
CHAPTER 17
Master Data Governance
In the previous chapters of Part IV, we concentrated on various implementation aspects of MDM. We have noted a few times throughout the book that Data Governance is a critical area that must be addressed to ensure a successful MDM implementation. Practically every description, reference, and discussion document published about MDM emphasizes the criticality of Data Governance for MDM. Without Data Governance it is impossible to successfully implement and operate an MDM program or solution.
In this chapter we will do a “deep dive” into Data Governance. We will seek to understand Data Governance challenges in more detail, especially as they relate to an implementation of complex MDM programs, and will recommend some solutions to the key Master Data Governance problems.
This chapter is organized into two major sections. The first section concentrates on the basics of MDM Data Governance definitions and frameworks. The second section concentrates on Data Governance as it relates to MDM and proposes some new advanced approaches to the Master Data Governance focus area. We conclude the chapter with a summary of recommendations on how to organize an MDM Data Governance program for effective adoption in a way that helps avoid common mistakes that may adversely impact a Data Governance program. Because of the importance and criticality of Data Governance we capitalize the spelling of this term throughout the book.
Basics of Data Governance
Let’s start this discussion with an overview of the history behind Data Governance.
Introduction to and History of Data Governance
Industry experts, practitioners, and analysts are all in agreement on the importance of Data Governance. Unfortunately, despite such a universal support for Data Governance, not many organizations have reached a Data Governance maturity or are on a fast track to it. At the same time, we often see that information governance is discussed ever more frequently by enterprise executive committees and boards of directors.
Data Governance initiatives cross functional, organizational, and system boundaries and are enormously challenging in creating and aligning an effective and efficient program within the current organizational culture, programs, and maturity level. Despite its challenges, Data Governance is increasingly viewed as an authoritative strategic initiative, mobilizing organizational resources to leverage data as an enterprise asset.
In contrast to this growing interest in Data Governance at the leadership level, many field data professionals, operations managers, and business managers often express some level of frustration in private discussions that the term “Data Governance” and the appreciation of the Data Governance as a discipline remain elusive. There are a number of reasons for this attitude toward Data Governance. To start with, Data Governance is perceived by many as a new umbrella buzzword for well-known terms from the past, such as business analysis, business process improvement, data quality improvement, program management, and so on. Moreover, many Data Governance programs are often too large, inefficient, and bureaucratic, even though they started as focused activities that were organized according to the recommendations of Data Governance thought leaders. But this perception of Data Governance as too abstract and bureaucratic can and does get addressed by following proven best practices and approaches to Data Governance. Examples of effective approaches to Data Governance programs include establishment of Data Governance boards or councils that have been holding regular (typically monthly) Data Governance meetings. Another effective approach is based on establishing communities of practices in data quality, data protection, data modeling, metadata, and other areas under the umbrella of Data Governance. For example, developing risk-based milestones for any Data Governance initiative will foster the early detection and mitigation of issues that would be costly in terms of opportunities and threats had they materialized later. These approaches often result in some degree of success in setting up Data Governance programs; however, most stakeholders are not satisfied with where they presently are in the area of Data Governance.
As per research work by David Waddington,1 only 8 percent of enterprises estimate their Data Governance as comprehensive. For the most part, companies report that their Data Governance exists in some specific areas—for example, data security, data protection, support for Basel II, and so on. Most enterprises do not see a way or don’t feel they have a need to reach higher levels of Data Governance maturity. These research results are consistent with what we see in the field.
It is difficult to pin down a specific point in time when the terms “Data Governance” and “Information Governance” were first introduced. As per Gwen Thomas, the founder of the Data Governance Institute (DGI),2 in 2003 an Internet search on “Data Governance” returned only 67 references. Since 2003, Data Governance is on an increasingly fast track to be adopted as a discipline. According to the InformationWeek, IBM will offer Data Governance consulting.3 IBM Corporation formed the IBM Data Governance Council4 in 2004. Interestingly enough, the MDM-CDI Institute was founded by Aaron Zornes, also in 2004. Whether it was a coincidence or not, some analysts call Data Governance and MDM “siblings” not just because of the timing but mostly due to considerable synergies between MDM and Data Governance. We believe that these synergies are not accidental. Both disciplines seek to bring better control over data management through an establishment of enterprise-wide authoritative sources, controls, good policies, sound practices, and ultimately establish methods of transition to information development–enabled enterprise.
Definitions of Data Governance
There exist numerous definitions of Data Governance. These definitions represent various views and program focus areas, which in turn yield multiple perspectives of what Data Governance is. Here are a few examples:
• In the first edition of our book,5 Data Governance is defined as “a process focused on managing data quality, consistency, usability, security, and availability of information.”
• The MDM Institute6 defines Data Governance as “the formal orchestration of people, processes, and technology to enable an organization to leverage data as an enterprise asset.”
• Jill Dyche and Evan Levy7 define Data Governance through the goal “to establish and maintain a corporate-wide agenda for data, one of joint decision-making and collaboration for the good of the corporation rather than individuals or departments, and one of balancing business innovation and flexibility with IT standards and efficiencies.”
• As per the IBM Data Governance Council,8 “Data Governance is a quality control discipline for accessing, managing, monitoring, maintaining, and protecting organizational information.”
• As per the Data Governance Institute,9 “Data Governance is the exercise of decision-making and authority for data-related matters.” A slightly longer definition from the same source reads as follows: “Data Governance is a system of decision rights and accountabilities for information-related processes, executed according to agreed-upon models which describe who can take what actions with what information, and when, under what circumstances, using what methods.”
The list of definitions for Data Governance can be easily expanded. There exist a number of great books on Data Governance and/or MDM10,11 and each of these books provides a somewhat different definition of Data Governance, which indicates that each of the definitions focuses on a different aspect of Data Governance. Most definitions concentrate on the cross-functional role of Data Governance. This is important because the cross-functional aspects of Data Governance are the primary differentiators between Data Governance and departmental business-driven data analysis and rules.
Data Governance Frameworks, Focus Areas, and Capability Maturity Model
The primary challenge of Data Governance is in that often it is too big to be approached holistically without a focus on a specific program, area, or need. Indeed, Data Governance overlaps with so many functions, processes, and technologies that it makes it practically impossible to embrace its scope holistically. Therefore, there is a pressing demand to break down the Data Governance discipline and program and to present them as a set of more manageable pieces that can be prioritized, aligned with organizational goals and economic impacts, and executed upon and scaled up over time with successful incremental adoption and growing organizational maturity. The key point here is that Data Governance is not optional and must be organized in a measurable, timely, compliant, and repeatable manner to realize true material value of enterprise data assets.
Data Governance frameworks serve this need. They break down Data Governance into more manageable pieces, which allow us to approach Data Governance in a structured, methodological way and improve communication and compliance around complex subjects.
Mike2.0 Framework
The open-source Mike2.0 methodology concentrates on Information Development.12 The methodology breaks down a Data Governance program into the following segments:
• Data Governance Strategy This area concentrates on the mission, charter, and strategic goals of the Data Governance program and aligns the Data Governance program with business and operational imperatives, focus areas, and priorities. These imperatives, focus areas, and priorities can change over time. The Data Governance strategy will evolve with the changes.
