
Chapter 11. Master Data Synchronization
11.1. Introduction
What is the qualitative difference between the traditional manner that data quality tools are used for data cleansing and the way they are used for master data management? To a large degree, the approaches are the same when it comes to the mechanics of parsing, standardization, corrections, and consolidation and merging. But whereas static data cleansing focuses on one data set at a time in isolation, the same techniques used for master data do so in an active environment with dependent applications demanding access to that core data asset, even as it is being assessed and reviewed for improvement.
In other words, the answer is related to the way that business application owners have specified their needs for consistency and synchronization of the critical data assets for both consolidation and use. Traditional approaches to data cleansing focus on a static view of data sets—extracting data from sources; normalizing their structure; submitting to the cleansing process; and creating a newly formed, cleansed data silo. To the contrary, though, the master data asset is not a separate data silo but an intrinsic component of the operational, analytical, or combined application architecture. In essence, one of the core concepts of MDM is the dynamic availability of a representative master data set that by definition provides a consistent view across the enterprise. Correspondingly, the concept of an isolated consolidation of extracted data sets into a static repository of cleansed records is inconsistent with the business needs for the dynamically managed master view.
Our expectations for the master data asset availability are defined in terms of synchronization—between the client applications and the master data set, as well as between the components of the master data set itself. Synchronization can be characterized at a more refined level by looking at specific aspects of the shared consistent view of uniquely referenced objects:
Within the context of the shared master data asset, each of these notions has a subtly different meaning, and a combination of the business requirements for these execution aspects contributes the ultimate drivers for the selection of the underlying MDM architecture. In this chapter, we examine the meanings and implications of these system concepts, a model in which some of the issues have been addressed, and how we can adapt that model to the MDM program.
11.2. Aspects of Availability and Their Implications
What do timeliness, currency, latency, consistency, coherence, and determinism mean in the context of synchronized master data? In Chapter 5 we explored the dimensions of data quality, yet the rules and thresholds for those dimensions are defined from the point of view of each of the business applications using the data sets. But as characteristics of a synchronized master view, these terms take on more operational meanings. Within each application, accesses to each underlying managed data set are coordinated through the internal system services that appropriately order and serialize data reads and writes. In this manner, consistency is maintained algorithmically, and the end users are shielded from having to be aware of the mechanics employed.
However, the nature of the different ways that master data are managed raises the question of consistency above the system level into the application service layer. This must be evaluated in the context of the degree of synchronization needed by the set of client applications using the master data asset. Therefore, the decisions regarding the selection of an underlying MDM architecture, the types of services provided, the application migration strategy, and the tools needed for integration and consolidation all depend on assessing the business process requirements (independently of the way the technology has been deployed!) for data consistency.
Each of the key characteristics impacts the maintenance of a consistent view of master data across the client application infrastructure, and each of the variant MDM architecture styles will satisfy demands across these different dimensions in different ways. Our goal is to first understand the measures of the dimensions of synchronization and how they address the consistency of master data. Given that understanding, the MDM architects would assess the applications that rely on the master data asset as well as the future requirements for applications that are planned to be developed and determine what their requirements are for master data synchronization. At this point, each of the architectural styles can be evaluated to determine how well each scores with respect to these dimensions. The result of these assessments provides input to inform the architect as to the best architecture to meet the organizational needs.
11.3. Transactions, Data Dependencies, and the Need for Synchrony
The need for synchronization is best illustrated using an example. Consider a company, WidgeCo, that for the benefit of its customers maintains a master product information management system that composes product data from multiple sources into a single view. Three suppliers sell a 3-inch widget, with unique product code WID-3IN, and for each of the suppliers (A, B, and C), there is an entry in the master data environment tracking the number of widgets the supplier has in stock and the current price at which the supplier is selling the widget.
Here are some of the use cases associated with that master product catalog:
▪ When one of WidgeCo's customers is interested in buying 3-inch widgets, a request is made from the master catalog to provide the best price and the quantity of widgets available at that price.
▪ When a customer makes a purchase, WidgeCo processes the transaction by forwarding the transaction to the supplier with the best price and arranging for drop shipping directly to the customer's location.
▪ Suppliers proactively provide data to WidgeCo, updating its product data.
In each of these use cases, the degree of synchronization and consistency of product data may impact whether the results of the transactions are what the customers think will happen. The issues emerge when the transactions triggered by these use cases are interleaved.
