
CHAPTER 10
Protecting Content for Secure Master Data Management
The Internet has brought about an information and connectivity revolution where enterprises, governments, and individuals all act as participants in the global interconnected, networked information ecosphere. The information assets available in this networked ecosphere continue to grow and expand their scope. Moreover, as enterprises aggregate data into large data warehouses and MDM Data Hub systems that use networked storage devices, these information assets become increasingly more valuable and at the same time more accessible. This networked ecosphere and the information it contains have become an attractive target for identity thieves, information thieves, and other malicious attackers who have learned to take advantage of the ubiquitous nature of the Internet, and therefore have defined new challenges for the entire spectrum of data security.
Data Security Evolution
Even as security practitioners are working diligently to develop new security solutions, the hackers do not stay idle. They continue to develop new security compromise techniques and approaches. These approaches include not only phishing and pharming (we discussed these in the previous chapter). The hackers and information thieves keep on building and distributing new spyware and malware at an ever-increasing rate. As a result, the number, the variety, and the size of security breaches continue to grow with no signs of slowing down.
For example, consider a high-profile 2009 security breach at Princeton, NJ, payment processor Heartland Payment Systems. According to the company, which processes payments for more than 250,000 businesses, this incident may have compromised tens of millions of credit and debit card transactions. If accurate, such figures may make the Heartland incident one of the largest data breaches ever reported. And this incident is not unique. The 2009 Washington Post article “Payment Processor Breach May Be Largest Ever”1 described the Heartland Payment System incident and offered a number of alarming facts:
• On December 23, 2008, RBS Worldpay, a subsidiary of Citizens Financial Group Inc., said a breach of its payment systems may have affected more than 1.5 million people.
• In March 2008, Hannaford Brothers Co. disclosed that a breach of its payment systems—also aided by malicious software—compromised at least 4.2 million credit and debit card accounts.
• In early 2007, TJX Companies Inc., the parent of retailers Marshalls and TJ Maxx, said a number of breaches over a three-year period exposed more than 45 million credit and debit card numbers.
• In 2005, a breach at payment card processor CardSystems Solutions jeopardized roughly 40 million credit and debit card accounts.
In 2009, the PGP Corporation and the Ponemon Institute published results of their annual U.S. Cost of a Data Breach Study.2 According to the study, data breach incidents cost U.S. companies $202 per compromised customer record in 2008, compared to $197 in 2007. Overall, the cost per compromised record has grown by 40 percent since 2005, with an average total per-incident cost in 2008 of $6.65 million, compared to an average per-incident cost of $6.3 million in 2007. These numbers include explicit and implicit costs attributed to the following:
• Discovery of the breach
• Escalation procedures
• Notification of the potential victims
• Recovery from security incidents in the form of fraud write-offs, legal costs, investigation costs, audits, credit report monitoring, IT and operational costs, and other redress activities
• Impact of customer defections
The overall cost of a security breach would also include other implicit costs often characterized by lost opportunities, legal liabilities, and noncompliance with federal and state regulations. The result could be not just a significant loss of revenue but the potential termination of business as customers lose trust in the business’s ability to protect personal and financial data and may decide to change their service providers, trading partners, and suppliers.
Incidents of data compromise are often classified as identity theft—the fastest-growing white-collar crime in the U.S. (we introduced identity theft in Chapter 8). The U.S. Federal Bureau of Investigation (FBI), the Computer Security Institute (CSI), and various identity theft watchdog organizations estimate that organized crime globally makes more money from identity theft than from selling illegal drugs.
What appears to be even more alarming is that the sources of these incidents and the security threats to organizations are no longer coming from outside the enterprise. Disgruntled or irresponsible employees and contractors can easily bypass traditional perimeter defenses and cause significant, long-lasting damage to organizations, their customers, and their reputation. According to published FBI reports, internal threats that originated inside the enterprise account for 50–80 percent of all security attacks.
Emerging Information Security Threats
The vast majority of information that is stored in digital form contains some confidential data—data that is the real target of a wide variety of security threats. We described some of these threats in previous chapters and the preceding section. In addition, the rapid growth of spyware and various forms of viruses has become one of the major threats to the security of the enterprise information.