• Data Governance Organization The key part of the Data Governance organization is the Data Governance Board. Some organizations use the term “Data Governance Council” or “Data Governance Committee.” This body is responsible for the direction of the Data Governance program and its alignment with business imperatives. The participants of the Data Governance Board can change as Data Governance focus areas and priorities are changing. Some roles and stakeholders should be considered as permanent members of the Data Governance Board—for example, the Chief Data Officer, Data Stewardship Managers, and the Chief Data Architect. Some other roles can vary based on the current focus area of the program; for example, different business stakeholders can be involved in different aspects of Data Governance and be area-specific representatives on the Data Governance Board. As the Data Governance journey evolves, the permanent members of the Board secure the continuity of the Data Governance development while area-specific Board members participate as needed based on the topics on the agenda of a specific Data Governance Board discussion. There are a number of good resources describing the challenges and methodology of building a Data Governance Board; see, for instance, publications by Gwen Thomas13 and Marty Moseley.14
• Data Governance Policies The need for Data Governance policies exists at two levels. At the executive level, Data Governance strategic corporate policies are articulated as principles and high-level imperatives. Some typical examples of principle-level policies are discussed by Malcolm Chisholm.15 A policy that declares that information is a key corporate asset and possibly defines roles accountable for this asset is a good example of a principle-based policy. More specific tactical policies are defined in the form of rules, standards, and high-level metrics. These policies represent “how-to” realizations of the strategic policies. This is more consistent with our tactical use of the term “policy” in Part III, when we discussed data security, visibility, and the privacy aspects of MDM.
• Data Governance Processes This segment of Data Governance defines the processes and procedures established by Data Governance in order to direct and control the proliferation of Data Governance strategies, policies, and directions across the enterprise. The processes can focus on specifics associated with critical entities and data elements. This area establishes accountabilities for Data Governance metrics and data stewardship functions in the context of specific Data Governance processes.
• Data Investigation and Monitoring This area concentrates on specific data issues that cause failure to comply with Data Governance policies and metrics. This area may need to establish more detailed processes and a data stewardship level to monitor, track, and resolve data issues.
• Technology and Architecture In this area, Data Governance stakeholders work closely with IT management and enterprise architects. The Data Governance role is to ensure open and common standards in data management. This is the area where Data Governance functions may overlap with corporate IT. As we will see later, Data Governance as an enterprise function can have its own specific tools and architectural components that enable Data Governance operations.
The Data Governance Institute Framework
The Data Governance Institute’s framework16 recognizes a number of Data Governance focus areas that a typical Data Governance program can align with. The list of typical focus areas includes:
• Policy, Standards, and Strategy with the primary concentration on Enterprise Data Management (EDM) and Business Process Reengineering (BPR)
• Data Quality
• Privacy/Compliance/Security
• Architecture/Integration
• Data Warehousing and Business Intelligence
The Data Governance Institute’s methodology is very thorough and easy to follow. It decomposes the framework into components and provides detailed descriptions to key Data Governance components.
That said, it should be noted that the Data Governance Institute’s framework places MDM under the umbrella of “Architecture/Integration.” As we will see later, MDM offers its own unique Data Governance aspects and characteristics that take Data Governance for MDM far beyond the “Architecture/Integration” focus area.
The IBM Data Governance Council Framework and Maturity Model
The IBM Data Governance Council has developed many sound and very detailed materials on how to componentize Data Governance. The methodology’s framework contains 11 categories that are somewhat similar (no surprise here) to what we have seen previously in the Mike2.0 and the Data Governance Institute frameworks. The categories defined by the IBM Data Governance Council are as follows:
• Organizational Structure and Awareness
• Stewardship
• Policy
• Value Generation
• Data Risk Management and Compliance
• Information Security and Privacy
• Data Architecture
• Data Quality Management
• Classifications and Metadata
• Information Lifecycle Management
• Audit Information, Logging, and Reporting
The IBM Data Governance Council has also developed and introduced a Data Governance maturity model in 2007.17 The model helps organizations understand where they stand in their Data Governance journey and provides a common measure that enables organizations to compare their Data Governance readiness with the readiness in other organizations.
The Data Governance maturity model follows the Capability Maturity Model developed by the Software Engineering Institute (SEI) in 1984. The IBM Data Governance Council’s model measures Data Governance maturity by placing the state of Data Governance of the evaluated organization on one of the following levels:
• Level 1: Initial Ad hoc operations that rely on individuals’ knowledge and decision making.
• Level 2: Managed Projects are managed but lack cross-project and cross-organizational consistency and repeatability.
• Level 3: Defined Consistency in standards across projects and organizational units is achieved.
• Level 4: Quantitatively Managed The organization sets quantitative quality goals leveraging statistical/quantitative techniques.
• Level 5: Optimizing Quantitative process improvement objectives are firmly established and continuously revised to manage process improvement.
As we can see from the definitions of Data Governance maturity for levels 4 and 5, properly defined metrics are absolutely critical if an organization seeks to reach high levels of Data Governance maturity. We will refer to this important point in the next section, when we discuss the need for MDM metrics and how these metrics should be defined from the Information Theory perspective.
Data Governance for Master Data Management
In the previous section of this chapter we discussed some basic, foundational topics of Data Governance. These included definitions of Data Governance, Data Governance frameworks, Data Governance focus areas, and the Capability Maturity Model for Data Governance.
In this section we will concentrate on Data Governance in the context of Master Data Management, which is the primary focus of this book, and will introduce the term “Master Data Governance” (MDG).
We will leverage the basics we discussed in the first section of this chapter and use them as a guide to get deeper into some new advanced areas of MDG.
As we mentioned in the previous sections, Master Data Management and Data Governance as disciplines formed almost at the same time (2003–2004), but in addition to this common timing, both disciplines make the definition of the authoritative sources of data one of the top priorities. This commonality reveals profound synergy between Data Governance and MDM.
Data Governance came into existence in order to address the complexity of enterprise data management. The need for cross-functional, cross-LOB, and cross-divisional standards and consistency in data management resulted in growing demand for Data Governance. Similarly, MDM reconciles data inconsistencies accumulated over the years in application silos by focusing on master data such as customer, product, location, and so on. As we learned from Part I of this book, master data is highly distributed across the enterprise, which is one of the key challenges that MDM resolves.
The synergies and similarities between strategic Data Governance goals and MDM objectives make MDG a great point of entry to start a comprehensive Data Governance program. Once MDG problems are addressed, it is much easier to resolve Data Governance problems in other focus areas.
In this section we will leverage our understanding of the Data Governance frameworks presented in the previous section and the Capability Maturity Model developed by the IBM Data Governance Council. For some of the categories we will limit our discussion to a brief summary and references, whereas other Data Governance categories, such as the data quality for master data (that is, master data quality, or MDQ) and MDQ metrics and processes, will be discussed in more detail. The focus and structure of this chapter is driven by the need to present some new areas and characteristics of MDG that have not been extensively discussed in other publications.
