
CHAPTER 14
Entity Resolution: Identification, Matching, Aggregation, and Holistic View of the Master Objects
As we already mentioned in Part I and discussed in more detail in Part II of this book, entity resolution—and in particular the ability to recognize, uniquely identify, match, and link entities—is at the heart of MDM. Specifically, we showed that a conceptual MDM data model that can support a customer-centric business such as retail banking, institutional banking, personal insurance, or commercial insurance is known as a party-centric model, and it may consist of a number of entities and attributes, including party/customer, party profile, account, party group, location, demographics, relationships, channels, products, events, and privacy preferences. Some of the key attributes of this model include identity attributes used to uniquely identify the party entities as a collection or cluster of individual detail-level records.
We also showed that when we deal with the Product domain, the challenge of identifying, matching, and linking entities is much harder, and not just for managing hierarchies of product entities, but for the fundamental activities of matching product entities that appear to be at the same levels in a given hierarchy. Moreover, we showed that the techniques and approaches to entity resolution in the Product domain are often based on semantics-driven rather than syntax-driven analysis. The semantics analysis is much more complex, and would make our discussion of entity identification harder to present within a single chapter. Therefore, in this chapter we focus our attention on discussing approaches, techniques, and concerns of the key aspect of entity resolution—entity identification—where the entity is the customer or a party.
The goal of entity identification is to enable and support accurate and timely information about each master entity. In the case of MDM for the Customer domain, entity identification enables the MDM system to create and maintain accurate and timely information about the customer (an individual or an organization) that has past, current, or potential future relationships with the enterprise regardless of what business unit actually owns those relationships. Clearly, the sales and marketing department will want to know the nature of interested parties that have or had some relationships or points of contact with the company but may never have been the company’s customer. Furthermore, a party may have multiple relationships with the enterprise. These relationships should be tracked across channels, lines of business, and contact types. In a variety of businesses, for legal and compliance reasons the company may need to know about the employees who are also the company’s customers.
A more complex question the company may want to answer is whether its employee or an existing customer has a professional relationship with other existing customers, for example, their attorney, accountant, or any other interested party.
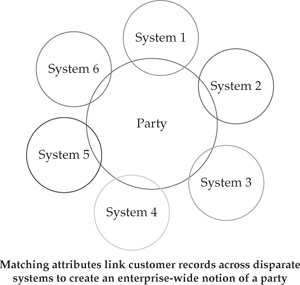
Generally speaking, the first step in entity identification is the ability to identify an entity in the most granular way that makes sense for the enterprise. The granularity level also depends on the way the source data is stored in legacy systems. Reconciling various degrees of granularity represents one of the challenges that needs to be addressed for efficient entity identification. Although this general approach can be applied to all types of entities, we want to turn our attention to the specifics of the MDM for the Customer domain because most of the challenges, approaches, and concerns of entity identifications can be effectively illustrated in the context of customer identification. More often than not, customer data resides in multiple systems that represent different business area silos. Figure 14-1 illustrates the integration of multiple disparate systems around the concept of a party. In the enterprise environment, it is quite common that the number of systems that need to be integrated ranges from 10 to 30 and sometimes even higher. Customer data in these systems is formatted, stored, and managed differently since these application systems tend to be highly heterogeneous because they are created and maintained by different departments and used for different purposes. Often various application systems maintain overlapping attributes and may support different levels of granularity and different data structures—for example, account-centric data vs. customer-centric data, household-level data, different touch points, channels, and so on.
FIGURE 14-1 System integration and a 360-degree view of customer/party
Holistic Entity View and a 360-Degree View of a Customer:Frequently Used Terms and Definitions
In order to recognize entities representing those individuals or parties that have one or more relationships with the firm, the granular-level information about the individuals or corporate customers must be assembled from all relevant records across the enterprise. This comprehensive view of the party entity is frequently referred to by business as a “360-degree view of a customer.” What are some key challenges in creating this view?
It is not always clear if the records that read Mike Johnson and M. Johnson represent the same individual entity even if the records show the same address, home phone number, and credit card number, as in Figure 14-2. Two records with the name M. Johnson at the same address may still belong to different people (for example, father and son). Indeed, if we consider Mike’s son Mack Johnson, then M. Johnson may represent Mike Johnson or Mack Johnson. Other scenarios are also possible.
On the other hand, two records for Mike Johnson at two different addresses may still represent the same individual who moved from one address to another. In this scenario one of the addresses was occupied by this individual in the past; see Figure 14-3.
In the case of customers residing in the United States, a service that can access National Change of Address (NCOA) information, which is maintained by the U.S. Postal Service, may be required to link the records in Figure 14-3 and associate them with the same individual. Similar address maintenance service exists in many other countries. Another variation on the theme could be a situation where Mike Johnson may have two or more addresses at a time (for example, the primary residence and a vacation home). In addition, both names and addresses can have different spellings, aliases, and so on.
An important concern to consider when creating a comprehensive 360-degree view of an entity such as a customer is the concern of overmatching. This scenario occurs when the records belonging to two or more customers are mistakenly assigned to a single individual. If the matching data is used for a marketing campaign, such an error may result in the marketing department not sending a marketing letter to a customer. However, when data is used for legal, medical, or financial purposes, a customer can be incorrectly linked to legal documents, financial statements, or medical records, which can have serious consequences for both the customer and the firm. For example, the firm may send a dividend check to a wrong individual or disclose sensitive information to a stranger.
Naturally, the reverse outcome of treating two or more records about the same entity as different entities is also possible, thus failing to deliver a comprehensive 360-degree entity view, and the matching process should have appropriate safeguards built into it to handle both scenarios.