Some of the better-known types of spyware include:
• General compromise enablers such as
• Botnet worms that can create a network of infected computers that can work in concert to perform any malicious activity, including but not limited to running Distributed Denial-of-Service (DDoS) attacks
• Downloaders that are designed to install potentially malicious programs on computers without the user’s knowledge or consent
• Identity grabbers that “complement” phishing and pharming activities by performing such actions as
• Theft of user identification, passwords, and other sensitive or confidential personal information
• Monitoring and capturing keystrokes that can enable a thief to steal user information such as passwords (this type of spyware is known as a “keylogger”)
• Hijacking a web browser in order to modify browser settings so that it can redirect the user to a pharming location or another bogus site
• Data theft enablers include:
• Banking Trojans Specialized software agents that monitor information entered into banking applications
• Backdoor Trojans A type of spyware that may allow hackers unrestricted remote access to a computer system when it is online
These and other types of spyware represent a real threat to enterprises and individual users alike. However, those spyware programs that are focused specifically on data compromise represent a serious challenge to the enterprise’s ability to comply with data protection regulations (many of these regulations are mentioned in Chapter 8 and also listed in the next section). These regulations are designed to protect sensitive and confidential customer and business financial data, including the following data categories:
• Customer and patient data
• Financial transactions
• Finance and accounting data
• Human resource data
• Confidential company performance and planning data
• Military data
• Legal data
• Intellectual property including design and research data
Interestingly, these data categories represent primary areas of the activities surrounding Master Data Management initiatives. As we discussed in Part II of the book, MDM solutions are information integration platforms that create and manage authoritative, accurate, timely, and secure systems of record for their respective areas of focus (customer, product, and so on). The goal of these MDM Data Hub solutions is to collect, integrate, and manage confidential data from a wide variety of sources in order to create a new system of record for the enterprise. Obviously, enterprises implementing these MDM solutions need to protect information stored in Data Hub systems from the compromise of unauthorized access and use.
Moreover, this information may represent highly confidential intellectual property that requires additional considerations for protecting the use of the information content even after the data is legitimately delivered to an authorized user. The latter information protection concern is the province of a special category of information asset protection technology known as Digital Rights Management (DRM) or Enterprise Rights Management (ERM). We briefly discuss ERM later in this chapter. In general, however, the need to protect information assets is driven by a number of factors, including customer expectations, business demands, competitive pressures, industry regulations, business policies, and so on. Recent adoption of regulatory compliance requirements—some of which are general, while others are specific to a particular domain such as public sector, life sciences, and financial services—has further emphasized this need for data protection.
Regulatory Drivers for Data Protection
Concerns over confidential data in general and customer data privacy and data security in particular have resulted in a broad range of legislative and regulatory requirements for data security. Failure to comply with these rules can result in civil and criminal liability. We have discussed some of these regulations in previous chapters of this book, and they are listed here for ease of reference. Examples of regulatory requirements that directly or indirectly focus on information security include:
• The Sarbanes-Oxley Act requires that executives know who has access to what information, and that proper security controls are in place to ensure data confidentiality and integrity.
• The Gramm-Leach-Bliley Act (GLBA) dictates that organizations must preserve the security and confidentiality of nonpublic personal information including personal financial data.
• The Health Information Portability and Accountability Act (HIPAA) directs health care providers to preserve the confidentiality of individual medical records. To the extent that some of this data becomes visible to the benefits departments of any organization (for example, the Human Resources and Payroll departments), HIPAA may have broader applicability than just health care providers.
• 21 Code of Federal Regulations (CFR) Part 11 In the pharmaceutical industry, the Federal Drug Administration (FDA) has established guidelines for any individual or organization governed by the FDA that uses electronic recordkeeping and electronic signatures, including requirements for auditable procedures to ensure the integrity of that data.
• The Children’s On-Line Privacy Protection Act (COPPA) establishes privacy protection guidelines for any organization holding information about children.
• California Senate Bill 1386 requires that any organization that loses a California citizen’s personal data must alert its California customers via “notification to major statewide media.”
• Nevada Law NRS 597.970 took effect October 1, 2008. It explicitly states that any business in the State of Nevada cannot transfer any personal information of a customer through an electronic transmission other than a facsimile to a person outside of the secure system of the business, unless the business uses encryption to ensure the security of electronic transmission.
• Massachusetts Law 201 CMR 17.00, scheduled to take effect in the first quarter of 2010, requires that any person or business dealing with the creation, access, delivery, and use of personal information about state residents has to implement a number of security protection measures, including user authentication protocols, secure access control measures, encryption on all wireless networks linked to personal information repositories, monitoring and encryption for all portable devices with personal information, and firewall protection for any database containing PII. The law further dictates that all system security software must be installed on all devices dealing with PII and be kept current; moreover, this law includes the requirement to implement and provide timely education and training of all persons affected by this law.
• The European Data Protection Directive establishes a set of rules that address the handling of all types of personal data. This directive requires organizations to ensure that
• Personal data must be kept confidential.
• Individuals should know in advance what information is collected about them, how it will be used and by whom, who has access/permissions to change that data, and how it will be stored.
Risks of Data Compromise
To summarize the concerns discussed in the preceding section, data security, privacy, integrity, and confidentiality are no longer optional requirements, and data compromises that violate these requirements can put an organization at significant risk. Some risk types associated with data security compromises include:
• Reputation risk Risk to earnings or revenue arising from negative public opinion.