To follow the example, consider this sequence of events:
1 A customer requests prices for widgets.
2 WidgeCo returns result saying that supplier A has WID-3IN for $19 each.
3 Supplier B forwards an update of product data including a reduction in cost for WID-3IN to $18 each.
4 The customer orders 100 units of WID-3IN.
At this point, some of a number of actions might happen:
A The customer's order is forwarded to supplier A, because at the time of the query, supplier A had the lowest price, or
B The customer's order is forwarded to supplier B, who had the lowest price when the order was placed, and
C The customer is charged for widgets at the rate of $19 each, which was the lowest price at the time of the query, or
D The customer is charged for widgets at the rate of $18 each, which was the lowest price at the time of the order.
The potential for confusion revolves around how the master system's underlying master product information was implemented. In a database management system (DBMS) application, all the transactions would have been ordered in some way to prevent the potential for confusion. But the final outcomes of the process may be different, depending on how the applications participating in the MDM system access the master data stores, how the master data stores are configured, and how the master data service layer interleaves components of these transactions.
In fact, these issues might have serious business impact if WidgeCo has specified policies regarding service-level compliance, either with the customers or with the suppliers. For example, one policy might specify that the customer always receives the lowest price, whereas another might specify that the supplier whose price was quoted always receives the order. In this example, both of those policies cannot be observed at the same time.
11.3.1. Data Dependency
What we see in this example is that the execution sequence of transactions defines the outcome, and this is driven by the fact that each individual transaction is dependent on the result of a previous transaction. The price charged to the customer when the order is made should be related to the price reported to the customer after the initial price request, if that is what the company has stated as its definitive policy.
Because any master object can be either read or written, we want to ensure that the data dependencies are observed within any transaction. The combinations of read/write dependencies by different applications can be characterized as follows:
Read after read. In this situation, one transaction reads a data element, followed by another transaction reading the same data element. Here, there are not likely to be any issues; because there is no modification to the master object between the two reads, their order can even be interchanged.
Read after write. Here, one transaction writes the master object, then another transaction reads the same master object. In this case, the read action is dependent on the completion of the write, and here we cannot interchange the order of execution.
Write after read. In this case, one transaction writes the master object, then another transaction reads the same master object. Similarly to the “read after write,” the value read is dependent on the successful completion of the preceding write, and here we cannot interchange the order of execution.
Write after write. In this case, one transaction writes the master object, then another transaction writes the same master object. The resulting persisted value is the last one that executed, and to some extent it does not matter which write “wins,” as long as every participating application sees the same winner.
This last point is the critical one: maintaining consistency and synchronicity is related to ensuring that all participating applications see a consistent ordering of data dependent actions.
11.3.2. Business Process Considerations
Different aspects of coordinating the management of product WID-3IN's virtual master record show how reliant our applications are on particular systemic support for data synchronization. For example, the result of the customer's query could have been different if supplier B's product update had arrived earlier in the sequence, as would be the ultimate cost per widget, which highlights how the timeliness of master data transactions impacts the business process. In fact, the intermediate update to the product's master record in the middle of the customer interaction demonstrates the importance of having the most current data available.
The amount of time that it takes for the specific actions to be communicated may also impact the final outcome, because if supplier B's update takes a long time to be made generally available (in other words, has a long latency), the customer will be charged the higher amount. At the same time, the view to the customer displayed one lowest price, whereas the updated master data set contained a different lowest price—a lack of consistency and coherence that could impact the end result. Lastly, had the customer requested the price twice, it is possible that the result would have been different each time, exhibiting nondeterministic behavior with respect to data access. In general, within the DBMS, all of the peculiarities of concurrent interactions between these different aspects are handled as a by-product of transaction serialization.
11.3.3. Serializing Transactions
The fact is that almost any high-level transaction in any operational system is composed of multiple subtransactions, each of which is executed within a defined sequence. At the same time, other applications may be simultaneously executing transactions touching the same data sets. So how are these transactions (and their corresponding subtransactions) executed in a way that ensures that they don't step all over each other? Although the complexity of transaction serialization, multiphased commits, and locking are beyond the scope of this book, a simple overview can be somewhat illuminating.
The basic principle is that the underlying transaction management system must ensure a number of assertions that will guarantee a consistent view:
1 Each application's transactions will be executed in an order consistent with the order in which they were requested.
2 All transactions from all applications will be seen to have been executed in the same order.
The impact of the first assertion is the guarantee of a total ordering of the transactions performed by each distinct application. The second assertion enforces a consistent ordering of interleaved transactions from the different applications to enforce the view of data dependencies as described in Section 11.3.1. Simply put, database management systems employ processes to enforce these assertions by intermittently “locking” the underlying data asset being modified during any specific set of subtransactions until the system is able to guarantee the consistency of the entire transaction. Locking a data object means that no other transaction can modify that object, and any reads are likely to see the value before the start of the transaction sequence. When that guarantee is assured, the database system commits all the modifications and then releases the locks on each individual data object.
