
CHAPTER 5
Data Management Concerns of MDM Architecture: Entities, Hierarchies, and Metadata
The preceding chapters discussed the enterprise architecture framework as the vehicle that helps resolve a multitude of complex and challenging issues facing MDM designers and implementers. As we focused on the complexity of the MDM architecture, we showed how to apply the enterprise architecture framework to the service-oriented view of the MDM platform, often called an MDM Data Hub. And we also discussed a set of services that any Data Hub platform should provide and/or support in order to deliver key data integration properties of matching, linking detail-level records, and entity and relationship resolution—services that enable the creation and management of a complete view of the products, organizational entities, accounts, customers, parties, and associations and relationships among master entities.
We also started a discussion of the services required to ensure the integrity of the data inside the Data Hub as well as the services designed to enable the synchronization and reconciliation of data changes between the Data Hub and the surrounding systems, applications, and data stores. The synchronization and reconciliation services are especially important because the value of the MDM solution becomes fully recognized only when the master data can be accessed by or delivered to the business consumers, and the delivery mechanisms have to be designed to streamline and improve enterprise-wide business processes using master data.
We discuss master data modeling in Chapter 7. There we explain what data models are to be maintained to support the whole spectrum of MDM requirements, including requirements for the master data models, their key characteristics, and design styles.
We have now reached the point where the discussion of the Data Hub architecture cannot continue without considering the issues and challenges of integrating a Data Hub platform into the overall enterprise information environment. To accomplish this integration, we need to analyze the Data Hub architecture components and services that support cross-system and cross-domain information management requirements. These requirements include challenges of the enterprise data strategy, data governance, data quality, a broad suite of data management technologies, and the organizational roles and responsibilities that enable the effective integration and interoperability between the Data Hub, its data sources, and its consumers (users and applications).
NOTE As we continue to discuss key issues and concerns of the MDM architecture, services, and components, we focus on the logical and conceptual architecture points of view, and thus we express the functional requirements of MDM services and components in architecture terms. These component and service requirements should not be interpreted literally as the prescription for a specific technical implementation. Some of the concrete implementation approaches—design and product selection guidelines that are based on the currently available industry best practices and state of the art in the MDM product marketplace—are provided in Part IV of this book.
Data Strategy
This chapter deals primarily with issues related to data management, data delivery, and data integration between a Data Hub system, its sources, and its consumers. In order to discuss the architecture concerns of data management, we need to expand the context of the enterprise architecture framework and its data management dimensions by introducing key concerns and requirements of the enterprise data strategy. Although these concerns include data technology and architecture components, the key insights of the enterprise data strategy are contained in its holistic and multidimensional approach to the issues and concerns related to enterprise-class information management. Those readers already familiar with the concepts of data strategy, data governance, and data stewardship can easily skip this section and proceed directly to the section titled “Managing Data in the Data Hub.”
The multifaceted nature of the enterprise data strategy includes a number of interrelated disciplines such as data governance, data quality, data modeling, data management, data delivery, data synchronization and integrity, data security and privacy, data availability, and many others. Clearly, any comprehensive discussion of the enterprise data strategy that covers these disciplines is well beyond the scope of this book. However, in order to define and explain MDM Data Hub requirements to support enterprise-level integration with existing and new applications and systems, at a minimum we need to introduce several key concepts behind data governance, data quality, and data stewardship. Understanding these concepts helps explain the functional requirements of those Data Hub services and components that are designed to find the “right” data in the “right” data store, to measure and improve data quality, and to enable business rules–driven data synchronization between the Data Hub and other systems. We address the concerns of data security and privacy in Part III of this book and additional implementation concerns in Part IV.
Guiding Principles of Information Architecture
Let’s start the discussion on data management concerns of MDM with a brief look at the definition and guiding principles of the information architecture.
The Gartner Group defines enterprise information architecture as that part of the enterprise architecture process that describes—through a set of requirements, principles, and models—the current state, future state, and guidance necessary to flexibly share and exchange information assets to achieve effective enterprise change.1
To paraphrase this, we can define enterprise information architecture (EIA) as the blueprint describing an approach to the creation, management, delivery, and analysis of semantically consistent information structures across existing data sources to find meaningful relations and enable opportunities for effectively exchanging, sharing, and leveraging information.
Using this definition as the guide, we’re now in a position to put forward key principles of enterprise information architecture. These principles are based on the analysis of best practices in enterprise information management, and we offer them here as an example and a recommendation only, with the understanding that there are numerous alternate sets of EIA principles. That said, we believe that principles like these are necessary for the enterprise to excel at leveraging data for the benefit of all of its stakeholders by providing better service and better financial returns.
The last point is a general statement about the value of EIA principles. However, because this discussion is offered in the context of Master Data Management, wherever possible, we have tried to be specific and concentrate on Master Data Management as one of the core components of the enterprise information architecture.
• Principle #1 Information architecture shall be driven by clearly articulated and properly documented business processes.
• Principle #2 No matter what application is used to create a piece of master data content, this content must be validated against the existing master data.
• Principle #3 Any data modifications/corrections to master data can be made only according to the rules and policies established by the business, including the rules of resolving data change conflicts; these changes will be made available to all downstream systems based on agreed upon SLAs.
• Principle #4 Every data item shall have an identified business owner, a custodian (steward), and a single authoritative source that is used by all enterprise stakeholders. We are not making any assumptions about how many systems will be used to capture and update the master data operationally. The authoritative source should obtain all updates in real time and make policy-based decisions about acceptance or rejection of the change for the purpose of enterprise use.
• Principle #5 The quality of data shall be measured in accordance with information quality standards established by the organization.
• Principle #6 Information architecture shall ensure data security, integrity, and appropriate access controls.
• Principle #7 Information architecture shall support the appropriate retention of data at the appropriate level of granularity.
• Principle #8 Sources, definitions, structures, and usage of shared and common information shall be standardized.
• Principle #9 Information architecture shall support the definition, assignment, persistence, and synchronization of unique identifiers for all business objects supported and used by the enterprise.
• Principle #10 Information architecture shall support flexible, accurate, and timely data integration, and promote the creation and maintenance of Master Data Management environments as authoritative systems of record (“single version of the truth”).
• Principle #11 Information architecture shall provide for consistent, metadata-driven definitions for all data under management.
• Principle #12 Information management will include and be based on well-defined data governance rules and policies administered and enforced by appropriately structured and empowered groups, including an Enterprise Data Governance group.
As you can see, these principles of information architecture are prescriptive and help articulate the role of Master Data Management in the overall enterprise information architecture context.
Data Governance
As we discuss Master Data Management, the notion of governance becomes one of the key concepts of effective, proactive, and predictable information management. In general, nontechnical terms, we can define governance as the set of processes and activities that manifest themselves in decisions that define expectations, grant power, or verify performance. In Chapter 17 we focus on data governance in more detail and focus on advanced concepts important for MDM specifically.
In the domain of Information Technology, we can find various branches of governance, including application governance, network governance, and information or data governance. The latter is an important discipline that has profound implications on the way MDM technology is selected, used, and creates value for the enterprise.
Using the general definition of governance shown in the preceding paragraph, we can offer the following working definition of data governance (sometimes called “information governance”).
Clearly, according to this definition, data governance becomes a critical component of any MDM initiative. Data governance helps organizations in making decisions about how to manage data, realize value from it, minimize cost and complexity, manage risk, and ensure compliance with ever-growing legal, regulatory, and other requirements. Governance allows organizations not only to create rules about information use, but also to apply effective processes and controls to make sure that the rules are being followed, and to deal with noncompliance and other issues. Data governance is at the forefront of many Information Technology initiatives and activities. The Data Governance Institute is one of the independent organizations that define the principles, standards, and frameworks of data governance.2
An integrated MDM data architecture emphasizes the need for and importance of data governance, especially if you consider that even successful MDM initiatives have to deal with a typical enterprise information landscape that contains not only the Data Hub but also many applications and databases that more often than not were developed independently, in a typical stovepipe fashion, and the information they use is often inconsistent, incomplete, and of different quality.
