
CHAPTER 6
MDM Services for Entity and Relationships Resolution and Hierarchy Management
In the previous chapters, we discussed several general topics related to Master Data Management architecture.
We organized these discussions in the context of the enterprise architecture framework and its various viewpoints, which we used to help address the complexity and the interconnected nature of components of the MDM solutions. Using the principles and goals of the architecture framework, we demonstrated several key requirements and features of the MDM architecture. We also showed key differences and common features between two classes of data management solutions: Master Data Management on the one hand, and the technologies from which MDM has evolved, including Customer Information File, data warehousing, operational data stores, and Customer Relationship Management, on the other hand.
The features and functions that have evolved into contemporary MDM solutions from their various predecessor technologies are driving our approach to leverage already-familiar data architecture and data management concepts and components. These concepts and components include, among other things, scalable and manageable database technology; metadata management; Extract, Transform, and Load (ETL) technologies; and data quality measurement and improvement technologies. We discuss the architecture viewpoints and design constructs dealing with these technologies in Chapters 4 and 5 and master data modeling constructs in Chapter 7.
Architecting an MDM System for Entity Resolution
We’re now ready to discuss those aspects of the MDM architecture that enable MDM-specific functionality. Using the MDM definition offered in Chapter 4, we can assert that Master Data Management architecture cannot be complete without considering components, functions, and services that enable the transformation of record-level detail data into a cleansed, rationalized, aggregated, sustainable, and leverageable system of record.
The architecture constructs discussed in previous chapters are primarily relevant to Master Data Management and may not apply to predecessor technologies such as CIF, EDW, and others. In order to discuss these MDM-specific architecture concerns, we will use the already-familiar approach of analyzing and defining MDM features, functions, components, and architecture viewpoints in the context of the enterprise architecture framework. Furthermore, we will look at how enterprise architecture framework concepts apply to the specific, well-defined variants of Master Data Management, including MDM for Customer Domain (sometimes referred to as Customer Data Integration, or CDI) and MDM for Product Domain (sometimes referred to as Product Information Management, or PIM), and concentrate our discussions on the design and requirements for the service components of MDM Data Hubs.
Recognizing Individuals, Groups, and Relationships
Although the scope of Master Data Management is extremely broad and includes parties and customers, products, hierarchies, reference data, and other data types and domains, we dedicate a significant effort to the discussion of the Customer or Party domain, where the Party is a type of entity that represents individuals, families/households, groups, and corporate or institutional customers.
NOTE For convenience and in order to avoid confusion of multiple terms, we’ll refer to MDM for Customer domain when we discuss both Customer and Party entities.
One of the reasons for this focus on the Party is due to the fact that Party or Customer master is a requirement for any business-to-consumer (B2C), government-to-citizen (G2C), or business-to-business (B2B) organization. Secondarily, the market size of the MDM for Customer Domain represents the largest MDM market share and thus deserves the highest level of attention. Many considerations relevant to MDM’s ability to recognize and manage entities in the Customer domain apply equally well to other domains. The specific concerns relevant to MDM Data Hub for Customer domain include capabilities that allow an organization to uniquely identify, recognize, and possibly aggregate (or enable aggregation of) individual records about the customers into groups or clusters of records, all of which describe a particular aspect of the entity that represents a given party.
For example, let’s consider a hypothetical family—the Johnson family. We will start with Mike Johnson, who has just become a customer of the neighborhood bank by opening a savings account with a minimum deposit. Such an action is considered trivial by the bank, and Mike is categorized by the bank’s CRM platform as a low-priority customer. However, the situation would change drastically if the bank knew that Mike Johnson is a member of a very affluent family and has relationships with other, already established customers of the bank’s Wealth Management and Private Banking business units. The immediate implication of this situation is that Mike Johnson and his extended household represent high-net-worth customers that may already provide or in the future will provide significant revenue to the bank.
Let’s further assume that Mike Johnson’s network of relationships includes family relationships, business relationships, and investment/trust relationships, as follows:
• Mike Johnson’s extended family consists of six individuals:
• Dan (Daniel) Johnson and Kathy Johnson (parents)
• Mike Johnson and his wife Susan
• Mack Johnson (Mike and Susan’s son)
• George Patterson (Susan’s brother)
• Ann Patterson (George’s wife)
• Mike Johnson’s family owns two businesses:
• Advanced Computer Graphics Inc.
• Leading Edge Marketing, LLP
• Mike Johnson’s family established and owns three trusts:
• Dan and Kathy Johnson Trust
• Mack Johnson Trust
• Patterson Trust Company
• Mike Johnson is a chief designer in the Advanced Computer Graphics company, where his father is the CEO. He is also a board member of the Patterson Trust Company and is a senior technical advisor for Leading Edge Marketing.
• Dan and Kathy Johnson have several accounts with the bank, and Dan often uses his nickname (Rusty). The bank classifies Dan and Kathy as high-net-worth, high-priority customers.
• George Patterson has established a business account with the bank and is considering opening a joint Wealth Management account with his wife.
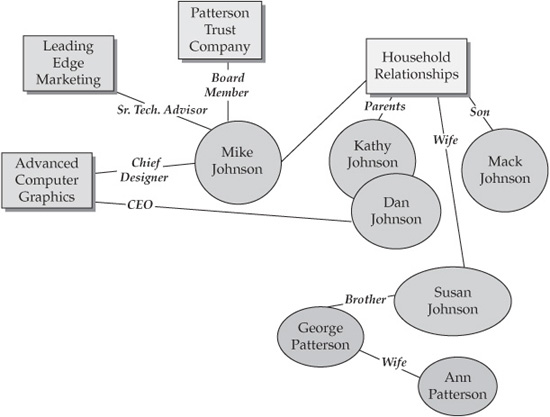
FIGURE 6-1 Johnson-Patterson family
A simplified graphical representation of the Johnson-Patterson family is shown in Figure 6-1.
An effective MDM solution would deliver an integration platform for customer data that contains a complete, integrated view not only of each individual in the Johnson household but also of the entire extended Johnson family. In order to accomplish this goal, the MDM platform has to support data models and functional capabilities that, for example, can recognize all relationships that Dan Johnson has with the bank as belonging to the same individual, even though Dan used an alias when he opened his private banking account. In the context of the Party data model, an account is a typical type of relationship that a party may have with the organization. Of course, there exist other relationship types, such as legal entities (see Chapter 7 for additional details on the MDM data model and the relationships it supports).