• Compliance risk Companies are now subject to numerous federal regulations such as the Sarbanes-Oxley Act, the Basel II Accord, the USA Patriot Act, the GrammLeach-Bliley Act, as well as state and local regulations such as California’s SB 1386, Nevada Law NRS 597.970, and Massachusetts Law 201 CMR 17.00, to name just a few.
• Operational/transactional risk Risk of direct or indirect loss from inadequate or failed internal processes, people, and systems, or from external events, including fraud. Data compromised at the enterprise level can increase operational risk by potentially impacting the stability and availability of the key enterprise systems.
• Third-party information sharing risk According to the letter and spirit of GLBA and the Office of the Comptroller of Currency (OCC) regulations such as OCC 2001-47, an organization is responsible for data privacy and confidentiality breaches even if these events happened at or were caused by an unaffiliated third-party data or service provider. This risk is particularly relevant as organizations move toward outsourcing and offshore implementation of many customer service and support tasks.
Managing these risks is a focus of data security and identity and access management or IAM (we introduced the concepts of IAM in Chapter 9). IAM and data security are complementary technology disciplines that offer a number of significant business benefits including organizational ability to
• Minimize fraud
• Meet compliance requirements of existing and emerging legislation
• Minimize legal exposure
• Improve competitive advantage
• Increase brand equity
• Enhance customer retention/loyalty
Technical Implications of Data Security Regulations
Although many of the data protection regulations do not cover all information, and rather concentrate only on business-confidential or personal information that could be used for identity theft or financial crime, the technical implications of these regulations are quite broad and impact many systems, applications, and data stores in a profound way. Obviously, MDM Data Hubs, as systems of authoritative information about various data domains, are at the center of these data protection concerns. Let’s consider what processes and technical capabilities have to be put in place in order to comply with the data protection requirements:
• Implement a data inventory and classification program and store the information about data location and usage in a securely controlled data inventory system (this could be implemented and managed as a component of the MDM Data Hub).
• Review/audit, document, and create a secure repository of records related to third-party providers to make sure they are aware of the data protection regulations and are ready to comply with them, including support for data encryption and policy-driven auditable access controls.
• Install and configure a strong perimeter defense solution, including a firewall and intrusion protection or (better yet) intrusion detection system.
• Configure the use of encryption on all wireless networks, preferably implementing WPA2 or stronger protocols.
• Use SSL/TLS to encrypt all network traffic, especially when your network is connected to the external Internet.
• Encrypt any data-at-rest, including both internal storage systems and data that is stored on remote sites, especially sites managed by third-party providers. This includes both traditional remote storage facilities and the infrastructure-as-a-service (IaaS) facilities, such as cloud storage solutions.
• Encrypt all backup offline media, such as tapes.
• Install security software that would encrypt all laptop computers and mobile devices such as BlackBerry PDAs, because these devices often carry personal or confidential data and are subject to loss and theft.
• Implement data obfuscation/data masking procedures that would render confidential data useless when the data files are used for offsite or offshore development and testing.
Even a cursory review of these actions shows that implementing an authoritative system of record, such as the MDM Data Hub, that is designed from the ground up as a data protection compliant system is not a small undertaking. We discuss various aspects of data security in the remainder of this chapter and in Chapter 11.
Data Security Overview
The foregoing discussion shows that data protection is a key business requirement of any organization. However, solving the data protection problem is a massive and very complex undertaking that requires a holistic view of information security and, in particular, knowledge of identities that can either cause harm or become victims of these new types of crime. As stated earlier, the set of technologies and processes dealing with issues related to digital identities is known as identity and access management. Information security is an overarching concept that, in addition to identity and access management, includes multilayered defense-in-depth approaches of defending a system against any particular attack using several different but complementary methods, including authentication, authorization and access control, entitlements and provisioning, enterprise rights management, and various data encryption solutions. The defense-in-depth strategy was developed by the National Security Agency (NSA)3 as a comprehensive approach to security using a variety of protection mechanisms, methods, and countermeasures.
This chapter deals with one particular aspect of identity management and information security—data security and protection.
The practice of safeguarding data is at the core of the Information Security discipline and is primarily concerned with the following factors (please see Chapter 9 for additional details on these factors):
• Data privacy and confidentiality Information should be available only to those who rightfully have access to it.
• Data integrity Information should be modified only by those who are authorized to do so via authorized actions.
• Data availability Information should be accessible to those who need it, when they need it.
In the context of data security, the term “data” includes, but is not limited to, data in databases or files, transactional data, operational policies and procedures, system design, organization policies and procedures, system status, and personnel schedules.