Data Quality Management
Let’s look at the area that is often at the very top of Data Governance priorities—Data Quality Management—and discuss it in the context of MDM (see also Lawrence Dubov’s series of blogs18 on this topic).
We have stated throughout the book that MDM Data Hub is an architectural concept and technology that is at the very core of most MDM implementations. At a high level, the MDM Data Hub’s function is to resolve the most important master entities that are distributed across the enterprise, and to understand their intra- and inter-relationships.
Modern MDM Data Hubs have grown into powerful, multifaceted service-oriented toolkits that match, link, merge, cleanse, validate, standardize, steward, and transform data. Modern MDM systems accomplish this by leveraging advanced algorithms and master data modeling patterns, and a variety of services, techniques, and user-friendly interfaces.
In order to unleash the power of the MDM Data Hub systems, MDG programs need to be implemented at the enterprise level. The MDG’s goal is to refine a variety of cross-functional business requirements that cannot be originated from individually focused business groups. Often, MDG should be able to understand and summarize cross-LOB business requirements and articulate them in the form of a sound enterprise-wide Data Governance strategy for master data. This strategy should be able to reconcile cross-departmental inconsistencies in rules, requirements, and standards in a timely, effective, and measurable manner.
One of the key questions MDG should address is how the MDM Data Hub will be leveraged to ensure the creation, maintenance, and proliferation of high-quality master data across the enterprise. In the absence of strong MDG thought leadership, MDM Data Hub technologies may be underused, never be able to achieve the expected ROI, and ultimately be perceived as a failed effort.
With the advances of MDM, we observe a growing confusion around the commonalities and differences between MDM and data quality programs. This confusion manifests itself in questions such as the following:
• Will an MDM initiative resolve our data quality issues? Is this the right approach to data quality?
• We are not sure where the boundaries are between MDM and data quality. How are these two related?
• We are confused and don’t know which of these two projects—MDM and MDG—
• Is data quality part of MDM, or is MDM part of data quality?
A list of these type of questions can be easily expanded, and no simple answer can resolve the confusion expressed by these questions. What is required is a comprehensive discussion and a blueprint on how MDM and MDG can help develop an effective data quality program along with the appropriate methods, techniques, metrics, and other considerations. Let’s discuss how MDG can effectively define the role of the MDM Data Hub as a tool and technique to prioritize data quality problems.
Data quality is an age-old problem for almost every enterprise. The sheer number and variety of data quality issues makes it difficult even to list and prioritize them. This may result in analysis-paralysis scenarios, where the needs and requirements for a data quality program are discussed for years and the program fails at inception.
MDG can help solve the question about data quality vs. data management by clearly stating its Master Data Management focus. MDM concentrates on master entities that are, as defined by the MDG and business, more important than others because they are widely distributed across the enterprise, they reside and are maintained in multiple systems and application silos, and they are used by many application systems and users. In other words, although master data entities may comprise only 3%–7% of an enterprise data model, their significance from the information value and data quality perspectives is disproportionally high. Bringing master data into order often solves 60%–80% of the most critical and difficult-to-fix data quality problems. These considerations define the MDG position that MDM is a great way to prioritize data quality problems and focus resources properly to maximize the return on a data quality effort. Although data quality priorities vary from system to system, MDG takes a lead in aligning data quality efforts and priorities across the enterprise.
Expressed differently, MDM is an efficient approach to addressing enterprise data quality problems, enabling organizations to cherry pick their biggest data quality and data management battles that will ensure the highest ROI.
Data Quality Processes
At a high level, MDM approaches data quality by defining two key continuous processes:
• MDM benchmark development The creation and maintenance of the data quality Benchmark Master—for example, a benchmark or high-quality authoritative source for customer, product, and location data. The MDM benchmark also includes the relationships between master entities.
• MDM benchmark proliferation Proliferation of the benchmark data to other systems, which can occur through the interaction of the enterprise systems with the MDM Data Hub via messages, Web Service calls, API calls, or batch processing.
In most modern MDM solutions, Data Hub technologies focus on the MDM benchmark development process and its challenges. This process creates and maintains the MDM benchmark record in a Data Hub. The process focuses not only on data integrity, completeness, standardization, validation, and stewardship but also on the record timeliness and accuracy. Data accuracy often requires verification of the content with the individuals who know what the accurate values for certain attributes are.
Data timeliness is treated slightly differently. When a new record is created or an existing record is changed in one of the operational systems, the Data Hub receives an update message with the shortest possible delay. The Data Hub processes the change by applying an update to the benchmark record based on the attribute survivorship rules defined by the business as part of its Data Governance. This process is designed to ensure that data timeliness meets the criteria specified by Data Governance, and thus at any point in time the Data Hub maintains the most current benchmark record for the master entity. This makes the Data Hub the benchmark or authoritative source for all practical purposes.
The benchmark proliferation process is equally important for data quality. It is no doubt a great accomplishment for an enterprise to define, create, and maintain the golden (benchmark) record in the Data Hub. That said, from the enterprise data quality perspective, a critical challenge remains. Enterprise stakeholders are looking to establish and maintain data quality in numerous systems across the enterprise. They care about the quality of data in the Data Hub mostly because it helps them solve their data quality problems in other data sources, applications, and systems. In this case, the Data Hub is viewed as just a technique helping to establish and maintain master data quality across the enterprise rather than the key component and ultimate goal of an MDM initiative.
MDG for Operational and Analytical MDMs
It is important for the MDG team to understand that analytical systems and operational systems interact with the MDM Data Hub differently. In analytical MDM, the data warehouse “passively” takes the content created and maintained by the MDM system to load and manage complex data warehousing dimensions. From this perspective, the quality of the data warehousing dimensions built from an MDM Data Hub inherits the quality of the master data, and is mostly a data-integration problem that requires relatively limited Data Governance involvement.
The operational MDM requires an integration of an MDM Data Hub with operational systems. The operational systems’ owners wish to retain control over each record in their application areas. Consequently, these systems cannot accept data feeds from the Data Hub in bulk, which would override the existing data. These systems can still benefit from the MDM Data Hub by leveraging the ability to search the Data Hub before a new record is created or edited in the source system (this is often referred to as a “lookup before create” capability) or by listening to the Data Hub messages and selectively accepting or rejecting the changes sent by the MDM Data Hub.
The operational MDM implementations are much more efficient than their analytical counterparts from the data quality perspective and require a much higher level of Data Governance involvement. Indeed, an operational MDM solution effectively addresses data quality issues at the point of entry, whereas the analytical MDM tackles data quality downstream from the MDM Data Hub. The “dirty” data created at the point of entry, once spread to multiple enterprise applications and systems, is next to impossible to cleanse. Hence, operational MDM is a real remedy for enterprise data quality problems.
Operational MDM reduces administrative overhead of redundant data entries, eliminates duplicates and inconsistencies, facilitates information sharing across enterprise applications and systems, and ultimately improves data quality by addressing the root cause of bad data.