Because these locking and multiphase commit protocols are engineered into the database management system, their effect is completely transparent to any application developer or any application user. But because there are many different approaches to implementing master data management, the importance of incorporating these same protocols at the service layer is related to the degree to which the business requirements specify the need for the master data to be synchronized.
11.4. Synchronization
What are the characteristics of synchrony and consistency? Using the characteristic dimensions enumerated earlier in this chapter, we can explore the degree to which we can describe synchrony, as well as provide a means for comparing business application requirements and implementation support. This process helps refine the selection criteria for an underlying MDM architecture. The dimensions of synchronization are shown in the sidebar.
▪ Timeliness. Refers to the ability to ensure the availability of master data to the client applications and stakeholders within a reasonable window from the time that the data were initially created or introduced into the enterprise. Timeliness is essentially a gauge of the maximum time it takes for master data to propagate across the system, as well as the time window in which the underlying replicas of master data have potentially inconsistent values.
▪ Currency. Corresponds to the degree of “freshness” of master data, which measures the update times and frequency associated with any “expiration” time of data values.
▪ Latency. Refers to the time between an application's request for information and the time of its delivery.
▪ Consistency. A measure of the degree to which each application's view of master data is not different than any other application's view.
▪ Coherence. The ability to maintain predictable synchronization between local copies of master data and any master repository, or between any two local copies.
▪ Determinism/idempotence. Means that when the same query is performed more than once, it returns the same result.
11.4.1. Application Infrastructure Synchronization Requirements
Clearly, many MDM environments are not specifically designated as tightly coupled transaction processing systems, which means that the requirements are going to be determined in the context of the degree to which there is simultaneous master data access, as well as how that is impacted by our dimensions of synchronization. Therefore, the process for determining the requirements for synchronization begins with asking a number of questions:
1 Is the master data asset supporting more of a transactional or an analytical environment? A transactional system will require a greater degree of synchronization than one that is largely used solely for analytics.
2 How many applications will have simultaneous access to master data? An environment with many applications touching the master data repository will probably have more data dependencies requiring consistency.
3 What is the frequency of modifications to master data? Higher frequency may require greater assurance of coherence.
4 What is the frequency of data imports and loads? This introduces requirements for data currency and timeliness of delivery.
5 How tightly coupled are the business processes supported by different master data sets? Siloed master object repositories may be of use for specific business objectives, but fully integrated business processes that operate on collections of master objects will demand greater degrees of synchrony.
6 How quickly do newly introduced data need to be integrated into the master environment? Rapid integration will suggest a high degree of timeliness and currency.
7 What is the volume of new master records each day?
8 How many applications are introducing new master records? (This question and the previous one focus on the potential for large numbers of simultaneous transactions and how that would impact the need for coordination.)
9 What are the geographical distribution points for master data? In a replicated environment, this would impose coherence and consistency constraints that may be bound by network data transfer bandwidth.
This is just a beginning; the answers to these questions will trigger additional exploration into the nature of coordinating access to master data. The degree of synchronization relates to the ways that applications are using master data. When there is a high overlap in use of the same assets, there will be a greater need for synchrony, and a low degree of overlap reduces the need for synchrony.
It is valuable to note that one of the biggest issues of synchrony in an MDM environment leveraging a services-oriented architecture (SOA) is the degree to which end point systems can consume updates. In this asynchronous paradigm, if some end point systems cannot consume updates, for example, or there's a huge backlog of updates, you may have both performance and consistency issues.
11.5. Conceptual Data Sharing Models
As is discussed in Chapter 9, the spectrum of MDM architectures ranges from the thin model embodied by the registry approach to the more comprehensive repository that captures the complete collection of master data attributes, with an increasing number of attributes being shared in different ways as the design moves along that spectrum. The registry and repository architectural styles describe data sharing models, and in fact we can consider a third data sharing model that supports the repository view.