Layered Security Framework
The protection of data can only be effective if considered as part of a comprehensive security strategy and end-to-end security framework. We started a general discussion of the layered security framework in Chapter 8. This chapter will take a closer look at this framework from the perspective of data protection. In the context of data protection, a layered security framework considers information as the core that needs to be protected from outside attackers and internal compromises caused by incompetence, lack of appropriate due diligence, or malicious intent.
The comprehensive end-to-end security framework defined in Chapter 8 offers a multilayered “defense-in-depth” approach that surrounds data and its users in several layers of security controls. This layered security framework consists of the following layers:
1. Perimeter
2. Network
3. Platform (host)
4. Application
5. Data
6. User
The diagram shown in Figure 10-1 depicts the security layers as well as the core security services for each layer.
We discussed specific security concerns for each layer of the framework in Chapters 8 and 9 of this book, and summarize these concerns in the following list for ease of reference:
• Perimeter security deals with security threats that arrive at the enterprise boundary via a network. Perimeter security has to support user authentication, authorization, and access control to the resources that reside inside the perimeter. The perimeter may consist of one or more firewalls protecting a network perimeter demilitarized zone (DMZ). The DMZ may contain web servers, e-mail gateways, network antivirus software, and Domain Name Servers (DNS) exposed to the Internet. It may also implement intrusion detection and intrusion prevention systems.
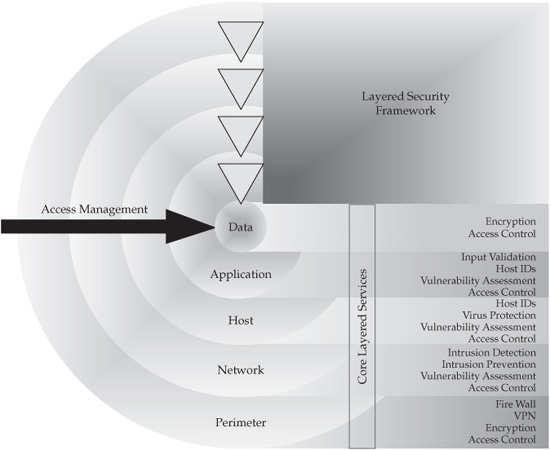
FIGURE 10-1 Layered security framework
• Network security deals with the authentication of the network user, authorizing access to the network resources, and protecting the information that flows over the network. Network security often uses technologies like transport layer security (SSL/TLS or IPSec), Public Key Infrastructure (PKI), and Virtual Private Network (VPN). It may also implement intrusion detection and intrusion prevention systems.
• Platform/host security deals with the security threats that affect the actual device and make it vulnerable to external or internal attacks. Platform security issues include authentication, authorization, and access control disciplines, and the security of the operating system, file system, application server, and other computing platform resources that can be broken into or taken over by a hostile agent.
• Application security deals with the need to protect not just access to the application execution environment but also access to the application code itself. Poorly protected applications can provide easy access to confidential data. Unprotected application code can be stolen or modified to create “back doors,” to insert spyware, worms, and Trojans. Therefore, it is very important to define and enforce a comprehensive set of application security standards and controls.
• Data security addresses the means and methods to protect the content of transactional, historical, dynamic, and static data that organizations acquire, create, store, and manipulate in order to conduct business operations. This includes not only traditional data files and databases but also the software that may represent significant information assets. Generally speaking, content security for all data under management falls into two categories: data-in-transit and data-at-rest.
• Data-in-transit is defined as any data moving between systems over network connections as well as data transferred between applications using file transfer mechanisms, messaging and queuing mechanisms, and/or ETL tools.
• Data-at-rest is defined as data residing in locally attached or networked data stores as well as data in archives (for example, tape backup).
Data security concerns for each of these two major categories are described in more detail in the following section.
Data-in-Transit Security Considerations
The techniques and technologies of data-in-transit protection represent a mature area of data protection and are reasonably well understood. These technologies include transport layer security (SSL/TLS or IPSec) as well as secure tunneling using Virtual Private Networks (VPNs). In the case of proprietary network protocols (for example, IBM Systems Network Architecture APPC/LU6.2), encryption options are available in some implementations, and typically these protocols are implemented over nonpublic wide-area networks that offer a certain degree of security by design.
The main principles behind the techniques used for data-in-transit protection include:
• Authentication between the sender and the receiver
• Encryption of the message payload while it traverses the network fabric
The advantages of using these data-in-transit techniques include:
• Maturity of the technology solutions.
• Protection of data content while in transit.
• Predictable performance impact.
• Application transparency: As a rule, networked applications don’t have to be changed
One consideration concerning data-in-transit solutions includes the need for client-resident components. For example, in a web-based environment, SSL/TLS solutions rely on the Web browser’s security features and usually do not require additional client-side software.
IPSec, on the other hand, requires client-side software installation. Since a typical legacy environment is not Web-based, IPSec may be the right choice for data-in-transit protection for legacy applications.