From the MDG perspective, the operational MDM is a powerful technique that enables the enterprise to bring its master data to an acceptable high-quality state without necessarily storing all master entities in a single data repository, keep the data in a high-quality state continuously, and avoid periodic cleansing projects that consume significant resources and have been often proven ineffective. To paraphrase the previous point, an operational MDM helps solve the Data Governance problem of ensuring a continuous data quality improvement in the operational systems while the operational systems’ users retain control over each record.
Data Governance also helps answer another hard question of maintaining data quality—how do we synchronize the source systems with the Data Hub without explicitly synchronizing them through data integration? These are some of the most foundational questions Data Governance and its MDM-focused variant—MDG—must address to achieve advanced Data Governance maturity levels.
In order to maintain a continuous synchronization with the Data Hub, a data quality improvement processes must be defined and built, progress measured, and accountabilities for the progress established. This consideration is very important but certainly not new. Any data framework and methodology, including those we discussed in the beginning of this chapter, require this process to be in place.
Let’s concentrate on two critical components of the quality improvement process that represent significant challenges but, once defined, enable continuous data quality processes for master data across the enterprise and ultimately lift the overall data quality. These components are
• Master Data Governance Policies for Data Quality
• Master Data Governance Metrics for Data Quality
Master Data Governance Policies for Data Quality
As we discussed in the first section, the Data Governance organization can have a variety of Data Governance focus areas and categories under the Data Governance umbrella. Often, for a given enterprise, some areas of Data Governance are more developed than others. For instance, to comply with increasingly stringent regulatory requirements, corporate executives of established firms have addressed certain key aspects of Data Governance as it relates to data security and privacy.
This is not necessarily true with respect to the quality of the master data. Although Data Governance organizations of large companies typically have a number of data-related policies, it is essential to develop a new policy or augment the existing policies to focus on data quality for key master data domains, such as Customer or Party data. Such a policy or policy augmentation should be brief and specifically define, at the executive level, the enterprise position on Customer/Party or Product data in the context of data quality. It is important to make sure that the policy states clearly whether the data will be viewed and managed as a local resource for some systems and applications or as an enterprise asset.
If the enterprise’s data and information philosophy states that enterprise data is just a resource for some applications, your organization is doomed to be reactive and address data issues after they had been discovered. If the corporate policy sees data only as an application resource, this policy does not position the organization to initiate and successfully execute a Master Data Governance (MDG) program and/or MDM. In terms of the Capability Maturity Model levels developed by the IBM Data Governance Council, it is impossible to reach advanced Data Governance levels if the organization looks at data (especially Party, Account, and Product data) as just a resource for departmental systems and applications.
It is much better for the firm if its master data policy defines data as a strategic enterprise asset that can be measured and have economic value. Indeed, if data is an enterprise asset, the asset’s metrics and accountabilities for these metrics must be established. This is similar to any other enterprise function, department, or LOB, such as sales, call center, marketing, risk management, and so on. For instance, for a sales organization, the revenue is typically the primary metric used to measure the success. For a call center, one of the primary metrics is the number of calls the organization processed monthly, quarterly, or annually. Marketing targets may include the number of campaigns, the number of marketing letters sent, and the quantitative outcomes of the campaigns.
When an enterprise forms a Data Governance organization responsible for master data, what is an equivalent of the metrics used by sales organizations, call centers, or any other enterprise functions? How will the success of the MDG be measured? This is the most fundamental question that represents a significant challenge for many Master Data Governance organization. Indeed, no organization can be given an executive power if there are no metrics quantifying the organizational success. Therefore, the master data–centric policy must mandate relevant, quantifiable metrics that are sponsored at the executive level of the enterprise.
It is important to note that no one department or function can articulate a comprehensive set of requirements for an enterprise MDM, and some departmental requirements may be in conflict with each other. An MDG organization needs an executive power to execute MDG and contribute to a successful implementation of MDM. To a certain degree, it is MDG’s requirements that play the role of business requirements for an enterprise MDM. MDG reconciles a variety of often contradictory and incomplete departmental requirements for MDM and brings these requirements to a common denominator across the enterprise.
Once the policy is defined at the executive level, the MDG organization receives a mandate to define the Data Governance metrics for master data quality.
Master Data Governance Metrics for Information Quality
Over the past decade, data quality has been a major focus for data management professionals, data governance organizations, and other data quality stakeholders across the enterprise. If we look back at the advanced levels of the IBM Data Governance Council’s CMM, its Level 4 (Quantitatively Managed) explicitly calls for “quantitative quality goals leveraging statistical / quantitative techniques.” Level 5 emphasizes the need for “...quantitative process improvement objectives firmly established and continuously revised to manage process improvement.” One more data point—on December 2, 2009, Gartner Research published an article titled “Predicts 2010: Enterprise Information Management Requires Staffing and Metrics Focus.” Gartner Research provides this article on request.
Demands for Master Data Governance metrics are growing not only in the minds of industry analysts. This need is recognized by the majority of data professionals implementing MDM solutions. Still, the quality of data remains low for many organizations. To a considerable extent this is caused by a lack of scientifically or at least consistently defined data quality metrics. Data professionals are still lacking a common methodology that would enable them to measure data quality objectively in terms of scientifically defined metrics and compare large data sets in terms of their quality across systems, departments, and corporations to create industry-wide standards. MDG should be able to report the results of data quality measurements to executive committees and even at the Board of Directors level in a way that is clearly understood and can be trusted.
In order to define the right executive level metrics we will start with a brief discussion of the existing data quality and data profiling metrics to understand why these metrics are not optimal for executive Data Governance reporting. Then we will discuss the characteristics of the metrics we are looking for to support executive Data Governance. Finally, we will define the model and the metrics that meet the requirements.
Even though many data profiling metrics exist, their usage is not scientifically justified. This elusiveness of data quality metrics creates a situation where the job performance of enterprise roles responsible for data quality lacks consistently defined criteria, which ultimately limits the progress in data quality improvements.
Clearly, we need a quantitative approach to data quality that, if developed and adopted by the data management and Data Governance communities, will enable data professionals to better prioritize data quality issues and take corrective actions proactively and efficiently.
The Existing Approaches to Quantifying Data Quality
At a high level there are two well-known and broadly used approaches to quantifying data quality. Typically both of them are used to a certain a degree by every enterprise.
The first approach is mostly application driven and often referred to as a “fit-for-purpose” approach. Oftentimes business users determine that certain application queries or reports do not return the right data. For instance, if a query that is supposed to fetch the top ten Q2 customers does not return some of the customer records the business expects to see, an in-depth data analysis follows. The data analysis may determine that some customer records are duplicated and some transaction records have incorrect or missing transaction dates.This type of finding can trigger additional activities aimed at understanding the data issues and defining corrective actions. Measured improvement in outcomes of marketing campaigns is another example of a “fit-for-purpose” metric.