Data governance strategy helps deliver appropriate data to properly authorized users where and when they need it. Moreover, data governance and its data quality component are responsible for creating data quality standards, data quality metrics, and data quality measurement processes that together help deliver acceptable quality data to the consumers— applications and end users.
Data quality improvement and assurance are no longer optional activities. For example, the 2002 Sarbanes-Oxley Act requires, among other things, that a business entity should be able to attest to the quality and accuracy of the data contained in its financial statements. Obviously, the classical “garbage in, garbage out” truism is still alive, and no organization can report high-quality financial data if the source data used to produce the financial numbers is of poor quality. To achieve compliance and to successfully implement an enterprise data governance and data quality strategy, the strategy itself should be treated as a value-added business proposition and sold to the organization’s stakeholders to obtain a management buy-in and commitment like any other business case. The value of improved data quality is almost self-evident and includes factors such as the enterprise’s ability to make better and more accurate decisions, to collect and analyze competitive trends, to formulate a better and more effective marketing strategy, to define a more attractive and compelling product, to gain deeper insights into the customer’s behavior, to understand the customer’s propensity to buy products and services, the probability of the customer’s engaging in high-risk transactions, the probability of attrition, and so on. The data governance strategy is not limited to data quality and data management standards and policies. It includes critically important concerns of defining organizational structures and job roles responsible for monitoring and enforcing compliance with these policies and standards throughout the organization.
Committing an organization to implement a robust data governance strategy requires an implementation plan that follows a well-defined and proven methodology. Several effective data governance methodologies are available, and we will discuss some of them in Chapter 17. No matter what data governance methodology is used, we can stipulate that a high-level data governance strategy should be aligned with and based on the key principles of the enterprise information architecture, discussed in the previous section. For the sake of completeness, this section reviews the key steps of a generic data governance strategy program as it may apply to the MDM Data Hub:
• Define a data governance process. This is the key in enabling monitoring and reconciliation of data between the Data Hub and its sources and consumers. The data governance process should cover not only the initial data load but also data refinement, standardization, and aggregation activities along the path of the end-to-end information flow. The data governance process includes such data management and data quality concerns as the elimination of duplicate entries and the creation of linking and matching keys. We will show in Chapter 6 that these unique identifiers help aggregate or merge individual records into groups or clusters based on certain criteria (for example, a household affiliation or a business entity). As the Data Hub is integrated into the overall enterprise data management environment, the data governance process should define the mechanisms that create and maintain valid cross-reference information using approaches such as Record Locator metadata that enables linkages between the Data Hub and other systems. In addition, a data governance process should contain steps that support manual corrections of false positive and negative matches as well as the exception processing of errors that cannot be handled automatically.
• Design, select, and implement a data management and data delivery technology suite. In the case of an MDM Data Hub, both data management and data distribution/delivery technologies play a key role in enabling a fully integrated MDM solution regardless of the MDM Use Pattern (Analytical or Operational MDM) and the architecture style of the Data Hub, be it a Registry, a Reconciliation Engine, or a Transaction Hub. Later in this chapter we use the principles and capabilities of service-oriented architecture (SOA) to discuss the data management and data delivery aspects of the Data Hub architecture and the related data governance strategy.
• Enable auditability and accountability for all data under management that is in scope for data governance strategy. Auditability is extremely important because it not only provides verifiable records of the data access activities but also serves as an invaluable tool to help achieve compliance with the current and emerging regulations, including the Gramm-Leach-Bliley Act and its data protection clause, the Sarbanes-Oxley Act, and the Basel II and III Capital Accords. Auditability works hand in hand with accountability of data management and data delivery actions. Accountability requires the creation and empowerment of several data governance roles within the organization, including data owners and data stewards. These roles should be created at appropriate levels of the organization and assigned to the dedicated organizational units or individuals.
Let’s briefly look at the concept of data stewards and their role in assessing, improving, and managing data quality. We will focus on these topics again in Part IV to discuss them in more detail.
Data Stewardship and Ownership
One of the key principles of the enterprise information architecture (Principle #4) states that every data item shall have an identified business owner and a custodian (steward).
As the name implies, data owners are those individuals or groups within the organization that are in the position to obtain, create, and have significant control over the content (and sometimes, access to and the distribution of) the data. Data owners often belong to a business rather than a technology organization. For example, an insurance agent may be the owner of the list of contacts of his or her clients and prospects.
The concept of data stewardship is different from data ownership. Data stewards do not own the data and do not have complete control over its use. Their role is to ensure that adequate, agreed-upon quality metrics are maintained on a continuous basis. In order to be effective, data stewards should work with data architects, database administrators, ETL (Extract, Transform, Load) designers, business intelligence and reporting application architects, and business data owners to define and apply appropriate data usage policies and data quality metrics. These cross-functional teams are responsible for identifying deficiencies in systems, applications, data stores, and processes that create and change data and thus may introduce or create data quality problems. One consequence of having a robust data stewardship program is its ability to help the members of the IT organization to enhance appropriate architecture components to improve data quality, availability, and integrity.
Data stewards must help create and actively participate in processes that would allow the establishment of business context–defined, measurable data quality goals. Only after an organization has defined and agreed with the data quality goals can the data stewards devise appropriate data quality improvement programs.
These data quality goals and improvement programs should be driven primarily by business units, so it stands to reason that in order to gain full knowledge of the data quality issues, their roots, and the business impact of these issues, a data steward should be a member of a business team. Regardless of whether a data steward works for a business team or acts as a “virtual” member of the team, the data steward has to be very closely aligned with the Information Technology group in order to discover and mitigate the risks introduced by inadequate data quality.
Extending this logic even further, we can say that a data steward would be most effective if he or she can operate as close to the point of data acquisition as technically possible. For example, a steward for customer contact and service complaint data that is created in a company’s service center may be most effective when operating inside that service center.
Finally, and in accordance with information architecture and data governance principles, data stewards have to be accountable for improving the data quality of the information domain they oversee. This means not only appropriate levels of empowerment but also the organization’s willingness and commitment to make the data steward’s data quality responsibility his or her primary job function, so that data quality improvement is recognized as an important business function that treats data as a valuable corporate asset.
Data Quality
Whether an enterprise is deploying an MDM solution or is using more traditional data management approaches (data warehouses, operational data stores, and so on), one undisputable fact about the value and use of data remains—any business process that is based on the assumption of having access to trustworthy, accurate, and timely data will produce invalid, unexpected, and meaningless results if this assumption is false and the processes that capture and manage the input data don’t recognize data quality shortcomings and don’t have mechanisms or steps in place to ensure the required data quality levels.
MDM Data Hub is a powerful concept with a rich set of value-added capabilities. But even the most sophisticated MDM solution can deliver a single view of master data only if it can trust the source data and the processes and systems that deliver that data into the Data Hub. In Part IV, we get into more implementation details on the topic of relationships between MDM and data quality and discuss master data quality processes and metrics.
In other words, we cannot discuss Master Data Management without paying serious attention to the issues of data quality, and recognizing that data quality for Master Data Management can be affected by two related factors—data quality of the input data collected from a variety of internal and external sources, and the impact on data quality that results from the shortcomings of the upstream business processes that handle input data before it is entered into the Data Hub. The notion that MDM data quality is linked to the efficiency and effectiveness of the upstream business processes is a profound concern that has become a topic of extensive discussions in the business and technology community that deal with not just data management but also with Business Process Management (BPM).
In this chapter, however, we concentrate on the data side of the data quality issues, because BPM is a large and complex topic in its own right and is outside the scope of this book.
Creating a new authoritative source from information of low quality is almost an impossible task. Similarly, when data quality is poor, matching and linking records for potential aggregation will most likely result in low match accuracy and produce an unacceptable number of false negative and false positive outcomes.
Valuable lessons about the importance of data quality are abundant, and data quality concerns confronted data architects, application designers, and business users even before the problem started to manifest itself in such early data integration programs as Customer Information Files (CIF), early implementations of data warehouses, Customer Relationship Management (CRM), and Business Intelligence (BI) solutions. Indeed, if you look at a data integration solution such as a data warehouse, published statistics show that as high as 75 percent of the data warehouse development effort is allocated to data preparation, validation, extraction, transformation, and loading (e.g., by using ETL tools). Over 50 percent of these activities are spent on cleansing and standardizing the data.
