need a query no more complicated than the following:
select movie_title, movie_year
from movies
inner join movie_credits mc1
on mc1.movie_id = movies.movie_id
inner join people actor1
on mc1.people_id = actor1.people_id
inner join roles actor_role
on mc1.role_id = actor_role.role_id
where actor_role.role_name = 'ACTOR'
and actor1.people_firstname = 'AMITABH'
and actor1.people_name = 'BACHCHAN'
order by movie_title, movie_year
This “tight-fit” query assumes nothing about our also knowing the name of the director, nor of a sufficient number of other actors, and hence there is no need for outer joins. Since we have already begun building our query dynamically, why not try to inject a little more intelligence in our building exercise, so as to obtain a query really built to order, exactly tailored to our needs? Our code will no doubt be more complicated. Is the complication worth it? The simple fact that we are now certain to return all the information available when given an actor’s name, even when we don’t know who directed a film, should be reason enough for an unqualified “yes.” But performance reasons also justify taking this step.
Nothing is as convincing as running a query in a loop a sufficient number of times to show the difference between two approaches: our “tight-fit” query is five times faster than the “one-size-fits-all” query. All other things aside, does it matter if our query executes in 0.001 second instead of 0.005 second? Not much, if our database is only queried now and then. But there may be a day when queries arrive at a rate higher than we can service and keep up with, and then we’ll have a problem. Queries will have to be queued, and the queue length will increase very quickly—as fast as the number of complaints about poor database performance. Simply put, going five times faster enables five times as many queries to be processed on the same hardware. (We will consider these issues in more detail in Chapter 9.)
Wrapping SQL in PHP
Let’s first start our PHP page with a smattering of regular HTML before the real PHP code:
<html>
<head>
<title>Query result</title>
</head>
<body>
<CENTER>
<table width="80%">
<TR><TH>Title</TH><TH>Year</TH><TR>
<?php
...
(Our page would probably be nicer with a stylesheet....)
Once we have our handle that represents the connection to the database, the very first thing to do is to get the values that were submitted to the entry screen. Since everything is stored in uppercase in our database we can convert the user-entered values directly to uppercase too. This is of course something that can be done in the SQL code, but it costs nothing to do it in the PHP code:
$title=strtoupper($_POST['title']);
$director=strtoupper($_POST['director']);
$actor1=strtoupper($_POST['actor1']);
$actor2=strtoupper($_POST['actor2']);
$actor3=strtoupper($_POST['actor3']);
We now have a technical problem linked to the implementation of PHP binding. Following is the process for binding variables in PHP:
We first write
?in the place of every parameter we want to pass to the query.Then we call the
bind_param( )method that takes as its first argument a string containing as many characters as we have values to bind, each character telling the type of the parameter we pass (in this case it will always besfor string), then a variable number of parameters—one per each value we want to bind.
All parameters are identified by position (the same is true with
JDBC, but not with all database systems and languages; for instance,
you will refer to bind variables by name in an SQLJ program). But our
main problem is the single call to bind_param( ), which is very convenient when
we know exactly how many parameters we have to bind, but is not so in
our case here, in which we do not know in advance how many values a
user will enter. It would be much more convenient in our case to have
a method allowing us to loop and bind values one by one.
One way to bind a variable number of values, which is not necessarily the most elegant, is to loop on all the variables we have received from the form, check which ones actually contain something, and store each value in the subsequent positions of an array. We have no problem doing this with our example since all the values we may get are character strings. If we were expecting something else—for instance the year when a movie was first shown—the most sensible approach would probably be to treat such a value as a string inside the PHP code and to convert it to a number or date in the SQL code.
We can use a $paramcnt
variable to count how many parameters were provided by the user of the
form, and store the values into a $params array:
$paramcnt=0;
if ($title != "") {
$params[$paramcnt] = $title;
$paramcnt++;
}
Things get a little more complicated with people names. Remember
that we have decided that having a single field to enter a name was
more user-friendly than having to enter the first and last names into
two separate fields. However, comparing the string entered by the user
to the concatenation of first name and last name in our people table would prevent the query from
using the index on the last name and might, moreover, yield wrong
results: if the user has mistakenly typed two spaces instead of one
between first name and last name, for instance, we shall not find the
person.
What we are therefore going to do is to split the entry field into first name and last name, assuming that the last name is the last word, and that the first name, which may be composed of 0, 1, or several words, is what precedes the last name. In PHP, we can easily write such a function which sets two parameters that are passed by reference:
function split_name($string, &$firstname, &$lastname)
{
/*
* We assume that the last name is the last element of the string,
* and that we may have several first names
*/
$pieces = explode(" ", $string);
$parts = count($pieces);
$firstnames = array_slice($pieces, 0, $parts - 1);
$firstname = implode(" ", $firstnames);
$lastname = $pieces[$parts - 1];
}
This function will allow us to split $director into $dfn and $dn, $actor1 into $a1fn and $a1n and so on, everything being coded on
the same model:
if ($director != "") {
/* Split firstname / name */
split_name($director, $dfn, $dln);
if ($dfn != "")
{
$params[$paramcnt] = $dfn;
$paramcnt++;
}
$params[$paramcnt] = $dln;
$paramcnt++;
}
Once we have inspected our parameters, all we have to do is to
build our query, being very careful to insert the parameter markers
for the bind variables in exactly the same order as they will appear
in the $params array:
$query = "select movie_title, movie_year "
."from movies";
/* Director was specified ? */
if ($director != "")
{
$query = $query." inner join movie_credits mcd"
." on mcd.movie_id = movies.movie_id"
." inner join people director"
." on mcd.people_id = director.people_id"
." inner join roles director_role"
." on mcd.role_id = director_role.role_id";
}
/* Any actor was specified ? */
if ($actor1.$actor2.$actor3 != "")
{
/*
* First the join on the ROLES table
*/
$query = $query." inner join roles actor_role";
/*
* Even if only one actor was specified, we may
* not necessarily find the name in $actor1 so careful
*/
$actcnt = 0;
if ($actor1 != "")
{
if ($actcnt == 0)
{
$query = $query." on";
}
else
{
$query = $query." and";
}
$query = $query." mc1.role_id = actor_role.role_id";
}
if ($actor2 != "")
{
...