An advantage of the fit-for-purpose approach to data quality is that it is aligned with specific needs of business functional groups and departments. A disadvantage of this approach is that it addresses data quality issues reactively based on a business request, observation, or even a complaint. Some data quality issues may not be easy to discover, and business users cannot decide which report is right and which one is wrong. The organization may eventually draw a conclusion that their data is bad but would not be able to indicate what exactly needs to be fixed in the data, which limits IT’s abilities to fix the issues. When multiple LOBs and business groups across the enterprise struggle with their specific data quality issues separately, it is difficult to quantify the overall state of data quality and define priorities of which data quality problems are to be addressed enterprise-wide and in what order.
The second approach is based on data profiling. Data-profiling tools intend to make a data quality improvement process more proactive and measurable. A number of data-profiling metrics are typically introduced to find and measure missing and invalid attributes, duplicate records, duplicate attribute values that are supposed to be unique, the frequency of attributes, the cardinality of attributes and their allowed values, standardization and validation of certain data formats for simple and complex attribute types, violations of referential integrity, and so on. A limitation of data-profiling techniques is in that an additional analysis is required to understand which of the metrics are most important for the business and why. It may not be easy to come up with a definitive answer and translate it into a data quality improvement action plan. A variety of data-profiling metrics are not based on science or a sound principle but rather driven by the ways relational database technologies can report on data quality issues.
Even though each of these two approaches has its advantages and value, a more strategic approach should be considered by Data Governance organizations. This approach should be able to provide a solid scientific foundation, principles, and models for data quality metrics inline with the requirements for levels 4 and 5 of the CMM developed by the IBM Data Governance Council. Later in this chapter we define such an approach that quantifies the value of master data quality for data sources as percentage points relative to the data quality in the MDM Data Hub.
Enterprise data analysts who know their data well often recognize that the data quality is low, but can’t identify ten top data quality issues. A data analyst may indicate that some customer records are lacking names, that the date of birth is often unavailable, or filler values are broadly used for the phone numbers and date of birth attributes and nonpublic information is inadequately protected from unauthorized users. The analysts may be able to name a few issues like that, which would point to the candidates to address within the fit-for-purpose approach. However, if data analysts are required to define a comprehensive set of data quality issues, the sheer number of known issues and the effort to discover them overall quickly becomes overwhelming. Indeed, even to define record-matching attributes for a deterministic MDM matching algorithm may typically require an evaluation of many hundreds of rules. The number of rules that would need to be defined and implemented to measure and improve the enterprise data quality overall is absolutely overwhelming, and approaches limited only to deterministic techniques to data quality are not viable. Therefore, there is a pressing demand for generic, sound scientific principle- and model-driven approaches to data quality that must coexist with deterministic rule-driven fit-for-purpose approaches. Jim Harris discussed somewhat similar needs and trends using the terms “The Special Theory of Data Quality” and “The General Theory of Data Quality.”19
Information Theory Approach to Data Quality for MDM
Previously, we identified the two primary data quality improvement processes:
• MDM Benchmark Development
• MDM Benchmark Proliferation
Let’s first assume that the MDM Benchmark Development process has succeeded and the “golden” record set G for master data (for example, Customer) is established and continuously maintained in the Data Hub. This “golden” record can be created dynamically or be persistent. There exist a number of data sources across the enterprise, each containing some Customer data attributes. This includes the source systems that feed the Data Hub and other data sources that may note be integrated with the Data Hub. We will define an external dataset g, such that its data quality is to be quantified with respect to G. For the purpose of this discussion, g can represent any data set, such as a single data source or a collection of sources. For more discussions on the applications of Information Theory to data quality for MDM, you can refer to the references at the end of this chapter.20,21
Our goal is to define metrics that compare the source data set g with the benchmark data set G. The data quality of the data set g will be characterized by how well it represents the benchmark entity G defined as the “golden view” for the Customer data.
At the end of the 1940s, Claude Shannon, known as the “Father of Information Theory,” published a few foundational articles on Information Theory.22 We will leverage the model that Shannon developed and applied to the transmission of a telegraph code. Figure 17-1 illustrates the idea and shows the similarity between the telegraph transmission problem and the benchmark proliferation model.
Shannon analyzed a scenario in which a telegraph code generated by a transmitter is sent through a channel that generates some noise as any real-life channel. Due to the noise in the transmission channel, the telegraph code received by the receiver can be distorted and therefore different from the signal originally sent by the transmitter. The theory developed by Shannon provides a solution that quantifies the similarity of the signal on the receiver end with the signal sent by the transmitter. The quality of the transmission channel is high if the received signal represents the original signal sent by the transmitter well. Conversely, if the quality of the transmission channel is low, the channel is considered noisy and its quality is low.
FIGURE 17-1 Transmission of telegraph code–the classic problem of Information Theory
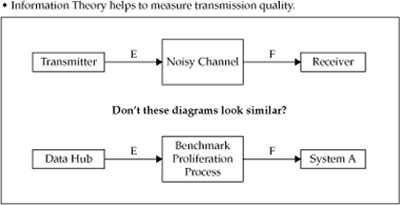
The two telegraph code transmission scenarios in Figure 17-2 illustrate two transmission channels: high quality (good) and noisy (bad).
The first example, in the top part of the figure, illustrates a high-quality channel. The receiver generates signals E1, E2, and E3 with probabilities 0.5, 0.3, and 0.2, respectively. The diagonal matrix in the top part of the figure represents a perfect quality transmission channel. The transmitter signals E1, E2, and E3 are translated into F1, F2, and F3, respectively. A good transmission channel requires consistency between the signals generated by the transmitter and the signals on the receiver end. The signals E and F do not have to be equal, but rather the transmission outcomes (F) must be consistent and predictable based on the original signals (E). But that’s exactly what we want for enterprise data quality: consistency and predictability!
We will apply the same transmitter/receiver model to the quality of the MDM Benchmark Proliferation process.
Information Theory is heavily based on probability theory and other concepts, with the notion of information entropy being the most important.
Note The term entropy is not unique to the Information Theory; it plays a key role in physics and other branches of science. Because this discussion is about information, we’ll use the term entropy to refer to Information Entropy. Shannon’s definition of entropy in Information Theory is a measure of the uncertainty over the true content of a message and is measured by a specific equation he stipulates.
Readers familiar with probability theory concepts and the meaning of the term entropy can skip the next few paragraphs and explanations pertaining to Figures 17-3 though 17-6. For those who are interested in an introduction to the notion of entropy, we provide a brief illustrative explanation of the term. This explanation will be helpful in better understanding the material in the remainder of this chapter.
Figure 17-3 introduces the term entropy for a simple example of a symmetrical coin.
FIGURE 17-2 An illustration of a good vs. bad transmission channel
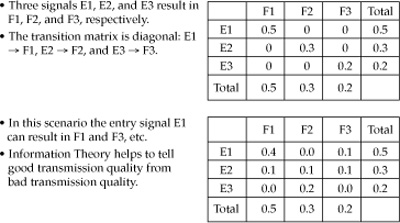
FIGURE 17-3 The entropy of a symmetrical coin
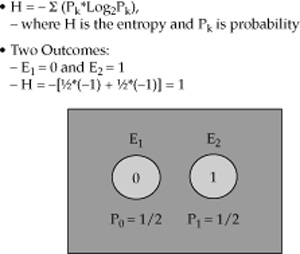
Once the coin is tossed and flipped, it can display two possible outcomes: 0 or 1, with equal probabilities of 0.5.