Even more importantly, the bank should recognize any member of the extended Johnson family as belonging to this extended family, and should be able to obtain a data view that shows the totality of the relationships the Johnson family and its members have already established and may establish with the bank in the future. Family relationships with businesses and organizations are key to understanding and leveraging the actual and potential relationships between a customer and the organization.
From the business model point of view, these capabilities in fact mean that an MDM system that manages not just individual customers but also all of their current and potential relationships would enable a transformation of an account-centric view of the Johnson household to an entity-centric (in this case, customer-centric) view that facilitates the new, better, and more rewarding customer experience that the bank can provide to both the Johnson and Patterson households and their business associations (see Figure 6-2).
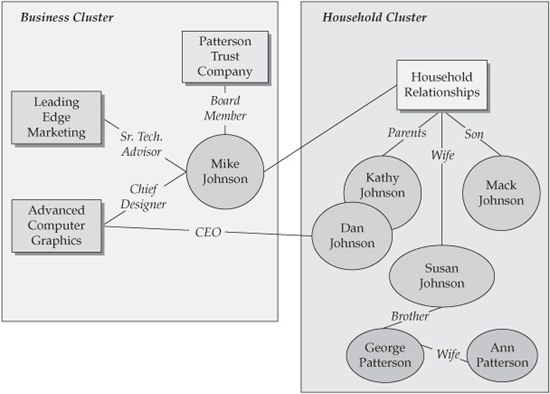
FIGURE 6-2 Customer relationship clustering
The ability to recognize and maintain these relationships is one of the key properties of the MDM Data Hub solutions no matter what architecture style is used (Registry, Reconciliation Engine/Hybrid, or full Transaction Data Hub). The process of creating the relationship links, which collects or groups individual records into higher-level clusters, starts with the very granular, low-level entity data (that is, accounts) and can extend its scope to include higher levels of abstractions, such as households, business associations, and other customer groups. This process requires that an MDM system implements a comprehensive data model and provides a set of functional services designed to support entity recognition, matching, and linking (these activities are collectively called “entity resolution” and are enabled by the corresponding Entity Resolution service of the MDM system). We discuss MDM data modeling concerns in Chapter 7, and entity recognition capabilities in more detail later in this chapter and in Chapters 14 and 15.
MDM and Party Data Model
One of the key features of an MDM solution designed to handle the matching and grouping requirements is the support for a data model that allows the creation and maintenance of arbitrary complex relationships. Such a data model may be reused from previous data modeling work done as part of a data management activity. Alternatively, an enterprise may develop an appropriate data model from scratch internally, acquire a model from an external source, or use a model that is included in the MDM product bundle that the enterprise has selected for the project implementation. Whatever the approach, the MDM data model should address the specific business needs of an organization. Chapter 7 discusses the key aspects of data modeling for MDM, and Chapters 14 and 15 offer additional discussion points on MDM data models and the impact of data model design on the Entity Resolution services.
To support complex functional requirements, many conceptual MDM data models contain at least the following major subject areas:
• A party/customer profile subject area that is populated with relevant party attributes, some of which are required for matching and linking of individual records
• A relationships subject area
• A metadata subject area that maintains record-level and attribute-level location information, attribute formats, domain constraints, and other relevant information
• An audit subject area
The first two subject areas are often industry specific and may be customized to support a particular line of business. For example, several industry-proven data models support property and casualty insurance or a retail banking business. These data models maintain customer/party profiles and relationships in the context of the industries they support. We briefly illustrate the key components of the conceptual domain-specific subject area in this chapter and offer more implementation-level concerns in Part IV of the book.
The remaining subject areas are created to support the Data Hub’s ability to become a reliable, accurate, and timely system of record. Some of these subject areas are created as part of the Data Hub data model, whereas others are created as separate data domains. For example, the metadata subject area is often implemented not as a part of the Data Hub data model but rather as a logical component of the metadata repository (metadata and other supporting subject areas of the Data Hub are discussed in more detail in Chapter 5).
A conceptual MDM data model that can support an entity-centric business such as retail banking, institutional banking, personal insurance, or commercial insurance is known as a “party-centric” model, and it may consist of a number of entities and attributes, including party/customer, party profile, account, party group, location, demographics, relationships, channels, products, events, and privacy preferences. Some of the key attributes of this model include identity attributes used to uniquely identify the party as a collection or cluster of individual detail-level records. Such a party-centric data model supports multiple party types, including organizations, customers, prospects, and so on. Figure 6-3 illustrates a highly simplified version of this conceptual model that is aligned with the insurance domain. Fundamental entities in this conceptual party model include the following:
• The Party entity, which represents a person or an organization, and can support an existing customer or a prospect. In our relationship example (see previous section in this chapter), a party could represent a member of the Johnson family.
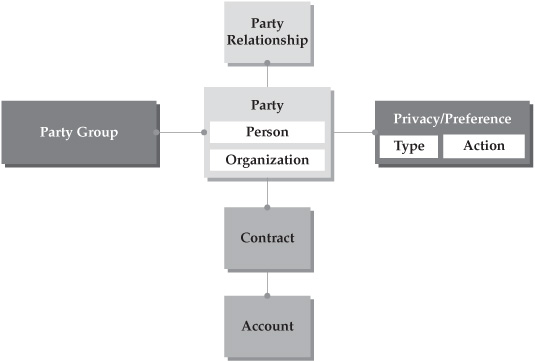
FIGURE 6-3 Simplified generic MDM party data model
• The Party group, which is an entity that represents a collection of individual parties affiliated with each other based on specific, well-defined criteria (for example, a household).
• Relationship-enabling entities, which support party-to-party relationships.
• Party-level privacy preferences, which can differ from one contract or account to another.
• The Party entity may have one or more contracts, each of which may have one or more accounts.
In practice, MDM implementations have to support party models that are much more extensive and complex.1,2
Entity Groupings and Hierarchies
One consequence of identifying, matching, and linking entities based on a predefined set of attributes is the ability to create entity groups. As mentioned, in the case of the individual customer/party domain, entities that represent individuals can be naturally grouped into clusters of households or families. Likewise, in the case of an institutional customer, some entities that represent various divisions of the same company can be grouped together to reflect a legal structure of the company. To illustrate this point, consider a large global organization that has multiple subsidiaries, some separated by the business focus (for example, a global diversified financial services firm may have an insurance subsidiary, a wealth management subsidiary, and so on) and by geography/location (for example, a U.S. bank, a Latin American broker-dealer, an Australian credit bureau, and so on). This situation is not an exclusive province of financial institutions; we see the same phenomenon in manufacturing, pharmaceutical, auto, advanced technologies, and other areas. For example, Ford Motor Company is a parent of a number of smaller manufacturers of Ford and other brands, such as Jaguar in United Kingdom (recently sold by Ford to Tata). All these legal entities can be grouped together to represent one common, global parent company, and MDM technology provides such identification, matching, and grouping capabilities to various domain types.