Although there is a wide variety of ETL and data-cleansing tools that address some of the data quality problems, data quality continues to be a complex, enterprise-wide challenge. Part of the complexity that needs to be addressed is driven by the ever-increasing performance requirements. A data-cleansing tool that would take more than 24 hours to cleanse a customer file is a poor choice for a real-time or a Web-based customer service application. As the performance and throughput requirements continue to increase, the functional and technical capabilities of the data quality tools sometimes struggle to keep up with the demand.
But performance is not the primary issue. A key challenge of data quality is an incomplete or unclear set of semantic definitions of what the data is supposed to represent, in what form, with what kind of timeliness requirements, and so on. These definitions are ideally stored in a metadata repository. However, our experience shows that even when an enterprise adapts a metadata strategy and implements a metadata repository, it often contains incomplete or erroneous (poor quality) definitions. We discuss metadata issues in more detail later in this chapter.
The quality of metadata may be low, not because organizations or data stewards do not work hard on defining it, but primarily because there are many data quality dimensions and contexts, each of which may require a different approach to the measurement and improvement of the data quality. For example, if we want to measure and improve address information about customers, there are numerous techniques and reference data sources that can provide an accurate view of a potentially misspelled or incomplete address. Similarly, if we need to validate a social security number or a driver license number, we can use a variety of authoritative sources of this information to validate and correct the data. The problem becomes much harder when we have to deal with names or similar attributes for which there is no predefined domain or a business rule. For example, “Alec” may be a valid name or a misspelled version of “Alex.” If evaluated independently, and not in the context of, say, postal information about a name and the address, this problem often requires human intervention to resolve the uncertainty.
Finally, as the sophistication of the data quality improvement process grows, so do its cost and processing requirements. It is not unusual to hear that an organization would be reluctant to implement an expensive data quality improvement system because, according to them, “So far the business and our customers have not complained, so the data quality issue must not be as bad as you describe.” This is not an invalid argument, although it may be somewhat shortsighted from the strategic point of view, especially because many aspects of data quality fall under government- and industry-regulated requirements.
Data Quality Tools and Technologies
Many tools automate portions of the tasks associated with cleansing, extracting, loading, and auditing data from existing data stores into a new target environment—be it a data warehouse or an MDM Data Hub. Most of these tools fall into one of several major categories:
• Profiling tools They tools enhance the accuracy and correctness of the data at the source. These tools generally compare the data in the source database to a set of business rules that are either explicitly defined or automatically inferred from a scan operation of the data file or a database catalog.
Profiling tools can determine the cardinality of certain data attributes, value ranges of the attributes in the data set, and the missing and incomplete data values, among other things. These tools would produce various data quality reports and can use their output to automate certain data-cleansing and data correction operations.
• Data-cleansing tools These tools employ various deterministic, probabilistic, or machine learning techniques to correct the data problems discovered by the profiling tools. These tools generally compare the data in the data source to a set of business rules and domain constraints stored in the metadata repository or in an external rules repository. Traditionally, these tools were designed to access external reference data such as a valid name and address file from an external “trusted” data provider (for example, Acxiom or Dun & Bradstreet) or an authoritative postal information file (for example, a National Change of Address [NCOA] file) or to use a service that validates social security numbers. The data-cleansing process improves the quality of the data and potentially adds new, accurate content. Therefore, this process is sometimes referred to as “data enrichment.”
• Data-parsing and standardization tools The parsers break a record into atomic units that can be used in subsequent steps. For example, such a tool would parse one contiguous address record into separate street, city, state, and ZIP code fields. Data standardization tools convert the data attributes to what is often called a canonical format or a canonical data model—a standard format used by all components of the data acquisition process and the target Data Hub.
• Data Extract, Transform, and Load (ETL) tools These are not data quality tools in the pure sense of the term. ETL tools are primarily designed to extract data from known structures of the source systems based on prepared and validated source data mapping, transforming input formats of the extracted files into a predefined target data store format (for example, a Data Hub), and loading the transformed data into a target data environment (for example, the Data Hub). Because ETL tools are aware of the target schema, they can prepare and load the data in a way that preserves various integrity constraints, including referential integrity and the domain integrity constraints. ETL tools can filter out records that fail a data validity check and usually produce exception reports used by data stewards to address data quality issues discovered at the load stage. This functionality helps ensure data quality and the integrity of the target data store, which is the reason we mentioned ETL tools in this section.
• Hybrid packages These packages may contain a complete set of ETL components enriched by a data parser and a standardization engine, the data profiling components, and the data-cleansing components. These extract, parse, standardize, cleanse, transform, and load processes are executed by a hybrid packaged software in sequence and load consistently formatted and cleansed data into the Data Hub.
Managing Data in the Data Hub
Armed with the knowledge of the role of the enterprise data strategy, we can discuss MDM Data Hub concerns that have to deal with acquiring, rationalizing, cleansing, transforming, and loading data into the Data Hub as well as the concerns of delivering the right data to the right consumer at the right time over the right channel. In this chapter, we also discuss interesting challenges and approaches of distributing and synchronizing data in the Data Hub with applications and systems used to source the data in the first place.
Let’s start with the already familiar Data Hub conceptual architecture that we first introduced in Chapter 4. This architecture shows the Data Hub data store and supporting services in the larger context of the data management architecture (see Figure 5-1). From the data strategy point of view, this architecture view depicts data sources that feed the loading process, the data access and data delivery interfaces, the ETL service layer, the Data Hub platform, and some generic consuming applications.
However, to better position our discussion of the data-related concerns, let’s transform our Data Hub conceptual architecture into a view that is specifically designed to emphasize data flows and operations related to managing data in and around the Data Hub.
Data Zone Architecture Approach
To address data management concerns of the Data Hub environment, we introduce the concept of the data zones and the supporting architectural components and services. The Data Zone architecture, illustrated in Figure 5-2, employs sound architecture principles of the separation of concerns and loose coupling.
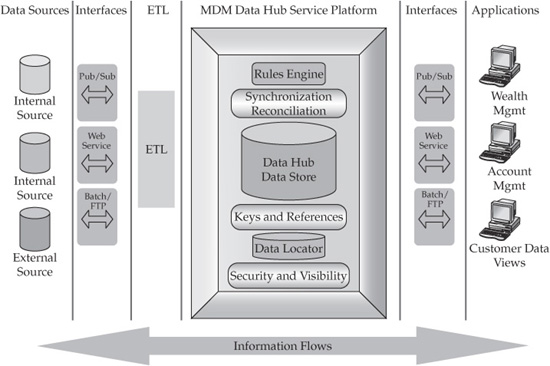
FIGURE 5-1 Conceptual Data Hub components and services architecture view
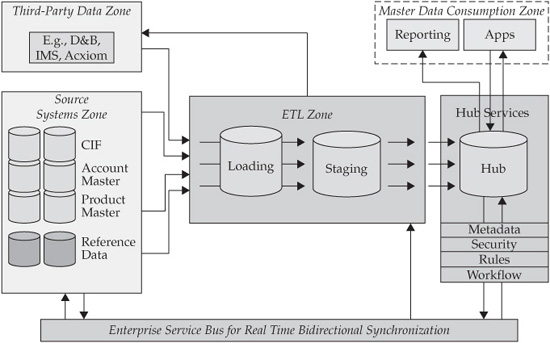
FIGURE 5-2 Data Hub architecture—Data Zone view
Turning to nature, consider the differences between simple and complex organisms. Whereas simple organisms contain several generic cells that perform all life-sustaining functions, a complex organism (for example, an animal) is “built” from a number of specialized “components” such as heart, lungs, eyes, and so on. Each of these components performs its functions in a cooperative fashion, together with other components of the body. In other words, when the complexity is low to moderate, having a few generic components simplifies the overall design. However, as the complexity of the system grows, the specialization of components helps address the required functionality in a focused fashion, by organizing groups of concerns into separate, designed-for-purpose components.