Another interesting approach to protecting data-in-transit deals with the message-level security that can be implemented on top of the transport layer protection. The message payload itself can be protected using a variety of techniques, for example, by using encryption for messages that are moving into and from message queuing systems. One approach to secure e-mail messaging is to use S/MIME (this feature is available in popular e-mail clients such as Microsoft Outlook and Outlook Express, and does not require additional software distribution).
A key consideration for data protection relates to the scope of protection. For example, some data-in-transit techniques protect data only between the client and the server (for example, between a Web browser and a Web server), thus leaving data in the open on the sending and receiving systems. An attacker can exploit these exposure points with relative ease. Therefore, security architects need to consider additional security measures that can complement “out-of-the-box” transport-level security to ensure a reasonable degree of data protection.
Security architects and system designers have to consider the following key requirements and considerations for data-in-transit protection:
• Minimize the number of encryption/decryption points to ensure a reasonable level of performance, throughput, and latency.
• Develop an integrated key management strategy across different network segments, especially if they use different encryption algorithms (for example, TLS and IPSec between Web-based networks and legacy systems).
To sum up, data-in-transit protection addresses some of the security concerns about data that is moving over networks. However, by itself, this protection is limited and does not address a number of the security concerns discussed earlier. For example, a network can be compromised, data payload can be intercepted (hijacked), data can be replayed or redirected to unintended destinations, and the network can become unavailable or can be used for denial-of-service or other types of attacks.
Therefore, relying on just data-in-transit protection is a necessary but not a sufficient approach to protecting data privacy, confidentiality, integrity, and availability.
Data-at-Rest Protection
Even if the network is secure, and appropriate access controls are in place, the sophistication of the attackers continues to outpace the defenders’ ability to detect and prevent new types of attacks in a timely manner, which can put the entire enterprise at risk.
Therefore, the scope of data security includes an approach that aims to protect data if/when all other security controls failed and the attacker got hold of data that is stored on a storage device. The goal of data-at-rest protection is to address this risk by making data unusable to unauthorized users even if such a user has managed to obtain proper network access credentials. Data-at-rest protection provides complementary protection capability that works equally well for defending the enterprise from both external and internal compromises. The latter point is very important since a significant number of all security breaches occur because of inappropriate, erroneous, or malicious actions on the parts of the employees.
In general, the technologies of data-at-rest security rely on authentication, access authorization and control, and payload encryption techniques. This section looks closely at the data-at-rest techniques that make the data unusable when the access controls and perimeter defenses are compromised. These techniques include:
• Data masking or data obfuscation As mentioned in the previous section, data masking procedures transform some or all data attributes in a source file or a database into a form that would change confidential data content or render confidential data useless. Data masking is often used as a preferred method of delivering data to an off-site facility for application and system testing. Depending on the technique used for data masking, data masking operation can be irreversible and the masked data becomes unusable by the business applications, which limits data masking applicability as a data protection technique. Therefore, we focus on the two other data-at-rest protection techniques – compression and encryption.
• Compression Data-loss-less protection schemes are often used to provide certain levels of protection while improving the operational throughput of data due to the reduced record/message length.
• Encryption Data encryption schemes are commonly implemented at the data, application, and operating-system levels. Almost all schemes involve encryption/decryption keys that must be available to all parties accessing the data. When the data is at-rest on a storage device, we can apply these general techniques at the following levels of granularity:
• Field-level protection In this case, the protection mechanism would encrypt or scramble the data in place, thus protecting each sensitive field individually. The data type and the field length would not change. This technique would not require any addition of new fields to any files.
• File or database protection In this case, the protection mechanism would encrypt the entire file or database, without separating sensitive data from the total data content.
• Block-level protection encrypts the entire device block.
In addition, as a general principle we should also consider physical security as an accepted means of protecting any facilities including data centers and data storage facilities (security gates, hard-to-compromise identification badges, background checks, security guards, and so on).
We need to consider these levels of data-at-rest protections in the context of the business and technical requirements that help determine technical and economical viability. The key requirements for software- and hardware-based data-at-rest security approaches include:
• Data type support Support for any form of data-at-rest, including files, databases, messages, and so on.
• Total application transparency If data is encrypted on a storage device, it has to be decrypted for every access to preserve and sustain application functionality; applications that use the protected data should not be aware of the cryptographic operations.
• Preserved database functionality If attributes used for database access are encrypted (for example, primary and foreign keys, indexes, and search arguments), then the database may become unusable.
• Encryption Use of strong encryption that is based on industry standards and proven encryption algorithms.
• Key management This is a key requirement for any data-at-rest encryption to be viable; for example, key management needs to address the following:
• Encryption/decryption keys have to be available to all applications producing and consuming protected data; this requirement presents a key distribution challenge.
• Keys have to change regularly so that the data protection scheme does not become stale and thus become vulnerable to being broken by a brute force attack.