An important consideration for this “natural” grouping is related to the fact that these domain entities are related to one another in a hierarchical fashion. We discussed hierarchies and MDM hierarchy management in Chapters 5, and in this chapter, and the relevant implication on the MDM data model in Chapter 7. Just to recap, in many cases a given data domain has at least one “official” hierarchy based on a specific, business-defined classification schema, sometimes supporting alternative views of the entities for different business purposes. For example, businesses tend to structure their sales organizations based on either products or geographies or cost centers. Modern MDM solutions are designed to not only support primary and alternative hierarchies; they can automatically create and manage entity groups based on the hierarchies to which these entities belong.
This entity grouping topic becomes more complicated if you consider the need to organize entities into groups that do not follow the “natural” affinity (for example, members of the household) or are not aligned with standard (for a given domain and business) hierarchies. Consider an example where an aircraft manufacturer decides to set up a group of some of its suppliers and partners in order to develop a new product as a virtual team. In this case, members of the groups can engage in research and development activities and start acquiring supplies and hiring personnel using a credit facility. In this case, an MDM system should recognize individual expense or revenue transactions performed against one of the group members as belonging to a larger virtual entity for the purpose of aggregating this data into a combined balance sheet.
Moreover, this group may enter into an agreement where the share of the revenue or the expenses is not split evenly among the members, so a straightforward aggregation may be inappropriate.
One approach to support these arbitrary complex entity groups is to create custom hierarchies (these may not be hierarchies in the pure sense of the term but rather define the rules of linking and aggregating for the group at large and each individual member) and then leverage the MDM system to manage the resulting balance sheets, combined risk exposures, and other business metrics.
Such entity groups can be defined both in the individual and institutional customer domains. For example, an investment club may invite members that are not related in any obvious way, but have to be treated as a group for the purpose of negotiating better brokerage commissions or a larger credit line with more advantageous terms.
Clearly, the challenge of managing entity groups is often related to the challenge of managing hierarchies. This challenge is exacerbated by the fact that hierarchies are not static, and can and do change with business restructuring, mergers and acquisitions, new product introductions, and other events. As we stated in Chapter 4, hierarchies are key aspects of creating and managing master data entities and entity groups, and a typical MDM system implements a certain level of hierarchy management, including entity-level matching, aggregation, and hierarchy realignment, by providing a rich set of services and management capabilities that can create and manage multiple hierarchies, including alternative hierarchies and custom, user-defined structures that can in turn support various types of entity groups.
We discuss hierarchies and entity groups in this chapter because their existence makes the challenge of entity resolution much harder. Indeed, the problem of entity resolution is multidimensional, where the matching process has to be designed to support both simple, same-grain-of-detail comparison of entities (such as two customer records) and the much more complex task of discovering whether two entities are related according to some hierarchical arrangement or because they belong to an implicit or explicit entity group.
Challenge of Product Identification, Recognition, and Linking
When we discuss the need to recognize, match, and link entities from the customer domain, the existing MDM solutions have been shown to do a reasonably good job. The primary enablers of entity resolution in MDM for customer domain include advancements in data quality technologies as well as the maturity of the techniques and algorithms focused on solving name- and address-matching problems. The majority of these techniques are syntax and/or pattern based, and are very successful in detecting and correcting typical data entry errors; in recognizing misspellings caused by phonetic interpretations of a given word; and in the handling of professional terminology, abbreviations (for example, St. and Street), synonyms, nicknames and alternative representations (for example, Mike and Michael), invalid postal codes, and other name and address issues.
Likewise, the challenge of matching entities in the customer domain that are organized into different hierarchies is addressed by many MDM products, and relies to a large extent on the patterns and explicit rules.
When we deal with the product domain, the challenge of matching and linking entities is much harder, and not just for managing hierarchies of product entities, but also in the fundamental activities of matching product entities that appear to be at the same levels of grainularity (hierarchy).
The root of the problem lies in the wide variety, intrinsic complexity, and limited standardization of product data. Because product data is not just domain specific but often source data specific (that is, often the same product is defined and described differently by the product manufacturer, developer, or provider), the typical syntax-based analysis and matching techniques prove to be ineffective. Indeed, product data, by its very nature, contains rich semantics that are based on the product purpose, the materials and components used for its development, the processes and instructions defining the product’s use, and a host of other factors. Moreover, the product definition standards are often limited to a given product type, and even then are often incomplete or not being followed. Examples abound: Consider computer products and accessories, clothing and shoes, furniture, and so on. Each of these product groups is described by its own set of attributes, and the value of these attributes is often driven by marketing considerations, and therefore tends to be different even in the same group. The result is the realization that there is almost no single and accurate way to describe products and thus leverage common product definition syntax to perform identification and matching.
For example, let’s look at a class of computer electronics products—specifically, laptop computers and accessories. In this case, “extended port replicator,” “quick connect docking station,” and “USB port extender” may be equally accurate descriptions and perfectly understandable to an educated buyer, but not very useful to a classical MDM system that requires syntax-based, structured information that is organized as a set of well-defined attributes, such as “class = Computer Accessory, item = Port Replicator, type = USB attached,” and so on, unless equivalent terms are explicitly defined for the matching software.
Moreover, some of these attributes only apply to specific product models/versions (in our example, not all port replicators can work with all laptop brands and models). This further complicates the product-matching problem because a successful matching technique should recognize, maintain, and use links between the related products (in our example, a complete list of laptop computers and the supported docking stations).
The conclusion is straightforward: In order for an MDM system to support entity resolution for a product domain, it should use a semantically driven approach to product recognition, matching, and linking that would reliably and effectively extract not just the product data attributes but would also extract and rationalize the “meaning” of these attributes in a way that eliminates ambiguity and provides consistency of definitions.