We briefly discussed the principle of loose coupling in the previous chapter when we looked at service-oriented architectures.
When we apply these architecture principles to the data architecture view of the Data Hub, we can clearly delineate several functional domains, which we call “zones.” The data zones shown in Figure 5-2 include the following:
• Source Systems zone
• Third-Party Data Provider zone
• ETL/Acquisition zone
• Hub Services zone
• Master Data Consumption zone
• Enterprise Service Bus zone
To make it very clear, this zone structure is a logical design construct that should be used as a guide to help solve the complexity of data management issues. The Zone Architecture approach allows architects to consider complex data management issues in the context of the overall enterprise data architecture, but address them within the context of a relevant zone. As a design guide, it does not mean that a Data Hub implementation has to include every zone and every component. A specific MDM implementation may include a small subset of the data zones and their respective processes and components.
Let’s review the key concerns addressed by the data zones shown in Figure 5-2.
• The Source Systems zone is the province of existing data sources, and the concerns of managing these sources include good procedural understanding of data structures; content; timeliness; update periodicity; and such operational concerns as platform support, data availability, data access interfaces, access methods to the data sources, batch window processing requirements, and so on. In addition to the source data, this zone contains enterprise reference data, such as code tables used by an organization to provide product name–to–product code mapping, state code tables, branch numbers, account type reference tables, and so on. This zone contains “raw material” that is loaded into the Data Hub and uses information stored in the metadata repository to determine data attributes, formats, source system names, and location pointers.
• The Third-Party Data Provider zone deals with external data providers and their information. An organization often purchases this information to cleanse and enrich input data prior to loading it into a target environment such as a Data Hub. For example, if the Data Hub is designed to handle customer information, the quality of the customer data loaded into the Data Hub would have a profound impact on the linking and matching processes as well as on the Data Hub’s ability to deliver an accurate and complete view of a customer. Errors, the use of aliases, and a lack of standards in customer name and address fields are most common and are the main causes of poor customer data quality. To rectify this problem an organization may decide to use a third-party data provider that specializes in maintaining an accurate customer name and address database (Acxiom, D&B, and so on). The third-party data provider usually receives a list of records from an organization, matches them against the provider’s database of verified and maintained records, and sends updated records back to the organization for processing. Thus, the third-party zone supporting this processing is concerned with the following processes:
• Creating a file extract of entity records to be sent to the provider
• Ensuring that the extracted records are protected and that only absolutely minimal necessary information is sent to the provider in order to protect confidential data
• Receiving an updated file of cleansed records enriched with accurate and perhaps additional information
• Making the updated file available for ETL processing
• Making appropriate changes to the content of the metadata repository for use by other data zones
Alternatively, an enterprise may look for third-party data to verify and enrich a set of financial instruments—for example, getting market or pricing information from authoritative sources of such data, including feeds from stock exchanges. In this case, the processes implemented inside the third-party zone may include the generation of service requests to receive necessary data from the external provider based on a previously established contract. Such requests may be executed as request-response messages using standard protocols, as real-time streaming data feeds, or as Web Services calls.
• The ETL/Acquisition zone is the province of ETL tools and their corresponding processes. These tools are designed to extract data from known structures of the source systems based on prepared and validated source-to-target data mapping; transforming input formats of the extracted files into a predefined target data store format (for example, a Data Hub); and loading the transformed data into the Data Hub using either a standard technique or a proprietary one. The transformations may be quite complex and can perform substitutions, aggregations, and logical and mathematical operations on data attribute values. ETL tools may access an internal or external metadata repository to obtain the information about the transformation rules, integrity constraints, and target Data Hub schema, and therefore can prepare and load the data while preserving various integrity constraints. Many proven, mature solutions can perform ETL operations in an extremely efficient, scalable fashion.
Modern ETL tools can parallelize all operations to achieve very high performance and throughput on very large data sets. These solutions can be integrated with an enterprise metadata repository and a BI tool repository.
• An effective design approach to the Acquisition/ETL data zone is to use a multistage data acquisition environment. To illustrate this point, we consider a familiar analogy of a loading dock for a “brick-and-mortar” warehouse facility. Figure 5-2 shows a two-stage conceptual Acquisition/ETL data zone, where the first stage, called the Loading zone, is acting as a recipient of the data extraction activities. Depending on the complexity and interdependencies involved in data cleansing, enrichment, and transformation, a Loading zone may serve as a facility where all input data streams are normalized and consolidated into a common, canonical format. The third-party data provider usually receives an appropriate set of data in such a canonical format. The Loading zone is a convenient place where the initial audit and profiling of input records can take place.
• The Staging zone, on the other hand, is a holding area for the already cleansed, enriched, and transformed data received from the Loading zone as well as the data processed by and received from a third-party data provider. The Staging zone data structure could be similar to that of the Data Hub. The benefits of having a Staging zone include efficiency in loading data into the Data Hub (often using a database-specific utility function, because the transformations are already completed). The Staging zone offers access to a convenient area to perform a record-level audit before completing the load operation. Finally, a Staging zone provides for an easy-to-use, efficient, and convenient Data Hub reload/recovery point that does not depend on the availability of the source systems.
• The Hub Services zone deals with the data management services that create and maintain the structures and the information content inside the Data Hub. We described the SOA reference architecture and several of these services in Chapter 4. In this chapter, we discuss Data Hub services that support data synchronization, data distribution, reconciliation of conflicting data changes, system and information integration, and metadata services that use a metadata repository to enforce semantic consistency of the information. Other MDM services (including Linking, Matching, Record Locator, and Attribute Locator services) are discussed in Chapter 6, and more implementation details of these services are provided in Part IV.
• The Master Data Consumption zone is concerned with data delivery–related issues such as formats, messages, protocols, interfaces, and services that enable effective and easy-to-use access to the required information, whether it resides in the Data Hub or in the surrounding systems. The Master Data Consumption zone is designed to provide data to support business applications including Business Intelligence applications, CRM, and functional applications such as account opening and maintenance, aggregated risk assessment, and others. The Master Data Consumption zone enables delivery and distribution of master data, especially reference data, to the requesting applications based on predefined and agreed-upon protocols. This distribution is governed by the service-level agreements (or Web Service contracts) between a Data Hub as a service provider and various service consumers. The Master Data Consumption zone supports persistent data delivery and virtual, just-in-time data integration technologies, including Enterprise Information Integration (EII) solutions. Like other zones, the Master Data Consumption zone takes advantage of the metadata repository to determine data definitions, data formats, and data location pointers.
• The Enterprise Service Bus (ESB) zone deals with technologies, protocols, message formats, interfaces, and services that support a message-based communication fabric between all components and services of the MDM data architecture. The goal of the ESB is to support the loosely coupled nature of the Data Hub service-oriented architecture (SOA) by providing a message-based integration mechanism that ensures guaranteed, once-and-only-once, sequence-preserving message delivery that can support transactional semantics if and when appropriate.
Now that we have reviewed the contents and purposes of the architecture zones, we can expand these concepts by including several high-level services that are available to various data architecture components, including the Data Hub. Many of these services are shown in the MDM Reference Architecture diagram (see Figure 5-3). Most of these services are a part of the Data Management Layer of the reference architecture, while some are located in the lower layers of the architecture.
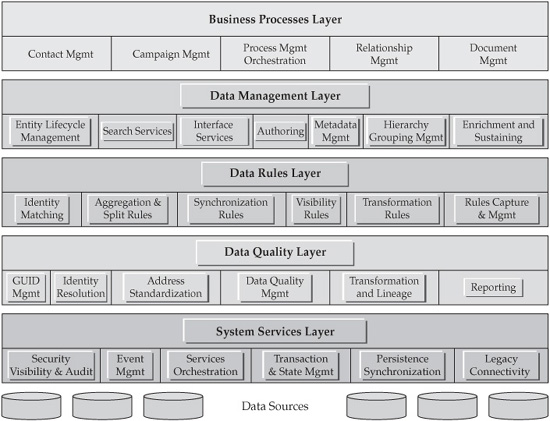
FIGURE 5-3 MDM SOA reference architecture
The list of MDM Data Hub service groups dealing with data management include:
• Integration services and Legacy Connectivity services
• Data Normalization and Enrichment services
• Data Hub Lifecycle Management services
• Data Synchronization and Reconciliation services
• Data Location and Delivery services
Many of these services are briefly described in Chapter 4. We discuss additional details of some of these services in the following sections as we continue the Data Zone architecture discussion.
