
CHAPTER 15
Beyond Party Match: Merge, Split, Party Groups, and Relationships
The previous chapter provided an in-depth discussion of how an MDM solution enables entity identification using various attribute- and record-level matching techniques. Although we discussed entity identification in general terms, we concentrated on the easier-to-explain Customer domain to describe the process of identification in a sufficient level of detail.
Merge and Split
We use the same approach and continue this discussion by taking a closer look at the complementary operations of entity merge and split, and will try to explain these operations both in general terms as well as using the specifics of merging and splitting entities in the Customer domain.
Merge
Chapter 14 showed how to match records and link them into match groups or clusters of affinity. Figure 15-1 illustrates how a match and link process can uniquely identify a Match Group 100.
Matching and linking operations represent a critical step in entity identification, but as the example in Figure 15-1 illustrates, in the case of customer identification, the records describing the individual contain some contradictions. For example, it is unclear what name, residential address, SSN, and so on, represent the “right” data about the individual. The MDM Data Hub has to solve this problem and decide what attributes should “survive” when the Hub merges records in the match group in order to create a single integrated customer record that represents a 360-degree view of the individual, including an integrated view of key customer metrics such as a complete and accurate net-worth or risk exposure of the customer.
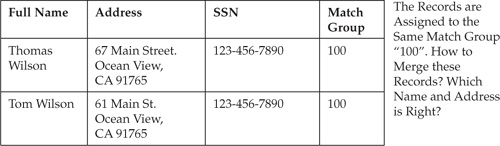
FIGURE 15-1 Linked records—candidates for merge
In general terms, a successful and flexible approach to merging match group records calls for the development and implementation of a hybrid automatic and manual user-guided process. This process should allow the user to select the correct attribute values for the entity in question. For example, when you look at the information about an individual, the “correctness” is typically determined by a human operator familiar with the individual, a data steward applying data governance guidance to attribute survivorship, or a systemic, automated process that can make this determination based on some predefined rules and certain additional information. Such information may include individual preferences captured via a service channel or reference information acquired from a trusted external data provider (for example, National Change of Address [NCOA]). In the latter case, an MDM system can assist the user in making the right decision by providing some default merge recommendations that can then be validated or overridden by the end user. The attribute survivorship decisions can be driven by simple rules or arbitrary complex business logic. For example, the survivorship of a particular attribute can be based on the source systems that hold the record, the value the record displays, the end user who entered the attribute value, and other factors. This indicates that the MDM Data Hub solution must maintain attribute-level data about the record’s source, time stamp of creation and modification, and certain user information, including user role and other identity attributes (often referred to as user credentials). Figure 15-2 shows a sample spreadsheet that can be used as a template for specifying default survivorship rules.
A pragmatic approach to developing merge capabilities for MDM Data Hub solutions states that each survivorship candidate attribute should be defined and uniquely identified in the Data Hub’s logical data model. If the project requirements call for the creation of a persistent merge history, we can extend the Data Hub data model by creating a history entity as shown in Figure 15-3.

FIGURE 15-2 A template defining attribute survivorship rules
This model supports the notion of inheritance of records merged from the same system or multiple legacy sources.
If two records are merged, the new “golden” record is created. The “golden” record may or may not inherit CUSTOMER_ID from one of the existing records. The attribute MERGED_TO_CUSTOMER_ID in the Customer History table points to the record created as a result of the merge in the table Customer (where the MERGED_TO value is equal to 1000).
As we have noted before, the creation and maintenance of a high-confidence “golden” record requires user input for practically any data domain that is managed in the MDM system. The technology organization supporting the MDM project should develop a user-friendly interface that allows end users to create entity groupings, display the duplicates, and choose the attribute values for the “golden” record.
Merge operations can be rather complex and impact other systems that are using or are used by the Data Hub. The changes in the data content that result from performing a merge operation should be propagated to other systems in order to synchronize their data content with the Data Hub as the master of the content. Additional complexity of the merge operation for the Party domain may be caused by the need to merge relationships, agreements, and other documents that have been tied to two or more separate party records before the merge. When two or more records are merged in the Data Hub, a merge transaction is sent to the consuming data warehouses and data marts. Often, merge processing can be automated and additive facts processed automatically; for instance, the total value of sales or total of all outstanding credit balances will be summarized over all merged customer records.