Semantics-based solutions for processing such complex data domains as product data have emerged from the area of academic research into the mainstream, and are now used in various areas of information technology, including Semantic Web, Artificial Intelligence, and many others. The key concept of semantics-based processing—ontology—is defined as a formal representation of a set of concepts within a given domain and the relationships between those concepts that can be used to make assertions about the properties of that domain.3 Modern MDM solutions can take advantage of the tools that are based on processing information ontologies to derive and operate on the semantic content as effectively as traditional tools operate on syntax-based constructs. Moreover, the realization of the need for semantics-based processing has a profound effect on the entity resolution design of MDM systems for the product domain, and also provides a new way to address data quality by measuring and managing the quality of data in the context of its meaning.
MDM Architecture for Entity Resolution
In the preceding chapter we showed that in order to create and maintain an authoritative, accurate, timely, and secure system of record, an MDM solution must support a number of capabilities that are designed not only to maintain the content, scope, and integrity of the core data model but also to enable the MDM Data Hub to be integrated and interoperate with established business processes, systems, and applications.
Figure 6-4 illustrates these service-based capabilities in the form of functional components at a conceptual level. Here, we show that the core MDM data store is surrounded by additional functional components that work in concert to enable the desired MDM functionality.
However, this picture represents only high-level conceptual component architecture. It does not show a view in which MDM functionality is available as a set of services that are published and consumed by the Data Hub in accordance with the service-oriented architecture (SOA) paradigm. In Chapter 4, we discussed the rationale and the benefits of the service-oriented architecture approach to designing complex integration-enabled software systems. Master Data Management solutions, by their very nature, belong to the category of complex integration-enabled systems. Therefore, applying SOA principles and concepts to the architecture of the MDM system is not only an appropriate but also an effective approach. The next section describes a high-level view of the MDM services aimed at solving identification, matching, linking, and grouping of master entities.
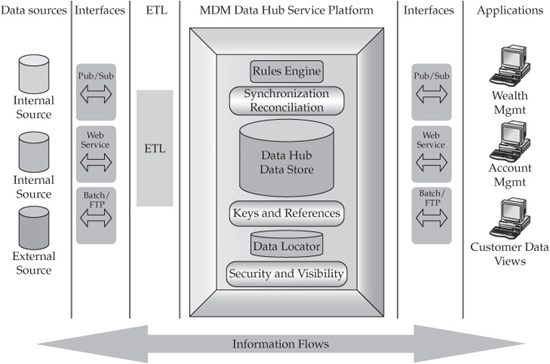
FIGURE 6-4 The conceptual architecture view addresses MDM-specific problem domains.
Key Services and Capabilities for Entity Resolution
Let’s start the discussion of the functional aspects of the MDM platform in the context of the MDM Data Hub reference architecture viewpoint described in Chapter 4. The MDM Reference Architecture viewpoint shown in Figure 6-5 is focused on key services that enable MDM entity management–related functionality. As a reminder, we offer an abbreviated definition of services-oriented architecture.
As shown in Figure 6-5, the MDM Reference Architecture includes a number of components and services designed to enable enterprise-scale MDM solutions. We arrange these components and services into functional architecture layers that emphasize the MDM services taxonomy. From a business point of view, the MDM Data Hub publishes and consumes coarse-grained functional business services that usually correspond to business functional requirements. Additionally, at the top layer of the architecture stack, the MDM services platform supports coarse-grained technical services. However, under the covers, the MDM platform supports fine-grained, lower-level services, some of which represent primitive, atomic services used to compose higher-level business services (we discuss this important point in Chapter 4). Some of the services provided by the MDM platform include internal, system-level, and infrastructure-level services that make the entire environment operational and manageable by the enterprise in a production environment. These supporting, infrastructure-level services include service coordination and orchestration, legacy integration service, systems instrumentation and management, error processing, and many others.
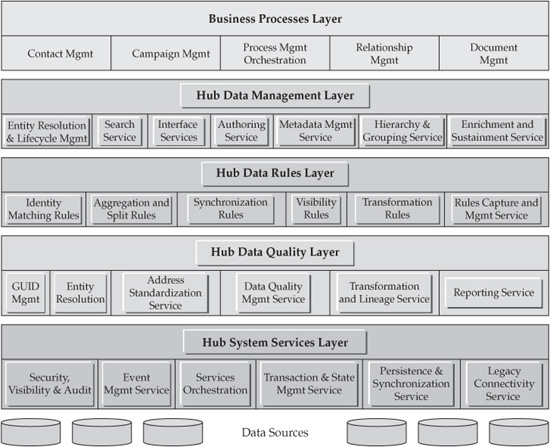
FIGURE 6-5 Data Hub reference architecture for MDM
Entity Resolution and MDM Reference Architecture
Let’s review these layers of services as they’re defined in the MDM Reference Architecture.
• The Data Management layer includes the following services:
• Interface services, which expose a published and consistent entry point to request MDM services.
• Entity Resolution and Life-Cycle Management services, which enable entity recognition by processing various levels of identities, and manage life stages of master data by supporting business interactions including traditional Create, Read, Update, and Delete (CRUD) activities.
• Search services, for easy access to the information managed by the MDM Data Hub.
• Authoring services, which allow MDM users to create (author), manage, customize/change, and approve definitions of master data (metadata), including hierarchies and entity groups. In addition, Authoring services enable users to manage (CRUD) specific instances of master data.
• Metadata Management service, which provides support for data management aspects of metadata creation, manipulation, and maintenance. The Metadata Management service supports a metadata repository and relies on and supports internal Data Hub services such as Attribute and Record Locator services and even Key Generation services.
• Hierarchy, Relationships, and Groupings Management services, which deliver functions designed to manage master data hierarchies, groupings, and relationships. These services can process requests from the Authoring services.
• Enrichment and sustaining services, which are focused on acquiring and maintaining the correct content of master data, controlled by external data references as user-driven adjustments.
• The Data Rules layer includes key services that are driven by business-defined rules for entity resolution, aggregation, synchronization, visibility and privacy, and transformation.
• The Data Quality layer includes services that are designed to validate and enforce data quality rules; resolve entity identification and hierarchical attributes; perform data standardization, reconciliation, and lineage; generate and manage global unique identifiers; and provide data quality profiling and reporting.
• The System Services layer includes a broad category of base services such as security data visibility, event management (these are designed to react to predefined events detected within the master data and to trigger appropriate actions); service orchestration; transaction and state management; system synchronization; and intersystem connectivity/data integration services, including Enterprise Information Integration services for federated data access.