Operational and Analytical MDM and Data Zones
As we described in Chapter 4, MDM is a complex set of technologies and design patterns. We described an approach to analyze MDM complexity that is based on various MDM classification dimensions. One of the dimensions that is particularly relevant to the discussion of information architecture and data management is the Use Pattern dimension, which differentiates MDM architectures based on how the master data is used—specifically, as an Analytical, Operational, or Collaborative MDM. In this section, we will map the two primary types of MDMs—Analytical and Operational—to the Data Zone architecture concept and show the similarities and differences in the ways the zones are defined. To set the stage for this discussion, let’s briefly review these types of MDMs:
• Analytical MDM Supports business processes and applications that use master data primarily to analyze business performance and provide appropriate reporting and analytical capabilities, often by directly interfacing with Business Intelligence tools and packages. Analytical MDM tends to be read-mostly. It usually does not change or create source data in the operational systems but does cleanse and enrich data in the MDM Data Hub. From the Data Zone architecture point of view, Analytical MDM can be architected to fully leverage the ETL zone, implement Data Cleansing and Lifecycle services in the Hub Services zone, and configure the Master Data Consumption zone and Data Delivery/Distribution services to act as a feeder into the enterprise data warehouse and domain-specific data marts. Clearly, Data Synchronization services aimed at keeping upstream systems in sync with the content of the Data Hub don’t play a significant role in this type of MDM. Nevertheless, the Data Zone architecture enables core functionality of the Analytical MDM by making sure that all zones’ components and services work in concert to create or enrich an accurate, integrated view of the master data inside the data warehouse, and provide key information to manage data warehouse dimensions, including necessary attributes to support slow-changing dimensions.
• Operational MDM Allows master data to be collected, changed, and used to process business transactions. The principal difference between Operational and Analytical MDMs is in that Operational MDM is designed to maintain the semantic consistency of the master data throughout the transactional activity and provides a mechanism to correct data quality issues by communicating necessary changes to the operational systems, where the data is usually created. By design, Operational MDM systems uses the full power of all data zones and leverage their services and functions to ensure that the accurate, single version of the truth is maintained in the MDM Data Hub and propagated to the core systems. Data Integration, Legacy Connectivity, Synchronization, Delivery and Distribution, Data Cleansing, Enrichment, and Lifecycle services all work in concert to support this MDM architecture.
In summary, although both Analytical and Operational MDM architecture styles map equally well onto the concept of the Data Zone architecture, their similarities and differences are clearly underlined and brought into focus by the way the data zones should be configured and integrated into the overall enterprise information architecture.
Loading Data into the Data Hub
The data architecture concerns discussed in the beginning of this section have a profound impact on the overall Data Hub architecture and, in particular, its data management and data delivery aspects. The Data Zone architecture view shown in Figure 5-2 can help define new, effective design patterns; additional services and components that would support any generic data integration platform; and, in particular, a Data Hub system for Master Data Management.
The level of abstraction of the Data Zone architecture is sufficiently high to be applicable equally well not only to the major types of MDMs—that is, Analytical and Operational MDMs—but also to all major styles of the Data Hub design, including Registry style, Reconciliation Hub style, and, ultimately, full Transaction Hub style. However, as we take a closer look at these design styles, we discover that the way the data is loaded and synchronized varies significantly from one style to another (see Chapter 4 for more details on these MDM architecture styles). Indeed, consider the key difference between these styles—the scope of data for which the Data Hub is the master. Here are some specifics:
• The Registry style of the MDM Data Hub architecture represents a Registry of unique master entity identifiers (created using identity attributes). It maintains only the identifying attributes. These attributes are used by an entity resolution service to identify which master entity records should be linked because they represent the same customer, product, location, and so on. The Data Hub matches and links the records that share the same identity. The Data Hub creates and maintains links with data sources that were used to obtain the identity attributes. The MDM Data Hub exposes a set of services that return a fully assembled holistic entity view to the consuming application to either retrieve or assemble a holistic entity view (for example, a customer, at run time). In the case of MDM for customer domain, the Registry-style Data Hub maintains some at least matching customer profile attributes that the Hub uses to generate a unique customer identifier; it can automatically generate and maintain links with all upstream systems that maintain data about the customers, and acts as the arbiter that determines which attribute values in the source systems are better than others by applying attribute survivorship rules across multiple systems.
• The Reconciliation Engine style (sometimes also called the Coexistence Hub) supports an evolutionary stage of the Data Hub that enables coexistence between the old and new masters, and by extension provides for a federated data ownership model that helps address both inter- and intra-organizational challenges of who controls which data. The Data Hub of this style is a system of record for some but not all data attributes. It provides active synchronization between itself and the systems that were used to create the Hub data content or still maintain some of the Hub data attributes inside their data stores. By definition of the “master,” the data attributes for which the Data Hub is the master need to be maintained, created, and changed in the Data Hub. These changes have to be propagated to the upstream and downstream systems that use these data attributes. The goal is to enable synchronization of the data content between the Data Hub and other systems on a continuous basis. The complexity of this scenario increases dramatically as some of the data attributes maintained in the Data Hub are not simply copied but rather derived using business-defined transformations on the attributes maintained in other systems.
• The Transaction Hub represents a design style where the Hub maintains all data attributes about the target subject area. In the case of a MDM Data Hub for customer domain, the subject area is the customer (individuals or businesses). In this case, the Data Hub becomes a “master” of customer information, and as such should be the source of all changes that affect any data attribute about the customer. This design approach demands that the Data Hub is engineered as a complete transactional environment that maintains its data integrity and is the sole source of changes that it propagates to all systems. This design also dictates that the systems integrated with the MDM Data Hub disable their data entry and maintenance interfaces as they relate to the given master data domain.
The conceptual Data Hub architecture shown in Figure 5-1 and its Data Zone viewpoint shown in Figure 5-2 should address the following common data architecture concerns:
• Batch and real-time input data processing Some or all data content in the Data Hub is acquired from existing internal and external data sources. The data acquisition process affects the Source System zone, the Third-Party Data Provider zone, and the Acquisition/ETL data zone. It uses several relevant services, including Data Integration services, Data Normalization and Enrichment services, Lifecycle Management services, Entity Resolution services (including Linking, Matching, and Key Generation services), and Metadata Management services that use Record Locator and Attribute Locator services. Moreover, the data-acquisition process can support two different modes—initial data load and delta processing of incremental changes. The former implies a full refresh of the Data Hub data content, and it is usually designed as a batch process. The data-processing mode may support either batch or real-time processing. In the case of batch design, the data processing, at least for the newly inserted records, can leverage the same technology components and services used for the initial data load. The technology suite that enables the initial load and batch data processing has to support high-performance, scalable ETL functionality that architecturally “resides” in the Acquisition/ETL data zone and usually represents a part of the enterprise data strategy and architecture framework. Real-time data processing, on the other hand, should take full advantage of service-oriented architecture, including the Enterprise Service Bus zone, and in many cases is implemented as a set of transactional services that include Data Hub Lifecycle Management services, Transaction and State Management services, and Synchronization services.
• Data quality processes To improve the accuracy of the matching and linking process, many Data Hub environments implement data cleansing, standardization, and enrichment preprocessing in the Third-Party Data Provider and Acquisition/ETL zones before the data is loaded into the Data Hub. These processes use Integration services and Data Normalization and Enrichment services, and frequently leverage external, industry-accepted reference data sources such as Dun & Bradstreet for business information or Acxiom for personal information. It should be noted that some Data Hub vendor solutions are very effective in record matching and linking without prior standardization. Any standardization process has a risk of loosing valuable information, which can adversely impact the quality of match if advanced matching algorithms are used. Still, standardization is often required for reasons other than record matching and linking.