The entropy H is defined as – Σ P kl log Pk, where the logarithm’s base is 2 and the symbol Σ signifies a summation over all possible outcomes. The entropy calculation yields H = 1 for a symmetrical coin, which is the maximum entropy for one coin.
FIGURE 17-4 The entropy of an asymmetrical coin
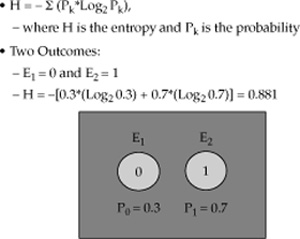
FIGURE 17-5 An extreme case: the entropy of a single outcome coin

We can generalize this discussion and arrive at the conclusion that the entropy is a measure of the predictability and uncertainty of the system’s behavior. Low entropy indicates that the system is easily predictable and orderly, while high entropy indicates that it is difficult to predict the system’s behavior because it is more chaotic.
The preceding paragraphs offered a brief explanation of how Information Theory measures the value of the information content by using the concept of entropy. Now we are in a position to review how this theory can be applied to quantify the information quality as a measure of uncertainty.
FIGURE 17-6 The joint entropy of two symmetrical coins

As mentioned, Information Theory says that the information quantity associated with the entity G is expressed in terms of the information entropy as follows:
H(G) = –σPk l log Pk, (1)
where Pk are the probabilities of the attribute (token) values in the “golden” data set G. The index k runs over all records in G and all attributes. H(G) can also be considered the quantity of information in the “golden” representation of entity G.
Similarly, for the source data set g, the quality of which is in question, we can write the following:
H(g) = –σ p il log pi, (2)
We will use lowercase p for the probabilities associated with g whereas the capital letter P is used for the probabilities characterizing the “golden” data set G in the MDM Data Hub.
The mutual entropy, which is also called mutual information, J(g,G), is defined as follows:
J(g,G) = H(g) + H(G) –H(g,G) (3)
In equation (3), H(g,G) is the joint entropy of g and G. It is expressed in terms of probabilities of combined events; for example, the probability that the last name equals “Smith” in the golden record G and the last name equals “Schmidt” in the source record g both represent the same customer, and in IT terms are linked by a single customer identifier. The behavior of the mutual entropy J qualifies this function as a good candidate for (?) quantifying the data quality of g with respect to G. When the data quality is low, the correlation between g and G is expected to be low. In an extreme case of a very low data quality, g doesn’t correlate with G and these data sets are independent. Then
H(g,G) = H(g) + H(G) (4)
and
J(g,G) = 0 (5)
If g represents G extremely well (for example, g = G), then H(g) = H(G) = H(g,G) and
J(g,G) = H(G) (6)
To make equations more intuitive, let’s apply them to the scenarios in Figure 17-2. We will obtain the following outcomes:
• Scenario 1 High-quality transmission with no noise in Figure 17-2:
H(E) = 1.485
H(F) = 1.485
H(E,F) = 1.485
J(E,F) = 1.485
• Scenario 2 Transmission with noise in Figure 17-2:
H(E) = 1.485
H(F) = 1.485
H(E,F) = 2.322
J(E,F) = 1.485 + 1.485 –2.322 = 0.648
As we can see, the mutual entropy demonstrates a very interesting and useful property. The mutual entropy is equal to the entropy of the individual golden data set G when the data source g is entirely consistent with G. Conversely, for the noisy channel in the second scenario in Figure 17-2, the mutual entropy J(g,G) = 0.648, which is significantly lower than the entropy of the golden source H(G) in the MDM Data Hub.
Let’s leverage this property and define transmission quality DQ as J(E,F)/H(F)*100%. An application of this formula to the noisy channel scenario yields the following:
DQ(E,F) = 0.648/1.485 *100% = 27.9%
Because we seek to apply the same model to data quality, we can now define the data quality of g with respect to G by the following equation:
DQ(g,G) = J(g,G)/H(G)*100%
Using this definition of data quality, we observe that DQ can change from 0 to 100%, where 0 indicates the data quality of g is minimal with respect to G (g does not represent G at all). When DQ = 100%, the data source g perfectly represents G and the data quality of g with respect to G is 100%.
The beauty of this approach is not only in its quantifiable nature, but also in the fact that it can be used to determine partial attribute/token-level data quality, a feature that can provide additional insights into what causes most significant data quality issues.
From the data quality process perspective, the data quality improvement should be performed iteratively. Changes in the source data may impact the golden record. Then equations (1) and (7) are applied again to recalculate the quantity of information and data quality characteristics.
To sum up, this section offers an Information Theory–based method for quantifying information assets and the data quality of the assets through equations (1) and (7). The proposed method leverages the notion of a “golden record” created and maintained in the MDM Data Hub, with the “golden record” used as the benchmark against which the data quality of other sources is measured.
Simple Illustrative Examples of Data Quality Calculations
Let’s apply our definition of data quality to a few simple examples to see how equation (7) works and what results it produces. In Figure 17-7, the records in the data source F differ from the benchmark records in the MDM Data Hub by only one attribute value, the state code where Larry resides.
The application of equation (7) yields DQ = 85.7%.
In Figure 17-8, a duplicate record with an incorrect value of the state in source system F causes a data quality issue, which yields DQ = 84.3%.
As Figure 17-9 shows, equivalencies applied consistently do not cause any data quality penalties within the proposed model. Even though all state codes are substituted with fully spelled state names, DQ = 100% if it is done consistently.
The Use of Matching Algorithm Metrics
If an organization has already acquired or developed software that can score two individual records for the purpose of probabilistic matching, the same software can be used for a comparison of the data sets g and G in the spirit of our Information Quality discussion.
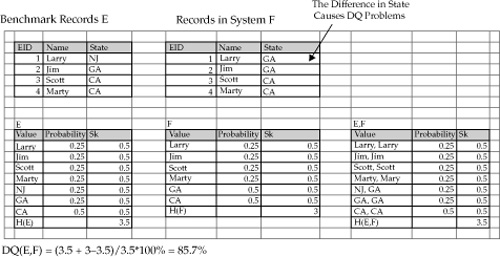
FIGURE 17-7 Data quality for discrepancy in the state value
The following equation yields results similar to equation (7):
![]()
where the index j runs over all golden records in the Data Hub; index i runs over all source system records that are linked to the benchmark record and reside in the system, the quality of which is measured; NG is the number of benchmark golden records in the MDM Data Hub; n i,j is the number of source records linked to the benchmark record j; and Score(a,b) stands for the matching score function that matches record a to record b. Similarly to equation (7), equation (8) yields 1 when the data quality is very high and scores lower than 1 when the data quality is less than perfect.