In preceding chapters, we have shown that the richness of this SOA-based MDM architecture allows an MDM Data Hub to create and maintain an authoritative system of master entities for one or more domains. In this chapter, however, we will focus our discussion on those MDM capabilities that are data-domain independent and are relevant to MDM Data Hub systems that integrate and manage customer data, organization data, reference data, and product data alike.
• Entity resolution, which includes identity recognition as well as matching and generation of global unique customer identifiers
• Persistence and maintenance of the entity identifiers and other information for which the Data Hub is the master
• Rules-based and data content–based synchronization to/from legacy systems
• Reconciliation and arbitration of data changes
• Attribute location service
• Data security and visibility
Let’s illustrate these key MDM capabilities and services by offering an alternative view of SOA-based MDM Data Hub Reference Architecture. This view is a high-level conceptual framework that attempts to group all MDM services into external and internal sets of services (see Figure 6-6). We will use this high-level view to discuss several additional considerations on how the MDM services framework enables both business functionality and enterprise-level integration between an MDM Data Hub and other systems and applications.
Specifically, in addition to the published business services, we can differentiate between two major groups of interoperable internal services. The first group includes atomic functional services such as Create, Read, Update, and Delete (CRUD). These atomic services are a part of the MDM Life-Cycle Management service but also can be combined to assemble higher-level, coarse-grained composite business services that execute business transactions (for example, a coarse-grained business service such as Search would provide “Find a Customer by Name” functionality, and the Authoring service would allow users to “Create Customer Profile”). This abstraction is very powerful; it enables the reuse of services and components and easy, almost declarative-style integration.
The second group is a set of technical management and operational services that hide the technical complexity of the design from the application and business service developers. The services in this group include support for transactional semantics, coordination, compensation, orchestration, synchronization, recovery, error management, auditing, and so on. Although these services abstract application developers from the underlying technical complexity, they interoperate with both atomic and business services in order to manage and execute business transactions against an MDM Data Hub.
Following the same approach defined in Chapter 4, we can illustrate the service-oriented nature of an MDM Data Hub by “wrapping” the core Data Hub platform in the layers of internal and external services. We have shown a high-level graphical representation of this SOA wrapping in Chapter 4 (refer to Figure 4-8). Figure 6-7 builds on the view shown in Figure 4-8 and provides additional service details.
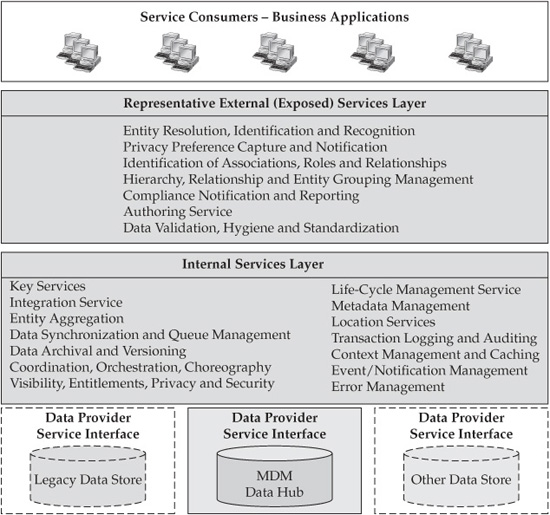
FIGURE 6-6 Data Hub as a service platform
Entity Recognition, Matching, and Generation of Unique Identifiers
The preceding sections of this chapter talked about the challenges and goals of identifying, matching, and linking master data entities, and set the stage to move from the general discussion about delivering key MDM capabilities for entity management to the point where we can focus our attention on the specific capabilities and services for entity resolution.
As before, we’ll use Customer domain as a background on which we explain key MDM services for entity resolution. As we stated earlier, one of the primary goals of an MDM solution for the Customer domain is to enable business transformation from an account-centric to a customer-centric enterprise by creating an authoritative system of record that provides an accurate and complete view of the customers, their groups, their relationships, and the way they may be organized into hierarchies.
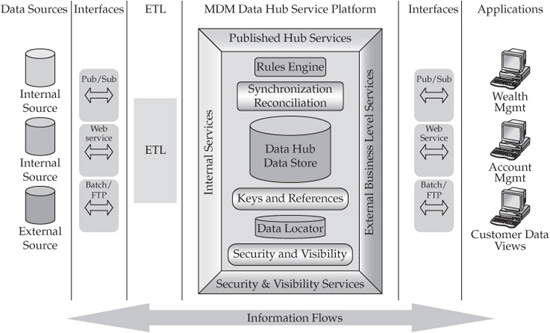
FIGURE 6-7 Services and MDM platform
When we deal with the Customer domain, the ability to recognize the fact that two or more detail-level records belong to the same party (individuals or organizations) is a paramount requirement for any MDM solution.
MDM technologies and services that enable this type of recognition are collectively known as entity resolution services and include the matching and linking of detail records and the creation and maintenance of unique identifiers as primary links to indicate the affinity of detail records to the same party.
Matching and Linking Services and Techniques
In the context of MDM for Customer domain, matching and linking is a highly specialized set of technologies that allows the user to identify party entities with a high degree of confidence.
The operation resulting in party identification allows a user of the MDM platform to construct a total view of a party from the detail-level records. Matching and linking technologies are very sophisticated, and many commercial products that offer these capabilities try to differentiate their matching and linking engines by using three value dimensions: accuracy of the match, speed of the match, and processing scalability. These characteristics are the result of the techniques and implementation approaches of the matching algorithms. It is not surprising, therefore, that many vendors keep their matching algorithms and techniques a closely guarded secret! We will discuss specific implementation concerns of the matching and linking services in Part IV.
NOTE As we discussed in previous sections, the matching and linking of product records is conceptually similar to the process of matching party records, but the techniques used for the product domain tend to be semantics based, rather than syntax, rule, and pattern based, which are predominant techniques for party matching.
The variety of matching and linking techniques for the Customer domain is rather large, and it would be beyond the scope of this book to cover them all. Therefore, in this chapter, we take a closer look at some of the best-known techniques used to achieve a high degree of accuracy in matching individual records. The algorithms we discuss in this section are proven to be very effective for entity resolution in the Customer domain; they are highly regarded within the area of the academic research and are effectively used in various technology solutions related to data quality.