NOTE Mapping Data Hub service to the data zones by using a service-oriented architecture approach allows Data Hub designers to abstract and isolate services from the actual location of the methods and functions that execute them regardless of which architecture zone these methods reside in.
Data Synchronization
As data content changes, a sophisticated and efficient synchronization activity between the “master” and the “slaves” has to take place on a periodic or an ongoing basis depending on the business requirements. Where the Data Hub is the master of some or all attributes of the entities in question, the synchronization flows have to originate from the Hub toward other systems. Complexity grows if existing business processes treat some applications and/or data stores as a master for certain attributes that are also stored in the Data Hub. In this case, every time one of these data attributes changes in the existing system, this change has to be delivered to the Data Hub for synchronization. One good synchronization design principle is to implement one or many unidirectional synchronization flows, as opposed to a more complex bidirectional synchronization. In either approach, the synchronization process may require transactional conflict-resolution mechanisms, compensating transaction designs, and other synchronization and reconciliation functionality, and often causes a revision or change to the existing business processes that rely on the availability of the golden record of master data.
A variety of reasons drive the complexity of data synchronization across multiple distributed systems. In the context of an MDM Data Hub, synchronization becomes difficult to manage when the entire data environment that includes the Data Hub and the legacy systems is in a peer-to-peer relationship. This is not an MDM-specific issue; however, if it exists, it may defeat the entire purpose and benefits of building an MDM platform. In this case, there is no clear master role assigned to a Data Hub or other systems for some or all data attributes, and thus changes to some “shared” data attributes may occur simultaneously but on different systems and applications. Synchronizing these changes may involve complex business rules–driven reconciliation logic. For example, consider a typical non-key attribute such as telephone number. Let’s assume that this attribute resides in the legacy Customer Information File (CIF), a customer service center (CRM) system, and also in the Data Hub, where it is used for the matching and linking of records. An example of a difficult scenario would be as follows:
• A customer changes his or her phone number and makes a record of this change via an online self-service channel that updates the CIF. At the same time, the customer contacts a service center and tells a customer service representative (CSR) about the change. The CSR uses a CRM application to make the change in the customer profile and contact records but mistypes the number. As the result, the CIF and the CRM systems now contain different information, and both systems are sending their changes to each other and to the Data Hub for the required record update.
• If the Data Hub receives two changes simultaneously, it will have to decide which information is correct or should take precedence before the changes are applied to the Hub record.
• If the changes arrive one after another over some time interval, the Data Hub needs to decide if the first change should override the second, or vice versa. This is not a simple “first-in first-serve” system because the changes can arrive into the Data Hub after the internal CIF and CRM processing is completed, and their timing does not have to coincide with the time when the change transaction was originally applied.
• Of course, you can extend this scenario by imagining a new application that accesses the Data Hub and can make changes directly to it. Then all systems participating in this change transaction are facing the challenge of receiving two change records and deciding which one to apply, if any.
This situation is not just possible but also quite probable, especially when you consider that the Data Hub has to be integrated into an existing enterprise data and application environment. Of course, should the organization implement a comprehensive data governance strategy and agree to recognize and respect data owners and data stewards, it will be in a position to decide on a single ownership for each data attribute under management. Unfortunately, not every organization is successful in implementing these data management principles. Therefore, we should consider defining conceptual Data Hub components that can perform data synchronization and reconciliation actions in accordance with a set of business rules enforced by a business rules engine (BRE).
Overview of Business Rules Engines
There are many definitions of business rules engine. The simplest one says that a business rules engine is a software system that executes one or more business rules in a runtime production environment.3 If we want to be more specific about business rules engines in the context of MDM Data Hub architecture, we can offer the following definition.
In general, a BRE supports functionality that helps register, classify, and manage the business rules it is designed to enforce. In addition, a BRE can provide functionality that detects inconsistencies within individual business rules (for example, a rule that violates business logic) as well as rule sets.
In the context of the MDM Data Hub Synchronization services, BRE software manages the rules that define how to reconcile the conflicts of bi-directional synchronization (clearly, a BRE software can be used to support other MDM capabilities, such as linking and matching, attribute survivorship, and so on). For example, if a date-of-birth attribute is changed in the CRM system supporting the service center and in the self-service Web channel, an organization may define a business rule that requires the changes to this attribute that came from the self-service channel to take precedence over any other changes. A more complex rule may dictate to accept changes to the date of birth only if the resulting age of the customer does not exceed the value of 65. There may be another business rule that would require a management approval in the case where the age value is greater than 65. The BRE would evaluate and enforce all rules that apply to a particular event. BRE technologies can also be used to define the workflows around data issues resolution, data stewardship, and in some applications typically powered by MDM (for example, customer on-boarding, account opening and management, and product modeling).
At a minimum, a full-function BRE will include the following components:
• Business rules repository A database that stores the business rules defined by the business users
• Business rules designer/editor An intuitive, easy-to-use, front-end application and user interface that allows users to define, design, document, and edit business rules
• A query and reporting component Allows users and rules administrators to query and report on existing rules
• Rules engine execution core The actual code that enforces the rules
Several types of business rules engines are available today that differ by at least the following two dimensions: by the way they enforce the rules and by the types of rules they support. The first dimension differentiates the engines that interpret business rules in a way similar to a script execution from the engines that “compile” business rules into an internal executable form to drastically increase the performance of the engine. The second dimension is driven by the types of rules—that is, inference rules and reaction rules. Here are some specifics:
• Inference engines support complex rules that require an answer to be inferred based on conditions and parameters. For example, an Inference BRE would answer a question such as, “Should this customer be offered an increased credit line?”
• Reaction rules engines evaluate reaction rules automatically based on the context of the event. The engine would provide an automatic reaction in the form of a real-time message, directive, feedback, or alert to a designated user. For example, if the customer age in the Data Hub was changed to qualify for mandatory retirement account distribution, the Reaction BRE would initiate the process of the retirement plan distribution by contacting an appropriate plan administrator.
Advanced BRE solutions support both types of business rules in either translator/interpreter or compilation mode. In addition, these engines support rules conflict detection and resolution, simulation of business rules execution for “what-if” scenarios, and policy-driven access controls and rule content security. Clearly, such an advanced BRE would be useful in supporting the complex data synchronization and conflict reconciliation requirements of the MDM Data Hub. Architecturally, however, a BRE may be implemented as a component of a Data Hub or as a general business rules engine that serves multiple lines of business and many applications. The former approach leads to a specialized BRE that is fine-tuned to effectively process reconciliation rules of a given style and context of the Data Hub. The latter is a general-purpose shared facility that may support a variety of business rules and applications, an approach that may require the BRE to support more complex rules-definition language syntax and grammar, and higher scalability and interoperability with the business applications. To isolate Data Hub design decisions from the specifics of the BRE implementation, we strongly recommend that companies take full advantage of the service-oriented approach to building a Data Hub environment and to encapsulating the BRE and its rules repository as a set of well-defined services that can be consumed by the Data Hub on an as-needed basis.
Data Delivery and Metadata Concerns
The complexities and issues of loading data into the Data Hub give rise to a different set of concerns. These concerns have to be solved in order to enable data consumers (systems, applications, and users) to find and use the right data and attest to its quality and accuracy. The Master Data Consumption zone addresses these concerns by providing a set of services that help find the right data, package it into the right format, and make available the required information to the authorized consumers. Although many of these concerns are typical for any data management and data delivery environment, it is important to discuss these concerns in the context of the MDM Data Hub and its Data Location service.
Data Zone Architecture and Distribution of Reference Data
One concern of master data distribution is centered on the distribution of a particular domain of master data—reference data. Although this concern applies to all types of master data, the reference data issues clearly underline the problem, primarily because practically every organization has a reference data system even if the MDM Data Hub is not yet implemented or even planned. We will discuss a number of implementation and governance issues that are specific to reference data as a subset of master data in Part IV.