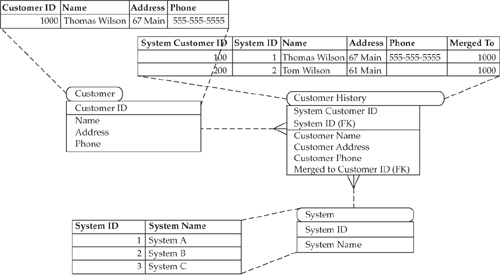
FIGURE 15-3 A model supporting merge history
The complexity of the merge processing is not the only challenge for entity management in an MDM Data Hub. The process of entity split can be even more complex.
Split
A split is an MDM process that is functionally opposite to a merge. Using the party model as the context, we can say that a split is required if information gathered from two or more parties has been mistakenly stored in a single party record. Figure 15-4 displays an example in which a record that was thought to represent one individual, Bill Johns, in reality represents two individuals, Bill Johns, Sr., and his son Bill Johns, Jr., with different dates of birth. Procedurally, the split would “undo” a merge operation provided that the appropriate information to perform the split is available even after the merge is done.
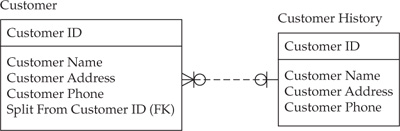
In this example, as soon as the mistake of the merge decision has been discovered, a corrective action is taken. Typically, this is a manual action that requires inputting additional information. In the example shown in Figure 15-4, Bill Johns, Sr., retains the Party ID (100) while a new Party ID (110) is created for Bill Johns, Jr. The MDM project’s technology team should plan on providing a user-friendly interface that allows the business user to perform the split process. Similarly, in order to merge, if the project requirements include split history support, we can further extend our MDM logical data model as shown in Figure 15-5. If documents, relationships, and other information had been tied to a party record before the split, all pieces of this information must be distributed between the records formed as a result of the split. This adds to the complexity of splits.
Unlike a merge, where additive information can be summarized automatically, automation may not be feasible for a split. Indeed, a split transaction requires a clear definition of the post-split state that may not be available in the system before the split.
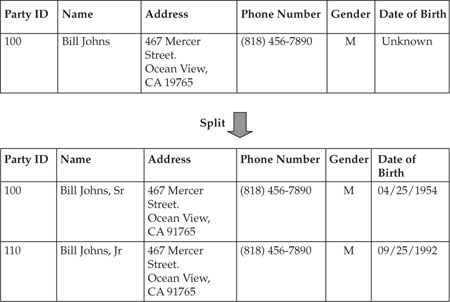
FIGURE 15-4 An example of a split
FIGURE 15-5 A logical data model representing a party split
Note As described in the Merge and Split sections above, the project team should plan for an additional modeling effort if the business functional requirements include support for merge and split within a single model. For the implementation to be successful, it is important to develop guidance principles about how to store and maintain enterprise entity identifiers generated by the Data Hub. In order to facilitate message exchanges between enterprise systems, it may be beneficial to develop a Key Lookup service that is capable of returning a system-specific identifier or translate master data identifiers across systems.
Relationships and Groups
Although solving entity identification problems is key to creating any MDM solution, it is not the end of the road for an MDM project. Indeed, the newly created MDM Data Hub contains the superset of entities from multiple source systems. Again, let’s use Customer and Party as entity types in order to illustrate a number of key concerns related to identification, merge, split, and other entity resolution operations.
Some of the party entities in the MDM Data Hub are current customers while others are still prospects or past customers who terminated their relationships with the firm for any number of reasons. Moreover, some of the parties may not be customers but are important to the organization since they are related to the current customers or provide some service to them. For example, an MDM Data Hub may contain information about spouses and children named as beneficiaries on customer accounts, trustees of the customer, or powerful and influential individuals who are designated as having power of attorney for some customers.