At a high level, we can classify all algorithmic approaches to record matching into the following groups:
• Deterministic algorithms These algorithms offer predictable behavior of the comparison and matching process that is based on the data itself. In a deterministic algorithm, each attribute is compared against the same attribute in another record, which results in either a match or a no-match. For example, the deterministic algorithm would compare a social security number in one record with the social security number in another—an operation that would find a match if these two values are equal. Because of this relative simplicity, a deterministic algorithm can deliver very high performance and throughput. Deterministic algorithms often require cleansing of the input data and format standardization in order to perform the match. Traditionally, deterministic algorithms had limited capability to handle such common data anomalies as blank fields, transposition of characters, common misspellings of known names and addresses, and abbreviations. Today, however, advanced deterministic algorithms can overcome this limitation by employing various fuzzy logic techniques and using phonetic functions and lists of equivalencies.
• Probabilistic algorithms These matching algorithms are based on various statistical probability theories; for example, see Scott Schumacher’s article.4 The advantage of the probabilistic algorithm is that it can learn to match records that initially had to be resolved by a direct user intervention. The matching process of a probabilistic algorithm consists of several steps:
• An analysis of the input data to determine precise frequencies for weighting and matching individual data elements
• A determination of the outcome of matching between records using derived statistical distribution of value frequencies.
• An assignment of the weight values for match attributes and a predefined match threshold
• A refinement of the match values through the user-guided value assignment process for those cases where the match confidence level is below the threshold
• Machine learning algorithms These sophisticated techniques are based on advanced research and development in the area of machine learning and artificial intelligence. These techniques allow the system not only to detect similarities between two entities based on a number of factors and rules, but also to learn to refine the matching process automatically over time. Many machine learning approaches are somewhat similar to fuzzy logic techniques, typically include probabilistic techniques, and allow the matching engine to learn how to match records based on calculated proximity values. These algorithms can discover and measure similarities between attributes and entire record values in a way similar to how a human brain may recognize two objects as being similar.
NOTE Machine learning and artificial intelligence algorithms that can process information ontologies could also support entity matching in the product domain.
• Hybrid algorithms As the name implies, these algorithms may use multistep processes that combine deterministic, probabilistic, and machine learning techniques that can also be enhanced by applying more advanced techniques, including phonetic conversion and matching. Hybrid algorithms may use formal matching rules in a deterministic fashion. Alternatively, they can enhance the probabilistic relevance of the variables (attributes) and weights to achieve higher matching rates. Many advanced algorithms may use heuristics (algorithmic techniques that use the observed and understood experience of searching for matches within a given domain), pattern-based matching techniques, and a number of other techniques. Of course, as new techniques become available, their implementations could be either a hybrid or a “pure” deterministic or probabilistic matching engine.
Regardless of how sophisticated and innovative the matching algorithms are, in practice no single technique or single algorithm can satisfy all the diverse matching requirements of the enterprise, especially if the enterprise already developed and successfully used empirical, proven, business area–specific matching rules that may contain a large number of exceptions. This is especially true when dealing with a multidomain MDM that includes complex matching challenges of product information.
In general, however, when deciding on which linking and matching technique is best suited for any given environment, the MDM designers and match solution architects should consider the following factors:
• Match accuracy This requirement is self-explanatory. Higher accuracy allows the enterprise to construct a more complete integrated view of the entity such as a customer—be it an individual or an organization—and to reduce the errors associated with assigning false positives (for example, incorrectly recognizing an individual as a member of a wrong household) or false negatives (for example, missing a key member of the household).
• Linking and matching speed This requirement is especially important in the case of online applications designed to recognize an entity (for example, an individual) in real time—for instance, a patient who is being admitted to the hospital and requires an emergency blood transfusion, or an airport security control point that has to recognize an individual as a potential threat before airplane boarding starts.
• Uniqueness and persistence of the link keys The linking and matching process can be very fast and accurate, but if the results of the match cannot be stored reliably in the Data Hub or another facility for follow-on processing, then the value of the matching becomes questionable. Therefore, a matching engine needs to be able to generate a unique identifier that the Data Hub would persist in its data store as a unique key. These key values must be unique in the name space of all possible Data Hub entity keys. In other words, if we’re dealing with an MDM Data Hub for a global retail enterprise that serves 100 million customers, each of which has one or more detail records (for example, account-level records), the link key should have a sufficient range of values to support the cardinality of all Hub customer entities (in our example, 100 million) rather than all detail-level records.
• Deterministic outcome The key generation service must be deterministic in the sense that if the underlying data did not change, then the key value for the same cluster of records should not change either.
• Scalability of the solution This is a classical system requirement. In the case of the linking and matching engine, it has to address numerous scalability concerns. These include the number of records to be matched, the number of various data sources, the number of user-defined matching rules, and the number of concurrent users that may request the matching operation either to recognize individuals or to generate unique identification keys. The latter requirement should address the concurrency and throughput concerns of the Data Hub environment where the matching engine has to support a prerequisite number of concurrent users, each of which is able to perform a required number of tasks in a unit of time— for example, a predefined number of transactions per second (TPS).
• Ease of use The algorithm and the engine that implements it should provide an easy-to-use, intuitive way for the users to define or customize matching criteria, to understand the reasons for the matching outcome, and to resolve potential uncertainties. The engine should not require the user to be an expert in mathematics or computer science. The intuitive way users can employ the tool may make all the difference between user acceptance and rejection.
Ease of Implementation and Administration
If the matching engine is external to the MDM platform (that is, not built in as a component of the MDM application or an MDM vendor product), the engine should not require a highly specialized computing platform such as a supercomputer, FPGA-based appliance (FPGA stands for Field Programmable Gate Array—a special purpose, high-performance computing device), and so on. The engine should comply with the enterprise infrastructure standards and should be easily integrated into the enterprise system architecture and infrastructure environments. And, finally, an external matching engine should interoperate with the MDM platform of choice (server hardware, software, and the DBMS).
Flexibility
The matching engine should be flexible to conform to ever-changing business requirements. For example, if the organization decides not to use certain data elements in order to protect customer privacy and confidentiality and to comply with applicable privacy regulations (for example, not to use social security numbers or unlisted telephone numbers), the MDM administrator should be able to easily configure the matching engine to implement these changes.
Ability to Adapt to the Business Requirements and to Implement Proven Existing Matching Rules
Many matching algorithms are very sophisticated and are finely tuned to achieve high matching accuracy. The engines that implement these algorithms are designed to preserve the integrity (and, in many cases, significant intellectual property) of these algorithmic techniques. This approach works for many organizations that would like to rely on the matching engine rather than on home-grown matching rules. However, there are organizations and/or business situations where custom-defined matching rules and manual processes must be followed to achieve the desired business outcome. In these cases, the matching engine should be able to use user-defined custom rules in conjunction with the internal algorithms in such a way that the custom rules could override the internal processing or, at a minimum, defer the match decision to a user-driven manual process of asserting the matching result.