A Reference MDM Data Hub, by definition, maintains a golden, accurate, and timely reference data record of ensured, measured data quality. This reference data needs to be delivered to consumers not only when it changes (as in data synchronization MDM processing) but also on demand. One approach that some organizations use to distribute reference data is to implement a data replication mechanism that allows each consuming application to acquire a “local” copy of the data and use it to support business processes. However, it is easy to see the problems with this approach:
• Using standard data replication techniques may create significant data redundancies, which result in extra storage, processing, and integration costs.
• Applications that acquired a “local” copy of the reference data may find it convenient to repurpose some of reference data attributes for a particular business process, thus potentially violating the data quality of the reference data because the Data Hub is not a part of this process.
• Changes to “local” copies of reference data don’t always get communicated back to the reference master, thus creating serious and often difficult-to-reconcile data quality and consistency issues.
Ignoring these issues and relying on an MDM engine to continue to maintain the required data quality of reference data is a short-sighted approach to reference data distribution. Indeed, MDM has capabilities to ensure the appropriate data quality, and its Master Data Consumption zone can implement various effective mechanisms to deliver the data to consumers automatically or on demand (either as a request or as a business event–driven action), but it cannot do it alone. The organization needs to recognize the problem and institute a set of policies and controls that address this reference data distribution issue at its core. For example, when an organization decides to implement a reference master data environment, it may stipulate the following:
• All reference data changes are versioned, and version references are available to all consumers.
• If the reference data is changed in the Reference Data Hub, its distribution should be implemented as an event-driven process, thus enabling the accurate view of reference data and the context of the change in business terms.
• Mass replication of reference data to all consumers without considering the semantics of the event that cause the distribution action and without implementing proper data quality controls should be avoided wherever possible.
• Data governance principles for reference data should clearly define the responsibilities and accountability of reference data owners, stewards, publishers, and consumers.
Data Zone Architecture and Hierarchy Management
As we discussed in Chapter 4, one important aspect of reference data is the hierarchical structure of many reference data domains. A hierarchy is defined according to some classification scheme, and changes to the scheme or the introduction of a new scheme results in creation of a new hierarchy. It is not unusual for an enterprise to organize its key reference data in different hierarchies according to the business requirements of a particular line of business. For example, consider a classical case of a customer reference master, where the customer entities represent institutional customers. In this case, a sales organization may use a customer hierarchy that reflects the legal entity structure of a parent company and its subsidiaries. At the same time, a marketing organization may use a location-based hierarchy that helps the marketing organization to refine its messages and campaigns according to the specific geographic and political concerns of a customer entity that operates in various regions of the global marketplace. Thus, we just defined two different hierarchies for the same domain. As business requirements change, and sales and marketing territories get realigned because of potential reorganization or a merge activity, these two hierarchies will have to change to reflect the changes in business conditions. In addition, a sales organization may decide to change the legal entity–based hierarchy to a version that is also based on the products that customers are using. It is easy to see that in the normal course of business activities, an enterprise can create several alternate hierarchies and continue to change them on a frequent basis.
Clearly, an MDM system will have to support these changes and maintain an appropriate degree of reference data integrity, versioning, and traceability, which is the province of the MDM Hierarchy Management services. Equally as important, however, an MDM system, and in particular its Master Data Consumption zone, has to implement a set of reference data delivery services that would provide a change impact analysis and deliver these hierarchy changes to downstream business systems that use the reference data to provide the enterprise with vitally important management and analytical data.
These requirements become particularly important in the case where the downstream system that consumes master data is an enterprise data warehouse and a set of dependent data marts that enable reporting, business intelligence, and other key business management functionality. As we showed in Chapter 4, the notion of hierarchy applies directly to the dimensions in a data warehouse data dimensional model, frequently referred to as a “star schema” or a “snowflake schema,” with the fact entities organized in a central table(s) and “surrounded” by dimensions that provide keys that point to each fact in the Fact Tables.4
A typical data warehouse design includes a robust dimensional data model and a set of services that support the acquisition, maintenance, relationships, and integrity of the fact data and dimensional data.
In some cases, these services and data models need to be rather complex to support complex business process that cause changes in the underlying dimensions and, therefore, in the values of the facts (for example, in cases where dimensional values change infrequently, the data warehousing system should define and maintain Slow Change Dimensions, or SCDs, which are the modeling constructs that enable a data warehouse to maintain the historical view of the values of the facts and allow the users to see the data as of a specific date, an activity referred to as “time travel”).
One benefit of MDM Hierarchy Management in conjunction with the Reference Data Delivery services deployed in the Master Data Consumption zone is that this architecture supports a system design option that allows the MDM system to maintain the data warehousing dimensions, including the management of their hierarchies in the MDM Data Hub instead of the data warehouse. As long as the Hierarchy Management service maintains the timely, accurate, and auditable view of hierarchy changes in a given dimension and supports the automatic synchronization of these changes across all related dimensions, the Master Data Consumption zone can implement a Data Delivery model that does the following:
• Propagate these reference data changes to the data stores that maintain the facts.
• Distribute the latest set of reference data directly to data marts that are used for management reporting and analytics.
Clearly, replacing data warehouse dimensions with the MDM Data Hub is just one design option, and not a mandatory configuration. However, because the Data Zone approach allows an MDM system to implement a loosely coupled connection between Hierarchy Management services in the Hub Services zone and Data Delivery services in the Master Data Consumption zone, it may be beneficial in some cases to allow for on-demand delivery of the accurate reference data rather than develop hierarchy management features inside the data warehousing environment.
Metadata and Attribute Location Services
As we look at the overall enterprise data landscape, we can see the majority of data values spread across the Data Hub and many heterogeneous source systems. Each of these systems may act as a master of some data attributes, and in extreme cases it is even possible that some data attributes have many masters. Every time a consumer requests a particular data record or a specific data attribute value, this request can be fulfilled correctly only when the requesting application “knows” what system it should access to get the requested data. This knowledge of the master relationship for each data attribute, as well as the knowledge of the name and location of the appropriate masters, is the responsibility of the Attribute Location service. Architecturally, it is an internal MDM Data Hub data service that is used by several higher-order services, including the Metadata Management service. Conceptually, the Attribute Location service acts as a directory for all data attributes under management, and this directory is active; that is, the directory is continuously updated as data attributes migrate or get promoted from old masters to the Data Hub—a natural evolution of an MDM environment from a Registry style to the Transaction Hub. Logically, however, this service is a subset of a larger service group called Metadata Management Services that supports and relies on an enterprise-wide metadata repository—a key component of any enterprise-wide data strategy and data architecture. The Metadata Repository role is much broader than just providing support for the Attribute Locator service, and also includes such internal Data Hub services as Record Locator and even Key Generation services.
Although a detailed discussion of metadata is beyond the scope of this book, we briefly discuss the basic premises behind metadata and the metadata repository in the section that follows. This section describes how a metadata repository helps enable just-in-time data delivery capabilities of some Data Hub implementations as well as some end-user applications such as real-time or operational Business Intelligence applications.
Metadata Basics
The most common definition of metadata is “data about data.” However, we can refine this definition to include more details. For example, we can define metadata as information about data’s structure (syntax) and meaning (semantics). Structural definitions describe the structure of the data objects and how the data is used, and include such familiar constructs as system catalogs for relational database management systems and XML schemas.
Semantic metadata provides a means to understand the meaning of data. For example, semantic metadata includes an explanation or description of the data entity in a data dictionary, commentary and annotations in documents, the content of the thesauri, and advanced information management concepts such as taxonomies of information patterns and ontologies.5
The power of metadata concepts includes metadata’s ability to be applied to itself by defining the structure and semantics of the metadata. In other words, if metadata is data about data, meta-metadata (also known as “meta-model”) is metadata about metadata— that is, it defines the structure and semantics of metadata. Examples of standardized meta-models include Unified Modeling Language (UML),6 Common Warehouse Meta-model (CWM),7 and Meta Object Facility, or MOF8 (a standard for meta-meta-models).
In principle, metadata is generated whenever data is created, acquired, added to, deleted from, or updated in any data store and data system in scope of the enterprise data architecture. Metadata provides a number of very important benefits to the enterprise, including the following:
• Consistency of definitions Metadata contains information about data that helps reconcile the differences in terminology such as “clients” and “customers,” “revenue” and “sales,” and so on.