FIGURE 14-2 Two records for Mike Johnson and M. Johnson with the same phone number and credit card number

FIGURE 14-3 Two records for Mike Johnson at different addresses
The business must identify the required match accuracy in terms of the level of confidence for both false negatives and false positives. Legal, financial, medical, and certain other applications of customer data integration typically require high-confidence data with the primary focus of avoiding false positives at any cost. Some compliance applications are relatively tolerant of false positives but need to avoid false negatives, for example, identifying suspects potentially involved in money laundering, drug trafficking, terrorism, and other criminal activities. In the latter case, the law enforcement officer wants to see all suspects who meet given suspect criteria, while realizing that some records may be false matches. False negatives in this scenario would mean an exclusion of potential criminals from the list of suspects. Once the initial “wide-net” list of records is produced systemically, a manual effort and analysis will be required to exclude false positives and finalize the list.
The sections that follow summarize some common reasons responsible for producing false positives and false negative matches.
Reasons for False Positives in Party Matching
With a typical match for individuals based on the name, address, phone number, and some other attributes, the primary reasons for false positives are as follows:
• Family members living at the same address with the same or similar first names or initials and possibly having joint accounts or trusts on which they have different roles (for example, Mike Johnson Sr. vs. Mike Johnson Jr.).
• Lack of differentiation between party types. For instance, if a customer Tom Kent opened a checking account with a firm, created a trust where he is a trustee, and has an account for his small business called “Tom Kent Associates,” the system may not be able to recognize the three parties as distinct entities (individual, trust, and small company).
• The use of invalid or incorrect data for multiple records—for example, records with an anonymous social security number (SSN) of 999-99-9999, which is often used when some entry is required but the right value is unknown.
• The use of a phone number as a personal number when it is shared by many people because it is a general number for a large organization.
Reasons for False Negatives in Party Matching
There are many reasons for false negative matches, most of them being related to data quality:
• The use of multiple versions of the same name
• Nicknames and aliases (Bill vs. William, Larry vs. Lawrence are the most common)
• Misspelled names
• Use of acronyms in organization names
• Names for international entities, such as individuals that may not fit the English–standard First Name–Middle Initial–Last Name structure
• Entity name changes
• As a result of the naturalization process
• As a result of marriage
• Organizational name changes as a result of rebranding, mergers, acquisitions, and company spin-offs
• Addresses
• Incorrect spelling
• Different abbreviations and spellings, including full spellings (Street vs. St., Avenue vs. Ave, Ave vs. Rd, St vs. Ct., and so on)
• Inability to parse certain formats
• Vanity addresses (multiple towns associated with a single ZIP code; the towns are used interchangeably in the mailing address)
• Address changes
• Phone numbers
• Inability to systemically parse some of the phone number formats
Attributes and Attribute Categories Commonly Used for Matching and Identification
The attributes used for matching and entity identification can be divided into the following three major categories:
• Identity attributes Used for direct matching
• Discriminating attributes Used to disqualify similar records
• Record type or record qualification attributes Used to determine which identification rules to apply
Identity Attributes
Identity attributes are the primary attributes used by the matching algorithm to directly identify an entity—for example, a name or SSN can be used to directly identify a customer. If identity attributes match two or more records, there is a good chance that the party/customer records are matched correctly. If a high-confidence match is required, a match on a single identity attribute may not be sufficient and multiple attributes should be taken into account. Good candidates for identity attributes include:
• Name Individual names (first, last, and middle initial) for persons and full business names for organizations are the most well-known identity attributes. Indeed, names were invented for identification purposes. From this perspective, the identification problem for individuals is as old as humankind.
• Key identifiers Since the vast majority of individuals’ names are not universally unique, people invented key identifiers such as social security numbers, tax identification numbers, driver’s license numbers, passport identifiers, patient numbers, student IDs, employee IDs, and so on, to identify individuals and organizations.
• Address The customer’s address is frequently used for identification purposes. It is not uncommon for a marketing campaign to target households (typically a family living in the same physical location) rather than individual customers or prospects.
• Phone Home phone numbers and cell phone numbers are frequently used for identification. Automated interactive customer service systems shortcut security questions when they recognize the customer phone number.
• Online identity attributes
• IP address
• Internet provider
• E-mail address
• Other online identifiers
• Product type, account number, and role In account-centric enterprises (the majority of businesses across all industry segments today belong to this category), the most credible customer information is stored and maintained at the account level. The firm recognizes a customer by examining the product type (for example, mortgage), account number, and the customer’s role (for example, co-borrower) on the account. Typically, account information is maintained by multiple systems across the enterprise, which makes these attributes good candidates for matching.
• Customer affiliations Customer affiliation information is frequently used as additional identity information. A typical example of an affiliation is customer’s employment information.
• Customer relationships and hierarchies This information is particularly critical and frequently used by organizations servicing high-net-worth customers. Every customer in these organizations is defined through a relationship with the firm or with other customers (individuals or groups) and then by name, address, and so on. Customer relationships can also be used as additional identification information. Hierarchies of institutional customers may also be important as identification attributes. We will discuss this in more detail in Chapter 15.
Note that most of the identity attributes can change over time, due to life events and normal business activities. Support for changes in identity attributes represents one of the key MDM requirements. Indeed, people and businesses move and change addresses, phones, and professional affiliations. For institutional customers, mergers and acquisitions cause additional complexities. Name changes are not unusual either. And they not limited to the name change as a result of marriage. The immigration and naturalization process in many countries includes a name change as part of the naturalization process.