• Keys have to be available for a long period of time so that the data can be recovered and used long after it was first encrypted (for example, recovery from archive storage).
• Performance The encryption/decryption operations are very computing-cycles-intensive and can drastically impact the performance of the entire environment.
• Manageability Support for operations and system/network management.
• Scalability Data-at-rest security solutions should scale up functionally and technically to cover the current and future data landscapes.
Data-at-Rest Solution Selection Considerations
When choosing a data-at-rest solution, we have to map the requirements listed in the preceding section and the business needs of the organization to the solution’s capabilities.
We should consider and assess these capabilities in line with the organization’s risk management strategy. For example, we can start by analyzing whether the solution is configurable and customizable in order to protect the highest risk areas first. Once the most vulnerable areas are covered, we have to assess the scalability and flexibility of the solution to easily and quickly cover other areas of data protection concerns. Some of the considerations for choosing a solution may be as follows:
• In general, field-level encryption has the largest negative impact on performance and may affect application transparency.
• Newer operating systems offer file-level encryption (for example, Microsoft’s Encrypted File System [EFS]).
• Some database management systems have built-in encryption capabilities.
• Some storage vendors offer proprietary encryption engines that operate on the storage device to perform encrypt/decrypt operations.
• Some specialized data-at-rest security vendors offer dedicated software and hardware appliances that operate on the entire storage subsystem.
While the last three options offer application transparency and deliver better performance than a field-level encryption, they are specific to the data formats and platforms supported. For example, database encryption will not support protection of non-database file structures. Similarly, EFS is not supported outside Microsoft operating environments. And built-in crypto-engines only work with the storage devices they are built for.
Specialized vendors of data-at-rest solutions differ in the choices of technologies, approaches, capabilities, performance, and supported platforms. Many support block-level encryption on the device. A large number of vendors offer hardware-based appliances that are installed on the I/O channel between the computer and the storage subsystem. These appliances deliver the best performance and the least performance penalty (some solutions claim to have under 1 percent performance penalty), total application transparency, manageability of the devices, scalability for the size of the protected data, and the number of consuming applications. Most of the current limitations of the appliance-based solutions revolve around the types of storage subsystems and the channel protocols used to exchange data between the CPU and the storage. For instance, almost all vendor solutions support Storage Area Network (SAN) and Network Attached Storage (NAS) architectures over Fibre Channel. Examples of the hardware-based data-at-rest security appliances include solutions from NetApp, SafeNet, and others.
Enterprise Rights Management
The collaborative nature of work in today’s global enterprise results in the need for individual workers and organizations to engage in frequent interactions with their colleagues, partners, suppliers, government agencies, and other parties. These interactions often include the need to exchange information over the network in order to achieve common business goals.
The information exchanged between collaborating parties is often of a very sensitive nature, and enterprises have to protect it to satisfy regulatory requirements and the company’s fiduciary obligations to its customers and other owners of this information.
In addition to the collaboration scenario, an organization that needs to distribute highly confidential data to its authorized customers has to be concerned about protecting this information is such a way that the information’s access and use are aligned with the organization’s business goals, customer legal rights, and service agreements (for example, a financial services company can distribute sensitive equity research reports to its top tier customers via a public network).
Three main concerns related to protecting data in the collaborative and information distribution environments have become painfully obvious. We already discussed two key concerns in this and the previous chapters:
• Access to any data that requires protection needs to be controlled, enforced, and audited based on the appropriate policies, user entitlements, and regulations.
• The information content needs to be protected from unauthorized use both while it traverses communication networks and while it “rests” on storage devices.
The third concern is a direct consequence of the proliferation of the digital content, a collaborative nature of the work, a sensitive content distribution business model, and the recognition of the intrinsic information value of data regardless of whether it is in the “original” form or in copies. To put it slightly differently, any copy of the data is as valuable as the “original” data itself.
Indeed, according to numerous studies, over 90 percent of all information created by corporations now exists in electronic form. Moreover, a significant portion of this information contains intellectual property that represents key market value for many business and individual content creators (such as authors, artist, researchers and analysts) alike. According to studies by companies such as PricewaterhouseCoopers, a significant component of the market value of a typical U.S. company resides in its intellectual property assets.
Thus, the third concern deals with the need to understand and protect the rights of access to and use of data content and to prevent potential IP leakage. Such concern becomes a reality when, for example, the data is initially acquired by an authorized user and then shared with a person who has no authority to use all or some of this data.
This concern often comes to light when a business defines a collaborative process that creates or uses protected intellectual property information. Such information may include research, discovery, or patent description; legal documents requiring protection; business transactions or business plans related to a proposed merger or acquisition; medical diagnosis and medical history of a patient being referred to another physician or a hospital; and many similar cases. In a collaborative situation, an authorized user can legitimately create and access this information, and then share it with a recipient outside the protected enterprise in order to perform a particular business task (for example, an external reviewer of the patent application). Clearly, sharing the protected information in this case creates opportunities for data leakage, misuse, and outright theft.