These relationships may represent a very attractive opportunity for the enterprise that is looking to increase its customer base and grow the share of its customers’ wallets. In order to take advantage of this opportunity, an MDM Data Hub has to support the notion of explicit and implicit party relationships and party groups. Specific requirements to support these features as well as their implementation priorities depend on the industry, line of business, and particular needs of the organization as defined in the business scope documentation for the project. Thus, we limit the discussion on these topics to a generic overview of the issues, concerns, and approaches to solving the party relationships and grouping challenge.
Direct Business Relationships with an Individual
We will use an example of retail financial services industry that includes brokerage, banking, and insurance to explain the notion of direct relationships. In this case, a relationship with an individual begins when the individual becomes a prospect (potential customer). Depending on the channel used, a financial services enterprise would create a party record for this individual that points to a new relationship between the enterprise and the individual. Depending on the architecture style of the MDM Data Hub, this party record for the individual is created either in the Hub or in one of the source systems. If the sales process was successful (for example, the individual decides to establish one or more relationships [for example, open an account] with the firm), the prospect becomes a customer. Depending on the individual situation and set of preferences, this newly created customer may have different roles on his or her accounts. In the example shown in Figure 15-6, John S. Smith is in the role of “Primary” on account 4736922239.
The attribute “Date Closed” in the Account table is blank, which identifies John Smith as an active customer. When the account is closed, this attribute is updated with the actual or effective event date. If this happens with all of John’s accounts, he assumes the role of a “Former Customer.”
Another type of direct relationship between an individual and an organization is an agreement according to which the individual provides services to some of the customers or works with prospects. The individuals can be employees of the firm or work on a contractual basis (for example, consider external consultants that provide some very specialized services, such as jumbo insurance policies, to a small group of enterprise customers). The individuals responsible for servicing accounts or interacting directly with customers or prospects can also be customers or prospects of the same enterprise, which means that, depending on the functions/services they perform, the individuals can have multiple roles and relationships with the enterprise.
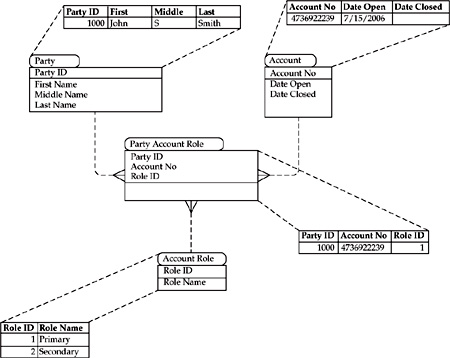
FIGURE 15-6 Data model and example illustrating a direct relationship between the enterprise and an individual
The importance of the relationships is not limited to financial services. Companies that provide products and services to customers either directly or through an intermediary want to get a greater share of each customer’s wallet, enable more compelling and higher value cross-sell and up-sell opportunities, and increase customer retention rates. However, they want to do so while gaining better control, and limiting, or even eliminating, relationships that are risky or not cost effective. Service and product provider companies may use multiple names to do business with your organization. Understanding relationships would help the organization to identify all the names a single company is using, which would reduce their risk exposure by better controlling how much credit is being extended to a single entity or closely related individuals, or individuals and organizations. For example, a small business owner could lease or purchase a computer under his own name and then lease or purchase another one under the company’s name. It may be important for the computer company to understand that this is the same person, especially if that same person were to apply for credit multiple times using different identity profiles, and the company were to issue credit multiple times to that same individual, which would create a high level of risk exposure.
Energy companies and other utilities that provide services to consumers and organizations face similar risks from customers they call “spinners.” Spinners are people who are notoriously bad customers, ordering service under different names and never paying for it. For example, an electric company might first put service in the husband’s name, then the wife’s, and then another household member’s name—and they don’t pay again and again. The same situation could occur with a company that uses different names. With spinners, it is extremely important to know how customers are related to each other, and how/if people and organizations are related.
For hospitality business and travel companies that operate loyalty programs, it is important that they develop a good understanding of the behavior of individual customers and also their spouses, partners, and other family members. This knowledge will help companies to develop better and more attractive offers to loyalty club members. It is not uncommon for people to buy hospitality and travel services based on family preferences rather than their individual preferences, so the companies having more information about how people are related will ultimately improve the bottom line.