Discriminating Attributes
Discriminating attributes are the attributes that are not typically used to match two entities. Instead, they are used to disqualify two or more similar records. For example, in the Customer domain, a father and son with the same name and address can be differentiated by the discriminating attribute “Date of Birth.” Typically, a strong discriminating attribute candidate should be static and have a well-defined set of distinct values (for example, Date of Birth or Gender).
Even if some identity attributes match across two or more records, there is a chance that the records still belong to different customers. Discriminating attributes help to distinguish between similar records that may or may not belong to the same customer. Typical discriminating attributes are:
• Individuals
• Date of birth (DOB)
• Date of death
• Gender
• Organizations
• Date of incorporation/establishment
• Date of closure
Discriminating attributes are often utilized in combination with identity attributes to reduce the probability of false positive matches. Typical situations in which discriminating attributes help include the following scenarios:
• Husband and wife or a parent and a child with the same first initial and last name—for example, J. Smith can be John Smith or Jane Smith, or, using our Johnson family example, M. Johnson can be Mike or Mack Johnson.
• Similarly, J. Smith can represent two brothers partnering in business. Assuming they were not born on the same date, the Date of Birth (DOB) attributes will help.
Unlike identity attributes, discriminating attributes typically have lower cardinality. From this perspective, Gender is a common discriminating attribute with a customary cardinality of 2. However, note that the cardinality of Gender is sometimes defined by a number greater than 2. There are local variations where, for example, a common discriminating attribute such as Gender can assume up to six distinct values. The cardinality of the DOB attribute is much higher in a typical customer data store that covers 50 years of customer life span for active customers, and using 365 days in a year, the cardinality of the DOB attribute is 18,250. While this number may appear large, for a multimillion-customer file this translates into hundreds or even thousands of individuals with the same date of birth.
Additional characteristics of discriminating attributes that are also important in terms of entity identification include:
• Stability
• Unlike identification attributes, which are made up by people and can change over time, in real time, or in one mass change operation (for example, a group of customers from the same retirement plan was reassigned to a new plan with different account numbers), the discriminating attributes for individuals are much less volatile. Indeed, your first name and middle initial are normally given by your parents, and the last name can change as a result of marriage or some other events. The DOB attribute should never change. Even though gender can be changed by modern medical science, it is still a relatively rare event.
• Similarly, when we deal with organizations, the Incorporation Date and Business Closure date do not change. This applies at least to formal organizations that are registered with the appropriate government agencies and assigned tax identifiers.
• Universality
• By their nature, every individual, regardless of the country of residence, citizenship, occupation, and other characteristics, has such attributes as Date of Birth and Gender, and they can be used for global identification. On the other hand, identification attributes such as social security numbers that are used as unique identifiers for individuals in the U.S. most likely cannot be used to identify individuals outside the U.S. To make it even more interesting, there are some exceptions when U.S. residents do not have an SSN either.
• Availability
• Gender is one of the most easily available attributes. Most customers do not keep their gender secret.
• Date of Birth is more difficult to obtain than Gender, but it is still easier to obtain than the social security number. Certain data privacy regulations discussed in Part III prohibit the disclosure and use of social security numbers for identification purposes.
• Ease of validation
• For Gender, the process is straightforward; for example, a typical rule allows for only “F” (Female), “M” (Male), and “U” (Unknown) values.
• Date validation routines are well known and are widely available in multiple products, including commonly used relational databases. It is important to note that common calendar and date formats are accepted and used globally. However, it is not easy to establish global validation rules for names and addresses. Indeed, multiple attempts to apply rules such as “Last Name must have more than one character” have been defeated. Even though such last names are infrequent, they do exist.
It is our recommendation to maintain the discriminating attributes in the best possible conditions in terms of data quality. Best of all, discriminating attributes should be defined as mandatory fields that have assigned values. In other words, in terms of database technology, the discriminating attributes should be defined as NOT NULL if possible. If this is not possible, data profiling and data quality maintenance on these attributes should be a priority task for data stewards.
The attributes of “Date of Birth” and “Business Incorporation/Establishment Date” are particularly important and attractive from the identification perspective. Even though these attributes are considered to be discriminating attributes (this is how they are commonly perceived), they can be successfully used for identification purposes as well.
Record Qualification Attributes
The record qualification or type attributes are used to provide additional metadata about the entity records. This information helps the matching algorithm to determine which identification rules should be applied to the record. The following attributes are typically used as record type identifiers:
• Party Type
• Country Attribute and Domestic vs. International Identifiers
• Leading Relationship (if a customer has multiple relationships with the enterprise, the most important relationship from the enterprise perspective is referred to as a Leading Relationship)
The need for record qualification attributes reinforces the assertion that the quality of an MDM solution depends not only on the narrow set of identification and discriminating attributes but also on a wider set of attributes that are typically included in the data scope of MDM projects. Consequently, for many organizations, MDM projects become drivers for enterprise-wide data quality improvement initiatives.