Likewise, a customer of a financial services organization may purchase a highly sensitive research report about a particular market situation; the customer may decide to make a copy of the report and to share it with some of the coworkers or friends, who in turn can share their copies with others. As a result, the information becomes widely distributed without proper controls, and the financial services company will be at risk of not being able to collect the revenue associated with the distribution of this report as well as the risk of uncontrolled distribution of sensitive information that can contain material non-public information.
For example, imagine that confidential information regarding a merger between two companies has been organized and stored as an Excel spreadsheet document. This document can be stored in a highly secured enterprise server that is protected by robust policy-based authentication and access control mechanisms. However, if this highly confidential document is accessed legitimately by a member of the M&A team and then given to an unauthorized third party either via e-mail, as a printed document, or as a copy on a removable storage device, the document no longer enjoys the protection it requires.
In other words, while secure data access can prevent unauthorized users from accessing confidential information, this may not stop the authorized user from copying the information and sharing it with others. And once that information moves outside the protection of the secured enterprise network, anyone can do with it what they will, and the owner’s ability to control that information is lost. This last point has become a business driver for the intellectual property protection of digital content in the retail marketplace. A well-known example of the need for IP and copyright protection includes electronic distribution and sharing of music and/or books over the Internet.
The area of concern we’ve just described is the focus of technologies collectively known as Digital Rights Management (DRM). And as the interconnected and collaborative nature of today’s networked business continues to embed itself tighter and tighter into the daily enterprise activities, DRM has often been referred to using a broader term, Enterprise Rights Management (ERM). Since the focus of this book is on enterprise solutions for Master Data Management, we will use the term ERM when discussing issues related to the protection of the digital content. To be specific, let’s define ERM.
In order to show specific functional components of ERM, we can restate the ERM definition as follows:
Enterprise Rights Management (ERM) is a set of technologies designed to
• Secure content using strong encryption.
• Enable protection persistence that prevents users and administrators from disabling the protection mechanisms.
• Provide security controls that automatically and assuredly monitor and audit all data access operations and events, including traditional Create, Read, Update, Delete (CRUD) operations as well as print, e-mail, copy/paste, file transfer, and screen capture.
• Minimize the impact of content protection on users and applications from both usability and performance points of view.
• Leverage existing enterprise authentication and authorization methods, including enterprise directory and provisioning systems to manage and control authorized users.
Master Data Management environments by their very nature require that the authoritative master data created and managed by MDM systems should be protected in a comprehensive and holistic way. This includes user authentication, authorization and access controls, data-intransit and data-at-rest protections, and the post-retrieval protection of the secured content based on the concepts of ERM. To put it another way, secure Master Data Management should integrate several information security disciplines and technologies, including ERM.
It’s important to note that similar to the requirements of data protection for data in-transit and at-rest (see previous sections), one of the key requirements in developing an ERM-capable MDM system system is the potential impact of ERM technologies and processes on user experience. Any system that creates drastically different or difficult-to-use methods to gain access to the content will make ERM adoption at best long and at worst impractical.
Combining these factors with the high visibility and strategic positioning of any Master Data Management initiative makes the transparency and the ease of use of the ERM solution some of the key success factors not only for selecting and deploying an ERM solution but for the entire MDM initiative.
ERM Processes and MDM Technical Requirements
Since an MDM solution may contain confidential or sensitive information assets, an MDM data integration platform such as a Data Hub for customer or product information would have to enable or implement some key ERM/DRM capabilities, including data model extensions, processes, and technologies.
Contemporary ERM systems can leverage basic ideas of symmetric and asymmetric encryption algorithms of the Public Key Infrastructure (PKI) technology and the rights management policy and the XML licensing standard known as XrML.
An ERM-enabled MDM system that uses XrML-expressed policies and rules should support at least two key processes: authoring and viewing.
An example of the authoring process that uses both symmetric and asymmetric key encryption would include the following steps:
• Create a publishing license that uses the XrML standard to define content entities and their rights.
• Encrypt the content, usually with a symmetric content key.
• Protect the content key by encrypting it with the public key of the ERM server.
• Digitally sign the publishing license and the encrypted content key.
• Attach the package that contains the signed publishing license to the content.
A corresponding viewing process will act in reverse and should include the following steps:
• Authenticate the user.
• Extract the content key and decrypt it using the user’s private key.
• Create a use license specifying the rights outlined in the publishing license.
• Decrypt the content and apply the use license to it to comply with the publishing license restrictions.