In healthcare, it is obvious that understanding how patients are related would be helpful for better understanding genetic diseases. Understanding relationships between patients and providers is also critical to support online portals and self-service applications. These solutions require data visibility, security, and eligibility, which can be effective only if the system “understands” what individual or organization is authorized to have access to a patient’s health record, the type of access, and so on. By providing physicians with an information portal that has complete patient detail—including how physicians are related to patients, how physicians are related to hospitals, how physicians are related to their offices, and what kind of plans they offer in each office—hospitals make it more convenient for physicians to interact with them, which ultimately results in more physician referrals and more revenue for the hospitals.
Relationship data is also critical for government agencies looking for criminals. For example, when the Homeland Security Agency is tracking terrorists or the police are looking for organized crime suspects, they need to see how people are related and who is connected to whom. Often, members of organized crime rings and terrorist groups operate behind some kind of a legitimate-appearing legal entity (façade), so understanding relationships, not only between people, but also between people and different kinds of associations, funds, and organizations, can be critically important.
Symmetric and Asymmetric Relationships
When dealing with individual customers and prospects, the enterprise needs to know the potential and actual “value” of the individual and his or her specific assets along with the roles the individual plays relative to the assets. To provide an effective personalized customer service, the enterprise needs to be able to recognize all of the individual’s assets managed by the firm across all lines of business. This goal can be achieved when the MDM Data Hub solves the party identification problem. As a result, the enterprise gains a clear view of its direct customers. The missing component of the equation is the assessment of the relationships between customers, particularly high-value customers. The fragment of a data model shown in Figure 15-7 represents a structure that can be used to support symmetric relationships between individuals—siblings, spouses, partners in business, and so on.
Figure 15-7 illustrates the relationship between John Smith and Mary Smith. Relationship ID = 1 points to “Spouse” for the relationship between John and Mary with Party IDs equal to 1000 and 1100 respectively.
We can also use the example of John and Mary to illustrate asymmetric relationships. If, for example, Mary is a high-value customer and John has no accounts with the firm, the enterprise will be able to recognize John only as an “indirect” customer through his relationship with Mary. The relationships that can be supported by the data structure shown in Figure 15-7 are limited to symmetric relationships where the result will not change if the columns in the table “Individual to Individual Relationship” are swapped. Indeed, if “John is Mary’s spouse” is a valid statement, the reverse statement is valid too: “Mary is John’s spouse.”
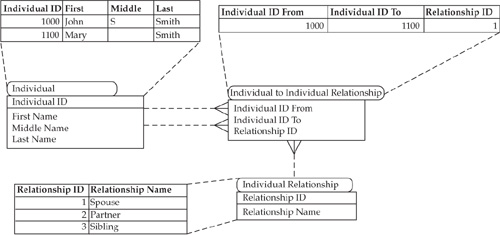
FIGURE 15-7 Data model and example illustrating a symmetric relationship between two individuals
Such symmetry does not hold for other types of relationships (for example, parent/child relationships or service provider/customer relationships). To support these relationship types, the two columns “Individual ID” in the table “Individual to Individual Relationship” should be changed to “Individual ID From” and “Individual ID To” to create an asymmetric relationship. This transformation is shown in Figure 15-8, where Larry Smith is John Smith’s father and Tom Logan is John’s accountant.
As per Lawrence Dubov’s article,1 there exist three MDM techniques to build entity relationships and hierarchies:
• Use an external trusted source of relationships or multiple trusted sources (“tree of truth”) and build your internal relationships and hierarchies comparing in-house data with the trusted sources.
• Define rules that will be used by the systems automatically to infer entity relationships. These rules can be based on common attribute values—for example, people sharing the same location are defined as a household. The locations can be matched exactly or probabilistically.
• Develop relationship matches and links manually using graphical interfaces enabling the user to perform the relationship building work with ease and efficiency.