Ability to Support Linking and Matching as a Service
This is a technical requirement of the service-oriented architecture (SOA) that helps implement and manage the linking and matching engine as a part of the enterprise architecture. If the engine makes its capabilities available as services, then the consumer (a user or an application) is isolated from the intricacies and complexities of the underlying algorithms and is only concerned with the consumption of the service and the interpretation of the results.
To summarize, the most effective matching engine will utilize a combination of deterministic, probabilistic, and machine learning algorithms to achieve the highest accuracy in the shortest time. And at the end of the day, the flexibility of the matching engine to support the business rules of the enterprise creates a winning combination of sophisticated technology and intuitive behavior that enables the best linking and matching process for the enterprise.
Aggregating Entity Information
Using the Matching and Linking service described in the preceding section, the Data Hub will recognize similar records and assign unique link keys to all records in such a way that all records with a given link key value can be grouped together or aggregated into a single entity. In the case of the MDM Party model shown in Figure 6-3, this entity is the Party, and the link key becomes the Party’s unique identifier and its primary key.
In principle, this process can be iterative, and it can match and link Party entities using some business-defined criteria. Therefore, a Matching and Linking service can use various business rules to generate different identifiers used to aggregate individual Party objects into even higher-level entities. Examples of these higher-level entities are households, business associations, and other types of customer groups. Depending on the desired depth of aggregation, the Matching and Linking service can generate a number of keys or identifiers that are unique in the corresponding name space of entities for which the matching operation is performed.
Once the identifiers are generated, the MDM Data Hub can use its internal Entity Aggregation service to merge appropriate records into the next-level entity. This merge operation can be automatic or user guided. For example, the Entity Aggregation Service component of the MDM Data Hub may use the unique identifiers to automatically “merge” account-level records into clusters representing individuals, and use next-level identifiers to merge individual-level records into uniquely identified groups such as households (see Figure 6-8). We discuss the merge process in more detail in Chapter 15.
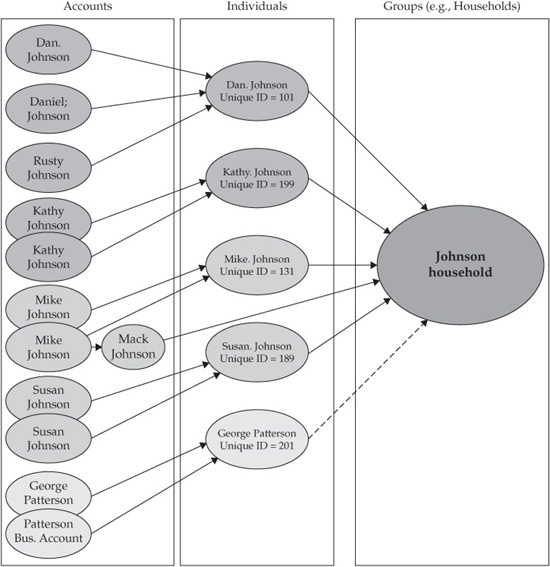
FIGURE 6-8 Mapping accounts to individuals and group
In practice, however, an automatic merge may be undesirable. This is because the matching algorithm may create false positive and false negative outcomes. Another consideration for not using an automatic merge is that, in some cases, the matching business rules are so complex and the number of exceptions is so great that the users would prefer that the system suggest a potential merge suspect while leaving the final decision to the user. Thus, the Entity Aggregation Service of the MDM Data Hub should be able to support both modes of operation: automatic and user-guided (or supervised) aggregation.
Data Hub Keys and Life-Cycle Management Services
The previous sections discussed the MDM Data Hub services designed to match and link individual records by generating persistent unique identifiers. These identifiers, while critically important, are not sufficient to synchronize and maintain the content of the Data Hub in relationship to the upstream and downstream data stores and applications. Indeed, the MDM Data Hub is not an isolated and disconnected environment. It should be a system of record for some information such as customer profile, organizational profile, organizational hierarchies, product reference, and other data domains. Depending on the MDM architecture style, the Data Hub may be just a Registry of the identification information, or a federated data environment that allows the Data Hub to “peacefully” coexist with other systems by maintaining some information inside the Data Hub and some pointers to data in external data stores, data for which the Data Hub is not the master. Ultimately, an MDM platform could be the full Transaction Data Hub and a completely self-contained master of the information that it manages. Regardless of the architecture style, an MDM Data Hub has to support a comprehensive data model and a number of specialized services designed to maintain data integrity inside the Data Hub. These specialized services also have to support the Data Hub’s ability to keep its content in sync with the providers and consumers of the master data that is stored in the Hub (the data management aspects of MDM data synchronization are discussed in Chapter 5).
Keeping a Data Hub in sync with its sources and consuming applications is not a trivial task. It requires a comprehensive design and the availability of a number of carefully orchestrated services and well-defined processes. To illustrate this point, let’s define several interdependent cooperative service classes designed to work in concert to support Data Hub synchronization consistency and data integrity:
• Key Generation service
• Record Locator service
• Synchronization service
• Reconciliation service
• Attribute Location service
We briefly discuss the Key Generation and Record Locator services in the next sections. The other services and additional architecture considerations of the MDM Data Hub solution are discussed in Chapter 5. Part IV of this book offers an in-depth look at the implementation aspects of these and other MDM services.
Key Management and Key Generation Service
First, let’s review some basic concepts related to the creation and management of Data Hub keys. As we stated in the beginning of this chapter, the MDM Data Hub data model contains a number of data entities and the relationships between the entities. The general principles of the enterprise data architecture and the relational data model dictate that every entity has at least one unique key, and depending on how the model is defined, one of these unique keys is known as the “primary key.” A data modeler defines the interrelationships between entities through the assignment and maintenance of the primary and foreign keys. These keys enable a key data model constraint of referential integrity, where a primary key of one entity (for example, a customer table) should exist in a related table as a foreign key.5 For example, a Party Profile table may have a unique Profile key. This table may be related to the Account table, which in turn contains unique Account keys. Further, each Profile may have one or more accounts. To link these two tables, Profile keys are inserted into the Account table as foreign keys for easy reference in such a way that for each Profile key in the Account table, there is a record in the Party Profile table with this key value.