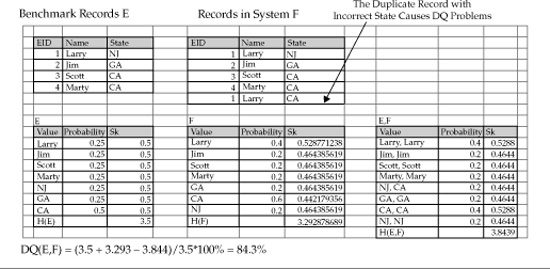
FIGURE 17-8 Effect of a duplicate value with an incorrect state value
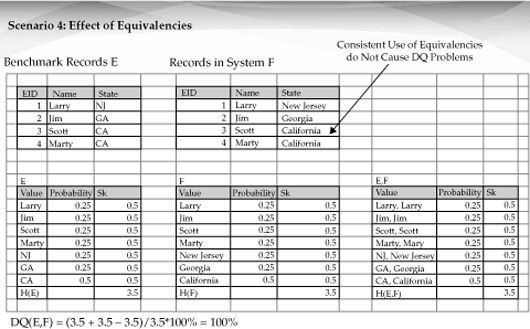
FIGURE 17-9 Effect of equivalencies
Note that the self-score Score(Gj, Gj) is a great metric for record completeness and can be used in multiple practical scenarios, including the evaluation of the completeness of the golden record in the MDM Data Hub. Figure 17-10 shows an illustrative distribution.23
The illustrative self-score distribution shows that a significant percentage of the records reside in the right part of the graph, which indicates that there are many records with a high level of completeness, corresponding to the self-scores between 16.5 and 19.5. In the left part of the graph there are some records on the tail of the distribution that show relatively low self-scores between 11.0 and 12.0. The average self-score of the distribution is around 17.5, while the 10 percent quintile is close to 13.0. The Data Governance Board can establish the target thresholds for the average self-score (for example, at 18.0, and 15.0 for the 10 percent quintile). This should initiate data stewardship activities. Most likely the low-scoring records on the left side of the distribution will be the data stewardship targets. Once additional data is provided, the completeness metrics will meet the Data Governance requirements. This example illustrates how the Data Governance organization can enable continuous master data quality improvement processes through a few aggregated Data Governance metrics for data quality.
Organizations can leverage equations (1),(7), and (8), as well as the self-score metrics in Figure 17-10, to augment the Data Governance policies for MDM and enable processes that will lead to advanced maturity levels of the CMM for Data Governance.
By using this quantitative approach consistently across organizations and industries, over time Data Governance organizations will accumulate valuable insights into how the metrics apply to real-world data characteristics and scenarios. Good Data Governance practices defining generally acceptable data quality thresholds will be developed. For instance, Data Governance may define an industry-specific target policy for, let’s say, P&C insurance business, to keep the quality of customer data above the 92 percent mark, which would result in the creation of additional, clearly articulated Data Governance policies based on statistically defined metrics. This methodology seems promising if the idea of the inclusion of the data quality in corporate books of records will ever come true. As per the IBM Data Governance Website, “IBM Council predicts data will become an asset on the balance sheet.”24 This scenario is likely to require the metrics discussed in this chapter.

FIGURE 17-10 An illustrative self-score distribution
The described approach can be incorporated into future products such as executive-level Data Governance dashboards and data quality analysis tools. MDG will be able to select information sources and assets that are to be measured, quantify them through the proposed metrics, measure the progress over time, and report the findings and recommended actions to executive management.
Even though we are mainly focusing on data quality in this chapter, there are other applications of data quality metrics. The quantity of information in equation (1) represents the overall significance of a corporate data set from the Information Theory perspective. From the M&A perspective, this method can be used to measure an additional amount of information that the joint enterprise will have compared to the information owned by the companies separately. The approach just described will measure both the information acquired due to the difference in the customer bases and the information quantity increment due to better and more precise and useful information about the existing customers. It may also determine the data migration and integration level of effort that will be required as part of M&A, as well as the integration of any authoritative external data.
How to Make Data Governance More Focused and Efficient
As we noted in the introductory part of this chapter, the primary challenge of Data Governance is in its elusiveness, ambiguity, and lack of clearly defined boundaries. This creates a market perception that “Data Governance” is an umbrella term for a new enterprise bureaucracy. Let’s summarize some good Data Governance practices that tackle this challenge and make Data Governance better defined, more manageable, and valuable.
Agile Data Governance
Marty Moseley has introduced agile Data Governance in a number of blogs and publications.25, 26 These publications recognize the challenge of an all-encompassing “top-down” approach to Data Governance and propose an alternative “bottom-up” approach that focuses on a single Data Governance area first and approaches Data Governance in more manageable chunks. Here are the seven agile Data Governance steps proposed and described by Moseley:
1. Selecting the project implementation team
2. Defining the size and scope of the data problem
3. Drafting the data steward team
4. Validating or disproving project assumptions
5. Establishing new policies for handling data
6. Enlisting internal IT groups and kicking off implementation
7. Comparing results, evaluating processes, and determining next steps
Similar considerations are brought by Rob Karel et al.27 of Forrester Research and expressed slightly differently by Mark Goloboy.28
Any team engaging in Data Governance should think about applying an agile, bottom-up, lightweight approach to Data Governance while preserving the longer term vision and objectives of strategic Data Governance.
Overlaps with Business Requirements Generated by Departments and Business Functions
Any team engaging in Data Governance should understand that their role is in finding a common denominator of cross-functional business requirements and standards as opposed to stepping on the toes of departmental business analysts. It is certainly a challenge to find the right balance between enterprise policies and standards on the one hand and giving enough flexibility to the departmental requirements with their business rules on the other.
The Data Governance initiative must add true measurable and accepted value. It must not be perceived as an impediment for changes needed at the accelerating speed of business to respond to market threats, market opportunities, and regulatory mandates.
Overlaps with the Enterprise IT
A Data Governance team should work closely with enterprise data, systems, and application architects to ensure that they are on the same page and, at the same time, see the boundaries separating Data Governance functions from those of the enterprise architects. Both groups are responsible for establishing and enforcing enterprise standards and consistent good practices. The best remedy to make it right is to develop a solid communications plan that includes all stakeholders and maintains continuous interactions between the groups. Communications and socialization of the MDG vision and strategy are key remedies for making Data Governance successful.
Data Governance and Data Governance Frameworks
A Data Governance team should choose one of the Data Governance frameworks and follow it as closely as feasible. We briefly described three Data Governance frameworks; many more frameworks are available. We are not recommending any particular framework over the others, just strongly suggesting that the Data Governance team selects a framework and uses it in practice. This will make their objectives and activities better defined and streamlined.
Processes and Metrics
We put a lot of focus in this chapter on Data Governance processes for master data quality and the corresponding metrics. The metrics we discussed are certainly a subset of metrics a Data Governance organization can use and should rely on. Both aggregate metrics and lower level detail metrics are important. The aggregate metrics provide visibility at the executive level, whereas more granular metrics are used on a daily basis to investigate the issues.