These processes may appear complex. However, there are a number of ERM products on the market today that implement these types of processes and transparently enforce ERM rules. Examples of these DRM products include Microsoft’s Rights Management System (RMS), Adobe Lifecycle Rights Management, IBM’s Content Manager, and many others.
ERM Use Case Examples
Let’s illustrate the way an ERM/DRM solution could be deployed in a Master Data Management Data Hub environment that is designed to store and manage confidential and sensitive data.
Ensuring Regulatory Compliance of Customer Information
Master Data Management solutions that collect and aggregate customer information in the data integration systems are known as MDM systems for Customer domain or Customer Data Integration (CDI) Data Hubs. As we stated in the previous chapters of this book, an MDM Data Hub for Customer domain is the integration point of all information about the customer. As such, the MDM Data Hub must enable the following functions:
• Protect customer information in the Data Hub from inappropriate or unauthorized access by internal and external users.
• In financial services in particular, a Data Hub must enforce strict visibility rules where a broker or an account manager must be able to access the information associated only with their customer and accounts, and prevent users from accessing information about other customers (we discuss visibility concerns and architecture approaches in greater detail in Chapter 11).
• Protect customer information from unintended use by those who have been authorized to access the information.
HIPAA Compliance and Protection of Personal Health Information
At a high level, the Health Insurance Portability and Accountability Act (HIPAA)’s Security and Privacy Rules define similar concerns. According to HIPAA regulations, health care organizations must, among other controls, implement the following:
• Establish policies, procedures, and technical measures that protect networks, computers, and other electronic devices.
• Protect the privacy of all individually identifiable health information that is stored for healthcare treatment and business operations.
• Restrict disclosures of protected health information (PHI) to the minimum needed for healthcare treatment and business operations.
• Establish new business agreements with business partners that would safeguard their use and disclosure of PHI.
• Assess and modify systems to ensure they provide adequate protection of patient data.
End users, healthcare providers, and organizations can easily violate these requirements if the appropriate controls are not put in place. Indeed, consider the following: A hospital’s office manager may have a perfectly legitimate reason to access patient health, insurance, and financial information. A common business practice may be to capture the patient’s profile, account, medical diagnosis, and treatment information into specially designed Microsoft Office documents or forms for planning, referral, or contact management purposes. However, since these documents can be printed or e-mailed, the very fact of their existence creates a new risk of exposure that can put the hospital at risk of noncompliance and privacy preference violations. These risks could easily translate into significant reputational damage to the hospital and potentially to the parent company managing a network of healthcare providers.
Other ERM Examples
Other examples of situations where ERM/DRM can play a significant role include Master Data Management implementations that support highly confidential information about impending mergers and acquisitions, equities research, scientific research, and patent processing and filing. In the government sector, ERM/DRM may protect information assets of military, law enforcement, and national security agencies as well as other government organizations. As you can see, the area of ERM applicability is very large, and as MDM solutions began to proliferate across various industries and areas of business focus, their respective implementations have to enable the protection of the information assets that these solutions are designed to aggregate and integrate.
To sum up, sophisticated information security and visibility architecture is a key component of any MDM implementation, especially those Data Hub systems that deal with personally identifiable or business-confidential information. Therefore, in addition to authentication, authorization, access control, and content protection, the security architecture for an MDM solution should consider and include an implementation of the ERM/DRM processes and technology as a part of the overall information security design.
Sound information-protection architecture should enforce policy-based and roles-based security to protect access to information from unauthorized users. Such architecture should enable an audit of data access actions and archiving of information for a legally required or enterprise-defined duration based on industry and government regulations. In addition, such comprehensive security architecture should employ an ERM/DRM solution to identify information objects such as documents and e-mail messages that contain regulated content (such as account numbers and social security numbers), apply appropriate protection techniques, and ensure that authorized users use confidential protected information in approved ways.
Let us conclude this discussion with the following observations:
• The need for information protection has become one of the key priorities of government agencies and commercial organizations—a priority that is driven and reinforced by regulatory and compliance pressures. However, while enforcing information protection is no longer an option for any commercial or government organization, there is no single “silver bullet” to accomplish this goal. Therefore, we strongly recommend using a layered “defense-in-depth” approach to protecting information assets.
• In the area of information protection, data-at-rest protection and ERM have emerged as hotly competitive areas of information security, areas that could easily become a competitive differentiator in situations when customers and organizations are looking for assurances that even if a security breach has occurred, the data acquired by such an action continues to be secure. This confidence in information security, confidentiality, and integrity reinforces the notion of trusted relationships between organizations and their customers.
References
1. http://voices.washingtonpost.com/securityfix/2009/01/payment_processor_ breach_may_b.html.
2. http://www.pgp.com/insight/newsroom/press_releases/2008_annual_study_ cost_of_data_breach.
3. http://www.nsa.gov/ia/_files/support/defenseindepth.pdf.