11.5.1. Registry Data Sharing
In the registry architectural style, the only shared components are the identifying attributes, whereas the existing data sets contain the data that compose the conceptual master asset. Although individual applications still control these component data sources, master data services can only impose synchronization control on the shared registry, in which case the identifying attributes become the focus of the synchronization requirements. The characterization of the levels of each synchronization dimension for the registry model is shown in Figure 11.1. Because data are available as master data as soon as they have been persisted to an application's data store, timeliness and currency of master data are both high. However, the existence of variant copies of records representing the same master entity means that consistency will be low, and, by definition, the absence of strict coordination between these copies means that coherence will be low. Lastly, because the consolidated view is materialized on demand (through federation), intervening changes between any two access requests may lead to differences in the result from two equivalent queries, which means that the level of determinism is low.
 |
| ▪Figure 11.1 Synchronization characteristics of the registry model. |
11.5.2. Repository Data Sharing
In the repository style, more master attributes are managed within a single conceptual data asset. If the data asset is truly a single data system comprising the entire set of data attributes, the focus of synchronization is the master data service layer's ability to flow data access transactions directly through to the underlying database platform to rely on its means for transaction serialization and so forth.
At the end of the spectrum representing the full-scale single repository, any updates to the master are immediately available to any of the client applications. Correspondingly, the levels of timeliness, currency, and consistency are high, as seen in Figure 11.2. In the case where there is only one underlying data system, there will be no issues with coherence between copies, and therefore the level of coherence is also high. Lastly, all changes will have been serialized according to the underlying data system's protocols, and subsequent queries are extremely likely to return largely similar, if not exactly the same, results; therefore, this approach will have a high degree of determinism.
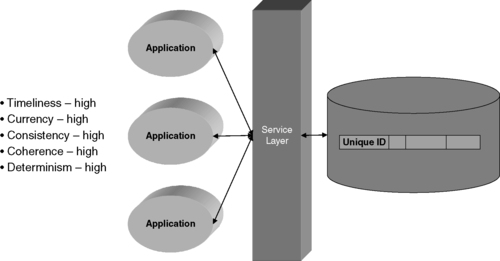 |
| ▪Figure 11.2 Synchronization dimensions for the repository model. |
11.5.3. Hybrids and Federated Repositories
Both ends of the spectrum seem to be covered; it is with the spectrum in between where we start to see issues, because the hybrid model (where some attributes are managed within a master repository and others are managed by the application) and the federated model (in which the conceptually monolithic data master is implemented via data replication and data distribution) are where we see multiple copies of what we believe to be unique instances of data.
In the hybrid approach, the applications are still driving the sequences of transactions, and with data writes needing to traverse multiple underlying database platforms, there is a new level of complexity for the managing record locking and multiple phases for committing transactions. Because the transactions may be broken up into chunks applied to different underlying databases, the transaction semantics may need to be engineered into the master data service layer.
A different issue arises in aspects of a replicated model (shown in Figure 11.3), in which copies of the master data asset are made available to different applications, allowing each to operate on its copy as if it were completely under application control. Modifications to a copy of a master object must be propagated back to any other replicated copies that exist across the enterprise.
 |
| ▪Figure 11.3 The synchronization characteristics of a hybrid model depend on the implementation. |
The different aspects of the underlying implementations mean that without details of how the master data asset is managed, it is difficult to project the determination of levels of our synchronization dimensions. For example, in the replicated model, maintaining coherence across the replicas becomes the critical activity, with all the other characteristics directly dependent on the degree of coherence. On the other hand, if there is not an expectation of a high degree of overlapping master data object accesses, engineering delayed consistency into the framework is an acceptable solution.
11.5.4. MDM, the Cache Model, and Coherence
Abstractly, the integrated view of master data begins to mimic a memory hierarchy not unlike the physical cache and memory models employed across most computer hardware systems. The master data repository itself represents the persistent storage, but the data from that asset are accessed and copied into versions both closer to and more easily by the using applications. For example, a replicated model essentially carries three levels of a memory hierarchy: the actual master version, a replica in a local data management asset, and individual records being manipulated directly by the application before commitment back through the local copy into the ultimate master copy.
Luckily, many of the issues regarding consistency and coherence across a cache memory environment have been addressed successfully to ensure that hardware caching and shared memory management will work at the hardware level. Because these are essentially solved problems, we can see the same approaches applied at the conceptual master data service level. In other words, we can apply a cache model to MDM in order to provide a framework for managing coherence across multiple copies. In this approach, there is an assumption that the applications store data to a local copy of the master data (whether that is a full replica or just a selection of attributes), which corresponds to the persistent version managed in the master repository (Figure 11.4).
 |
| ▪Figure 11.4 The virtual cache model shows local copies of master data managed by each application. |
Whenever a copy of a master record is updated in one of the application replicas, some protocol must be followed to ensure that the update is made consistent with the persistent master as well as the other application replicas. Examples of protocols include the ones shown in the sidebar.