Party Type
Data about master entities such as customer often exists in different data stores within a firm and tends to be very heterogeneous, both from the format and the system representation perspectives. Consequently, from the matching perspective, it is important for the matching algorithm to qualify the record type to determine appropriate matching rules for that record type. The Party Type attribute characterizes the type of party/customer this record belongs to. The most common Party Types are Individual (retail customers, citizen, patient) and Organization (wholesale, commercial, business, government agency). Typical attributes for individuals are quite different from those for organizations. The most obvious example illustrating this distinction is the set of the name attributes. For an individual, first name, last name, and middle initial are typical while businesses are characterized by full business names that usually include the type of the business entity (for example, “Inc.” for Incorporated entity, “LLC” for Limited Liability Corporation, “Ltd.” for Limited, and so on)
Some attributes, such as Gender, provide information about a person but do not apply to businesses. Social Security numbers for living individuals are unique within the U.S. Unfortunately, this uniqueness does not hold true if the matching record set includes both individuals and businesses. Even the Business Tax Identification Number can be the same as an individual SSN. The list of examples illustrating the differences between individual and organizational records can be significantly extended. The bottom line here is that the matching algorithm needs the Party Type as an important record-qualifying attribute since different matching rules apply to different Party Type entities.
We have to point out that individual customers are somewhat easier to identify since, in general, individuals can be better “defined.” For example, each individual is identified by his or her unique DNA. Even though the DNA data is not typically available for most MDM systems, this does not change the fact that, conceptually, individuals are better defined for recognition than organizations are. The latter can frequently be viewed as subjects of fuzzy matching and identification. Indeed, the Party Type of “Organization” is often subcategorized, where the subcategories depend on the industry segment in which the “Organization” operates. In financial services organizations, the subcategory list may include such party types as trust, fund, estate, annuity, association, and so on. A party subcategory might be important in refining the rules on how the customer record should be processed by the matching algorithm.
As we stated before, product matching is even more complex than organization matching, and it involves a variety of sophisticated approaches and algorithms that are often based on semantics processing.
Country Attribute and Domestic vs. International Identifiers
The country attribute is important for correct name and address recognition. As we discussed in Part I of the book, different rules apply to names with different ethnic backgrounds. Accordingly, advanced customer matching and recognition algorithms that use probabilistic models can take advantage of the country and geography information (for example, state or province data) to improve the accuracy of matching.
In the case of an address, the address structure and ultimately the party recognition and identification depend on the way addresses are defined in a given country. Therefore, it is important to determine the country type for each record that has to be matched. In many cases, when the country data is not reliable, it is important to differentiate between U.S. domestic addresses and international addresses. This distinction is important for U.S.-centric MDM solutions because U.S. domestic addresses are normally better defined and therefore can be processed in a more automated fashion, while international addresses require more manual intervention. Even if the MDM system is designed to access an external knowledge base from a “trusted” data provider such as Acxiom or Dun & Bradstreet, it is important to know that the commercially available U.S. domestic name and address information are more accurate and complete than international name and address data for most foreign countries.
Leading Relationship and Relationship Level
Another important piece of the entity identification metadata is the information about the details of a customer’s relationships with the firm. This information can be used by the MDM system to identify the most profitable low-/high-risk customers (individuals and institutional customers) and the relationship managers who are responsible for maintaining the corresponding customers’ accounts. The Leading Relationship information is particularly important since it can help prioritize the way customer records have to be cleansed up and processed for identification.
When we consider an individual Customer domain (as opposed to institutional customers), we see that the personal information about the individual customers is typically more complete and accurate than data about the prospects. It is a good practice to maintain a special attribute that indicates whether the party is a customer or a prospect. A person is considered to be a customer if he or she has at least one relationship (for example, account) with the firm. In the case of a customer, some minimum information is not just required but is in fact mandatory in order to open an account. For prospects that are only potential customers, minimum data requirements can be much less restrictive. Consequently, the expected accuracy of matching for prospects is lower than that for customers. Similarly, the expected accuracy for primary customers is higher than that for secondary customers (for example, a spouse listed on the account as a beneficiary), third-party vendors, and so on.
The identification accuracy of the most profitable customers is a business imperative that is aimed at increasing the customer’s level of satisfaction, so it is not unusual to invoke a manual identification process to reduce the number of identification errors. In order to support a manual customer identification effort, it is critical to know who in the firm is primarily responsible for the relationship. Thus, an MDM system must maintain the attributes that link customer information with the relationship owners. For example, a financial services firm would have to know and maintain information about customer relationship managers, financial advisors, agents, and account managers who manage the relationship with the customer.
Customer Identification, Matching Process, and Models
Let’s continue our discussion on customer identification by taking a closer look at the identification processes and concerns as they apply to individual customers and prospects.
Minimum Data Requirements
A prerequisite to effective customer identification and matching is the consideration of minimum data requirements for any record to be included as a matching candidate. This notion is reflected in Figure 14-4.
If the minimum data requirements are not met, the record may require additional manual processing (for example, additional data must be collected, entered, or changed). Data change is required if an attribute value is determined to be invalid. Figure 14-4 shows six combinations of attributes. If a record does not meet any of the requirements specified here, the matching algorithm will exclude the record from the matching process and report it as a data quality exception.
An alternative approach to the minimum data requirements is based on the probabilistic self-scoring of an entity record. A matching score that is typically used to quantify a similarity or dissimilarity of two records can be used in self-scoring when a record is scored to itself. Higher self-scores indicate that the record contains a higher amount of identifying information. An advantage of this method is in that it doesn’t require any deterministic business rules.1 The method takes into account not only what attributes are populated but also recognizes the frequency of the values (or the uncertainty of randomly matching the values). For instance, in the U.S., “John Smith” as a name will self-score lower than any other less frequent name. Consequently, a record with a rare name will score higher than a record with more commonly used names.
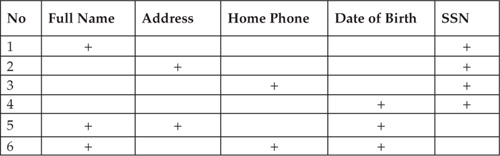
FIGURE 14-4 An example of a minimum requirements definition
Matching Modes
From a systemic perspective, the identification process consists of two high-level steps: record match and record merge.