Data Governance Software
There is a significant difference in how the two “siblings” (MDM and Data Governance) have formed and evolved over the last seven years. MDM has shaped a software market with the MDM Data Hubs as the core new technologies. Master Data Management software products are continually evaluated by industry analysts such as the Gartner Group and Forrester Research. Unlike MDM, Data Governance has not evolved as a software market. Data Governance is not associated with any specifically defined type of software products, although, as per Gwen Thomas,29 a variety of software products such as ETL tools, metadata tools, information quality tools, and so on, can be considered under the umbrella of Data Governance software.
With this extremely broad field of Data Governance–related software solutions, it is fairly clear why many IT managers and practitioners call the term “Data Governance” elusive and ambiguous. Indeed, when an area is defined too broadly, it doesn’t seem actionable.
A number of software companies have approached Data Governance within the roadmaps of their product strategy perspectives rather than by developing new tools from scratch.30–32 This is an interesting trend that recently formed in Data Governance, and it appears that this trend may eventually start changing the face of Data Governance by making the area better defined through association with certain core software capabilities.
Data Governance and Edward Deming Principles
W. Edwards Deming,33 one of the founders of the quality control discipline, developed 14 principles that have been considered by many a basis for the transformation of American industry and the economic miracle with the Japanese economy after WWII. Some of the principles are highly applicable to information quality and Data Governance. This is especially true for the following principle (principle #3):
“Cease dependence on inspection to achieve quality. Eliminate the need for inspection on a mass basis by building quality into the product in the first place.”
In the context of MDG, this principle mandates continuous data quality improvement processes embedded in everyday operations as opposed to massive data-cleansing exercises that are proven ineffective.
Conclusion
We started this chapter with a description of Data Governance basics, including definitions, frameworks, and the Capability Maturity Model. We tried to avoid broad general discussions on the topic, as these are readily available in numerous publications and through a variety of online sources.
Instead, we focused on the areas that, we believe, are critical for the success of Data Governance and, at the same time, are insufficiently developed and/or covered in the industry. Given the focus of this book on MDM, we concentrated our discussions on Master Data Governance. We strongly believe that this is the area of Data Governance that will become the next breakthrough in helping organizations achieve advanced levels of Data Governance maturity.
The next Data Governance challenge is in the translation of Data Governance metrics into direct and indirect financial impact on the organization. This is a very challenging and critically important area that is currently still in the embryonic stage, even though some research work has been done in this direction.34
References
1. Waddington, David. “Adoption of Data Governance by Business.” Information Management Magazine, December 1, 2008. http://www.information-management.com/issues/2007_54/10002198-1.html.
2. http://www.datagovernance.com/.
3. http://www.informationweek.com/news/global-cio/showArticle.jhtml?articleID=196603592.
4. http://www.ibm.com/ibm/servicemanagement/data-governance.html.
5. Berson, Alex and Dubov, Lawrence. Master Data Management and Customer Data Integration for a Global Enterprise. McGraw-Hill (July 2007), p. 382.
6. http://www.tcdii.com/whatIsDataGovernance.html.
7. Dyche, Jill, Levy, Jill, and Levy, Evan. Customer Data Integration: Reaching a Single Version of the Truth. John Wiley (2006).
8. http://www.ibm.com/ibm/servicemanagement/data-governance.html.
9. http://www.datagovernance.com/glossary-governance.html.
10. Sarsfield, Steve. The Data Governance Imperative. IT Governance, Ltd. (April 23, 2009).
11. Loshin, David. Master Data Management. The MK/OMG Press (September 28, 2008).
12. http://mike2.openmethodology.org/wiki/Information_Governance_Solution_ Offering.
13. The Data Governance Institute. “Governance Roles and Responsibilities.” http:// www.datagovernance.com/adg_data_governance_roles_and_responsibilities.html.
14. Moseley, Marty. “Building Your Data Governance Board.” March 18, 2010. http:// www.datagovernance.com/adg_data_governance_roles_and_responsibilities.html.
15. Chisholm, Malcolm. “Principle Based Approach to Data Governance.” http:// www.b-eye-network.com/channels/1395/view/10746/.
16. http://www.datagovernance.com/dgi_framework.pdf.
17. ftp://ftp.software.ibm.com/software/tivoli/whitepapers/LO11960-USEN-00_10.12.pdf.
18. Dubov, Lawrence. “Confusion: MDM vs. Data Quality.” http://blog.initiate.com/index.php/2009/12/01/confusion-mdm-vs-data-quality/.
19. Harris, Jim. “The General Theory of Data Quality.” August 12, 2009. http://www.linkedin.com/news?viewArticle=&articleID=73683436&gid=45506&articleURL= http%3A%2F%2Fwww%2Eocdqblog%2Ecom%2Fhome%2Fpoor-data-quality-is-a-virus%2Ehtml&urlhash=-0w3&trk=news_discuss.
20. Dubov, Lawrence and Jim Cushman. “Data Quality Reporting for Senior Management, Board of Directors, and Regulatory Agencies,” October 20, 2009. http://blog.initiate.com/index.php/2009/10/20/data-quality-reporting-for-senior-management-board-of-directors-and-regulatory-agencies/.
21. Dubov, Lawrence. “Quantifying Data Quality with Information Theory: Information Theory Approach to Data Quality for MDM,” August 14, 2009.http://mike2.openmethodology.org/blogs/information-development/2009/08/14/quantifying-data-quality-with-information-theory/.
22. Shannon, C.E. “A Mathematical Theory of Communication,” Bell System Technical Journal, 27, July and October, 1948. pp. 379–423, 623–656.
23. The authors are grateful to Dr. Scott Schumacher for the illustrative self-score distribution materials.
24. http://www.ibm.com/ibm/servicemanagement/us/en/data-governance.html
25. Moseley, Marty. “Agile Data Governance: The Key to Solving Enterprise Data Problem.” Information Management, September 18, 2008. http://www.information-management.com/specialreports/2008_105/10001919-1.html.
26. Moseley, Marty. “Seven Steps to Agile Data Governance.” Information Management, November 20, 2008. http://www.information-management.com/spec ialreports/2008_105/10001919-1.html.
27. Karel, Rob, et al. “A Truism For Trusted Data: Think Big, Start Small. A Bottom-Up Valuation Approach For Your Data Quality Initiative.” Forrester, July 28, 2008. http://www.forrester.com/rb/Research/truism_for_trusted_data_think_big%2C_ start/q/id/46308/t/2.
28. Goloboy, Mark. “Lightweight Data Governance: The Starting Point.” Boston Data, Technology and Analytics. June 22, 2009. http://www.markgoloboy. com/2009/06/22/lightweight-data-governance-a-starting-point/.
29.http://www.datagovernance.com/software.html.
30. http://www.informatica.com/solutions/data_governance/Pages/index.aspx.
31. http://www.initiate.com/services/Pages/BusinessManagementConsulting.aspx.
32. http://www.dataflux.com/Solutions/Business-Solutions/Data-Governance.aspx?gclid=COe8g_elvqECFRUhDQod0x6UhQ.
33. http://en.wikipedia.org/wiki/W._Edwards_Deming.
34. Wende, Kristin and Otto, Boris. “A Contingency Approach to Data Governance.” In Proceedings of the Twelfth International Conference on Information Quality (ICIQ-07).