▪ Write-through. This occurs when a modification to a local copy of master data is also written directly at the same time into the master repository. In this case, all the other applications that maintain copies of the same master objects must be notified that their copies are no longer current and that before using the record it must be refreshed from the persistent master.
▪ Write-back. This occurs when a modification to a local copy is written back to the persistent master at some time after the modification was made to local copy. In this case, there is no direct notification to other applications with copies at the time of modification, but there is likely to be at the time of writing back to the persistent master.
▪ Refresh notification. The process by which “stale” copies of mater records are marked as inconsistent or out of date when an application is notified that the master record has been updated. At that point, the application can determine whether or not the copy should be updated immediately.
▪ Refresh on read. A process by which stale copies are reloaded when an application requires reading or modifying the local copy after the persistent master record has been updated.
The processes will be handled ultimately within the master data service layer at the component services level. The determination of when local copies are updated becomes a policy management issue, especially with respect to performance. For example, immediately refreshing copies marked as stale may lead to an increase in network interactions, with data moving from a single resource (the persistent master) to the applications' copies, even if the data are not needed at that point, creating a performance bottleneck and increase in bandwidth requirements. On the other hand, delaying updates until the data are read may cause performance issues when generating reports against the local copies if many records are invalid and need to be accessed before the report can be run. The implication is that managing synchronization and coherence within the replicated/distributed/federated approaches to deploying a master repository impacts the performance aspects of the client applications, and, yet again, we see that the decisions regarding implementation of the underlying master data architecture depend on business application requirements for consistency and synchronization.
11.6. Incremental Adoption
A different way of considering the synchronization challenge involves the incremental adoption of master data management within the enterprise. There are essentially two aspects to MDM adoption: absorbing new data sources into the master asset and applications adopting the master repository. In this section, we explore some of the issues associated with synchronization when new data sources and applications are integrated into the master data environment.
11.6.1. Incorporating and Synchronizing New Data Sources
In Chapter 10 we looked at the challenges of master data consolidation—the process of creating the initial master data repository. Because there is no existing master data asset at the beginning of the program, the initial consolidation does not incur any additional demands for data synchronization. However, as soon as the initial version is moved into production, any subsequent data source incorporated into the master data asset is likely to not be aligned with that master data set.
Incorporating new data sources without intending to “sunset” them will always create the situation of one data silo lagging behind the other in terms of maintaining consistency. Therefore, think twice before considering absorbing data sources that will probably be retained as data stores for applications (such as specialized business tools) that will not be migrating to integrating with the master environment. That being said, there will always be situations in which there are data sets that will be absorbed into the master repository even though they will not be eliminated. Some of the issues that need to be addressed basically focus on coordination between the two data sets (and their client applications).
When there are applications that still use the data source but not the master data asset, that data source must remain in production. In this case, when is the data set synchronized with the master? The best scenario would impose the same level of coherence on that data as the replicated/distributed/federated approach, yet this is unlikely for a few reasons. First, the level of effort necessary for full coherence is probably close to the level of effort necessary for full integration, but maintaining segregation implies constraint on some assets (resource, time, staff), preventing the full integration. Second, isolation of the data and its services may create a barrier that limits the ability to invoke master data services from within the client applications. The alternate suggestion is periodic, one-way synchronization. Similar to the consolidation process, we can apply the integration process in a batch mode applied via the consolidation services within the master data service layer.
The other issue, which may be of lesser concern, is synchronizing the master data back with the segregated data source. The decision to do so should be left to the discretion of the manager/owner of that data source's client applications.
11.6.2. Application Adoption
When application managers prepare to adopt the use of the master repository, their production applications may need to run in a dual mode, with modifications being made to the existing source and the master data asset. This introduces yet another synchronization challenge—maintaining consistency between the data set to be retired and the master data asset. However, as we will explore in Chapter 12, the dual operation model should be handled transparently as part of the master data services layer.
11.7. Summary
Ultimately, the synchronization requirements feed into the selection process for an underlying architecture style, because we can see that the different choices for implementing a master data management system will support different degrees of synchronization within varying levels of systemic performance. Evaluating the characteristics of the different usage scenarios described in Chapter 9, assessing the number of participating applications, assessing the number of operational/transactional systems as opposed to analytical systems, determining the frequency of modifications, updates, and batch loads, and so on will help in driving the decision as to whether the most appropriate underlying architecture style should be based on a registry, full-scale hub repository or some hybrid version.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.