• Clarity of relationships Metadata helps resolve ambiguity and inconsistencies when determining the associations between entities stored throughout the data environment. For example, if a customer declares a “beneficiary” in one application, and this beneficiary is called a “participant” in another application, metadata definitions would help clarify the situation.
• Clarity of data lineage Data lineage is one of the key capabilities of metadata management and provides the functionality to determine where data comes from, how it is transformed, and where it is going. Data lineage metadata maintains the trace of information as it traverses various systems. Specifically, the data lineage aspect of metadata maintains information about the origins of a particular data set and can be granular enough to define information at the attribute level; metadata may maintain allowed values for a data attribute as well as its proper format, location, owner, and steward. Operationally, metadata may maintain auditable information about users, applications, and processes that create, delete, or change data, the exact timestamp of the change, and the authorization that was used to perform these actions.
In addition to the structural and semantic classifications of metadata, we also recognize three broad categories of metadata:
• Business metadata This includes definitions of data files and attributes in business terms. It may also contain definitions of business rules that apply to these attributes, data owners and stewards, data quality metrics, and similar information that helps business users to navigate the “information ocean.” Some reporting and business intelligence tools provide and maintain an internal repository of business-level metadata definitions used by these tools.
• Technical metadata This is the most common type of metadata. Technical metadata is created and used by the tools and applications that create, manage, and use data. For example, some best-in-class ETL tools maintain internal metadata definitions used to create ETL directives, mappings, or scripts. Technical metadata is a key metadata type used to build and maintain the enterprise data environment. Technical metadata typically includes database system names, table and column names and sizes, data types and allowed values, and structural information such as primary and foreign key attributes and indices. In the case of MDM architecture, technical metadata will contain subject areas defining attribute and record location reference information.
• Operational metadata This type of metadata contains information that is available in operational systems and runtime environments. It may contain data file size, date and time of last load, updates, and backups, as well as the names of the operational procedures and scripts that have to be used to create, update, restore, or otherwise access data.
All these types of metadata have to be persistent and available in order to provide necessary and timely information to manage often heterogeneous and complex data environments such as those represented by various Data Hub architecture styles. A metadata management facility that enables the collection, storage, maintenance, and dissemination of metadata information is called a “metadata repository.”
Topologically, metadata repository architecture defines one of the following three styles:
• Centralized metadata repository
• Distributed metadata repository
• Federated or hybrid metadata repository
The centralized architecture is the traditional approach to building a metadata repository. It offers efficient access to information, adaptability to additional data stores, scalability to capture additional metadata, and high performance. However, like any other centralized architecture, a centralized metadata repository is a single point of failure. It requires continuous synchronization with the participants of the data environment, it may become a performance bottleneck, and it may negatively affect the quality of the metadata. Indeed, the need to copy information from various applications and data stores into the central repository may compromise data quality if the proper data validation procedures are not a part of the data acquisition process.
A distributed architecture avoids the concerns and potential errors of maintaining copies of the source metadata by accessing up-to-date metadata from all systems’ metadata repositories in real time. Distributed metadata repositories offer superior metadata quality because the users see the most current information about the data. However, because a distributed architecture requires real-time availability of all participating systems, a single system failure may potentially bring the metadata repository down. Also, as source systems’ configurations change, or as new systems become available, a distributed architecture needs to adapt rapidly to the new environment, and this degree of flexibility may require a temporary shutdown of the repository.
A federated or a hybrid approach leverages the strengths and mitigates the weaknesses of both distributed and centralized architectures. Like a distributed architecture, the federated approach can support real-time access to metadata from source systems. It can also centrally and reliably maintain metadata definitions or at least references to the proper locations of the accurate definitions in order to improve performance and availability.
Regardless of the architecture style of the metadata repository, any implementation should recognize and address the challenge of semantic integration. This is a well-known problem in metadata management that manifests itself in the system’s inability to integrate information properly because some data attributes may have similar definitions but have completely different meanings. The reverse is also true. A trivial example is the task of constructing an integrated view of the office staff hierarchy for a company that was formed because of a merge of two entities. If you use job titles as a normalization factor, a “vice president” in one company may be equal to a “partner” in another. Not having these details explained clearly in the context becomes a difficult problem to solve systematically. The degree of difficulty grows with the diversity of the context. Among the many approaches to solving this challenge is an effective application of information semantics concepts such as ontologies. From the metadata repository point of view, the repository design has to be “ontology aware” and provide the capability to link the context to the information itself and the rules by which this context should be interpreted.
Enterprise Information Integration and Integrated Data Views
Enterprise Information Integration (EII) is a set of technologies that leverage information collected and stored in the enterprise metadata repository to deliver accurate, complete, and correct data to all authorized consumers of such information without the need to create or use persistent data storage facilities.
The fundamental premise of EII is to enable authorized users with just-in-time and transparent access to all the information they are entitled to. Part III of this book discusses the concepts of the “authorized user” and “entitlements.”
This capability of delivering transparent access to information that is distributed across several, possibly heterogeneous data stores is what makes EII technology a viable and attractive data access component of the service-oriented architecture (SOA) that supports these types of distributed data environments (for example, an enterprise MDM system). We can further state that, conceptually, EII technologies complement other solutions found in the Master Data Consumption zone by defining and delivering virtualized views of integrated data that can be distributed across several data stores, including an MDM Data Hub.
EII data views are based on the data requests and metadata definitions of the data under management. These views are independent from the technologies of the physical data stores used to construct these views.
Moreover, advanced EII solutions can support information delivery across a variety of channels, including the ability to render the result set on any computing platform, including various mobile devices. Looking at the MDM Reference Architecture (refer to Figure 5-2), we can see that EII components that deliver requested data views to the consumers (users or applications) should be designed, implemented, and supported in conjunctions with the Data Location and Data Delivery services discussed in the previous sections of this chapter.
Although, strictly speaking, EII is not a mandatory part of the MDM Data Hub architecture, it is easy to see that using EII services allows a Data Hub to deliver the value of an integrated information view to the consuming applications and users more quickly, at a lesser cost, and in a more flexible and dynamic fashion.
In other words, a key part of any MDM Data Hub design is the capability of delivering data to consuming applications periodically and on demand in agreed-upon formats. However, being able to deliver data from the Data Hub is not the only requirement for the Master Data Consumption zone. Many organizations are embarking on the evolutionary road to a Data Hub design and implementation that supports both the Analytical and Operational styles of MDM. In this scenario, the Data Hub becomes a source of analytical and operational data for the Business Intelligence suites (Analytical MDM) and Servicing CRM (Operational MDM). This approach expands the role of the Data Hub from the data integration target to the master data source that feeds value-added business applications. This expanded role of the Data Hub and the increased information value of data managed by the Data Hub require an organizational recognition of the importance of an enterprise data strategy; broad data governance; clear and actionable data quality metrics, especially appointed data stewards that represent business units; and the existence and continuous support of an enterprise metadata repository.
The technical, business, and organizational concerns of data strategy, data governance, data management, and data delivery that were discussed in this chapter are some of the key factors necessary to make any MDM initiative a useful, business value–enhancing proposition.
References
1. Newman, David, Nicholas Gall, and Anne Lapkin. “Gartner Defines Enterprise Information Architecture.” February 2008. http://www.gartner.com/DisplayDocument?doc_cd=154071.
2. http://www.datagovernance.com/fw_the_DGI_data_governance_framework.html.
3. http://en.wikipedia.org/wiki/Business_rules_engine.
4. Kimball, Ralph, Margy Ross, Bob Becker, and Joy Mundy. Kimball’s Data Warehouse Toolkit Classics: The Data Warehouse Toolkit, 2nd Edition; The Data Warehouse Lifecycle, 2nd Edition; The Data Warehouse ETL Toolkit. Wiley (April 2009).
5. http://www.merriam-webster.com/dictionary/ontology.
6. http://www.uml.org/.
7. http://www.omg.org/technology/documents/modeling_spec_catalog.htm.
8. http://www.omg.org/mof/.