These methods can be used individually or in combination to achieve varying levels of success in terms of identifying and understanding symmetric and asymmetric, one-to-many and many-to-many relationships. Each of these three methods has its benefits, areas of applicability, and limitations. In full-scale enterprise MDM implementations, all three methods can be beneficially used to create a comprehensive view of relationships.
When an organization is using an external trusted source, it relies on that source’s data and matches its internal records against the external data to help establish which of its records are related. This approach is frequently used to establish and maintain the hierarchies of customer or product data. Maintenance of corporate hierarchies is a critical task from the credit risk perspective, marketing, territory alignment, and so on. Structurally, each of the hierarchies is represented by a single root with an unlimited number of layers below. Applications typically display and manage these hierarchies in a tree view.
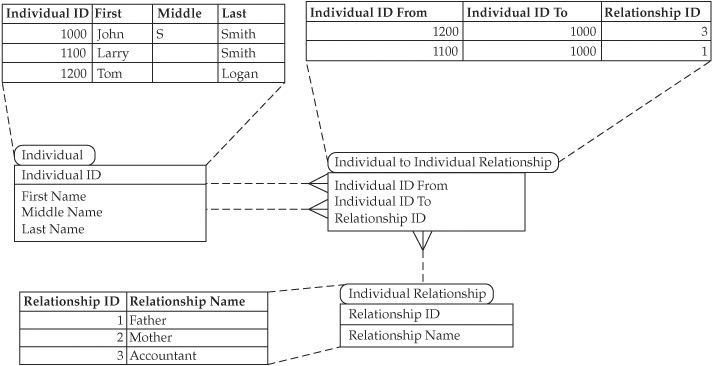
FIGURE 15-8 Data model and example illustrating an asymmetric relationship between two individuals
For global MDM implementations, it is often important to build a solution capable of using multiple country-specific data providers and decision tree logic. This logic can “decide” which of the trusted external sources is the best to use for a given internal record.
The second approach to establishing relationships includes creating rules for matching algorithms to determine which records are related and how. Rules can be used to algorithmically infer relationships and to validate relationship rules. For example, a Data Hub should be able to define the rules for the identification of people who work for the same employer, belong to the same professional group, or are part of the same household. These rules can be simple or quite complex to include fuzzy and probabilistic matching. Relationship validation rules can be used to specify that a company is allowed to have only one parent or a patient must be associated with at least one provider. When a validation rule is violated, an alert is generated and human review of the data exception is required. If, for example, a company is found to have two parent companies, a validation rule is violated, which causes the rules engine to generate a data exception that will be sent in a data stewardship queue for review and processing.
Human intervention is often necessary to resolve rule violations and other data anomalies. However, there are also instances where organizations want to determine how data is related but cannot use an external source or create a specific rule to establish a relationship. In those situations organizations must rely on manual methods to establish relationships and links between data. For this reason, data stewardship processes and technologies should be seamlessly integrated with MDM technologies in organizations that want to establish a relationship-centric view of the enterprise.
A sound relationship management strategy that combines all three approaches enables enterprises to build comprehensive MDM solutions with a balanced use of advanced algorithms and business user input.
Households and Groups
MDM capabilities that support the discovery of relationships between parties should include the ability to recognize customers’ Households or Party Groups. Indeed, the members of these entities are related or connected in some way, and although they may or may not be direct customers at present, they certainly represent an opportunity for the enterprise to convert them into direct customers. The term Party Group is used to denote a group of individuals or business partners that are connected in some implicit or explicit way and should be considered as a customer from the firm’s relationship perspective (when the relationships are based on the family structures, these Party Groups are sometimes referred to as “Family Groups”). The term “Household” is typically limited to the family members residing at the same address.
If the MDM Data Hub can recognize Households and Party Groups, the enterprise can offer customized products and services to the group’s members proactively even before they are recognized as high-value individual customers. Understanding these relationships provides the enterprise with a competitive advantage and opportunity to improve overall customer experience, strengthen customer relationships, and reduce customer attrition.