Merge and split processing is discussed in some detail in Chapter 15. This chapter is focused on the implementation issues of record matching. The goal of the record match process is to create Match Groups. Each group contains one or more records that represent the same party. Typically, once the Match Groups are identified, the goal is to eliminate duplicate records and create a unique “Golden copy” of each entity (in this case, customer) record. Depending on the business requirements, the creation of a Golden copy may not be mandatory. Moreover, some MDM implementations require keeping multiple linked records without removing duplicates.
The Match Group is used to systemically identify parties. This may or may not be identical to Party ID, which is the ultimate “Golden copy” identifier for a Party. If an end-user input is required to assert the Match Group value, then the terms Party and Match Group may have different meanings. In this context, the Party identifier represents a true single holistic customer view created by an matching process, possibly with the assistance of a subject matter human expert while the Match Group identifier is the best the system could do to automatically identify the customer in order to assist the expert.
Operationally, we can distinguish between batch and online matching modes. Batch matching applies to a process in which a large number of records must be processed to cluster individual records and assign a unique Party ID to each Match Group. Note that the Party ID is a unique identifier for each cluster representing a single customer. During the initial “unseeded” match, all records are assigned to Match Groups (see Figure 14-5). It is not unusual for the batch-matching process to process a complete multimillion-record customer database and to run for extended period of time.
Online matching is part of daily ongoing activities when new party records are created, deleted, deactivated, or updated (see Figure 14-6). Online matching is a “seeded” process, where each new record is matched against the existing records with assigned Match Groups identifiers and/or Party IDs.
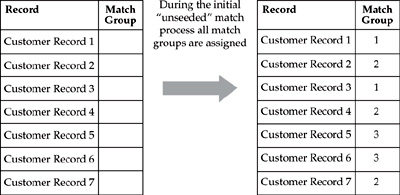
FIGURE 14-5 Initial match process
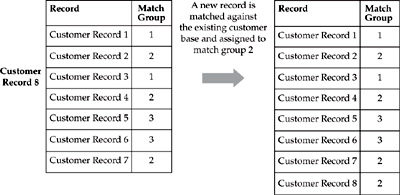
FIGURE 14-6 An Online, real-time, or near-real-time match
In this example, the addition of a record does not cause any Match Group changes. However, this is not always true. As we will discuss later in this chapter, a new record can “chain” two or more other records, which results in changes of the Match Group assignment for the existing records.
Defining Matching Rules for Customer Records
This section lists the typical steps used to define matching rules for customer records. Note that at a high level, these rules apply to the matching of any entities that carry identifying attributes and support syntax-based or pattern-based matching (for example, contacts or institutional customers).
First, we need to identify the matching attributes. All attributes that should be used for matching need to be identified. This includes all types of the attributes previously discussed:
• Identity attributes
• Discrimination attributes
• Record qualification attributes
Defining Matching Rules at the Attribute or Attribute Group Level
This section discusses factors that need to be considered when two attributes are compared for matching, and how to quantify them. The types of match operations that we need to consider in order to understand the factors affecting the match outcome include the following:
• Exact match Within this comparison model, two attributes are considered to be matched if they are represented by two equal attribute values, for example, character strings after the removal of padding spaces, carriage returns, and other characters that are not meaningful for string comparisons in the context of customer matching.
• Match with the use of “common sense” standardization rules These standardization rules cover a number of “common sense” rules about individual names and addresses—for example, match Steve to Steven, Ave. to Avenue, St. to Street, and names that sound similar (for instance, Stacy matches with Stacey).
• Match with the use of knowledge-based intelligence This category of matching involves rules that can be implemented based only on the facts available in the knowledge databases and data libraries. For instance, a knowledge base can hold data about the streets available in each town, valid ranges for street addresses, vanity addresses, and the National Change of Address (NCOA) data.
• Probabilistic attribute match A Probabilistic Attribute Match algorithm utilizes frequency-based data analysis for attribute value distribution on the attributes in the customer database. For instance, a probabilistic approach will take into account that the first name “John” is much more frequent in the database than the first name “Dushan.” From the probabilistic approach perspective, a match on a less frequent attribute value is statistically more significant than a match on an attribute value that is very frequent in the database. It should be pointed out that customer locality or geography can affect and even reverse the attribute frequency ratio. Indeed, the first name “Dushan” will be more frequent in the Balkans than the first name “John.” Frequency-based matching typically improves the accuracy of matching by 4–10 percent. An advantage of a probabilistic approach is the transparency of explicitly defined deterministic rules. In a probabilistic approach, matching results are more difficult to interpret because the matching engine does its “magic” under the covers.
Matching Quantification Once all factors driving a match decision are established, the model should also define how the attribute match will be quantified. The simplest case is a binary decision. The result of an attribute-to-attribute comparison can be presented as
Match = True
or
Match = False
More complex algorithms take into account various degrees of the confidence level of an attribute match. The confidence is at the maximum level for exact matches and decreases as the match becomes “fuzzier.” The confidence parameters need to be set and tuned in terms of the rules that define match outcome values. In clustering or K-nearest neighbor2 algorithms, the attribute match confidence is expressed through the “distance” between the two attribute values. The exact match would be characterized by the distance value of zero (distance = 0). As the match becomes less certain, the distance between the two values grows. There are several variations of these algorithms where, for example, different match weights are used to reflect different confidence levels.