}
if ($actor3 != "")
{
...
}
/*
* Then join on MOVIE_CREDITS and PEOPLE
*/
if ($actor1 != "")
{
$query = $query." inner join movie_credits mc1"
." on mc1.movie_id = movies.movie_id"
." inner join people actor1"
." on actor1.people_id = mc1.people_id";
}
if ($actor2 != "")
{
...
}
if ($actor3 != "")
{
...
}
}
/*
* We are done with the FROM clause; we are using the old 1=1
* trick to avoid checking each time whether it is the very
* first condition or not - the latter case requires an 'and'.
*/
$query = $query." where 1=1";
/*
* Be VERY careful to add parameters in the same order they were
* stored into the $params array
*/
if ($title != "")
{
$query = $query." and movies.movie_title like concat(?, '%')";
}
/* Director was specified ? */
if ($director != "")
{
$query = $query." and director_role.role_name = 'DIRECTOR'";
if ($dfn != "")
{
/*
* Use like instead of regular equality for the first name, it will
* work with some abbreviations or initials.
*/
$query = $query
." and director.people_firstname like concat(?, '%')";
}
$query = $query." and director.people_name = ?";
}
if ($actor1.$actor2.$actor3 != "")
{
$query = $query." and actor_role.role_name = 'ACTOR'";
if ($actor1 != "")
{
...
}
if ($actor2 != "")
{
...
}
if ($actor3 != "")
{
...
}
}
Once our query is ready, we call the prepare( ) method, then bind our variables;
this is where our code is not very pretty, since we can have between 1
and 9 variables to bind and handle, and each variable must be handled
separately:
/* create a prepared statement */
if ($stmt = $mysqli->prepare($query)) {
/*
* Bind parameters for markers
*
* This is the messiest part.
* We can have anything between 1 and 9 parameters in all (all strings)
*/
switch ($paramcnt)
{
case 1 :
$stmt->bind_param("s", $params[0]);
break;
case ...
...
break;
case 9 :
$stmt->bind_param("sssssssss", $params[0],
$params[1],
$params[2],
$params[3],
$params[4],
$params[5],
$params[6],
$params[7],
$params[8]);
break;
default :
break;
}
Et voilà! We are done and just have to execute the query and display the result:
/* execute query */
$stmt->execute( );
/* fetch values */
$stmt->bind_result($mt, $my);
while ($row = $stmt->fetch( ))
{
printf ("<tr><TD>%s</TD><TD>%d</TD></TR>
", $mt, $my);
}
/* close statement */
$stmt->close( );
}
else
{
printf("Error: %s
", $mysqli->sqlstate);
}
?>
</TABLE>
</CENTER>
Obviously, the code here is significantly more complicated than if we had tried to have one single query.
It may seem surprising, after I have advocated pushing as much work as possible onto the DBMS side, to now find me defending the use of complicated code to build as simple a SQL statement as possible. Doing as much work on the SQL side as possible makes sense when it is work that has to be performed. But joining three times as many tables as are needed in the average query, with some of these useless joins not necessarily being very efficient (especially when they happen to be against complex views) makes no sense at all.
By intelligently building the query, we tightly control what is executed in terms of security, correctness of the result, and performance. Any simpler solution bears risks of sacrificing at least one of these aspects.
To summarize, there are at least three mistakes that are very commonly made in queries that take a variable number of search criteria:
First of all, it is quite common to see the values against which the columns of the tables are compared being concatenated with the statement-in-making, thus resulting in a magnificent, totally hardcoded statement. Even where queries are supposed to be absolutely unpredictable, you usually find a few queries that are issued again and again by the users, with only the constants varying. Some constants are susceptible to a high degree of variability (such as entity identifiers, as opposed to date formats or even status codes). It isn’t much work to replace these constants by a parameter marker, the syntax of which depends on the language (for instance
'?') and then to bind the actual value to this parameter marker. This will result in much less work for the server, which will not need to re-analyze the statement each time it is issued, and in particular will not need to determine each time a best execution plan, that will always be the same. And no user will be able to bypass any additional restriction you may want to add to the query, which means that by binding variables you will plug a serious security issue at the same time.A second mistake is usually to try to include in the query everything that may matter. It is not because a search criterion may refer to data stored in one table that this table must appear in the
fromclause. I have already alluded to this issue in the previous chapters, but thefromclause should only contain the tables from which we return data, as well as the tables enabling us to join them together. As we have seen in Chapter 6, existence tests should be solved by subqueries—which are no more difficult to generate dynamically than a regular condition in awhereclause.The most important mistake is the one-size-fits-all philosophy. Behind every generic query are usually hidden three or four families of queries. Typically, input data is made up of identifiers, status values, or some ranges of dates. The input values may be strong, efficient criteria, or weak ones, or indeed anything in between (sometimes an additional criterion may reinforce a weak one by narrowing the scope). From here, trying to build several alternate queries in an intelligent fashion, as in the various cases of Chapter 6, is the only sound way out, even if it looks more complicated.