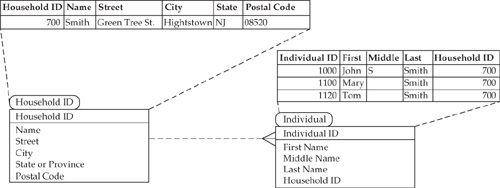
FIGURE 15-9 Data model and example illustrating the concept of Household or Party Group
Recognizing the totality of customer relationships allows organizations to create cross-sell and up-sell opportunities and increase the share of wallet within each Household and a Party Group. The association between individuals and households is depicted in Figure 15-9. The Household/Party Group structure shown in Figure 15-9 is limited in that one individual cannot cross Household/Party Groups.
Customer Groups
The notion of a Customer Group avoids the single-group limitation by defining a structure in which an individual can belong to multiple groups. For example, a group of individuals having a common interest can open an account and by doing so establishes a direct relationship with the enterprise, where the newly created Customer Group is playing the role of a customer. Members of a Customer Group don’t have to be related to each other in the same way the members of the Family Group are. In fact, Customer Groups could be considered as artificial constructs created for a particular, often transient business purpose. A Customer Group can be formal (that is, includes businesses, organizations, legal entities, and associations that have a legal status and are recognized as legal entities) or informal. Figure 15-10 illustrates the notion of a Customer Group.
It follows from the example that Mary Turner and Larry Goldberg serve on the “ABC Board of Directors,” Larry as the “Chair” and Mary as a “Member.”
Note The notion of a Customer Group represents a special case of the entity-grouping capability of an MDM solution. It is easy to imagine that many entity classes can be grouped together in order to enable certain business-driven features—for example, a group of accounts can allow a special tax treatment; a group of products can be created to provide specialized, dedicated support and preferential pricing; and so on.
Relationship Challenges of Institutional Customers and Contacts
The Basel Committee2 and other regulatory bodies require that corporations, shareholders, signatories, and other decision-making individuals and groups in positions of power and control be identifiable with the required degree of reliability. These requirements have direct implications on how an MDM Data Hub should recognize individuals who represent institutions and act on their behalf. In this discussion, we are using the term “institutional contact” to define individuals who represent institutions and act on their behalf. This is different from a situation where the customer is an institution and the MDM Data Hub manages legal entities, their relationships, groupings, and hierarchies as customers in their own right. We call these customers “institutional customers.”
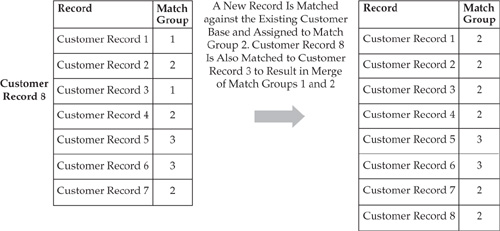
FIGURE 15-10 Data model and example illustrating the concept of a Customer Group
The recognition challenge in the case of institutional contacts is complicated by the fact that these individuals may use the identification attributes provided to them by their institution. For example, a trader working for a major brokerage house may be identified by his or her exchange registration number rather than by name and social security number. When such an institutional contact interacts with the enterprise on his or her firm’s behalf, the enterprise must recognize these types of relationships and the role the individual and the firm can assume in the relationships. This is a difficult problem that can be addressed differently depending on the set of business rules and allowed roles that vary from industry to industry and from one institution type to another. For example, the roles and rules may depend on whether the corporation represented by an individual is listed on a recognized stock exchange. In general, these complex relationships can be maintained by the structure shown in Figure 15-11.
In the preceding example, Mary Turner and Larry Goldberg work for ABC Corporation. Mary’s role is “Decision Maker” (could be CEO, CFO, and so on). while Larry is an employee.