Referential integrity is one of the principal features of the majority of Relational Database Management Systems (RDBMS) that support the MDM system. Many MDM solutions are deployed on standards-based commercial RDBMS platforms. However, because a typical MDM solution uses a number of other keys, many MDM engines offer additional key management services designed to maintain the integrity and consistency of the MDM Data Hub.
As shown in Chapter 7, at design time, a Data Hub data modeler constructs the logical and physical data models that include primary and foreign keys. However, having a key placeholder is not enough—the values of these keys need to be available for any operation where data in the Data Hub is added, changed, or deleted. Moreover, the values of these keys need to be created and placed in appropriate records in such a way that they do not violate referential integrity and other constraints. These key values need to be available prior to loading data into the Data Hub so that the load operation can create a well-formed Data Hub data store. Likewise, any action that results in the addition of a data record (for example, a new account) has to be carefully designed to make sure that the appropriate values for the primary and foreign keys are available and that the resulting operation does not violate the referential integrity of the Data Hub.
The generation and maintenance of all keys required for the operation and the sustainability of the MDM Data Hub is the responsibility of the Key Generation service. This service has to be flexible, adaptable, and scalable, and should support any number of keys defined in the MDM Data Hub data model. For example, the Key Generation Service should efficiently generate primary keys for every record stored in the Data Hub and insert foreign keys for all related entities inside the Data Hub data model. This service also needs to capture and maintain “natural” keys that get loaded into the Data Hub from all data sources. The Key Generation service needs to interface with the Matching and Linking service (discussed in previous sections) in order to store and manage various unique identifiers created by the Matching and Linking process.
As the Data Hub matures and begins to support additional data attributes and entities, the Key Generation service would need to rapidly and easily adapt to new requirements and generate new sets of keys as required by the service consumers, which include data load processes as well as business applications that can add, change, and delete records.
Record Locator Services
An MDM Data Hub is an information integration platform that, by definition, integrates information collected from various data sources. A Data Hub data model is designed to easily aggregate individual records that came into the Data Hub from a variety of sources into linked groups. The resulting logical and physical data structures inside the Data Hub are different from the data stores used to load the Data Hub. In other words, in the majority of all MDM implementation cases, there is no simple one-to-one mapping between the records in the Data Hub and its sources. And this is the reason why an MDM Data Hub needs to support a service capability that enables such mapping.
This mapping becomes necessary as soon as the Data Hub is loaded with data and correctly seeded with entity keys. At that point, the Data Hub can act as the authoritative reference of the information for which it is the master. However, as the consuming applications begin to use Data Hub information, a number of use cases need to be considered to maintain the integrity and accuracy of the data (many of these cases are discussed in Chapter 5):
• Consuming applications may request information that is only partially stored in the Data Hub, with the remainder still residing in the source system from which the Data Hub was initially loaded—a typical scenario for the Registry and Coexistence Hub architecture styles.
• As data in the Data Hub gets updated by users and application, the Data Hub would have to propagate the changes to the systems that were used to load the Data Hub in the first place (Hub-to-Source synchronization).
• The data for which the Data Hub is not the master resides in the old legacy systems of record. If this data is also loaded into the Data Hub, it has to be updated in step with the updates to the original source system (Source-to-Hub synchronization).
The challenge of these use cases is to find appropriate records in the source systems based on the records stored in the Data Hub, and vice versa. This is the responsibility of another important Data Hub service—the Record Locator service.
The Record Locator service is a metadata-based service that creates and maintains a persistent transactional subject area inside a metadata repository store. The Record Locator service leverages a metadata repository and maps Data Hub keys and keys used by other systems as they participate in the loading and updating of data inside the Data Hub. This mapping represents a special type of metadata that may be implemented as a subject area in the Data Hub metadata repository (metadata is briefly discussed Chapters 4 and 5).
Conceptually, this metadata area is a directory that can be represented as a table that contains a row for each Data Hub record. Each row contains a primary key of the Data Hub detail record, and as many columns as there are external record keys. Again, this is certainly only a conceptual view. Logical and physical models would require normalization. The key values are loaded into this table during operations that create records in the Data Hub. The primary key can be obtained from the Linking and Matching service or, if desired, from the Key Generation service, as long as that key value exists in the Data Hub record.
In our Source-to-Hub use case, the Record Locator service would identify the impacted records in the Data Hub caused by the changes received by one or more source systems. In the Hub-to-Source scenario, the Record Locator service would perform a reverse operation and would identify external (to the Hub) systems and individual records impacted by changes applied to the Data Hub.
The Key Generation service and Record Locator service are necessary functional components of any MDM solution, whether developed in-house or implemented as an MDM vendor product. The architecture requirements for these services include service-oriented implementation, scalability, reliability, flexibility, and support for transactional semantics. The latter means that when, for example, a Data Hub creates, updates, or deletes a data record, this operation will succeed only if the update operations for Key Generation and Record Locator services also complete successfully. In this case, the Data Hub will commit all the changes to the Data Hub data store and to the metadata repository. If any of the component transactions (Hub data operation, Key Generation, or CRUD operations on Record Locator metadata) fail, then the entire transaction should fail, and the Data Hub has to roll the partial changes back to their pre-transaction state.
The foregoing discussion of Data Hub services would not be complete if we did not mention other MDM functions and services such as Transaction Coordination, Synchronization and Reconciliation service, Rules Management service, Metadata-driven Attribute Location service, Change Management service, Hub Data Load service, Security and Visibility service, and many others. We discuss some of these services in the Chapters 4 and 5, and their implementation aspects are covered in Part IV of the book.
References
1. Silverston, Len. The Data Model Resource Book, Revised Edition, Vol. 1: A Library of Universal Data Models For All Enterprises. Wiley Computer Publishing (March 2001).
2. Silverston, Len and Agnew, Paul. The Data Model Resource Book, Vol. 3: Universal Patterns for Data Modeling. Wiley Computer Publishing (January 2009).
3. http://en.wikipedia.org/wiki/Ontology_(information_science).
4. Schumacher, Scott. “Probabilistic Versus Deterministic Data Matching: Making an Accurate Decision.” Information Management Special Reports, January 2007. http://www.information-management.com/specialreports/20070118/1071712-1.html.
5. Berson, Alex and Smith, Stephen. Data Warehousing, Data Mining, and OLAP. McGraw-Hill ( November 1997).