Record-Level Match
Once the attribute-level match has been performed, it is time to expand the matching process to include the record-level match. There are a few ways to combine attribute-level matches and convert them into a record-level match.
Binary Rules for the Attribute and Record Match In this scenario, based on the attribute match defined as binary, the record match is defined by a number of explicitly specified matching rules. These rules can be simply codified in the “M” of “N” model (M of the total attributes N match). Figure 14-7 illustrates this approach.
The match criteria shown in Figure 14-7 require a match of any three attributes or attribute groups (M = 3) out of the five available (N = 5). The “M” of “N” model requires that in order for two records to be considered a match, M out of N attributes or groups of attributes should match. In the following example, there are five attribute groups or individual attributes:
• Full Name
• Address
• Phone
• Date of Birth
• SSN
Since three of them match within this rule, the two records match.
Typically, a simple rule such as “M” of “N” will not hold true from a match accuracy perspective when the record structures are complex and include many descriptive attributes that don’t have strict domain constraints. Moreover, given the complexity of enterprise data, the number of explicitly defined match rules can easily reach several hundreds, which further complicates the matching process. Lastly, in order to achieve the desired accuracy, the rules can become fairly complex and include conditional logic with dependencies on multiple attributes. Overall, the result of the computation is expressed in terms of a binary match/no match decision for the records. For instance, a rule may read: If the social security numbers match and the last names match, then the records are determined to be a match unless two valid and different dates of birth are found in the records.
Binary Rule for the Attribute Match and Score for Record Match In this scenario, assuming that the Binary Attribute match is true, the Record Match is defined through a score. First, we define attribute match weights for each attribute. Then the overall record-to-record matching score is computed as a total over the field of matching scores. Then, the calculated record score is compared with the matching threshold. If the computed value exceeds the threshold, the two records are considered to be a match.

FIGURE 14-7 A simple “M” of “N” attributes match scenario
Scoring for Both the Attribute Match and the Record Match In this scenario, the scores obtained from the attribute-level calculations and optionally weighted by the relative attribute weights are used to compute the record-level score. If the computed value exceeds the threshold, then the two records are considered to be a match.
It should be pointed out that one of the advantages of scoring methodologies is based on the fact that the matching requirements can be defined in a more compact form than the requirements defined explicitly in term of a great number of complex business rules. The scoring models allow for ease in defining matching iterations and testing procedures. This is particularly important since any matching process requires multiple iterations to reach the required level of accuracy.
Defining the Thresholds
As we discussed in the preceding section, the scoring models require a definition of match accuracy threshold. A higher threshold will make the matching more conservative, which means that the procedure will minimize false positive matches. A higher threshold will also result in a higher tolerance to false negatives. This is a disadvantage of any single-threshold model. A more flexible model should include two thresholds, as shown in Figure 14-8. In the figure, the scoring values are segmented into three areas: confident match, confident mismatch, and the “gray” area where additional information or human input is required to determine the match.
Effect of Chaining
Another important consideration in the matching process is the effect of chaining. Chaining is a situation where two or more records are assigned to the same Match Groups even though they should not be matched by using the rules defined by a direct record-to-record match. Instead, the records are “chained” by a third record that is directly matched to the first two records.
The accuracy of matching and performance may be impacted by how the matching algorithm handles chaining. A chaining scenario is illustrated in Figure 14-9.
In this example, we assume that the matching rule requires three attribute group matches for the records to be linked to the same party. The second record is linked to the first one on the Full Name, Phone, and Date of Birth. The third record is linked to the second one on the Full Name, Address, and Phone. Since three matching attributes are required to directly link records, the third record is not directly linked to the first one because only two attribute groups, Full Name and Phone, are matched for these records. Nevertheless, the first record and the third record are linked to each other indirectly through the second record.

FIGURE 14-8 Two thresholds segment the scoring values into three areas
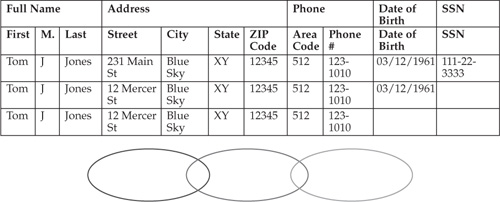
FIGURE 14-9 Effect of chaining for customer records
In order to understand the potential difficulties with chaining, we should note that the result of chaining depends on the order in which the records were processed. If Record 3 is processed after Record 1 but before Record 2, then Record 3 will not be linked to Record 1 and therefore will be assigned a different Party ID. When Record 2 is processed, it will be assigned its own Party ID. Consequently, three records will not be linked in the first pass. This may create matching accuracy and/or performance and scalability issues. Today, advances in developing matching algorithms allow MDM systems to achieve reliable scalability characteristics by aligning the processing time with the number of matching records.
As we pointed out earlier, there are situations where a new record can cause a Match Group recalculation in other records. Figure 14-10 illustrates this point.
In this figure, Customer Record 8 is found to match a record from Match Group 2 and a record from Match Group 3. This results in the merge of Match Groups 2 and 3. From a business perspective, this means that an addition of a new record led the matching algorithm to a conclusion that Match Groups 2 and 3 represent the same entity record.
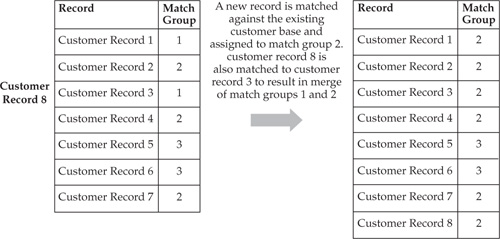
FIGURE 14-10 An example where a new record cause Match Group changes in existing records
Similarly, an update or a deletion of a customer record can cause changes in Match Group assignments of other records. For instance, if Customer Record 8 is deleted, the process in Figure 14-10 may be reversed and the three Match Groups may be created.