Relationship Challenges of Institutional Customers
Dealing with institutional customers (institutions), their contacts, and their inter-relationships is extremely challenging. In addition to the data quality and clerical issues common to both individual and institutional customers, there is frequently a lack of a solid definition of what constitutes an institutional customer. This is particularly true in cases where a firm has multiple relationships with the institutions represented by various individuals. In this case, the firm may have multiple customers with the same customer tax identifier. This indicates that the tax identification number may not be granular enough to uniquely identify the customers representing institutions. As we stated in the previous section, separate relationships can exist between individuals acting on behalf of different corporations, lines of business, geographic locations, divisions, and departments. Likewise, separate relationships can exist between the enterprise and the institution at the parent company level, the subsidiary level, line of business, division, and so on. In general, the notion of customer relationship can become very uncertain and would depend on how the customer relationship managers wish to define the customer. Different units within the organization may have different granularity needs for customer relationship definition. Moreover, when dealing with large institutional customers, MDM solutions face additional challenges that result from merger and acquisition activities. For example, corporations, their business units, and their lines of business may change names as a result of mergers and acquisitions, rebranding, internal reorganizations, and so on. The relationships between parent companies and their subsidiaries are also unstable. The same applies to the organizational hierarchies of institutional customers and, consequently, to their relationships with the enterprise. Institutional customers may require different customer definitions for the same customer depending on the line of business, a channel, or other conditions. For example, a business unit responsible for shipping is likely to identify customers by a mailing label that includes the name of the organization and its address. From the sales organization’s perspective, each customer relationship is identified through the relationship’s contacts. As a result, institutional relationships require more complex and, at the same time, more flexible data models than those built for individual customers. Of course, we recognize that in general the number of institutional customers is much smaller than the number of individual customers, and that fact helps MDM Data Hub systems to effectively manage institutional relationships.
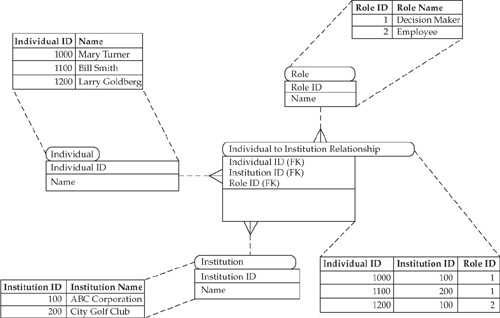
FIGURE 15-11 Data model and example illustrating relationships between institutional contacts and individuals
Another challenge presented by institutional customers is the need to correlate customer records in order to remediate customer hierarchy changes. Left unmanaged, hierarchy changes can create a perception that the hierarchy of institutional customers is incorrect, incomplete, and unreliable. Incorrect institutional customer hierarchy data can negatively affect the enterprise in multiple ways. For financial services companies that deal with the institutional customer (for example, investment banks), incorrect customer hierarchy data may cause failures in trading, erroneous financial reporting, lost marketing opportunities, failure in Anti-Money Laundering (AML) and Know Your Customer (KYC) processing, and other business and regulatory issues. This challenge is rapidly coming to the forefront of business concerns for any enterprise that supports institutional customers, and many MDM solutions are being developed or modified today to address this concern.
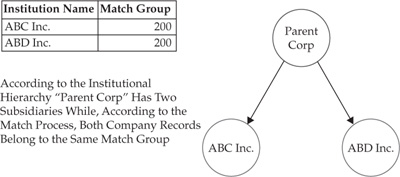
To illustrate the problem in its simplest form, consider an institutional hierarchy where each node is either the root with no parents or a leaf that can have only one parent. Figure 15-12 illustrates this situation by showing two institutions, ABC and ABD, that are in fact the subsidiaries of one parent company.
However, if we apply a customer-level matching process, it may identify ABC and ABD as likely to be the same institutional customer whose name was changed or misspelled. This happens because the institutional customer hierarchy and the associated relationship data represent a new piece of information never used by the matching process designed to handle individuals. In principle, this problem can be addressed in one of two ways: modifying the matching process to include hierarchy-based relationship data, or changing the relationship hierarchy traversal to leverage the results of the matching process.
In either situation, an MDM system should be extended to accommodate additional business rules and workflows that can handle institutional customer hierarchies. Then the modified MDM-system will be able to identify, profile, quantify, and remediate errors in matching the institutional hierarchy data by mapping hierarchy nodes to integrated customer entities.