Break Groups and Performance Considerations
In practice, performance concerns about matching records in a very large data set can be addressed effectively if we apply a matching algorithm on smaller sets of records called break groups. There are other optimization techniques that allow MDM systems to achieve acceptable levels of performance and scalability. Many of these techniques are the subject of published and ongoing research, and are well beyond the scope of this book. Nevertheless, the performance of the matching process, in combination with its accuracy, is one of the topics presented by practically all MDM vendors as their competitive “differentiator.” Many claims have been made that a particular proprietary technique can match hundreds of millions or even billions of records in practically near-real time. While we’re not going to dispute these claims, we want to turn the reader’s attention to a set of considerations designed to separate the reality of match scalability from the marketing hype. The discussion that follows describes an analytical approach to matching performance that is based on the concept of break groups.
When a matching algorithm runs against a data set, in general, it has to evaluate match/no match conditions for all records in the data set in a pair-wise fashion. The total time spent on matching depends to a large degree on the time spent on the match/no match evaluation for the record pairs.
Using this as a base, let’s consider a simple model where the data set contains N records. Assume that M attributes are used for the match. Let t be the time required to evaluate the matching conditions for a given attribute for a given pair of records. The number of pairs of records can be evaluated through the number of combinations of N divided by 2, which yields N× (N–1)/2. The time required to perform the match/no match decisions for all record pairs is
T = t × M × N × (N–1)/2
Given that N>> 1, we arrive at
T ? t × M ×N2/2
The value of t depends on a number of factors such as hardware, complexity of comparison, and so on. For this evaluation we will use t = 10–8 s. For typical values of M = 20 and N = 30,000,000, the factor M × N2/2 evaluates to 1016. Assuming a single process, with this number of comparison operations, the time required to complete matching is T = 108 s, which is over three years. This indicates that it is practically impossible to get a reasonable matching performance on a very large data set using the current state of the art in conventional computing platforms. Of course, this process can be parallelized into multiple parallel streams using grid/cloud computing platforms, the MapReduce3 computing paradigm, and other approaches. In general, the optimization goal is to decrease the number of comparisons in each comparison job stream by orders of magnitude to get meaningful performance results. This can be achieved by using break groups that segment the data set into smaller sets of records so that record matches are possible only within the break groups and never across them.
Let’s evaluate the change in the number of comparisons as a result of creating B break groups. For simplicity, let’s assume that all break groups are equal and hence each of the groups contains N / B records. Then the time required to perform the match/no match decisions for all record pairs within each group is
TB? t × M × N 2/(2 × B 2)
If matching is performed in break groups sequentially, the total computation time is
T? t × M × N2/(2 × B)
We can conclude that the number of comparisons is inversely proportional to the number of break groups. Using parallel processing platforms, parallel database systems, and/or approaches such as MapReduce in conjunctions with the break groups approach can drastically improve the total match time for large data sets. The break group algorithm supports software- and hardware-based parallelism since matching within each of the break groups does not depend upon matching in all other break groups.
Regardless of the particular choice of parallel processing system option, we can define the optimum configuration for the break groups. Let’s assume that out of M critical attributes used for matching, some attributes are more important than others. From the matching-engine configuration perspective, this means that higher weights were assigned to these attributes than to other attributes. In this case, we can select a small subset of the most important attributes K << M so that any two records cannot possibly match if none of the K attributes match. We will also assume that since the selected K attributes are so important, at least one of the K attributes must contain a value; otherwise, the record does not meet the minimum data requirements and will be excluded from the matching process. We can define a break group on the K attributes as follows: Any two records belong to the same break group if and only if they have a match on at least one attribute of the K selected attributes. From the performance perspective, it is important to realize that the number of break groups defined this way is high, which is caused by the high cardinality of the values in the selected K fields.
To illustrate these points, assume that K = 3 and the three selected attributes are the credit card number, full name, and the phone number. The data is loaded from multiple systems and not all of the three attribute values are available for each record. However, at least one of the three attributes must have a value to meet the minimum data requirements. The number of break groups B defined this way is very high, and the match engine should be able to perform the first pass of the match process to assign break group keys based on simplified matching conditions that include only the selected K fields. The second pass will be performed within a large number B of break groups.
We can now summarize the findings of this section as follows:
• For a multimillion-record data set, a matching process can achieve a reasonably good performance if it can identify break groups with high cardinality—that is, the number of break groups is high and the average number of records in each group is low.
• The matching engine should be selected with the break-group matching capability in mind.
• The matching engine should be able to support hardware- and software-based parallel processing to perform matching within break groups in parallel.
Similarity Libraries and Fuzzy Logic for Attribute Comparisons
Individuals use different names such as legal names, aliases, nicknames, and so on. The matching algorithm should take into account the connections between names like “Bill” and “William” or “Larry” and “Lawrence.” Name alias libraries (these aliases are also known as “equivalencies”) that are based on human knowledge must be built and made available to the matching engine to link this type of string values. Such a library should maintain only commonly used names. Otherwise, if unusual aliases are in the library, the probability of overmatching increases. For instance, if John Michael Smith wants to use an alias JM, such an alias should not be placed in the library.