FIGURE 15-12 A simple institutional hierarchy that conflicts with institutional customer identification
Need for Persistent Match Group Identifiers
Match Groups may or may not have to be persisted. If a match engine is used to find potential matches in a few party records, it is not necessary to persist a match group even though such persistence may be beneficial from the search performance perspective. There are maintenance cost trade-offs in implementing this. As soon as we persist something that can change, we have to capture and manage the change, which is a complex task. Indeed, match groups can change if critical match attributes change. This can trigger a chain of events within and outside the matching process. What if legal documents have already been tagged by the Match Group Identifiers? Can we allow a systemic change of the identifier? The answer is most likely negative.
Generally speaking, Match Group Identifiers should be persisted but carefully managed when the records representing individuals and/or organizations are linked to other entities. The creation and maintenance of relationships and hierarchies are typical situations that require the Match Group Identifier to be persisted.
There are scenarios where the Match Group Identifiers do not need to be persisted. For instance, if a match process is used only to eliminate duplicates and create merged records that will be used for a stand-alone marketing campaign, the goal can be achieved without storing and therefore managing the Match Group Identifiers. Another typical scenario occurs when the matching process is only used for computer-assisted manual data de-duping. In some situations with very conservative requirements for match and merge, only the end users can provide the ultimate match, link, and merge decisions. In these situations the Match Group Identifier is not equal to the “golden copy” Party ID, but is treated as an intermediate attribute assisting the end user with customer identification key assignment.
Even though some specific needs may not require the generation and storage of the Match Group Identifiers, the general intent to create and maintain a single unique “golden copy” of the Party ID across the enterprise is a good idea that aligns the MDM Data Hub design with the strategic intent of the Master Data Management initiative.
Additional Considerations for Customer Identifiers
Whether you operate in an account-centric enterprise and are planning for a transition to a customer-centric enterprise, or a transition to a customer-centric business is already under way, the majority of data access requests still rely on the account numbers for inquiries, updates, deletes, and other operations. It probably makes no sense to try to get rid of account numbers as entity identifiers and a communication exchange vehicle that all participants are familiar with and clearly understand.
So what will happen when the migration to the customer-centric view is complete? Would it be a good idea to maintain account numbers and associated entities in the customer-centric world? So far, we presented the customer identifier solely as a technical artifact, a key that is generated, maintained, and used by the system with no exposure to the end user. Depending on a given project’s requirements, this may continue to be the case. Alternatively, the customer identifier may be exposed to end-user applications and users may be trained to use the customer identifier in conjunction with or even instead of the traditional account number in order to search for customer groups, family groups, relationships, customer agreements, and other related entities. If the business requirements specifically ask for customer identifiers to be exposed to end-user applications, then the project team needs to carefully plan and design the rules for generating and using customer identifiers prior to the first MDM Data Hub deployment.
Here are some considerations related to the generation of customer identifiers:
• The key must be unique. This sounds obvious, but we do not want to miss this critical requirement here.
• The key should have a check digit or other data integrity check rule so that the integrity of the key can be confirmed.
• We do not recommend defining key ranges unless there are very compelling reasons, such as established business processes and an inflexible technology infrastructure.
• Generally speaking, the use of intelligent (meaningful) keys is not a good practice because it limits the solution’s flexibility and adaptability to changing business conditions.
The key length should be sufficient to provide unique identification for all entities in the MDM Data Hub.
An identifier that conforms to the technical requirements in this list is referred to as a “well-formed identifier” and is a primary vehicle that enables entity identification.
To reiterate, entity identification is a key component of entity resolution and represents one of the primary functional requirements for any MDM Data Hub solution. As the scope and size of master data managed by the MDM Data Hub increases over time, the requirement to create and maintain well-formed identifiers may be extended to include relationships, entity groups, and other attributes and constructs that are selected to act as enablers of the enterprise-wide deployment of a Master Data Management environment that provides meaningful business benefits, including the ability to transform the enterprise into an entity relationship–centric model.
References
1. Dubov, Lawrence. “Master Data Management: The Importance of Relationships Management,” Information Management, March 19, 2009. http://www.information-management.com/specialreports/2009_132/10015070-1.html.
2. http://www.bis.org/list/bcbs/index.htm.