A similar problem exists for addresses. It is not unusual for multiple small towns to be served by one postal office. In this case the town names can be used interchangeably. The mail will be delivered anyway. From the MDM perspective this means that two town aliases can be used for a given address. A similar condition exists for street names. This situation is known as vanity addresses. For example, a 5th Avenue address in Manhattan, New York, USA, sounds better than 86th Street, Lincoln Center sounds more prestigious than West 66th Street, and so on. Such vanity addresses are used as aliases for locations that are close to the “real” address but are used because they sound prestigious and expensive. As in the name libraries, address-alias libraries based on human knowledge must be built to link this type of string values. The National Change of Address (NCOA) database is a good example of where additional libraries should be used to achieve good matching results.
Similarity libraries cannot resolve the matching problems when the names or addresses are misspelled. Phonetic conversion algorithms (many of them based on fuzzy logic) are used in this case. Typically, fuzzy logic is required when comparing names, addresses, and other textual attributes. This type of comparison is one of the greatest MDM challenges. The fuzzy logic algorithms provide inexact match comparisons. SOUNDEX4 is the most widely known phonetic algorithm, developed in the beginning of the twentieth century. There are many modifications of this algorithm. They convert character strings into digital codes in such a way that phonetically similar strings acquire the same code values. These routines are included in many libraries of standard string-comparison functions.
NYSIIS is another phonetic algorithm, which was developed in 1970. The acronym NYSIIS stands for “New York State Identification and Intelligence System.” This algorithm is said to improve SOUNDEX matching capabilities by 2.7 percent. For details please refer to the website of the National Institute of Standards and Technology.5
A more recent sophisticated inexact string comparison algorithm known as Bipartite Graph Matching (BGM)6 is based on mathematical modeling that simulates the human notion of similarity. We will touch on BGM in vendor products again in Chapter 18 of this book.
Summary of Data-Matching Requirements and Solutions
Let us summarize the key considerations that should be used to evaluate data-matching solutions and engines. This summary can be also used as a decision-making checklist for MDM designers and product evaluators. As a base we will use the list originally published by Initiate Systems (2004) in the white paper, “Initiate Customer Data Integration and Customer Data Matching: Achieving a 360-Degree Customer View,” and make some changes and additions that come from our implementation experience.
• Accuracy and key characteristics of matching algorithm:
• Support for history of attribute changes as they relate to matching.
• Support probabilistic and/or deterministic matching algorithms.
• Support for single- and/or dual-threshold capabilities.
• Support for a “human similarity” match that utilizes learning algorithms. Instead of defining matching rules explicitly, which sometimes is not easy, the end users do manual matching on a “training” set. The matching engine infers the rules from the training set and provides a “human similarity” match.
• Ability to use National Change of Address and other reference data services for matching accuracy.
• Batch load
• Implementation of chaining scenarios and how the scenarios affect performance
• Support for initial load with required performance
• Scalability: time of processing as a function of the number of records
• Real time
• Real-time processing for new customer records and record updates, merges, splits, and so on.
• Implementation of chaining scenarios in real time
• Architecture
• SOA compliance and support for Web services
• Data exchange solution architecture between the matching engine and the primary database
• Platforms supported: operating systems and databases
• Support for parallel processing
• Openness of the solution and support for integration and iterative improvements
• Flexibility of configuration and customization
• Matching parameters supported
• Solution customization; languages supported, if any
• Merge and split (these points are discussed in more detail in Chapter 15)
• Support for data merge and data survivorship rules
• Support for symmetric split
• Support for asymmetric spit
• Solution change control
• Solution change-control capabilities are important to support the history of configuration changes. It is important in some cases to review what configuration was used at some point in the past.
• Operational complexity
• Matching file preparation
• Match/merge configuration setup
• Creation of the matching data set
• Reporting
• Change configuration reporting
• Reporting in support of operational processing
• Error processing
• Automatic error processing
• Support for manual entry to resolve errors and conditions when the algorithm cannot resolve matching
• Ability to work with country-specific plug-ins for data matching, including name and address aliases, phonetic and string similarity algorithms, transliteration problems, and differences in the character set codes
• Two different competing approaches can be used here. The first approach assumes that name and address standardization is performed first. Then a match is executed against persistently stored standardized names and addresses and other attributes participating in the match process. This approach is most common. It generates standardized names and addresses that are beneficial for other purposes beyond matching.
• There is an alternative approach. It suggests that higher match accuracy can be achieved if the record is matched as is with all fuzziness and the library issues resolved dynamically in a holistic manner for all attributes participating in the matching process.
To sum up, this chapter discusses key issues and approaches associated with entity identification and matching, with the specific focus on the Customer domain. This topic is one of the core requirements and benefits of any MDM project and has profound implications for the way business processes and applications are affected by a new authoritative system of record created and managed by an MDM Data Hub.
References
1. Dubov, Lawrence. “Quantifying Data Quality with Information Theory: Information Theory Approach to Data Quality for MDM.” http://mike2.openmethodology.org/blogs/information-development/2009/08/14/quantifying-data-quality-with-information-theory/.
2. Berson, Alex, Smith, Stephen, and Thearling, Kurt. Building Data Mining Applications for CRM. McGraw-Hill (December 1999).
3. Dean, Jeffrey and Ghemawat, Sanjay. “MapReduce: Simplified Data Processing on Large Clusters.” Google, Inc., 2004.
4. http://www.archives.gov/publications/general-info-leaflets/55.html.
5. http://www.itl.nist.gov/div897/sqg/dads/HTML/nysiis.html.
6. http://www.mcs.csueastbay.edu/~simon/handouts/4245/hall.html.